
Case Study on Integrated Architecture for In-Memory and In-Storage Computing



Abstract
:1. Introduction
- This paper makes the following contributions:
- The requirements of the task are analyzed from the memory and storage points of view.
- An integrated architecture for in-memory and in-storage computing is proposed, and its implementation is verified on a prototyping system.
- Possible performance improvement is shown in terms of execution time and energy.
2. Background and Related Work
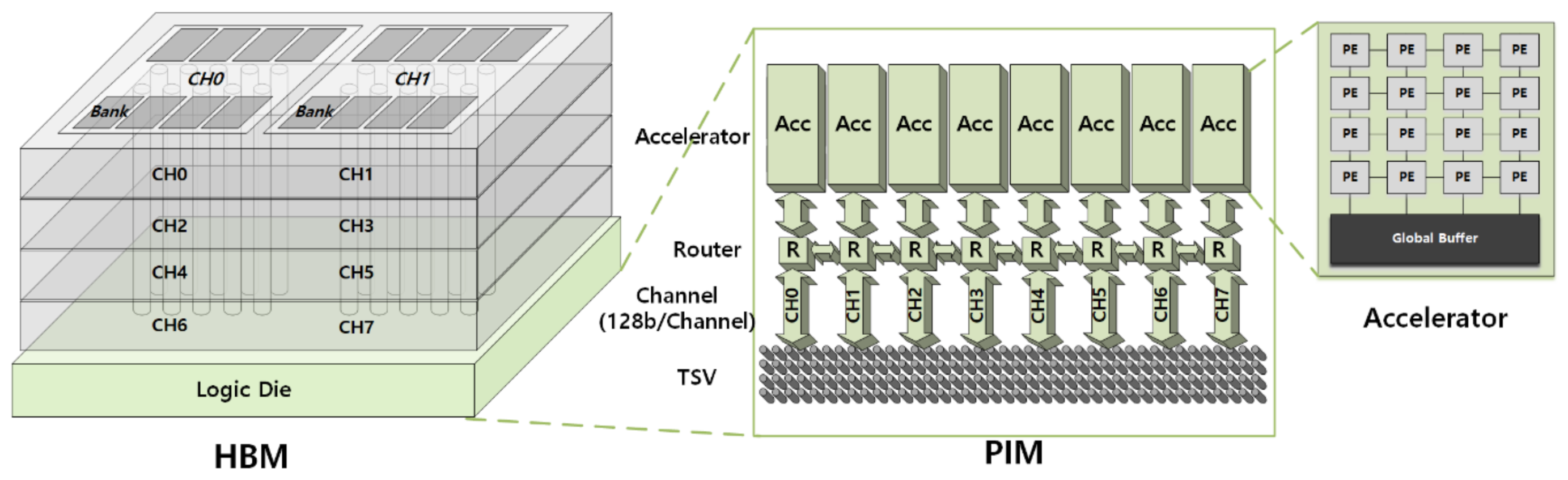
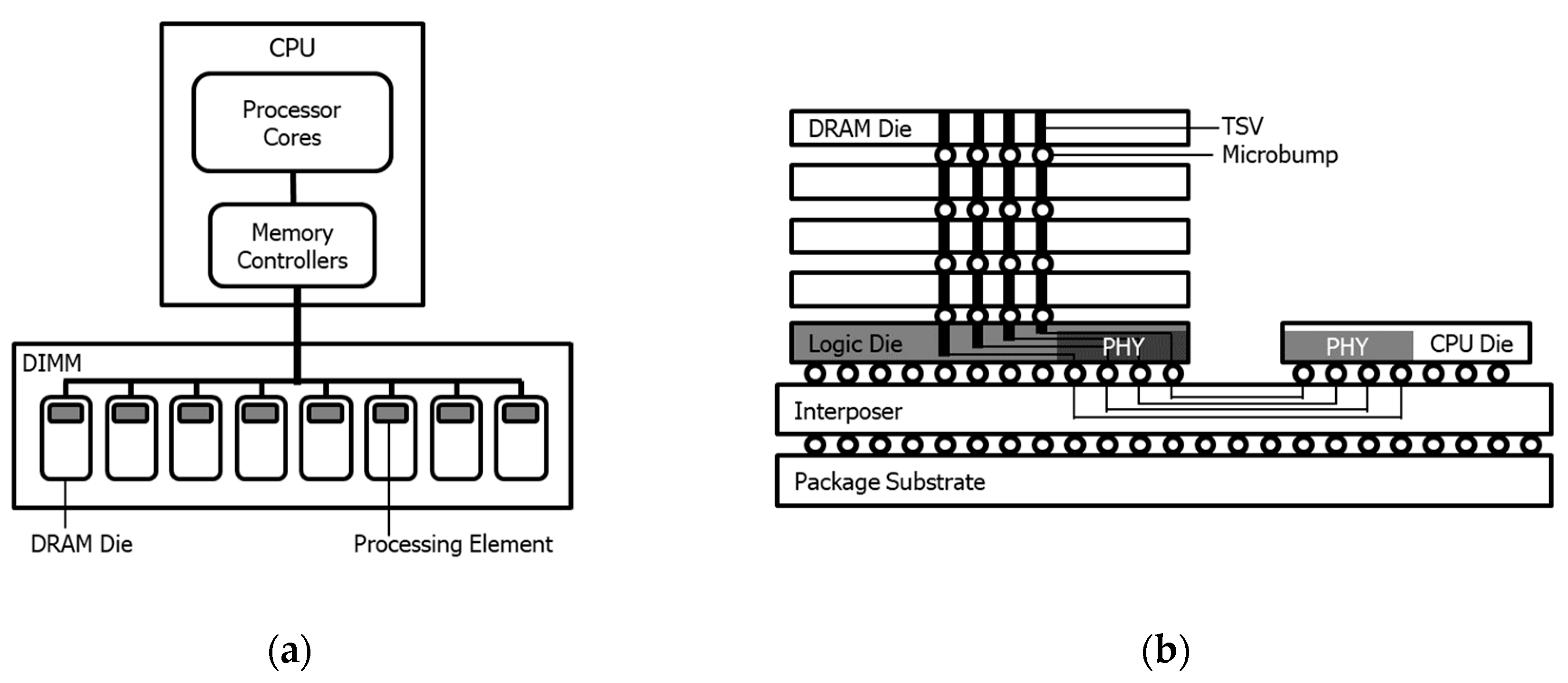
2.1. In-Memory Computing
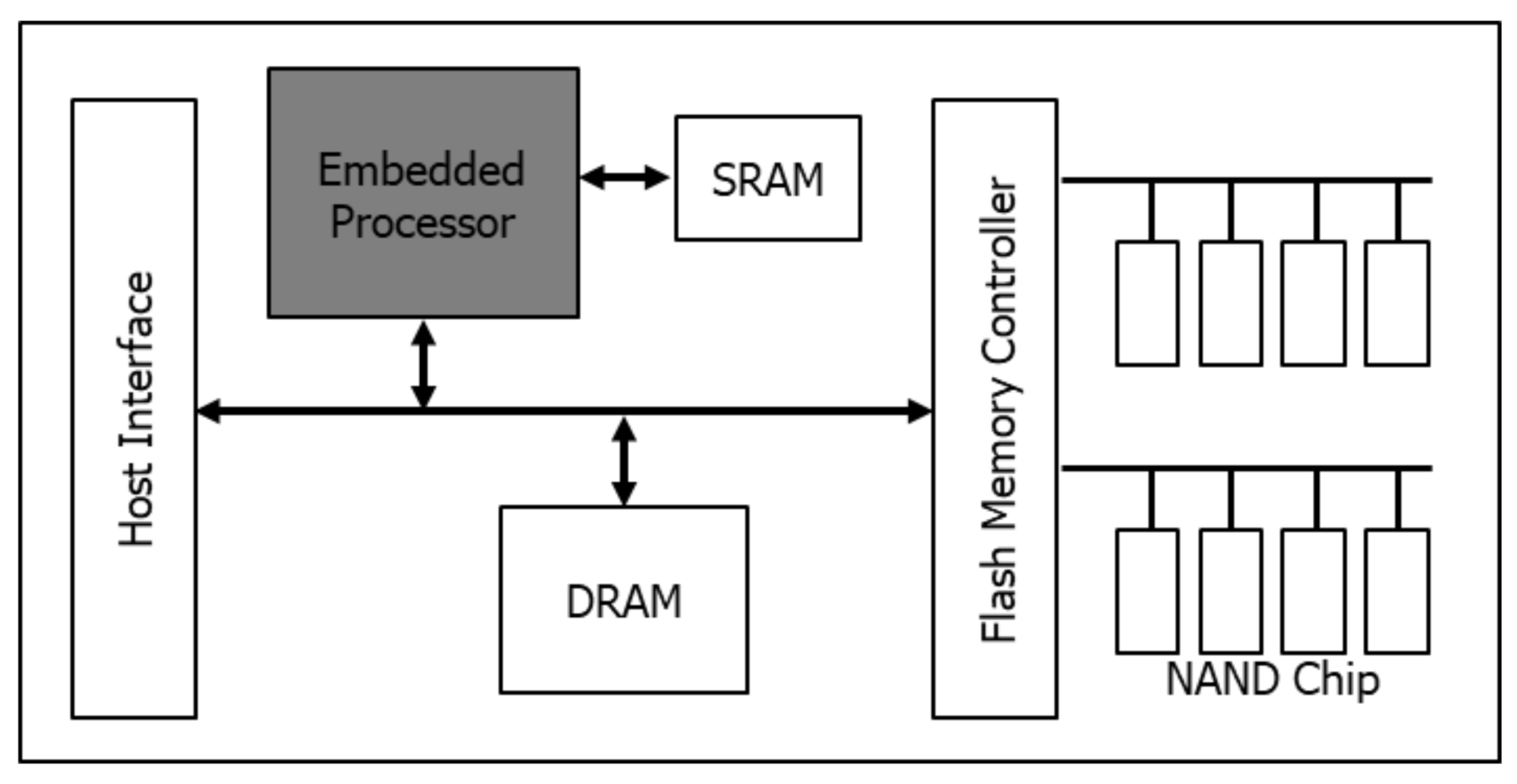
2.2. In-Storage Computing
2.3. Integrated Solution of In-Memory and In-Storage Computing
3. A Case Study on Integrated Architecture for In-Memory and In-Storage Computing
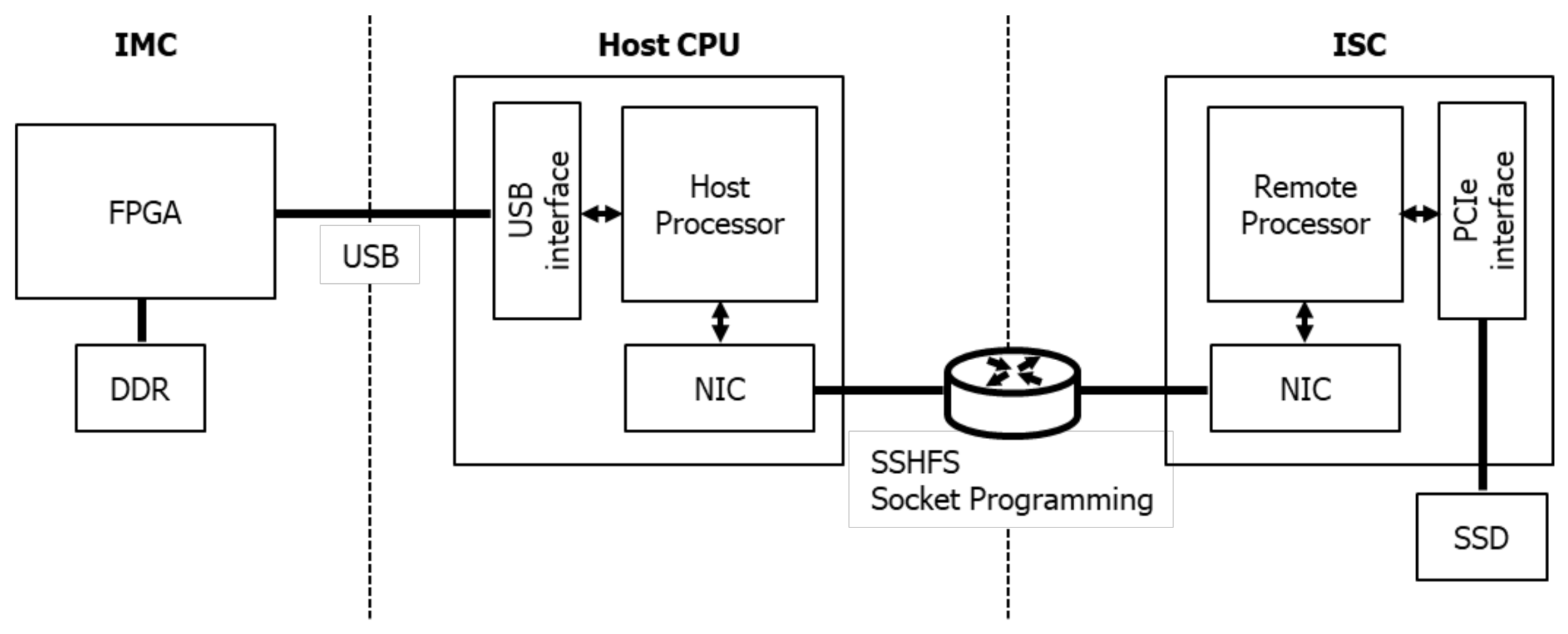
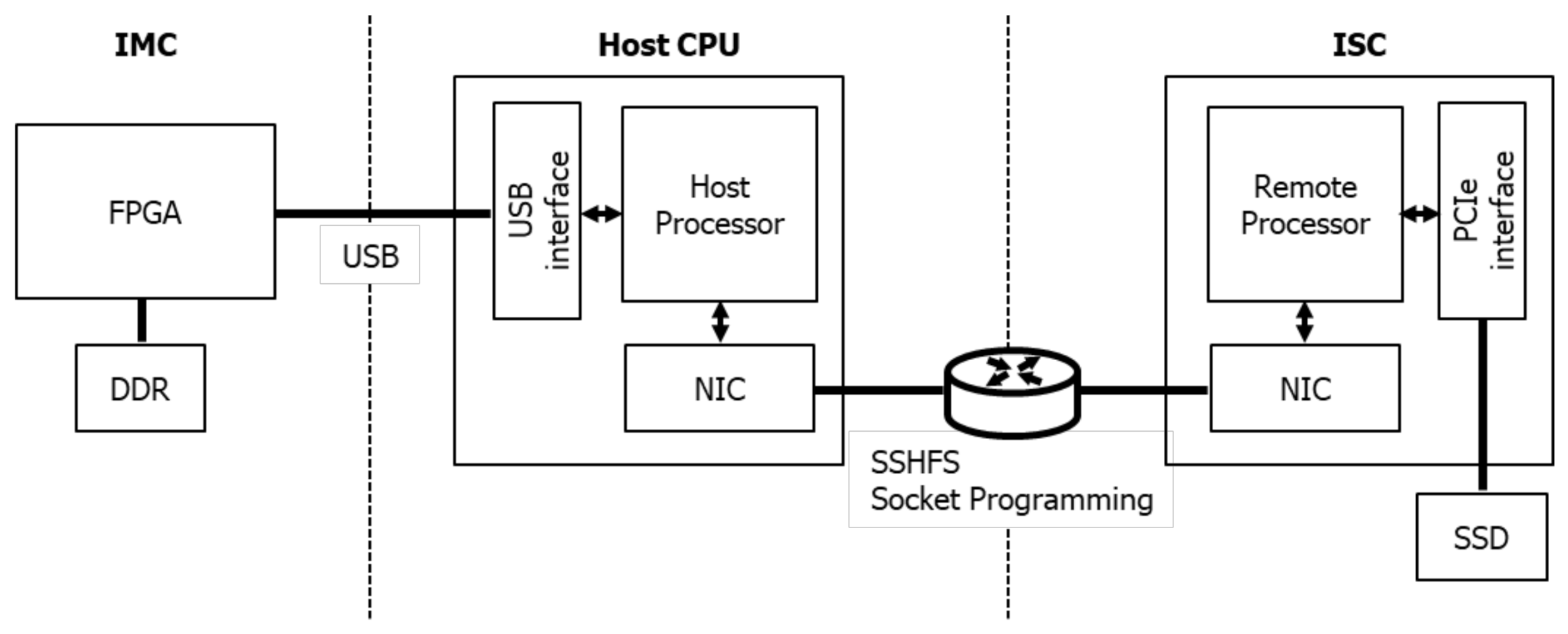
3.1. Prototype Platform
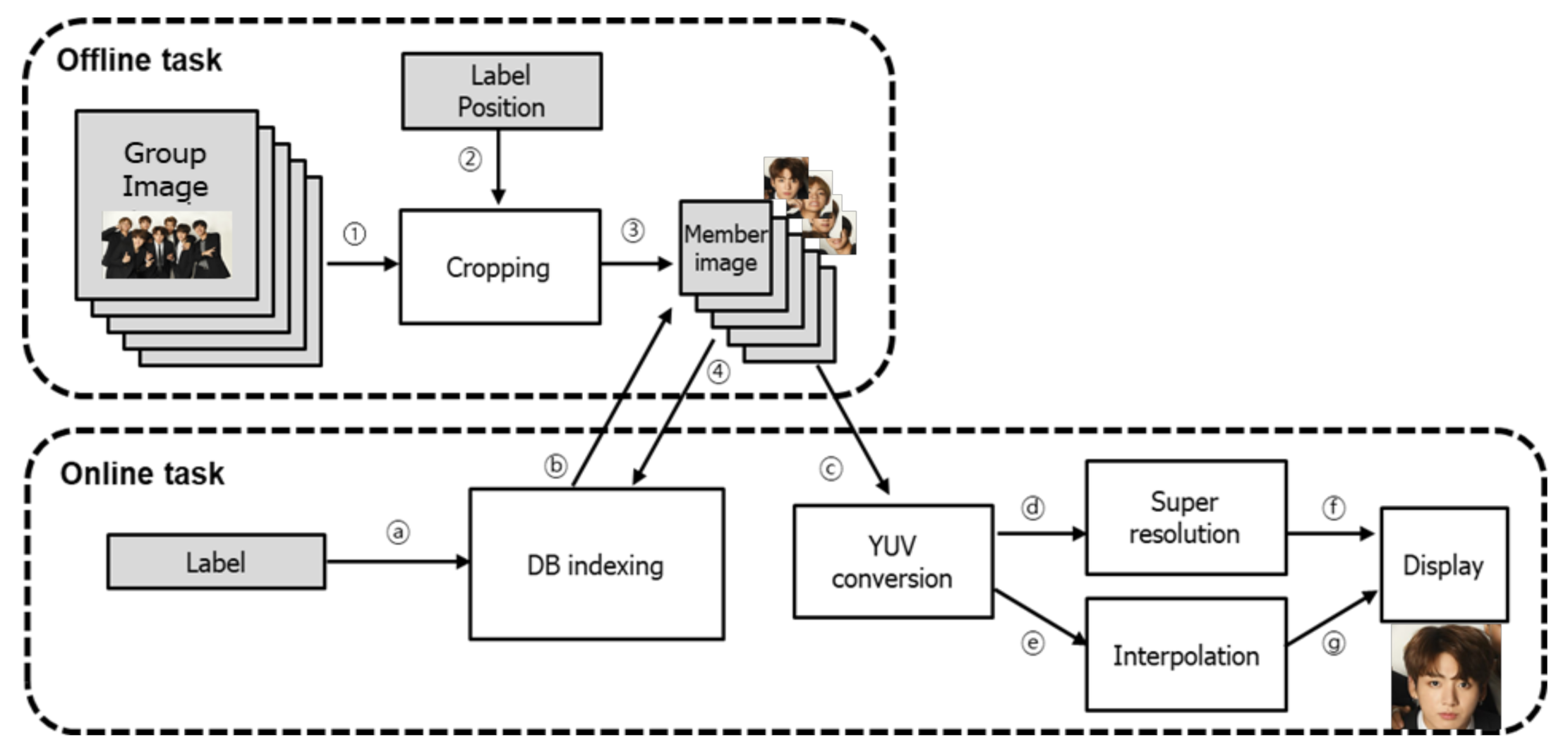
3.2. Workload Analysis from the Perspective of Data Accesses
3.3. Application to Integrated In-Memory and In-Storage Computing
4. Experimental Results
4.1. Experimental Environment
4.2. Processing Time and Energy Comparison for On-Line Phase
4.3. Processing Time and Energy Comparison for Off-Line Phase
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Balasubramonian, R.; Chang, J.; Manning, T.; Moreno, J.H.; Murphy, R.; Nair, R.; Swanson, S. Near-data processing: Insights from a micro-46 workshop. IEEE Micro 2014, 34, 36–42. [Google Scholar] [CrossRef]
- Li, S.; Niu, D.; Malladi, K.T.; Zheng, H.; Brennan, B.; Xie, Y. Drisa: A dram-based reconfigurable in-situ accelerator. In Proceedings of the 2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Cambridge, MA, USA, 14–18 October 2017; pp. 288–301. [Google Scholar]
- Gu, B.; Yoon, A.S.; Bae, D.H.; Jo, I.; Lee, J.; Yoon, J.; Kang, J.U.; Kwon, M.; Yoon, C.; Cho, S.; et al. Biscuit: A framework for near-data processing of big data workloads. ACM Sigarch Comput. Archit. News 2016, 44, 153–165. [Google Scholar] [CrossRef]
- Eckert, C.; Wang, X.; Wang, J.; Subramaniyan, A.; Iyer, R.; Sylvester, D.; Blaaauw, D.; Das, R. Neural cache: Bit-serial in-cache acceleration of deep neural networks. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018; pp. 383–396. [Google Scholar]
- Jiang, Z.; Yin, S.; Seo, J.S.; Seok, M. C3SRAM: In-Memory-Computing SRAM macro based on capacitive-coupling computing. IEEE Solid-State Circuits Lett. 2019, 2, 131–134. [Google Scholar] [CrossRef]
- Seshadri, V.; Lee, D.; Mullins, T.; Hassan, H.; Boroumand, A.; Kim, J.; Kozuch, M.A.; Mutlu, O.; Gibbons, P.B.; Mowry, T.C. Ambit: In-memory accelerator for bulk bitwise operations using commodity DRAM technology. In Proceedings of the 2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Cambridge, MA, USA, 14–18 October 2017; pp. 273–287. [Google Scholar]
- Asghari-Moghaddam, H.; Son, Y.H.; Ahn, J.H.; Kim, N.S. Chameleon: Versatile and practical near-DRAM acceleration architecture for large memory systems. In Proceedings of the 2016 49th annual IEEE/ACM international symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–13. [Google Scholar]
- Farmahini-Farahani, A.; Ahn, J.H.; Morrow, K.; Kim, N.S. NDA: Near-DRAM acceleration architecture leveraging commodity DRAM devices and standard memory modules. In Proceedings of the 2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), Burlingame, CA, USA, 7–11 February 2015; pp. 283–295. [Google Scholar]
- Hsieh, K.; Ebrahimi, E.; Kim, G.; Chatterjee, N.; O’Connor, M.; Vijaykumar, N.; Mutlu, O.; Keckler, S.W. Transparent offloading and mapping (TOM) enabling programmer-transparent near-data processing in GPU systems. ACM Sigarch Comput. Archit. News 2016, 44, 204–216. [Google Scholar] [CrossRef]
- Zhang, D.; Jayasena, N.; Lyashevsky, A.; Greathouse, J.L.; Xu, L.; Ignatowski, M. TOP-PIM: Throughput-oriented programmable processing in memory. In Proceedings of the 23rd international symposium on High-performance parallel and distributed computing, Vancouver, BC, Canada, 23–27 June 2014; pp. 85–98. [Google Scholar]
- Li, S.; Xu, C.; Zou, Q.; Zhao, J.; Lu, Y.; Xie, Y. Pinatubo: A processing-in-memory architecture for bulk bitwise operations in emerging non-volatile memories. In Proceedings of the 53rd Annual Design Automation Conference, Austin, TX, USA, 5–9 June 2016; pp. 1–6. [Google Scholar]
- Kang, W.; Wang, H.; Wang, Z.; Zhang, Y.; Zhao, W. In-memory processing paradigm for bitwise logic operations in STT–MRAM. IEEE Trans. Magn. 2017, 53, 1–4. [Google Scholar]
- Chi, P.; Li, S.; Xu, C.; Zhang, T.; Zhao, J.; Liu, Y.; Wang, Y.; Xie, Y. Prime: A novel processing-in-memory architecture for neural network computation in reram-based main memory. Acm Sigarch Comput. Archit. News 2016, 44, 27–39. [Google Scholar] [CrossRef]
- Acharya, A.; Uysal, M.; Saltz, J. Active disks: Programming model, algorithms and evaluation. ACM Sigops Oper. Syst. Rev. 1998, 32, 81–91. [Google Scholar] [CrossRef]
- Seshadri, S.; Gahagan, M.; Bhaskaran, S.; Bunker, T.; De, A.; Jin, Y.; Liu, Y.; Swanson, S. Willow: A user-programmable {SSD}. In Proceedings of the 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14), Broomfield, CO, USA, 4–6 November 2014; pp. 67–80. [Google Scholar]
- Zhang, J.; Kwon, M.; Kim, H.; Kim, H.; Jung, M. Flashgpu: Placing new flash next to gpu cores. In Proceedings of the 2019 56th ACM/IEEE Design Automation Conference (DAC), Las Vegas, NV, USA, 2 June 2019; pp. 1–6. [Google Scholar]
- Do, J.; Kee, Y.S.; Patel, J.M.; Park, C.; Park, K.; DeWitt, D.J. Query processing on smart ssds: Opportunities and challenges. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 1221–1230. [Google Scholar]
- Wang, J.; Park, D.; Kee, Y.S.; Papakonstantinou, Y.; Swanson, S. Ssd in-storage computing for list intersection. In Proceedings of the 12th International Workshop on Data Management on New Hardware, San Francisco, CA, USA, 27 June 2016; pp. 1–7. [Google Scholar]
- Kim, S.; Oh, H.; Park, C.; Cho, S.; Lee, S.W.; Moon, B. In-storage processing of database scans and joins. Inf. Sci. 2016, 327, 183–200. [Google Scholar] [CrossRef]
- Park, D.; Wang, J.; Kee, Y.S. In-storage computing for Hadoop MapReduce framework: Challenges and possibilities. IEEE Trans. Comput. 2016. [Google Scholar] [CrossRef]
- Lee, J.; Kim, H.; Yoo, S.; Choi, K.; Hofstee, H.P.; Nam, G.J.; Nutter, M.R.; Jamsek, D. Extrav: Boosting graph processing near storage with a coherent accelerator. Proc. Vldb Endow. 2017, 10, 1706–1717. [Google Scholar] [CrossRef]
- Cho, B.Y.; Jeong, W.S.; Oh, D.; Ro, W.W. Xsd: Accelerating mapreduce by harnessing the GPU inside an SSD. In Proceedings of the 1st Workshop on Near-Data Processing, Davis, CA, USA, 8 December 2013. [Google Scholar]
- Kaplan, R.; Yavits, L.; Ginosar, R. Prins: Processing-in-storage acceleration of machine learning. IEEE Trans. Nanotechnol. 2018, 17, 889–896. [Google Scholar] [CrossRef]
- Alian, M.; Min, S.W.; Asgharimoghaddam, H.; Dhar, A.; Wang, D.K.; Roewer, T.; McPadden, A.; O’Halloran, O.; Chen, D.; Xiong, J.; et al. Application-transparent near-memory processing architecture with memory channel network. In Proceedings of the 2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Fukuoka, Japan, 20–24 October 2018; pp. 802–814. [Google Scholar]
- Dhar, A.; Huang, S.; Xiong, J.; Jamsek, D.; Mesnet, B.; Huang, J.; Kim, N.S.; Hwu, W.M.; Chen, D. Near-memory and in-storage FPGA acceleration for emerging cognitive computing workloads. In Proceedings of the 2019 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Miami, FL, USA, 15–17 July 2019; pp. 68–75. [Google Scholar]
- Lee, J.; Kim, S.; Kim, S.; Park, J.; Sohn, K. Context-aware emotion recognition networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 10143–10152. [Google Scholar]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2016, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Gao, M.; Pu, J.; Yang, X.; Horowitz, M.; Kozyrakis, C. Tetris: Scalable and efficient neural network acceleration with 3d memory. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, Xi’an, China, 8–12 April 2017; pp. 751–764. [Google Scholar]
- Muralimanohar, N.; Balasubramonian, R.; Jouppi, N.P. CACTI 6.0: A tool to model large caches. Hp Lab. 2009, 1, 1–24. [Google Scholar]
- Kahng, A.B.; Li, B.; Peh, L.S.; Samadi, K. ORION 2.0: A fast and accurate NoC power and area model for early-stage design space exploration. In Proceedings of the 2009 Design, Automation & Test in Europe Conference & Exhibition (DATE), Nice, France, 20–24 April 2009; pp. 423–428. [Google Scholar]
- Chandrasekar, K.; Weis, C.; Akesson, B.; Wehn, N.; Goossens, K. DRAMPower: Open-Source Dram Power & Energy Estimation Tool. Available online: http://www.drampower.info (accessed on 17 July 2021).
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The gem5 simulator. Acm Sigarch Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Kim, J.S.; Oh, C.S.; Lee, H.; Lee, D.; Hwang, H.R.; Hwang, S.; Na, B.; Moon, J.; Kim, J.G.; Park, H.; et al. A 1.2 V 12.8 GB/s 2 Gb Mobile Wide-I/O DRAM With 4 x 128 I/Os Using TSV Based Stacking. IEEE J. Solid-State Circuits 2011, 47, 107–116. [Google Scholar] [CrossRef]
- Chandrasekar, K.; Weis, C.; Akesson, B.; Wehn, N.; Goossens, K. System and circuit level power modeling of energy-efficient 3D-stacked wide I/O DRAMs. In Proceedings of the 2013 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 18–22 March 2013; pp. 236–241. [Google Scholar]
- Jangam, S.; Bajwa, A.A.; Thankkappan, K.K.; Kittur, P.; Iyer, S.S. Electrical characterization of high performance fine pitch interconnects in silicon-interconnect fabric. In Proceedings of the 2018 IEEE 68th Electronic Components and Technology Conference (ECTC), San Diego, CA, USA, 29 May–1 June 2018; pp. 1283–1288. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Data Flow | Data Size | Latency Requirement |
|---|---|---|---|
| Focus fancam | Cropping (①, ②, ③) | 150 KB, 12 bytes, 20 KB | Slow |
| Index table update (④) | 64 bytes | Slow | |
| Index table retrieval (ⓐ, ⓑ) | 4 bytes, 64 bytes | Fast | |
| YUV conversion (ⓒ, ⓓ, ⓔ) | 20 KB, 256 KB, 128 KB | Fast | |
| Y super resolution (ⓓ, ⓕ) | 256 KB, 1 MB | Fast | |
| UV interpolation (ⓔ, ⓖ) | 128 KB, 512 KB | Fast |
| Tasks | Runtime (ms) | Energy (mJ) | ||
|---|---|---|---|---|
| Baseline | Proposed IMC | Baseline | Proposed IMC | |
| YUV Conversion | 566.7 | 63,958 | ||
| SR | 2307.6 | 72.8 | 260,691 | 336 |
| Interpolation | 11.1 | 1254 | ||
| Data Movement | 8.5 | 1.0 | 8640 | 6810 |
| Total | 2893.9 | 651.6 | 334,543 | 72,358 |
| Case | DRAM Type (Density) | Bandwidth (GB/s) | Total I/O Pins | Channel | Accelerator | Global Buffer (KB) |
|---|---|---|---|---|---|---|
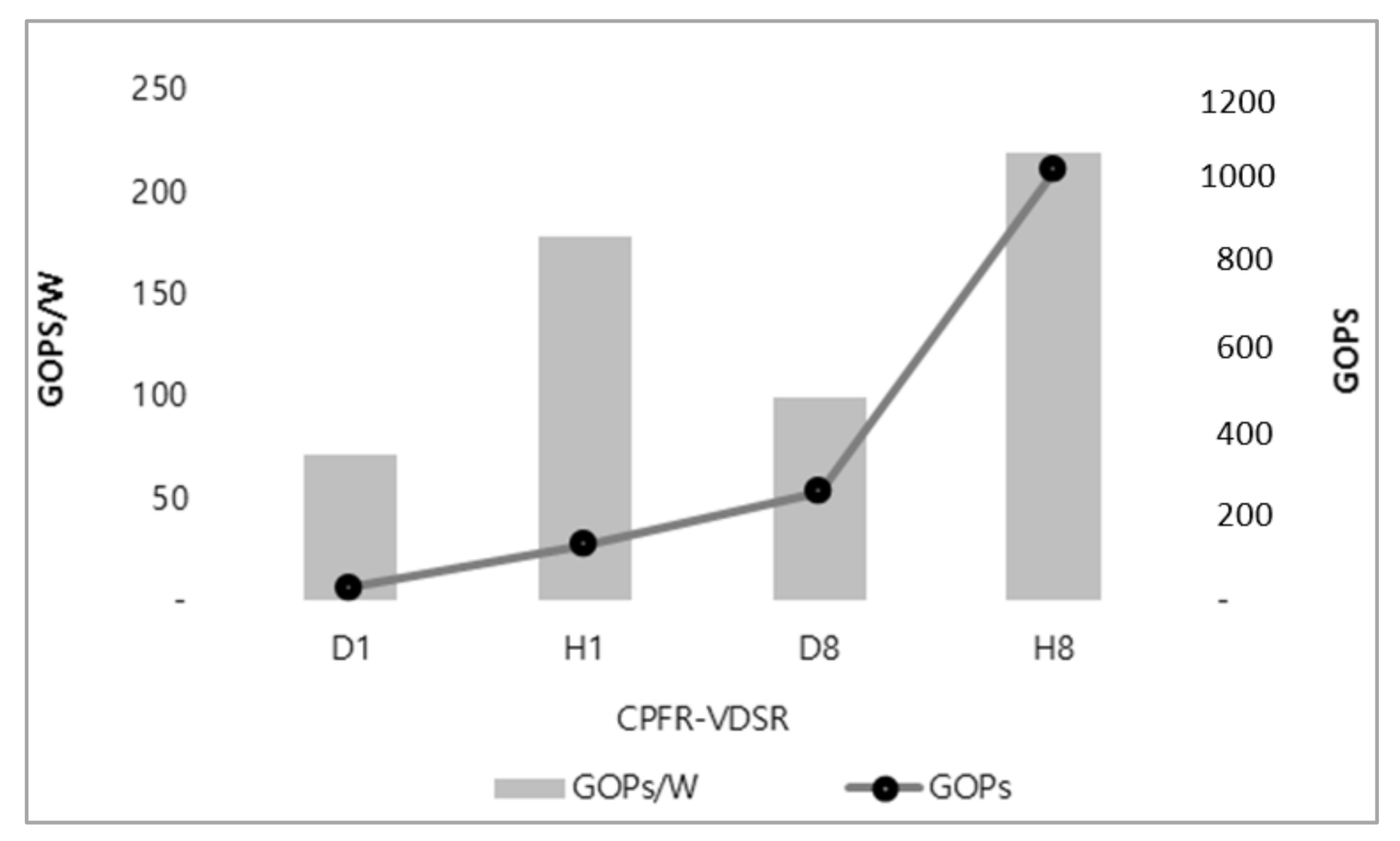
| D1 | DDR4 (512MB) | 2.4 | 8 | 1 | 1 | 108 |
| H1 | HBM2 (512MB) | 32.0 | 128 | 1 | 1 | 64 |
| D8 | DDR4 (4GB) | 19.2 | 64 | 8 | 8 | 864 |
| H8 | HBM2 (4GB) | 256.0 | 1024 | 8 | 8 | 512 |
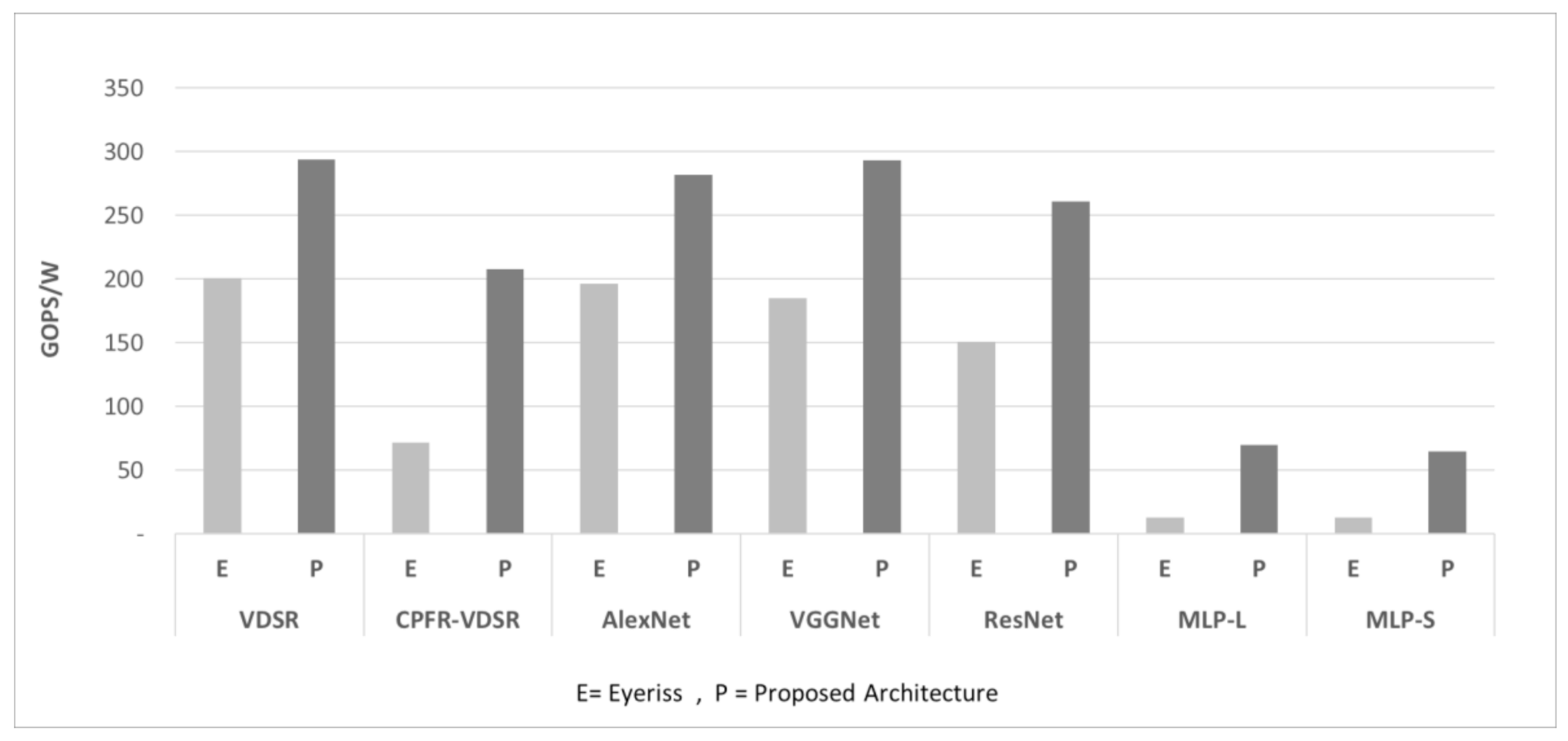
| CPU | Core | CoreMark/Mhz | GOPS | GOPS/w | Power (W) |
|---|---|---|---|---|---|
| i7-7700k (Baseline) | 4 | 6.05 | 140.2 | 1.24 | 113.1 |
| Cortex R5 (Proposed ISC) | 2 | 3.47 | 12.8 | 5.61 | 2.3 |
| CPU | Time | Energy (J) | |||
|---|---|---|---|---|---|
| (ms) | Processing | DRAM | SSD | Total | |
| i7-7700k (baseline) | 115 | 12.980 | 2.459 | 0.007 | 15.446 |
| Cortex R5 (proposed ISC) | 1258 | 2.868 | 0.718 | 0.046 | 3.632 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Kim, S.-H.; Lee, H.-J.; Rhee, C.-E. Case Study on Integrated Architecture for In-Memory and In-Storage Computing. Electronics 2021, 10, 1750. https://doi.org/10.3390/electronics10151750
Kim M, Kim S-H, Lee H-J, Rhee C-E. Case Study on Integrated Architecture for In-Memory and In-Storage Computing. Electronics. 2021; 10(15):1750. https://doi.org/10.3390/electronics10151750
Chicago/Turabian StyleKim, Manho, Sung-Ho Kim, Hyuk-Jae Lee, and Chae-Eun Rhee. 2021. "Case Study on Integrated Architecture for In-Memory and In-Storage Computing" Electronics 10, no. 15: 1750. https://doi.org/10.3390/electronics10151750
APA StyleKim, M., Kim, S.-H., Lee, H.-J., & Rhee, C.-E. (2021). Case Study on Integrated Architecture for In-Memory and In-Storage Computing. Electronics, 10(15), 1750. https://doi.org/10.3390/electronics10151750