
Social Media Toxicity Classification Using Deep Learning: Real-World Application UK Brexit

 ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
- Propose an efficient deep learning model to classify toxic comments from user generated contents in social media;
- Build our model based on the Bidirectional Encoder Representations from Transformers (BERT) model;
- The BERT pre-trained model is fine-tuned on a Kaggle public dataset, “Toxic Comment Classification Challenge”, and has been evaluated on two different datasets, collected from Twitter in two different periods, using Twitter API by applying several search terms and hashtags such such as #Brexit, #BrexitBetrayal, and #StopBrexit;
- We compare the BERT base model to three models, namely, Multilingual BERT, RoBERTa, and DistilBERT to verify its performance.
2. Related Work
2.1. Applications of User Generated Contents in Social Media
2.2. Applications of Bidirectional Encoder Representations from Transformers (BERT)
3. Methodology
3.1. Pre-Processing
3.2. BERT for Toxic Comments Classification
3.3. Model Fine-Tuning for Toxic Comments Classification
4. Twitter Data Retrieval and Cleaning
5. Experiments and Results
5.1. Fine-Tuning BERT
5.2. Prediction Results
5.3. Tweets Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abualigah, L.; Gandomi, A.H.; Elaziz, M.A.; Hussien, A.G.; Khasawneh, A.M.; Alshinwan, M.; Houssein, E.H. Nature-Inspired Optimization Algorithms for Text Document Clustering—A Comprehensive Analysis. Algorithms 2020, 13, 345. [Google Scholar] [CrossRef]
- Uhls, Y.T.; Ellison, N.B.; Subrahmanyam, K. Benefits and costs of social media in adolescence. Pediatrics 2017, 140, S67–S70. [Google Scholar] [CrossRef] [PubMed]
- Souri, A.; Hosseinpour, S.; Rahmani, A.M. Personality classification based on profiles of social networks’ users and the five-factor model of personality. Hum. Centric Comput. Inf. Sci. 2018, 8, 24. [Google Scholar] [CrossRef]
- Morente-Molinera, J.A.; Kou, G.; Samuylov, K.; Ureña, R.; Herrera-Viedma, E. Carrying out consensual Group Decision Making processes under social networks using sentiment analysis over comparative expressions. Knowl. Based Syst. 2019, 165, 335–345. [Google Scholar] [CrossRef]
- Risch, J.; Krestel, R. Aggression identification using deep learning and data augmentation. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), Santa Fe, NM, USA, 25 August 2018; pp. 150–158. [Google Scholar]
- Subramani, S.; Wang, H.; Vu, H.Q.; Li, G. Domestic violence crisis identification from facebook posts based on deep learning. IEEE Access 2018, 6, 54075–54085. [Google Scholar] [CrossRef]
- Subramani, S.; Michalska, S.; Wang, H.; Du, J.; Zhang, Y.; Shakeel, H. Deep Learning for Multi-Class Identification From Domestic Violence Online Posts. IEEE Access 2019, 7, 46210–46224. [Google Scholar] [CrossRef]
- Abualigah, L.; Gandomi, A.H.; Elaziz, M.A.; Hamad, H.A.; Omari, M.; Alshinwan, M.; Khasawneh, A.M. Advances in Meta-Heuristic Optimization Algorithms in Big Data Text Clustering. Electronics 2021, 10, 101. [Google Scholar] [CrossRef]
- Abualigah, L.M.Q. Feature Selection And Enhanced Krill Herd Algorithm For Text Document Clustering; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Ahmad, S.; Asghar, M.Z.; Alotaibi, F.M.; Awan, I. Detection and classification of social media-based extremist affiliations using sentiment analysis techniques. Hum. Centric Comput. Inf. Sci. 2019, 9, 24. [Google Scholar] [CrossRef]
- Budiharto, W.; Meiliana, M. Prediction and analysis of Indonesia Presidential election from Twitter using sentiment analysis. J. Big Data 2018, 5, 51. [Google Scholar] [CrossRef]
- Prabhu, B.A.; Ashwini, B.; Khan, T.A.; Das, A. Predicting Election Result with Sentimental Analysis Using Twitter Data for Candidate Selection. In Innovations in Computer Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2019; pp. 49–55. [Google Scholar]
- Cury, R.M. Oscillation of tweet sentiments in the election of João Doria Jr. for Mayor. J. Big Data 2019, 6, 42. [Google Scholar] [CrossRef]
- Al Shehhi, A.; Thomas, J.; Welsch, R.; Grey, I.; Aung, Z. Arabia Felix 2.0: A cross-linguistic Twitter analysis of happiness patterns in the United Arab Emirates. J. Big Data 2019, 6, 33. [Google Scholar] [CrossRef]
- Pong-inwong, C.; Songpan, W. Sentiment analysis in teaching evaluations using sentiment phrase pattern matching (SPPM) based on association mining. Int. J. Mach. Learn. Cybern. 2018, 10, 2177–2186. [Google Scholar] [CrossRef]
- Aloufi, S.; El Saddik, A. Sentiment identification in football-specific tweets. IEEE Access 2018, 6, 78609–78621. [Google Scholar] [CrossRef]
- Amato, F.; Castiglione, A.; Moscato, V.; Picariello, A.; Sperlì, G. Multimedia summarization using social media content. Multimed. Tools Appl. 2018, 77, 17803–17827. [Google Scholar] [CrossRef]
- Amato, F.; Moscato, V.; Picariello, A.; Sperlí, G. Multimedia social network modeling: A proposal. In Proceedings of the 2016 IEEE Tenth International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 4–6 February 2016; pp. 448–453. [Google Scholar]
- Li, Z.; Fan, Y.; Jiang, B.; Lei, T.; Liu, W. A survey on sentiment analysis and opinion mining for social multimedia. Multimed. Tools Appl. 2019, 78, 6939–6967. [Google Scholar] [CrossRef]
- Angadi, S.; Reddy, R.V.S. Survey on Sentiment Analysis from Affective Multimodal Content. In Smart Intelligent Computing and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 599–607. [Google Scholar]
- Chiranjeevi, P.; Santosh, D.T.; Vishnuvardhan, B. Survey on Sentiment Analysis Methods for Reputation Evaluation. In Cognitive Informatics and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 53–66. [Google Scholar]
- Alaei, A.R.; Becken, S.; Stantic, B. Sentiment analysis in tourism: Capitalizing on big data. J. Travel Res. 2019, 58, 175–191. [Google Scholar] [CrossRef]
- Kwak, H.; Blackburn, J.; Han, S. Exploring cyberbullying and other toxic behavior in team competition online games. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 3739–3748. [Google Scholar]
- O’Keeffe, G.S.; Clarke-Pearson, K. The impact of social media on children, adolescents, and families. Pediatrics 2011, 127, 800–804. [Google Scholar] [CrossRef] [PubMed]
- Whittaker, E.; Kowalski, R.M. Cyberbullying via social media. J. Sch. Violence 2015, 14, 11–29. [Google Scholar] [CrossRef]
- Fox, J.; Cruz, C.; Lee, J.Y. Perpetuating online sexism offline: Anonymity, interactivity, and the effects of sexist hashtags on social media. Comput. Hum. Behav. 2015, 52, 436–442. [Google Scholar] [CrossRef]
- Lapidot-Lefler, N.; Barak, A. Effects of anonymity, invisibility, and lack of eye-contact on toxic online disinhibition. Comput. Hum. Behav. 2012, 28, 434–443. [Google Scholar] [CrossRef]
- Kim, H.; Chang, Y. Managing Online Toxic Disinhibition: The Impact of Identity and Social Presence. SIGHCI 2017 Proceedings. Available online: https://aisel.aisnet.org/sighci2017/1 (accessed on 1 February 2021).
- Joyce, B.; Deng, J. Sentiment analysis of tweets for the 2016 US presidential election. In Proceedings of the 2017 IEEE MIT Undergraduate Research Technology Conference (URTC), Cambridge, MA, USA, 3–5 November 2017; pp. 1–4. [Google Scholar]
- You, Q.; Luo, J.; Jin, H.; Yang, J. Robust image sentiment analysis using progressively trained and domain transferred deep networks. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Hussain, A. Convolutional MKL based multimodal emotion recognition and sentiment analysis. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 439–448. [Google Scholar]
- Li, X.; Xie, H.; Chen, L.; Wang, J.; Deng, X. News impact on stock price return via sentiment analysis. Knowl. Based Syst. 2014, 69, 14–23. [Google Scholar] [CrossRef]
- Wöllmer, M.; Weninger, F.; Knaup, T.; Schuller, B.; Sun, C.; Sagae, K.; Morency, L.P. Youtube movie reviews: Sentiment analysis in an audio-visual context. IEEE Intell. Syst. 2013, 28, 46–53. [Google Scholar] [CrossRef]
- Arias, M.; Arratia, A.; Xuriguera, R. Forecasting with twitter data. ACM Trans. Intell. Syst. Technol. (TIST) 2013, 5, 8. [Google Scholar] [CrossRef]
- Jansen, B.J.; Zhang, M.; Sobel, K.; Chowdury, A. Twitter power: Tweets as electronic word of mouth. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 2169–2188. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A.; Mirjalili, S.; Abd Elaziz, M.; Gandomi, A.H. The arithmetic optimization algorithm. Comput. Methods Appl. Mech. Eng. 2021, 376, 113609. [Google Scholar] [CrossRef]
- Abualigah, L.; Yousri, D.; Abd Elaziz, M.; Ewees, A.A.; Al-qaness, M.; Gandomi, A.H. Aquila Optimizer: A novel meta-heuristic optimization Algorithm. Comput. Ind. Eng. 2021, 107250. [Google Scholar]
- Ringsquandl, M.; Petkovic, D. Analyzing political sentiment on Twitter. In Proceedings of the 2013 AAAI Spring Symposium Series, Stanford, CA, USA, 25–27 March 2013. [Google Scholar]
- Kušen, E.; Strembeck, M. Politics, sentiments, and misinformation: An analysis of the Twitter discussion on the 2016 Austrian Presidential Elections. Online Soc. Netw. Media 2018, 5, 37–50. [Google Scholar] [CrossRef]
- Haselmayer, M.; Jenny, M. Sentiment analysis of political communication: Combining a dictionary approach with crowdcoding. Qual. Quant. 2017, 51, 2623–2646. [Google Scholar] [CrossRef]
- Rathan, M.; Hulipalled, V.R.; Venugopal, K.; Patnaik, L. Consumer insight mining: Aspect based Twitter opinion mining of mobile phone reviews. Appl. Soft Comput. 2018, 68, 765–773. [Google Scholar]
- Anastasia, S.; Budi, I. Twitter sentiment analysis of online transportation service providers. In Proceedings of the 2016 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Malang, Indonesia, 15–16 October 2016; pp. 359–365. [Google Scholar]
- Pagolu, V.S.; Reddy, K.N.; Panda, G.; Majhi, B. Sentiment analysis of Twitter data for predicting stock market movements. In Proceedings of the 2016 International Conference on Signal Processing, Communication, Power and Embedded System (SCOPES), Paralakhemundi, India, 3–5 October 2016; pp. 1345–1350. [Google Scholar]
- Alomari, E.; Mehmood, R. Analysis of tweets in Arabic language for detection of road traffic conditions. In International Conference on Smart Cities, Infrastructure, Technologies and Applications; Springer: Berlin/Heidelberg, Germany, 2017; pp. 98–110. [Google Scholar]
- Al-qaness, M.A.; Abd Elaziz, M.; Hawbani, A.; Abbasi, A.A.; Zhao, L.; Kim, S. Real-Time Traffic Congestion Analysis Based on Collected Tweets. In Proceedings of the 2019 IEEE International Conferences on Ubiquitous Computing & Communications (IUCC) and Data Science and Computational Intelligence (DSCI) and Smart Computing, Networking and Services (SmartCNS), Shenyang, China, 21–23 October 2019; pp. 1–8. [Google Scholar]
- Frank, M.R.; Mitchell, L.; Dodds, P.S.; Danforth, C.M. Happiness and the patterns of life: A study of geolocated tweets. Sci. Rep. 2013, 3, 2625. [Google Scholar] [CrossRef]
- Giachanou, A.; Crestani, F. Like it or not: A survey of twitter sentiment analysis methods. ACM Comput. Surv. (CSUR) 2016, 49, 1–41. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mai, I.; Marwan, T.; Nagwa, E.M. Imbalanced Toxic Comments Classification Using Data Augmentation and Deep Learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 875–878. [Google Scholar] [CrossRef]
- Wulczyn, E.; Thain, N.; Dixon, L. Ex machina: Personal attacks seen at scale. In Proceedings of the 26th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 May 2017; pp. 1391–1399. [Google Scholar]
- Saeed, H.H.; Shahzad, K.; Kamiran, F. Overlapping Toxic Sentiment Classification Using Deep Neural Architectures. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 1361–1366. [Google Scholar]
- Georgakopoulos, S.V.; Tasoulis, S.K.; Vrahatis, A.G.; Plagianakos, V.P. Convolutional neural networks for toxic comment classification. In Proceedings of the 10th Hellenic Conference on Artificial Intelligence, Patras, Greece, 9–12 July 2018; p. 35. [Google Scholar]
- Fang, W.; Luo, H.; Xu, S.; Love, P.E.; Lu, Z.; Ye, C. Automated text classification of near-misses from safety reports: An improved deep learning approach. Adv. Eng. Inform. 2020, 44, 101060. [Google Scholar] [CrossRef]
- Fan, B.; Fan, W.; Smith, C.; Garner, H. Adverse drug event detection and extraction from open data: A deep learning approach. Inf. Process. Manag. 2020, 57, 102131. [Google Scholar] [CrossRef]
- Moradi, M.; Dorffner, G.; Samwald, M. Deep contextualized embeddings for quantifying the informative content in biomedical text summarization. Comput. Methods Programs Biomed. 2020, 184, 105117. [Google Scholar] [CrossRef]
- Wang, Q.; Ji, Z.; Wang, J.; Wu, S.; Lin, W.; Li, W.; Ke, L.; Xiao, G.; Jiang, Q.; Xu, H.; et al. A study of entity-linking methods for normalizing Chinese diagnosis and procedure terms to ICD codes. J. Biomed. Inform. 2020, 105, 103418. [Google Scholar] [CrossRef]
- Koroleva, A.; Kamath, S.; Paroubek, P. Measuring semantic similarity of clinical trial outcomes using deep pre-trained language representations. J. Biomed. Inform. 2019, 4, 100058. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Y.; Zhang, Q.; Ren, Y.; Qiu, T.; Ma, J.; Sun, Q. Extracting comprehensive clinical information for breast cancer using deep learning methods. Int. J. Med Inform. 2019, 132, 103985. [Google Scholar] [CrossRef]
- Chen, F.; Yuan, Z.; Huang, Y. Multi-source data fusion for aspect-level sentiment classification. Knowl. Based Syst. 2020, 187, 104831. [Google Scholar] [CrossRef]
- Gao, Z.; Feng, A.; Song, X.; Wu, X. Target-Dependent Sentiment Classification with BERT. IEEE Access 2019, 7, 154290–154299. [Google Scholar] [CrossRef]
- Yin, X.; Huang, Y.; Zhou, B.; Li, A.; Lan, L.; Jia, Y. Deep Entity Linking via Eliminating Semantic Ambiguity With BERT. IEEE Access 2019, 7, 169434–169445. [Google Scholar] [CrossRef]
- He, J.; Zhao, L.; Yang, H.; Zhang, M.; Li, W. HSI-BERT: Hyperspectral Image Classification Using the Bidirectional Encoder Representation From Transformers. IEEE Trans. Geosci. Remote Sens. 2019, 58, 165–178. [Google Scholar] [CrossRef]
- Lee, L.H.; Lu, Y.; Chen, P.H.; Lee, P.L.; Shyu, K.K. NCUEE at MEDIQA 2019: Medical text inference using ensemble BERT-BiLSTM-Attention model. In Proceedings of the 18th BioNLP Workshop and Shared Task, Wurzburg, Germany, 16–20 September 2019; pp. 528–532. [Google Scholar]
- Liu, J.; Ng, Y.C.; Wood, K.L.; Lim, K.H. Ipod: An industrial and professional occupations dataset and its applications to occupational data mining and analysis. arXiv 2019, arXiv:1910.10495. [Google Scholar]
- Zhang, Z.; Zhang, Z.; Chen, H.; Zhang, Z. A Joint Learning Framework With BERT for Spoken Language Understanding. IEEE Access 2019, 7, 168849–168858. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A Primer in BERTology: What we know about how BERT works. arXiv 2020, arXiv:2002.12327. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Chung, S.W.; Kim, Y. The Truth behind the Brexit Vote: Clearing away Illusion after Two Years of Confusion. Sustainability 2019, 11, 5201. [Google Scholar] [CrossRef]




















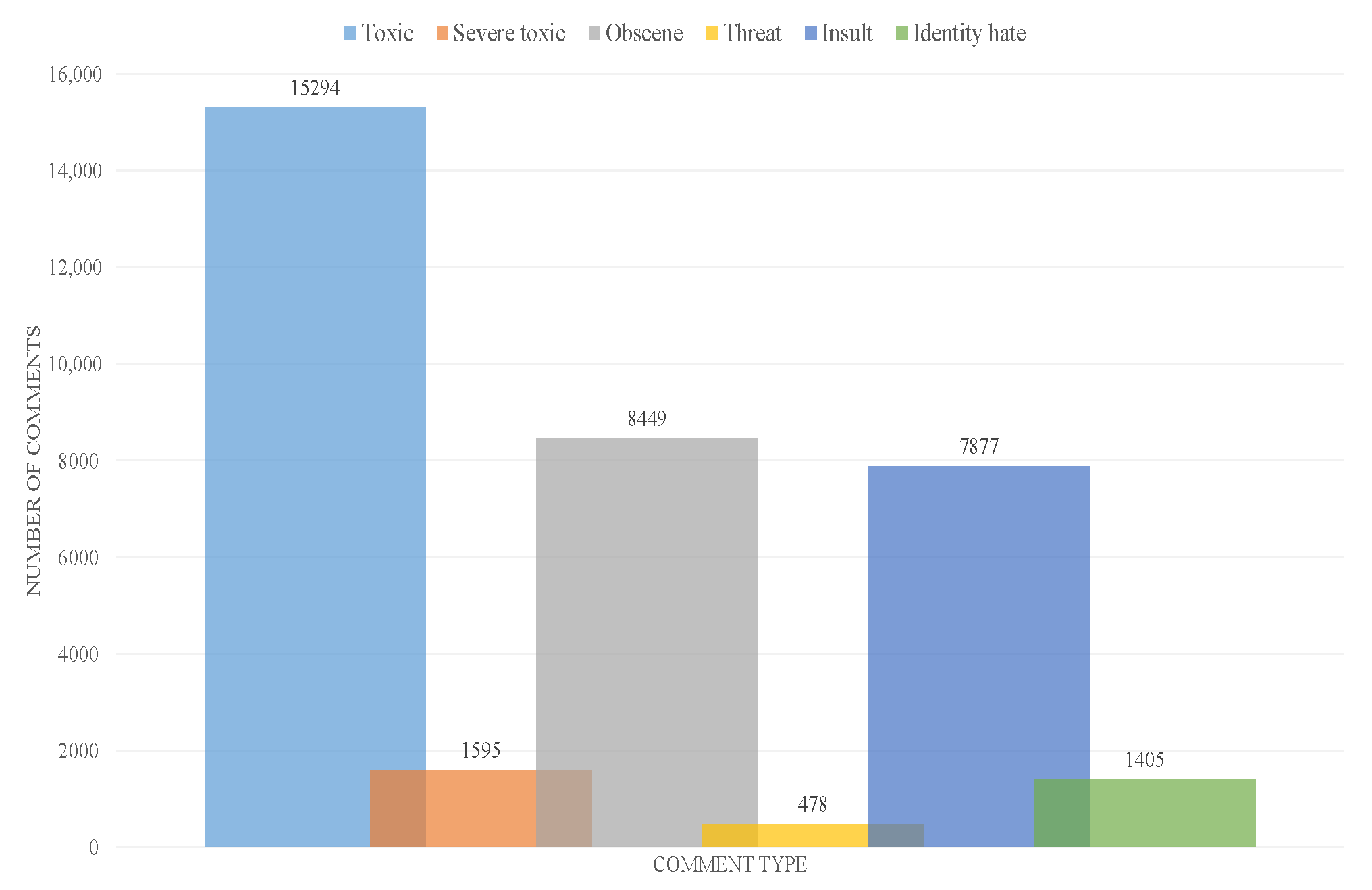{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Private Score | Public Score |
|---|---|---|
| BERT base | 0.9860 | 0.9856 |
| Multilingual BERT | 0.9845 | 0.9852 |
| RoBERTa | 0.9772 | 0.9772 |
| DistilBERT | 0.9851 | 0.9848 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, H.; Du, W.; Dahou, A.; Ewees, A.A.; Yousri, D.; Elaziz, M.A.; Elsheikh, A.H.; Abualigah, L.; Al-qaness, M.A.A. Social Media Toxicity Classification Using Deep Learning: Real-World Application UK Brexit. Electronics 2021, 10, 1332. https://doi.org/10.3390/electronics10111332
Fan H, Du W, Dahou A, Ewees AA, Yousri D, Elaziz MA, Elsheikh AH, Abualigah L, Al-qaness MAA. Social Media Toxicity Classification Using Deep Learning: Real-World Application UK Brexit. Electronics. 2021; 10(11):1332. https://doi.org/10.3390/electronics10111332
Chicago/Turabian StyleFan, Hong, Wu Du, Abdelghani Dahou, Ahmed A. Ewees, Dalia Yousri, Mohamed Abd Elaziz, Ammar H. Elsheikh, Laith Abualigah, and Mohammed A. A. Al-qaness. 2021. "Social Media Toxicity Classification Using Deep Learning: Real-World Application UK Brexit" Electronics 10, no. 11: 1332. https://doi.org/10.3390/electronics10111332
APA StyleFan, H., Du, W., Dahou, A., Ewees, A. A., Yousri, D., Elaziz, M. A., Elsheikh, A. H., Abualigah, L., & Al-qaness, M. A. A. (2021). Social Media Toxicity Classification Using Deep Learning: Real-World Application UK Brexit. Electronics, 10(11), 1332. https://doi.org/10.3390/electronics10111332