
A Cross-Layer Framework for Designing and Optimizing Deeply-Scaled FinFET-Based Cache Memories †

Abstract
:1. Introduction
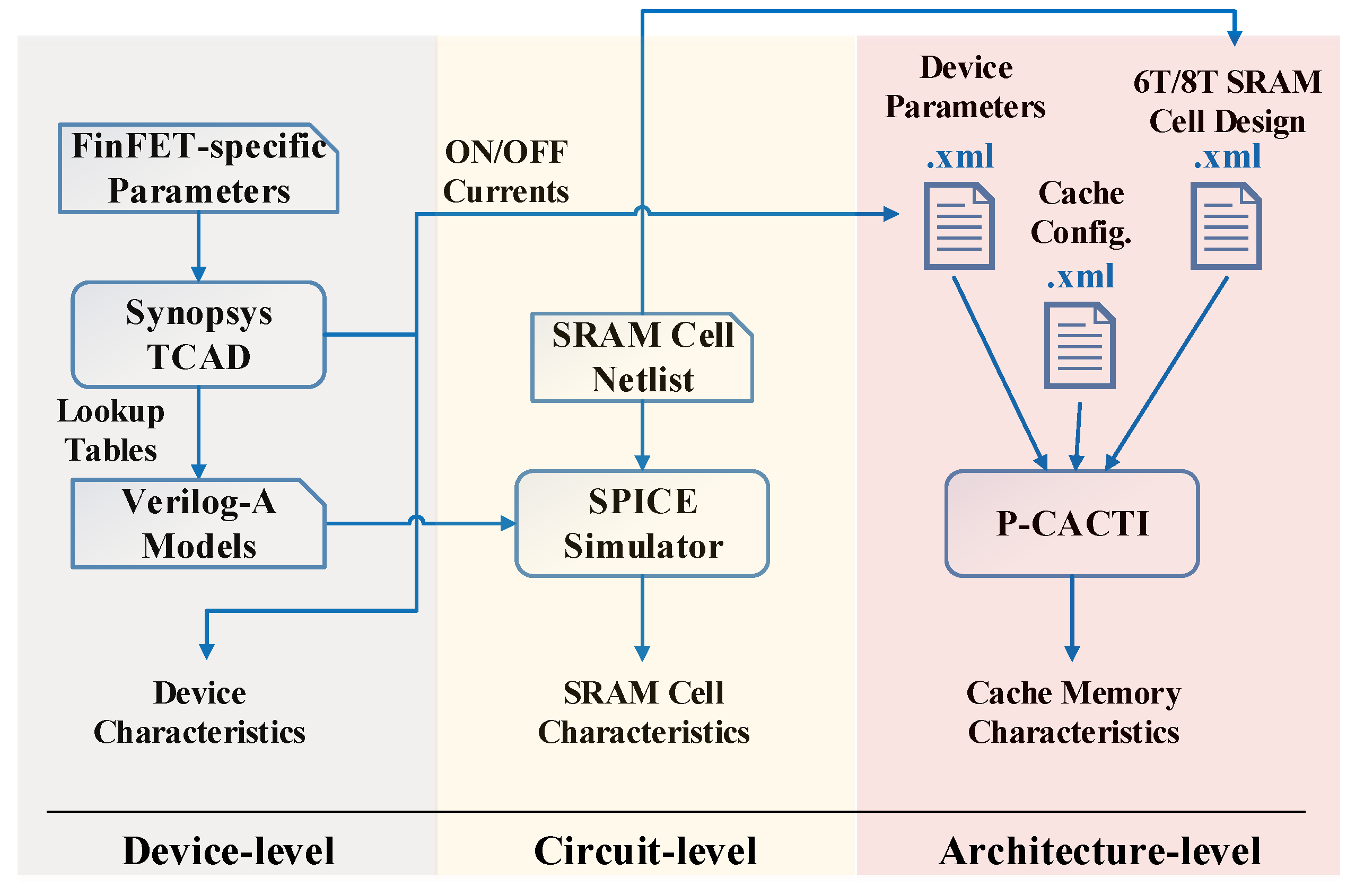
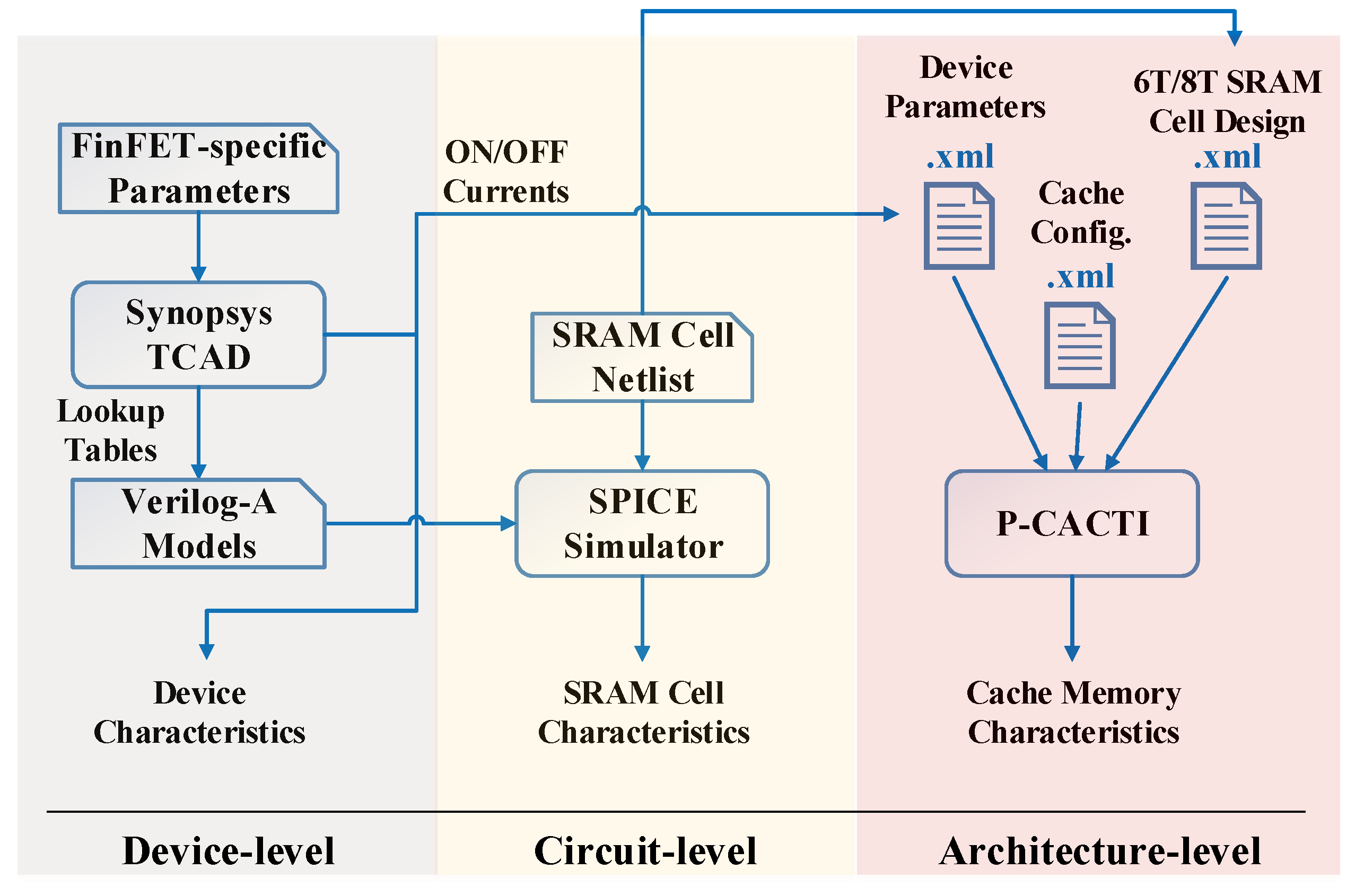
2. Device-Level Design and Optimization
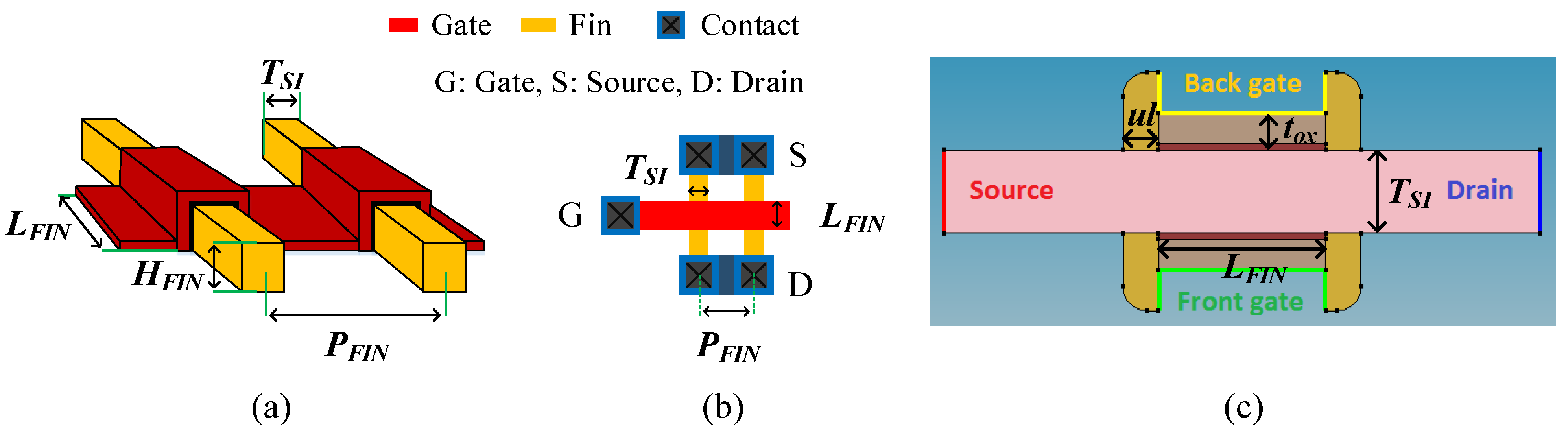
2.1. FinFET Devices


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter name | Value | Parameter name | Value |
|---|---|---|---|
| Gate length () | 7 nm | Gate oxide material | SiO + HfO |
| Fin width () | 3.5 nm | Source/Drain doping | 1 × 10 cm |
| Fin height () | 14 nm | Gate work function (NFET) | 4.4 eV |
| Gate oxide thickness () | 1.3 nm | Gate work function (PFET) | 4.9 eV |
| Gate underlap () | 1.5 nm | Fin pitch () | = 10.5 nm |
| Device | Parameter | Value | Device | Parameter | Value |
|---|---|---|---|---|---|
| low_tsi | 3.2 nm | low_tox | 1.1 nm | ||
| high_tsi | 3.8 nm | high_tox | 1.5 nm | ||
| high_ul | 2.25 nm | high_l | 8 nm |
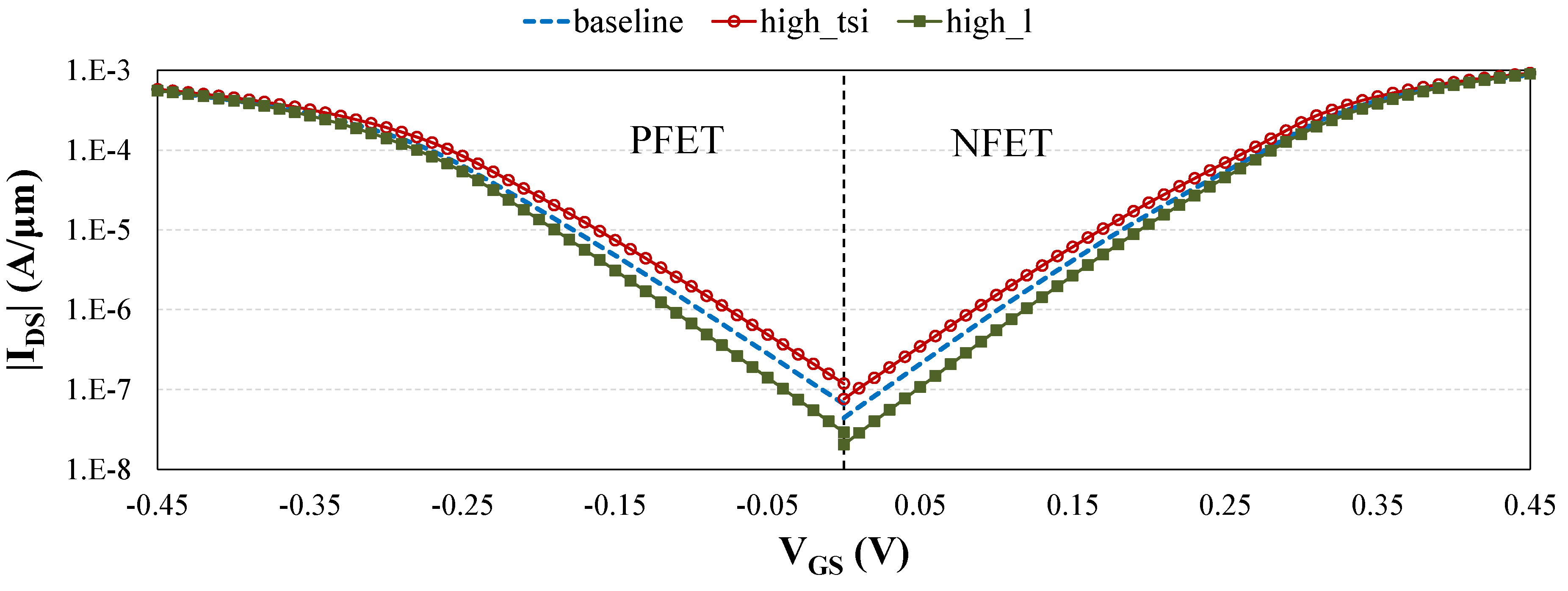
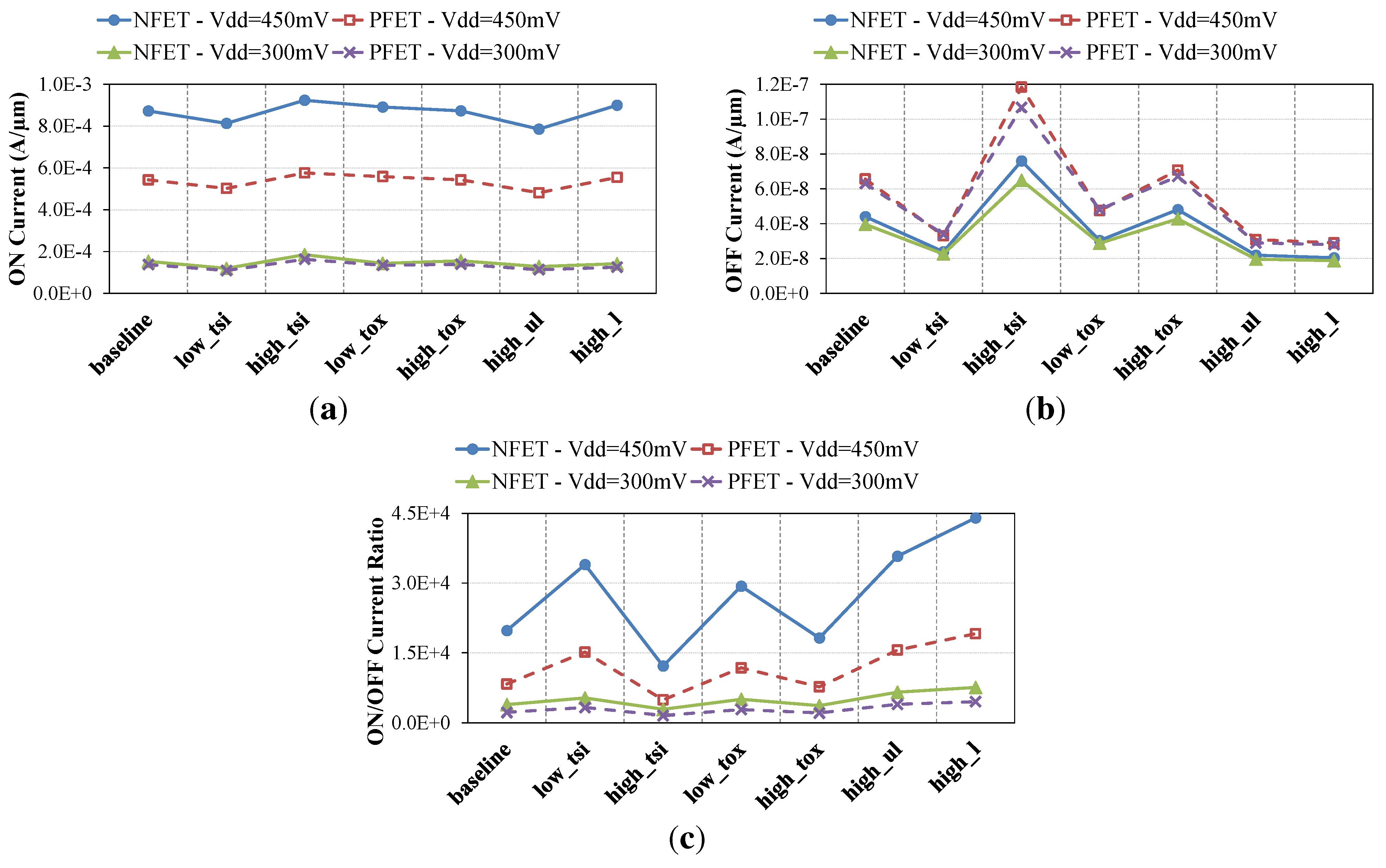
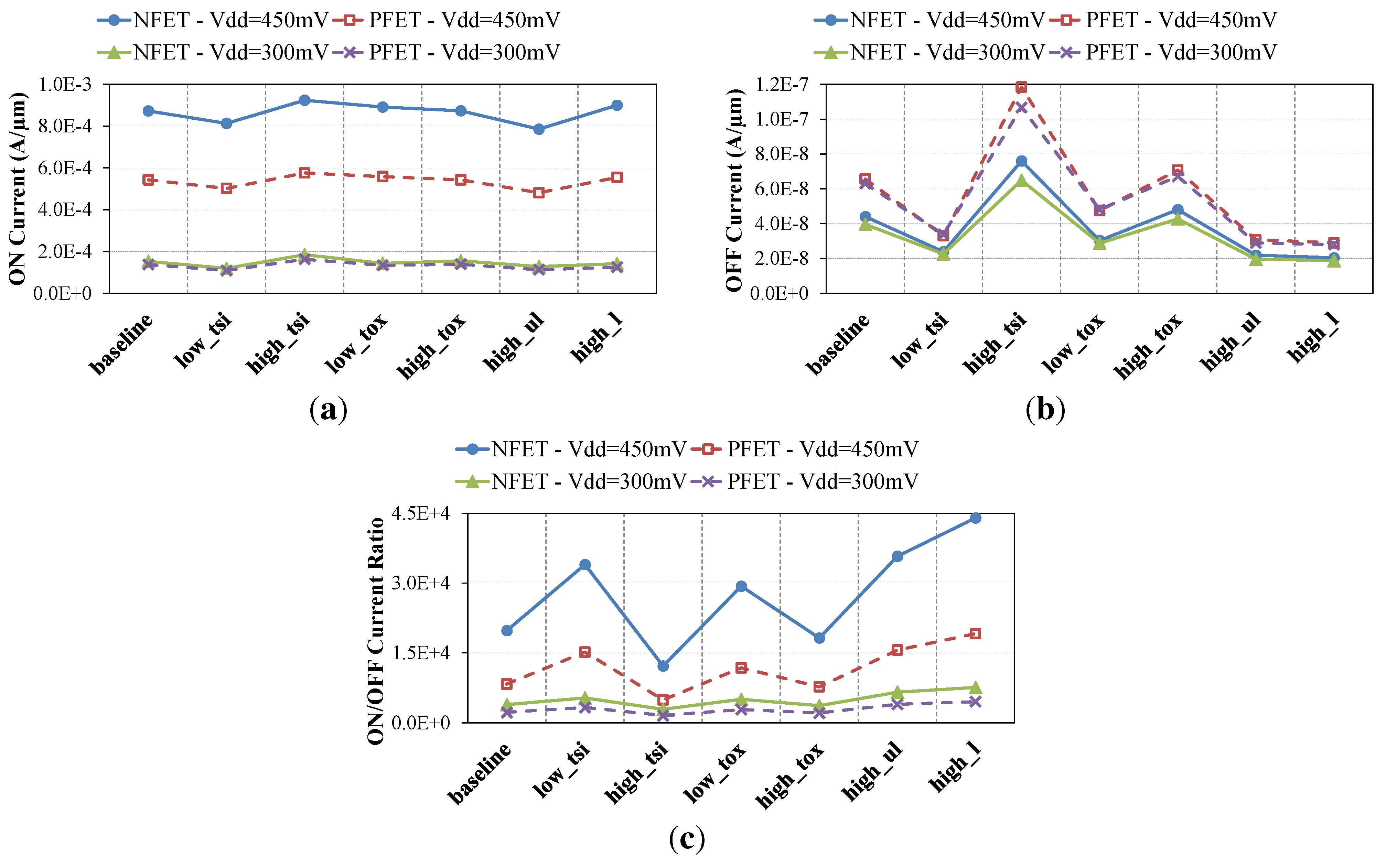
2.2. Device-Level Comparison
3. Circuit-Level Design and Optimization
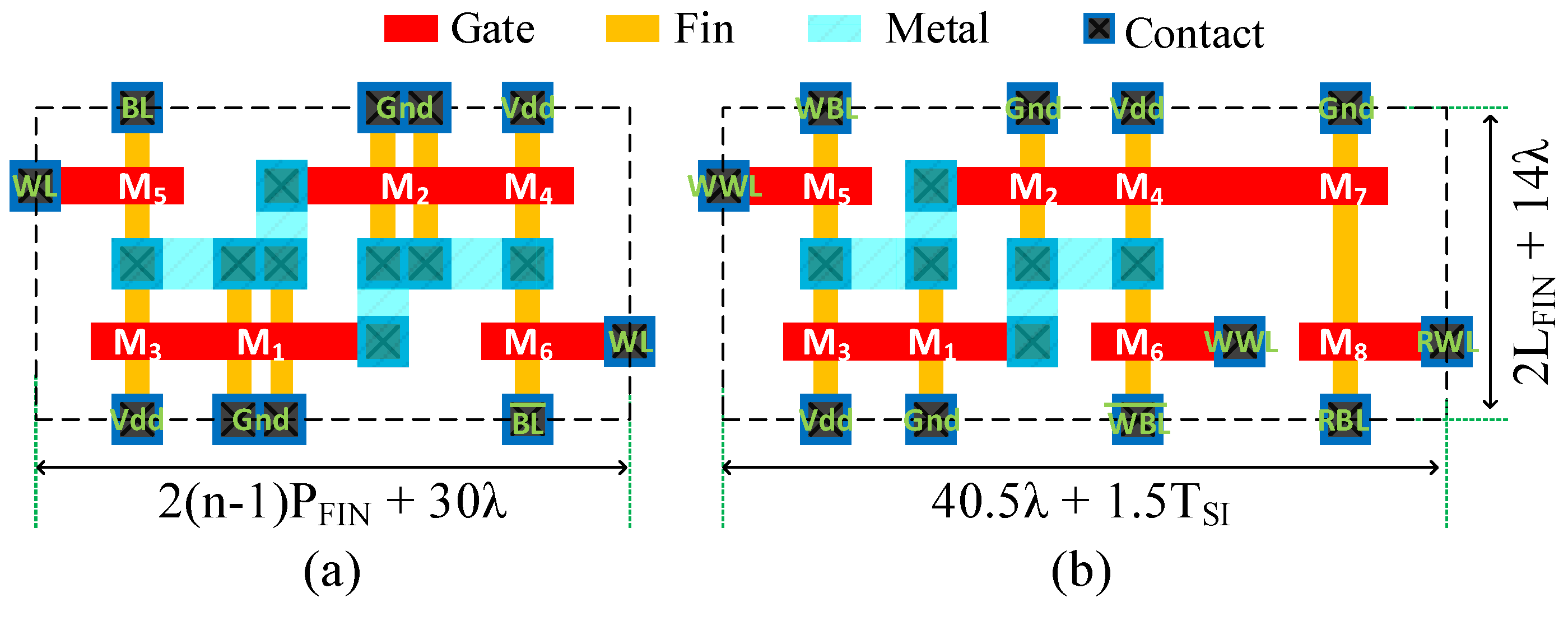
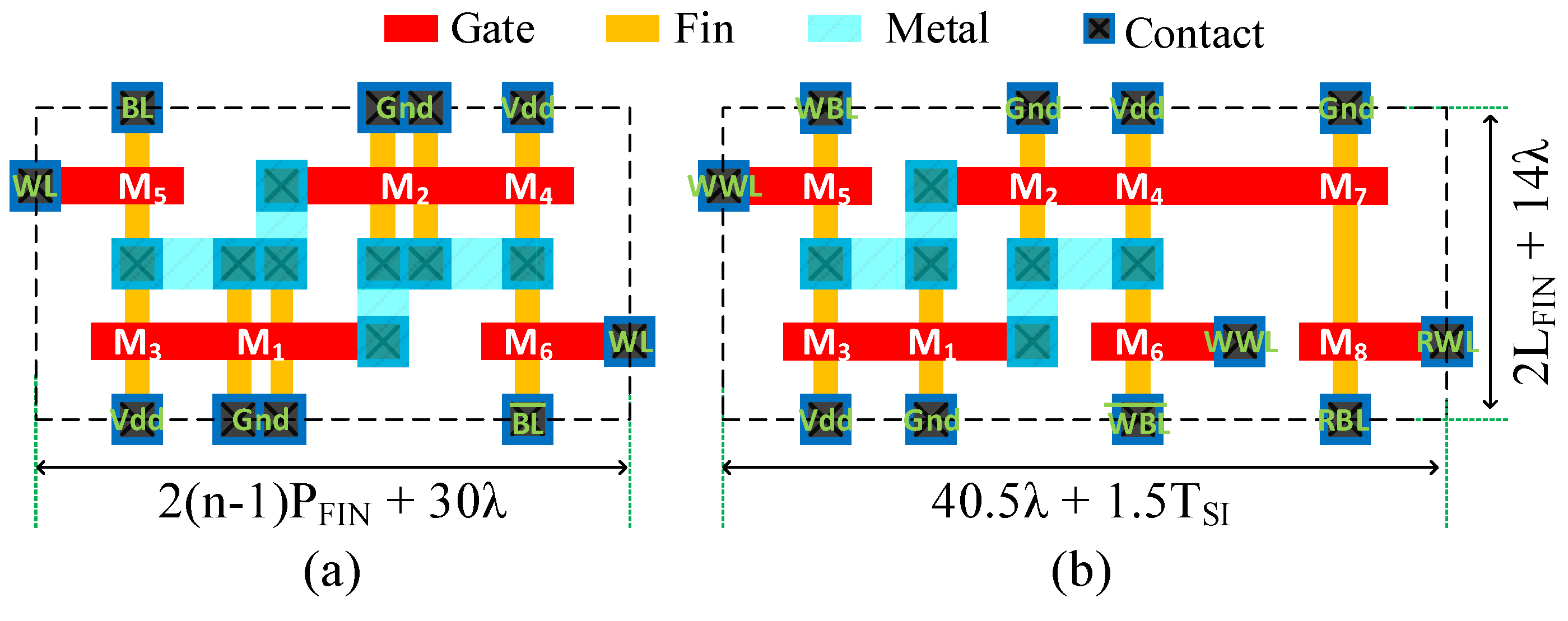
3.1. SRAM Cells
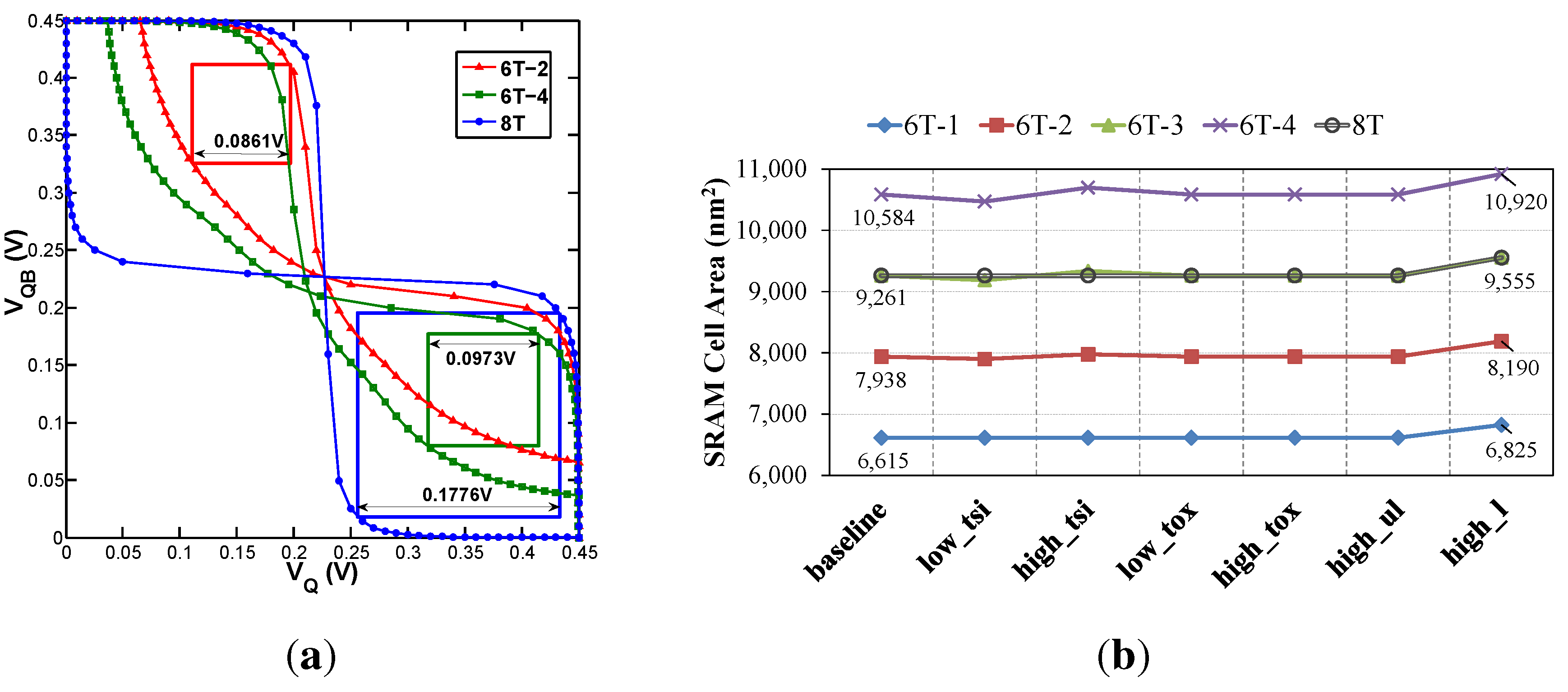
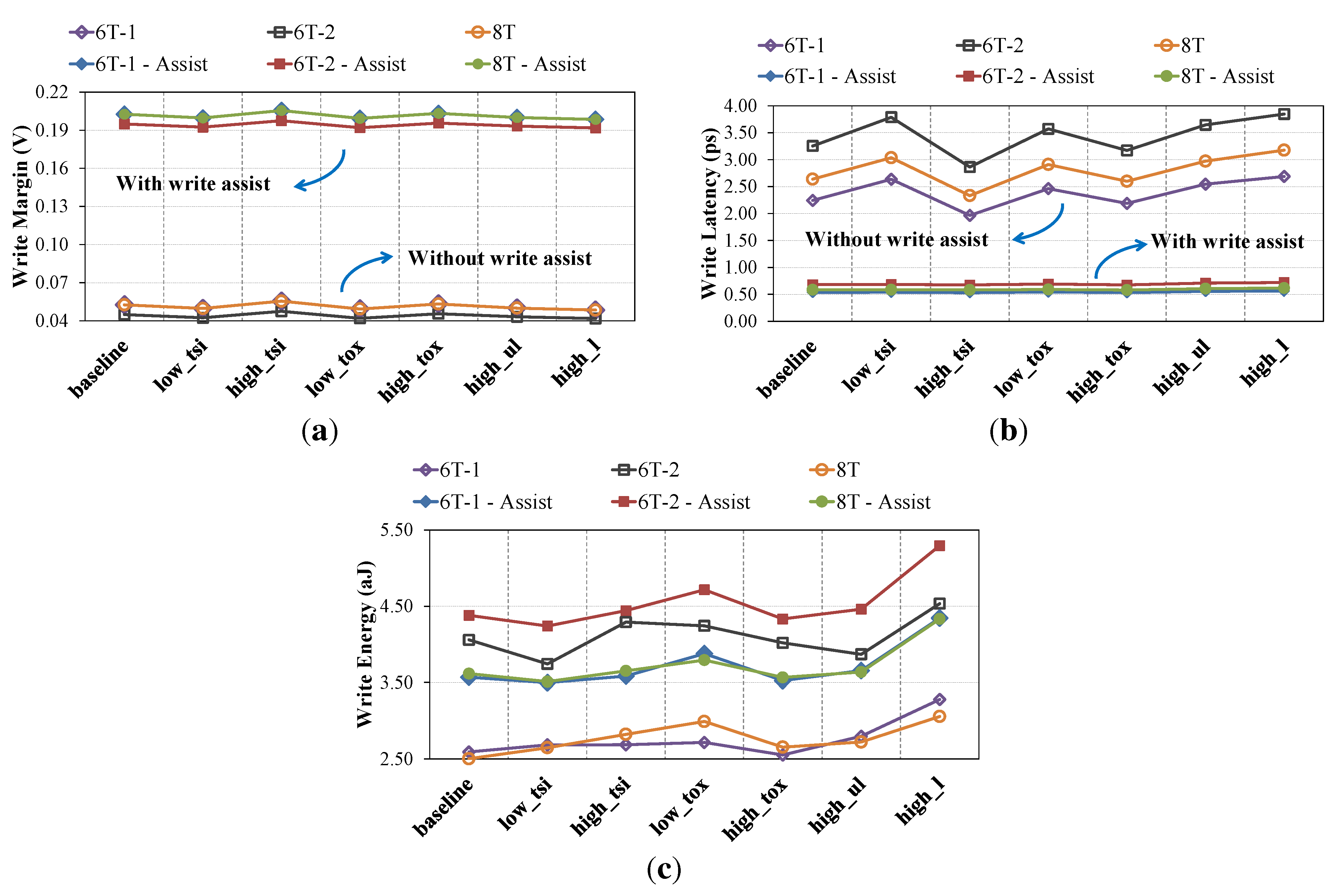
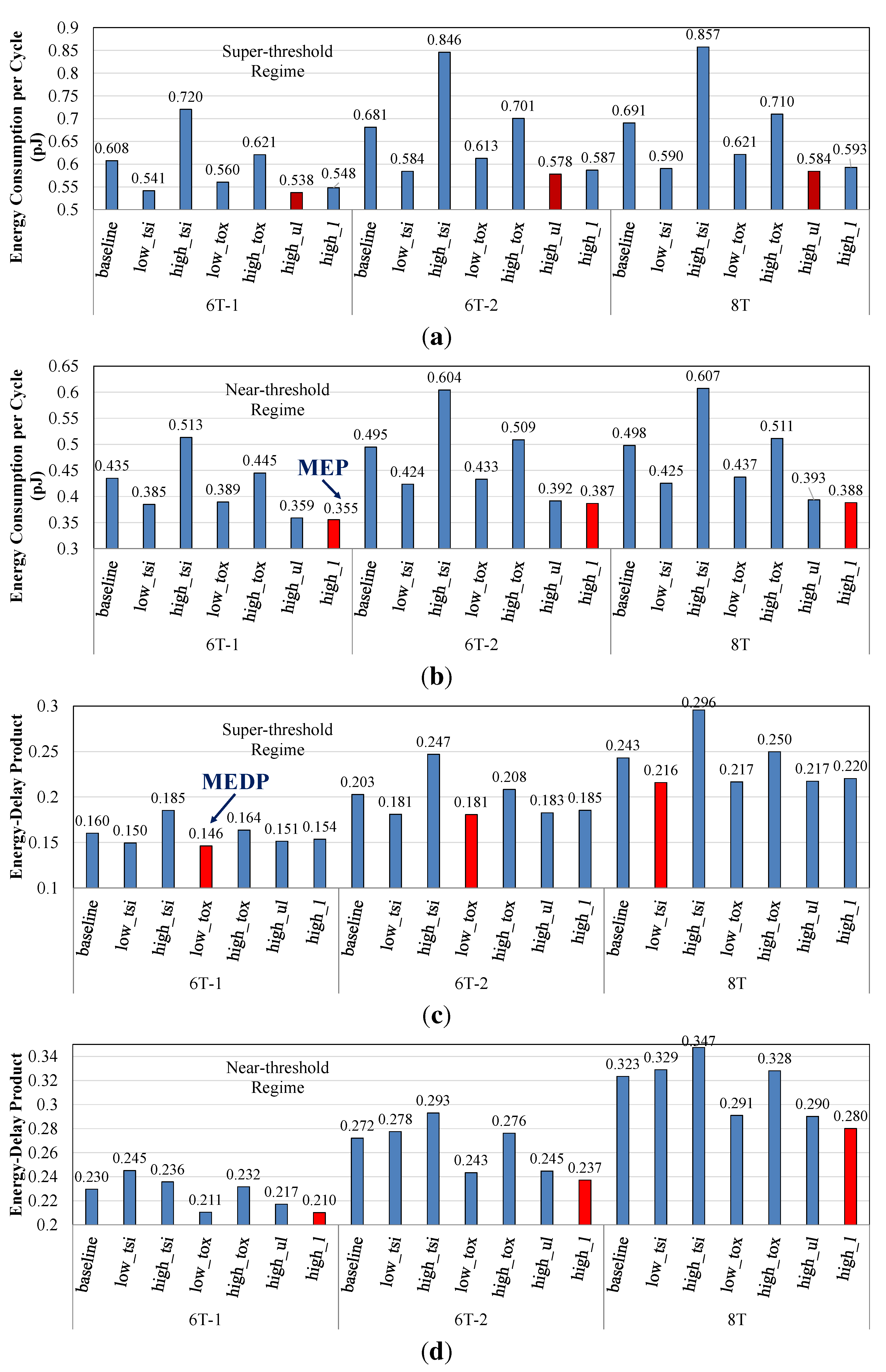
3.2. Circuit-Level Comparison
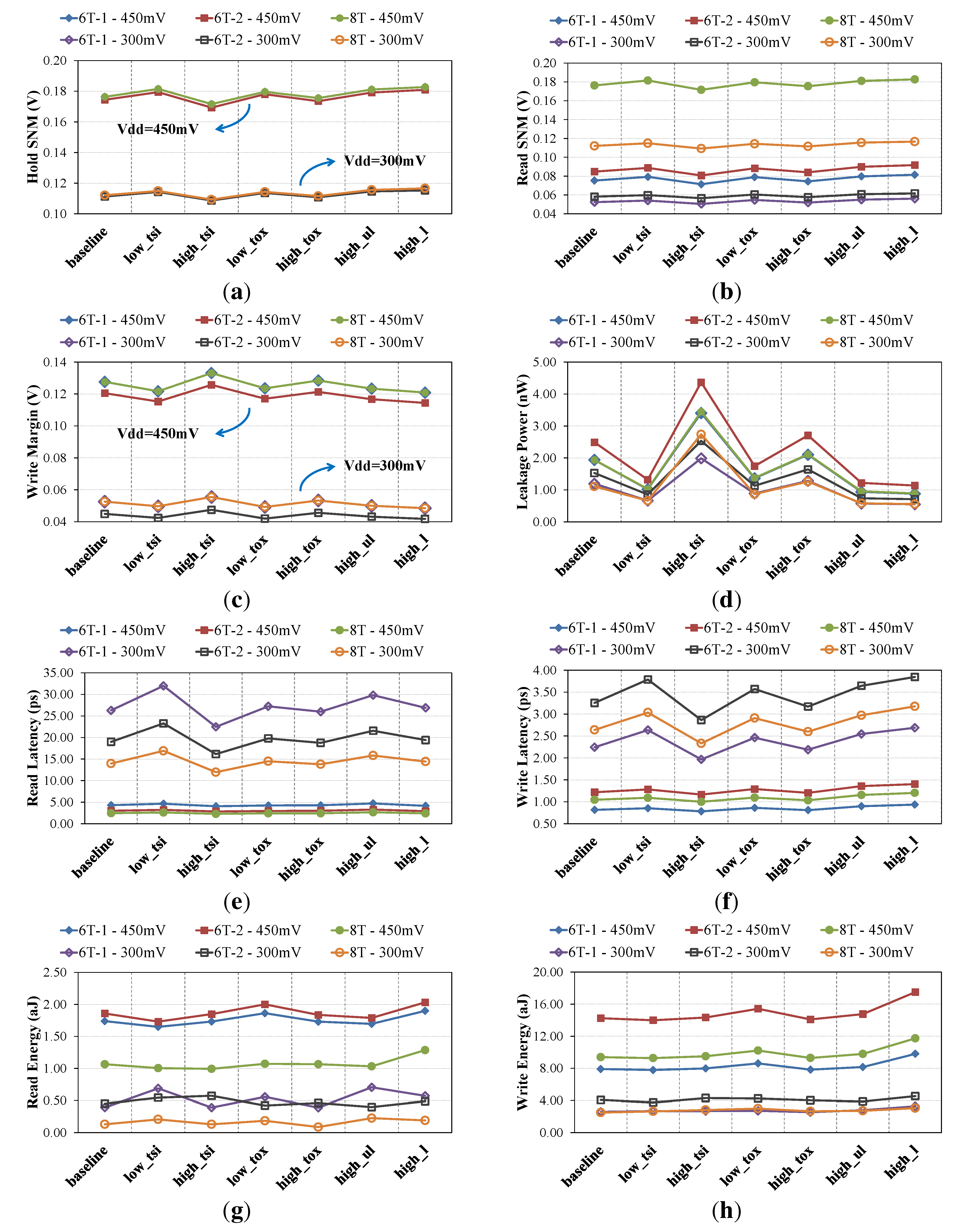
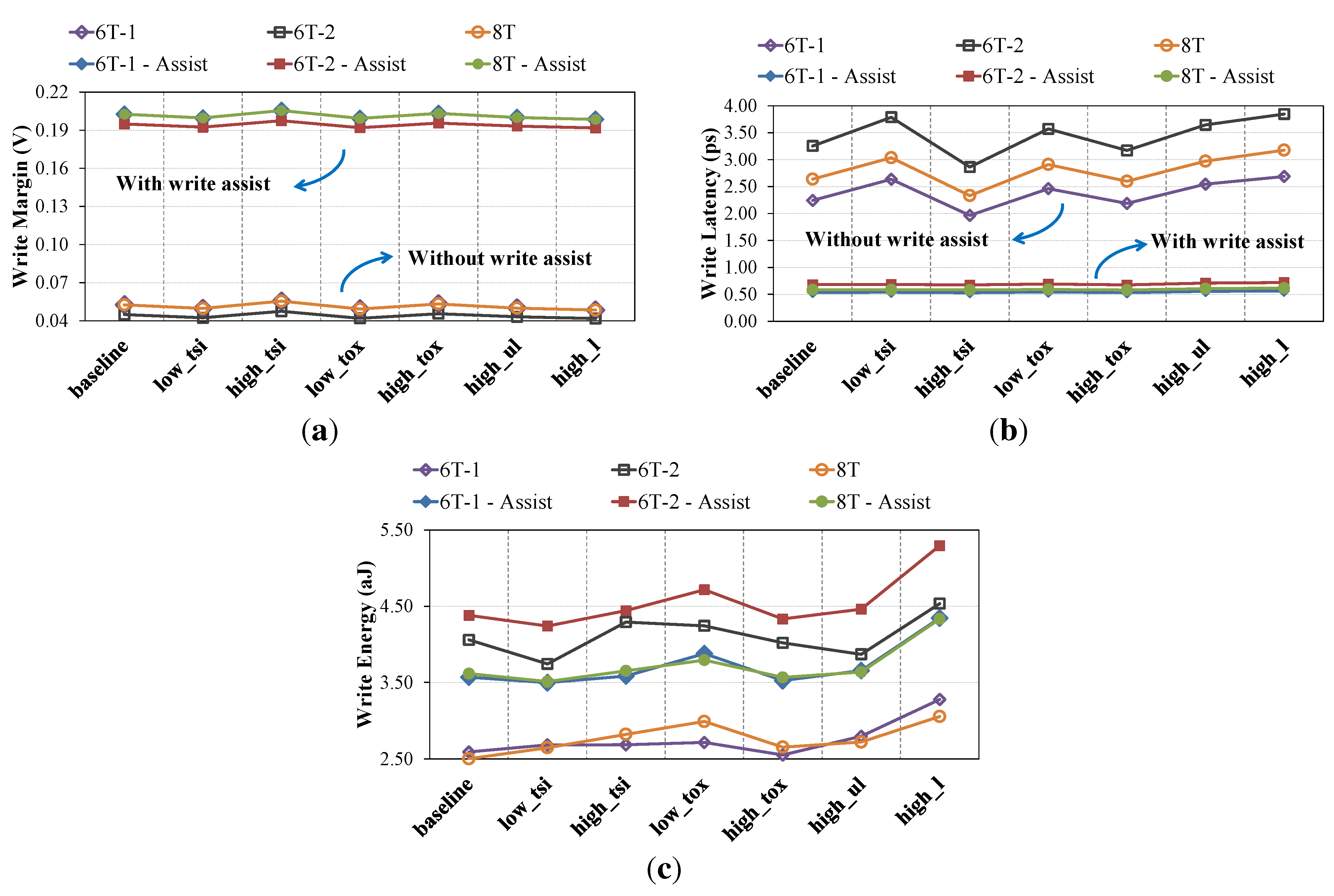
4. Architecture-Level Design and Evaluation
4.1. Cache Memories
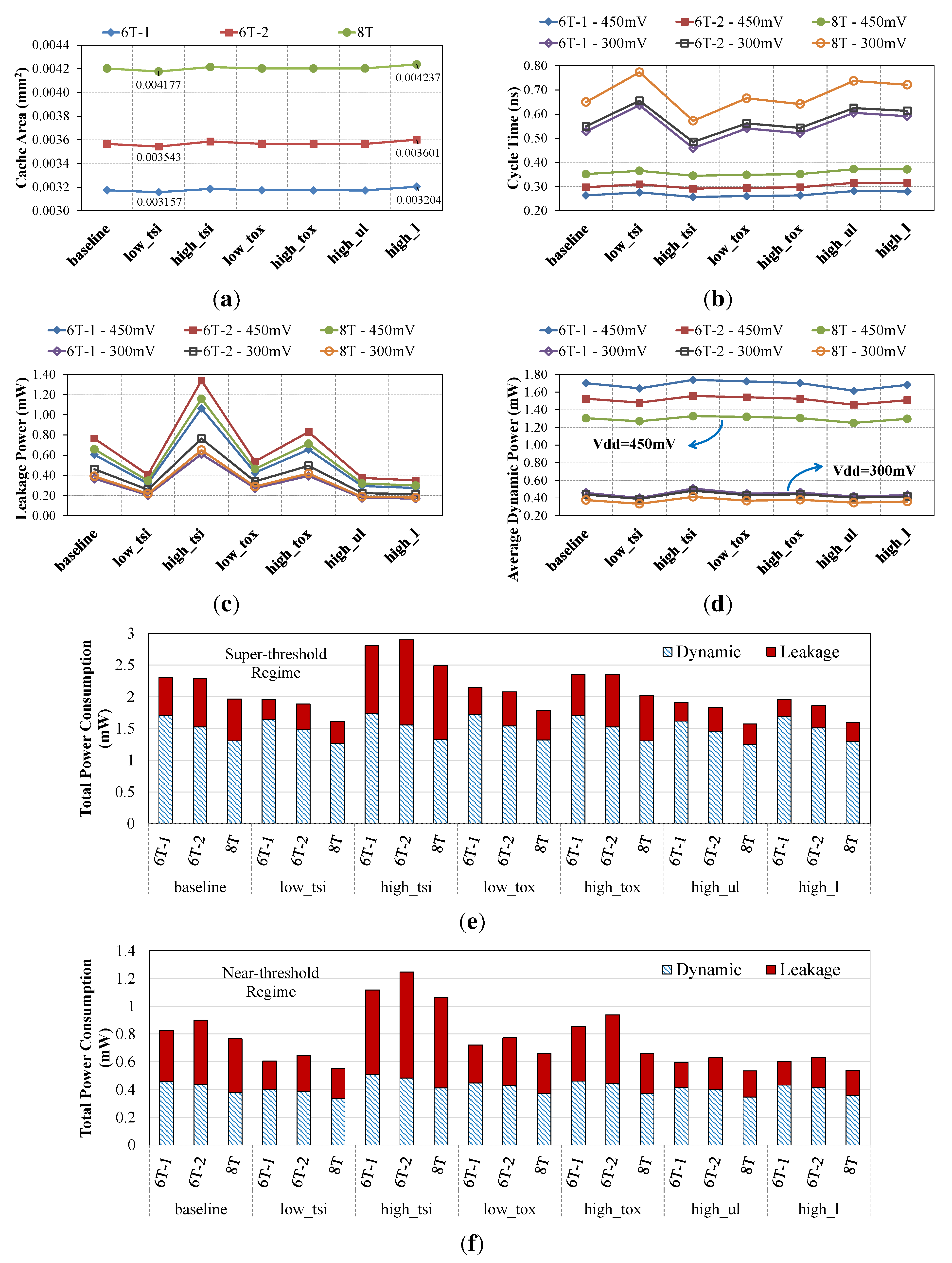
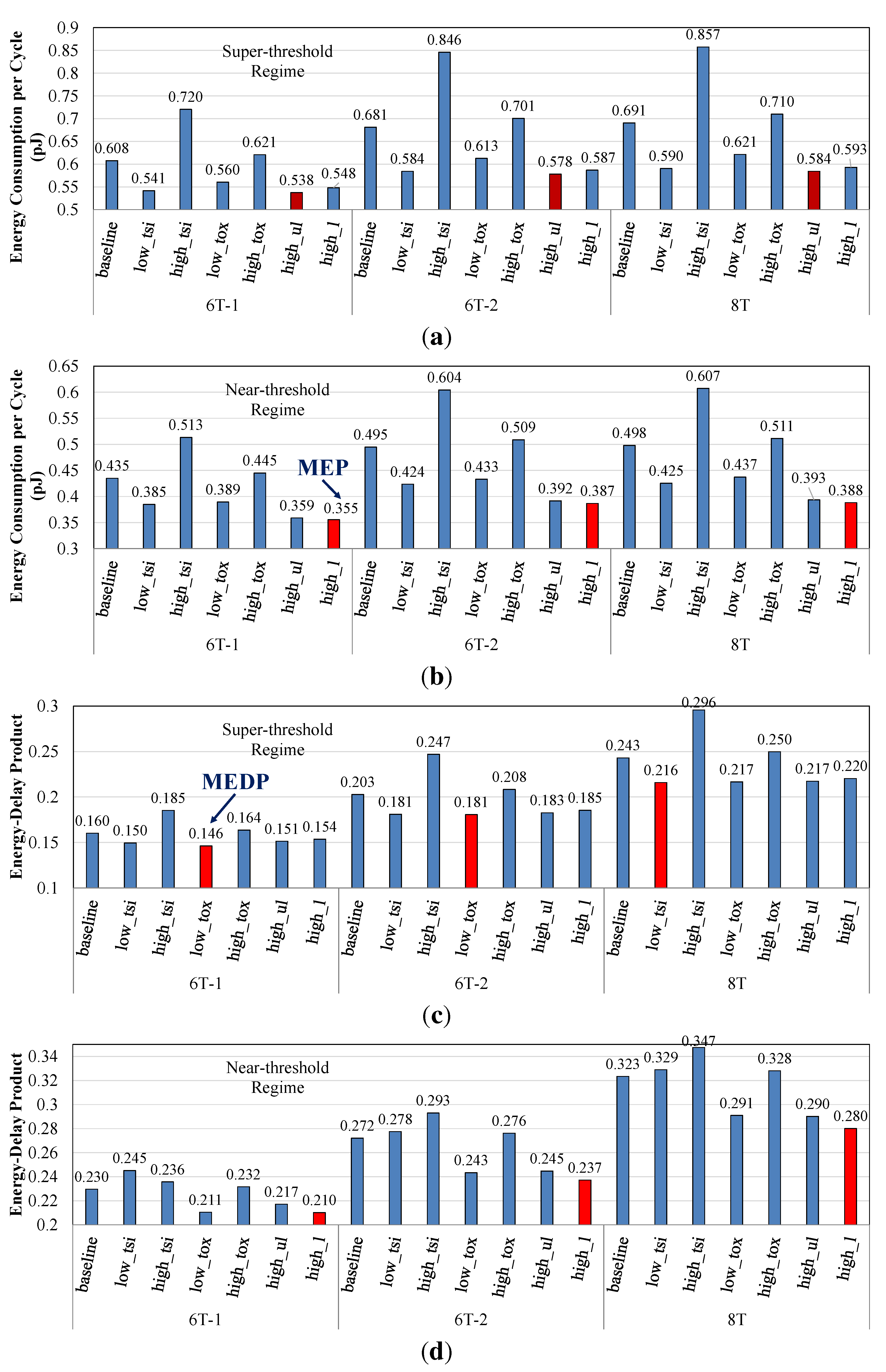
4.2. Architecture-Level Comparison
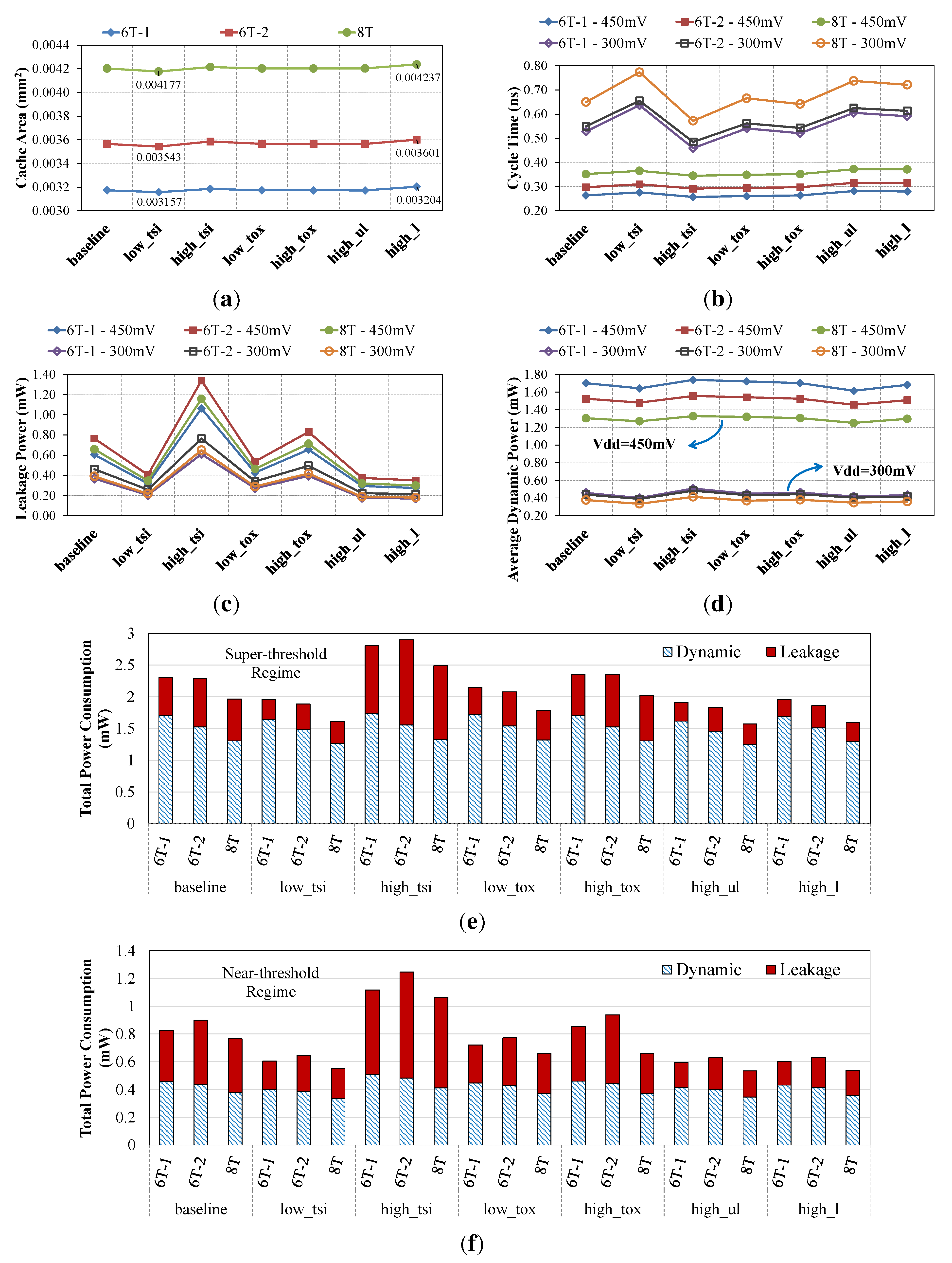
5. Conclusions and Future Work
- Device-level variability analysis: By assuming a Gaussian distribution for , , work function and doping concentration, as well as proper standard deviation values for each parameter, we can perform Monte Carlo simulations in TCAD in order to derive the distributions of the threshold voltage and drain-source current for our FinFET devices. Lookup tables are still extracted for nominal values.
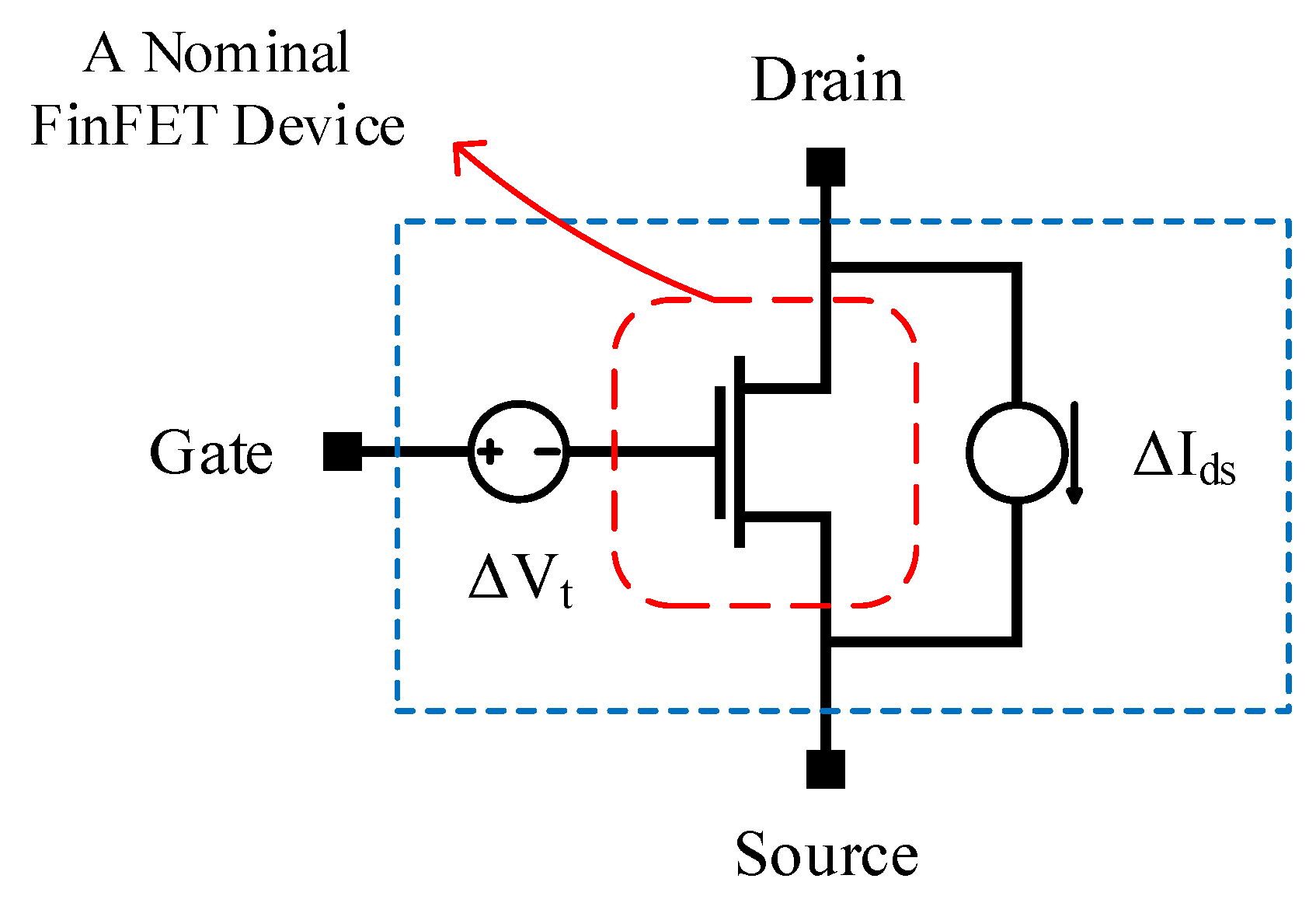
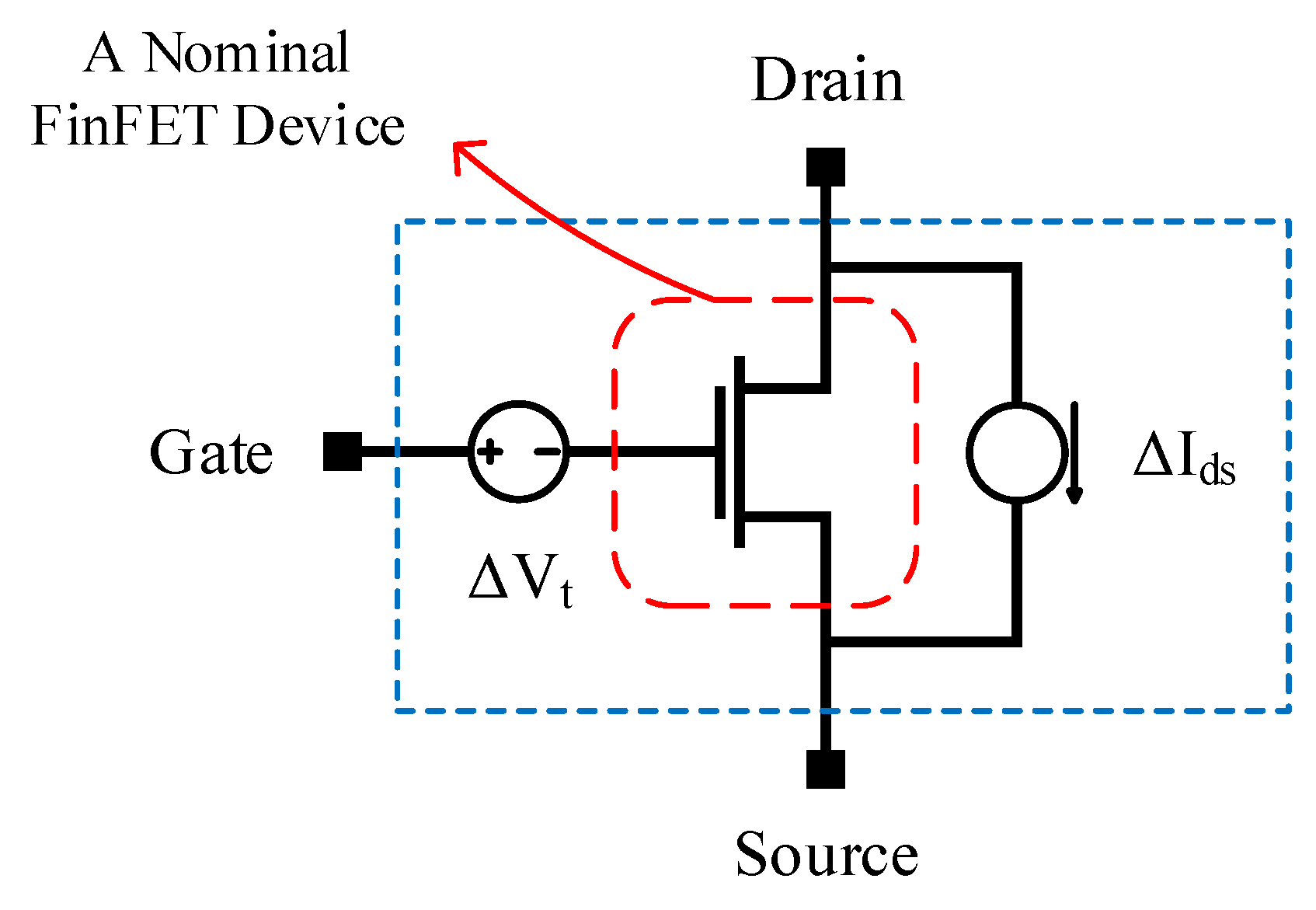
- Variability analysis of SRAM cells: Each transistor of the SRAM cell is modeled as shown in Figure 11 [27]. More specifically: (i) a voltage source is inserted on the gate terminal in order to inject variations on the threshold voltage; and (ii) a current source is added between drain and source terminals in order to introduce variations on the saturation current. Next, Monte Carlo simulations on N samples are performed, and for each sample, the hold/read/write SNMs are measured using HSpice simulations. Mean, μ, and standard deviation, σ, for each operation are then calculated. For a high-yield SRAM cell, we should have . However, using an error-correcting code (ECC) may relax the threshold value of the . Furthermore, to speed-up the circuit-level Monte Carlo simulations, importance sampling or stratified sampling canbe adopted.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Nowak, E.; Aller, I.; Ludwig, T.; Kim, K.; Joshi, R.; Chuang, C.T.; Bernstein, K.; Puri, R. Turning Silicon on its Edge [Double Gate CMOS/FinFET Technology]. IEEE Circuits Devices Mag. 2004, 20, 20–31. [Google Scholar] [CrossRef]
- Tang, S.; Chang, L.; Lindert, N.; Choi, Y.K.; Lee, W.C.; Huang, X.; Subramanian, V.; Bokor, J.; King, T.J.; Hu, C. FinFET—A Quasi-Planar Double-Gate MOSFET. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 5–7 February 2001; pp. 118–119.
- Matsukawa, T.; O’uchi, S.; Endo, K.; Ishikawa, Y.; Yamauchi, H.; Liu, Y.X.; Tsukada, J.; Sakamoto, K.; Masahara, M. Comprehensive Analysis of Variability Sources of FinFET Characteristics. In Proceedings of the Symposium on VLSI Technology, Honolulu, HI, USA, 16–18 June 2009; pp. 118–119.
- Wang, X.; Brown, A.; Cheng, B.; Asenov, A. Statistical Variability and Reliability in Nanoscale FinFETs. In Proceedings of the IEEE International Electron Devices Meeting (IEDM), Washington, DC, USA, 5–7 December 2011; pp. 5.4.1–5.4.4.
- Lin, X.; Wang, Y.; Pedram, M. Joint sizing and adaptive independent gate control for FinFET circuits operating in multiple voltage regimes using the logical effort method. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 18–21 November 2013; pp. 444–449.
- Pilo, H.; Arsovski, I.; Batson, K.; Braceras, G.; Gabric, J.; Houle, R.; Lamphier, S.; Radens, C.; Seferagic, A. A 64 Mb SRAM in 32 nm High-k Metal-Gate SOI Technology with 0.7 V Operation Enabled by Stability, Write-Ability and Read-Ability Enhancements. IEEE J. Solid State Circuits 2012, 47, 97–106. [Google Scholar]
- Pilo, H.; Adams, C.; Arsovski, I.; Houle, R.; Lamphier, S.; Lee, M.; Pavlik, F.; Sambatur, S.; Seferagic, A.; Wu, R.; et al. A 64Mb SRAM in 22 nm SOI technology featuring fine-granularity power gating and low-energy power-supply-partition techniques for 37% leakage reduction. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 17–21 February 2013; pp. 322–323.
- Baravelli, E.; Marchi, L.D.; Speciale, N. {VDD} Scalability of FinFET SRAMs: Robustness of Different Design Options against LER-induced Variations. Solid State Electron. 2010, 54, 909–918. [Google Scholar] [CrossRef]
- Guo, Z.; Balasubramanian, S.; Zlatanovici, R.; King, T.J.; Nikolic, B. FinFET-based SRAM design. In Proceedings of the International Symposium on Low Power Electronics and Design (ISLPED), San Diego, CA, USA, 8–10 August 2005; pp. 2–7.
- Synopsys Technology Computer-Aided Design (TCAD). Available online: http://www.synopsys.com/tools/tcad (accessed on 31 July 2015).
- Goud, A.; Gupta, S.; Choday, S.; Roy, K. Atomistic tight-binding based evaluation of impact of gate underlap on source to drain tunneling in 5 nm gate length Si FinFETs. In Proceedings of the 71st Annual Device Research Conference (DRC), Notre Dame, IN, USA, 23–26 June 2013.
- Chen, S.; Wang, Y.; Lin, X.; Xie, Q.; Pedram, M. Performance prediction for multiple-threshold 7nm-FinFET-based circuits operating in multiple voltage regimes using a cross-layer simulation framework. In Proceedings of the IEEE SOI-3D-Subthreshold Microelectronics Technology Unified Conference (S3S), Millbrae, CA, USA, 6–9 October 2014.
- Gupta, P.; Kahng, A.B.; Sharma, P.; Sylvester, D. Selective Gate-length Biasing for Cost-effective Runtime Leakage Control. In Proceedings of the Design Automation Conference (DAC), San Diego, CA, USA, 7–11 June 2004; pp. 327–330.
- Seevinck, E.; List, F.; Lohstroh, J. Static-Noise Margin Analysis of MOS SRAM Cells. IEEE J. Solid State Circuits 1987, 22, 748–754. [Google Scholar] [CrossRef]
- Chang, L.; Fried, D.; Hergenrother, J.; Sleight, J.; Dennard, R.; Montoye, R.; Sekaric, L.; McNab, S.; Topol, A.; Adams, C.; et al. Stable SRAM Cell Design for the 32 nm Node and Beyond. In Proceedings of the Symposium on VLSI Technology, Kyoto, Japan, 14–16 June 2005; pp. 128–129.
- Muralimanohar, N.; Balasubramonian, R.; Jouppi, N. Optimizing NUCA Organizations and Wiring Alternatives for Large Caches with CACTI 6.0. In Proceedings of the 40th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Chicago, IL, USA, 1–5 December 2007; pp. 3–14.
- Shafaei, A.; Wang, Y.; Lin, X.; Pedram, M. FinCACTI: Architectural Analysis and Modeling of Caches with Deeply-Scaled FinFET Devices. In Proceedings of the IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Tampa, FL, USA, 9–11 July 2014; pp. 290–295.
- P-CACTI. Available online: http://sportlab.usc.edu/download/pcacti/ (accessed on 31 July 2015).
- Carlson, T.; Heirman, W.; Eeckhout, L. Sniper: Exploring the level of abstraction for scalable and accurate parallel multi-core simulation. In Proceedings of the International Conference for High Performance Computing. Networking, Storage and Analysis (SC), Seatle, WA, USA, 12–18 November 2011; pp. 1–12.
- Bienia, C.; Li, K. PARSEC 2.0: A New Benchmark Suite for Chip-Multiprocessors. In Proceedings of the 5th Annual Workshop on Modeling, Benchmarking and Simulation, Austin, TX, USA, 21 June 2009.
- Woo, S.C.; Ohara, M.; Torrie, E.; Singh, J.P.; Gupta, A. The SPLASH-2 Programs: Characterization and Methodological Considerations. In Proceedings of the 22nd Annual International Symposium on Computer Architecture (ISCA), Santa Margherita Ligure, Italy, 22–24 June 1995; pp. 24–36.
- Karl, E.; Guo, Z.; Conary, J.; Miller, J.; Ng, Y.G.; Nalam, S.; Kim, D.; Keane, J.; Bhattacharya, U.; Zhang, K. A 0.6V 1.5GHz 84Mb SRAM Design in 14 nm FinFET CMOS Technology. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 22–26 February 2015; pp. 1–3.
- Song, T.; Rim, W.; Jung, J.; Yang, G.; Park, J.; Park, S.; Baek, K.H.; Baek, S.; Oh, S.K.; Jung, J.; et al. A 14 nm FinFET 128Mb 6T SRAM with VMIN-enhancement techniques for low-power applications. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 9-13 Feb. 2014; pp. 232–233.
- Chen, Y.H.; Chan, W.M.; Wu, W.C.; Liao, H.J.; Pan, K.H.; Liaw, J.J.; Chung, T.H.; Li, Q.; Chang, G.; Lin, C.Y.; et al. A 16 nm 128Mb SRAM in high-k metal-gate FinFET technology with write-assist circuitry for low-VMIN applications. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 9–13 February 2014; pp. 238–239.
- Shafaei, A.; Chen, S.; Wang, Y.; Pedram, M. A Cross-Layer Framework for Designing and Optimizing Deeply-Scaled FinFET-Based SRAM Cells under Process Variations. In Proceedings of the 20th Asia and South Pacific Design Automation Conference (ASP-DAC), Chiba, Japan, 19–22 January 2015.
- Dierickx, B.; Miranda, M.; Dobrovolny, P.; Kutscherauer, F.; Papanikolaou, A.; Marchal, P. Propagating variability from technology to system level. In Proceedings of the International Workshop on Physics of Semiconductor Devices (IWPSD), Mumbai, India, 16–20 December 2007; pp. 74–79.
- Royer, P.; Lopez-Vallejo, M. Using pMOS Pass-Gates to Boost SRAM Performance by Exploiting Strain Effects in Sub-20-nm FinFET Technologies. IEEE Trans. Nanotechnol. 2014, 13, 1226–1233. [Google Scholar] [CrossRef]
- Lee, C.Y.; Jha, N. CACTI-FinFET: An integrated delay and power modeling framework for FinFET-based caches under process variations. In Proceedings of the Design Automation Conference (DAC), San Diego, CA, USA, 5–9 June 2011; pp. 866–871.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shafaei, A.; Chen, S.; Wang, Y.; Pedram, M. A Cross-Layer Framework for Designing and Optimizing Deeply-Scaled FinFET-Based Cache Memories. J. Low Power Electron. Appl. 2015, 5, 165-182. https://doi.org/10.3390/jlpea5030165
Shafaei A, Chen S, Wang Y, Pedram M. A Cross-Layer Framework for Designing and Optimizing Deeply-Scaled FinFET-Based Cache Memories. Journal of Low Power Electronics and Applications. 2015; 5(3):165-182. https://doi.org/10.3390/jlpea5030165
Chicago/Turabian StyleShafaei, Alireza, Shuang Chen, Yanzhi Wang, and Massoud Pedram. 2015. "A Cross-Layer Framework for Designing and Optimizing Deeply-Scaled FinFET-Based Cache Memories" Journal of Low Power Electronics and Applications 5, no. 3: 165-182. https://doi.org/10.3390/jlpea5030165
APA StyleShafaei, A., Chen, S., Wang, Y., & Pedram, M. (2015). A Cross-Layer Framework for Designing and Optimizing Deeply-Scaled FinFET-Based Cache Memories. Journal of Low Power Electronics and Applications, 5(3), 165-182. https://doi.org/10.3390/jlpea5030165