
A Hybrid YOLOv4 and Particle Filter Based Robotic Arm Grabbing System in Nonlinear and Non-Gaussian Environment

 ,
,
Abstract
:1. Introduction
- (1)
- In this paper, the most widely used contemporary YOLO algorithm is analyzed theoretically and compared with other algorithms. In addition, three distances and FPS are tested using the latest YOLOv4 algorithm as well as commonly used detection algorithms to achieve efficient detection of YOLOv4 in real-time. The average recognition accuracy reaches 98.5% and the FPS is maintained at around 22 FPS.
- (2)
- The laboratory tests on different filters with filtering and prediction functions are run under simulated situations in this paper. With the existence of environmental interference, the exquisite filtering and prediction functions of the PF algorithm are fulfilled. Its MSE of the filter error is 7.1537 × 10−6 and its MSE of the prediction error is 1.356 × 10−5, indicating that it can effectively reduce the impact of the environment to get the predicted position of the target object at the next moment more accurately.
- (3)
- In this paper, we use a grabbing system that combines YOLOv4 and PF algorithms to conduct a large number of comparative experiments. YOLOv4 can maintain an accuracy of nearly 99.50% while recognizing the object from a proper distance. Additionally, its recognition speed meets the requirements of real-time and the ability of PF to adjust the sudden disturbances is also significantly higher than that of other filter algorithms such as KF. Therefore, the grabbing system can accomplish the successful grasp at a rate of nearly 88% even at a higher movement speed.
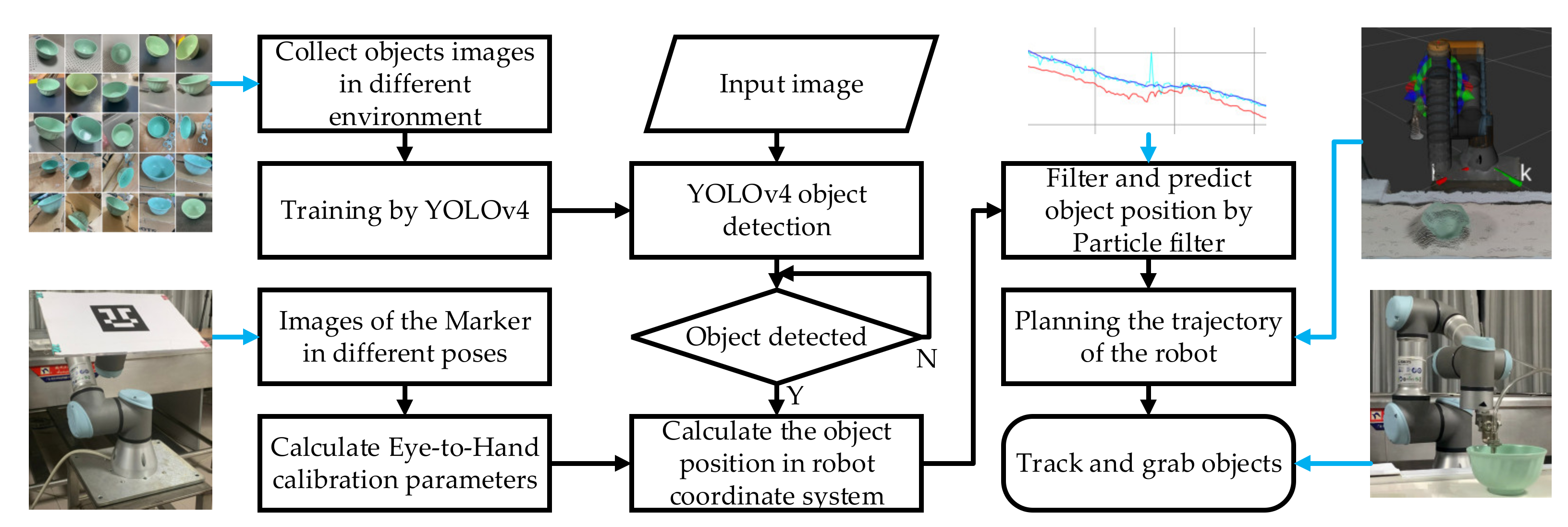
2. Framework of Moving Target Tracking and Grabbing Strategy
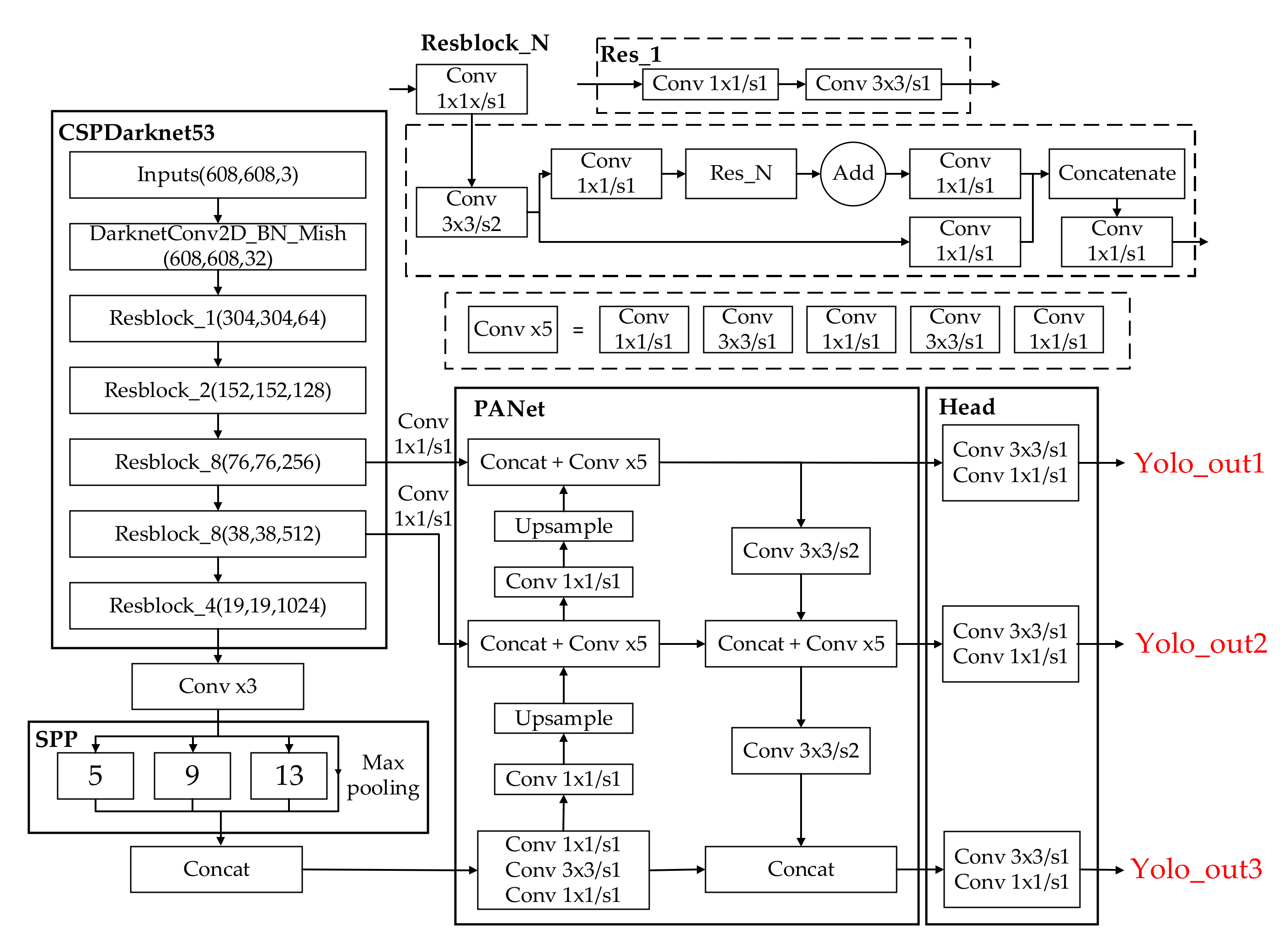
3. Target Recognition Based on YOLOv4 Algorithm
3.1. YOLOv4 Algorithm Structure
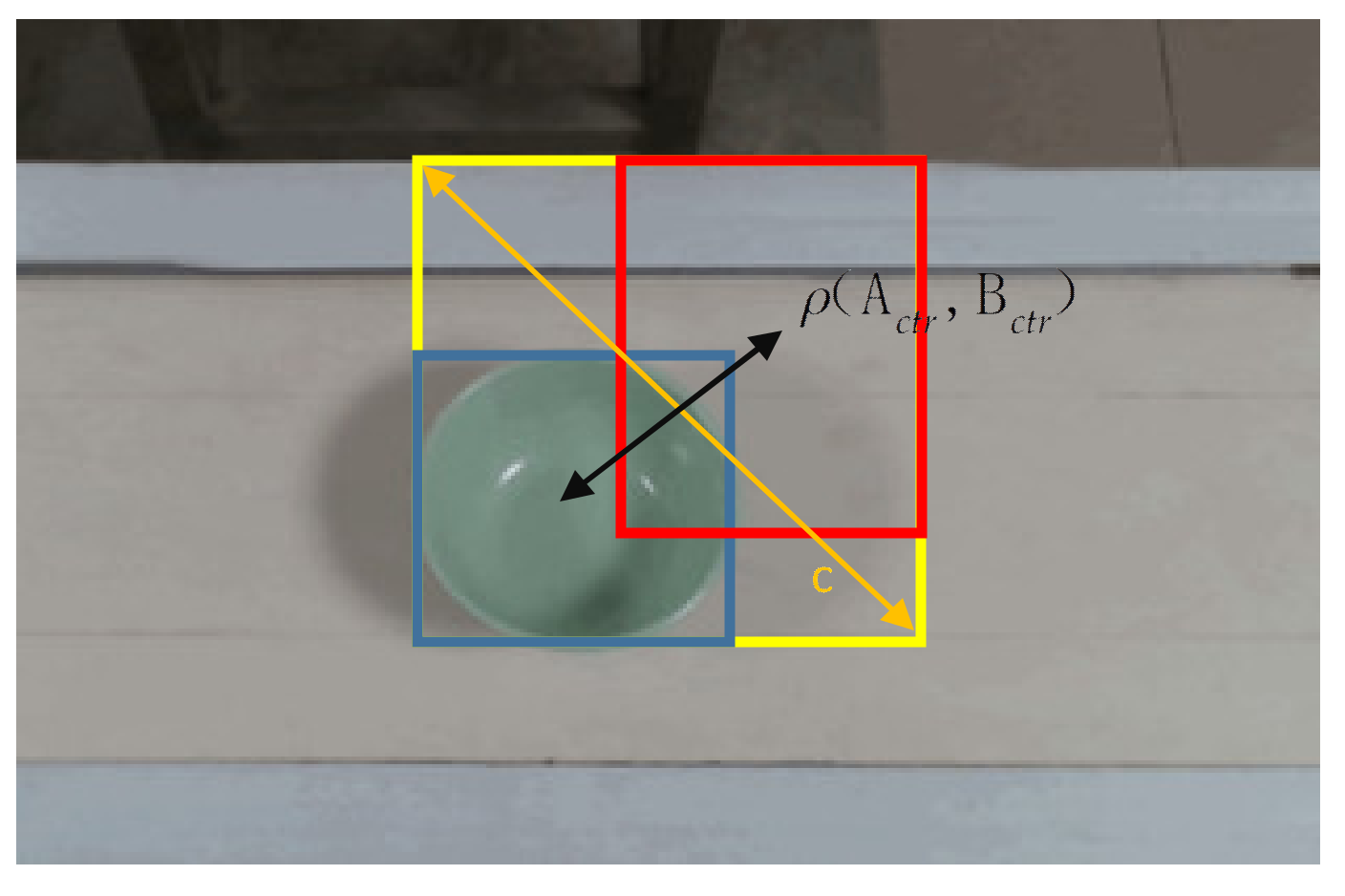
3.2. The Loss of YOLOv4
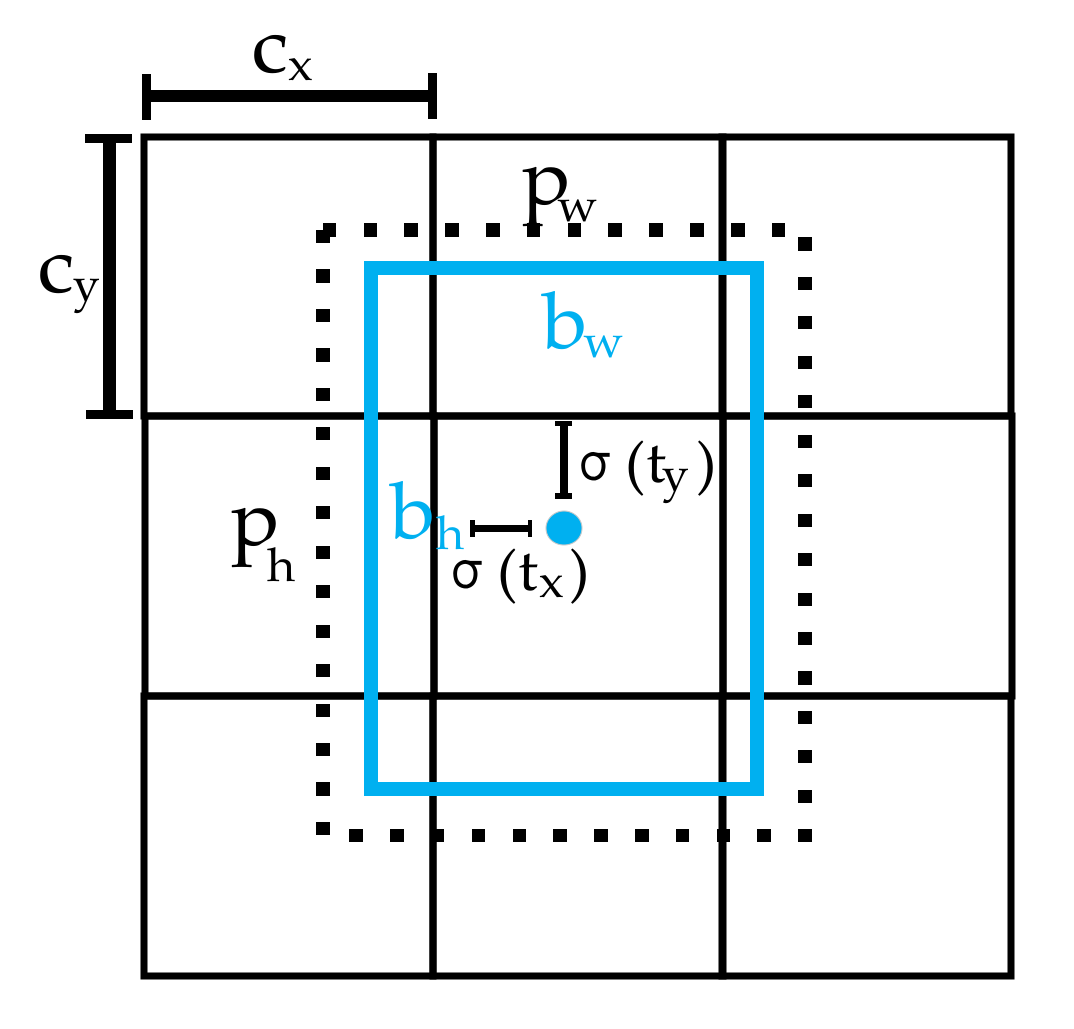
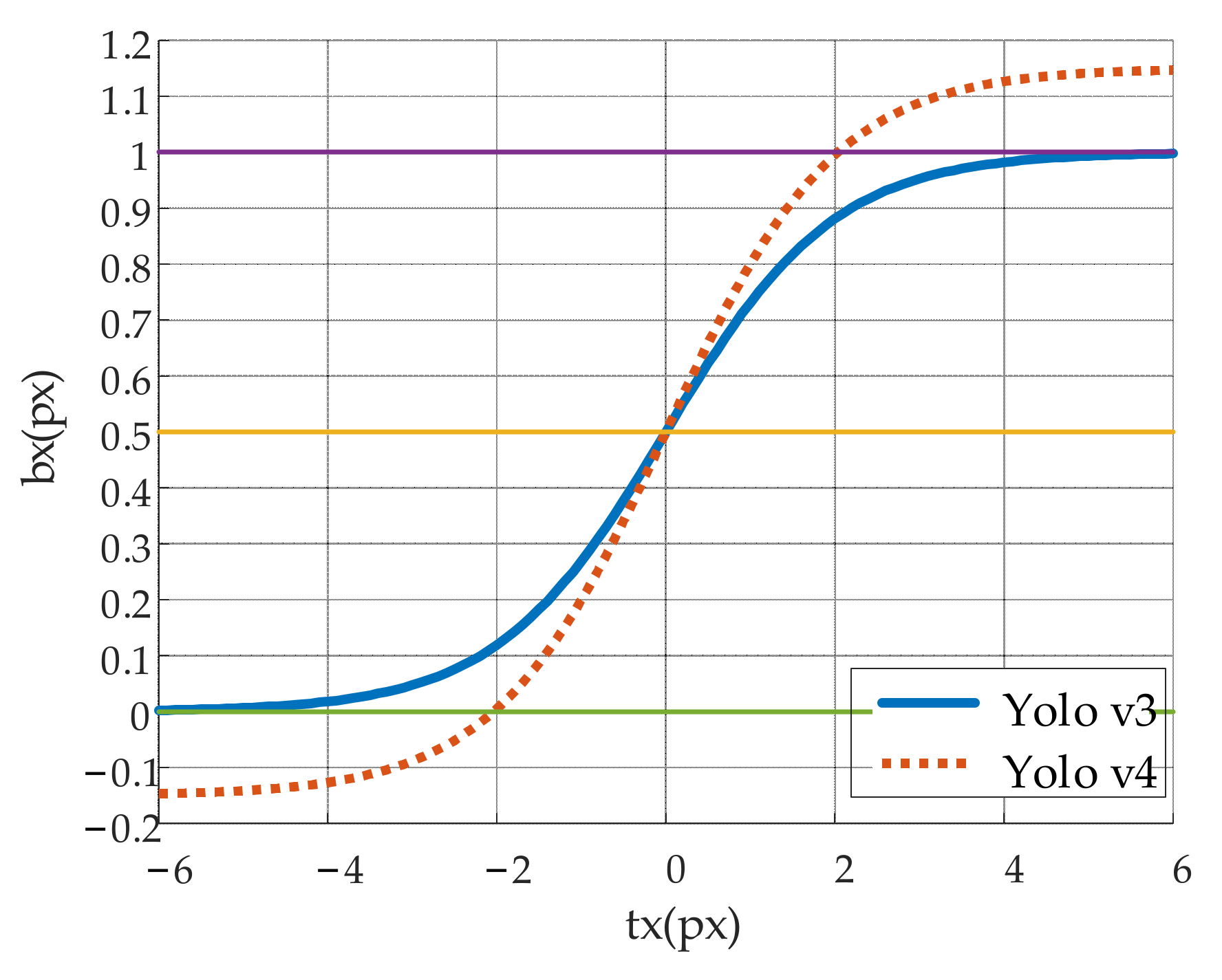
3.3. Target Position Coordinate Calculation
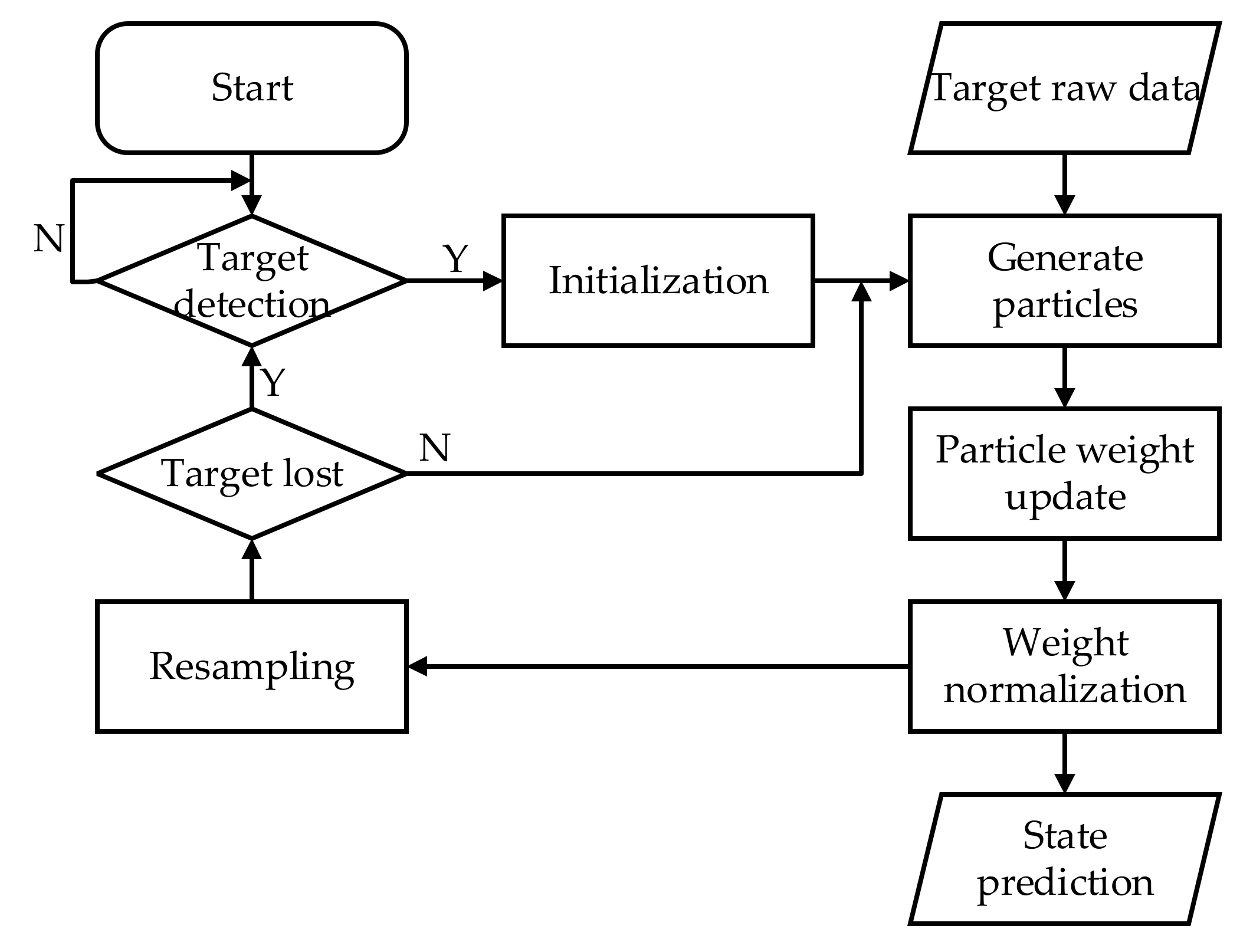
4. Target Tracking Algorithm
Target Tracking Based on Particle Filter Algorithm
- (1)
- Initialization: with the prior condition probability p(x0) of the system state, the posterior probability distribution used to represent the target state at time k represents the sample set of corresponding weights , where the state set from 0 to k is represented by .where in Equation (18) is using the expected sampling selection, and Ns is the number of particles sampled to the current moment.
- (2)
- State update: If the bounding box of object detection appears in successive frames of the system, it means that the object is not subject to false detection. It is necessary to extract the target object according to the detection bounding box and use the importance density function to calculate it. The target state particle set , particle weight , assuming the importance density function, is . From the following Equation (19), a new particle set can be obtained through the particle set and .The posterior probability density function is expressed by the following Equation (20).
- (3)
- Particle weight update: When the system predicts and generates the particle set at the next moment according to the transition matrix F, the particle weight is updated according to the following Equation (21).If , then the importance density function only depends on and . It also means that in the calculation process, only the particles need to be stored without considering the particle set and the previous observations . The laboratory environment can be regarded as approximate white noise, so . The importance weight value can be expressed as , using the Bhattacharyya distance to calculate the similarity between the reference target template and the candidate template. Based on the similarity measurement, the particle weight update basis is shown as Equation (22):R represents the variance of Gaussian distribution. i represents the ith particle, and represents the Bhattacharyya distance of the ith particle.
- (4)
- Weight normalization: perform the normalization operation of the following equation on the updated particle weights in the model.
- (5)
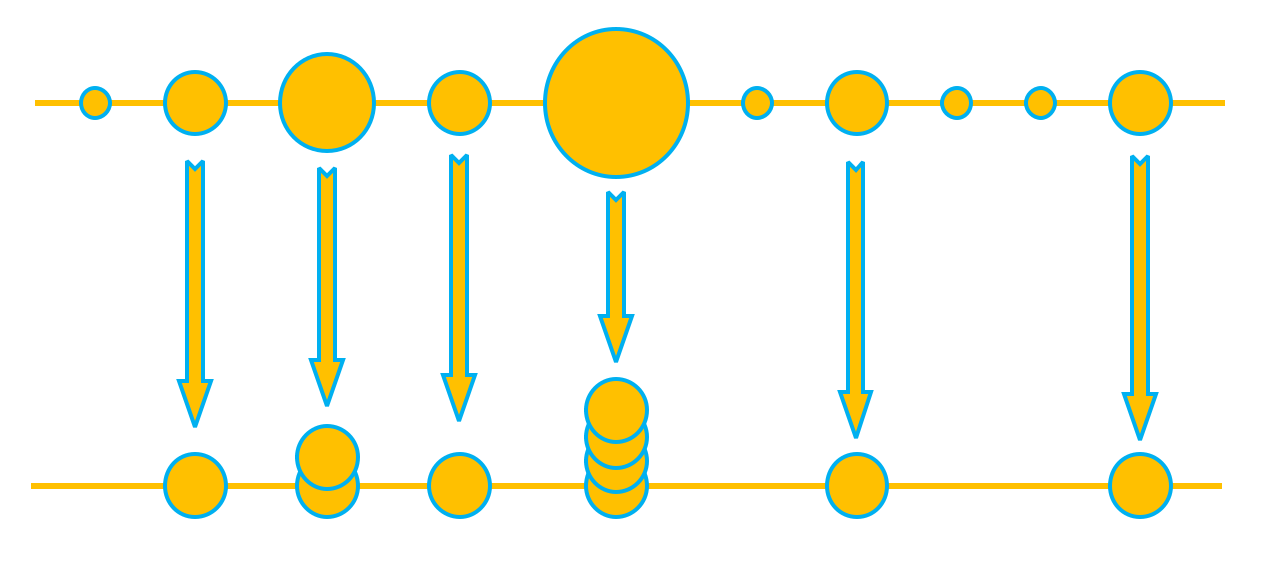
- Resampling: since the particles degenerate after multiple iterations, resampling is needed to solve this problem. Particles should be selected based on . Thus, we could obtain the cumulative distribution function (CDF) as shown in Equation (25).Then, using binary search algorithm with N particles uniformly distributed in 0–1 random variable to find particles with high weights. Before resampling, the particle sample set and the weight are in an orderly pair . After resampling, they are transformed as , as shown in Figure 6. The circle in the figure represents the particle and the area represents the weight. Before resampling, the corresponding weight of each particle is . After resampling, the total number of particles remains unchanged. The important particles with heavier weight have multiple particles scattered, while the particles with particularly small weights are discarded. In this way, after resampling, each particle has the same weight, which is 1/N.
- (6)
- State output: use the weighting criterion as Equation (26) to determine the final position of the target:
- (7)
- Prediction: In order to use the PF to predict the position of the target object after a certain time Δt of movement, the state information of the target position at the current moment obtained by the RGB-D sensor is output through the PF and then multiplied by the transition matrix F. After repeating Δt/dt times, multiply the observation matrix H to the left to get the next position as Equation (28).
| Algorithm 1. Target object tracking and predicting algorithm based on PF |
|
5. Experiments and Results
5.1. Experimental Environment and Data Set
5.2. Comparison of Object Detection Algorithms
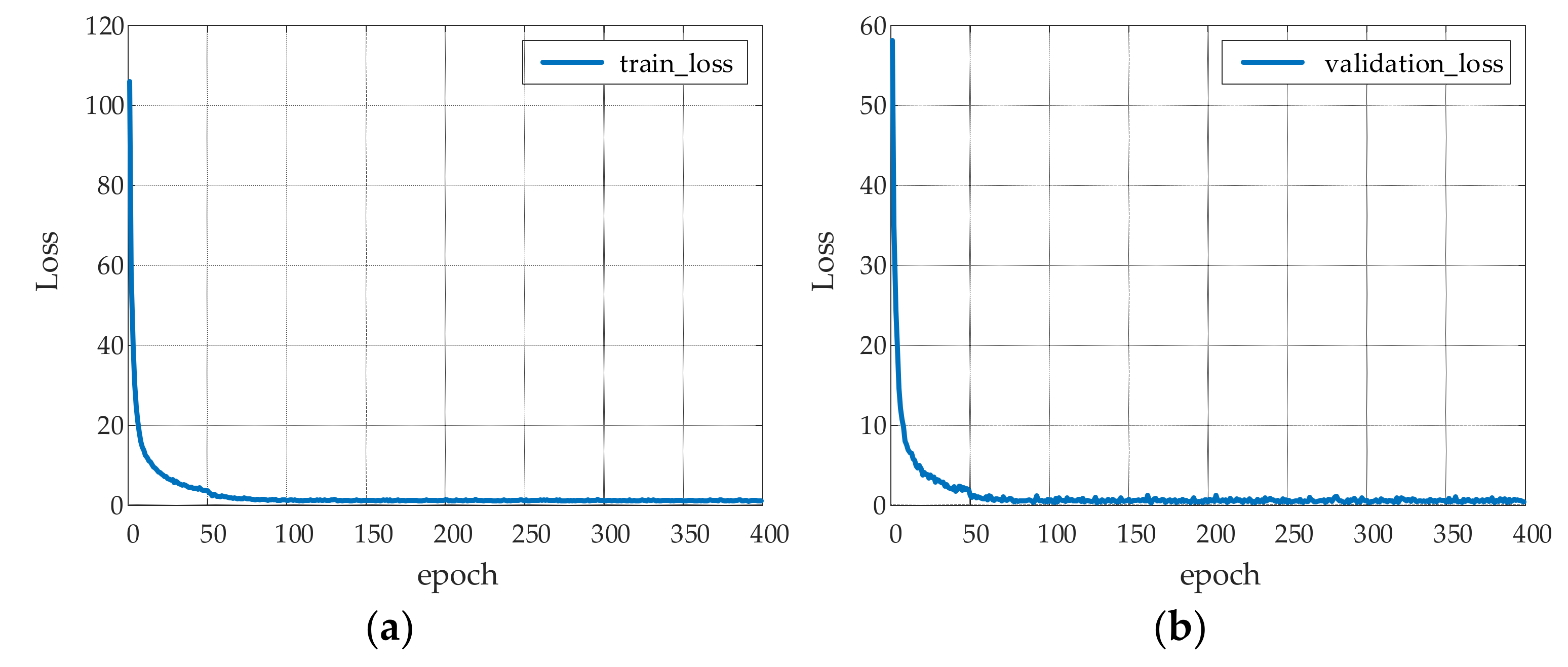
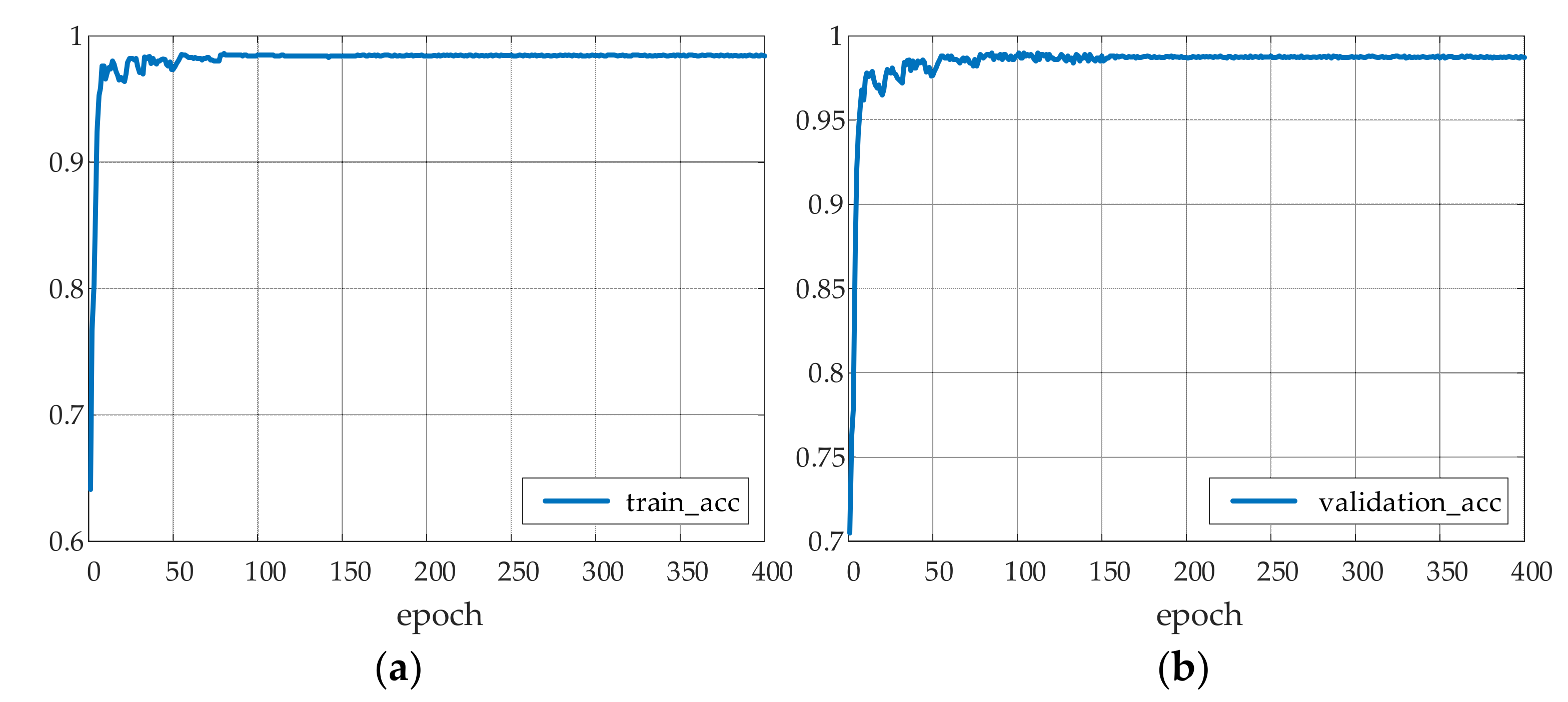
5.3. YOLOv4 Network Training Process and Result Analysis
- 76 × 76: (1703, 1989) (2033, 1336) (2165, 2251)
- 38 × 38: (927, 1381) (1309, 1831) (1459, 873)
- 19 × 19: (315, 380) (453, 508) (638,674)
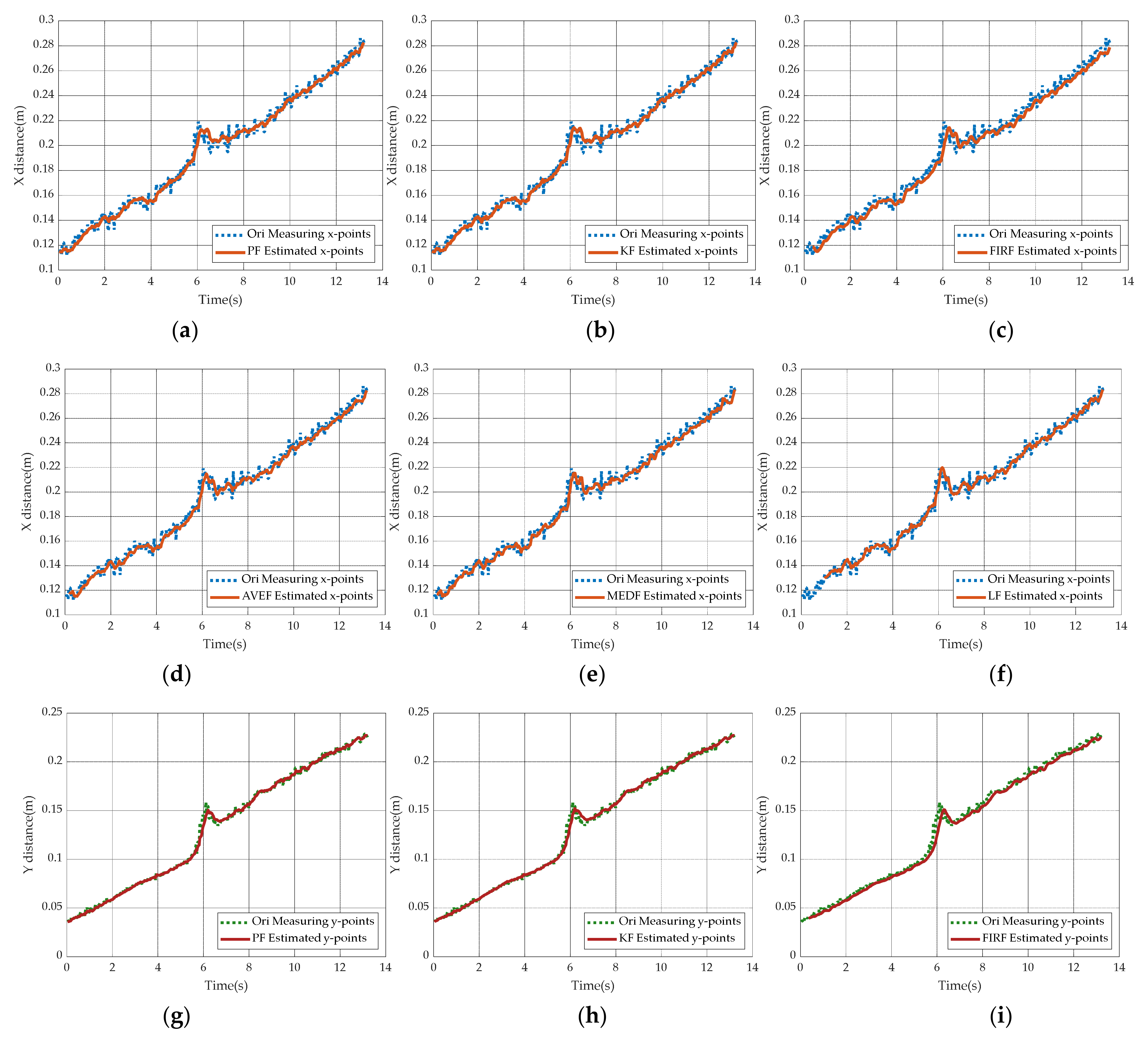
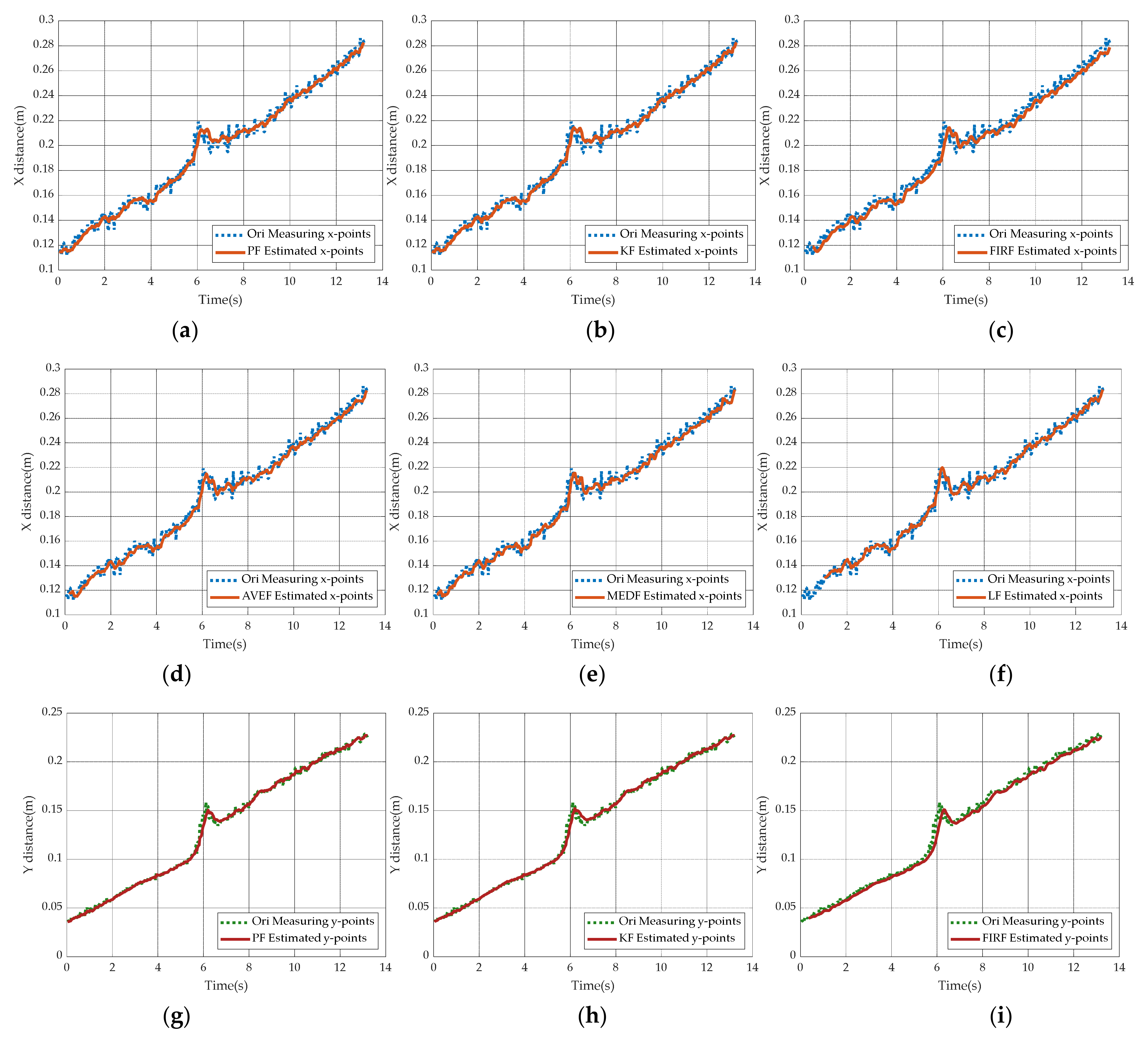
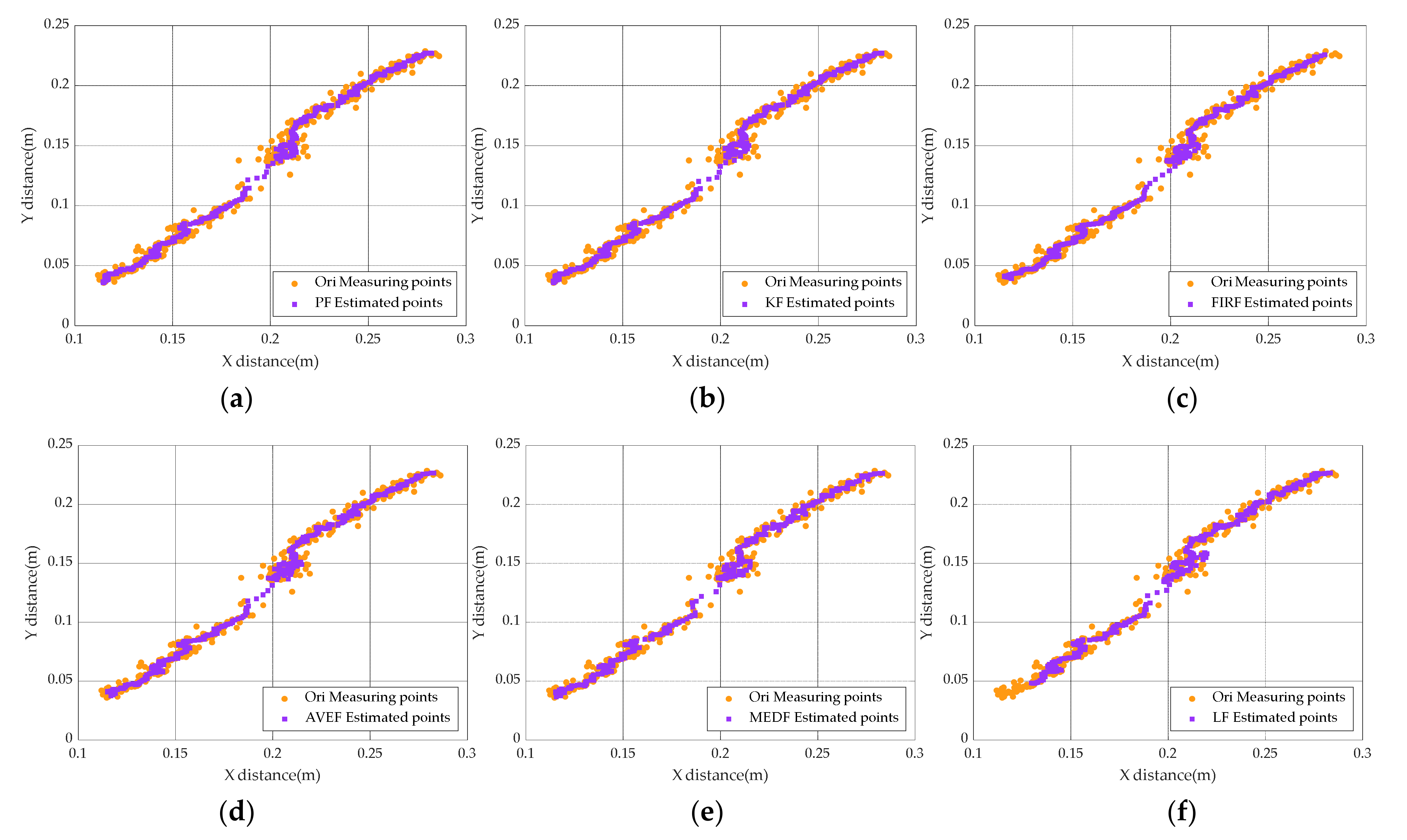
5.4. Simulation Comparison under Different Filter-Based Target Tracking Methods
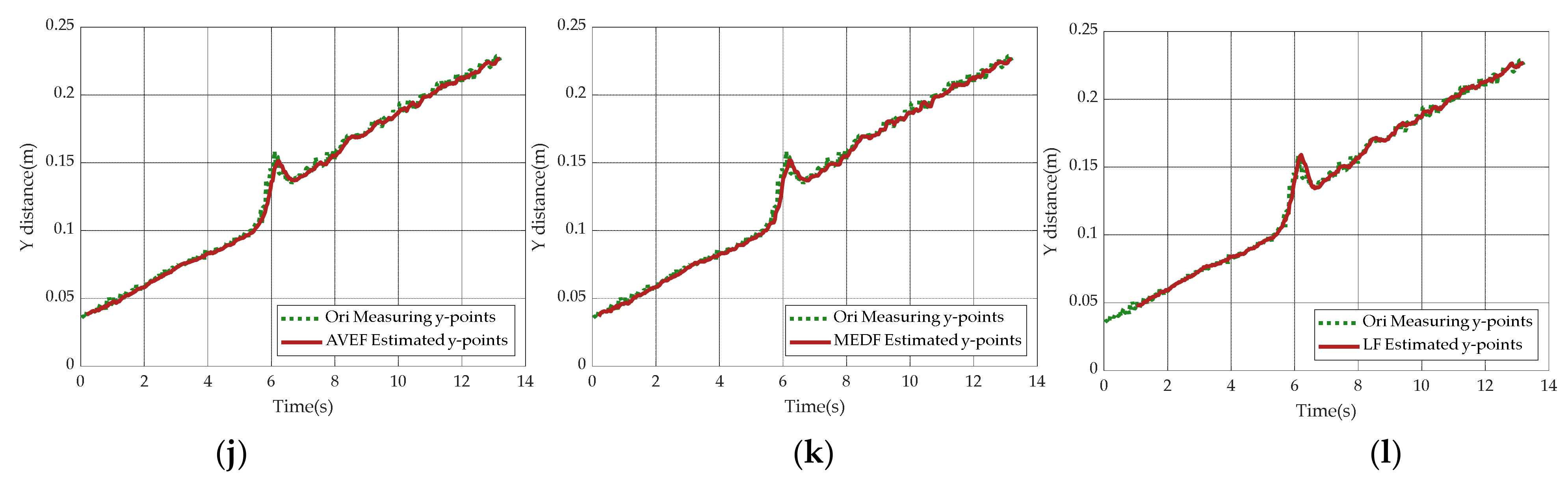
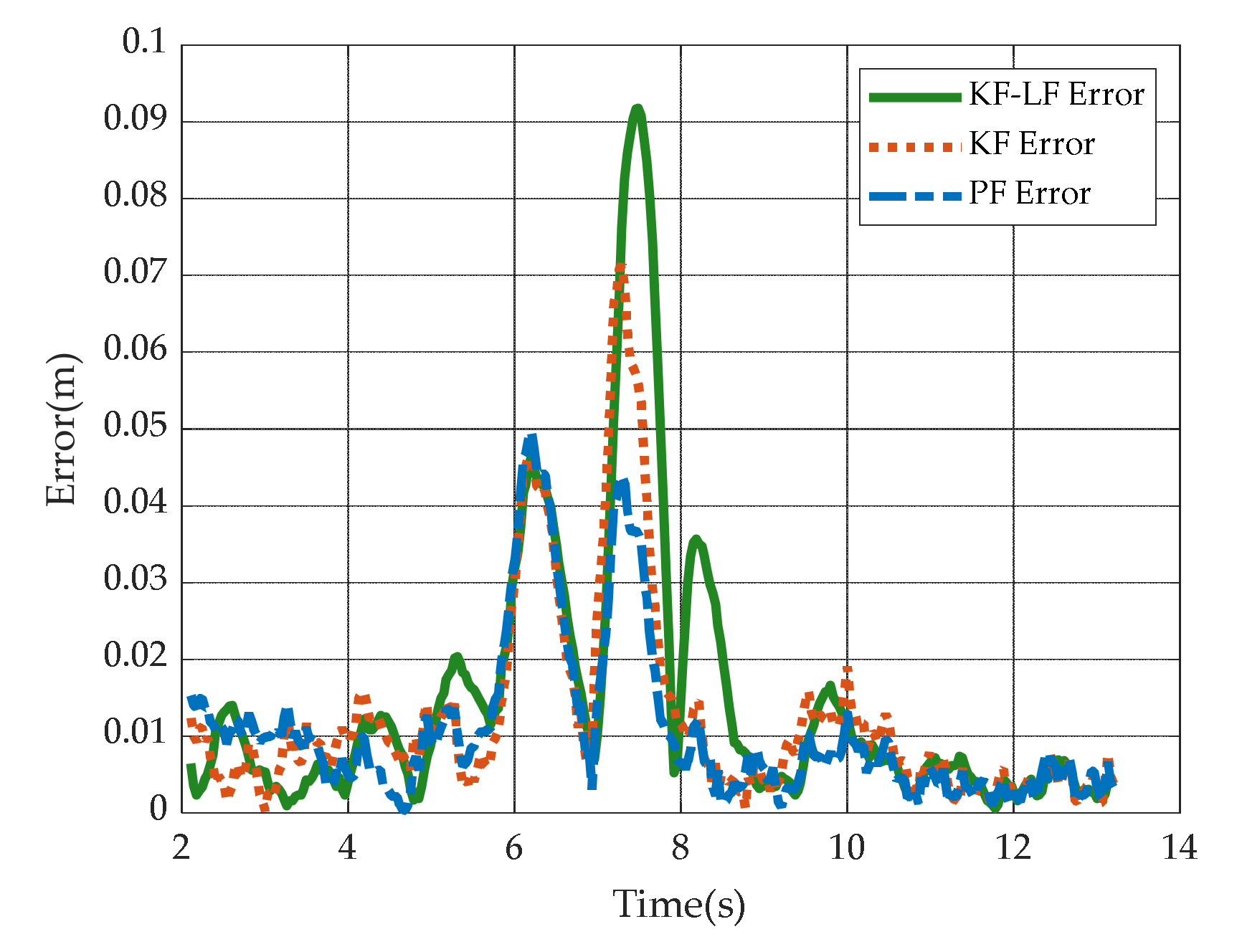
5.5. Simulation Comparison under Different Filter-Based Target Predicting Methods
5.6. Particle Filter in Robotic Arm
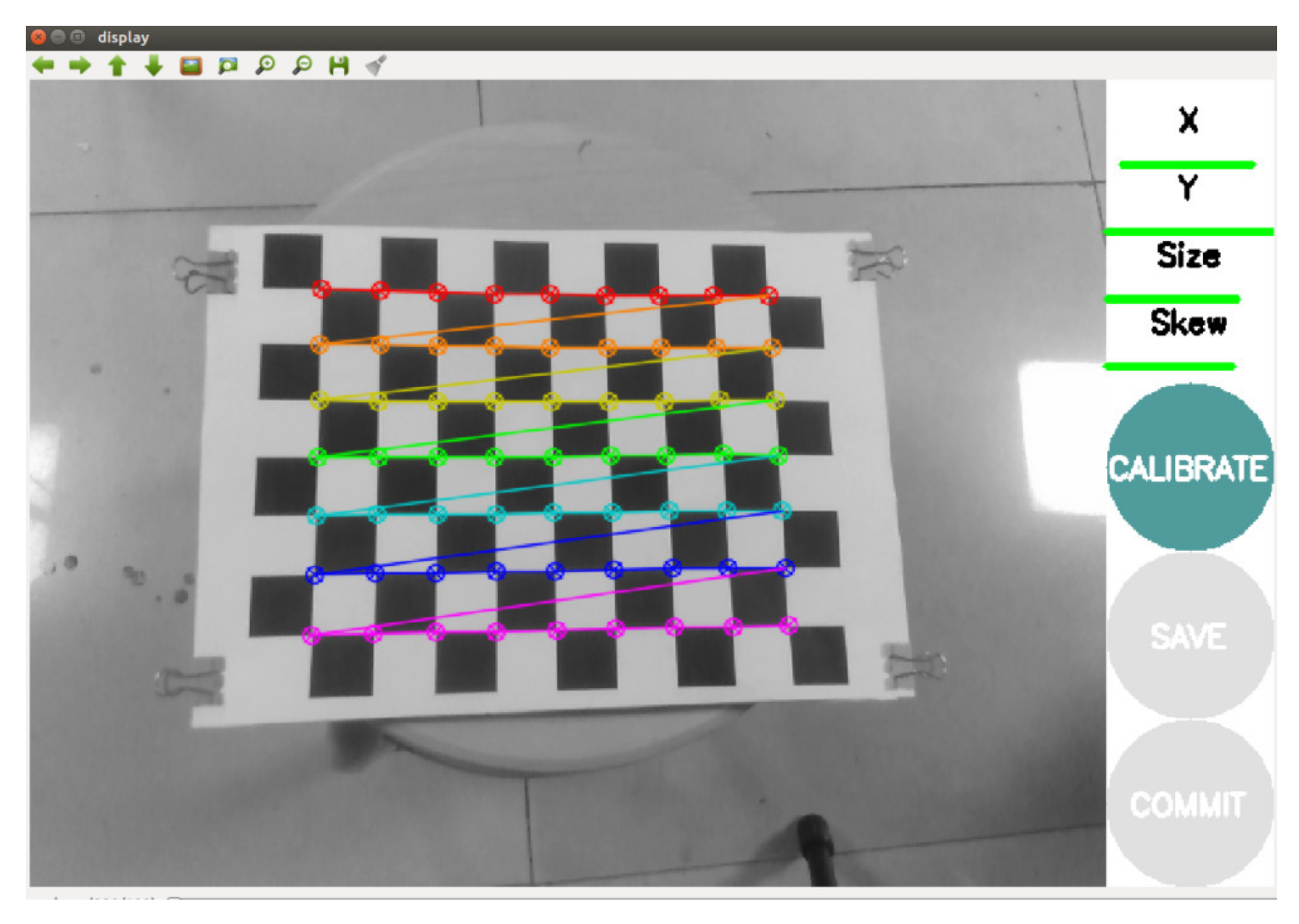
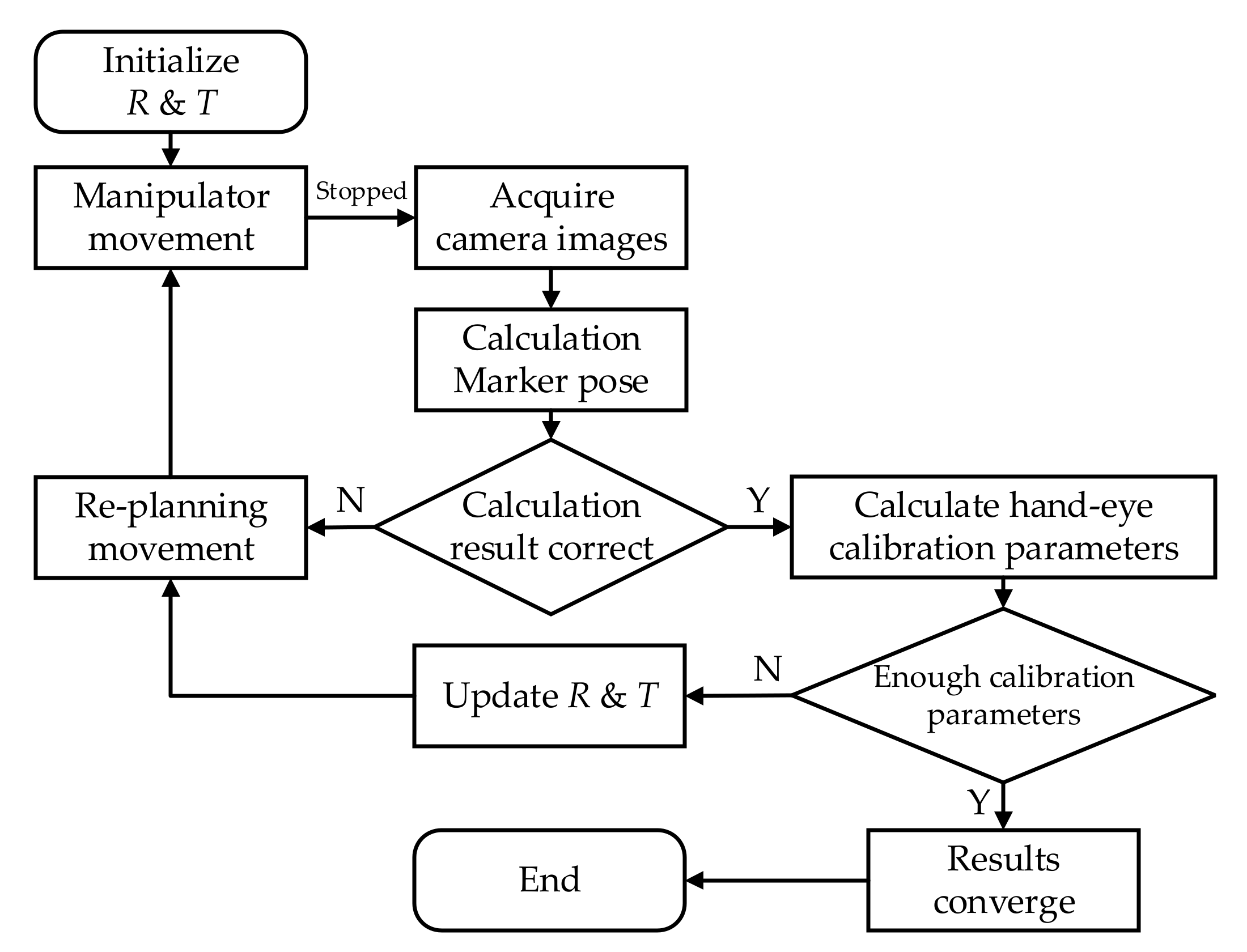
5.7. Eye-to-Hand Calibration System
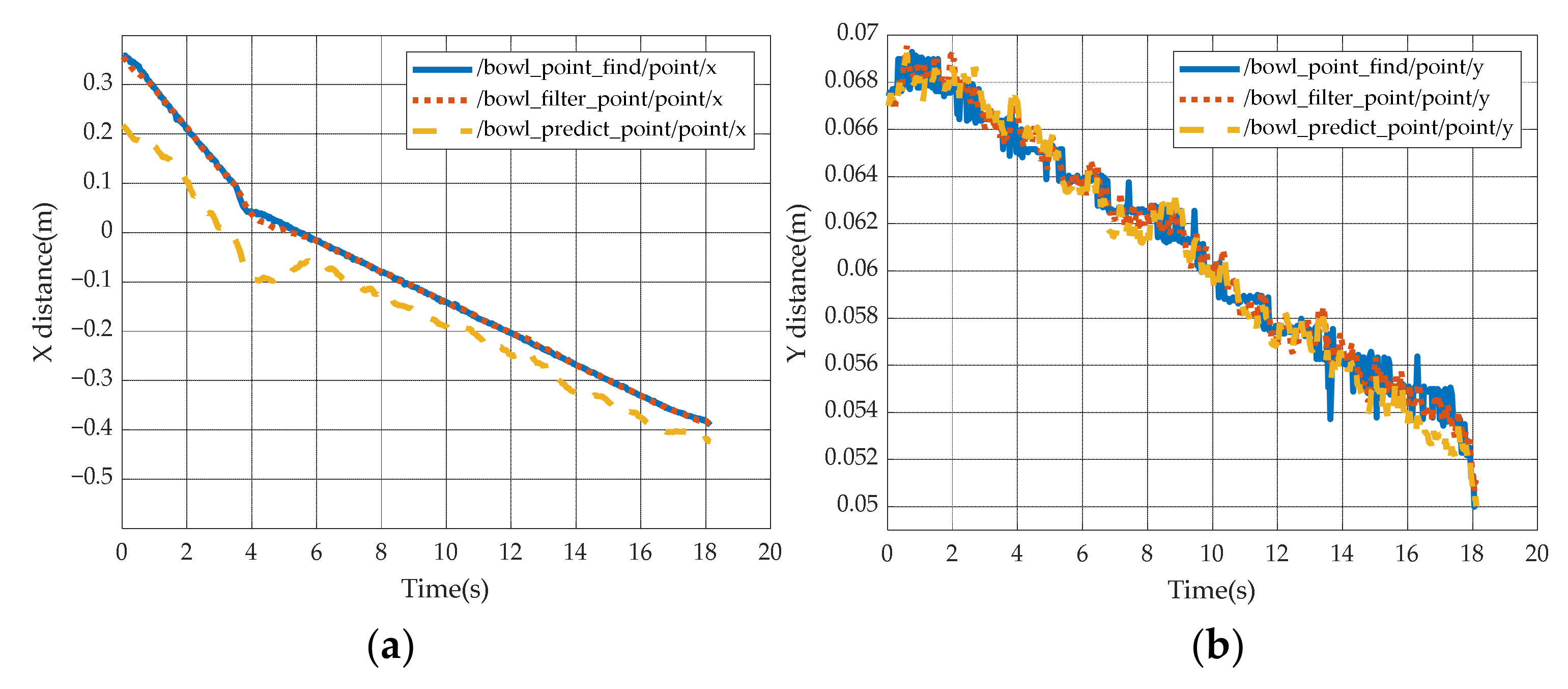
5.8. Experiment of Robotic Arm Tracking, Predicting and Grabbing
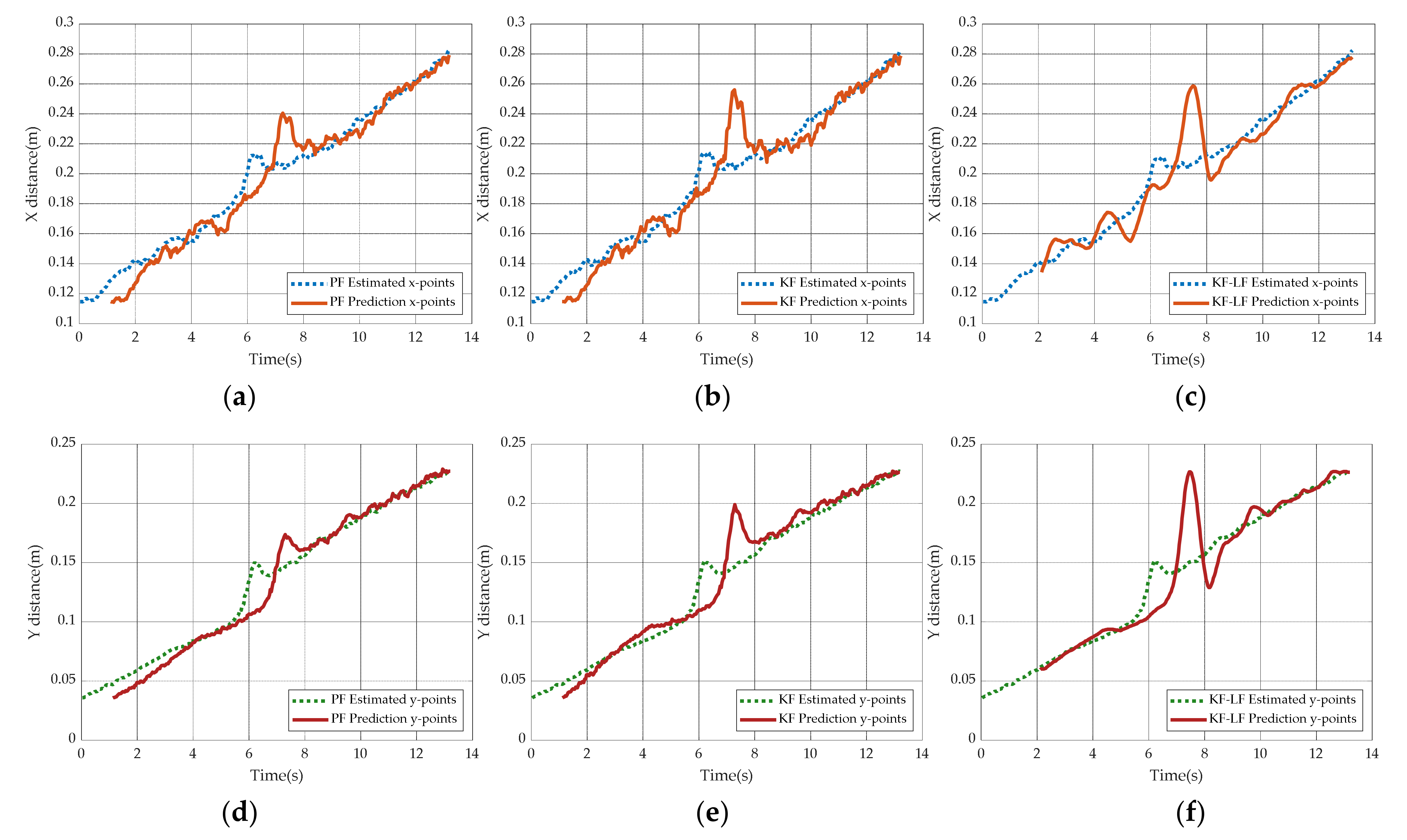
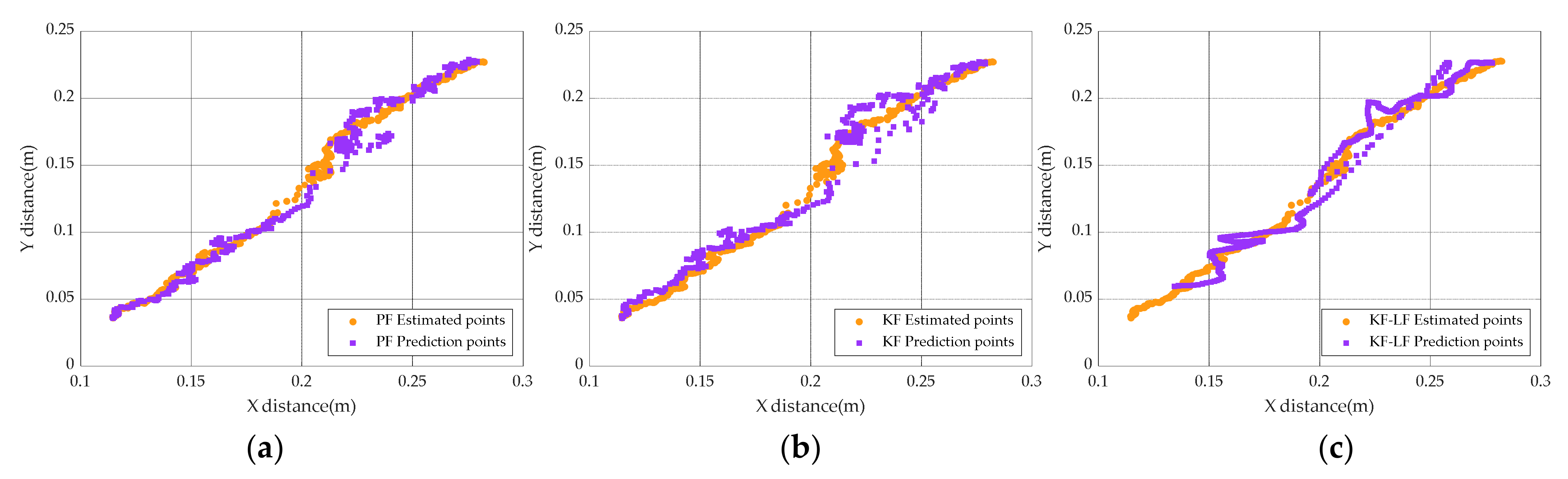
- Firstly, get the predicted points captured by the robotic arm according to the PF as shown in Figure 20.
- Secondly, plan the path of the robotic arm to the predicted point through MoveIt!.
- Thirdly, the UR3 controller powers on the gripper. Powering on in advance will reduce the waiting time of the gripper at the grab point so that the grab action can be completed more efficiently.
- Finally, the UR3 controller controls the robotic arm to reach the designed grab point according to the planned path. After completing the grab, it will then leave. And the experimental results are shown in Figure 21.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Strandhagen, J.W.; Alfnes, E.; Strandhagen, J.O.; Vallandingham, L.R. The fit of Industry 4.0 applications in manufacturing logistics: A multiple case study. Adv. Manuf. 2017, 5, 344–358. [Google Scholar] [CrossRef] [Green Version]
- Su, S.; Xu, Z.; Yang, Y. Research on Robot Vision Servo Based on image big data. J. Phys. Conf. Ser. 2020, 1650, 032132. [Google Scholar] [CrossRef]
- Lu, C. Kalman tracking algorithm of ping-pong robot based on fuzzy real-time image. J. Intell. Fuzzy Syst. 2020, 38, 1–10. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, W. Vision-based robot sorting system. In IOP Conference Series: Materials Science and Engineering, Proceedings of the International Conference on Manufacturing Technology, Materials and Chemical Engineering, Wuhan, China, 14–16 June 2019; IOP Publishing: Bristol, UK, 2019; Volume 592, p. 012154. [Google Scholar]
- Ren, Y.; Sun, H.; Tang, Y.; Wang, S. Vision Based Object Grasping of Robotic Manipulator. In Proceedings of the 2018 24th International Conference on Automation and Computing, Newcastle upon Tyne, UK, 6–7 September 2018; pp. 1–5. [Google Scholar]
- Marturi, N.; Kopicki, M.; Rastegarpanah, A.; Rajasekaran, V.; Adjigble, M.; Stolkin, R.; Leonardis, A.; Bekiroglu, Y. Dynamic grasp and trajectory planning for moving objects. Auton. Robot. 2019, 43, 1241–1256. [Google Scholar] [CrossRef]
- Zhou, H.; Chou, W.; Tuo, W.; Rong, Y.; Xu, S. Mobile Manipulation Integrating Enhanced AMCL High-Precision Location and Dynamic Tracking Grasp. Sensors 2020, 20, 6697. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhao, Y.; Li, H. Positioning and Grabbing Technology of Industrial Robot Based on Vision. Acad. J. Manuf. Eng. 2019, 17, 137–145. [Google Scholar]
- Wei, H.; Peng, D.; Zhu, X.; Wu, D. A target tracking algorithm for vision based sea cucumber grabbing. In Proceedings of the 2016 IEEE International Conference on Information and Automation, Ningbo, China, 1–3 August 2016; pp. 608–611. [Google Scholar]
- Kang, H.; Zhou, H.; Wang, X.; Chen, C. Real-time fruit recognition and grasping estimation for robotic apple harvesting. Sensors 2020, 20, 5670. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 December 2020).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Rajendran, S.P.; Shine, L.; Pradeep, R.; Vijayaraghavan, S. Real-time traffic sign recognition using YOLOv3 based detector. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies, Kanpur, India, 6–8 July 2019; pp. 1–7. [Google Scholar]
- Peng, J.; Liu, W.; You, T.; Wu, B. Improved YOLO-V3 Workpiece Detection Method for Sorting. In Proceedings of the 2020 5th International Conference on Robotics and Automation Engineering, Guangzhou, China, 19–22 November 2020; pp. 70–75. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. Available online: https://arxiv.org/abs/2004.10934 (accessed on 8 December 2020).
- Hong, Z.; Xu, L.; Chen, J. Artificial evolution based cost-reference particle filter for nonlinear state and parameter estimation in process systems with unknown noise statistics and model parameters. J. Taiwan Inst. Chem. Eng. 2020, 112, 377–387. [Google Scholar] [CrossRef]
- Patel, H.A.; Thakore, D.G. Moving object tracking using kalman filter. Int. J. Comput. Sci. Mob. Comput. 2013, 2, 326–332. [Google Scholar]
- Weng, S.K.; Kuo, C.M.; Tu, S.K. Video object tracking using adaptive Kalman filter. J. Vis. Commun. Image Represent. 2006, 17, 1190–1208. [Google Scholar] [CrossRef]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Schonfeld, D.; Mohamed, M. Robust video stabilization based on particle filter tracking of projected camera motion. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 945–954. [Google Scholar] [CrossRef]
- Bastani, V.; Marcenaro, L.; Regazzoni, C. A particle filter based sequential trajectory classifier for behavior analysis in video surveillance. In Proceedings of the 2015 IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 3690–3694. [Google Scholar]
- Jiang, Z.; Zhao, L.; Li, S.; Jia, Y. Real-time object detection method based on improved YOLOv4-tiny. arXiv 2020, arXiv:2011.04244. Available online: https://arxiv.org/abs/2011.04244 (accessed on 8 December 2020).
- Ju, M.; Luo, H.; Wang, Z.; Hui, B.; Chang, Z. The application of improved YOLO V3 in multi-scale target detection. Appl. Sci. 2019, 9, 3775. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Zheng, H.; Wang, Y.; Cao, Y.; Guo, S. Study on the Evaluation Method of Sound Phase Cloud Maps Based on an Improved YOLOv4 Algorithm. Sensors 2020, 20, 4314. [Google Scholar] [CrossRef]
- Huang, Y.Q.; Zheng, J.C.; Sun, S.D.; Yang, C.F.; Liu, J. Optimized YOLOv3 Algorithm and Its Application in Traffic Flow Detections. Appl. Sci. 2020, 10, 3079. [Google Scholar] [CrossRef]
- Kim, W.; Cho, H.; Kim, J.; Kim, B.; Lee, S. YOLO-Based Simultaneous Target Detection and Classification in Automotive FMCW Radar Systems. Sensors 2020, 20, 2897. [Google Scholar] [CrossRef]
- Chang, C.; Ansari, R. Kernel particle filter for visual tracking. IEEE Signal Process. Lett. 2005, 12, 242–245. [Google Scholar] [CrossRef]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. Ieee Trans. Pattern Anal. Mach. Intell. 2013, 36, 1442–1468. [Google Scholar]
- Gong, Z.; Qiu, C.; Tao, B.; Bai, H.; Yin, Z.; Ding, H. Tracking and grasping of moving target based on accelerated geometric particle filter on colored image. Sci. China Technol. Sci. 2020, 64, 755–766. [Google Scholar] [CrossRef]
- Bowl Test Set. Available online: https://github.com/Caiyu51/Bowl_test_set (accessed on 7 December 2020).
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4203–4212. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Berger, E.; Wheeler, R.; Ng, A. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 17 May 2009; Volume 3, p. 5. [Google Scholar]
- Chitta, S. MoveIt!: An introduction. In Robot Operating System (ROS); Springer: Cham, Switzerland, 2016; pp. 3–27. [Google Scholar]
- Marchand, É.; Spindler, F.; Chaumette, F. ViSP for visual servoing: A generic software platform with a wide class of robot control skills. IEEE Robot. Autom. Mag. 2005, 12, 40–52. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | APClose | APMedium | APFar | FPS |
|---|---|---|---|---|
| HSV | 90.4% | 91.1% | 89.5% | - |
| Faster R-CNN | 99.6% | 99.7% | 99.1% | 3 |
| RefineDet [34] | 95.1% | 96.6% | 95.3% | 24 |
| RetinaNet [35] | 95.5% | 95.9% | 94.8% | 14 |
| YOLOv3 | 96.1% | 97.3% | 95.6% | 19 |
| YOLOv4 | 99.3% | 99.5% | 96.7% | 22 |
| Filter | MSE | |
|---|---|---|
| Filter Error | Prediction Error | |
| PF | 7.1537 × 10−6 | 1.1356 × 10−4 |
| KF | 7.2296 × 10−6 | 1.8455 × 10−4 |
| FIRF | 4.9 × 10−3 | - |
| AVEF | 8.1293 × 10−6 | - |
| MEDF | 1.0993 × 10−5 | - |
| LF | 6.9699 × 10−6 | - |
| KF-LF | - | 3.3175 × 10−4 |
| Parameter | PF | KF | KF-LF |
|---|---|---|---|
| N | 32768 | - | - |
| q1 | 4 × 10−6 | 5 | 5 |
| q2 | 2 × 10−6 | 2 | 2 |
| q3 | 1 × 10−7 | 0.5 | 0.5 |
| R | 0.0001 | 100 | 100 |
| 30 | 30 | 30 |
| Internal parameters | fx (Normalized focal length on the x-axis): | 617.0269 |
| fy (Normalized focal length on the y-axis): | 616.1555 | |
| m0 (Image center horizontal coordinate): | 325.1717 | |
| n0(Image center vertical coordinate): | 225.4922 | |
| Distortion | 0.1601, −0.3411, −0.0057, −0.0013, 0 | |
| T | position x: | 0.4242 |
| position y: | 0.5054 | |
| position z: | 0.8581 | |
| R | orientation x: | 0.5391 |
| orientation y: | 0.2321 | |
| orientation z: | −0.7407 | |
| orientation w: | 0.3267 | |
| Aq | v = 2 cm/s | v = 6 cm/s | v = 10 cm/s | v = 14 cm/s |
|---|---|---|---|---|
| PF | 98.20% | 95.40% | 91.60% | 88.60% |
| KF | 92.40% | 90.60% | 86.60% | 84.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, M.; Cai, Q.; Zheng, B.; Shi, J.; Ni, Z.; Wang, J.; Lin, H. A Hybrid YOLOv4 and Particle Filter Based Robotic Arm Grabbing System in Nonlinear and Non-Gaussian Environment. Electronics 2021, 10, 1140. https://doi.org/10.3390/electronics10101140
Gao M, Cai Q, Zheng B, Shi J, Ni Z, Wang J, Lin H. A Hybrid YOLOv4 and Particle Filter Based Robotic Arm Grabbing System in Nonlinear and Non-Gaussian Environment. Electronics. 2021; 10(10):1140. https://doi.org/10.3390/electronics10101140
Chicago/Turabian StyleGao, Mingyu, Qinyu Cai, Bowen Zheng, Jie Shi, Zhihao Ni, Junfan Wang, and Huipin Lin. 2021. "A Hybrid YOLOv4 and Particle Filter Based Robotic Arm Grabbing System in Nonlinear and Non-Gaussian Environment" Electronics 10, no. 10: 1140. https://doi.org/10.3390/electronics10101140
APA StyleGao, M., Cai, Q., Zheng, B., Shi, J., Ni, Z., Wang, J., & Lin, H. (2021). A Hybrid YOLOv4 and Particle Filter Based Robotic Arm Grabbing System in Nonlinear and Non-Gaussian Environment. Electronics, 10(10), 1140. https://doi.org/10.3390/electronics10101140