
A Proposal for a Tokenized Intelligent System: A Prediction for an AI-Based Scheduling, Secured Using Blockchain


Abstract
1. Introduction
2. Literature Review
3. Methodology
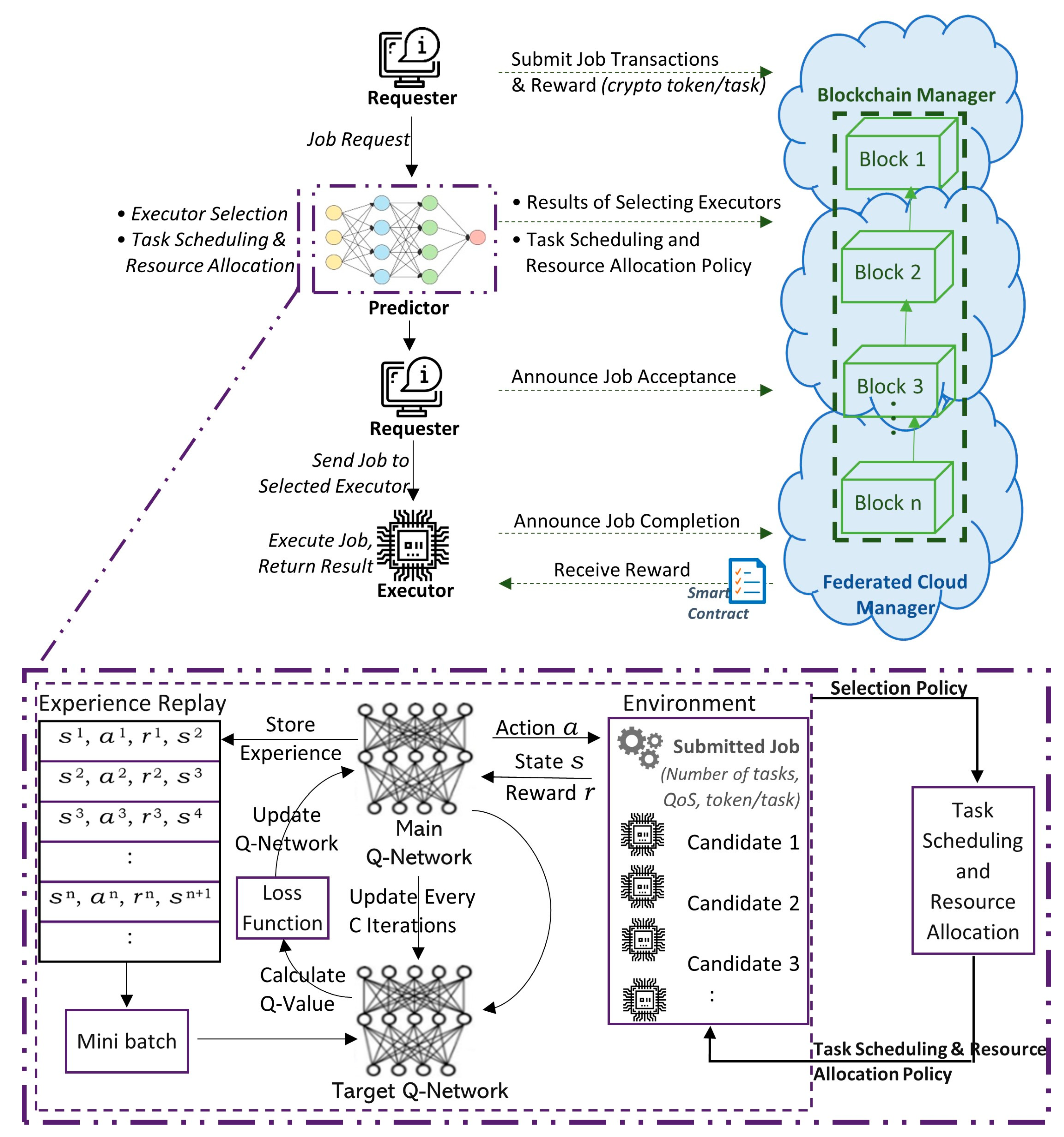
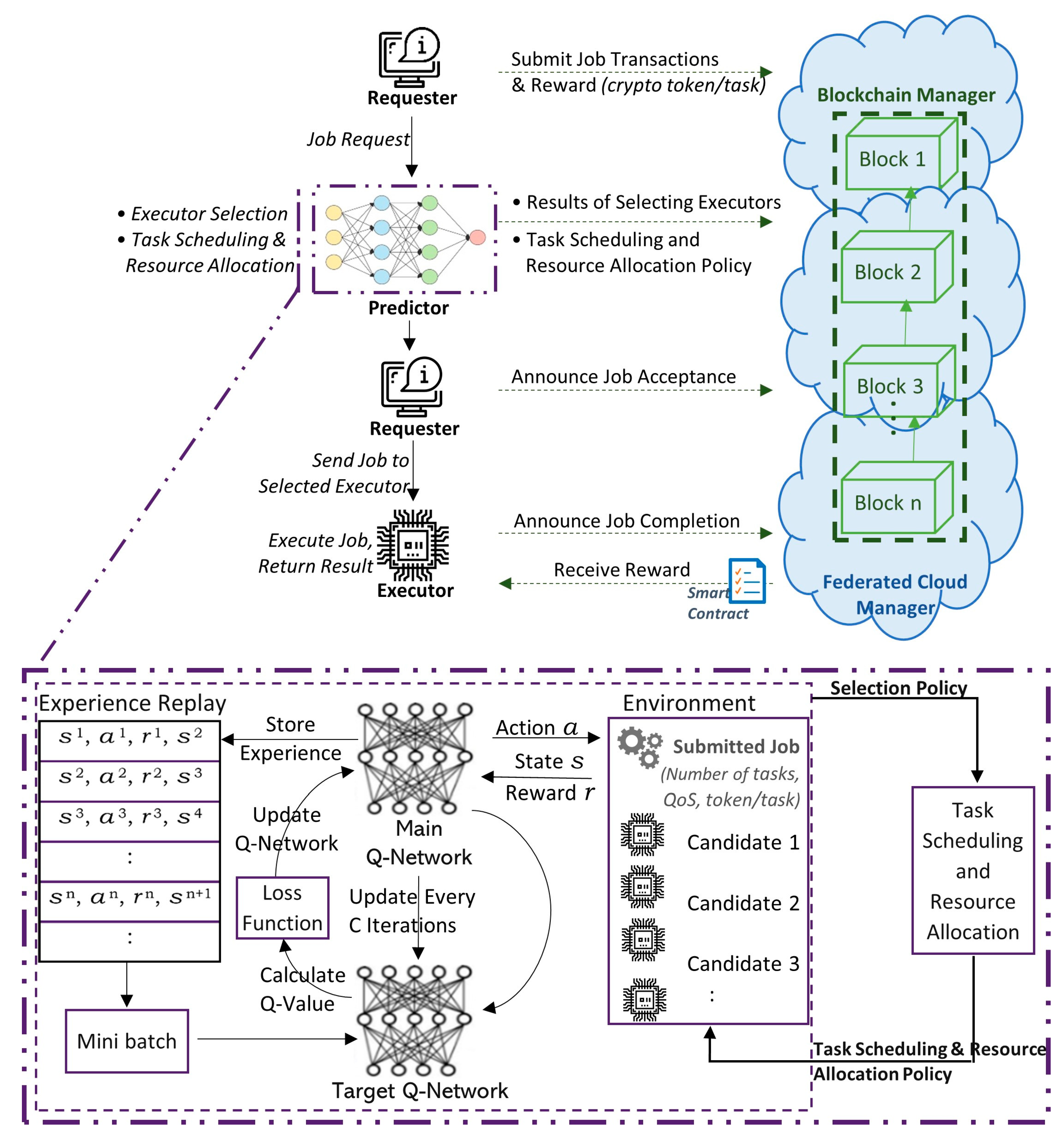
3.1. Workflow of the Proposed System
- Estimating the “state-action” value function that is correspondent to an action–value function (offline DNN construction, steps 4 to 6 in Algorithm 2);
- Action selection and dynamic network updating (online dynamic Deep Q-Learning, steps from 7 to 23 in Algorithm 2).
| Algorithm 1: Workflow |
 |
| Algorithm 2: Predictor Algorithm |
 |
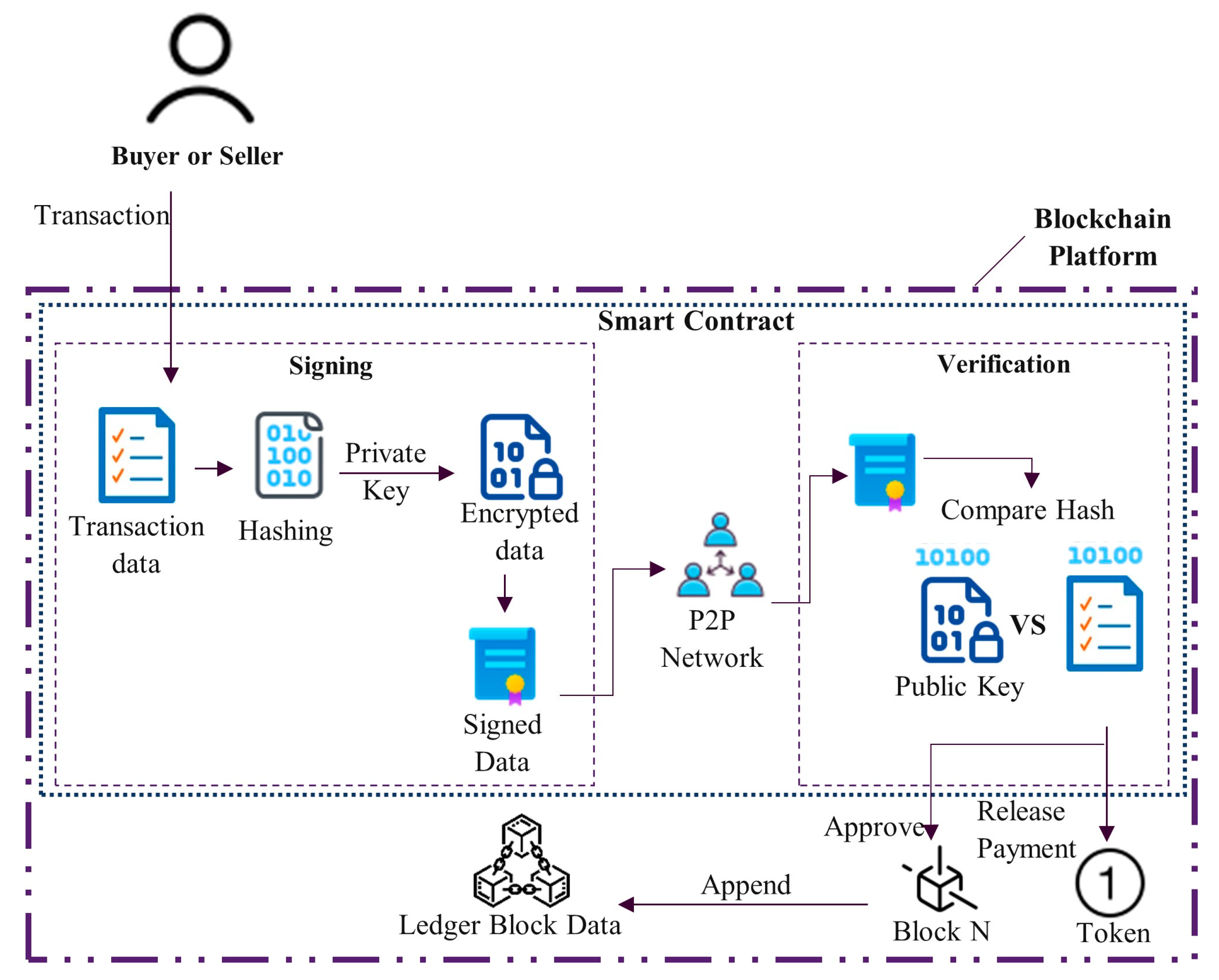
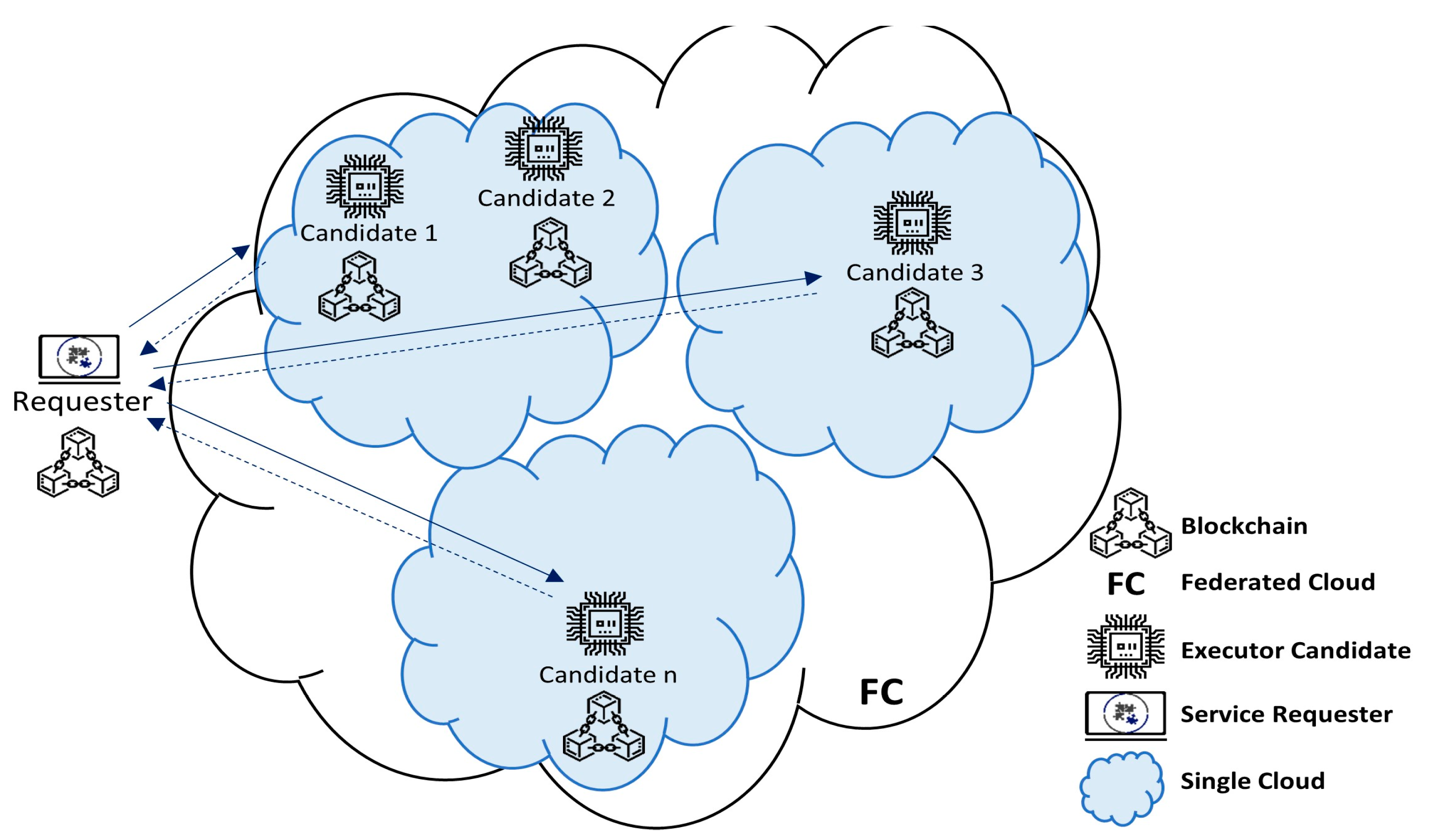
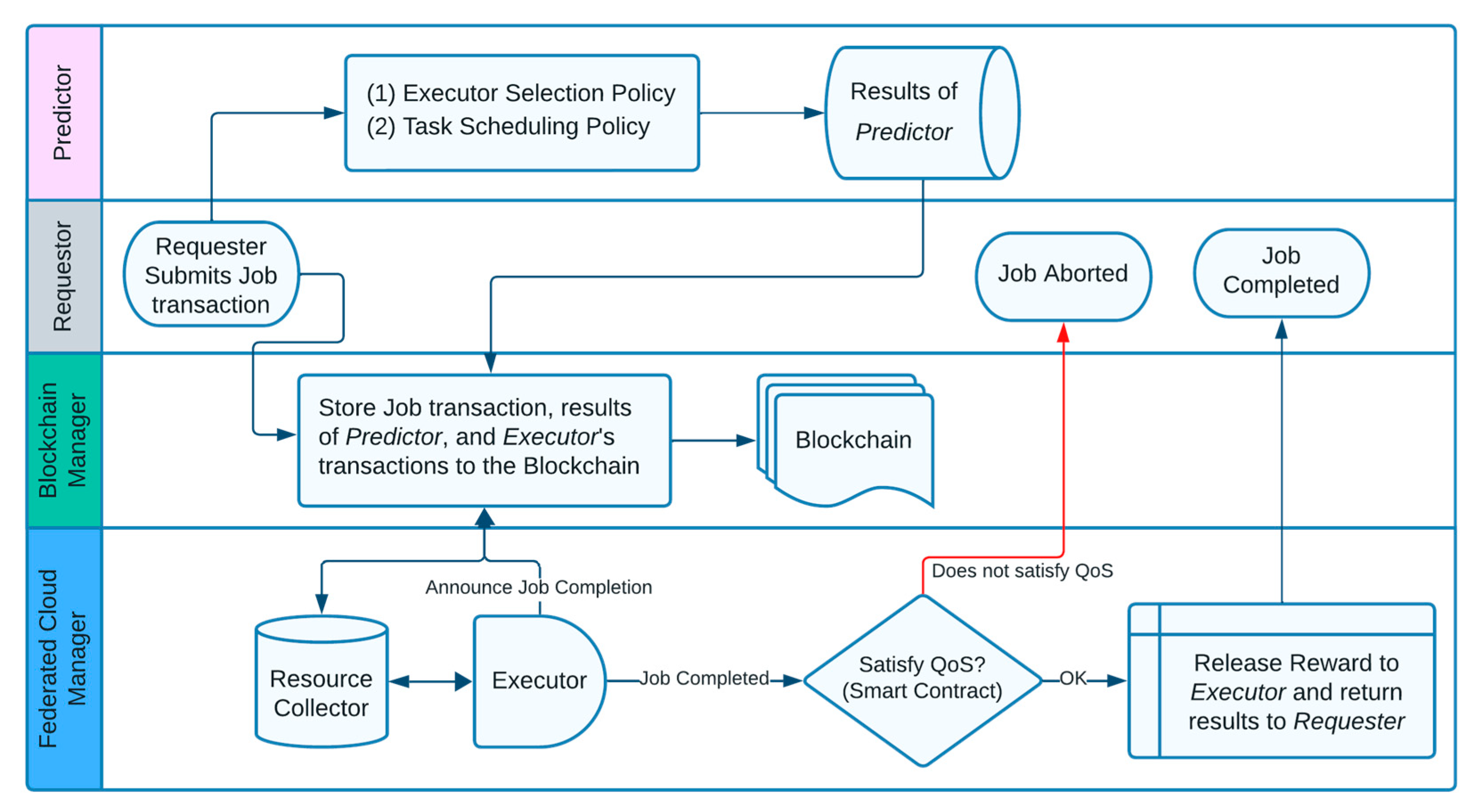
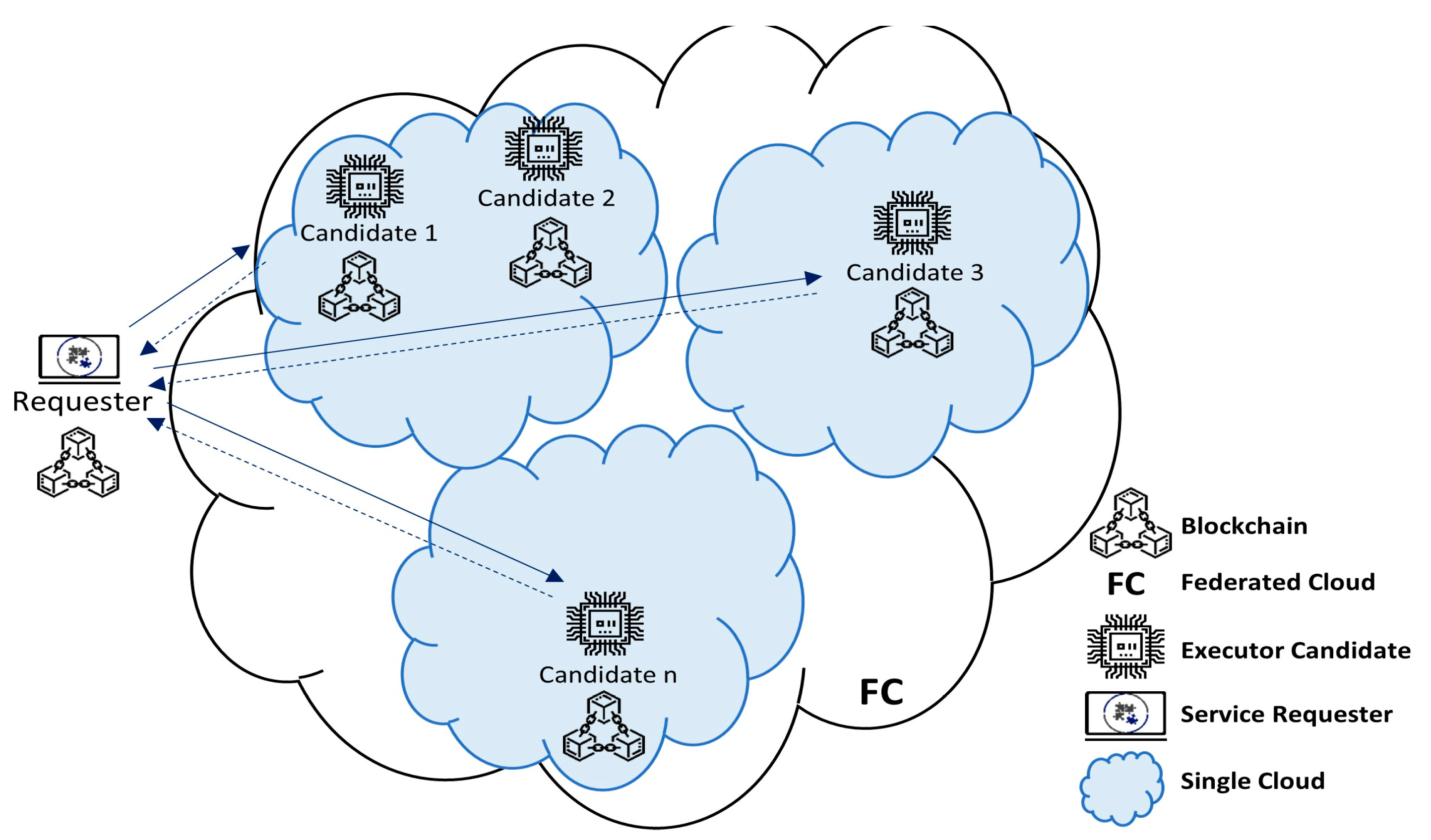
3.2. System Design and Architecture
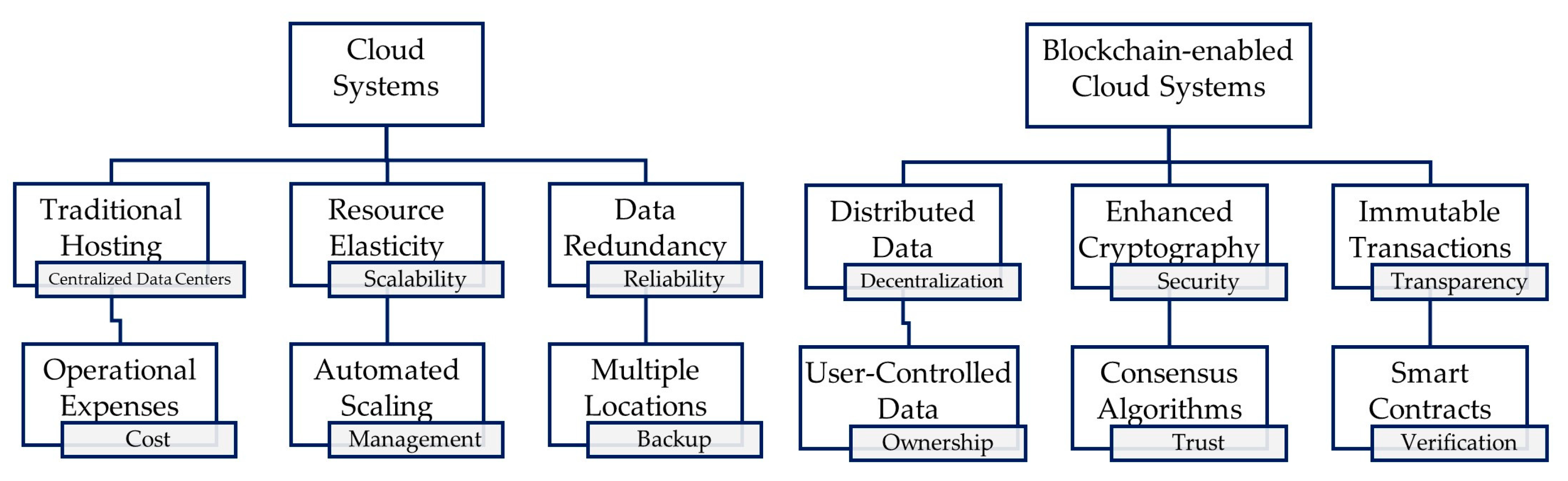
- Reliability is guaranteed through the availability of multiple (redundant) executors;
- Maintainability is achieved as we can modify to improve or adapt new consensus mechanisms, executor evaluation criteria, Predictor’s learning pattern enhancements, included cloud, or individual service providers, etc.;
- Interoperability is also managed as we can communicate with specific providers through their respective API, and also with participants through Blockchain;
- Security features are ensured through immutability and smart contract capabilities.
4. Results
4.1. Experimental Details and Settings
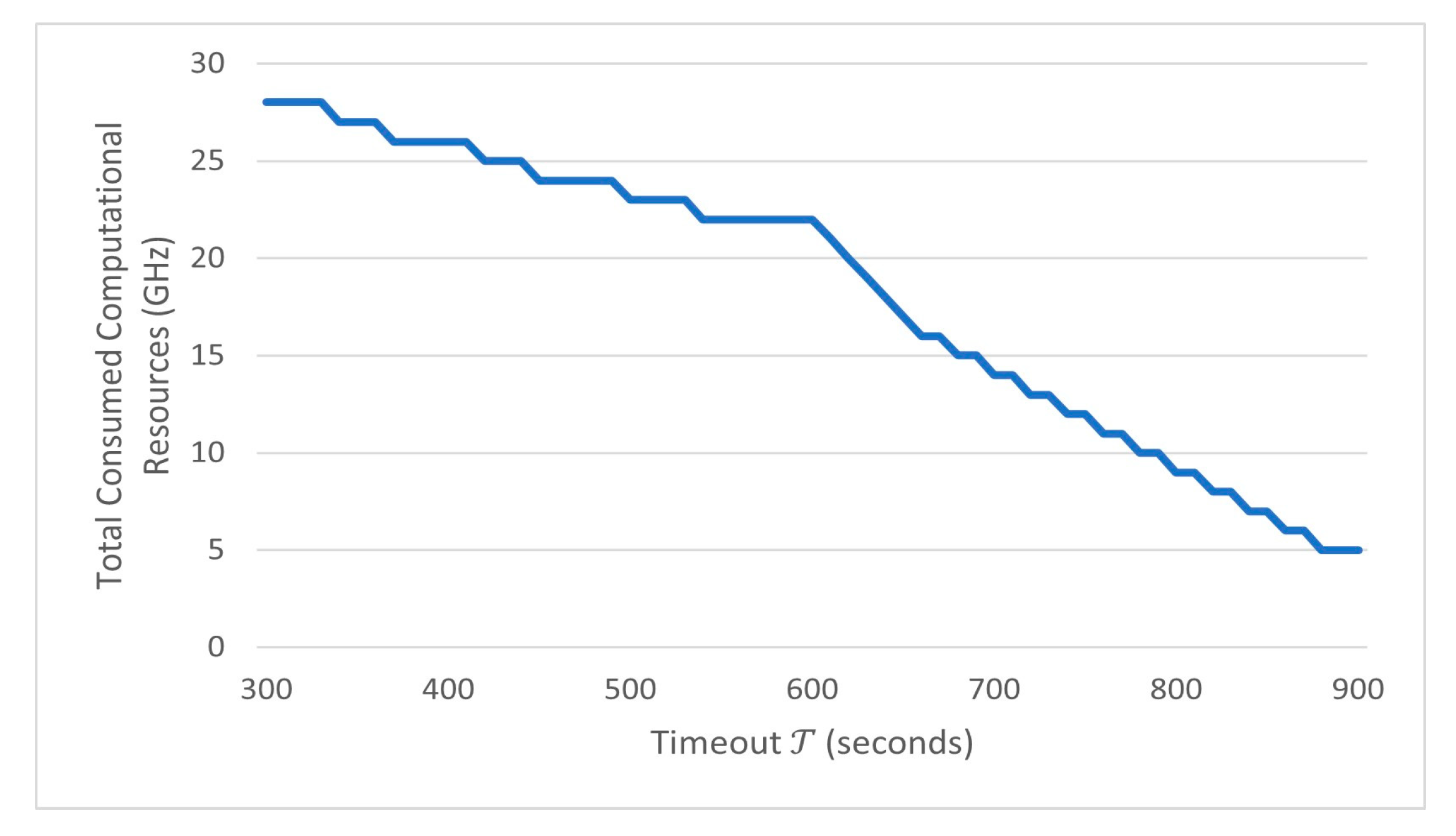
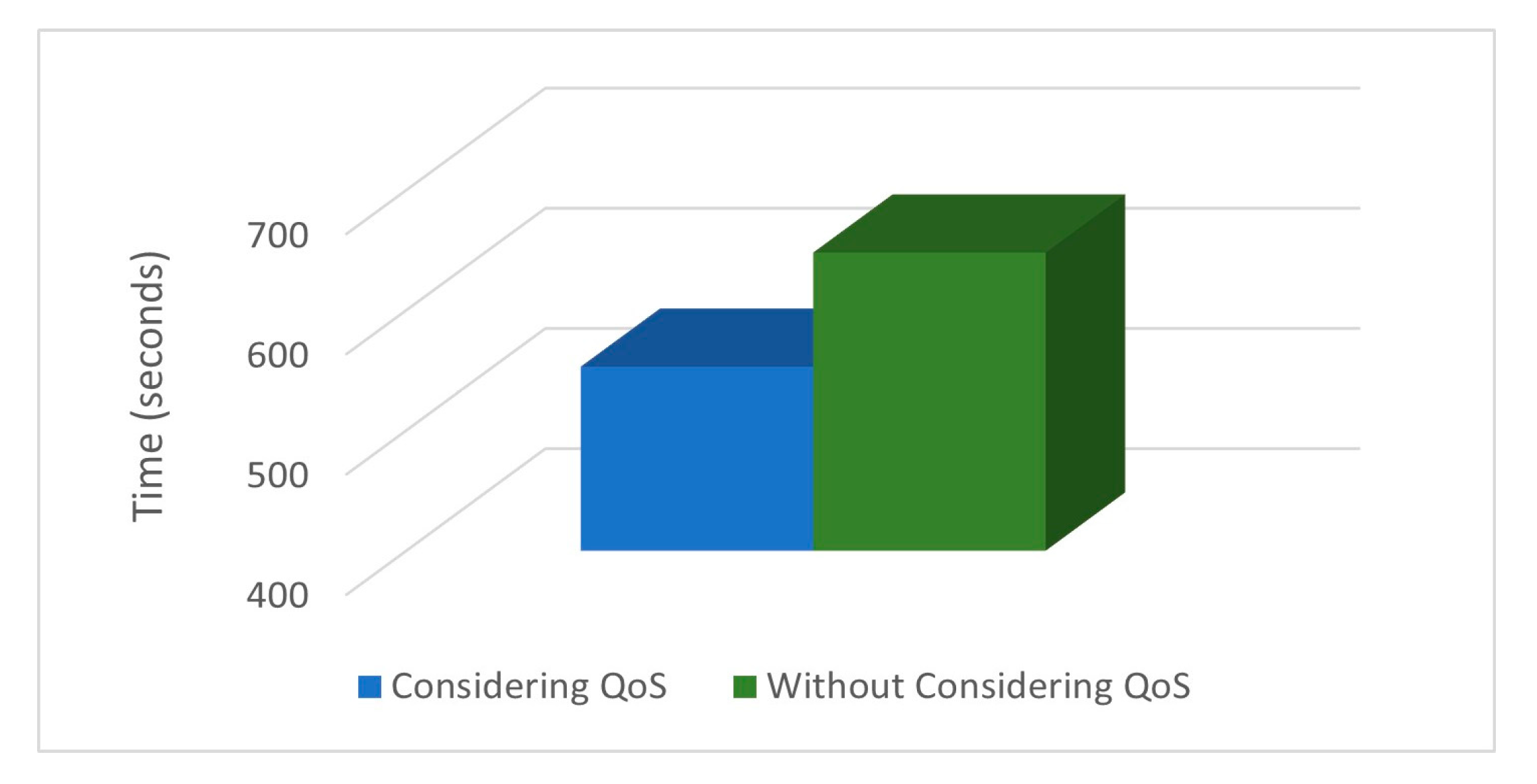
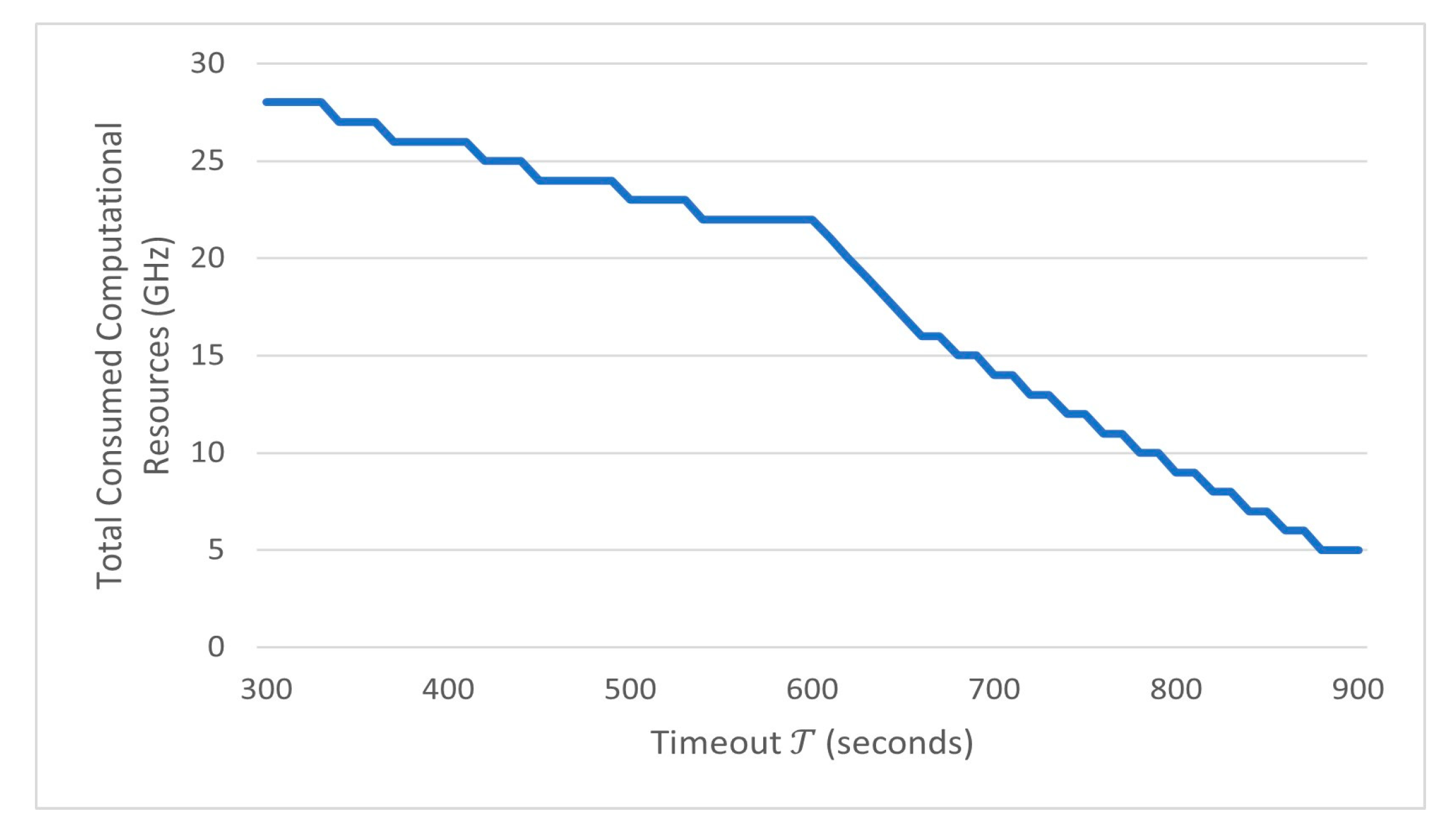
4.2. Performance Evaluation
4.3. Discussion
5. Conclusions
- Efficient task scheduling and resource allocation by leveraging the DQL for more optimization; such algorithms excel at learning from interactions and making sequential decisions based on the requirements of different tasks through adapting to the dynamic conditions, resulting in an optimized performance and utilization;
- Tokenized incentives and rewards for independent service providers (executors) who contribute their resources or compute power to task execution to ensure fairness;
- Transparent and trustworthy task execution through the utilization of the immutable Blockchain technology, which helps with verifying the execution of tasks, enhancing trust and reducing the reliance on centralized authorities and single cloud providers;
- Distributed and secured task execution responsibilities among participants by leveraging Blockchain’s decentralized nature. This enhances system resilience, reduces single points of failure, and improves security against malicious activities.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Barreto, L.; Fraga, J.; Siqueira, F. Conceptual Model of Brokering and Authentication in Cloud Federations. In Proceedings of the 2015 IEEE 4th International Conference on Cloud Networking (CloudNet), Niagara Falls, ON, Canada, 5–7 October 2015; pp. 303–308. [Google Scholar]
- Bohn, R.B.; Chaparadza, R.; Elkotob, M.; Choi, T. The Path to Cloud Federation through Standardization. In Proceedings of the 2022 13th International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 19–21 October 2022; pp. 942–946. [Google Scholar]
- Zhao, Y.; Zhang, J.; Cao, Y. Manipulating Vulnerability: Poisoning Attacks and Countermeasures in Federated Cloud–Edge–Client Learning for Image Classification. Knowl.-Based Syst. 2023, 259, 110072. [Google Scholar] [CrossRef]
- Verma, A.; Bhattacharya, P.; Bodkhe, U.; Saraswat, D.; Tanwar, S.; Dev, K. FedRec: Trusted Rank-Based Recommender Scheme for Service Provisioning in Federated Cloud Environment. Digit. Commun. Netw. 2023, 9, 33–46. [Google Scholar] [CrossRef]
- Magdy, Y.; Azab, M.; Hamada, A.; Rizk, M.R.M.; Sadek, N. Moving-Target Defense in Depth: Pervasive Self- and Situation-Aware VM Mobilization across Federated Clouds in Presence of Active Attacks. Sensors 2022, 22, 9548. [Google Scholar] [CrossRef] [PubMed]
- Badshah, A.; Ghani, A.; Siddiqui, I.F.; Daud, A.; Zubair, M.; Mehmood, Z. Orchestrating Model to Improve Utilization of IaaS Environment for Sustainable Revenue. Sustain. Energy Technol. Assess. 2023, 57, 103228. [Google Scholar] [CrossRef]
- Alharbe, N.; Aljohani, A.; Rakrouki, M.A.; Khayyat, M. An Access Control Model Based on System Security Risk for Dynamic Sensitive Data Storage in the Cloud. Appl. Sci. 2023, 13, 3187. [Google Scholar] [CrossRef]
- Alashhab, Z.R.; Anbar, M.; Singh, M.M.; Hasbullah, I.H.; Jain, P.; Al-Amiedy, T.A. Distributed Denial of Service Attacks against Cloud Computing Environment: Survey, Issues, Challenges and Coherent Taxonomy. Appl. Sci. 2022, 12, 12441. [Google Scholar] [CrossRef]
- Kollu, V.N.; Janarthanan, V.; Karupusamy, M.; Ramachandran, M. Cloud-Based Smart Contract Analysis in FinTech Using IoT-Integrated Federated Learning in Intrusion Detection. Data 2023, 8, 83. [Google Scholar] [CrossRef]
- Pol, P.S.; Pachghare, V.K. A Review on Trust-Based Resource Allocation in Cloud Environment: Issues Toward Collaborative Cloud. Int. J. Semant. Comput. 2023, 17, 59–91. [Google Scholar] [CrossRef]
- Lee, J.; Kim, B.; Lee, A.R. Priority Evaluation Factors for Blockchain Application Services in Public Sectors. PLoS ONE 2023, 18, e0279445. [Google Scholar] [CrossRef]
- Krichen, M.; Ammi, M.; Mihoub, A.; Almutiq, M. Blockchain for Modern Applications: A Survey. Sensors 2022, 22, 5274. [Google Scholar] [CrossRef]
- Tyagi, A.K.; Dananjayan, S.; Agarwal, D.; Thariq Ahmed, H.F. Blockchain—Internet of Things Applications: Opportunities and Challenges for Industry 4.0 and Society 5.0. Sensors 2023, 23, 947. [Google Scholar] [CrossRef] [PubMed]
- Nawrocki, P.; Osypanka, P.; Posluszny, B. Data-Driven Adaptive Prediction of Cloud Resource Usage. J. Grid Comput. 2023, 21, 6. [Google Scholar] [CrossRef]
- Abdel-Hamid, L. An Efficient Machine Learning-Based Emotional Valence Recognition Approach Towards Wearable EEG. Sensors 2023, 23, 1255. [Google Scholar] [CrossRef] [PubMed]
- Lei, B.; Zhou, J.; Ma, M.; Niu, X. DQN Based Blockchain Data Storage in Resource-Constrained IoT System. In Proceedings of the 2023 IEEE Wireless Communications and Networking Conference (WCNC), Glasgow, UK, 26–29 March 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Katib, I.; Assiri, F.Y.; Althaqafi, T.; AlKubaisy, Z.M.; Hamed, D.; Ragab, M. Hybrid Hunter–Prey Optimization with Deep Learning-Based Fintech for Predicting Financial Crises in the Economy and Society. Electronics 2023, 12, 3429. [Google Scholar] [CrossRef]
- Albeshri, A. SVSL: A Human Activity Recognition Method Using Soft-Voting and Self-Learning. Algorithms 2021, 14, 245. [Google Scholar] [CrossRef]
- Al-Ghamdi, A.S.A.-M.; Ragab, M.; AlGhamdi, S.A.; Asseri, A.H.; Mansour, R.F.; Koundal, D. Detection of Dental Diseases through X-Ray Images Using Neural Search Architecture Network. Comput. Intell. Neurosci. 2022, 2022, 3500552. [Google Scholar] [CrossRef] [PubMed]
- Jambi, K.M.; Khan, I.H.; Siddiqui, M.A. Evaluation of Different Plagiarism Detection Methods: A Fuzzy MCDM Perspective. Appl. Sci. 2022, 12, 4580. [Google Scholar] [CrossRef]
- Denizdurduran, B.; Markram, H.; Gewaltig, M.-O. Optimum Trajectory Learning in Musculoskeletal Systems with Model Predictive Control and Deep Reinforcement Learning. Biol. Cybern. 2022, 116, 711–726. [Google Scholar] [CrossRef]
- Majid, A.Y.; Saaybi, S.; Francois-Lavet, V.; Prasad, R.V.; Verhoeven, C. Deep Reinforcement Learning Versus Evolution Strategies: A Comparative Survey. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–19. [Google Scholar] [CrossRef]
- Tefera, M.K.; Zhang, S.; Jin, Z. Deep Reinforcement Learning-Assisted Optimization for Resource Allocation in Downlink OFDMA Cooperative Systems. Entropy 2023, 25, 413. [Google Scholar] [CrossRef]
- Özcan, E.; Drake, J.H.; Burke, E.K. A Modified Choice Function Hyper-Heuristic Controlling Unary and Binary Operators. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015. [Google Scholar]
- Ortiz-Bayliss, J.C.; Terashima-Marín, H.; Conant-Pablos, S.E. Combine and Conquer: An Evolutionary Hyper-Heuristic Approach for Solving Constraint Satisfaction Problems. Artif. Intell. Rev. Int. Sci. Eng. J. 2016, 46, 327–349. [Google Scholar] [CrossRef]
- Espinoza-Nevárez, D.; Ortiz-Bayliss, J.C.; Terashima-Marín, H.; Gatica, G. Selection and Generation Hyper-Heuristics for Solving the Vehicle Routing Problem with Time Windows. In Proceedings of the GECCO 2016 Companion—Genetic and Evolutionary Computation Conference, Denver, CO, USA, 20–24 July 2016; Association for Computing Machinery, Inc.: New York, NY, USA, 2016; pp. 139–140. [Google Scholar]
- Zubaydi, H.D.; Varga, P.; Molnár, S. Leveraging Blockchain Technology for Ensuring Security and Privacy Aspects in Internet of Things: A Systematic Literature Review. Sensors 2023, 23, 788. [Google Scholar] [CrossRef] [PubMed]
- Alam, T. Blockchain-Based Internet of Things: Review, Current Trends, Applications, and Future Challenges. Computers 2023, 12, 6. [Google Scholar] [CrossRef]
- Samy, A.; Elgendy, I.A.; Yu, H.; Zhang, W.; Zhang, H. Secure Task Offloading in Blockchain-Enabled Mobile Edge Computing with Deep Reinforcement Learning. IEEE Trans. Netw. Serv. Manag. 2022, 19, 4872–4887. [Google Scholar] [CrossRef]
- Lin, K.; Gao, J.; Han, G.; Wang, H.; Li, C. Intelligent Blockchain-Enabled Adaptive Collaborative Resource Scheduling in Large-Scale Industrial Internet of Things. IEEE Trans. Ind. Inform. 2022, 18, 9196–9205. [Google Scholar] [CrossRef]
- Xiao, H.; Qiu, C.; Yang, Q.; Huang, H.; Wang, J.; Su, C. Deep Reinforcement Learning for Optimal Resource Allocation in Blockchain-Based IoV Secure Systems. In Proceedings of the 2020 16th International Conference on Mobility, Sensing and Networking (MSN), Tokyo, Japan, 17–19 December 2020; pp. 137–144. [Google Scholar]
- Gao, S.; Wang, Y.; Feng, N.; Wei, Z.; Zhao, J. Deep Reinforcement Learning-Based Video Offloading and Resource Allocation in NOMA-Enabled Networks. Future Internet 2023, 15, 184. [Google Scholar] [CrossRef]
- Fang, C.; Zhang, T.; Huang, J.; Xu, H.; Hu, Z.; Yang, Y.; Wang, Z.; Zhou, Z.; Luo, X. A DRL-Driven Intelligent Optimization Strategy for Resource Allocation in Cloud-Edge-End Cooperation Environments. Symmetry 2022, 14, 2120. [Google Scholar] [CrossRef]
- Quan, T.; Zhang, H.; Yu, Y.; Tang, Y.; Liu, F.; Hao, H. Seismic Data Query Algorithm Based on Edge Computing. Electronics 2023, 12, 2728. [Google Scholar] [CrossRef]
- Todorović, M.; Matijević, L.; Ramljak, D.; Davidović, T.; Urošević, D.; Jakšić Krüger, T.; Jovanović, Đ. Proof-of-Useful-Work: BlockChain Mining by Solving Real-Life Optimization Problems. Symmetry 2022, 14, 1831. [Google Scholar] [CrossRef]
- Cheng, Y.; Cao, Z.; Zhang, X.; Cao, Q.; Zhang, D. Multi Objective Dynamic Task Scheduling Optimization Algorithm Based on Deep Reinforcement Learning. J. Supercomput. Int. J. High-Perform. Comput. Des. Anal. Use 2023, 79, 1–29. [Google Scholar] [CrossRef]
- Jain, V.; Kumar, B. QoS-Aware Task Offloading in Fog Environment Using Multi-Agent Deep Reinforcement Learning. J. Netw. Syst. Manag. 2022, 31, 7. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, H.; Chen, H.; Yan, Y.; Huang, J.; Xiong, A.; Yang, S.; Chen, J.; Guo, S. A Federated Learning Multi-Task Scheduling Mechanism Based on Trusted Computing Sandbox. Sensors 2023, 23, 2093. [Google Scholar] [CrossRef] [PubMed]
- Lakhan, A.; Mohammed, M.A.; Nedoma, J.; Martinek, R.; Tiwari, P.; Kumar, N. DRLBTS: Deep Reinforcement Learning-Aware Blockchain-Based Healthcare System. Sci. Rep. 2023, 13, 4124. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Alwakeel, A.M.; Alwakeel, M.M.; Alharbi, L.A.; Althubiti, S.A. A Heuristic Deep Q Learning for Offloading in Edge Devices in 5 g Networks. J. Grid Comput. 2023, 21, 37. [Google Scholar] [CrossRef]
- Neves, M.; Vieira, M.; Neto, P. A Study on a Q-Learning Algorithm Application to a Manufacturing Assembly Problem. J. Manuf. Syst. 2021, 59, 426–440. [Google Scholar] [CrossRef]
- Gao, J.; Niu, K. A Reinforcement Learning Based Decoding Method of Short Polar Codes. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Nanjing, China, 29 March 2021; pp. 1–6. [Google Scholar]
- Kardani-Moghaddam, S.; Buyya, R.; Ramamohanarao, K. ADRL: A Hybrid Anomaly-Aware Deep Reinforcement Learning-Based Resource Scaling in Clouds. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 514–526. [Google Scholar] [CrossRef]
- Yi, D.; Zhou, X.; Wen, Y.; Tan, R. Efficient Compute-Intensive Job Allocation in Data Centers via Deep Reinforcement Learning. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1474–1485. [Google Scholar] [CrossRef]
- Zhang, S.; Lee, J.-H. Analysis of the Main Consensus Protocols of Blockchain. ICT Express 2020, 6, 93–97. [Google Scholar] [CrossRef]
- Liu, G.; Chen, C.-Y.; Han, J.-Y.; Zhou, Y.; He, G.-B. NetDAO: Toward Trustful and Secure IoT Networks without Central Gateways. Symmetry 2022, 14, 1796. [Google Scholar] [CrossRef]
- Ahamed, Z.; Khemakhem, M.; Eassa, F.; Alsolami, F.; Basuhail, A.; Jambi, K. Deep Reinforcement Learning for Workload Prediction in Federated Cloud Environments. Sensors 2023, 23, 6911. [Google Scholar] [CrossRef]
- TRON|Decentralize the Web. Available online: https://tron.network/ (accessed on 18 July 2023).
- Delegated Proof of Stake (DPOS)—BitShares Documentation. Available online: https://how.bitshares.works/en/master/technology/dpos.html (accessed on 20 July 2023).
- Dubey, S.R.; Singh, S.K.; Chaudhuri, B.B. Activation Functions in Deep Learning: A Comprehensive Survey and Benchmark. Neurocomputing 2022, 503, 92–108. [Google Scholar] [CrossRef]
- AzurePublicDatasetV2. Available online: https://github.com/Azure/AzurePublicDataset/blob/master/AzurePublicDatasetV2.md (accessed on 4 August 2023).
- Datasets/Titanic.Csv at Master Datasciencedojo/Datasets. Available online: https://github.com/datasciencedojo/datasets/blob/master/titanic.csv (accessed on 1 October 2023).
- Blockchain File Sharing & Storage—Kaleido Document Exchange. Available online: https://www.kaleido.io/blockchain-platform/document-exchange (accessed on 16 October 2023).
- Bachani, V.; Bhattacharjya, A. Preferential Delegated Proof of Stake (PDPoS)—Modified DPoS with Two Layers towards Scalability and Higher TPS. Symmetry 2023, 15, 4. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| FCM | Federated Cloud Manager |
| Predictor | Deep Reinforcement Learning agent |
| BCM | Blockchain manager |
| RC | Resource Collector |
| Number of tasks | |
| Timeout, the assumed QoS | |
| Reward (token per task) | |
| Job | , , and |
| Scheduling profile | |
| Computational resource allocation profile | |
| Task scheduling and resource allocation policy | |
| Candidates set; the potential executors not yet selected | |
| Executors set; the selected executors from the candidates set |
| Notation | Parameter | Configuration |
|---|---|---|
| - | Number of episodes | 1000 episodes |
| α | Learning rate | 0.01 |
| γ | Discount factor | 0.95 |
| ε | Epsilon-Greedy parameter | 1.0 |
| ε-decay | Reducing factor of exploration rate | 0.995 |
| ER | Experience Replay | 10,000 steps |
| - | Minibatch Size | 32 experiences |
| TRX | Native token of Tron Blockchain | Tron Blockchain |
| Tron | Blockchain network | Testnet network |
| SR Node | Blockchain super representative node | 1 node |
| Candidate | Blockchain participant nodes | 7 candidates |
| Q | Reward of successful execution per task | 1 TRX |
| Size of each task | 500,000 bytes | |
| x | Computation intensity | 5 cycles/byte |
| Weight of stake | 0.05 | |
| V | Reputation value | 0.1 |
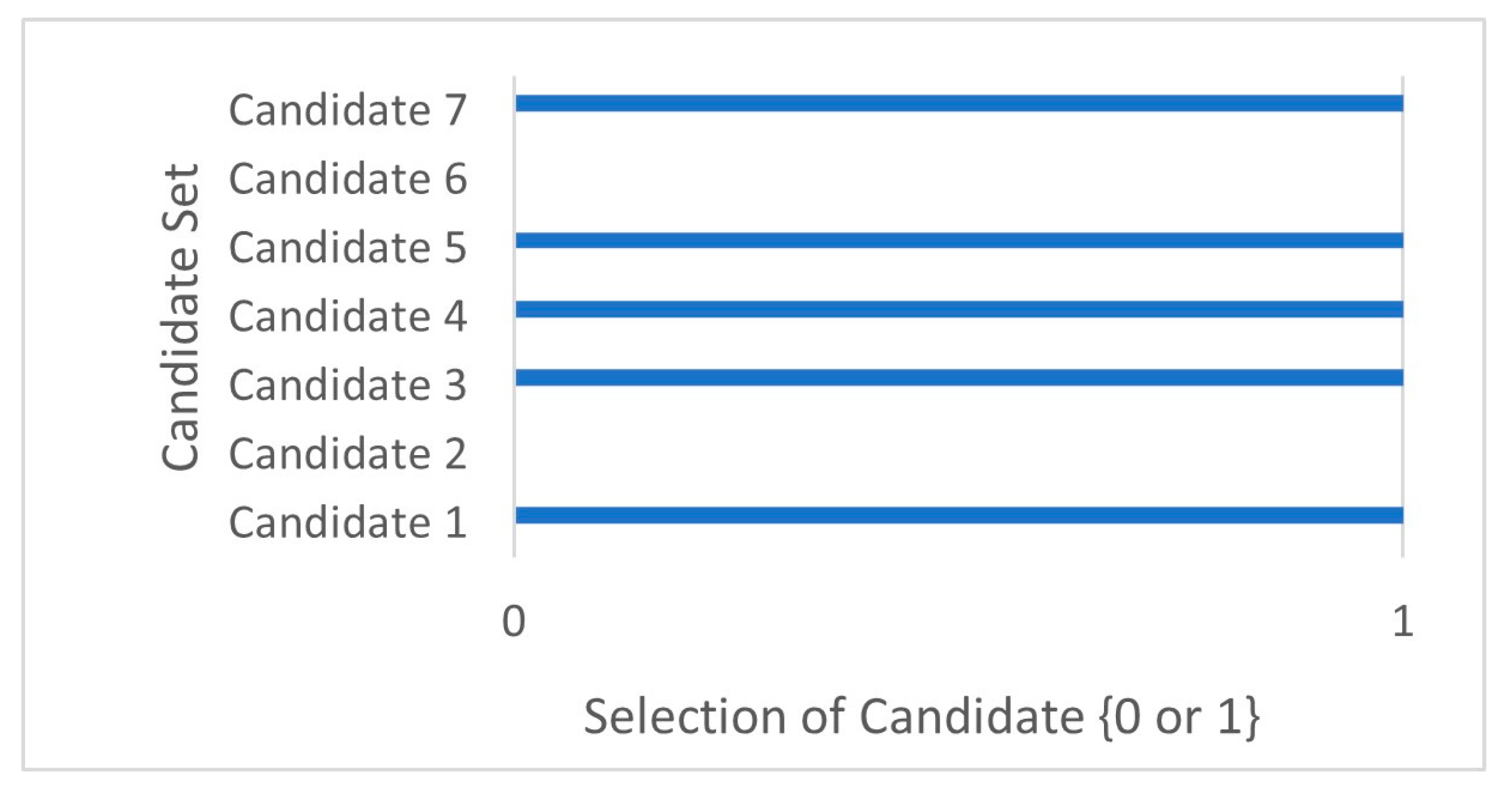
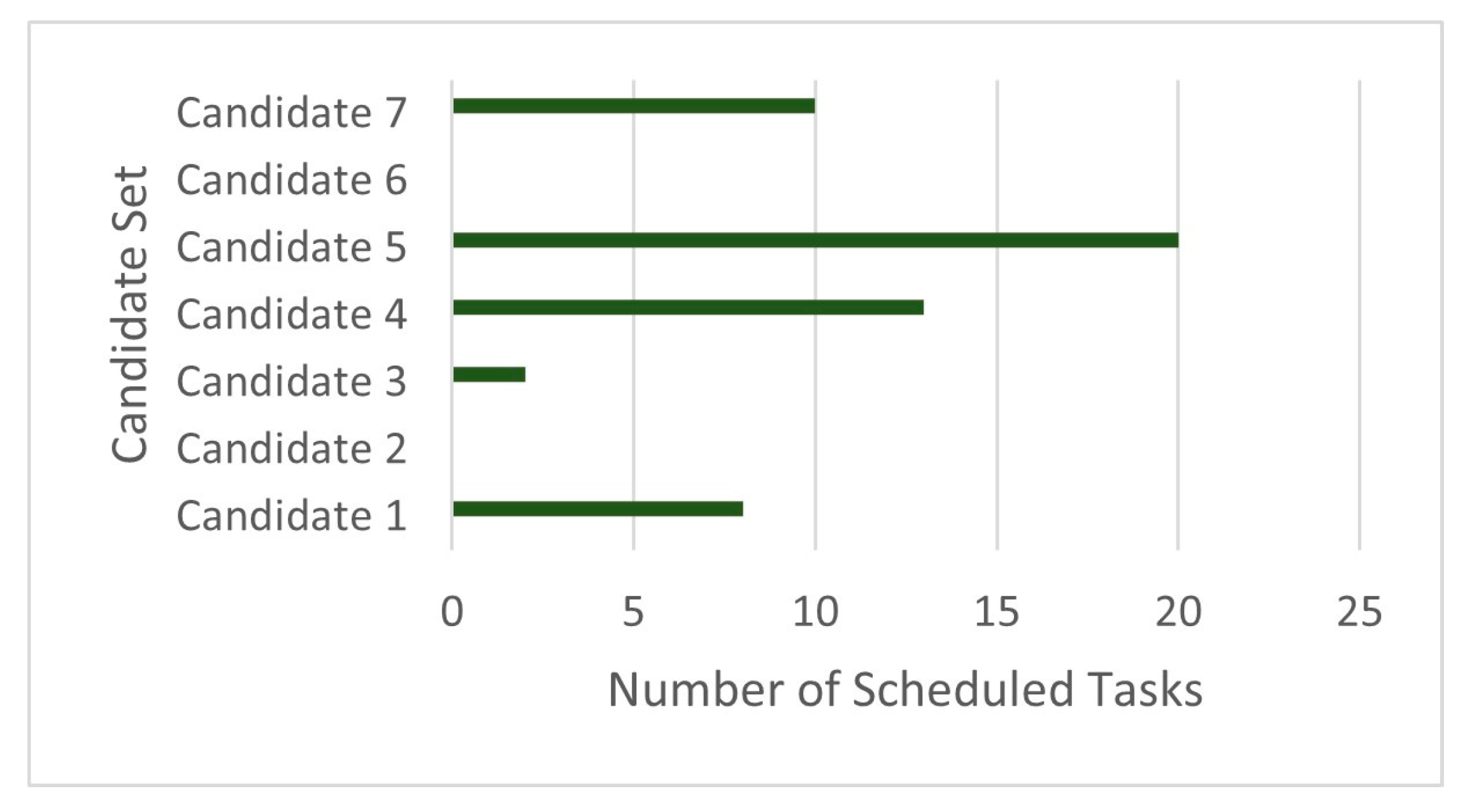
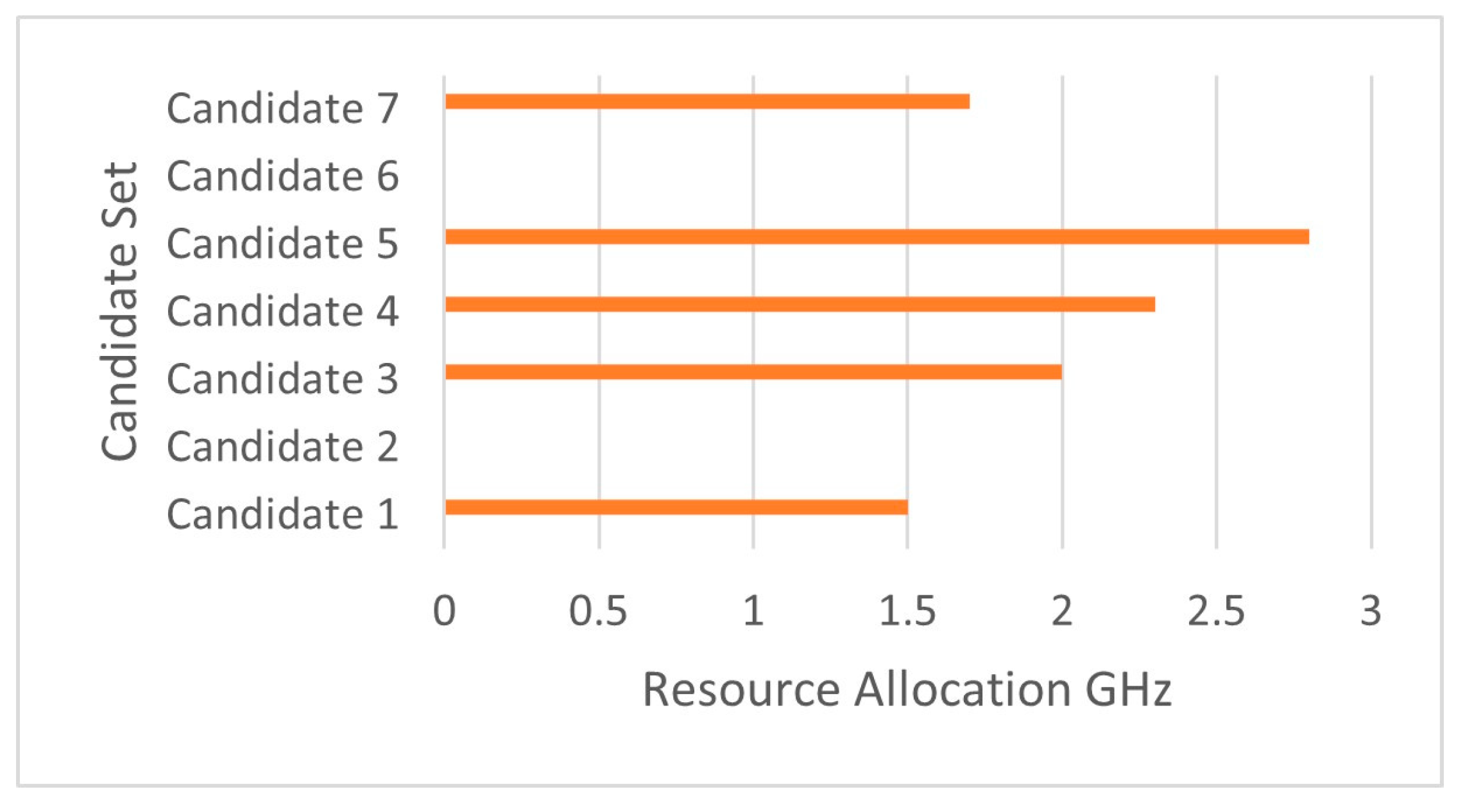
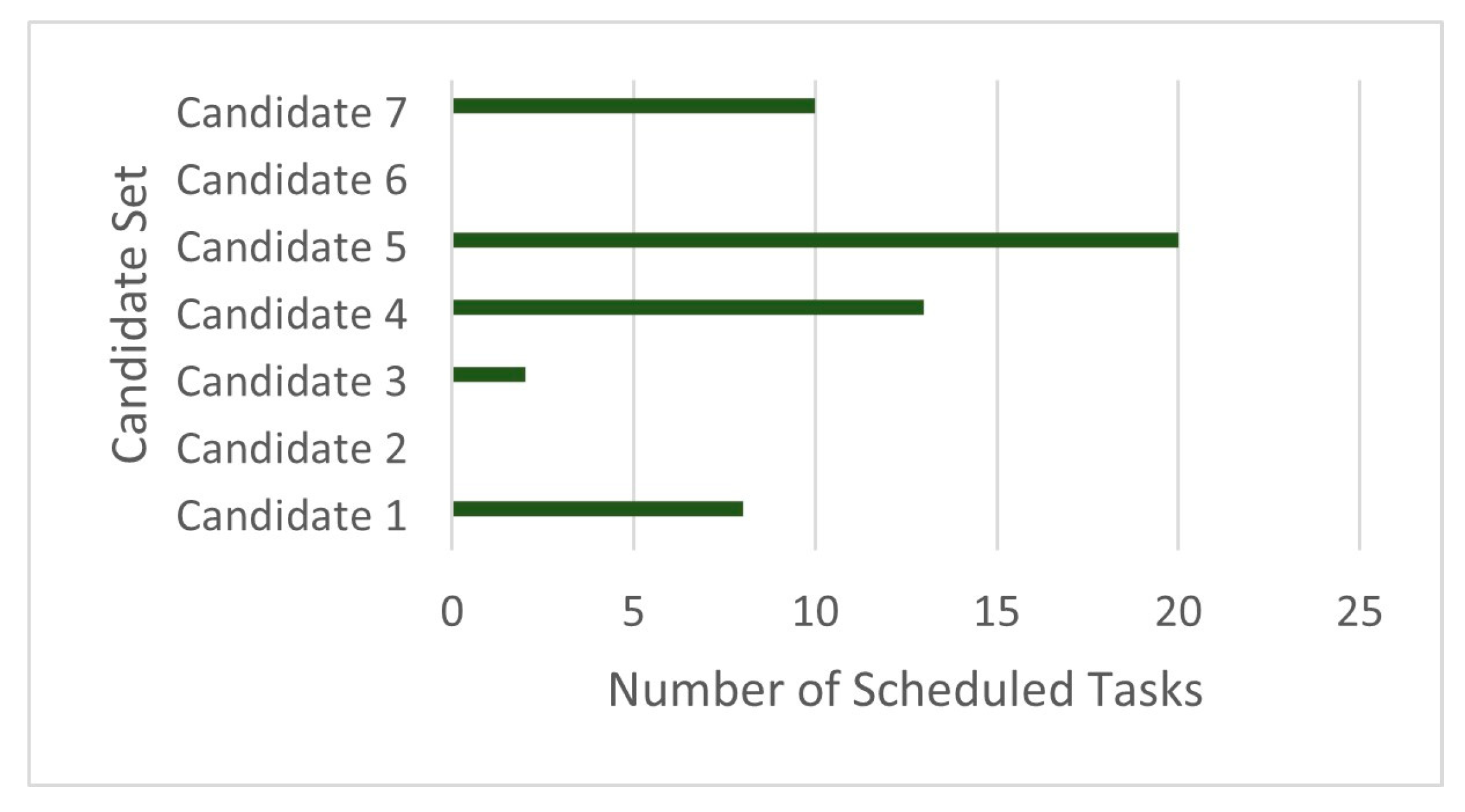
| Candidate | Selection of Candidate | Number of Scheduled Tasks | Resource Allocation |
|---|---|---|---|
| 1 | 1 | 8 | 1.5 |
| 2 | 0 | 0 | 0 |
| 3 | 1 | 2 | 2 |
| 4 | 1 | 13 | 2.3 |
| 5 | 1 | 20 | 2.8 |
| 6 | 0 | 0 | 0 |
| 7 | 1 | 10 | 1.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Younis, O.; Jambi, K.; Eassa, F.; Elrefaei, L. A Proposal for a Tokenized Intelligent System: A Prediction for an AI-Based Scheduling, Secured Using Blockchain. Systems 2024, 12, 84. https://doi.org/10.3390/systems12030084
Younis O, Jambi K, Eassa F, Elrefaei L. A Proposal for a Tokenized Intelligent System: A Prediction for an AI-Based Scheduling, Secured Using Blockchain. Systems. 2024; 12(3):84. https://doi.org/10.3390/systems12030084
Chicago/Turabian StyleYounis, Osama, Kamal Jambi, Fathy Eassa, and Lamiaa Elrefaei. 2024. "A Proposal for a Tokenized Intelligent System: A Prediction for an AI-Based Scheduling, Secured Using Blockchain" Systems 12, no. 3: 84. https://doi.org/10.3390/systems12030084
APA StyleYounis, O., Jambi, K., Eassa, F., & Elrefaei, L. (2024). A Proposal for a Tokenized Intelligent System: A Prediction for an AI-Based Scheduling, Secured Using Blockchain. Systems, 12(3), 84. https://doi.org/10.3390/systems12030084