
Multiple-Searching Genetic Algorithm for Whole Test Suites


Abstract
1. Introduction
2. Whole Test Suites
2.1. Genetic Algorithm
2.2. Genetic Algorithm for Software Testing
2.3. Chromosome Representation
- Primitive statements are the variable declarations with values, include declaring array with size.
- int defaultParser0 = 24;
- String[] stringArray0 = new String[6];
- Field statements are the statements that refer to variables of objects.
- SourceMapFormat sourceMapFormat0 = SourceMapFormat.DEFAULT;
- Constructor statements involve creating new objects and calling the existing constructor in the test class.
- Options options0 = new Options();
- Method statements concern the existing method involving the test class.
- Options options1 = options0.addOption("", true, (String) null);
- Precision.round(1.0, Integer.MIN_VALUE);
- Assignment statements assign values to variables of objects or array elements.
- stringArray0[0] = "q";
- float[] floatArray0 = new float[6];
2.4. Fitness Function
- Line coverage is a basic criterion used to measure how many test suites can execute statement lines. The statements must be reached at least once. These statement lines exclude the comment lines. As a consequence, the fitness function for line coverage is computed according to Equation (1).
- Branch coverage aims to cover control statements, be it the decision-making or loop statements. The control statements are executed to obtain outcomes both true and false. This means at least one test suite executes the control statement to obtain a true result, and at least one more time to obtain a false result. Therefore, the fitness function measures how many test suites can reach control statements. The fitness function for branch coverage is defined as Equation (2).
- Direct branch coverage includes the control statements in methods that are called directly by test suites. With the execution of the control statements through an indirect method call, it is difficult to cover those control statements. The indirect method call is a calling method within another method. The fitness function of direct branch coverage uses the same f(TBC) as that of branch coverage but only focuses on the control statements in methods directly called.
- Exception coverage involves handling exceptions in the test class. The exception is some problems that occur at runtime. Therefore, generated test suites must create exceptions in the test class and throw them. The fitness function of exception coverage cannot be computed as a percentage because some exceptions are unintended, undeclared, or thrown to the external method. Equation (4) defines the fitness function of exception coverage:
- Weak mutation coverage involves modifying a location in the test class (called mutant) and observing the outcomes of the original and mutant versions. In the event that the outcomes of both are the same, this indicates that the test suites are unable to execute faults or that the mutant is never executed [35,36]. The fitness function of weak mutation coverage is computed using Equation (5):
- Output coverage is used to cover the returned value of the method by means of mapping a return type to abstract values. The abstract values are possible returned values based on the given return data type of method. There is at least one test suite that calls a method in the test class to return a value that corresponds to each abstract value. Equation (7) shows a list of abstract values:
- Method coverage relates to creating test suites to execute all methods in the test class. The fitness function of method coverage is defined as Equation (9):
- Method coverage (no exception) aims to cover all methods in the test class without throwing an exception. When the method calls and receives the invalid parameters or invalid states, the method will throw the exception. This results in test suites of the method coverage achieving a high fitness value. Consequently, method coverage (no exception) requires that all methods are directly called through test suites and that executions are terminated when they occur. The fitness function of method coverage (no exception) is the same as the fitness function of method coverage.
2.5. EvoSuite
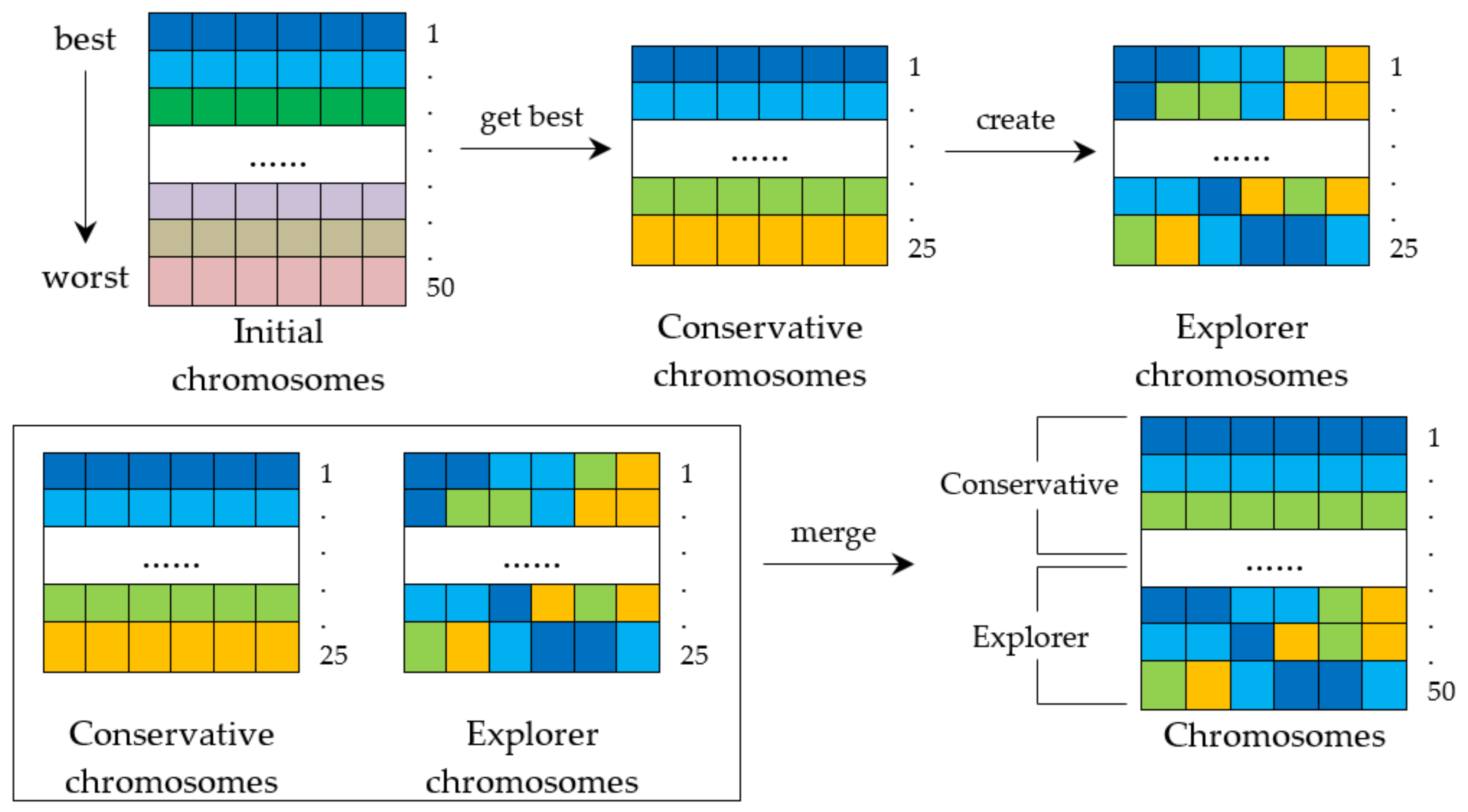
2.6. Multiple-Searching Genetic Algorithm
| Algorithm1 Pseudocode for explorer chromosomes |
| 1: //Collect genes in each position of conservative chromosomes 2: for i = 1 to the number of conservative chromosomes 3: for j = 1 to the length of chromosomes 4: Select ith gene of jth conservative chromosome 5: Keep the selected gene to ith candidate set 6: end for 7: end for 8: //Create explorer chromosomes 9: for i = 1 to the number of conservative chromosomes 10: for j = 1 to the number of candidate set 11: Select one gene in jth candidate set 12: Keep the selected gene to jth gene of ith explorer chromosome 13: end for 14: end for 15: return explorer chromosomes |
3. Experimental Evaluation
3.1. Problem Instance
3.2. Parameter Tuning
3.3. Evaluation Metrics
4. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jaffari, A.; Yoo, C.J.; Lee, J. Automatic Test Data Generation Using the Activity Diagram and Search-Based Technique. Appl. Sci. 2020, 10, 3397. [Google Scholar] [CrossRef]
- Sato, V. Specification-based Test Case Generation with Constrained Genetic Programming. In Proceedings of the 20th International Conference on Software Quality, Reliability and Security Companion (QRS-C), Macau, China, 11–14 December 2020; pp. 98–103. [Google Scholar] [CrossRef]
- Vats, P.; Mandot, M.; Mukherjee, S.; Sharma, N. Test Case Prioritization & Selection for an Object Oriented Software using Genetic Algorithm. Int. J. Eng. Adv. Technol. 2020, 9, 349–354. [Google Scholar] [CrossRef]
- Shamshiri, S.; Rojas, J.M.; Gazzola, L.; Fraser, G.; McMinn, P.; Mariani, L.; Arcuri, A. Random or Evolutionary Search for Object-Oriented Test Suite Generation? Softw. Test. Verif. Reliab. 2017, 28, e1660. [Google Scholar] [CrossRef]
- Marijan, D.; Gotlieb, A. Software Testing for Machine Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13576–13582. [Google Scholar] [CrossRef]
- Salman, Y.D.; Hashim, N.D.; Rejab, M.M.; Romli, R.; Mohd, H. Coverage Criteria for Test Case Generation Using UML State Chart Diagram. AIP Conf. Proc. 2017, 1891, 020125. [Google Scholar] [CrossRef]
- Fraser, G.; Arcuri, A. Whole test suite generation. IEEE Trans. Softw. Eng. 2013, 39, 276–291. [Google Scholar] [CrossRef]
- Amman, P.; Offutt, J. Introduction to Software Testing, 2nd ed.; Cambridge University Press: New York, NY, USA, 2016; pp. 17–19. [Google Scholar]
- Tsai, C.F.; Tsai, C.W.; Chen, C. A novel algorithm for multimedia multicast routing in a large scale network. J. Syst. Softw. 2004, 72, 431–441. [Google Scholar] [CrossRef]
- Khamprapai, W.; Tsai, C.F.; Wang, P. Analyzing the Performance of the Multiple-Searching Genetic Algorithm to Generate Test Cases. Appl. Sci. 2020, 10, 7264. [Google Scholar] [CrossRef]
- Fraser, G.; Arcuri, A. A Large-Scale Evaluation of Automated Unit Test Generation Using EvoSuite. ACM Trans. Softw. Eng. Methodol. 2014, 24, 1–42. [Google Scholar] [CrossRef]
- Arcuri, A.; Iqbal, M.Z.; Briand, L. Random Testing: Theoretical Results and Practical Implications. IEEE Trans. Softw. Eng. 2012, 38, 258–277. [Google Scholar] [CrossRef]
- Rojas, J.M.; Vivanti, M.; Arcuri, A.; Fraser, G. A detailed investigation of the effectiveness of whole test suite generation. Empir. Softw. Eng. 2017, 22, 852–893. [Google Scholar] [CrossRef]
- Fraser, G.; Arcuri, A.; McMinn, P. A Memetic Algorithm for whole test suite generation. J. Syst. Softw. 2015, 103, 311–327. [Google Scholar] [CrossRef]
- Fraser, G.; Arcuri, A. EvoSuite: On The Challenges of Test Case Generation in the Real World. In Proceedings of the sixth International Conference on Software Testing, Verification and Validation, Luxembourg, 18–22 March 2013; pp. 362–369. [Google Scholar] [CrossRef]
- Cui, X.; Yang, J.; Li, J.; Wu, C. Improved Genetic Algorithm to Optimize the Wi-Fi Indoor Positioning Based on Artificial Neural Network. IEEE Access 2020, 8, 74914–74921. [Google Scholar] [CrossRef]
- Rivera, G.; Cisneros, L.; Sanchez-Solis, P.; Rangel-Valdez, N.; Rodas-Osollo, J. Genetic Algorithm for Scheduling Optimization Considering Heterogeneous Containers: A Real-World Case Study. Axioms 2020, 9, 27. [Google Scholar] [CrossRef]
- Hassanat, A.; Almohammadi, K.; Alkafaween, E.; Abunawas, E.; Hammouri, A.; Prasath, V.B.S. Choosing Mutation and Crossover Ratios for Genetic Algorithms—A Review with a New Dynamic Approach. Information 2019, 10, 390. [Google Scholar] [CrossRef]
- Li, X.; Wang, Z.; Sun, Y.; Zhou, S.; Xu, Y.; Tan, G. Genetic algorithm-based content distribution strategy for F-RAN architectures. ETRI J. 2019, 41, 348–357. [Google Scholar] [CrossRef]
- Drachal, K.; Pawłowski, M. A Review of the Applications of Genetic Algorithms to Forecasting Prices of Commodities. Economies 2021, 9, 6. [Google Scholar] [CrossRef]
- Chiesa, M.; Maioli, G.; Colombo, G.I.; Piacentini, L. GARS: Genetic Algorithm for the identification of a Robust Subset of features in high-dimensional datasets. BMC Bioinform. 2020, 21, 54. [Google Scholar] [CrossRef]
- Hardi, S.M.; Zarlis, M.; Effendi, S.; Lydia, M.S. Taxonomy Genetic Algorithm for Implementation Partially Mapped Crossover In Travelling Salesman Problem. J. Phys. Conf. Ser. 2020, 1641, 012104. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, M.; Ersoy, O.K.; Sun, K.; Bi, Y. An Improved Real-Coded Genetic Algorithm Using the Heuristical Normal Distribution and Direction-Based Crossover. Comput. Intel. Neurosc. 2019, 2019, 4243853. [Google Scholar] [CrossRef] [PubMed]
- Mishra, D.B.; Mishra, R.; Acharya, A.A.; Das, K.N. Test Data Generation for Mutation Testing Using Genetic Algorithm. In Soft Computing for Problem Solving. Advances in Intelligent Systems and Computing; Bansal, J., Das, K., Nagar, A., Deep, K., Ojha, A., Eds.; Springer: Cham, Switzerland, 2019; Volume 817, pp. 857–867. [Google Scholar] [CrossRef]
- Yang, S.; Man, T.; Xu, J.; Zeng, F.; Li, K. RGA: A lightweight and effective regeneration genetic algorithm for coverage-oriented software test data generation. Inf. Softw. Technol. 2016, 76, 19–30. [Google Scholar] [CrossRef][Green Version]
- Zhu, Z.; Xu, X.; Jiao, L. Improved evolutionary generation of test data for multiple paths in search-based software testing. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017; pp. 612–620. [Google Scholar] [CrossRef]
- Wang, R.; Sato, Y.; Liu, S. Mutated Specification-Based Test Data Generation with a Genetic Algorithm. Mathematics 2021, 9, 331. [Google Scholar] [CrossRef]
- Albadr, M.A.; Tiun, S.; Ayob, M.; AL-Dhief, F. Genetic Algorithm Based on Natural Selection Theory for Optimization Problems. Symmetry 2020, 12, 1758. [Google Scholar] [CrossRef]
- Wang, Y.M.; Zhao, G.Z.; Yin, H.L. Genetic algorithm with three dimensional chromosome for large scale scheduling problems. In Proceedings of the 10th World Congress on Intelligent Control and Automation, Beijing, China, 6–8 July 2012; pp. 362–367. [Google Scholar] [CrossRef]
- Fraser, G.; Zeller, A. Mutation-Driven Generation of Unit Tests and Oracles. IEEE Trans. Softw. Eng. 2012, 38, 278–292. [Google Scholar] [CrossRef]
- Fraser, G. A Tutorial on Using and Extending the EvoSuite Search-Based Test Generator. In Search-Based Software Engineering; Colanzi, T., McMinn, P., Eds.; Springer: Cham, Switzerland, 2018; Volume 11036, pp. 106–130. [Google Scholar] [CrossRef]
- Salahirad, A.; Almulla, H.; Gay, G. Choosing the fitness function for the job: Automated generation of test suites that detect real faults. Softw. Test. Verif. Reliab. 2019, 29, e1701. [Google Scholar] [CrossRef]
- Rojas, J.M.; Campos, J.; Vivanti, M.; Fraser, G.; Arcuri, A. Combining Multiple Coverage Criteria in Search-Based Unit Test Generation. In Search-Based Software Engineering; Barros, M., Labiche, Y., Eds.; Springer: Cham, Switzerland, 2015; Volume 9275, pp. 93–108. [Google Scholar] [CrossRef]
- Gay, G. The Fitness Function for the Job: Search-Based Generation of Test Suites that Detect Real Faults. In Proceedings of the IEEE International Conference on Software Testing, Verification and Validation (ICST), Tokyo, Japan, 13–17 March 2017; pp. 345–355. [Google Scholar] [CrossRef]
- Shin, K.W.; Lim, D.J. Model-Based Test Case Prioritization Using an Alternating Variable Method for Regression Testing of a UML-Based Model. Appl. Sci. 2020, 10, 7537. [Google Scholar] [CrossRef]
- Hariri, F.; Shi, A. SRCIROR: A toolset for mutation testing of C source code and LLVM intermediate representation. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 860–863. [Google Scholar] [CrossRef]
- Fraser, G.; Rojas, J.M.; Campos, J.; Arcuri, A. EVOSUITE at the SBST 2017 Tool Competition. In Proceedings of the 10th International Workshop on Search-Based Software Testing, Buenos Aires, Argentina, 22–23 May 2017; pp. 39–41. [Google Scholar] [CrossRef]
- Almasi, M.M.; Hemmati, H.; Fraser, G.; Arcuri, A.; Benefelds, J. An Industrial Evaluation of Unit Test Generation: Finding Real Faults in a Financial Application. In Proceedings of the 39th International Conference on Software Engineering: Software Engineering in Practice Track (ICSE-SEIP), Buenos Aires, Argentina, 20–28 May 2017; pp. 263–272. [Google Scholar] [CrossRef]
- Fraser, G.; Arcuri, A. Achieving scalable mutation-based generation of whole test suites. Empir. Softw. Eng. 2015, 20, 783–812. [Google Scholar] [CrossRef]
- Rojas, J.M.; Fraser, G.; Arcuri, A. Seeding strategies in search-based unit test generation. Softw. Test. Verif. Reliab. 2016, 26, 366–401. [Google Scholar] [CrossRef]
- Agapie, A.; Wright, A.H. Theoretical analysis of steady state genetic algorithms. Appl. Math. 2014, 59, 509–525. [Google Scholar] [CrossRef]
- Corus, D.; Oliveto, P. Standard Steady State Genetic Algorithms Can Hillclimb Faster Than Mutation-Only Evolutionary Algorithms. IEEE Trans. Evol. Comput. 2018, 22, 720–732. [Google Scholar] [CrossRef]
- Stoica, F.; Boitor, C.G. Using the Breeder genetic algorithm to optimize a multiple regression analysis model used in prediction of the mesiodistal width of unerupted teeth. Int. J. Comput. Commun. 2014, 9, 62–70. [Google Scholar] [CrossRef]
- Yusran, Y.; Rahman, Y.A.; Gunadin, I.C.; Said, S.M.; Syafaruddin, S. Mesh grid power quality enhancement with synchronous distributed generation: Optimal allocation planning using breeder genetic algorithm. Prz. Elektrotech. 2020, 1, 84–88. [Google Scholar] [CrossRef]
- Osaba, E.; Martinez, A.D.; Lobo, J.L.; Ser, J.D.; Herrera, F. Multifactorial Cellular Genetic Algorithm (MFCGA): Algorithmic Design, Performance Comparison and Genetic Transferability Analysis. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Grano, G.; Titov, T.V.; Panichella, S.; Gall, H.C. Branch coverage prediction in automated testing. J. Softw. Evol. Process. 2019, 31, e2158. [Google Scholar] [CrossRef]
- Vera-Pérez, O.L.; Danglot, B.; Monperrus, M.; Baudry, B. A comprehensive study of pseudo-tested methods. Empir. Softw. Eng. 2019, 24, 1195–1225. [Google Scholar] [CrossRef]
- Mosayebi, M.; Sodhi, M. Tuning genetic algorithm parameters using design of experiments. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference Companion, Cancún, Mexico, 8–12 July 2020; pp. 1937–1944. [Google Scholar] [CrossRef]
- Arcuri, A.; Fraser, G. Parameter tuning or default values? An empirical investigation in search-based software engineering. Empir. Softw. Eng. 2013, 18, 594–623. [Google Scholar] [CrossRef]
- Aston, E.; Channon, A.; Belavkin, R.V.; Gifford, D.R.; Krašovec, R.; Knight, C.G. Critical Mutation Rate has an Exponential Dependence on Population Size for Eukaryotic-length Genomes with Crossover. Sci. Rep. 2017, 7, 15519. [Google Scholar] [CrossRef] [PubMed]
- Bashir, M.B.; Nadeem, A. Improved Genetic Algorithm to Reduce Mutation Testing Cost. IEEE Access 2017, 5, 3657–3674. [Google Scholar] [CrossRef]
- Li, Y.B.; Sang, H.B.; Xiong, X.; Li, Y.R. An Improved Adaptive Genetic Algorithm for Two-Dimensional Rectangular Packing Problem. Appl. Sci. 2021, 11, 413. [Google Scholar] [CrossRef]
- Lee, J.; Kang, S.; Jung, P. Test coverage criteria for software product line testing: Systematic literature review. Inf. Softw. Technol. 2020, 122, 106272. [Google Scholar] [CrossRef]
- Masri, W.; Zaraket, F.A. Chapter Four—Coverage-Based Software Testing: Beyond Basic Test Requirements. In Advances in Computers; Memon, A.M., Ed.; Elsevier: Amsterdam, The Netherlands, 2016; Volume 103, pp. 79–142. [Google Scholar] [CrossRef]
- Alian, M.; Suleiman, D.; Shaout, A. Test Case Reduction Techniques—Survey. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 264–275. [Google Scholar] [CrossRef]
- Flemström, D.; Potena, P.; Sundmark, D.; Afzal, S.; Bohlin, M. Similarity-based prioritization of test case automation. Softw. Qual. J. 2018, 26, 1421–1449. [Google Scholar] [CrossRef]
- Jung, P.; Kang, S.; Lee, J. Efficient Regression Testing of Software Product Lines by Reducing Redundant Test Executions. Appl. Sci. 2020, 10, 8686. [Google Scholar] [CrossRef]
- Gay, G. Generating Effective Test Suites by Combining Coverage Criteria. In Search-Based Software Engineering; Menzies, T., Petke, J., Eds.; Springer: Cham, Switzerland, 2017; Volume 10452, pp. 65–82. [Google Scholar] [CrossRef]
- Antinyan, V.; Derehag, J.; Sandberg, A.; Staron, M. Mythical Unit Test Coverage. IEEE Softw. 2018, 35, 73–79. [Google Scholar] [CrossRef]
- Inozemtseva, L.; Holmes, R. Coverage is not strongly correlated with test suite effectiveness. In Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, 31 May–7 June 2014; pp. 435–445. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case Study | No. of Lines | No. of Classes | No. of Branches |
|---|---|---|---|
| Closure Compiler | 102,535 | 816 | 15,357 |
| Commons CLI | 1480 | 22 | 961 |
| Commons Codec | 5545 | 68 | 3050 |
| Commons Email | 1505 | 20 | 209 |
| Commons Jelly | 4688 | 95 | 636 |
| Commons Math3 | 65,389 | 918 | 28,450 |
| Commons Numbers | 317 | 5 | 225 |
| Guava | 52,884 | 578 | 16,859 |
| Java Certificate Transparency | 955 | 30 | 178 |
| JGraphT | 26,401 | 368 | 12,039 |
| Joda Time | 19,441 | 166 | 9924 |
| NanoXML | 1882 | 26 | 738 |
| Parallel Colt | 122,923 | 761 | 66,671 |
| Truth | 4117 | 58 | 223 |
| Total | 410,062 | 3931 | 155,520 |
| Algorithm | #T | #S | Mutation Score | Coverage Score | p-Value | (MSGA:Others) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Avg. | CI | σ | Avg. | CI | σ | |||||
| MSGA | 29,063.5000 | 115,118.8667 | 0.3958 | (0.3944, 0.3972) | 0.0038 | 0.5567 | (0.5556, 0.5578) | 0.0029 | - | - |
| Standard GA | 19,665.5667 | 71,463.5000 | 0.3644 | (0.3622, 0.3666) | 0.0059 | 0.5142 | (0.5125, 0.5158) | 0.0044 | <0.00001 | 1 |
| Steady-State GA | 25,156.8000 | 95,555.2667 | 0.3761 | (0.3745, 0.3777) | 0.0042 | 0.5258 | (0.5247, 0.5268) | 0.0029 | <0.00001 | 1 |
| Breeder GA | 19,896.5667 | 72,086.6000 | 0.3668 | (0.3657, 0.3680) | 0.0031 | 0.5137 | (0.5128, 0.5146) | 0.0023 | <0.00001 | 1 |
| Cellular GA | 19,722.2000 | 67,968.6667 | 0.3633 | (0.3614, 0.3652) | 0.0051 | 0.5044 | (0.5032, 0.5056) | 0.0032 | <0.00001 | 1 |
| Random Search | 28,553.0667 | 119,981.8333 | 0.3809 | (0.3796, 0.3823) | 0.0036 | 0.5404 | (0.5392, 0.5416) | 0.0032 | <0.00001 | 0.9944 |
| Correlation Matrix | #T | #S | Mutation Score | Coverage Score |
|---|---|---|---|---|
| #T | 1.0000 | 0.9755 | −0.1786 | −0.0149 |
| #S | - | 1.0000 | −0.2050 | −0.0487 |
| Mutation score | - | - | 1.0000 | 0.3552 |
| Coverage score | - | - | - | 1.0000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khamprapai, W.; Tsai, C.-F.; Wang, P.; Tsai, C.-E. Multiple-Searching Genetic Algorithm for Whole Test Suites. Electronics 2021, 10, 2011. https://doi.org/10.3390/electronics10162011
Khamprapai W, Tsai C-F, Wang P, Tsai C-E. Multiple-Searching Genetic Algorithm for Whole Test Suites. Electronics. 2021; 10(16):2011. https://doi.org/10.3390/electronics10162011
Chicago/Turabian StyleKhamprapai, Wanida, Cheng-Fa Tsai, Paohsi Wang, and Chi-En Tsai. 2021. "Multiple-Searching Genetic Algorithm for Whole Test Suites" Electronics 10, no. 16: 2011. https://doi.org/10.3390/electronics10162011
APA StyleKhamprapai, W., Tsai, C.-F., Wang, P., & Tsai, C.-E. (2021). Multiple-Searching Genetic Algorithm for Whole Test Suites. Electronics, 10(16), 2011. https://doi.org/10.3390/electronics10162011