Low-Cost Low-Power Acceleration of a Microwave Imaging Algorithm for Brain Stroke Monitoring

 ,
,  ,
,  ,
,  and
and
Abstract
1. Introduction
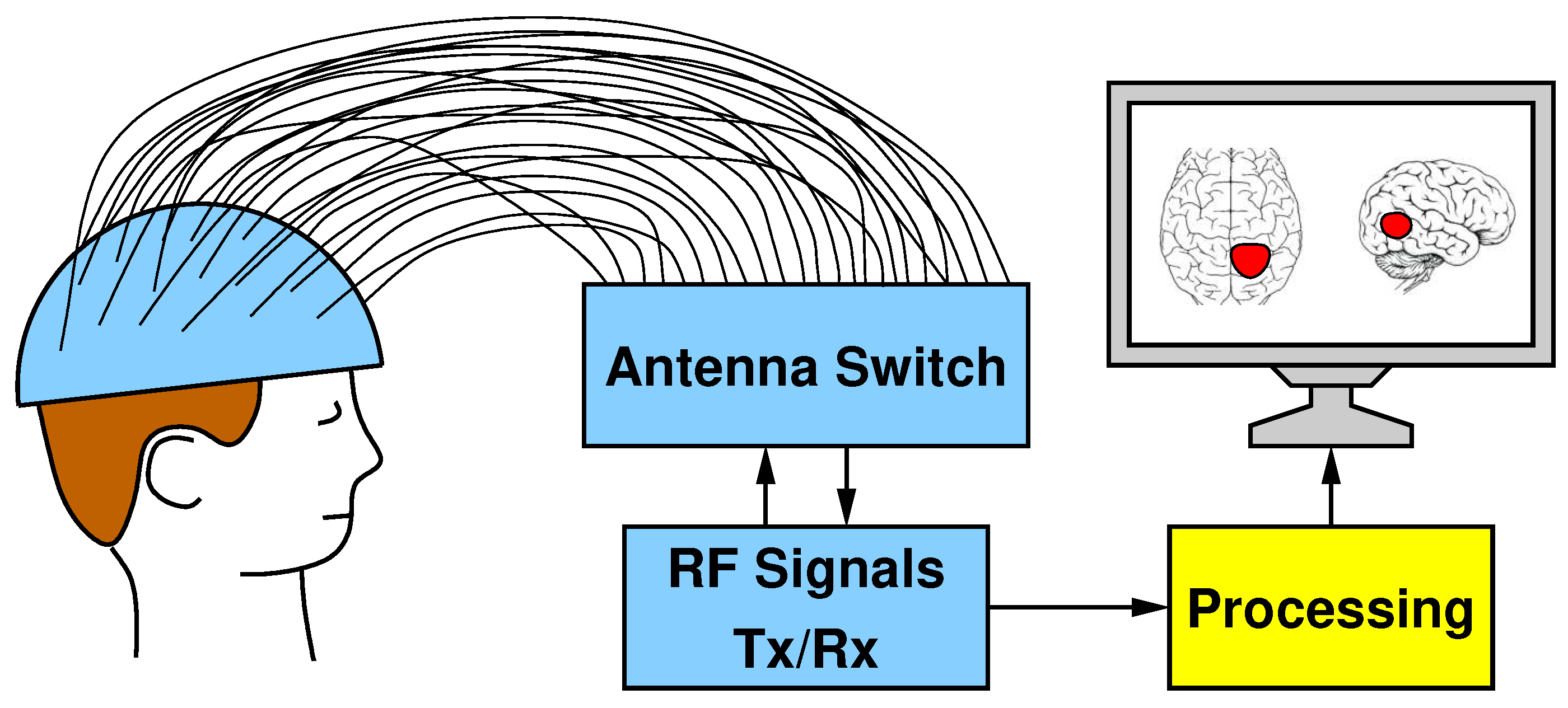
2. Stroke Monitoring Microwave Imaging System for Stroke Follow-Up Monitoring
2.1. MI Algorithm
| Algorithm 1 Pseudo-code of the original software implementation |
|
3. Hardware Implementation
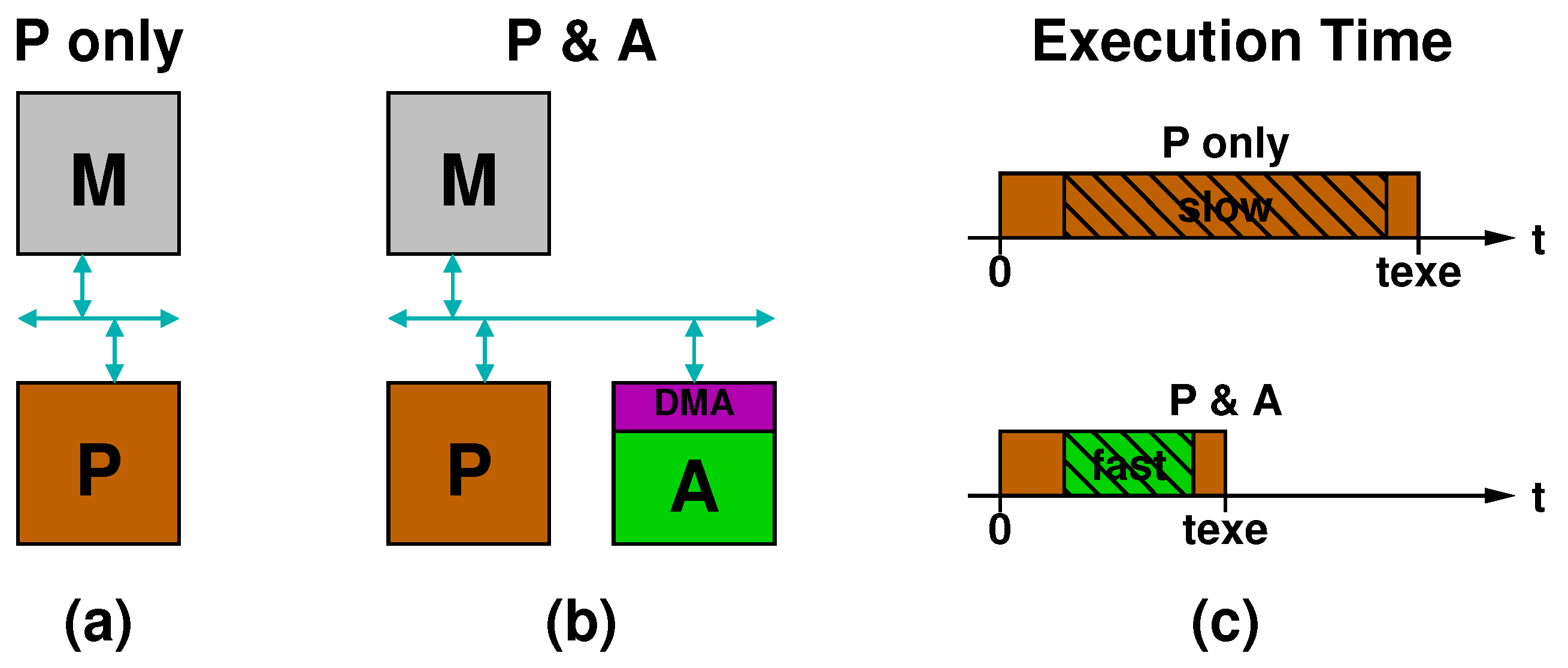
3.1. Speeding Computation Up With a Specialized Accelerator
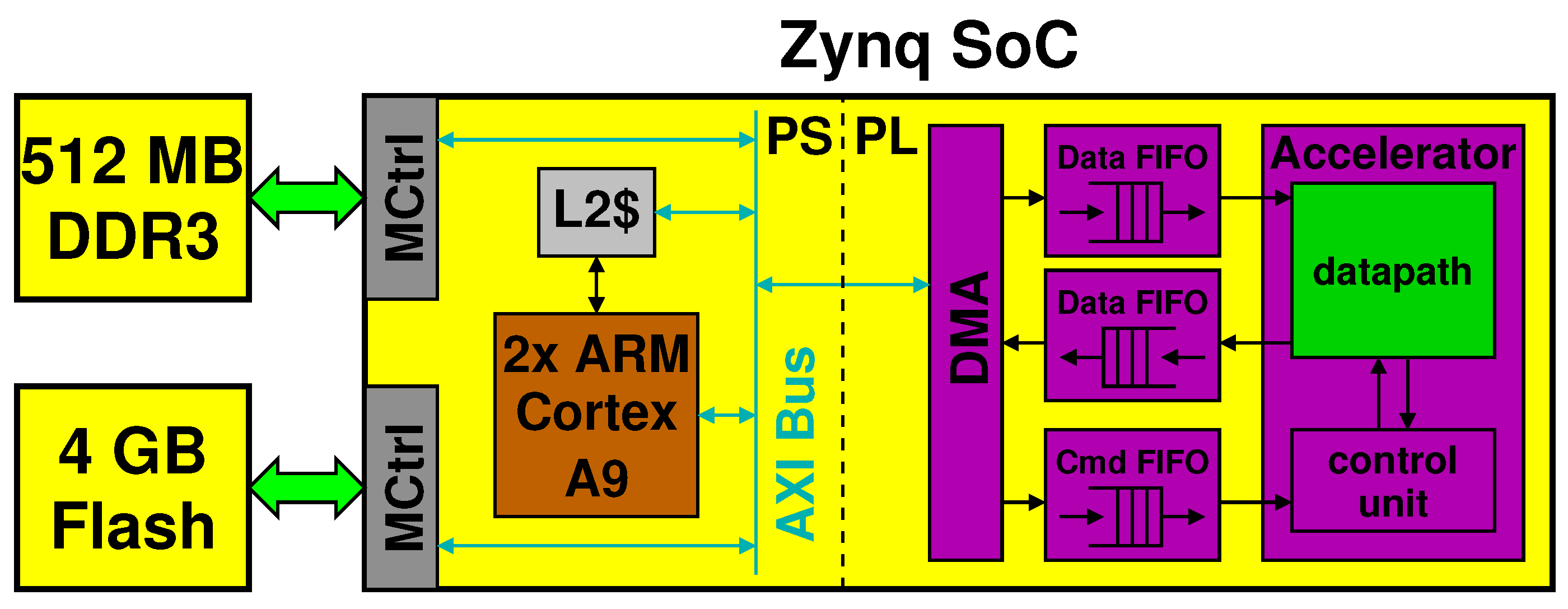
3.2. Hardware Platform
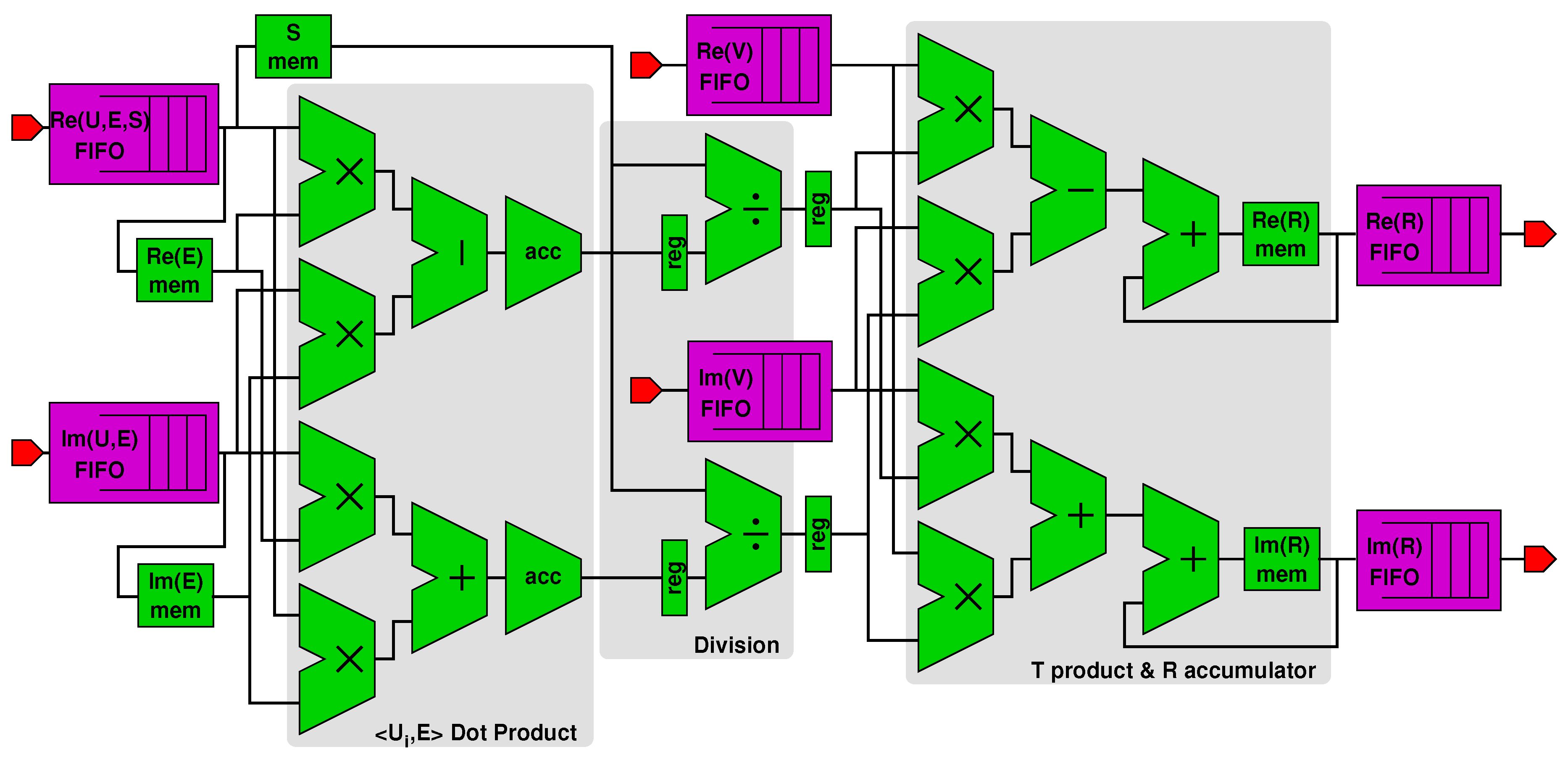
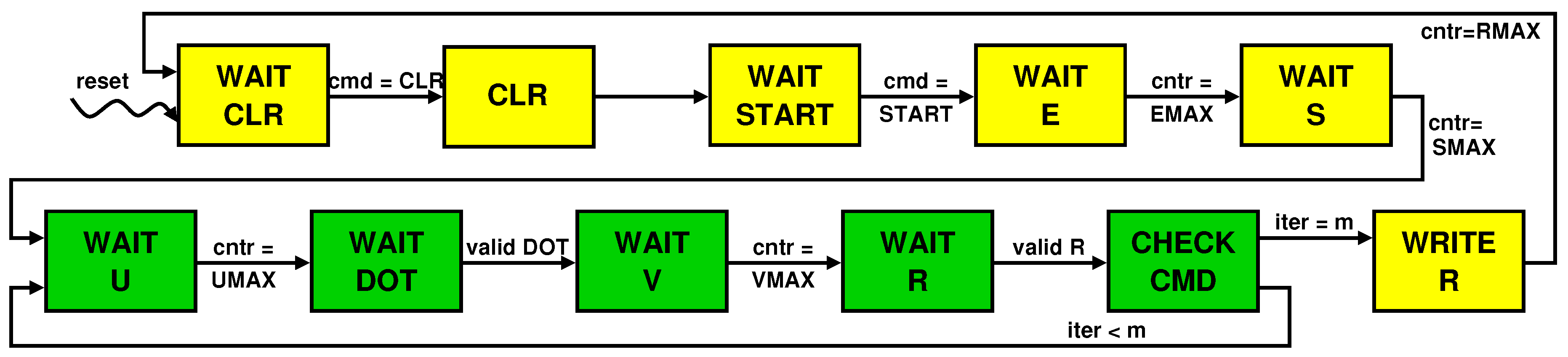
3.3. Accelerator Design
- A first subblock computes the dot product x between complex vectors and (fetched from an on-chip memory), resulting in variables and stored in proper registers (see Line 8 in Algorithm 1).
- A second divider subblock computes and starting from and and from the singular value (Line 9). The singular values are stored in and loaded from an on-chip memory within the PL part of the Zynq, as shown in figure.
- A third subblock accumulates values with the newly computed and (Lines 10–11). The values of are also stored in their own on-chip memory.
| Algorithm 2 Pseudo-code of the hardware-accelerated implementation |
|
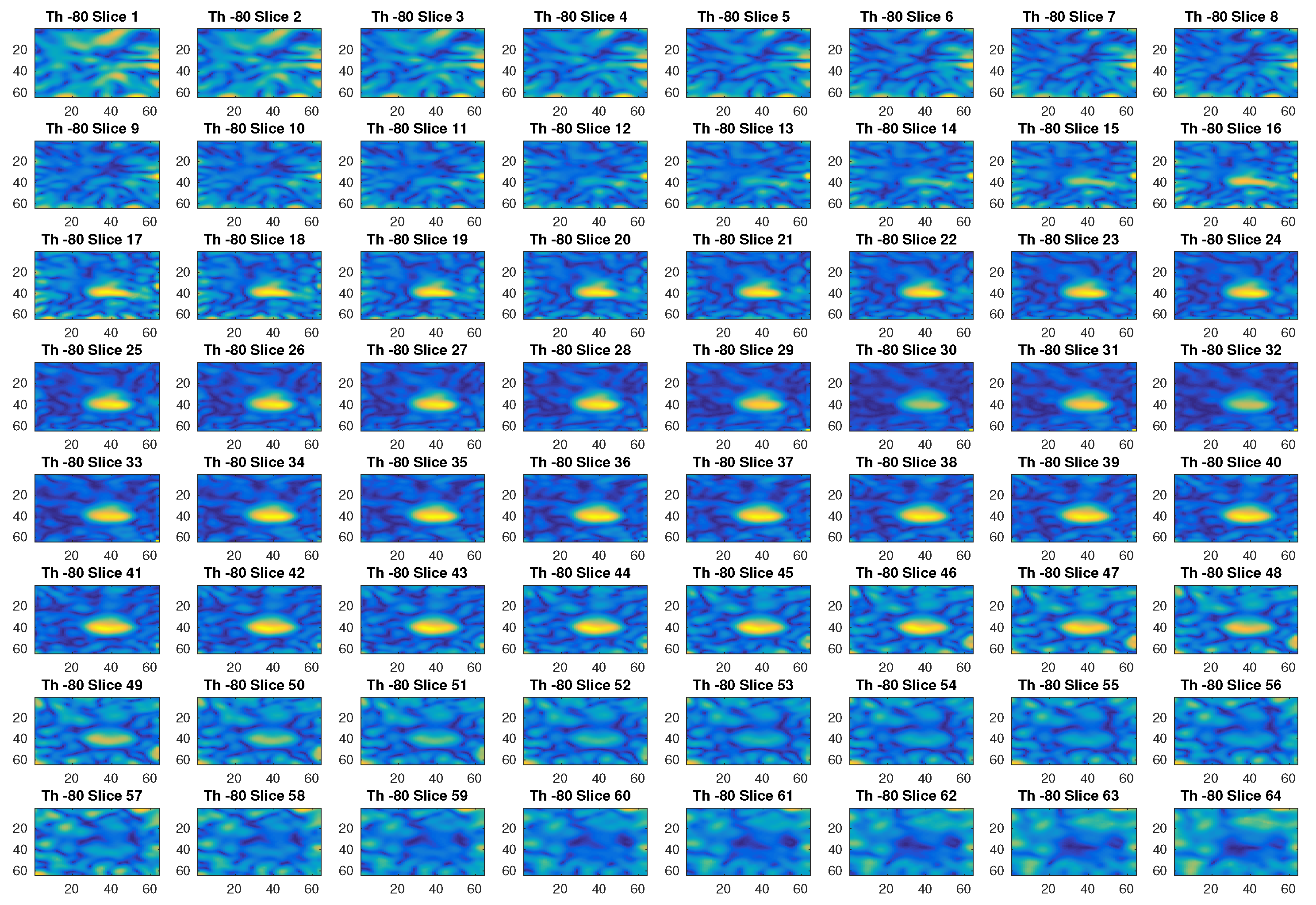
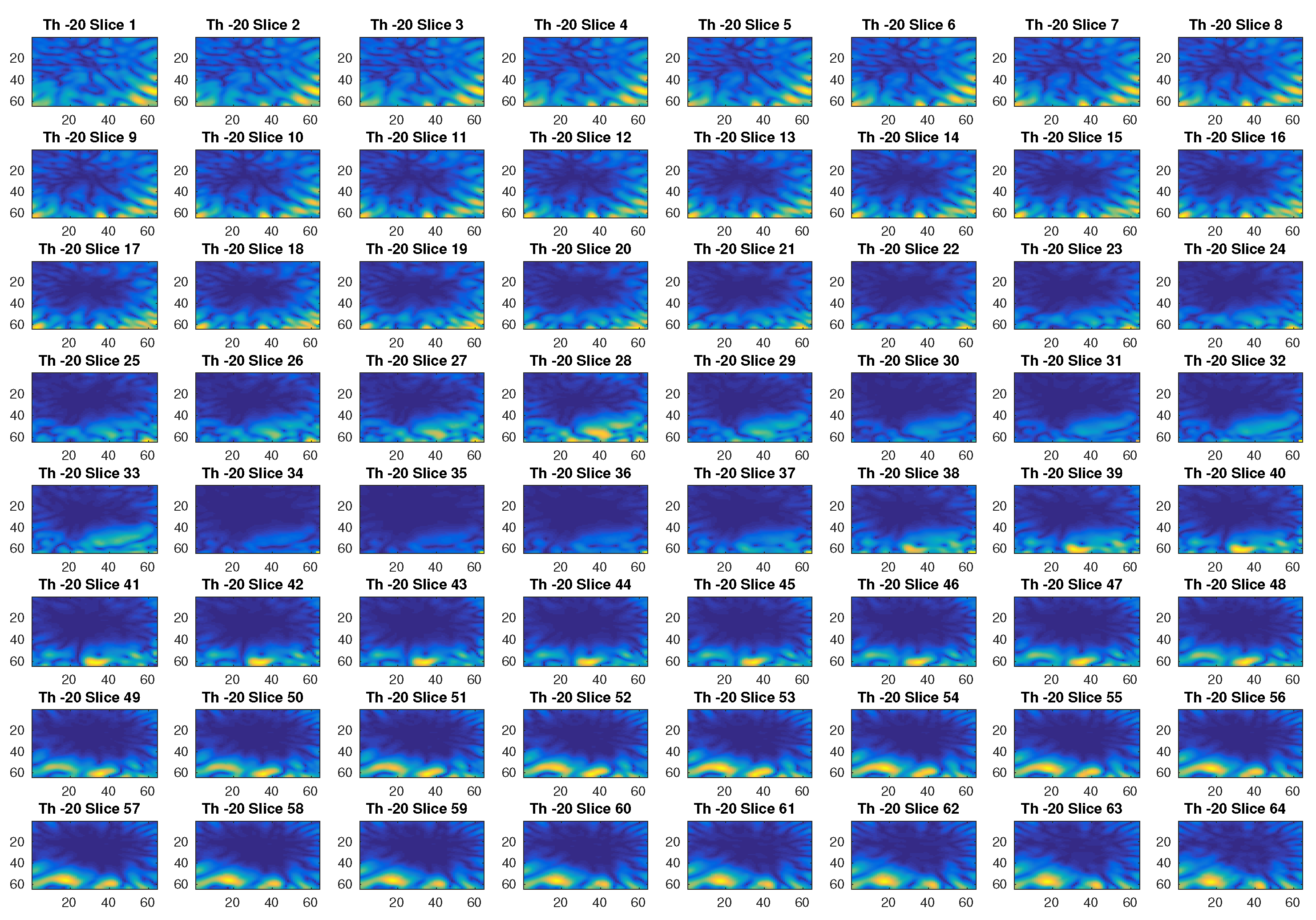
4. Results
5. Related Work
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| MI | Microwave Imaging |
| SVD | Singular Value Decomposition |
| TSVD | Truncated SVD |
| FPGA | Field Programmable Gate Array |
| PSoC | Programmable System-on-Chip |
| CPU | Central Processing Unit |
| DMA | Direct Memory Access |
| FP | Floating Point |
| PS | Processing System |
| PL | Programmable Logic |
| FIFO | First-in First-out |
References
- Mackay, J.; Mensah, G. The Atlas of Heart Disease and Stroke; World Health Organization: Geneve, Switzerland, 2004. [Google Scholar]
- Meaney, P. Microwave Imaging and Emerging Applications. Int. J. Biomed. Imaging 2012. [Google Scholar] [CrossRef] [PubMed]
- Semenov, S.Y.; Corfield, D.R. Microwave Tomography for Brain Imaging: Feasibility Assessment for Stroke Detection. Int. J. Antennas Propag. 2008. [Google Scholar] [CrossRef]
- Nikolova, N.K. Microwave Imaging for Breast Cancer. IEEE Microw. Mag. 2011, 12, 78–94. [Google Scholar] [CrossRef]
- Zeng, X.; Fhager, A.; He, Z.; Persson, M.; Linner, P.; Zirath, H. Development of a Time Domain Microwave System for Medical Diagnostics. IEEE Trans. Instrum. Meas. 2014, 63, 2931–2939. [Google Scholar] [CrossRef]
- Pagliari, D.J.; Pulimeno, A.; Vacca, M.; Tobon, J.A.; Vipiana, F.; Casu, M.R.; Solimene, R.; Carloni, L.P. A low-cost, fast, and accurate microwave imaging system for breast cancer detection. In Proceedings of the 2015 IEEE Biomedical Circuits and Systems Conference (BioCAS), Atlanta, GA, USA, 22–24 October 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Casu, M.R.; Vacca, M.; Tobon, J.A.; Pulimeno, A.; Sarwar, I.; Solimene, R.; Vipiana, F. A COTS-Based Microwave Imaging System for Breast-Cancer Detection. IEEE Trans. Biomed. Circ. Syst. 2017, 11, 804–814. [Google Scholar] [CrossRef] [PubMed]
- Persson, M.; Fhager, A.; Trefná, H.D.; Yu, Y.; McKelvey, T.; Pegenius, G.; Karlsson, J.; Elam, M. Microwave-Based Stroke Diagnosis Making Global Prehospital Thrombolytic Treatment Possible. IEEE Trans. Biomed. Eng. 2014, 61, 2806–2817. [Google Scholar] [CrossRef] [PubMed]
- Bertero, M.; Boccacci, P. Introduction to Inverse Problems in Imaging; CRC Press: Bristol, UK, 1998. [Google Scholar]
- Scapaticci, R.; Bucci, O.M.; Catapano, I.; Crocco, L. Differential Microwave Imaging for Brain Stroke Followup. Int. J. Antennas Propag. 2014. [Google Scholar] [CrossRef]
- Eigen. Available online: http://eigen.tuxfamily.org (accessed on 26 September 2018).
- Xillinux. Available online: http://xillybus.com/xillinux (accessed on 26 September 2018).
- Vasquez, J.A.T.; Scapaticci, R.; Turvani, G.; Vacca, M.; Sarwar, I.; Casu, M.R.; Dassano, G.; Joachimowicz, N.; Duchěne, B.; Bellizzi, G.; et al. A feasibility study for cerebrovascular diseases monitoring via microwave imaging. In Proceedings of the 2017 International Conference on Electromagnetics in Advanced Applications (ICEAA), Verona, Italy, 11–15 September 2017; pp. 1280–1282. [Google Scholar] [CrossRef]
- Stevanovic, M.N.; Scapaticci, R.; Crocco, L. Brain stroke monitoring using compressive sensing and higher order basis functions. In Proceedings of the 2017 11th European Conference on Antennas and Propagation (EUCAP), Paris, France, 19–24 March 2017; pp. 2742–2745. [Google Scholar] [CrossRef]
- Bisio, I.; Estatico, C.; Fedeli, A.; Lavagetto, F.; Pastorino, M.; Randazzo, A.; Sciarrone, A. Brain Stroke Microwave Imaging by Means of a Newton-Conjugate-Gradient Method in Lp Banach Spaces. IEEE Trans. Microw. Theory Tech. 2018, 66, 3668–3682. [Google Scholar] [CrossRef]
- Mohammed, B.J.; Abbosh, A.M.; Mustafa, S.; Ireland, D. Microwave System for Head Imaging. IEEE Trans. Instrum. Meas. 2014, 63, 117–123. [Google Scholar] [CrossRef]
- Mobashsher, A.T.; Abbosh, A.M.; Wang, Y. Microwave System to Detect Traumatic Brain Injuries Using Compact Unidirectional Antenna and Wideband Transceiver With Verification on Realistic Head Phantom. IEEE Trans. Microw. Theory Tech. 2014, 62, 1826–1836. [Google Scholar] [CrossRef]
- Bashri, M.S.R.; Arslan, T. Low-cost and compact RF switching system for wearable microwave head imaging with performance verification on artificial head phantom. IET Microw. Antennas Propag. 2018, 12, 706–711. [Google Scholar] [CrossRef]
- Scapaticci, R.; Donato, L.D.; Catapano, I.; Crocco, L. A Feasibility Study on Microwave Imaging for Brain Stroke Monitoring. Prog. Electromagn. Res. Boke Monit. 2012, 40. [Google Scholar] [CrossRef]
- Scapaticci, R.; Tobon, J.; Bellizzi, G.; Vipiana, F.; Crocco, L. A Feasibility Study on Microwave Imaging for Brain Stroke Monitoring. IEEE Trans. Antennas Propag. 2018. [Google Scholar] [CrossRef]
- Ruvio, G.; Solimene, R.; Cuccaro, A.; Ammann, M.J. Comparison of Noncoherent Linear Breast Cancer Detection Algorithms Applied to a 2-D Numerical Model. IEEE Antennas Wirel. Propag. Lett. 2013, 12, 853–856. [Google Scholar] [CrossRef]
- Xu, M.; Thulasiraman, P.; Noghanian, S. Microwave tomography for breast cancer detection on Cell broadband engine processors. J. Parallel Distrib. Comput. 2012, 72, 1106–1116. [Google Scholar] [CrossRef]
- Shahzad, A.; O’Halloran, M.; Glavin, M.; Jones, E. A novel optimized parallelization strategy to accelerate microwave tomography for breast cancer screening. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 2456–2459. [Google Scholar]
- Elahi, M.; Shahzad, A.; Glavin, M.; Jones, E.; O’Halloran, M. GPU accelerated Confocal microwave imaging algorithms for breast cancer detection. In Proceedings of the 2015 9th European Conference on Antennas and Propagation (EuCAP), Lisbon, Portugal, 13–17 April 2015; pp. 1–2. [Google Scholar]
- Casu, M.R.; Colonna, F.; Crepaldi, M.; Demarchi, D.; Graziano, M.; Zamboni, M. UWB Microwave Imaging for Breast Cancer Detection: Many-core, GPU, or FPGA? ACM Trans. Embed. Comput. Syst. 2014, 13, 109:1–109:22. [Google Scholar] [CrossRef]
- Pagliari, D.J.; Casu, M.R.; Carloni, L.P. Acceleration of microwave imaging algorithms for breast cancer detection via High-Level Synthesis. In Proceedings of the 2015 33rd IEEE International Conference on Computer Design (ICCD), New York, NY, USA, 18–21 October 2015; pp. 475–478. [Google Scholar] [CrossRef]
- Pagliari, D.J.; Casu, M.R.; Carloni, L.P. Accelerators for Breast Cancer Detection. ACM Trans. Embed. Comput. Syst. 2017, 16, 80:1–80:25. [Google Scholar] [CrossRef]
- Cong, J. Customizable domain-specific computing. IEEE Des. Test Comput. 2011, 28, 6–15. [Google Scholar] [CrossRef]
- Amaro, J.; Yiu, B.Y.S.; Falcao, G.; Gomes, M.A.C.; Yu, A.C.H. Software-based high-level synthesis design of FPGA beamformers for synthetic aperture imaging. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2015, 62, 862–870. [Google Scholar] [CrossRef] [PubMed]
- Ibrahim, A.; Hager, P.A.; Bartolini, A.; Angiolini, F.; Arditi, M.; Thiran, J.; Benini, L.; Micheli, G.D. Efficient Sample Delay Calculation for 2-D and 3-D Ultrasound Imaging. IEEE Trans. Biomed. Circ. Syst. 2017, 11, 815–831. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Note |
|---|---|---|
| NV | 24 | Number of transmitter antennas |
| NM | 24 | Number of receiver antennas |
| NC | 18,690 | Total grid points in 3D volume |
| −80 dB | Minimum threshold | |
| −10 dB | Maximum threshold | |
| 10 dB | Threshold step |
| Data | Type | Size (FP) |
|---|---|---|
| Complex Vector | ||
| Real Vector | ||
| Complex Matrix | ||
| Complex Matrix | (37,380,1152) | |
| Complex Vector |
| Resource | Utilization |
|---|---|
| LUTs | 19.04% |
| FFs | 14.2% |
| BRAM | 100% |
| DSPs | 14.55% |
| IOBs | 38% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarwar, I.; Turvani, G.; Casu, M.R.; Tobon, J.A.; Vipiana, F.; Scapaticci, R.; Crocco, L. Low-Cost Low-Power Acceleration of a Microwave Imaging Algorithm for Brain Stroke Monitoring. J. Low Power Electron. Appl. 2018, 8, 43. https://doi.org/10.3390/jlpea8040043
Sarwar I, Turvani G, Casu MR, Tobon JA, Vipiana F, Scapaticci R, Crocco L. Low-Cost Low-Power Acceleration of a Microwave Imaging Algorithm for Brain Stroke Monitoring. Journal of Low Power Electronics and Applications. 2018; 8(4):43. https://doi.org/10.3390/jlpea8040043
Chicago/Turabian StyleSarwar, Imran, Giovanna Turvani, Mario R. Casu, Jorge A. Tobon, Francesca Vipiana, Rosa Scapaticci, and Lorenzo Crocco. 2018. "Low-Cost Low-Power Acceleration of a Microwave Imaging Algorithm for Brain Stroke Monitoring" Journal of Low Power Electronics and Applications 8, no. 4: 43. https://doi.org/10.3390/jlpea8040043
APA StyleSarwar, I., Turvani, G., Casu, M. R., Tobon, J. A., Vipiana, F., Scapaticci, R., & Crocco, L. (2018). Low-Cost Low-Power Acceleration of a Microwave Imaging Algorithm for Brain Stroke Monitoring. Journal of Low Power Electronics and Applications, 8(4), 43. https://doi.org/10.3390/jlpea8040043