1. Introduction
Powered by recent significant Deep Neural Network (DNN) advancements in the field of Natural Language Processing (NLP), chatbots are becoming increasingly popular technology in real-time customer services [
1]. The chatbot research area has already a long history dating back to 1966 [
2]. The very first chatbot ELIZA, introduced by MIT Artificial Intelligence Laboratory, was adjusted to communicate with people suffering from psychological issues. ELIZA was examining keywords from the user’s input and was prompting answers based on a pre-defined set of rules. Today chatbots are widely used in Marketing, Education, Healthcare, and other sectors. They even are created to entertain in interactive theater performances [
3]. However, this pandemic especially revealed the necessity of chatbots in the news media [
4], hospitals, or the healthcare system managing huge flows of incoming questions [
5].
Chatbots provide support (usually adjusted to a single domain and able to answer FAQ-type questions), skills (do not need to be aware of the context, only comprehend a determined set of commands), or perform a virtual assistant (connecting both previous types) role. According to their primary goal, chatbots can be classified into informative (provide information), conversational (simulate human-like behavior in continuous conversations with a user), and task-based (provide a service or help a user in a pre-determined task). Depending on their proximity to a user and provided services, chatbots can communicate inter-personally (pass user’s information, but do not necessarily remember it), intra-personally (act like user’s companions), or inter-agent-like (communicate with other chatbots). Based on an accessible or trained knowledge domain, chatbots can be grouped into closed (responding accurately to a limited set of questions on specific topics) and open (able to answer questions of any topics) domain types. Input processing manner and nature of response determine if a chatbot is generative or intent detection-based. Generative chatbots usually require huge amounts of training data and can learn how to generate responses from it. Intent detection-based chatbots are functioning as classifiers and therefore are limited to pre-defined responses. Despite advanced algorithms, any of these chatbot types cannot be prevented from failures in real-case user dialog scenarios. However, intend detection-based ones are more robust compared to generative and typically used in production chatbots, therefore chosen as our research direction.
Usually, chatbots are composed of four different components: Natural Language Understanding (NLU) (responsible for comprehension of user’s requests meaning and structure), Dialog Management (controls a smooth flow of a conversation), Content (a template of how a chatbot must respond), and External Data (extracts data from external web services or databases). However, NLU has considered the most essential component: without understanding the user’s request, all other components become secondary. Consequently, this research is focused on the improvement of the NLU component.
In general, the NLP area is completely dominated by research on the English language, which is resource-rich. In the machine learning (and especially deep learning) era, this fact explains why so much research has been conducted for English, and many accurate tools have been developed. However, no less important is paying attention to less popular and less-resourced languages that must constantly chase English. The gap is mostly due to less quality, quantity, or availability of resources: training datasets, corpora, monolingual refined embeddings, etc. A lack of resources or their proprietary usage often becomes an obstacle that hinders progress for such languages (especially complex ones, having a small number of speakers). Therefore, the goal of this research is to find measures how to address this sensitive multilingualism problem. One straightforward way is to choose available benchmark English datasets but translate (or machine translate, if possible) them into target languages. Hence, in this research, we rely on an assumption that machine translation does not distort data to such an extent that it degrades its quality significantly to become unsuitable for training NLU models, especially knowing that the quality of machine translation tools is significantly improved recently due to neural-based approaches. We even assume this problem is possible to tackle without machine translation by just employing multilingual transformers (as pre-trained vectorization models) able to capture sentence semantics. As an object of our research, we have chosen English, German, French, Lithuanian, Latvian, and Portuguese languages as our target languages. Such choice was performed on purpose: it includes different language groups (Germanic, Romance, and Baltic languages) and covers languages having different amounts of resources.
2. Related Work
Despite the fact that multilingual chatbots are in high demand usually, support of several languages is based on language identification first and application of an appropriate monolingual NLU model afterward. Consequently, there is very little related research on multilingualism in the scientific literature as well. Nevertheless, we will take a broader look at the methodologies used for creating NLU models.
According to the Scopus paper analysis by [
6], the rapid growth of interest in chatbots is especially visible after 2016, with a special focus on innovative DNN technology in recent years. The essence of this related work analysis is to highlight methodologies that could be the most effective for the intent detection task. Additionally, it can be performed the best via comparative analysis under the same experimental conditions (same datasets, the same distribution for training/testing, etc.).
One of the most popular benchmark datasets is the ATIS (Airline Travel Information Systems) dataset introduced in [
7] consisting of 17 intent categories, ~11 words per utterance with 4478, 500, and 893 utterances in train, development, and test subsets, respectively. Moreover, this dataset consists of speech transcripts and therefore represents a spoken language that is even more difficult to process compared to normative. With the best technique, the accuracy for this dataset reaches ~0.99 [
8]. Indeed, besides intent detection, authors also tackle a slot-filling task (that searches for a specific piece of information as named entities or things) and prove that both tasks benefit the most from solving them jointly via their cross-impact. Their novel offered Bi-model based RNN semantic frame parsing approach (especially with a decoder) applied on jointly trained word embeddings was able to surpass other previously applied techniques. The second-best approach [
9], using ATIS for intent detection, is based on the transformer-capsule model, especially suitable to model hierarchical relationships. GloVe embeddings [
10] were fed into the transformer encoder (with 12-heads attention and feed-forward layer with 300 hidden dimensions), and then the produced vector was passed into a capsule network (composed of 100 capsules with 15 dimensions in each). Despite these authors demonstrated slightly lower performance compared to [
8], it is in a range of ~0.99 of the accuracy. The competitively high accuracy of ~0.98 on ATIS was achieved with less refined technologies already in 2016 [
11]. These authors tackled intent detection and slot-filling tasks independently and jointly, proving that their joint model gains over independent ones. They test an encoder-decoder model with aligned inputs in which the Bidirectional Long Short-Term Memory (BiLSTM) network is used on the encoder side and unidirectional LSTM on the decoder. Besides, the authors complemented their model with an attention mechanism, which improved the accuracy even further. The accuracy of ~0.98 on ATIS is achieved with the BERT-based model [
12]. The architecture is composed of a BERT base model with fine-tuning as the encoder module and two decoders. The encoder represents an utterance grasping knowledge between the intent detection and slot-filling tasks, and then the first decoder performs intent detection. Then, the stack-propagation framework (enabling backpropagation down the stacked models) concatenates the output of the intent detection decoder and representations from the encoder as the input for the slot-filling decoder. Both intent detection and slot-filling sub-models are jointly learned by optimizing them simultaneously.
Another popular NLU benchmark dataset is SNIPS, introduced in [
13]. This dataset contains 16 thousand crowdsourced queries distributed among seven intents with ~9 words per utterance. Similar to ATIS, this dataset also contains spoken language. The best accuracy reaching ~0.97 on this dataset is achieved with the BERT-based stack-propagation framework [
12], giving promising results on ATIS as well. The method incorporating the contextual information at the representation and task-specific level allows achieving ~0.94 of the accuracy on SNIPS [
14]. The context of each word is obtained via max-pooling over the outputs of BiLSTM for all sentence words except the target one. Thus, this first level aims to use the context of each word to predict the label of that word. The second level uses global context information to predict sentence-level labels. The range of ~0.92 of the accuracy can be achieved with another bidirectional interrelated slot-filling and intent detection model [
15]. This method is based on the BiLSTM architecture as in [
14]. It uses separate computed context vectors and separate attention mechanisms for slot and intent tasks.
When the dataset is stable (as in the experiments with the benchmark collections), the most often choice increasing the accuracy is the right choice of the methodology. Some authors address this issue by adding new training instances that expand the dataset but do not fundamentally change it. The innovative adversarial training approach jointly solving intent detection and slot-filling tasks with ATIS and SNIPS datasets injects perturbed inputs (adversarial examples) into the training data [
16]. The perturbed word/character embeddings add a little noise to utterances that do not fool the model, but on the contrary, make it more robust. The classifier authors use a combination of LSTM encoder-decoder with a stacked CRF applied on top of the BERT-large embedding model. The authors claim, their joint adverbial training model that applies a balance factor as a regularization term to the final loss function reaches state-of-the-art performance on the ATIS and SNIPS datasets.
The authors in [
17] explore three datasets, i.e., HWU64 (containing ~25.7 thousand instances, 64 intents, ~7 words per instance), CLINC150 (~23.7 thousand instances, 150 intents, ~8 words per instance), and BANKING77 (~13 thousand customer service queries, 77 intents, ~12 words per instance). Unlike previous benchmark datasets (having 17 and 7 intents in ATIS and SNIPS, respectively), HWU64, CLINIC150, BANKING77 contain many more intents making this task even more complex. The authors imply dual sentence encoders (learned from interactions between input/context and relevel responses and therefore encapsulating conversational knowledge) such as USE (Universal Sentence Encoder) and ConverRT to support intent detection. The experimental investigation demonstrates the superiority of dual sentence embeddings over the fixed or fine-tuned BERT-large models, which is especially apparent with smaller intents (covered with ~10–30 cases).
The intent detection problem, which is the most relevant in chatbots, is tackled for other purposes as well. The authors [
18] are solving the e-mail overload problem by classifying them into two intents: “to read” or “to do”. The authors test context-free word embeddings (word2vec and GloVe), contextual word embeddings (ELMo and BERT), and sentence embeddings (DAN-based USE and Transformer-based USE), proving the superiority of ELMo, followed by Transformer-based USE and then DAN-based USE. This research compares a huge variety of word and sentence embedding types and once again proves that sentence embeddings are also a very powerful tool for intent detection problems.
As can be seen, some researchers tackle problems having more or fewer intents, whereas others are focused on a few-shot intent detection scarcity problems of emerging classes. The authors in [
19] offer the novel BiLSTM-based Semantic Matching and Aggregation Network approach. Their approach distills semantic components from utterances via multihead self-attention with additional dynamic regularization constraints. They experimentally compare their offered approach to 6 more methods (Matching Network, Prototypical Network, Relation Network, Hybrid Attention-based Prototypical Network, Hierarchical Prototypical Network, Multi-level Matching, and Aggregation Network) and prove their method achieves the best performance on two datasets. A very similar problem [
20] is tackled with the novel two-fold pseudolabeling technique. The pseudolabeling process takes embedded user utterances and passes them to a hierarchical clustering method (in a bottom-up tree-manner), then the process goes top-down a tree and expands nodes having multiple labeled sentences with different labels. Once the pseudolabels are retrieved, the method performs BERT fine-tuning-based intent detection, which is a common solution for intent detection problems.
The other important intent detection direction covers multiple intents in the same utterance problems. The authors in [
21] solve joint multiple intent detection and slot-filling problems with the Adaptive Graph-Interactive Framework method. Firstly, the self-attentive BiLSTM encoder represents some utterance which is then passed to the multilabel intent detection decoder, which computes context vectors using self-attention. Afterward, the adaptive intent-slot graph interaction layer leverages information about the multiple intents for slot prediction. Next to the offered method, authors also test more five state-of-the-art approaches (Attention BiRNN, Slot-Gated Atten, Bi-Model, SF-ID Network, Stack-Propagation), proving their offered method is superior on MixATIS and MixSNIPS datasets (appropriate ATIS and SNIPS versions but containing multiple intents). Either few-shot or multiple intent problems have additional mechanisms that go beyond the common intent detection problem-solving. However, parts responsible for the intent detection are tackled with the DNN-based techniques typically used for the common intent detection problems. Other intent detection monolingual research covers non-English languages; however, applied methods are in the same DNN-based trend.
Previously summarized approaches focus only on monolingual research, therefore, do not reveal their all potential. Recently some popular commercial virtual assistants (as Google Home, Amazon, Apple Siri) were scaled to more regions and languages. Multilingual chatbots are gaining more and more attention from the scientific community as well. Thus, we direct our further method analysis towards multilingual intent detection problems (working well if applied separately on several languages) with a special focus on cross-lingual (working well if applied jointly on several languages) approaches. The paper [
22] describes the offered joint model for intent detection and named entity recognition. The method firstly maps input tokens into share-space word embedding and then feeds them into the encoder to extract context information. Afterward, this content is propagated to downstream tasks. For the transfer learning experiments, authors train on high-resource languages and then: (1) transfer both encoder and decoder to a new multilingual model with fine-tuning; (2) transfer only encoder with fixed parameters to new multilingual model; (3) transfer only encoder with available learning rate by gradually freezing embeddings with training steps during fine-tuning. If precisely, authors use initial concatenated fastText embeddings trained on a three-filter Convolutional Neural Network (CNN); BiLSTM as the encoder; a multilayer perceptron for intent detection and CRF sequence labeler for NER with gelu activation function as the decoder. The authors applied their methods to English (~2.2 million utterances, 316 intents, and 282 slots), Spanish (~3 million utterances, 365 intents, 311 slots), Italian (~2.5 utterances, 379 intents, 324 slots), and Hindi (~0.4 million utterances, 302 intents, 267 slots) datasets. They observe performance improvements in all models with transfer learning, with the largest improvement with encoder transfer. The authors in [
23] use the multilingual dataset containing annotated utterances in English (~43 thousand), Spanish (~8.6 thousand), and Thai (~5 thousand) and covering 3 domains, 12 intents, and 11 slots. They evaluate cross-lingual transfer methods based on (1) translated training data; (2) cross-lingual pre-trained embeddings; (3) multilingual machine translation encoder as contextual word representations. The joint intent detection and slot-filling model at first use a sentence classification model to identify the domain and then a domain-specific model to jointly predict intent and slots. The method architecture has self-attention BiLSTM and Conditional Random Fields (CRF) layers. The method is tested with several types of word embeddings (zero, XLU, encoder, CoVe, multilingual CoVE, and multilingual CoVE + autoencoder) trained by authors and available pre-trained ELMo encoders for Spanish. The authors found that languages with limited data benefit from cross-lingual learning. Despite it, multilingual contextual word representations outperform cross-lingual static embeddings. Due to these findings, the authors have to highlight a need for more refined cross-lingual methods. Another interesting cross-lingual research [
24] uses a dataset containing ~6.9 thousand utterances across 16 COVID-19 specific intents in English, Spanish, French, and German languages. The authors explore: (1) monolingual and multilingual model baselines; (2) cross-lingual transfer from English to other languages; (3) zero-shot (in which only English data is used for training and model selection) code-switching for Spanglish (combining words and idioms from Spanish and English). These authors tested fastText, XLM-R, and ELMo embeddings. Authors prove that lower results are obtained under a zero-shot setting, and XLM-R cross-lingual sentence embeddings significantly outperform their other cross-lingual solutions. Another cross-lingual research [
25], for the first time, presents multilingual modeling without degrading per-language performance. It demonstrates the robustness of pre-trained multilingual language models leading to significant performance gains for cross-lingual transfer tasks as natural language inference (15 languages), NER (English, Dutch, Spanish, and German), question answering (English, Spanish, German, Arabic, Hindi, Vietnamese and Chinese). Their XLM-Rbase (L = 12, H = 768, A = 12,270 million params) and XLM-R (L = 24, H = 1024, A = 16,550 million params) models outperform mBERT (compared to BERT for English, mBERT is trained on 104 languages with a shared word piece vocabulary, which allows the model to share embeddings across languages). The authors demonstrate their models significantly outperform mBERT on cross-lingual tasks, perform especially well on low-resourced languages.
Despite there is no consensus on which method is the best for intent detection problems, it effectively narrows the set of choices giving us guidance on which techniques are the most promising. However, as it can be seen from the related work analysis, very little has been carried out in the cross-lingual direction when transferring models (trained in downstream tasks) across different languages. The plentifulness of data resources for the English language and relatively little research carried out on some languages inspire us (1) to rely on machine translation tools when preparing datasets for target languages and (2) to seek cross-lingual-based solutions where less-resourced languages could benefit from others. The contribution of our research is due to the following reasons, we: (1) perform our experiments under monolingual and several cross-lingual settings; (2) tackle intent detection problem when training on English alone and testing on other target languages; (3) compare different approaches and embedding types over six languages (English, German, French, Latvian, Lithuanian, and Portuguese); (4) use a very small dataset (in which each intent is covered by a relatively small number of instances).
3. Methodology
The research question of our paper is how to create the multilingual intent detection method (by offering the vectorization technique, classifier, model, and training data usage strategy) without having annotated training data necessary prepared in the target language. To answer this research question, we choose several languages differing by their characteristics. The creation of such a multilingual method would open opportunities for other researchers solving intent detection problems to rely more on machine-translated data and cross-lingual approaches. If our hypotheses would be valid for all tested languages (taken from different language groups and differing in various characteristics), we anticipate that the offered multilingual method could also be applied for the broader group of languages (at least for Germanic, Romance, Balto-Slavic groups) having pre-trained multilingual BERT vectorization models. Moreover, the obtained know1edge about the offered methodology possibilities and boundaries could also be used in other supervised machine learning tasks. Thus, our offered approach (based on the machine-translated data or cross-lingual models) could be a superior alternative to previous approaches, typically demanding training data necessary created only for the target language.
Our research result is the different approach to the classification type problem (i.e., intent detection) solving and the type of result is the offered new technique able to tackle multilingual intent detection problems. Different approaches (combining vectorization techniques, classifiers, models) are tested on real datasets (for English, German, French, Lithuanian, Latvian, and Portuguese languages) under several training data usage strategies (relying on the machine-translated data and/or cross-lingual models) in the carefully designed controlled experiment with statistically significant results. The type of the performed research validation is the analysis. Thus, the research question (how to create multilingual intent detection method without annotated training data necessary prepared in the target language), the expected result (a technique/method able to solve multilingual intent detection problems without annotated training data necessary prepared in the target language) with the analysis research validation (as the controlled experiment) are combined into our research strategy. This strategy was applied and evaluated with accuracy, precision, recall, f-score metrics (typically used in the evaluation of intent detection problems); the obtained results with different approaches were compared to see if differences are statistically significant. Our research question would be confirmed if applying multilingual methods on target languages (not having training data but relying on the machine-translated English data and/or cross-lingual models) would achieve similar accuracy levels as with the monolingual methods on the English language with the original dataset.
3.1. Formal Description of the Task
The intent detection problem is a typical example of a supervised text classification task. Formally, such a task is determined as follows:
Let D = {d1, d2, …, dn} be a set of documents (questions/statements an input from a user). Let C = {c1, c2, …, cm} be a set of intents (classes). We have a closed-set classification problem where m is limited, and each cj is defined in advance. Besides, we solve a single-label classification problem because each di ∈ D can be attached to only one cj ∈ C.
Let function η be a classification function that maps di into their correct classes: D → C. Let DL ⊂ D be a training set of labeled instances (pairs of documents and their correct intents (di, cj)) used to train a model.
Let Г be a classification method that, from labeled instances, can learn a model (which is the approximation of η).
Our solving intent detection task aims to offer a classification method Г that can find the best approximation of η, achieving as high an intent detection accuracy as possible on unseen instances (D – DL) also.
3.2. Datasets
The intent detection problem (described in
Section 3.1) can be tackled with the appropriate dataset. For this reason, we have used the manually prepared English dataset that contains fluent questions and related answers about the app
Tildės Biuras (more about it in
https://www.tilde.lt/tildes-biuras accessed on 13 November 2020) prices, licenses, supported languages, and used technologies. Instances in the dataset were shuffled and randomly split into training and testing subsets by keeping the proportion for training and testing equal to 80% and 20% instances per intent, respectively (
Table 1). The dataset covers only ~8.9 instances per intent on average in the training dataset, which means the solving intent detection task is challenging. Despite it, our case is by no means exceptional. There are many benchmark datasets with even fewer instances per intent on average (e.g., in [
26]). Moreover, such datasets reflect the expectations of real customers that want to achieve the best possible chatbot’s accuracy with minimum effort.
Despite our available dataset is only in the English language, we plan to use it in a way that could prove that English resources could perfectly serve in solving intent detection problems for other languages as well. As the object of research, next to English (EN), we have chosen one more Germanic language (i.e., German (DE)), two Romance languages (French (FR) and Portuguese (PT)), and two Baltic languages (Lithuanian (LT) and Latvian (LV)), differing from each other by such characteristics as morphology, derivational systems, sentence structures, etc.
The EN training dataset (in
Table 1) was Google machine-translated, whereas the testing dataset was manually translated into DE, FR, LT, LV, and PT languages. Such preparation was carried out on purpose. We simulate the common condition when training data is not available for some languages but can be easily prepared with the help of machine translation. The review of machine-translated data revealed that despite some not very precise translations, the gist in texts is retained, and therefore, automatic machine translation is a reliable way to translate the training data. The testing dataset is manually prepared because the intent detection model is usually tested by real users writing questions in their language. The sizes of datasets in different languages are in
Table 2.
3.3. Used Approaches
The goal of this section is to offer the best
Г (presented in
Section 3.1) for our solving supervised intent detection tasks. Therefore, we need to find the best combination of text representation and classification techniques.
For the text representation (vectorization) we have investigated the following approaches:
Word embeddings. BERT (Bidirectional Encoder Representations from Transformers) [
27] is a transformers model pre-trained on a large raw corpus in a self-supervised manner (by automatically generating inputs and labels from texts). Its learning is based on masked language modeling and next sentence prediction phases. The masked language modeling process takes a sentence, randomly masks some words, and then learns how to predict them. This way, the model learns bidirectional sentence representations. Thus, BERT is robust to word disambiguation problems: words written equally but with different meanings are represented with different vectors based on their context. Afterward, the next sentence prediction process learns to determine if two sentences follow each other in a sequence. This training manner allows learning inner language representations that later can be used to extract features for downstream classification tasks. In our experiments, we have investigated 4 monolingual English BERT models, i.e.,
bert-base-cased,
bert-base-uncased,
bert-large-cased, and
bert-large-uncased. The difference between
base and
large models is in the number of stacked encoder layers (12 vs. 24 for base and large, respectively), attention heads (12 vs. 16), parameters (110 million vs. 340 million), and hidden layers (768 vs. 1024). Cased models are sensitive to the letter-casing and, vice versa, uncased models are not. We also investigated multilingual BERT models
bert-base-multilingual-cased and
bert-base-multilingual-uncased (a detailed description of used BERT transformer models can be found in
https://huggingface.co/transformers/pretrained_models.html accessed on 13 November 2020), both trained on Wikipedia texts of 104 languages, including all languages that we use in this research.
Sentence embeddings. Besides, BERT we have tested several models tuned to be used for text/sentence embedding generation [
28]. The output of such transformer models is pooled to generate a fixed-size representation. In our experiments next to sentence BERT, we have RoBERTa [
29], DistilBERT [
30], DistilUSE, and XLNet [
31] transformer models. RoBERTa is an optimized BERT approach. It does not have the next sentence prediction phase and, instead of masked language modeling, performs dynamic masking by changing masked tokens during training epochs. Besides, RoBERTa is trained on much larger amounts of data. DistilBERT is the smaller approximation of the BERT transformer model, retaining only half of its layers (with ~66 million parameters). Besides, DistilBERT even does not have token-type embeddings and the pooler. The DistilUSE transformer model is similar to DistilBERT, but it uses an additional down-projection layer on top of DistilBERT. The XLNet transformer, instead of masked language modeling, uses permutation language modeling in which all tokens are predicted but in random order. Besides, XLNet is trained on much larger amounts of data compared to BERT. We have experimented with 4 monolingual English sentence embedding models:
roberta-base-nli-stsb-mean-tokens,
roberta-large-nli-stsb-mean-tokens,
bert-large-nli-stsb-mean-tokens,
distilbert-base-nli-stsb-mean-tokens and 4 multilingual sentence embedding models:
distiluse-base-multilingual-cased-v2,
xlm-r-distilroberta-base-paraphrase-v1,
xlm-r-bert-base-nli-stsb-mean-tokens,
distilbert-multilingual-nli-stsb-quora-ranking (more about these models can be found in
https://www.sbert.net/docs/pretrained_models.html accessed on 13 November 2020). The
nli and
stsb notations stand for training on the Natural Language Inference data and testing on Semantic Textual Similarity Benchmark dataset, respectively. The
mean-tokens notation represents the mean pooling with taking an attention mask into account.
Paraphrase means that training is performed on millions of paraphrased sentences.
Quora-ranking determines that the model is expanded by training it with contrastive loss and multiple negative ranking loss functions on the Quora Duplicate questions dataset.
For the intent detection, we have investigated the following approaches:
BERT-w + CNN. The Convolutional Neural Network (CNN) classifier introduced in [
32] was applied on top of concatenated BERT word embeddings. In our experiments, we have used the 1D CNN method adjusted for text [
33] with the optimized architecture and hyper-parameter values in various language processing tasks, including intent detection for English, Estonian, Latvian, Lithuanian, and Russian(see Figure 3 in [
34]). We reuse the architecture and hyper-parameter set of CNN in our experiments without any further optimization. The advantage of CNN is that it learns how to recognize patterns independently of their position in the text. Thus, the CNN method gets the vectorized texts (i.e., determining the length sequences of the corresponding word embeddings) on the input and learns to detect relevant patterns (consisting of 2, 3, or more adjacent tokens, so-called n-grams) (regardless of their position in the text) having the major impact on prediction of the right class.
BERT-w + BERT. The BERT transformer model can be used in various classification tasks, including intent detection. If precisely, the pre-trained BERT model is fine-tuned with just one additional output layer of neurons corresponding to classes. Despite the parameters of such a model still have to be modified to adjust to the downstream intent detection task, the advantage of such an approach is that the pre-trained BERT model weights already encode a lot of information about the language. Since bottom layers are already well learned, the tuning process only slightly adjusts them in the way their output could serve as features in text classification.
BERT-s + FFNN. BERT sentence embeddings as features are fed into the Feed Forward Neural Network (FFNN) as the classifier.
BERT-s + COS. This approach, unlike previously described classification-based approaches, does not learn any generalized model. It simply stores all training data and computes the similarity between the testing instance and all training instances. The testing instance is assigned with the label of the training instance with which the similarity is the largest. The similarity between sentence embeddings is calculated using the cosine similarity measure [
35].
These four approaches were implemented using a python 3.8.5 programming language with Tensorflow 2.3.1, Keras 2.4.3, and PyTorch 1.6.0 libraries. The word and sentence transformer models were taken from the huggingface repository.
Datasets (
Section 3.2) and previously described machine learning methods were evaluated under the following training data usage strategies for tackling the data scarcity problem:
Monolingual machine-translated (we call this strategy MT-based due to conciseness). Both training and testing are conducted in the same target language. These experiments will demonstrate the performance of monolingual models trained on machine-translated data. Results with the manually prepared EN dataset are particularly important: it will reveal what level of accuracy should be pursued with other languages. Results with other languages will reveal how far the results for other languages with translated texts lag.
Cross-lingual. Under this condition, training is conducted on the EN training dataset alone, but testing is conducted on the testing dataset of some other target language (e.g., DE, FR, LT, LV, and PT). These experiments do not use machine-translated training data at all but rely on multilingual BERT models. This will test the ability of BERT-based models to capture semantic similarities between the same texts written in different languages.
Combined. These experiments combine the previous two approaches: the training is conducted on two datasets of two languages, i.e., original EN plus the machine-translated target language. Such experiments will reveal if both training data preparation methods are complementary. This will also help answer the question of whether it is sufficient to rely on BERT-based models alone or whether the role of the machine translator (or training data in the target language) is nevertheless crucial.
Cross-lingual without any target language data (we abbreviate it to train all due to conciseness). Under this condition, training is conducted on all training datasets of all languages (both manually for EN and machine translated for other, but necessary excluding the target language). This represents the scenario when no target language data can be obtained (even machine-translated). We propose that by training on data machine-translated to multiple other languages, we can facilitate semantic interfaces between languages in BERT-based models. In case of success, these experiments can be especially beneficial for languages for which machine-translated data cannot be obtained or are of very poor quality.
4. Experiments and Results
The experimental investigation is based on the hypothesis that it is possible to find a good multilingual intent detection method that does not require original training data specifically prepared for the target language (in our case: German, French, Lithuanian, Latvian, and Portuguese) to achieve similar accuracy levels as with the monolingual method applied on the original dataset (in our case the original dataset is in English).
We have performed experiments under the controlled conditions in which some parameters were kept stable to see the impact of varied ones. We have controlled: different training and testing language pairs, vectorization types, classification approaches, and models. The randomness in our experiments was introduced (1) by selecting language representatives from several groups of languages and (2) by shuffling instances in our datasets (presented in
Section 3.2) and randomly splitting them into training (80%) and testing (20%) subsets. Moreover, in each run, the training dataset part was once again shuffled and randomly split into training (80%) and validation (20%) subsets. This randomness guarantees that the training does not bind to the specific training instances, but at the same time, similar experimental conditions for the results to remain comparable are maintained.
The performance of each trained model was evaluated with the
accuracy,
precision,
recall, and
f-score metrics presented in Equations (1)–(4), respectively. The evaluation of
accuracy,
precision,
recall, and
f-score metrics was performed using
sklearn.metrics in python.
where
tp and
tn represent correctly predicted
ci and
cj instances, respectively;
fp –
cj incorrectly predicted as
ci, and
fn –
ci incorrectly predicted as
cj.
The
accuracy,
precision,
recall, and
f-score values were averaged in five runs, and the confidence intervals were calculated for all approaches (in
Section 3.3) except BERT-s + COS. The BERT-s + COS method is a memory-based approach that simply stores all training data and computes the similarity between each testing instance and all training instances. Since vectors representing training and testing instances are stable, each run results in absolutely the same predicted labels for the training dataset instances. There is no deviation in results; therefore, upper/lower bounds values of confidence intervals are always equal to 0.
A model is considered reasonable if the calculated accuracy is above random (Equation (5)) and majority (Equation (6)) baselines.
where
P(
cj) is a probability of a class.
In our experiments, random and majority baselines are equal to ~0.04 and ~0.09, respectively. The low random baseline value demonstrates the difficulty of the task in which a “random guess” could not be “a solution”; the low majority baseline value shows that the dataset is not biased towards any class.
When comparing different evaluation results is important to determine if differences between them are statistically significant. For this purpose, the McNemar test [
36] with 95% of confidence (
α = 0.05) has been used. Differences are considered statistically significant if the calculated
p-value is below
α = 0.05. The evaluation of statistical significance was performed using
statsmodels.stats.contingency_tables module in python.
During experiments under the
MT-based strategy, we have tested all four approaches (described in
Section 3.2). Evaluation results with BERT-w + CNN, BERT-w + BERT, BERT-s + FFNN, and BERT-s + COS are presented in
Table A1,
Table A2,
Table A3, and
Table A4, respectively. EN results are obtained on original data and represent the top-line. To see clearly which approach is the best for each target language, we have summarized accuracies in
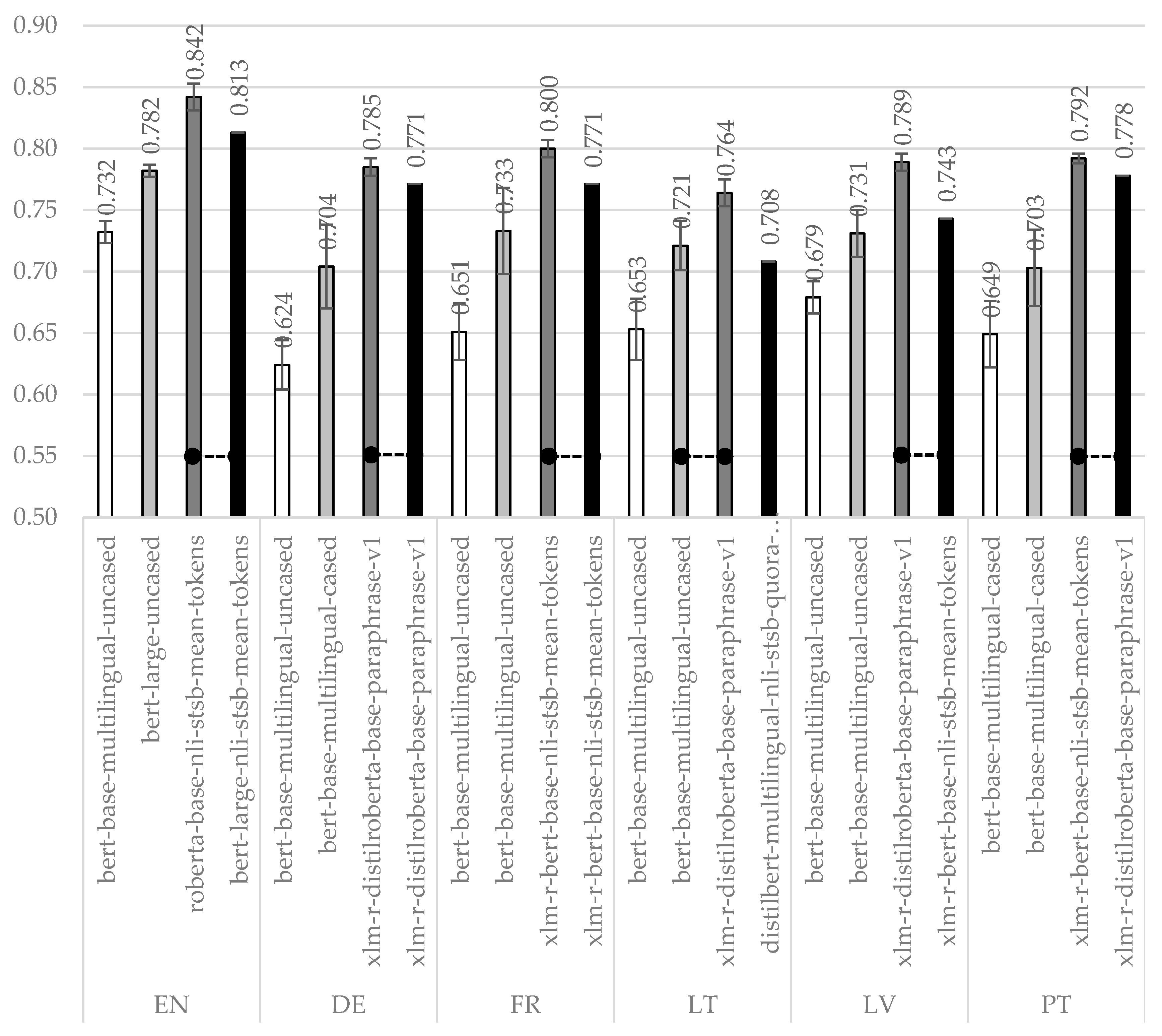
Figure 1. Methods based on sentence embeddings outperform methods based on word embeddings. The winner is BERT-s + FFNN followed by BERT-s + COS, despite differences between their accuracies for most languages are not statistically significant. The experimental investigation revealed that all four metrics (
accuracy,
precision,
recall, and
f-score) demonstrate similar trends. For comparison purposes, we have selected
accuracy as the main metric in this and further experiments. It is the most common metric, besides, suitable for our dataset not biased towards major classes.
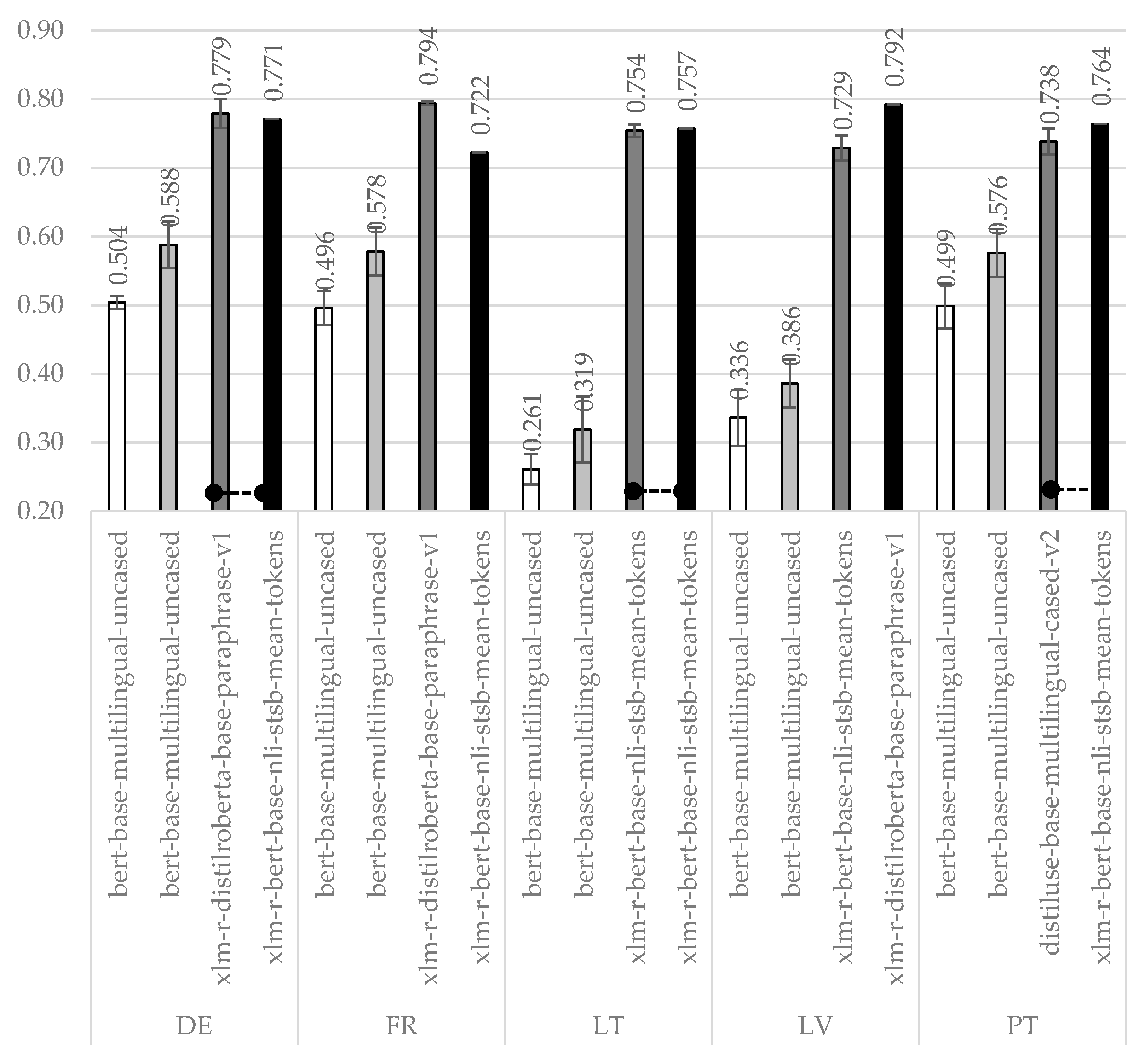
Next, experiments were performed under the cross-lingual strategy: i.e., when training multilingual models on the original EN training dataset alone and testing on some other target language.
The results of BERT-w + CNN, BERT-w + BERT, BERT-s + FFNN, and BERT-s + COS approaches under the
cross-lingual strategy are summarized in
Table A5,
Table A6,
Table A7, and
Table A8, respectively. The summary of the highest accuracies for each target language is presented in
Figure 2.
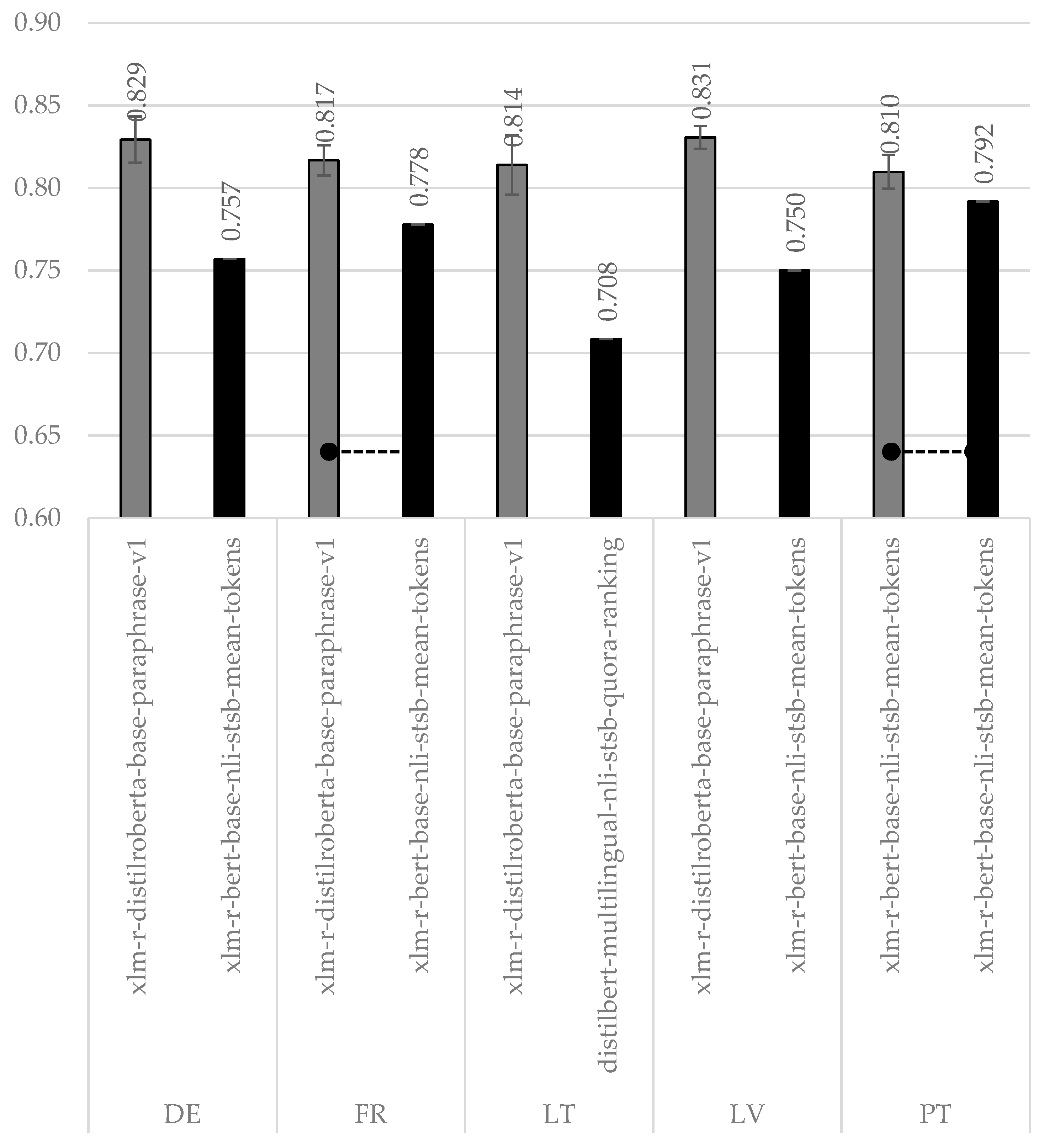
A combination of the first two data preparation approaches under the
combined strategy also was evaluated. The training was performed on two datasets of two languages (i.e., EN + the target language), whereas testing was conducted on the testing dataset of the target language. We have shrunk the set of testing approaches to BERT-s + FFNN and BERT-s + COS because only they demonstrated good performance under the cross-lingual condition. The accuracies for BERT-s + FFNN and BERT-s + COS are summarized in
Table A9 and
Table A10, respectively. The best accuracies for each target language are presented in
Figure 3.
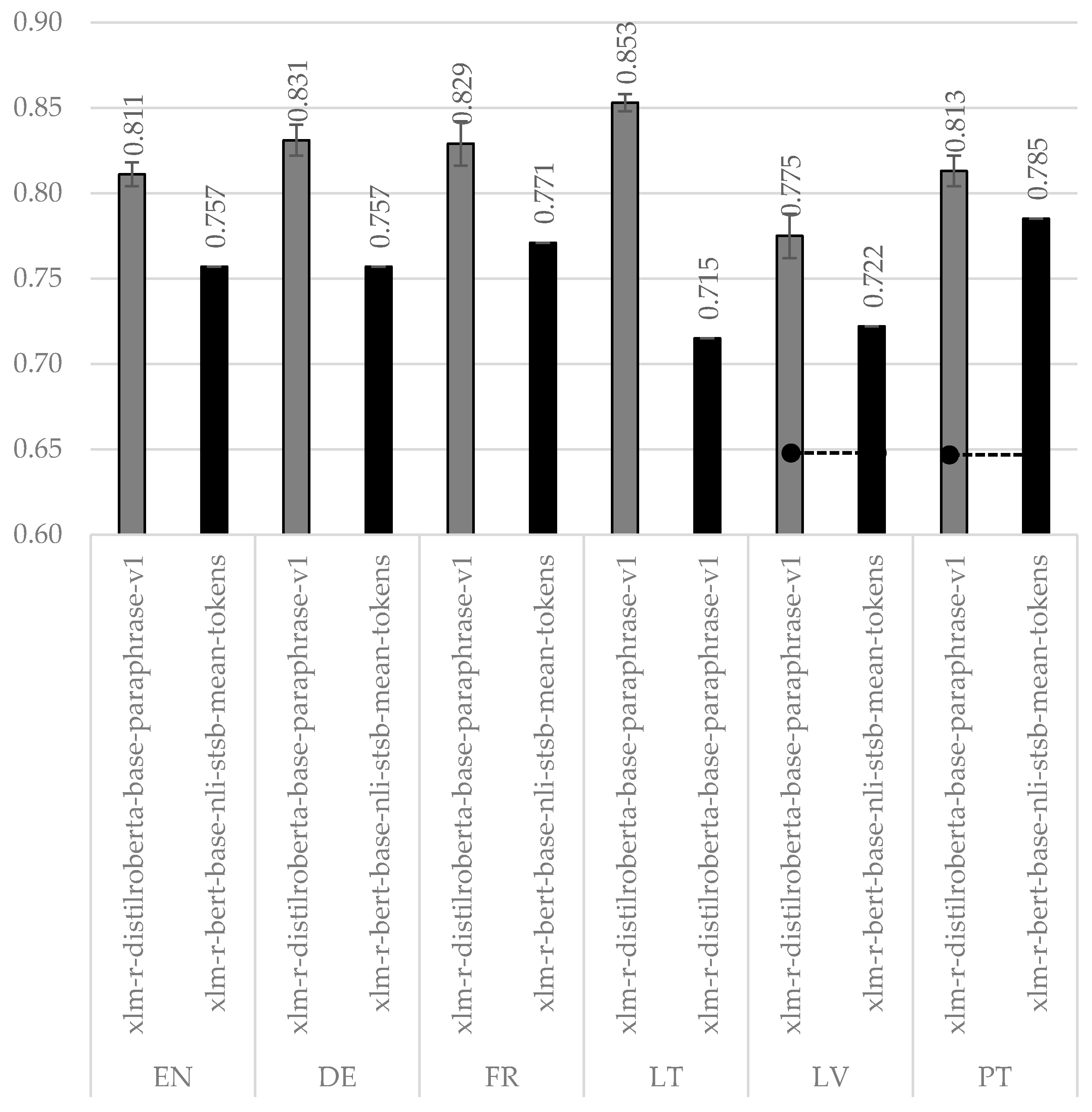
Finally, experiments under the
train all strategy were performed. During these experiments, training was conducted on all training datasets for all languages (excluding the target one) and testing was performed on the testing dataset of the target language. The accuracies for BERT-s + FFNN and BERT-s + COS approaches are summarized in
Table A11 and
Table A12, respectively. The best accuracies for each target language are presented in
Figure 4.
5. Discussion
Zooming into tables in
Appendix A and figures allows us to make the statement that all results can be considered reasonable for solving intent detection tasks because they exceed random and majority baselines.
The best overall accuracy (equal to ~0.842) under the monolingual MT-based condition is achieved on the original English language dataset. This result represents our top-line, which will be used for comparison purposes to other approaches and languages. The most accurate approach (i.e., BERT-s + FFNN) uses the pre-trained roberta-base-nli-stsb-mean-tokens BERT model that is adjusted for the English language alone. It also explains why this particular model outperforms multilingual pre-trained sentence embeddings (i.e., xlm-r-distilroberta-base-paraphrase-v1 and xlm-r-bert-base-nli-stsb-mean-tokens).
Experiments with the machine-translated training data (i.e. under the MT-based strategy) clearly show that this approach is successful. The best performer again is BERT-s + FFNN, with the machine-translated training data for all target languages allows achieving the best accuracies in the range (0.764–0.800) that is still rather close to our top-line.
In the cross-lingual experiments (under the cross-lingual strategy), the best-achieved accuracies are in the accuracy range (0.757–0.794). As we can see, they exceed the threshold of 75%, which is a surprisingly good result without having any training instances in target languages. For German and French, BERT-s + FFNN is a better option, whereas for Lithuanian, Latvian, and Portuguese, on the contrary, BERT-s + COS outperforms BERT-s + FFNN. However, it is still difficult to make hard conclusions on which of these approaches is the better option because differences are not statistically significant for German, Lithuanian, and Portuguese languages. Of the four multilingual sentence embedding models, the xlm-r-bert-base-nli-stsb-mean-tokens pre-trained sentence transformer model seems to be a slightly better option for Lithuanian and Portuguese, whereas xlm-r-distilroberta-base-paraphrase-v1 for German, French, and Latvian.
Both experiments under
MT-based or
cross-lingual strategies reveal the superiority of sentence transformers over word transformers. Word embedding-based methods use sequences of concatenated word vectors to represent input texts of the pre-determined length. Due to it, even specific functional words (as articles, modal verbs, etc.) or sentence word-order greatly influence vectors representing those texts. In this respect, languages with relatively free word-order in a sentence (e.g., Lithuanian or Latvian) seem to more suffering: corresponding vectors are more diverse, and therefore it is more difficult to tune the model to be better generalize for some downstream tasks. This phenomenon is especially visible in
Figure 2: the training is conducted with the English language; therefore, a model cannot adjust to different word orders. However, a sentence is not a sequence of words but their cumulative semantical meaning. Despite different syntactic and grammatical rules in different languages, the meanings of sentences in different languages remain the same. Sentence embeddings accumulate the meaning of the vectorized text as a whole and therefore seem a more natural and more appropriate way to represent texts for any language.
Results under the combined strategy show that MT-based and cross-lingual strategies are complementary. The best-achieved accuracies exceed the threshold of 80%, are in the interval [0.810–0.831], and are very close to our top-line equal to ~0.842. It seems that having machine-translated training instances in the target language (besides the training instances in English) boosts the accuracy level by ~5%, and this increase is considered statistically significant. In this setting BERT-s + FFNN approach is superior to BERT-s + COS, except for French and Portuguese languages, for which differences between these two approaches are insignificant. The best performing sentence embedding model is xlm-r-distilroberta-base-paraphrase-v1, except for Portuguese. The xlm-r-bert-base-nli-stsb-mean-tokens is the best for Portuguese, however the difference from xlm-r-distilroberta-base-paraphrase-v1 is less than 0.3% and insignificant.
The interval of the best-achieved accuracies under the train all strategy is much wider (0.775–0.853) compared to all previously discussed, which means that larger diversity in the training data does not always lead to better performance. At the same time, it demonstrates how strongly the accuracy depends on the target language. If the Latvian language benefits the least, Lithuanian, on the contrary, benefits the most. Additionally, it is very difficult to explain why two similar Baltic languages (Lithuanian and Latvian) obtain such contradictory results. Surprisingly, the accuracy (~0.853) for the Lithuanian language even slightly exceeds our top-line. It allows us to conclude cautiously that very good results can be achieved even without any data in the target language, only with the correctly chosen technique. The best approach under the train all strategy is also BERT-s + FFNN, whereas for Latvian and Portuguese, BERT-s + COS from BERT-s + FFNN differ insignificantly.
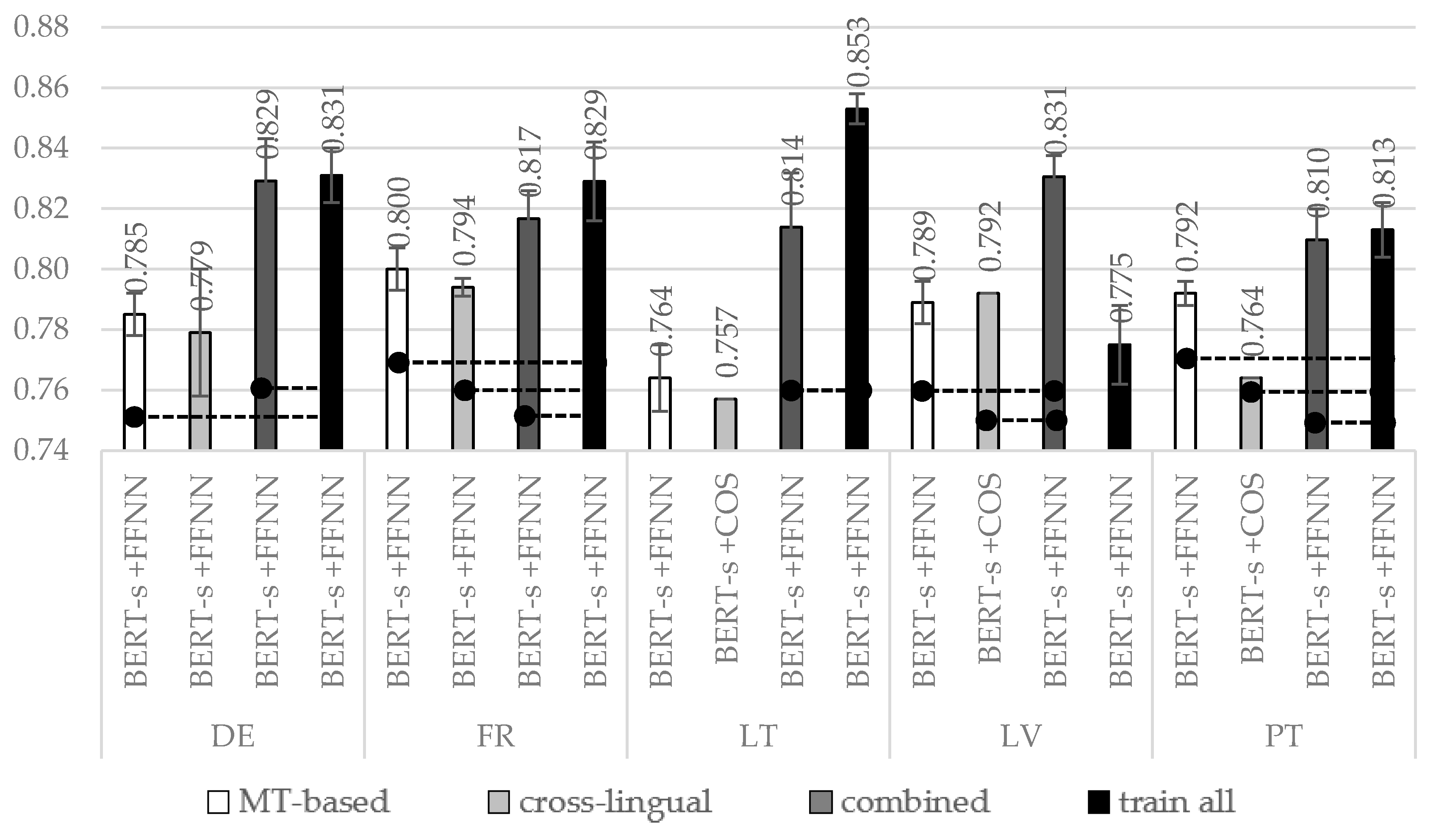
To be able to compare the performance of all four training data usage strategies, we have summarized the best-achieved accuracies in
Figure 5. The winner is the
train all with the BERT-s + FFNN method, followed by
combined (except for Latvian, where it is vice versa).
Overall, the results seem promising, especially having in mind that experiments for these target languages (i.e., German, French, Lithuanian, Latvian, and Portuguese) were performed without any original training data. Intent detection experiments strongly rely on the quality of machine translations (under MT-based, combined, and train all strategies). The review of German, French, Latvian, Lithuanian, and Portuguese machine translations confirmed that even though the translations are not always very precise, the gist is still retained. Despite this, Google is not the only machine translation tool, and it is always recommended to choose the best one. Moreover, the training data (even in the machine-translated form) for these languages is not mandatory. Rather good results can be achieved only with cross-lingual models transferred from training on English alone. All of it encourages us to continue experiments in the future by testing more approaches, more models on more datasets for more languages.
6. Conclusions and Future Work
In this research, we attempt to solve a two-fold problem: (1) a supervised intent detection problem for several languages (English, German, French, Lithuanian, Latvian, and Portuguese); (2) the annotated data scarcity problem, because such training data for some languages does not exist. For this reason, the English training dataset (containing 41 intent) was Google machine-translated into five target languages.
The intent detection problem was solved by using two BERT-based vectorization types (i.e., word and sentence embeddings) together with three eager learning classifiers (CNN, BERT fine-tuning, FFNN) and one lazy learning approach (Cosine similarity as the memory-based method). The annotated data scarcity problem was tackled by testing the following training data usage strategies: MT-based (when relying on the machine-translated training data), cross-lingual (when training on either English alone), combined (cross-lingual complemented with the machine-translated instances of the target language), and train all (cross-lingual complemented with the machine-translated instances in multiple languages excluding the target one). The experiments revealed the superiority of the combined and train all strategies on all five target languages. The experiments revealed the superiority of sentence transformers over word embeddings; in particular, FFNN applied on top of BERT-based sentence embeddings over the rest.
The best accuracy of ~0.842 (which is also our top-line) on the English language dataset is achieved with completely monolingual models (monolingual vectorization and monolingual classification method). However, without the original training dataset, similar accuracy levels equal to ~0.831, ~0.829, ~0.853, ~0.831, and ~0.813 were achieved for other languages like German, French, Lithuanian, Latvian, and Portuguese, respectively.
Thus, our research investigation claims the hypothesis that regardless of the tested language, the multilingual intent detection problem can be solved effectively (reaching similar accuracy levels >0.8 as in the monolingual experiments with the original English dataset) even without training data originally prepared for the target language. It allows us to assume that this hypothesis holds for the other languages (at least similar to the tested ones: i.e., from Germanic, Romanic, and Balto-Slavic branches). Moreover, since the intent detection problem is a typical text classification problem, the findings of this research allow us to assume that multilingual text classification problems can also be solved with similar approaches. In future research, it would be interesting to investigate both assumptions by including more languages, more domains, and solving other text classification problems.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




