
An Empirical Performance Evaluation of Multiple Intel Optane Solid-State Drives

Abstract
1. Introduction
2. Related Work
2.1. Performance Evaluation of Fast Storage Devices
2.2. Study on Redundant Array of Independent Disks Schemes
3. Experimental Setup
3.1. NVMe SSD
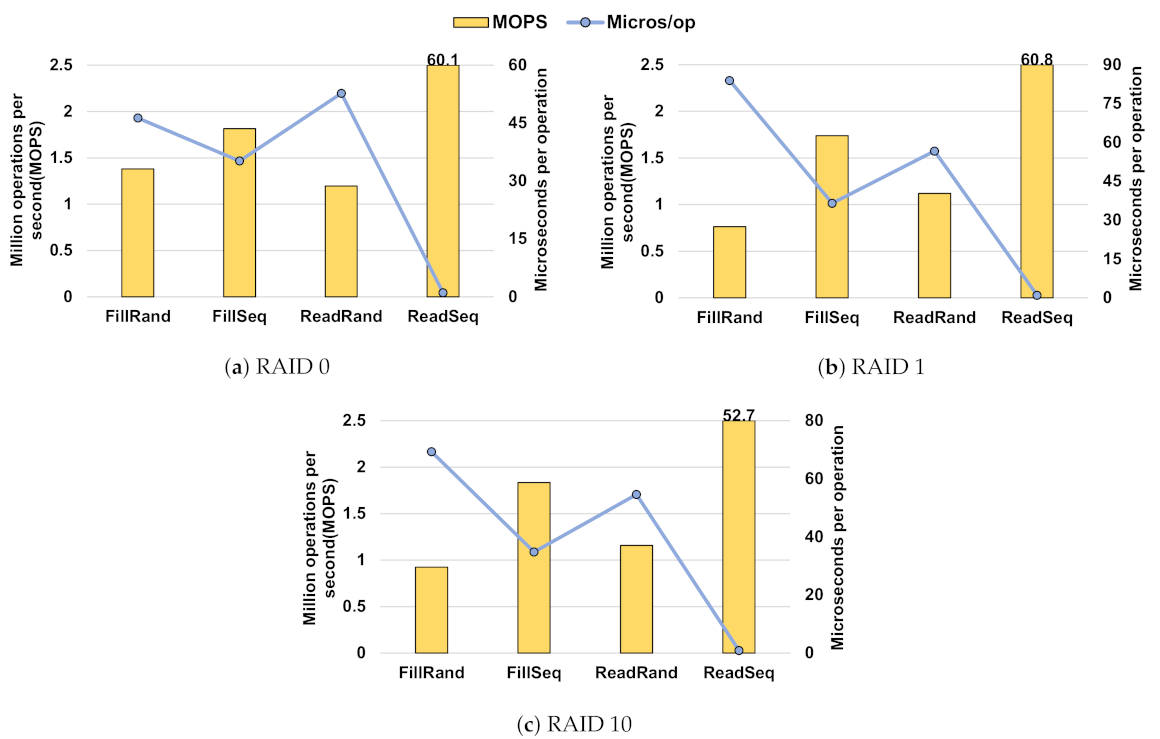
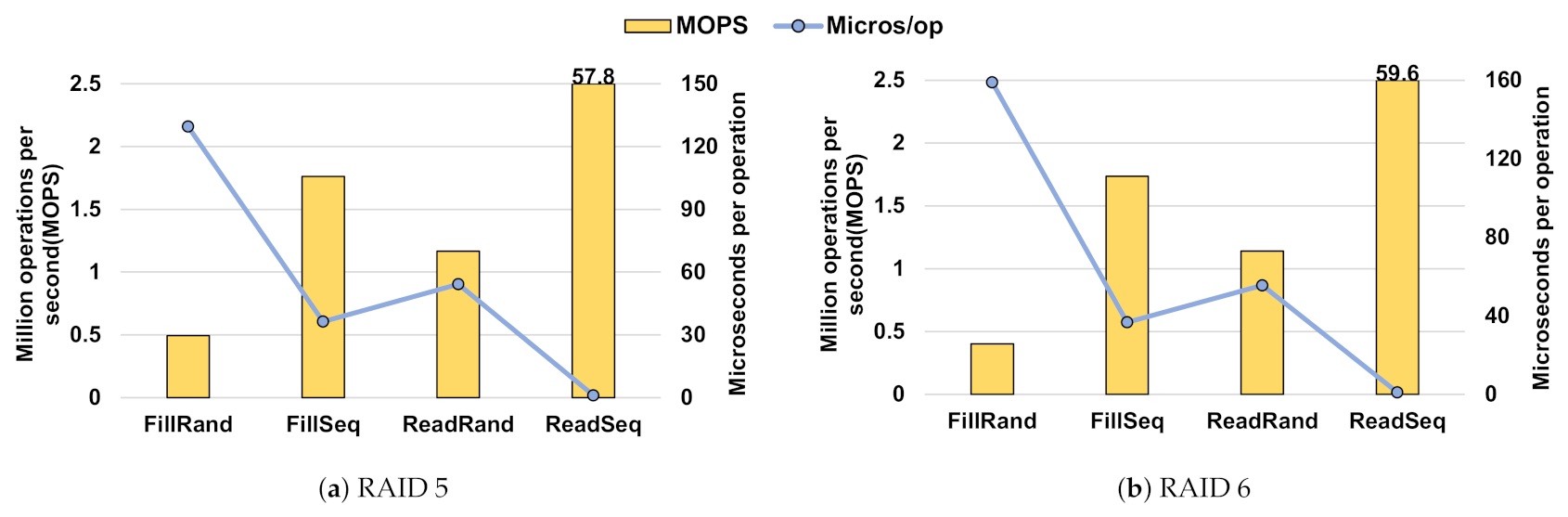
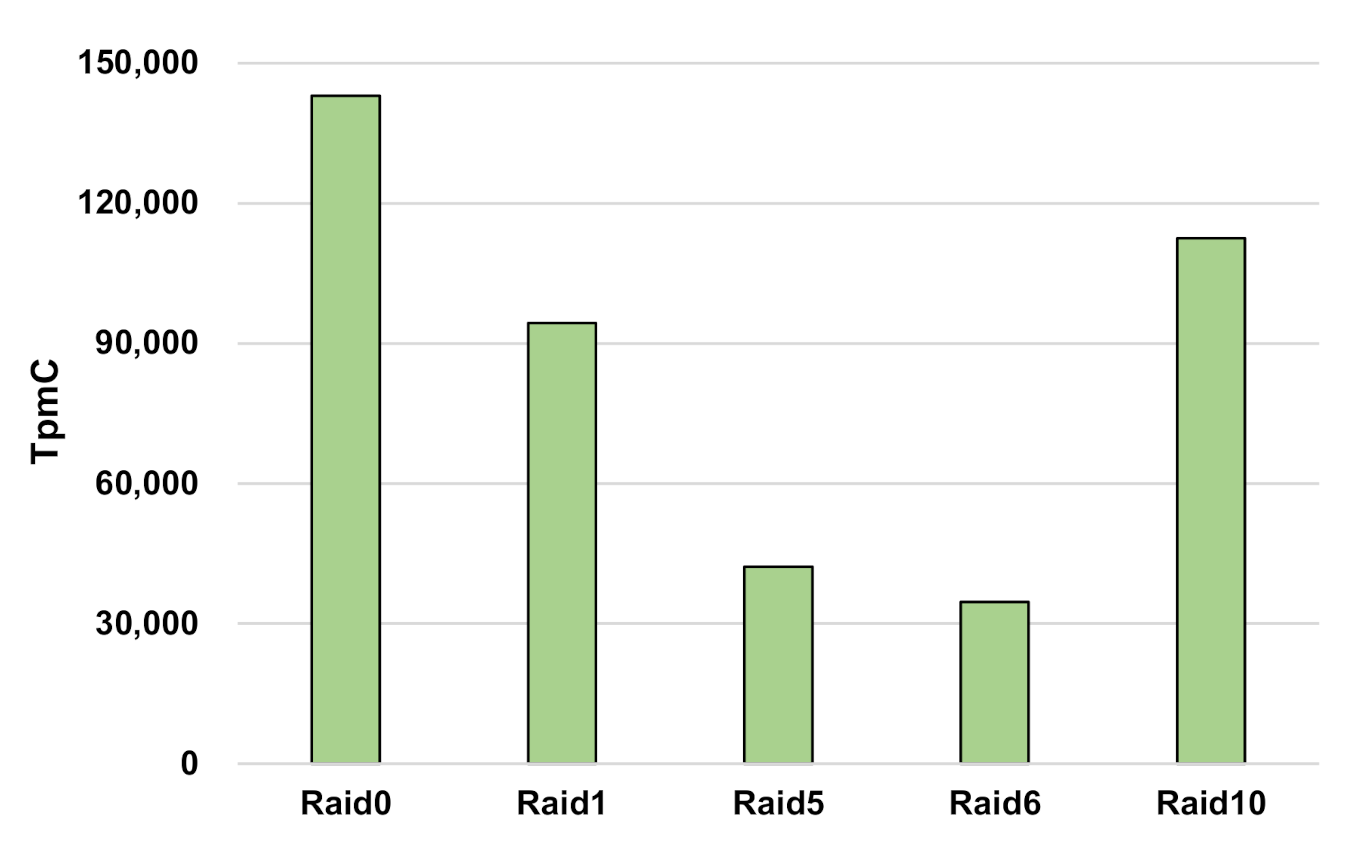
3.2. Redundant Array of Independent Disks
- Raid 0 provides a striping strategy;
- Raid 1 provides a mirroring strategy;
- Raid 5 provides striping with parity;
- Raid 6 provides striping with double-parity;
- Raid 10 provides a stripe of mirrors (a combination of RAID 1 and 0).
3.3. Setup
4. Experiment
4.1. Synthesis Benchmark
4.2. Database Benchmark
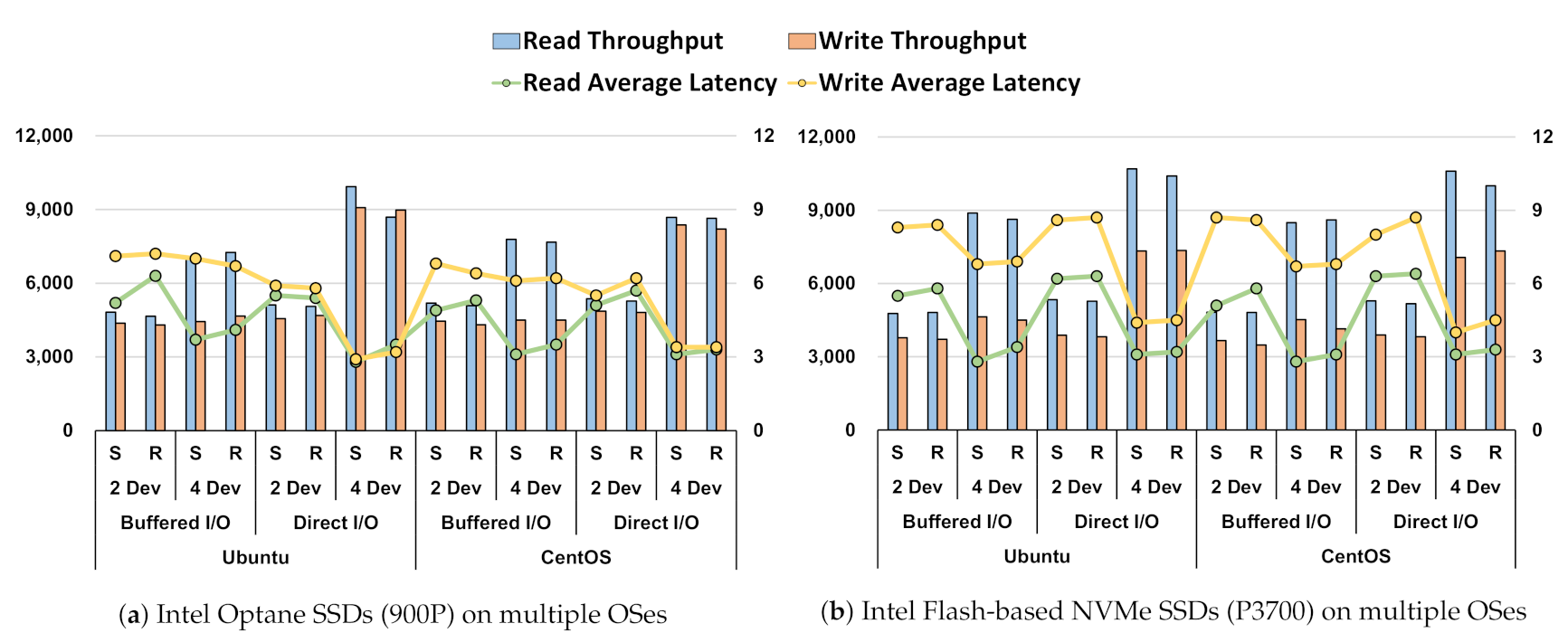
4.3. Performance Comparison under Multiple OSes and SSDs
4.4. Comparison with Related Works
5. Summary and Implication
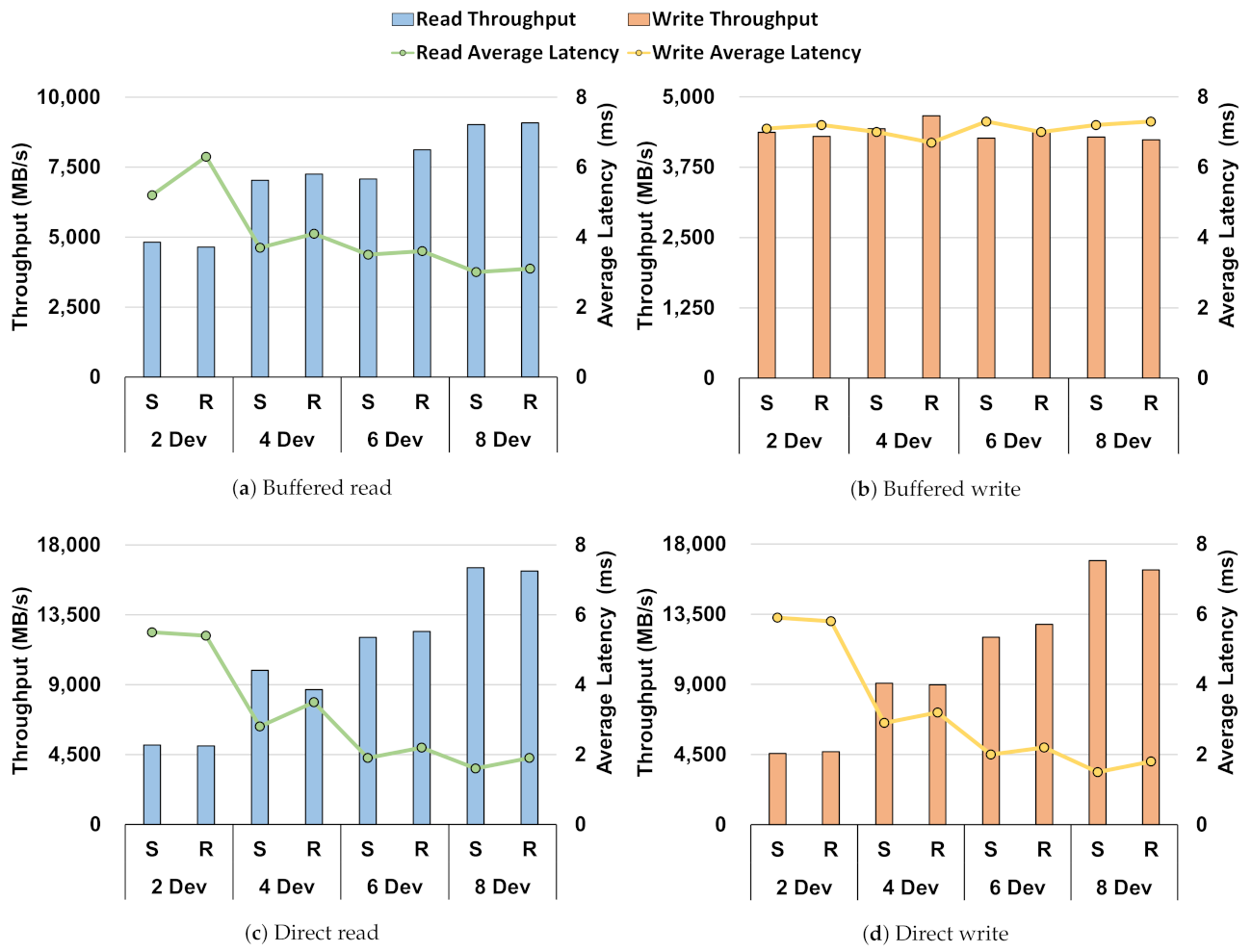
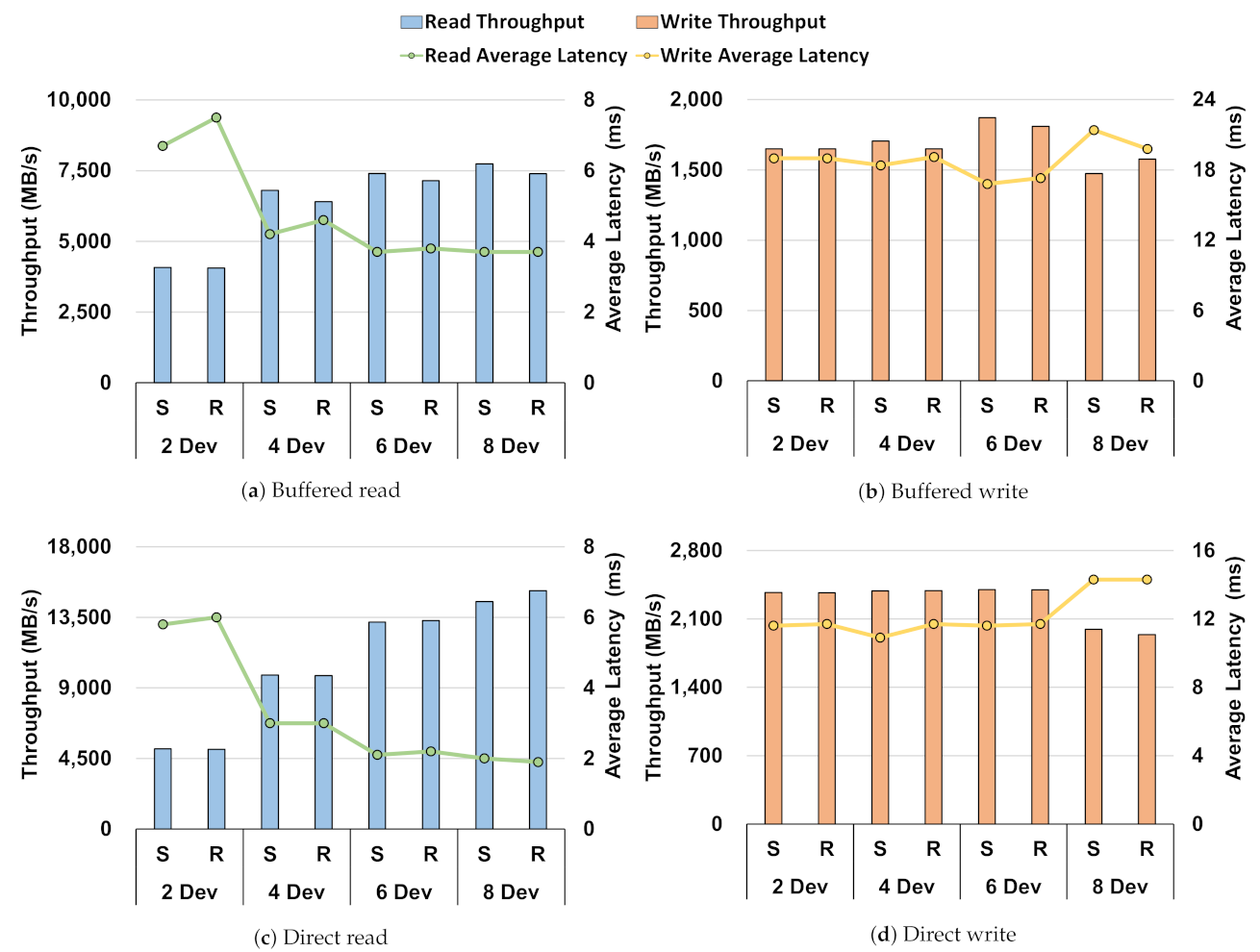
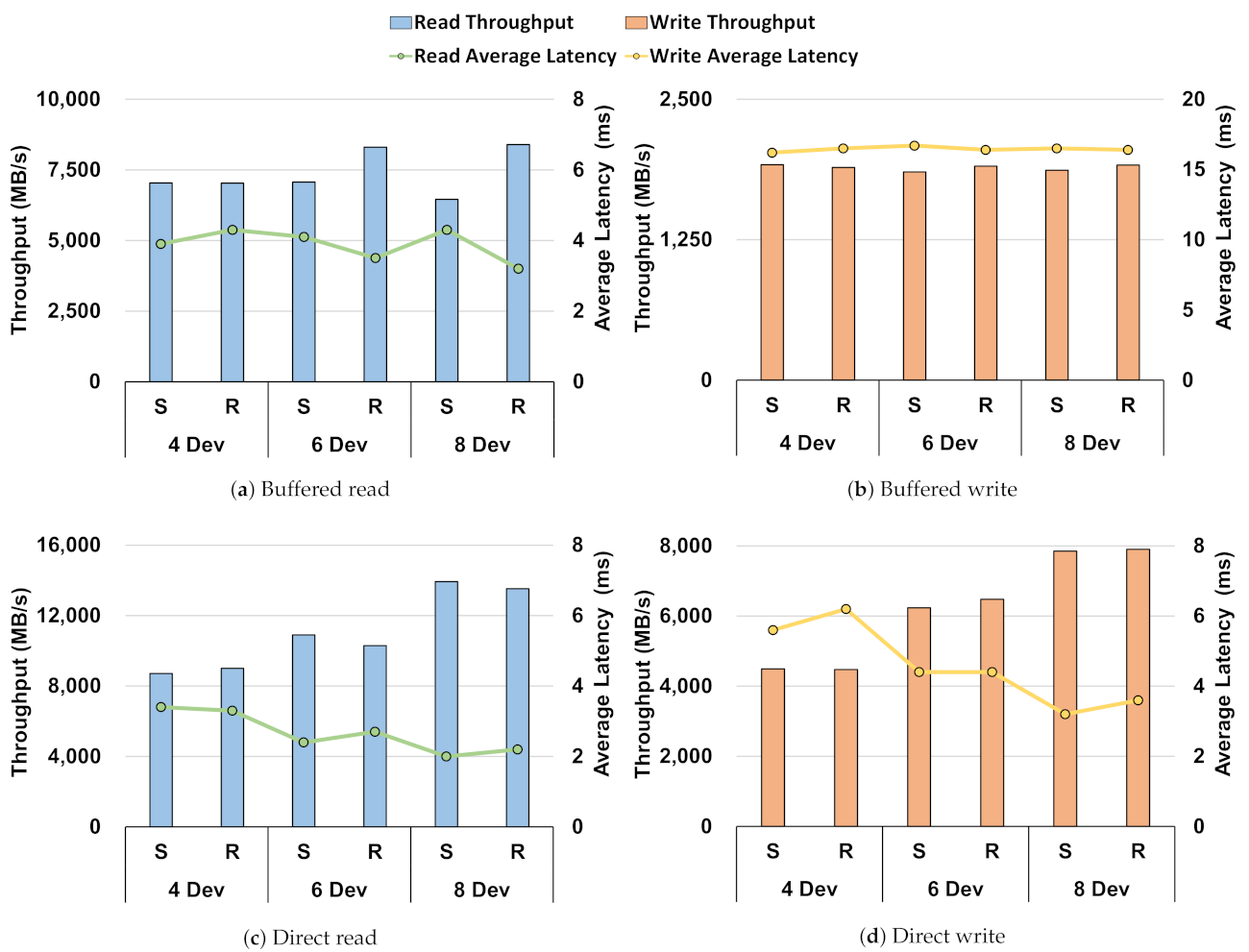
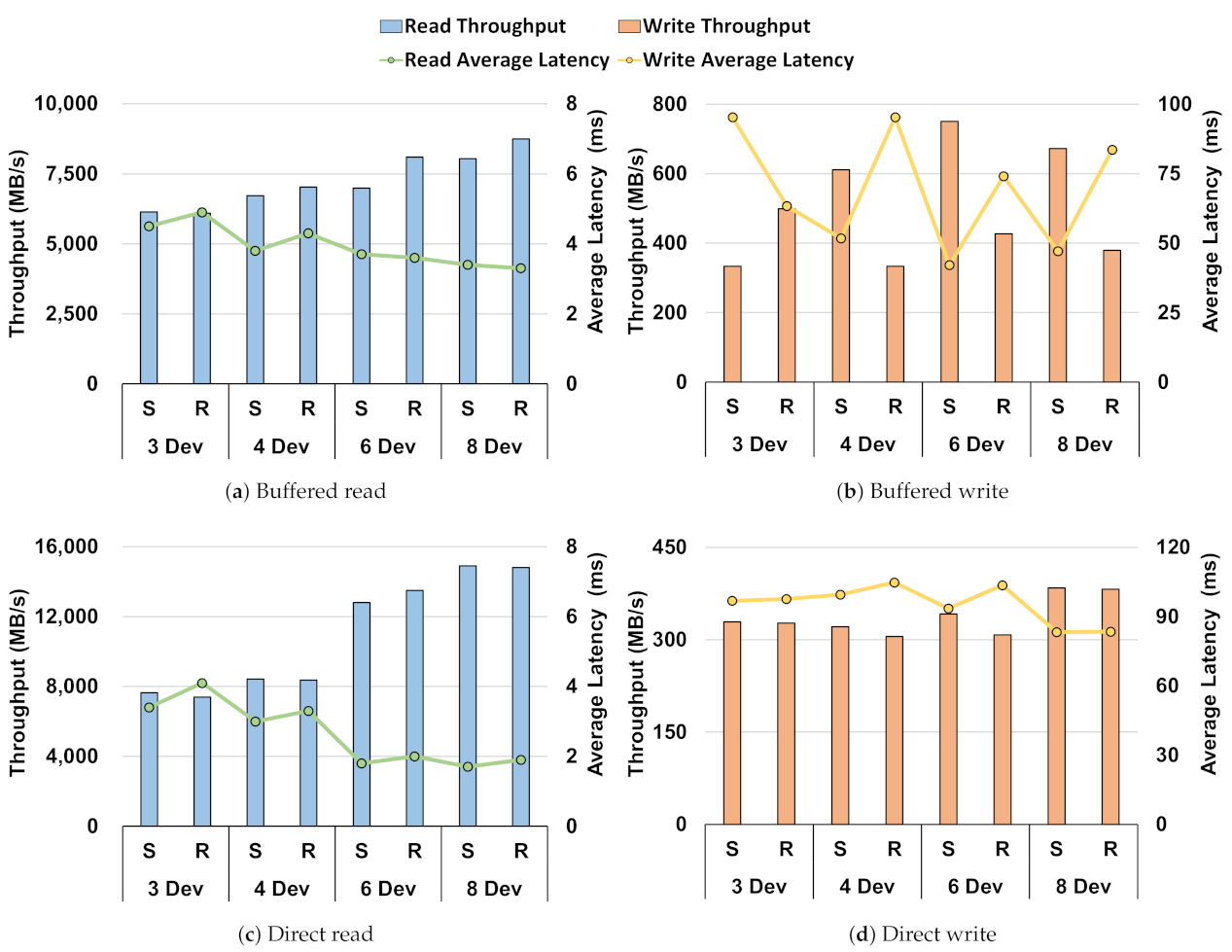
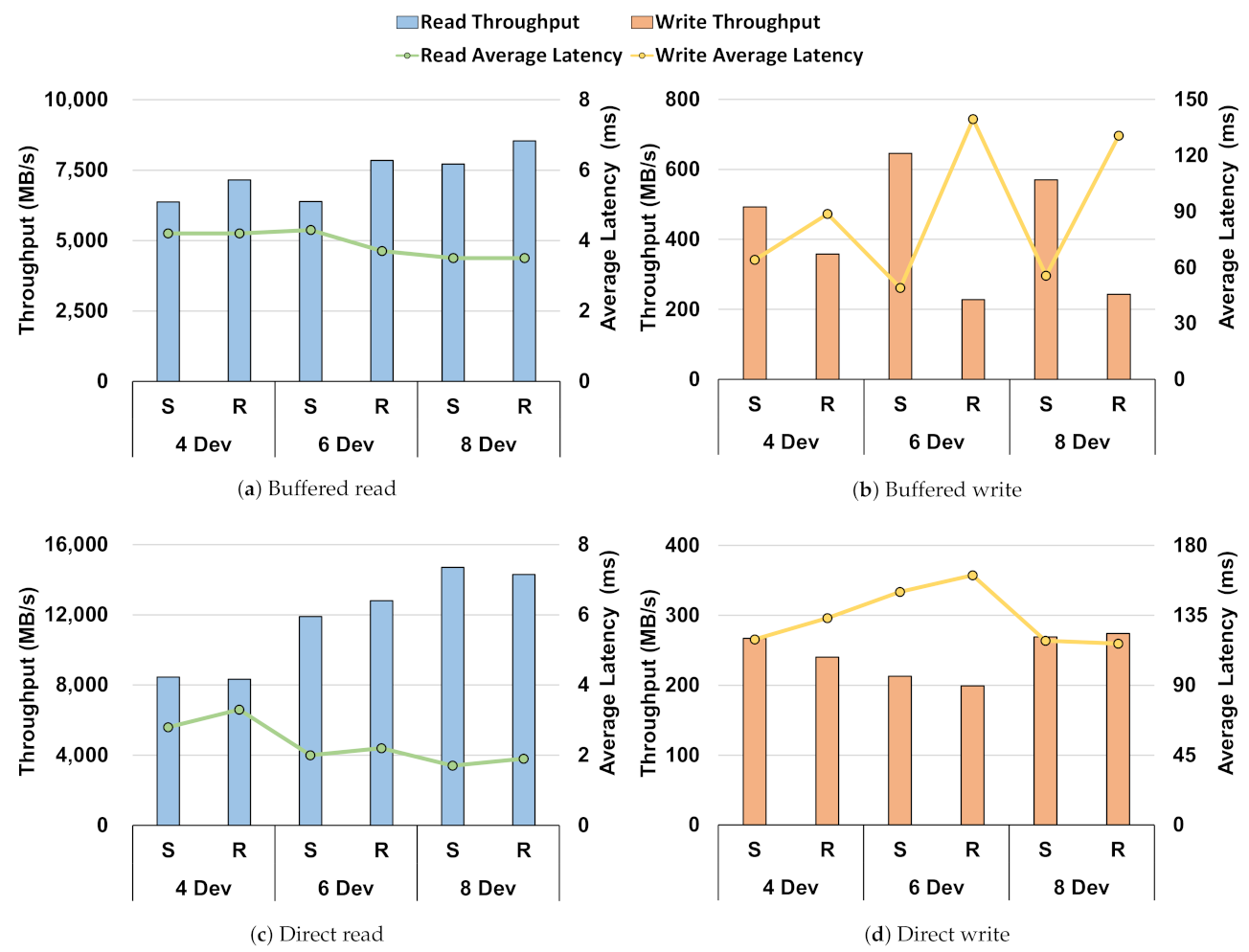
- Through the performance baseline of the Intel Optane SSD in the Section 3, we showed no difference in performance between direct I/O and buffered I/O in a single-device environment. However, when compared in a RAID environment, through Figure 1, Figure 2, Figure 3, Figure 4 and Figure 5, there was a difference in performance. This showed that the storage stack had an overhead;
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Venkatesh, M.; Sumalatha, M.; SelvaKumar, C. Improving public auditability, data possession in data storage security for cloud computing. In Proceedings of the 2012 International Conference on Recent Trends in Information Technology, Chennai, India, 19–21 April 2012; pp. 463–467. [Google Scholar]
- Aceto, G.; Botta, A.; De Donato, W.; Pescapè, A. Cloud monitoring: A survey. Comput. Netw. 2013, 57, 2093–2115. [Google Scholar] [CrossRef]
- Yang, T.; Shia, B.C.; Wei, J.; Fang, K. Mass data analysis and forecasting based on cloud computing. JSW 2012, 7, 2189–2195. [Google Scholar] [CrossRef]
- Grossman, R.L. The case for cloud computing. IT Prof. 2009, 11, 23–27. [Google Scholar] [CrossRef]
- Jian-Hua, Z.; Nan, Z. Cloud computing-based data storage and disaster recovery. In Proceedings of the 2011 International Conference on Future Computer Science and Education, Xi’an, China, 20–21 October 2011; pp. 629–632. [Google Scholar]
- Son, Y.; Kang, H.; Han, H.; Yeom, H.Y. An empirical evaluation and analysis of the performance of NVM express solid state drive. Clust. Comput. 2016, 19, 1541–1553. [Google Scholar] [CrossRef]
- Xu, Q.; Siyamwala, H.; Ghosh, M.; Suri, T.; Awasthi, M.; Guz, Z.; Shayesteh, A.; Balakrishnan, V. Performance analysis of NVMe SSDs and their implication on real world databases. In Proceedings of the 8th ACM International Systems and Storage Conference, Haifa, Israel, 26–28 May 2015; pp. 1–11. [Google Scholar]
- Google Cloud Platform. Available online: https://cloud.google.com/compute/docs/disks/local-ssd (accessed on 10 April 2021).
- Amazon Web Service. Available online: https://docs.aws.amazon.com/ko_kr/AWSEC2/latest/UserGuide/ssd-instance-store.html (accessed on 10 April 2021).
- Han, J.; Zhu, G.; Lee, E.; Lee, S.; Son, Y. An Empirical Evaluation and Analysis of Performance of Multiple Optane SSDs. In Proceedings of the 2021 International Conference on Information Networking (ICOIN), Jeju Island, Korea, 13–16 January 2021; pp. 541–545. [Google Scholar]
- Son, Y.; Choi, J.W.; Eom, H.; Yeom, H.Y. Optimizing the file system with variable-length I/O for fast storage devices. In Proceedings of the 4th Asia-Pacific Workshop on Systems, Singapore, 29–30 July 2013; pp. 1–6. [Google Scholar]
- Son, Y.; Song, N.Y.; Han, H.; Eom, H.; Yeom, H.Y. A user-level file system for fast storage devices. In Proceedings of the 2014 International Conference on Cloud and Autonomic Computing, London, UK, 8–12 September 2014; pp. 258–264. [Google Scholar]
- Son, Y.; Han, H.; Yeom, H.Y. Optimizing file systems for fast storage devices. In Proceedings of the 8th ACM International Systems and Storage Conference, Haifa, Israel, 26–28 May 2015; pp. 1–6. [Google Scholar]
- Wu, K.; Arpaci-Dusseau, A.; Arpaci-Dusseau, R. Towards an Unwritten Contract of Intel Optane {SSD}. In Proceedings of the 11th {USENIX} Workshop on Hot Topics in Storage and File Systems (HotStorage 19), Renton, WA, USA, 8–9 July 2019. [Google Scholar]
- Kim, H.; Seshadri, S.; Dickey, C.L.; Chiu, L. Evaluating phase change memory for enterprise storage systems: A study of caching and tiering approaches. In Proceedings of the 12th {USENIX} Conference on File and Storage Technologies ({FAST} 14), Santa Clara, CA, 16–19 February 2014; pp. 33–45. [Google Scholar]
- Bhimani, J.; Yang, J.; Yang, Z.; Mi, N.; Xu, Q.; Awasthi, M.; Pandurangan, R.; Balakrishnan, V. Understanding performance of I/O intensive containerized applications for NVMe SSDs. In Proceedings of the 2016 IEEE 35th International Performance Computing and Communications Conference (IPCCC), Las Vegas, NV, USA, 9–11 December 2016; pp. 1–8. [Google Scholar]
- Menon, J. A performance comparison of RAID-5 and log-structured arrays. In Proceedings of the Fourth IEEE International Symposium on High Performance Distributed Computing, Washington, DC, USA, 2–4 August 1995; pp. 167–178. [Google Scholar]
- Patterson, D.A.; Gibson, G.; Katz, R.H. A case for redundant arrays of inexpensive disks (RAID). In Proceedings of the 1988 ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 1–3 June 1988; pp. 109–116. [Google Scholar]
- Chen, S.; Towsley, D. A performance evaluation of RAID architectures. IEEE Trans. Comput. 1996, 45, 1116–1130. [Google Scholar] [CrossRef]
- Li, Y.; Lee, P.P.; Lui, J.C. Stochastic analysis on RAID reliability for solid-state drives. In Proceedings of the 2013 IEEE 32nd International Symposium on Reliable Distributed Systems, Braga, Portugal, 30 September–3 October 2013; pp. 71–80. [Google Scholar]
- Islam, N.S.; Wasi-ur Rahman, M.; Lu, X.; Panda, D.K. High performance design for HDFS with byte-addressability of NVM and RDMA. In Proceedings of the 2016 International Conference on Supercomputing, Istanbul, Turkey, 1–3 June 2016; pp. 1–14. [Google Scholar]
- Hady, F.T.; Foong, A.; Veal, B.; Williams, D. Platform storage performance with 3D XPoint technology. Proc. IEEE 2017, 105, 1822–1833. [Google Scholar] [CrossRef]
- 3D XPoint Technology. Available online: https://www.micron.com/products/advanced-solutions/3d-xpoint-technology (accessed on 10 April 2021).
- Intel Optane Technology. Available online: https://www.intel.com/content/www/us/en/architecture-and-technology/intel-optane-technology.html/ (accessed on 10 April 2021).
- Schnjakin, M.; Meinel, C. Evaluation of cloud-raid: A secure and reliable storage above the clouds. In Proceedings of the 2013 22nd International Conference on Computer Communication and Networks (ICCCN), Nassau, Bahamas, 30 July–2 August 2013; pp. 1–9. [Google Scholar]
- Fitch, D.; Xu, H. A RAID-based secure and fault-tolerant model for cloud information storage. Int. J. Softw. Eng. Knowl. Eng. 2013, 23, 627–654. [Google Scholar] [CrossRef]
- Pirahandeh, M.; Kim, D.H. Energy-aware GPU-RAID scheduling for reducing energy consumption in cloud storage systems. In Computer Science and its Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 705–711. [Google Scholar]
- Mathur, A.; Cao, M.; Bhattacharya, S.; Dilger, A.; Tomas, A.; Vivier, L. The new ext4 filesystem: Current status and future plans. In Proceedings of the Linux Symposium, Citeseer, Ottawa, Ontario, Canada 27–30 June 2007; Volume 2, pp. 21–33. [Google Scholar]
- FIO Benchmark. Available online: https://github.com/axboe/fio (accessed on 10 April 2021).
- Chen, S.; Ailamaki, A.; Athanassoulis, M.; Gibbons, P.B.; Johnson, R.; Pandis, I.; Stoica, R. TPC-E vs. TPC-C: Characterizing the new TPC-E benchmark via an I/O comparison study. ACM Sigmod Rec. 2011, 39, 5–10. [Google Scholar] [CrossRef]
- Ahmed, M.; Uddin, M.M.; Azad, M.S.; Haseeb, S. MySQL performance analysis on a limited resource server: Fedora vs. Ubuntu Linux. In Proceedings of the 2010 Spring Simulation Multiconference, Orlando, FL, USA, 11–15 April 2010; pp. 1–7. [Google Scholar]
- Ghoshal, D.; Canon, R.S.; Ramakrishnan, L. I/o performance of virtualized cloud environments. In Proceedings of the Second International Workshop on Data Intensive Computing in the Clouds, Seattle, WA, USA, 14 November 2011; pp. 71–80. [Google Scholar]
- Zhang, J.; Li, P.; Liu, B.; Marbach, T.G.; Liu, X.; Wang, G. Performance analysis of 3D XPoint SSDs in virtualized and non-virtualized environments. In Proceedings of the 2018 IEEE 24th International Conference on Parallel and Distributed Systems (ICPADS), Singapore, 11–13 December 2018; pp. 1–10. [Google Scholar]
- Yang, M.; Peng, B.; Yao, J.; Guan, H. A Throughput-Oriented NVMe Storage Virtualization with Workload-Aware Management. IEEE Trans. Comput. 2020. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flash-Based SATA SSD | Flash-Based NVMe SSD | Optane SSD | ||||
|---|---|---|---|---|---|---|
| Buffered I/O | Direct I/O | Buffered I/O | Direct I/O | Buffered I/O | Direct I/O | |
| Sequential Read | 220 MB/s | 211 MB/s | 2485 MB/s | 2563 MB/s | 2558 MB/s | 2553 MB/s |
| Random Read | 194 MB/s | 207 MB/s | 2478 MB/s | 2585 MB/s | 2554 MB/s | 2556 MB/s |
| Sequential Write | 256 MB/s | 170 MB/s | 2011 MB/s | 1925 MB/s | 2499 MB/s | 2445 MB/s |
| Random Write | 194 MB/s | 162 MB/s | 1995 MB/s | 1953 MB/s | 2468 MB/s | 2445 MB/s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Zhu, G.; Lee, S.; Son, Y. An Empirical Performance Evaluation of Multiple Intel Optane Solid-State Drives. Electronics 2021, 10, 1325. https://doi.org/10.3390/electronics10111325
Han J, Zhu G, Lee S, Son Y. An Empirical Performance Evaluation of Multiple Intel Optane Solid-State Drives. Electronics. 2021; 10(11):1325. https://doi.org/10.3390/electronics10111325
Chicago/Turabian StyleHan, Jaehyun, Guangyu Zhu, Sangmook Lee, and Yongseok Son. 2021. "An Empirical Performance Evaluation of Multiple Intel Optane Solid-State Drives" Electronics 10, no. 11: 1325. https://doi.org/10.3390/electronics10111325
APA StyleHan, J., Zhu, G., Lee, S., & Son, Y. (2021). An Empirical Performance Evaluation of Multiple Intel Optane Solid-State Drives. Electronics, 10(11), 1325. https://doi.org/10.3390/electronics10111325