1. Introduction
The Internet is becoming increasingly affordable, and therefore, Internet users are increasing daily. As a consequence, the amount of data transferred over the Internet is also increasing. This has led to a data overload, where users are flooded with knowledge and information [
1]. The rapid growth in data has led to a new era of information. These data are used to build innovative, more efficient, and effective systems. In this era of big data, the recommender engine is a category among data sieving systems, which aims to predict the ratings a user will assign to objects of interest over the Internet. Herein, a movie recommender engine is considered as an adaptation of the big data approach. Generally, a recommendation engine is a filtering-based system, which filters the search results for quality and hence provide items that are more relevant to the search items based on a user’s search history [
2]. These recommendation engines are used to predict the preferences of a user or the rating that a user would give to an item of interest. Such recommender systems are present in various websites and are used for information retrieval and information extraction from distributed and heterogeneous data sources [
3,
4].
Recently, recommendation systems have become a crucial aspect of several research areas and are used in various information retrieval platforms, such as Amazon, Netflix, and YouTube. They generate recommendations based on the user’s search history and the platform, such as LinkedIn, Facebook, Amazon, and Netflix. These platforms aim to serve users by providing them with an improved experience [
5]. Hence, a recommender engine is a type of data analyzing and sieving system. Such systems are becoming increasingly well known and are found in various areas, such as theatre, movies, news, books, cooking, sports, etc. Currently, most applications (such as Netflix, Spotify, and different multimedia social networks) provide engaging facilities to improve the user’s experience. These applications highly depend on the effectiveness of their recommendation systems. Additionally, these recommender systems provide the users with unlimited access to the complete digital world through behavior, experiences, preferences, and interests. These systems help to analyze click-through rates and revenue for companies; they also have positive effects on the user experience and create user satisfaction. This functionality provides an improved user experience and achieves lower cancellation rates by saving costs [
6].
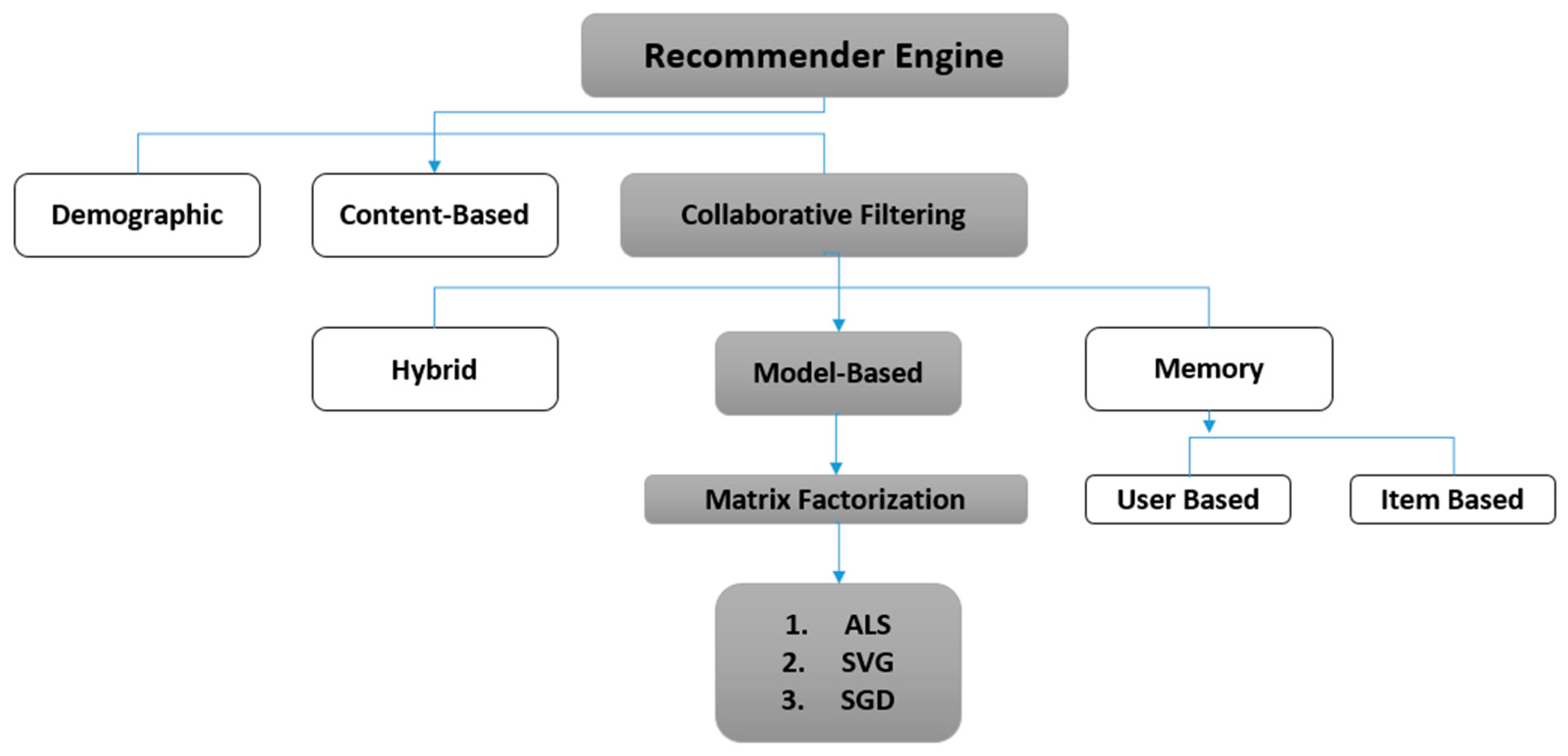
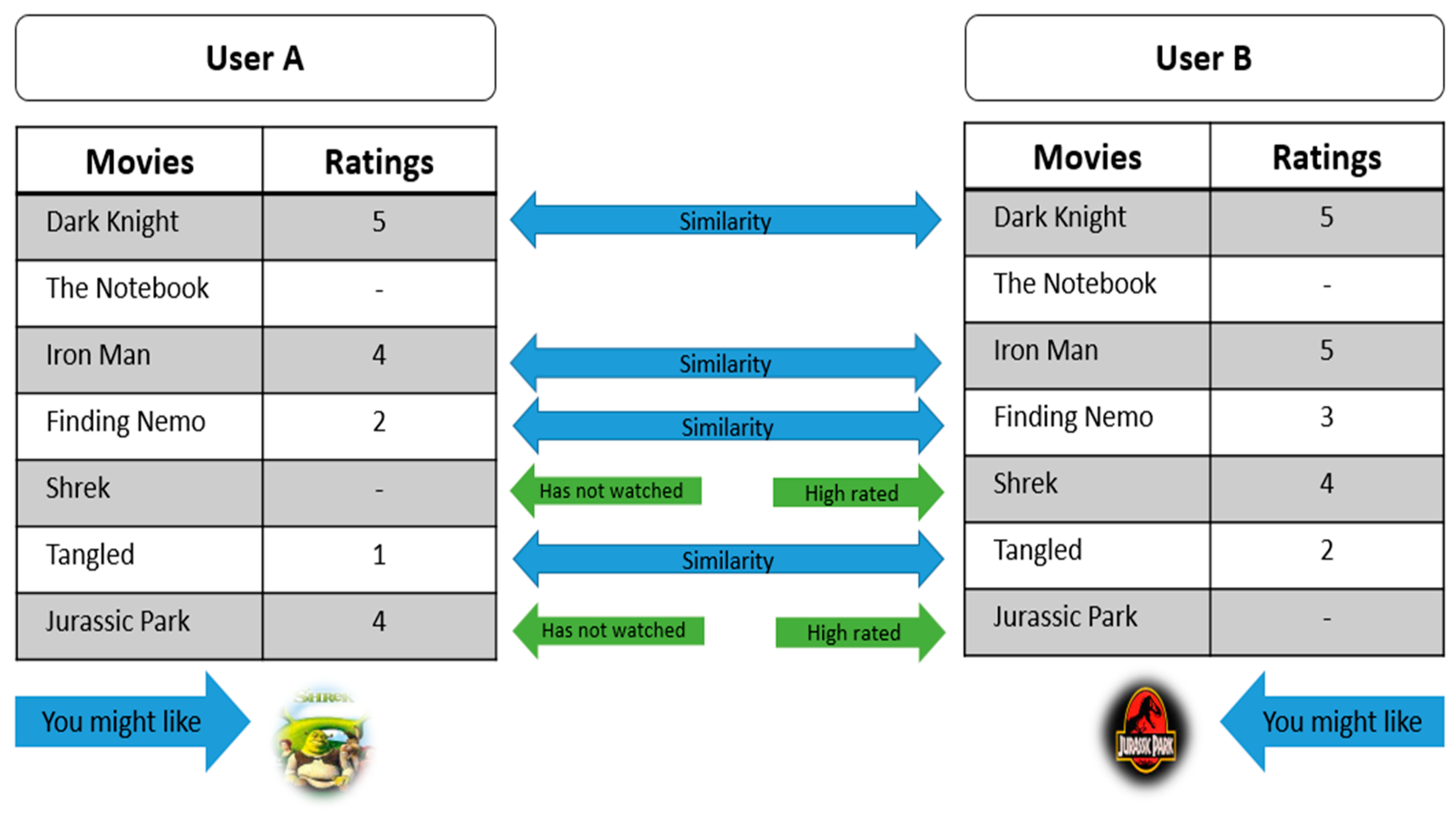
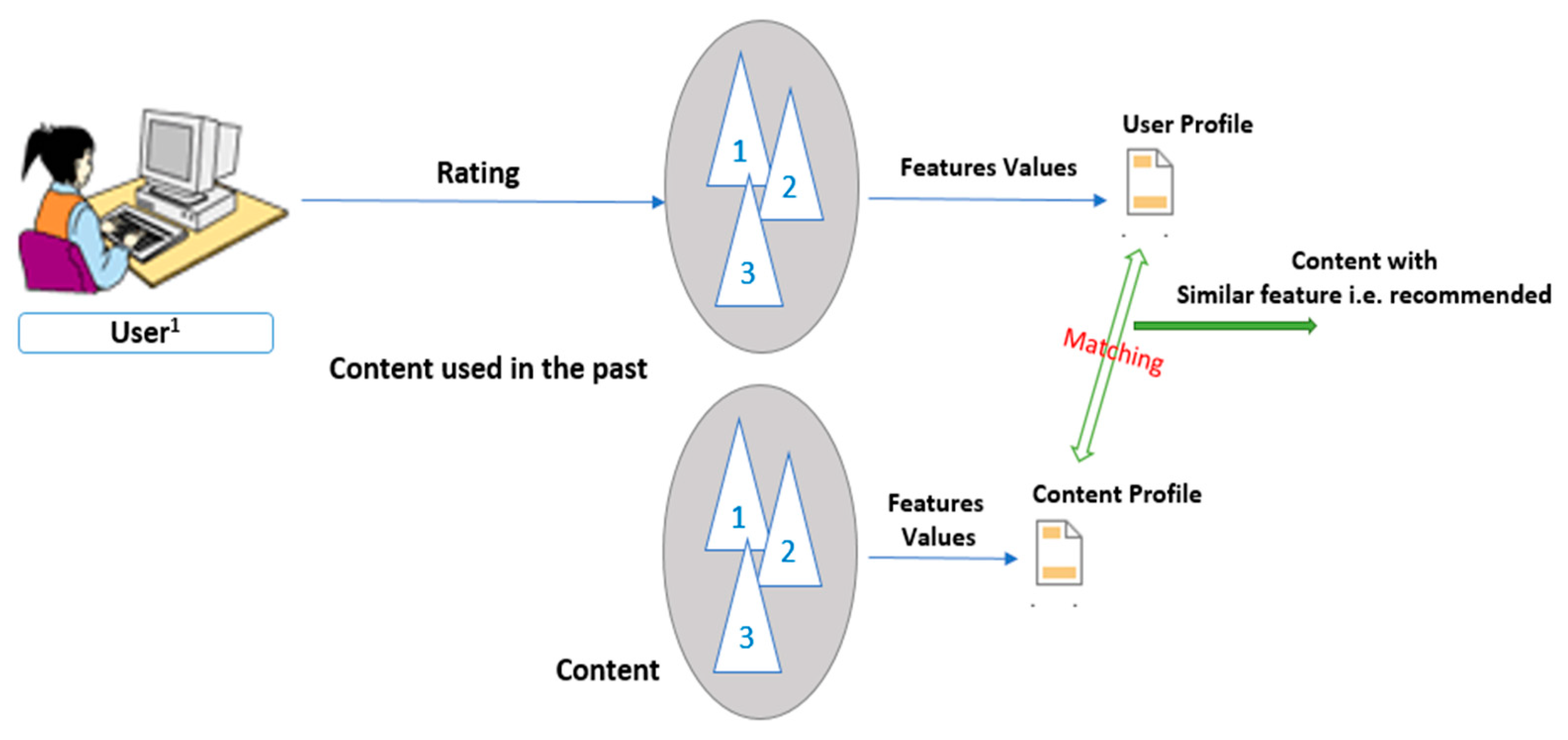
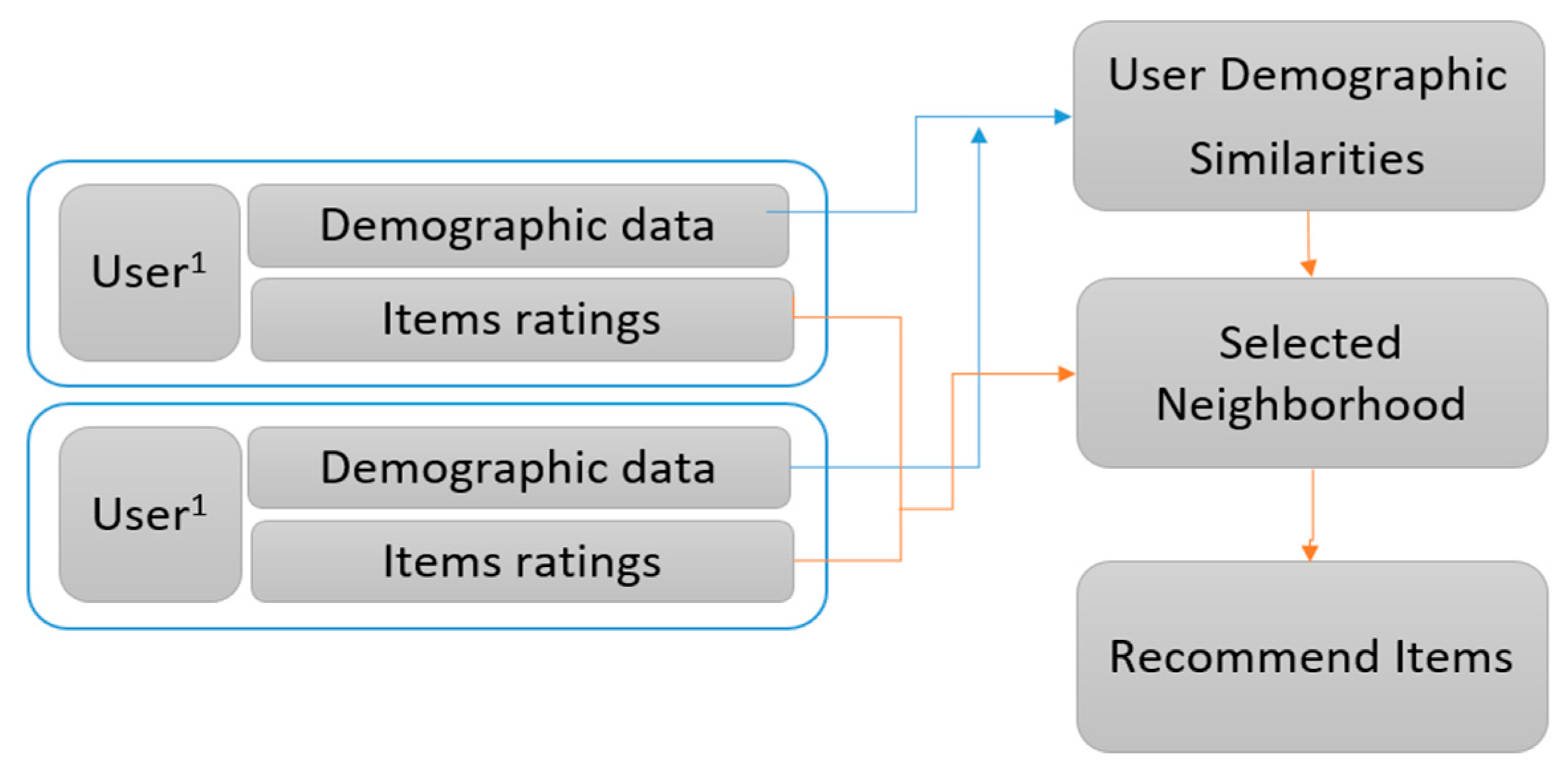
In the movie or any recommender system (RS), the main approach is stepwise, where at first, users rate different items, and then the system makes predictions about the user’s ratings for an item that has not yet been rated [
7]. Thus, the new predictions are built upon the existing ratings with similar ratings of the most active user. Towards this, collaborative filtering and content-based algorithms are used most frequently. The collaborative filtering (CF) scheme enables user-based applications to reproduce personalized recommendations more quickly and effectively. The recommendation system uses machine learning algorithms to create collaborative filtering based on training data and then uses the model to make more efficient predictions [
8].
Any recommendation system works more efficiently with big data, which is the driving force behind it. As data grow exponentially, it is a significant struggle to extract data from heterogeneous sources [
9]. The big data in movie recommendations supply a large amount of user data, such as the behavior of all viewers, activity on the site, the ratings and filtering movies based on ratings and other viewers’ data [
10].
Apache Spark, which is a high-performance, openly accessible, open-source, and clustering-based computing system [
11], is freely available framework and was used to analyze the big data analytics that resolves constant, iterative, or continual algorithms in the memory space. This supports an extensive set of tools developed with APIs and MLlib [
12]. Spark supports a broader span of components, scope, and performance than the function used in Hadoop, i.e., MapReduce, in many supervised learning-based models [
13]. Its functions use a resilient distributed dataset (RDD) for programming purposes. However, the potential strength is the execution of parallel programs. Spark provides various libraries and tools, such as Scala, Python, and R, which help to manage data and increase its scalability [
14].
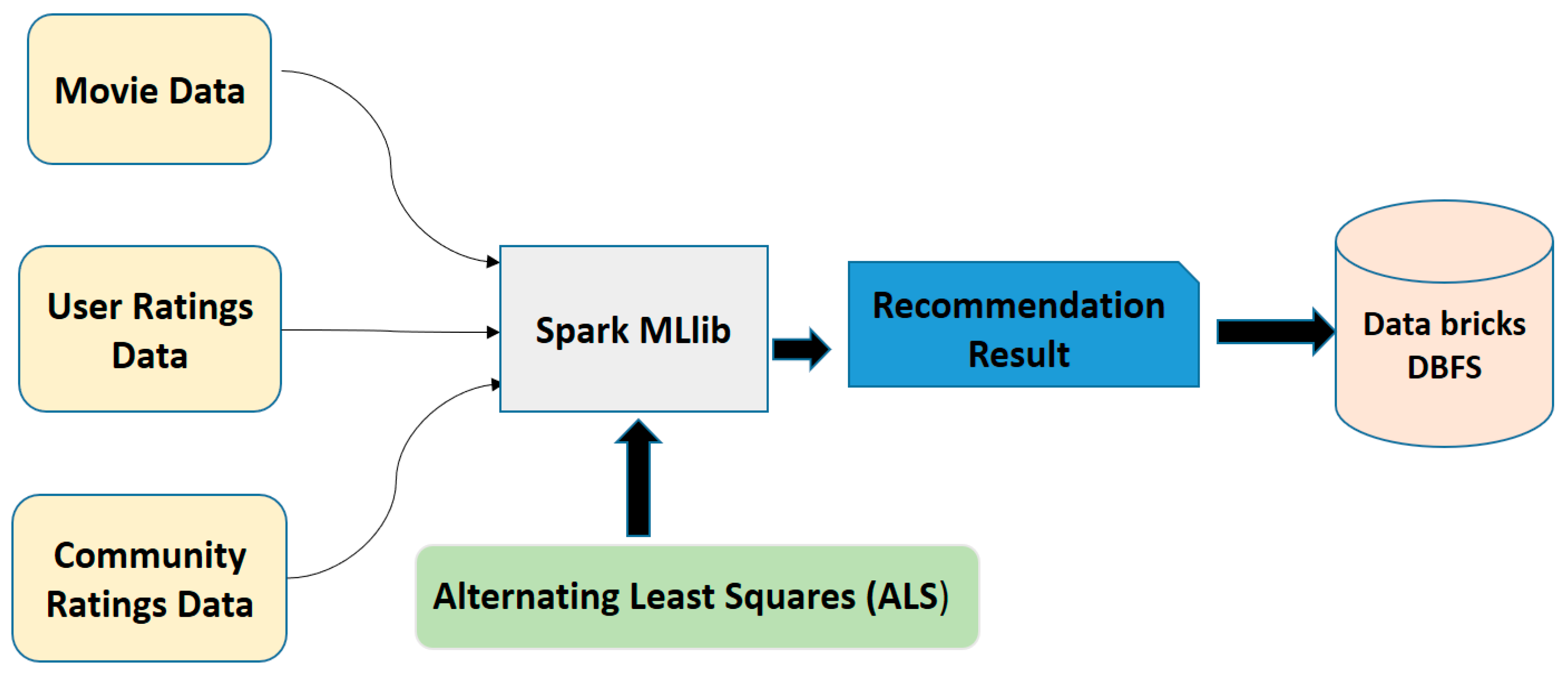
Our recommendation engine was built on matrix factorization and the alternating least squared (ALS) model by using Spark machine learning (ML) libraries. These machine learning application programming interfaces (APIs), which are available in Spark, are commonly known as MLlib [
15]. This single library of machine learning supports multiple algorithms such as clustering, classification, frequent pattern matching, Spark ML, linear regression, linear algebra, and recommendations.
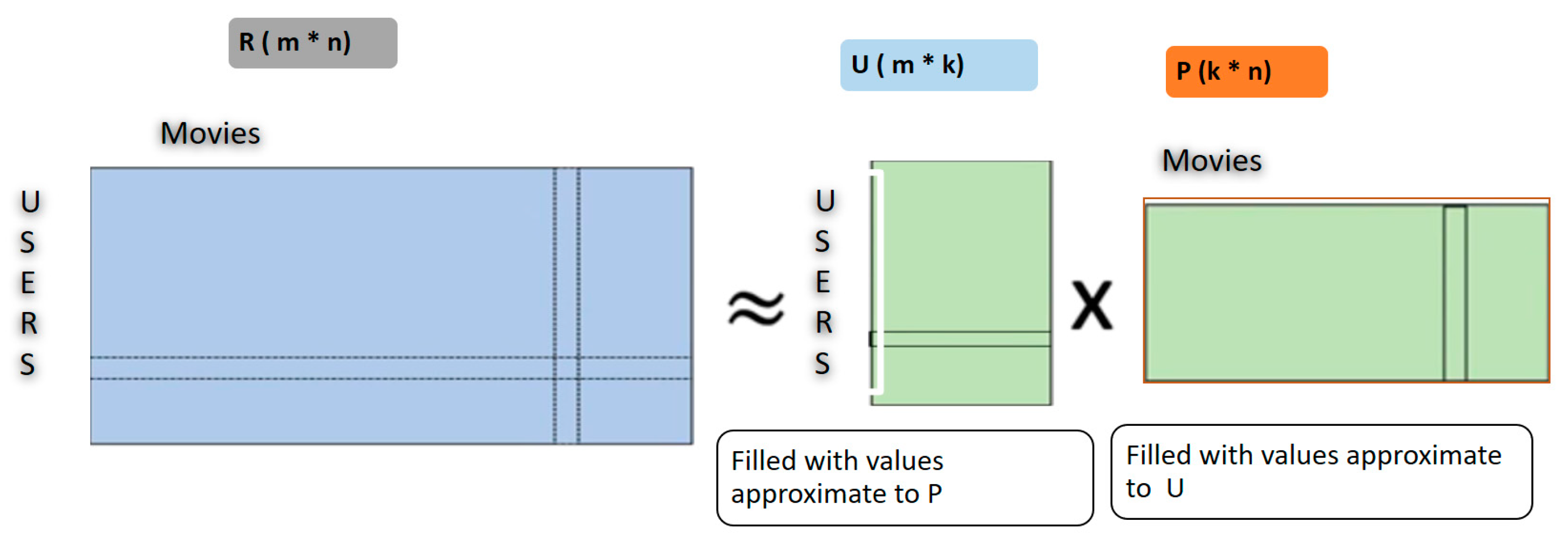
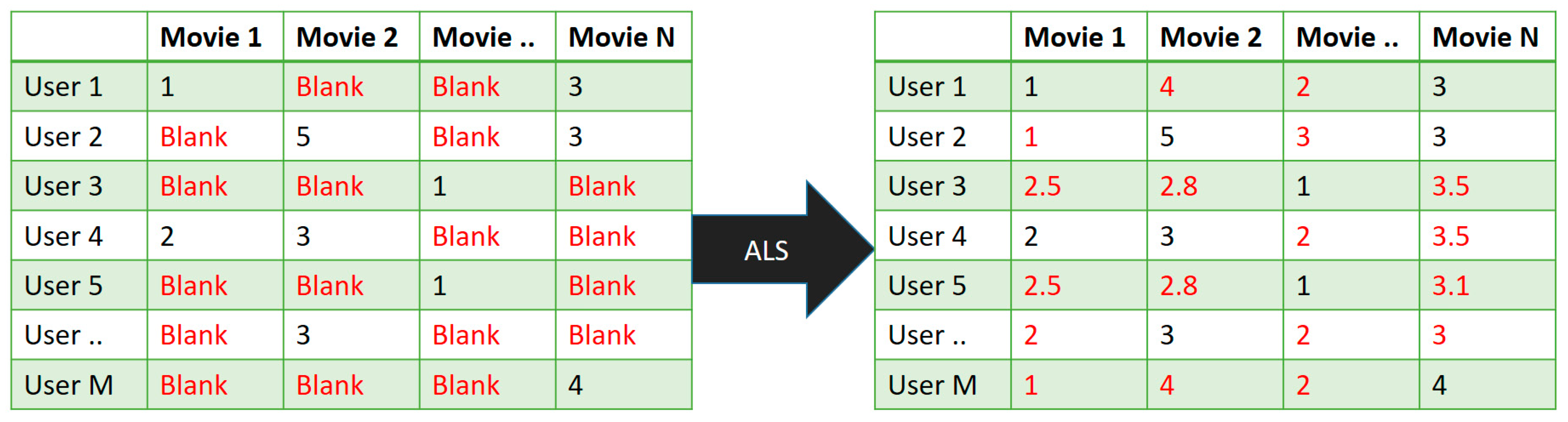
Herein, we used collaborative filtering to avoid the cold-start problem. This technique fills the missing values in the user’s item-based matrix through Spark MLlib. Our proposed RS divided the rating dataset into matrices, which were item and user based along with latent features. Furthermore, to avoid the creation of a new model at every instance, we utilized elements that were extracted from the new user matrix. Here, we simply multiplied the matrix to attain the required points in less time. Through this categorization process of the recommendation engine into several collective services, the system’s complexity can be minimized, and a robust collaborative system can be implemented by training continuous models. Toward this, the acquired data were given explicit ratings in the cases where the data were slightly too small. This model-based approach has one major advantage: it was able to recommend a large number of data items to a large number of users as compared to other models. It works well with sparse matrices instead of memory-based methods.
The novelty of this research is selecting several parameters of ALS that can help to build a robust recommendation system, which solves the scalability problem. The aim is to direct users to items, which are most relevant to them. This could be based on past behavior on that platform or on users who have similar profiles to a given user; therefore, the system would recommend something, which their friends like, which is the field of information extraction. In this regard, we propose a movie recommendation system using the big data approach. The main contributions of this paper are as follows:
We propose a recommender engine that predicts top ratings for movies. Our system is implemented using collaborative filtering through Apache Spark ML libraries in cloud-based platform databricks.
For this, we applied a model-based approach along with matrix factorization and the ALS method, which is used to more efficiently learn all latent features. It analyzed the ALS algorithm’s parameters, which include rank, lambda, and iterations.
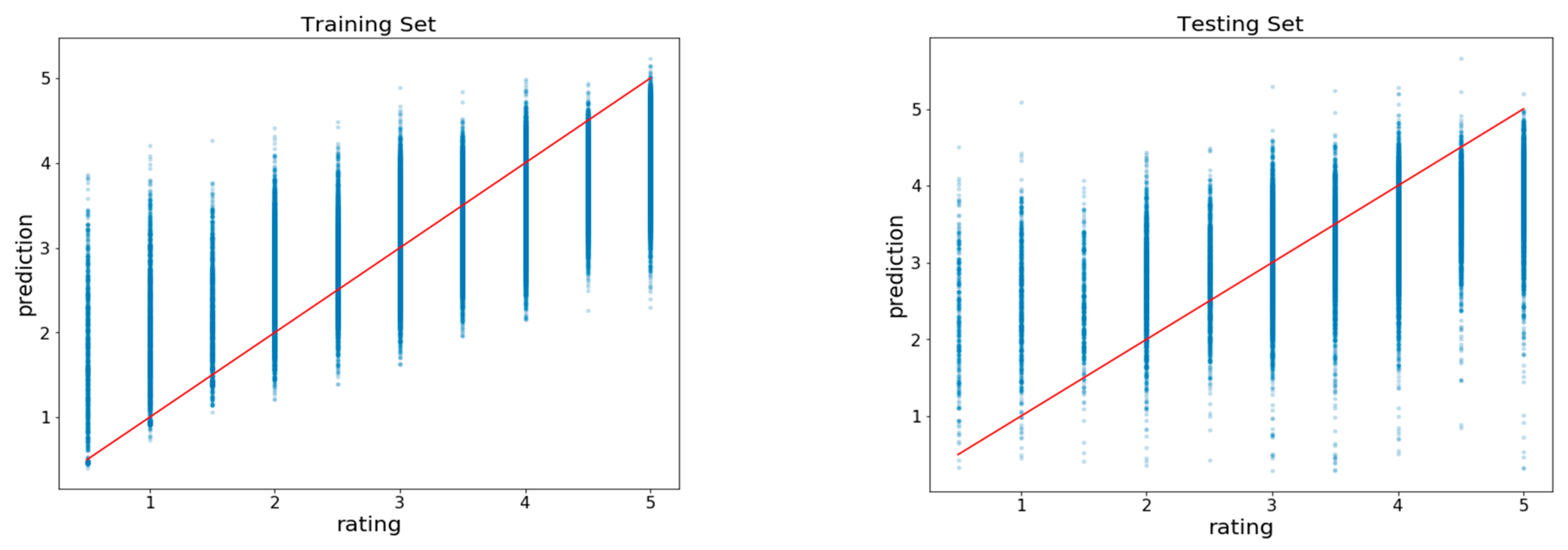
We achieved an RMSE of 0.9761 with slightly shorter predictions than the existing methods, since they only represented the top 25 predictions.
We further improved the root mean square error (RMSE) score, obtaining more predictions (up to 1000) with 97% accuracy, and our algorithm took just 517 s to predict these ratings with significant accuracy.
This paper is organized into six sections:
Section 2 represents the literature review, background, and the context of why the system is essential in modern applications.
Section 3 provides a description of the basic structure and approaches of the recommendation engine.
Section 4 describes the datasets.
Section 5 describes the methodology used to predict ratings and the implementation of models.
Section 6 analyzes the experimental procedure and results of the implemented models.
Section 7 describes the conclusion and presents some future directions.
2. Related Work
As the recommender system is often duped, a hybrid algorithm system was introduced by using Apache Spark to improve the efficiency of the recommender system for parallel processing. It used both structured and unstructured data by avoiding excessive information through hybrid and user-based collaboration. Significant problems were adaptability, frozen start, meagerness, and perturbability (unaccountability); the algorithm on big data can reduce the problem of scalability. However, the strength was using different combinations of collaborative filtering algorithms to overcome the freeze start problem and provide a potential recommender system [
16].
The approach used was user–user, item–item, or user–item similarity, and this idea of linear combination was well implemented. Future directions for recommender systems is evolving rapidly, so in the future, the implementation of Apache Spark and R-language will be examined. The collaboration of Spark and R formats at a distributed level will make a Spark that will provide newly gathered data [
17]. In another paper, scalability was discussed and resolved by using the query-based approach with the help of Apache Hivemall, which evaluates similarities and dissimilarities on each node. Consequently, non-parallelism within this issue was common, but using the collaborative approach, the speed and the growth of datasets, the scalability issue was resolved and had improved extensibility and execution time than the sequential method. The extensibility of the system, the speedup, and execution-time of each node was recorded, and the results showed that the total execution time of the multi-criteria methodology using Hive was far superior to the single consequent non-parallel approach. The knowledge gap was the one constraint that needs to be resolved in the communication process within the network for higher efficiency [
18].
In this paper, the researcher described Spark terminology used for real-time execution with combined algorithms, based on two modes—user-level and item-level. Two more algorithmic techniques were used to resolve the constraint of deficiency, sparsity, and extensibility [
19]. Recommender systems helped to overcome the issue of excessive flooding of information based on the history of a user’s likes and dislikes by providing suggestions. The literature review of this paper concerned various methods of how features can be extracted. The study discussed ALS (altering least square), Scala programming language, and Clustering K-means; the last two were the main algorithms used to control the limitations of CF extensibility sparseness [
20]. The study ML libraries were used to build a required recommendation system, but the lambda system also seemed capable of handling such a large amount of data. Lambda structures, SparkML libs, direct and indirect data collection, auto analysis techniques, and different training models were used to perform a real-time analysis of big data [
21].
Recently, machine learning (ML)-based models [
22,
23,
24] have been implemented in various domains, which discussed time limitations, specification, accuracy with efficacy, and intricate issues. However, the potential strengths were auto analysis, high adaptability, and user data collection from big data environments through recommendation. The experimental results showed that Apache Spark and machine learning collect data about viewers’ preferences and processes; the results provide highly accurate recommendations in listed form. The recommender system helps users to select items from the huge number of options on social service applications, such as Netflix and YouTube, for user ease [
25].
In 2021, the authors implemented stock market [
26], Black Friday sale [
27] and Amazon food review [
28] predictions using Naive Bayes, and other machine learning models on Spark MLlib achieved above 90% accuracy with a good running time. The author developed a system that described how meaningful information could be extracted from gigantic raw data, with the implementation of several algorithms based on data mining. The experimental results showed authentic results with larger datasets in all circumstances if accurate models were obtained [
29]. The study compared four different RS models based on a combination of user similarity and trust weighted propagation. The accuracy of back propagation and singular value decomposition was under 70%. The problem was the high value of the optimal score recommendation only [
30].
The most common framework that was implemented in this paper is Spark and then ALS (altering least squares), Lambda architecture, and the K-means algorithm, which was utilized mainly for clustering purposes. The researcher noticed that the weakness of this was the unnecessary sequential comparison of the smaller dataset, although the strength was the Spark machine learning libraries. The experimental results, which were taken from comparing the MSE (mean squared error) and WCSS (sum of cluster squared error), showed that the real-time processing of the size of datasets could be improved by enhancing the WCSS by growing various clusters. Evaluating two algorithms could provide improved results as the number of clusters was increasing and needed further optimization [
31].
Generally, they discussed two types of Spark ML-based strainer systems. The first was specificity based, and the second was interactive or hybrid based. The future directions were given by discussing more advanced algorithms, such as matrix factorization, which would enhance the specificity and accuracy, and rapidity based on previous content used by the user and in-memory utilization [
32]. In this study, they examined and evaluated models and the Spark-based SARF methodology using a huge amount of data by matching queries to users with correct results and higher quality. With the recent growth in data, the search recommendation engine is used to resolve excessive information issues. In this paper, the SARF algorithm was used, which built joins, resilient distributed datasets (RDD), and filters based on Spark. The main issues are cold start, deficiency, and sparseness problems; CF was used with a hybrid algorithm that provides accurate data, and it is likely that it also resolved the problem of cold start [
33].
As data are increasing day-by-day, to analyze these huge volumes of datasets, and for the convenience of the user, a small enhanced application of the suggestion system is the integration of the analytics of big data whose base was built upon the Spark framework with several combined CF algorithms. The frameworks used in this paper, for data streaming purposes and machine learning libraries, with graphs, SQL, matrices, Spark’s join, filters, RDDs, and MapReduce functions are discussed in this paper. Weaknesses were scantiness and strength within the improved version of ALS that helped to obtain more accurate results [
34]. This paper introduced a significant approach in this big data era, attained the desired suggestions by the recommender system, and presented the ALS model with several Spark machine learning libraries (Spark-ML and MLlib). Related work or an algorithm/approach CF was used but for filtering purposes only. In this paper, the ALS model was used for predicting movies. This paper introduced a significant approach in this big data era to attain the most-desired suggestions by recommender systems; these ALS models with several Spark machine learning libraries (Spark-ML) were introduced. The model in this study outperformed the existing model and improved the root mean squared error (RMSE) by approximately 0.97613. Additionally, it showed an accuracy of 97%, outperforming the state-of-the-art, which had only 91%. Moreover, the methodology, performance evaluation, and performance analysis were conducted on the dataset taken from Movielens. It concluded that analytics based on collaborative filtering using the ALS model reduced the common sparsity problem [
35].
Our proposed RS is based on user-level and item-level filtering, which is derived from collaborative filtering through the big data framework Spark. Although the dataset is large, we used ALS that categorized the rating dataset into a matrix that was item-based and user-based along with latent features. Thus, when we recombined them, we obtained a new matrix by multiplying the divided matrices. The new matrix may have a missing entry that represents the movies and predictions and may cause a cold-start problem. If there are any missing entries, the system fills the space based on user and item-level similarities. To avoid the creation of a new model every time, we utilized elements that are extracted from the new user matrix that simply multiplied the matrix to obtain the points in a much quicker time. Experimental results show that the outcomes of the proposed algorithm are productive and successful. Additionally, it provides quick, top-rated predictions of movies. In future investigations, we need to focus on more mining-related approaches to obtain knowledge about user-related paradigms.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}