
Optimizing and Visualizing Drone Station Sites for Cultural Heritage Protection and Research Using Genetic Algorithms


Abstract
1. Introduction
1.1. Research Background
1.2. Working Definition of “Drone Station”
1.3. Literature Review
1.4. Assumptions and Research Questions
2. Methods
2.1. Genetic Algorithm as an Optimization Method and Its Application
2.1.1. General Procedure of Simulation and Optimization Using Genetic Algorithm
2.1.2. Decision Variables, Objective Function, and Constraints
2.2. Application to the Problem Setting
2.2.1. Chromosome Representation—Decision Variables
2.2.2. Constraints
2.2.3. Fitness Function—Objective Function
N-Covered(x,y)
Land_Cost(x,y)
2.2.4. Selection
2.2.5. Crossover and Offspring Generation
2.2.6. Mutation
2.2.7. Termination Condition
2.3. Visualization Strategy
2.4. Parameter Tuning Procedure
3. Results
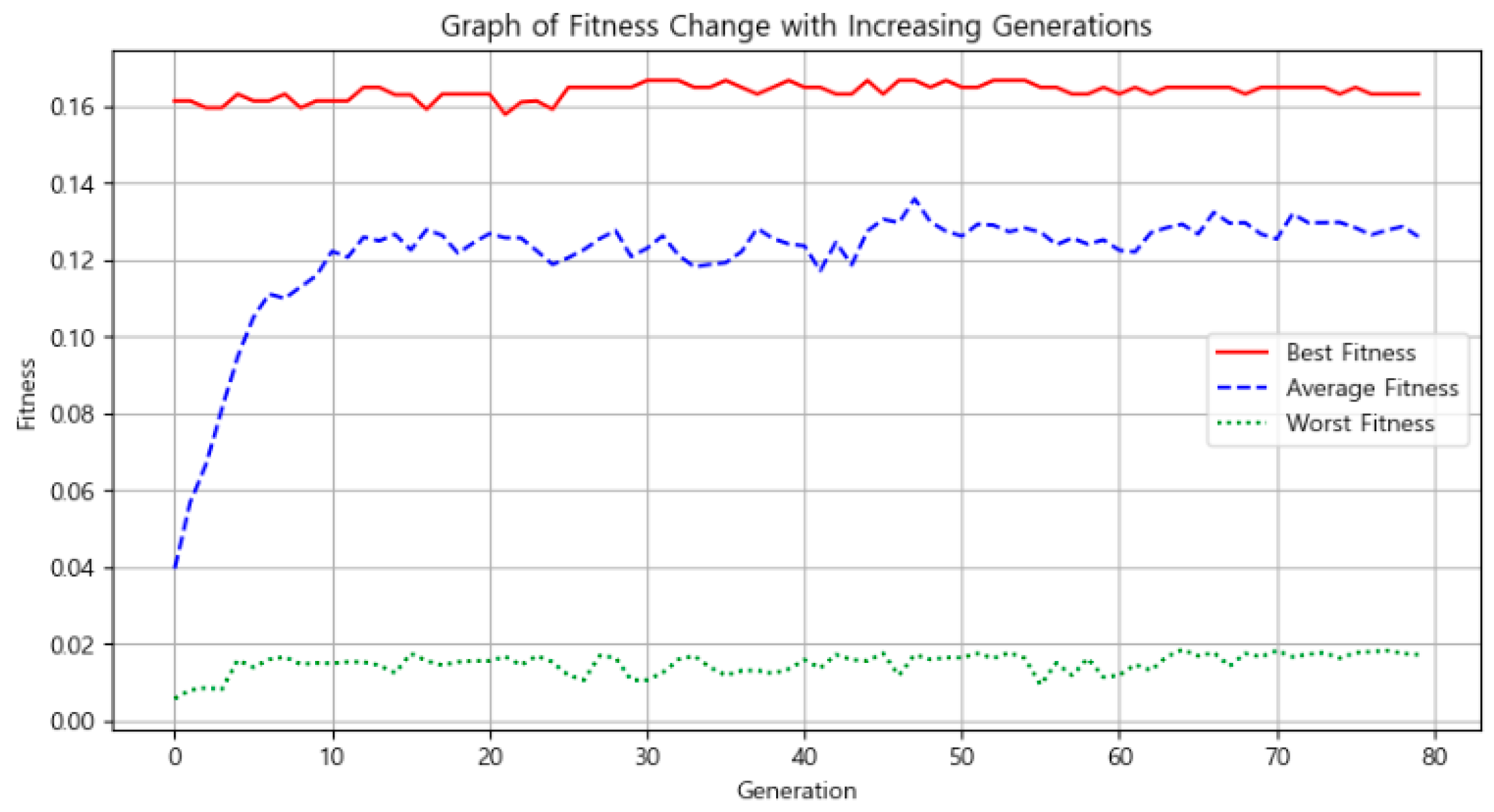
3.1. Optimization Results: Identifying the Economically Optimal Location Using a Genetic Algorithm
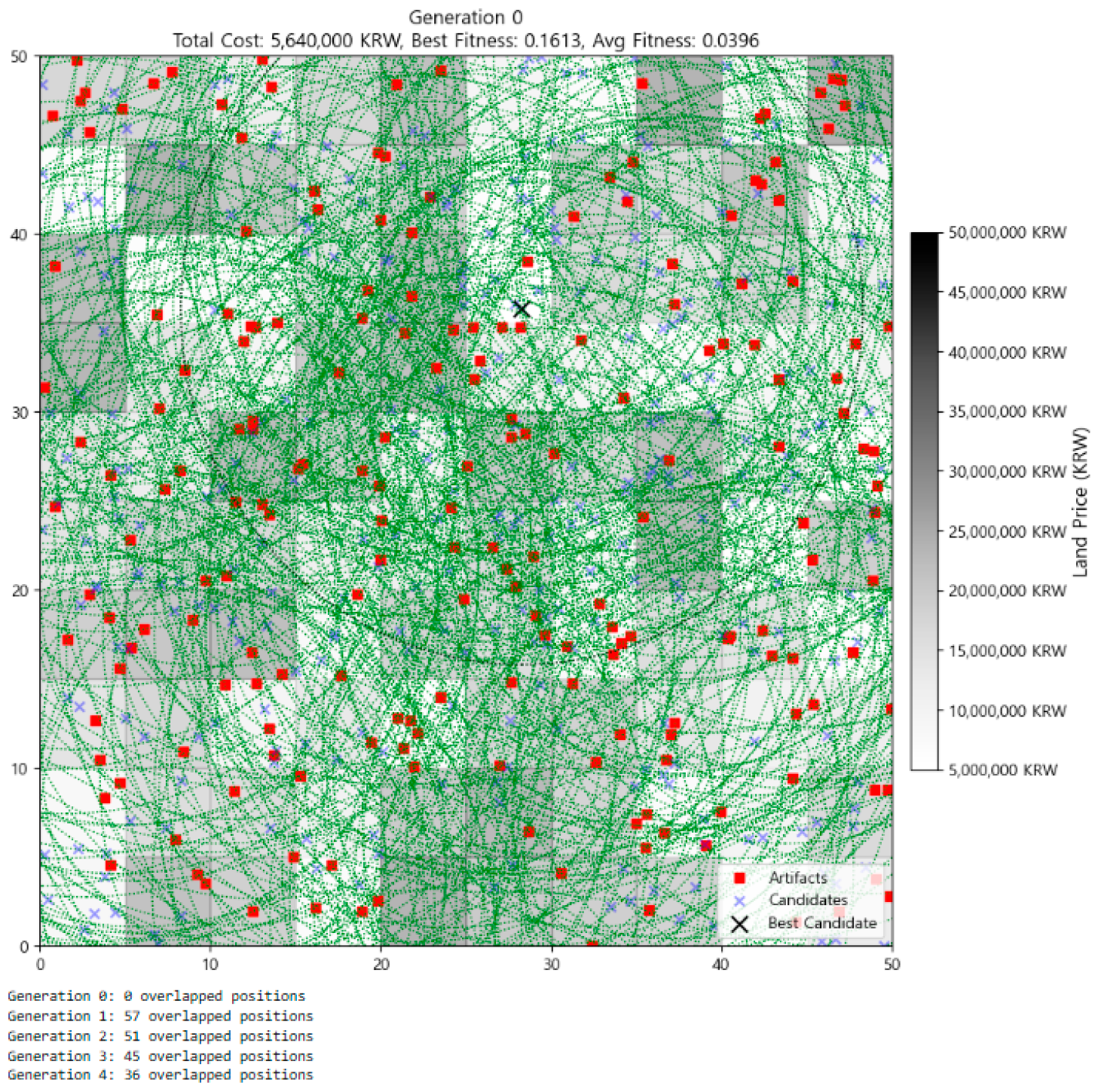
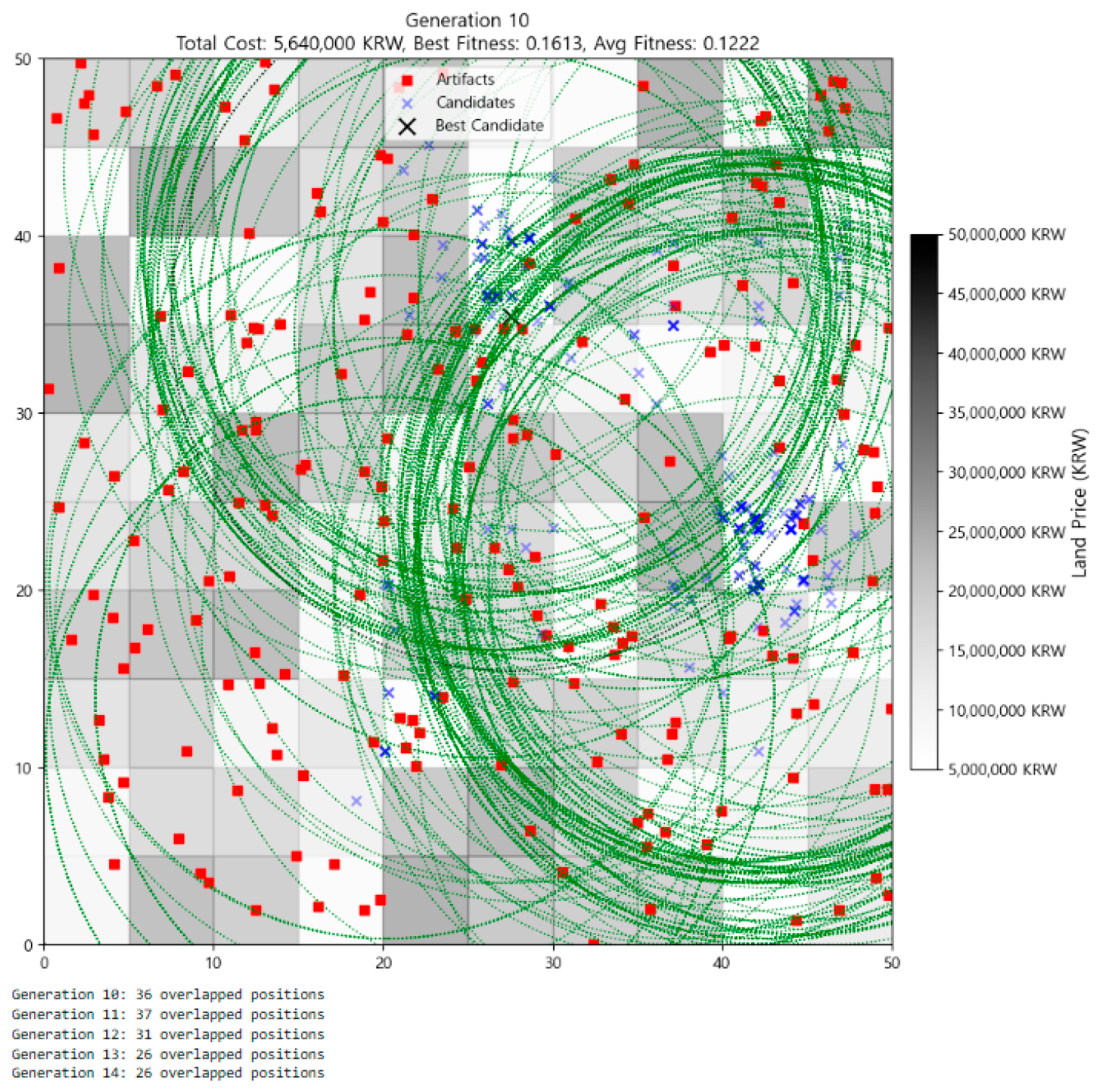
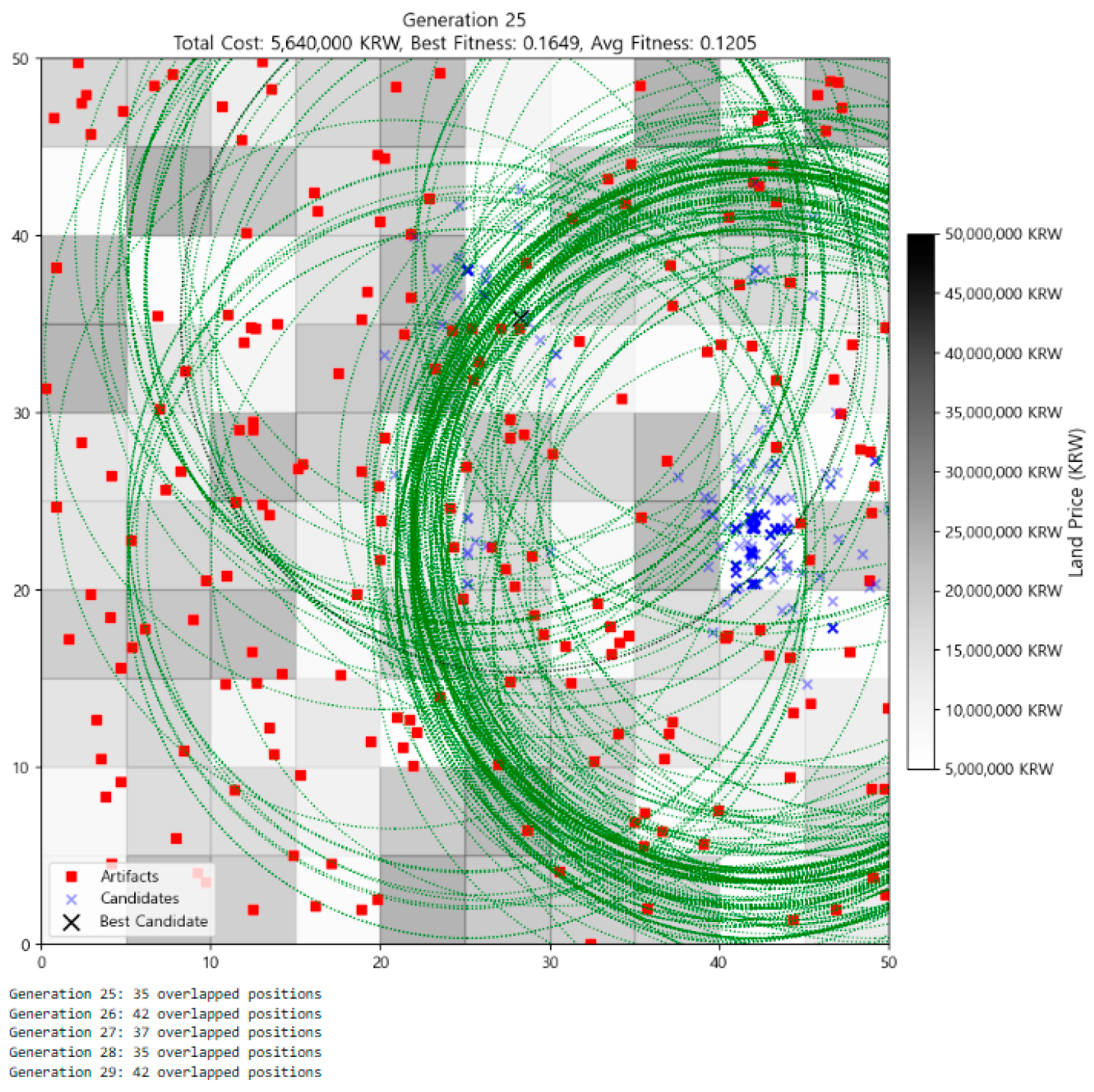
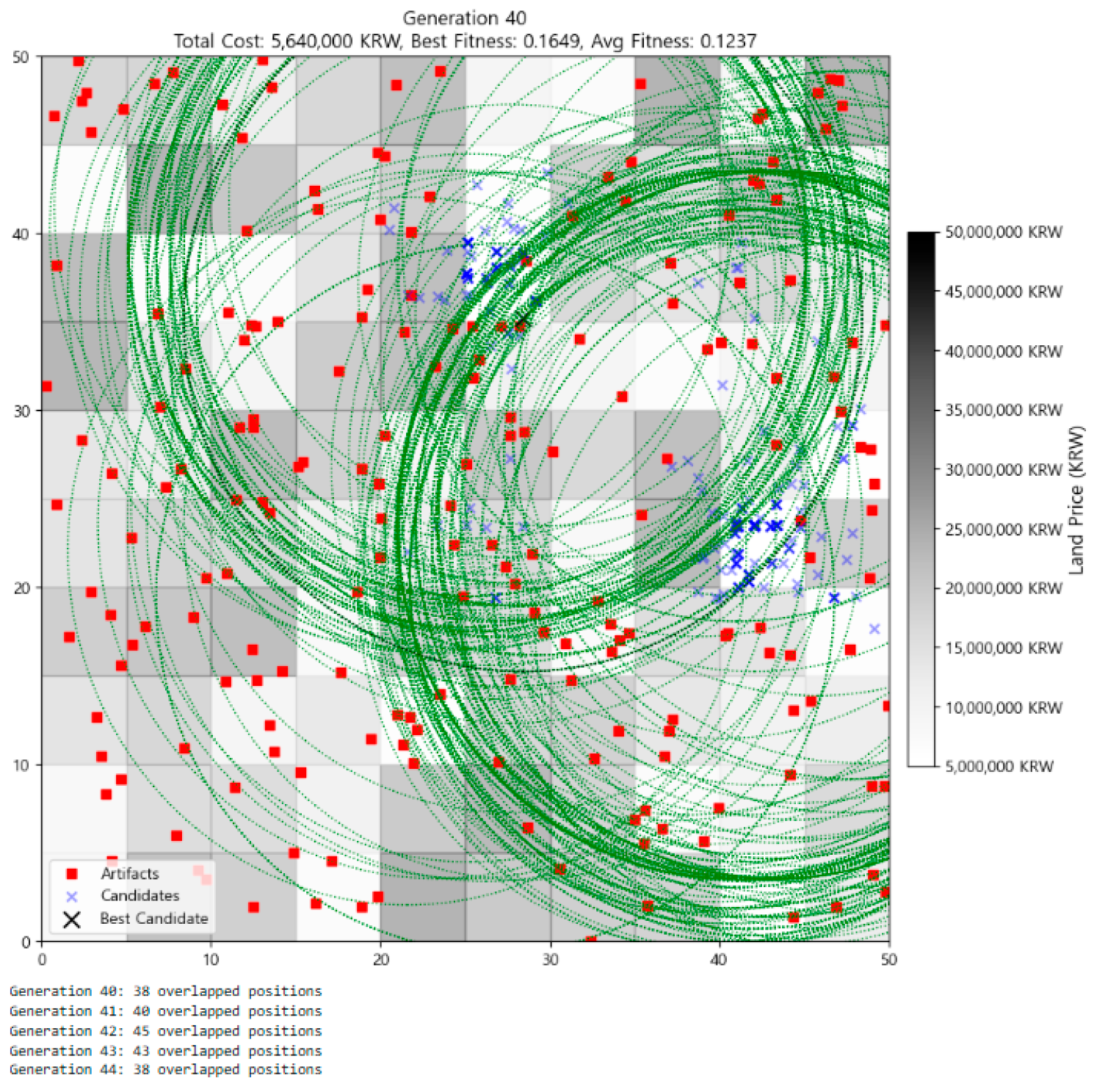
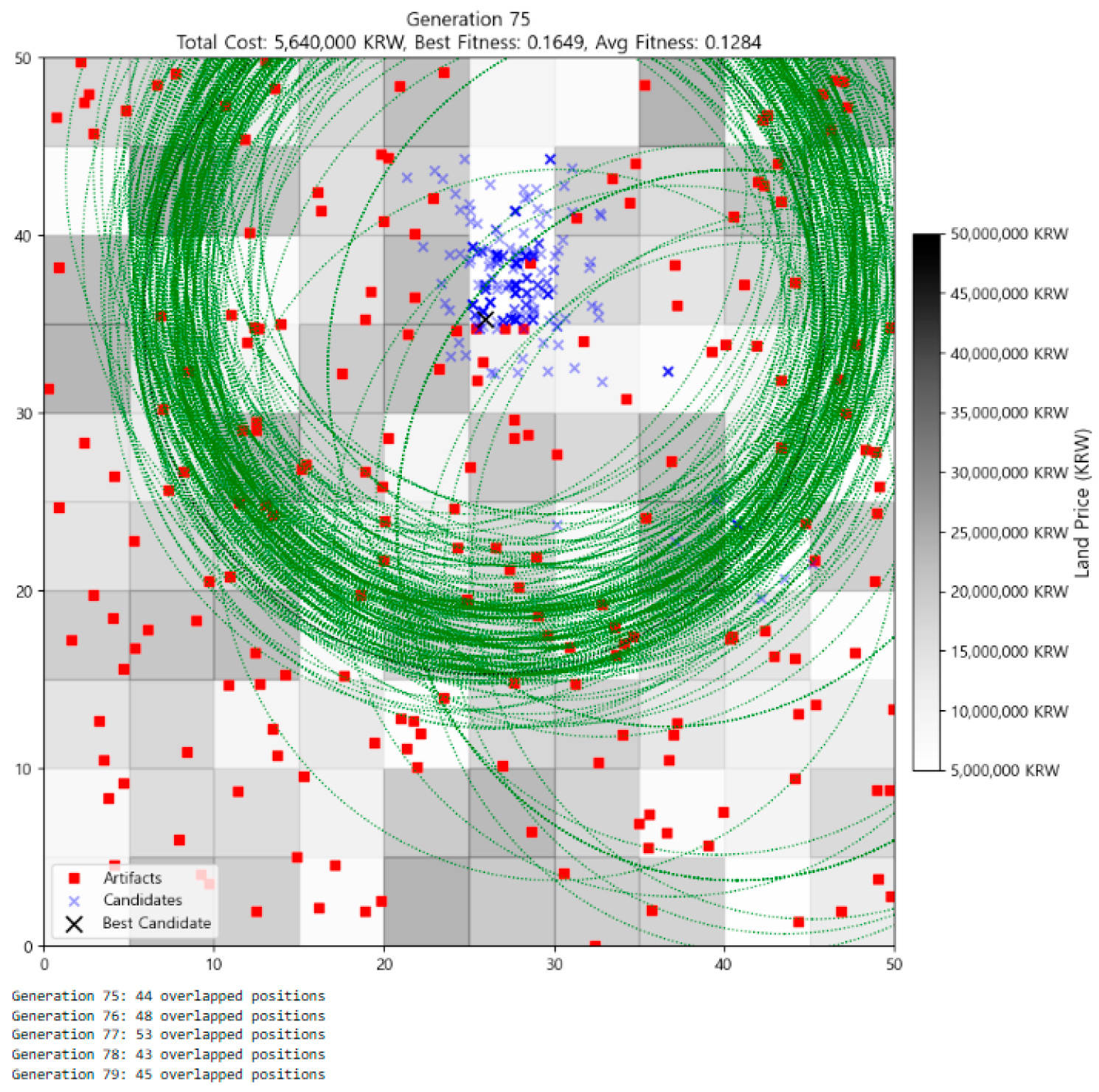
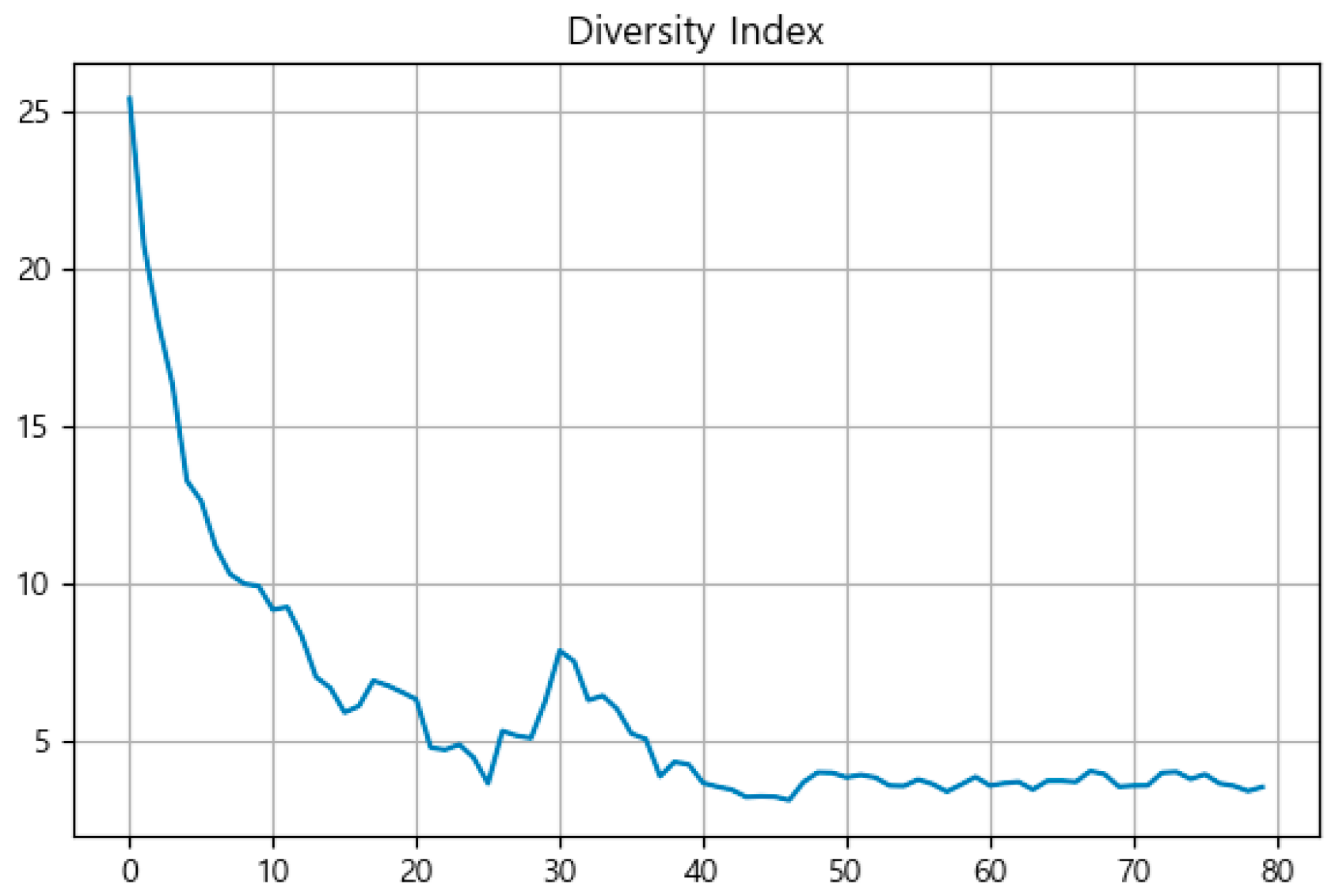
3.2. Visualization of Optimization Process
3.3. Comparing Competence of GA with Random Placement as Baseline
3.4. Results of Parameter Tuning Process
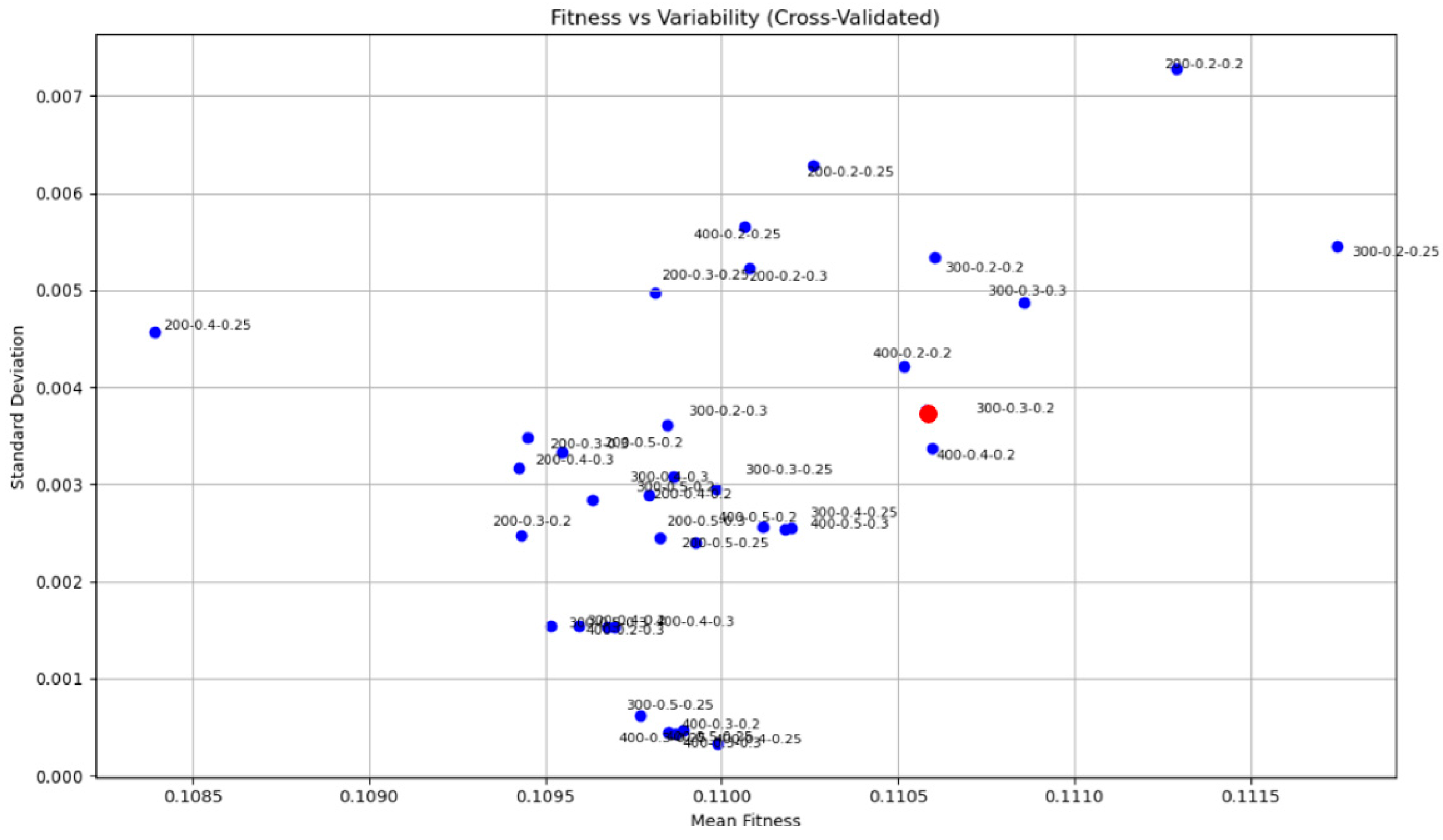
3.4.1. Descriptive Analysis of Parameter Combinations: Mean and Variability of Fitness
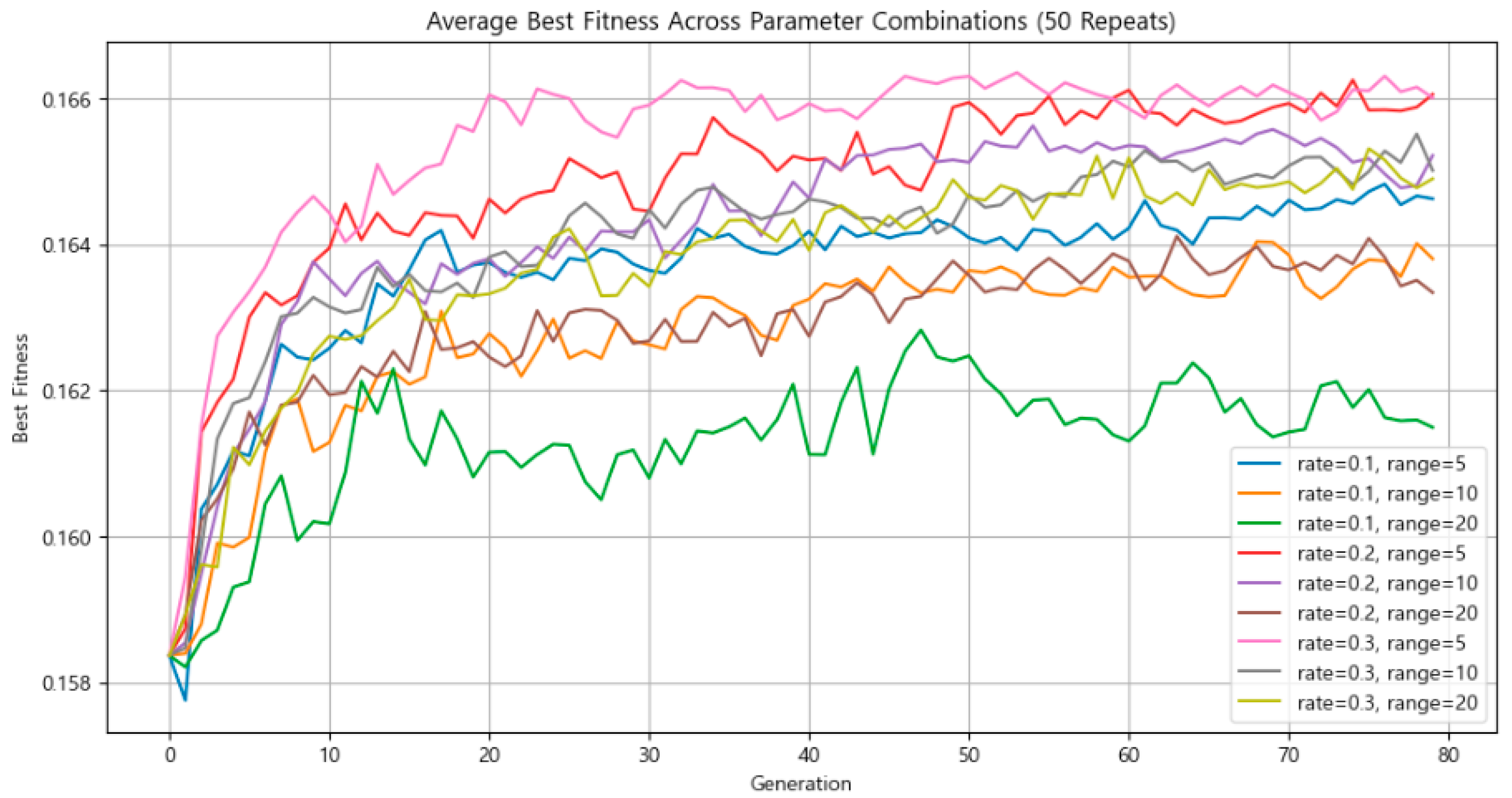
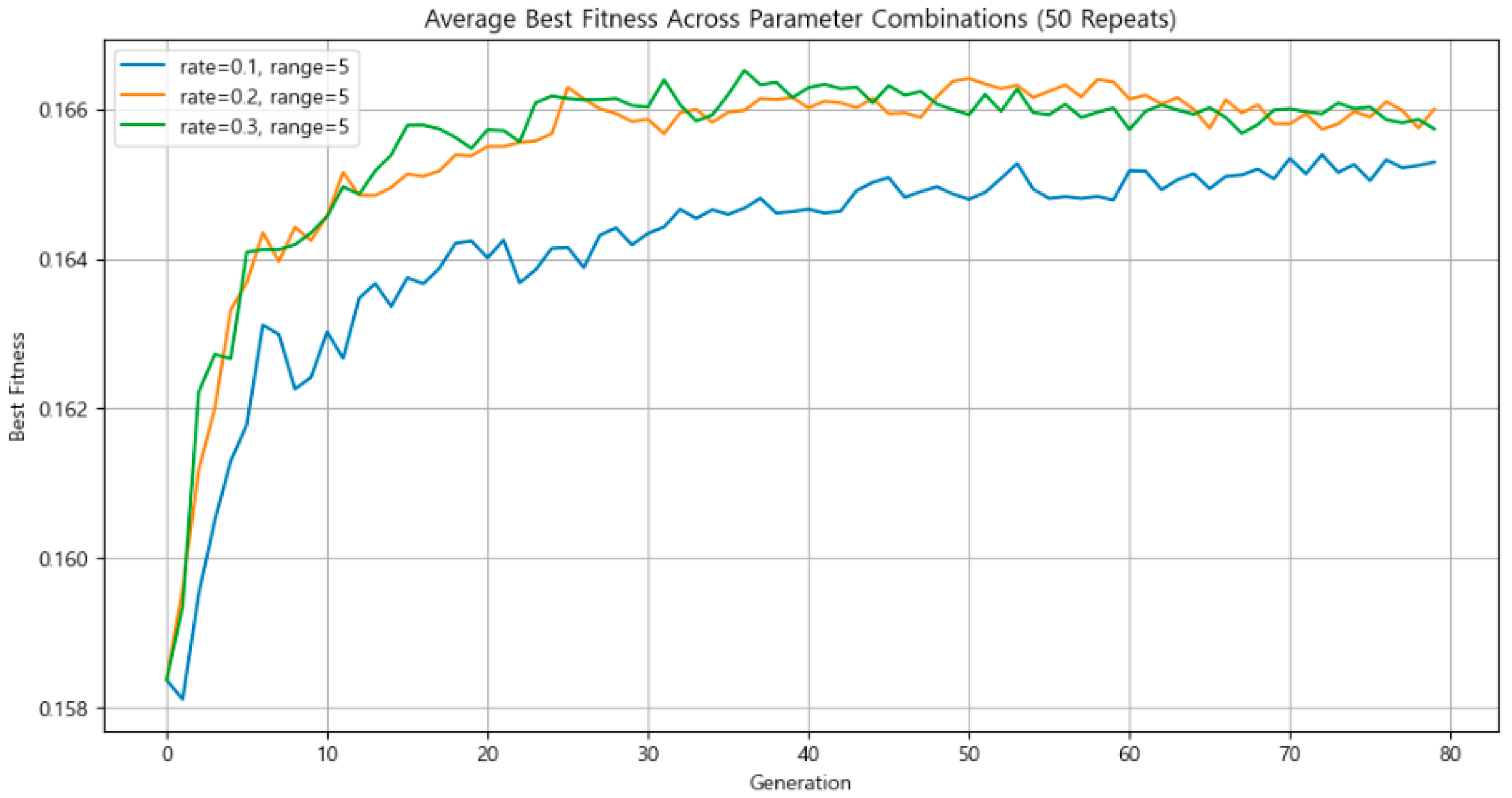
3.4.2. Mutation Intensity and Mutation Rate
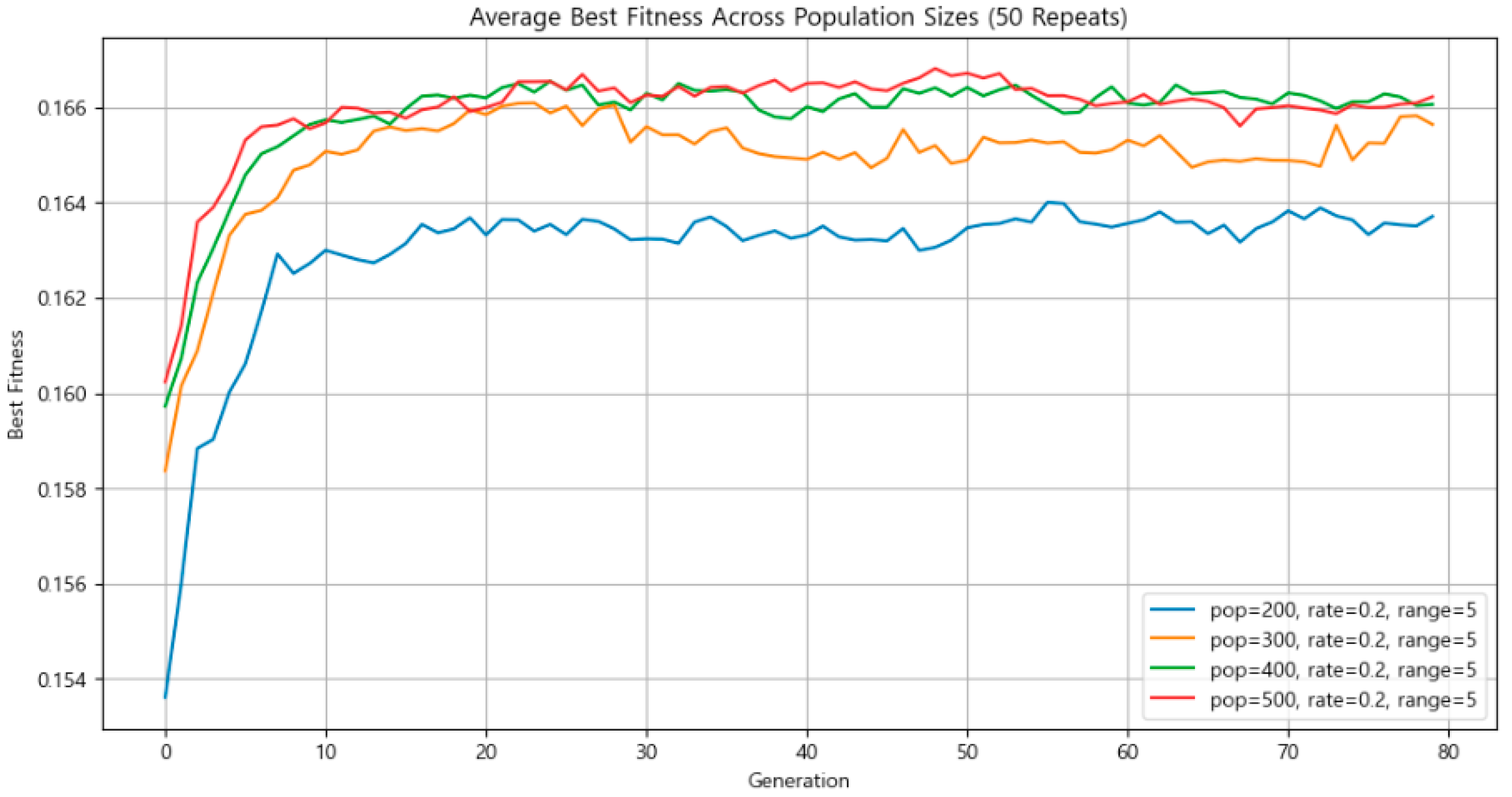
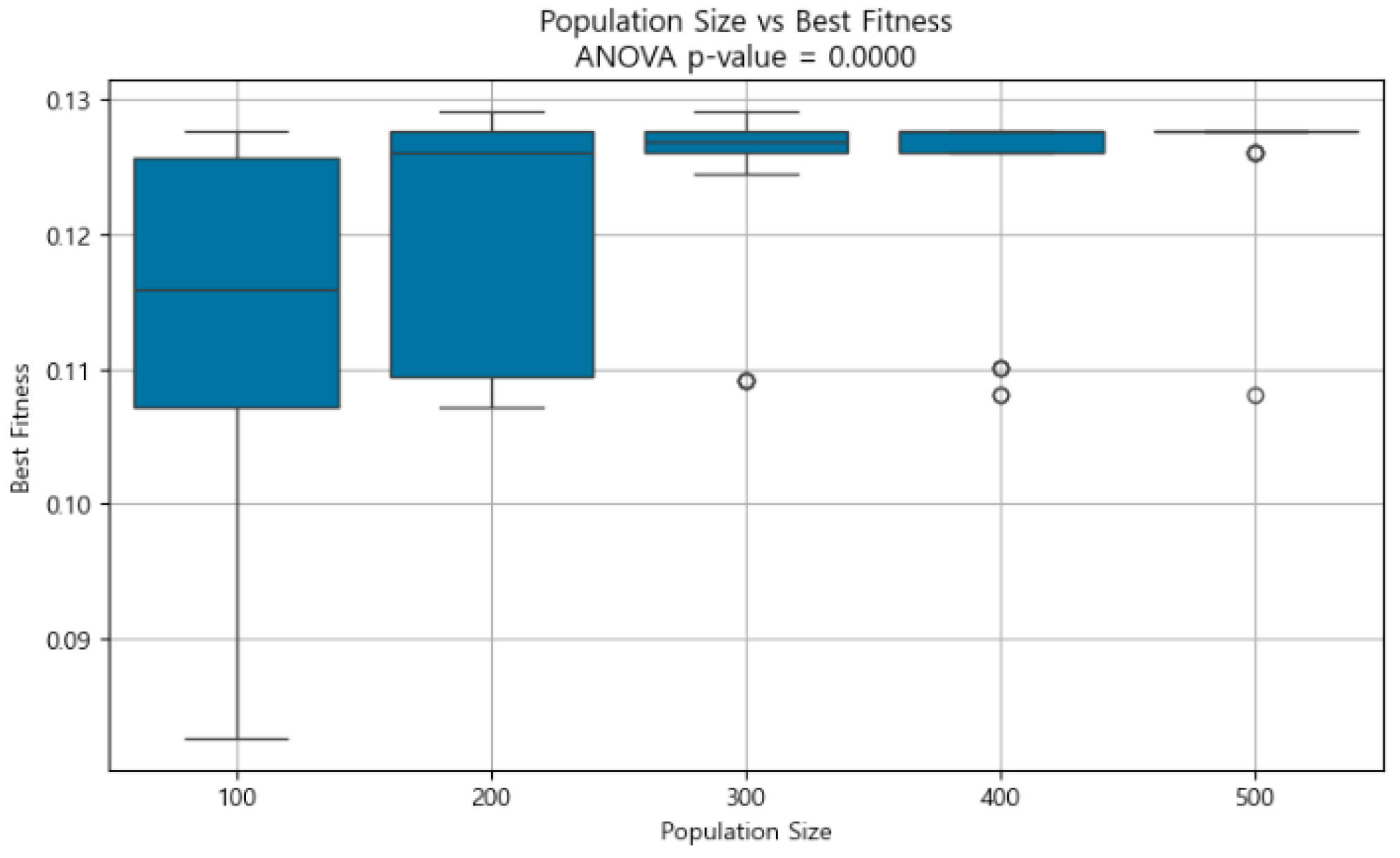
3.4.3. Population Size
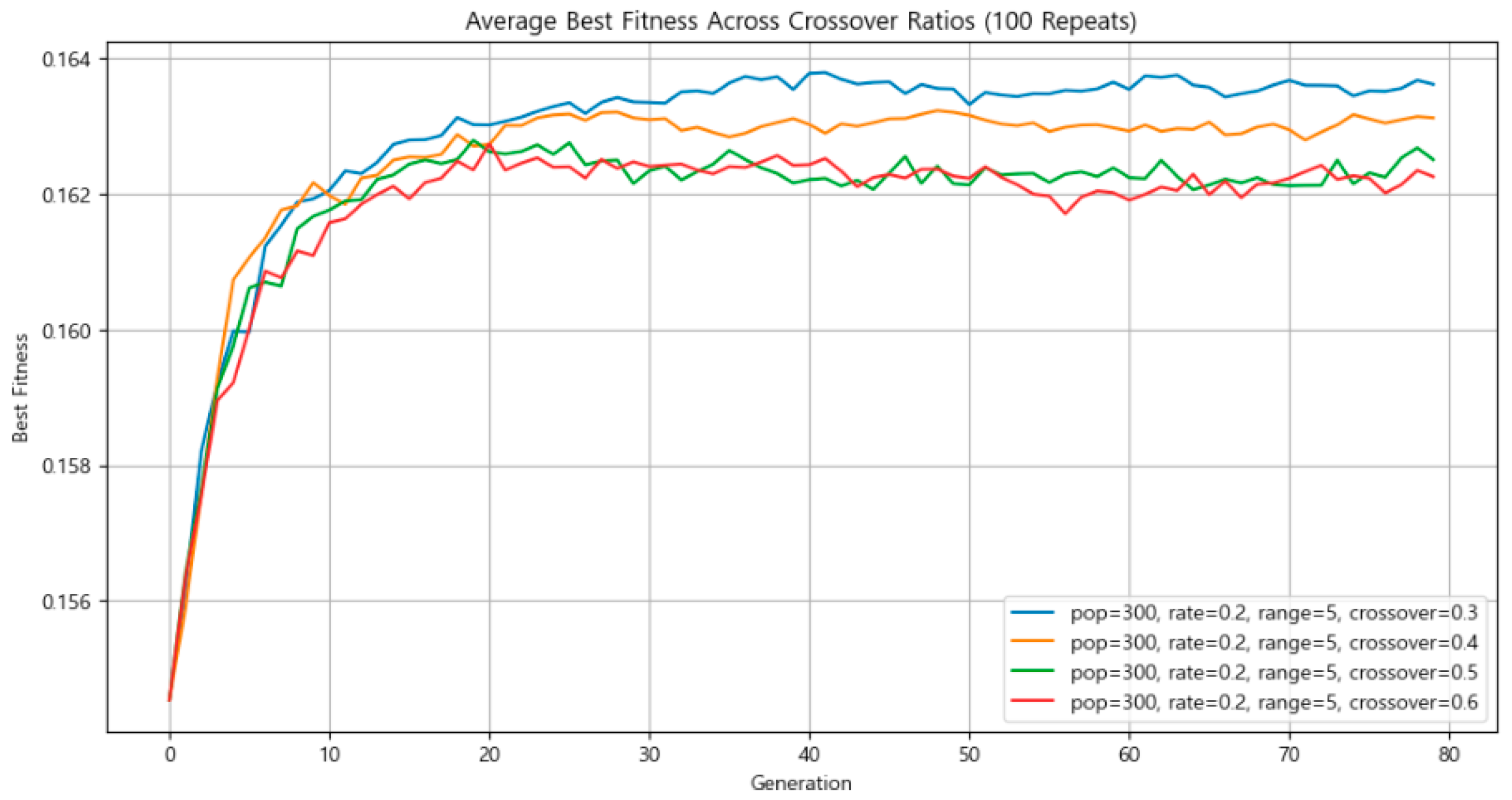
3.4.4. Crossover Rate
3.5. Statistical Evaluation of Parameter Tuning: Robustness and Sensitivity Analyses
3.5.1. One-Way ANOVA: Single-Factor Sensitivity Analysis
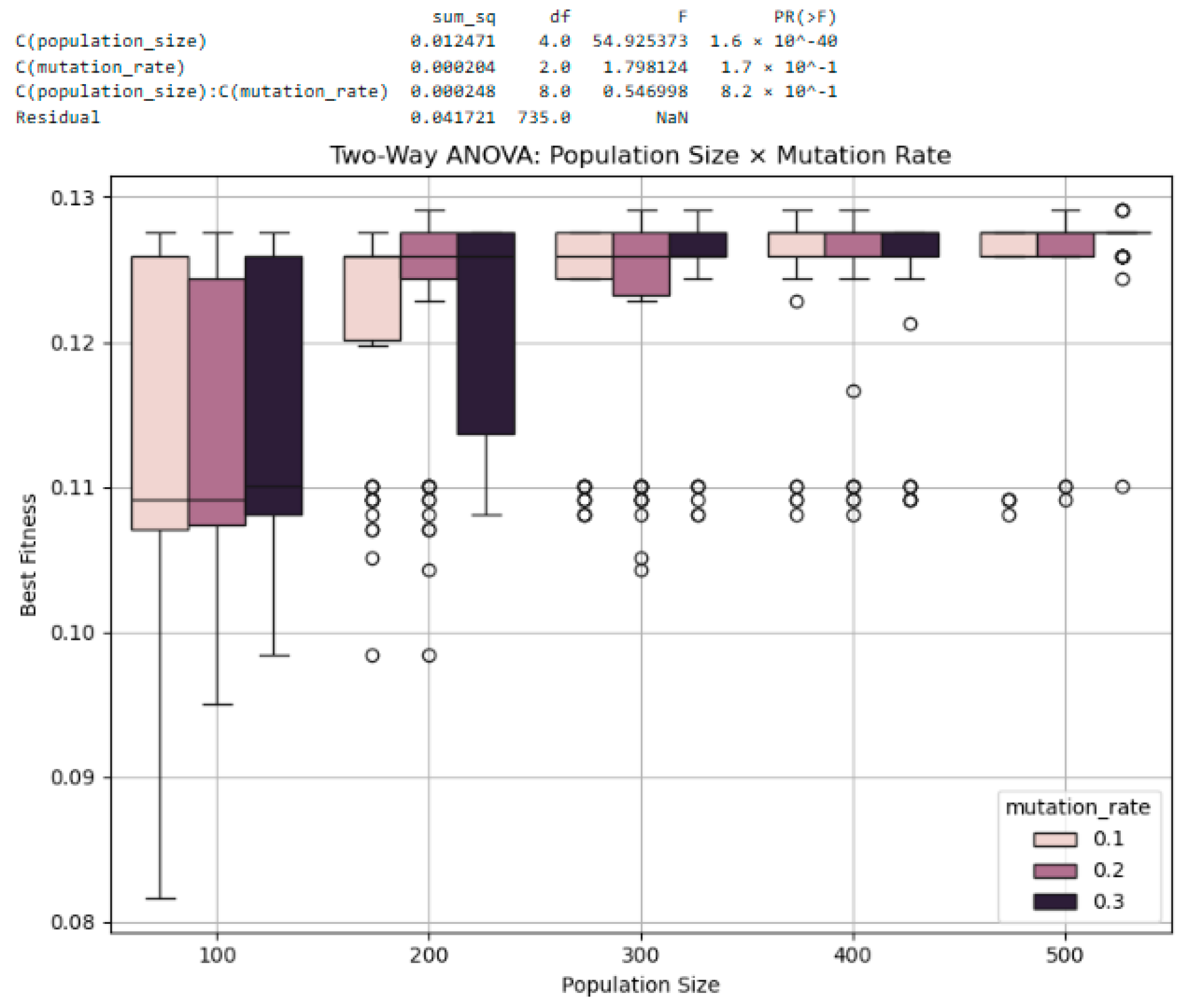
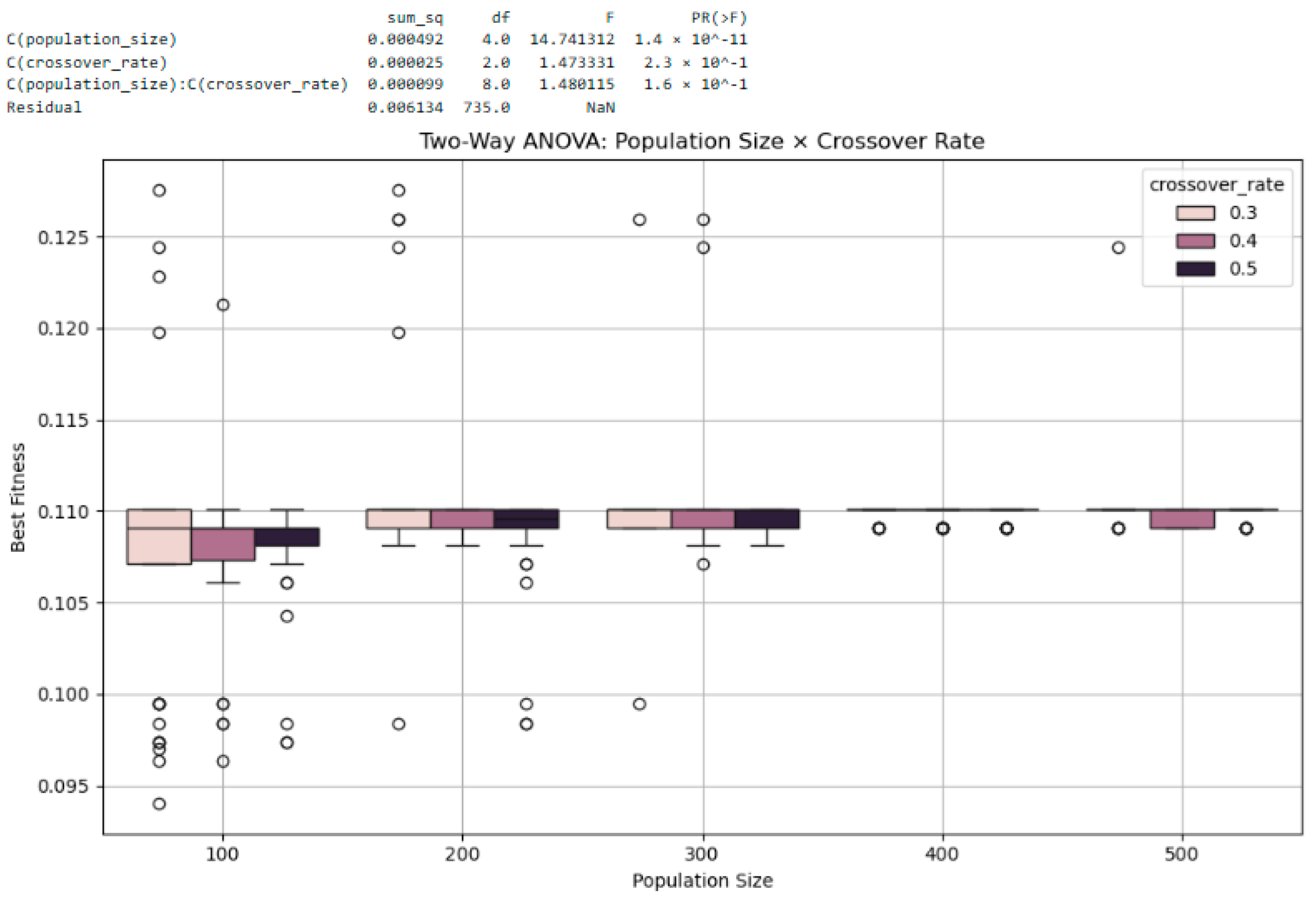
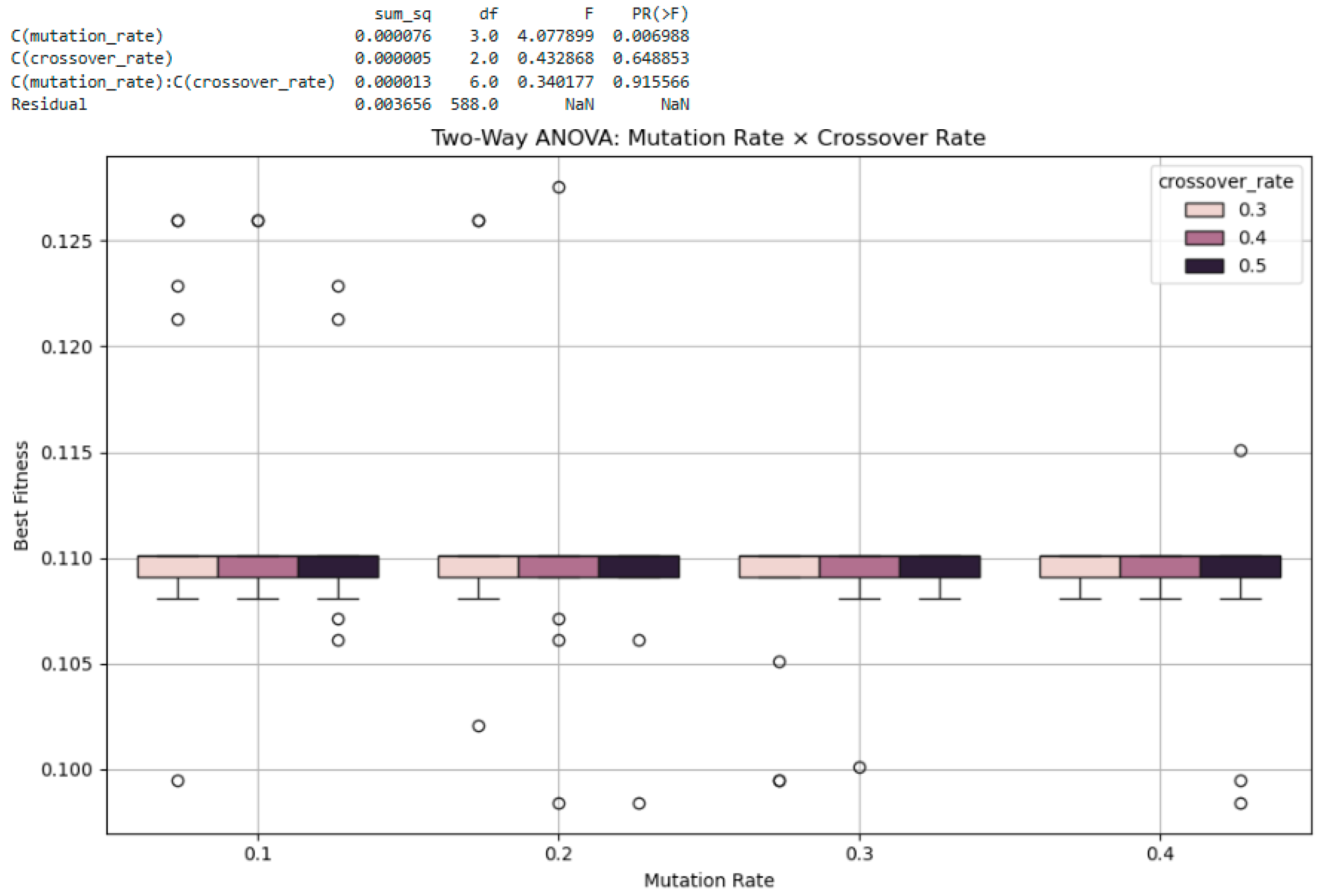
3.5.2. Two-Way ANOVA: Interaction Effects and Multi-Factor Sensitivity
4. Discussion
4.1. Feasibility and Performance of Economic Site Optimization
4.2. Contributions of Visualization to Economic Site Optimization
4.3. Interpreting the Results of Parameter Tuning
4.4. Enhancing the Realism of the Model
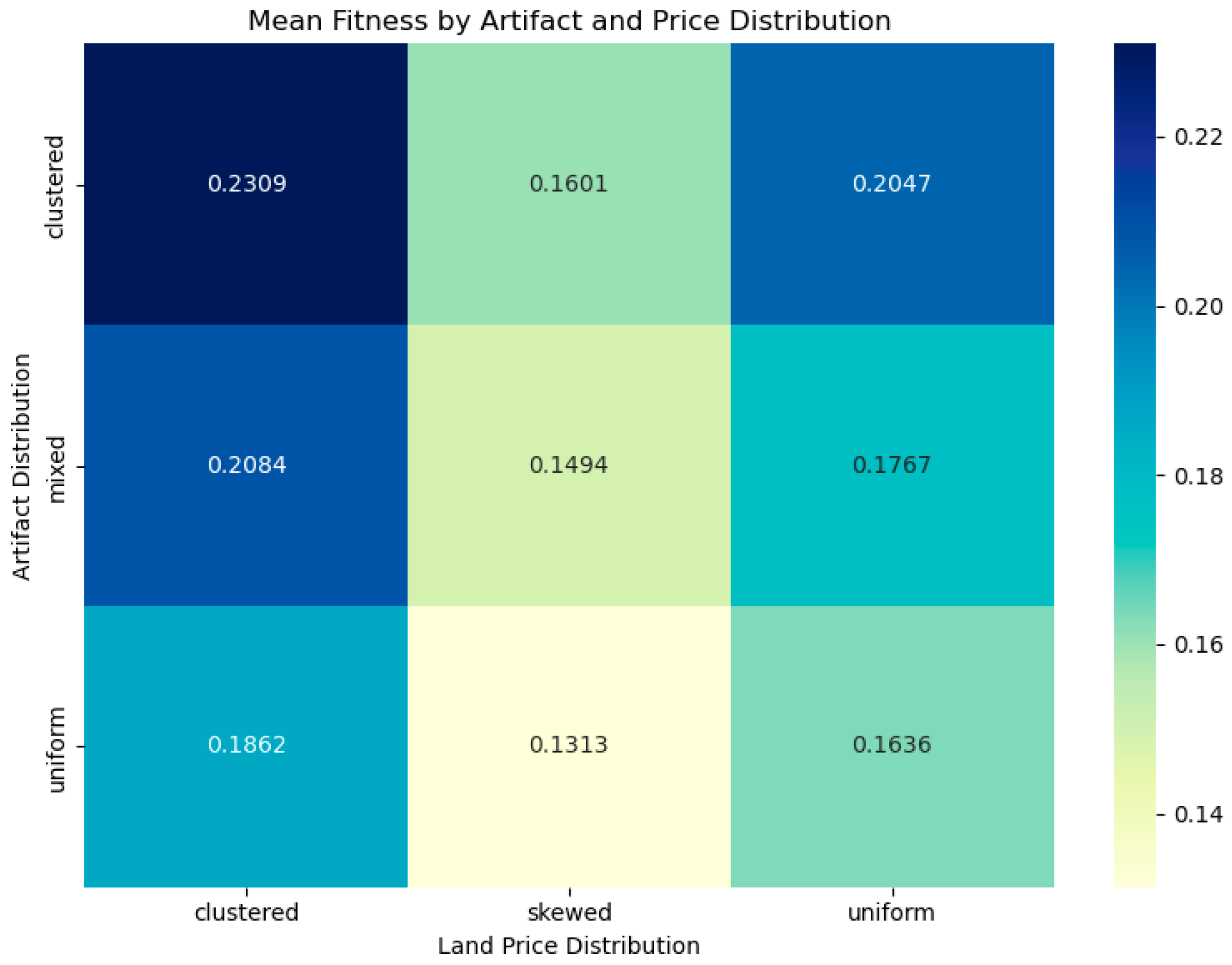
4.4.1. Artifact Density and Spatial Distribution
4.4.2. Integration of Elevation-Based Construction Cost and Distance-Based Access Cost and Cost Model Sensitivity Analysis
- -
- Land prices were randomly drawn from a uniform distribution between KRW 5,000,000 and KRW 50,000,000.
- -
- Construction cost was computed by applying a multiplier (ranging from 1.0 to 1.8) to a fixed base cost of KRW 10,000,000, proportionally increasing with elevation (from 0 to 800 m in 100 m steps).
- -
- Access cost was modeled as KRW 100,000 per kilometer of Euclidean distance from the region’s geometric center (i.e., the point (25 km, 25 km)), representing a hypothetical urban core.
4.4.3. Scaling up the Problem: Effects on GA and GA + HC Performance
5. Conclusions
5.1. Summary of Findings and Contributions
5.2. Limitations and Future Research Directions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | Meanwhile, as generations progress, it may appear that the number of individuals is decreasing. However, this is an illusion caused by individuals increasingly overlapping at the same location. The actual number of individuals remains constant at 300 throughout all generations, a fact that can be confirmed with code output such as print(f“Generation {gen}: {len(individuals)} individuals”). |
| 2 | The identification of optimal parameter values often depends on how many simulation iterations are required for the GA to reach the optimal solution. The parameter configuration that results in the fewest iterations needed to achieve the optimum is typically regarded as the optimal setting. |
References
- Lee, T.H.; Kang, J.W.; Ohk, Y.J.; Kim, J.H.; Lee, S.Y. Development of Remote Drone Station System for Water Disaster Management. In Proceedings of the Korean Society of Civil Engineers (KSCE) Convention, Chonnam, Republic of Korea, 18 October 2023. [Google Scholar]
- Kim, D.H.; Lee, J.H.; Cheon, W.Y. A Study on Application of Unmanned Aerial Vehicles (UAV) in the Disaster and Safety Field of Cultural Properties. J. Natl. Herit. 2020, 5, 225–232. [Google Scholar]
- Ko, M.H.; Kang, S.J. A Study on the Photogrammetric Data Acquisition for the Disaster Prevention of Wooden Architectural Properties with Unmanned Aerial Vehicles (UAV). In Proceedings of the Annual Conference of Architectural Institute of Korea (AIK), Gangwon, Republic of Korea, 25 October 2023. [Google Scholar]
- Ko, S.J. Buan County Selected for “Cultural Heritage Drone Station Construction” Project. Available online: https://www.newsis.com/view/?id=NISX20210118_0001309044 (accessed on 18 January 2021).
- Heo, U.H.; Lee, W.Y. A study on the utilization of drones and aerial photographs for searching ruins with a focus on topographic analysis. MUNHWAJAE Korean J. Cult. Herit. Stud. 2018, 51, 22–37. [Google Scholar]
- Klüver, C.; Klüver, J.; Schmidt, J. Modelling Complex Processes through Nature-Inspired Methods: Soft Computing and Related Techniques, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Lee, G.S.; Choi, Y.W.; Lee, M.H.; Kim, S.G.; Cho, G.S. Reconnaissance Surveying for Cultural Assets using Unmanned Aerial Vehicle. J. Korean Cadastre Inf. Assoc. 2016, 18, 25–34. [Google Scholar]
- DJI Enterprise. Utilizing LiDAR to Discover Ancient Mayan Civilizations. Available online: https://enterprise-insights.dji.com/blog/utilizing-lidar-to-discover-ancient-mayan-civilizations (accessed on 20 March 2025).
- Jeon, Y.G.; Lee, M.S.; Kim, Y.R.; Lee, M.H.; Choi, M.J.; Choi, K.H. Utilization of Hyperspectral Image Analysis for Monitoring of Stone Cultural Heritages. J. Conserv. Sci. 2015, 31, 395–402. [Google Scholar]
- Ko, H.J.; Yoon, S.J.; Oh, H.; Roh, K.; Kim, E.; Kim, S.; Lim, H.; Choi, S. Planning on R&D for Securing Disaster Response and Enhancing Resilience; National Disaster Management Research Institute: Ulsan, Republic of Korea, 2019. [Google Scholar]
- Koza, J.R. Genetic Programming; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Park, J.M.; Choi, Y.J. Utilization of Drone for Strengthening Safety Management of Wooden Cultural Assets: Focused on Fire Prevention. Korean Secur. J. 2021, 67, 217–233. [Google Scholar]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization, and Machine Learning; Addison-Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems; MIT Press: Cambridge, MA, USA, 1975. [Google Scholar]
- Köhler-Bußmeier, M. Koordinierte Selbstorganisation und Selbstorganisierte Koordination: Eine Formale Spezifikation Reflexiver Selbstorganisation in Multiagentensystemen Unter Spezieller Berücksichtigung der Sozialwissenschaftlichen Perspektive. Habilitation Thesis, University of Hamburg, Hamburg, Germany, 2008. [Google Scholar]
- Korean Heritage Service Channel. Using Drones for Cultural Heritage Analysis?! Heritage Meets Science. Available online: https://youtu.be/qC0yg0xaDvE (accessed on 15 September 2022).
- Kim, M.H. Haman County to Protect Cultural Heritage via Drones. Available online: https://www.knnews.co.kr/news/articleView.php?idxno=1406256 (accessed on 12 June 2023).
- Weicker, K. Evolutionäre Algorithmen, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Stewart, T.; Janssen, R.; van Herwijnen, M. A Genetic Algorithm Approach to Multi-Objective Land Use Planning. Comput. Oper. Res. 2004, 31, 2293–2313. [Google Scholar] [CrossRef]
- Jaramillo, J.H.; Bhadury, J.; Batta, R. On the Use of Genetic Algorithms for Location Problems. Comput. Oper. Res. 2002, 29, 761–779. [Google Scholar] [CrossRef]
- Xie, Y.; Shaw, W.J.; Wang, W.; Seiple, T.E.; Rishel, J.P.; Rutz, F.C.; Chapman, E.G.; Allwine, J. A Genetic Algorithm Used to Optimize the Siting of Meteorological Monitoring Stations. In Proceedings of the International Conference on Genetic and Evolutionary Methods (GEM’07), Las Vegas, NV, USA, 25–28 June 2007; Arabnia, H.R., Yang, J.Y., Yang, M.Q., Eds.; CSREA Press: Athens, GA, USA, 2007; pp. 81–87. [Google Scholar]
- Altiparmak, F.; Gen, M.; Lin, L.; Paksoy, T. A Genetic Algorithm Approach for Multi-Objective Optimization of Supply Chain Networks. Comput. Ind. Eng. 2006, 51, 196–215. [Google Scholar] [CrossRef]
- Bi, H.; Gu, Y.; Lu, F.; Mahreen, S. Site Selection of Electric Vehicle Charging Station Expansion Based on GIS-FAHP-MABAC. J. Clean. Prod. 2025, 507, 145557. [Google Scholar] [CrossRef]
- Park, I.O.; Kim, W.J. A Study on the Optimal Planning for Dong Office Location by Genetic Algorithm. IE Interfaces 2009, 22, 223–233. [Google Scholar]
- Zadeh, L.A. Fuzzy Logic, Neural Networks, and Soft Computing. Commun. ACM 1994, 37, 77–84. [Google Scholar] [CrossRef]
- Seising, R.; Sanz, V. Soft Computing in Humanities and Social Sciences; Springer: Berlin/Heidelberg, Germany, 2012; Volume 273. [Google Scholar]
- Hwang, H.S. Evolutionary Computation and Evolutionary Design by Computers; Naeha Publishing: Seoul, Republic of Korea, 2002. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Population_Size | Crossover_Rate | Mutation_Rate | Mean_Fitness | Std_Fitness |
|---|---|---|---|---|
| 200 | 0.2 | 0.20 | 0.111288 | 0.007285 |
| 200 | 0.2 | 0.25 | 0.110261 | 0.006290 |
| 200 | 0.2 | 0.30 | 0.110077 | 0.005221 |
| 200 | 0.3 | 0.20 | 0.109432 | 0.002478 |
| 200 | 0.3 | 0.25 | 0.109812 | 0.004969 |
| 200 | 0.3 | 0.30 | 0.109451 | 0.003481 |
| 200 | 0.4 | 0.20 | 0.109793 | 0.002889 |
| 200 | 0.4 | 0.25 | 0.108393 | 0.004567 |
| 200 | 0.4 | 0.30 | 0.109425 | 0.003176 |
| 200 | 0.5 | 0.20 | 0.109546 | 0.003336 |
| 200 | 0.5 | 0.25 | 0.109927 | 0.002395 |
| 200 | 0.5 | 0.30 | 0.109827 | 0.002448 |
| 300 | 0.2 | 0.20 | 0.110605 | 0.005339 |
| 300 | 0.2 | 0.25 | 0.111744 | 0.005458 |
| 300 | 0.2 | 0.30 | 0.109845 | 0.003606 |
| 300 | 0.3 | 0.20 | 0.110579 | 0.003760 |
| 300 | 0.3 | 0.25 | 0.109986 | 0.002958 |
| 300 | 0.3 | 0.30 | 0.110857 | 0.004875 |
| 300 | 0.4 | 0.20 | 0.109517 | 0.001542 |
| 300 | 0.4 | 0.25 | 0.110198 | 0.002556 |
| 300 | 0.4 | 0.30 | 0.109864 | 0.003080 |
| 300 | 0.5 | 0.20 | 0.109634 | 0.002844 |
| 300 | 0.5 | 0.25 | 0.109770 | 0.000627 |
| 300 | 0.5 | 0.30 | 0.109597 | 0.001545 |
| 400 | 0.2 | 0.20 | 0.110518 | 0.004219 |
| 400 | 0.2 | 0.25 | 0.110066 | 0.005654 |
| 400 | 0.2 | 0.30 | 0.109677 | 0.001530 |
| 400 | 0.3 | 0.20 | 0.109870 | 0.000432 |
| 400 | 0.3 | 0.25 | 0.109850 | 0.000444 |
| 400 | 0.3 | 0.30 | 0.109990 | 0.000329 |
| 400 | 0.4 | 0.20 | 0.110596 | 0.003369 |
| 400 | 0.4 | 0.25 | 0.109890 | 0.000465 |
| 400 | 0.4 | 0.30 | 0.109697 | 0.001529 |
| 400 | 0.5 | 0.20 | 0.110118 | 0.002565 |
| 400 | 0.5 | 0.25 | 0.109850 | 0.000444 |
| 400 | 0.5 | 0.30 | 0.110178 | 0.002544 |
| sum_sq | df | F | PR (>F) | |
|---|---|---|---|---|
| C(artifact_mode) | 0.219392 | 2 | 53.323560 | 1.337471 × 10−22 |
| C(price_mode) | 0.571244 | 2 | 138.842114 | 3.246550 × 10−53 |
| C(artifact_mode):C(price_mode) | 0.011162 | 4 | 1.356488 | 2.472519 × 10−1 |
| Residual | 1.832941 | 891.0 | NaN | NaN |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Noh, Y. Optimizing and Visualizing Drone Station Sites for Cultural Heritage Protection and Research Using Genetic Algorithms. Systems 2025, 13, 435. https://doi.org/10.3390/systems13060435
Kim S, Noh Y. Optimizing and Visualizing Drone Station Sites for Cultural Heritage Protection and Research Using Genetic Algorithms. Systems. 2025; 13(6):435. https://doi.org/10.3390/systems13060435
Chicago/Turabian StyleKim, Seok, and Younghee Noh. 2025. "Optimizing and Visualizing Drone Station Sites for Cultural Heritage Protection and Research Using Genetic Algorithms" Systems 13, no. 6: 435. https://doi.org/10.3390/systems13060435
APA StyleKim, S., & Noh, Y. (2025). Optimizing and Visualizing Drone Station Sites for Cultural Heritage Protection and Research Using Genetic Algorithms. Systems, 13(6), 435. https://doi.org/10.3390/systems13060435