
Head Detection Based on DR Feature Extraction Network and Mixed Dilated Convolution Module


Abstract
:1. Introduction
2. Related Works
2.1. Image Feature Extraction Network
2.2. Head Detection
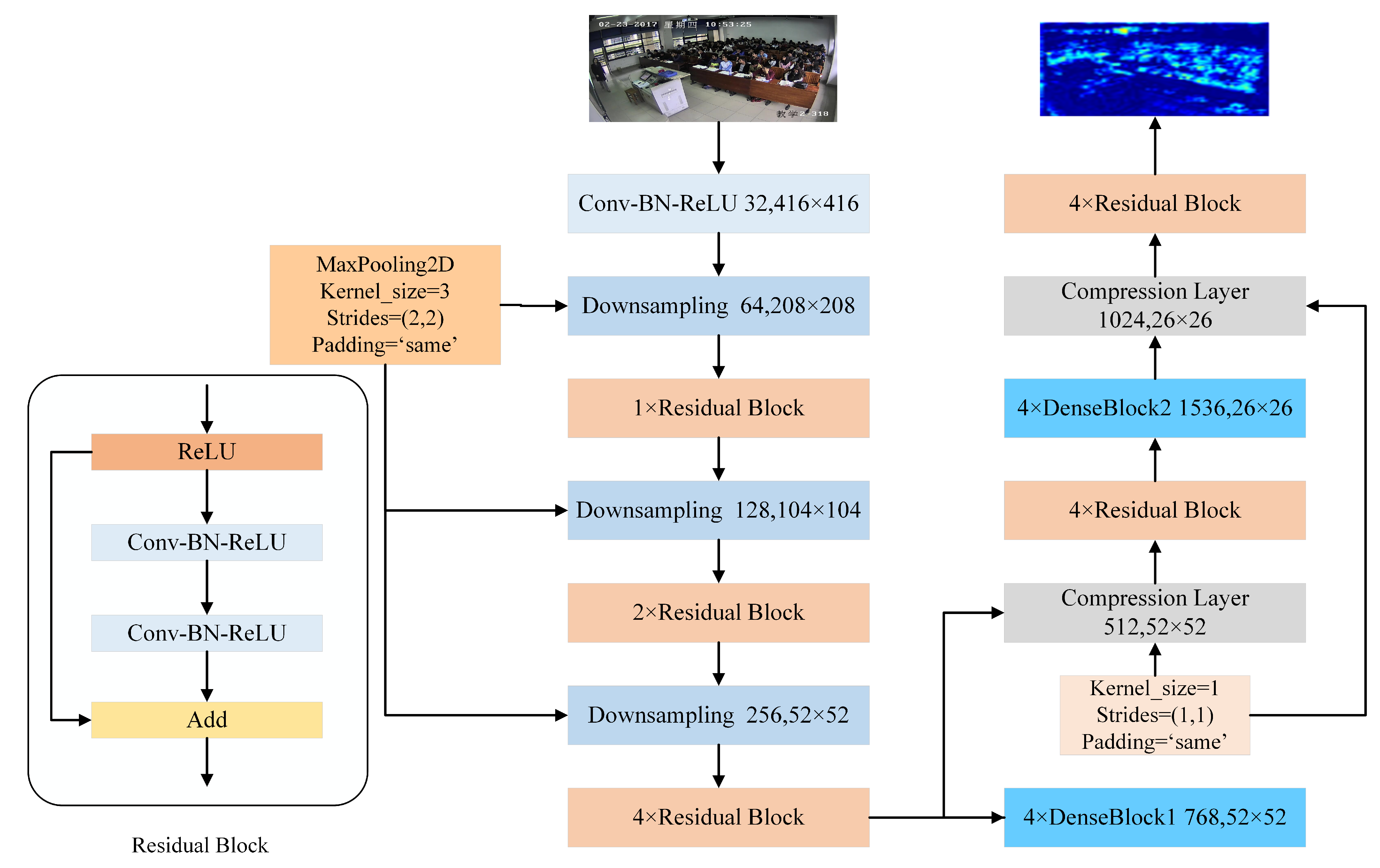
3. Proposed Methodology
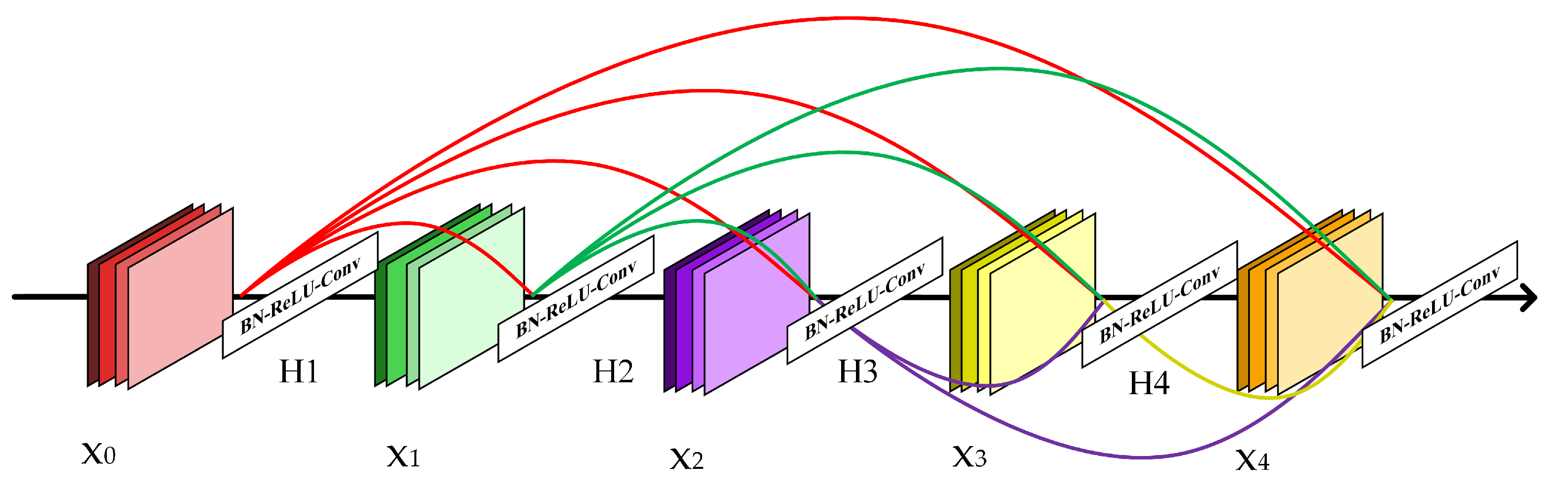
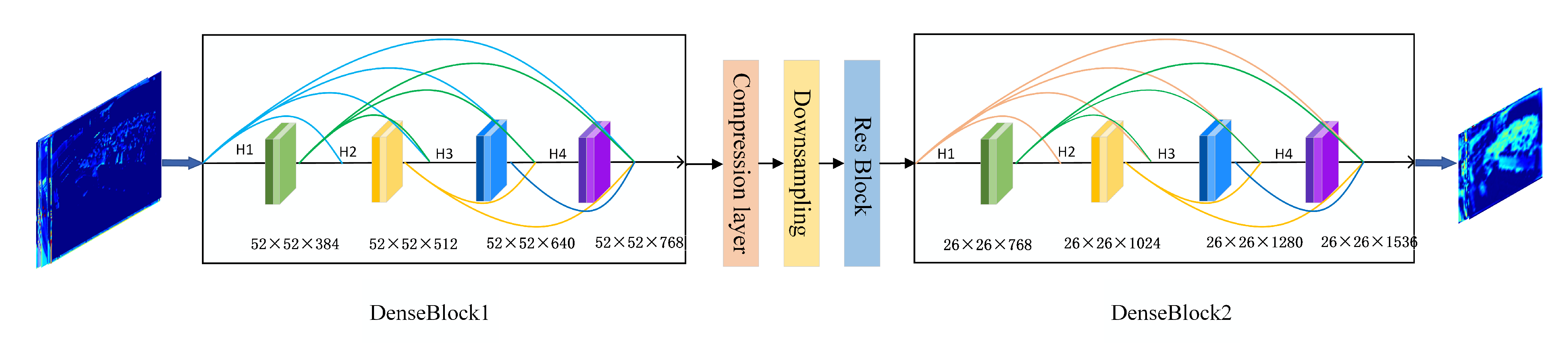
3.1. DR-Net: ResNet Combined with DenseNet for Feature Extraction Network
3.2. Mixed Dilated Convolution
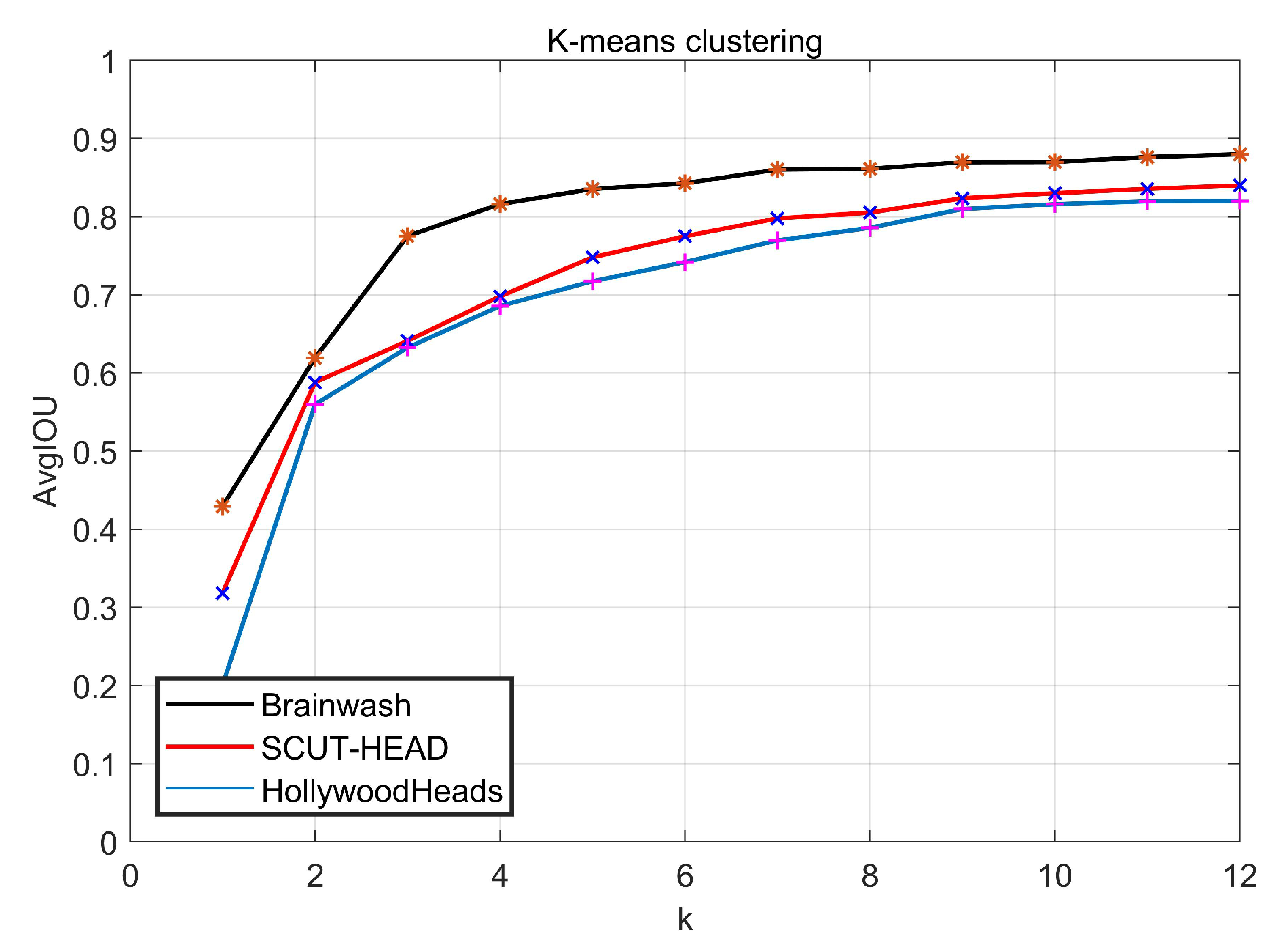
3.3. K-Means for Anchor Boxes
| Algorithm 1 Pseudocode for the algorithm to generate the new anchor boxes. |
| 1. Randomly create K cluster centers:, refers to the width and height of the anchor boxes. [t] 2. . initial For to do If { } End For 3. Regenerate new cluster centers: 4. Repeat step 2 and step 3 until the clusters converge. |
4. Experiment
4.1. Datasets
4.2. Evaluation Metrics
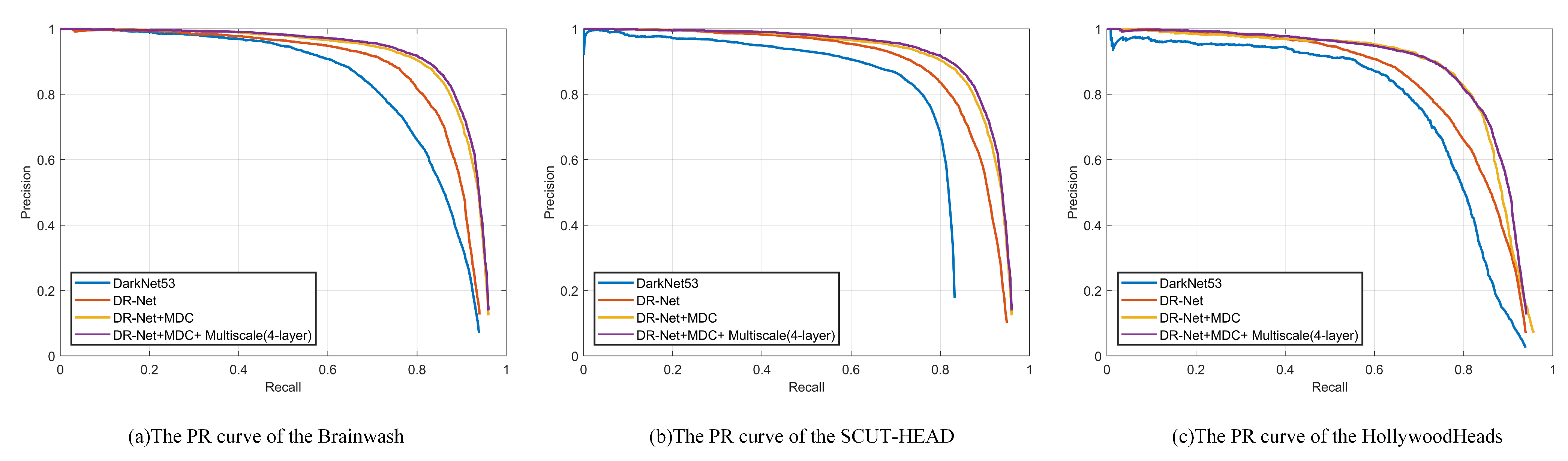
4.3. Ablation Study
5. Results
5.1. Results on the Brainwash Dataset
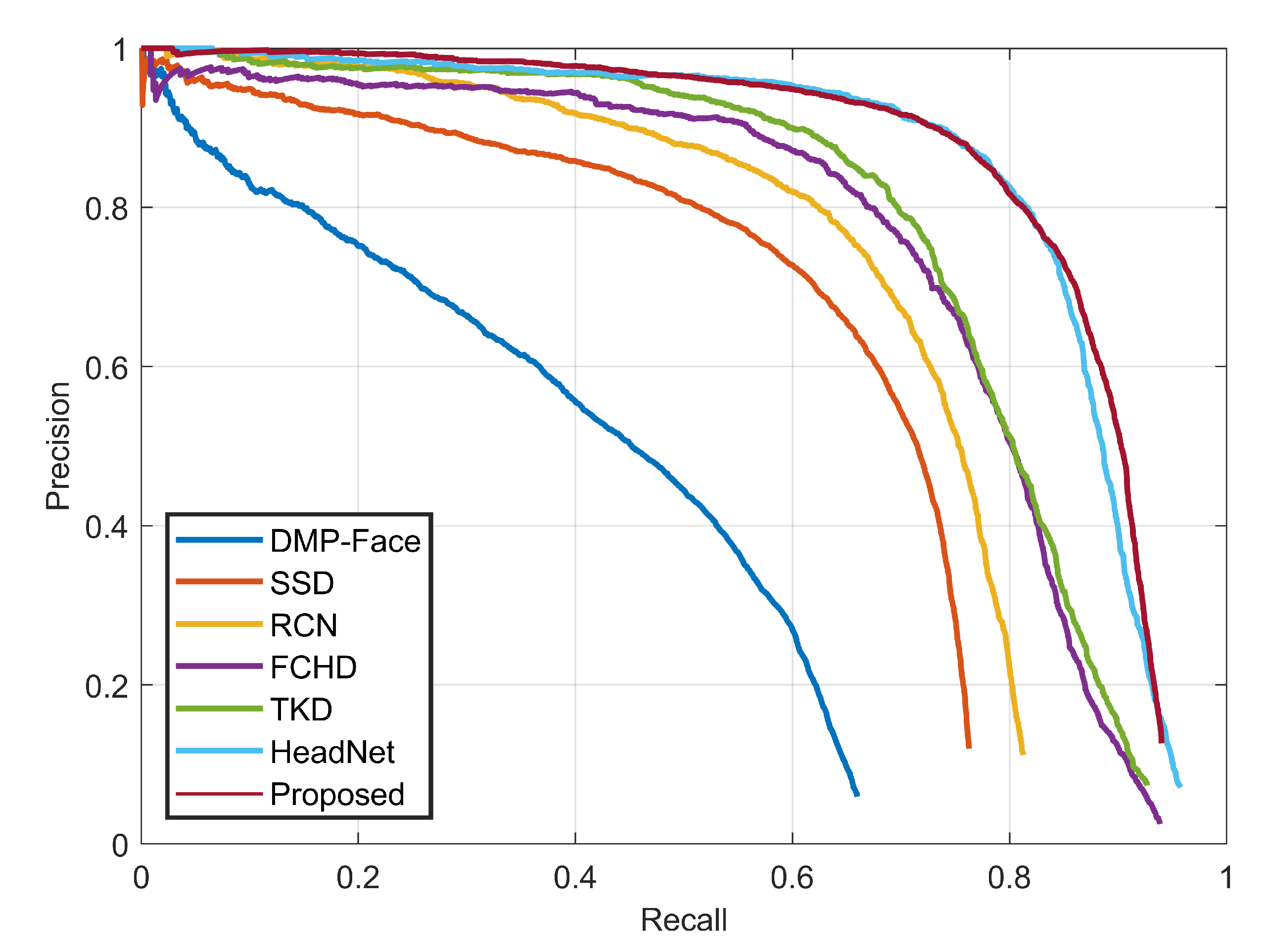
5.2. Results on the HollywoodHeads Dataset
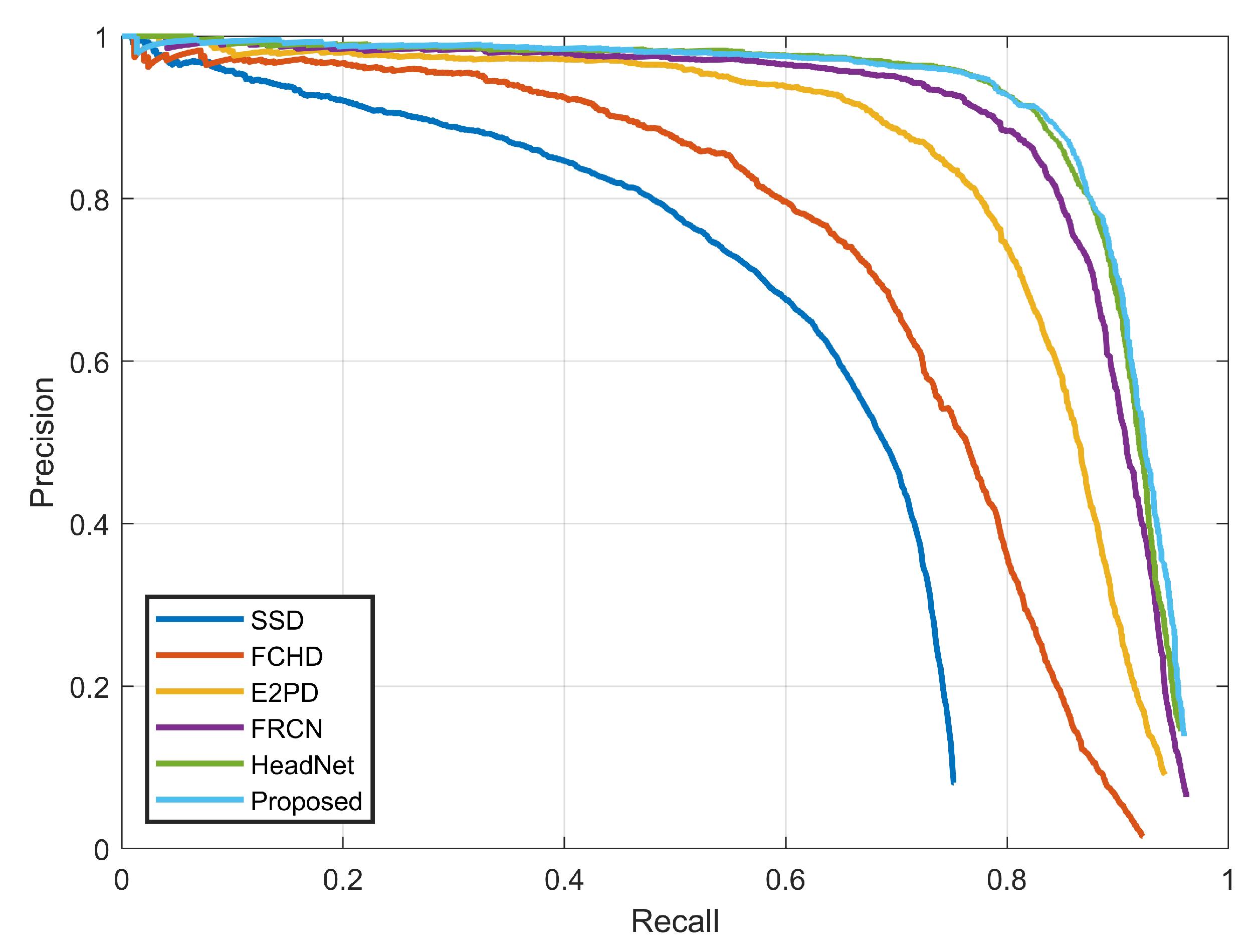
5.3. Results on the SCUT-HEAD Dataset
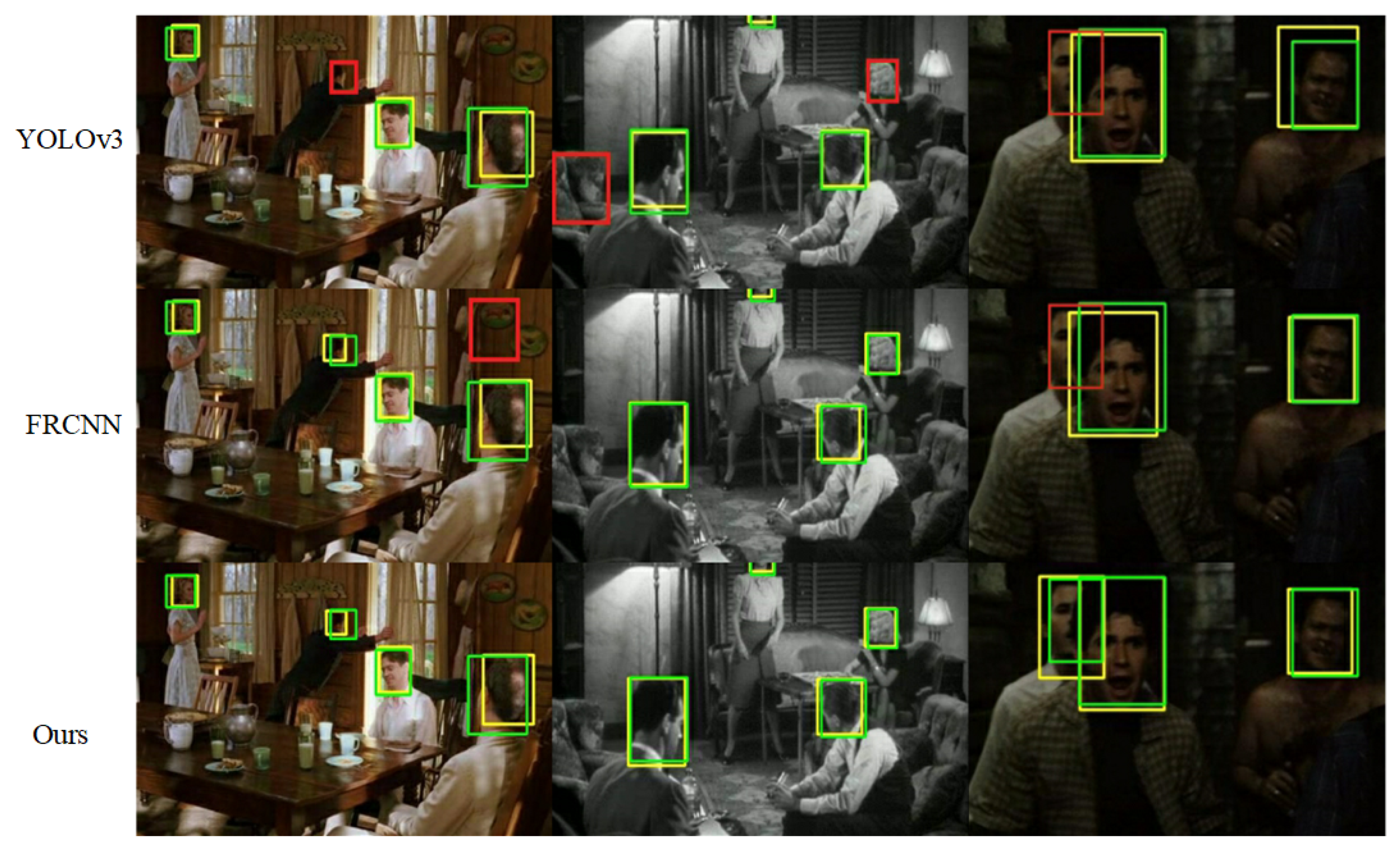
5.4. Qualitative Results on Three Datasets
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, L.; Huang, Y.; Lu, H.; Yang, Y. Pose-invariant embedding for deep person re-identification. IEEE Trans. Image Process. 2019, 28, 4500–4509. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, Y.; Dehghan, A.; Shah, M. On detection, data association and segmentation for multi-target tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2146–2160. [Google Scholar] [CrossRef] [PubMed]
- Yao, H.; Zhang, S.; Hong, R.; Zhang, Y.; Xu, C.; Tian, Q. Deep representation learning with part loss for person re-identification. IEEE Trans. Image Process. 2019, 28, 2860–2871. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kondo, Y. Automatic Drive Assist System, Automatic Drive Assist Method, and Computer Program. U.S. Patent App. 15/324,582, 20 July 2017. [Google Scholar]
- Basalamah, S.; Khan, S.D.; Ullah, H. Scale driven convolutional neural network model for people counting and localization in crowd scenes. IEEE Access 2019, 7, 71576–71584. [Google Scholar] [CrossRef]
- Choi, J.W.; Yim, D.H.; Cho, S.H. People counting based on an IR-UWB radar sensor. IEEE Sens. J. 2017, 17, 5717–5727. [Google Scholar] [CrossRef]
- Ballotta, D.; Borghi, G.; Vezzani, R.; Cucchiara, R. Fully convolutional network for head detection with depth images. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 752–757. [Google Scholar]
- Stewart, R.; Andriluka, M.; Ng, A.Y. End-to-end people detection in crowded scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2325–2333. [Google Scholar]
- Vu, T.H.; Osokin, A.; Laptev, I. Context-aware CNNs for person head detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2893–2901. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Shalev-Shwartz, S.; Singer, Y.; Srebro, N.; Cotter, A. Pegasos: Primal estimated sub-gradient solver for svm. Math. Program. 2011, 127, 3–30. [Google Scholar] [CrossRef] [Green Version]
- Margineantu, D.D.; Dietterich, T.G. Pruning adaptive boosting. In ICML; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1997; Volume 97, pp. 211–218. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer SOCIETY conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Vora, A.; Chilaka, V. FCHD: Fast and accurate head detection in crowded scenes. arXiv 2018, arXiv:1809.08766. [Google Scholar]
- Li, W.; Li, H.; Wu, Q.; Meng, F.; Xu, L.; Ngan, K.N. Headnet: An end-to-end adaptive relational network for head detection. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 482–494. [Google Scholar] [CrossRef]
- Ranjan, R.; Patel, V.M.; Chellappa, R. A deep pyramid deformable part model for face detection. In Proceedings of the 2015 IEEE 7th International Conference on Biometrics Theory, Applications and Systems (BTAS), Arlington, VA, USA, 8–11 September 2015; pp. 1–8. [Google Scholar]
- Bajestani, M.F.; Yang, Y. Tkd: Temporal knowledge distillation for active perception. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Village, CO, USA, 1–5 March 2020; pp. 953–962. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1227–1236. [Google Scholar]
- Sun, Z.; Peng, D.; Cai, Z.; Chen, Z.; Jin, L. Scale mapping and dynamic re-detecting in dense head detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1902–1906. [Google Scholar]
- Peng, D.; Sun, Z.; Chen, Z.; Cai, Z.; Xie, L.; Jin, L. Detecting heads using feature refine net and cascaded multi-scale architecture. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2528–2533. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D-DBL of DenseBlock1 | D-DBL of DenseBlock2 |
|---|---|
| Conv(1 × 1 × 64) | Conv(1 × 1 × 128) |
| BN | BN |
| Leaky-ReLU | Leaky-ReLU |
| Conv(3 × 3 × 128) | Conv(3 × 3 × 256) |
| BN | BN |
| Leaky-ReLU | Leaky-ReLU |
| Number | Block Name | Layers | Filter | Size | Output |
|---|---|---|---|---|---|
| Conv Block | Convolutional | 32 | 3 × 3 | 416 × 416 × 32 | |
| Convolutional | 32 | 3 × 3/2 | 208 × 208 × 64 | ||
| Convolutional | 32 | 1 × 1 | |||
| 1 × | Res Block | Convolutional | 64 | 3 × 3 | |
| Residual | 208 × 208 × 64 | ||||
| Downsampling | Convolutional | 128 | 3 × 3/2 | 104 × 104 × 128 | |
| Convolutional | 64 | 1 × 1 | |||
| 2 × | Res Block | Convolutional | 128 | 3 × 3 | |
| Residual | 104 × 104 × 128 | ||||
| Downsampling | Convolutional | 256 | 3 × 3/2 | 52 × 52 × 256 | |
| Convolutional | 128 | 1 × 1 | |||
| 4 × | Res Block | Convolutional | 256 | 3 × 3 | |
| Residual | 52 × 52 × 256 | ||||
| Convolutional | 64 | 1 × 1 | |||
| 4 × | DenseBlock1 | Convolutional | 128 | 3 × 3 | |
| Residual | 52 × 52 × 768 | ||||
| Compression | Convolutional | 1024 | 1 × 1 | 52 × 52 × 512 | |
| Downsampling | Convolutional | 512 | 3 × 3/2 | 26 × 26 × 512 | |
| Convolutional | 256 | 1 × 1 | |||
| 4 × | Res Block | Convolutional | 512 | 3 × 3 | |
| Residual | 26 × 26 × 512 | ||||
| Convolutional | 128 | 1 × 1 | |||
| 4 × | DenseBlock2 | Convolutional | 256 | 3 × 3 | |
| Residual | 26 × 26 × 1536 | ||||
| Compression | Convolutional | 2048 | 1 × 1 | 26 × 26 × 1024 | |
| Downsampling | Convolutional | 1024 | 3 × 3/2 | 13 × 13 × 1024 | |
| Convolutional | 512 | 1 × 1 | |||
| 4 × | Res Block | Convolutional | 1024 | 3 × 3 | |
| Residual | 13 × 13 × 1024 |
| Dataset | Brainwash | HollywoodHeads | SCUT-HEAD |
|---|---|---|---|
| (9,13), (11,17), (13,20), | (5,10), (6,13), (7,16), | (4,10), (6,12), (7,15), | |
| Clusters | (13,16), (14,19), (16,24), | (9,21), (14,30), (26,55), | (9,18),(12,23), (16,29), |
| (20,28), (24,34), (33,44) | (45,91), (74,162), (127,263) | (23,39), (33,57), (54,94) |
| Hollywood | Brainwash | (Part A, Part B) | |
|---|---|---|---|
| Year | 2015 | 2015 | 2018 |
| Number of images | 224,740 | 11,917 | (2000, 2405) |
| Heads per picture(Avg) | 1.65 | 7.89 | (33.6, 18.26) |
| Head Density | Sparse | Medium Dense | Dense |
| Training Set | 216,719 | 10,917 | (1600, 1600) |
| Validation Set | 6719 | 500 | (200, 200) |
| Test Set | 1032 | 500 | (200, 205) |
| Method | AP@0.5 | FPS (Average) | ||
|---|---|---|---|---|
| Brainwash | HollywoodHeads | SCUT-HEAD | ||
| Darknet-53 (Baseline) | 0.835 | 0.757 | 0.782 | 21 |
| DR-Net | 0.874 | 0.807 | 0.863 | 23 |
| DR-Net+MDC | 0.921 | 0.848 | 0.90 | 15 |
| DR-Net+MDC+ Multiscale (4-Layer) | 0.924 | 0.852 | 0.91 | 9 |
| Methods | Backbone | AP@0.5 |
|---|---|---|
| SSD [12] | VGG16 | 0.568 |
| FCHD [34] | VGG16 | 0.70 |
| E2PD [8] | GoogLeNet+LSTM | 0.821 |
| FRCN [15] | VGG16 | 0.878 |
| HeadNet [35] | ResNet-101 | 0.91 |
| Proposed | DR-Net+MDC | 0.921 |
| Methods | Backbone | AP@0.5 |
|---|---|---|
| DPM-Face [36] | - | 0.37 |
| SSD [12] | VGG16 | 0.621 |
| FRCN [15] | VGG16+ResNet | 0.698 |
| FCHD [34] | VGG16 | 0.74 |
| TKD [37] | LSTM | 0.75 |
| HeadNet [35] | ResNet-101 | 0.83 |
| Proposed | DR-Net+MDC | 0.848 |
| Methods | PartA | PartB | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| FRCN [15] | 0.86 | 0.78 | 0.82 | 0.87 | 0.81 | 0.84 |
| SSD [12] | 0.84 | 0.68 | 0.76 | 0.80 | 0.66 | 0.72 |
| YOLOv3 [13] | 0.91 | 0.78 | 0.82 | 0.74 | 0.67 | 0.70 |
| R-FCN [32] | 0.87 | 0.78 | 0.82 | 0.90 | 0.84 | 0.86 |
| R-FCN+FRN [40] | 0.89 | 0.83 | 0.86 | 0.92 | 0.84 | 0.88 |
| SMD [39] | 0.92 | 0.90 | 0.90 | 0.94 | 0.89 | 0.91 |
| Proposed | 0.91 | 0.92 | 0.91 | 0.92 | 0.92 | 0.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Zhang, Y.; Xie, J.; Wei, Y.; Wang, Z.; Niu, M. Head Detection Based on DR Feature Extraction Network and Mixed Dilated Convolution Module. Electronics 2021, 10, 1565. https://doi.org/10.3390/electronics10131565
Liu J, Zhang Y, Xie J, Wei Y, Wang Z, Niu M. Head Detection Based on DR Feature Extraction Network and Mixed Dilated Convolution Module. Electronics. 2021; 10(13):1565. https://doi.org/10.3390/electronics10131565
Chicago/Turabian StyleLiu, Junwen, Yongjun Zhang, Jianbin Xie, Yan Wei, Zewei Wang, and Mengjia Niu. 2021. "Head Detection Based on DR Feature Extraction Network and Mixed Dilated Convolution Module" Electronics 10, no. 13: 1565. https://doi.org/10.3390/electronics10131565
APA StyleLiu, J., Zhang, Y., Xie, J., Wei, Y., Wang, Z., & Niu, M. (2021). Head Detection Based on DR Feature Extraction Network and Mixed Dilated Convolution Module. Electronics, 10(13), 1565. https://doi.org/10.3390/electronics10131565