


Effective Multi-Class Sentiment Analysis Using Fine-Tuned Large Language Model with KNIME Analytics Platform

Abstract
1. Introduction
2. Related Work
2.1. Comparative Analysis of Sentiment Analysis Research
2.2. Large Language Models and Fine-Tuning
Head-to-Head Technical Comparison of DPO, KTO, and ORPO
2.3. LLM Fine-Tuning Framework Unsloth
- Speed and memory optimization: Unsloth reduces the fine-tuning time significantly and minimizes memory usage by up to 74%, enabling efficient processing of large models even on limited hardware;
- Compatibility: It supports GPUs from NVIDIA, AMD, and Intel, integrating seamlessly with Hugging Face tools like Transformers and PEFT;
- Open source: The platform’s community-driven, open-source model fosters innovation and accessibility through benchmarks and reproducible workflows [29].
2.4. Baseline LLM: Mistral NeMo
2.5. LLM-Driven Multi-Class Sentiment Analysis
- Understanding: LLMs excel at discerning and interpreting nuanced sentiment expressions across varying contexts, thereby enhancing the accuracy of distinguishing closely related sentiment classes;
- Scalability and adaptability: Pre-trained LLMs can be easily fine-tuned for domain-specific applications, offering versatility across diverse industries and tasks;
- Reduction in pre-processing overhead: Unlike traditional methods, LLM-based sentiment analysis requires minimal data pre-processing, streamlining implementation.
2.6. KNIME for LLM Implementation
3. Methodology
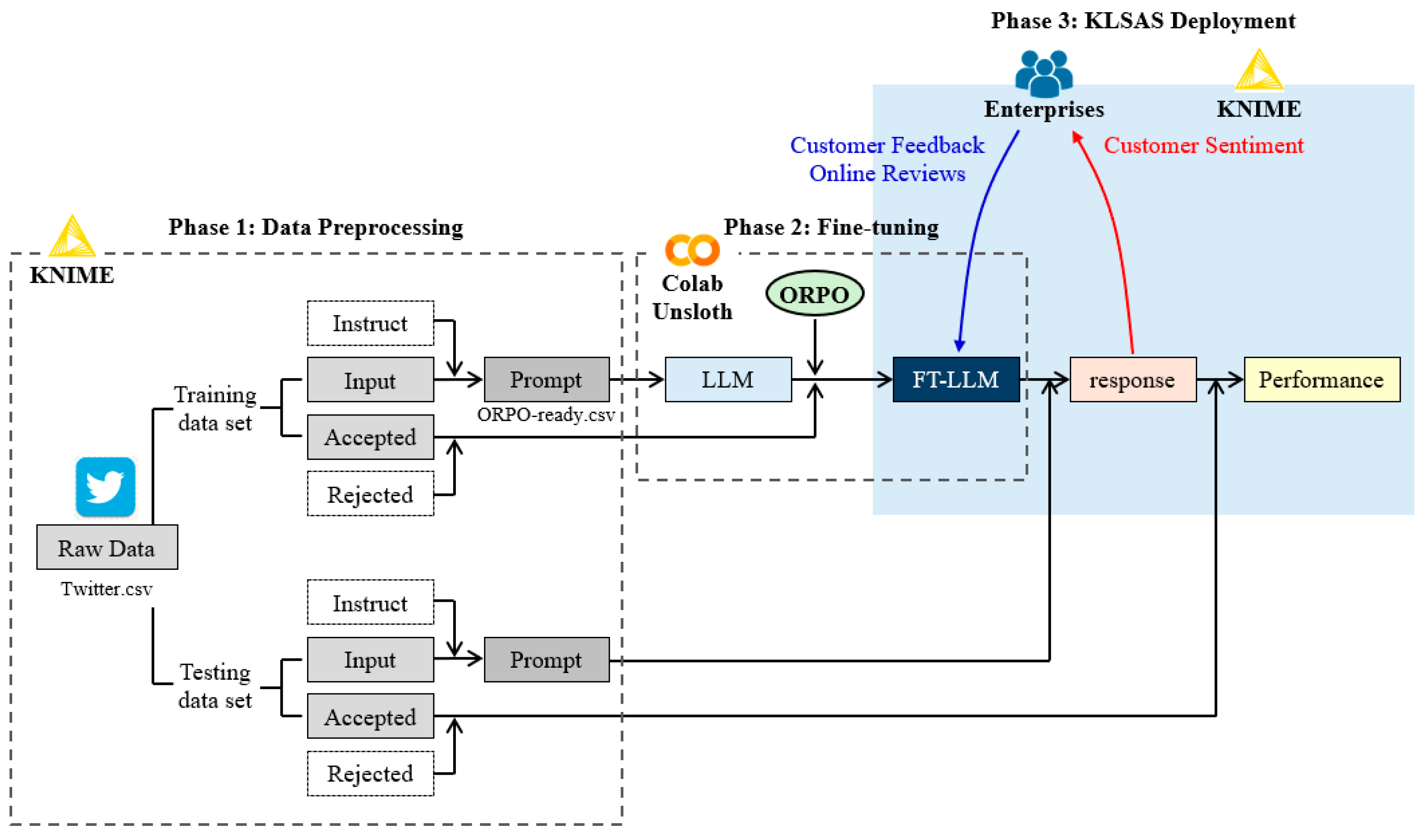
3.1. Data Preparation for ORPO Fine-Tuning
- “@VirginAmerica your inflight team makes the experience #amazing!” (positive);
- “@USAirways where is your email address?” (neutral);
- “@VirginAmerica you suck!” (negative).
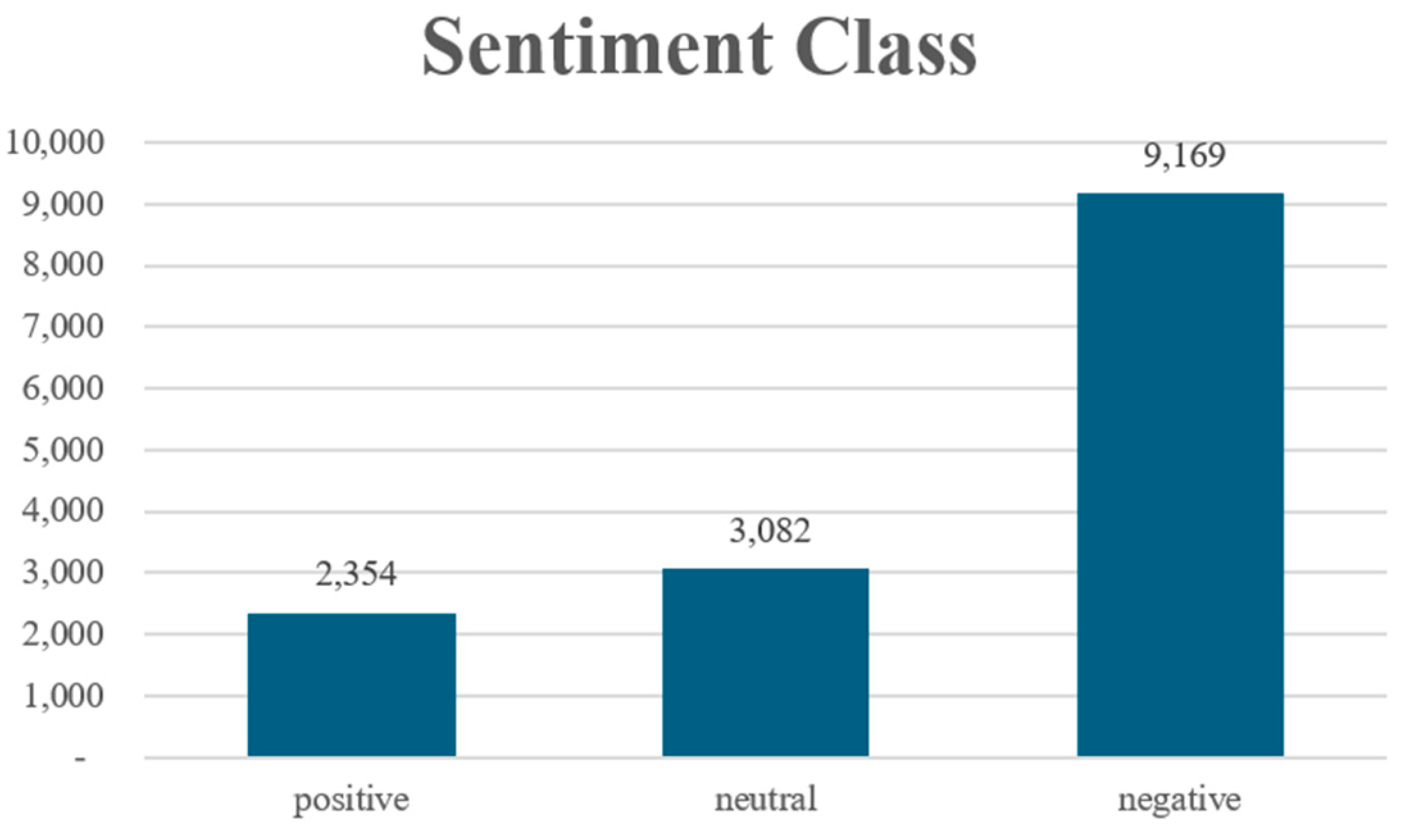
- Data cleaning: Core columns (text and airline_sentiment) were extracted, while irrelevant information was filtered out. The text column contains passengers’ tweets commenting on airlines, and the airline_sentiment column represents the sentiment label manually assigned by the dataset providers based on the emotional tone expressed in the text (i.e., “positive,” “neutral,” or “negative”);
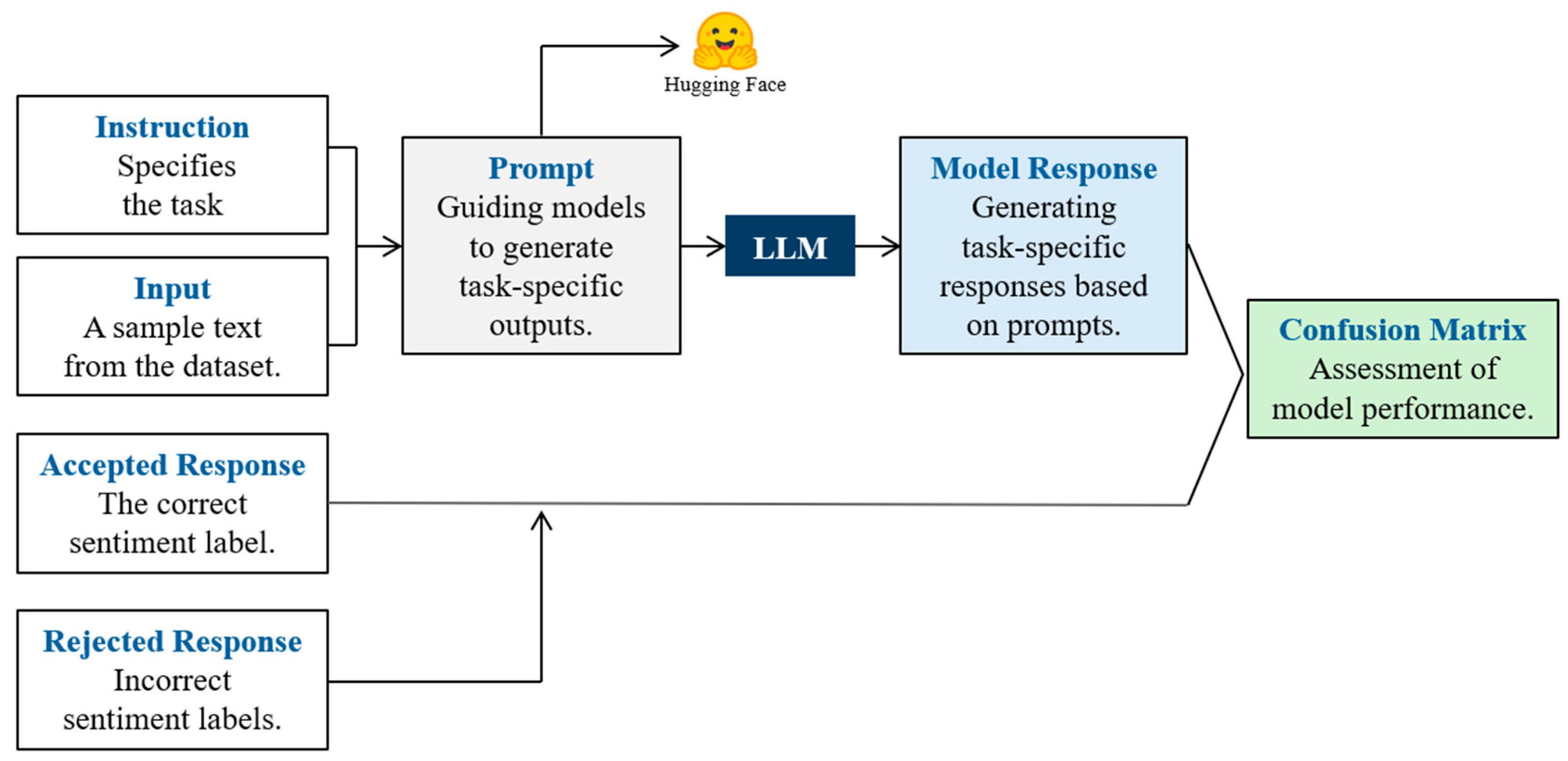
- Data augmentation: To prepare the dataset for ORPO training, each entry was converted into a quadruplet sample (instruction/input/accepted response/rejected Response). For example, for a sample labeled as “neutral,” the rejected responses would be “positive” and “negative.”;
- Instruction/prompt: Specifies the classification task,e.g., “Classify the input using one of these labels: neutral, positive, and negative:”;
- Input: A sample tweet from the dataset,e.g., “@USAirways where is your email address?”;
- Accepted response: The correct sentiment label,e.g., “neutral”;
- Rejected responses: The incorrect sentiment labels,e.g., “positive” and “negative”;
- Format conversion: The structured data was converted into the JSON format and published on Hugging Face. This version includes the augmented dataset preprocessed via KNIME.
3.2. Unsloth Framework for LLM Fine-Tuning
- 4-bit quantization for reduced memory usage;
- LoRA (low-rank adaptation) with rank 16 for efficient parameter updates;
- Gradient checkpointing with Unsloth’s optimized implementation;
- Learning rate scheduling using AdamW optimizer with 8-bit precision.
3.3. Development of KLSAS with ORPO-Tuned Mistral-Nemo Model and KNIME
4. Implementation
4.1. Experimental Setup and Configuration
4.2. Dataset Preparation for ORPO Fine-Tuning with Unsloth
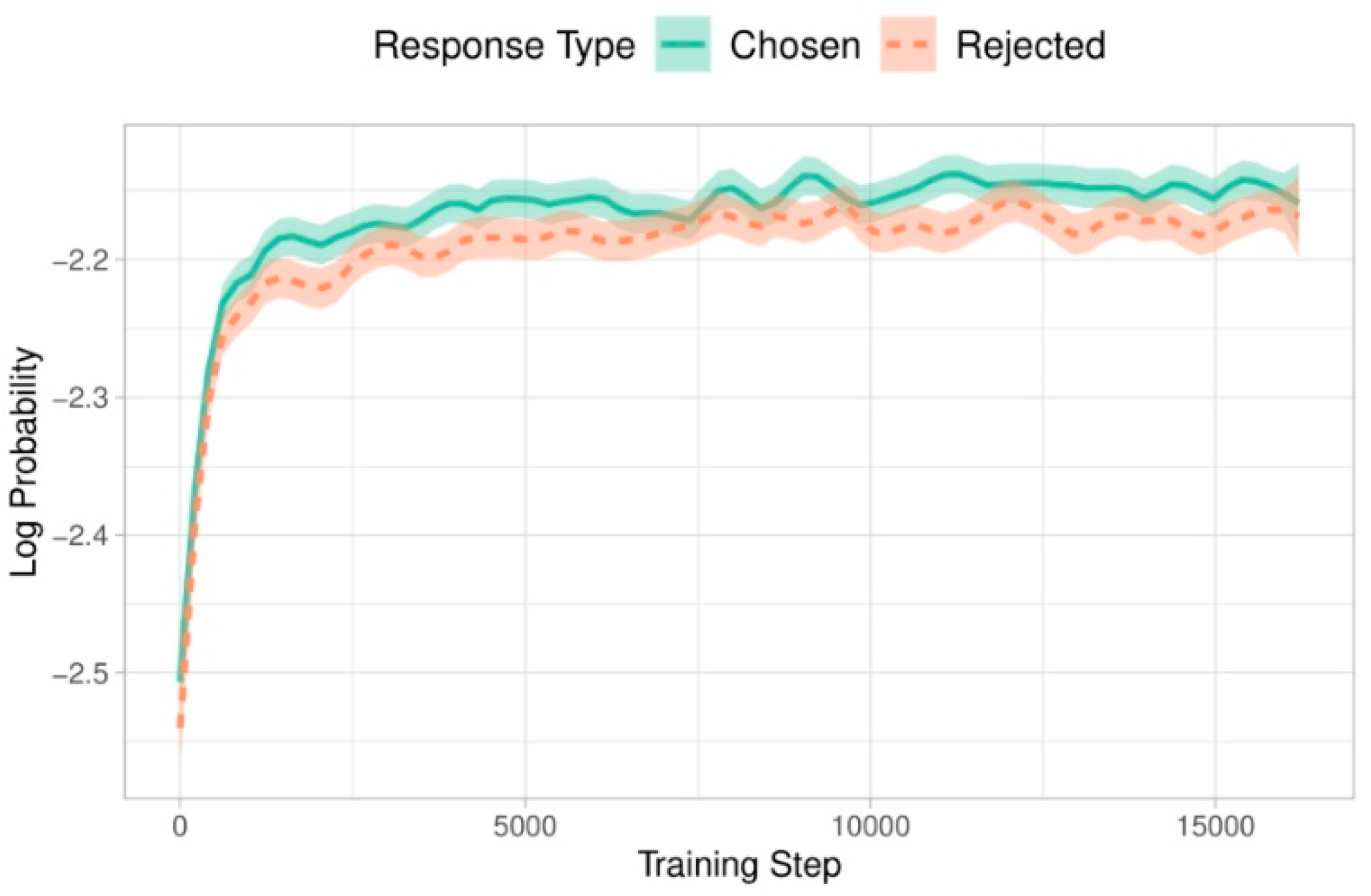
4.3. Fine-Tuning LLM with ORPO Using Unsloth
- Base model: Mistral-Nemo-Instruct-2407-bnb-4bit;
- Sequence length: 4096 tokens with automatic RoPE scaling;
- Memory optimization: 4-bit quantization;
- Parameter efficiency: Low-rank adaptation (LoRA) with rank 16;
- Performance enhancement: Unsloth-optimized gradient checkpointing;
- Optimization algorithm: AdamW optimizer with 8-bit precision;
4.4. Development of KLSAS with KNIME and ORPO-Tuned Model
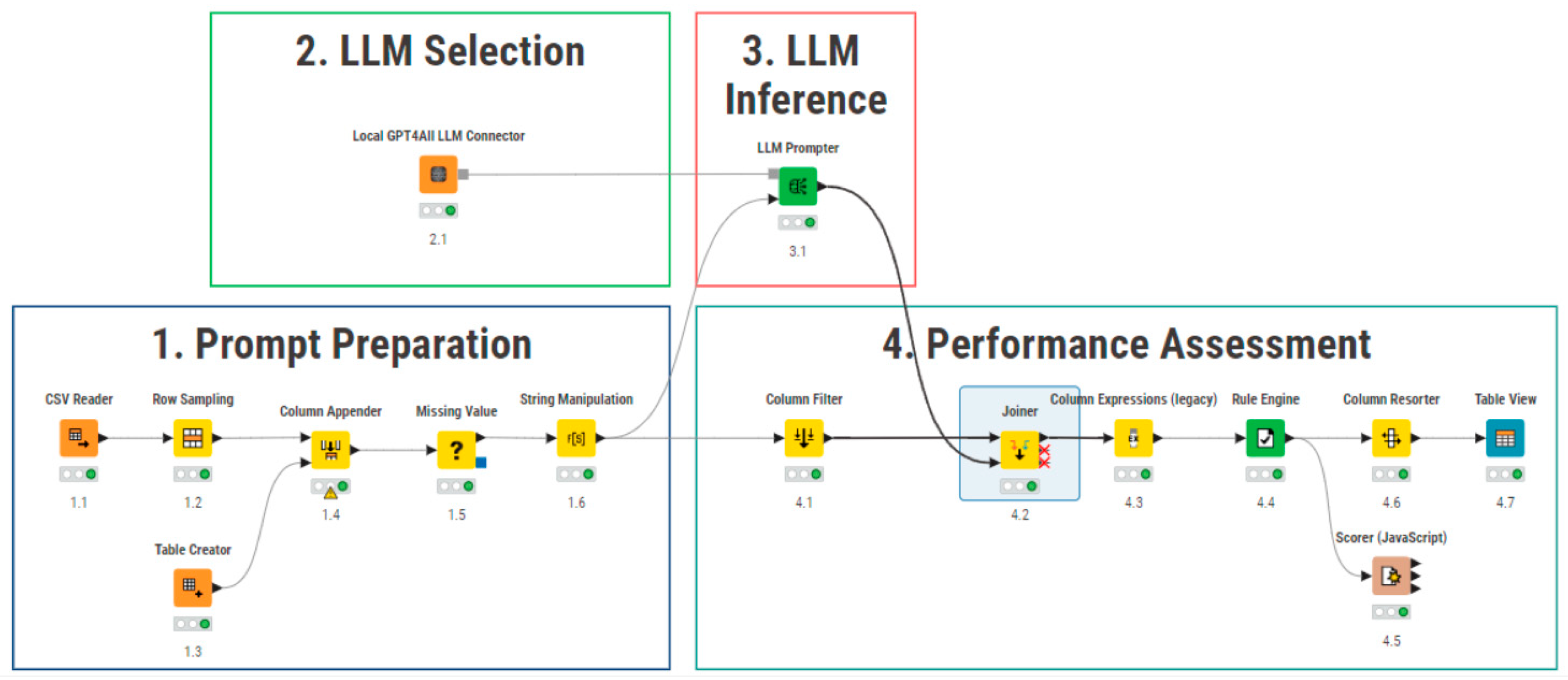
- Prompt preparation: Data preprocessing and formatting;
- Model selection: Selection of the base model or ORPO-tuned model;
- Model inference: Sentiment generation for input text;
- Performance evaluation: Comprehensive model assessment.
5. Discussion of Experimental Results
5.1. Sentiment Classification Performance Analysis
- Negative sentiment classification (90.00% recall)
- Successfully identified 45 out of 50 negative samples;
- Demonstrated robust performance in detecting negative expressions;
- Minor confusion with neutral sentiment (five misclassifications).
- Neutral sentiment classification (88.00% recall)
- Correctly classified 44 neutral samples with high accuracy;
- Exhibited occasional confusion with negative sentiment, resulting in seven misclassifications;
- Demonstrated consistent performance across diverse expression patterns, showcasing robust contextual understanding;
- Achieved a significant performance improvement compared to the baseline model (60% recall).
- Positive sentiment classification (82.00% recall)
- Successfully identified 41 positive samples with reasonable accuracy;
- Experienced a higher misclassification rate compared to other sentiment categories;
- Displayed notable confusion with neutral sentiment, resulting in seven misclassifications, indicating room for refinement in distinguishing positive and neutral expressions.
5.2. Statistical Significance Analysis
5.3. Analysis of Neutral Sentiment Misclassification
5.4. Key Factors in Neutral Sentiment Classification Challenges
- Absence of explicit emotional indicators
- Pure factual statements often lack clear sentiment markers;
- The system tends to default to negative classification in ambiguous cases;
- Examples from samples 2 and 5 demonstrate this challenge.
- Contextual ambiguity
- Expressions can carry multiple interpretations depending on context;
- The model struggles with contextual nuances in samples 1, 4, and 6.
- Annotation consistency issues
- The subjective nature of neutral sentiment leads to inconsistent training data;
- Variation in human interpretation affects model learning;
- Sample 3 illustrates the challenge of consistent annotation.
5.5. Ablation Study
- SFT (NLL only) achieves moderate overall accuracy (78.67%) with high neutral recall (94%) but suffers in the negative (72%) and positive (70%) classes;
- DPO improves negative recall to 98%, yet degrades neutral (68%) and positive (66%) performance, yielding a slight drop in accuracy (77.33%);
- ORPO (full) attains the best balance, with an 86.00% overall accuracy (κ = 0.79) and uniformly strong recall across the negative (90%), neutral (88%), and positive (80%) classes.
6. Conclusions
- Integration complexity: ORPO’s unified loss eliminates separate SFT + RLHF stages, reducing development overhead significantly and simplifying integration into existing fine-tuning pipelines. Furthermore, conventional NLP methods often involve labor-intensive text pre-processing steps, such as tokenization, removing punctuation and stopwords, and part-of-speech tagging, before training a model for inferencing. In contrast, the ORPO-tuned model eliminates the need for pre-processing during inference while delivering superior performance;
- Accessible interfaces: Our KNIME-based KLSAS workflow transforms the complex process of sentiment analysis into drag-and-drop nodes, lowering technical barriers for non-programmers.
- Fine-tuning an LLM for neutral sentiment analysis: The paper customizes an existing LLM to effectively handle neutral sentiment analysis, addressing a specific gap in sentiment classification;
- Development of a KLSAS system: The fine-tuned LLM is integrated into a KLSAS system, enhancing its functionality and real-world applicability;
- Providing open-source resources: The paper offers open-source code, the fine-tuned LLM, and clear deployment steps for the KLSAS system, facilitating easy implementation for enterprises.
6.1. Limitations
6.2. Ethical Considerations
- Human-in-the-loop: Always involve human oversight for critical decisions (e.g., moderating flagged content);
- Transparent data handling: Clearly communicate how the preference data was collected, ensuring it is representative and free from demographic bias;
- Privacy preservation: Anonymize the user text and avoid linking predictions to personally identifiable information.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Availability of Code and Resources
- Source code for ORPO fine-tuning using the Unsloth framework;
- The KLSAS workflow implemented in KNIME;
- Processed training and evaluation datasets in JSONL format;
- Model files for inference, including GGUF format for local LLM deployment;
- Documentation and instructions for reproduction and deployment.
| 1 | The Complete code can be acquired at Google Colab. Available online: https://drive.google.com/file/d/1_W-koRTRdwlDyEqEvGcgVH3h7sO4EpsK/view?usp=drive_link (accessed on 9 March 2025). |
| 2 | The Iecjsu/Airline-Sentiment-ORPO-Train Dataset. https://huggingface.co/datasets/iecjsu/airline-sentiment-ORPO-train (accessed on 10 March 2025). |
| 3 | The Iecjsu/Airline-Sentiment-Eval.Jsonl Dataset. Available online: https://huggingface.co/datasets/iecjsu/airline-sentiment-eval.jsonl (accessed on 12 March 2025). |
| 4 | The Iecjsu/Mistral-Nemo-IT-2407-ORPOall-f16 Model. Available online: https://huggingface.co/iecjsu/Mistral-Nemo-IT-2407-ORPOall-f16 (accessed on 15 March 2025). |
References
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020. [Google Scholar] [CrossRef]
- Kaur, P.; Kashyap, G.S.; Kumar, A.; Nafis, M.T.; Kumar, S.; Shokeen, V. From Text to Transformation: A Comprehensive Review of Large Language Models’ Versatility. arXiv 2024. [Google Scholar] [CrossRef]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Ling, C.; Zhao, X.; Lu, J.; Deng, C.; Zheng, C.; Wang, J.; Chowdhury, T.; Li, Y.; Cui, H.; Zhao, T.; et al. Beyond One-Model-Fits-All: A Survey of Domain Specialization for Large Language Models. arXiv 2023. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. Practical and ethical considerations in the effective use of emotion and sentiment lexicons. Nat. Lang. Eng. 2022, 28, 121–138. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Singapore, 6–10 December 2023; pp. 38–45. [Google Scholar] [CrossRef]
- Hou, X.; Zhao, Y.; Liu, Y.; Yang, Z.; Wang, K.; Li, L.; Luo, X.; Lo, D.; Grundy, J.C.; Wang, H. Large Language Models for Software Engineering: A Systematic Literature Review. ACM Trans. Softw. Eng. Methodol. 2023, 33, 1–79. [Google Scholar] [CrossRef]
- Duan, J.; Zhang, S.; Wang, Z.; Jiang, L.; Qu, W.; Hu, Q.; Wang, G.; Weng, Q.; Yan, H.; Zhang, X.; et al. Efficient Training of Large Language Models on Distributed Infrastructures: A Survey. arXiv 2024. [Google Scholar] [CrossRef]
- Lee, C.P. Design, Development, and Deployment of Context-Adaptive AI Systems for Enhanced User Adoption. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, Proceedings of the CHI’24: CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Hong, J.; Lee, N.; Thorne, J. ORPO: Monolithic preference optimization without reference model. arXiv 2024. [Google Scholar] [CrossRef]
- Berthold, M.R.; Cebron, N.; Dill, F.; Gabriel, T.R.; Kötter, T.; Meinl, T.; Ohl, P.; Thiel, K.; Wiswedel, B. KNIME: The Konstanz Information Miner. In Studies in Classification, Data Analysis, and Knowledge Organization; Springer Nature: Berlin/Heidelberg, Germany, 2022; pp. 319–326. [Google Scholar] [CrossRef]
- Ordenes, F.V.; Silipo, R. Machine learning for marketing on the KNIME Hub: The development of a live repository for marketing applications. J. Bus. Res. 2021, 137, 393–410. [Google Scholar] [CrossRef]
- Hasib, K.M.; Habib, M.A.; Towhid, N.A.; Showrov, M.I.H. A novel deep learning based sentiment analysis of twitter data for us airline service. In Proceedings of the 2021 International Conference on Information and Communication Technology for Sustainable Development (ICICT4SD), Dhaka, Bangladesh, 27–28 February 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 450–455. [Google Scholar] [CrossRef]
- Patel, A.; Oza, P.; Agrawal, S. Sentiment analysis of customer feedback and reviews for airline services using language representation model. Procedia Comput. Sci. 2023, 218, 2459–2467. [Google Scholar] [CrossRef]
- Rustam, F.; Ashraf, I.; Mehmood, A.; Ullah, S.; Choi, G.S. Tweets classification on the base of sentiments for US airline companies. Entropy 2019, 21, 1078. [Google Scholar] [CrossRef]
- Umer, M.; Ashraf, I.; Mehmood, A.; Kumari, S.; Ullah, S.; Sang Choi, G. Sentiment analysis of tweets using a unified convolutional neural network-long short-term memory network model. Comput. Intell. 2021, 37, 409–434. [Google Scholar] [CrossRef]
- Fan, L.; Li, L.; Ma, Z.; Lee, S.; Yu, H.; Hemphill, L. A Bibliometric Review of Large Language Models Research from 2017 to 2023. ACM Trans. Intell. Syst. Technol. 2023, 15, 1–25. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023. [Google Scholar] [CrossRef]
- Golovanov, S.; Kurbanov, R.; Nikolenko, S.I.; Truskovskyi, K.; Tselousov, A.; Wolf, T. Large-Scale Transfer Learning for Natural Language Generation. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Chang, H.; Park, J.; Ye, S.; Yang, S.; Seo, Y.; Chang, D.; Seo, M. How Do Large Language Models Acquire Factual Knowledge During Pretraining? arXiv 2024. [Google Scholar] [CrossRef]
- Liu, P.J.; Lin, K.W.; Fullmer, D.; Means, B.; Thickstun, M.; Wang, M.; Kosaraju, V.; Chen, M.; Sohl-Dickstein, J.; Liang, P. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Adv. Neural Inf. Process. Syst. 2022, 35, 1950–1965. [Google Scholar] [CrossRef]
- Xu, L.; Xie, H.; Qin, S.J.; Tao, X.; Wang, F.L. Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment. arXiv 2023. [Google Scholar] [CrossRef]
- Casper, S.; Davies, X.; Shi, C.; Gilbert, T.K.; Scheurer, J.; Rando, J.; Freedman, R.; Korbak, T.; Lindner, D.; Freire, P.J.; et al. Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback. arXiv 2023. [Google Scholar] [CrossRef]
- Rafailov, R.; Sharma, A.; Mitchell, E.; Ermon, S.; Manning, C.D.; Finn, C. Direct preference optimization: Your language model is secretly a reward model. Adv. Neural Inf. Process. Syst. 2023, 36, 53728–53741. [Google Scholar] [CrossRef]
- Unsloth. 70% + 20% VRAM Reduction. 2024. Available online: https://unsloth.ai/blog/unsloth-checkpointing (accessed on 12 December 2024).
- Han, D. Introducing Unsloth: 30x Faster LLM Training. 2023. Available online: https://unsloth.ai/introducing (accessed on 10 December 2024).
- Nvidia. NeMo Framework: Advancing AI Research and Applications. 2023. Available online: https://developer.nvidia.com/nemo (accessed on 10 December 2024).
- Mistral, A.I. Mistral NeMo: Extending the Boundaries of Contextual Processing. 2023. Available online: https://mistral.ai/news/mistral-nemo/ (accessed on 15 December 2024).
- Mohammad, S.; Kiritchenko, S.; Zhu, X. NRC-Canada: Building the state-of-the-art in sentiment analysis of tweets. In Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), Proceedings of the Second Joint Conference on Lexical and Computational Semantics (SEM), Atlanta, Georgia, 13–14 June 2013; Manandhar, S., Yuret, D., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 321–327. Available online: https://aclanthology.org/S13-2053/ (accessed on 12 May 2025).
- Zhang, Y.; Wallace, B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, Taipei, Taiwan, 1 December 2017; pp. 253–263. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. arXiv 2022. [Google Scholar] [CrossRef]
- Liu, L.; Fu, X.; Kötter, T.; Sturm, K.; Haubold, C.; Guan, W.; Bao, S.; Wang, F. Geospatial Analytics Extension for KNIME. SoftwareX 2024, 25, 101627. [Google Scholar] [CrossRef]
- Sundberg, L.; Holmström, J. Democratizing artificial intelligence: How no-code AI can leverage machine learning operations. Bus. Horiz. 2023, 66, 777–788. [Google Scholar] [CrossRef]
- Kaggle. Twitter US Airline Sentiment. 2024. Available online: https://www.kaggle.com/datasets/crowdflower/twitter-airline-sentiment (accessed on 12 November 2024).
- Zhou, Z.; Zhang, Q.; Kumbong, H.; Olukotun, K. LowRA: Accurate and Efficient LoRA Fine-Tuning of LLMs under 2 Bits. arXiv 2025, arXiv:2502.08141. [Google Scholar]
- Chen, J.-M.; Chao, Y.-H.; Wang, Y.-J.; Shieh, M.-D.; Hsu, C.-C.; Lin, W.-F. QuantTune: Optimizing Model Quantization with Adaptive Outlier-Driven Fine Tuning. arXiv 2024, arXiv:2403.06497. [Google Scholar]
- Daniel; Michael. Finetune Phi-3 with Unsloth. Unsloth AI Blog 2024. 23 May 2024. Available online: https://unsloth.ai/blog/phi3 (accessed on 20 March 2025).
- Han-Chen, D. Make LLM Fine-Tuning 2× Faster with Unsloth and TRL. Hugging Face Engineering Blog 2024. 10 January 2024. Available online: https://huggingface.co/blog/unsloth-trl (accessed on 1 March 2025).
- Zeng, G. On the confusion matrix in credit scoring and its analytical properties. Commun. Stat.-Theory Methods 2019, 49, 2080–2093. [Google Scholar] [CrossRef]
- Li, Y.-S.; Guo, C.-Y. Random logistic machine (RLM): Transforming statistical models into machine learning approach. Commun. Stat.-Theory Methods 2023, 53, 7517–7525. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2011, arXiv:2010.16061. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Study | Model | Accuracy | Neutral Recall | Feature Extract |
|---|---|---|---|---|---|
| 1 | This Study | KLSAS | 86% * | 88% * | Transformer |
| 2 | Rustam et al. [18] | VC (LR+SGD) | 79.20% | 77% | TF-IDF |
| 3 | Rustam et al. [18] | LR | 78.70% | 75% | TF-IDF |
| 4 | Rustam et al. [18] | ETC | 77.20% | 75% | TF |
| 5 | Rustam et al. [18] | SGD | 79.20% | 74% | TF-IDF |
| 6 | Rustam et al. [18] | CC | 79.10% | 74% | TF-IDF |
| 7 | Rustam et al. [18] | SVM | 78.50% | 74% | TF-IDF |
| 8 | Rustam et al. [18] | ETC | 76.10% | 74% | TF-IDF |
| 9 | Rustam et al. [18] | RF | 75.80% | 74% | TF-IDF |
| 10 | Rustam et al. [18] | CC | 78.90% | 73% | TF |
| 11 | Rustam et al. [18] | LR | 78% | 73% | TF |
| 12 | Rustam et al. [18] | RF | 76.30% | 73% | TF |
| 13 | Rustam et al. [18] | VC (LR+SGD) | 79.10% | 72% | TF |
| 14 | Rustam et al. [18] | SGD | 79.20% | 71% | TF |
| 15 | Rustam et al. [18] | SVM | 77.30% | 70% | TF |
| 16 | Rustam et al. [18] | GBM | 74% | 70% | TF |
| 17 | Rustam et al. [18] | ADB | 74.50% | 69% | TF |
| 18 | Rustam et al. [18] | ADB | 74.60% | 68% | TF-IDF |
| 19 | Rustam et al. [18] | GBM | 73.40% | 66% | TF-IDF |
| 20 | Umer et al. [19] | SGD | 79.20% | 65% | TF-IDF |
| 21 | Umer et al. [19] | VC (LR+SGDC) | 79.20% | 65% | TF-IDF |
| 22 | Umer et al. [19] | SVM | 78.50% | 61% | TF-IDF |
| 23 | Umer et al. [19] | RF | 75.80% | 61% | TF-IDF |
| 24 | Rustam et al. [18] | DT | 67.20% | 59% | TF |
| 25 | Rustam et al. [18] | DT | 68.60% | 55% | TF-IDF |
| 26 | Umer et al. [19] | VC (LR+SGDC) | 78.20% | 49% | word2vec |
| 27 | Umer et al. [19] | SGD | 78.20% | 48% | word2vec |
| 28 | Umer et al. [19] | SVM | 78.00% | 48% | word2vec |
| 29 | Patel & Agrawal [17] | KNN | 67% | 47% | |
| 30 | Patel & Agrawal [17] | BERT | 83% | 46% | Transformer |
| 31 | Patel & Agrawal [17] | DT | 67% | 43% | |
| 32 | Patel & Agrawal [17] | RF | 77% | 37% | |
| 33 | Umer et al. [19] | RF | 73.70% | 28% | word2vec |
| 34 | Rustam et al. [18] | GNB | 43.80% | 24% | TF-IDF |
| 35 | Rustam et al. [18] | GNB | 41.80% | 23% | TF |
| 36 | Patel & Agrawal [17] | ADB | 72% | 8% | |
| 37 | Patel & Agrawal [17] | LR | 65% | 0% | |
| 38 | Patel & Agrawal [17] | SVM | 65% | 0% |
| Method | Number of Optimization Stages | Reliance on Reference Policy | Computational Overhead | Stability |
|---|---|---|---|---|
| DPO | Two (SFT → Preference) | Requires a separate reward/ reference model | High (extra reward-model training) | Moderate (RL stage can fluctuate) |
| KTO | Two (SFT → Utility Alignment) | Requires a reference policy (binary utility calibration) | Moderate–High (utility function tuning) | Moderate (utility nonlinearity adds noise) |
| ORPO | One (Unified SFT+Preference) | Reference-free (no external policy needed) | Low (single stage, no extra model) | High (faster, more stable convergence) |
| Parameter | Value |
|---|---|
| Base Model | Mistral-Nemo-Instruct-2407-bnb-4bit |
| Sequence Length | 4096 tokens (auto RoPE scaling) |
| Quantization | 4-bit |
| LoRA Rank | 16 |
| Optimizer | AdamW (8-bit precision) |
| Gradient Checkpointing | Unsloth-optimized implementation |
| Learning Rate Schedule | Cosine decay with 5% warmup |
| ORPO λ Term | 0.4 |
| Step | KNIME Node | Configuration |
|---|---|---|
| 1. Prompt Preparation | 1.1 CSV Reader | Read from: Mountpoint, Local Mode: File File: path of your computer/filename.csv |
| 1.2 Row Sampling | Sampling Method Absolute = 150 Stratified sampling = label Absolute = 150 Stratified sampling = label☑ Use random seed = 100 | |
| 1.3 Table Creator | Table Creator Settings Column name = instruct Row0 = Classify the following text using one of these labels: neutral, positive, and negative: | |
| 1.4 Column Appender |  Generate new RowIDs Generate new RowIDs | |
| 1.5 Missing Value | Column Settings instruct = Previous Value | |
| 1.6 String Manipulation | Expression = join($instruct$, “\”“,$text$,”\” “) Append Column = prompt | |
| 2. Model Selection | 2.1 Local GPT4All LLM Connector | Model path: Your path/Mistral-Nemo-IT-2407-ORPOall-f16.gguf Model parameters: default |
| 3. Model Inference | 3.1 LLM Prompter | Prompt column = prompt Response column name = Response |
| 4. Model Performance Evaluation | 4.1 Column Filter | Column filter = Manual Includes = text, label, prompt |
| 4.2 Joiner | Match=Any of the following Top input (‘left’ table) = RowID Bottom input (’right’ table) = RowID Compare values in join columns by = Value and type ☑ Matching rows | |
| 4.3 Column Expressions | Expressions: removeChars(lowerCase(column(“Response”))) | |
| 4.4 Rule Engine | Expressions: $response$ LIKE “*neutral*”=>“neutral” $response$ LIKE “*positive*”=>“positive” $response$ LIKE “*negative*”=>“negative” TRUE => “unclassified” Replace column = response | |
| 4.5 Scorer (Jav Script) | Title = Score View Subtitle = Confusion Matrix Actual column = label Predicted column = response | |
| 4.6 Column Resorter | Column = text, label, instruct, Response, response | |
| 4.7 Table Viewer | Display column = Manual Includes = label, response ☑ Show RowIDs |
| Negative (Predicted) | Neutral (Predicted) | Positive (Predicted) | ||
|---|---|---|---|---|
| Negative (Actual) | 48 | 2 | 0 | 96.00% |
| Neutral (Actual) | 18 | 30 | 2 | 60.00% |
| Positive (Actual) | 3 | 12 | 35 | 70.00% |
| 69.57% | 68.18% | 94.59% |
| Negative (Predicted) | Neutral (Predicted) | Positive (Predicted) | ||
|---|---|---|---|---|
| Negative (Actual) | 45 | 5 | 0 | 90.00% |
| Neutral (Actual) | 6 | 44 | 0 | 88.00% |
| Positive (Actual) | 2 | 7 | 41 | 82.00% |
| 84.91% | 78.57% | 100.00% |
| Text | Discussions | |
|---|---|---|
| 1 | @united any plans of restating nonstop service between IAD and South Florida? We miss our flights to FLL. | Analysis: The commenter asks about plans to restore nonstop flights between IAD and South Florida and expresses, “We miss our flights to FLL.” Reason: The model may interpret “miss our flights” as regret or dissatisfaction, classifying it as negative. Additionally, inquiring about flight restoration may be seen as dissatisfaction with current services. Inference: Ambiguity in sentiment and context dependency. “Miss our flights” could mean nostalgia (neutral) or disappointment (negative), requiring context for proper interpretation. |
| 2 | @united how come it’s cheaper to fly to BKK than NRT even though to get to BKK you take an extra flight, from NRT! | Analysis: The commenter questions the pricing strategy, noting that it is cheaper to fly to BKK than NRT, despite requiring an additional flight from NRT. Reason: The model may interpret “how come” and the exclamation mark as dissatisfaction or complaint, classifying it as negative. Inference: Lacks clear emotional markers. It simply states a question without containing overt sentiment words. |
| 3 | @USAirways also, can you explain why, when I checked in, on the US Airways site, & picked “Standby for 1st” I was not put on the list? | Analysis: The commenter asks why they were not placed on the standby list for first class despite selecting the option during check-in. Reason: The model may interpret “can you explain why” as dissatisfaction or complaint, classifying it as negative. Inference: Annotation inconsistency and human judgment differences. Customer inquiries can be interpreted as either “neutral” or “dissatisfaction,” leading to confusion during model training. |
| 4 | Thanks, @chasefoster. Was just about to book a flight to UK using @AmericanAir, but after reading this exchange, there’s no way. I’ve sent | Analysis: The commenter thanks someone and states they were planning to book a flight with @AmericanAir but decided against it after reading an exchange. Reason: The phrase “there’s no way” expresses strong rejection, leading the model to classify it as dissatisfaction with @AmericanAir. Inference: Ambiguity in sentiment and context dependency. “There’s no way” requires contextual judgment. |
| 5 | @AmericanAir this receipt doesn’t show the evoucher value nor does it mention having used an evoucher. | Analysis: The commenter points out that the receipt does not show the e-voucher value or mention its use. Reason: The model may interpret phrases like “doesn’t show” and “nor does it mention” as dissatisfaction or complaint, classifying it as negative. Inference: Lacks clear emotional markers. It simply “states a problem” without containing overt sentiment words. |
| 6 | @AmericanAir I am trying to switch my flight to AA 1359 I am currently on AA 2401 at 6:50 am MONDAY morn then AA2586! Help Me!! | Analysis: The commenter is trying to change their flight and is requesting assistance. Reason: The use of “Help Me!!” and multiple exclamation marks may lead the model to interpret the tone as anxiety or dissatisfaction, classifying it as negative. Inference: Ambiguity in sentiment and context dependency. The exclamation marks require context for accurate interpretation. |
| Model | Accuracy | Cohen’s k | Negative Recall | Neutral Recall | Positive Recall |
|---|---|---|---|---|---|
| SFT (NLL only) | 78.67% | 0.680 | 72.00% | 94.00% | 70.00% |
| DPO | 77.33% | 0.660 | 98.00% | 68.00% | 66.00% |
| ORPO (full) | 86.00% | 0.790 | 90.00% | 88.00% | 80.00% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, J.-C.; Su, N.-J.; Lin, Y.-B. Effective Multi-Class Sentiment Analysis Using Fine-Tuned Large Language Model with KNIME Analytics Platform. Systems 2025, 13, 523. https://doi.org/10.3390/systems13070523
Shen J-C, Su N-J, Lin Y-B. Effective Multi-Class Sentiment Analysis Using Fine-Tuned Large Language Model with KNIME Analytics Platform. Systems. 2025; 13(7):523. https://doi.org/10.3390/systems13070523
Chicago/Turabian StyleShen, Jin-Ching, Nai-Jing Su, and Yi-Bing Lin. 2025. "Effective Multi-Class Sentiment Analysis Using Fine-Tuned Large Language Model with KNIME Analytics Platform" Systems 13, no. 7: 523. https://doi.org/10.3390/systems13070523
APA StyleShen, J.-C., Su, N.-J., & Lin, Y.-B. (2025). Effective Multi-Class Sentiment Analysis Using Fine-Tuned Large Language Model with KNIME Analytics Platform. Systems, 13(7), 523. https://doi.org/10.3390/systems13070523