
A Survey on Adversarial Deep Learning Robustness in Medical Image Analysis



Abstract
1. Introduction
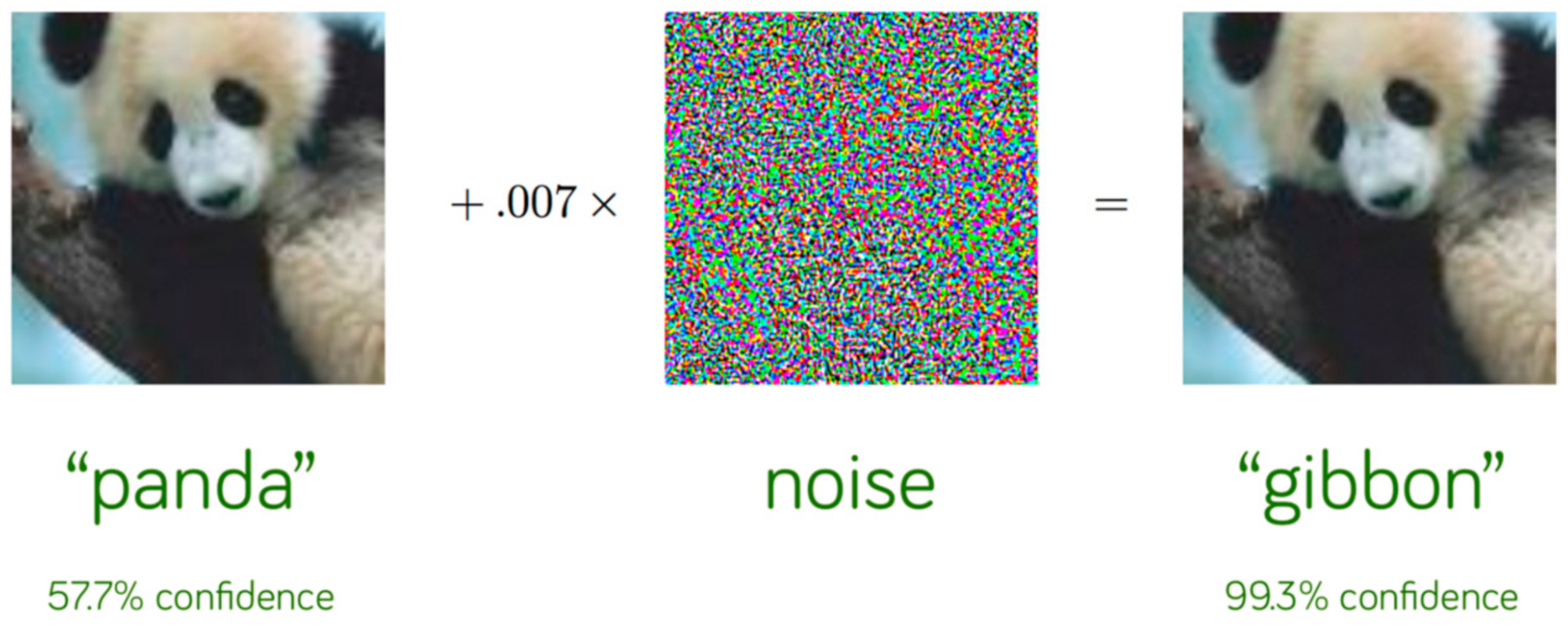
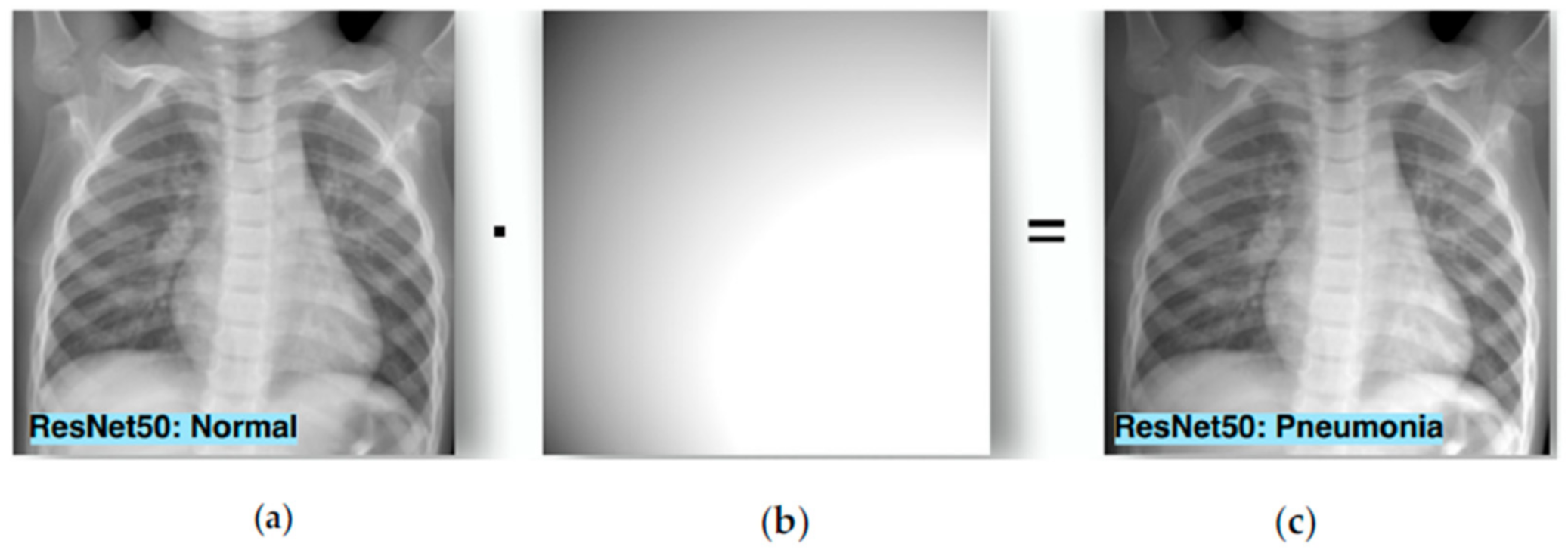
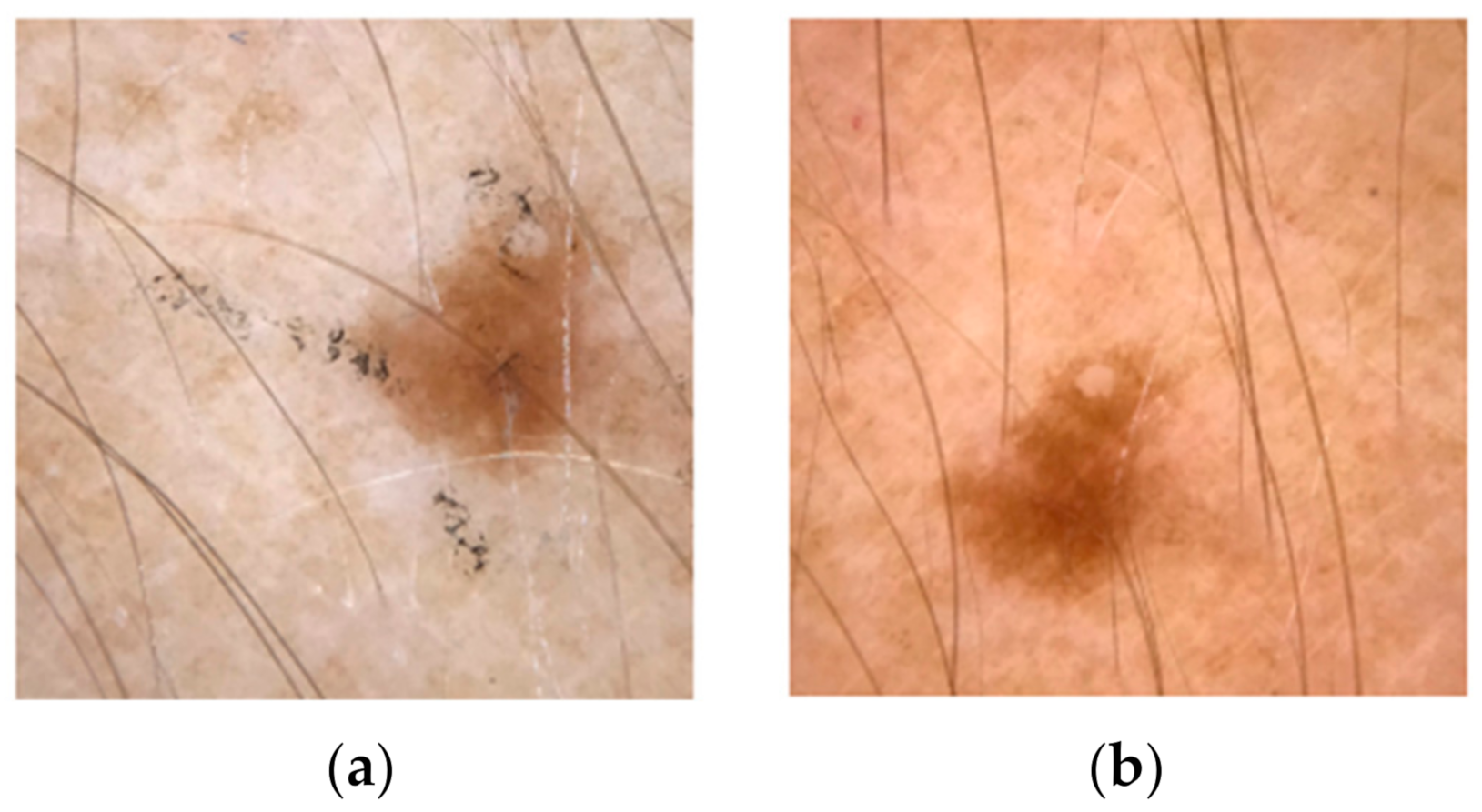
- Until now, most existing studies have been done in natural images. Natural images have numerous differences from medical images and this is an important reason to study how adversarial attacks affect medical images. First of all, we lack big datasets with annotated labels due to the high cost and time consumption. In combination with the fact that the normal class is often overrepresented we result in slow convergence and overfitting. Another difference between these two types of images is that medical data often contain quantitative information while nature does not. Contrary to natural images, the orientation is usually not related to medical image analysis. In addition, there are various tasks in which the differences between the classes are very small. For example, an X-ray with early-stage pneumonia is quite similar to a normal one. Another difference is that natural images are generated from RGB cameras while most medical images are not. However, Finlayson et al. [20] showed that medical images can also be affected by adversarial examples. According to Ma et al. [21] medical DL models are more vulnerable than natural images models for two reasons: (1) the characteristic biological texture of medical images has many areas that can be easily fooled; and (2) modern DL models are quite deep as they are designed for natural images processing and this can lead to overparameterization in medical image analysis that increases vulnerability. However, attacks in medical images are detected more easily than in a natural image as adversarial features are linearly separated from normal features while in natural images adversarial examples are similar to normal. Even if adversarial attacks on medical imaging are an extreme case, robust machine learning (ML) focuses on these cases and according to Caliva et al. [22], this point of view is significant as medical image analysis hides many dangers and abnormalities which can be extreme cases as well.
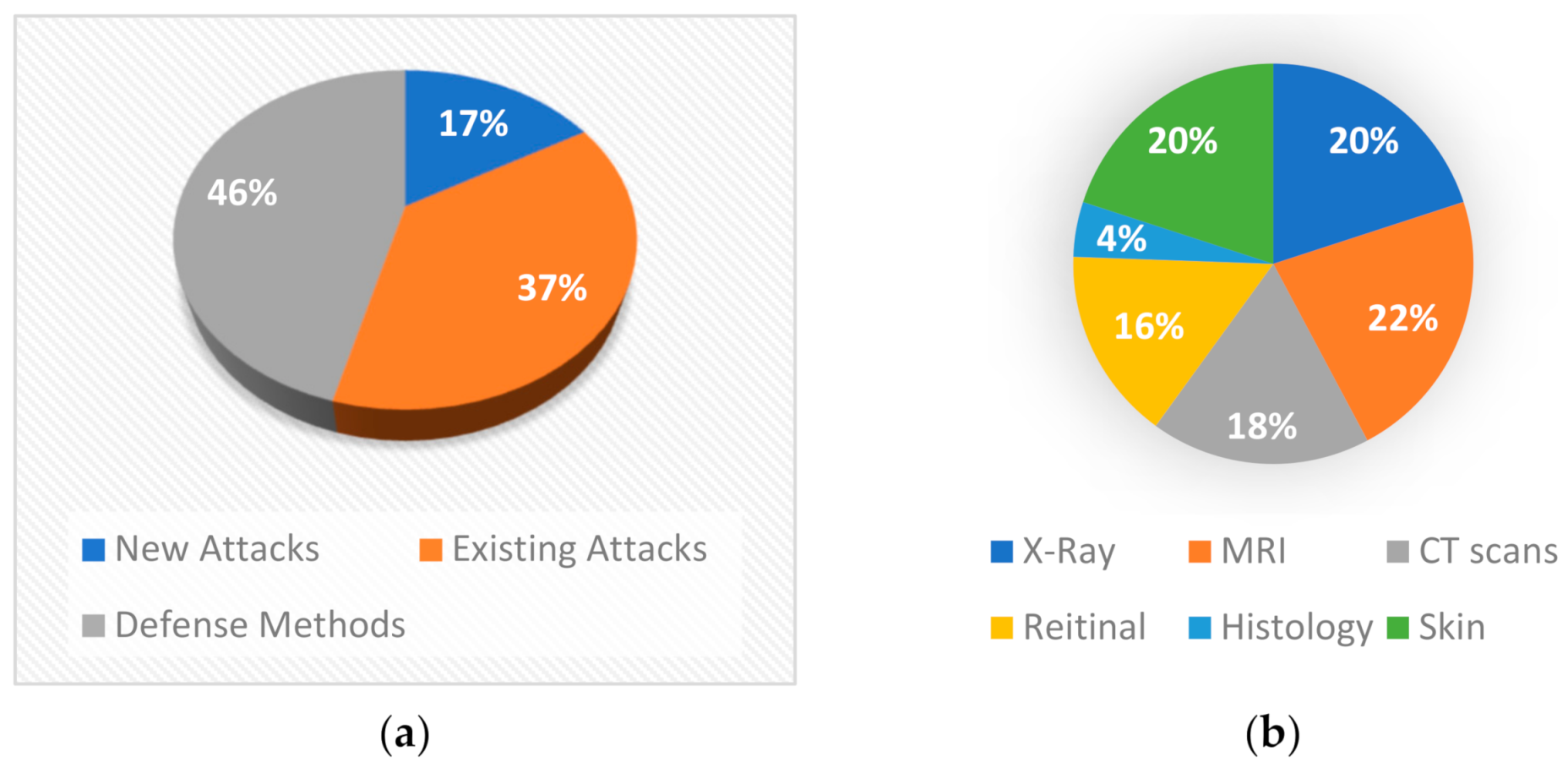
- The field of adversarial attacks is relatively new and especially for medical applications. In Figure 3, we show the papers that have been done per year, on this field. We use app dimensions [23] tool to find how many papers have been done, by using as keywords “adversarial attack” and “medical”. We can see that the interest has been increased rapidly from 2018 to 2020. A short survey about adversarial attacks on the medical domain has been done by Sipola et al. [24]. However, it contains only a few studies about attacks by providing information about the consequences of these attacks, but without defense or detection mechanisms. Our paper contains much more studies about medical images and adversarial attacks. We also present not only attacks but also defenses, detections and new attacks designed for medical image analysis.
2. Literature Analysis
3. Medical Image Analysis
3.1. Classification—Diagnosis
3.2. Detection
3.3. Segmentation
4. General Adversarial Examples
4.1. Adversarial Attacks
4.2. Adversarial Defenses
5. Adversarial Medical Image Analysis
5.1. Existing Adversarial Attacks on Medical Images
5.2. Adversarial Attacks for Medical Images
5.3. Defenses—Attack Detection
5.4. Benefits of Adversarially Robust Models
6. Implementation Aspects
6.1. Open-Source Libraries
6.2. Source Codes and Datasets
7. Discussion
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Apostolidis, K.; Amanatidis, P.; Papakostas, G. Performance Evaluation of Convolutional Neural Networks for Gait Recognition. In Proceedings of the 24th Pan-Hellenic Conference on Informatics, Athens Greece, 20–22 November 2020; pp. 61–63. [Google Scholar] [CrossRef]
- Sidiropoulos, G.K.; Kiratsa, P.; Chatzipetrou, P.; Papakostas, G.A. Feature Extraction for Finger-Vein-Based Identity Recognition. J. Imaging 2021, 7, 89. [Google Scholar] [CrossRef] [PubMed]
- Filippidou, F.P.; Papakostas, G.A. Single Sample Face Recognition Using Convolutional Neural Networks for Automated Attendance Systems. In Proceedings of the 2020 Fourth International Conference on Intelligent Computing in Data Sciences (ICDS), Fez, Morocco, 21–23 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Shankar, K.; Zhang, Y.; Liu, Y.; Wu, L.; Chen, C.-H. Hyperparameter Tuning Deep Learning for Diabetic Retinopathy Fundus Image Classification. IEEE Access 2020, 8, 118164–118173. [Google Scholar] [CrossRef]
- Maliamanis, T.; Papakostas, G.A. Machine Learning Vulnerability in Medical Imaging. In Machine Learning, Big Data, and IoT for Medical Informatics, 1st ed.; Elsevier: Amsterdam, The Netherlands, 2021; Available online: https://www.elsevier.com/books/machine-learning-big-data-and-iot-for-medical-informatics/xhafa/978-0-12-821777-1 (accessed on 4 June 2021).
- Tyukin, I.Y.; Higham, D.J.; Gorban, A.N. On Adversarial Examples and Stealth Attacks in Artificial Intelligence Systems. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. arXiv 2014, arXiv:1312.6199. Available online: http://arxiv.org/abs/1312.6199 (accessed on 4 June 2021).
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2015, arXiv:1412.6572. Available online: http://arxiv.org/abs/1412.6572 (accessed on 4 June 2021).
- Schmidt, L.; Santurkar, S.; Tsipras, D.; Talwar, K.; Mądry, A. Adversarially Robust Generalization Requires More Data. arXiv 2018, arXiv:1804.11285. Available online: http://arxiv.org/abs/1804.11285 (accessed on 4 June 2021).
- Ilyas, A.; Santurkar, S.; Tsipras, D.; Engstrom, L.; Tran, B.; Madry, A. Adversarial Examples Are Not Bugs, They Are Features. arXiv 2019, arXiv:1905.02175. Available online: http://arxiv.org/abs/1905.02175 (accessed on 4 June 2021).
- Maliamanis, T.; Papakostas, G. Adversarial computer vision: A current snapshot. In Proceedings of the Twelfth International Conference on Machine Vision (ICMV 2019), Amsterdam, The Netherlands, 31 January 2020; p. 121. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in Machine Learning: From Phenomena to Black-Box Attacks using Adversarial Samples. arXiv 2016, arXiv:1605.07277. Available online: http://arxiv.org/abs/1605.07277 (accessed on 4 June 2021).
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Examples in the Physical World. arXiv 2017, arXiv:1607.02533. Available online: http://arxiv.org/abs/1607.02533 (accessed on 4 June 2021).
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. In Proceedings of the 2018 Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018. [Google Scholar] [CrossRef]
- Meng, D.; Chen, H. MagNet: A Two-Pronged Defense against Adversarial Examples. arXiv 2017, arXiv:1705.09064. Available online: http://arxiv.org/abs/1705.09064 (accessed on 4 June 2021).
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2019, arXiv:1706.06083. Available online: http://arxiv.org/abs/1706.06083 (accessed on 4 June 2021).
- Paschali, M.; Conjeti, S.; Navarro, F.; Navab, N. Generalizability vs. Robustness: Investigating Medical Imaging Networks Using Adversarial Examples. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018; Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11070, pp. 493–501. [Google Scholar] [CrossRef]
- Mangaokar, N.; Pu, J.; Bhattacharya, P.; Reddy, C.K.; Viswanath, B. Jekyll: Attacking Medical Image Diagnostics using Deep Generative Models. In Proceedings of the 2020 IEEE European Symposium on Security and Privacy (EuroS&P), Genoa, Italy, 7–11 September 2020; pp. 139–157. [Google Scholar] [CrossRef]
- Finlayson, S.G.; Bowers, J.D.; Ito, J.; Zittrain, J.L.; Beam, A.L.; Kohane, I.S. Adversarial attacks on medical machine learning. Science 2019, 363, 1287–1289. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Niu, Y.; Gu, L.; Wang, Y.; Zhao, Y.; Bailey, J.; Lu, F. Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems. arXiv 2020, arXiv:1907.10456. Available online: http://arxiv.org/abs/1907.10456 (accessed on 4 June 2021).
- Calivá, F.; Cheng, K.; Shah, R.; Pedoia, V. Adversarial Robust Training of Deep Learning MRI Reconstruction Models. arXiv 2021, arXiv:2011.00070. Available online: http://arxiv.org/abs/2011.00070 (accessed on 4 June 2021).
- Dimensions. Available online: https://app.dimensions.ai/discover/publication (accessed on 9 August 2021).
- Sipola, T.; Puuska, S.; Kokkonen, T. Model Fooling Attacks Against Medical Imaging: A Short Survey. ISIJ 2020, 46, 215–224. [Google Scholar] [CrossRef]
- Tian, B.; Guo, Q.; Juefei-Xu, F.; Chan, W.L.; Cheng, Y.; Li, X.; Xie, X.; Qin, S. Bias Field Poses a Threat to DNN-based X-Ray Recognition. arXiv 2021, arXiv:2009.09247. Available online: http://arxiv.org/abs/2009.09247 (accessed on 4 June 2021).
- Chen, C.; Qin, C.; Qiu, H.; Ouyang, C.; Wang, S.; Chen, L.; Tarroni, G.; Bai, W.; Rueckert, D. Realistic Adversarial Data Augmentation for MR Image Segmentation. arXiv 2020, arXiv:2006.13322. Available online: http://arxiv.org/abs/2006.13322 (accessed on 4 June 2021).
- Makary, M.A.; Daniel, M. Medical error—the third leading cause of death in the US. BMJ 2016, i2139. [Google Scholar] [CrossRef] [PubMed]
- Lichtenberg, F.R. The quality of medical care, behavioral risk factors, and longevity growth. Int. J. Health Care Financ. Econ. 2011, 11, 1–34. [Google Scholar] [CrossRef] [PubMed]
- Beinfeld, M.T.; Gazelle, G.S. Diagnostic Imaging Costs: Are They Driving Up the Costs of Hospital Care? Radiology 2005, 235, 934–939. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. arXiv 2020, arXiv:1911.02685. Available online: http://arxiv.org/abs/1911.02685 (accessed on 4 June 2021). [CrossRef]
- Lo, S.-C.B.; Lou, S.-L.A.; Lin, J.; Freedman, M.T.; Chien, M.V.; Mun, S.K. Artificial convolution neural network techniques and applications for lung nodule detection. IEEE Trans. Med. Imaging 1995, 14, 711–718. [Google Scholar] [CrossRef] [PubMed]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning. arXiv 2017, arXiv:1711.05225. Available online: http://arxiv.org/abs/1711.05225 (accessed on 4 June 2021).
- Korolev, S.; Safiullin, A.; Belyaev, M.; Dodonova, Y. Residual and Plain Convolutional Neural Networks for 3D Brain MRI Classification. arXiv 2017, arXiv:1701.06643. Available online: http://arxiv.org/abs/1701.06643 (accessed on 4 June 2021).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. Available online: http://arxiv.org/abs/1409.1556 (accessed on 4 June 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chen, Y.-W.; Jain, L.C. (Eds.) Deep Learning in Healthcare: Paradigms and Applications; Springer International Publishing: Cham, Switzerland, 2020; Volume 171. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A Survey on Deep Learning in Medical Image Analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Payer, C.; Štern, D.; Bischof, H.; Urschler, M. Regressing Heatmaps for Multiple Landmark Localization Using CNNs. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016; Ourselin, S., Joskowicz, L., Sabuncu, M.R., Unal, G., Wells, W., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9901, pp. 230–238. [Google Scholar] [CrossRef]
- Setio, A.A.A.; Traverso, A.; de Bel, T.; Berens, M.S.N.; van den Bogaard, C.; Cerello, P.; Chen, H.; Dou, Q.; Fantacci, M.E.; Geurts, B.; et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: The LUNA16 challenge. Med. Image Anal. 2017, 42, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Setio, A.A.A.; Ciompi, F.; Litjens, G.; Gerke, P.; Jacobs, C.; van Riel, S.J.; Wille, M.M.W.; Naqibullah, M.; Sanchez, C.I.; van Ginneken, B. Pulmonary Nodule Detection in CT Images: False Positive Reduction Using Multi-View Convolutional Networks. IEEE Trans. Med. Imaging 2016, 35, 1160–1169. [Google Scholar] [CrossRef]
- Platania, R.; Shams, S.; Yang, S.; Zhang, J.; Lee, K.; Park, S.-J. Automated Breast Cancer Diagnosis Using Deep Learning and Region of Interest Detection (BC-DROID). In Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Boston, MA, USA, 20–23 August 2017; pp. 536–543. [Google Scholar] [CrossRef]
- Horry, M.J.; Chakraborty, S.; Paul, M.; Ulhaq, A.; Pradhan, B.; Saha, M.; Shukla, N. COVID-19 Detection Through Transfer Learning Using Multimodal Imaging Data. IEEE Access 2020, 8, 149808–149824. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. Available online: http://arxiv.org/abs/1505.04597 (accessed on 4 June 2021).
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.-W.; Heng, P.A. H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation from CT Volumes. arXiv 2018, arXiv:1709.07330. Available online: http://arxiv.org/abs/1709.07330 (accessed on 4 June 2021). [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. arXiv 2016, arXiv:1606.04797. Available online: http://arxiv.org/abs/1606.04797 (accessed on 4 June 2021).
- Drozdzal, M.; Vorontsov, E.; Chartrand, G.; Kadoury, S.; Pal, C. The Importance of Skip Connections in Biomedical Image Segmentation. arXiv 2016, arXiv:1608.04117. Available online: http://arxiv.org/abs/1608.04117 (accessed on 4 June 2021).
- Jin, Q.; Meng, Z.; Pham, T.D.; Chen, Q.; Wei, L.; Su, R. DUNet: A deformable network for retinal vessel segmentation. Knowl. Based Syst. 2019, 178, 149–162. [Google Scholar] [CrossRef]
- Xu, H.; Ma, Y.; Liu, H.-C.; Deb, D.; Liu, H.; Tang, J.-L.; Jain, A.K. Adversarial Attacks and Defenses in Images, Graphs and Text: A Review. Int. J. Autom. Comput. 2020, 17, 151–178. [Google Scholar] [CrossRef]
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial Attacks and Defenses in Deep Learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. arXiv 2017, arXiv:1608.04644. Available online: http://arxiv.org/abs/1608.04644 (accessed on 4 June 2021).
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The Limitations of Deep Learning in Adversarial Settings. arXiv 2015, arXiv:1511.07528. Available online: http://arxiv.org/abs/1511.07528 (accessed on 4 June 2021).
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal Adversarial Perturbations. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 86–94. [Google Scholar] [CrossRef]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial Examples for Semantic Segmentation and Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1378–1387. [Google Scholar] [CrossRef]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble Adversarial Training: Attacks and Defenses. arXiv 2020, arXiv:1705.07204. Available online: http://arxiv.org/abs/1705.07204 (accessed on 4 June 2021).
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A. Mitigating Adversarial Effects Through Randomization. arXiv 2018, arXiv:1711.01991. Available online: http://arxiv.org/abs/1711.01991 (accessed on 4 June 2021).
- Guo, Y.; Zhang, C.; Zhang, C.; Chen, Y. Sparse DNNs with Improved Adversarial Robustness. arXiv 2019, arXiv:1810.09619. Available online: http://arxiv.org/abs/1810.09619 (accessed on 4 June 2021).
- Wang, Y.; Jha, S.; Chaudhuri, K. Analyzing the Robustness of Nearest Neighbors to Adversarial Examples. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 5133–5142. [Google Scholar]
- Liu, X.; Li, Y.; Wu, C.; Hsieh, C.-J. Adv-BNN: Improved Adversarial Defense through Robust Bayesian Neural Network. arXiv 2019, arXiv:1810.01279. Available online: http://arxiv.org/abs/1810.01279 (accessed on 4 June 2021).
- Xiao, C.; Deng, R.; Li, B.; Yu, F.; Liu, M.; Song, D. Characterizing Adversarial Examples Based on Spatial Consistency Information for Semantic Segmentation. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11214, pp. 220–237. [Google Scholar] [CrossRef]
- Ma, X.; Li, B.; Wang, Y.; Erfani, S.M.; Wijewickrema, S.; Schoenebeck, G.; Song, D.; Houle, M.E.; Bailey, J. Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality. arXiv 2018, arXiv:1801.02613. Available online: http://arxiv.org/abs/1801.02613 (accessed on 4 June 2021).
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On Detecting Adversarial Perturbations. arXiv 2017, arXiv:1702.04267. Available online: http://arxiv.org/abs/1702.04267 (accessed on 4 June 2021).
- Finlayson, S.G.; Chung, H.W.; Kohane, I.S.; Beam, A.L. Adversarial Attacks Against Medical Deep Learning Systems. arXiv 2019, arXiv:1804.05296. Available online: http://arxiv.org/abs/1804.05296 (accessed on 4 June 2021).
- FDA Permits Marketing of Artificial Intelligence-Based Device to Detect Certain Diabetes-Related Eye. Available online: https://www.healthcare.digital/single-post/2018/04/20/fda-permits-marketing-of-artificial-intelligence-based-device-to-detect-certain-diabetes (accessed on 4 June 2021).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. Available online: http://arxiv.org/abs/1704.04861 (accessed on 4 June 2021).
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar] [CrossRef]
- Wetstein, S.C.; González-Gonzalo, C.; Bortsova, G.; Liefers, B.; Dubost, F.; Katramados, I.; Hogeweg, L.; van Ginneken, B.; Pluim, J.P.W.; de Bruijne, M.; et al. Adversarial Attack Vulnerability of Medical Image Analysis Systems: Unexplored Factors. arXiv 2020, arXiv:2006.06356. Available online: http://arxiv.org/abs/2006.06356 (accessed on 4 June 2021).
- Cheng, G.; Ji, H. Adversarial Perturbation on MRI Modalities in Brain Tumor Segmentation. IEEE Access 2020, 8, 206009–206015. [Google Scholar] [CrossRef]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Bermudez, C.; Chen, Y.; Landman, B.A.; Vorobeychik, Y. Anatomical context protects deep learning from adversarial perturbations in medical imaging. Neurocomputing 2020, 379, 370–378. [Google Scholar] [CrossRef]
- Huq, A.; Pervin, M.T. Analysis of Adversarial Attacks on Skin Cancer Recognition. In Proceedings of the 2020 International Conference on Data Science and Its Applications (ICoDSA), Bandung, Indonesia, 5–6 August 2020; pp. 1–4. [Google Scholar] [CrossRef]
- On the Assessment of Robustness of Telemedicine Applications against Adversarial Machine Learning Attacks | SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-3-030-79457-6_44?error=cookies_not_supported&code=3acd5697-d1ba-4ca5-8077-3d1b5d9bae9a (accessed on 10 August 2021).
- Pal, B.; Gupta, D.; Rashed-Al-Mahfuz, M.; Alyami, S.A.; Moni, M.A. Vulnerability in Deep Transfer Learning Models to Adversarial Fast Gradient Sign Attack for COVID-19 Prediction from Chest Radiography Images. Appl. Sci. 2021, 11, 4233. [Google Scholar] [CrossRef]
- Bortsova, G.; Dubost, F.; Hogeweg, L.; Katramados, I.; de Bruijne, M. Adversarial Heart Attack: Neural Networks Fooled to Segment Heart Symbols in Chest X-Ray Images. arXiv 2021, arXiv:2104.00139. Available online: http://arxiv.org/abs/2104.00139 (accessed on 10 August 2021).
- Anand, D.; Tank, D.; Tibrewal, H.; Sethi, A. Self-Supervision vs. Transfer Learning: Robust Biomedical Image Analysis Against Adversarial Attacks. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1159–1163. [Google Scholar] [CrossRef]
- Mendeley Data—Labeled Optical Coherence Tomography (OCT) and Chest X-Ray Images for Classification. Available online: https://data.mendeley.com/datasets/rscbjbr9sj/2 (accessed on 5 June 2021).
- Petitjean, C.; Zuluaga, M.A.; Bai, W.; Dacher, J.-N.; Grosgeorge, D.; Caudron, J.; Ruan, S.; Ayed, I.B.; Cardoso, M.J.; Chen, H.-C.; et al. Right ventricle segmentation from cardiac MRI: A collation study. Med. Image Anal. 2015, 19, 187–202. [Google Scholar] [CrossRef]
- Noroozi, M.; Favaro, P. Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles. arXiv 2017, arXiv:1603.09246. Available online: http://arxiv.org/abs/1603.09246 (accessed on 4 June 2021).
- Paul, R.; Schabath, M.; Gillies, R.; Hall, L.; Goldgof, D. Mitigating Adversarial Attacks on Medical Image Understanding Systems. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1517–1521. [Google Scholar] [CrossRef]
- Paul, R.; Hawkins, S.H.; Schabath, M.B.; Gillies, R.J.; Hall, L.O.; Goldgof, D.B. Predicting malignant nodules by fusing deep features with classical radiomics features. J. Med. Imaging 2018, 5, 1. [Google Scholar] [CrossRef]
- Risk Susceptibility of Brain Tumor Classification to Adversarial Attacks|SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-3-030-31964-9_17 (accessed on 4 June 2021).
- Miyato, T.; Maeda, S.; Koyama, M.; Nakae, K.; Ishii, S. Distributional Smoothing with Virtual Adversarial Training. arXiv 2016, arXiv:1507.00677. Available online: http://arxiv.org/abs/1507.00677 (accessed on 4 June 2021).
- Brain Tumor Dataset. Available online: https://figshare.com/articles/dataset/brain_tumor_dataset/1512427 (accessed on 4 June 2021).
- Shah, A.; Lynch, S.; Niemeijer, M.; Amelon, R.; Clarida, W.; Folk, J.; Russell, S.; Wu, X.; Abramoff, M.D. Susceptibility to misdiagnosis of adversarial images by deep learning based retinal image analysis algorithms. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 1454–1457. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. Available online: http://arxiv.org/abs/1606.02147 (accessed on 4 June 2021).
- Abràmoff, M.D.; Lou, Y.; Erginay, A.; Clarida, W.; Amelon, R.; Folk, J.C.; Niemeijer, M. Improved Automated Detection of Diabetic Retinopathy on a Publicly Available Dataset Through Integration of Deep Learning. Invest. Ophthalmol. Vis. Sci. 2016, 57, 5200. [Google Scholar] [CrossRef] [PubMed]
- Kovalev, V.; Voynov, D. Influence of Control Parameters and the Size of Biomedical Image Datasets on the Success of Adversarial Attacks. In Pattern Recognition and Information Processing; Ablameyko, S.V., Krasnoproshin, V.V., Lukashevich, M.M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 1055, pp. 301–311. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, Z.; Zhou, Y.; Xia, Y.; Shen, W.; Fishman, E.K.; Yuille, A.L. Volumetric Medical Image Segmentation: A 3D Deep Coarse-to-fine Framework and Its Adversarial Examples. arXiv 2019, arXiv:2010.16074. Available online: http://arxiv.org/abs/2010.16074 (accessed on 4 June 2021). [CrossRef]
- Roth, H.R.; Lu, L.; Farag, A.; Shin, H.-C.; Liu, J.; Turkbey, E.; Summers, R.M. DeepOrgan: Multi-level Deep Convolutional Networks for Automated Pancreas Segmentation. arXiv 2015, arXiv:1506.06448. Available online: http://arxiv.org/abs/1506.06448 (accessed on 4 June 2021).
- Zhou, Y.; Xie, L.; Fishman, E.K.; Yuille, A.L. Deep Supervision for Pancreatic Cyst Segmentation in Abdominal CT Scans. arXiv 2017, arXiv:1706.07346. Available online: http://arxiv.org/abs/1706.07346 (accessed on 4 June 2021).
- Allyn, J.; Allou, N.; Vidal, C.; Renou, A.; Ferdynus, C. Adversarial attack on deep learning-based dermatoscopic image recognition systems: Risk of misdiagnosis due to undetectable image perturbations. Medicine 2020, 99, e23568. [Google Scholar] [CrossRef] [PubMed]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef]
- Hirano, H.; Minagi, A.; Takemoto, K. Universal adversarial attacks on deep neural networks for medical image classification. BMC Med. Imaging 2021, 21, 9. [Google Scholar] [CrossRef] [PubMed]
- Hirano, H.; Koga, K.; Takemoto, K. Vulnerability of deep neural networks for detecting COVID-19 cases from chest X-ray images to universal adversarial attacks. PLoS ONE 2020, 15, e0243963. [Google Scholar] [CrossRef]
- Wang, L.; Lin, Z.Q.; Wong, A. COVID-Net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images. Sci. Rep. 2020, 10, 19549. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. ChestX-ray8: Hospital-Scale Chest X-Ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar] [CrossRef]
- ISIC Archive. Available online: https://www.isic-archive.com/ (accessed on 5 June 2021).
- Diabetic Retinopathy Detection|Kaggle. Available online: https://www.kaggle.com/c/diabetic-retinopathy-detection (accessed on 5 June 2021).
- Feinman, R.; Curtin, R.R.; Shintre, S.; Gardner, A.B. Detecting Adversarial Samples from Artifacts. arXiv 2017, arXiv:1703.00410. Available online: http://arxiv.org/abs/1703.00410 (accessed on 4 June 2021).
- Byra, M.; Styczynski, G.; Szmigielski, C.; Kalinowski, P.; Michalowski, L.; Paluszkiewicz, R.; Ziarkiewicz-Wroblewska, B.; Zieniewicz, K.; Nowicki, A. Adversarial Attacks on Deep Learning Models for Fatty Liver Disease Classification by Modification of Ultrasound Image Reconstruction Method. arXiv 2020, arXiv:2009.03364. Available online: http://arxiv.org/abs/2009.03364 (accessed on 4 June 2021).
- Chen, P.-Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.-J. ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar] [CrossRef]
- Ozbulak, U.; Van Messem, A.; De Neve, W. Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation. arXiv 2019, arXiv:1907.13124. Available online: http://arxiv.org/abs/1907.13124 (accessed on 4 June 2021).
- Pena-Betancor, C.; Gonzalez-Hernandez, M.; Fumero-Batista, F.; Sigut, J.; Medina-Mesa, E.; Alayon, S.; Gonzalez de la Rosa, M. Estimation of the Relative Amount of Hemoglobin in the Cup and Neuroretinal Rim Using Stereoscopic Color Fundus Images. Investig. Ophthalmol. Vis. Sci. 2015, 56, 1562–1568. [Google Scholar] [CrossRef] [PubMed]
- Codella, N.C.F.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.W.; Kalloo, A.; Liopyris, K.; Mishra, N.; Kittler, H.; et al. Skin Lesion Analysis Toward Melanoma Detection: A Challenge at the 2017 International Symposium on Biomedical Imaging (ISBI), Hosted by the International Skin Imaging Collaboration (ISIC). arXiv 2018, arXiv:1710.05006. Available online: http://arxiv.org/abs/1710.05006 (accessed on 4 June 2021).
- Chen, L.; Bentley, P.; Mori, K.; Misawa, K.; Fujiwara, M.; Rueckert, D. Intelligent Image Synthesis to Attack a Segmentation CNN Using Adversarial Learning. arXiv 2019, arXiv:1909.11167. Available online: http://arxiv.org/abs/1909.11167 (accessed on 4 June 2021).
- Kugler, D. Physical Attacks in Dermoscopy: An Evaluation of Robustness for clinical Deep-Learning. J. Mach. Learn. Biomed. Imaging 2021, 7, 1–32. [Google Scholar]
- Yao, Q.; He, Z.; Lin, Y.; Ma, K.; Zheng, Y.; Zhou, S.K. A Hierarchical Feature Constraint to Camouflage Medical Adversarial Attacks. arXiv 2021, arXiv:2012.09501. Available online: http://arxiv.org/abs/2012.09501 (accessed on 4 June 2021).
- Shao, M.; Zhang, G.; Zuo, W.; Meng, D. Target attack on biomedical image segmentation model based on multi-scale gradients. Inf. Sci. 2021, 554, 33–46. [Google Scholar] [CrossRef]
- REFUGE Challenge: A unified framework for evaluating automated methods for glaucoma assessment from fundus photographs—ScienceDirect. Available online: https://www.sciencedirect.com/science/article/abs/pii/S1361841519301100 (accessed on 10 August 2021).
- Alom, M.Z.; Yakopcic, C.; Hasan, M.; Taha, T.M.; Asari, V.K. Recurrent residual U-Net for medical image segmentation. J. Med. Imag. 2019, 6, 1. [Google Scholar] [CrossRef]
- Attention U-Net: Learning Where to Look for the Pancreas. Available online: https://arxiv.org/abs/1804.03999 (accessed on 10 August 2021).
- Qi, G.; Gong, L.; Song, Y.; Ma, K.; Zheng, Y. Stabilized Medical Image Attacks. arXiv 2021, arXiv:2103.05232. Available online: http://arxiv.org/abs/2103.05232 (accessed on 10 August 2021).
- Semi-Supervised Classification with Graph Convolutional Networks. Available online: https://arxiv.org/abs/1609.02907 (accessed on 10 August 2021).
- Attentive CT Lesion Detection Using Deep Pyramid Inference with Multi-scale Booster|SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-3-030-32226-7_34?error=cookies_not_supported&code=b33ccaa9-9f15-438c-8f5b-b2aabb1aa1fa (accessed on 10 August 2021).
- Wu, D.; Liu, S.; Ban, J. Classification of Diabetic Retinopathy Using Adversarial Training. IOP Conf. Ser. Mater. Sci. Eng. 2020, 806, 012050. [Google Scholar] [CrossRef]
- He, X.; Yang, S.; Li, G.; Li, H.; Chang, H.; Yu, Y. Non-Local Context Encoder: Robust Biomedical Image Segmentation against Adversarial Attacks. AAAI 2019, 33, 8417–8424. [Google Scholar] [CrossRef]
- Novikov, A.A.; Lenis, D.; Major, D.; Hladůvka, J.; Wimmer, M.; Bühler, K. Fully Convolutional Architectures for Multi-Class Segmentation in Chest Radiographs. arXiv 2018, arXiv:1701.08816. Available online: http://arxiv.org/abs/1701.08816 (accessed on 4 June 2021).
- Sarker, M.M.K.; Rashwan, H.A.; Akram, F.; Banu, S.F.; Saleh, A.; Singh, V.K.; Chowdhury, F.U.H.; Abdulwahab, S.; Romani, S.; Radeva, P.; et al. SLSDeep: Skin Lesion Segmentation Based on Dilated Residual and Pyramid Pooling Networks. arXiv 2018, arXiv:1805.10241. Available online: http://arxiv.org/abs/1805.10241 (accessed on 4 June 2021).
- Hwang, S.; Park, S. Accurate Lung Segmentation via Network-Wise Training of Convolutional Networks. arXiv 2017, arXiv:1708.00710. Available online: http://arxiv.org/abs/1708.00710 (accessed on 4 June 2021).
- Yuan, Y. Automatic skin lesion segmentation with fully convolutional-deconvolutional networks. IEEE J. Biomed. Health Inform. 2019, 23, 519–526. [Google Scholar] [CrossRef] [PubMed]
- Taghanaki, S.A.; Das, A.; Hamarneh, G. Vulnerability Analysis of Chest X-Ray Image Classification Against Adversarial Attacks. arXiv 2018, arXiv:1807.02905. Available online: http://arxiv.org/abs/1807.02905 (accessed on 4 June 2021).
- Ren, X.; Zhang, L.; Wei, D.; Shen, D.; Wang, Q. Brain MR Image Segmentation in Small Dataset with Adversarial Defense and Task Reorganization. In Machine Learning in Medical Imaging; Suk, H.-I., Liu, M., Yan, P., Lian, C., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11861, pp. 1–8. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Ourselin, S.; Vercauteren, T. Automatic Brain Tumor Segmentation using Cascaded Anisotropic Convolutional Neural Networks. arXiv 2018, arXiv:1709.00382. Available online: http://arxiv.org/abs/1709.00382 (accessed on 4 June 2021). [CrossRef]
- Pervin, M.T.; Tao, L.; Huq, A.; He, Z.; Huo, L. Adversarial Attack Driven Data Augmentation for Accurate and Robust Medical Image Segmentation. arXiv 2021, arXiv:2105.12106. Available online: http://arxiv.org/abs/2105.12106 (accessed on 10 August 2021).
- Liu, S.; Setio, A.A.A.; Ghesu, F.C.; Gibson, E.; Grbic, S.; Georgescu, B.; Comaniciu, D. No Surprises: Training Robust Lung Nodule Detection for Low-Dose CT Scans by Augmenting with Adversarial Attacks. arXiv 2020, arXiv:2003.03824. Available online: http://arxiv.org/abs/2003.03824 (accessed on 4 June 2021). [CrossRef] [PubMed]
- National Lung Screening Trial Research Team the National Lung Screening Trial: Overview and Study Design. Radiology 2011, 258, 243–253. [CrossRef] [PubMed]
- Vatian, A.; Gusarova, N.; Dobrenko, N.; Dudorov, S.; Nigmatullin, N.; Shalyto, A.; Lobantsev, A. Impact of Adversarial Examples on the Efficiency of Interpretation and Use of Information from High-Tech Medical Images. In Proceedings of the 2019 24th Conference of Open Innovations Association (FRUCT), Moscow, Russia, 8–12 April 2019; pp. 472–478. [Google Scholar] [CrossRef]
- The Lung Image Database Consortium (LIDC) and Image Database Resource Initiative (IDRI): A Completed Reference Database of Lung Nodules on CT Scans. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3041807/ (accessed on 5 June 2021).
- Dvořák, P.; Menze, B. Local Structure Prediction with Convolutional Neural Networks for Multimodal Brain Tumor Segmentation. In Medical Computer Vision: Algorithms for Big Data; Menze, B., Langs, G., Montillo, A., Kelm, M., Müller, H., Zhang, S., Cai, W., Metaxas, D., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9601, pp. 59–71. [Google Scholar] [CrossRef]
- Bernard, O.; Lalande, A.; Zotti, C.; Cervenansky, F.; Yang, X.; Heng, P.-A.; Cetin, I.; Lekadir, K.; Camara, O.; Gonzalez Ballester, M.A.; et al. Deep Learning Techniques for Automatic MRI Cardiac Multi-Structures Segmentation and Diagnosis: Is the Problem Solved? IEEE Trans. Med. Imaging 2018, 37, 2514–2525. [Google Scholar] [CrossRef]
- Cheng, K.; Caliva, F.; Shah, R.; Han, M.; Majumdar, S.; Pedoia, V. Addressing the False Negative Problem of Deep Learning MRI Reconstruction Models by Adversarial Attacks and Robust Training. Proc. Mach. Learn. Res. 2020, 121, 121–135. [Google Scholar]
- Putzky, P.; Welling, M. Invert to Learn to Invert. arXiv 2019, arXiv:1911.10914. Available online: http://arxiv.org/abs/1911.10914 (accessed on 4 June 2021).
- Park, H.; Bayat, A.; Sabokrou, M.; Kirschke, J.S.; Menze, B.H. Robustification of Segmentation Models Against Adversarial Perturbations in Medical Imaging. arXiv 2020, arXiv:2009.11090. Available online: http://arxiv.org/abs/2009.11090 (accessed on 4 June 2021).
- Marcus, D.S.; Wang, T.H.; Parker, J.; Csernansky, J.G.; Morris, J.C.; Buckner, R.L. Open Access Series of Imaging Studies (OASIS): Cross-sectional MRI Data in Young, Middle Aged, Nondemented, and Demented Older Adults. J. Cogn. Neurosci. 2007, 19, 1498–1507. [Google Scholar] [CrossRef]
- Taghanaki, S.A.; Abhishek, K.; Azizi, S.; Hamarneh, G. A Kernelized Manifold Mapping to Diminish the Effect of Adversarial Perturbations. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 11332–11341. [Google Scholar] [CrossRef]
- Uwimana1, A.; Senanayake, R. Out of Distribution Detection and Adversarial Attacks on Deep Neural Networks for Robust Medical Image Analysis. arXiv 2021, arXiv:2107.04882. Available online: http://arxiv.org/abs/2107.04882 (accessed on 10 August 2021).
- Daza, L.; Pérez, J.C.; Arbeláez, P. Towards Robust General Medical Image Segmentation. arXiv 2021, arXiv:2107.04263. Available online: http://arxiv.org/abs/2107.04263 (accessed on 10 August 2021).
- Reliable Evaluation of Adversarial Robustness with an Ensemble of Diverse Parameter-Free Attacks. Available online: http://proceedings.mlr.press/v119/croce20b.html (accessed on 10 August 2021).
- Huang, Y.; Würfl, T.; Breininger, K.; Liu, L.; Lauritsch, G.; Maier, A. Some Investigations on Robustness of Deep Learning in Limited Angle Tomography. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018; Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11070, pp. 145–153. [Google Scholar] [CrossRef]
- Xue, F.-F.; Peng, J.; Wang, R.; Zhang, Q.; Zheng, W.-S. Improving Robustness of Medical Image Diagnosis with Denoising Convolutional Neural Networks. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2019; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.-T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11769, pp. 846–854. [Google Scholar] [CrossRef]
- Tripathi, A.M.; Mishra, A. Fuzzy Unique Image Transformation: Defense Against Adversarial Attacks on Deep COVID-19 Models. arXiv 2020, arXiv:2009.04004. Available online: http://arxiv.org/abs/2009.04004 (accessed on 4 June 2021).
- Defending Deep Learning-Based Biomedical Image Segmentation from Adversarial Attacks: A Low-Cost Frequency Refinement Approach|SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-3-030-59719-1_34 (accessed on 4 June 2021).
- Xu, M.; Zhang, T.; Li, Z.; Liu, M.; Zhang, D. Towards evaluating the robustness of deep diagnostic models by adversarial attack. Med. Image Anal. 2021, 69, 101977. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zou, D.; Yi, J.; Bailey, J.; Ma, X.; Gu, Q. Improving adversarial robustness requires revisiting misclassified examples. In Proceedings of the International Conference on Learning Representations, Virtual, 27–30 April 2020. [Google Scholar]
- Li, X.; Zhu, D. Robust Detection of Adversarial Attacks on Medical Images. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1154–1158. [Google Scholar] [CrossRef]
- Li, X.; Pan, D.; Zhu, D. Defending against Adversarial Attacks on Medical Imaging AI System, Classification or Detection? arXiv 2020, arXiv:2006.13555. Available online: http://arxiv.org/abs/2006.13555 (accessed on 4 June 2021).
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.S.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 2018, 172, 1122–1131.e9. [Google Scholar] [CrossRef]
- Lee, S.; Lee, H.; Yoon, S. Adversarial Vertex Mixup: Toward Better Adversarially Robust Generalization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 269–278. [Google Scholar] [CrossRef]
- Liu, X.; Xiao, T.; Si, S.; Cao, Q.; Kumar, S.; Hsieh, C.-J. How Does Noise Help Robustness? Explanation and Exploration under the Neural SDE Framework. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 279–287. [Google Scholar] [CrossRef]
- Qin, Y.; Wang, X.; Beutel, A.; Chi, E.H. Improving Uncertainty Estimates through the Relationship with Adversarial Robustness. arXiv 2020, arXiv:2006.16375. Available online: http://arxiv.org/abs/2006.16375 (accessed on 10 August 2021).
- Yi, M.; Hou, L.; Sun, J.; Shang, L.; Jiang, X.; Liu, Q.; Ma, Z.-M. Improved OOD Generalization via Adversarial Training and Pre-training. arXiv 2021, arXiv:2105.11144. Available online: http://arxiv.org/abs/2105.11144 (accessed on 10 August 2021).
- Papernot, N.; Faghri, F.; Carlini, N.; Goodfellow, I.; Feinman, R.; Kurakin, A.; Xie, C.; Sharma, Y.; Brown, T.; Roy, A.; et al. Technical Report on the CleverHans v2.1.0 Adversarial Examples Library. arXiv 2018, arXiv:1610.00768. Available online: http://arxiv.org/abs/1610.00768 (accessed on 4 June 2021).
- Rauber, J.; Zimmermann, R.; Bethge, M.; Brendel, W. Foolbox Native: Fast adversarial attacks to benchmark the robustness of machine learning models in PyTorch, TensorFlow, and JAX. JOSS 2020, 5, 2607. [Google Scholar] [CrossRef]
- Nicolae, M.-I.; Sinn, M.; Tran, M.N.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; et al. Adversarial Robustness Toolbox v1.0.0. arXiv 2019, arXiv:1807.01069. Available online: http://arxiv.org/abs/1807.01069 (accessed on 4 June 2021).
- Goodman, D.; Xin, H.; Yang, W.; Yuesheng, W.; Junfeng, X.; Huan, Z. Advbox: A Toolbox to Generate Adversarial Examples that Fool Neural Networks. arXiv 2020, arXiv:2001.05574. Available online: http://arxiv.org/abs/2001.05574 (accessed on 4 June 2021).
- Ding, G.W.; Wang, L.; Jin, X. advertorch v0.1: An Adversarial Robustness Toolbox based on PyTorch. arXiv 2019, arXiv:1902.07623. Available online: http://arxiv.org/abs/1902.07623 (accessed on 4 June 2021).
- Ling, X.; Ji, S.; Zou, J.; Wang, J.; Wu, C.; Li, B.; Wang, T. DEEPSEC: A Uniform Platform for Security Analysis of Deep Learning Model. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 673–690. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Attacks | Models | Modality | Task | Performance Degradation (%) |
|---|---|---|---|---|---|
| [18] | FGSM, DF, JSMA | Inception, MobileNet, SegNet, U-Net, DenseNet | Dermoscopy, MRI | Classification, Segmentation | 6–24%/19–40% |
| [62] | PGD | ResNet50 | Fundoscopy, Dermoscopy, X-ray | Classification | 50–100% |
| [69] | UAP | U-Net | MRI | Segmentation | Up to 65% |
| [71] | UAP | DNN, Hybrid DNN | MRI | Classification | Not provided |
| [72] | FGSM, PGD | VGG16, MobileNet | Dermoscopy | Classification | Up to 75% |
| [76] | FGSM, PGD | VGG11, U-Net | X-ray, MRI | Classification, Segmentation | Up to 100% |
| [80] | FGSM, One-pixel attack | CNN | CT scans | Classification | 28–36%/2–3% |
| [82] | FGSM, VAT, Noise -based attack | CNN | MRI | Classification | 69%/34%/24% |
| [85] | I-FGSM | CNN, Hybrid lesion-bassed model | Fundoscopy | Classification | 45%/0.6% |
| [89] | PGD | Inception V3 | X-ray, Histology | Classification | Up to 100% |
| [90] | FGSM, I-FGSM | ResDSN Coarse | CT scans | Segmentation | 86% |
| [93] | Image Dependent Perturbation | DenseNet201 | Dermoscopy | Classification | 17% |
| [95] | UAP | VGGNets, InceptionResNetV2, ResNet50, DenseNets | Dermoscopy, Fundoscopy, X-ray | Classification | Up to 72% |
| [96] | UAP | COVIDNet | X-ray | Classification | Up to 45% |
| [21] | FGSM, PGD, C&W, BIM | ResNet50 | X-ray, Dermoscopy, Fundoscopy | Classification | Up to 100% |
| [74] | FGSM | VGG-16, InceptionV3 | CT scans, X-ray | Classification | Up to 90% |
| [75] | PGD | Similar to U-Net | X-ray | Segmentation | Up to 100% |
| [73] | FGSM | Custom CNN | Mammography | Classification | Up to 30% |
| Reference | Attack Name | Models | Modality | Task | Performance Degradation (%) |
|---|---|---|---|---|---|
| [102] | Fatty Liver Attack | InceptionResNetV2 | Ultrasound | Classification | 48% |
| [104] | ASMA | U-Net | Fundoscopy, Dermoscopy | Segmentation | 98% success rate on targeted prediction |
| [107] | Multi-organ Segmentation Attack | U-Net | CT scans | Segmentation | Up to 85% |
| [25] | AdvSBF | ResNet50, MobileNet, DensNet121 | X-ray | Classification | Up to 39% |
| [108] | Physical World Attacks | ResNet, InceptionV3, InceptionResNetV2, MobileNet, Xception | Dermoscopy | Classification | Up to 60% |
| [109] | HFC | VGG16, ResNet 50 | Fundoscopy, X-ray | All tasks | Up to 99.5% |
| [110] | MSA | U-Net, R2U-Net, Attention U-Net, Attention R2U-Net | Fundoscopy, Dermoscopy | Segmentation | 98% success rate on targeted prediction |
| [114] | SMIA | ResNet, U-Net, Custom CNNs | Fundoscopy, Endoscopy, CT-scans | Classification Segmentation | Up to 27% |
| References | Tested Attacks | Models | Modality | Task | Performance |
|---|---|---|---|---|---|
| [21,60,101] | FGSM, BIM, PGD, C&W | ResNet50 | X-ray, Dermoscopy, Fundoscopy | Classification | Detects adversarial example with up to 100% accuracy |
| [124] | FGSM | CNN | MRI | Segmentation | Improves baseline methods up to 1.5% |
| [127] | PGD | 3D ResNets | CT scans | Classification | Improves baseline methods up to 10% and 35% in perturbed data |
| [129] | FGSM, JSMA | CNN | CT scans, MRI | All tasks | Improves baseline methods up to 2% |
| [26] | VAT | UNet | MRI | Segmentation | Improves baseline methods up to 3% |
| [117] | PGD | ResNet32 | Fundoscopy | Classification | Accuracy increased by 40% |
| [118] | I-FGSM | U-Net, InvertNet, SLSDeep, NWCN, DCNN | X-ray | Segmentation | The dice score metric is reduced by only up to 11% |
| [123] | Gradient-based, Score-based, Decision-based | NasnetLarge, InceptionResNetV2 | X-ray | Classification | Accuracy increased by up to 9% |
| [133] | FNAF | U-Net, I-RIM | MRI | Reconstruction | Up to 72% more resilient |
| [22] | FNAF | U-Net, I-RIM | MRI | Reconstruction | Up to 72% more resilient |
| [135] | DAG | SegNet, U-Net, DenseNet | All modalities | Segmentation | Detects adversarial samples with 98% ROC_AUC |
| [137] | FGSM, I-FGSM, PGD, MIM, C&W | U-Net, V-Net, InceptionResNetV2 | Dermoscopy, X-ray | Segmentation, Classification | The accuracy is reduced by only up to 29% |
| [141] | Limited Angle | U-Net | CT scans | Reconstruction | Not provided |
| [142] | FGSM, I-FGSM, C&W | CNN | Fundoscopy, X-ray | Classification | The accuracy is reduced by only up to 24% |
| [143] | FGSM, BIM, PGD, C&W, DF | CNN | X-ray, CT scans | Classification | The accuracy is reduced by only up to 2% |
| [144] | ASMA | ResNet-50, U-Net, DenseNet | Dermoscopy, Fundoscopy | Classification, Segmentation | The accuracy is reduced by only up to 2% |
| [147] | FGSM, BIM, PGD, MIM | DenseNet121 | X-ray | Classification | Detects adversarial samples with up to 97.5% accuracy |
| [148] | FGSM, PGD, C&W | ResNet18 | Fundoscopy | Classification | Prediction accuracy under attack is 86.4% |
| [126] | FGSM | U-Net | CT-Scans | Segmentation | Improves baseline methods up to 9% in terms of IoU |
| [138] | FGSM, BIM, C&W DeepFool | VGG, ResNet | Microscopy | Classification | Detects adversarial samples with up to 99.95% accuracy |
| [139] | APGD-CE, APGD-DLR, FAB-T, Square Attack | ROG | CT-Scans, MRI | Segmentation | Improves baseline methods up to 20% in terms of IoU |
| [145] | PGD, GAP | CheXNet, InceptionV3, Custom CNN | Dermoscopy, X-ray, Fundoscopy | Classification | Improves standard defense method (adversarial training) by up to 9% |
| Library | Programming Language/Framework | Link (Accessed on 7 June 2021) |
|---|---|---|
| CleverHans | Python/JAX, PyTorch, and TF2 | https://github.com/cleverhans-lab/cleverhans |
| Foolbox | Python/PyTorch, JAX, TF | https://foolbox.readthedocs.io/en/stable/ |
| ART | Python/TF, Keras | https://adversarial-robustness-toolbox.readthedocs.io/en/stable/ |
| Advbox | Python/PaddlePaddle, PyTorch, Caffe2, Keras, TF | https://github.com/advboxes/AdvBox |
| AdverTorch | Python/PyTorch | https://github.com/BorealisAI/advertorch |
| DEEPSEC | Python/PyTorch | https://github.com/kleincup/DEEPSEC |
| Reference | Method Type | Link (Accessed on 7 June 2021) |
|---|---|---|
| [62] | Attack | https://github.com/sgfin/adversarial-medicine |
| [96] | Attack | https://github.com/hkthirano/UAP-COVID-Net |
| [22] | Defense | https://github.com/fcaliva/fastMRI_BB_abnormalities_annotation |
| [71] | Attack | https://github.com/yvorobey/adversarialMI |
| [90] | Attack | https://github.com/yulequan/HeartSeg |
| [109] | Attack Detection | KD and BU (Detection Method) https://github.com/rfeinman/detecting-adversarial-samples LID and MAHA (Detection Method) https://github.com/pokaxpoka/deep_Mahalanobis_detector |
| [104] | Attack | https://github.com/utkuozbulak/adaptive-segmentation-mask-attack |
| [144] | Defense | https://github.com/qiliu08/frequency-refinement-defense |
| [147] | Attack Detection | https://github.com/xinli0928/MGM |
| [145] | Defense | https://github.com/MengtingXu1203/EvaluatingRobustness |
| [139] | Defense | https://github.com/BCV-Uniandes/ROG |
| [114] | Attack | https://github.com/imogenqi/SMA |
| [138] | Defense | https://github.com/shriyakabra97/malaria-parasite-detection |
| Dataset Name | Dataset Size | Modality | Link (Accessed on 7 June 2021) |
|---|---|---|---|
| Chest X-ray | 5856 | X-ray | https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia |
| RSNA | 29.7 k | X-ray | https://www.kaggle.com/c/rsna-pneumonia-detection-challenge |
| NIH Chest X-ray 14 | 112 k | X-ray | https://www.kaggle.com/nih-chest-xrays/data |
| APTOS | 5590 | Fundoscopy | https://www.kaggle.com/c/aptos2019-blindness-detection |
| Diabetic Retinopathy Detection | 35 k | Fundoscopy | https://www.kaggle.com/c/diabetic-retinopathy-detection |
| OASIS | 373–2168 | MRI | https://www.oasis-brains.org/ |
| HAM10000 | 10 k | Dermatoscopic | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/DBW86T |
| ISIC 2018 | 3594 | Dermatoscopic | https://challenge.isic-archive.com/data |
| LUNA 16 | 888 | CT-Scans | https://luna16.grand-challenge.org/Data/ |
| BraTS 2018 | 1689 | MRI | https://mrbrains18.isi.uu.nl/ |
| BraTS 2019 | 1675 | MRI | https://www.med.upenn.edu/cbica/brats-2019/ |
| JSRT | 247 | X-ray | http://db.jsrt.or.jp/eng.php |
| NLST | 75 k | CT-Scans | https://cdas.cancer.gov/nlst/ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Apostolidis, K.D.; Papakostas, G.A. A Survey on Adversarial Deep Learning Robustness in Medical Image Analysis. Electronics 2021, 10, 2132. https://doi.org/10.3390/electronics10172132
Apostolidis KD, Papakostas GA. A Survey on Adversarial Deep Learning Robustness in Medical Image Analysis. Electronics. 2021; 10(17):2132. https://doi.org/10.3390/electronics10172132
Chicago/Turabian StyleApostolidis, Kyriakos D., and George A. Papakostas. 2021. "A Survey on Adversarial Deep Learning Robustness in Medical Image Analysis" Electronics 10, no. 17: 2132. https://doi.org/10.3390/electronics10172132
APA StyleApostolidis, K. D., & Papakostas, G. A. (2021). A Survey on Adversarial Deep Learning Robustness in Medical Image Analysis. Electronics, 10(17), 2132. https://doi.org/10.3390/electronics10172132