
PageRank Implemented with the MPI Paradigm Running on a Many-Core Neuromorphic Platform



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Background
2.1. PageRank Algorithm
- is the PageRank value of target page A
- N is the total number of pages in the domain
- n is the number of pages such that a link exists involving both and A
- is the total number of outgoing links for
- d is the so-called damping factor, used for tuning; its typical value is 0.85.
2.2. Neuromorphic Platforms
- BrainScaleS [14]: the project goal is to provide a hardware platform emulating biological neurons at higher-than-real-time speed. It is realized with transistors working above threshold. Synapses and neurons can be externally configured through high-end FPGAs, and analogue synapses are delivered using wafer-scale integration. The target of this architecture is the simulation of SNNs in accelerated time, so that a simulation that would normally require months or years can be executed in minutes/hours.
- Dynap-SEL [15]: a VLSI chip, its name stands for Dynamic Asynchronous Processor Scalable and Learning. It counts 5 neuromorphic cores and neurons are connected via a multi-router hierarchical organization following a mesh schema. Two different grids are laid out: 16x16 and 4x4. This architecture has been developed targeting edge computing applications belonging to the IoT and Industry 4.0 domains.
- Loihi [16]: designed by Intel in 2017. It is a self-learning neuromorphic research chip, composed of 128 cores, counting around 130.000 neurons. The whole architecture follows a digital implementation, exploiting an asynchronous design to reduce power consumption. The architecture has potential applications as a SNN-based coprocessor in heterogeneous SoCs.
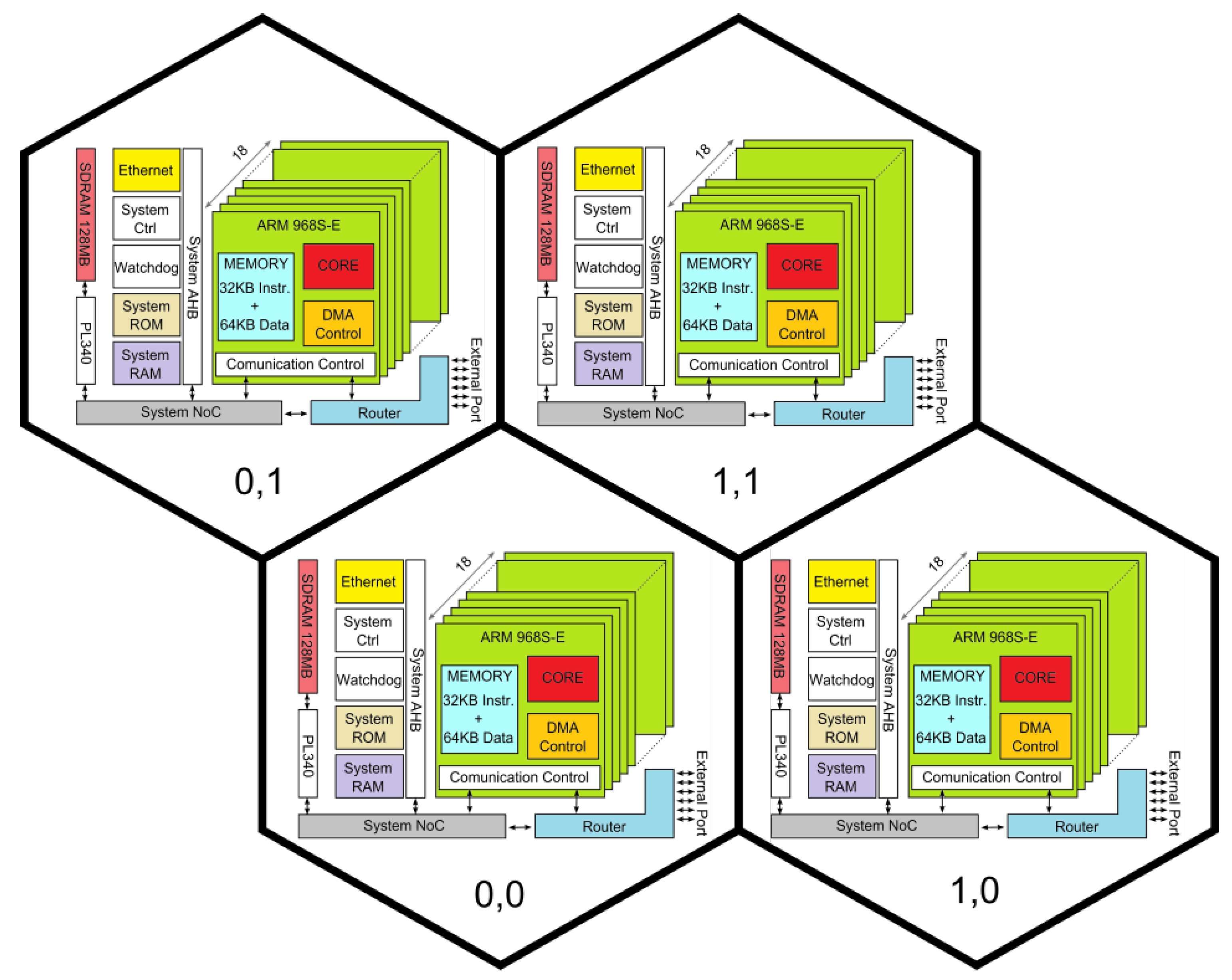
2.3. SpiNNaker Architecture and SW Stack
- P2P (Point-to-Point): a core transmits, through the monitor processor, to another core placed on the same chip or on a different chip.
- Multicast: a single core transmits simultaneously to a subset of cores, placed on the connected chips.
- Broadcast: a single core transmits simultaneously to every other core on the board.
2.4. Previous PageRank Implementation on SpiNNaker Using SpyNNaker
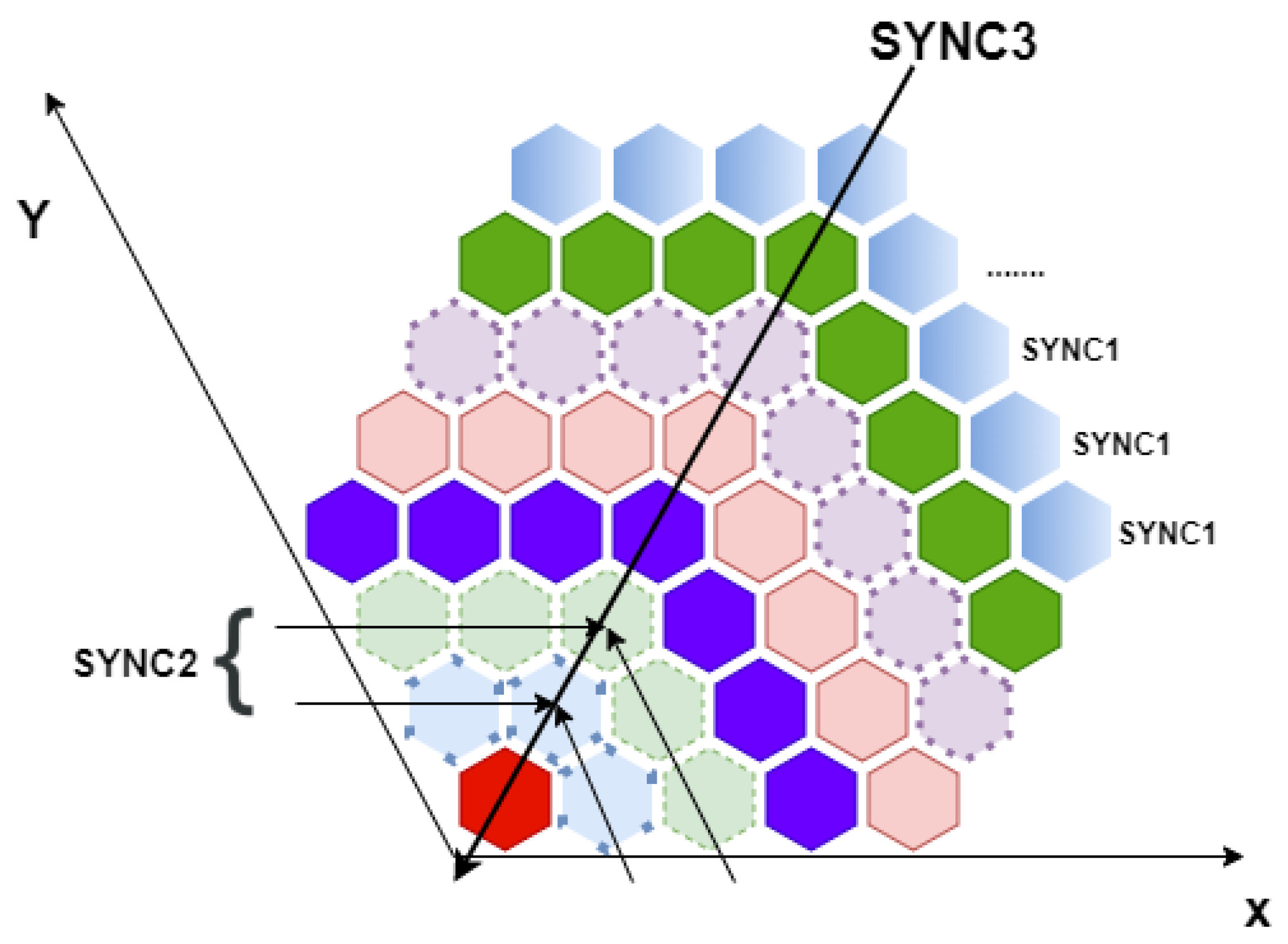
2.5. SpinMPI
- (1)
- Chip level: a SYNC1 packet is sent to all cores within a SpiNNaker chip. Once all synchronization packets have been collected, a SYNC2 packet is prepared and sent to the upper level.
- (2)
- Ring level: chips with the same distance from chip (0, 0) constitute a ring. The chips labeled with are the SYNC2 managers, responsible for collecting the synchronization packets of the group. Each ring master knows how many SYNC1 packets should be produced; once they have received all the expected packets, they produce a SYNC3.
- (3)
- Board level: all level 2 managers send SYNC3 packets to the level 3 manager, i.e., chip (0, 0). Once all level 2 managers have sent their packet, the level 3 manager sends a SYNCunlock, i.e., an ACK packet, over MPI Broadcast. This concludes the synchronization phase.
3. Methods
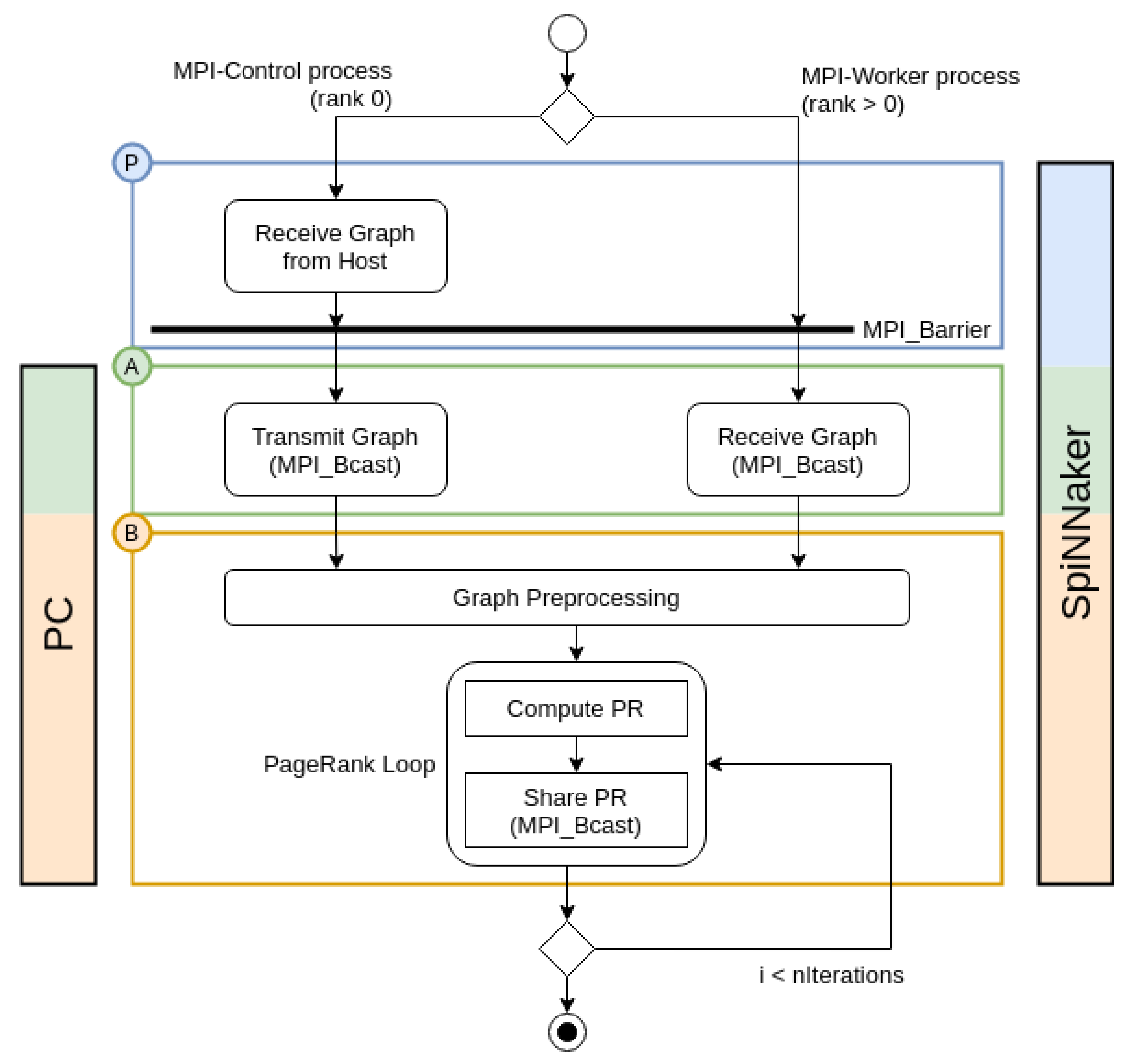
3.1. Implementation of PageRank with MPI
3.2. Adaptation of PageRank with MPI for SpiNNaker
4. Results and Discussion
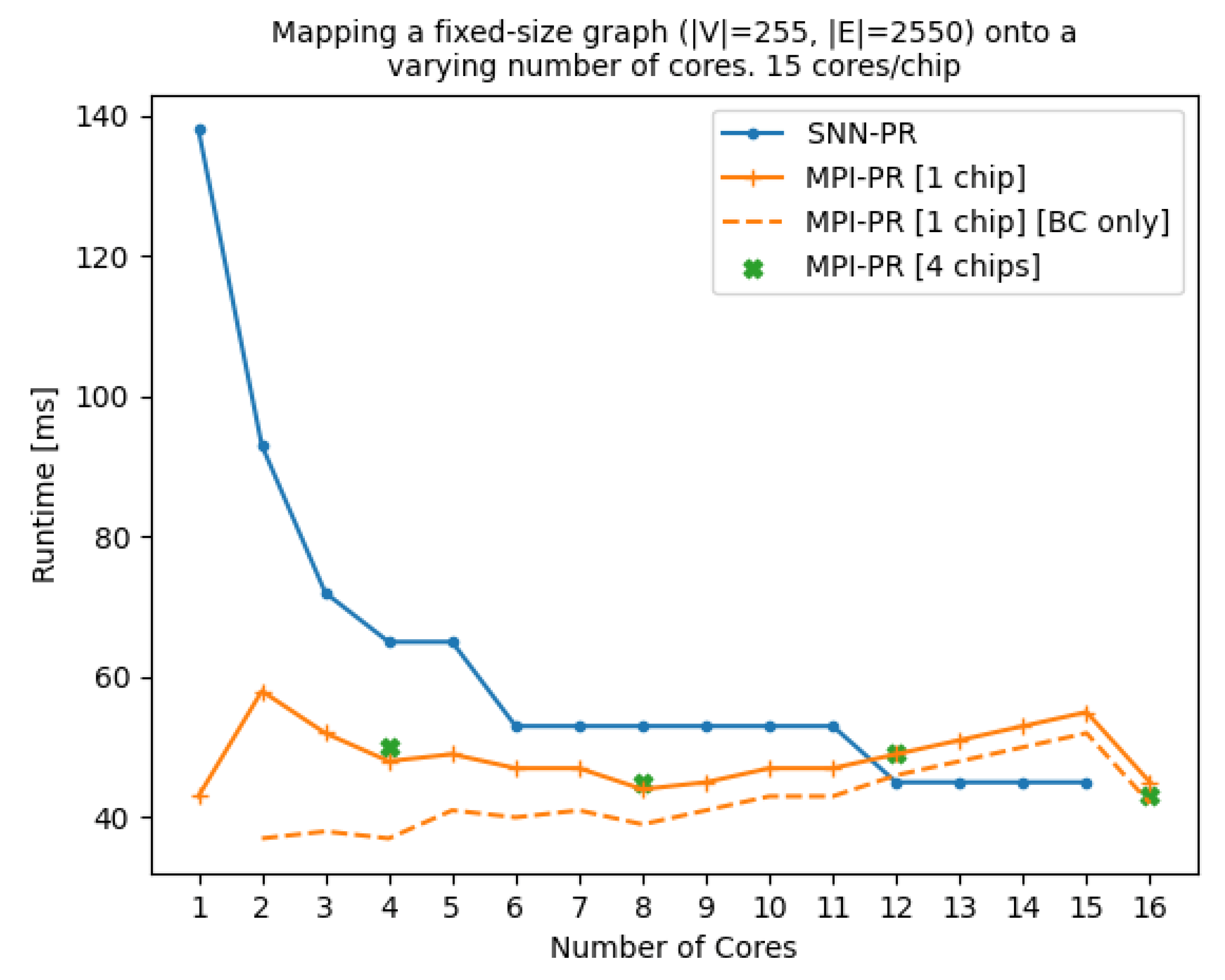
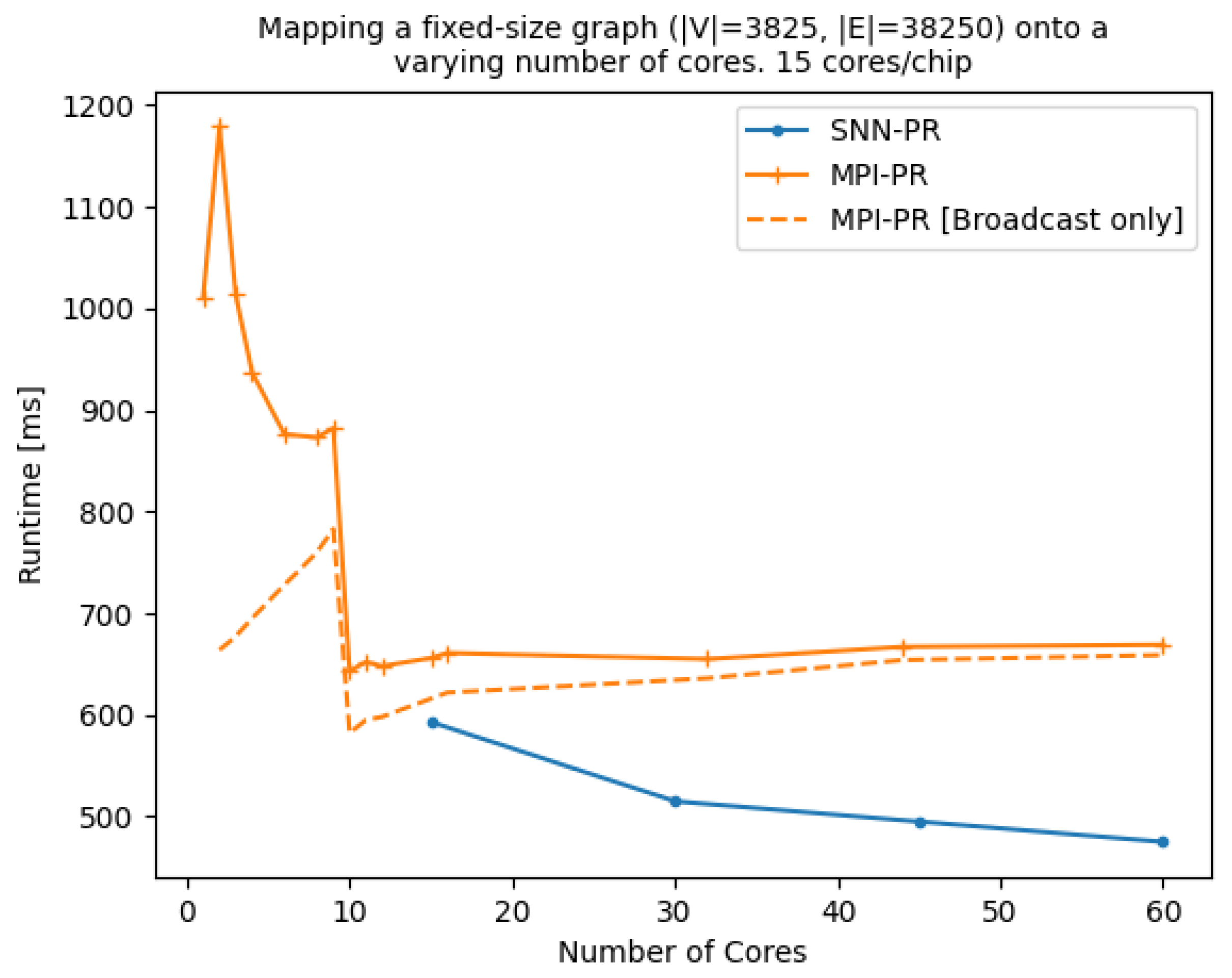
4.1. Comparison with Previous Versions of PageRank on SpiNNaker
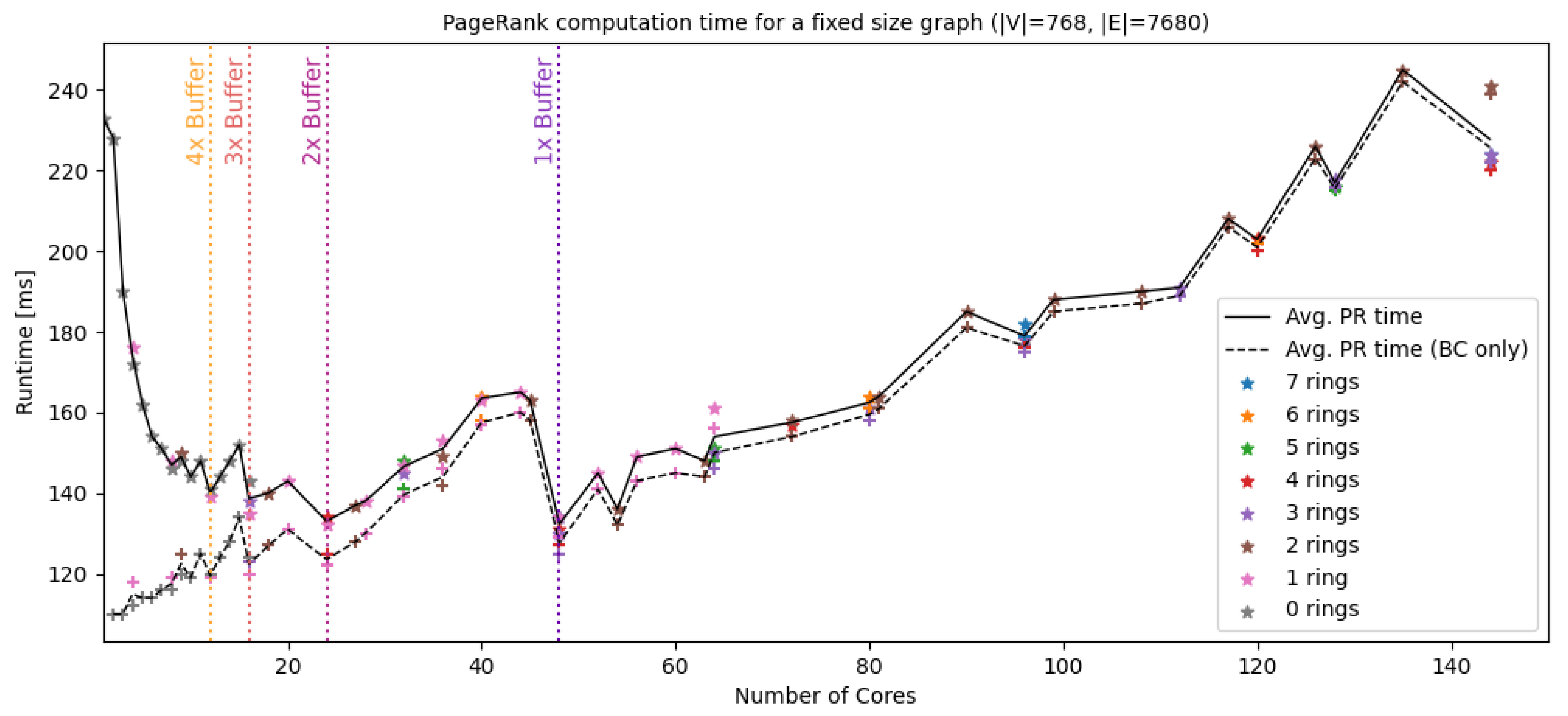
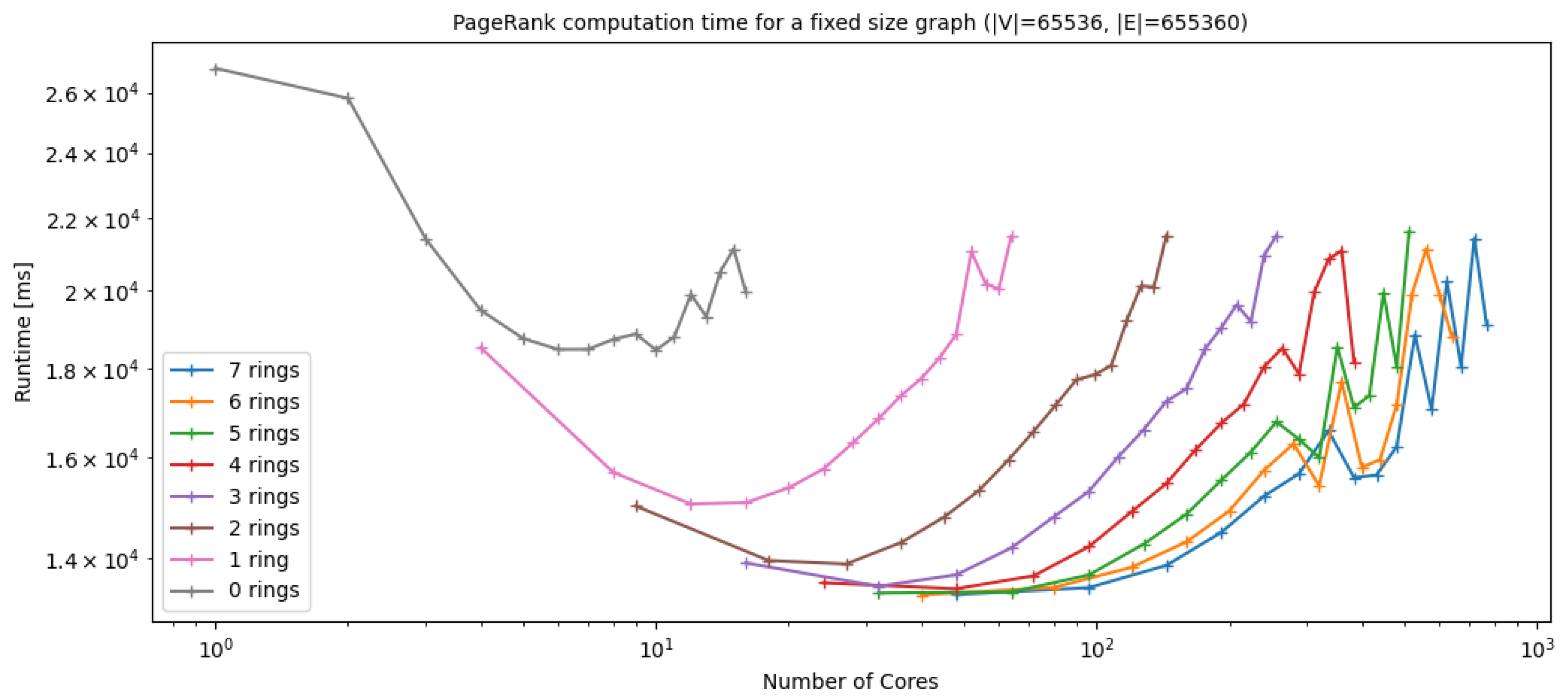
4.2. SpinMPI Performance Analysis on PageRank
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SpiNNaker | Spiking Neural Network Architecture |
| Dynap-SEL | Dynamic Asynchronous Processor Scalable and Learning |
| BrainScaleS | Brain-inspired multiscale computation in neuromorphic hybrid systems |
| DTCM | Tightly Coupled Data Memory |
| SNN-PR | SNN-based implementation of PageRank for SpiNNaker |
| MPI-PR | MPI-based implementation of PageRank for SpiNNaker |
References
- Kasabov, N.K. From von Neumann Machines to Neuromorphic Platforms. In Time-Space, Spiking Neural Networks and Brain-Inspired Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2019; pp. 661–677. [Google Scholar]
- Christensen, D.V.; Dittmann, R.; Linares-Barranco, B.; Sebastian, A.; Gallo, M.L.; Redaelli, A.; Slesazeck, S.; Mikolajick, T.; Spiga, S.; Menzel, S.; et al. 2021 Roadmap on Neuromorphic Computing and Engineering. arXiv 2021, arXiv:2105.05956. [Google Scholar]
- Schuman, C.D.; Potok, T.E.; Patton, R.M.; Birdwell, J.D.; Dean, M.E.; Rose, G.S.; Plank, J.S. A survey of neuromorphic computing and neural networks in hardware. arXiv 2017, arXiv:1705.06963. [Google Scholar]
- Young, A.R.; Dean, M.E.; Plank, J.S.; Rose, G.S. A Review of Spiking Neuromorphic Hardware Communication Systems. IEEE Access 2019, 7, 135606–135620. [Google Scholar] [CrossRef]
- Blin, L.; Awan, A.J.; Heinis, T. Using Neuromorphic Hardware for the Scalable Execution of Massively Parallel, Communication-Intensive Algorithms. In Proceedings of the 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), Zurich, Switzerland, 17–20 December 2018; pp. 89–94. [Google Scholar]
- Sugiarto, I.; Liu, G.; Davidson, S.; Plana, L.A.; Furber, S.B. High performance computing on spinnaker neuromorphic platform: A case study for energy efficient image processing. In Proceedings of the 2016 IEEE 35th International Performance Computing and Communications Conference (IPCCC), Las Vegas, NV, USA, 9–11 December 2016; pp. 1–8. [Google Scholar]
- Rhodes, O.; Bogdan, P.A.; Brenninkmeijer, C.; Davidson, S.; Fellows, D.; Gait, A.; Lester, D.R.; Mikaitis, M.; Plana, L.A.; Rowley, A.G.; et al. sPyNNaker: A Software Package for Running PyNN Simulations on SpiNNaker. Front. Neurosci. 2018, 12, 816. [Google Scholar] [CrossRef]
- Jin, X.; Furber, S.; Woods, J. Efficient modelling of spiking neural networks on a scalable chip multiprocessor. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 2812–2819. [Google Scholar]
- Brown, A.D.; Furber, S.B.; Reeve, J.S.; Garside, J.D.; Dugan, K.J.; Plana, L.A.; Temple, S. SpiNNaker—Programming model. IEEE Trans. Comput. 2015, 64, 1769–1782. [Google Scholar] [CrossRef]
- Gropp, W.D.; Gropp, W.; Lusk, E.; Skjellum, A. Using MPI: Portable Parallel Programming with the Message-Passing Interface; MIT Press: Cambridge, MA, USA, 1999; Volume 1. [Google Scholar]
- Barchi, F.; Urgese, G.; Macii, E.; Acquaviva, A. An Efficient MPI Implementation for Multi-Core Neuromorphic Platforms. In Proceedings of the 2017 New Generation of CAS (NGCAS), Genova, Italy, 6–9 September 2017; pp. 273–276. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab: Austin, TX, USA, 1999; Available online: http://ilpubs.stanford.edu:8090/422 (accessed on 29 April 2020).
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Schemmel, J.; Grübl, A.; Hartmann, S.; Kononov, A.; Mayr, C.; Meier, K.; Millner, S.; Partzsch, J.; Schiefer, S.; Scholze, S.; et al. Live demonstration: A scaled-down version of the brainscales wafer-scale neuromorphic system. In Proceedings of the 2012 IEEE International Symposium on Circuits and Systems (ISCAS), Seoul, Korea, 20–23 May 2012; p. 702. [Google Scholar]
- Moradi, S.; Qiao, N.; Stefanini, F.; Indiveri, G. A scalable multicore architecture with heterogeneous memory structures for dynamic neuromorphic asynchronous processors (dynaps). IEEE Trans. Biomed. Circuits Syst. 2017, 12, 106–122. [Google Scholar] [CrossRef] [PubMed]
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Furber, S.B.; Galluppi, F.; Temple, S.; Plana, L. The spinnaker project. Proc. IEEE 2014, 102, 652–665. [Google Scholar] [CrossRef]
- Furber, S.; Lester, D.; Plana, L.; Garside, J.; Painkras, E.; Temple, S.; Brown, A. Overview of the SpiNNaker System Architecture. Comput. IEEE Trans. 2013, 62, 2454–2467. [Google Scholar] [CrossRef]
- Rowley, A.G.D.; Brenninkmeijer, C.; Davidson, S.; Fellows, D.; Gait, A.; Lester, D.; Plana, L.A.; Rhodes, O.; Stokes, A.; Furber, S.B. SpiNNTools: The execution engine for the SpiNNaker platform. Front. Neurosci. 2019, 13, 231. [Google Scholar] [CrossRef] [PubMed]
- Urgese, G.; Barchi, F.; Macii, E. Top-down profiling of application specific many-core neuromorphic platforms. In Proceedings of the 2015 IEEE 9th International Symposium on Embedded Multicore/Many-core Systems-on-Chip, Turin, Italy, 23–25 September 2015; pp. 127–134. [Google Scholar]
- Urgese, G.; Barchi, F.; Macii, E.; Acquaviva, A. Optimizing network traffic for spiking neural network simulations on densely interconnected many-core neuromorphic platforms. IEEE Trans. Emerg. Top. Comput. 2018, 6, 317–329. [Google Scholar] [CrossRef]
- Barchi, F.; Urgese, G.; Siino, A.; Di Cataldo, S.; Macii, E.; Acquaviva, A. Flexible on-line reconfiguration of multi-core neuromorphic platforms. IEEE Trans. Emerg. Top. Comput. 2019. [Google Scholar] [CrossRef]
- Malewicz, G.; Austern, M.H.; Bik, A.J.; Dehnert, J.C.; Horn, I.; Leiser, N.; Czajkowski, G. Pregel: A System for Large-Scale Graph Processing. In SIGMOD ’10: Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data; Association for Computing Machinery: New York, NY, USA, 2010; pp. 135–146. [Google Scholar]
- Urgese, G.; Barchi, F.; Parisi, E.; Forno, E.; Acquaviva, A.; Macii, E. Benchmarking a Many-Core Neuromorphic Platform with an MPI-Based DNA Sequence Matching Algorithm. Electronics 2019, 8, 1342. [Google Scholar] [CrossRef]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Forno, E.; Salvato, A.; Macii, E.; Urgese, G. PageRank Implemented with the MPI Paradigm Running on a Many-Core Neuromorphic Platform. J. Low Power Electron. Appl. 2021, 11, 25. https://doi.org/10.3390/jlpea11020025
Forno E, Salvato A, Macii E, Urgese G. PageRank Implemented with the MPI Paradigm Running on a Many-Core Neuromorphic Platform. Journal of Low Power Electronics and Applications. 2021; 11(2):25. https://doi.org/10.3390/jlpea11020025
Chicago/Turabian StyleForno, Evelina, Alessandro Salvato, Enrico Macii, and Gianvito Urgese. 2021. "PageRank Implemented with the MPI Paradigm Running on a Many-Core Neuromorphic Platform" Journal of Low Power Electronics and Applications 11, no. 2: 25. https://doi.org/10.3390/jlpea11020025
APA StyleForno, E., Salvato, A., Macii, E., & Urgese, G. (2021). PageRank Implemented with the MPI Paradigm Running on a Many-Core Neuromorphic Platform. Journal of Low Power Electronics and Applications, 11(2), 25. https://doi.org/10.3390/jlpea11020025