Near-Threshold Voltage Design Techniques for Heterogenous Manycore System-on-Chips

Abstract
1. Introduction
2. NTV Circuit Design Methodology
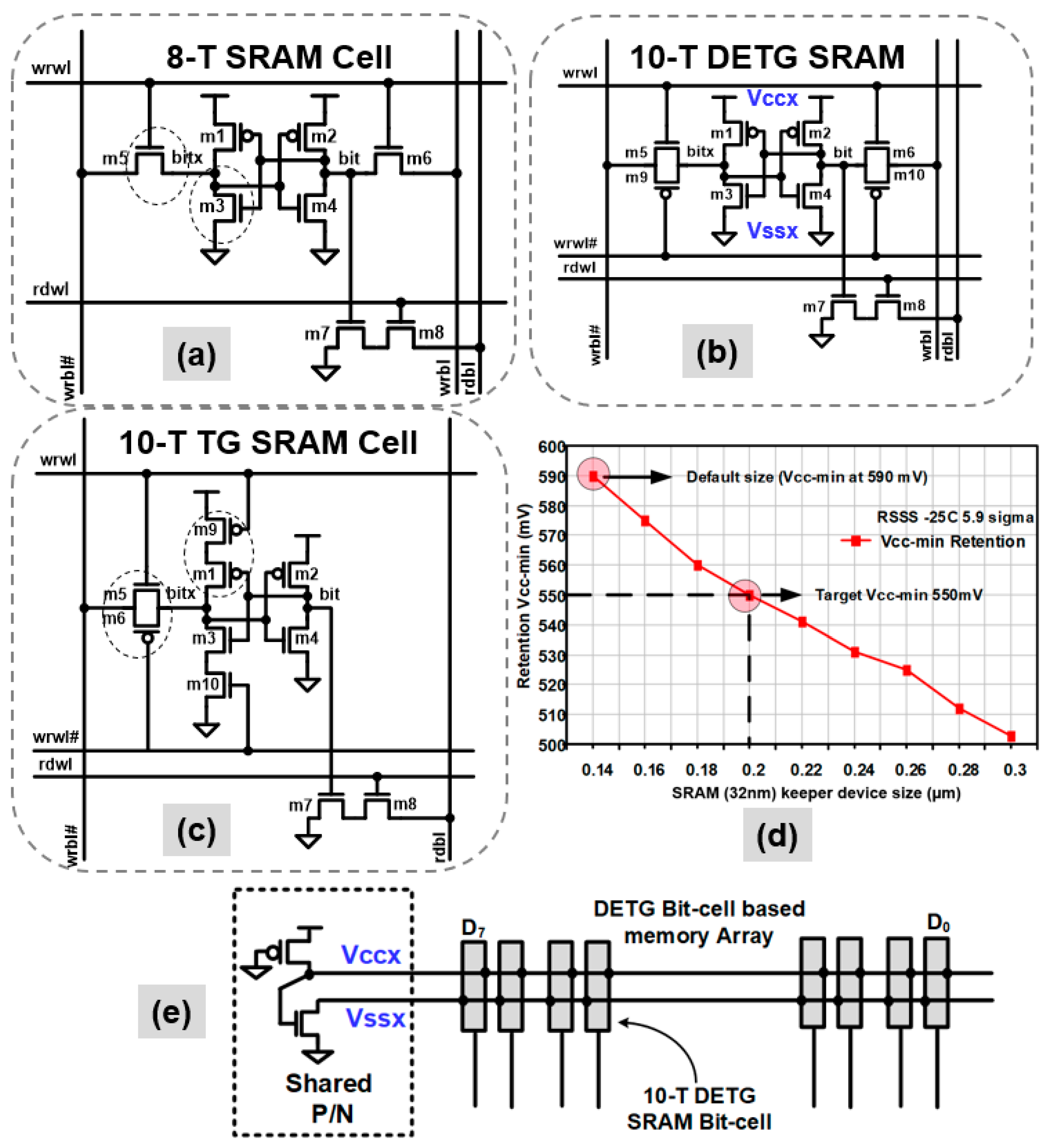
2.1. SRAM Memory and Register File (RF) Optimizations
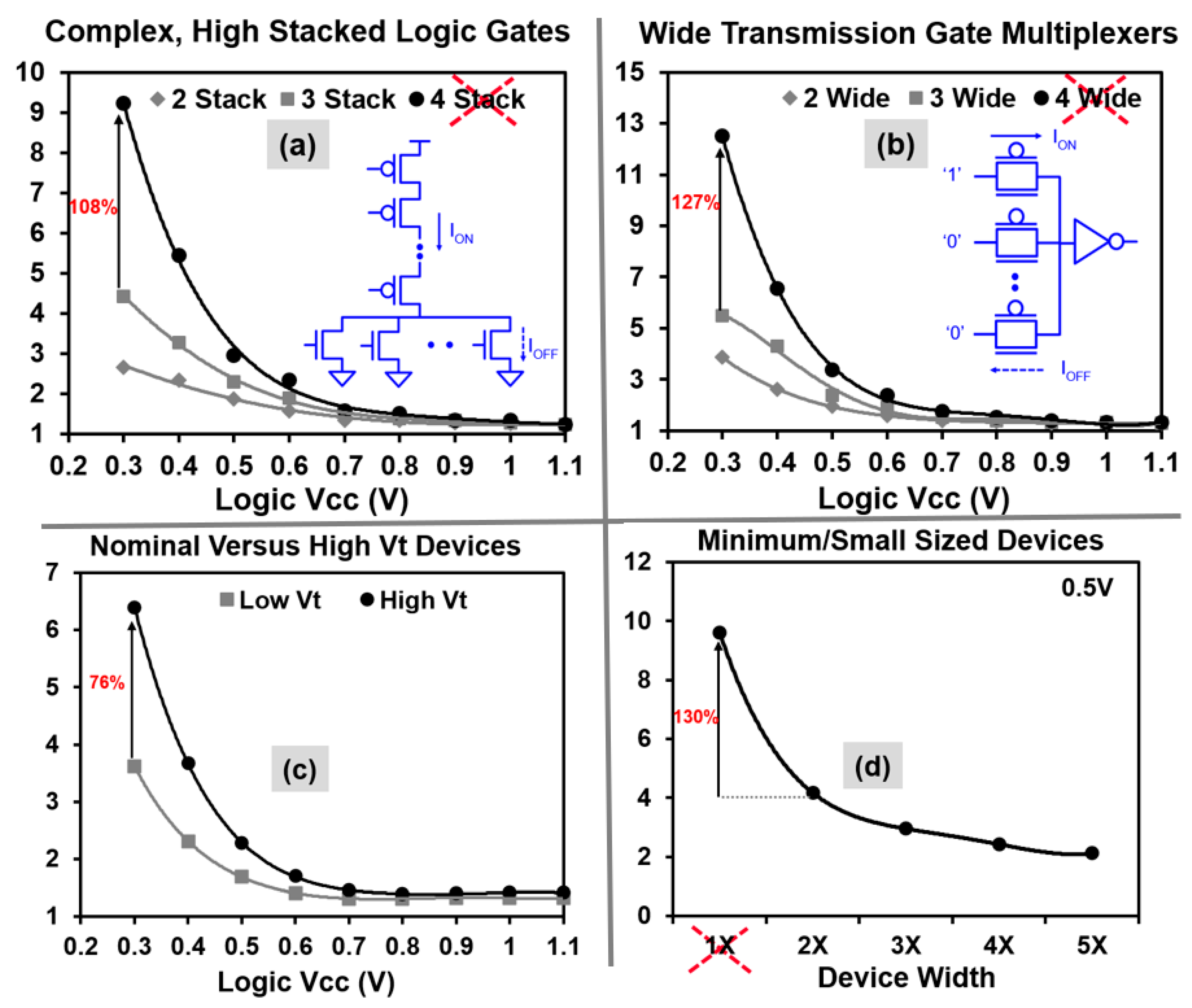
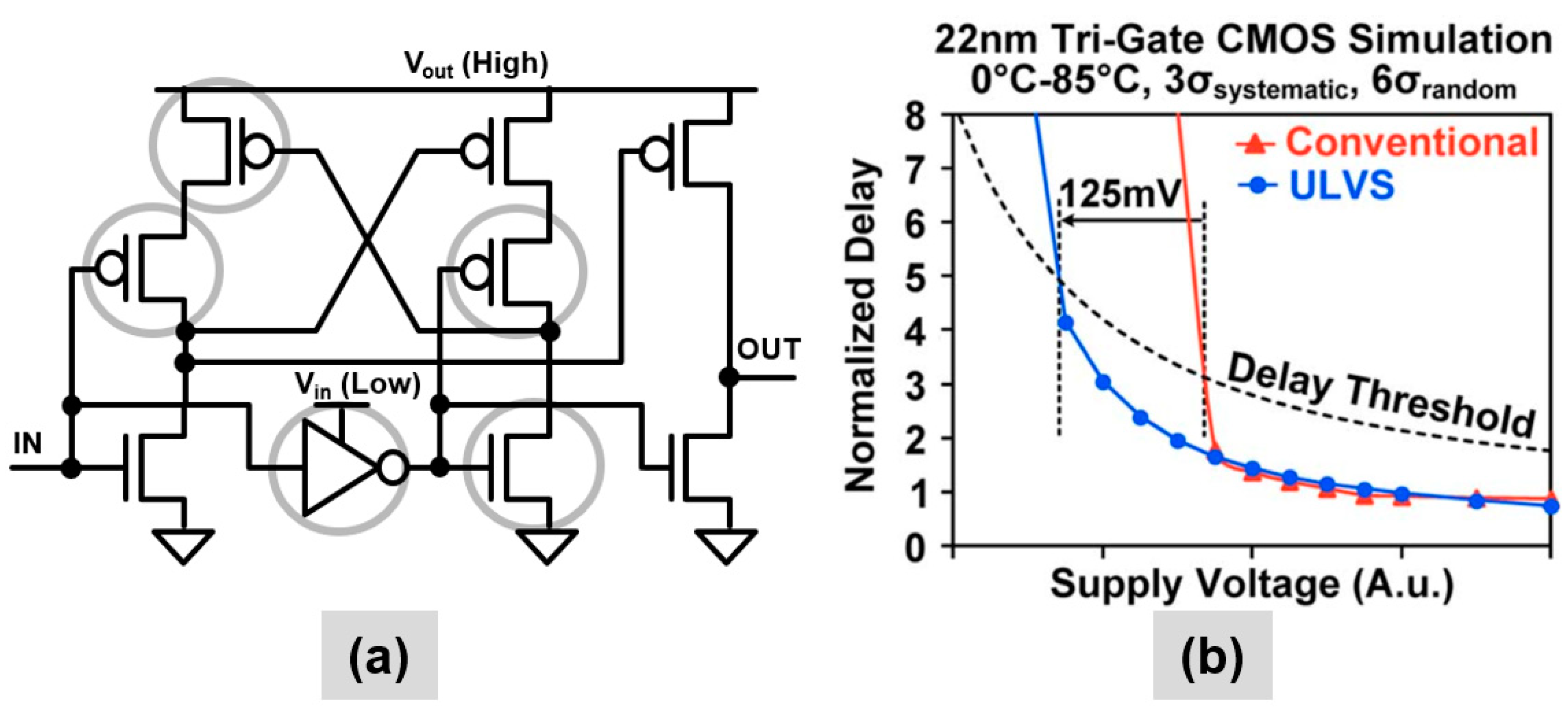
2.2. Combinational Cells Design Criteria
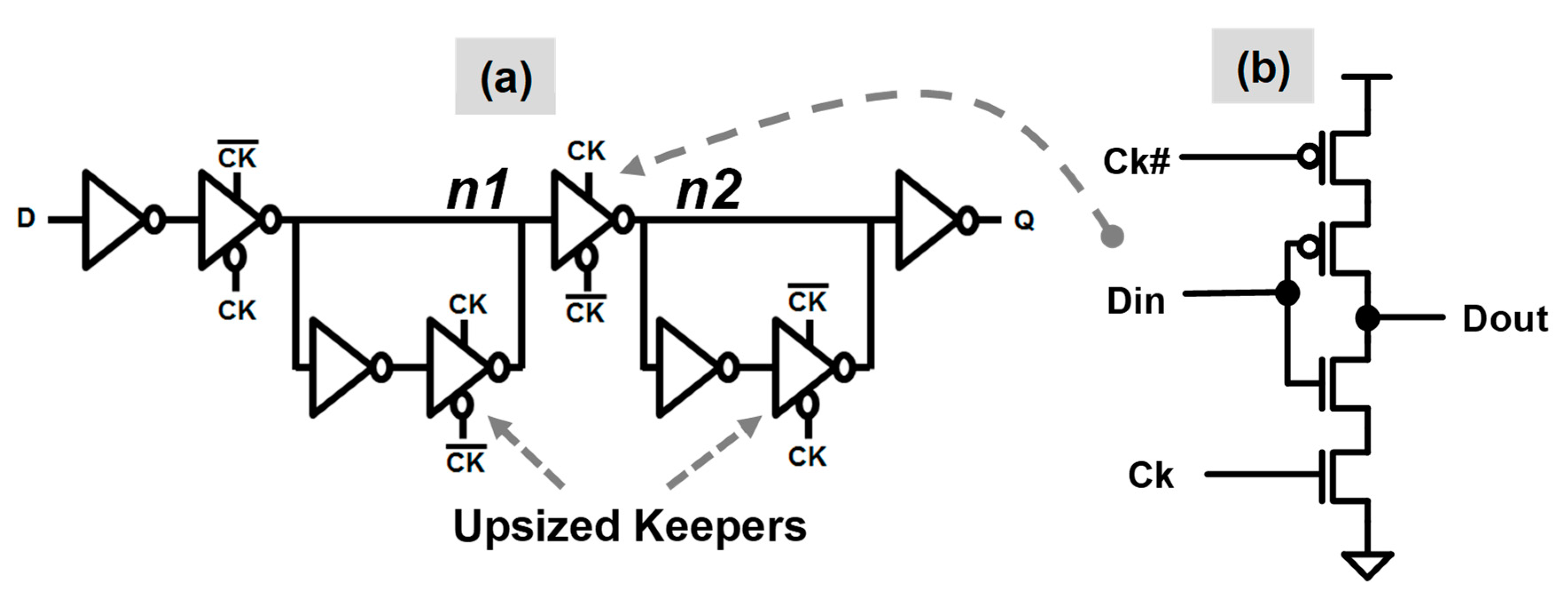
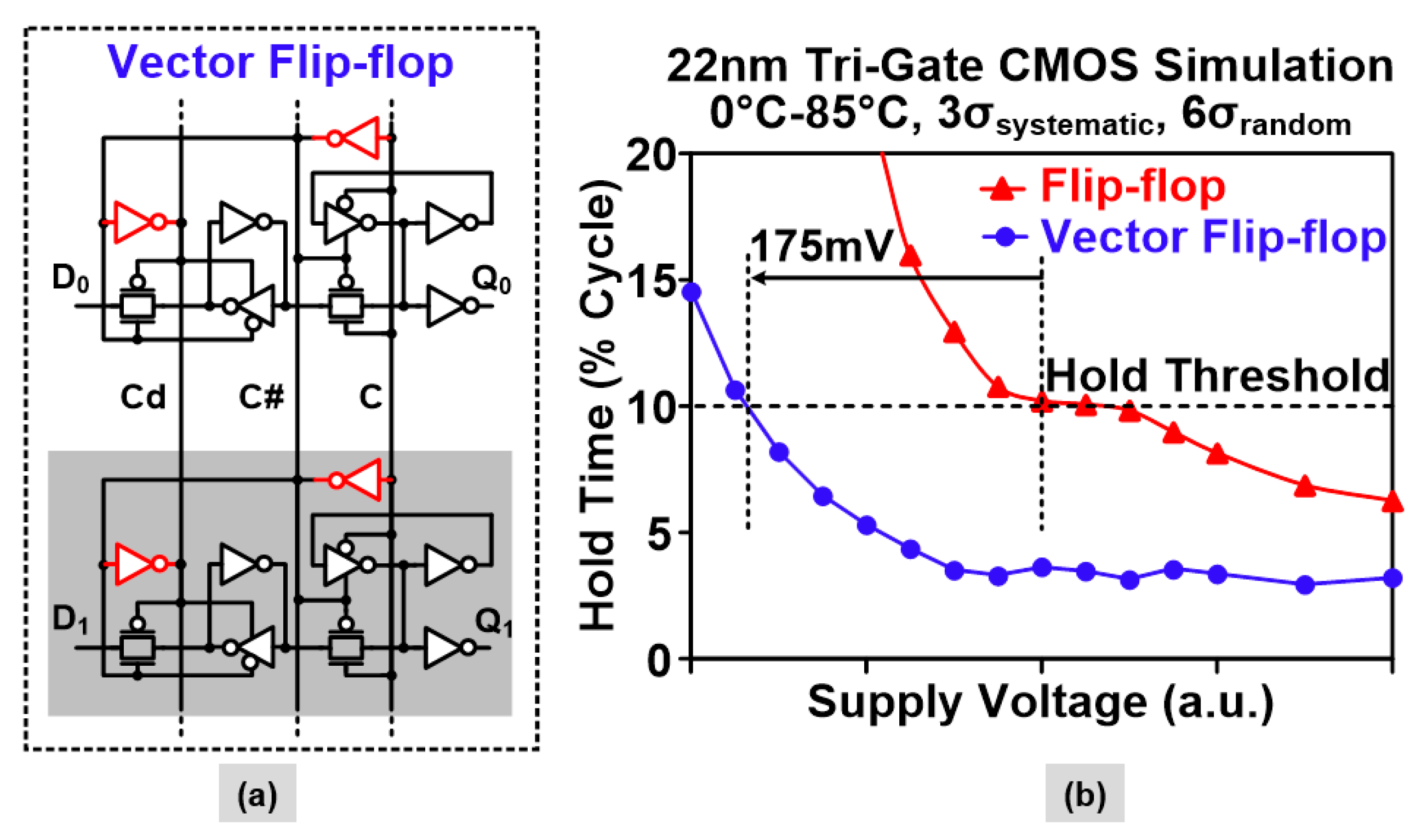
2.3. Sequential Circuit Optimizations
2.4. Level Shifter Circuit Optimizations
3. Architecture Driven NTV Resilient NoC Fabrics
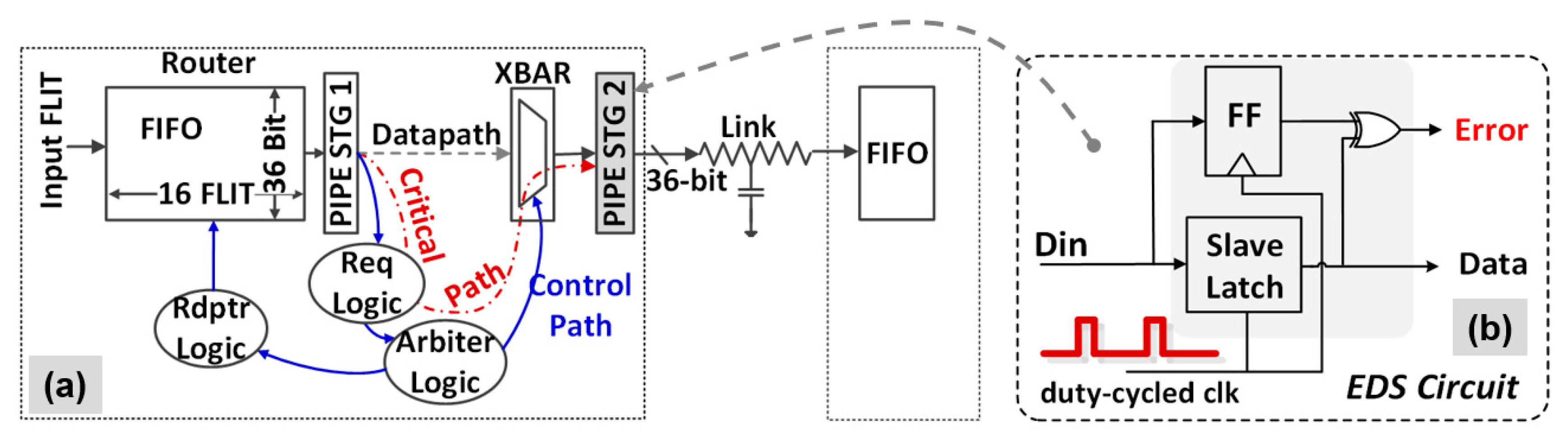
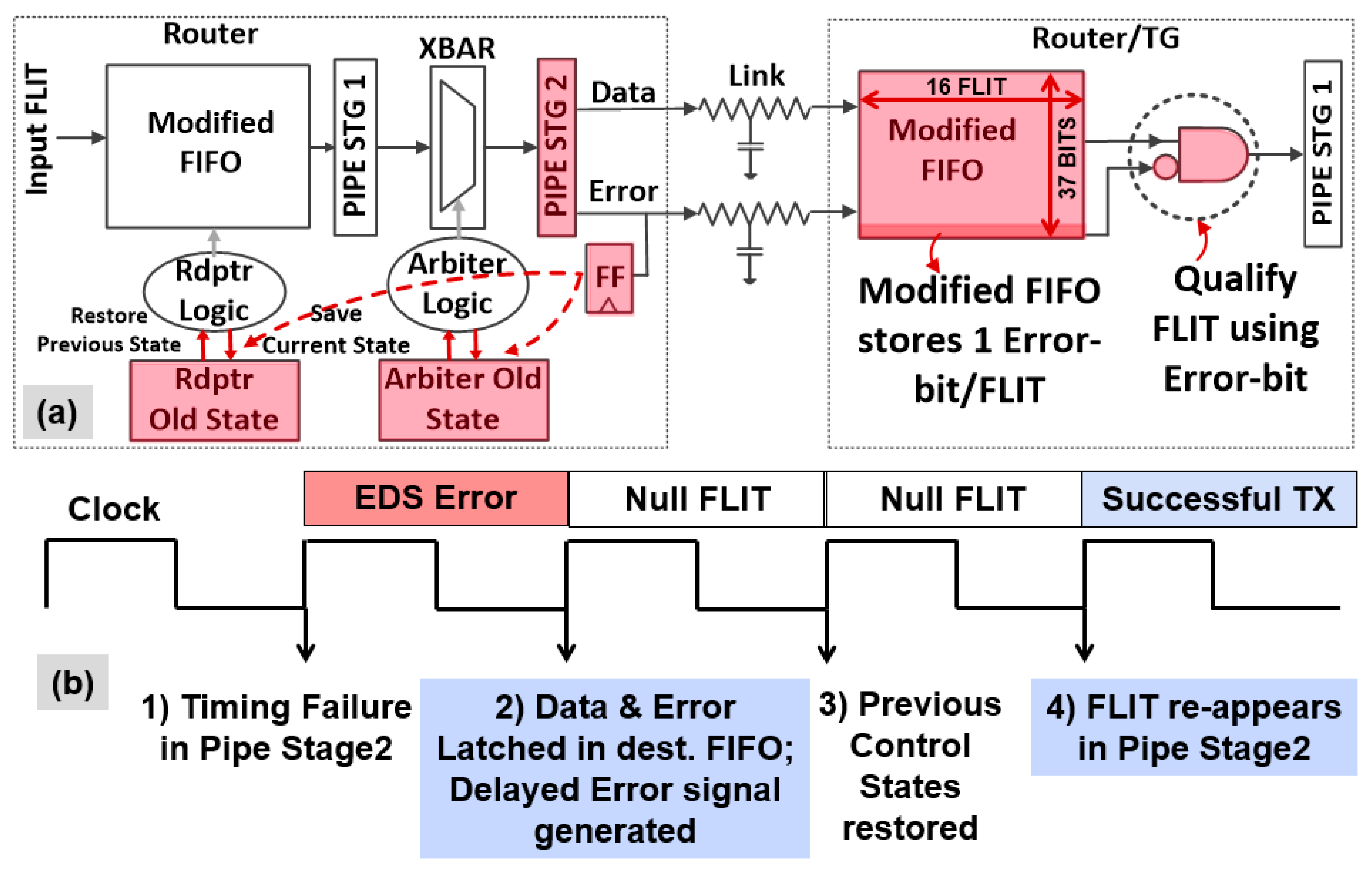
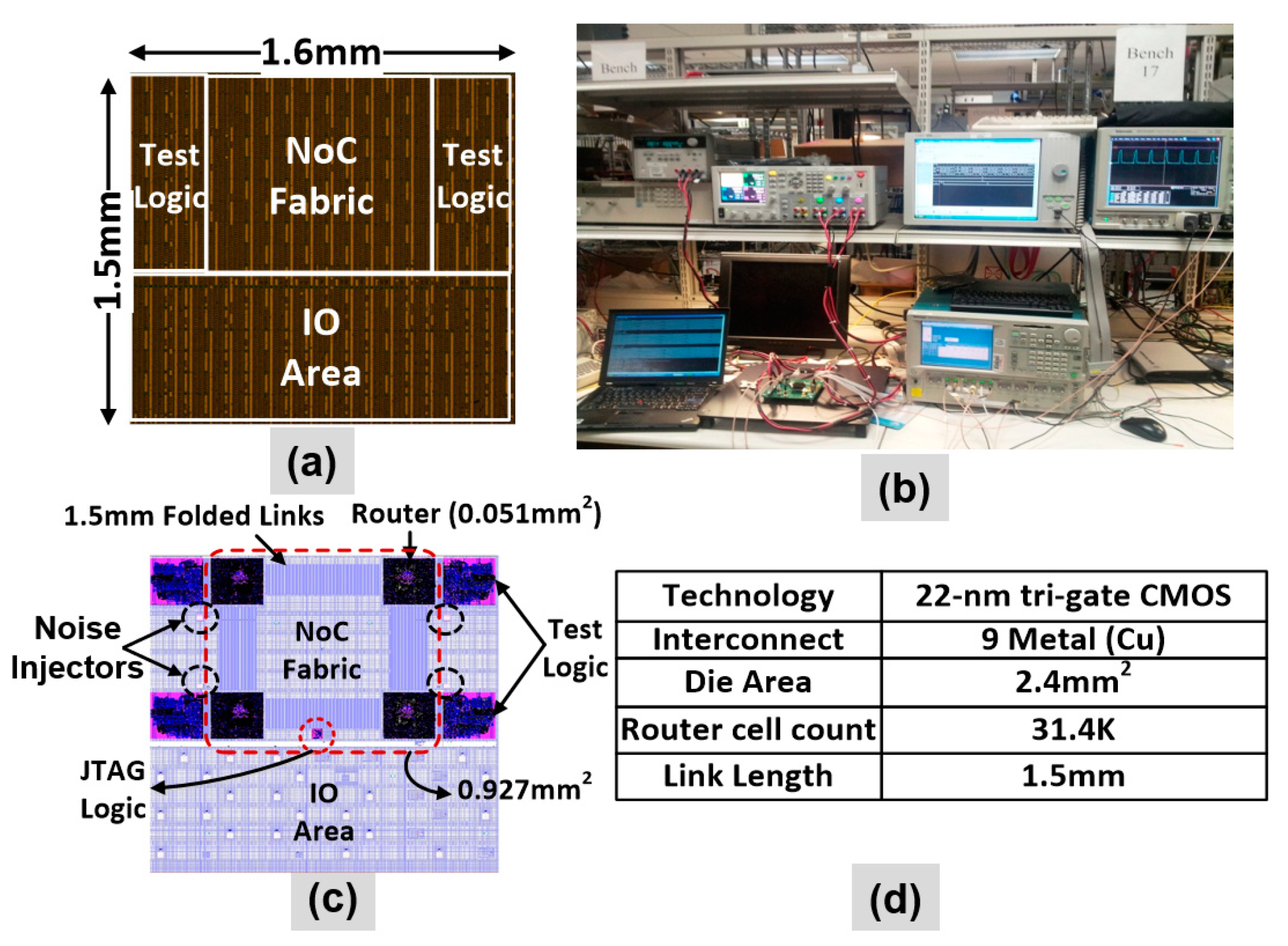
Resilient Router Architecture and Design
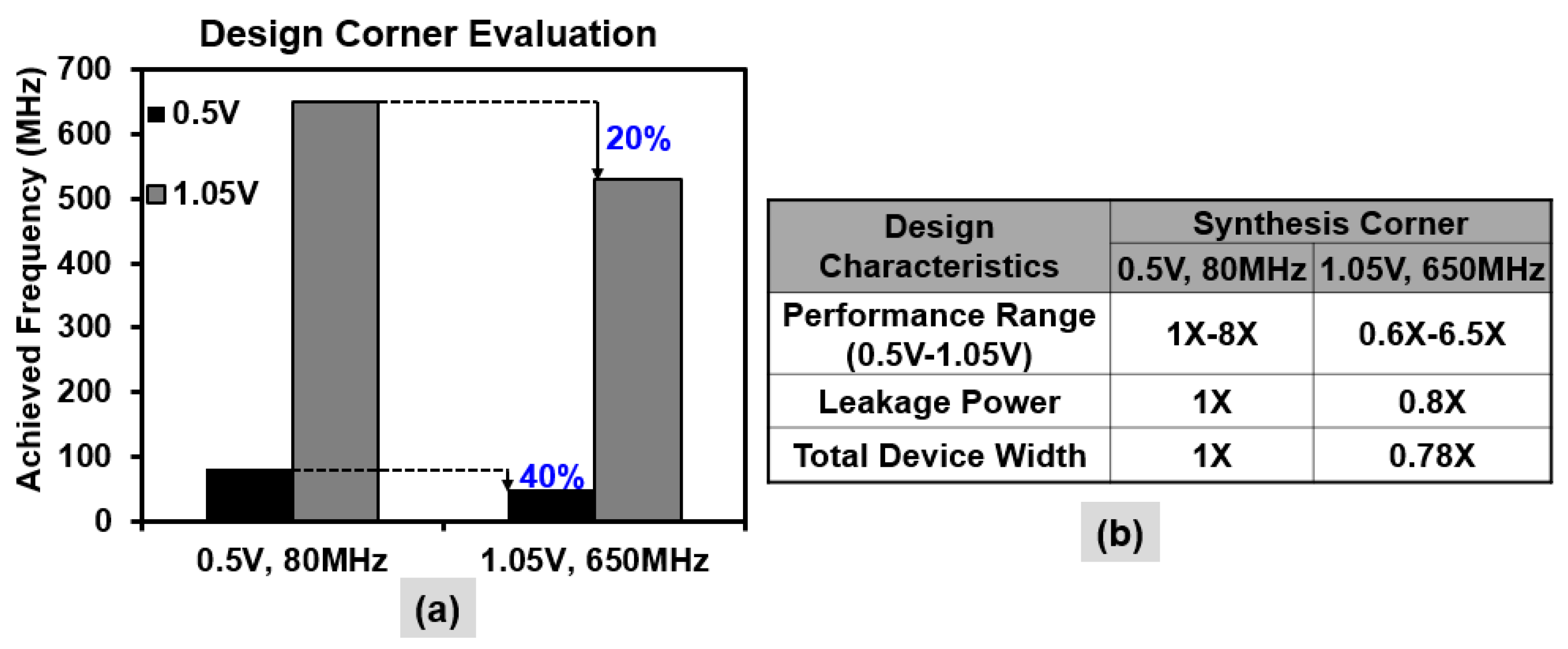
4. Designing for Wide-Dynamic Range: Tools, Flows and Methodologies
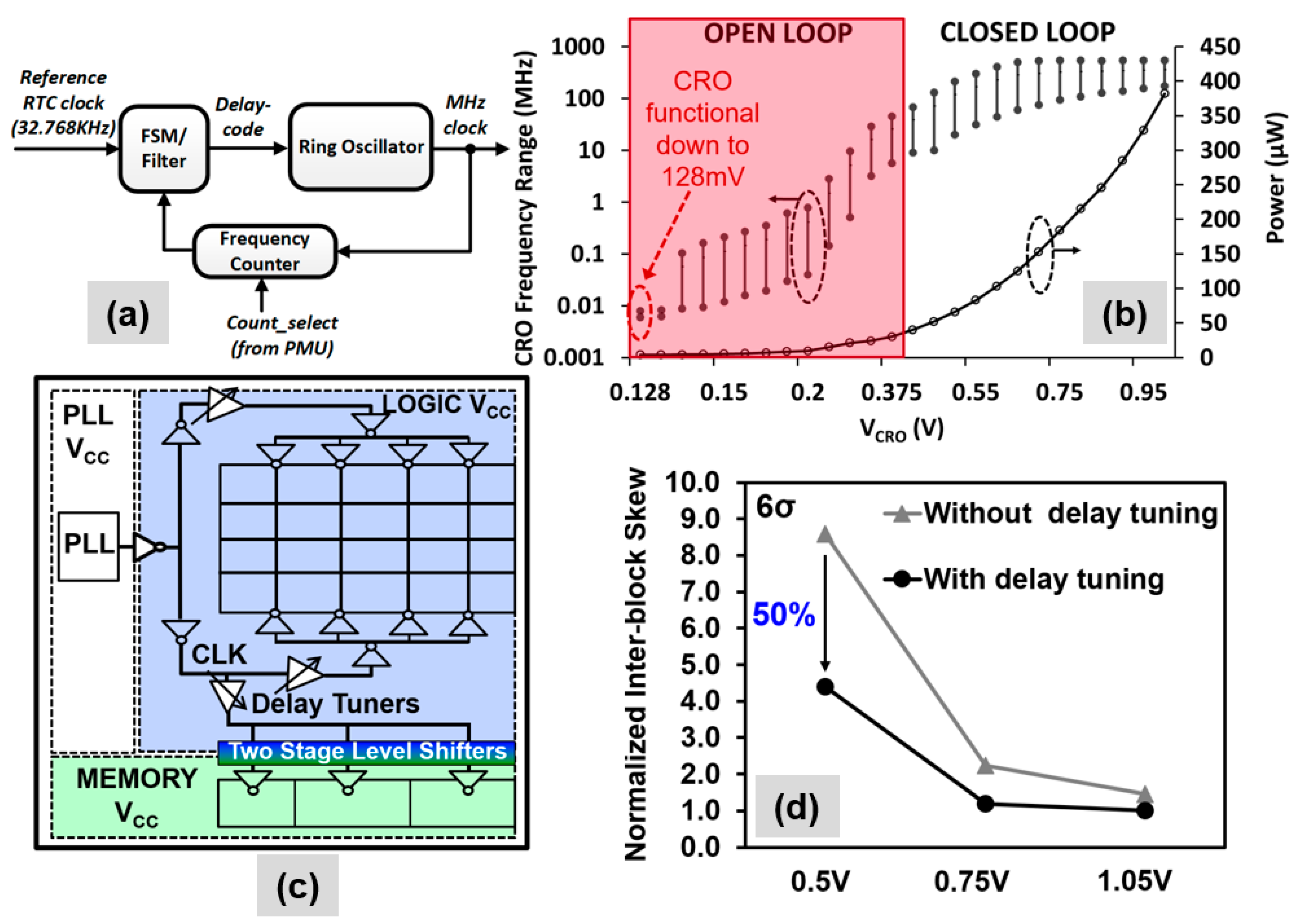
NTV Clocking Architecture
5. Key Results from Experimental NTV Prototypes
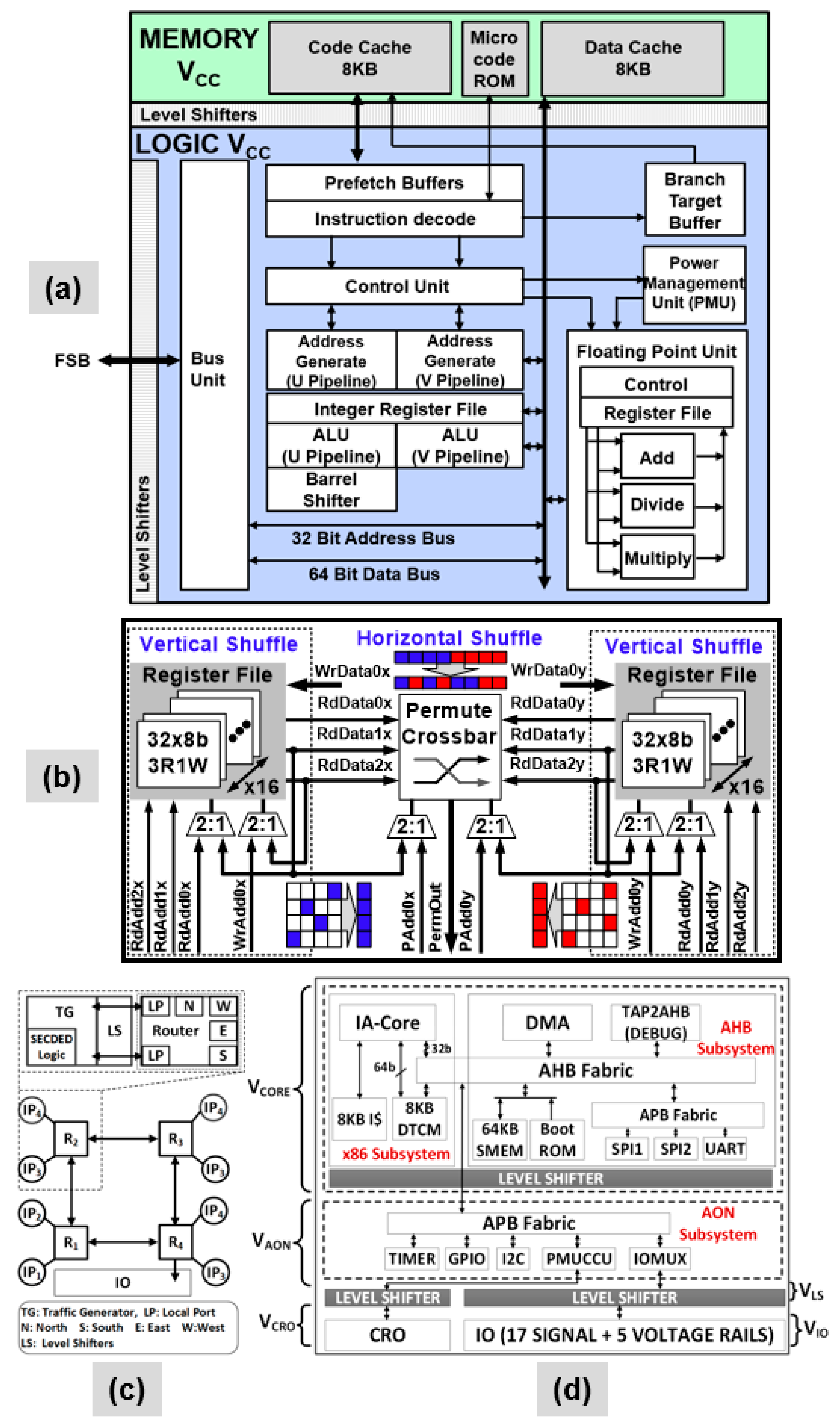
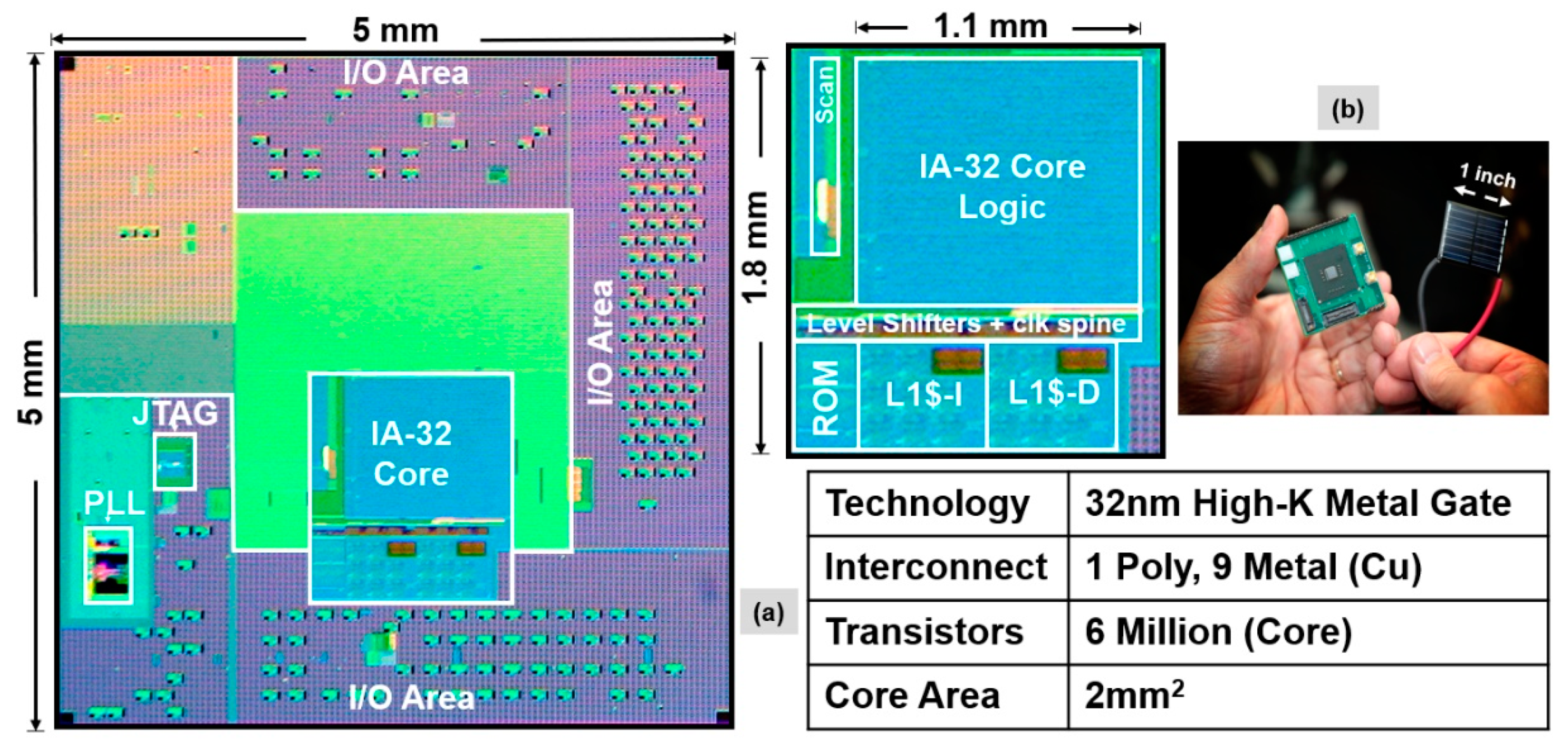
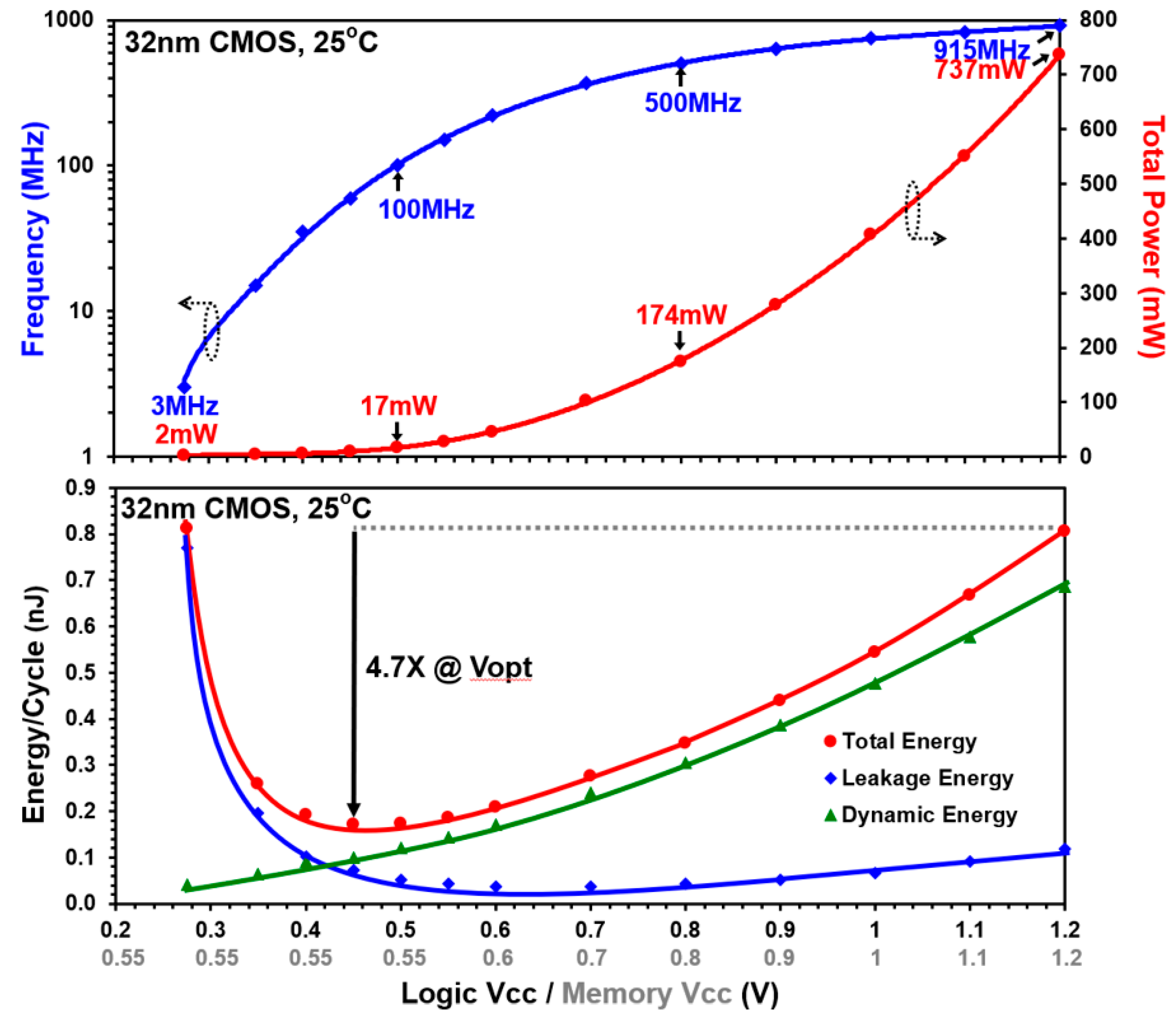
5.1. NTV-CPU Results
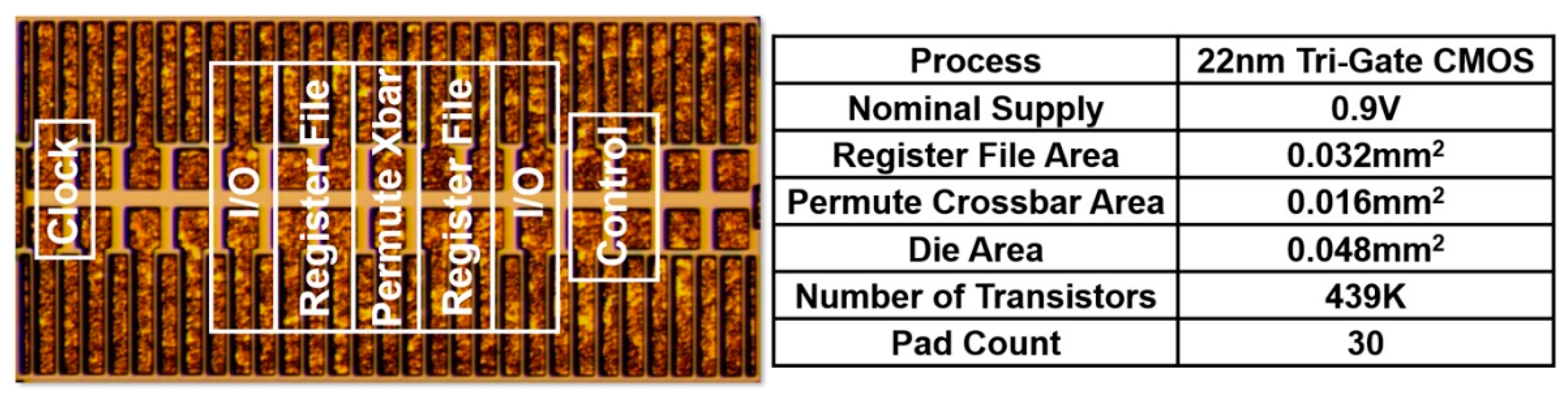
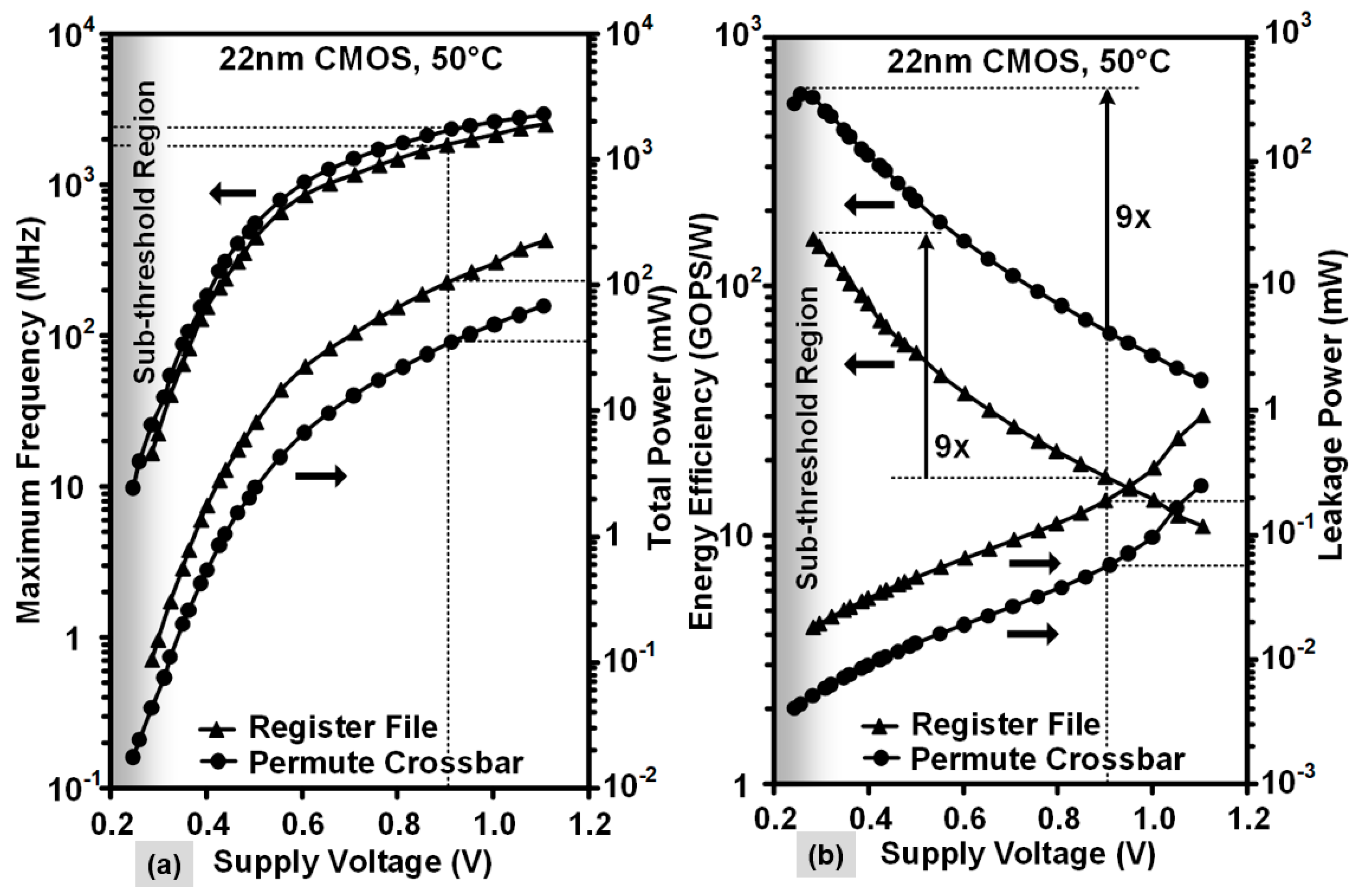
5.2. NTV-SIMD Engine Results
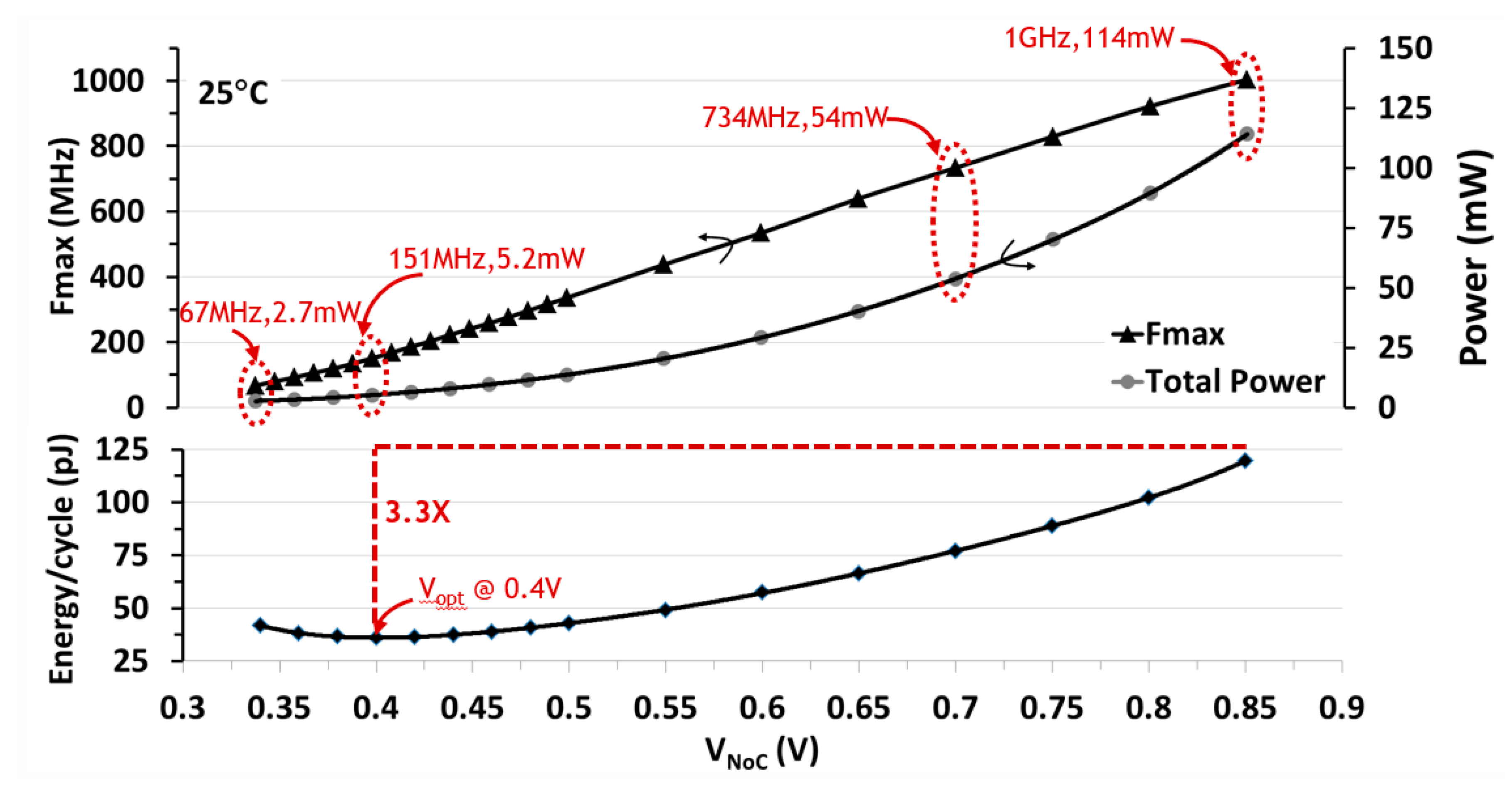
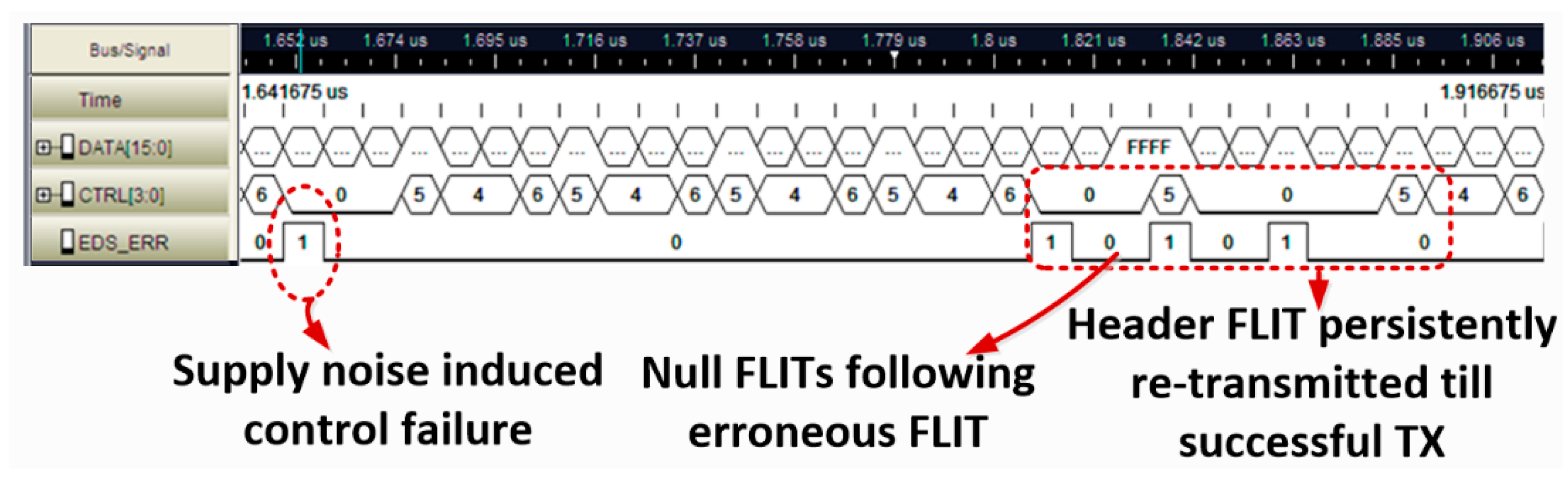
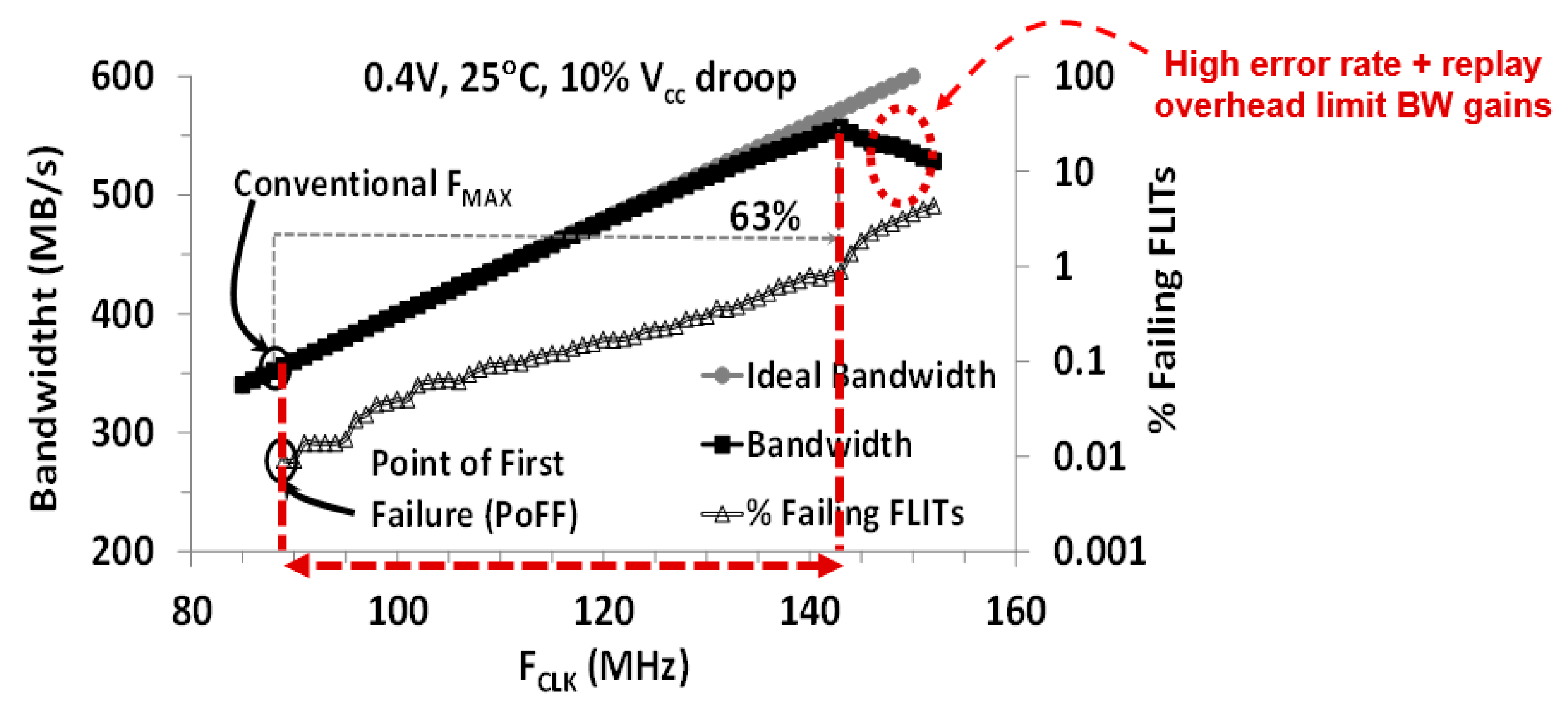
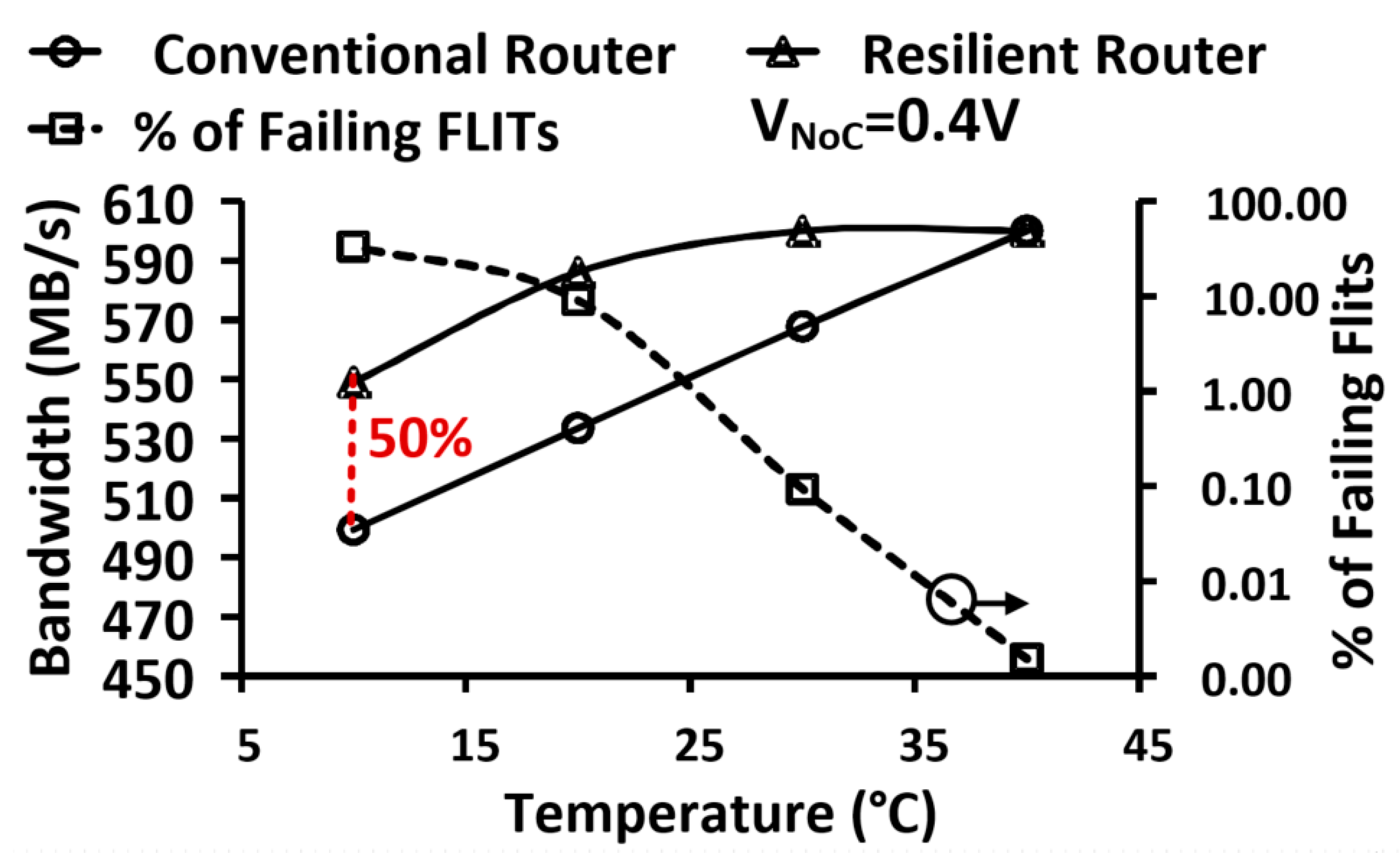
5.3. NTV-NoC Measurement Results and Learnings
Resilience to Inverse Temperature Dependence Effects
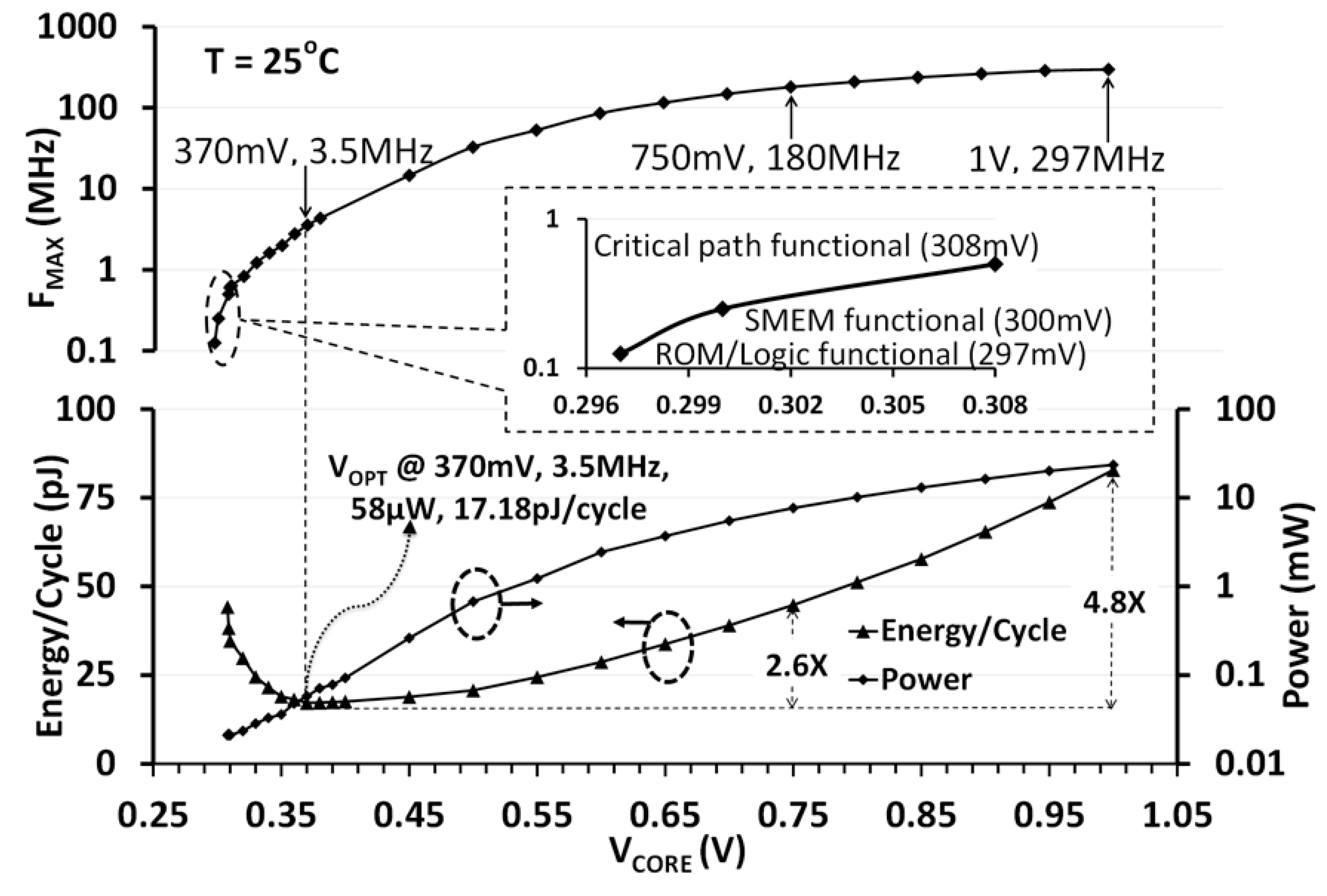
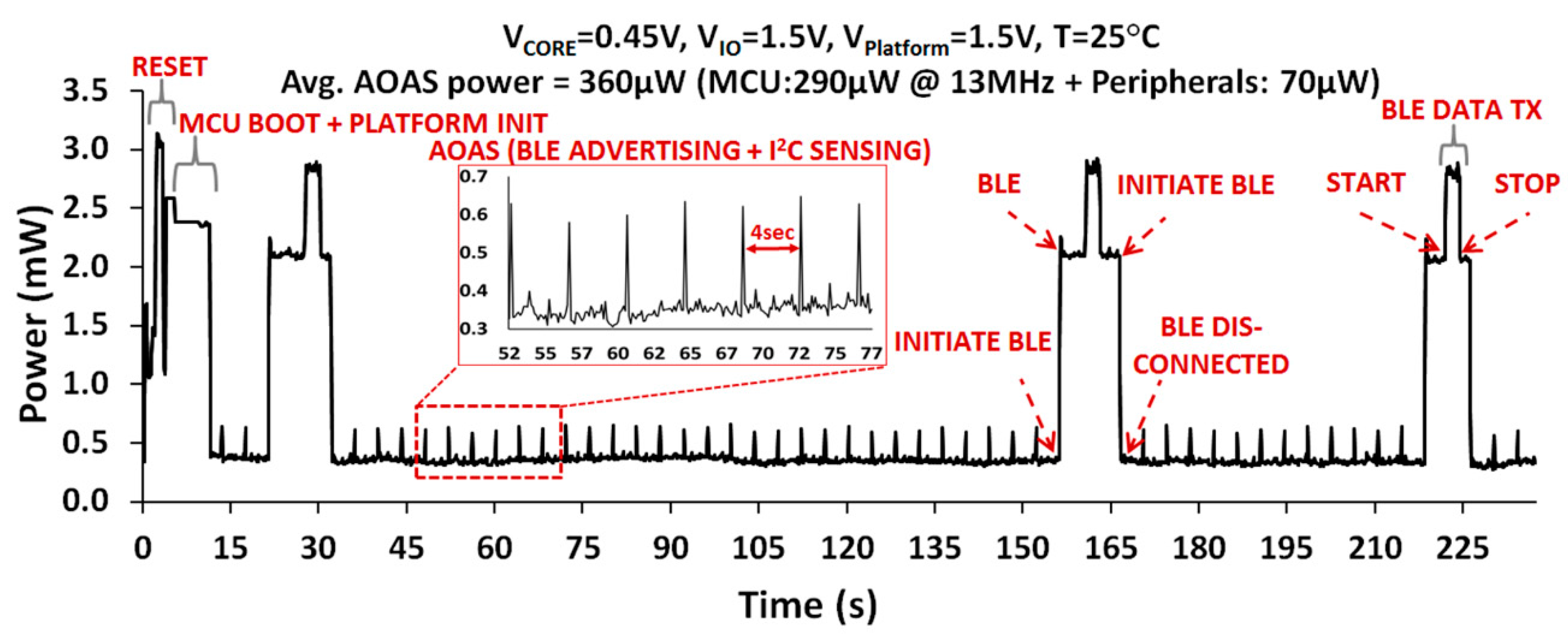
5.4. NTV-MCU Measurement Results and WSN Operation
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ronald, G.; Dreslinski, M.; Wieckowski, D.; Blaauw, D.; Sylvester, D.; Mudge, T. Near-threshold computing: Reclaiming Moore’s law through energy efficient integrated circuits. Proc. IEEE 2010, 98, 253–266. [Google Scholar]
- De, V.; Vangal, S.; Krishnamurthy, R. Near Threshold Voltage (NTV) Computing. IEEE Des. Test 2016, 34, 1. [Google Scholar] [CrossRef]
- Hanson, S.; Zhai, B.; Bernstein, K.; Blaauw, D.; Bryant, A.; Chang, L.; Das, K.K.; Haensch, W.; Nowak, E.J.; Sylvester, D.M. Ultra low-voltage, minimum energy CMOS. IBM J. Res. Dev. 2006, 50, 469–490. [Google Scholar] [CrossRef]
- Jan, C.-H.; Agostinelli, M.; Buehler, M.; Chen, Z.-P.; Choi, S.-J.; Curello, G.; Deshpande, H.; Gannavaram, S.; Hafez, W.; Jalan, U.; et al. A 32nm SoC platform technology with 2nd generation high-k/metal gate transistors optimized for ultra low power, high performance, and high density product applications. IEEE Int. Electron Devices Meet. 2009, 1–4. [Google Scholar] [CrossRef]
- Schutz, J. A 3.3V 0.6um BiCMOS Superscalar Microprocessor. In Proceedings of the International Solid State Circuits Conference, Digest of Technical Papers, San Francisco, CA, USA, 16–18 February 1994; pp. 202–203. [Google Scholar]
- Jain, S.; Khare, S.; Yada, S.; Ambili, V.; Salihundam, P.; Ramani, S.; Muthukumar, S.; Srinivasan, M.; Kumar, A.; Gb, S.K.; et al. A 280mV-to-1.2V wide-operating-range IA-32 processor in 32nm CMOS. In Proceedings of the 2012 IEEE International Solid-State Circuits Conference, Digest of Technical Papers, San Francisco, CA, USA, 19–23 February 2012; pp. 66–68. [Google Scholar]
- Flachs, B.; Asano, S.; Dhong, S.; Hofstee, P.; Gervais, G.; Kim, R.; Le, T.; Liu, P.; Leenstra, J.; Liberty, J.; et al. A streaming processing unit for a CELL processor. In Proceedings of the ISSCC 2005 IEEE International Digest of Technical Papers Solid-State Circuits Conference, San Francisco, CA, USA, 10 February 2005; Volume 1, pp. 134–135. [Google Scholar] [CrossRef]
- Hsu, S.; Agarwal, A.; Anders, M.; Mathew, S.; Kaul, H.; Sheikh, F.; Krishnamurthy, R. A 280mV-to-1.1V 256b reconfigurable SIMD vector permutation engine with 2-dimensional shuffle in 22nm CMOS. In Proceedings of the 2012 IEEE International Solid-State Circuits Conference, Institute of Electrical and Electronics Engineers, San Francisco, CA, USA, 19–23 February 2012; pp. 178–180. [Google Scholar]
- Jan, C.-H.; Bhattacharya, U.; Brain, R.; Choi, S.-J.; Curello, G.; Gupta, G.; Hafez, W.; Jang, M.; Kang, M.; Komeyli, K.; et al. A 22nm SoC platform technology featuring 3-D tri-gate and high-k/metal gate, optimized for ultra low power, high performance and high density SoC applications. In Proceedings of the 2012 International Electron Devices Meeting, San Francisco, CA, USA, 10–13 December 2012; pp. 311–314. [Google Scholar] [CrossRef]
- Paul, S.; Abbott, M.; Kishinevsky, E.; Aseron, P.; Vangal, S.; De, V.; Taylor, G. A 3.6 GB/s 1.3 mW 400 mV 0.051 mm2 near-threshold voltage resilient router in 22-nm tri-gate CMOS. In Proceedings of the VLSI Circuits Symposium Digest of Technical Papers, Kyoto, Japan, 12–14 June 2013; pp. C30–C31. [Google Scholar]
- Paul, S.; Honkote, V.; Kim, R.; Majumder, T.; Aseron, P.; Grossnickle, V.; Sankman, R.; Mallik, D.; Jain, S.; Vangal, S.; et al. An energy harvesting wireless sensor node for IoT systems featuring a near-threshold voltage IA-32 microcontroller in 14nm tri-gate CMOS. In Proceedings of the 2016 IEEE Symposium on VLSI Circuits (VLSI-Circuits), Honolulu, HI, USA, 15–17 June 2016; pp. 1–2. [Google Scholar] [CrossRef]
- Vangal, S.R.; Howard, J.; Ruhl, G.; Dighe, S.; Wilson, H.; Tschanz, J.; Finan, D.; Singh, A.P.; Jacob, T.; Jain, S.; et al. An 80-Tile Sub-100-W TeraFLOPS Processor in 65-nm CMOS. IEEE J. Solid-State Circuits 2008, 43, 29–41. [Google Scholar] [CrossRef]
- Vangal, S.; Singh, A.P.; Howard, J.; Dighe, S.; Borkar, N.; Alvandpour, A. A 5.1GHz 0.34mm2 Router for Network-on-Chip Applications. In Proceedings of the 2007 IEEE Symposium on VLSI Circuits, Kyoto, Japan, 14–16 June 2007; pp. 42–43. [Google Scholar] [CrossRef]
- Jan, C.H.; Al-Amoody, F.; Chang, H.Y.; Chang, T.; Chen, Y.W.; Dias, N.; Hafez, W.; Ingerly, D.; Jang, M.; Karl, E.; et al. A 14 nm SoC platform technology featuring 2nd generation tri-gate transistors, 70 nm gate pitch, 52 nm metal pitch, and 0.0499 µm2 SRAM cells, optimized for low power, high performance and high density SoC products. In Proceedings of the 2015 Symposium on VLSI Technology (VLSI Technology), Kyoto, Japan, 16–18 June 2015. [Google Scholar]
- Intel Corporation. Intel Quark Processors. Available online: http://www.intel.com/content/www/us/en/embedded/products/quark/overview.html (accessed on 1 April 2020).
- Raychowdhury, A.; Geuskens, B.; Kulkarni, J.P.; Tschanz, J.; Bowman, K.; Karnik, T.; Lu, S.-L.; De, V.; Khellah, M.M. PVT-and-aging adaptive wordline boosting for 8T SRAM power reduction. In Proceedings of the 2010 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 7–11 February 2010; pp. 352–353. [Google Scholar] [CrossRef]
- Kulkarni, J.P.; Geuskens, B.; Karnik, T.; Khellah, M.; Tschanz, J.; De, V. Capacitive-coupling wordline boosting with self-induced VCC collapse for write VMIN reduction in 22-nm 8T SRAM. In Proceedings of the 2012 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 19–23 February 2012; pp. 234–236. [Google Scholar] [CrossRef]
- Pinckney, N.; Sewell, K.; Dreslinski, R.G.; Fick, D.; Mudge, T.; Sylvester, D.; Blaauw, D. Assessing the performance limits of parallelized near-threshold computing. In Proceedings of the 49th Annual Design Automation Conference, Association for Computing Machinery (ACM), San Francisco, CA, USA, 3–7 June 2012; p. 1147. [Google Scholar]
- Tschanz, J.; Lam, C.; Shuman, M.; Tokunaga, C.; Somasekhar, D.; Tang, S.; Finan, D.; Karnik, T.; Borkar, N.; Kurd, N.; et al. Adaptive Frequency and Biasing Techniques for Tolerance to Dynamic Temperature-Voltage Variations and Aging. In Proceedings of the 2007 IEEE International Solid-State Circuits Conference Digest of Technical Papers, San Francisco, CA, USA, 11–15 February 2007; pp. 292–604. [Google Scholar]
- Tschanz, J.; Bowman, K.; Walstra, S.; Agostinelli, M.; Karnik, T.; De, V. Tunable replica circuits and adaptive voltage-frequency techniques for dynamic voltage, temperature, and aging variation tolerance. In Proceedings of the 2009 Symposium on VLSI Circuits, Digest of Technical Papers, Kyoto, Japan, 16–18 June 2009; pp. 112–113. [Google Scholar]
- Bowman, K.A.; Tschanz, J.W.; Kim, N.S.; Lee, J.C.; Wilkerson, C.B.; Lu, S.-L.L.; Karnik, T.; De, V. Energy-Efficient and Metastability-Immune Resilient Circuits for Dynamic Variation Tolerance. IEEE J. Solid-State Circuits 2008, 44, 49–63. [Google Scholar] [CrossRef]
- Rossi, D.; Metra, C.; Nieuwland, A.K.; Katoch, A. New ECC for crosstalk effect minimization. IEEE Des. Test Comput. 2005, 22, 340–348. [Google Scholar] [CrossRef]
- Amin, C.S.; Menezes, N.; Killpack, K.; Dartu, F.; Choudhury, U.; Hakim, N.; Ismail, Y.I. Statistical static timing analysis. In Proceedings of the 42nd Design Automation Conference, Association for Computing Machinery (ACM), Anaheim, CA, USA, 13–17 June 2005; p. 652. [Google Scholar]
- Singhee, A.; Singhal, S.; Rutenbar, R.A. Practical, fast Monte Carlo statistical static timing analysis: Why and how. In Proceedings of the 2008 IEEE/ACM International Conference on Computer-Aided Design, San Jose, CA, USA, 10–13 November 2008; pp. 190–195. [Google Scholar]
- Cho, M.; Khellah, M.; Chae, K.; Ahmed, K.; Tschanz, J.; Mukhopadhyay, S. Characterization of Inverse Temperature Dependence in logic circuits. In Proceedings of the IEEE 2012 Custom Integrated Circuits Conference, San Jose, CA, USA, 9–12 September 2012; pp. 1–4. [Google Scholar]
- Han, S.; Guo, D.; Wang, X.; Mocuta, A.C.; Henson, W.K.; Rim, K. Reverse Temperature Dependence of Circuit Performance in High-k/Metal-Gate Technology. IEEE Electron Device Lett. 2009, 30, 1344–1346. [Google Scholar]
- Warneke, B.; Last, M.; Liebowitz, B.; Pister, K. Smart Dust: Communicating with a cubic-millimeter computer. Computer 2001, 34, 44–51. [Google Scholar] [CrossRef]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ISSCC 2012 [6] | ISSCC 2012 [8] | VLSI 2013 [10] | VLSI 2016 [11] | |
|---|---|---|---|---|
| NTV Design | 32-b ×86 CPU | SIMD Engine | 2D NoC fabric | mm-scale MCU |
| Intel CMOS Technology | 32-nm high-K/metal-gate | 22-nm Tri-gate | 22-nm Tri-gate | 14nm Tri-gate |
| Die Area (mm2) | 2 | 0.048 | Router: 0.051 2 × 2 Mesh: 0.93 | 0.79 |
| VDD range and VOPT (V) | 0.28–1.2 (VOPT = 0.45) | 0.24–1.1 (VOPT = 0.26) | 0.34–0.85 (VOPT = 0.4) | 0.308–1.0 (VOPT = 0.37) |
| Frequency range (MHz) | 3–915 | 10–2900 | 0.5–297 | 67–1000 |
| Energy @ VOPT Benefit | 170pJ/cyclea, 4.7× | 1.9pJ/cycle, 9× | 36pJ/cycleb, 3.3× | 17.18pJ/cyclec, 4.8× |
| Total on-chip memory | 8KB I$ + 8KB D$ | 1KB Reg. file (RF) memory | None | 8KB I$ + 8KB DTCM + 64KB SMEM + 16KB BootROM |
| 8T SRAM Device Type. | Gate Pitch | Normalized Frequency (0.5V) | Normalized Leakage (0.5V, 25C) | 14 nm Bit-Cell Area (µm2) |
|---|---|---|---|---|
| Standard performance (SP) | 70nm | 5× | 26× | 0.100 µm2 |
| Ultralow power (ULP, NTV MCU Memory) | 84nm | 1× | 1× | 0.155 µm2 (1.55×) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vangal, S.; Paul, S.; Hsu, S.; Agarwal, A.; Krishnamurthy, R.; Tschanz, J.; De, V. Near-Threshold Voltage Design Techniques for Heterogenous Manycore System-on-Chips. J. Low Power Electron. Appl. 2020, 10, 16. https://doi.org/10.3390/jlpea10020016
Vangal S, Paul S, Hsu S, Agarwal A, Krishnamurthy R, Tschanz J, De V. Near-Threshold Voltage Design Techniques for Heterogenous Manycore System-on-Chips. Journal of Low Power Electronics and Applications. 2020; 10(2):16. https://doi.org/10.3390/jlpea10020016
Chicago/Turabian StyleVangal, Sriram, Somnath Paul, Steven Hsu, Amit Agarwal, Ram Krishnamurthy, James Tschanz, and Vivek De. 2020. "Near-Threshold Voltage Design Techniques for Heterogenous Manycore System-on-Chips" Journal of Low Power Electronics and Applications 10, no. 2: 16. https://doi.org/10.3390/jlpea10020016
APA StyleVangal, S., Paul, S., Hsu, S., Agarwal, A., Krishnamurthy, R., Tschanz, J., & De, V. (2020). Near-Threshold Voltage Design Techniques for Heterogenous Manycore System-on-Chips. Journal of Low Power Electronics and Applications, 10(2), 16. https://doi.org/10.3390/jlpea10020016