
AMA: An Ageing Task Migration Aware for High-Performance Computing


Abstract
1. Introduction
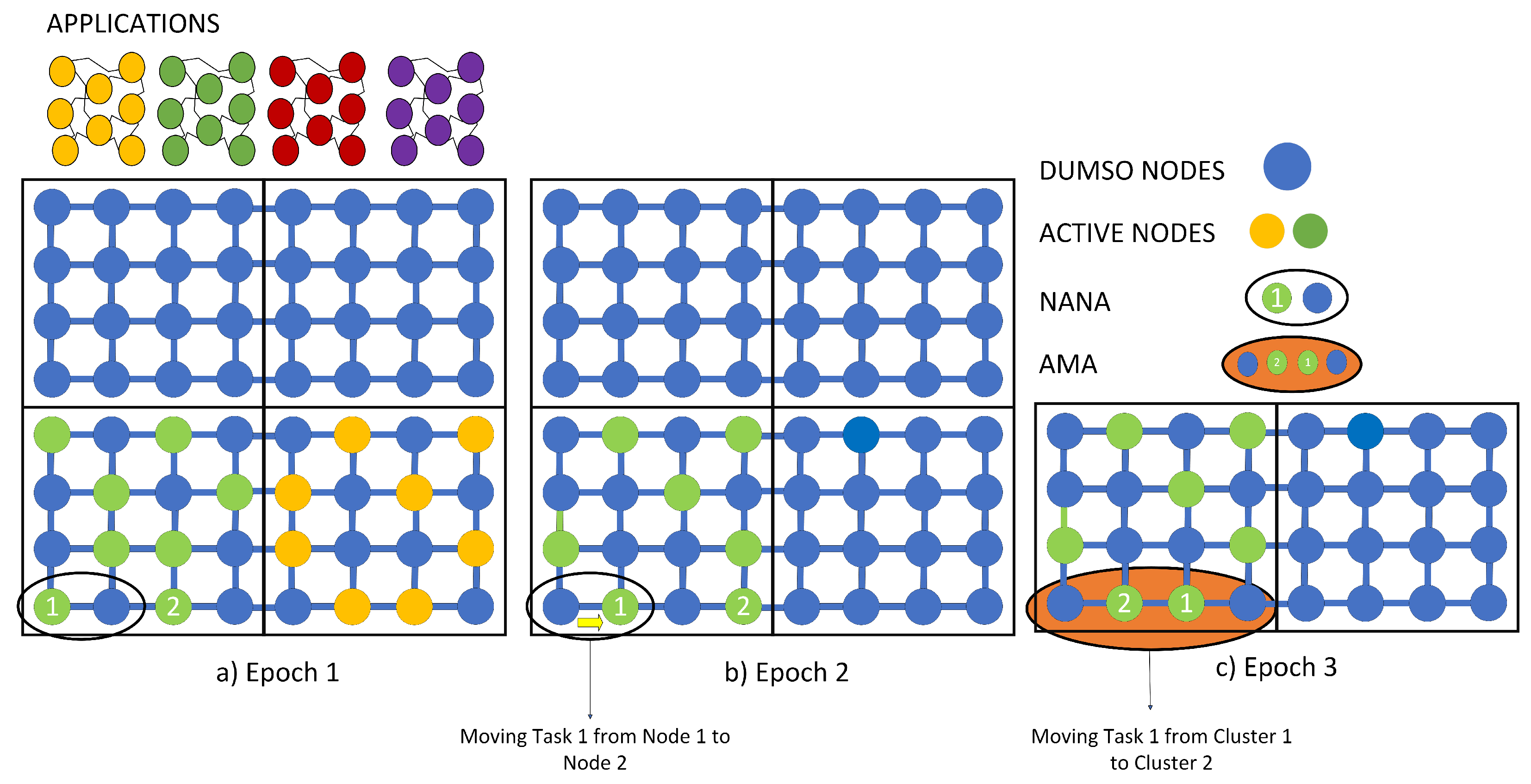
- A dynamic mapping approach to improve the ageing of many-core nodes. The proposed framework is built on our previous contribution ABENA [23];
- The proposed architecture migrates tasks between two nodes depending on the MTTF after an epoch and also during an epoch;
- DVFS and Task Migration are used to reduce the frequency to maintain the temperature of nodes under the temperature constraint.
2. Related Work
3. System Model and Problem Formulation
3.1. Many-Core Platform Model
3.2. Problem Statement
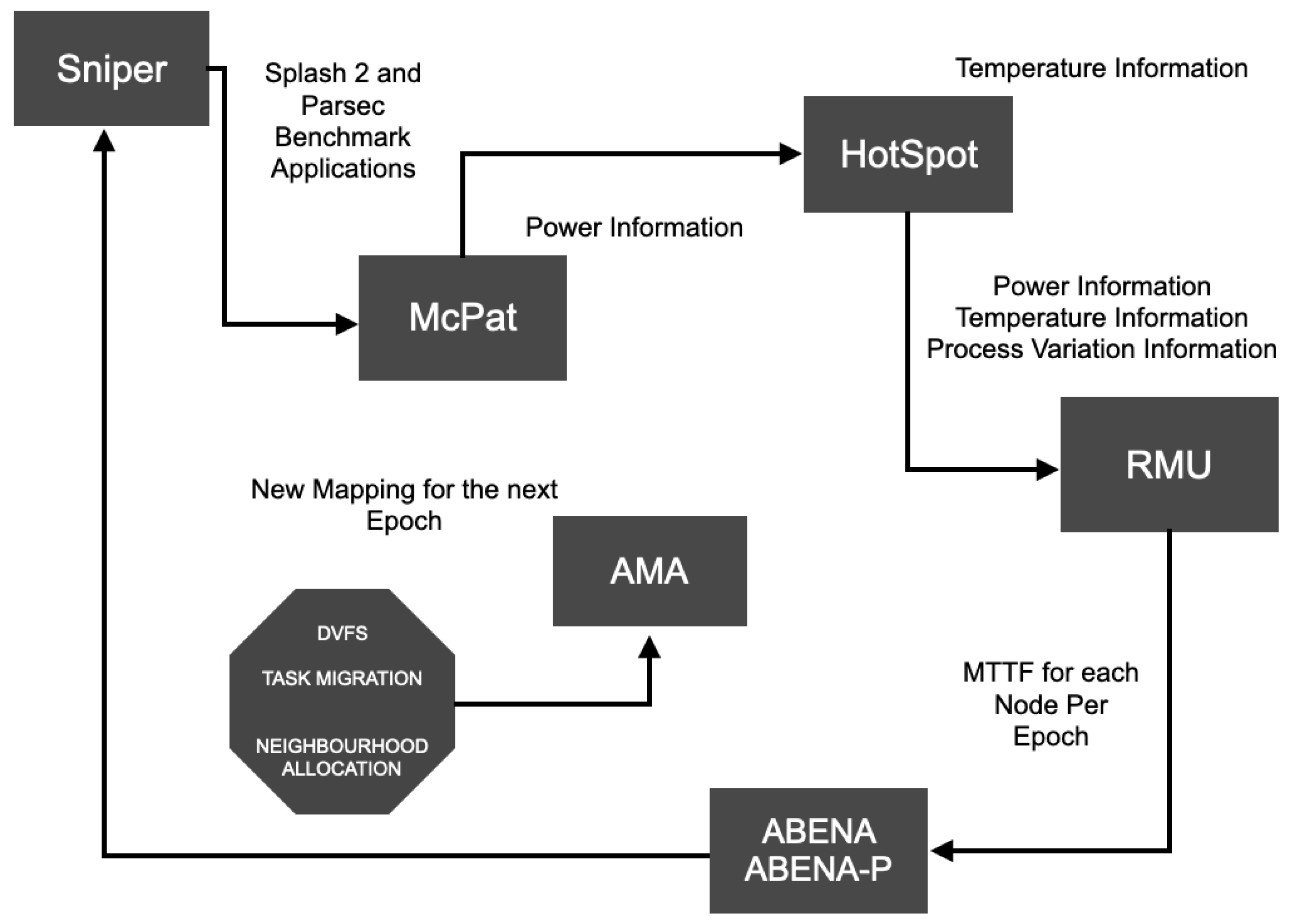
3.3. ABENA 2.0 Overview
| Algorithm 1: ABENA Periodic [23] |
 |
AMA: Ageing Task Migration Aware for High-Performance Computing
| Algorithm 2: AMA Algorithm |
 |
4. Experimental Evaluation
4.1. Experimental Setup
4.2. Results
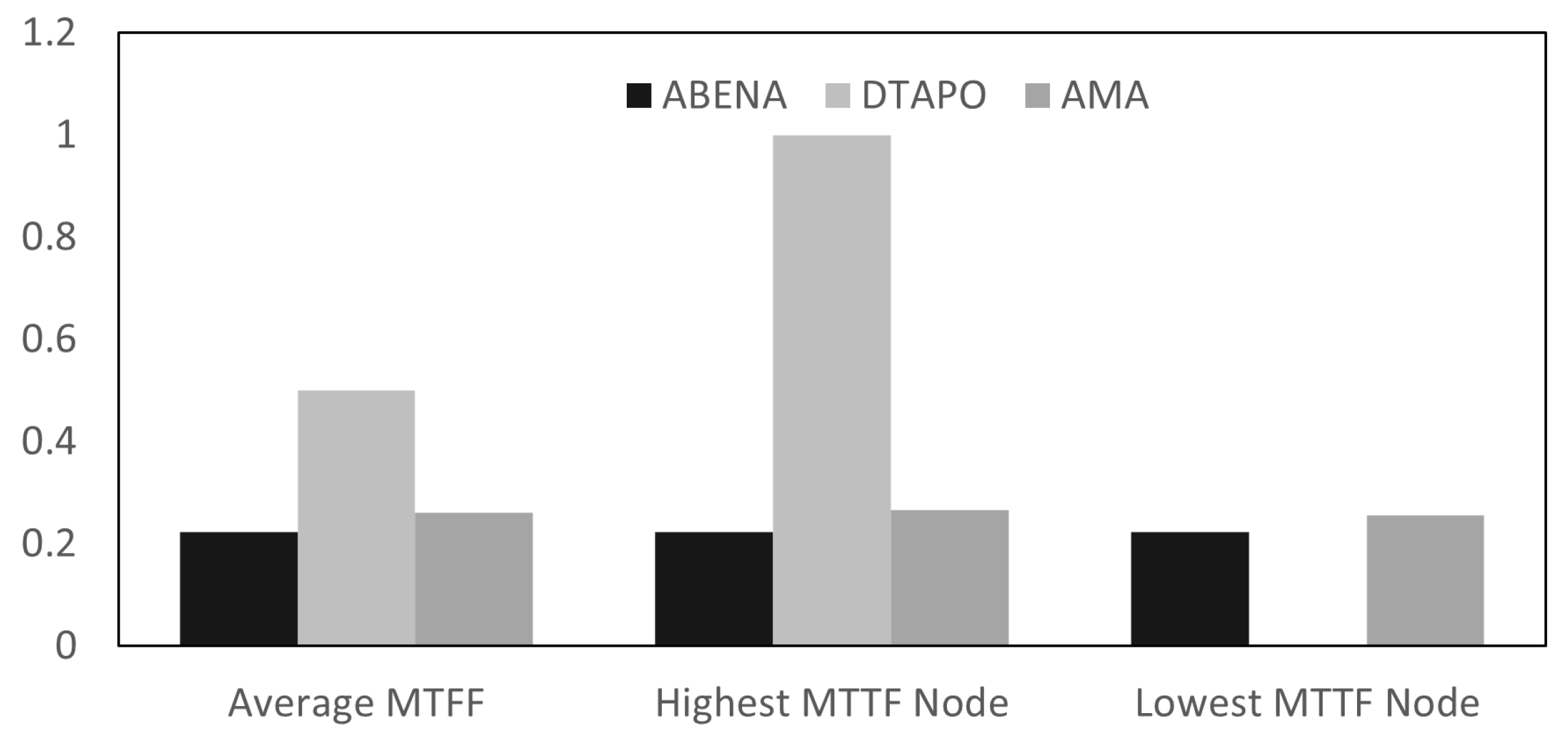
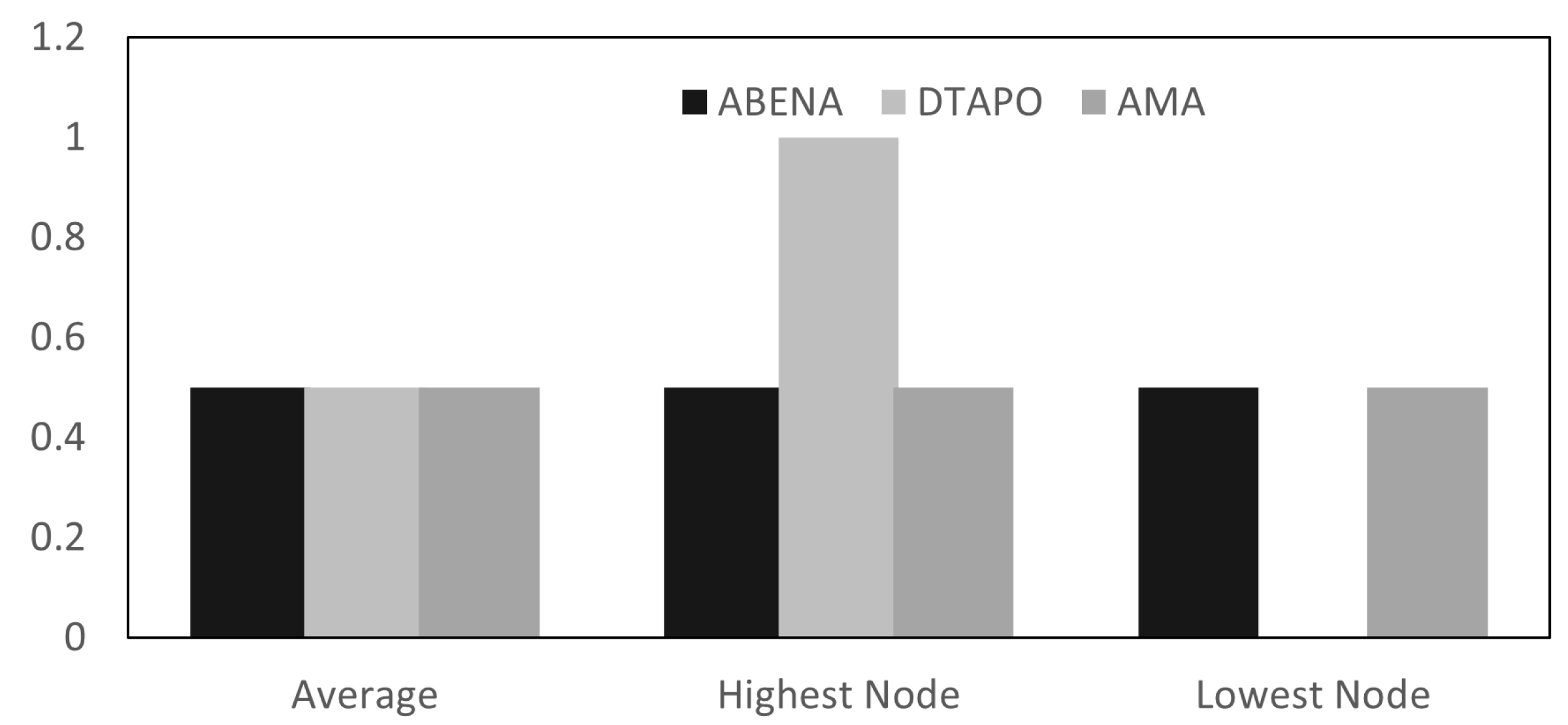
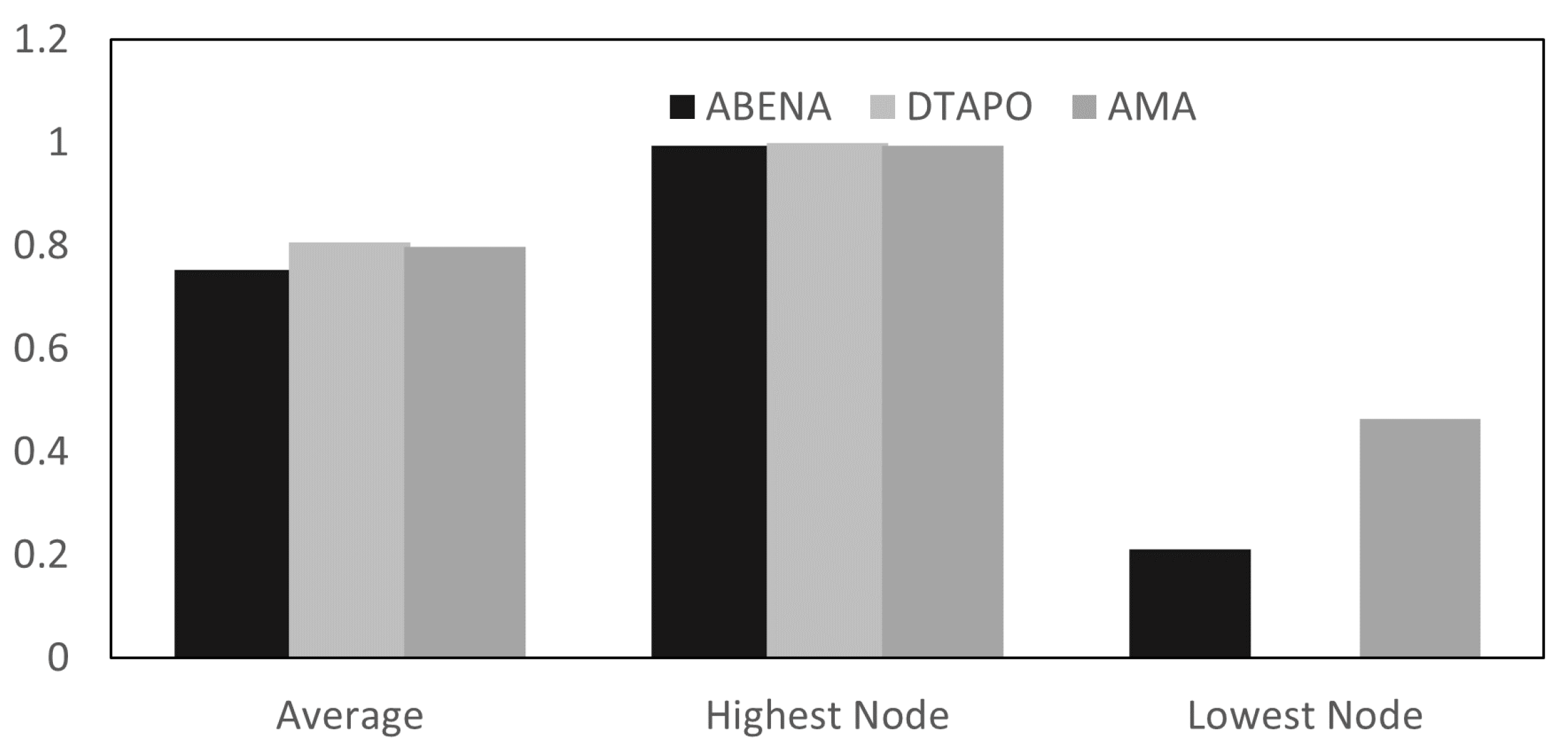
4.3. Average Comparison of MTTF
4.4. Average Comparison of Temperature
4.5. Comparison of Utilisation
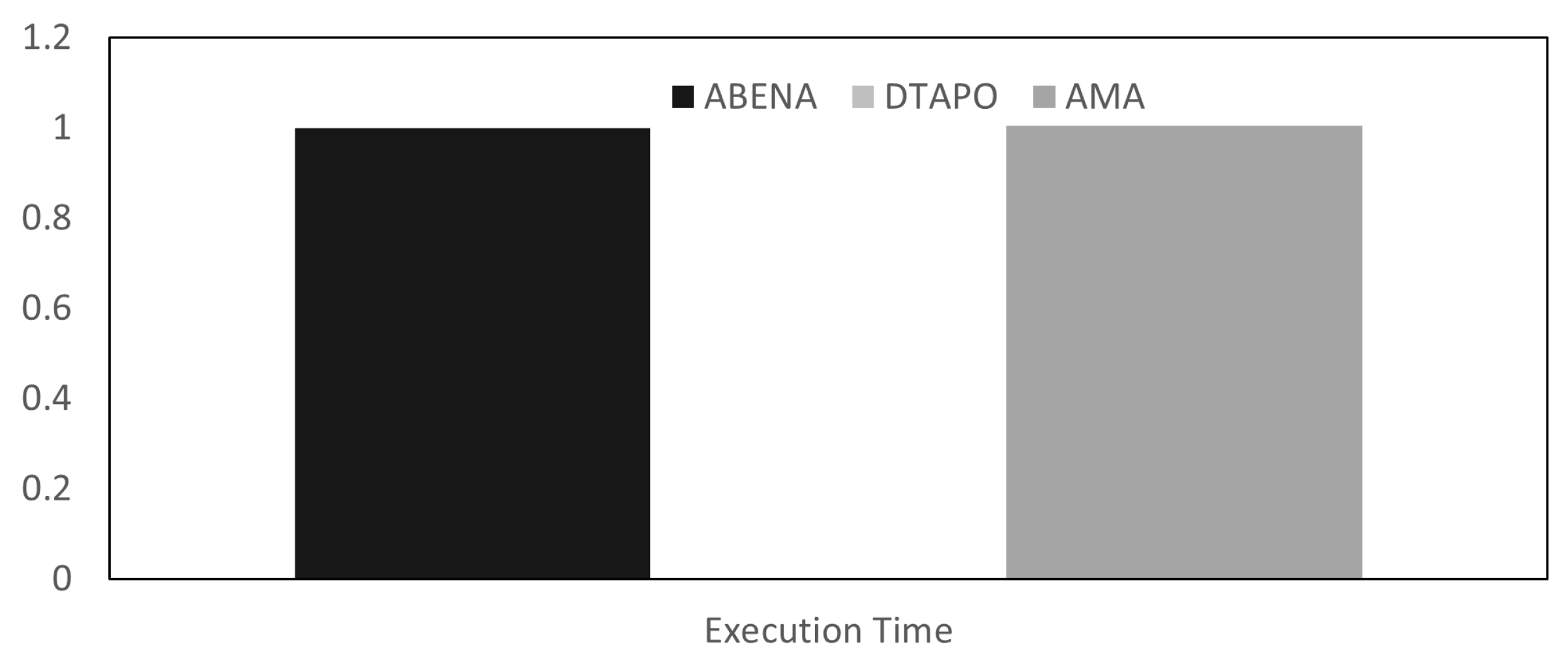
4.6. Execution Time
5. Summary
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Henkel, J.; Khdr, H.; Pagani, S.; Shafique, M. New trends in dark silicon. In Proceedings of the 52nd Annual Design Automation Conference, San Francisco, CA, USA, 8–12 June 2015. [Google Scholar]
- Li, M.; Liu, W.; Yang, L.; Chen, P.; Chen, C. Chip Temperature Optimization for Dark Silicon Many-Core Systems. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 941–953. [Google Scholar] [CrossRef]
- Sha, S.; Wen, W.; Ren, S.; Quan, G. M-Oscillating: Performance Maximization on Temperature-Constrained Multi-Core Processors. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 2528–2539. [Google Scholar] [CrossRef]
- Niknam, S.; Pathania, A.; Pimentel, A.D. T-TSP: Transient-Temperature Based Safe Power Budgeting in Multi-/Many-Core Processors. Power 2021, 4, 8. [Google Scholar]
- Chen, X.; Peh, L.S. Leakage power modeling and optimization in interconnection networks. In Proceedings of the 2003 International Symposium on Low Power Electronics and Design; 2003. Available online: https://ieeexplore.ieee.org/document/1231841 (accessed on 2 March 2023).
- Mohammed, M.S.; Al-Dhamari, A.K.; Ab Rahman, A.A.H.; Paraman, N.; Al-Kubati, A.A.; Marsono, M.N. Temperature-Aware Task Scheduling for Dark Silicon Many-Core System-on-Chip. In Proceedings of the 2019 8th International Conference on Modeling Simulation and Applied Optimization (ICMSAO), Manama, Bahrain, 15–17 April 2019. [Google Scholar]
- Mohammed, M.S.; Al-Kubati, A.A.; Paraman, N.; Ab Rahman, A.A.H.; Marsono, M.N. DTaPO: Dynamic Thermal-Aware Performance Optimization for Dark Silicon Many-Core Systems. Electronics 2020, 9, 1980. [Google Scholar] [CrossRef]
- Mohammed, M.S.; Paraman, N.; Ab Rahman, A.A.H.; Ghaleb, F.A.; Al-Dhamari, A.; Marsono, M.N. PEW: Prediction-Based Early Dark Cores Wake-up Using Online Ridge Regression for Many-Core Systems. IEEE Access 2021, 9, 124087–124099. [Google Scholar] [CrossRef]
- Bashir, Q.; Shehzad, M.N.; Awais, M.N.; Baig, S.; Dogar, M.G.; Rashid, A. An online temperature-aware scheduling technique to avoid thermal emergencies in multiprocessor systems. Comput. I Electr. Eng. 2018, 70, 83–98. [Google Scholar] [CrossRef]
- Bashir, Q.; Shehzad, M.N.; Awais, M.N.; Farooq, U.; Hamayun, M.T.; Ali, I. A scheduling based energy-aware core switching technique to avoid thermal threshold values in multi-core processing systems. Microprocess. Microsyst. 2018, 61, 296–305. [Google Scholar] [CrossRef]
- Feng, C.; Liao, Z.; Lu, Z.; Jantsch, A.; Zhao, Z. Performance analysis of on-chip bufferless router with multi-ejection ports. In Proceedings of the 2015 IEEE 11th International Conference on ASIC (ASICON), Chengdu, China; 2015. Available online: https://ieeexplore.ieee.org/document/7517174 (accessed on 2 March 2023).
- Fallin, C.; Craik, C.; Mutlu, O. CHIPPER: A low-complexity bufferless deflection router. In Proceedings of the 2011 IEEE 17th International Symposium on High Performance Computer Architecture; 2011. Available online: https://ieeexplore.ieee.org/document/5749724 (accessed on 2 March 2023).
- Daya, B.K.; Peh, L.S.; Chandrakasan, A.P. Towards High-Performance Bufferless NoCs with SCEPTER. IEEE Comput. Archit. Lett. 2016, 15, 62–65. [Google Scholar] [CrossRef]
- Li, C.; Ampadu, P. A compact low-power eDRAM-based NoC buffer. In Proceedings of the 2015 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED); 2015. Available online: https://ieeexplore.ieee.org/abstract/document/7273500 (accessed on 2 March 2023).
- Nasirian, N.; Bayoumi, M. Low-latency power-efficient adaptive router design for network-on-chip. In Proceedings of the 2015 28th IEEE International System-on-Chip Conference (SOCC); 2015. Available online: https://ieeexplore.ieee.org/abstract/document/7406965 (accessed on 2 March 2023).
- DiTomaso, D.; Kodi, A.K.; Louri, A.; Bunescu, R. Resilient and Power-Efficient Multi-Function Channel Buffers in Network-on-Chip Architectures. IEEE Trans. Comput. 2015, 64, 3555–3568. [Google Scholar] [CrossRef]
- Zheng, H.; Louri, A. EZ-Pass: An Energy amp; Performance-Efficient Power-Gating Router Architecture for Scalable NoCs. IEEE Comput. Archit. Lett. 2015, 17, 88–91. [Google Scholar] [CrossRef]
- Fang, J.; Cai, M.; Leng, Z.; Liu, S. A Perspective from Exploiting Heterogeneity on Networks-on-Chip Based on Dark Silicon Mitigation. In Proceedings of the 2016 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 15–17 December 2016. [Google Scholar]
- Wang, J.; Tim, Y.; Wong, W.F.; Ong, Z.L.; Sun, Z.; Li, H.H. A coherent hybrid SRAM and STT-RAM L1 cache architecture for shared memory multicores. In Proceedings of the 2014 19th Asia and South Pacific Design Automation Conference (ASP-DAC); 2014. Available online: https://ieeexplore.ieee.org/document/6742958 (accessed on 2 March 2023).
- Li, J.; Xue, C.J.; Xu, Y. STT-RAM based energy-efficiency hybrid cache for CMPs. In Proceedings of the 2011 IEEE/IFIP 19th International Conference on VLSI and System-on-Chip; 2011. Available online: https://ieeexplore.ieee.org/abstract/document/6081626 (accessed on 2 March 2023).
- Shen, F.; He, Y.; Zhang, J.; Jiang, N.; Li, Q.A.; Li, J. Feedback Learning Based Dead Write Termination for Energy Efficient STT-RAM Caches. Chin. J. Electron. 2017, 26, 460–467. [Google Scholar] [CrossRef]
- Chakraborty, S.; Kapoor, H.K. Static energy reduction by performance linked dynamic cache resizing. In Proceedings of the 2016 IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC); 2016. Available online: https://ieeexplore.ieee.org/document/7753549 (accessed on 2 March 2023).
- Ofori-Attah, E.; Agyeman, M.O. An Ageing-Aware and Temperature Mapping Algorithm For Multi-Level Cache Nodes. IEEE Access 2022, 11, 19162–19172. [Google Scholar] [CrossRef]
- Das, A.; Kumar, A.; Veeravalli, B. Reliability-driven task mapping for lifetime extension of networks-on-chip based multiprocessor systems. In Proceedings of the 2013 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 18–22 March 2013. [Google Scholar]
- Yeh, L.T.; Chu, R.C.; Janna, W.S. Thermal Management of Microelectronic Equipment: Heat Transfer Theory, Analysis Methods, and Design Practices. ASME Press Book Series on Electronic Packaging. Appl. Mech. Rev. 2003, 56, B46–B48. [Google Scholar] [CrossRef]
- Bowman, K.A.; Duvall, S.G.; Meindl, J.D. Impact of die-to-die and within-die parameter fluctuations on the maximum clock frequency distribution for gigascale integration. IEEE J. Solid-State Circuits 2002, 37, 183–190. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, H.; Dick, R.P.; Wang, H.; Shang, L. Thermal vs Energy Optimization for DVFS-Enabled Processors in Embedded Systems. In Proceedings of the 8th International Symposium on Quality Electronic Design (ISQED’07); 2007. Available online: https://ieeexplore.ieee.org/document/4149035 (accessed on 2 March 2023).
- Kolpe, T.; Zhai, A.; Sapatnekar, S.S. Enabling Improved Power Management in Multicore Processors through Clustered DVFS. In Proceedings of the 2011 Design, Automation & Test in Europe; 2011. Available online: https://ieeexplore.ieee.org/document/5763052 (accessed on 2 March 2023).
- Hameed, F.; Al Faruque, M.A.; Henkel, J. Dynamic Thermal Management in 3D Multi-Core Architecture through Run-Time Adaptation. In Proceedings of the 2011 Design, Automation & Test in Europe; 2011. Available online: https://ieeexplore.ieee.org/document/5763053 (accessed on 2 March 2023).
- Isci, C.; Contreras, G.; Martonosi, M. Live, Runtime Phase Monitoring and Prediction on Real Systems with Application to Dynamic Power Management. In Proceedings of the 2006 39th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO’06); 2006. Available online: https://ieeexplore.ieee.org/document/4041860 (accessed on 2 March 2023).
- Pricopi, M.; Mitra, T. Task Scheduling on Adaptive Multi-Core. IEEE Trans. Comput. 2014, 63, 2590–2603. [Google Scholar] [CrossRef]
- Sahin, O.; Varghese, P.T.; Coskun, A.K. Just enough is more: Achieving sustainable performance in mobile devices under thermal limitations. In Proceedings of the 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD); 2015. Available online: https://ieeexplore.ieee.org/document/7372658 (accessed on 2 March 2023).
- Khdr, H.; Pagani, S.; Sousa, E.; Lari, V.; Pathania, A.; Hannig, F.; Shafique, M.; Teich, J.; Henkel, J. Power Density-Aware Resource Management for Heterogeneous Tiled Multicores. IEEE Trans. Comput. 2017, 66, 488–501. [Google Scholar] [CrossRef]
- Haghbayan, M.H.; Miele, A.; Rahmani, A.M.; Liljeberg, P.; Tenhunen, H. A Lifetime-Aware Runtime Mapping Approach for Many-core Systems in the Dark Silicon Era. In Proceedings of the 2016 Design, Automation & Test in Europe Conference & Exhibition (DATE), 2016, Dresden, Germany; Available online: https://dl.acm.org/doi/abs/10.5555/2971808.2972005 (accessed on 2 March 2023).
- Rathore, V.; Chaturvedi, V.; Singh, A.K.; Srikanthan, T.; Shafique, M. Longevity Framework: Leveraging Online Integrated Aging-Aware Hierarchical Mapping and VF-Selection for Lifetime Reliability Optimization in Manycore Processors. IEEE Trans. Comput. 2021, 70, 1106–1119. [Google Scholar] [CrossRef]
- Gnad, D.; Shafique, M.; Kriebel, F.; Rehman, S.; Sun, D.; Henkel, J. Hayat: Harnessing Dark Silicon and variability for aging deceleration and balancing. In Proceedings of the 52nd Annual Design Automation Conference; 2015. Available online: https://ieeexplore.ieee.org/document/7167366 (accessed on 2 March 2023).
- Wen, S.; Wang, X.; Singh, A.K.; Jiang, Y.; Yang, M. Performance Optimization of Many-Core Systems by Exploiting Task Migration and Dark Core Allocation. IEEE Trans. Comput. 2022, 71, 92–106. [Google Scholar] [CrossRef]
- Trevor, E. Carlson and Wim Heirman and Stijn Eyerman and Ibrahim Hur and Lieven Eeckhout, An Evaluation of High-Level Mechanistic Core Models. ACM Trans. Archit. Code Optim. (TACO) 2014, 11, 1–25. [Google Scholar]
- Li, S.; Ahn, J.H.; Strong, R.D.; Brockman, J.B.; Tullsen, D.M.; Jouppi, N.P. McPAT: An integrated power, area, and timing modeling framework for multicore and manycore architectures. In Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture; 2009. Available online: https://ieeexplore.ieee.org/document/5375438 (accessed on 2 March 2023).
- Zhang, R.; Stan, M.R.; Skadron, K. HotSpot 6.0: Validation, Acceleration and Extension. Available online: https://libraopen.lib.virginia.edu/downloads/9g54xh74w (accessed on 19 March 2023).
- Srinivasan, J.; Adve, S.V.; Bose, P.; Rivers, J.A. The case for lifetime reliability-aware microprocessors. In Proceedings of the 31st Annual International Symposium on Computer Architecture; 2004. Available online: https://ieeexplore.ieee.org/document/1310781 (accessed on 2 March 2023).
- Carlson, T.E.; Heirman, W.; Eeckhout, L. Sniper: Exploring the level of abstraction for scalable and accurate parallel multi-core simulation. Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis; 2011. Available online: https://ieeexplore.ieee.org/abstract/document/6114398 (accessed on 19 March 2023).
- Woo, S.C.; Ohara, M.; Torrie, E.; Singh, J.P.; Gupta, A. The SPLASH-2 programs: Characterization and methodological considerations. ACM SIGARCH Comput. Archit. News 1995, 23, 24–36. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Application | fft |
| Temperature threshold | 90 |
| Failure Mechanism | TDDB |
| L1 Instruction Cache | 32 kB, 4-way set-associative, 64B Block Size |
| L2 Cache | 51 kB, 4-way set-associative, 64B Block Size |
| L3 Cache | 8129, 23 Block Size |
| Technology | 22 nm |
| Network size | 8 × 8 NoC |
| Algorithm | ABENA-P |
| DVFS | No |
| Parameter | Utilisation (%) | Temperature (°) | Av. MTTF | Highest MTTF |
|---|---|---|---|---|
| Task 1 | 52–53 | 74–77 | 469.225 | 542 |
| Tasks 2–8 | 93–95 | 71–77 | 463.53 | 492 |
| Parameter | Value |
|---|---|
| Nodes | 64 |
| Core Frequency | 1 GHZ |
| Core Size | ×5.71 |
| L1 Data Cache | 32 kB, 4-way set-associative, 64B Block Size |
| L1 Instruction Cache | 32 kB, 4-way set-associative, 64B Block Size |
| L2 Cache | 512 kB, 4-way set-associative, 64B Block Size |
| L3 Cache | 8129, 23 Block Size |
| Applications | Radix, oceans, fft, barnes |
| Technology | 22 nm |
| Network size | 8 × 8 NoC |
| Temperature threshold | 90 |
| Failure Mechanism | TDDB |
| Algorithm | AMA |
| Voltage (in V) | Frequency (in MHz) |
|---|---|
| 1 | 1000 |
| 0.9 | 900 |
| 0.8 | 800 |
| 0.7 | 700 |
| 0.6 | 600 |
| 0.5 | 500 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ofori-Attah, E.; Agyeman, M.O. AMA: An Ageing Task Migration Aware for High-Performance Computing. J. Low Power Electron. Appl. 2023, 13, 36. https://doi.org/10.3390/jlpea13020036
Ofori-Attah E, Agyeman MO. AMA: An Ageing Task Migration Aware for High-Performance Computing. Journal of Low Power Electronics and Applications. 2023; 13(2):36. https://doi.org/10.3390/jlpea13020036
Chicago/Turabian StyleOfori-Attah, Emmanuel, and Michael Opoku Agyeman. 2023. "AMA: An Ageing Task Migration Aware for High-Performance Computing" Journal of Low Power Electronics and Applications 13, no. 2: 36. https://doi.org/10.3390/jlpea13020036
APA StyleOfori-Attah, E., & Agyeman, M. O. (2023). AMA: An Ageing Task Migration Aware for High-Performance Computing. Journal of Low Power Electronics and Applications, 13(2), 36. https://doi.org/10.3390/jlpea13020036