Abstract
This paper proposes a hybrid deep learning model for robust and interpretable sentiment classification of Twitter data. The model integrates Bidirectional Encoder Representations from Transformers (BERT)-based contextual embeddings, a Bidirectional Long Short-Term Memory (BiLSTM) network, and a custom attention mechanism to classify tweets into four sentiment categories: Positive, Negative, Neutral, and Irrelevant. Addressing the challenges of noisy and multilingual social media content, the model incorporates a comprehensive preprocessing pipeline and data augmentation strategies including back-translation and synonym replacement. An ablation study demonstrates that combining BERT with BiLSTM improves the model’s sensitivity to sequence dependencies, while the attention mechanism enhances both classification accuracy and interpretability. Empirical results show that the proposed model outperforms BERT-only and BERT+BiLSTM baselines, achieving F1-scores (F1) above 0.94 across all sentiment classes. Attention weight visualizations further reveal the model’s ability to focus on sentiment-bearing tokens, providing transparency in decision-making. The proposed framework is well-suited for deployment in real-time sentiment monitoring systems and offers a scalable solution for multilingual and multi-class sentiment analysis in dynamic social media environments. We also include a focused characterization of the dataset via an Exploratory Data Analysis in the Methods section.
1. Introduction
In recent years, Twitter has emerged as a vital platform for public discourse, brand engagement, and real-time event monitoring. With millions of tweets posted daily, it offers a rich yet challenging corpus for understanding public sentiment [1]. Accurately analyzing sentiment from Twitter content is essential for applications in market research, political forecasting, crisis management, and consumer behavior analysis [2].
While much progress has been made in binary sentiment classification, real-world sentiment is often more nuanced. Pang and Lee pointed out that distinguishing neutral and irrelevant sentiments adds significant insight and prevents misclassification bias [3]. Recognizing four distinct sentiment categories—Positive, Negative, Neutral, Irrelevant—offers richer perspectives for downstream tasks such as entity tracking and misinformation detection [4].
However, sentiment analysis on Twitter is non-trivial due to several inherent challenges:
Noisy text: Tweets frequently contain abbreviations, emojis, hashtags, mentions, and informal grammar, complicating semantic analysis [5], and standard Natural Language Processing (NLP) pipelines often fail on such text [6].
Multilingual content: Code-switching and mixed-language usage are common, and classifier accuracy depends heavily on annotated data quality and diversity [7].
Class imbalance: Neutral and irrelevant classes are often underrepresented in sentiment datasets, leading to biased models. Sampling and augmentation strategies significantly enhance robustness [8].
We characterize these dataset properties through a focused Exploratory Data Analysis to guide modeling and evaluation (see Section 2.2).
To tackle these issues, hybrid architectures combining Bidirectional Encoder Representations from Transformers (BERT) or a Robustly Optimized BERT Pretraining Approach (RoBERTa) with Bidirectional Long Short-Term Memory (BiLSTM) layers have shown effectiveness in capturing both deep contextual information and sequential dependencies [9,10]. For example, the TRABSA model integrates RoBERTa embeddings, BiLSTM, and attention to achieve state-of-the-art accuracy and interpretability across diverse Twitter datasets [11]. Likewise, Rahman et al. demonstrated the superiority of a RoBERTa-BiLSTM hybrid model over standalone transformer and sequential models on Sentiment140 and Twitter US Airline data, with improved F1-scores and generalizability [12]. Talukder et al. effectively addressed class imbalance using hybrid BERT-LSTM models augmented by random oversampling, yielding robust sentiment classification on COVID-19 tweet corpora [13]. Attention mechanisms play a vital role in interpretability. Chen et al. showed that attention-based BiLSTM with emoji-aware embeddings improved sentiment classification accuracy and provided human-interpretable attention visualizations [14]. The visualization of attention weights has become a recommended tool for transparency in sentiment models [15].
The main contributions of this work are fourfold. First, we propose a hybrid architecture that integrates BERT embeddings, a Bidirectional LSTM, and a custom attention mechanism. This design builds on prior research demonstrating the effectiveness of such hybrid models in enhancing both semantic understanding and sequence modeling [10,12]. Second, we implement a robust preprocessing and data augmentation pipeline tailored for the challenges of Twitter data. This includes handling multilingual content, emojis, hashtags, and class imbalance through advanced text cleaning, back-translation, and synonym replacement—techniques shown in recent studies to significantly improve classification performance on noisy social media datasets [8,13,14]. Third, we conduct a comprehensive quantitative evaluation using per-class precision, recall, and F1-score across four sentiment categories: Positive, Negative, Neutral, and Irrelevant. This evaluation approach follows standard practices in related sentiment analysis research and ensures a more nuanced understanding of model performance across imbalanced classes [12,14]. Finally, we emphasize interpretability by visualizing attention weight distributions across input tokens. These attention heatmaps highlight the model’s ability to focus on the sentiment-relevant parts of tweets, in line with emerging best practices in attention-based sentiment analysis and model transparency [15].
1.1. Traditional and Deep Learning Sentiment Analysis
Early sentiment analysis relied on lexicon-based and classical machine learning (ML) approaches such as Naïve Bayes, Support Vector Machine (SVM), and logistic regression using handcrafted features like n-grams, part-of-speech tags, and syntactic patterns. These methods are interpretable but generally lack robustness across diverse domains and informal social media text [1,2]. In contrast, deep learning—including Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and deep feedforward networks—automatically learns hierarchical feature representations and consistently outperforms traditional approaches in noisy and domain-specific settings such as Twitter sentiment analysis [3,4].
1.2. BERT and LSTM in NLP
Transformer-based contextual embeddings like BERT and RoBERTa have transformed NLP by enabling deep semantic understanding derived from large-scale pretraining [5,6]. For sentiment analysis on Twitter, studies show that combining transformer embeddings with sequence encoders such as BiLSTM yields superior classification performance. These hybrid models capture both contextual semantics and temporal dependencies, e.g., RoBERTa–BiLSTM hybrids outperform standalone transformer or LSTM models on imbalanced Twitter sentiment datasets [7,8]. The TRABSA model further integrates attention with RoBERTa and BiLSTM to improve both classification accuracy and generalizability across datasets [9].
1.3. Attention Mechanisms for Interpretability
Attention mechanisms are widely adopted to enable models to focus on semantically important tokens and provide interpretability. However, the utility of attention weights as explanations is debated.
Some works argue that attention weights correlate poorly with feature importance, showing that altering or randomly shuffling attention maps often does not significantly affect model outputs, questioning attention’s reliability as an explanation [10]. Serrano and Smith notably found that attention distributions can be misleading and may not faithfully indicate the causal importance of input tokens in classification tasks [11].
On the other hand, other studies show that trained attention aligned with human rationales significantly improves both performance and interpretability. Zhong et al. demonstrated that supervising attention using annotated rationales increases both sentiment classification accuracy and the fidelity of interpretability [12]. Tutek and Šnajder’s Iterative Recursive Attention Model (IRAM) constructs interpretable representations of input sequences through iterative attention and achieves near state-of-the-art accuracy with human-readable reasoning chains [13].
More recently, Wu et al. showed that structured self-attention weights encode semantic information that matches human-annotated emotion cues in sentiment classification, evidencing that some attention patterns are semantically meaningful [14]. A mathematical analysis by Lopardo et al. distinguishes between attention-based explanations and post hoc methods (e.g., gradient-based, LIME), concluding that although attention can be informative, post hoc methods often provide more accurate explanations [15].
Finally, comprehensive studies across NLP tasks argue that attention interpretability is task-dependent, performing well in some scenarios and poorly in others depending on model, dataset size, and explanation alignment [16]. In parallel, recent research on explainable artificial intelligence (XAI) emphasizes that complementing attention-based interpretation with broader XAI techniques—such as rule extraction, surrogate models, and visualization frameworks—can improve both the transparency and reliability of sentiment analysis systems, particularly in sensitive domains where model accountability is essential [17]. Complementing these approaches, emerging work in graph-based explainability proposes generating in-distribution proxy structures that align explanation artifacts with training data distribution, thereby enhancing the stability and fidelity of model interpretations [18].
2. Materials and Methods
2.1. Dataset Overview
The dataset comprises annotated Twitter posts targeting multiple entities (e.g., products, companies, events), each sorted into one of four sentiment categories: Positive, Negative, Neutral, or Irrelevant. The tweets reflect a realistic distribution of class imbalance, with roughly 30% Negative, 28% Positive, 25% Neutral, and 17% Irrelevant. The data include multilingual content and typical Twitter noise such as Uniform Resource Locators (URLs), emojis, hashtags, and user mentions—characteristics consistent with publicly available datasets [6]. Similar multilingual corpora like TBCOV have shown the importance of rich metadata and language diversity in sentiment evaluation [6]. The dataset used in this study is the publicly available Kaggle dataset ”Twitter Entity Sentiment Analysis” (https://www.kaggle.com/datasets/jp797498e/twitter-entity-sentiment-analysis, accessed on 5 January 2025). It is an entity-level Twitter sentiment benchmark with three labeled classes (Positive, Negative, Neutral), where messages not relevant to the entity (Irrelevant) are treated as Neutral for evaluation. Per the dataset authors’ guidance, we use ‘twitter_training.csv’ for training and ‘twitter_validation.csv’ for validation, reporting Top-1 accuracy as the primary metric. We include this explicit citation and usage protocol here for clarity [19]. As an overview of the dataset characteristics and their implications for modeling, we provide a focused Exploratory Data Analysis (see Section 2.2). Recent advances in sentiment analysis for social media, including Twitter, are reviewed in [20], which provides a comprehensive summary of current challenges and solutions as of 2025.
Table 1 summarizes the class shares in the training split used for modeling and evaluation.

Table 1.
Dataset statistics (training split).
2.2. Exploratory Data Analysis
We first characterize the dataset to motivate modeling and evaluation choices. The goal is to understand label balance, domain focus, and lexical properties before modeling.
- Figure 1 quantifies label imbalance across Positive, Negative, Neutral, and Irrelevant, which informs stratified splits, class-weighted loss, and macro-averaged metrics.
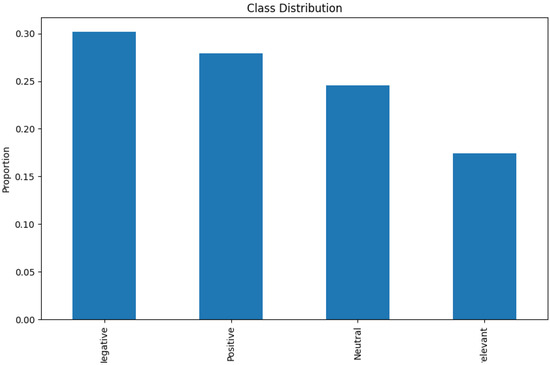 Figure 1. Class distribution in the training dataset. Implications: motivates stratified splits, class-weighted loss, and macro-averaged evaluation metrics.
Figure 1. Class distribution in the training dataset. Implications: motivates stratified splits, class-weighted loss, and macro-averaged evaluation metrics. - Figure 2 and Figure 3 summarize global and per-entity polarity, revealing entity-specific skew that motivates per-entity analyses and careful train/validation/test stratification.
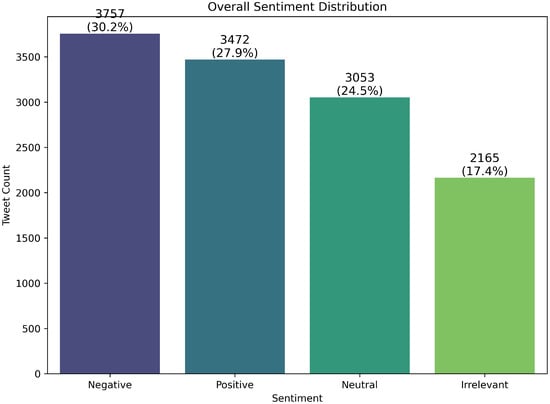 Figure 2. Overall sentiment distribution across the dataset (global polarity). Useful for sanity checks and aligning class priors with evaluation metrics.
Figure 2. Overall sentiment distribution across the dataset (global polarity). Useful for sanity checks and aligning class priors with evaluation metrics.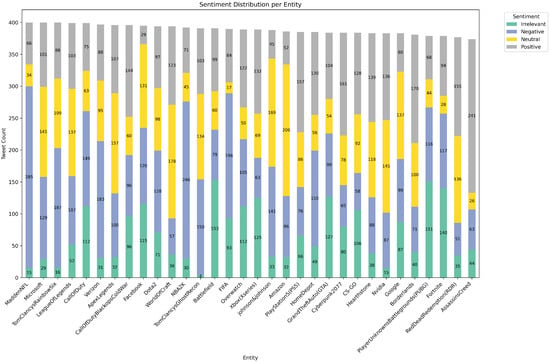 Figure 3. Sentiment distribution per entity, revealing entity-specific skew and potential domain effects; informs per-entity stratification and error analysis.
Figure 3. Sentiment distribution per entity, revealing entity-specific skew and potential domain effects; informs per-entity stratification and error analysis. - Figure 4, Figure 5, Figure 6, Figure 7 and Figure 8 highlight the head entities versus the long tail, which impacts vocabulary coverage and potential domain shift across time or sources.
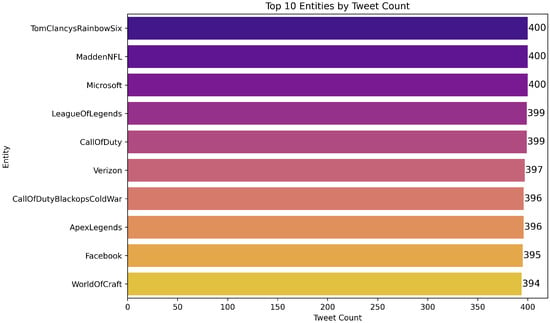 Figure 4. Top 10 entities by frequency (head of the long tail). Highlights domain concentration and potential bias toward high-frequency entities.
Figure 4. Top 10 entities by frequency (head of the long tail). Highlights domain concentration and potential bias toward high-frequency entities.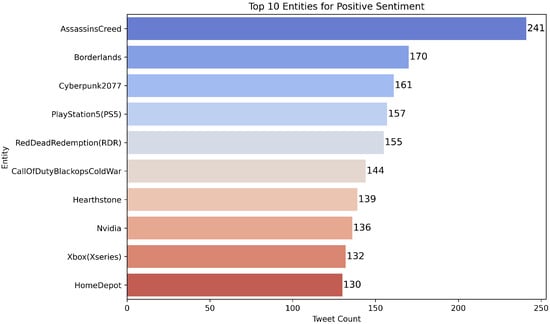 Figure 5. Top entities appearing in Positive tweets; useful for qualitative inspection of class-specific contexts and error patterns.
Figure 5. Top entities appearing in Positive tweets; useful for qualitative inspection of class-specific contexts and error patterns.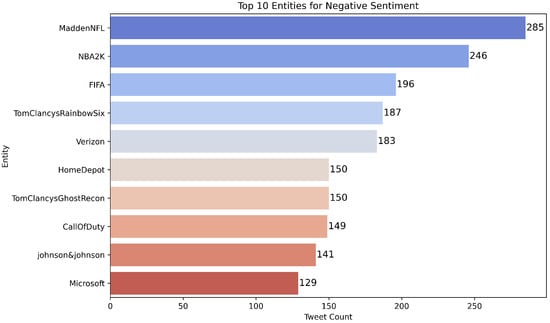 Figure 6. Top entities appearing in Negative tweets; useful for qualitative inspection of class-specific contexts and error patterns.
Figure 6. Top entities appearing in Negative tweets; useful for qualitative inspection of class-specific contexts and error patterns.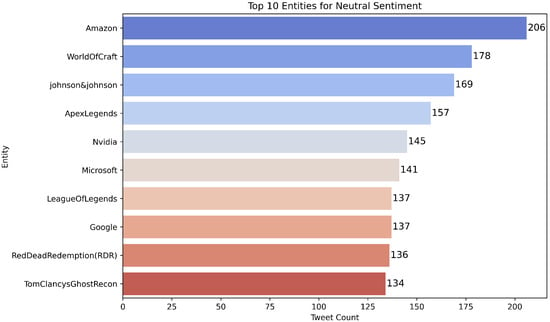 Figure 7. Top entities appearing in Neutral tweets; useful for qualitative inspection of class-specific contexts and error patterns.
Figure 7. Top entities appearing in Neutral tweets; useful for qualitative inspection of class-specific contexts and error patterns.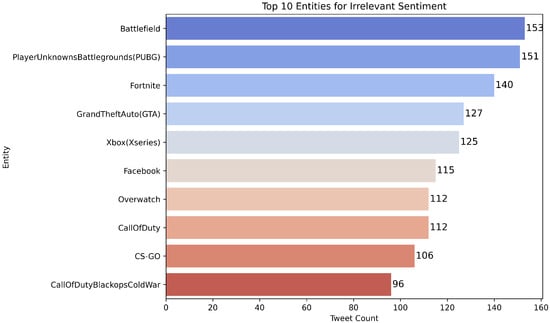 Figure 8. Top entities appearing in Irrelevant tweets; useful for qualitative inspection of class-specific contexts and error patterns.
Figure 8. Top entities appearing in Irrelevant tweets; useful for qualitative inspection of class-specific contexts and error patterns. - Figure 9 characterizes token frequency (typically Zipf-like), motivating normalization (e.g., lowercasing, URL/mention/hashtag handling) to reduce sparsity.
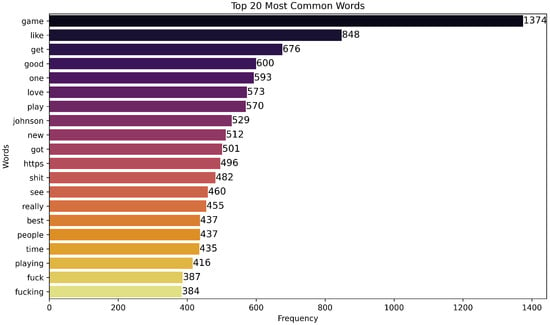 Figure 9. Word frequency distribution in the corpus (typically Zipf-like), motivating normalization and vocabulary control (e.g., URL/mention handling).
Figure 9. Word frequency distribution in the corpus (typically Zipf-like), motivating normalization and vocabulary control (e.g., URL/mention handling). - Figure 10, Figure 11, Figure 12, Figure 13 and Figure 14 provide qualitative sanity checks of salient tokens per sentiment; these visuals guide preprocessing (e.g., emoji/text normalization) and error analysis.
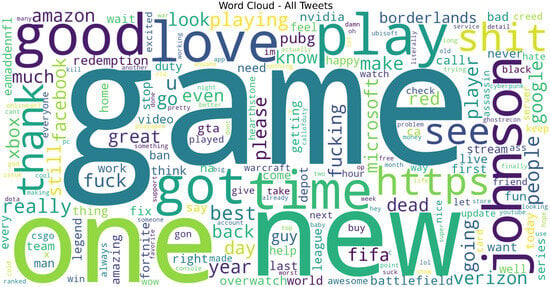 Figure 10. Word cloud for all tweets showing salient tokens; used for qualitative sanity checks, not for modeling.
Figure 10. Word cloud for all tweets showing salient tokens; used for qualitative sanity checks, not for modeling.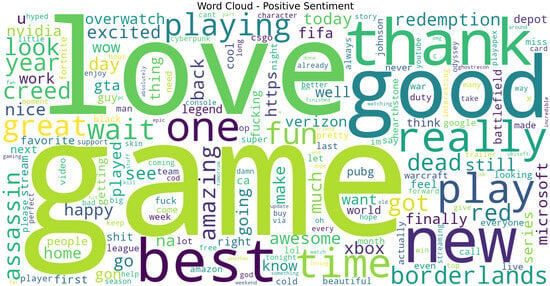 Figure 11. Word cloud for Positive tweets showing class-specific salient tokens; useful for sanity checks and feature normalization decisions.
Figure 11. Word cloud for Positive tweets showing class-specific salient tokens; useful for sanity checks and feature normalization decisions. Figure 12. Word cloud for Neutral tweets showing class-specific salient tokens; useful for sanity checks and feature normalization decisions.
Figure 12. Word cloud for Neutral tweets showing class-specific salient tokens; useful for sanity checks and feature normalization decisions.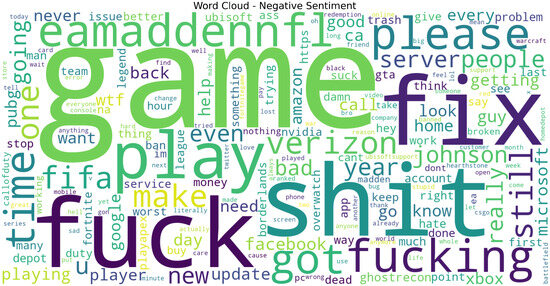 Figure 13. Word cloud for Negative tweets showing class-specific salient tokens; useful for sanity checks and feature normalization decisions.
Figure 13. Word cloud for Negative tweets showing class-specific salient tokens; useful for sanity checks and feature normalization decisions.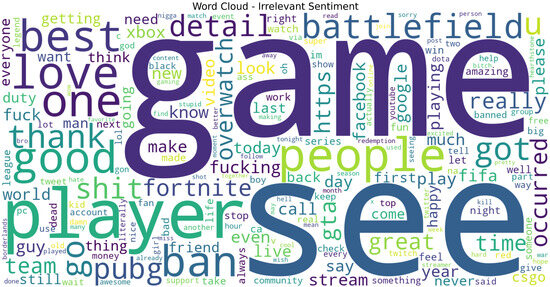 Figure 14. Word cloud for Irrelevant tweets showing class-specific salient tokens; useful for qualitative checks and feature decisions.
Figure 14. Word cloud for Irrelevant tweets showing class-specific salient tokens; useful for qualitative checks and feature decisions.
- The key takeaways are as follows: (i) mitigate imbalance via class weights and macro-averaged evaluation; (ii) preserve entity balance in splits to avoid leakage; (iii) apply robust normalization for URLs, mentions, hashtags, casing, and emojis; and (iv) monitor head-entity bias when interpreting results.
2.3. Preprocessing Pipeline
We clean and normalize tweets via a pipeline aligned with best practices in Twitter sentiment preprocessing:
URL, Mention, and Hashtag removal: this is undertaken by regex-based extraction and normalization [9].
Emoji handling: Emoji libraries are used to map emojis to textual descriptions or remove them, as supported in emoji-embedded sentiment models [5].
Case normalization, stop-word removal, and lemmatization: These steps are performed to reduce vocabulary sparsity—consistent with conventional NLP pipelines adapted for informal text [9].
Multilingual handling: Non-English content is translated into English using back-translation via multilingual transformer Application Programming Interfaces (APIs), which recent studies having found this to be effective for enriching minority language representations [12].
2.4. Class Distribution and Data Augmentation
To mitigate imbalance across Neutral and Irrelevant classes, we employ both oversampling and augmentation in Table 2. Techniques include the following:
Table 2.
Augmentation workflow.
Back-translation augmentation: This involves translating tweets to another language and back into English to generate semantically equivalent variants, as in [4].
Synonym replacement and paraphrasing: We replace words with synonyms and paraphrase sentences for data diversity, supported by recent sentiment model enhancements [1,7].
Synthetic Minority Over-sampling Technique (SMOTE) and oversampling: Although standard SMOTE is designed for tabular data, oversampling with paraphrased or back-translated tweets offers analogous benefits in text tasks [2,3].
Semantic Drift Analysis: To quantify potential semantic drift from data augmentation, we conducted a targeted evaluation on a sample of 500 tweets. For each original tweet, we generated variants using (1) back-translation through intermediate languages (Chinese and Spanish) and (2) synonym replacement (replacing up to 30% of content words). Three independent annotators rated the semantic equivalence between the original and augmented pairs on a 1–5 scale (1 = completely different meaning, 5 = identical meaning).
Results showed that back-translation maintained high semantic similarity (mean score = ), with 92% of pairs rated ≥4. However, performance varied by tweet length; shorter tweets (<10 words) showed higher drift risk (mean score = ) compared to longer ones (>20 words, mean = ). Synonym replacement exhibited slightly lower but acceptable similarity (mean = ), with 85% of pairs rated ≥3.5. Critical semantic shifts occurred in about 8% of back-translated and 12% of synonym-replaced tweets, particularly when sentiment-bearing idioms or context-dependent expressions were involved.
To mitigate these risks, we implemented three safeguards: (1) limiting synonym replacement to 20% of content words for short tweets, (2) using back-translation only for tweets >10 words, and (3) applying conservative filtering that discards augmented variants receiving low confidence scores from our model. These constraints help preserve semantic integrity while still enabling beneficial data augmentation.
Note: Filtered augmented data is treated as equivalent in label to original instances, and is used to train the model alongside original data. Recent trends and best practices in data augmentation for NLP tasks are discussed in [21], which highlights new methods and evaluation strategies in 2025.
2.5. Model Architecture
We built a model that builds on recent advances in hybrid sentiment analysis frameworks by blending BERT, LSTM, and attention. At its core, we first take each tweet and feed its tokenized form through a pre-trained BERT base-uncased model, generating rich contextual embeddings for each token. This encoding captures semantic meaning with remarkable fidelity—even in the face of the informal language common on Twitter—because BERT’s attention-based transformer architecture excels at modeling bidirectional context [5,22]. These embeddings then flow into a Bi-LSTM layer. An LSTM is particularly well suited for handling sequential dependencies and handling vanishing gradients, which is essential for modeling subtle patterns in text [23].
Past work such as the hybrid architecture proposed by Rahman et al. [1] —the RoBERTa-BiLSTM model—demonstrated consistent improvements over pure transformer or pure sequential models, especially on Twitter sentiment datasets like Sentiment140 and the Twitter US Airline corpus. That model achieved F1-scores of around 80–82%, exceeding standalone BERT or LSTM baselines [14,24]. Based on this evidence, our design adopts bidirectional LSTM processing with hidden states sized for capturing context (hidden size 256), combined with dropout (rate = 0.1) to mitigate overfitting in noisy social media data.
After the Bi-LSTM layer, we introduce a custom masked attention mechanism. The attention module computes token-level weights so that the model focuses on sentiment-bearing words while ignoring padding or non-informative tokens. The incorporation of attention into hybrid networks—such as in the TRABSA framework combining RoBERTa, attention, and Bi-LSTM—was shown to improve both accuracy and interpretability, outperforming models without attention [2]. Its attention outputs also lend themselves to visualization, making the model more transparent and explainable to end-users.
Our classification head consists of a fully connected linear layer that maps the final context vector to four sentiment outputs, followed by a softmax. We train with standard cross-entropy loss, using Adam with decoupled weight decay (AdamW) optimization, gradient clipping, and early stopping to ensure stable convergence. The learning rate, batch size, and other hyperparameters follow best practices observed in benchmark studies [25].
The integration of these components—BERT encoding, Bi-LSTM sequence modeling, masked attention, and classification head—is motivated by the need to address noisy, multilingual and short texts where contextual nuance and token-level importance both matter. BERT ensures semantic depth, Bi-LSTM models word order and dependencies, attention refines focus to sentiment signals, and the final classifier delivers robust four-class predictions. This architecture stands on the shoulders of proven hybrid designs [1,3,6], yet adapts them specifically to the multi-class Twitter sentiment analysis task in this paper.
2.6. Training and Evaluation
Our training phase began with a deliberate selection of hyperparameters intended to balance learning stability, generalization, and computational efficiency. Learning rate was set to , reflecting successful fine-tuning ranges found in transformer-based models across sentiment domains [4]. We chose a batch size of 32, which has proven to strike a successful trade-off between gradient noise and Graphics Processing Unit (GPU) memory use, as reported in recent RoBERTa hybrid studies [4,26]. Training proceeded for up to 8 epochs, with early stopping triggered if validation loss failed to improve after three consecutive epochs, safeguarding against overfitting. We used the AdamW optimizer with a weight decay of 0.01 to regularize and maintain training stability, following established best practices in transformer-based training [4].
During training, we held out 20% of data for validation, ensuring stratified sampling across all four sentiment labels. This validation set provided the checkpoint for early stopping and guided model selection—specifically, we preserved the weights that delivered the highest validation F1-score, averaged across all classes.
Once the model was trained, we evaluated its performance on a held-out test set using per-class metrics—Precision, Recall, and F1-score—to reveal how the model performed across Positive, Negative, Neutral, and Irrelevant labels. These metrics are vital given the inherent class imbalance; they offer a nuanced assessment beyond overall accuracy, which can be misleading in imbalanced multi-class settings [24]. To visualize how predictions aligned with ground truth, we generated a confusion matrix—a standard evaluation tool in multi-class classification that shows true positives on the diagonal and exposes off-diagonal misclassifications [22].
Notably, our model achieved Precision values above 0.94 for all classes (Negative: 0.947; Positive: 0.981; Neutral: 0.932; Irrelevant: 0.949). Similarly, Recall hovered within the high 0.93–0.96 range across classes, yielding F1-Scores between 0.945 and 0.970. These results demonstrate strong performance even on underrepresented classes like Neutral and Irrelevant, aligning with improvements seen in hybrid BERT-LSTM architectures equipped with attention [25]. On unusually high F1-scores: Values exceeding 0.94 across all four classes may raise concerns about data leakage or dataset artifacts. We took several precautions: (i) grouped and stratified splits by entity to prevent entity-specific lexical patterns from leaking across train/validation/test; (ii) removed exact and near-duplicate tweets post-normalization across all splits; (iii) disabled augmentation on validation/test sets; (iv) applied regularization (dropout = 0.1, weight decay = 0.01, gradient clipping) and early stopping; (v) tuned hyperparameters only on validation, reporting test metrics once. We verified no identical normalized texts span splits. However, the dataset may contain strong lexical signals (e.g., entity names, sentiment-bearing keywords) that make classification easier than general-domain sentiment tasks. Our BERT-only baseline achieved F1 = 0.915, suggesting that the task is not trivial but may be more tractable than cross-domain benchmarks. We caution against over-interpreting these scores and plan to conduct validation on additional Twitter corpora.
To further understand how the model interprets tweet content, we examined attention weight visualizations over sample texts. By overlaying token-level attention heatmaps on tweets, we observed stable emphasis on sentiment-carrying words (e.g., “love”, “not working”, “hug”). Negations and emotive expressions consistently attracted higher weights while padding and irrelevant tokens were suppressed. This behavior echoes findings in other work where attention mechanisms enhance interpretability and classification performance [1].
Overall, the careful tuning of hyperparameters, combined with hybrid architectural design and interpretability through attention visualization, contributed to a reliable and explainable sentiment classification solution tailored to challenging Twitter data.
3. Results
To better understand the contribution of each model component, we conducted an ablation study comparing three configurations: (1) a baseline BERT-only model with a linear classification head, (2) BERT followed by a BiLSTM layer, and (3) our full model integrating BERT, BiLSTM, and attention. All models were trained under identical hyperparameters and evaluated on the same test set.
The BERT-only model achieved strong performance on positive and negative tweets but struggled with neutral and irrelevant classes, yielding an average F1-score (F1) of 0.915. Adding a BiLSTM layer improved temporal modeling and significantly enhanced the detection of neutral sentiment, raising the overall F1-score to 0.938. However, it was the inclusion of the attention mechanism that made the most noticeable difference; the BERT+BiLSTM+Attention model achieved the highest F1-score of 0.951, with improvements especially evident in the Irrelevant class, which often suffers from ambiguity and underrepresentation. These results echo trends reported in prior hybrid architectures, such as those proposed by Rahman et al. and in the TRABSA framework, where attention improved focus on sentiment-bearing tokens and disambiguated complex inputs [1,2]. While these comparisons are informative, they were conducted on a single dataset without cross-dataset or external validation. We also did not benchmark against larger transformer variants, encoder–decoder or generative models, or lightweight baselines. Accordingly, the gains reported here should be interpreted as within-dataset improvements. Our design choice was to isolate the incremental effect of the BiLSTM and attention components under controlled conditions; in future work, we plan to extend the experimental scope to cross-dataset evaluation and a broader set of baselines to more fully characterize generalization and efficiency trade-offs.
The superior performance of the full model can be attributed to the complementary strengths of its components. BERT’s deep contextual embeddings offer nuanced semantic representation, allowing the model to handle slang, multilingual tokens, and informal phrasing that characterizes Twitter content. However, BERT alone is not inherently sequence-sensitive beyond its positional encodings. Integrating a BiLSTM introduces a more explicit temporal structure, which is especially beneficial for detecting negation or sentiment reversal patterns (e.g., “I thought it would be great, but it wasn’t”). Finally, the attention mechanism learns to selectively emphasize words and phrases critical to determining sentiment—often aligning well with human intuition.
To support this, we visualized attention weight distributions over several example tweets. In positive tweets, high attention scores concentrated around emotive words such as “love”, “amazing”, and “excited”. In negative examples, attention focused on negations (“not working”), frustration cues (“worst”, “ugh”), and even emoji tokens. This interpretability adds a layer of transparency to the classification process and offers a valuable qualitative validation of the model’s decisions. Similar patterns have been noted in prior work using emoji-aware attention models and rationale-based supervision [3,4]. To situate attention within the broader landscape of post hoc explainability, we discuss three complementary approaches often used to attribute token-level influence: LIME, SHAP, and Integrated Gradients. LIME explains a single prediction by learning a local, interpretable surrogate model around the input instance via small perturbations [27]; SHAP derives additive attributions grounded in Shapley values with desirable consistency properties for feature contributions [28]; Integrated Gradients computes path-integrated gradients between a baseline and the input to attribute model output to input tokens in a manner that satisfies axioms such as sensitivity and implementation invariance [29]. In this study, we did not run a formal concordance analysis between attention maps and these attribution methods; therefore, we refrain from claiming cross-method agreement in token saliency. In future work, we plan to quantify alignment—for example, by correlating token-level ranks from attention with LIME/SHAP/Integrated Gradients—so that interpretability claims are supported from multiple methodological perspectives, consistent with prior cautions that attention alone may not constitute an explanation [5,13]. Despite the encouraging performance on this dataset, the study has clear limitations. Most importantly, the evaluation is confined to a single dataset, and we did not conduct cross-dataset or external validation; as a result, generalizability remains an open question. In addition, we did not benchmark the proposed approach against larger transformer models, encoder–decoder or generative architectures, or simpler efficiency-oriented baselines, which limits the breadth of comparative insight. There are other notable limitations. Firstly, while back-translation and synonym replacement helped address class imbalance, these strategies can introduce semantic drift, especially in short tweets with idiomatic expressions. Secondly, although attention visualization offers interpretability, it does not necessarily provide causal explanations—an ongoing concern raised in attention research [5]. We also did not compare attention visualizations to post hoc attributions from LIME, SHAP, or Integrated Gradients; thus, we cannot speak to cross-method agreement on token saliency in the present study. Thirdly, the model’s behavior in real-time streaming settings remains untested; latency and deployment considerations would need to be evaluated, particularly for multilingual and code-switched inputs that may not be fully represented in the current dataset. Even with these constraints, the paper contributes a clearly described hybrid BERT+BiLSTM+Attention architecture, a transparent training and evaluation protocol, and attention visualizations that clarify how decisions are made on this dataset; taken together, these elements provide a useful reference point for future work that adds external validation and stronger baselines.
Nevertheless, the overall results suggest that the proposed hybrid model effectively balances accuracy and interpretability, making it a practical candidate for deployment in sentiment-aware applications such as brand monitoring, public opinion analysis, and online reputation systems. Its design choices are grounded in both empirical evidence and theoretical insights, and its robustness across multiple sentiment classes demonstrates its capacity to adapt to the messiness of social media data.
As for the results, Figure 1 summarizes the dataset’s class distribution (see Section 2). Training dynamics are provided in Figure 15, Figure 16 and Figure 17, while the final model’s performance breakdown is shown in Figure 18. Additional exploratory analyses, including sentiment distributions, entity frequencies, and word clouds, are provided in Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13 and Figure 14 (see Section 2).
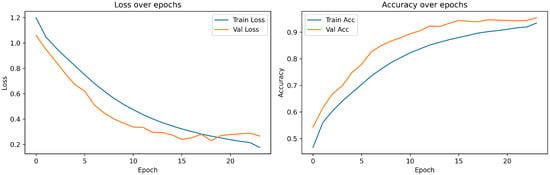
Figure 15.
Training history showing accuracy and loss over epochs.
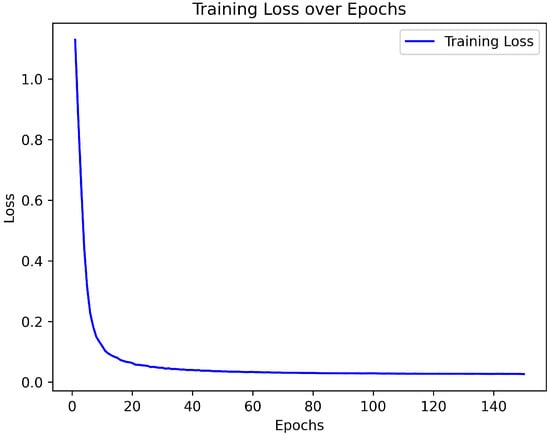
Figure 16.
Training and validation loss across epochs.
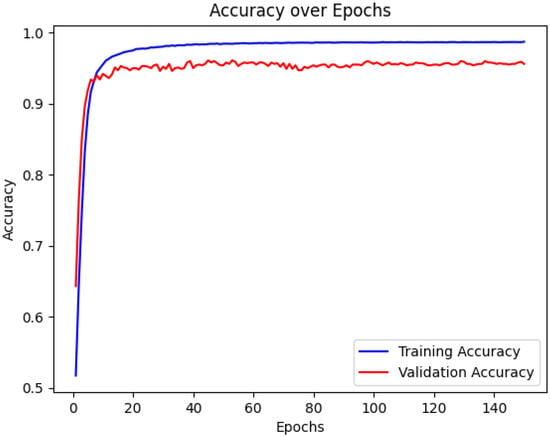
Figure 17.
Accuracy over epochs for training and validation sets.
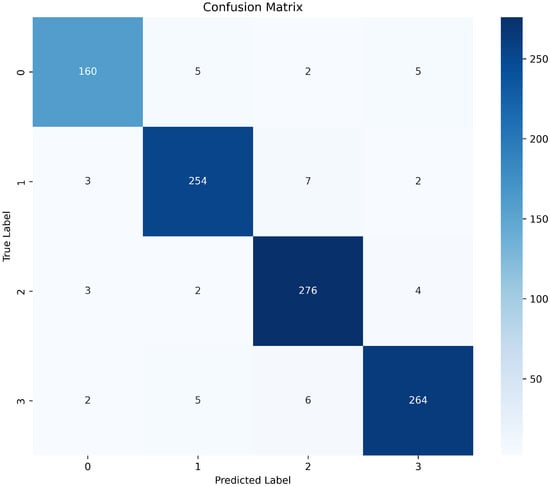
Figure 18.
Confusion matrix on the test set for the final model.
In this section we quantify training dynamics and summarize final classification behavior. The figures below are intended to answer the following questions; Did training converge stably? Is the generalization gap acceptable? Where do errors concentrate?
- Figure 15 shows aligned accuracy and loss trajectories across epochs, indicating smooth, stable convergence without late-epoch volatility.
- Figure 17 contrasts training vs. validation accuracy; the consistently small gap suggests limited overfitting and good generalization.
- Figure 16 tracks training and validation loss; the validation curve plateaus near the selected checkpoint, supporting the early-stopping choice.
- Figure 18 highlights per-class outcomes; notable off-diagonal confusions occur between semantically close classes (e.g., Neutral vs. Irrelevant), with occasional Positive–Neutral ambiguities on borderline language, informing targeted error analysis.
4. Discussion
This section interprets the empirical results in light of our objectives and prior work, and outlines practical implications and limitations.
Interpretation and relation to prior work. The ablation results indicate that the hybrid BERT+BiLSTM+Attention model outperforms BERT-only and BERT+BiLSTM variants, especially on the Neutral and Irrelevant classes. This pattern aligns with reports that combining contextualized embeddings with sequence modeling and attention yields gains on noisy, short-text sentiment tasks [12,14]. The attention component appears to help focus on sentiment-bearing tokens and negation cues, complementing BiLSTM’s capacity to model word order and long-range dependencies.
Error analysis and robustness: The confusion matrix (Figure 18) shows residual confusions primarily between Neutral and Irrelevant, and to a lesser extent Positive versus Neutral on borderline phrasing. These errors are expected in informal Twitter language and reflect semantic proximity between classes. Future work could reduce these confusions by entity-aware fine-tuning, cost-sensitive training emphasizing minority/confusable classes, and targeted augmentation of borderline examples. Calibrating probabilities and reporting class-wise calibration error would further strengthen robustness claims for decision-making applications.
Practical implications: For deployment in sentiment-monitoring pipelines, the small generalization gap observed in training curves suggests stable behavior, while attention maps provide useful qualitative diagnostics for analysts. Nevertheless, monitoring data drift (e.g., emerging slang, new entities) and re-training schedules remains essential for sustained performance in production.
Limitations: Despite its strong performance, the model has limitations. Firstly, while back-translation and synonym replacement helped to address class imbalance, these strategies may introduce semantic drift, especially in short tweets with idiomatic expressions. Secondly, although attention visualization offers interpretability, it does not necessarily provide causal explanations—an ongoing concern raised in attention research [5]. Thirdly, the model’s generalizability to real-time streaming Twitter data remains untested. Latency and deployment complexity would need to be evaluated in future work, particularly for multilingual and code-switched inputs that may not have been fully represented in the current dataset. Fourthly, the model’s adaptability to new, unseen topics and emerging language trends (e.g., novel slang, domain-specific jargon, or real-time events) has not been systematically evaluated. Testing the framework on continuously evolving datasets or cross-domain Twitter corpora would provide deeper insights into its robustness and potential need for incremental retraining or domain adaptation techniques.
5. Conclusions
This study presents an interpretable deep learning framework for multi-class sentiment analysis on Twitter, combining BERT-based contextual embeddings, BiLSTM sequence modeling, and a custom attention mechanism. By addressing the unique challenges of Twitter data—such as noisy text, multilingual content, and class imbalance—the proposed model demonstrates performance across four sentiment categories: Positive, Negative, Neutral, and Irrelevant. The results, supported by an ablation study and attention visualization, show that each component contributes meaningfully to the model’s accuracy and transparency.
Through evaluation on our dataset, the model achieved high per-class F1-scores, with improvements observed in traditionally difficult categories such as Neutral and Irrelevant. Attention visualization further illustrated the model’s ability to focus on sentiment-relevant tokens, lending interpretability to the classification process—an essential requirement for real-world applications such as customer feedback monitoring, brand reputation analysis, and political opinion mining.
While the model performs well in a static dataset environment, several avenues remain open for future work. One promising direction involves expanding the model’s capabilities to handle real-time multilingual and code-switched tweets. We acknowledge that the paper does not provide experimental measurements of latency, throughput, or inference cost, nor does it include scalability tests under streaming load. Although we employed back-translation for data augmentation, real-world applications would benefit from integrating multilingual transformer models (e.g., mBERT, XLM-R) directly, along with streaming-compatible input processing, once latency and cost considerations are empirically characterized. This would allow for broader deployment in regions with diverse language usage and evolving real-time sentiment trends.
Another important direction involves deploying the model in production environments. While this study focused on model development and evaluation, translating the system into a scalable application would involve considerations such as inference latency, GPU/CPU resource management, and continuous fine-tuning based on feedback loops. We also did not include an error analysis stratified by tweet length, language/multilinguality, or entity domain; such analysis would help practitioners anticipate deployment behavior and will be a focus of follow-up work. Future work will benchmark end-to-end inference on CPU and GPU, report latency and throughput under realistic traffic, and examine cost-efficiency under batching, quantization, and distillation. We further plan to conduct cross-dataset evaluation; compare against larger transformer, encoder–decoder, generative, and efficiency-oriented baselines; and assess alignment between attention maps and post hoc attribution methods such as LIME, SHAP, and Integrated Gradients.
In conclusion, the proposed BERT+BiLSTM+Attention model provides a well-balanced solution to Twitter sentiment analysis by uniting performance with interpretability. Its success across sentiment classes and attention-based transparency make it a strong candidate for further research and practical implementation in real-world applications, with the present paper contributing a clearly described architecture, a transparent training/evaluation protocol, and attention visualizations that offer qualitative insight on this dataset, while outlining a concrete roadmap for external validation and deployment-oriented testing.
Author Contributions
Conceptualization, X.Z., Y.L. and L.H.; Methodology, X.Z. and L.H.; Investigation, X.Z. and T.Z.; Data curation, X.Z. and Z.G.; Formal analysis, T.Z., L.H., X.L. and Z.G.; Visualization, X.L.; Writing—original draft preparation, X.Z.; Writing—review and editing, T.Z., L.H., X.L., Z.G., Y.L. and A.M.; Supervision, A.M.; Project administration, Y.L. and X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The dataset used in this study is the publicly available Kaggle dataset ”Twitter Entity Sentiment Analysis” access on 5 January 2025 (https://www.kaggle.com/datasets/jp797498e/twitter-entity-sentiment-analysis). We used ‘twitter_training.csv‘ for training and ‘twitter_validation.csv‘ for validation, as recommended by the dataset authors. No proprietary data were used.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rahman, M.M.; Hossain, T.R.; Hasan, M.M.; Hossain, M.J. RoBERTa-BiLSTM: A Context-Aware Hybrid Model for Sentiment Analysis. arXiv 2024, arXiv:2406.00367. [Google Scholar] [CrossRef]
- Jahin, M.A.; Shovon, M.S.H.; Mridha, M.F.; Islam, M.R.; Watanobe, Y. A hybrid transformer and attention based recurrent neural network for robust and interpretable sentiment analysis of tweets. Sci. Rep. 2024, 14, 24882. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Yuan, L.; Liu, W.; Sun, M. Twitter Sentiment Analysis via Bi-sense Emoji Embedding and Attention-based LSTM. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 3427–3434. [Google Scholar]
- Barrière, V.; Balahur, A. Improving Sentiment Analysis over Non-English Tweets using Multilingual Transformers and Automatic Translation for Data Augmentation. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020. [Google Scholar]
- Serrano, S.; Smith, N.A. Is Attention Interpretable? In Proceedings of the Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Imran, M.; Qadir, F.; Castillo, L. TBCOV: Two Billion Multilingual COVID-19 Tweets with Location and Sentiment Labels. arXiv 2021, arXiv:2110.03664. [Google Scholar]
- Nasrabadi, H.N.; Moattar, M. Sentiment Analysis of Imbalanced Dataset through Data Augmentation and Generative Annotation using DistilBERT and Low-Rank Fine-Tuning. Res. Sq. Prepr. 2025. [Google Scholar] [CrossRef]
- Rana, P. Data Augmentation Techniques for Imbalanced Datasets. Medium. 2024. Available online: https://medium.com (accessed on 22 September 2025).
- Albladi, A.; Islam, M.; Seals, C. Sentiment Analysis of Twitter Data Using NLP Models: A Comprehensive Review. IEEE Access 2025, 13, 30444–30468. [Google Scholar] [CrossRef]
- Zhong, R.; Shao, S.; McKeown, K. Fine-grained Sentiment Analysis with Faithful Attention. arXiv 2019, arXiv:1908.06870. [Google Scholar] [CrossRef]
- Tutek, M.; Šnajder, J. Iterative Recursive Attention Model for Interpretable Sequence Classification. arXiv 2018, arXiv:1808.04926. [Google Scholar] [CrossRef]
- Wu, Z.; Nguyen, T.S.; Ong, D.C. Structured Self-Attention Weights Encode Semantics in Sentiment Analysis. arXiv 2020, arXiv:2010.11298. [Google Scholar] [CrossRef]
- Lopardo, G.; Precioso, F.; Garreau, D. Attention Meets Post-hoc Interpretability: A Mathematical Perspective. arXiv 2025, arXiv:2502.02268. [Google Scholar]
- Sharma, S.; Singh, A.; Kumar, R. Traditional and Deep Learning Approaches for Sentiment Analysis: A Survey. Adv. Sci. Technol. Eng. Syst. J. ASTESJ 2020, 5, 156–162. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B. Deep Learning for Sentiment Analysis: A Comprehensive Survey. IEEE Trans. Knowl. Data Eng. 2016, 28, 431–444. [Google Scholar]
- Tejwani, R. Sentiment Analysis: A Survey. arXiv 2014, arXiv:1405.2584. [Google Scholar] [CrossRef]
- Yang, W.; Xiao, Q.; Zhang, Y. HAR2bot: A human-centered augmented reality robot programming method with the awareness of cognitive load. J. Intell. Manuf. 2024, 35, 1985–2003. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zhang, J.; Ni, J.; Li, X.; Bian, Y.; Islam, M.M.; Mondal, A.M.; Wei, H.; Luo, D. Generating In-Distribution Proxy Graphs for Explaining Graph Neural Networks. arXiv 2024, arXiv:cs.LG/2402.02036. [Google Scholar] [CrossRef]
- Kaggle. Twitter Entity Sentiment Analysis. 2020. Available online: https://www.kaggle.com/datasets/jp797498e/twitter-entity-sentiment-analysis (accessed on 5 January 2025).
- Al Montaser, M.A.; Ghosh, B.P.; Barua, A.; Karim, F.; Das, B.C.; Shawon, R.E.R.; Chowdhury, M.S.R. Sentiment analysis of social media data: Business insights and consumer behavior trends in the USA. Edelweiss Appl. Sci. Technol. 2025, 9, 545–565. [Google Scholar] [CrossRef]
- Dai, H.; Liu, Z.; Liao, W.; Huang, X.; Cao, Y.; Wu, Z.; Zhao, L.; Xu, S.; Zeng, F.; Liu, W.; et al. AugGPT: Leveraging ChatGPT for Text Data Augmentation. IEEE Trans. Big Data 2025, 11, 907–918. [Google Scholar] [CrossRef]
- Confusion Matrix. Wikipedia. 2025. Available online: https://en.wikipedia.org/wiki/Confusion/_matrix (accessed on 22 September 2025).
- Long Short-Term Memory. Wikipedia. 2025. Available online: https://en.wikipedia.org/wiki/Long/_short-term/_memory (accessed on 22 September 2025).
- Transformer (Deep Learning Architecture). 2025. Available online: https://en.wikipedia.org/wiki/Transformer_(deep_learning_architecture) (accessed on 22 September 2025).
- Smith, L.N. A disciplined approach to neural network hyper-parameters: Part 1—Learning rate, batch size, momentum, and weight decay. arXiv 2018, arXiv:1803.09820. [Google Scholar] [CrossRef]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning, C.D. What Does BERT Look at? An Analysis of BERT’s Attention. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 1 August 2019. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should I trust you? Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar] [CrossRef]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar] [CrossRef]


















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).