
A Review on Speech Emotion Recognition Using Deep Learning and Attention Mechanism


Abstract
:1. Introduction
2. Scope and Methodology
Evaluation Metrics
- Precision is the ratio of all correctly positively classified samples (true positive—TP) to all positive classified samples (TP and false positive—FP). For K-class evaluation, the precision is computed as follows:
- Recall is the ratio of all correctly positively classified samples (TP) to the number of all samples in a tested subgroup (TP and false negative FN). Recall indicates a class-specific recognition accuracy. Similarly, as in the case of precision, the recall for a multiclass classification problem is computed as the average of recalls for individual classes.
- In the literature, the multiclass recall is referred to as unweighted average recall (UAR), which is recommended metric for SER. UAR corresponds to unweighted accuracy (UA), computed similarly as the average over individual class accuracies.
- Weighted accuracy is often given as weighted average recall (WAR), which is computed as the class-specific recalls weighted by the number of per-class instances sk according to (3). This metric is also interchangeable with weighted accuracy (WA; or accuracy), which is defined as correct predictions over a total number of predictions. Note that evaluation metrics were not clearly defined in previous works. Thus, we unified them as described above.
- F1 score is defined as the harmonic mean of the precision and recall.
- Pearson’s correlation coefficient (PCC; ρ) measures the correlation between the true and predicted values (x and y, respectively). Given the pairs of values {(xn, yn)}, n = 1, 2, …, N, Pearson’s correlation coefficient is computed as follows:
- Concordance Correlation Coefficient (CCC; ρc) examines the relationship between the true and predicted values from a machine learning model. CCC lies in the range of [−1, 1], where 0 indicates no correlation and 1 is perfect agreement or concordance.
3. Speech Emotion Recognition and Deep Learning
3.1. Databases of Emotional Speech
- Simulated (acted): Professional actors express emotions through scripted scenarios.
- Elicited (induced): Emotions are created via artificially induced situations. With this approach, it is possible to achieve more natural recordings and simultaneously to have control over the emotional and lexical content of recordings.
- Spontaneous (natural): Spontaneous audio recordings are being extracted from various reality shows. The disadvantage of real-world audio samples is that they may be distorted by background noise and reverberation [30]. Another drawback is that the natural or spontaneous databases often contain unbalanced emotional categories.

{kind=link}
{kind=link}
{kind=link}
| Database | Language | Num. of Subjects | Num. of Utterances | Discrete Labels | Dim. Labels | Modality |
|---|---|---|---|---|---|---|
| AESDD [33] | Greek | 3 F/2 M | 500 | A, D, F, H, S | – | A |
| EmoDB [34] | German | 5 F/5 M | 500 | A, B, D, F, H, N, S | – | A |
| eNTERFACE’05 [35] | English | 42 | 5 utt./emotion | A, D, F, H, N, S, Sr | – | A, V |
| FAU-AIBO [36] | German | 30 F/21 M (children) | 18 216 | A, B, Em, He, I, J, M, N, O, R, Sr | – | A |
| IEMOCAP [37] | English | 5 F/5 M | 10,039 | A, D, E, F, Fr, H, N, s, Sr | √ | A, V, T, MCF |
| MSP-PODCAST [38] | English | – | 62,140 | A, D, F, H, S, Sr, N, C, O | √ | A |
| Polish DB [39] | Polish | 4 F/4 M | 240 | A, B, F, J, N, S | – | A |
| RAVDESS [40] | English | 12 F/12 M | 104 | A, D, F, H, N, S, Sr | √ | A, V |
| RECOLA [41] | French | 46 (27) 1 | – | – | √ | A, V, ECG, EDA |
| SAVEE [42] | English | 4 M | 480 | A, D, F, H, S, Sr, N | – | A, V |
3.2. Acoustic Features
- The INTERSPEECH 2009 (IS09) [51] feature set consists of fundamental frequency, voicing probability, frame energy, zero-crossing rate, and 12 MFCCs and their first-order derivatives. With statistical functionals applied to LLDs, 384-dimensional feature vectors can be obtained.
- The feature set of the INTERSPEECH 2010 (IS10) paralinguistic challenge [52] contains 1582 features, which are obtained in three steps: (1) a total of 38 LLDs are smoothed by low-pass filtration, (2) their first order regression coefficients are added, and (3) 21 functionals are applied.
- The extended Geneva minimalistic acoustic parameter set (eGeMAPS) [53] contains LLD features, which paralinguistic studies have suggested as most related to emotions. The eGeMAPS consists of 88 features: the arithmetic mean and variation of 18 LLDs, 8 functionals applied to pitch and loudness, 4 statistics over the unvoiced segments, 6 temporal features, and 26 additional cepstral parameters and dynamic parameters.
- The INTERSPEECH 2013 computational paralinguistic challenge (ComParE) [54] is another feature set from the openSMILE extractor, which is mostly used to recognise emotions. ComParE consists of 6373 features based on extraction of 64 LLDs (prosodic, cepstral, spectral, sound quality), adding their time derivates (delta features), and applying statistical functions.
3.3. Data-Driven Features
3.4. Temporal Variations Modelling
3.5. Transfer Learning
3.6. Generalisation Techniques
3.6.1. Data Augmentation
3.6.2. Cross-Domain Recognition
3.7. DNN Systems Comparison
| References | Audio Parametrisation | Applied Techniques | Reported Accuracy |
|---|---|---|---|
| Ntalampiras et al. [44]; 2012 | Log-likelihood fusion level with optimally integrated feature sets | Simple logistic recognition | 93.4% WA |
| Huang et al. [85]; 2014 | Spectrogram | semi-CNN with SVM | 85.2% WA |
| Yogesh et al. [48]; 2017 | BSFs, BCFs, IS10 (1632 features) FS: PSOBBO | ELM | 90.31% WA |
| Zhang et al. [11]; 2018 | 3D Log-mels (static, Δ, ΔΔ) DCNN–DTPM | linear SVM | 87.31% WA |
| Zhao et al. [62]; 2019 | Log-mel spectrograms | 2D CNN LSTM | 95.89% WA |
| Lech et al. [84]; 2020 | Spectrograms converted into RGB | AlexNet (real-time SER) | 82% WA |
| References | Audio Parametrisation | Applied Techniques | Weighted Accuracy | Unweighted Accuracy |
|---|---|---|---|---|
| Emotions: A, E + H, N, S | ||||
| Fayek et al. [15]; 2017 | MFB | LSTM–RNN | 61.71% WA | 58.05% UA |
| DNN | 62.55% WA | 58.78% UA | ||
| CNN | 64.78% WA | 60.89% UA | ||
| Aldeneh and Provost [14]; 2017 | 40 MFB Speed data augment. | CNN | – | 61.8% UA |
| Xia and Liu [10]; 2017 | 1582 features from IS10 DBN with MTL | SVM | 60.9% WA | 62.4% UA |
| Kurpukdee et al. [60]; 2017 | ConvLSTM–RNN phoneme-based feature extractor | SVM | 65.13% WA | – |
| Sahu et al. [76]; 2018 | 1582-dimensional openSMILE feature space Augment. with GAN | SVM | – | 60.29% UA |
| Luo et al. [63]; 2018 | 6373 HSFs features Log-mel spec. | DNN/CRNN | 60.35% WA | 63.98% UA |
| Chatziagapi et al. [77]; 2019 | Mel-scaled Spectrograms Augment. with GAN | CNN(VGG19) | – | 53.6% UA |
| Emotions: A, H, N, S | ||||
| Lee and Tashev [13]; 2015 | Segment-level features + DNN | ELM | 52.13% WA * | 57.91% UA * |
| Tzinis and Potamianos [17]; 2017 | Statistical features over 3 s segments | LSTM | 64.16% WA | 60.02% UA |
| Satt et al. [64]; 2017 | STFT spectrograms | CNN–BiLSTM | 68.8% WA * | 59.4% UA * |
| Ma et al. [65]; 2018 | Variable length spectrograms | CNN–BiGRU | 71.45% WA * | 64.22% UA * |
| Yenigalla et al. [4]; 2018 | Phoneme embedding and spectrogram | 2 CNN channels | 73.9% WA * | 68.5% UA * |
| Wu et al. [88]; 2019 | Spectrograms | CNN–GRU–SeqCap | 72.73% WA | 59.71% UA |
| Xi et al. [16]; 2019 | Magnitude spectrograms | Residual Adapter on VoxCeleb2 | 72.73% WA * | 67.58% UA * |
| Mustaqeem and Kwon [59]; 2019 | Noise reduction Spectrograms | DSCNN | 84% WA | 82% UA |
4. Speech Emotion Recognition with Attention Mechanism
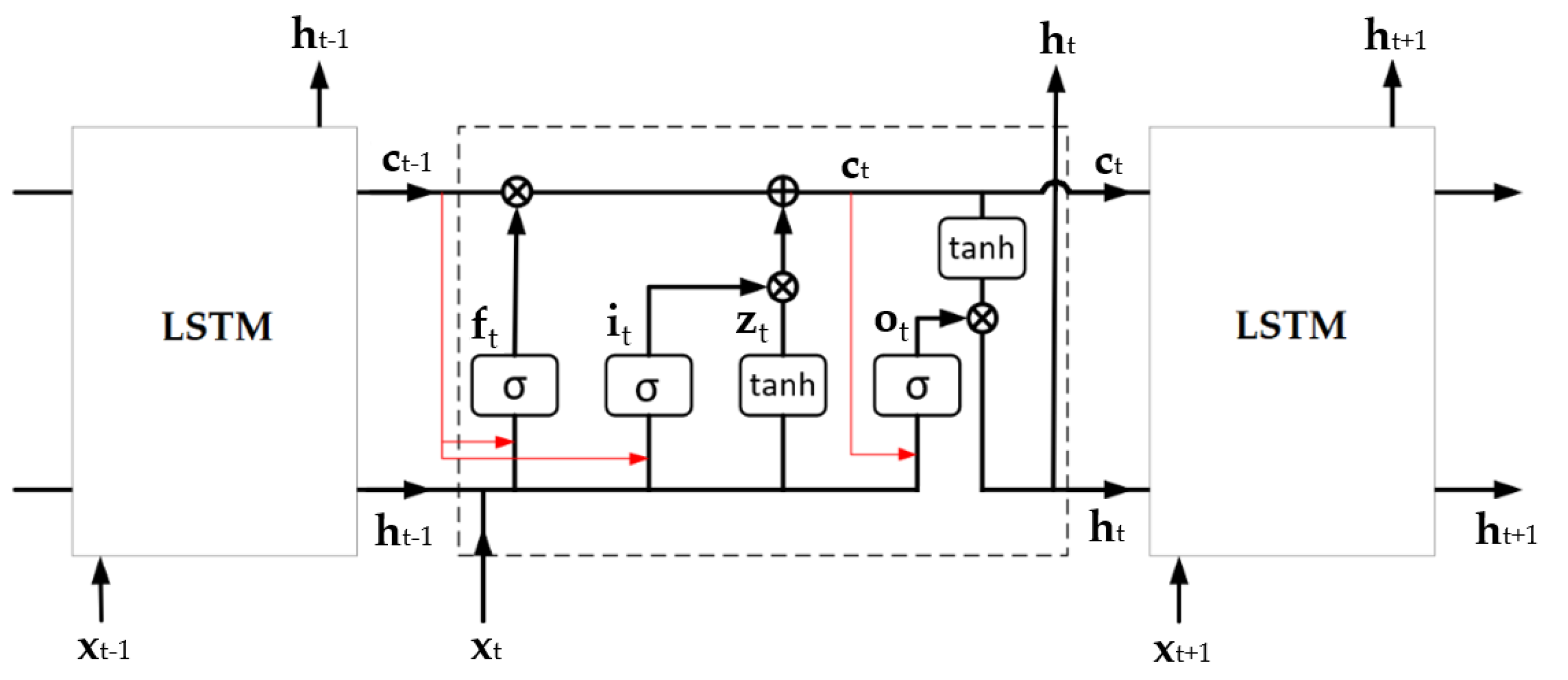
4.1. LSTM–RNN
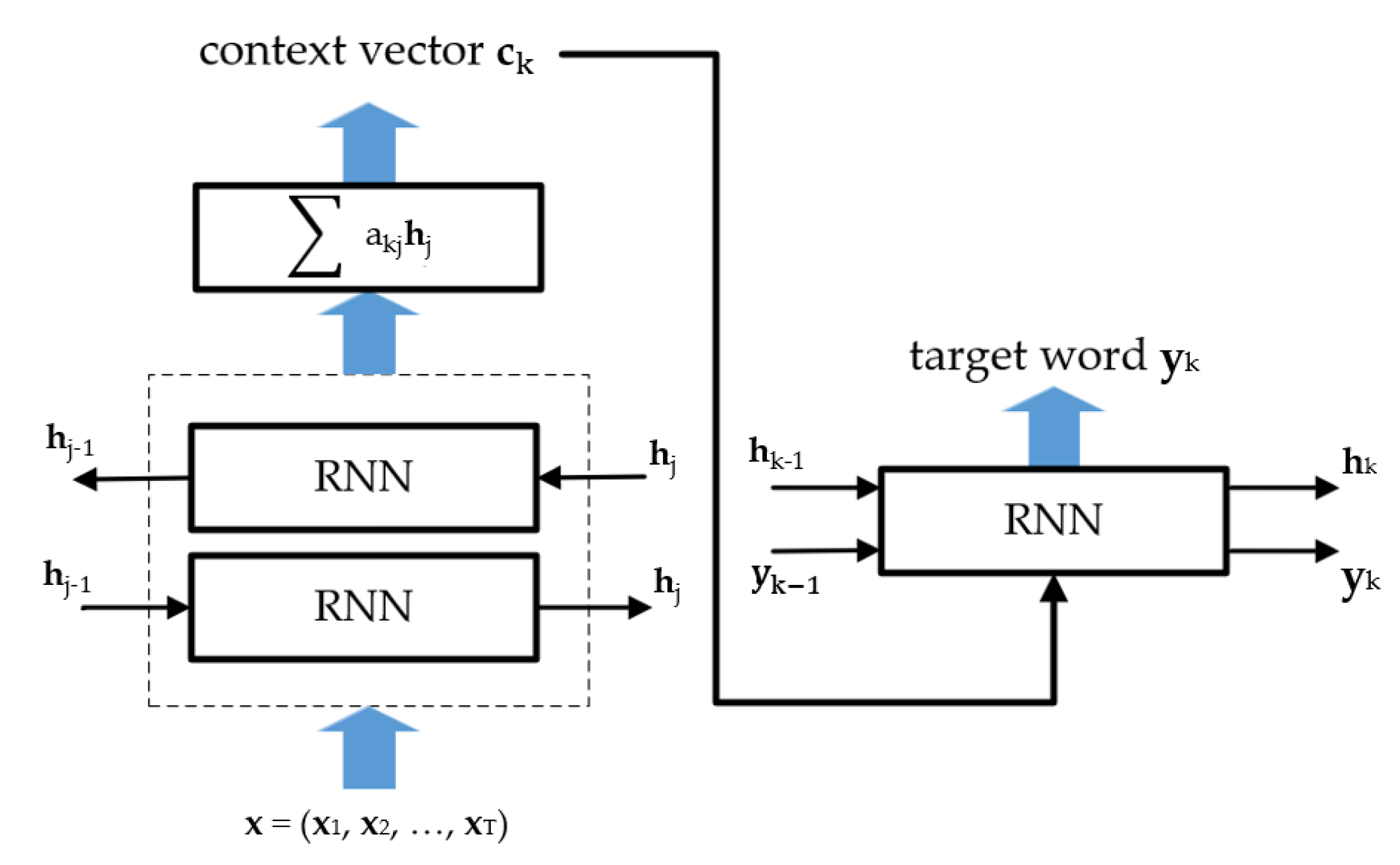
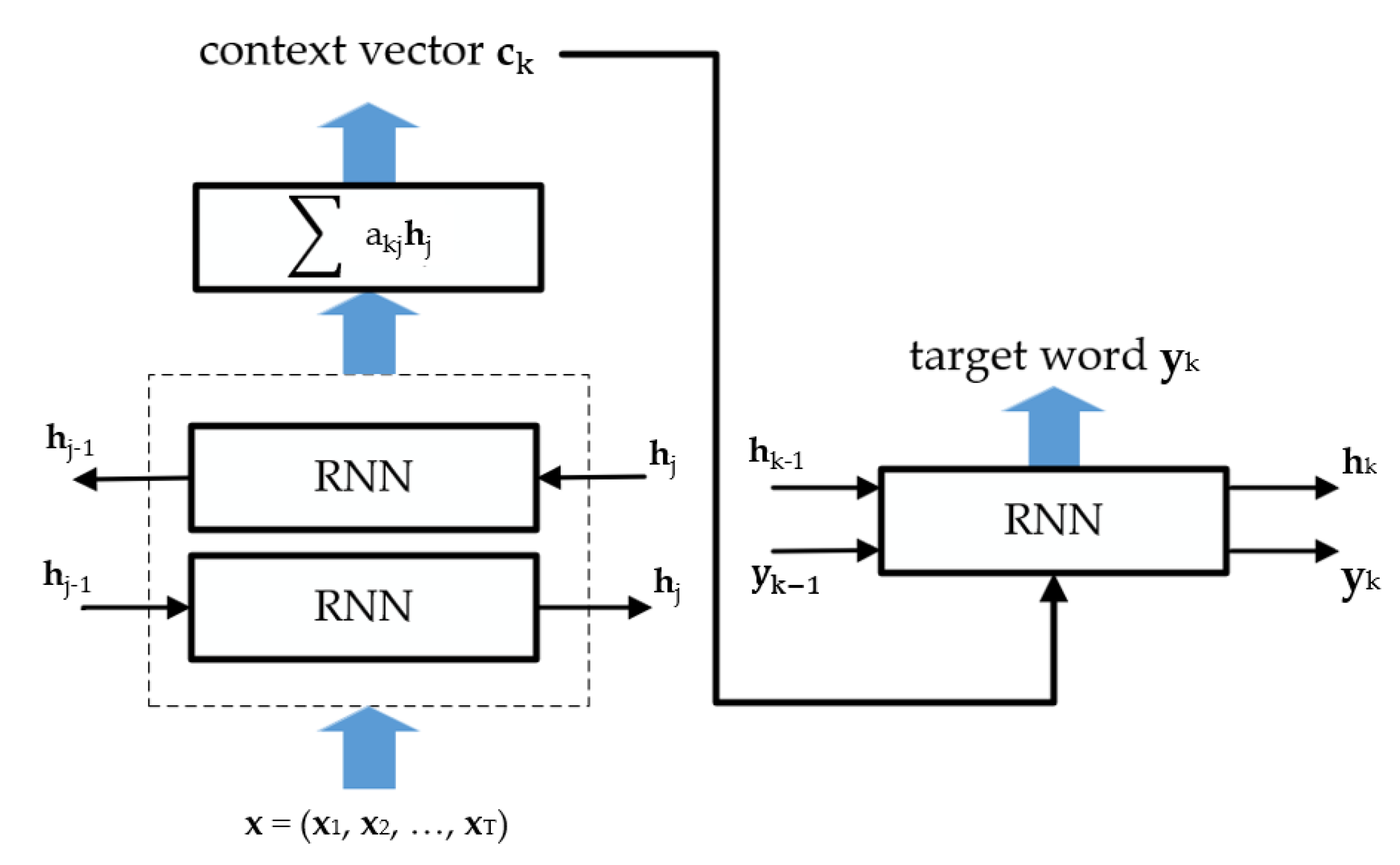
4.2. Attention Mechanism
AM Modifications
4.3. Attention Mechanism in Speech Emotion Recognition
4.3.1. Attentive Deep Recurrent Neural Networks
4.3.2. Attentive Deep Convolutional Neural Network
4.3.3. Attentive Convolutional–Recurrent Deep Neural Network
5. Impact of Attention Mechanism on SER
- AM has improved over the last years and a growing trend of AM use can be observed. Certainly, the performance improvement when using AM is evidenced by many research studies on SER [18,20,69,92,102,103,104,107,108,111]. On the other hand, two works [63,68] did not report improvements when using AM. Learning the attention weights for emotional representations of speech seems to be a reasonable way to address the variability of emotional clues across utterance; however, we have to note that the resulting benefit in terms of accuracy increment is not always so obvious. As seen from Table 10 and Table 11, the properly configured systems without AM may outperform the systems with AM (although one may argue about the correctness of such judgment due to different testing conditions among published works). The reason for ambiguity might be that AM-based SER system performance is subject to implementation issues as follows:
- The implementation of appropriate AM can be linked to various factors such as the derivation of accurate context information from speech utterances. As in NLP, the better the contextual information obtained from the sequence, the better the performance of the system. The duration of divided segments significantly influences the accuracy of emotion recognition [20,63,86]. Therefore, appropriate input sequence lengths must be determined in order to effectively capture the emotional context.
- Proper representation of emotional speech is also an important part of deriving contextual information. RNN is suitable for modelling long sequences. Extraction of higher-level statistical functions from multiple LLDs over speech segments with a combination of LSTM [18] can be compared to 32 LLDs with BiLSTM and local AM [18]. Transfer learning is a suitable solution particularly for small emotional datasets [16]. However, more works should be considered to make conclusions. End-to-end systems that combined CNN as feature extractor and RNN for modelling of the long-term contextual dependencies achieved high performance on IEMOCAP data and on EmoDB [62,106]. Various combinations of RNN and CNN are able to outperform separate systems [62,107]. The two-channel CNN taking phoneme embeddings and spectrograms on input seem to further improve the accuracy [4]. Thus, it can be beneficial to allow the model to learn different kinds of features. Moreover, leveraging multitask Learning for both the discrete and continuous recognition tasks improves the accuracy of SER systems [10,112]. CRNN architecture together with multitask learning was a part of the state-of-the-art solution on IEMOCAP proposed in [108]. Here, AM clearly improved system performance.
- Recurrent networks provide temporal representation for the whole utterance and better results are obtained with its aggregation by pooling for further recognition [18,20]. Several works compare different pooling strategies. The attention pooling is able to outperform global max pooling and global average pooling (GAP) [18,102,107]. The same was true for the attention pooling strategy for convolutional feature maps in [92] (attention-based pooling outperformed GAP). It can be concluded that learning of the attention weights indeed allows the model to adapt itself to changes in emotional speech.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations and Acronyms
| Abbreviation | Meaning |
| AM | Attention Mechanism |
| BiGRU | Bidirectional Gated Recurrent Unit |
| BiLSTM | Bidirectional Long Short-Term Memory |
| CCC | Concordance Correlation Coefficient |
| CLDNN | Convolutional Long Short-Term Memory Deep Neural Network |
| CNN | Convolutional Neural Network |
| DANN | Domain Adversarial Neural Network |
| DBN | Deep Belief Network |
| DCNN | Deep Convolutional Neural Network |
| DNN | Deep Neural Networks |
| DSCNN | Deep Stride Convolutional Neural Network |
| DTPM | Discriminant Temporal Pyramid Matching |
| ECG | Electro-Cardiogram |
| EDA | Electro-Dermal Activity |
| ELM | Extreme Learning Machine |
| FC | Fully Connected layer |
| FCN | Fully Convolutional Network |
| FS | Feature Selection |
| GAN | Generative Adversarial Network |
| GeWEC | Geneva Whispered Emotion Corpus |
| GRU | Gated Recurrent Unit |
| HMM | Hidden Markov Model |
| HSF | High-Level Statistical Functions |
| LSTM | Long Short-Term Memory |
| MFB | Log-Mel Filter-Bank |
| MFCCs | Mel-Frequency Cepstral Coefficients |
| MTL | Multitask Learning |
| NLP | Natural Language Processing |
| NN | Neural Network |
| PCA | Principal Component Analysis |
| ResNet | Residual Neural Network |
| RFE | Recursive Feature Elimination |
| RNN | Recurrent Neural Network |
| SER | Speech Emotion Recognition |
| STFT | Short Time Fourier Transform |
| SVM | Support Vector Machine |
| WoS | Web of Science |
References
- Burkhardt, F.; Ajmera, J.; Englert, R.; Stegmann, J.; Burleson, W. Detecting anger in automated voice portal dialogs. In Proceedings of the Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Hossain, M.S.; Muhammad, G.; Song, B.; Hassan, M.M.; Alelaiwi, A.; Alamri, A. Audio–Visual Emotion-Aware Cloud Gaming Framework. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 2105–2118. [Google Scholar] [CrossRef]
- Oh, K.; Lee, D.; Ko, B.; Choi, H. A Chatbot for Psychiatric Counseling in Mental Healthcare Service Based on Emotional Dialogue Analysis and Sentence Generation. In Proceedings of the 2017 18th IEEE International Conference on Mobile Data Management (MDM), Daejeon, Korea, 29 May–1 June 2017; pp. 371–375. [Google Scholar]
- Yenigalla, P.; Kumar, A.; Tripathi, S.; Singh, C.; Kar, S.; Vepa, J. Speech Emotion Recognition Using Spectrogram & Phoneme Embedding. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Deriche, M.; Abo absa, A.H. A Two-Stage Hierarchical Bilingual Emotion Recognition System Using a Hidden Markov Model and Neural Networks. Arab. J. Sci. Eng. 2017, 42, 5231–5249. [Google Scholar] [CrossRef]
- Pravena, D.; Govind, D. Significance of incorporating excitation source parameters for improved emotion recognition from speech and electroglottographic signals. Int. J. Speech Technol. 2017, 20, 787–797. [Google Scholar] [CrossRef]
- Bandela, S.R.; Kumar, T.K. Stressed speech emotion recognition using feature fusion of teager energy operator and MFCC. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–5 July 2017; pp. 1–5. [Google Scholar]
- Koolagudi, S.G.; Murthy, Y.V.S.; Bhaskar, S.P. Choice of a classifier, based on properties of a dataset: Case study-speech emotion recognition. Int. J. Speech Technol. 2018, 21, 167–183. [Google Scholar] [CrossRef]
- New, T.L.; Foo, S.W.; Silva, L.C.D. Classification of stress in speech using linear and nonlinear features. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003 Proceedings (ICASSP ’03), Hong Kong, China, 6–10 April 2003; Volume 2, p. II-9. [Google Scholar]
- Xia, R.; Liu, Y. A Multi-Task Learning Framework for Emotion Recognition Using 2D Continuous Space. IEEE Trans. Affect. Comput. 2017, 8, 3–14. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W. Speech Emotion Recognition Using Deep Convolutional Neural Network and Discriminant Temporal Pyramid Matching. IEEE Trans. Multimed. 2018, 20, 1576–1590. [Google Scholar] [CrossRef]
- Cummins, N.; Amiriparian, S.; Hagerer, G.; Batliner, A.; Steidl, S.; Schuller, B.W. An Image-based Deep Spectrum Feature Representation for the Recognition of Emotional Speech. In Proceedings of the 25th ACM International Conference on Multimedia; Association for Computing Machinery: New York, NY, USA, 2017; pp. 478–484. [Google Scholar]
- Lee, J.; Tashev, I. High-level feature representation using recurrent neural network for speech emotion recognition. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Aldeneh, Z.; Provost, E.M. Using regional saliency for speech emotion recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2741–2745. [Google Scholar]
- Fayek, H.M.; Lech, M.; Cavedon, L. Evaluating deep learning architectures for Speech Emotion Recognition. Neural Netw. 2017, 92, 60–68. [Google Scholar] [CrossRef]
- Xi, Y.; Li, P.; Song, Y.; Jiang, Y.; Dai, L. Speaker to Emotion: Domain Adaptation for Speech Emotion Recognition with Residual Adapters. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 513–518. [Google Scholar]
- Tzinis, E.; Potamianos, A. Segment-based speech emotion recognition using recurrent neural networks. In Proceedings of the 2017 Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; pp. 190–195. [Google Scholar]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Sarma, M.; Ghahremani, P.; Povey, D.; Goel, N.K.; Sarma, K.K.; Dehak, N. Emotion Identification from Raw Speech Signals Using DNNs. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 3097–3101. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1412–1421. [Google Scholar]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Anagnostopoulos, C.-N.; Iliou, T.; Giannoukos, I. Features and classifiers for emotion recognition from speech: A survey from 2000 to 2011. Artif. Intell. Rev. 2015, 43, 155–177. [Google Scholar] [CrossRef]
- Swain, M.; Routray, A.; Kabisatpathy, P. Databases, features and classifiers for speech emotion recognition: A review. Int. J. Speech Technol. 2018, 21, 93–120. [Google Scholar] [CrossRef]
- Schuller, B.W. Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends. Commun. ACM 2018, 61, 90–99. [Google Scholar] [CrossRef]
- Sailunaz, K.; Dhaliwal, M.; Rokne, J.; Alhajj, R. Emotion detection from text and speech: A survey. Soc. Netw. Anal. Min. 2018, 8, 28. [Google Scholar] [CrossRef]
- Khalil, R.A.; Jones, E.; Babar, M.I.; Jan, T.; Zafar, M.H.; Alhussain, T. Speech Emotion Recognition Using Deep Learning Techniques: A Review. IEEE Access 2019, 7, 117327–117345. [Google Scholar] [CrossRef]
- Akçay, M.B.; Oğuz, K. Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 2020, 116, 56–76. [Google Scholar] [CrossRef]
- Kamińska, D.; Sapiński, T.; Anbarjafari, G. Efficiency of chosen speech descriptors in relation to emotion recognition. EURASIP J. Audio Speech Music Process. 2017, 2017, 3. [Google Scholar] [CrossRef] [Green Version]
- Bakker, I.; van der Voordt, T.; Vink, P.; de Boon, J. Pleasure, Arousal, Dominance: Mehrabian and Russell revisited. Curr. Psychol. 2014, 33, 405–421. [Google Scholar] [CrossRef]
- Truong, K.P.; Van Leeuwen, D.A.; De Jong, F.M. Speech-based recognition of self-reported and observed emotion in a dimensional space. Speech Commun. 2012, 54, 1049–1063. [Google Scholar] [CrossRef]
- Vryzas, N.; Kotsakis, R.; Liatsou, A.; Dimoulas, C.A.; Kalliris, G. Speech Emotion Recognition for Performance Interaction. J. Audio Eng. Soc. 2018, 66, 457–467. [Google Scholar] [CrossRef]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.; Weiss, B. A database of German emotional speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; Volumn 5, pp. 1517–1520. [Google Scholar]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’ 05 Audio-Visual Emotion Database. In Proceedings of the 22nd International Conference on Data Engineering Workshops (ICDEW’06), Atlanta, GA, USA, 3–7 April 2006; p. 8. [Google Scholar]
- Steidl, S. Automatic Classification of Emotion Related User States in Spontaneous Children’s Speech; Logos-Verlag: Berlin, Germany, 2009. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.-C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Lotfian, R.; Busso, C. Building Naturalistic Emotionally Balanced Speech Corpus by Retrieving Emotional Speech from Existing Podcast Recordings. IEEE Trans. Affect. Comput. 2019, 10, 471–483. [Google Scholar] [CrossRef]
- Kamińska, D.; Sapiński, T. Polish Emotional Speech Recognition Based on the Committee of Classifiers. Przeglad Elektrotechniczny 2017, 2016, 101–106. [Google Scholar] [CrossRef] [Green Version]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [Green Version]
- Ringeval, F.; Sonderegger, A.; Sauer, J.S.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013. [Google Scholar] [CrossRef] [Green Version]
- Haq, S.; Jackson, P. Speaker-dependent audio-visual emotion recognition. In Proceedings of the AVSP, Norwich, UK, 10–13 September 2009. [Google Scholar]
- Ringeval, F.; Schuller, B.; Valstar, M.; Jaiswal, S.; Marchi, E.; Lalanne, D.; Cowie, R.; Pantic, M. AV + EC 2015—the first affect recognition challenge bridging across audio, video, and physiological data. In Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge, Brisbane, Australia, 26–30 October 2015. [Google Scholar]
- Ntalampiras, S.; Fakotakis, N. Modeling the Temporal Evolution of Acoustic Parameters for Speech Emotion Recognition. IEEE Trans. Affect. Comput. 2012, 3, 116–125. [Google Scholar] [CrossRef]
- Liu, G.K. Evaluating Gammatone Frequency Cepstral Coefficients with Neural Networks for Emotion Recognition from Speech. arXiv 2018, arXiv:1806.09010. [Google Scholar]
- Fahad, M.S.; Deepak, A.; Pradhan, G.; Yadav, J. DNN-HMM-Based Speaker-Adaptive Emotion Recognition Using MFCC and Epoch-Based Features. Circuits Syst. Signal Process. 2021, 40, 466–489. [Google Scholar] [CrossRef]
- Kerkeni, L.; Serrestou, Y.; Raoof, K.; Mbarki, M.; Mahjoub, M.A.; Cleder, C. Automatic speech emotion recognition using an optimal combination of features based on EMD-TKEO. Speech Commun. 2019, 114, 22–35. [Google Scholar] [CrossRef]
- YogeshC, K.; Hariharan, M.; Ngadiran, R.; Adom, A.H.; Yaacob, S.; Berkai, C.; Polat, K. A new hybrid PSO assisted biogeography-based optimization for emotion and stress recognition from speech signal. Expert Syst. Appl. 2017, 69, 149–158. [Google Scholar] [CrossRef]
- Liu, Z.-T.; Wu, M.; Cao, W.-H.; Mao, J.-W.; Xu, J.-P.; Tan, G.-Z. Speech emotion recognition based on feature selection and extreme learning machine decision tree. Neurocomputing 2018, 273, 271–280. [Google Scholar] [CrossRef]
- Chen, L.; Mao, X.; Xue, Y.; Cheng, L.L. Speech emotion recognition: Features and classification models. Digit. Signal Process. 2012, 22, 1154–1160. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A. The Interspeech 2009 Emotion Challenge. In Proceedings of the 10th Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009; pp. 312–315. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A.; Burkhardt, F.; Devillers, L.; Müller, C.; Narayanan, S. The INTERSPEECH 2010 paralinguistic challenge. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, 26–30 September 2010; pp. 2794–2797. [Google Scholar]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The Geneva Minimalistic Acoustic Parameter Set (GeMAPS) for Voice Research and Affective Computing. IEEE Trans. Affect. Comput. 2016, 7, 190–202. [Google Scholar] [CrossRef] [Green Version]
- Weninger, F.; Eyben, F.; Schuller, B.W.; Mortillaro, M.; Scherer, K.R. On the Acoustics of Emotion in Audio: What Speech, Music, and Sound have in Common. Front. Psychol. 2013, 4, 292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, C.; Narayanan, S.S. Deep convolutional recurrent neural network with attention mechanism for robust speech emotion recognition. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 583–588. [Google Scholar]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech Emotion Recognition from Spectrograms with Deep Convolutional Neural Network. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Korea, 13–15 February 2017; pp. 1–5. [Google Scholar]
- Vrysis, L.; Tsipas, N.; Thoidis, I.; Dimoulas, C. 1D/2D Deep CNNs vs. Temporal Feature Integration for General Audio Classification. J. Audio Eng. Soc. 2020, 68, 66–77. [Google Scholar] [CrossRef]
- Hajarolasvadi, N.; Demirel, H. 3D CNN-Based Speech Emotion Recognition Using K-Means Clustering and Spectrograms. Entropy 2019, 21, 479. [Google Scholar] [CrossRef] [Green Version]
- Mustaqeem; Kwon, S. A CNN-assisted enhanced audio signal processing for speech emotion recognition. Sensors 2020, 20, 183. [Google Scholar] [CrossRef] [Green Version]
- Kurpukdee, N.; Koriyama, T.; Kobayashi, T.; Kasuriya, S.; Wutiwiwatchai, C.; Lamsrichan, P. Speech emotion recognition using convolutional long short-term memory neural network and support vector machines. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1744–1749. [Google Scholar]
- Lim, W.; Jang, D.; Lee, T. Speech emotion recognition using convolutional and Recurrent Neural Networks. In Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Korea, 13–16 December 2016; pp. 1–4. [Google Scholar]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar] [CrossRef]
- Luo, D.; Zou, Y.; Huang, D. Investigation on Joint Representation Learning for Robust Feature Extraction in Speech Emotion Recognition. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 152–156. [Google Scholar]
- Satt, A.; Rozenberg, S.; Hoory, R. Efficient Emotion Recognition from Speech Using Deep Learning on Spectrograms. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Ma, X.; Wu, Z.; Jia, J.; Xu, M.; Meng, H.; Cai, L. Emotion Recognition from Variable-Length Speech Segments Using Deep Learning on Spectrograms. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 3683–3687. [Google Scholar]
- Khorram, S.; Aldeneh, Z.; Dimitriadis, D.; McInnis, M.; Provost, E.M. Capturing Long-term Temporal Dependencies with Convolutional Networks for Continuous Emotion Recognition. arXiv 2017, arXiv:1708.07050. Cs. [Google Scholar]
- Tzirakis, P.; Zhang, J.; Schuller, B.W. End-to-End Speech Emotion Recognition Using Deep Neural Networks. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5089–5093. [Google Scholar]
- AlBadawy, E.A.; Kim, Y. Joint Discrete and Continuous Emotion Prediction Using Ensemble and End-to-End Approaches. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 366–375. [Google Scholar]
- Zhang, Y.; Du, J.; Wang, Z.; Zhang, J.; Tu, Y. Attention Based Fully Convolutional Network for Speech Emotion Recognition. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 1771–1775. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Tamulevičius, G.; Korvel, G.; Yayak, A.B.; Treigys, P.; Bernatavičienė, J.; Kostek, B. A Study of Cross-Linguistic Speech Emotion Recognition Based on 2D Feature Spaces. Electronics 2020, 9, 1725. [Google Scholar] [CrossRef]
- Etienne, C.; Fidanza, G.; Petrovskii, A.; Devillers, L.; Schmauch, B. CNN+LSTM Architecture for Speech Emotion Recognition with Data Augmentation. arXiv 2018, arXiv:1802.05630, 21–25. [Google Scholar]
- Vryzas, N.; Vrysis, L.; Matsiola, M.; Kotsakis, R.; Dimoulas, C.; Kalliris, G. Continuous Speech Emotion Recognition with Convolutional Neural Networks. J. Audio Eng. Soc. 2020, 68, 14–24. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS 2014), Montréal, QC, Canada, 18–22 November 2014; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Sahu, S.; Gupta, R.; Espy-Wilson, C. On Enhancing Speech Emotion Recognition using Generative Adversarial Networks. arXiv 2018, arXiv:1806.06626. Cs. [Google Scholar]
- Chatziagapi, A.; Paraskevopoulos, G.; Sgouropoulos, D.; Pantazopoulos, G.; Nikandrou, M.; Giannakopoulos, T.; Katsamanis, A.; Potamianos, A.; Narayanan, S. Data Augmentation Using GANs for Speech Emotion Recognition. In Proceedings of the INTERSPEECH 2019, Graz, Austria, 15–19 September 2019; pp. 171–175. [Google Scholar]
- Fu, C.; Shi, J.; Liu, C.; Ishi, C.T.; Ishiguro, H. AAEC: An Adversarial Autoencoder-based Classifier for Audio Emotion Recognition. In Proceedings of the 1st International on Multimodal Sentiment Analysis in Real-life Media Challenge and Workshop (MuSe’20), Seattle, WA, USA, 16 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 45–51. [Google Scholar]
- Deng, J.; Xu, X.; Zhang, Z.; Frühholz, S.; Schuller, B. Universum Autoencoder-Based Domain Adaptation for Speech Emotion Recognition. IEEE Signal Process. Lett. 2017, 24, 500–504. [Google Scholar] [CrossRef]
- Abdelwahab, M.; Busso, C. Domain Adversarial for Acoustic Emotion Recognition. arXiv 2018, arXiv:1804.07690. Cs Eess. [Google Scholar] [CrossRef] [Green Version]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. arXiv 2016, arXiv:1505.07818. Cs Stat. [Google Scholar]
- Zheng, W.; Zheng, W.; Zong, Y. Multi-scale discrepancy adversarial network for crosscorpus speech emotion recognition. Virtual Real. Intell. Hardw. 2021, 3, 65–75. [Google Scholar] [CrossRef]
- Noh, K.J.; Jeong, C.Y.; Lim, J.; Chung, S.; Kim, G.; Lim, J.M.; Jeong, H. Multi-Path and Group-Loss-Based Network for Speech Emotion Recognition in Multi-Domain Datasets. Sensors 2021, 21, 1579. [Google Scholar] [CrossRef]
- Lech, M.; Stolar, M.; Best, C.; Bolia, R. Real-Time Speech Emotion Recognition Using a Pre-trained Image Classification Network: Effects of Bandwidth Reduction and Companding. Front. Comput. Sci. 2020, 2, 14. [Google Scholar] [CrossRef]
- Huang, Z.; Dong, M.; Mao, Q.; Zhan, Y. Speech Emotion Recognition Using CNN. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 801–804. [Google Scholar]
- Neumann, M.; Vu, N.T. Attentive Convolutional Neural Network Based Speech Emotion Recognition: A Study on the Impact of Input Features, Signal Length, and Acted Speech. arXiv 2017, arXiv:1706.00612. [Google Scholar] [CrossRef] [Green Version]
- Latif, S.; Rana, R.; Qadir, J.; Epps, J. Variational Autoencoders for Learning Latent Representations of Speech Emotion: A Preliminary Study. arXiv 2020, arXiv:1712.08708. [Google Scholar]
- Wu, X.; Liu, S.; Cao, Y.; Li, X.; Yu, J.; Dai, D.; Ma, X.; Hu, S.; Wu, Z.; Liu, X.; et al. Speech Emotion Recognition Using Capsule Networks. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6695–6699. [Google Scholar]
- Papakostas, M.; Spyrou, E.; Giannakopoulos, T.; Siantikos, G.; Sgouropoulos, D.; Mylonas, P.; Makedon, F. Deep Visual Attributes vs. Hand-Crafted Audio Features on Multidomain Speech Emotion Recognition. Computation 2017, 5, 26. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; ISBN 978-0-262-03561-3. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Song, Y.; McLoughlin, I.V.; Guo, W.; Dai, L.-R. An Attention Pooling based Representation Learning Method for Speech Emotion Recognition. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; International Speech Communication Association: Hyderabad, India, 2018. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qata, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1724–1734. [Google Scholar]
- Karmakar, P.; Teng, S.W.; Lu, G. Thank you for Attention: A survey on Attention-based Artificial Neural Networks for Automatic Speech Recognition. arXiv 2021, arXiv:2102.07259. [Google Scholar]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. arXiv 2019, arXiv:1904.02874. [Google Scholar]
- Lin, Z.; Feng, M.; dos Santos, C.N.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A Structured Self-attentive Sentence Embedding. arXiv 2017, arXiv:1703.03130. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for Aspect-level Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 606–615. [Google Scholar]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. Effective Attention Modeling for Aspect-Level Sentiment Classification. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; Association for Computational Linguistics: Santa Fe, NM, USA, 2018; pp. 1121–1131. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS 2015), Montréal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2015; Volume 1, pp. 577–585. [Google Scholar]
- Han, K.; Yu, D.; Tashev, I. Speech Emotion Recognition Using Deep Neural Network and Extreme Learning Machine. In Proceedings of the 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Huang, C.-W.; Narayanan, S.S. Attention Assisted Discovery of Sub-Utterance Structure in Speech Emotion Recognition. In Proceedings of the INTERSPEECH 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 1387–1391. [Google Scholar]
- Tao, F.; Liu, G. Advanced LSTM: A Study about Better Time Dependency Modeling in Emotion Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2906–2910. [Google Scholar]
- Xie, Y.; Liang, R.; Liang, Z.; Huang, C.; Zou, C.; Schuller, B. Speech Emotion Classification Using Attention-Based LSTM. IEEEACM Trans. Audio Speech Lang. Process. 2019, 27, 1675–1685. [Google Scholar] [CrossRef]
- Xie, Y.; Liang, R.; Liang, Z.; Zhao, L. Attention-Based Dense LSTM for Speech Emotion Recognition. IEICE Trans. Inf. Syst. 2019, E102.D, 1426–1429. [Google Scholar] [CrossRef] [Green Version]
- Girdhar, R.; Ramanan, D. Attentional Pooling for Action Recognition. arXiv 2017, arXiv:1711.01467. CsCV. [Google Scholar]
- Chen, M.; He, X.; Yang, J.; Zhang, H. 3-D Convolutional Recurrent Neural Networks with Attention Model for Speech Emotion Recognition. IEEE Signal Process. Lett. 2018, 25, 1440–1444. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, Y.; Zhang, Z.; Wang, H.; Zhao, Y.; Li, C. Exploring Spatio-Temporal Representations by Integrating Attention-based Bidirectional-LSTM-RNNs and FCNs for Speech Emotion Recognition. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 272–276. [Google Scholar]
- Li, Y.; Zhao, T.; Kawahara, T. Improved End-to-End Speech Emotion Recognition Using Self Attention Mechanism and Multitask Learning. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Dangol, R.; Alsadoon, A.; Prasad, P.W.C.; Seher, I.; Alsadoon, O.H. Speech Emotion Recognition UsingConvolutional Neural Network and Long-Short TermMemory. Multimed. Tools Appl. 2020, 79, 32917–32934. [Google Scholar] [CrossRef]
- Alex, S.B.; Mary, L.; Babu, B.P. Attention and Feature Selection for Automatic Speech Emotion Recognition Using Utterance and Syllable-Level Prosodic Features. Circuits Syst. Signal Process. 2020, 39, 5681–5709. [Google Scholar] [CrossRef]
- Zheng, C.; Wang, C.; Jia, N. An Ensemble Model for Multi-Level Speech Emotion Recognition. Appl. Sci. 2020, 10, 205. [Google Scholar] [CrossRef] [Green Version]
- Parthasarathy, S.; Busso, C. Jointly Predicting Arousal, Valence and Dominance with Multi-Task Learning. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 1103–1107. [Google Scholar]


| Year | Scopus | WoS | ||
|---|---|---|---|---|
| General SER | Attention SER | General SER | Attention SER | |
| 2016 | 519 | 34 | 344 | 30 |
| 2017 | 631 | 42 | 348 | 24 |
| 2018 | 829 | 82 | 446 | 54 |
| 2019 | 979 | 125 | 415 | 63 |
| 2020 | 886 | 133 | 325 | 59 |
| References | Description of the Content |
|---|---|
| [23]; 2011 | A comprehensive survey discusses acoustic features, classification methods (both traditional and artificial neural networks (ANNs)), and multimodal approaches. The authors pointed out that some of the existing databases were not sufficient for automatic SER and the development of benchmark emotional speech databases is necessary. |
| [24]; 2015 | Survey from 2000 to 2011 describing various features (considering non-linguistic and linguistic information) and feature selection methods, and providing a comparison of classification performance of traditional classifiers, ANNs, and their combinations. The major shortcoming for direct comparison of SER systems is considered to be a lack of uniformity in the way the methods are evaluated and assessed. |
| [25]; 2018 | The review provides a thorough description of emotion datasets and speech features (excitation source, prosodic and vocal tract features) from 2000 to 2017. It also discusses the classification of emotions in general. |
| [26]; 2018 | A review article, which traces 20 years of progress in SER. The author discusses the techniques of representation of emotional speech (considering audio and textual features) and the ongoing trends. Benchmark results of the SER challenges are also provided. |
| [27]; 2018 | The survey covers existing emotion detection research efforts, emotion models, datasets, detection techniques, their features, limitations, and some possible future directions. Emotion analysis from text is also thoroughly described. |
| [28]; 2019 | Review of the deep learning techniques for SER: RNN, recursive neural network, deep belief network (DBN), CNN, and auto encoder (AE). |
| [29]; 2020 | A review discusses current methodologies in SER. It covers a wide area of SER topics such as emotional models, databases, features, pre-processing methods, supporting modalities, and classifiers. The authors address challenges in SER: the need for natural datasets with a sufficient amount of data; they also pointed out that unsatisfactory results are still being achieved with cross-language scenarios. |
| References | Audio Parametrization | Classification Method | Reported Accuracy (ρc) | |
|---|---|---|---|---|
| Trigeorgis et al. [19]; 2016 | Raw signal (6 s long sequences) | end-to-end CNN–BiLSTM | 0.686 A | 0.261 V |
| Khorram et al. [66]; 2018 | MFB | Down/Up CNN | 0.681 A | 0.502 V |
| Tzirakis et al. [67]; 2018 | Raw signal (20 s long sequences) | end-to-end CNN–LSTM | 0.787 A | 0.440 V |
| AlBadawy and Kim [68]; 2018 | MFB | Deep BLSTM | 0.697 A | 0.555 V |
| Dot | |
| General | |
| Concatenation |
| Location-based AM | |
| Content-based AM | |
| Hybrid AM |
| References | Techniques of Audio Parametrisation | Proposed Machine Learning Method | Database (Emotions) |
|---|---|---|---|
| IEMOCAP | |||
| Huang and Narayanan [101]; 2016 | 28 LLDs: 13 MFCC, F0, Δ | BiLSTM | A, H, N, S |
| Mirsamadi et al. [18]; 2017 | F0, voice probab., frame energy, ZCR, 12 MFCC, Δ | BiLSTM—weighted-pooling with local attention | A, H, N, S |
| Neumann and Vu [86]; 2017 | Max. length of the utterance: 7.5 s MFB (26) | Attentive CNN with MTL | A, E + H, N, S A–V |
| Tao and Liu [102]; 2018 | 13 MFCC, ZCR, energy, entropy of energy, spectral characteristics, 12 D chroma, chroma dev., HR, pitch | DNN–BiLSTM–MTL with Advanced LSTM | A, H, N, S |
| Zhao et al. [107]; 2018 | 743 features + PCA | Att–BiLSTM–FCN | A, E + H, N, S |
| Sarma et al. [20]; 2018 | Raw waveform front end | TDNN–LSTM–attention | A, H, N, S |
| Chen et al. [106]; 2018 | 3D Log-mel spectrograms | Attention-based convolutional RNN (ACRNN) | A, H, N, S |
| Li et al. [92]; 2018 | Spectrogram (2 s segments with 1 s overlap) | CNN–TF–Att.pooling | A, H, N, S |
| Xie et al. [104]; 2019 | The ComParE frame-level features | LSTM with skipped connections | A, E, Fr, N, S |
| Zhang et al. [69]; 2019 | Spectrogram (variable utterance length) | Fully convolutional network + attention layer | A, H, N, S |
| Li et al. [108]; 2019 | Mel spectrogram + Δ, ΔΔ (max. length of the utterances: 7.5 s) | CNN–BiLSTM–MTL: + Attention mechanism | A, E + H, N, S |
| Alex et al. [110]; 2020 | Prosodic and spectral features extracted at various levels + RFE | Fusion of three separate DNNs + Attention at the syllable-level | A, E + H, N, S |
| Zheng et al. [111]; 2020 | (1) Spectrogram (2) Spectrogram + PCA (3) LLDs and their HSFs; spectrogram and CRNN with attention m. | Ensemble model: (1) two-channel CNN (2) GRU with attention m. (3) BiLSTM with attention m. | A, E + H, N, S |
| Dangol et al. [109]; 2020 | Silence/noise removal 3D Log-mel spectrograms | Relation-aware attention-based 3D CNN–LSTM | A, H, N, S |
| Other databases | |||
| Huang and Narayanan [55]; 2017 | MFB | CLDNN with convolutional attention mechanism | eNTERFACE’05 |
| Chen et al. [106]; 2018 | 3D Log-mel spectrograms | Attention-based convolutional RNN (ACRNN) | EmoDB full data set |
| Xie et al. [103]; 2019 | The ComParE frame-level features (openSMILE) | LSTM with attention gate and time/frequency attention | CASIA, (6) eNTERFACE (6) GEMEP (12) |
| Xie et al. [104]; 2019 | The ComParE frame-level features (openSMILE) | LSTM with skipped connections | eNTERFACE (6) |
| Dangol et al. [109]; 2020 | Silence/noise removal 3D Log-mel spectrograms | Relation-aware attention-based 3D CNN and LSTM | EmoDB SAVEE |
| References | AM | Description of System | Emotions | WA | UA |
|---|---|---|---|---|---|
| Recurrent architectures | |||||
| [101]; 2016 | √ | 28 LLDs BiLSTM | A, H, N, S | 59.33% | 49.96% |
| [18]; 2017 | √ | 32 LLDs BiLSTM—with local AM | A, H, N, S | 63.5% | 58.8% |
| [17]; 2017 | × | Statistical features over 3 s segments and LSTM | A, H, N, S | 64.16% | 60.02% |
| [102]; 2018 | √ | LLDs Advanced LSTM | A, H, N, S | 55.3% | – |
| Convolutional architectures | |||||
| [92]; 2018 | √ | Spectrograms CNN–TF–Att.pooling | A, H, N, S (improvised) | 71.75% | 68.06% |
| [4]; 2018 | × | Phoneme embedding and spectrogram Two CNN channels | A, H, N, S (improvised) | 73.9% | 68.5% |
| [69]; 2019 | √ | Spectrogram and FCN + attention layer | A, H, N, S (improvised) | 70.4% | 63.9% |
| [16]; 2019 | × | Magnitude spectrograms Residual Adapter on VoxCeleb2 | A, H, N, S (improvised) | 72.73% | 67.58% |
| Combination of CNN and RNN | |||||
| [64]; 2017 | × | Spectrograms CNN–BiLSTM | A, H, N, S (improvised) | 68.8% | 59.4% |
| [20]; 2018 | √ | Raw waveform front end TDNN–LSTM–attention | A, H, N, S | 70.1% | 60.7% |
| [65]; 2018 | × | Spectrograms CNN–BiGRU | A, H, N, S (improvised) | 71.45% | 64.22% |
| [106]; 2018 | √ | 3Dlog-mel spec.; Att.–CRNN | A, H, S, N (improvised) | – | 64.74% |
| [88]; 2019 | × | Spectrograms CNN–GRU–SeqCap | A, H, N, S | 72.73% | 59.71% |
| Hybrid systems | |||||
| [13]; 2015 | × | Segment-level features DNN–ELM | A, H, N, S (improvised) | 52.13% | 57.91% |
| [13]; 2015 | × | 32 LLDs BiLSTM–ELM | A, H, N, S (improvised) | 62.85% | 63.89% |
| [10]; 2017 | × | DBN–MTL feat. Extract. SVM classifier | A, H, N, S | 60.9% | 62.4% |
| References | AM | Description of System | Emotions | WA | UA |
|---|---|---|---|---|---|
| Convolutional architectures | |||||
| [86]; 2017 | √ | MFB; Attentive CNN with MTL | A, E + H, N, S A–V | 56.10% | – |
| [14]; 2017 | × | MFB and CNN | A, E + H, N, S | – | 61.8% |
| [15]; 2017 | × | Log-mel spectrogram ConvNet | A, E + H, N, S | 64.78% | 60.89% |
| [77]; 2019 | × | Mel-scaled spectrograms Augment. With GAN CNN(VGG19) | A, E + H, N, S | – | 53.6% |
| Combination of CNN and RNN | |||||
| [107]; 2018 | √ | 743 features + PCA Att–BiLSTM–FCN | A, E + H, N, S | 59.7% | 60.1% |
| [108]; 2019 | √ | Log-mel spectrograms, Δ, ΔΔ; CNN–BiLSTM with MTL | A, E + H, N, S | 81.6% | 82.8% |
| Hybrid systems and ensemble models | |||||
| [60]; 2017 | × | ConvLSTM feature extractor | SVM | 65.13% | – |
| [63]; 2018 | × | HSFs–DNN Log-mel spec.-CRNN | A, E + H, N, S | 60.35% | 63.98% |
| [76]; 2018 | × | 1582-dimensional openSMILE feature space Augment. With GAN | SVM | – | 60.29% |
| [111]; 2020 | √ | Ensemble model | A, E + H, N, S | 75% | 75% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lieskovská, E.; Jakubec, M.; Jarina, R.; Chmulík, M. A Review on Speech Emotion Recognition Using Deep Learning and Attention Mechanism. Electronics 2021, 10, 1163. https://doi.org/10.3390/electronics10101163
Lieskovská E, Jakubec M, Jarina R, Chmulík M. A Review on Speech Emotion Recognition Using Deep Learning and Attention Mechanism. Electronics. 2021; 10(10):1163. https://doi.org/10.3390/electronics10101163
Chicago/Turabian StyleLieskovská, Eva, Maroš Jakubec, Roman Jarina, and Michal Chmulík. 2021. "A Review on Speech Emotion Recognition Using Deep Learning and Attention Mechanism" Electronics 10, no. 10: 1163. https://doi.org/10.3390/electronics10101163