
An Efficient Hardware Design for a Low-Latency Traffic Flow Prediction System Using an Online Neural Network



Abstract
:1. Introduction
2. Related Work
2.1. Software Implementation of Online Neural Networks
2.2. Hardware Implementation of Neural Networks
3. Adopted Machine Learning Models
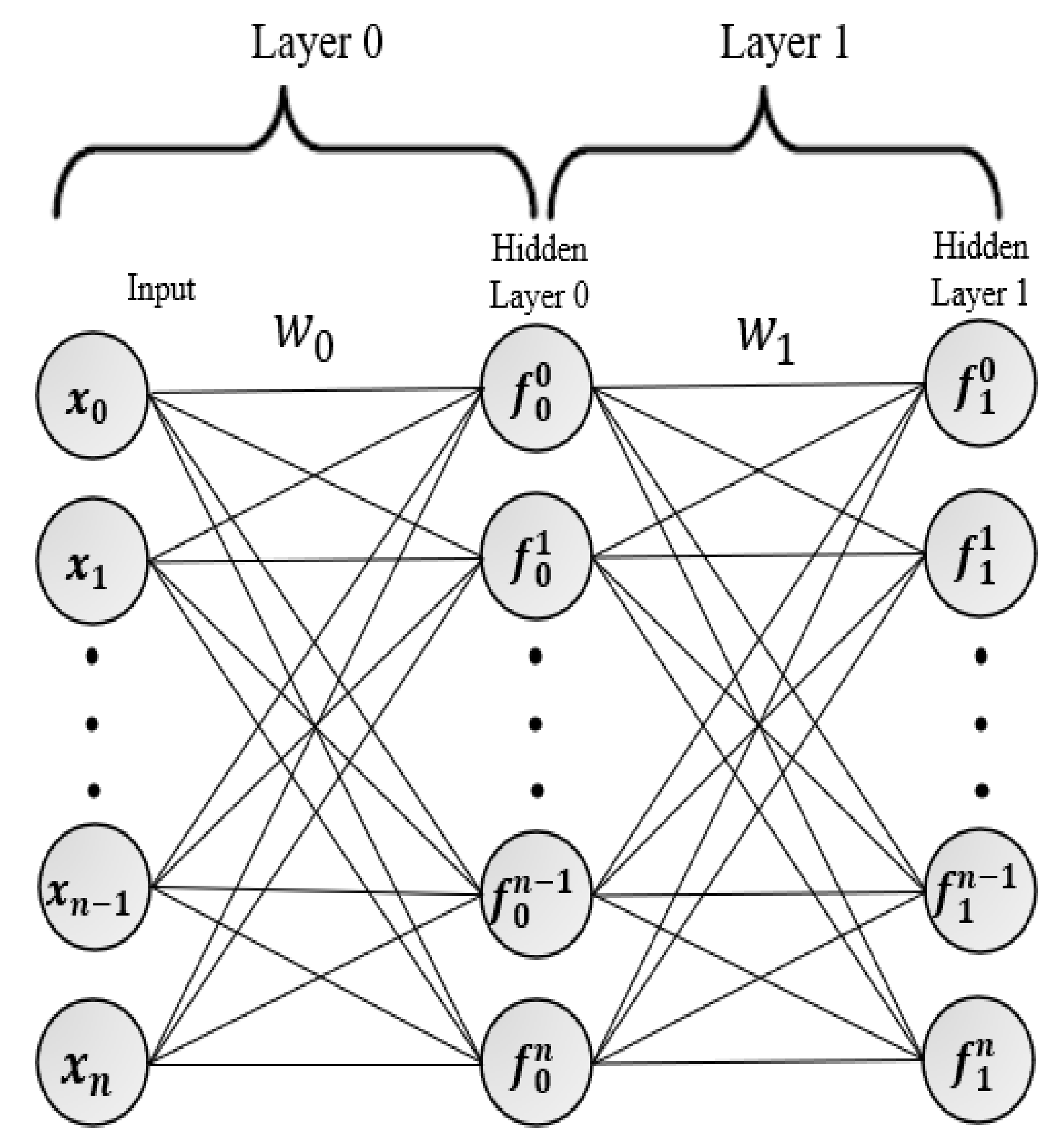
3.1. Multi-Layer Perceptron (MLP)
3.2. Multiple Linear Regression (MLR)
4. Adaptive Momentum (ADAM)
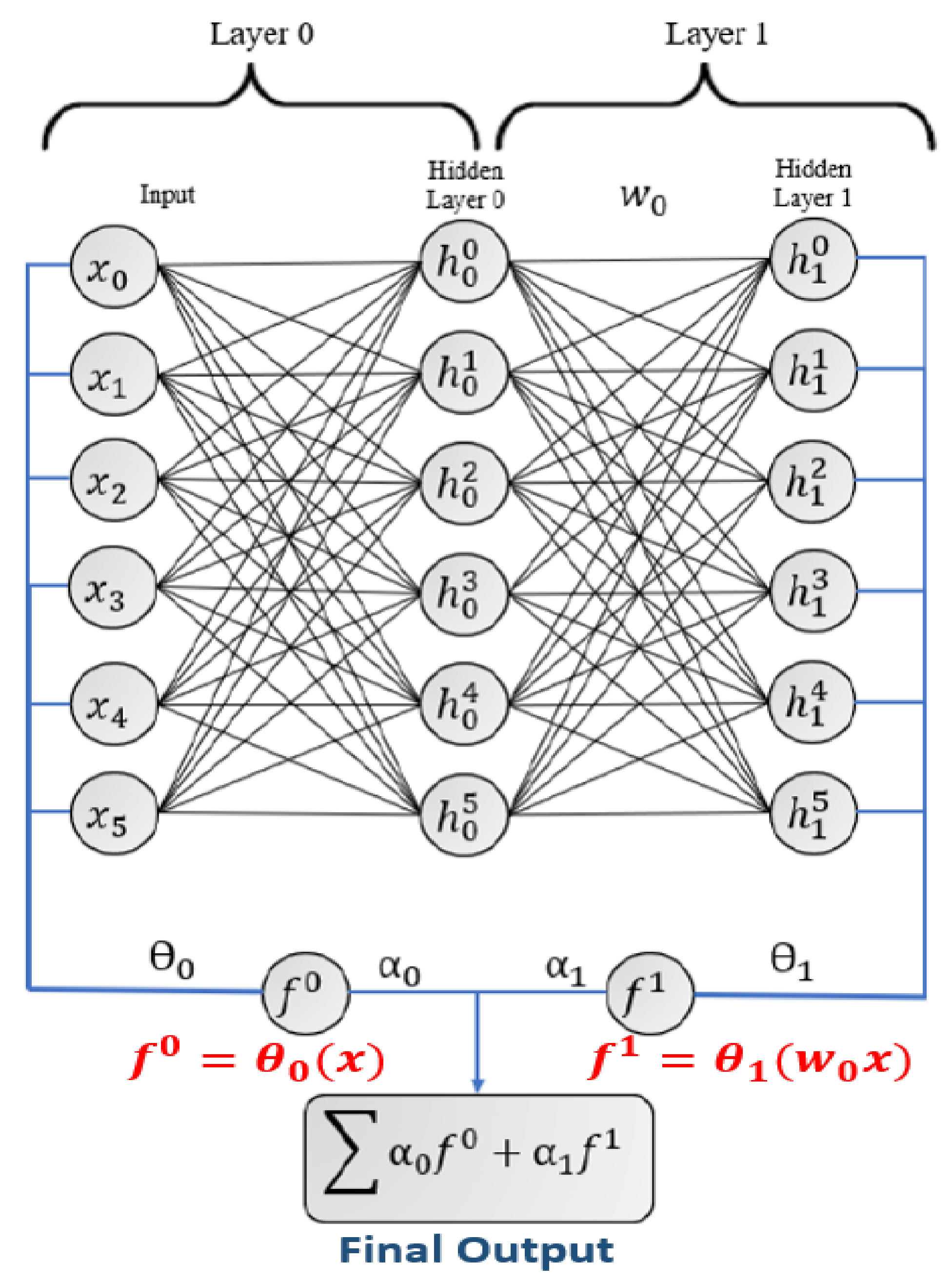
5. Online Neural Network (ONN) Model
5.1. Hedge Backpropagation (HBP) Prediction
5.2. Online Neural Network (ONN) Training
- The model overcomes the vanishing gradient by letting the gradient to be back propagated from shallower classifiers.
- The model depth is adaptive because each classifier output has its own weight that is trained based on its performance.
- weights let the model act as a shallow network at the beginning of the training, allowing for faster convergence and then exploiting a deeper network as it proceeds with training.
- The hedging provides better convergence for non-stationary datasets unlike previous online learning algorithms.
- In comparison with a normal MLP, HBP provides better final predictions. This is a result of the output weighed summation from each classifier, which acts now as an ensemble model.
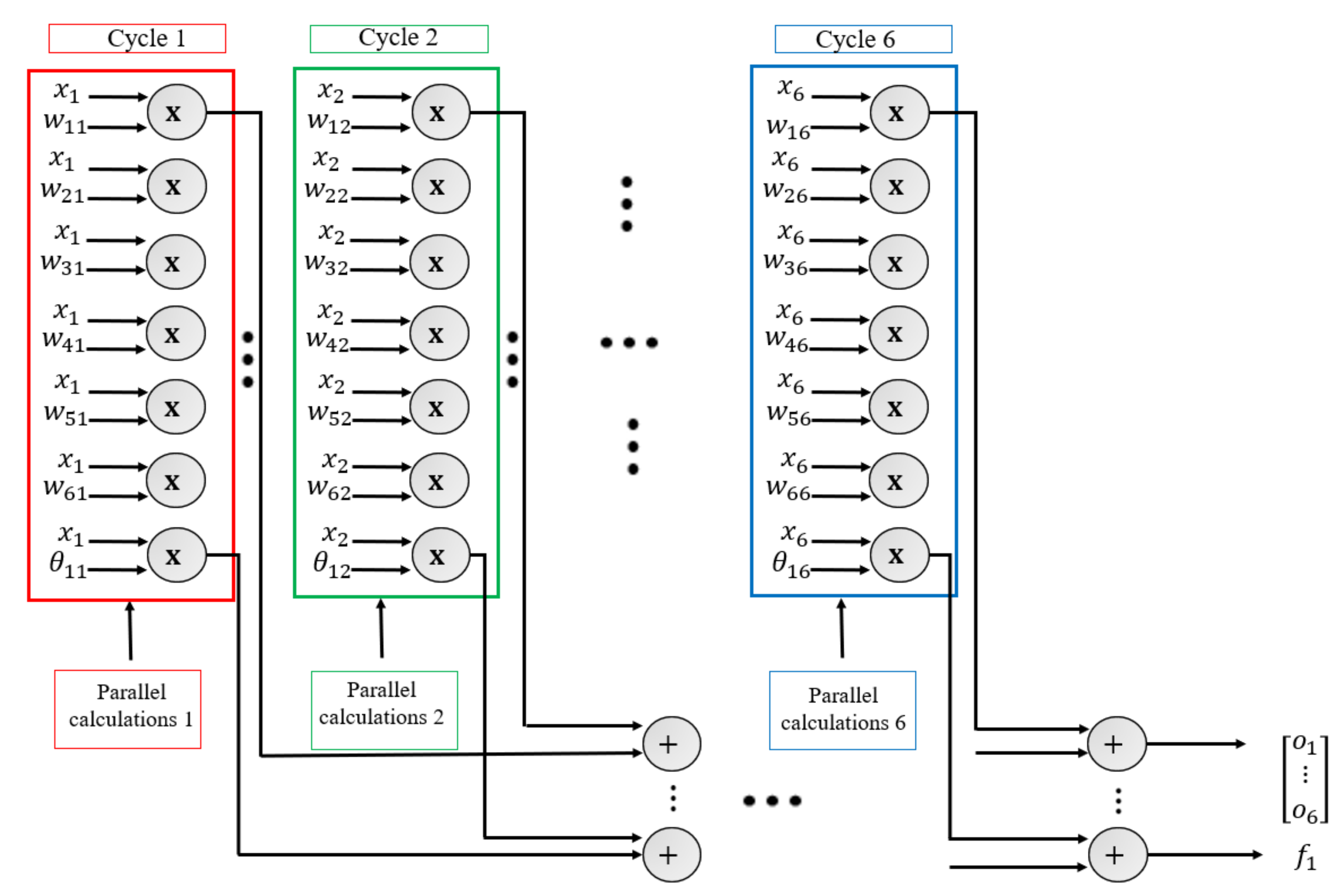
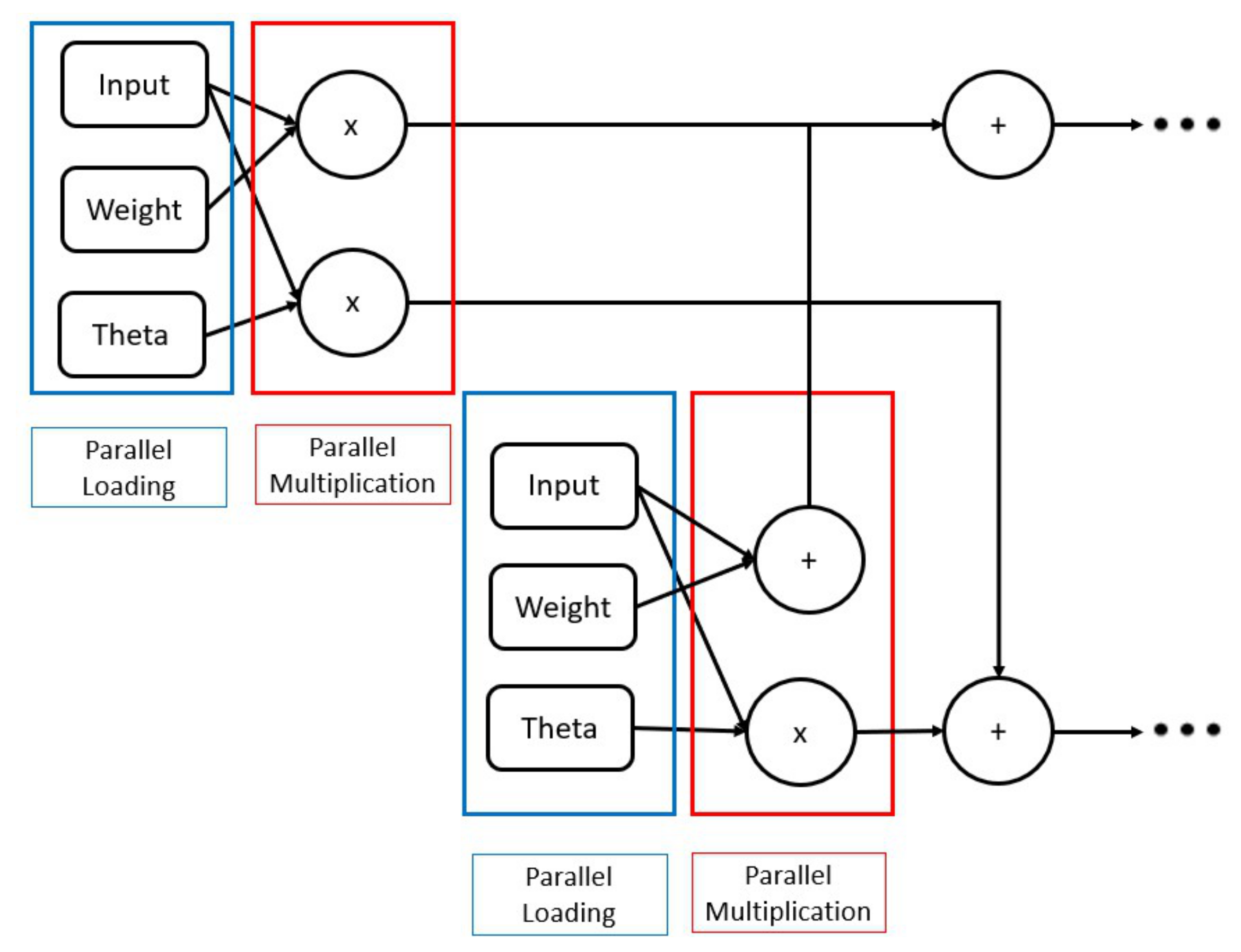
6. Hardware Architecture
6.1. Dataset Description
6.2. Implementation
- Pipelining: Pipelining pragma is used in high-level synthesis optimization techniques to improve the throughput of the system. This was conducted by allowing concurrent operations to take place inside the algorithm.
- Allocation: This pragma is responsible for defining the limited number of resources inside a kernel. Consequently, it restricts the number of RTL examples and hardware resources such as (DSPs and BRAM) used for implementing particular loops, functions, operations, or cores.
- Partitioning: Partitioning pragma is for arrays. It breaks up the large array into smaller arrays or individual elements (buffers). As a result, the accelerator can access the data, simultaneously resulting in high throughput but consumes high area resources.
6.2.1. Accelerator Design for the Distributed Memory Architecture
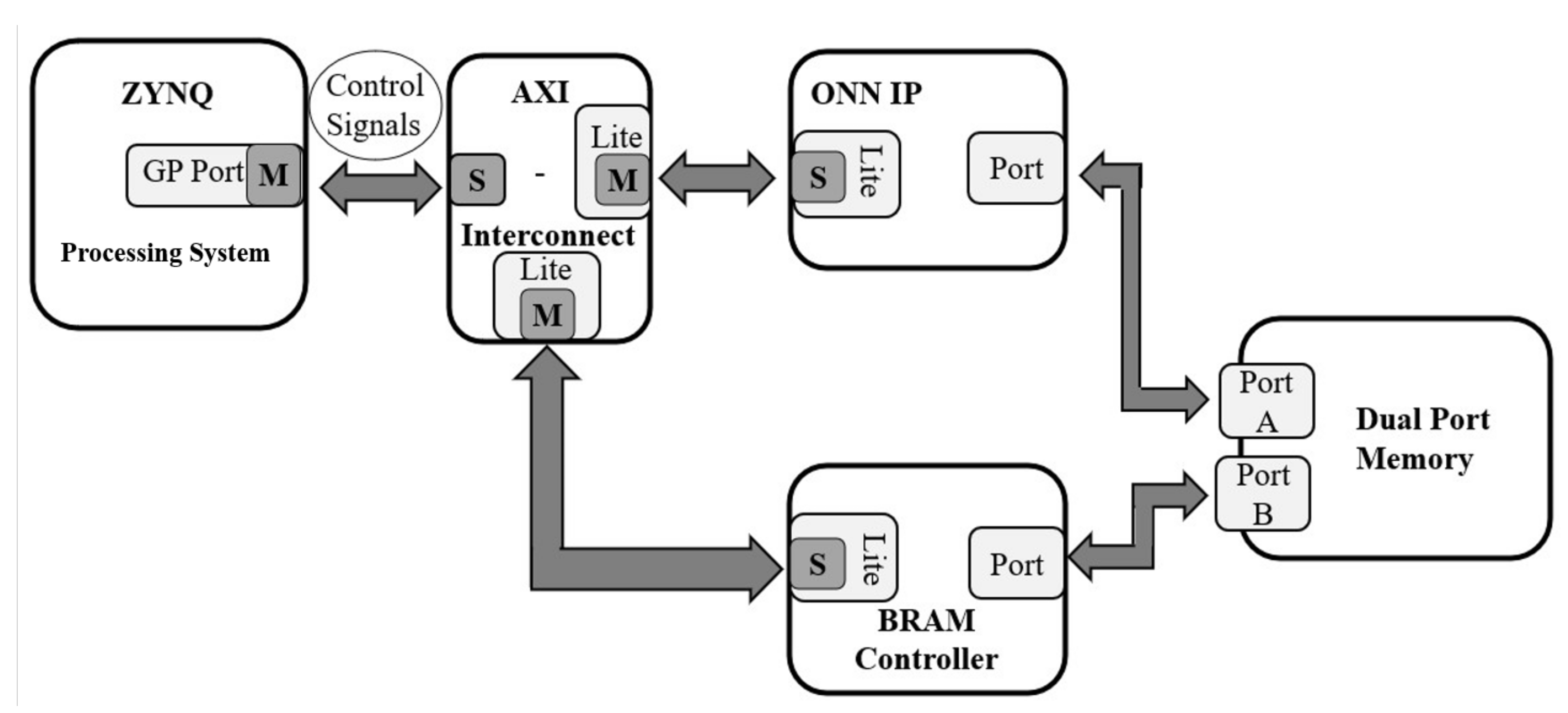
6.2.2. Accelerator Design for the BRAM Architecture
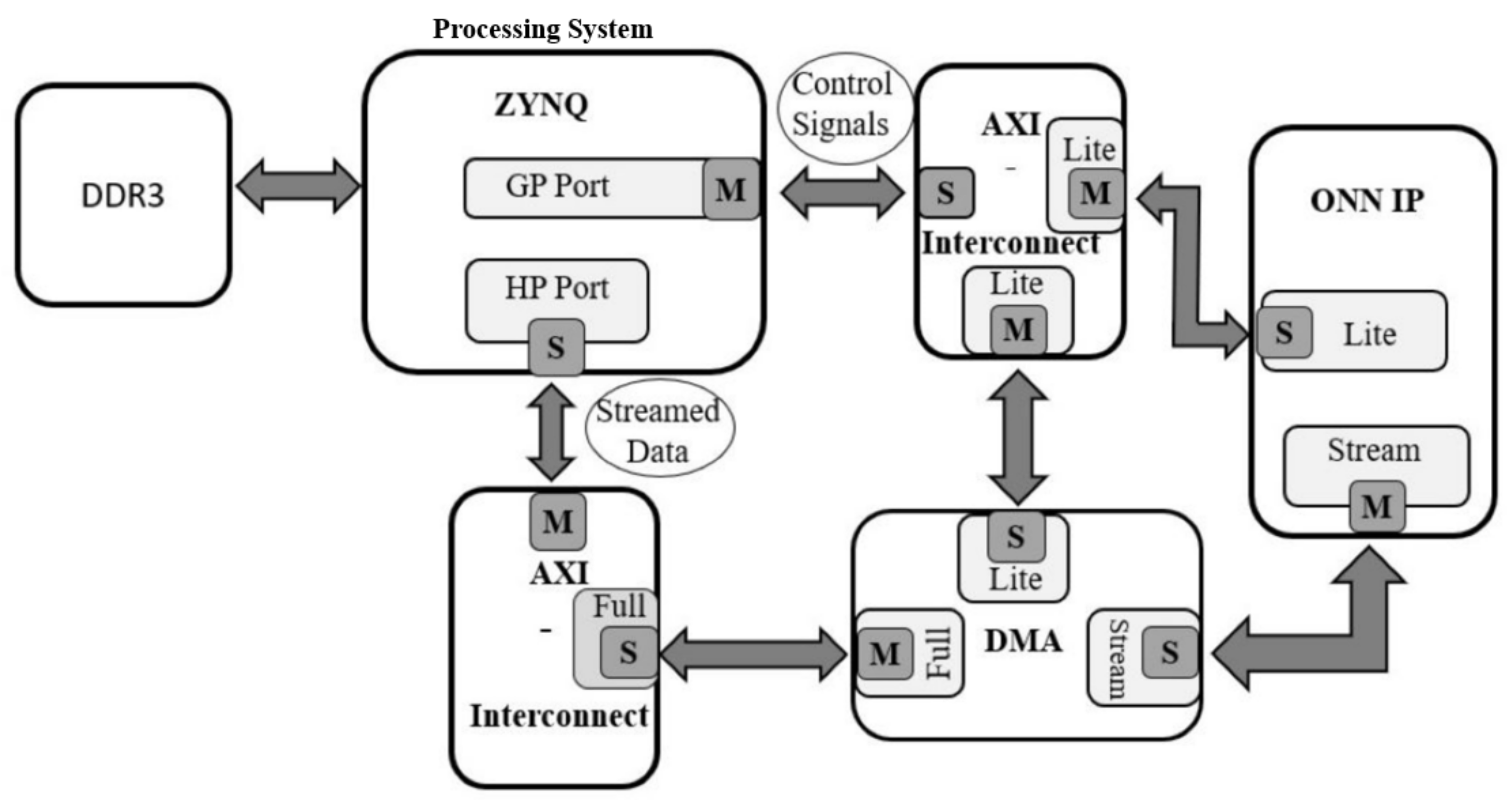
6.2.3. Accelerator Design for the DDR Architecture
6.2.4. Whole System for the BRAM Design
6.2.5. Whole System for DDR Design
6.2.6. Whole System for the Distributed Memory Design
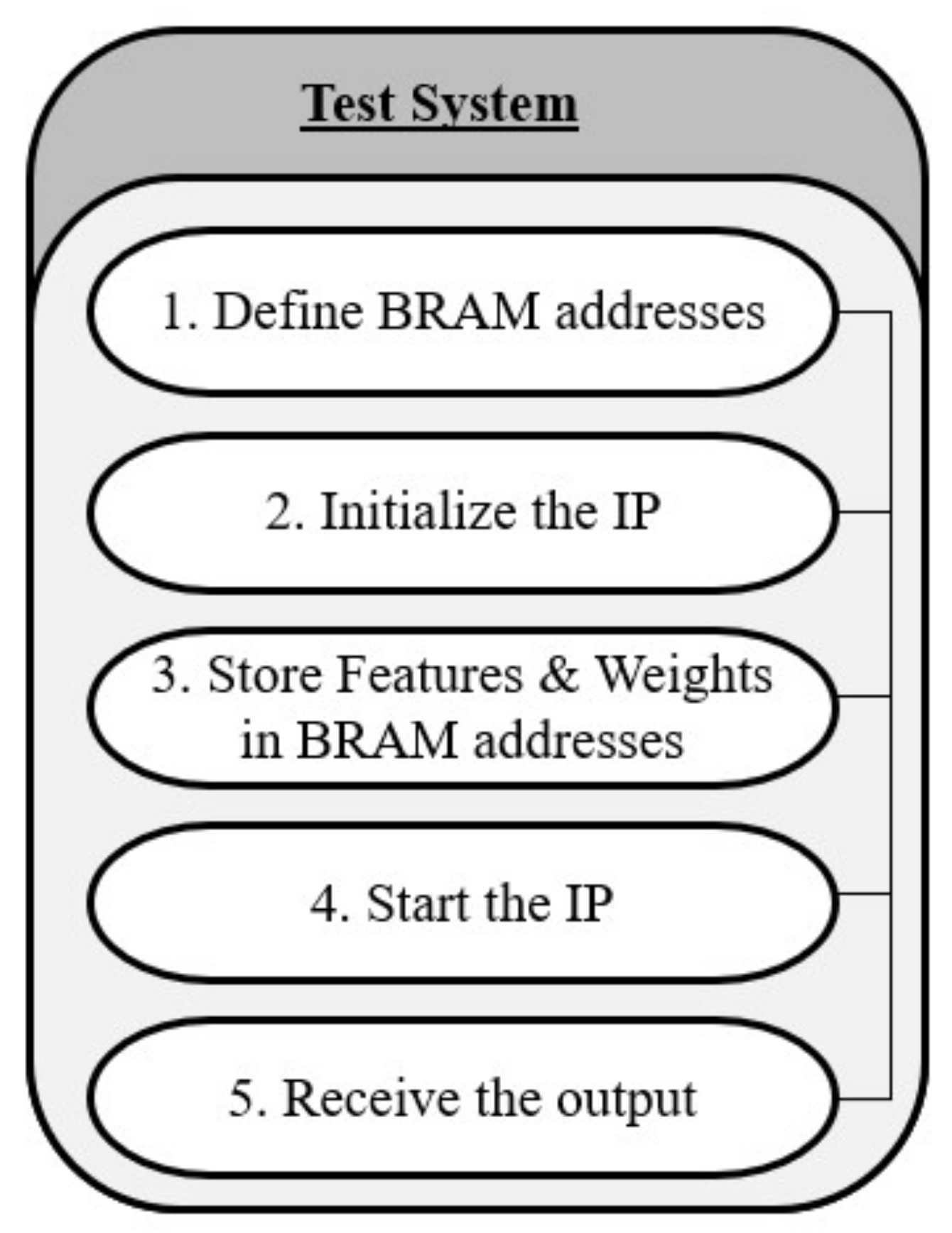
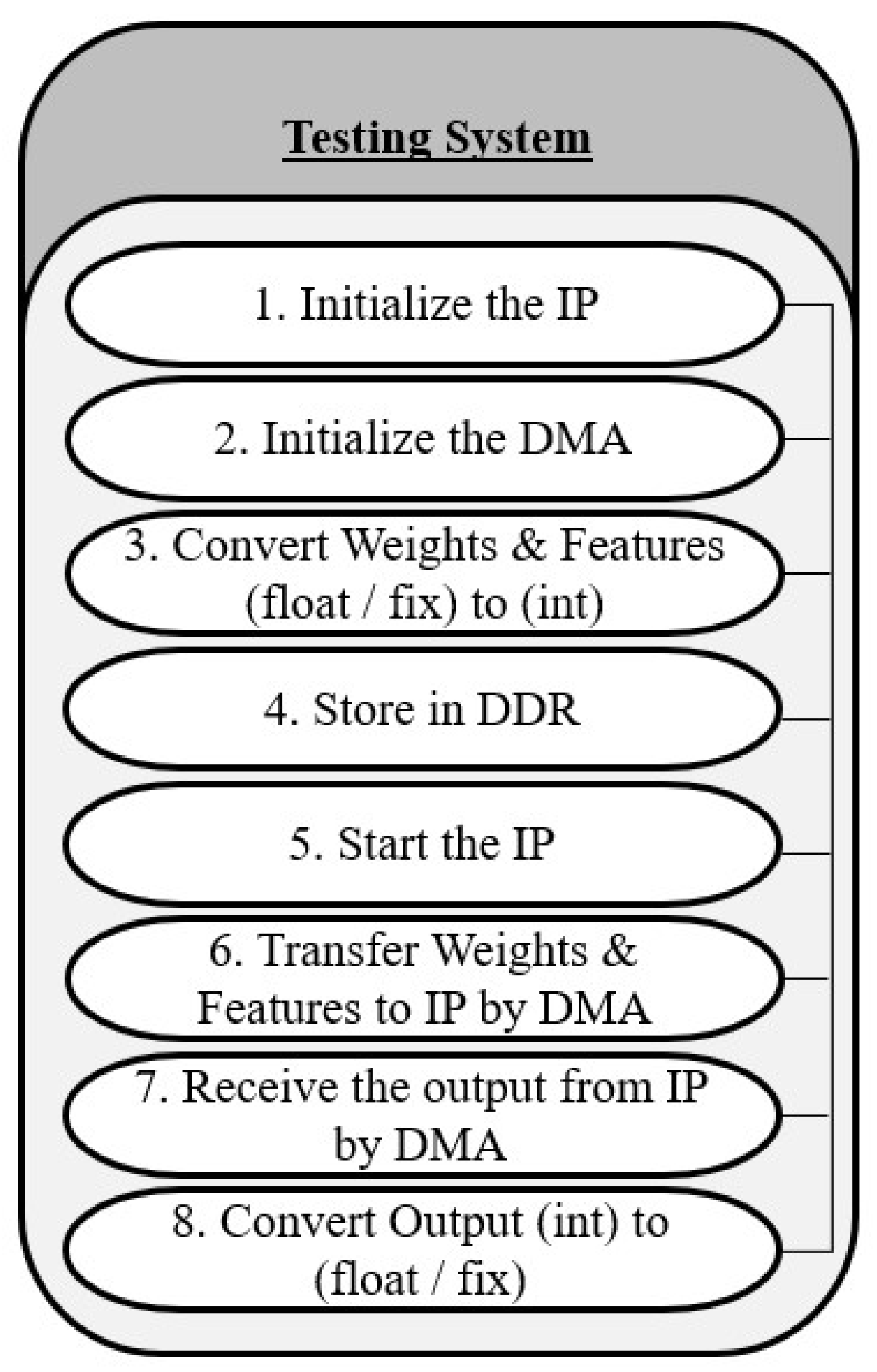
6.2.7. SDK Testing Environment
7. Results and Discussion
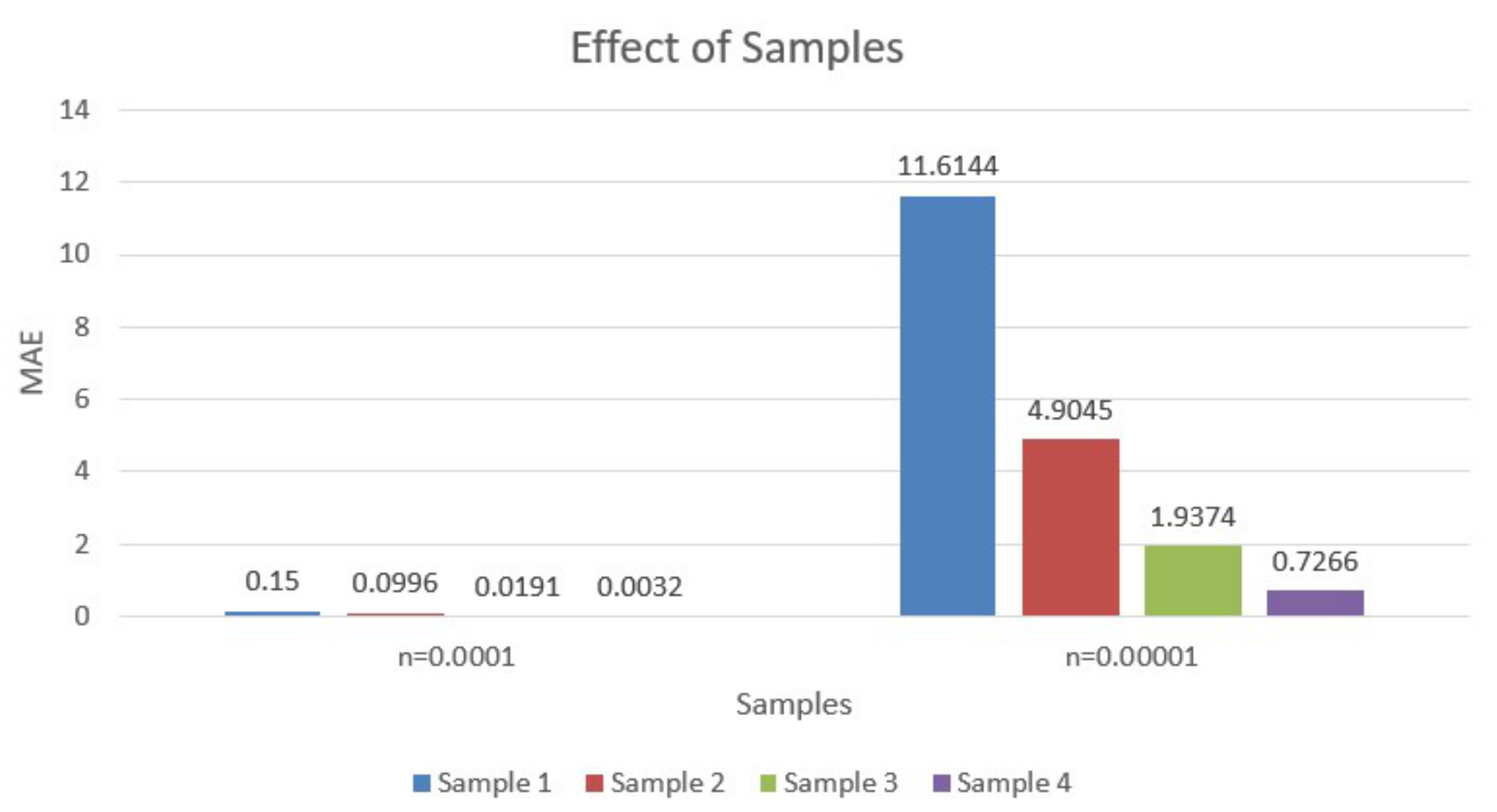
7.1. Performance Evaluation for Each Sample Set
7.2. Hardware Timing Analysis
- IP model: The code that converts int to float for the DDR architecture consumes some time inside the IP block, unlike the BRAM architecture, which stores the weight inside it in float or fixed without converting them to the integer format. Hence, BRAM IP block is faster than DDR block.
- System: Routing and placement inside any FPGA affects the timing of the system. The DDR is placed as an external memory on the PS side of the zedboard, while the BRAM is located inside the PL. This means that the BRAM is located closer to the IP than DDR. Therefore, the communication time between the IP and the BRAM is faster and that the latency is lower than DDR.
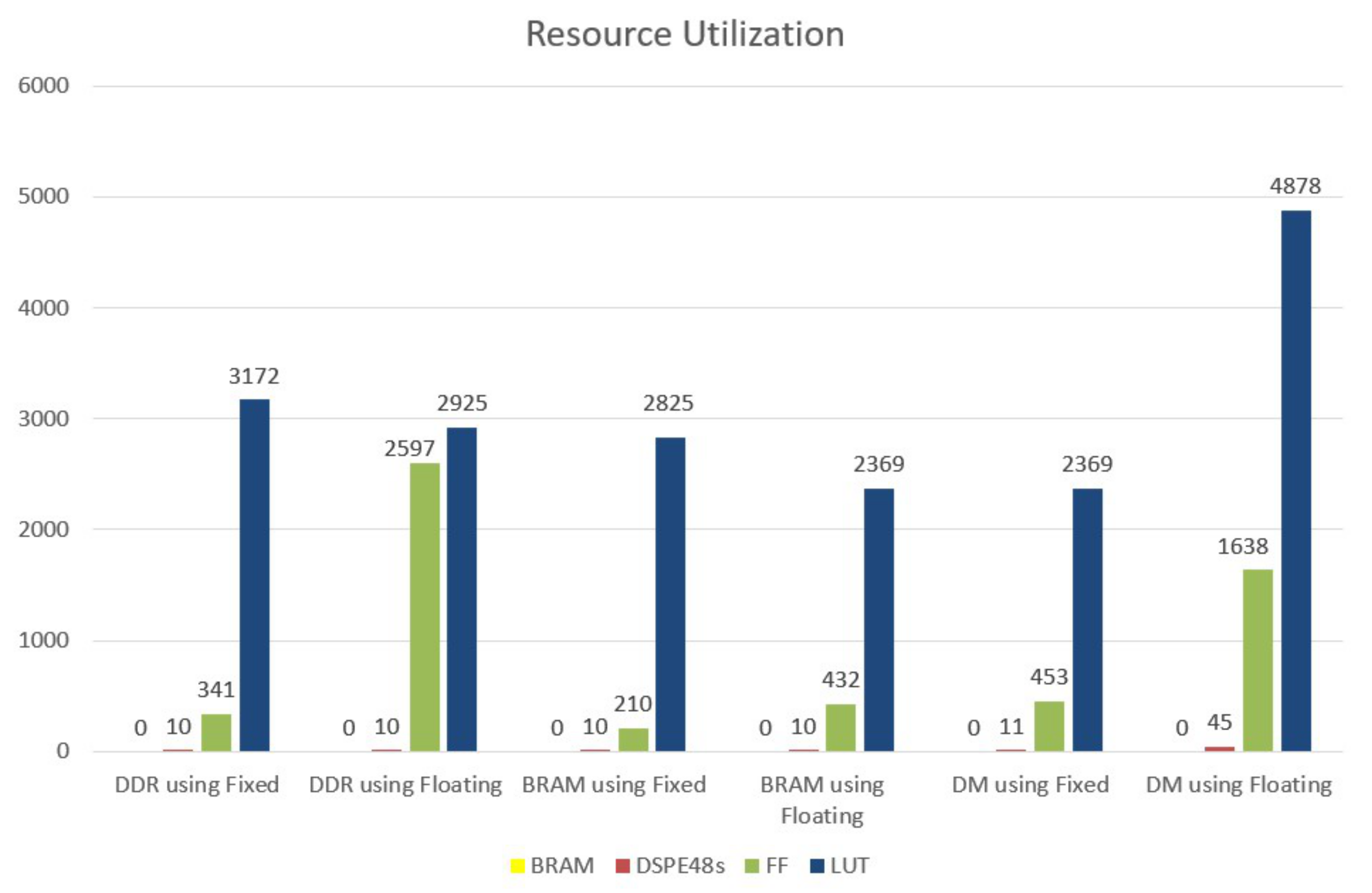
7.3. Hardware Resource Utilization Analysis
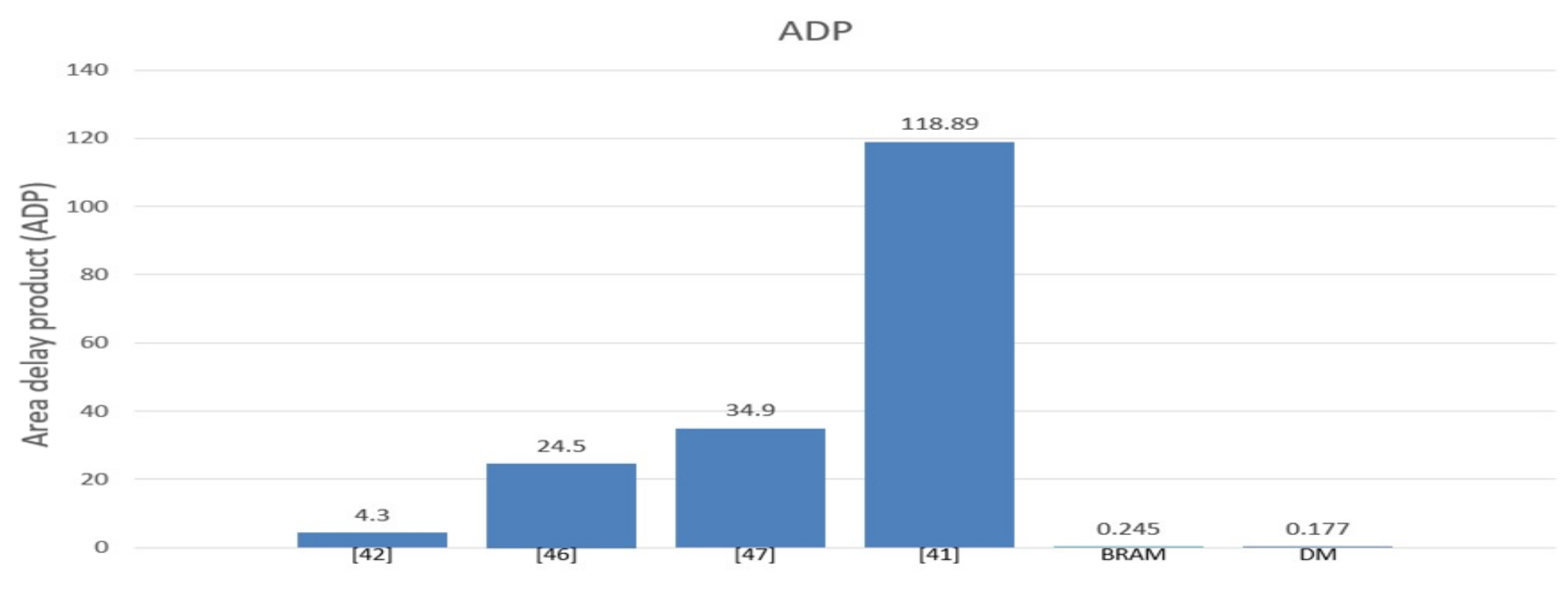
7.4. Area-Delay Product (ADP)
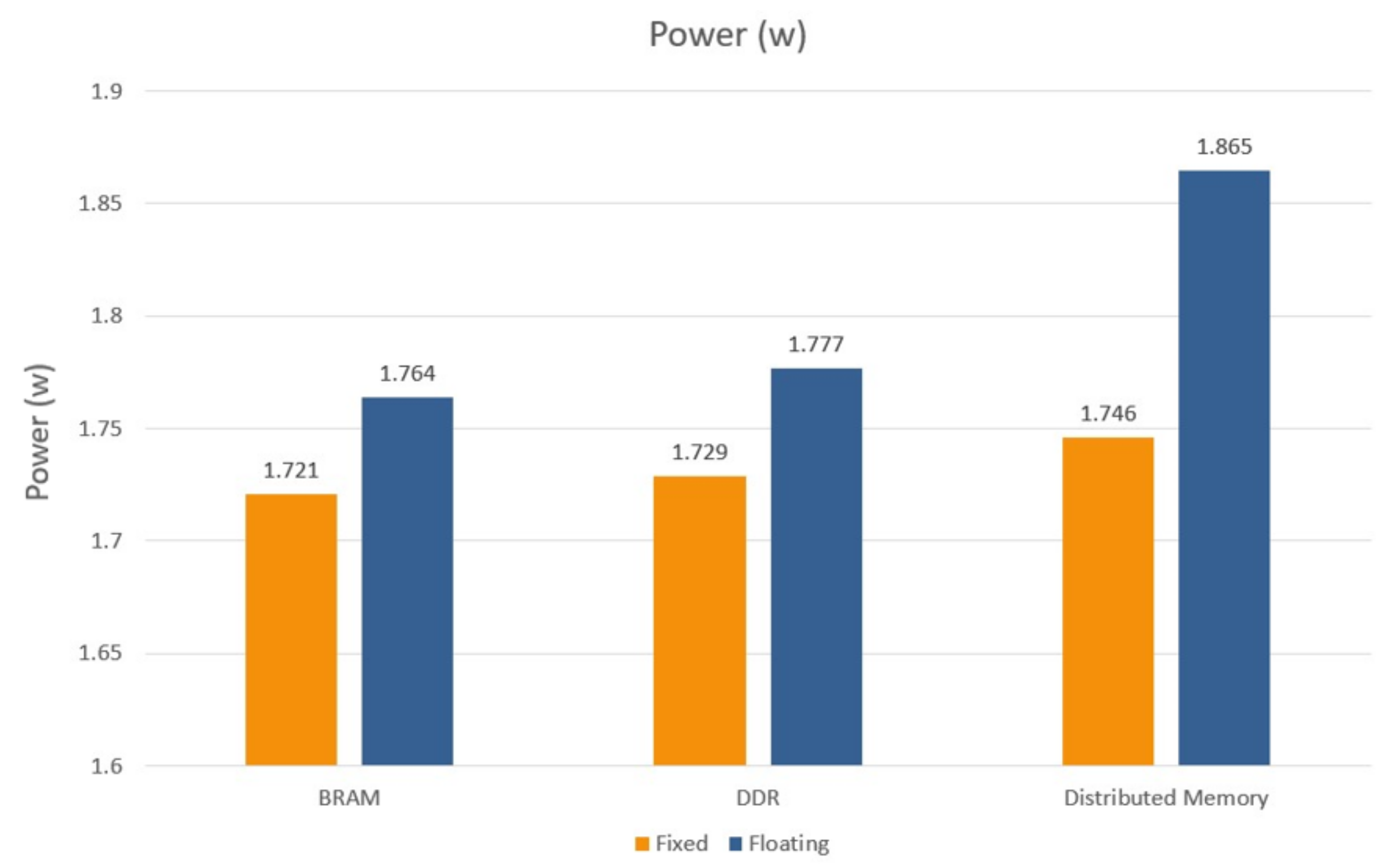
7.5. Power Consumption Analysis
7.6. Online Compatibility
7.7. Comparison with Existing Works
8. Conclusions
9. Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ADAM | (Adaptive Momentum) |
| ADP | (Area-Delay Product) |
| AI | (Artificial Intelligence) |
| ANN | (Artificial Neural Network) |
| AXI | (Advance eXtensible Interface) |
| BRAM | (Block RAM) |
| CalTrans | (California Transportation Agencies) |
| CNN | (Convolution Neural Network) |
| DBN | (Deep Belief Network) |
| DCRNN | (Diffusion Convolutional Recurrent Neural Network) |
| DSP | (Digital Signal Processing) |
| FF | (Flip Flop) |
| FPGA | (Field-Programmable Gate Array) |
| GBRT | (Gradient Boosting Regression Trees) |
| GD | Gradient Descent |
| HDL | (Hardware Design Language) |
| HLS | (High Level Synthesis) |
| ITS | (Intelligent Transport System) |
| LR | (Linear Regression) |
| LUT | (Look-Up Table) |
| LSTM | (Long Short Term Memory) |
| MAE | (Mean Absolute Error) |
| ML | (Machine Learning) |
| MLR | (Multiple Linear Regression) |
| MLP | (Multi-Layer Perceptron) |
| MTL | (Multi-Task regression Layer) |
| NN | (Neural Networks) |
| PeMs | (Performance Measurement System) |
| PL | (Programmable Logic) |
| PS | (Processing System) |
| Relu | (Rectifier Linear Unit) |
| RF | (Random Forest) |
| RMSE | (Root Mean Square Error) |
| RMSprop | (Root Mean Square Propagation) |
| SAE | (Stacked Auto Encoder) |
| SDK | (Software Development Kit) |
| SGD | (Stochastic Gradient Descent) |
| SVR | (Support Vector) |
| XGB | (Extreme Gradient Boosting Regression Trees) |
References
- Petrosino, A.; Maddalena, L. Neural networks in video surveillance: A perspective view. In Handbook on Soft Computing for Video Surveillance; Chapman and Hall/CRC: Boca Raton, FL, USA, 2012. [Google Scholar]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech Recognition Using Deep Neural Networks: A Systematic Review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Havaei, M.; Davy, A.; Warde-Farley, D.; Biard, A.; Courville, A.; Bengio, Y.; Pal, C.; Jodoin, P.; Larochelle, H. Brain Tumor Segmentation with Deep Neural Networks. Med. Image Anal. 2017, 35, 18–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, Y.; Hu, Z.; Uchimura, K.; Murayama, N. Driver Inattention Monitoring System for Intelligent Vehicles: A Review. IEEE Trans. Intell. Transp. Syst. 2011, 12, 596–614. [Google Scholar] [CrossRef]
- Goswami, S.; Chakraborty, S.; Ghosh, S.; Chakrabarti, A.; Chakraborty, B. A review on application of data mining techniques to combat natural disasters. Ain Shams Eng. J. 2016, 9, 365–378. [Google Scholar] [CrossRef] [Green Version]
- Ngai, E.W.; Xiu, L.; Chau, D.C. Application of data mining techniques in customer relationship management: A literature review and classification. Expert Syst. Appl. 2009, 36, 2592–2602. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, Y.; Zhan, D.; Liu, Z.; Jiang, Y. Complex Object Classification: A Multi-Modal Multi- Instance Multi-Label Deep Network with Optimal Transport. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2594–2603. [Google Scholar]
- Ghazwan, J. Application of neural network to optimize oil field production. Asian Trans. Eng. 2012, 2, 10–23. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training very deep networks. arXiv 2015, arXiv:1507.06228. [Google Scholar]
- Tan, H.H.; Lim, K.H. Vanishing Gradient Mitigation with Deep Learning Neural Network Optimization. In Proceedings of the 2019 7th International Conference on Smart Computing & Communications (ICSCC), Sarawak, Malaysia, 28–30 June 2019; pp. 1–4. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML’15), Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Choromanska, A.; Henaff, M.; Mathieu, M.; Arous, G.; LeCun, Y. The loss surfaces of multilayer networks. J. Mach. Learn. Res. 2015, 38, 192–204. [Google Scholar]
- Zhang, C.; Liu, L.; Lei, D.; Yuan, Q.; Zhuang, H.; Hanratty, T.; Han, J. TrioVecEvent: Embedding-Based Online Local Event Detection in Geo-Tagged Tweet Streams. In Proceedings of the 23rd ACM SIGKDD International Conference, Halifax, NS, Canada, 13–17 August 2017; pp. 595–604. [Google Scholar]
- Sahoo, D.; Pham, Q.; Lu, J.; Hoi, S.C.H. Online Deep Learning: Learning Deep Neural Networks on the Fly. arXiv 2017, arXiv:1711.03705. [Google Scholar]
- Yang, Y.; Zhou, D.; Zhan, D.; Xiong, H.; Jiang, Y. Adaptive Deep Models for Incremental Learning: Considering Capacity Scalability and Sustainability. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD’19), Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 74–82. [Google Scholar]
- Pratama, M.; Za’in, C.; Ashfahani, A.; Soon, O.; Ding, W. Automatic Construction of Multi-layer Perceptron Network from Streaming Examples. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM 2019), Beijing, China, 3–7 November 2019. [Google Scholar]
- Zinkevich, M. Online convex programming and generalized infinitesimal gradient ascent. In Proceedings of the Twentieth International Conference on Machine Learning (ICML’03), Washington, DC, USA, 21–24 August 2003; pp. 928–935. [Google Scholar]
- Hanafy, Y.A.; Gazya, M.; Mashaly, M.; Abd El Ghany, M.A. A Comparison between Adaptive Neural Networks Algorithms for Estimating Vehicle Travel Time. In Proceedings of the 15th International Conference on Computer Engineering and Systems (ICCES 2020), Cairo, Egypt, 15–16 December 2020. [Google Scholar]
- Kumar, K.; Parida, M.; Katiyar, V.K. Short term traffic flow prediction in heterogeneous condition using artificial neural network. Transport 2013, 30, 1–9. [Google Scholar] [CrossRef]
- Ma, X.; Dai, Z.; He, Z.; Ma, J.; Wang, Y.; Wang, Y. Learning Traffic as Images: A Deep Convolutional Neural Network for Large-Scale Transportation Network Speed Prediction. Sensors 2017, 17, 818. [Google Scholar] [CrossRef] [Green Version]
- Jin, Y.L.; Xu, W.R.; Wang, P.; Yan, J.Q. SAE network: A deep learning method for traffic flow prediction. In Proceedings of the 5th International Conference on Information, Cybernetics, and Computational Social Systems (ICCSS), Hangzhou, China, 16–19 August 2018; pp. 241–246. [Google Scholar]
- Zhao, X.; Gu, Y.; Chen, L.; Shao, Z. Urban Short-Term Traffic Flow Prediction Based on Stacked Autoencoder. In 19th COTA International Conference of Transportation Professionals; American Society of Civil Engineers: Nanjing, China, 2019; pp. 5178–5188. [Google Scholar]
- Zhao, P.; Cai, D.; Zhang, S.; Chen, F.; Zhang, Z.; Wang, C.; Li, J. Layerwise Recurrent Autoencoder for General Real-world Traffic Flow Forecasting. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018. [Google Scholar] [CrossRef]
- Alajali, W.; Zhou, W.; Wen, S. Traffic Flow Prediction for Road Intersection Safety. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 812–820. [Google Scholar]
- Sharma, B.; Agnihotri, S.; Tiwari, P.; Yadav, P.; Nezhurina, M. Ann based short-term traffic flow forecasting in undivided two lane highway. J. Big Data 2018, 5, 1–16. [Google Scholar] [CrossRef]
- Romeiko, X.X.; Guo, Z.; Pang, Y.; Lee, E.K.; Zhang, X. Comparing Machine Learning Approaches for Predicting Spatially Explicit Life Cycle Global Warming and Eutrophication Impacts from Corn Production. Sustainability 2020, 12, 1481. [Google Scholar] [CrossRef] [Green Version]
- Pun, L.; Zhao, P.; Liu, X. A multiple regression approach for traffic flow estimation. IEEE Access 2019, 7, 35998–36009. [Google Scholar] [CrossRef]
- Huang, W.; Song, G.; Hong, H.; Xie, K. Deep architecture for traffic flow prediction: Deep belief networks with multitask learning. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2191–2201. [Google Scholar] [CrossRef]
- Zhang, J.; Zheng, Y.; Qi, D. Deep spatio-temporal residual networks for citywide crowd flows prediction. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI’17), San Francisco, CA, USA, 4–9 February 2017; pp. 1655–1661. [Google Scholar]
- Yu, R.; Li, Y.; Shahabi, C.; Demiryurek, U.; Liu, Y. Deep Learning: A Generic Approach for Extreme Condition Traffic Forecasting. In Proceedings of the SIAM International Conference on Data Mining, Houston, TX, USA, 30 July 2017; pp. 777–785. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar]
- Zhou, J.; Chang, H.; Cheng, X.; Zhao, X. A Multiscale and High-Precision LSTM-GASVR Short-Term Traffic Flow Prediction Model. Complexity 2020. [Google Scholar] [CrossRef]
- Rusu, A.A.; Rabinowitz, N.C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; Hadsell, R. Progressive Neural Networks. arXiv 2016, arXiv:1606.04671. [Google Scholar]
- Jin, R.; Hoi, S.; Yang, T. Online multiple kernel learning: Algorithms and mistake bounds. In International Conference on Algorithmic Learning Theory; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6331, pp. 390–404. [Google Scholar]
- Sahoo, D.; Hoi, S.; Zhao, P. Cost Sensitive Online Multiple Kernel Classification. In Proceedings of the Eighth Asian Conference on Machine Learning, Hamilton, New Zealand, 16–18 November 2016; Volume 63, pp. 65–80. [Google Scholar]
- Lee, S.-W.; Lee, C.-Y.; Kwak, D.-H.; Kim, J.; Kim, J.; Zhang, B.-T. Dual-memory deep learning architectures for lifelong learning of everyday human behaviors. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI), New York, NY, USA, 9–15 July 2016; pp. 1669–1675. [Google Scholar]
- Yoon, J.; Yang, E.; Lee, J.; Hwang, S.J. Lifelong learning with dynamically expandable networks. arXiv 2017, arXiv:1708.01547. [Google Scholar]
- Misra, J.; Saha, I. Artifcial neural networks in hardware: A survey of two decades of progress. Neurocomputing 2010, 74, 239–255. [Google Scholar] [CrossRef]
- Subadra, M.; Lakshmi, K.P.; Sundar, J.; MathiVathani, K. Design and implementation of multilayer perceptron with on-chip learning in virtex-e. AASRI Procedia 2014, 6, 82–88. [Google Scholar]
- Gaikwad, N.B.; Tiwari, V.; Keskar, A.; Shivaprakash, N.C. Efficient fpga implementation of multilayer perceptron for real-time human activity classification. IEEE Access 2019, 7, 26696–26706. [Google Scholar] [CrossRef]
- Ortigosa, E.M.; Ortigosa, P.M.; Cañas, A.; Ros, E.; Agís, R.; Ortega, J. Fpga implementation of multi-layer perceptrons for speech recognition. In Field Programmable Logic and Application; Springer: Berlin/Heidelberg, Germany, 2003; pp. 1048–1052. [Google Scholar]
- Basterretxea, K.; Echanobe, J.; del Campo, I. A wearable human activity recognition system on a chip. In Proceedings of the 2014 Conference on Design and Architectures for Signal and Image Processing, Madrid, Spain, 8–10 October 2014; pp. 1–8. [Google Scholar]
- Chalhoub, N.; Muller, F.; Auguin, M. Fpga-based generic neural network architecture. In Proceedings of the 2006 International Symposium on Industrial Embedded Systems, Antibes Juan-Les-Pins, France, 18–20 October 2006; pp. 1–4. [Google Scholar]
- Alilat, F.; Yahiaoui, R. Mlp on fpga: Optimal coding of data and activation Function. In Proceedings of the 10th IEEE International Conference on Intelligent Data Acqui-sition and Advanced Computing Systems: Technology and Applications (IDAACS), Metz, France, 18–21 September 2019; Volume 1, pp. 525–529. [Google Scholar]
- Zhai, X.; Ali, A.A.S.; Amira, A.; Bensaali, F. MLP Neural Network Based Gas Classification System on Zynq SoC. IEEE Access 2016, 4, 8138–8146. [Google Scholar] [CrossRef]
- Pano-Azucena, A.; Tlelo-Cuautle, E.; Tan, S.; Ovilla-Martinez, B.; de la Fraga, L. Fpga-based implementation of a multilayer perceptron suitable for chaotic time series prediction. Technologies 2018, 6, 90. [Google Scholar] [CrossRef] [Green Version]
- Jia, T.; Guo, T.; Wang, X.; Zhao, D.; Wang, C.; Zhang, Z.; Lei, S.; Liu, W.; Liu, H.; Li, X. Mixed natural gas online recognition device based on a neural network algorithm implemented by an fpga. Sensors 2019, 19, 2090. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.; Sanjeevi, S.; Suma, V.; Talashi, A. Fpga implementation of a trained neural network. IOSR J. Electron. Commun. Eng. IOSR JECE 2015, 10, 45–54. [Google Scholar]
- Zhang, L. Artificial neural network model-based design and fixed-point FPGA implementation of hénon map chaotic system for brain research. In Proceedings of the 2017 IEEE XXIV International Conference on Electronics, Electrical Engineering and Computing (INTERCON), Cusco, Peru, 15–18 August 2017; pp. 1–4. [Google Scholar]
- Bahoura, M. FPGA Implementation of Blue Whale Calls Classifier Using High-Level Programming Tool. Electronics 2016, 5, 8. [Google Scholar] [CrossRef] [Green Version]
- Bratsas, C.; Koupidis, K.; Salanova, J.-M.; Giannakopoulos, K.; Kaloudis, A.; Aifadopoulou, G. A Comparison of Machine Learning Methods for the Prediction of Traffic Speed in Urban Places. Sustainability 2020, 12, 142. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hoi, S.C.H.; Sahoo, D.; Lu, J.; Zhao, P. Online Learning: A Comprehensive Survey. arXiv 2018, arXiv:1802.02871. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of online learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Caltrans, Performance Measurement System (PeMS). Available online: http://pems.dot.ca.gov/ (accessed on 17 May 2020).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Batch Size | MAE |
|---|---|---|
| MLP | 1 | 0.077 |
| MLP | 5 | 0.107 |
| MLP | 10 | 0.126 |
| MLP | 15 | 0.074 |
| MLR | 41,126 | 0.0519 |
| HBP | 1 | 0.001 |
| Memory | Operation | System Time (ns) | IP Time (ns) |
|---|---|---|---|
| DDR | Fixed | 8440 | 450 |
| Floating | 9640 | 940 | |
| BRAM | Fixed | 560 | 420 |
| Floating | 1560 | 850 | |
| DM | Fixed | 340 | 150 |
| Floating | 1540 | 840 |
| Work | Topology | Memory | Data Precision | LUT | FF | BRAM | DSP | Latency ns | ADP |
|---|---|---|---|---|---|---|---|---|---|
| [41] | 7-6-5 | Distributed Memory | Fixed 16 bits | 3466 | 569 | 0 | 81 | 270 | 4.3 |
| [45] | 32-3-4 | Distributed Memory | Fixed 8 bit | 2798 | 1538 | 7 | 12 | 680 | 24.5 |
| [46] | 12-3-1 | Distributed Memory | Fixed 24 bit | 4032 | 2863 | 2 | 28 | 540 | 34.9 |
| [51] | 12-7-3 | Distributed Memory | Fixed 24 bit | 21,648 | 13,330 | 2 | 219 | 19,968 | 252,380 |
| [43] | 14-19-19-7 | Distributed Memory | Fixed 16 bits | 5432 | 2175 | 65 | 19 | 800 | 1167 |
| [40] | 2-2-1 | Distributed Memory | Floating | 61,386 | 32,015 | 0 | 0 | 605 | 118.89 |
| This Work | 6-1/6-1 | BRAM | Fixed 24 bit | 2825 | 210 | 0 | 10 | 420 | 0.245 |
| This Work | 6-1/6-1 | Distributed Memory | Fixed 24 bit | 2222 | 604 | 0 | 11 | 150 | 0.177 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hanafy, Y.A.; Mashaly, M.; Abd El Ghany, M.A. An Efficient Hardware Design for a Low-Latency Traffic Flow Prediction System Using an Online Neural Network. Electronics 2021, 10, 1875. https://doi.org/10.3390/electronics10161875
Hanafy YA, Mashaly M, Abd El Ghany MA. An Efficient Hardware Design for a Low-Latency Traffic Flow Prediction System Using an Online Neural Network. Electronics. 2021; 10(16):1875. https://doi.org/10.3390/electronics10161875
Chicago/Turabian StyleHanafy, Yasmin Adel, Maggie Mashaly, and Mohamed A. Abd El Ghany. 2021. "An Efficient Hardware Design for a Low-Latency Traffic Flow Prediction System Using an Online Neural Network" Electronics 10, no. 16: 1875. https://doi.org/10.3390/electronics10161875
APA StyleHanafy, Y. A., Mashaly, M., & Abd El Ghany, M. A. (2021). An Efficient Hardware Design for a Low-Latency Traffic Flow Prediction System Using an Online Neural Network. Electronics, 10(16), 1875. https://doi.org/10.3390/electronics10161875