
A High-Accuracy Stochastic FIR Filter with Adaptive Scaling Algorithm and Antithetic Variables Method



Abstract
:1. Introduction
- The relationship between representation noise and represented values of a stochastic bit stream is theoretically analyzed, and it is found that stochastic computing can achieve high accuracy in certain value intervals, providing a potential way to improve the accuracy even with the same stochastic bit stream length.
- An adaptive scaling algorithm (ASA) is proposed for the SFIR to scale both the input signals and coefficients into low-noise regions.
- A novel antithetic variables method (AV) is proposed to further improve the accuracy, and the theoretical proof is also provided.
- The hardware architecture of the proposed ASA–SFIR and ASA–AV–SFIR is designed and implemented, which demonstrates high-accuracy performance advantages with respect to the existing SFIR filters.
2. Theoretical Background
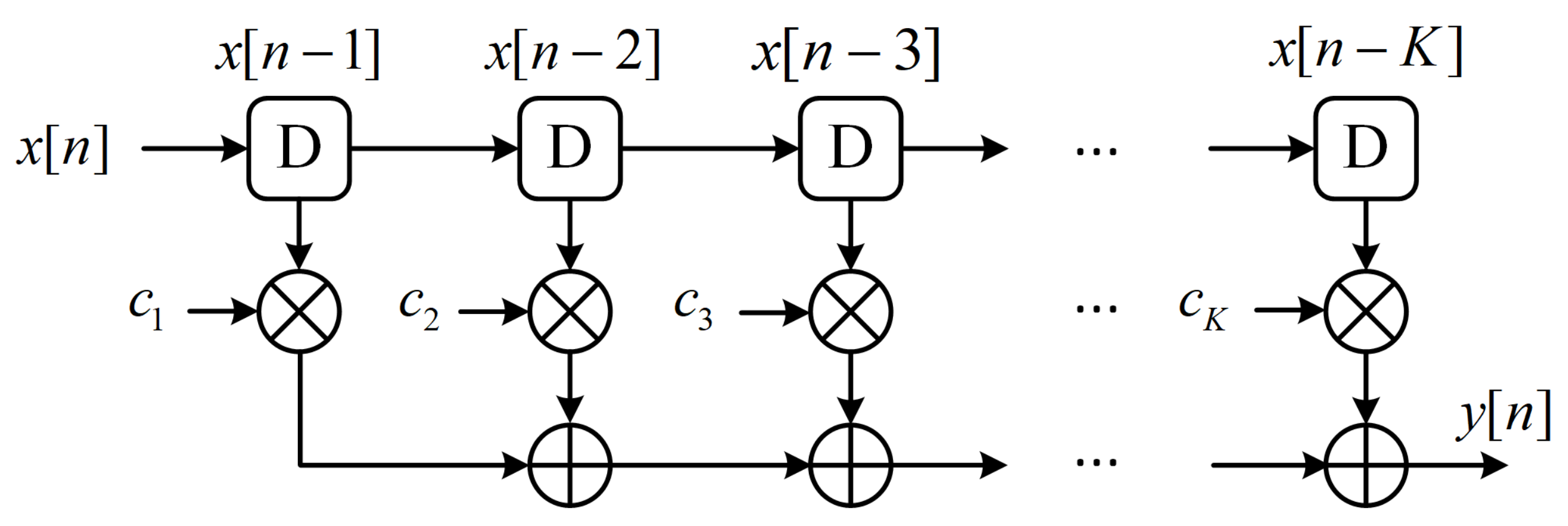
2.1. FIR Filter
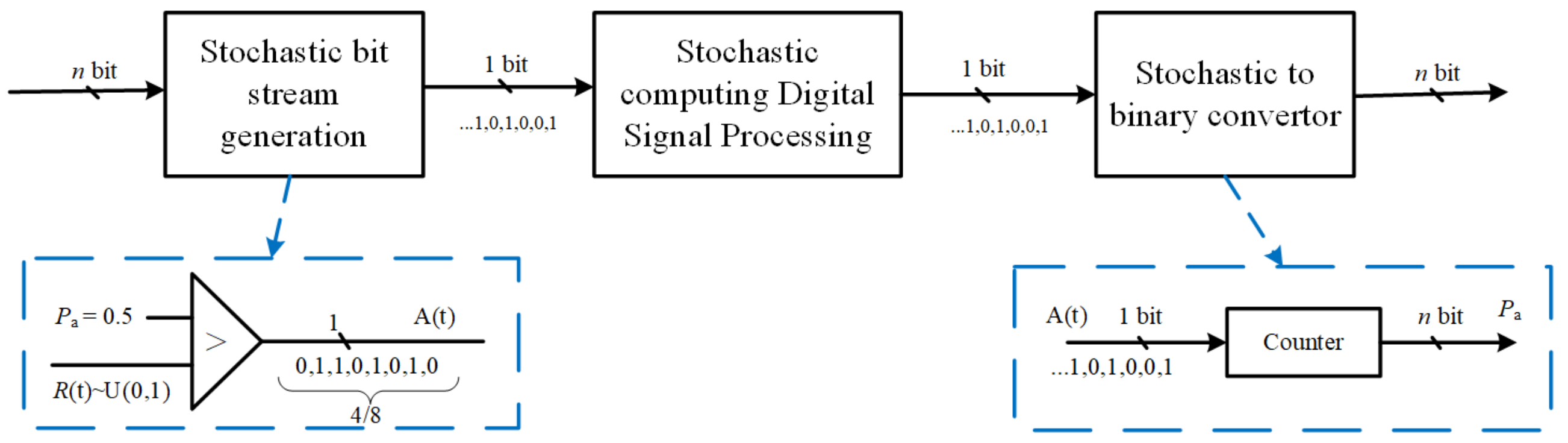
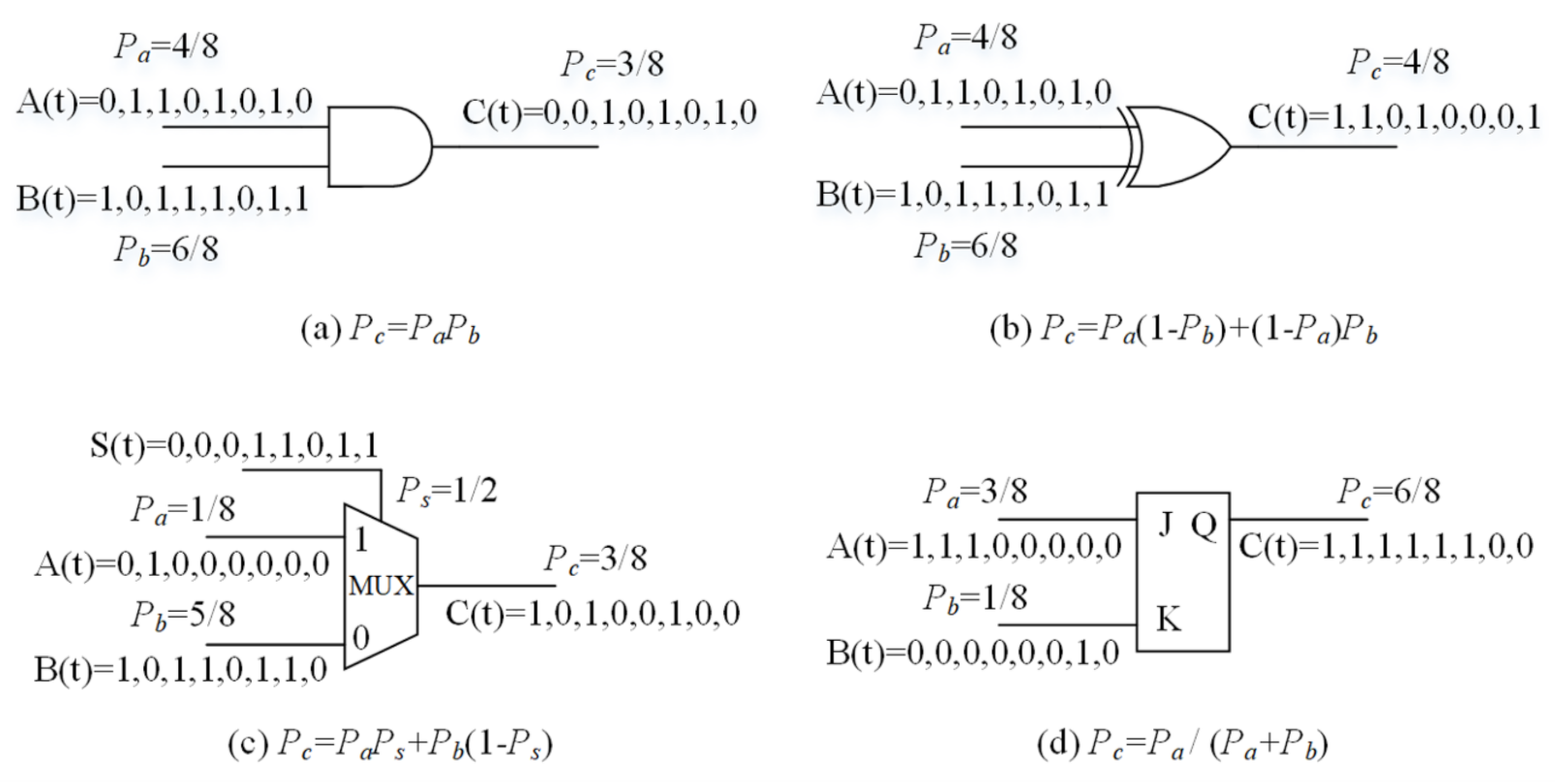
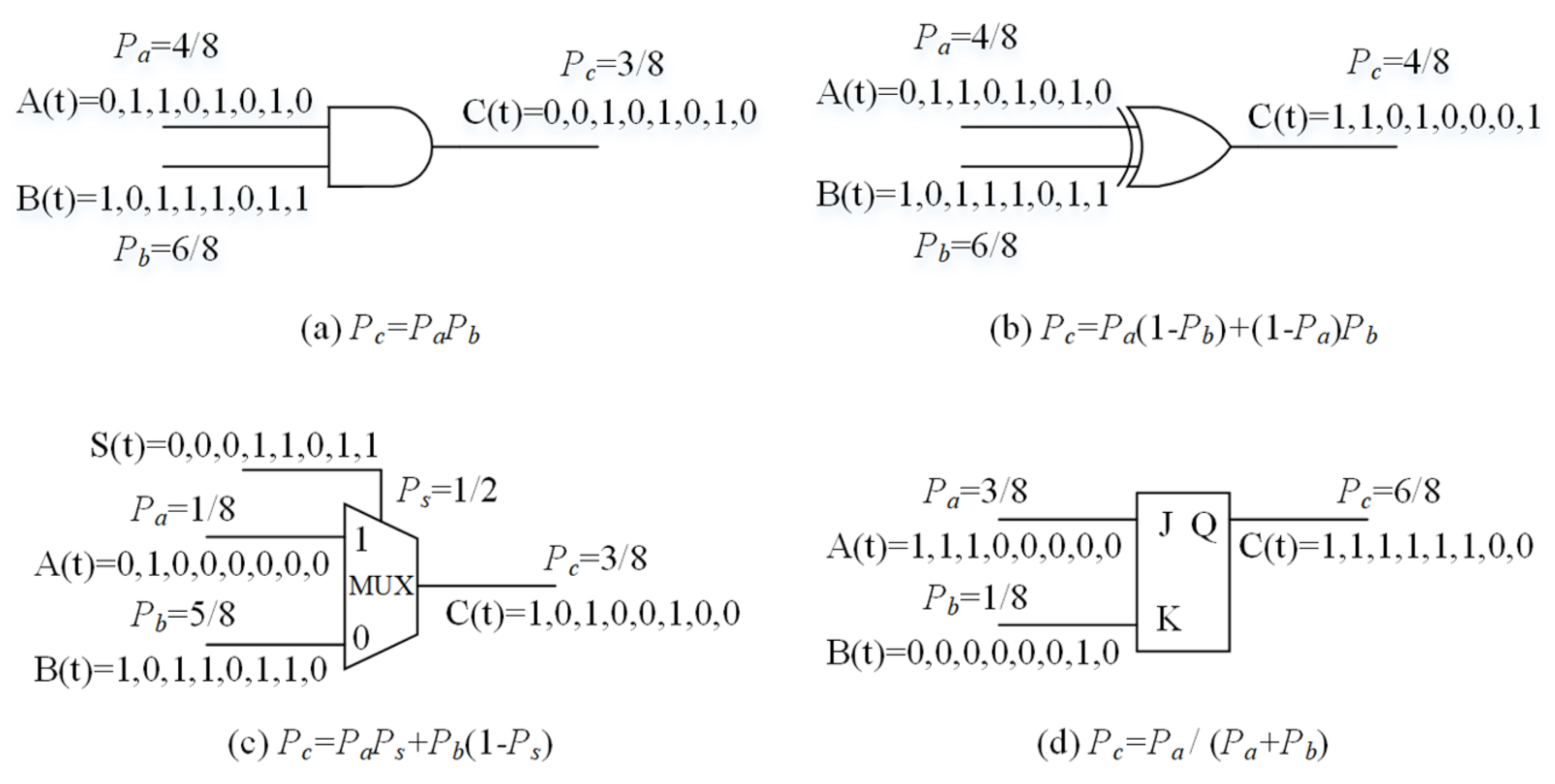
2.2. Stochastic Computing
- For a numerical value , the unipolar format can be utilized to transform it to bit stream by comparing it with a uniform distributed random number , where . The corresponding hardware architecture of unipolar format stochastic computing is shown as “stochastic bit stream generation” in Figure 2.
2.3. Stochastic FIR Filter
3. Stochastic FIR Filter with Adaptive Scaling
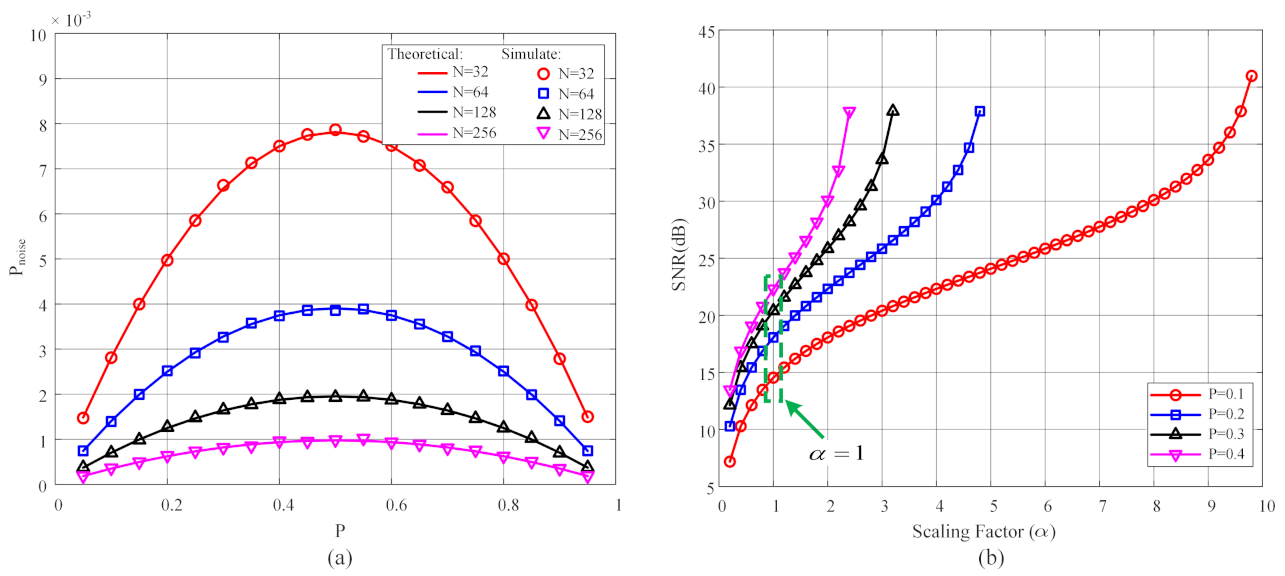
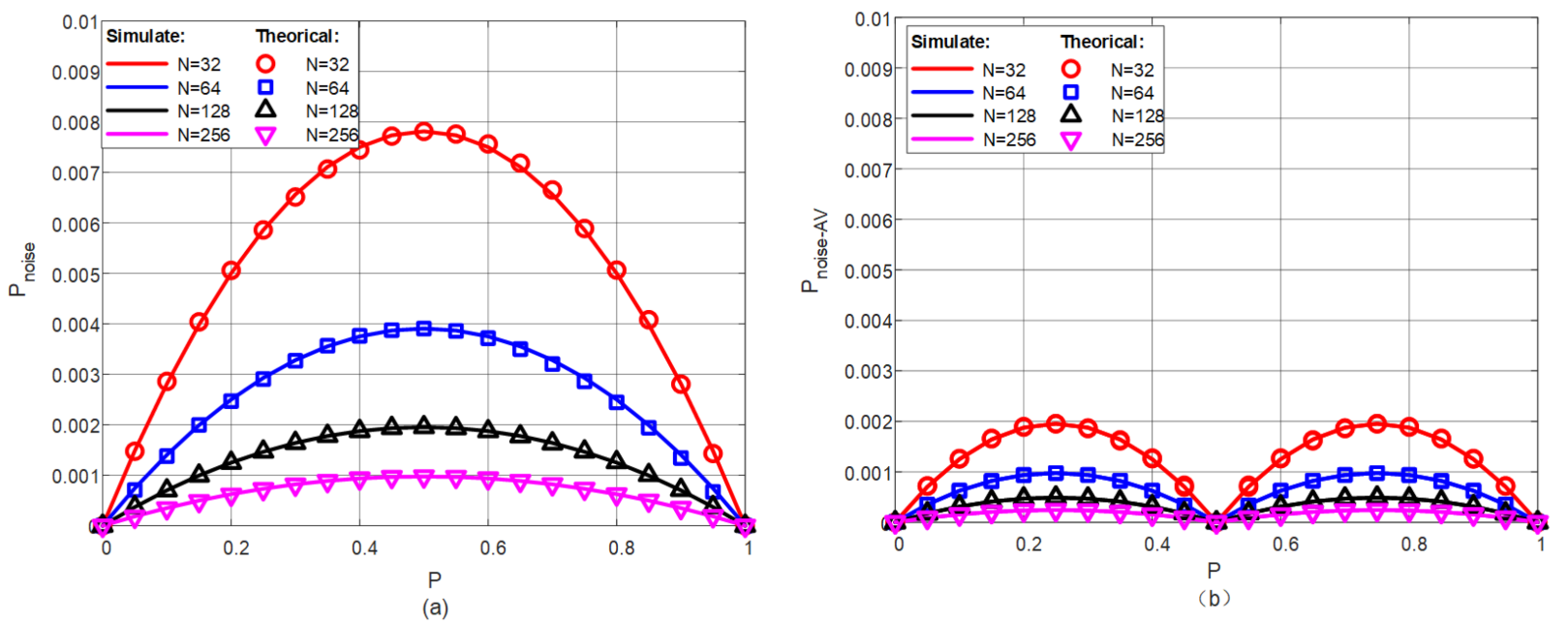
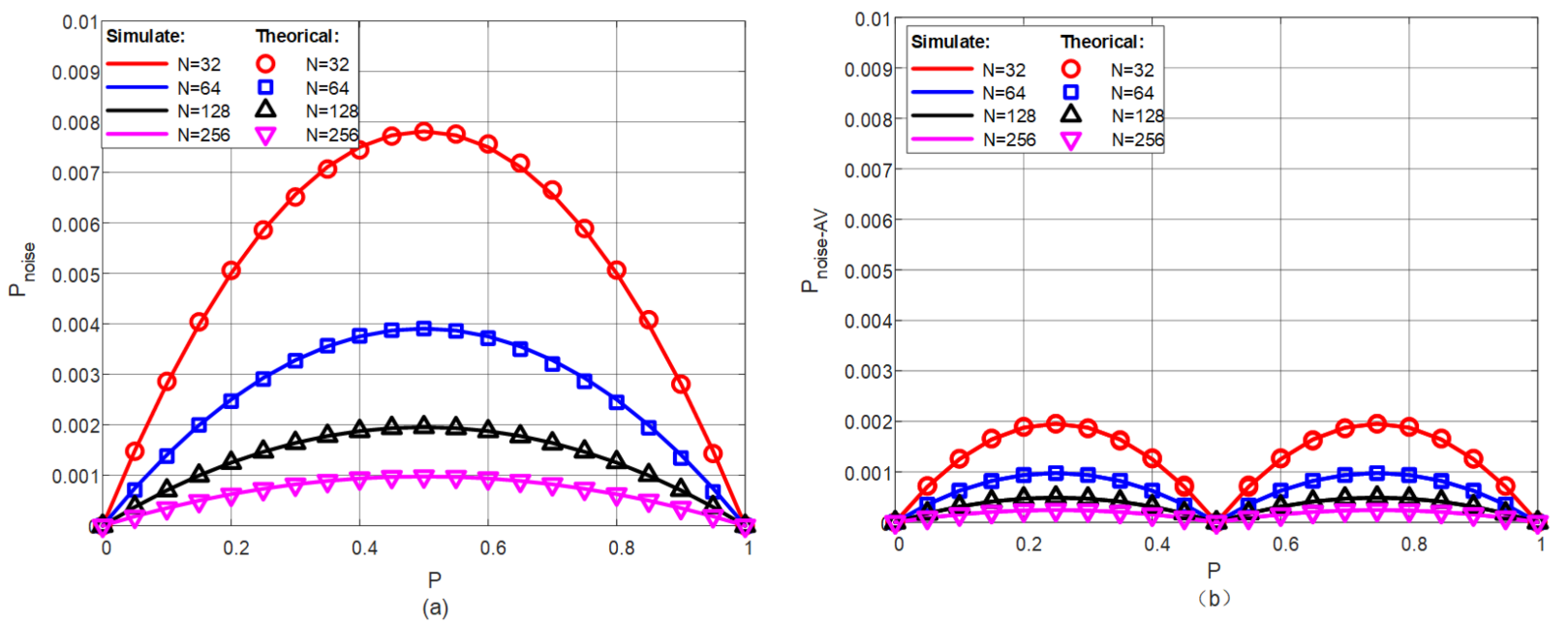
3.1. Noise Analysis of Stochastic Bit Stream
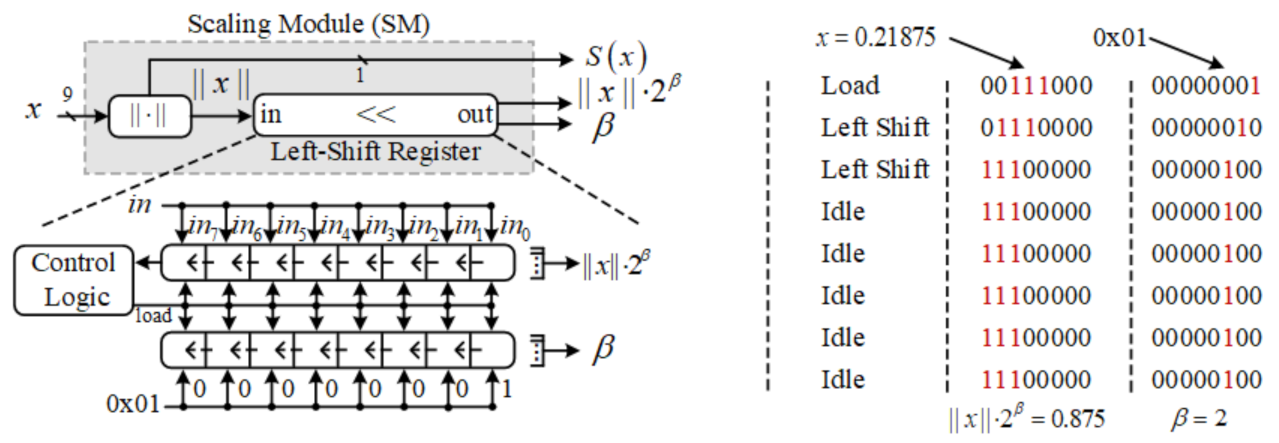
3.2. Adaptive Scaling Algorithm
| Algorithm 1 Adaptive Scaling Algorithm (ASA) |
|
3.3. Antithetic Variables Method
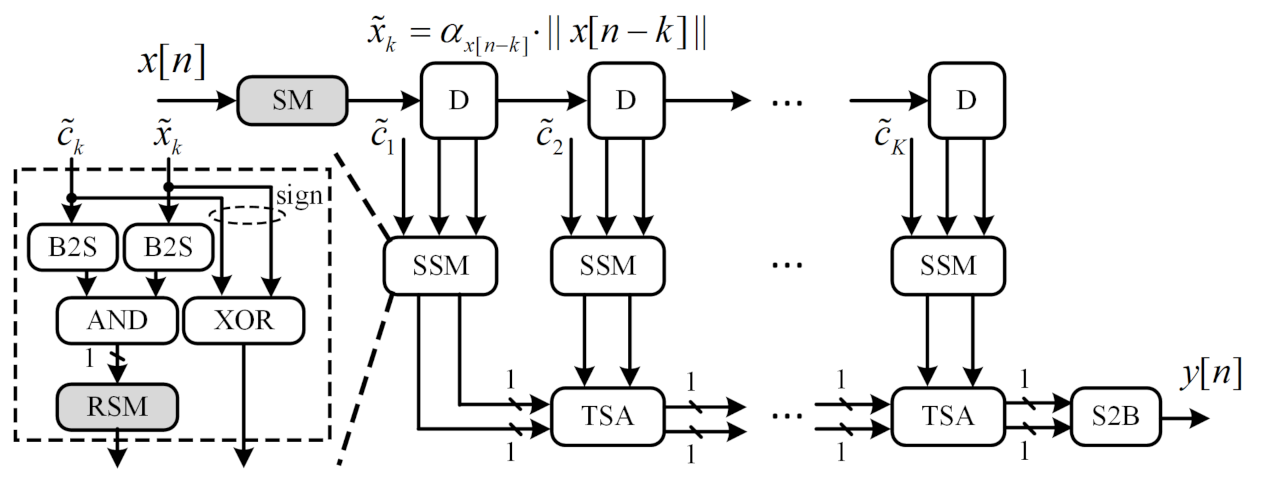
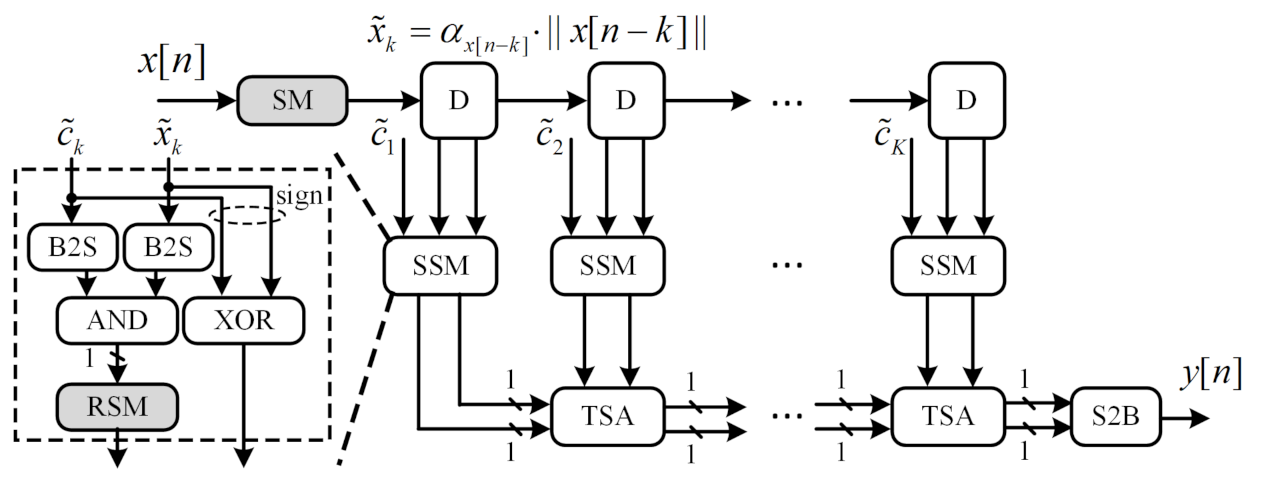
3.4. Stochastic FIR Filter with ASA and AV
- Step 1:
- The FIR filter coefficient is initially scaled up to , while the input signal is scaled up to in real-time using SM module.
- Step 2:
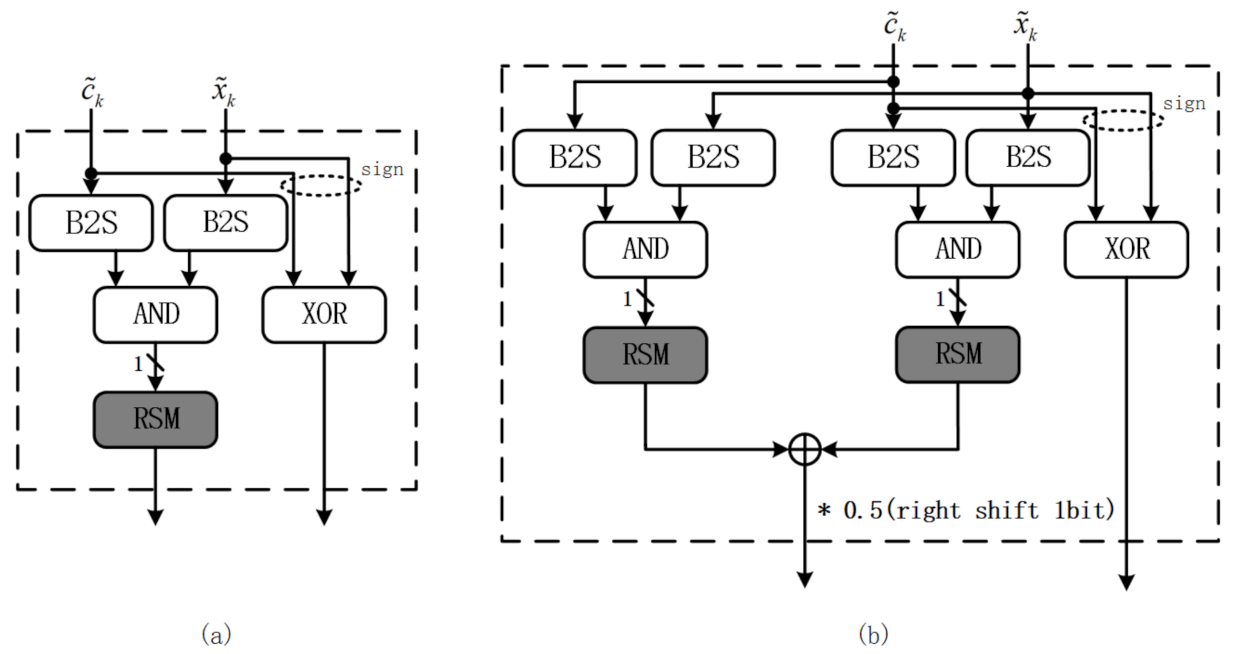
- In the scaled stochastic multiplication module (SSM), the sign bit and are extracted from and , respectively, while the magnitude bit-streams , are transformed from and , respectively, using B2S module.
- Step 3:
- Afterward, The multiplication on sign bit and magnitude bit-streams are mapped into “XOR” logic and ”AND” logic, respectively. The bit-wise re-scaling operation is implemented by the RSM module.
- Step 4:
- Finally, The outputs of the SSM module are summed up with the TSM module and transformed back to binary format using the S2B module.
4. Evaluation and Implementation
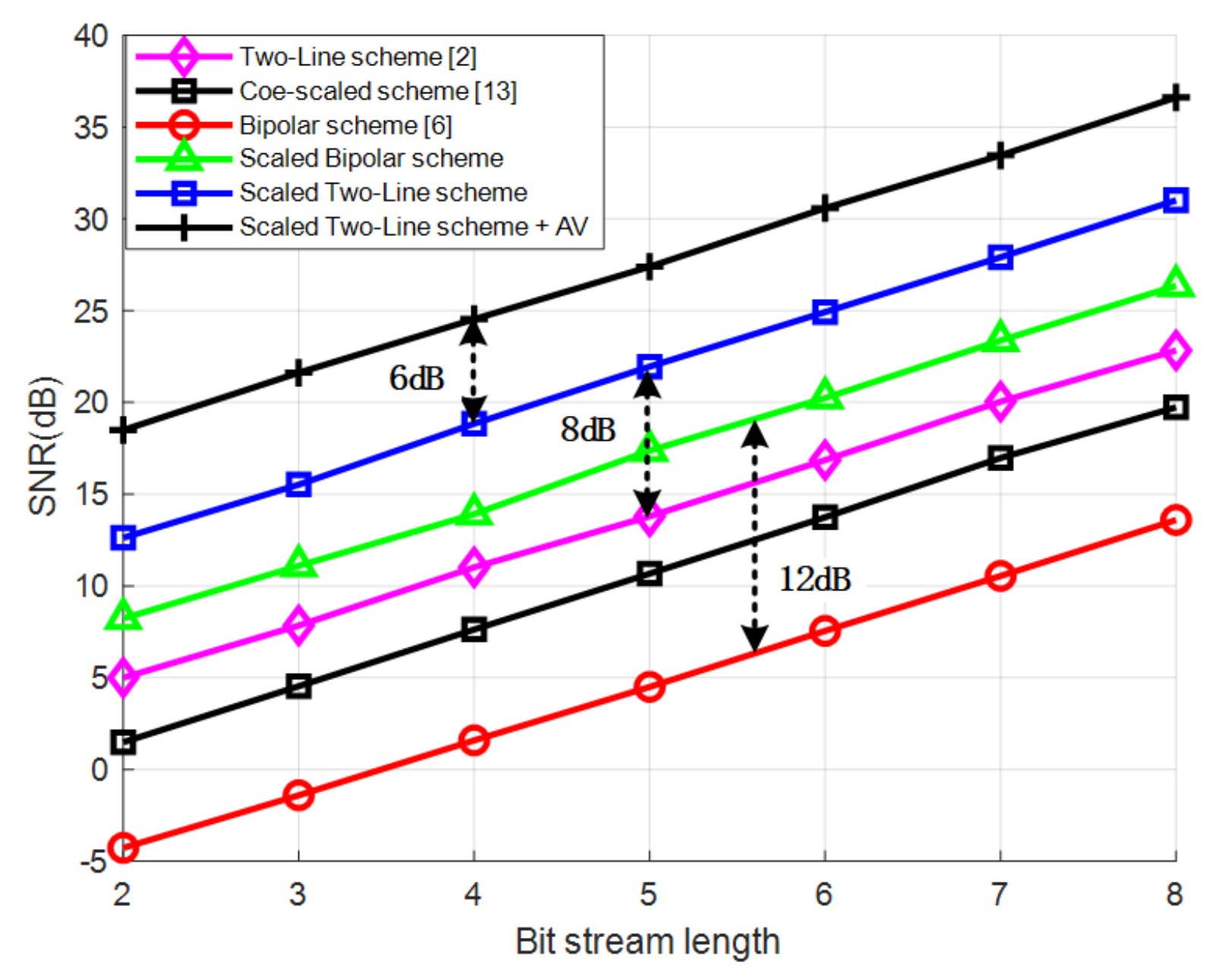
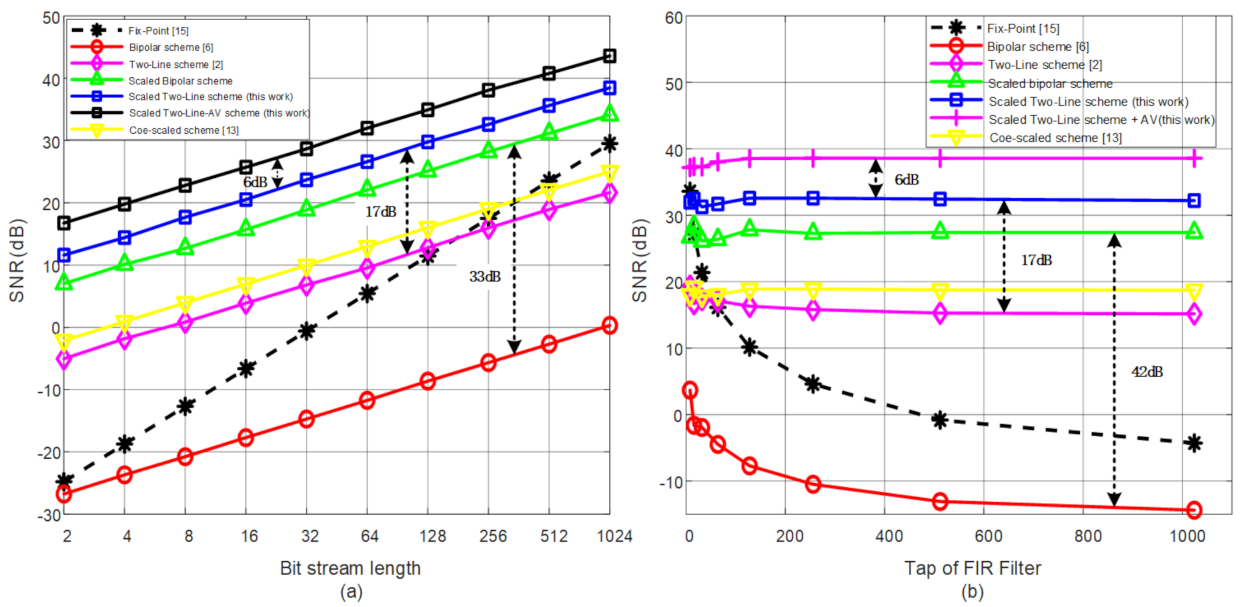
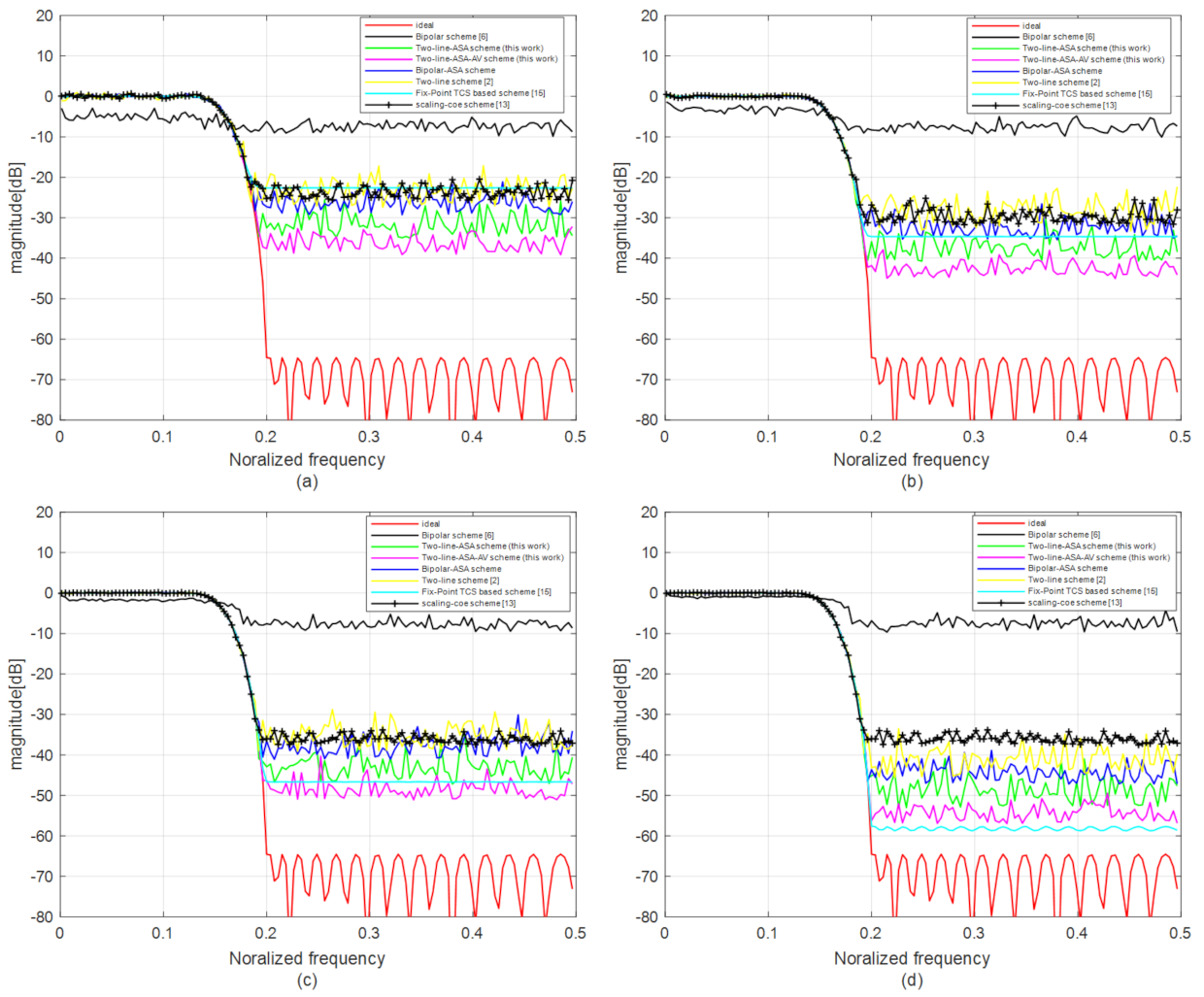
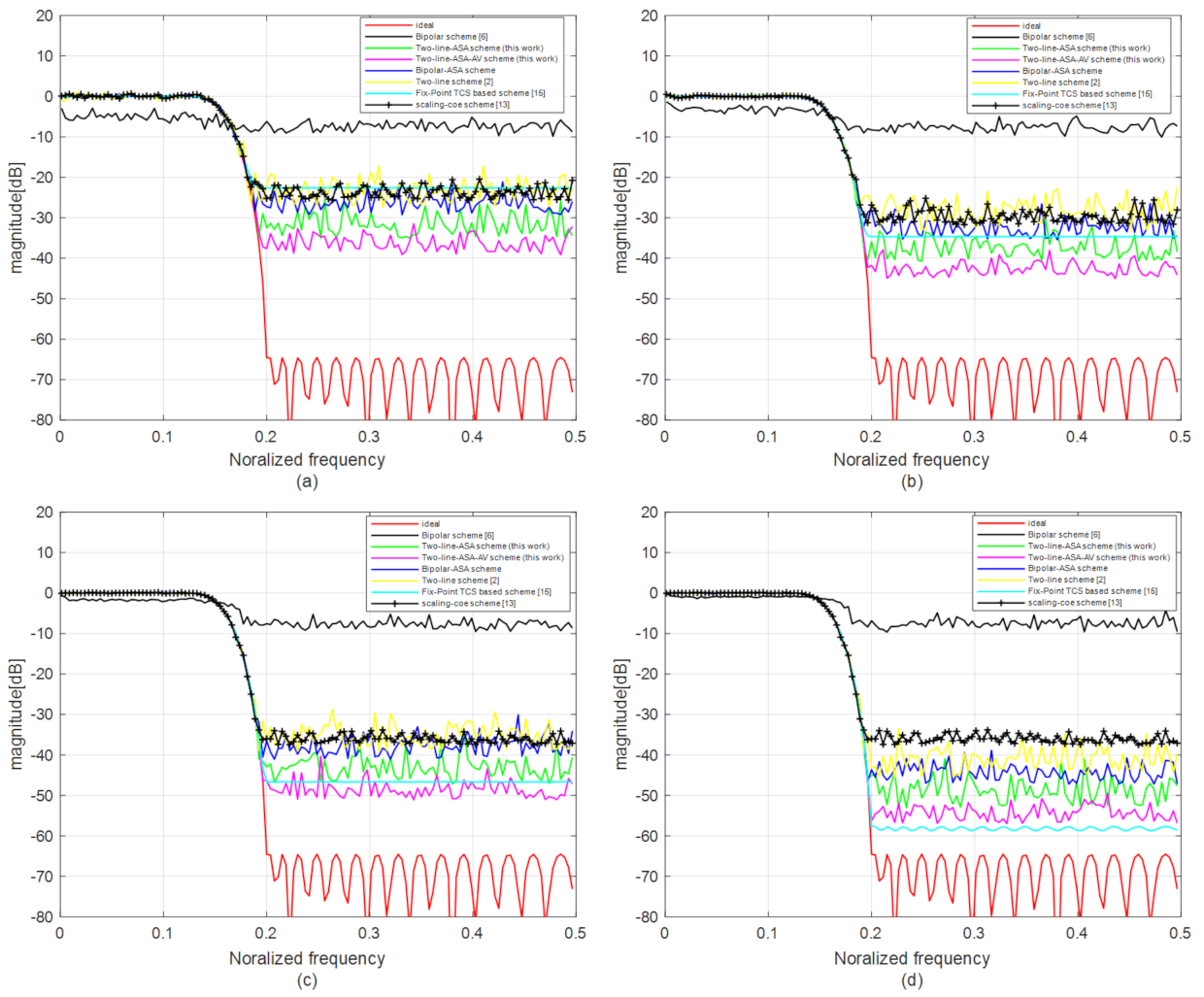
4.1. Performance Simulation
4.2. Hardware Implementation
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jiang, Q. FIR Filter Banks for Hexagonal Data Processing. IEEE Trans. Image Process. 2008, 17, 1512–1521. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, B.; Wang, Y. High-accuracy FIR filter design using stochastic computing. In Proceedings of the IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburgh, PA, USA, 11–13 July 2016; pp. 128–133. [Google Scholar]
- Chen, J.; Hu, J.; Sobelman, G.E. Stochastic MIMO Detector Based on the Markov Chain Monte Carlo Algorithm. IEEE Trans. Signal Process. 2014, 62, 1454–1463. [Google Scholar] [CrossRef]
- Alaghi, A.; Qian, W.; Hayes, J.P. The Promise and Challenge of Stochastic Computing. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 1515–1531. [Google Scholar] [CrossRef]
- Liu, Y.; Venkataraman, H.; Zhang, Z.; Parhi, K.K. Machine learning classifiers using stochastic logic. In Proceedings of the IEEE 34th International Conference on Computer Design (ICCD), Scottsdale, AZ, USA, 2–5 October 2016; pp. 408–411. [Google Scholar]
- Chang, Y.; Parhi, K.K. Architectures for digital filters using stochastic computing. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 2697–2701. [Google Scholar]
- Koshita, S.; Onizawa, N.; Abe, M.; Hanyu, T.; Kawamata, M. Realization of FIR digital filters based on stochastic/binary hybrid computation. In Proceedings of the International Symposium on Multiple-Valued Logic, Sapporo, Japan, 18–20 May 2016; pp. 223–228. [Google Scholar]
- Abbaszadeh, A.; Azerbaijan, A.; Sadeghipour, K.D. A new hardware efficient reconfigurable fir filter architecture suitable for FPGA applications. In Proceedings of the 17th DSP 2011 International Conference on Digital Signal Processing, Corfu, Greece, 6–8 July 2011; pp. 4–7. [Google Scholar]
- Arash Ardakani, F.L.; Gross, W.J. Hardware implementation of FIR/IIR digital filters using integral stochastic computation. In Proceedings of the ICASSP 2016, Shanghai, China, 20–25 March 2016; pp. 6540–6544. [Google Scholar]
- Chen, J.; Hu, J. A novel FIR filter based on stochastic logic. In Proceedings of the IEEE International Symposium on Circuits and Systems, Beijing, China, 19–23 May 2013; pp. 2050–2053. [Google Scholar]
- Brown, B.D.; Card, H.C. Stochastic neural computation I: Computational elements. IEEE Trans. Comput. 2001, 50, 891–905. [Google Scholar] [CrossRef]
- Ichihara, H.; Sugino, T.; Ishii, S.; Iwagaki, T.; Inoue, T. Compact and accurate digital filters based on stochastic computing. IEEE Trans. Emerg. Top. Comput. 2019, 7, 31–43. [Google Scholar] [CrossRef]
- Kim, K.; Kim, J.; Yu, J.; Seo, J.; Lee, J.; Choi, K. Dynamic energy-accuracy trade-off using stochastic computing in deep neural networks. In Proceedings of the ACM Press the 53rd Annual Design Automation Conference, Austin, TX, USA, 5–9 June 2016; pp. 1–6. [Google Scholar]
- Koshita, S.; Onizawa, N.; Abe, M.; Hanyu, T.; Kawamata, M. High-Accuracy and Area-Efficient Stochastic FIR Digital Filters Based on Hybrid Computation. IEICE Trans. Inf. Syst. 2017, 100, 1592–1602. [Google Scholar] [CrossRef] [Green Version]
- Han, K.; Hu, J.; Chen, J.; Lu, H. A low complexity sparse code multiple access detector based on stochastic computing. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 65, 769–782. [Google Scholar] [CrossRef]
- Toral, S.L.; Quero, J.M.; Franquelo, L.G. Stochastic pulse coded arithmetic. In Proceedings of the IEEE International Symposium on Circuits and Systems, Geneva, Switzerland, 28–31 May 2000; Volume 3, p. 1. [Google Scholar]
- Han, K.; Wang, J.; Gross, W.J.; Hu, J. Stochastic bit-wise iterative decoding of polar codes. IEEE Trans. Signal Process. 2018, 67, 1138–1151. [Google Scholar] [CrossRef]
- Parhi, K.K. VLSI Digital Signal Processing Systems: Design and Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Wong, C.C.; Chang, H.C. Reconfigurable turbo decoder with parallel architecture for 3GPP LTE system. IEEE Trans. Circuits Syst. II Express Briefs 2010, 57, 566–570. [Google Scholar] [CrossRef]
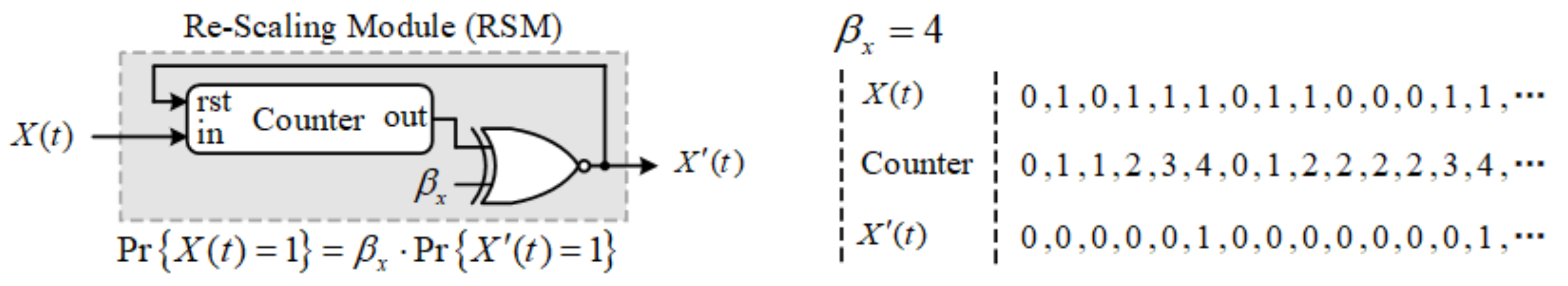

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SFIR Schemes | Bipolar SFIR [6] | Two-Line SFIR [2] | MUX SFIR [12] | Binary FIR (Fix-Point) | ASA-SFIR (This Work) | AV-ASA-SFIR (This Work) | |
|---|---|---|---|---|---|---|---|
| CMOS Tech. | 90 nm | 90 nm | 90 nm * | 90 nm | 90 nm | 90 nm | 90 nm |
| Filter Tap | 64 | 64 | 64 | 64 | 64 | 64 | 64 |
| Bit Stream Length (bits) | 256 | 256 | 256 | – | 256 | 256 | 16 |
| Fix-Point Width (bits) | – | – | – | 9 | – | – | – |
| SNR (dB) | −4.41 | 17.21 | – | 23.51 | 31.38 | 37.40 | 25.64 |
| Error () | 34.42 | 2.8 | 2.38 | 1.5 | 0.39 | 0.2 | 0.85 |
| Clock (MHz) | 800 | 750 | – | 200 | 750 | 750 | 750 |
| Area (um) | 18,304 | 44,800 | ≈14,000 ** | 229,452 | 49,286 | 59,121 | 59,121 |
| Power (mW) | – | – | – | 2.40 | 1.913 | 2.31 | 2.31 |
| Latency (ns) | 320.00 | 341.32 | – | 5.00 | 341.32 | 341.32 | 21.33 |
| Throughout (MSample/s) | 3.13 | 2.92 | – | 200.00 | 2.92 | 2.92 | 46.88 |
| Hardware Efficiency (MS/s/mm) | 0.17 | 0.07 | – | 0.87 | – | – | 0.79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhu, Y.; Han, K.; Wang, J.; Hu, J. A High-Accuracy Stochastic FIR Filter with Adaptive Scaling Algorithm and Antithetic Variables Method. Electronics 2021, 10, 1937. https://doi.org/10.3390/electronics10161937
Zhang Y, Zhu Y, Han K, Wang J, Hu J. A High-Accuracy Stochastic FIR Filter with Adaptive Scaling Algorithm and Antithetic Variables Method. Electronics. 2021; 10(16):1937. https://doi.org/10.3390/electronics10161937
Chicago/Turabian StyleZhang, Ying, Yubin Zhu, Kaining Han, Junchao Wang, and Jianhao Hu. 2021. "A High-Accuracy Stochastic FIR Filter with Adaptive Scaling Algorithm and Antithetic Variables Method" Electronics 10, no. 16: 1937. https://doi.org/10.3390/electronics10161937
APA StyleZhang, Y., Zhu, Y., Han, K., Wang, J., & Hu, J. (2021). A High-Accuracy Stochastic FIR Filter with Adaptive Scaling Algorithm and Antithetic Variables Method. Electronics, 10(16), 1937. https://doi.org/10.3390/electronics10161937