1. Introduction
As we become better at using data to enable the use of more complex artificial neural network models, interest in data utilization has attracted the attention of all of society and is starting to be utilized on all devices [
1,
2]. As various devices begin to participate in training, research is being conducted on how to use a computing model in an environment where computing devices and data are distributed, as opposed to a centralized system with the typical deep learning models [
3]. Recently, there has also been a series of active studies on federated learning, which considers privacy more than existing distributed computing models [
4,
5,
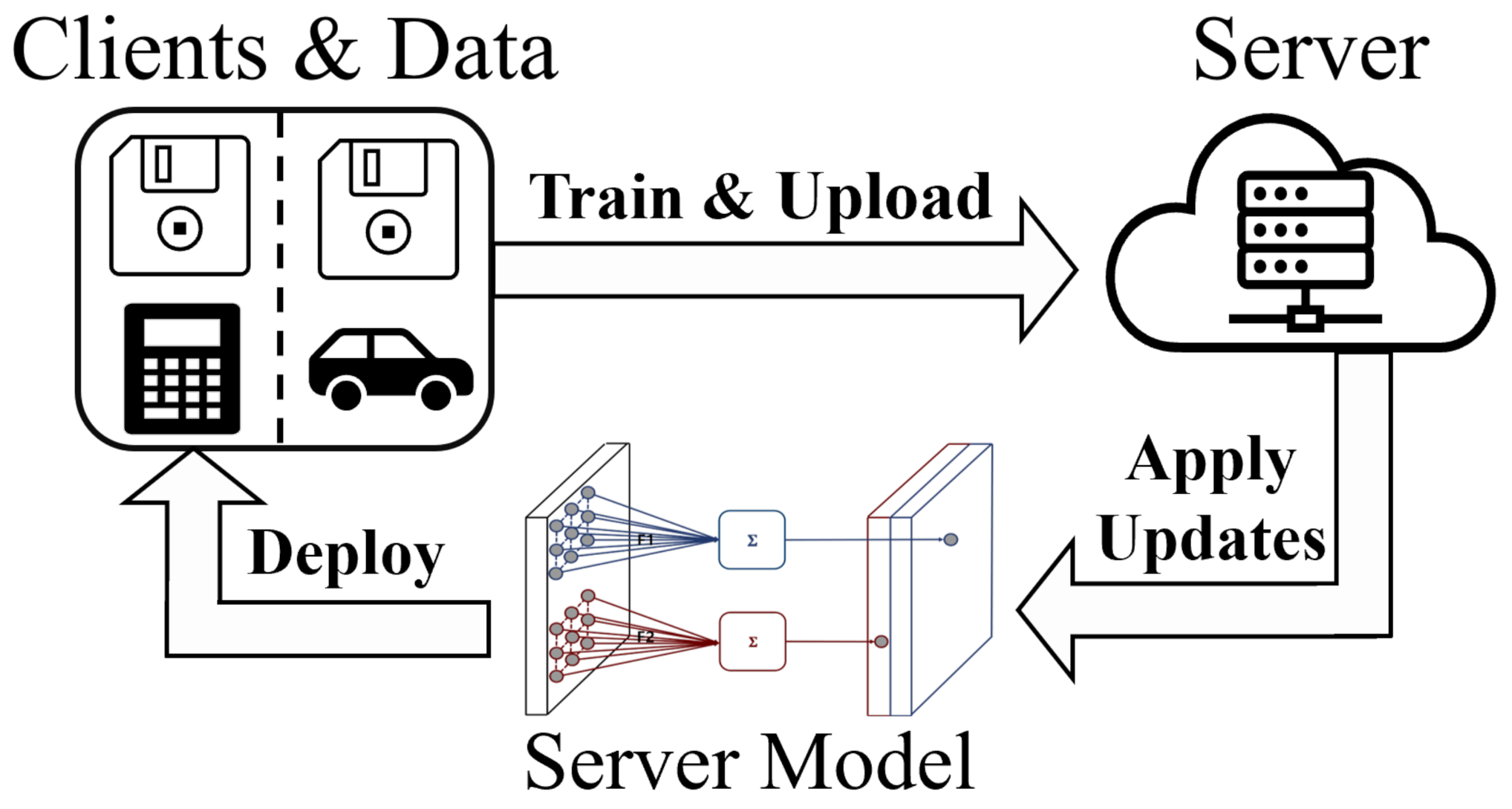
6]. What is common between federated learning and the existing distributed computing is that there is a central server and that distributed computing devices are connected to it. The difference is whether or not the central server has the information and control authority of the distributed environment. Federated learning, designed with a widely deployed server model and uncontrollable distributed devices in mind, is in the spotlight because it respects increasing data privacy and allows data to be utilized by assuaging users’ concerns with using their distributed data. A typical implementation of federated learning is shown in
Figure 1.
Training a server model while respecting data privacy presents the following challenges: First, individual computing devices have different characteristics. They have a broad impact on learning, including when a device will be online, what computational power is available, whether the device will launch hostile attacks on the server, and whether communication with the server can be reliably delivered [
7,
8]. Therefore, it is necessary to design a robust algorithm to train the server model even when clients have different characteristics.
Second, the data are distributed on local devices, and any attempt by the server to move these data would violate the users’ data privacy, while the data distribution of each client remains unknown. The ideal situation is when the distribution of data is independent across all devices and follows the same probability distribution, but the distribution of actual data varies greatly by each user. When training a server model that needs to be optimized for the entire dataset, the fact that the exact data of the client are not known reduces the performance of the server model. In federated learning, training is especially more difficult because it assumes a very large number of clients and different data distributions.
Third, communication with the server is not free. In general, as more devices and larger amounts of information are synchronized more frequently, the training difficulty of the server model decreases, but unrestricted communication with user devices can be dangerous [
7,
9,
10]. For example, if it takes 100 rounds of communication to deploy and train a 100 MB server model, with an assumption that 100 communications are made from 1 million devices, the communication charges incurred from the communication traffic increase extraordinarily.
If the server model converges quickly through the improvement of the learning algorithm, training can be completed with fewer communications. We propose a method to achieve fast convergence of the server model while communicating in a smaller size, which is a method to train a server model on the server by deploying a derived variant of the server model to the client in a federated learning environment. In the proposed method, when the server model is distributed, some layers of the server model are probabilistically deleted, and the derived model, which has a smaller size and a different structure, is distributed to the client, and the client trains it. Clients participating in every communication round train models with arbitrarily derived structures, and the results of this training are selectively applied to the common part between the derived model and the server model. This method of distributing the derived model in various sizes considering devices with various computing powers is advantageous in terms of communication cost compared to fully deploying the server model.
The advantages of the proposed federated learning algorithm are summarized as follows.
By distributing the server model to the client as a smaller derivative model, the communication cost is reduced, simultaneously providing superior training efficiency over the standard method.
Models distributed to clients do not require any additional computational work such as decompression and can be used for local data training as they are.
Because the client does not know the complete structure of the server model, it provides protection against potential attacks such as malicious gradient uploads.
The remainder of the paper starts with a presentation of the background, including related works. Then, related works will be discussed. This is followed by a presentation of the proposed method. Based on this, we present twelve federated learning experiments. Finally, a conclusion is drawn, and an outlook on future work is described.
2. Background
2.1. Federated Learning
Federated learning aims to learn statistical models in a distributed environment. There are differences from existing distributed environment computing [
11,
12], edge computing [
13,
14], and fog computing [
15,
16]. Previous studies have focused on directly utilizing the computing resources of distributed devices such as Internet of Things devices. On the other hand, in federated learning, the focus is on the privacy of data resources, the availability of distributed devices, and the cost of communicating with a central server. These differences are as follows. 1. Data reside in distributed devices, and these data must not be interrogated or inferred. 2. Devices participating in training have different characteristics, including availability of devices, data bias, computing performance, and communication delay. In addition, these characteristics are neither arbitrarily adjusted nor predictable by the server. 3. For training the server model, devices communicate with the server regularly, and the required communication cost should be considered. These characteristics make it difficult to apply the previously researched distributed computing techniques, and when training an arbitrary model, the training efficiency is degraded compared to the general environment.
Assuming that
N device owners
participating in federated learning each have their own data
, it would be reasonable to see that each set of data has different distributions
. In the traditional method, all the data sets
that are collected as a single object are trained, but in federated learning, transferring raw data is prohibited. For example, let
be the label space in the data
d. When all the data are collected in the server, each data point
x in
d has a probability such that
, while
has the label
) in distributed devices. Each device trains its own model
only with the data it has. To train a neural network, we aim to minimize its loss function, and in doing so, a cross entropy function can be used as a loss function such as
, where
is the truth label, and
is the probability for the
class from the model output. When the server has the entire dataset
d and has to update
, the parameter of the model, we use the gradients for the entire training dataset:
, where
is the learning rate. However, to train the server model
in federated learning, it collects the gradients of the loss function
ℓ from the clients, instead of the clients’ data:
The number of data points in each device is
, and
represents loss functions of a model
with
. In a traditional environment, it is possible to optimize all the data at the same time by collecting each datum in the center and performing training, but in federated learning, only the results of learning are obtained without collecting distributed data. In this method of training the server model by collecting the results of several trainings, the difficulty of training the server model as above increases as the distribution of data varies as higher in general. In order to increase the training performance in consideration of the distribution of data, several studies have been conducted on how to collect and apply training results in each client [
17].
2.2. Related Works
Deep learning technology is being used to utilize big data and is a field that is being actively researched [
18,
19]. Deep learning can extract high-level features from many low-level samples and learn hierarchical features of the data. It has been successfully used in computer vision, speech recognition, and natural language processing [
20,
21,
22,
23]. As this data-driven model has been successfully utilized, the importance of data collection has increased, and regulations have also increased [
24]. In response to this trend, there was a need for a method to effectively train a deep learning model, and federated learning technology is being actively studied. In federated learning, both the amount of computation consumed by the client and the cost of communicating with the server must be considered. Unlike centralized systems in data centers, clients are unreliable with low bandwidth connections, so it is important to minimize communication costs with servers. Methods used in existing deep learning studies can be used to reduce communication costs. Quantization of the model, which converts a neural network with floating-point numbers into a neural network with lower bitwidth numbers, can effectively compress the model size with minimal performance degradation. This can be easily applied to federated learning [
25,
26]. There are many other methods, but not all of them are intuitively applicable to federated learning. Such a problem of finding a trade-off between communication cost and model performance is still an open question, and various attempts are being made to solve it [
27,
28].
There are three ways to reduce the communication cost: to compress the information sent from the client to the server; to let the server compress and distribute the model; or to achieve fewer communication rounds by improving the training efficiency. Several studies have been conducted on client-to-server communication compression, and its effectiveness has been shown [
29,
30,
31]. How much communication cost can be reduced depends on the network the client is using, and the efficiency of these methods may vary. Although there is no study evaluating the effect of using the three methods at the same time, these methods alone can effectively reduce the communication cost, and the effect depends on the system configuration. For example, since home networks typically have larger download bandwidths than uploads, compressing client-to-server communications can be more effective than other methods. When sending updates to the model, aggressive lossy compression is sometimes used to approximate updates to actively reduce the communication size. Since federated learning assumes a very large number of clients, performance degradation can be minimized by averaging.
It is a general training method to distribute the models from the server to the client as is, but training them is possible even by compressing and distributing them. There is a study analyzing the effect of compressing and distributing a model in the server on the convergence of training [
32]. Caldas proposes to distribute the compressed model on the server [
33]. According to his study, clients unpack the distributed model, train it, and then compress it again and upload it to the server. Although the structure of the model trained on the client is the same as that of the server, it has been shown that the communication cost can be effectively reduced through weight subsampling and quantization of the model. Hamer, on the other hand, proposes a method to train an ensemble model in federated learning and presents a method to find the optimal mixture weight by distributing a pretrained partial model to a client [
34]. In this method, the client and server exchange only a part of the model constituting the ensemble, thereby lowering the communication cost.
A computationally efficient training method can reduce the total number of training steps required for convergence, which in turn reduces the communication cost. Some training techniques used in deep learning can be intuitively applied to federated learning, and sometimes not. An example of an overall training method improvement designed for federated learning is FedAverage proposed by McMahan [
35]. This study is one of the first papers that introduced the concept of federated learning, and it shows that as the local computation of the client increases, the training of the server model can also be accelerated.
3. Method
In general, when training a deep neural network model, the structure of the model is set to fixed because if the structure changes, performance convergence can be difficult. However, regarding the prerequisites of federated learning, it is still possible to consider model transformations as part of the overall learning process. (1) Clients have to download a new server model for every communication. (2) Each client has its own data distribution and computational performance, so a common server model is not always optimal. (3) Considering the fact that the total number of clients is very large, we propose a new federated learning method.
The overall structure follows the federated learning method proposed by McMahan [
35], where the server creates a server model and distributes it to clients. Clients train the distributed model, using all the data they have. The model that has undergone a certain amount of training in the client is uploaded back to the server, and the server updates the server model by collecting the trained models. The parameter update of the server model is adjusted so that all clients contribute at the same rate in one communication round.
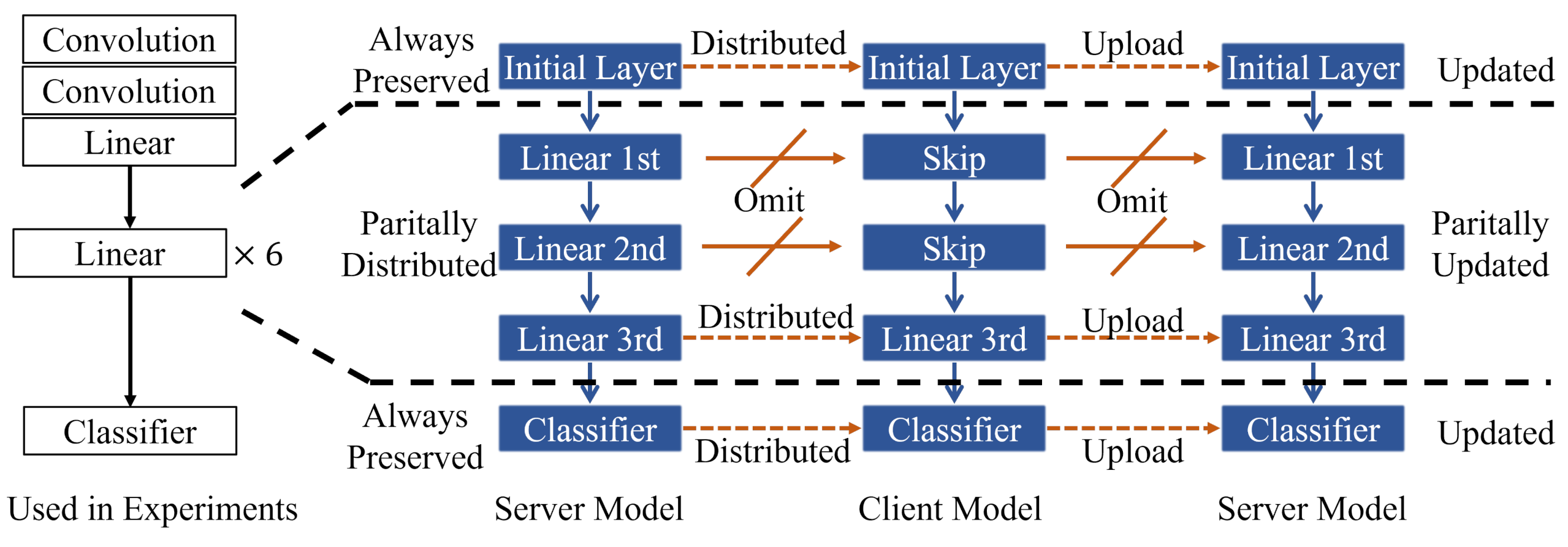
Before distributing the model to the client, the server creates a model with a smaller structure by probabilistically removing the intermediate layers so that the distributed model has a size smaller than or equal to the size of the server model. The method of generating the model with the new structure is shown in lines 9–14 of Algorithm 1 and in
Figure 2. In the server model, two parts coexist with a structure that does not always change and a part whose structure changes probabilistically. In the part where the structure is stochastically changed, the intermediate layers are deleted with a probability of
p, and the other part copies the server model as it is. We design the server model so that intermediate layers of the server model have the same input and output dimensions, so that there is no problem even if the intermediate structure is changed. As the number of skipped parts increases, the deformed model has a smaller size, and the communication cost is reduced thanks to its reduced structure.
The proposed algorithm considers that it can be an advantage for the client to have a smaller derivative model than the server model. A derived model can be created by omitting some structures from the entire structure of the server model. When the size of the model is reduced, it is possible to train local data with less communication and computational costs. Aside from the fact that the size of the model benefits communication costs, the size of the model also affects how well the client generalizes the local data. In a federated learning environment, the more the distribution of local data differs from the distribution of the entire dataset, the smaller the number of biased data may be. In this case, if the client has a smaller model, it gains an advantage in generalizing the local data. The results trained from the client can be selectively applied to the server model as follows.
| Algorithm 1: FederatedPartial. T is the number of communication rounds, B is the local minibatch size, E is the numberof local epochs, is the learning rate, i and j are indices of layers to be replaced, and p is the probability of being distributed. |
![Electronics 10 02081 i001]() |
The client trains the distributed model with local data and sends the entire model to the server. The server needs to selectively apply updates because the models it receives have a different structure from the server model. For this, the server selects only the common parts applicable to the server model among the whole structure of the received model and applies the update. When applying updates, the updates are adjusted and applied so that each client contributes the same proportion.
4. Experiment
In order to deploy and train a model with a structure different from the server model and to find out whether there is a benefit in the cost of convergence when actual convergence is achieved, an image classification model has been designed upon which federated learning is performed and analyzed. In the experiment, it is assumed that 100 clients participate, and only 20% of clients participate in training for every communication round. The experimental parameters used in the experiment are shown in
Table 1.
There are two datasets to be used for the image classification model, MNIST and Fashion-MNIST, and the distribution of the dataset is artificially adjusted to assume a federated learning environment [
36,
37]. The MNIST dataset has numbers from 0 to 9 as labels and contains grayscale images of handwritten digits. Fashion-MNIST has 10 types of fashion items as labels and consists of grayscale pictures of them. Both datasets consist of 60,000 training data points and 10,000 test data points with an image size of 28 × 28. Examples of images in the datasets are shown in
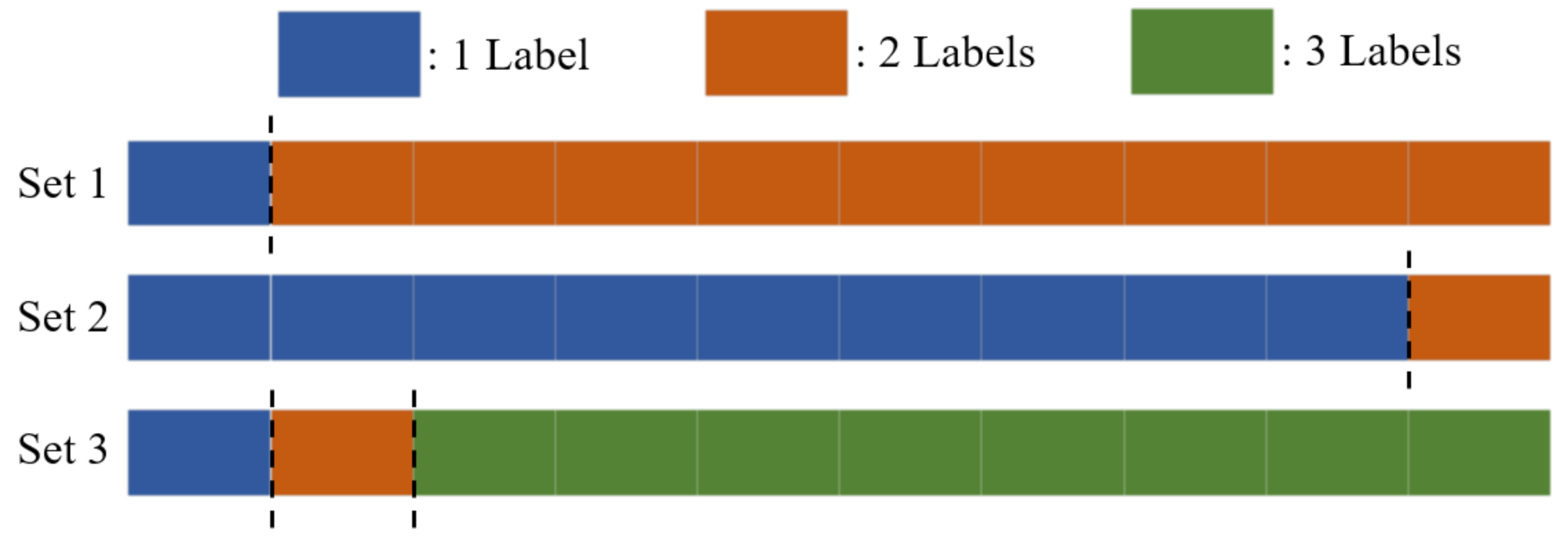
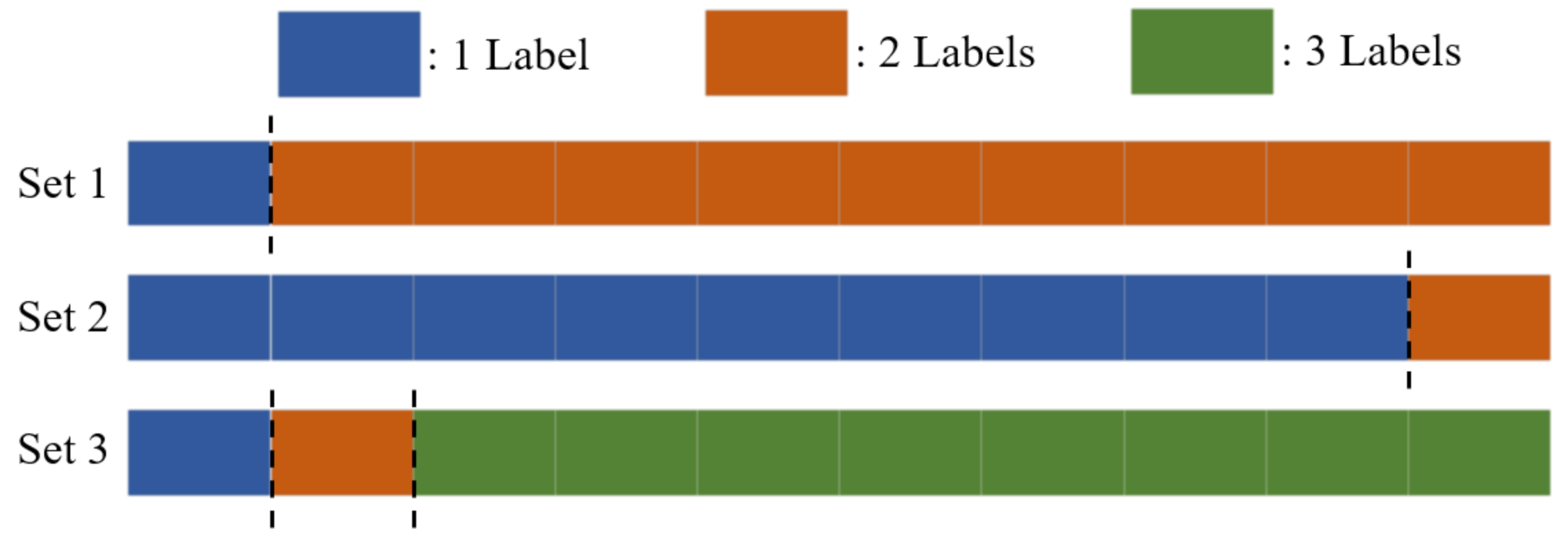
Figure 3. In order to ensure that the distribution of the local data of each client is clearly different from the entire dataset, the data are distributed so that each client has a maximum of one to three labels. There are three types of data distributions to 100 clients: (1) 10 clients have 1 label, and the remaining 90 clients have 2 labels; (2) 90 clients have 1 label, and the remaining 10 clients have 2 labels; (3) 10 clients have 1 label, another 10 clients have 2 labels, and the remaining 80 clients have 3 labels. The three situations are depicted in
Figure 4.
The model used in the experiment is an artificial neural network model composed of a combination of a convolutional layer and a linear layer. Each layer goes through the ELU activation function, and some layers are replaced with Skip layers at the deployment time. This model has 14,911 parameters, with downloads and uploads made by 100 clients per one communication round, resulting in a total communication cost of 2,982,200. When a new model is created to distribute the model to the client, the middle part of the server model is newly designed and deployed each time. An example of the deployment process for this model is shown in
Figure 2.
Using the federated averaging algorithm proposed by McMahan [
35] as a standard, twelve experiments were designed by combining the standard method, the proposed method, and three distributions of two datasets. Unlike the proposed method, the standard method does not undergo transformation in the deployment and update of the server model. Both methods were tested with the same parameters such as maximum communication round, running rate, and batch size.
In order to evaluate the effectiveness of the proposed method in federated learning, it is necessary to measure how much communication cost is consumed until the server model has a certain accuracy. At this time, it is necessary to determine how to measure the cost by considering the characteristics of federated learning: that the learning curve is not smooth and fluctuates greatly. There is a gap between when the target performance is first achieved and when it stably converges beyond the target performance. In our experiment, we recorded the communication cost when the server model satisfied the target performance more than three times within five communication times. The target performance measure of the server model is set as the inference accuracy of the server model for the entire dataset. The target performance was set to an accuracy of 0.8, each experiment was repeated four times, and the cost of the four trials was averaged.
5. Discussion
Twelve experiments were conducted to compare the standard method and the proposed method, and the results are recorded in
Table 1. In the three data distributions of Fashion-MNIST, FederatedPartial reached the target performance with a cost 0.6–0.7 times smaller compared to the standard method.
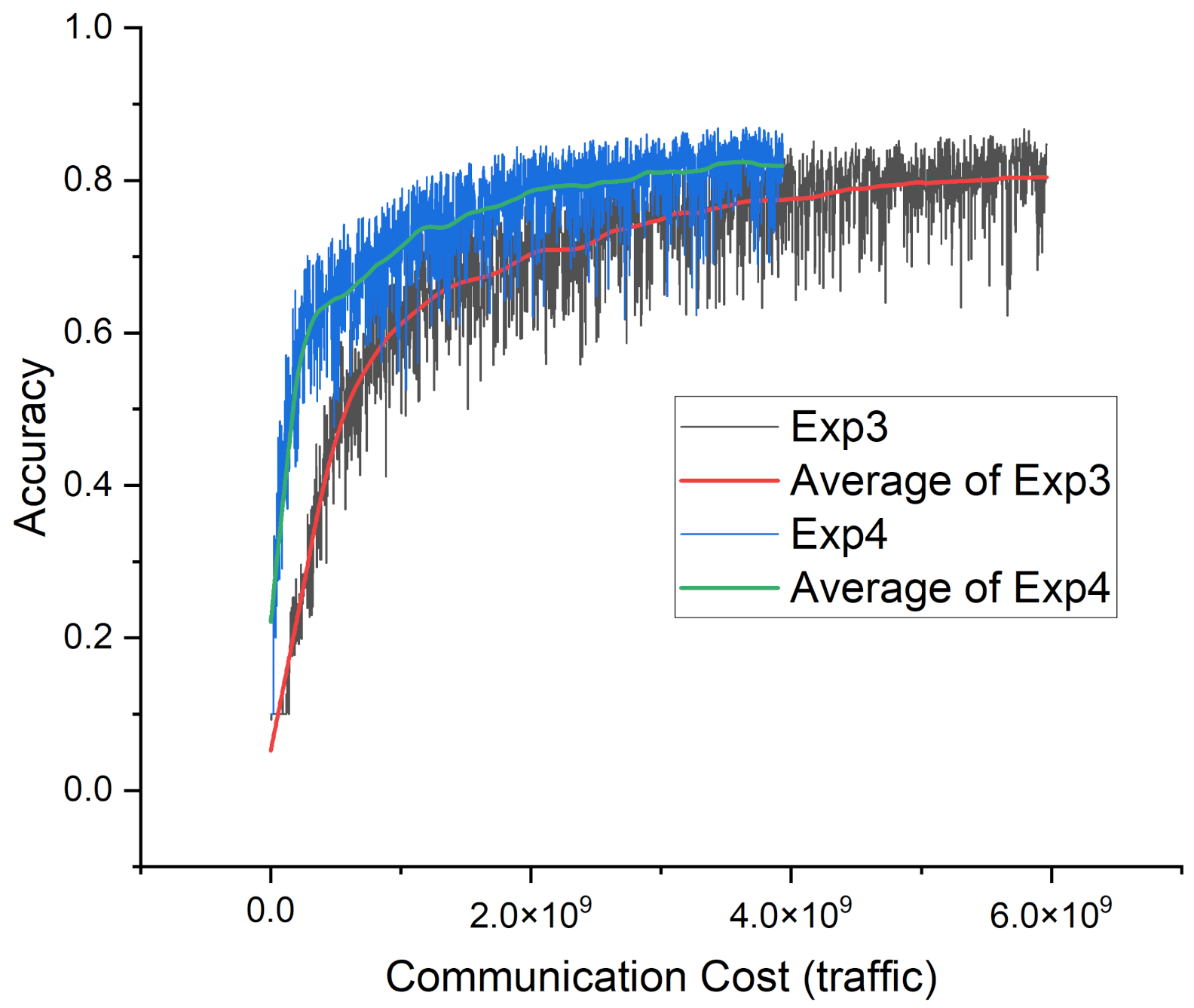
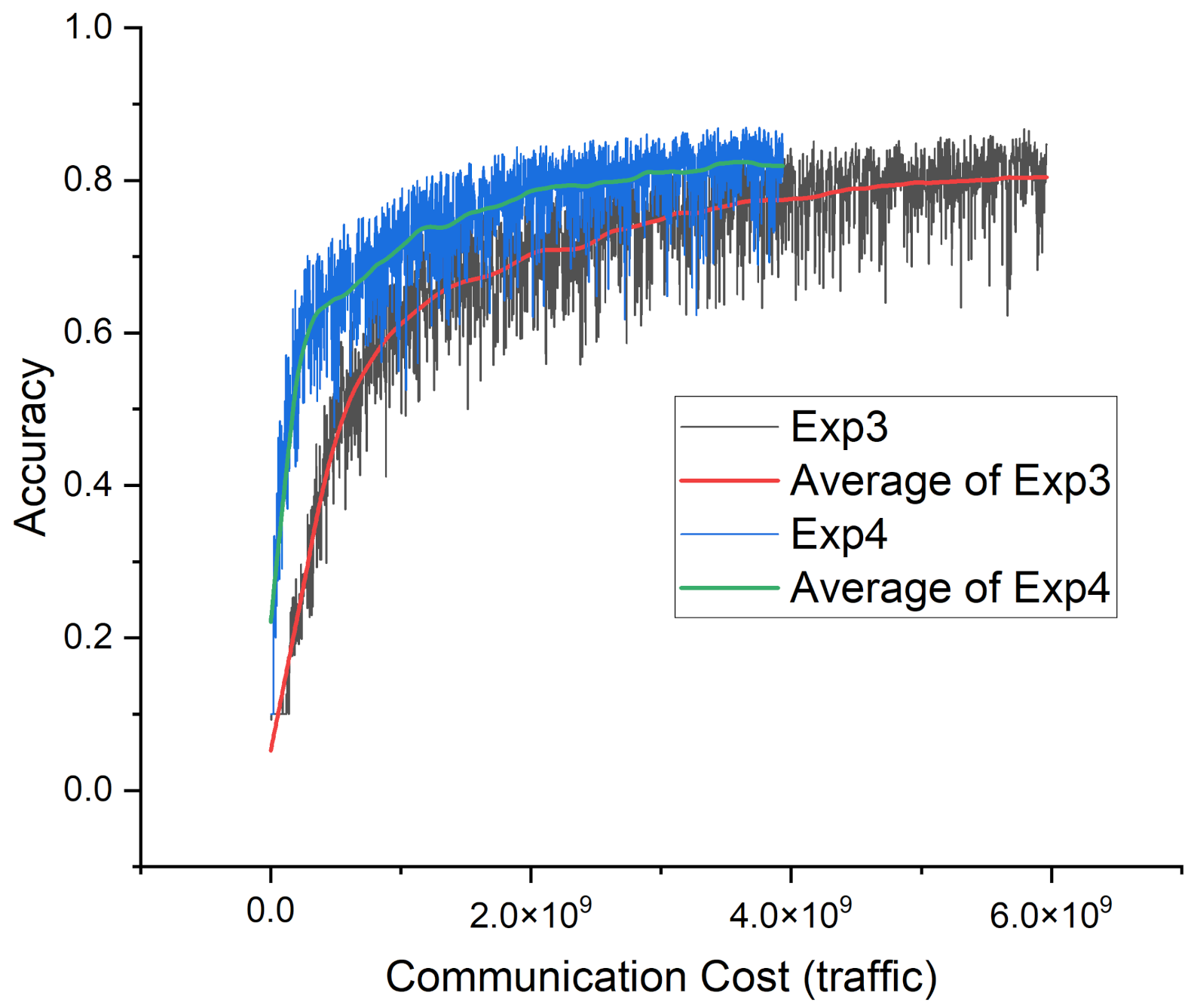
Figure 5 shows the learning curves of Exp3 and Exp4.
In the most extreme case of data distribution difference (90, 10), FederatedPartial required 0.612 times less cost than the standard method, but it required 0.672 times less cost in the less localized data (10, 90). This is because FederatedPartial has a greater effect when the data distribution difference between clients is large, which can be interpreted as the relationship between the data and model size of each client. When one client has a large difference from the distribution of the entire dataset, it means that the data have very few variants, with which it is easier to train via a smaller model. FederatedPartial distributes server models of various sizes to clients and shows that the training efficiency of the central server model can also be increased by distributing a server model suitable for clients that need a smaller model to increase the client’s learning efficiency.
In federated learning, it is generally known that the greater the difference in the data distribution of each client, the more difficult it is to train. In Exp5, compared to Exp1, a little more cost was required to reach the target performance. Exp5 is designed so that each client has three labels of data, which is closer to the original dataset distribution than the data distribution in Exp1, but Exp5 recorded a higher cost than Experiment 1. This shows that the difference between the data distribution of each client and the distribution of the original dataset affects the training, and how the client group is divided also affects the training of the server model. This difference also appears in the comparison between Exp7 and Exp11 using the MNIST dataset. It can be seen that the server model suffers slightly from training when there is a diverse group of clients.
In an experiment using the MNIST dataset, FederatedPartial was able to train the server model using a traffic cost 0.22 to 0.28 times smaller than the standard method to reach the target performance. All six experiments showed the same tendency as the experiment conducted on Fashion-MNIST. The structure of the FedParitial algorithm and the server model used to train MNIST and Fashion-MNIST is the same, but FederatedPartial showed a higher effect in MNIST. This phenomenon seems to have been possible because FederatedPartial appropriately provides a model suitable for the size of the client data when the server model has a large and complex model, but the data the client has only require a simple model. Compared to Fashion-MNIST, MNIST can be sufficiently trained with a simpler model, and this difference can be seen as the reason for the difference in the efficiency of the algorithms proposed in the two datasets.
Both the standard method and the proposed method showed a reduction in communication cost but showed different ratios of efficiency in both the number of communications and communication traffic. In Exp1 and 2, for the server model to reach the target performance, FederatedPartial required a cost of traffic 0.569 times smaller and a cost of communication rounds 0.892 times smaller compared to the standard method. In all comparative experiments, the reduction in traffic cost was greater, which means that the total cost of traffic consumed by the standard method is not essential. In federated learning, what is more important in learning the server model is not the size of the communication but the importance of the information contained in the communication and frequent synchronization between the client and the server model. When applying the federated learning technology, whether the traffic cost or the number of communications should take precedence with regards to the system configuration and the characteristics of the client still remains questionable, so further research on this difference in efficiency is needed.
6. Conclusions
In this study, we showed that the training of a server model is possible even when deploying it in various structures and sizes. With the proposed FederatedPartial method, it was possible to achieve the target performance of the server model at a lower cost compared to the standard method in terms of the number of communications and communications traffic. In our federated learning experiments, different efficiencies were shown depending on the difference between the distribution of data from the client and the distribution of the entire dataset, but when the server model was large enough to learn the entire dataset, it showed a noticeable communication cost reduction efficiency. It is worth further researching the relationship between the reduction of communication cost and the data distribution of clients, as well as the multi-objective optimization of communication traffic and communication frequency.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}