Efficacy of Topology Scaling for Temperature and Latency Constrained Embedded ConvNets



Abstract
1. Introduction
2. Background
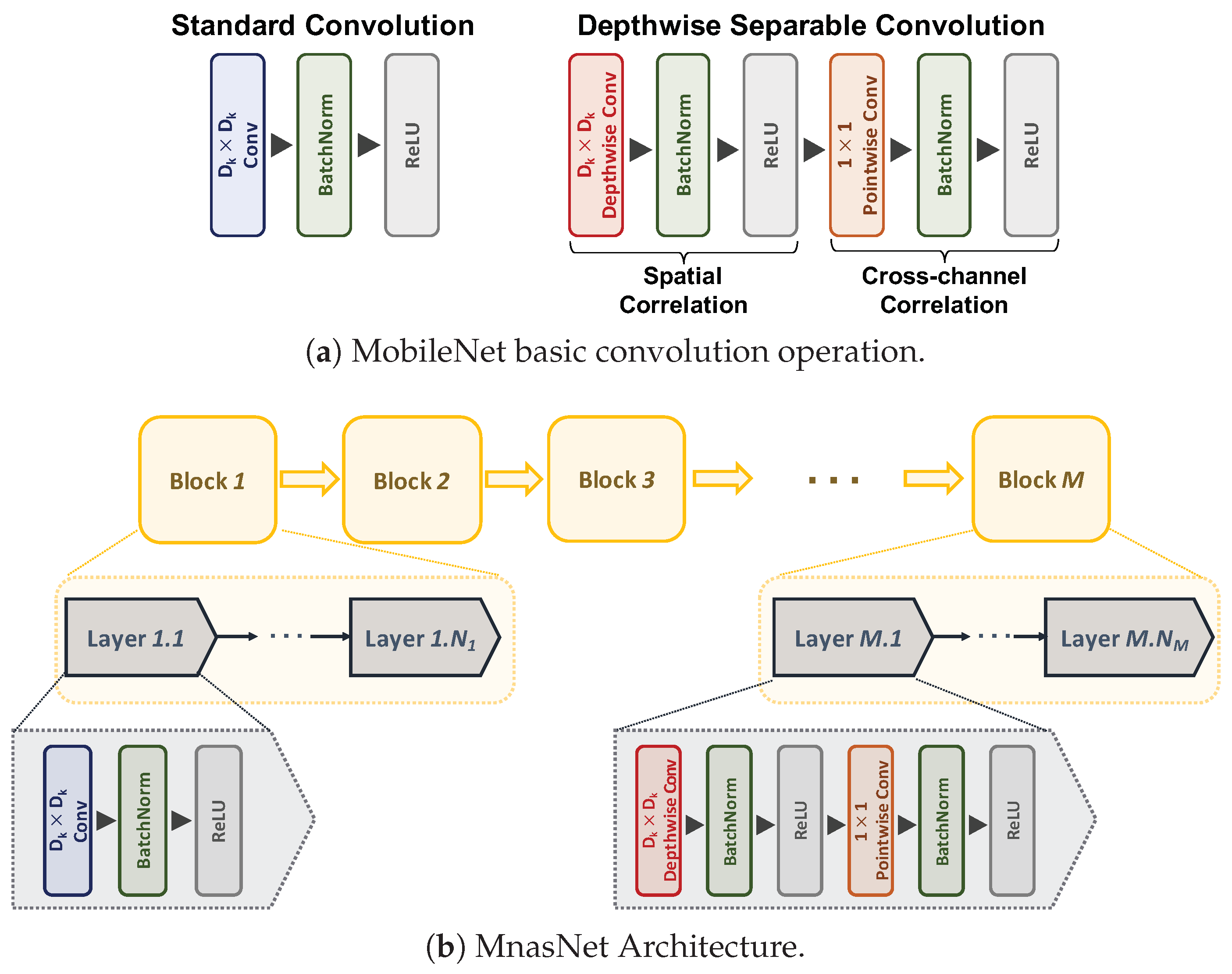
2.1. ConvNets for Mobile Applications: MobileNet and MnasNet
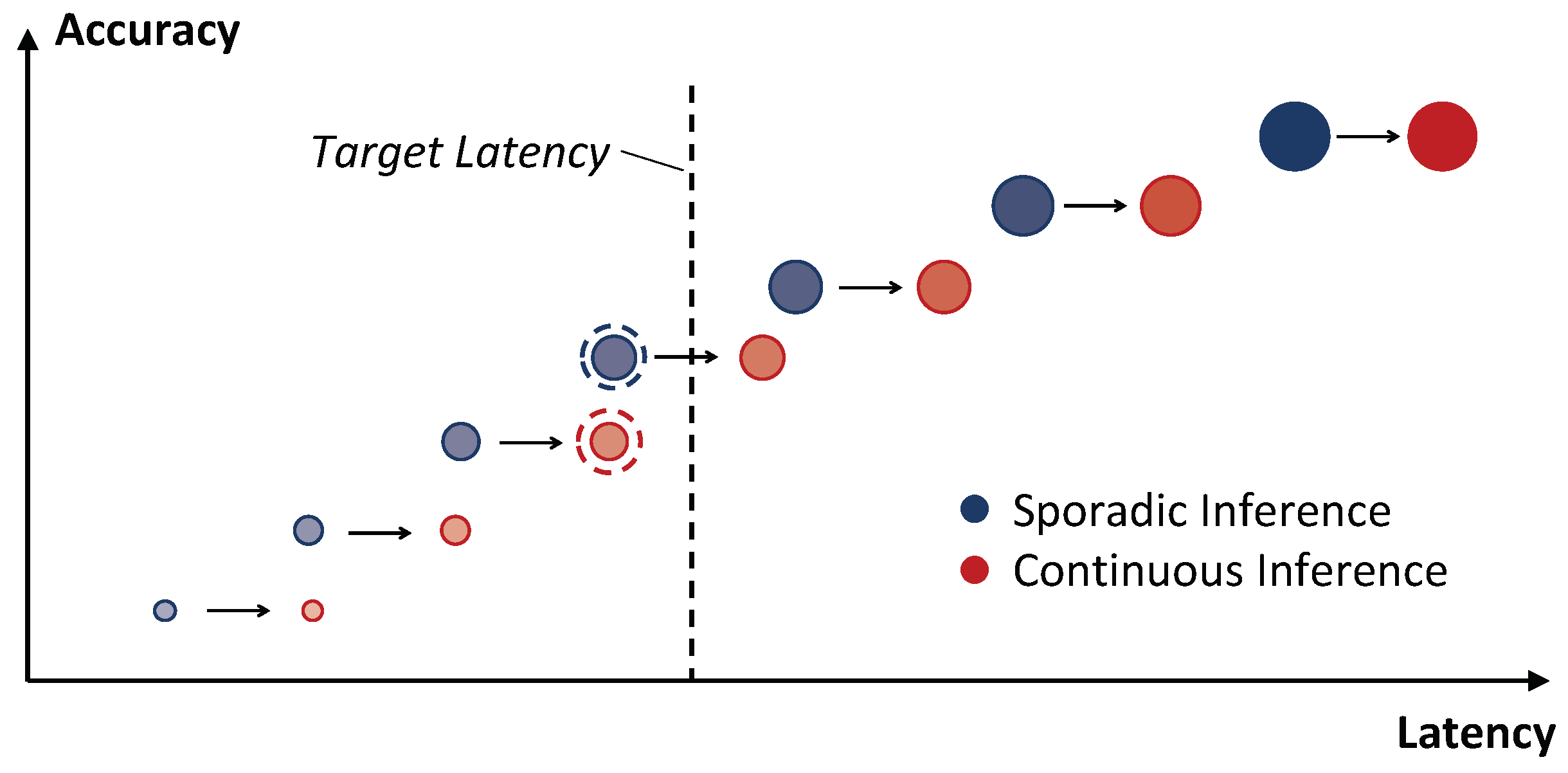
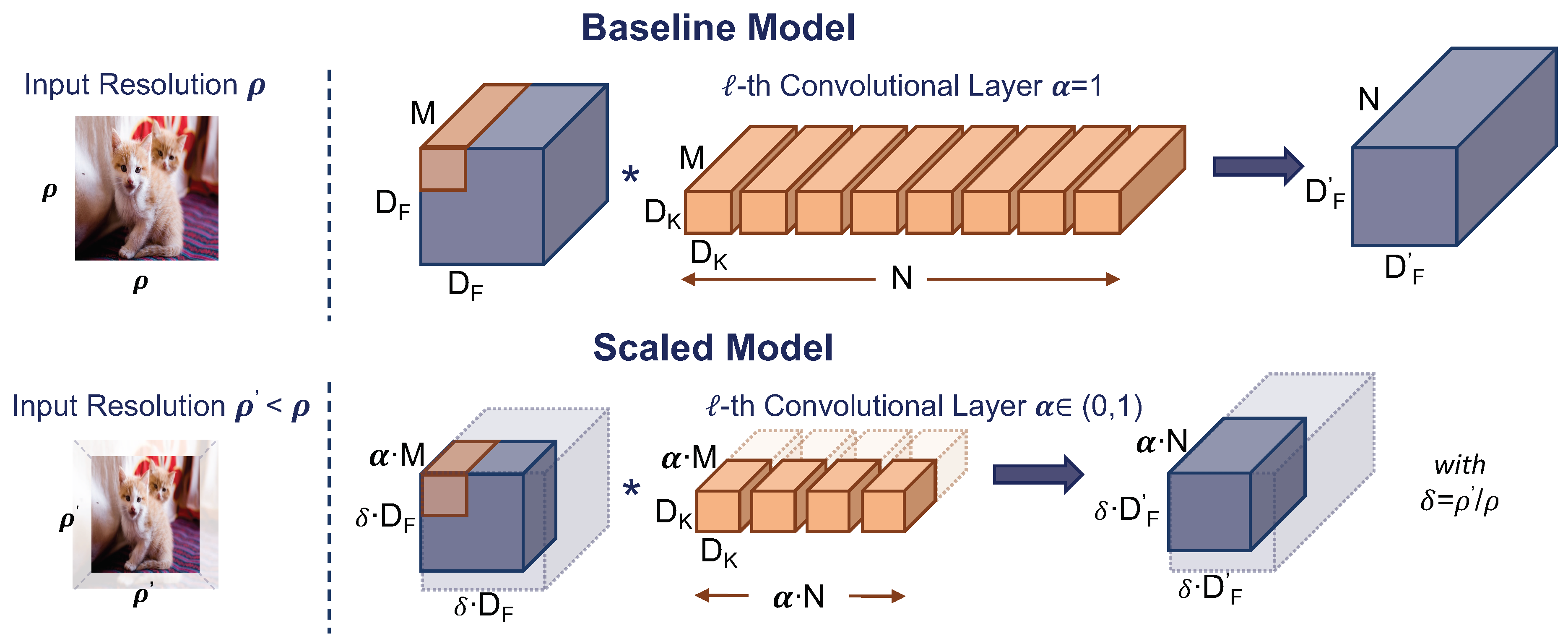
2.2. ConvNets Topology Scaling
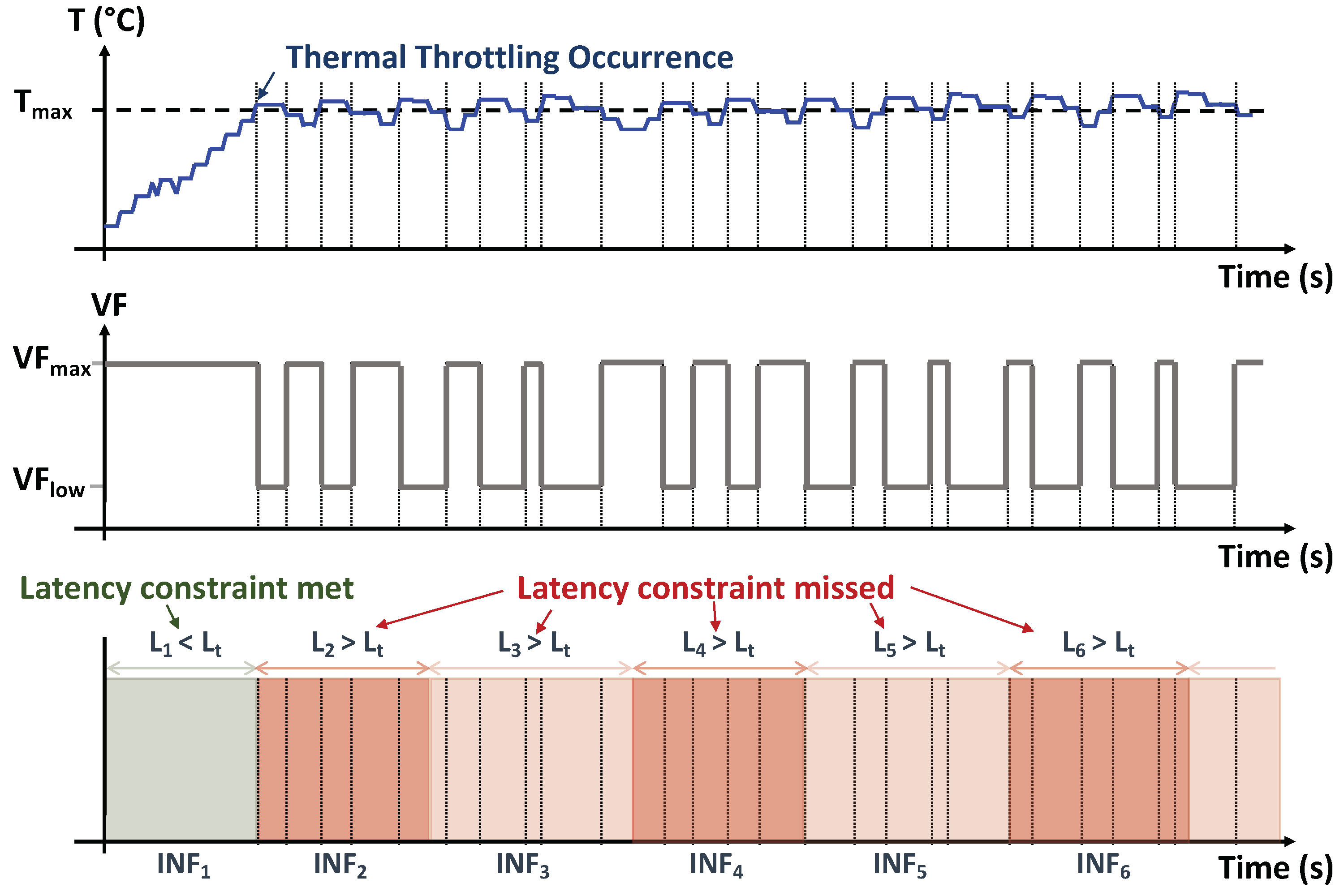
2.3. Thermal Design Power Management
3. Related Works
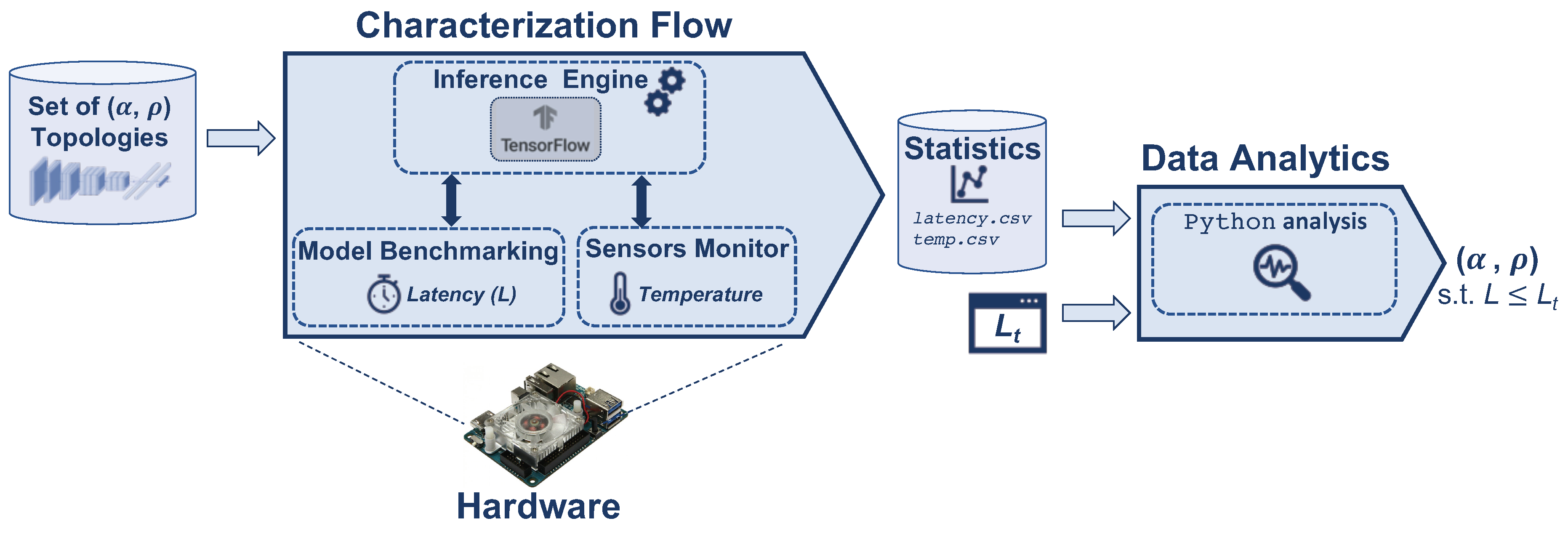
4. Latency and Temperature Characterization
5. Experimental Setup and Results
5.1. Experimental Setup
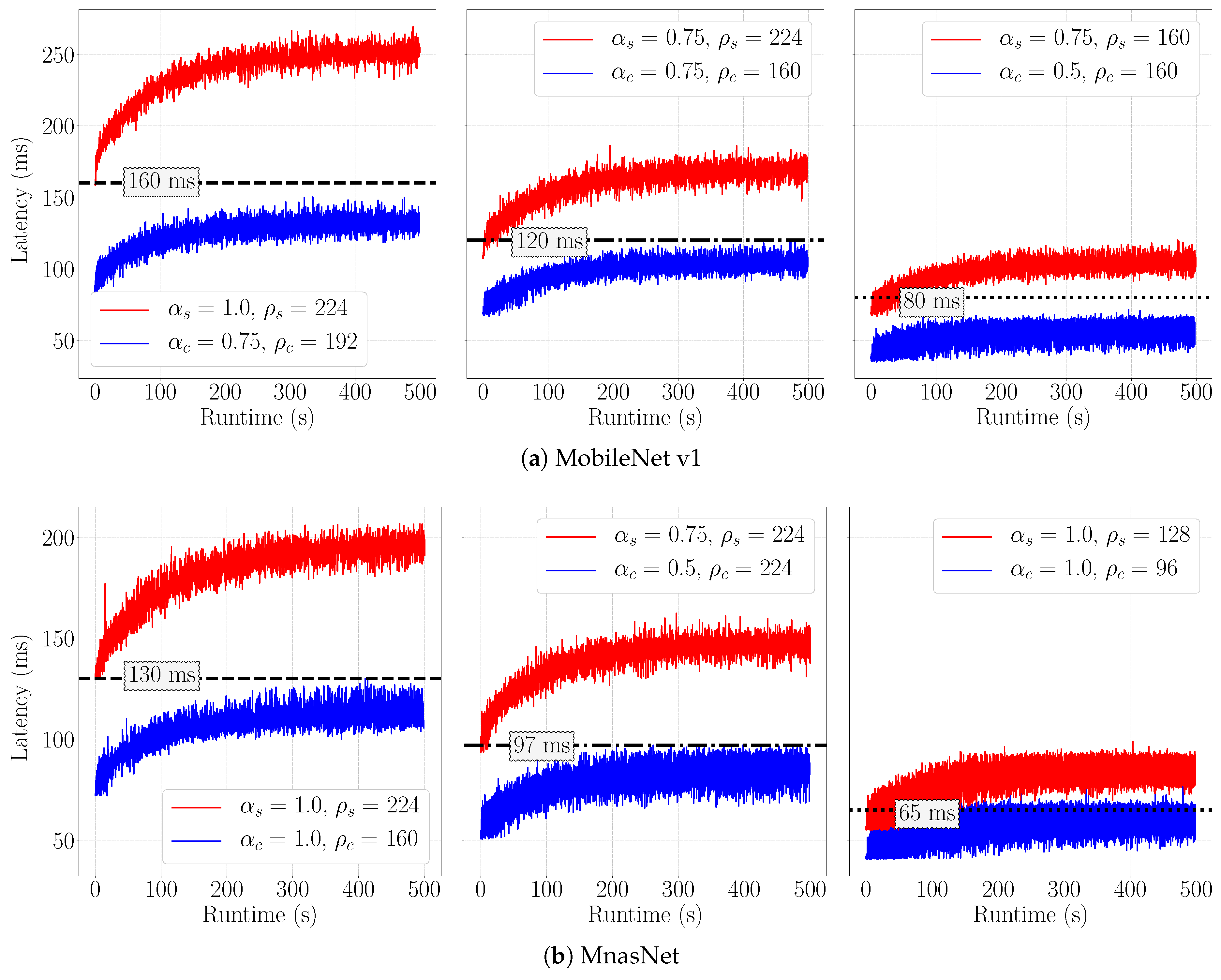
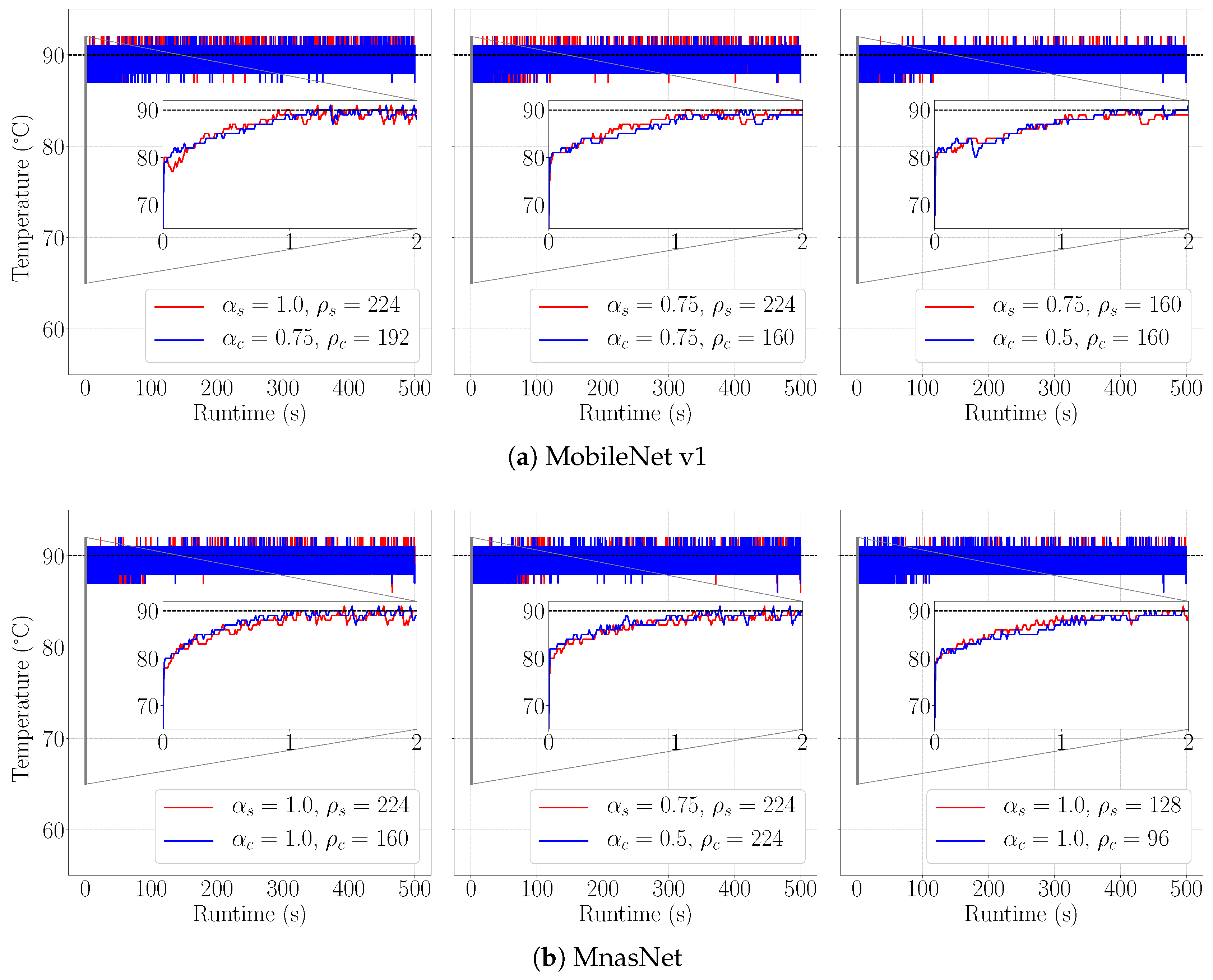
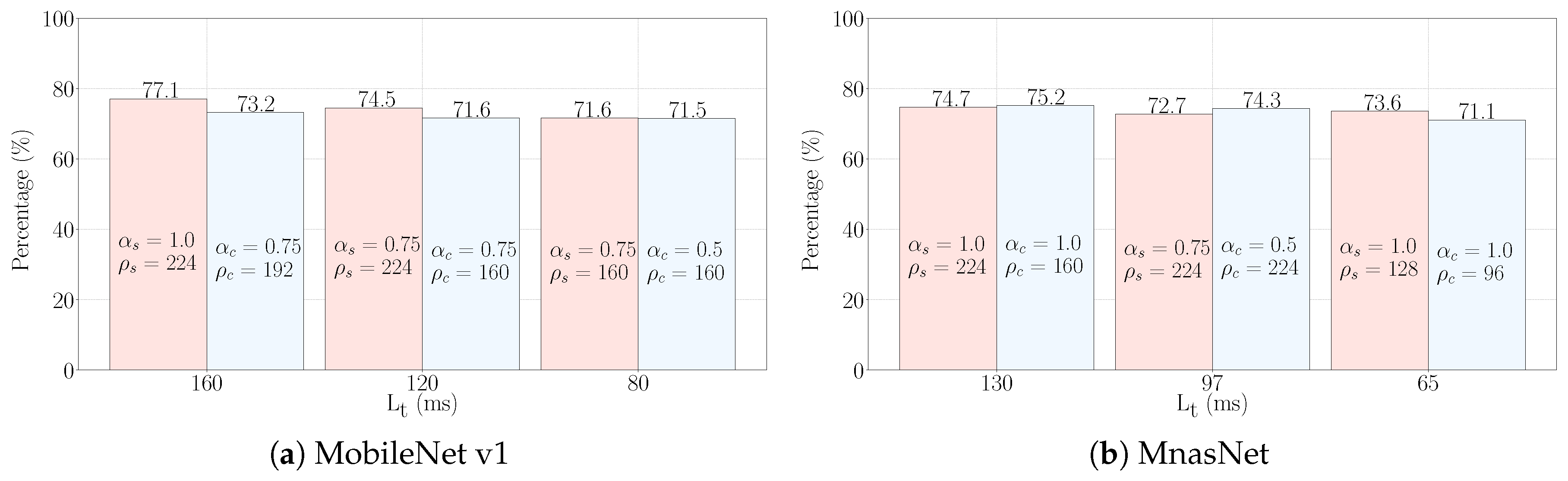
5.2. Results
6. Discussion and Final Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Seidenari, L.; Baecchi, C.; Uricchio, T.; Ferracani, A.; Bertini, M.; Bimbo, A.D. Deep artwork detection and retrieval for automatic context-aware audio guides. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2017, 13, 35. [Google Scholar] [CrossRef]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. Deepsense: A unified deep learning framework for time-series mobile sensing data processing. In Proceedings of the 26th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, Perth, Australia; pp. 351–360.
- Wang, A.; Chen, G.; Yang, J.; Zhao, S.; Chang, C.Y. A comparative study on human activity recognition using inertial sensors in a smartphone. IEEE Sens. J. 2016, 16, 4566–4578. [Google Scholar] [CrossRef]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2704–2713. [Google Scholar]
- Yang, T.J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. Netadapt: Platform-aware neural network adaptation for mobile applications. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 285–300. [Google Scholar]
- Cheng, A.C.; Dong, J.D.; Hsu, C.H.; Chang, S.H.; Sun, M.; Chang, S.C.; Pan, J.Y.; Chen, Y.T.; Wei, W.; Juan, D.C. Searching toward pareto-optimal device-aware neural architectures. In Proceedings of the International Conference on Computer-Aided Design, San Diego, CA, USA, 5–8 November 2018; p. 136. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv, 2017; arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Dai, X.; Zhang, P.; Wu, B.; Yin, H.; Sun, F.; Wang, Y.; Dukhan, M.; Hu, Y.; Wu, Y.; Jia, Y.; et al. Chamnet: Towards efficient network design through platform-aware model adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11398–11407. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2820–2828. [Google Scholar]
- Khan, O.; Kundu, S. Hardware/software co-design architecture for thermal management of chip multiprocessors. In Proceedings of the 2009 Design, Automation & Test in Europe Conference & Exhibition, Nice, France, 20–24 April 2009; pp. 952–957. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Peluso, V.; Rizzo, R.G.; Calimera, A.; Macii, E.; Alioto, M. Beyond ideal DVFS through ultra-fine grain vdd-hopping. In IFIP/IEEE International Conference on Very Large Scale Integration-System on a Chip; Springer: Berlin/Heidelberg, Germany, 2016; pp. 152–172. [Google Scholar]
- Ignatov, A.; Timofte, R.; Chou, W.; Wang, K.; Wu, M.; Hartley, T.; Van Gool, L. Ai benchmark: Running deep neural networks on android smartphones. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Almeida, M.; Laskaridis, S.; Leontiadis, I.; Venieris, S.I.; Lane, N.D. EmBench: Quantifying Performance Variations of Deep Neural Networks across Modern Commodity Devices. In Proceedings of the 3rd International Workshop on Deep Learning for Mobile Systems and Applications, Seoul, Korea, 21 June 2019; pp. 1–6. [Google Scholar]
- Peluso, V.; Rizzo, R.G.; Cipolletta, A.; Calimera, A. Inference on the Edge: Performance Analysis of an Image Classification Task Using Off-The-Shelf CPUs and Open-Source ConvNets. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 454–459. [Google Scholar]
- Velasco-Montero, D.; Femández-Bemi, J.; Carmona-Gálán, R.; Rodríguez-Vázquez, A. On the Correlation of CNN Performance and Hardware Metrics for Visual Inference on a Low-Cost CPU-based Platform. In Proceedings of the 2019 International Conference on Systems, Signals and Image Processing (IWSSIP), Osijek, Croatia, 5–7 June 2019; pp. 249–254. [Google Scholar]
- Lee, J.; Chirkov, N.; Ignasheva, E.; Pisarchyk, Y.; Shieh, M.; Riccardi, F.; Sarokin, R.; Kulik, A.; Grundmann, M. On-device neural net inference with mobile gpus. arXiv, 2019; arXiv:1907.01989. [Google Scholar]
- Peluso, V.; Rizzo, R.G.; Calimera, A. Performance Profiling of Embedded ConvNets under Thermal-Aware DVFS. Electronics 2019, 8, 1423. [Google Scholar] [CrossRef]
- Wu, C.J.; Brooks, D.; Chen, K.; Chen, D.; Choudhury, S.; Dukhan, M.; Hazelwood, K.; Isaac, E.; Jia, Y.; Jia, B.; et al. Machine learning at facebook: Understanding inference at the edge. In Proceedings of the 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), Washington, DC, USA, 16–20 February 2019; pp. 331–344. [Google Scholar]
- Hardkernel. Odroid-XU4 User Manual. Available online: https://magazine.odroid.com/wp-content/uploads/odroid-xu4-user-manual.pdf (accessed on 8 November 2019).
- Exynos 5 Octa 5422 Processor: Specs, Features. Available online: https://www.samsung.com/semiconductor/minisite/exynos/products/mobileprocessor/exynos-5-octa-5422/ (accessed on 8 November 2019).
- TensorFlow Lite. Available online: https://www.tensorflow.org/lite (accessed on 8 November 2019).
- Linaro Toolchain. Available online: https://www.linaro.org/downloads/ (accessed on 8 November 2019).
- TensorFlow Lite Hosted Models. Available online: https://www.tensorflow.org/lite/guide/hosted_models (accessed on 8 November 2019).
- Brooks, D.; Dick, R.P.; Joseph, R.; Shang, L. Power, thermal, and reliability modeling in nanometer-scale microprocessors. IEEE Micro 2007, 27, 49–62. [Google Scholar] [CrossRef]
- Egilmez, B.; Memik, G.; Ogrenci-Memik, S.; Ergin, O. User-specific skin temperature-aware DVFS for smartphones. In Proceedings of the 2015 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 1217–1220. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Width multiplier | |
| Input resolution | |
| Target latency | |
| Safety temperature threshold | |
| Idle temperature | |
| Voltage-frequency level for maximum performance | |
| Voltage-frequency level for thermal throttling | |
| (, ) | Solution meeting in sporadic inference |
| (, ) | Solution meeting in continuous inference |
| Model | Size (MB) | ||
|---|---|---|---|
| MobileNet | 1.0 | 224, 192, 160, 128 | 16.9 |
| 0.75 | 224, 192, 160, 128 | 10.3 | |
| 0.5 | 224, 192, 160, 128 | 5.3 | |
| 0.25 | 224, 192, 160, 128 | 1.9 | |
| MnasNet | 1.0 | 224, 192, 160, 128, 96 | 17.0 |
| 0.75 | 224 | 12.0 | |
| 0.5 | 224 | 8.5 |
| (a) MobileNet v1. | (b) MnasNet. | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| (ms) | Inference | Top-1 (%) | (ms) | Inference | Top-1 (%) | ||||
| 160 | Sporadic | 1.0 | 224 | 71.0 | 130 | Sporadic | 1.0 | 224 | 74.08 |
| Continuous | 0.75 | 192 | 67.1 | Continuous | 1.0 | 160 | 70.63 | ||
| 120 | Sporadic | 0.75 | 224 | 68.3 | 97 | Sporadic | 0.75 | 224 | 71.72 |
| Continuous | 0.75 | 160 | 65.2 | Continuous | 0.5 | 224 | 68.03 | ||
| 80 | Sporadic | 0.75 | 160 | 65.2 | 65 | Sporadic | 1.0 | 128 | 67.32 |
| Continuous | 0.5 | 160 | 59.0 | Continuous | 1.0 | 96 | 62.33 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peluso, V.; Rizzo, R.G.; Calimera, A. Efficacy of Topology Scaling for Temperature and Latency Constrained Embedded ConvNets. J. Low Power Electron. Appl. 2020, 10, 10. https://doi.org/10.3390/jlpea10010010
Peluso V, Rizzo RG, Calimera A. Efficacy of Topology Scaling for Temperature and Latency Constrained Embedded ConvNets. Journal of Low Power Electronics and Applications. 2020; 10(1):10. https://doi.org/10.3390/jlpea10010010
Chicago/Turabian StylePeluso, Valentino, Roberto Giorgio Rizzo, and Andrea Calimera. 2020. "Efficacy of Topology Scaling for Temperature and Latency Constrained Embedded ConvNets" Journal of Low Power Electronics and Applications 10, no. 1: 10. https://doi.org/10.3390/jlpea10010010
APA StylePeluso, V., Rizzo, R. G., & Calimera, A. (2020). Efficacy of Topology Scaling for Temperature and Latency Constrained Embedded ConvNets. Journal of Low Power Electronics and Applications, 10(1), 10. https://doi.org/10.3390/jlpea10010010