
Direct-Virtio: A New Direct Virtualized I/O Framework for NVMe SSDs


Abstract
:1. Introduction
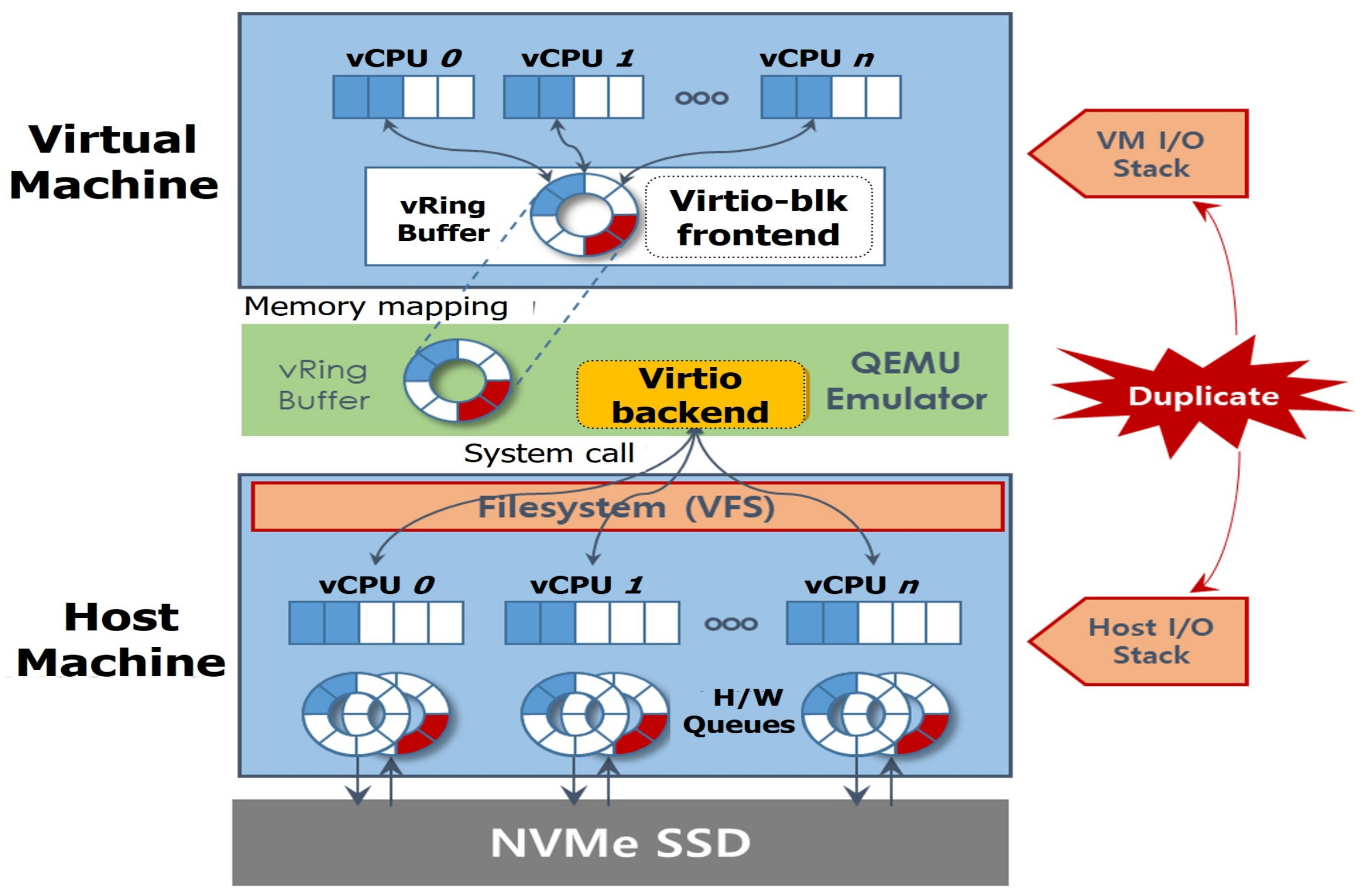
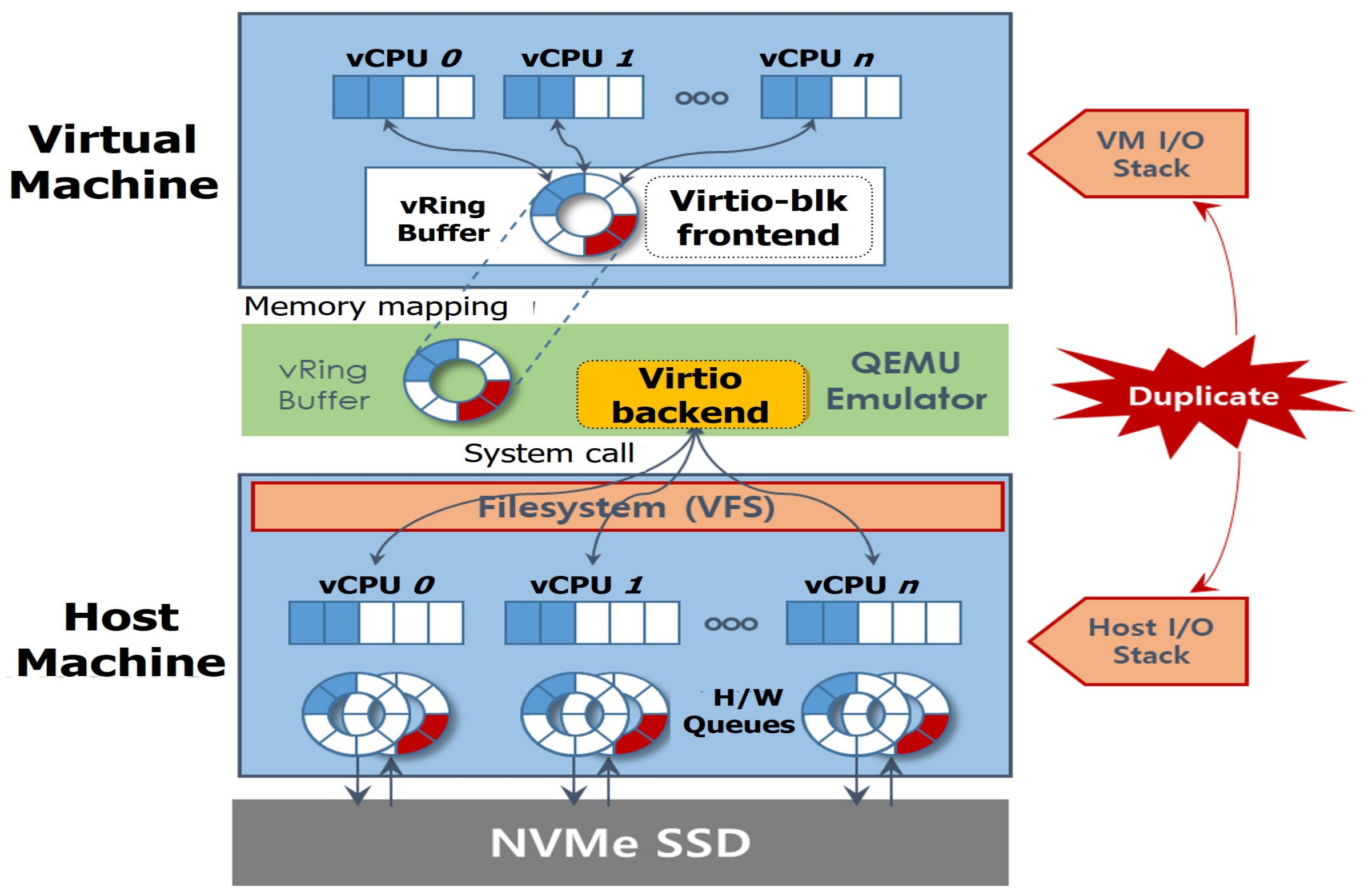
- We observe that the existing I/O virtualization framework suffers from performance degradation due to the duplicated I/O stacks.
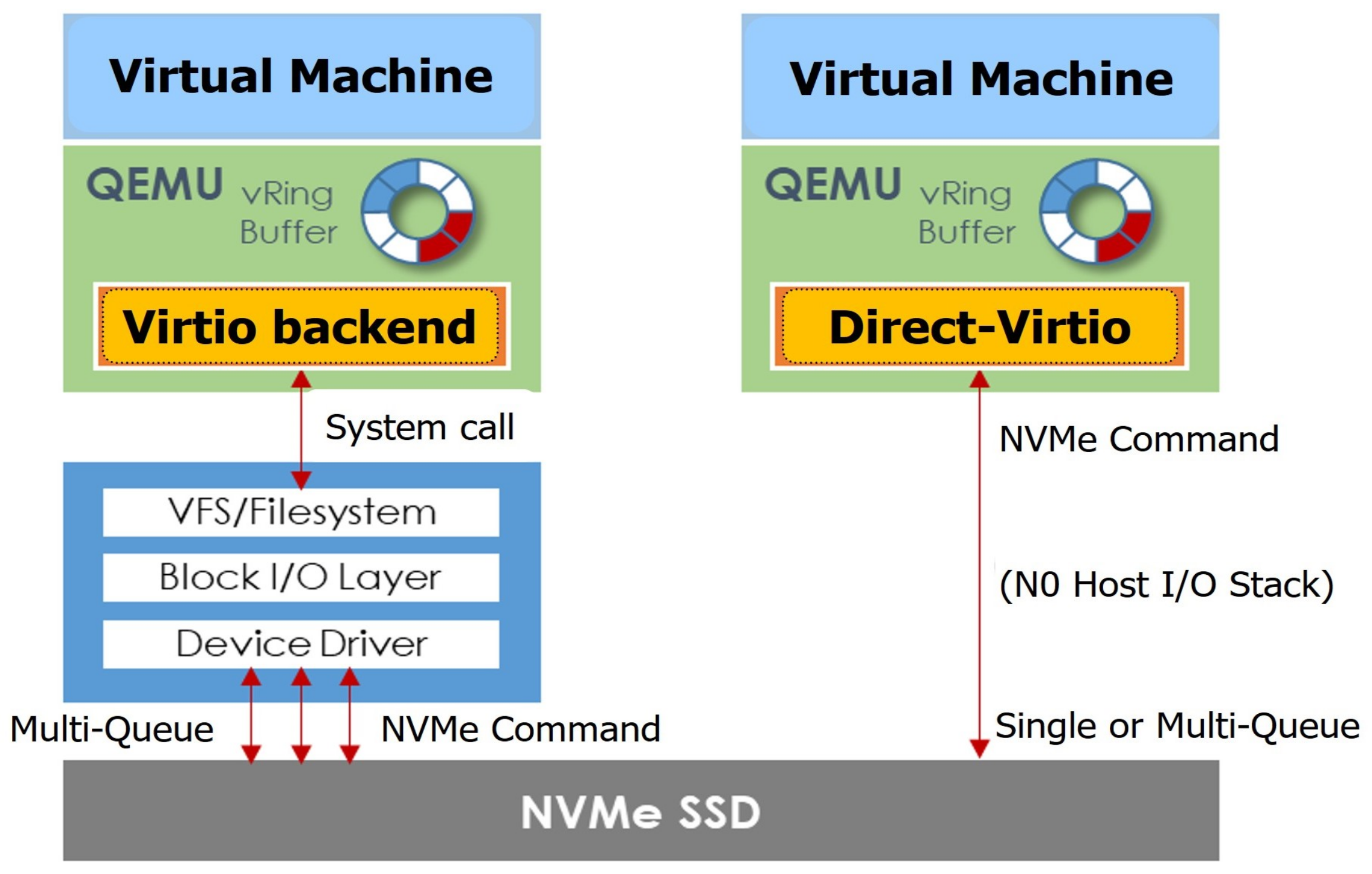
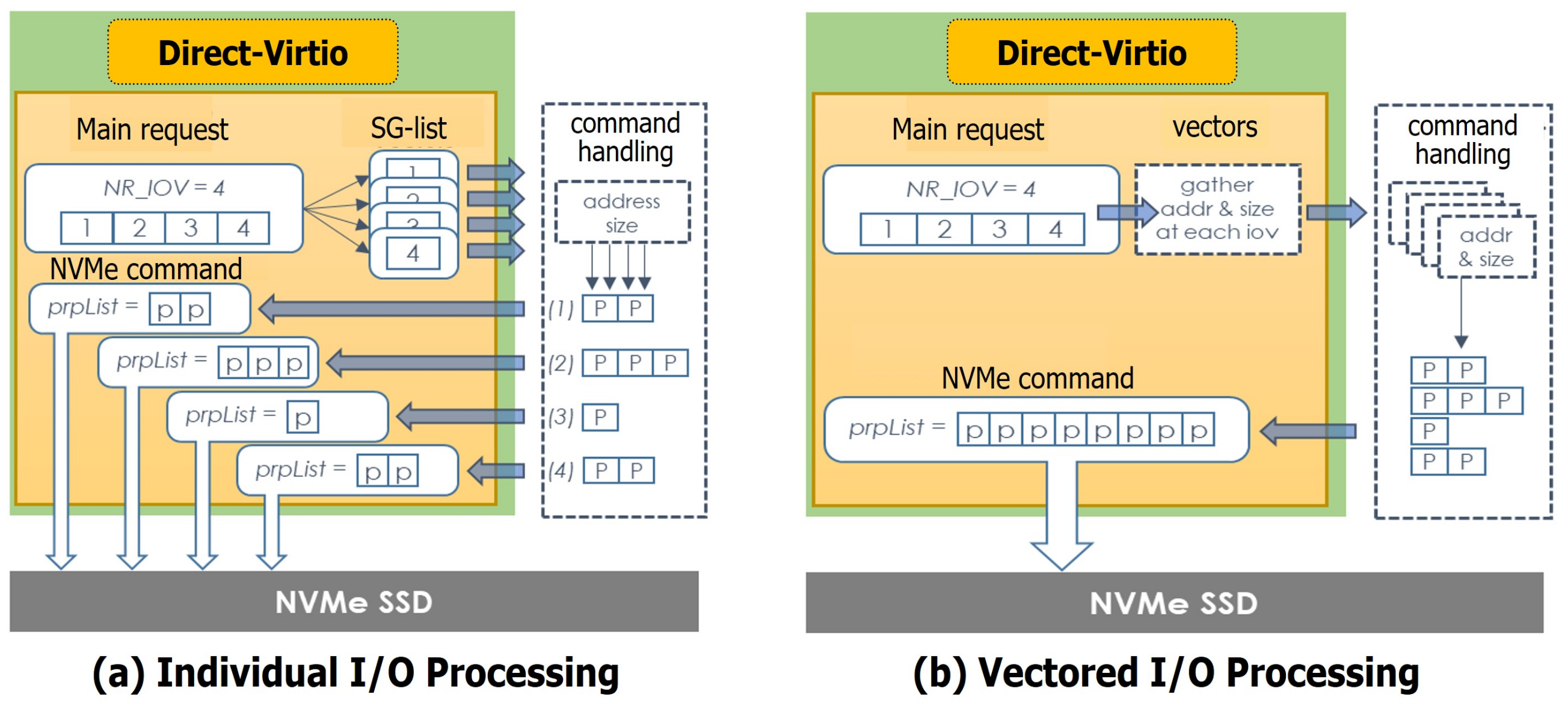
- We design a new I/O virtualization framework with three concepts; user-level direct access, vectored I/O and adaptive polling.
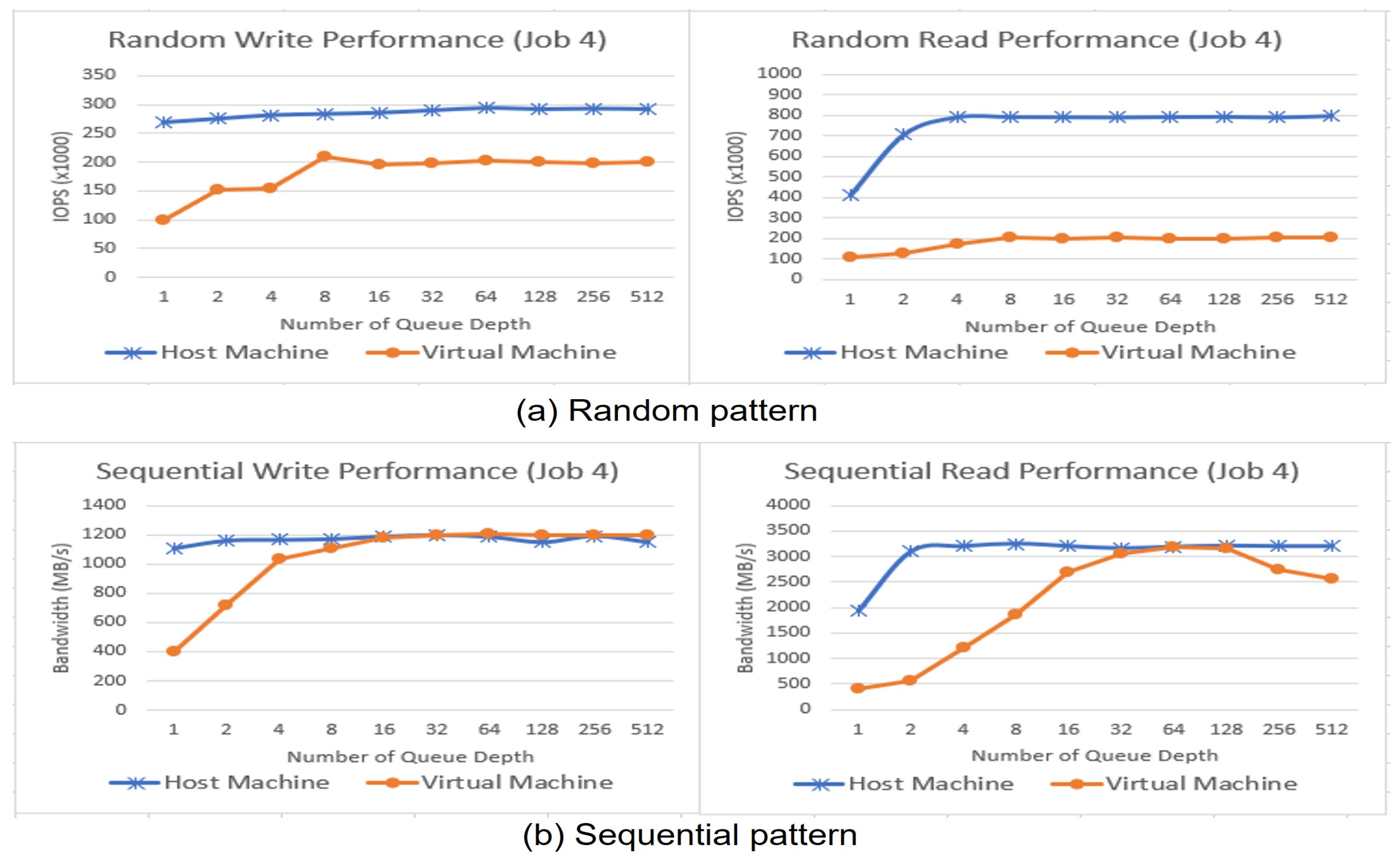
- We present several quantitative evaluation results with diverse configurations such as different number of jobs, queue depths and reference patterns.
2. Background
2.1. NVMe SSDs and I/O Virtualization
2.2. Motivation
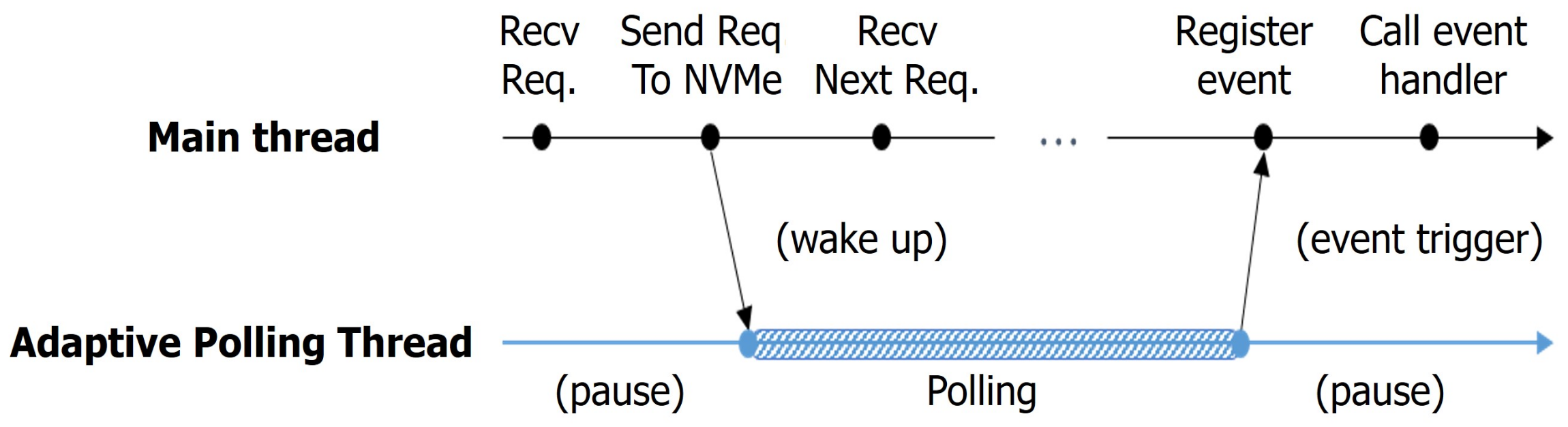
3. Design
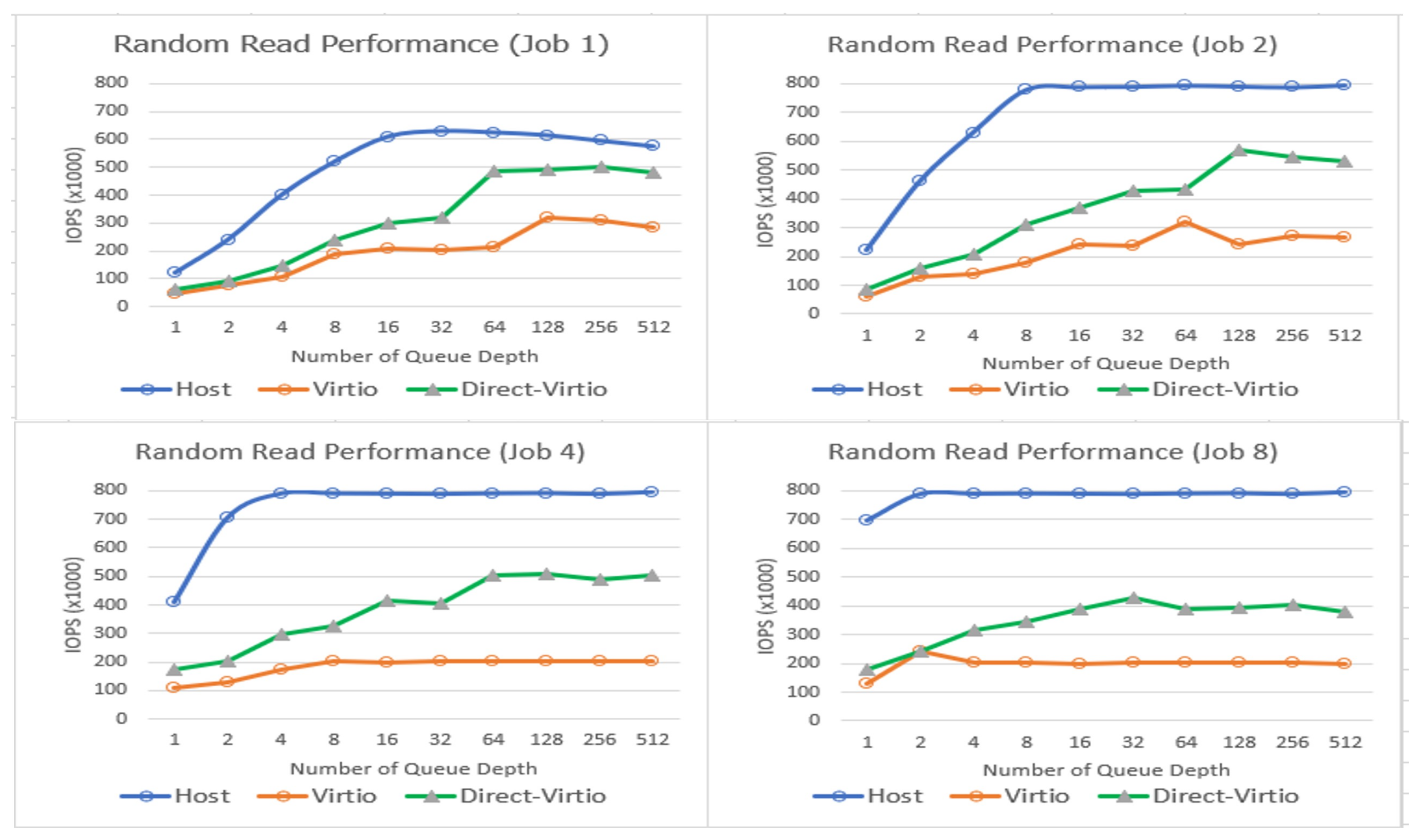
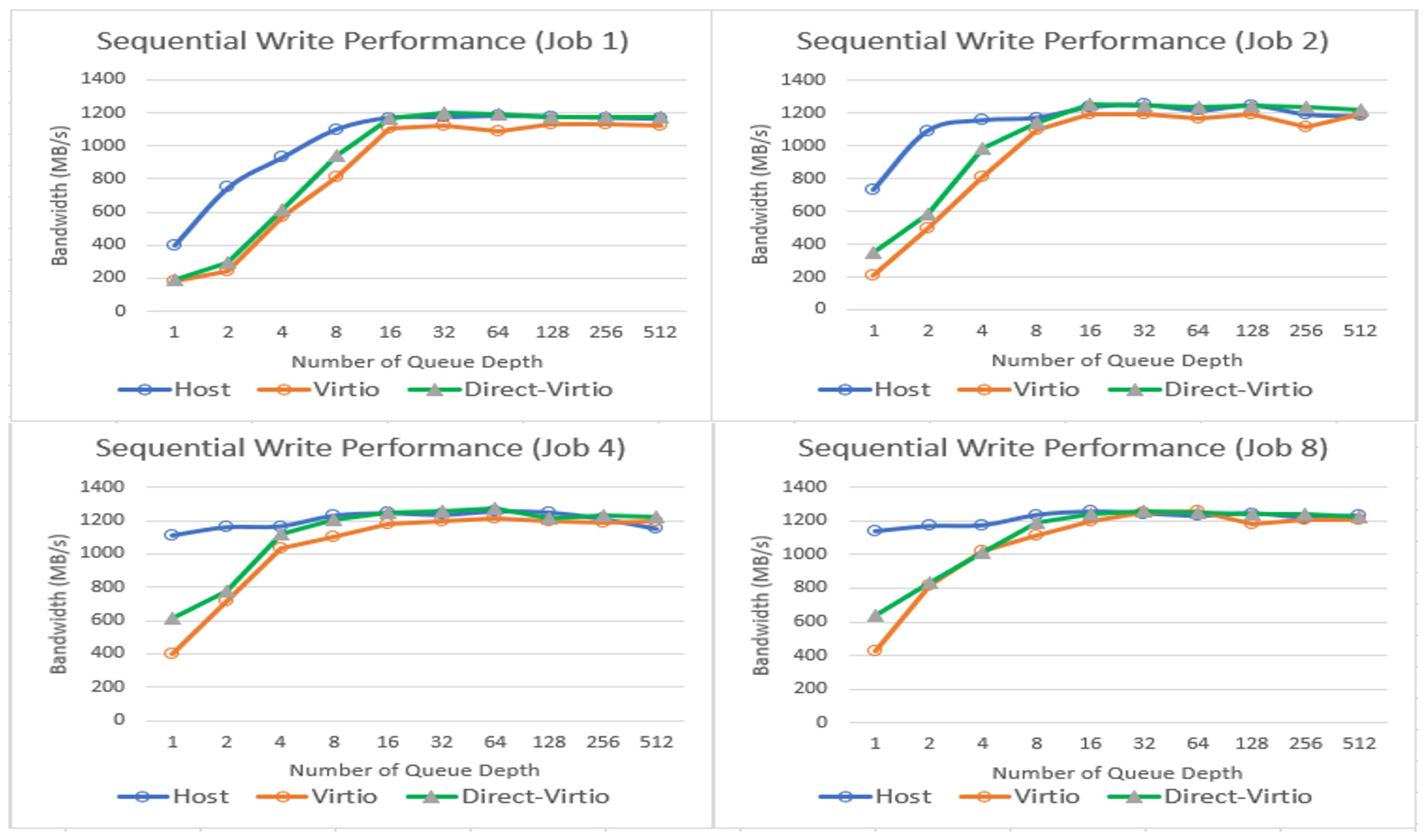
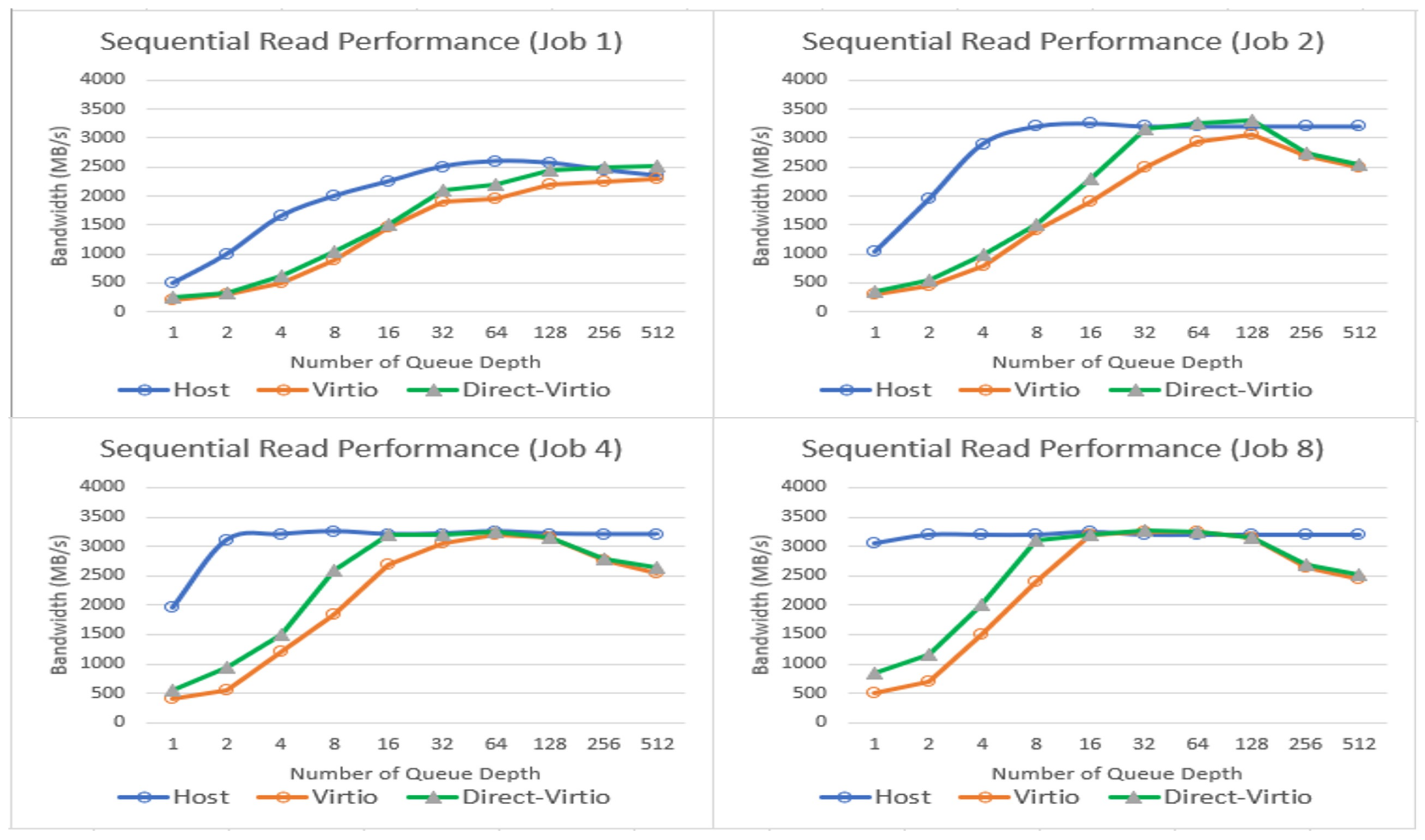
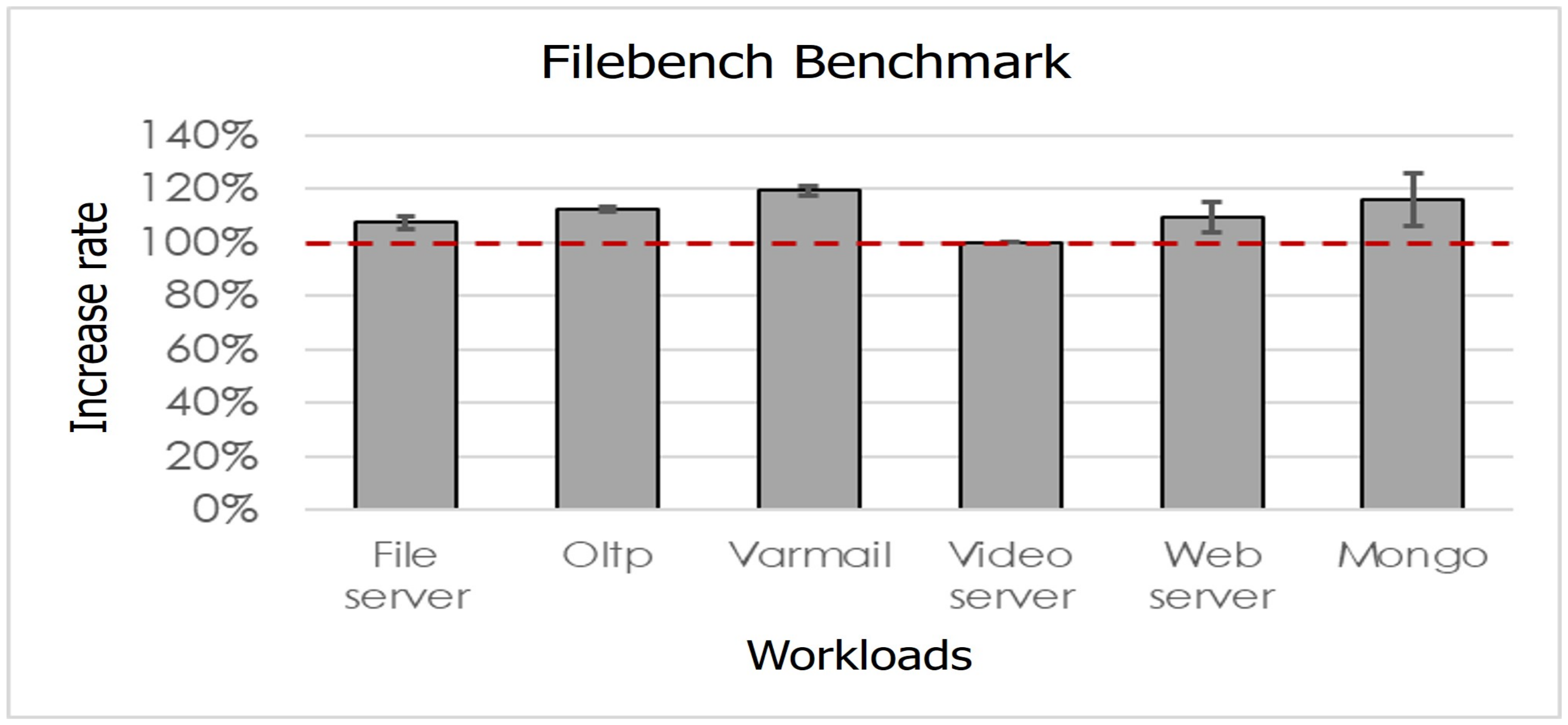
4. Evaluation
5. Related Work
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Barham, P.; Dragovic, B.; Fraser, K.; Hand, S.; Harris, T.; Ho, A.; Neugebauer, R.; Pratt, I.; Warfield, A. Xen and the Art of Virtualization. In Proceedings of the 19th ACM Symposium on Operating Systems Principles (SOSP), Bolton Landing (Lake George), NY, USA, 19–22 October 2003. [Google Scholar]
- Younge, A.; Henschel, R.; Brown, J.; Laszewski, G.; Qiu, J.; Fox, G. Analysis of Virtualization Technologies for High Performance Computing Environments. In Proceedings of the IEEE 4th International Conference on Cloud Computing (Cloud), Washington, DC, USA, 4–9 July 2011. [Google Scholar]
- Muller, T.; Knoll, A. Virtualization Techniques for Cross Platform Automated Software Builds, Tests and Deployment. In Proceedings of the 4th International Conference on Software Engineering Advances (ICSEA), Porto, Portugal, 20–25 September 2009. [Google Scholar]
- Lee, S.-H.; Kim, J.-S.; Seok, J.-S.; Jin, H.-W. Virtualization of Industrial Real-Time Networks for Containerized Controllers. Sensors 2019, 19, 4405. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- An Oracle White Paper. Oracle VM VirtualBox Overview. Available online: https://www.oracle.com/assets/oracle-vm-virtualbox-overview-2981353.pdf (accessed on 27 July 2021).
- Kivity, A.; Kamay, Y.; Laor, D.; Lublin, U.; Liguori, A. KVM: The Linux Virtual Machine Monitor. In Proceedings of the Linux Symposium, Ottawa, ON, Canada, 27–30 July 2007. [Google Scholar]
- Shuja, J.; Gani, A.; Bilal, K.; Khan, S. A Survey of Mobile Device Virtualization: Taxonomy and State-of-the-Art. ACM Comput. Surv. 2016, 49, 1. [Google Scholar] [CrossRef]
- Cherkasova, L.; Gupta, D.; Vahdat, A. Comparison of the Three CPU Schedulers in Xen. Available online: https://www.hpl.hp.com/personal/Lucy_Cherkasova/papers/per-3sched-xen.pdf (accessed on 27 July 2021).
- A VMware White Paper. VMware® vSphere™: The CPU Scheduler in VMware ESX® 4.1. Available online: https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/vmw_vsphere41_cpu_schedule_esx-white-paper.pdf (accessed on 27 July 2021).
- Wang, H.; Isci, C.; Subramanian, L.; Choi, J.; Qian, D.; Mutlu, O. A-DRM: Architecture-aware Distributed Resource Management of Virtualized Clusters. In Proceedings of the 11th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments (VEE), Istanbul, Turkey, 14–15 March 2015. [Google Scholar]
- Waldspurger, C. Memory Resource Management in VMware ESX Server. In Proceedings of the 5th Symposium on Operating Systems Design and Implementation (OSDI), Boston, MA, USA, 9–11 December 2002. [Google Scholar]
- Gandhi, J.; Basu, A.; Hill, M.; Swift, M. Efficient Memory Virtualization: Reducing Dimensionality of Nested Page Walks. In Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Cambridge, UK, 13–17 December 2014. [Google Scholar]
- Jia, G.; Han, G.; Wang, H.; Yang, X. Static Memory Deduplication for Performance Optimization in Cloud Computing. Sensors 2017, 17, 968. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Russell, R. Virtio: Towards a de facto standard for virtual I/O devices. ACM SIGOPS Oper. Syst. Rev. 2008, 42, 5. [Google Scholar] [CrossRef]
- Tian, K.; Zhang, Y.; Kang, L.; Zhao, Y.; Dong, Y. coIOMMU: A Virtual IOMMU with Cooperative DMA Buffer Tracking for Efficient Memory Management in Direct I/O. In Proceedings of the 2020 USENIX Annual Technical Conference (ATC), Virtual Event (online), 15–17 July 2020. [Google Scholar]
- Muench, D.; Isfort, O.; Mueller, K.; Paulitsch, M.; Herkersdorf, A. Hardware-Based I/O Virtualization for Mixed Criticality Real-Time Systems Using PCIe SR-IOV. In Proceeding of the IEEE 16th International Conference on Computational Science and Engineering, Sydney, Australia, 3–5 December 2013. [Google Scholar]
- Williamson, A. Vfio: A User’s Perspective. In KVM Forum. 2012. Available online: https://www.linux-kvm.org/images/b/b4/2012-forum-VFIO.pdf (accessed on 27 July 2021).
- Yang, Z.; Liu, C.; Zhou, Y.; Liu, X.; Cao, G. SPDK Vhost-NVMe: Accelerating I/Os in Virtual Machines on NVMe SSDs via User Space Vhost Target. In Proceedings of the IEEE 8th International Symposium on Cloud and Service Computing (SC2), Paris, France, 18–21 November 2018. [Google Scholar]
- An Intel White Paper. Enabling Intel® Virtualization Technology Features and Benefits. Available online: https://www.intel.com/content/dam/www/public/us/en/documents/white-papers/virtualization-enabling-intel-virtualization-technology-features-and-benefits-paper.pdf (accessed on 27 July 2021).
- Bellard, F. QEMU, a Fast and Portable Dynamic Translator. In Proceedings of the 2005 USENIX Annual Technical Conference (ATC), Anaheim, CA, USA, 10–15 April 2005. [Google Scholar]
- Flexible I/O. Available online: https://fio.readthedocs.io/en/latest/fio_doc.html (accessed on 27 July 2021).
- Tarasov, V.; Zadok, E.; Shepler, S. Filebench: A Flexible Framework for File System Benchmarking. Login Usenix Mag. 2016, 41, 1. [Google Scholar]
- NVMe Specification. Available online: https://nvmexpress.org/specifications/ (accessed on 27 July 2021).
- Kim, H.; Lee, Y.; Kim, J. NVMeDirect: A user-space I/O framework for application-specific optimization on NVMe SSDs. In Proceedings of the 8th USENIX Conference on Hot Topics in Storage and File Systems, Santa Clara, CA, USA, 12–14 July 2017. [Google Scholar]
- Xue, S.; Zhao, S.; Chen, Q.; Deng, G.; Liu, Z.; Zhang, J.; Song, Z.; Ma, T.; Yang, Y.; Zhou, Y.; et al. Spool: Reliable Virtualized NVMe Storage Pool in Public Cloud Infrastructure. In Proceedings of the 2020 USENIX Annual Technical Conference (ATC), Virtual Event, 15–17 July 2020. [Google Scholar]
- Peng, B.; Zhang, H.; Yao, J.; Dong, Y.; Xu, Y.; Guan, H. MDev-NVMe: A NVMe Storage Virtualization Solution with Mediated Pass-Through. In Proceedings of the 2020 USENIX Annual Technical Conference (ATC), Boston, MA, USA, 11–13 July 2018. [Google Scholar]
- Kim, T.; Kang, D.; Lee, D.; Eom, Y. Improving performance by bridging the semantic gap between multi-queue SSD and I/O virtualization framework. In Proceedings of the 31st Symposium on Mass Storage Systems and Technologies (MSST), Santa Clara, CA, USA, 30 May–5 June 2015. [Google Scholar]
- Xia, L.; Lange, J.; Dinda, P.; Bae, C. Investigating virtual pass-through I/O on commodity devices. ACM SIGOPS Oper. Syst. Rev. 2009, 43, 3. [Google Scholar] [CrossRef]
- Jones, M. Virtio: An I/O Virtualization Framework for Linux. Available online: https://developer.ibm.com/articles/l-virtio/ (accessed on 27 July 2021).
- Bjørling, M.; Axboe, J.; Nellans, D.; Bonnet, P. Linux block IO: Introducing multi-queue SSD access on multi-core systems. In Proceedings of the 6th International Systems and Storage Conference (SYSTOR), Haifa, Israel, 30 June–7 July 2013. [Google Scholar]
- Kivity, A. Different I/O Access Methods for Linux, What We Chose for Scylla, and Why. Available online: https://www.scylladb.com/2017/10/05/io-access-methods-scylla/ (accessed on 27 July 2021).
- NVMe Command Set Specifications. Available online: https://nvmexpress.org/developers/nvme-command-set-specifications/ (accessed on 27 July 2021).
- Yang, J.; Minturn, D.; Hady, F. When Poll Is Better than Interrupt. In Proceedings of the 10th USENIX Conference on File and Storage Technologies (FAST), San Jose, CA, USA, 14–17 February 2012. [Google Scholar]
- Yang, Z.; Harris, J.; Walker, B.; Verkamp, D.; Liu, C.; Chang, C.; Cao, G.; Stern, J.; Verma, V.; Paul, L. SPDK: A Development Kit to Build High Performance Storage Applications. In Proceedings of the IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Hong Kong, China, 11–14 December 2017. [Google Scholar]
- Kourtis, K.; Ioannou, N.; Koltsidas, I. Reaping the performance of fast NVM storage with uDepot. In Proceedings of the 17th USENIX Conference on File and Storage Technologies (FAST), Boston, MA, USA, 25–28 February 2019. [Google Scholar]
- Lingenfelter, D. Measuring the Workload on Drives on a Linux System Using the Blktrace Tool. Available online: https://www.seagate.com/files/www-content/ti-dm/_shared/images/measure-workload-on-drives-tp662-1409us.pdf (accessed on 27 July 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Specification |
|---|---|
| Host machine | Intel i7-6700 (8 core), 64 GB DRAM, 1.2 TB NVMe SSD |
| Linux kernel | 4.4.0 (Ubuntu-14.04.5 LTS), KVM virtualization |
| QEMU | 2.8.0 |
| Virtual machine | 4 CPUs, 32GB DRAM, NVMe hardware queues |
| Benchmarks | Fio, Filebench |
| Workload | Block Size Rate | Random Rate |
|---|---|---|
| File server | 4 KB(26%) 60 KB (16%) 64 K (26%) | Mix |
| Oltp | 4 KB(98%) | Random |
| Varmail | 4 KB(60%) 8 KB, 12 LB, 16 KB (each 7%) | Random |
| Video server | 60 KB(47%) 64 KB (47%) | Sequential |
| Web server | 4 KB(11%) 60 KB (22%) 64 K (28%) | Mix |
| Mongo | 4 KB(48%) 64 K (18%) | Mix |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Park, H.; Choi, J. Direct-Virtio: A New Direct Virtualized I/O Framework for NVMe SSDs. Electronics 2021, 10, 2058. https://doi.org/10.3390/electronics10172058
Kim S, Park H, Choi J. Direct-Virtio: A New Direct Virtualized I/O Framework for NVMe SSDs. Electronics. 2021; 10(17):2058. https://doi.org/10.3390/electronics10172058
Chicago/Turabian StyleKim, Sewoog, Heekwon Park, and Jongmoo Choi. 2021. "Direct-Virtio: A New Direct Virtualized I/O Framework for NVMe SSDs" Electronics 10, no. 17: 2058. https://doi.org/10.3390/electronics10172058
APA StyleKim, S., Park, H., & Choi, J. (2021). Direct-Virtio: A New Direct Virtualized I/O Framework for NVMe SSDs. Electronics, 10(17), 2058. https://doi.org/10.3390/electronics10172058