
AI-Enabled Efficient and Safe Food Supply Chain



Abstract
1. Introduction
2. Materials and Methods
2.1. Fully Convolutional Networks
2.2. Long Short-Term Memories
2.3. Convolutional–Recurrent Neural Networks
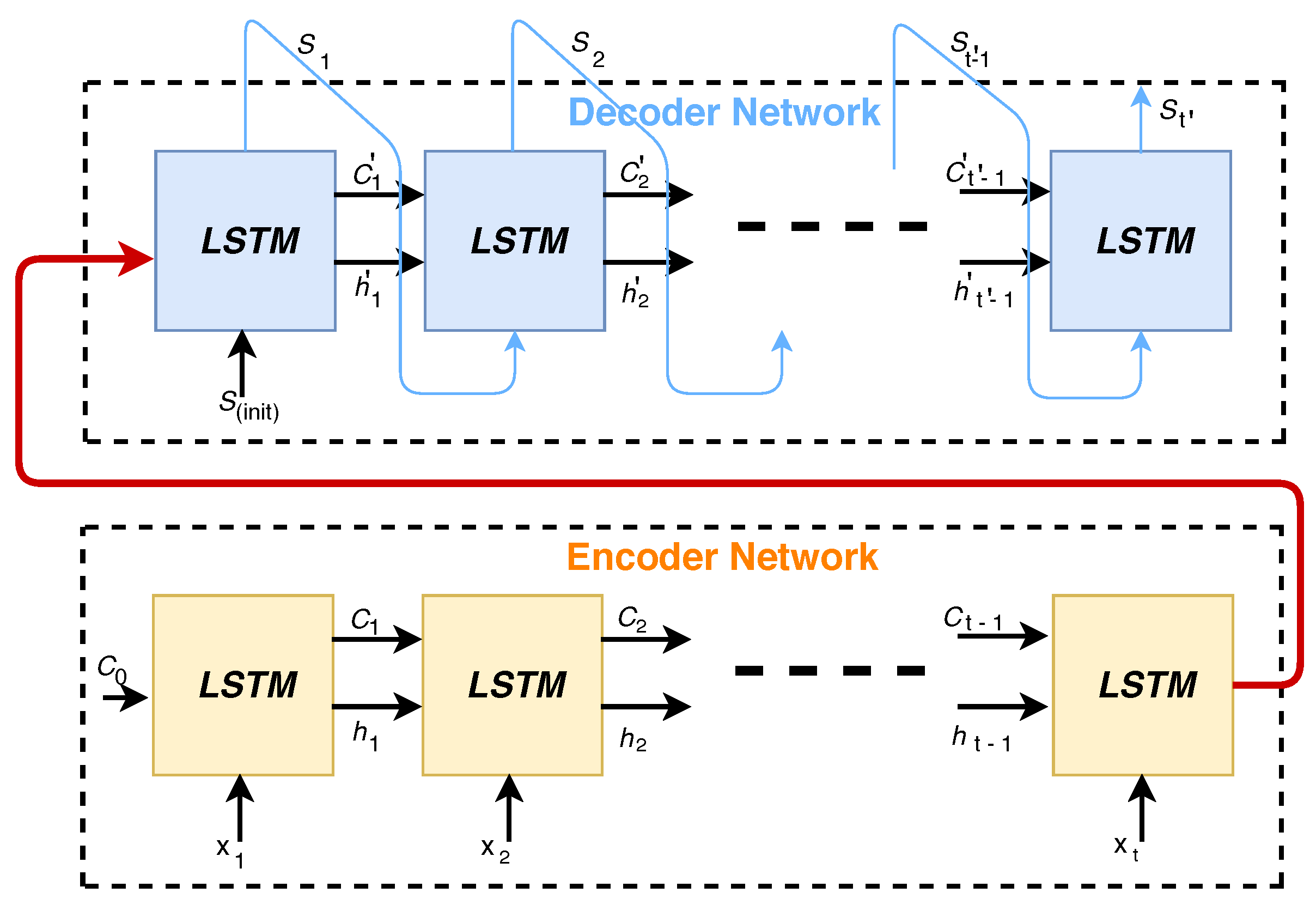
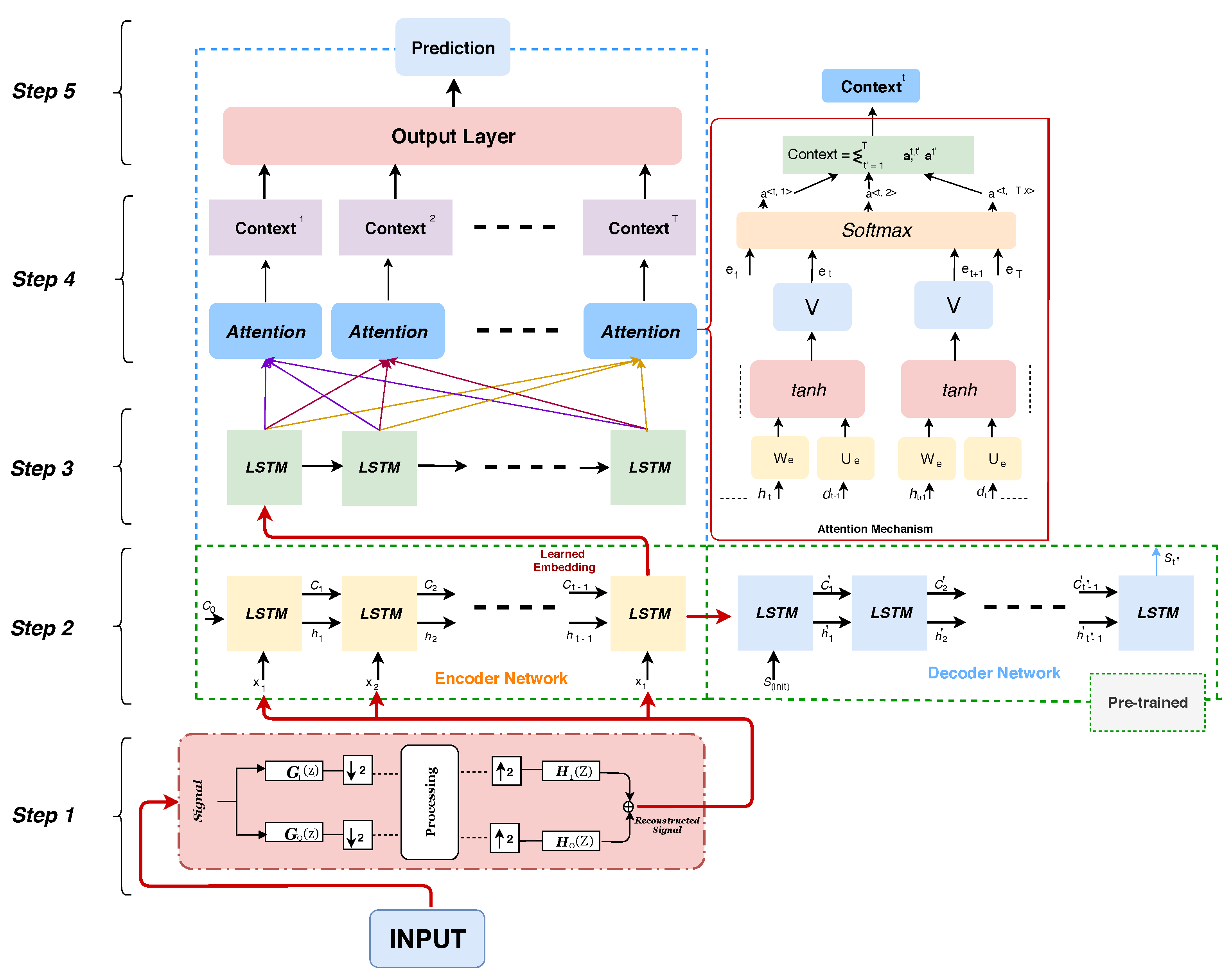
2.4. Encoder–Decoder Model
2.5. Attention Mechanisms
2.6. Performance Visualization
2.6.1. Class Activation Mapping
2.6.2. Latent Variable Adaptive Clustering
2.7. Domain Adaptation
3. Experimental Study
- -
- Food production in greenhouse environments, with a focus on predicting yield and optimizing crop growth and harvesting.
- -
- Food storage and maintenance in retailing refrigerator systems, with a focus on reducing energy consumption and CO2 production, whilst keeping food safe.
- -
- Food distribution and consumption with a focus on quality control of retail packaging, through visual inspection of the food expiry date, while aiming to reduce food waste and avoid public health problems.
3.1. Food Production in Greenhouse Environments
3.1.1. Plant Growth Prediction
3.1.2. Yield Prediction
3.2. Food Retailing Refrigeration Systems
- -
- Model parallelism (TensorFlow, Microsoft CNTK), where a single deep model is trained using a group of hardware instances and a single data set.
- -
- Data parallelism, where each hardware instance is trained across different data.
- -
- Hybrid parallelism, where a group of hardware trains a single model, but multiple groups can be trained simultaneously with independent data sets.
- -
- Automatic selection, where different parts of the training/test process are tiled, with different forms of parallelism between tiles.
3.3. Quality Control in Retail Food Packaging
3.3.1. The FCN-CRNN Approach for Expiry Date Recognition
3.3.2. Latent Variable Based Expiry Date Verification
3.3.3. Domain Adaptation for Multi-Source Expiry Date Recognition
4. Discussion
4.1. Food Production in Greenhouses
4.2. Food Storage and Maintenance in Refrigeration Systems
4.3. Food Distribution and Consumption
Author Contributions
Funding
Conflicts of Interest
References
- European Commission Communication. A ‘Farm to Fork’ Strategy for a Fair, h. Environmentally-Friendly Food System (COM (2020) 81 Final). Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:52020DC0381 (accessed on 27 April 2021).
- European Commission Sectoral Watch. Technological Trends of the Agri-Food Industry. Available online: https://ati.ec.europa.eu/reports/sectoral-watch/technological-trends-agri-food-industry (accessed on 27 April 2021).
- European Commission Coordinated Plan on Artificial Intelligence 2021 Review. Available online: https://digital-strategy.ec.europa.eu/en/library/coordinated-plan-artificial-intelligence-2021-review (accessed on 27 April 2021).
- Vandegehuchte, M.W.; Guyot, A.; Hubau, M.; De Groote, S.R.; De Baerdemaeker, N.J.; Hayes, M.; Welti, N.; Lovelock, C.E.; Lockington, D.A.; Steppe, K. Long-term versus daily stem diameter variation in co-occurring mangrove species: Environmental versus ecophysiological drivers. Agric. For. Meteorol. 2014, 192, 51–58. [Google Scholar] [CrossRef]
- Cohen, S.; Gijzen, H. The implementation of software engineering concepts in the greenhouse crop model hortisim1. Acta Hortic. 1998, 456, 431–440. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine Learning in Agriculture: A Review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Daniel, J.; Andrés, P.U.; Héctor, S.; Miguel, B.; Marco, T. A survey of artificial neural network-based modeling in agroecology. In Soft Computing Applications in Industry; Springer: Berlin/Heidelberg, Germany, 2008; pp. 247–269. [Google Scholar]
- Kanai, S.; Adu-Gymfi, J.; Lei, K.; Ito, J.; Ohkura, K.; Moghaieb, R.; El-Shemy, H.; Mohapatra, R.; Mohapatra, P.; Saneoka, H.; et al. N-deficiency damps out circadian rhythmic changes of stem diameter dynamics in tomato plant. Plant Sci. 2008, 174, 183–191. [Google Scholar] [CrossRef]
- Moon, J.G.; Berglund, L.J.; Domire, Z.; An, K.N.; O’Driscoll, S.W. Stem diameter and micromotion of press fit radial head prosthesis: A biomechanical study. J. Shoulder Elb. Surg. 2009, 18, 785–790. [Google Scholar] [CrossRef]
- Todorovski, L.; Džeroski, S. Integrating knowledge-driven and data-driven approaches to modeling. Ecol. Model. 2006, 194, 3–13. [Google Scholar] [CrossRef]
- Atanasova, N.; Todorovski, L.; Džeroski, S.; Kompare, B. Application of automated model discovery from data and expert knowledge to a real-world domain: Lake Glumsø. Ecol. Model. 2008, 212, 92–98. [Google Scholar] [CrossRef]
- Abreu, J.F.P.; Meneses, C.G. Tompousse, a model of yield prediction for tomato crops: Calibration study for unheated plastic greenhouses. In Proceedings of the XXV International Horticultural Congress, Part 9: Computers and Automation, Electronic Information in Horticulture, Brussels, Belgium, 2–7 August 1998; pp. 141–150. [Google Scholar]
- Abreu, J.F.P.; Meneses, C.G. Predicting the weekly fluctuations in glasshouse tomato yields. In Proceedings of the IV International Symposium on Models for Plant Growth and Control in Greenhouses: Modeling for the 21st Century—Agronomic and Greenhouse Crop Models, Beltsville, MD, USA, 1998; pp. 19–23. [Google Scholar]
- Fan, X.R.; Kang, M.Z.; Heuvelink, E.; de Reffye, P.; Hu, B.G. A knowledge-and-data-driven modeling approach for simulating plant growth: A case study on tomato growth. Ecol. Model. 2015, 312, 363–373. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, L.T.; Yan, Z.; Chen, Z.; Li, P. An Efficient Deep Learning Model to Predict Cloud Workload for Industry Informatics. IEEE Trans. Ind. Inf. 2018, 14, 3170–3178. [Google Scholar] [CrossRef]
- Granell, R.; Axon, C.; Wallom, D.; Layberry, R. Power-use profile analysis of non-domestic consumers for electricity tariff switching. Energy Effic. 2016, 9, 825–841. [Google Scholar] [CrossRef]
- Pallonetto, F.; De Rosa, M.; Milano, F.; Finn, D.P. Demand response algorithms for smart-grid ready residential buildings using machine learning models. Appl. Energy 2019, 239, 1265–1282. [Google Scholar] [CrossRef]
- Panagiotidis, P.; Effraimis, A.; Xydis, G.A. An R-based forecasting approach for efficient demand response strategies in autonomous micro-grids. Energy Environ. 2019, 30, 63–80. [Google Scholar] [CrossRef]
- Pearson, S.; May, D.; Leontidis, G.; Swainson, M.; Brewer, S.; Bidaut, L.; Frey, J.G.; Parr, G.; Maull, R.; Zisman, A. Are Distributed Ledger Technologies the panacea for food traceability? Glob. Food Secur. 2019, 20, 145–149. [Google Scholar] [CrossRef]
- Thota, M.; Kollias, S.; Swainson, M.; Leontidis, G. Multi-source domain adaptation for quality control in retail food packaging. Comput. Ind. 2020, 123, 103293. [Google Scholar] [CrossRef]
- Gong, L.; Thota, M.; Yu, M.; Duan, W.; Swainson, M.; Ye, X.; Kollias, S. A novel unified deep neural networks methodology for use by date recognition in retail food package image. Signal Image Video Process. 2021, 15, 449–457. [Google Scholar] [CrossRef]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2642–2651. [Google Scholar]
- Kim, K.; Cheon, Y.; Hong, S.; Roh, B.; Park, M. PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection. arXiv 2016, arXiv:1608.08021. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised Learning of Video Representations using LSTMs. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Proceedings of Machine Learning Research. Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 843–852. [Google Scholar]
- Geng, Z.; Chen, G.; Han, Y.; Lu, G.; Li, F. Semantic relation extraction using sequential and tree-structured LSTM with attention. Inf. Sci. 2020, 509, 183–192. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Kollias, D.; Tagaris, A.; Stafylopatis, A.; Kollias, S.; Tagaris, G. Deep neural architectures for prediction in healthcare. Complex Intell. Syst. 2018, 4, 119–131. [Google Scholar] [CrossRef]
- Wingate, J.; Kollia, I.; Bidaut, L.; Kollias, S. Unified deep learning approach for prediction of Parkinson’s disease. IET Image Process. 2020, 14, 1980–1989. [Google Scholar] [CrossRef]
- Kollias, D.; Vlaxos, Y.; Seferis, M.; Kollia, I.; Sukissian, L.; Wingate, J.; Kollias, S.D. Transparent Adaptation in Deep Medical Image Diagnosis. In Proceedings of the Trustworthy AI—Integrating Learning, Optimization and Reasoning—First International Workshop, TAILOR 2020, Virtual Event, 4–5 September 2020; Revised Selected Papers; Lecture Notes in Computer Science. Heintz, F., Milano, M., O’Sullivan, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12641, pp. 251–267. [Google Scholar]
- Ribeiro, F.D.S.; Calivá, F.; Swainson, M.; Gudmundsson, K.; Leontidis, G.; Kollias, S.D. Deep Bayesian Self-Training. Neural Comput. Appl. 2020, 32, 4275–4291. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 443–450. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning Transferable Features with Deep Adaptation Networks. arXiv 2015, arXiv:1502.02791. [Google Scholar]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised Representation Learning: Transfer Learning with Deep Autoencoders. In Proceedings of the 24th International Conference on Artificial Intelligence, IJCAI’15, Buenos Aires, Argentina, 25–31 July 2015; pp. 4119–4125. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems—Volume 2, Montreal, QC, Canada, 8–13 December 2014; NIPS’14. MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the 32nd International Conference on International Conference on Machine Learning—Volume 37, JMLR.org, ICML’15, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Shen, J.; Qu, Y.; Zhang, W.; Yu, Y. Wasserstein Distance Guided Representation Learning for Domain Adaptation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th Innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, LO, USA, 2–7 February 2018; McIlraith, S.A., Weinberger, K.Q., Eds.; AAAI Press: Palo Alto, CA, USA, 2018; pp. 4058–4065. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M.; Balduzzi, D.; Li, W. Deep reconstruction-classification networks for unsupervised domain adaptation. In Proceedings of the 14th European Conference on Computer Vision (ECCV 2016), Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin, Germany, 2016; Volume 9908, pp. 597–613. [Google Scholar] [CrossRef]
- Kollias, D.; Zafeiriou, S. Training Deep Neural Networks with Different Datasets In-the-wild: The Emotion Recognition Paradigm. In Proceedings of the 2018 International Joint Conference on Neural Networks, IJCNN 2018, Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Ben Taieb, S.; Bontempi, G.; Atiya, A.; Sorjamaa, A. A review and comparison of strategies for multi-step ahead time series forecasting based on the NN5 forecasting competition. Expert Syst. Appl. 2011, 39, 7067–7083. [Google Scholar] [CrossRef]
- Duchesne, L.; Houle, D. Modelling day-to-day stem diameter variation and annual growth of balsam fir (Abies balsamea (L.) Mill.) from daily climate. For. Ecol. Manag. 2011, 262, 863–872. [Google Scholar] [CrossRef]
- Alhnaity, B.; Kollias, S.; Leontidis, G.; Jiang, S.; Schamp, B.; Pearson, S. An autoencoder wavelet based deep neural network with attention mechanism for multi-step prediction of plant growth. Inf. Sci. 2021, 560, 35–50. [Google Scholar] [CrossRef]
- Tsapatsoulis, N.; Kollias, S. Face detection in color images and video sequences. In Proceedings of the 2000 10th Mediterranean Electrotechnical Conference, Information Technology and Electrotechnology for the Mediterranean Countries, MeleCon 2000 (Cat. No.00CH37099), Lemesos, Cyprus, 29–31 May 2000; Volume 1296, pp. 498–502. [Google Scholar]
- Jones, J.; Kenig, A.; Vallejos, C. Reduced State-Variable Tomato Growth Model. Trans. ASABE 1999, 42, 255–265. [Google Scholar] [CrossRef]
- Heuvelink, E. Tomato Growth and Yield: Quantitative Analysis and Synthesis; Oxford University Press: Oxford, UK, 1996. [Google Scholar]
- Qaddoum, E.K.; Hines, D.I. Yield Prediction for Tomato Greenhouse Using EFuNN. ISRN Artif. Intell. 2013, 2013, 430986. [Google Scholar] [CrossRef]
- Alhnaity, B.; Pearson, S.; Leontidis, G.; Kollias, S. Using Deep Learning to Predict Plant Growth and Yield in Greenhouse Environments. In Proceedings of the International Symposium on Advanced Technologies and Management for Innovative Greenhouses: GreenSys2019, Angers, France, 16–20 June 2019; Volume 1296, pp. 425–431. [Google Scholar]
- Panda, D.; Awan, A.A.; Subramoni, H. High performance distributed deep learning: A beginner’s guide. In Proceedings of the 24th Symposium on Principles and Practice of Parallel Programming, Washington, DC, USA, 16–20 February 2019; pp. 452–454. [Google Scholar]
- Onoufriou, G.; Bickerton, R.; Pearson, S.; Leontidis, G. Nemesyst: A hybrid parallelism deep learning-based framework applied for internet of things enabled food retailing refrigeration systems. Comput. Ind. 2019, 113, 103133. [Google Scholar] [CrossRef]
- Dede, E.; Govindaraju, M.; Gunter, D.; Canon, R.S.; Ramakrishnan, L. Performance Evaluation of a MongoDB and Hadoop Platform for Scientific Data Analysis. In Proceedings of the 4th ACM Workshop on Scientific Cloud Computing, Science Cloud ’13, New York, NY, USA, 17 June 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 13–20. [Google Scholar]
- Nemesyst. Available online: https://github.com/DreamingRaven/Nemesyst (accessed on 27 April 2021).
- Bradley, P.; Coke, A.; Leach, M. Financial incentive approaches for reducing peak electricity demand, experience from pilot trials with a UK energy provider. Energy Policy 2016, 98, 108–120. [Google Scholar] [CrossRef]
- Grünewald, P.; Torriti, J. Demand response from the non-domestic sector: Early UK experiences and future opportunities. Energy Policy 2013, 61, 423–429. [Google Scholar] [CrossRef]
- Albayati, I.; Postnikov, A.; Bingham, C.; Bickerton, R.; Zolotas, A.; Pearson, S. Aggregated power profile of a large network of refrigeration compressors following FFR DSR events. In Proceedings of the Internationak Conference on Energy Engineering, Cambridge, UK, 25–26 June 2018. [Google Scholar]
- Saleh, I.M.; Postnikov, A.; Arsene, C.; Zolotas, A.C.; Bingham, C.; Bickerton, R.; Pearson, S. Impact of Demand Side Response on a Commercial Retail Refrigeration System. Energies 2018, 11, 371. [Google Scholar] [CrossRef]
- The Food and Agriculture Organization (FAO). Available online: http://www.fao.org/home/en/ (accessed on 27 April 2021).
- Mori, S.; Suen, C.; Yamamoto, K. Historical review of OCR research and development. Proc. IEEE 1992, 80, 1029–1058. [Google Scholar] [CrossRef]
- Ribeiro, F.D.S.; Gong, L.; Calivá, F.; Swainson, M.; Gudmundsson, K.; Yu, M.; Leontidis, G.; Ye, X.; Kollias, S.D. An End-to-End Deep Neural Architecture for Optical Character Verification and Recognition in Retail Food Packaging. In Proceedings of the 2018 IEEE International Conference on Image Processing, ICIP 2018, Athens, Greece, 7–10 October 2018; pp. 2376–2380. [Google Scholar]
- Suh, S.; Lee, H.; Lee, Y.O.; Lukowicz, P.; Hwang, J. Robust Shipping Label Recognition and Validation for Logistics by Using Deep Neural Networks. In Proceedings of the 2019 IEEE International Conference on Image Processing, ICIP 2019, Taipei, Taiwan, 22–25 September 2019; pp. 4509–4513. [Google Scholar]
- Katyal, N.; Kumar, M.; Deshmukh, P.; Ruban, N. Automated Detection and Rectification of Defects in Fluid-Based Packaging using Machine Vision. In Proceedings of the IEEE International Symposium on Circuits and Systems, ISCAS 2019, Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Tian, Z.; Huang, W.; He, T.; He, P.; Qiao, Y. Detecting Text in Natural Image with Connectionist Text Proposal Network. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Shi, B.; Bai, X.; Belongie, S. Detecting Oriented Text in Natural Images by Linking Segments. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3482–3490. [Google Scholar]
- Tesseract-ocr. 2018. Available online: https://github.com/tesseract-ocr/tesseract (accessed on 27 April 2021).
- Baek, J.; Kim, G.; Lee, J.; Park, S.; Han, D.; Yun, S.; Oh, S.J.; Lee, H. What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4714–4722. [Google Scholar]
- Kollias, D.; Bouas, N.; Vlaxos, Y.; Brillakis, V.; Seferis, M.; Kollia, I.; Sukissian, L.; Wingate, J.; Kollias, S. Deep Transparent Prediction through Latent Representation Analysis. arXiv 2020, arXiv:2009.07044. [Google Scholar]
- Kollias, S.D.; Anastassiou, D. A unified neutral network approach to digital image halftoning. IEEE Trans. Signal Process. 1991, 39, 980–984. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. IJCV 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Martindale, W.; Duong, L.; Hollands, T.; Swainson, M. Testing the data platforms required for the 21st century food system using an industry ecosystem approach. Sci. Total Environ. 2020, 724, 137871. [Google Scholar] [CrossRef]
- Martindale, W.; Wright, I.; Korir, L.; Opiyo, A.M.; Karanja, B.; Nyalala, S.; Kumar, M.; Pearson, S.; Swainson, M. Framing food security and food loss statistics for incisive supply chain improvement and knowledge transfer between Kenyan, Indian and United Kingdom food manufacturers. Emerald Open Res. 2020, 2, 12. [Google Scholar] [CrossRef]
- Kirk, R.; Cielniak, G.; Mangan, M. L*a*b*Fruits: A Rapid and Robust Outdoor Fruit Detection System Combining Bio-Inspired Features with One-Stage Deep Learning Networks. Sensors 2020, 20, 275. [Google Scholar] [CrossRef]
- Xiong, Y.; Ge, Y.; Grimstad, L.; From, P.J. An autonomous strawberry-harvesting robot: Design, development, integration, and field evaluation. J. Field Robot. 2020, 37, 202–224. [Google Scholar] [CrossRef]
- Jiang, S.; Kaiser, M.; Yang, S.; Kollias, S.D.; Krasnogor, N. A Scalable Test Suite for Continuous Dynamic Multiobjective Optimization. IEEE Trans. Cybern. 2020, 50, 2814–2826. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Yang, S. A Strength Pareto Evolutionary Algorithm Based on Reference Direction for Multiobjective and Many-Objective Optimization. IEEE Trans. Evol. Comput. 2017, 21, 329–346. [Google Scholar] [CrossRef]
- Optimization of Multi-period Three-echelon Citrus Supply Chain Problem. J. Optim. Ind. Eng. 2020, 13, 39–53.
- Fakhrzad, M.B.; Goodarzian, F. A new multi-objective mathematical model for a Citrus supply chain network design: Metaheuristic algorithms. J. Optim. Ind. Eng. 2020, 14, 111–128. [Google Scholar]
- Kollia, I.; Kollias, S.D. A Deep Learning Approach for Load Demand Forecasting of Power Systems. In Proceedings of the IEEE Symposium Series on Computational Intelligence, SSCI 2018, Bangalore, India, 18–21 November 2018; pp. 912–919. [Google Scholar]
- Musavi, M.; Bozorgi-Amiri, A. A multi-objective sustainable hub location-scheduling problem for perishable food supply chain. Comput. Ind. Eng. 2017, 113, 766–778. [Google Scholar] [CrossRef]
- Dwivedi, A.; Jha, A.; Prajapati, D.; Sreenu, N.; Pratap, S. Meta-heuristic algorithms for solving the sustainable agro-food grain supply chain network design problem. Mod. Supply Chain. Res. Appl. 2020, 2, 161–177. [Google Scholar] [CrossRef]
- Trustworthy AI—Integrating Learning, Optimisation and Reasoning. Available online: https://tailor-network.eu (accessed on 27 April 2021).
- Claire Network. Available online: https://claire-ai.org/network/ (accessed on 27 April 2021).
- Kollia, I.; Simou, N.; Stamou, G.; Stafylopatis, A. Interweaving Knowledge Representation and Adaptive Neural Networks. In Proceedings of the Workshop on Inductive Reasoning and Machine Learning on the Semantic Web, Heraklion, Greece, 1 June 2009. [Google Scholar]
- Glimm, B.; Kazakov, Y.; Kollia, I.; Stamou, G.B. Using the TBox to Optimise SPARQL Queries. In Proceedings of the 26th International Workshop on Description Logics, Ulm, Germany, 23–26 July 2013; Eiter, T., Glimm, B., Kazakov, Y., Krötzsch, M., Eds.; CEUR: Aachen, Germany, 2013; Volume 1014, pp. 181–196. [Google Scholar]
- Kollia, I.; Glimm, B.; Horrocks, I. Answering Queries over OWL Ontologies with SPARQL. In Proceedings of the 8th International Workshop on OWL: Experiences and Directions (OWLED 2011), San Francisco, CA, USA, 5–6 June 2011; Dumontier, M., Courtot, M., Eds.; CEUR: Aachen, Germany, 2011; Volume 796. [Google Scholar]
- Kollias, D.; Yu, M.; Tagaris, A.; Leontidis, G.; Stafylopatis, A.; Kollias, S.D. Adaptation and contextualization of deep neural network models. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence, SSCI 2017, Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RMSE | |||
|---|---|---|---|
| Method | One Step Prediction | Two Step Prediction | Three Step Prediction |
| SVR | 0.65 | 0.70 | 0.82 |
| RFR | 0.74 | 0.66 | 0.72 |
| MLP | 0.0034 | 0.0045 | 0.0048 |
| LSTM | 0.0031 | 0.0033 | 0.0054 |
| WT-ED-LSTM | 0.0028 | 0.0033 | 0.0042 |
| ED-LSTM-AM | 0.0034 | 0.0030 | 0.0046 |
| WT-ED-LSTM-AM | 0.0026 | 0.0028 | 0.0029 |
| Method | Missing Detection (%) | False Alarm (%) | Accuracy (%) |
|---|---|---|---|
| FCN | 1.67 | 0.28 | 98.20 |
| CTPN [69] | 2.79 | 16.57 | 92.20 |
| Seglink [70] | 5.71 | 12.53 | 93.73 |
| Method | Accuracy (%) |
|---|---|
| CRNN | 95.44 |
| TPS-ReSNet-BiLSTM-Att [72] | 94.57 |
| Tesseract OCR [71] | 31.12 |
| Method | Accuracy (%) |
|---|---|
| Single-Source DA | 84.14 |
| Two-Source Combined DA | 85.05 |
| Three-Source Combined DA | 86.13 |
| Multi(2)-Source DA | 90.53 |
| Multi(3)-Source DA | 92.50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kollia, I.; Stevenson, J.; Kollias, S. AI-Enabled Efficient and Safe Food Supply Chain. Electronics 2021, 10, 1223. https://doi.org/10.3390/electronics10111223
Kollia I, Stevenson J, Kollias S. AI-Enabled Efficient and Safe Food Supply Chain. Electronics. 2021; 10(11):1223. https://doi.org/10.3390/electronics10111223
Chicago/Turabian StyleKollia, Ilianna, Jack Stevenson, and Stefanos Kollias. 2021. "AI-Enabled Efficient and Safe Food Supply Chain" Electronics 10, no. 11: 1223. https://doi.org/10.3390/electronics10111223
APA StyleKollia, I., Stevenson, J., & Kollias, S. (2021). AI-Enabled Efficient and Safe Food Supply Chain. Electronics, 10(11), 1223. https://doi.org/10.3390/electronics10111223