
3D Expression-Invariant Face Verification Based on Transfer Learning and Siamese Network for Small Sample Size


Abstract
:1. Introduction
- Develop a face recognition method with the Siamese network that converts the face recognition problem from a single network classification problem to a facial pattern search problem.
- The distance-based face-matching process was replaced by a small, fully connected neural network trained with different face sample pairs, which effectively reduced the computational cost of face matching.
- Utilizing the transfer learning to pre-train the network to improve the network efficiency and training speed when the sample size is small.
2. Materials and Methods
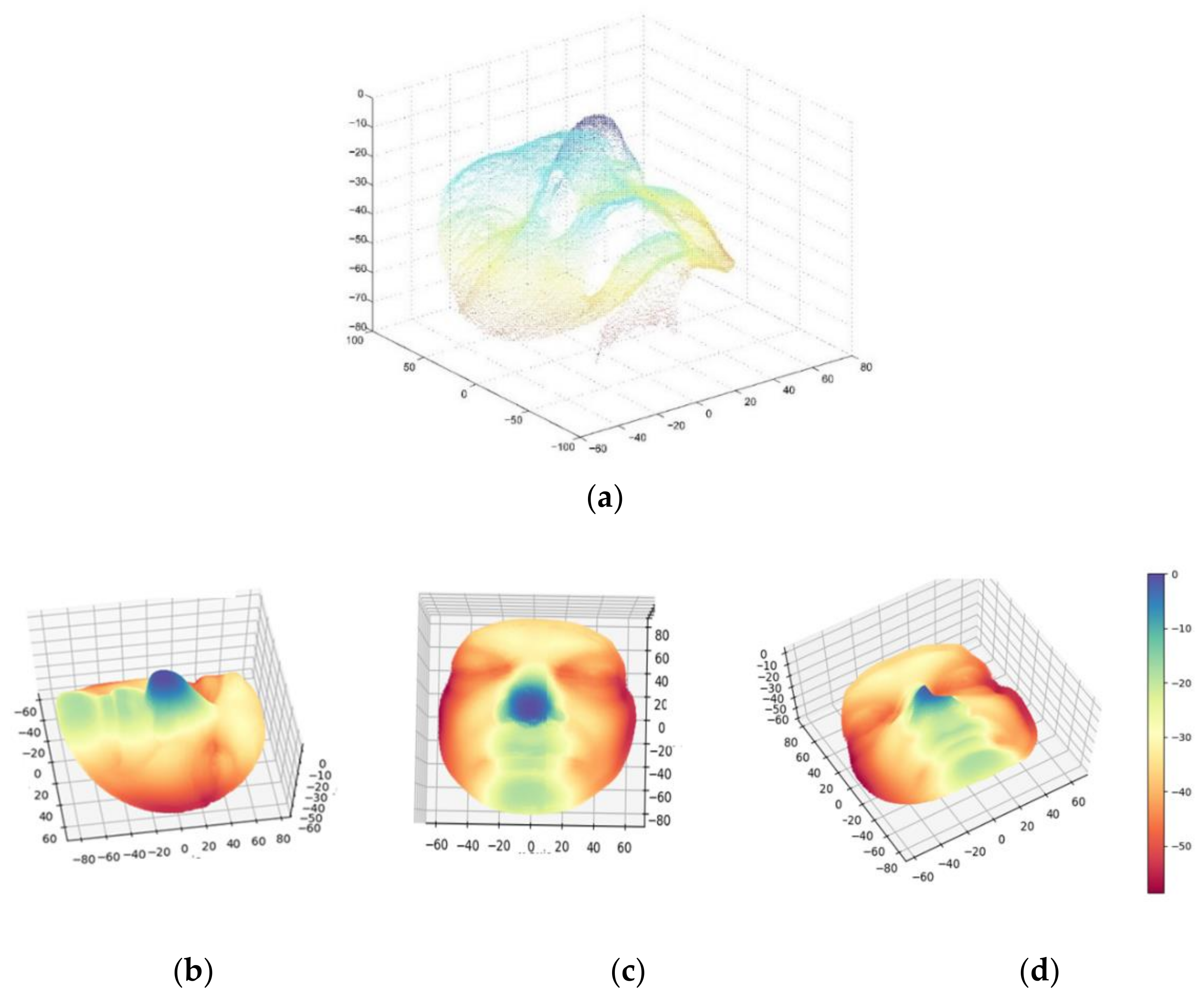
2.1. Dataset and Facial Scan Pre-Processing
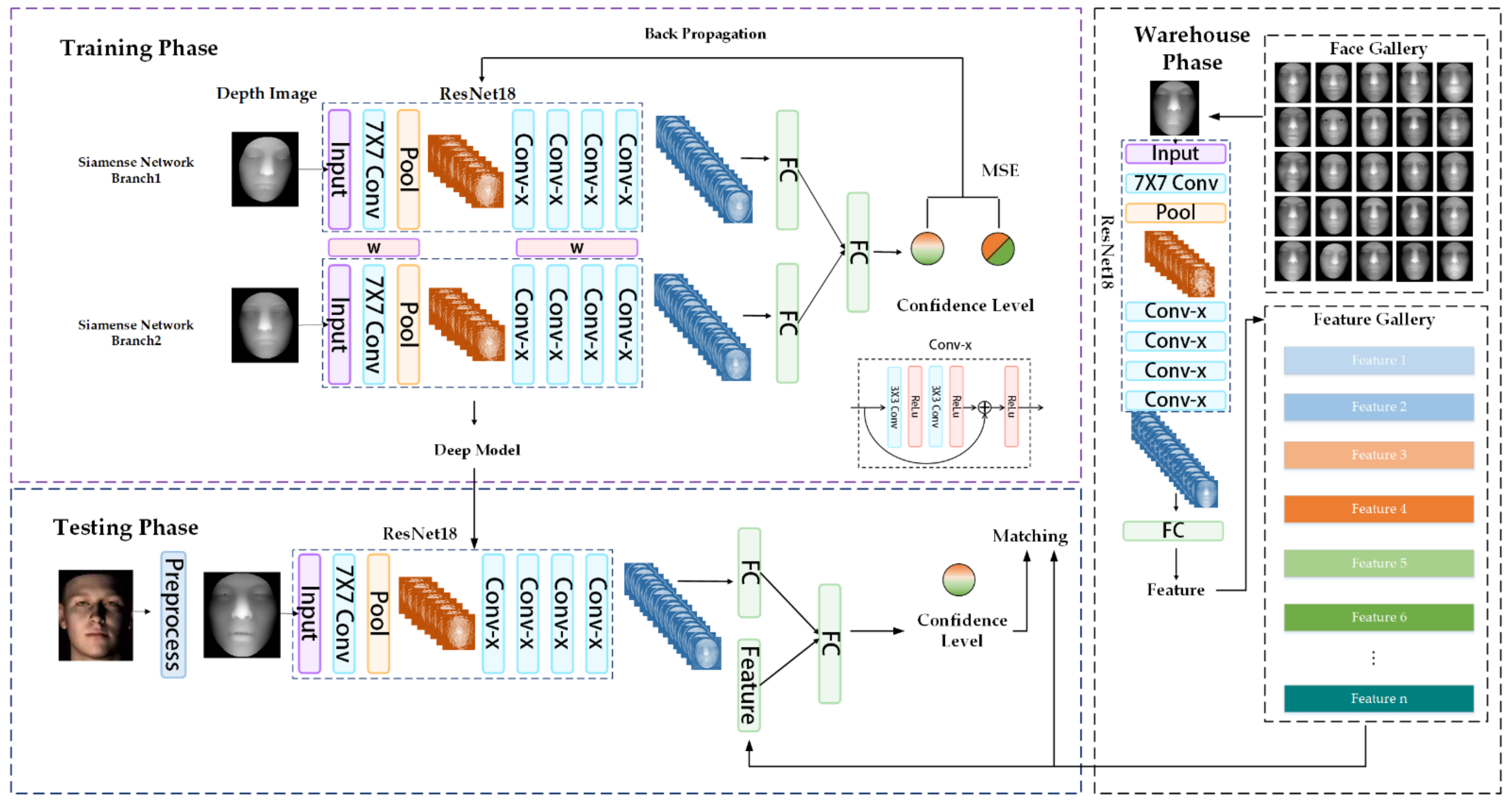
2.2. Method
2.2.1. Transfer Learning of Convolutional Neural Network Model for Face Recognition
2.2.2. Siamese Network for Face Recognition
3. Results and Discussion
3.1. Evaluating the Effectiveness of Transfer Learning CNN
3.2. Evaluating the Effectiveness of Transfer Siamese Neural Network
3.3. Evaluating the Performance of Different Methods on Face Recognition
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, X.; Gao, Y. Face recognition across pose: A review. Pattern Recognit. 2009, 42, 2876–2896. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Deng, W. Deep face recognition: A survey. Neurocomputing 2021, 429, 215–244. [Google Scholar] [CrossRef]
- Manju, D.; Radha, V. A Novel Approach for Pose Invariant Face Recognition in Surveillance Videos. Procedia Comput. Sci. 2020, 167, 890–899. [Google Scholar] [CrossRef]
- Kim, D.; Hernandez, M.; Choi, J.; Medioni, G. Deep 3D face identification. IEEE Int. Jt. Conf. Biom. 2018, 2018, 133–142. [Google Scholar] [CrossRef] [Green Version]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, present, and future of face recognition: A review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Lei, Y.; Bennamoun, M.; Hayat, M.; Guo, Y. An efficient 3D face recognition approach using local geometrical signatures. Pattern Recognit. 2014, 47, 509–524. [Google Scholar] [CrossRef]
- Tang, H.; Yin, B.; Sun, Y.; Hu, Y. 3D face recognition using local binary patterns. Signal Process. 2013, 93, 2190–2198. [Google Scholar] [CrossRef]
- Cardia Neto, J.B.; Marana, A.N. Utilizing deep learning and 3DLBP for 3D Face recognition. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany; Volume 10657 LNCS, pp. 135–142. [CrossRef]
- Cai, Y.; Lei, Y.; Yang, M.; You, Z.; Shan, S. A fast and robust 3D face recognition approach based on deeply learned face representation. Neurocomputing 2019, 363, 375–397. [Google Scholar] [CrossRef]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Bhiksha, R.; Song, L. SphereFace: Deep Hypersphere Embedding for Face Recognition Weiyang. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J. CosFace: Large Margin Cosine Loss for Deep Face Recognition Hao. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5265–5274. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. ArcFace: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4685–4694. [Google Scholar] [CrossRef] [Green Version]
- Meng, Q.; Zhao, S.; Huang, Z.; Zhou, F. MagFace: A Universal Representation for Face Recognition and Quality Assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TE, USA, 21–24 June 2021; pp. 14225–14234. [Google Scholar]
- Xiao, Y.; Li, J.; Du, B.; Wu, J.; Chang, J.; Zhang, W. MeMu: Metric correlation Siamese network and multi-class negative sampling for visual tracking. Pattern Recognit. 2020, 100, 107170. [Google Scholar] [CrossRef]
- Kim, H.I.; Park, R.H. Siamese adversarial network for object tracking. Electron. Lett. 2019, 55, 88–90. [Google Scholar] [CrossRef]
- Ahmed, N.K.; Hemayed, E.E.; Fayek, M.B. Hybrid siamese network for unconstrained face verification and clustering under limited resources. Big Data Cogn. Comput. 2020, 4, 19. [Google Scholar] [CrossRef]
- Wang, G.; Wang, S.; Chi, W.; Liu, S.; Fan, D. A Person Reidentification Algorithm Based on Improved Siamese Network and Hard Sample. Math. Probl. Eng. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Sameer, V.U.; Naskar, R. Deep siamese network for limited labels classification in source camera identification. Multimed. Tools Appl. 2020, 79, 28079–28104. [Google Scholar] [CrossRef]
- Figueroa-Mata, G.; Mata-Montero, E. Using a convolutional siamese network for image-based plant species identification with small datasets. Biomimetics 2020, 5, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chang, S.; Li, W.; Zhang, Y.; Feng, Z. Online siamese network for visual object tracking. Sensors 2019, 19, 1858. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, F.; Zhao, Q.; Liu, X.; Zeng, D. Joint Face Alignment and 3D Face Reconstruction with Application to Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 664–678. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Phillips, P.J.; Flynn, P.J.; Scruggs, T.; Bowyer, K.W.; Chang, J.; Hoffman, K.; Marques, J.; Min, J.; Worek, W. Overview of the face recognition grand challenge. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 947–954. [Google Scholar] [CrossRef]
- Koenderink, J.J.; van Doorn, A.J. Surface shape and curvature scales. Image Vis. Comput. 1992, 10, 557–564. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl.-Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T. Evaluation of transfer learning algorithms using different base learners. In Proceedings of the 2017 IEEE 29th International Conference on Tools with Artificial Intelligence, Boston, MA, USA, 6–8 November 2017; pp. 187–196. [Google Scholar] [CrossRef]
- Lisa, T.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Urbonas, A.; Raudonis, V.; Maskeliunas, R.; Damaševičius, R. Automated identification of wood veneer surface defects using faster region-based convolutional neural network with data augmentation and transfer learning. Appl. Sci. 2019, 9, 4898. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Simon, H. Neural Networks and Learning Machines; Pearson Education India: London, UK, 2010. [Google Scholar]
- Mahoor, M.H.; Abdel-Mottaleb, M. Face recognition based on 3D ridge images obtained from range data. Pattern Recognit. 2009, 42, 445–451. [Google Scholar] [CrossRef]
- Deng, X.; Da, F.; Shao, H.; Jiang, Y. A multi-scale three-dimensional face recognition approach with sparse representation-based classifier and fusion of local covariance descriptors. Comput. Electr. Eng. 2020, 85, 106700. [Google Scholar] [CrossRef]
- Li, H.; Huang, D.; Morvan, J.M.; Chen, L.; Wang, Y. Expression-robust 3D face recognition via weighted sparse representation of multi-scale and multi-component local normal patterns. Neurocomputing 2014, 133, 179–193. [Google Scholar] [CrossRef] [Green Version]
- Lei, Y.; Guo, Y.; Hayat, M.; Bennamoun, M.; Zhou, X. A Two-Phase Weighted Collaborative Representation for 3D partial face recognition with single sample. Pattern Recognit. 2016, 52, 218–237. [Google Scholar] [CrossRef]


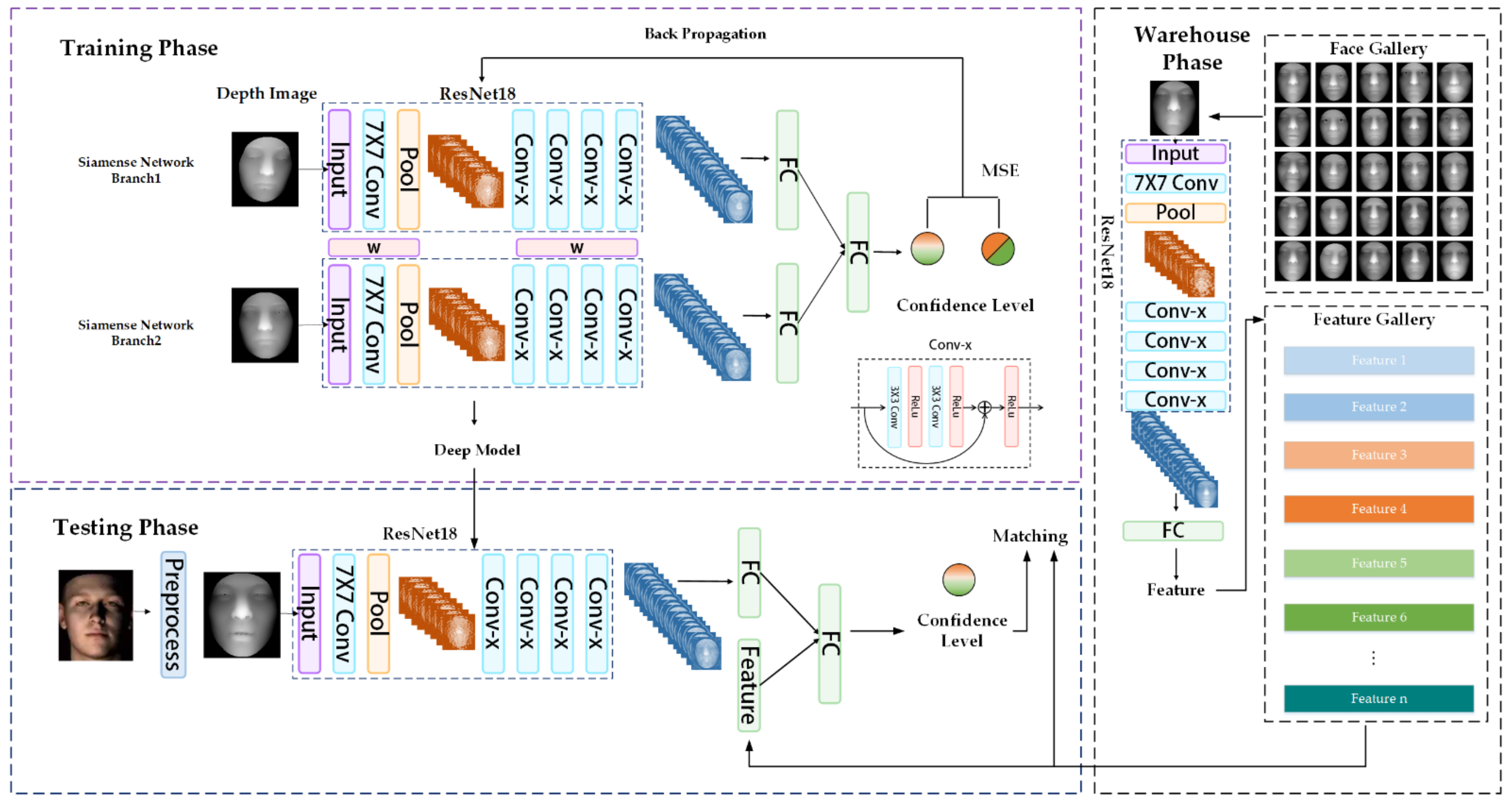





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
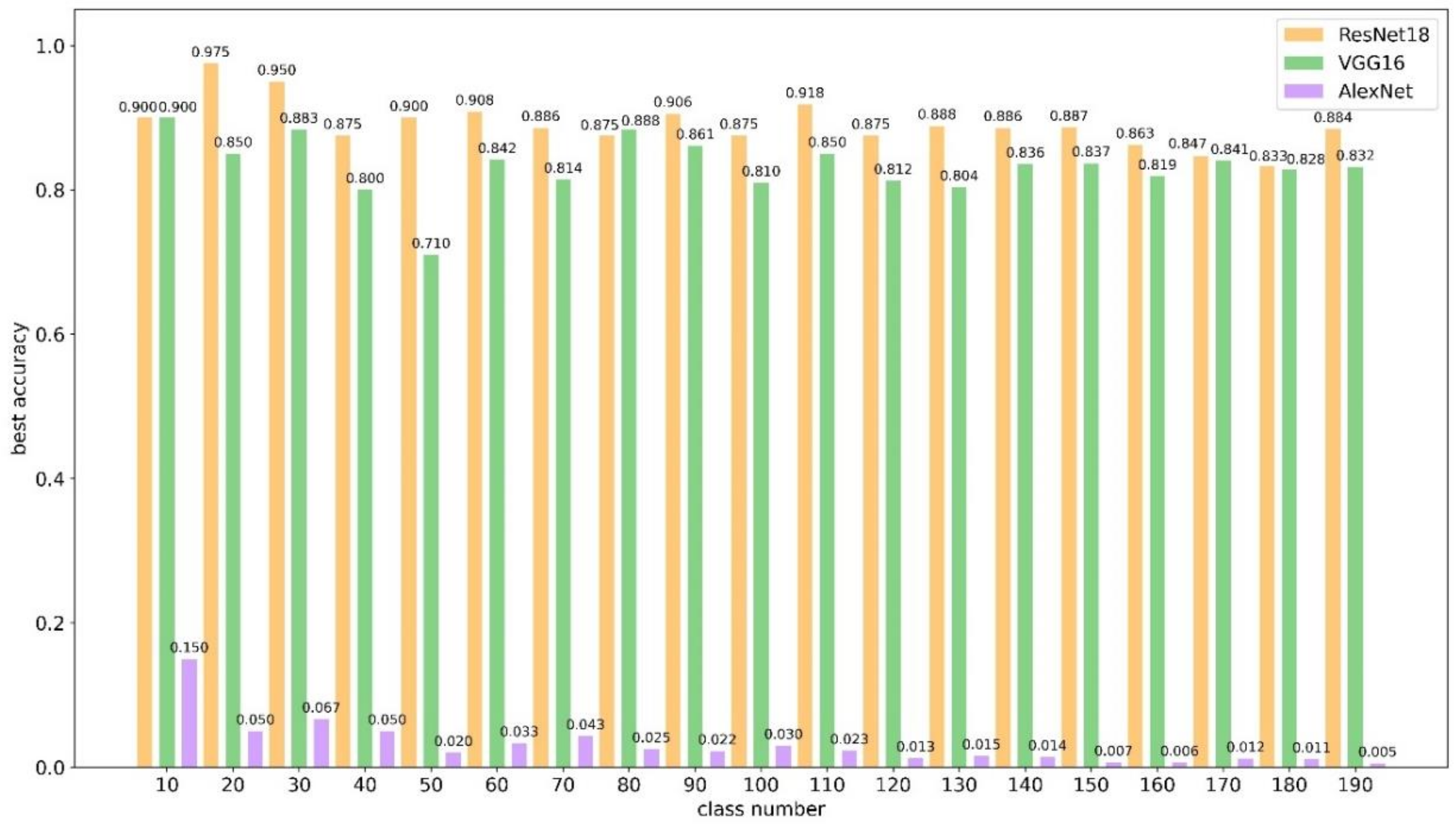{kind=link}
{kind=link}
| Layer Name | Output Size | Branch1 | Branch2 |
|---|---|---|---|
| Conv1 | , , stride | , , stride | |
| Conv2.x | Max pooling, stride | Max pooling, stride | |
| Conv3.x | |||
| Conv4.x | |||
| Conv5.x | |||
| FC1 | Average pool, 500-d fc | Average pool, 500-d fc | |
| FC2 | Average pool, 1-d fc | ||
| Number of Classes | With Transfer Learning | Without Transfer Learning | ||||
|---|---|---|---|---|---|---|
| ResNet18 | VGG16 | AlexNet | ResNet18 | VGG16 | AlexNet | |
| 10 | 94.2 ± 1.5 | 86.7 ± 1.9 | 91.7 ± 1.9 | 90.8 ± 1.5 | 91.7 ± 1.9 | 11.7 ± 1.9 |
| 20 | 89.2 ± 1.5 | 86.7 ± 0.9 | 75.8 ± 1.9 | 95.4 ± 1.8 | 83.3 ± 1.9 | 5.8 ± 1.5 |
| 30 | 95.5 ± 1.3 | 89.4 ± 1.8 | 80.0 ± 1.5 | 93.9 ± 1.3 | 88.3 ± 1.5 | 7.3 ± 1.8 |
| 40 | 98.0 ± 0.9 | 74.6 ± 1.4 | 74.2 ± 0.9 | 87.9 ± 1.4 | 80.4 ± 1.4 | 4.6 ± 1.8 |
| 50 | 92.0 ± 0.9 | 87.0 ± 0.9 | 72.7 ± 1.1 | 91.0 ± 1.2 | 70.3 ± 0.8 | 2.7 ± 0.8 |
| 60 | 97.3 ± 1.0 | 86.4 ± 1.0 | 66.1 ± 1.0 | 91.1 ± 0.9 | 84.2 ± 1.1 | 3.0 ± 0.9 |
| 70 | 96.4 ± 0.9 | 91.4 ± 0.6 | 65.7 ± 0.7 | 89.3 ± 0.6 | 82.1 ± 0.6 | 4.8 ± 0.9 |
| 80 | 96.0 ± 0.5 | 88.0 ± 0.2 | 72.1 ± 0.9 | 86.9 ± 0.5 | 88.8 ± 0.8 | 2.3 ± 0.7 |
| 90 | 94.3 ± 0.7 | 95.0 ± 0.7 | 71.8 ± 0.7 | 90.2 ± 0.7 | 86.3 ± 0.6 | 2.4 ± 0.6 |
| 100 | 94.8 ± 0.4 | 91.3 ± 0.5 | 74.8 ± 0.6 | 87.7 ± 0.5 | 81.2 ± 0.7 | 3.3 ± 0.6 |
| 110 | 96.2 ± 0.3 | 92.6 ± 0.5 | 68.3 ± 0.5 | 91.3 ± 0.4 | 84.8 ± 0.5 | 2.3 ± 0.4 |
| 120 | 94.3 ± 0.6 | 93.8 ± 0.4 | 68.0 ± 0.5 | 87.6 ± 0.2 | 81.5 ± 0.3 | 1.2 ± 0.6 |
| 130 | 97.3 ± 0.5 | 93.7 ± 0.4 | 71.2 ± 0.3 | 88.4 ± 0.5 | 80.8 ± 0.3 | 1.6 ± 0.6 |
| 140 | 94.7 ± 0.4 | 93.8 ± 0.4 | 64.2 ± 0.4 | 88.8 ± 0.4 | 83.8 ± 0.4 | 1.2 ± 0.4 |
| 150 | 95.9 ± 0.3 | 91.0 ± 0.4 | 71.1 ± 0.4 | 88.4 ± 0.4 | 83.6 ± 0.4 | 0.8 ± 0.2 |
| 160 | 95.4 ± 0.3 | 92.1 ± 0.4 | 67.4 ± 0.4 | 86.3 ± 0.3 | 82.2 ± 0.3 | 0.8 ± 0.2 |
| 170 | 96.0 ± 0.2 | 93.4 ± 0.3 | 66.7 ± 0.2 | 84.6 ± 0.3 | 84.2 ± 0.3 | 1.1 ± 0.3 |
| 180 | 94.5 ± 0.3 | 91.2 ± 0.2 | 64.7 ± 0.3 | 83.4 ± 0.3 | 83.0 ± 0.2 | 1.1 ± 0.3 |
| 190 | 96.0 ± 0.3 | 92.8 ± 0.2 | 63.2 ± 0.2 | 88.1 ± 0.2 | 83.1 ± 0.3 | 0.7 ± 0.2 |
| Number of Classes | Convolutional Network | Transfer Convolutional Network | Transfer Siamese Network |
|---|---|---|---|
| 20 | 95.4 ± 1.8 | 89.2 ± 1.5 | 93.2 ± 1.8 |
| 50 | 91.0 ± 1.2 | 92.0 ± 0.9 | 94.6 ± 0.6 |
| 80 | 86.9 ± 0.5 | 96.0 ± 0.5 | 97.1 ± 0.5 |
| 110 | 91.3 ± 0.4 | 96.2 ± 0.3 | 97.3 ± 0.3 |
| 140 | 88.8 ± 0.4 | 94.7 ± 0.4 | 97.7 ± 0.1 |
| 170 | 84.6 ± 0.3 | 96.0 ± 0.2 | 97.6 ± 0.1 |
| 190 | 88.1 ± 0.2 | 96.0 ± 0.3 | 97.7 ± 0.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zou, H.; Sun, X.; Zhu, T.; Ni, C. 3D Expression-Invariant Face Verification Based on Transfer Learning and Siamese Network for Small Sample Size. Electronics 2021, 10, 2128. https://doi.org/10.3390/electronics10172128
Li Z, Zou H, Sun X, Zhu T, Ni C. 3D Expression-Invariant Face Verification Based on Transfer Learning and Siamese Network for Small Sample Size. Electronics. 2021; 10(17):2128. https://doi.org/10.3390/electronics10172128
Chicago/Turabian StyleLi, Zhenye, Hongyan Zou, Xinyan Sun, Tingting Zhu, and Chao Ni. 2021. "3D Expression-Invariant Face Verification Based on Transfer Learning and Siamese Network for Small Sample Size" Electronics 10, no. 17: 2128. https://doi.org/10.3390/electronics10172128
APA StyleLi, Z., Zou, H., Sun, X., Zhu, T., & Ni, C. (2021). 3D Expression-Invariant Face Verification Based on Transfer Learning and Siamese Network for Small Sample Size. Electronics, 10(17), 2128. https://doi.org/10.3390/electronics10172128