1. Introduction
The implementation of a financial security strategy was made a high priority in China’s 14th Five-Year Plan, which includes the aim to “improve financial risk prevention, early warning, handling, and accountability systems”. Frequent black swan incidents have accentuated the shocks of systemic risk on global production activities and enterprise financial stability. Thus, using systemic risk indicators to improve predictions of financial distress is of academic and practical value. Against this backdrop, it is of great practical significance to optimize the prediction model of financial distress in Chinese enterprises by combining systemic risk indicators with cutting-edge machine learning algorithms, so as to effectively warn enterprises of financial risks. This will not only help investors adjust investment strategies and assist enterprises in accurately identifying potential risks but also help regulatory agencies improve the risk monitoring and early warning mechanism in key areas, identify weak links vulnerable to systemic risk, and provide a certain reference for China to effectively improve the financial risk disposal mechanism.
China’s A-share market, as one of the largest emerging capital markets in the world, exhibits unique characteristics. Government intervention is significant, with policy changes exerting a significant influence on the market. Retail investors constitute a high proportion, leading to more emotional and volatile behaviors. Additionally, China’s A-share market faces challenges such as weak regulation, information asymmetry, and high market volatility. With China boasting the world’s only complete set of industrial categories, the development of listed industrial sector enterprises in China’s A-share market reflects the country’s industrialization process and the adjustment of its industrial structure. Other emerging economies can learn from China’s experience by focusing on the development trajectory of industrial sector enterprises, the level of support from capital markets, and government policy guidance to promote the healthy development of domestic industrial enterprises and capital markets. This, in turn, objectively promotes the development and integration of global emerging markets and fosters the healthy growth of the global economy. This underscores the unique value and significance of the development of listed industrial sector enterprises in China’s A-share market, serving as a paradigm for other emerging economy markets.
As of 2022, the listed industrial sector enterprises in China account for
of the A-share market, significantly driving GDP growth and employment stability. However, the industrial sector has faced mounting systemic risk factors due to a confluence of events, including deleveraging policies, slowing economic growth, the 2015 Chinese stock market crash, the Sino-US trade frictions, and the COVID-19 pandemic [
1,
2,
3]. These challenges have also exacerbated financial risks [
4,
5,
6]. Given the interconnectedness within the market, a widespread financial crisis in key industries could propagate risk contagion through various channels, such as technological linkages, commercial credit channels, information interconnections, and emotional spillovers, affecting other industries and potentially spreading to the entire economic and financial system [
7,
8,
9]. Hence, combining systemic risk indicators with cutting-edge machine learning algorithms to optimize financial distress early warning models in China’s industrial sector proves beneficial. This aids financial institutions and investors in early risk detection and loss mitigation. Furthermore, it assists regulatory bodies in establishing a robust multi-channel default resolution mechanism for preventing and resolving financial risks, thereby improving the credit environment in the capital market.
Financial distress prediction for businesses fundamentally falls within the realm of binary classification problems, primarily based on predictive models to classify enterprises into normal and at-risk categories. As statistical methods have evolved, predictive models for financial distress warning have continuously been updated. Beaver (1966) was the first to propose a univariate statistical model, examining the predictive capabilities of 29 financial ratios for forecasting corporate financial distress within 1 to 5 years before it occurs [
10]. In 1968, Altman (1968) introduced a multivariate Z-score model, selecting five independent variables to form the Z-score index. A Z-score below
and
indicates an enterprise’s proximity to bankruptcy and the potential for bankruptcy, respectively [
11]. Subsequently, Ohlson (1980) introduced conditional probability regression models to estimate the probability of corporate bankruptcy, addressing the limitation of Z-scores lacking economic significance [
12]. With the iterative advancement of modeling techniques, recent researchers have attempted to incorporate methods such as fuzzy set theory, Bayesian networks, survival analysis, decision trees, support vector machines, and artificial neural networks, as well as combinations of the above-mentioned approaches into corporate financial distress prediction models [
13]. These methods have further relaxed the requirements on data distribution, enhancing the accuracy and robustness of predictions.
It is worth noting that the corporate financial distress warning dataset usually exhibits a significant class imbalance, with a much larger number of normal enterprises compared to those at risk. Modeling directly with imbalanced samples would result in a bias towards the majority class, leading to a loss of model warning capability. In the context of imbalanced financial distress warning datasets, current research primarily focuses on improvements at both the data and algorithm levels. Data-level processing involves altering the class distribution in the original dataset to reduce or eliminate the imbalance, followed by constructing new models based on balanced datasets. Specific resampling methods include oversampling [
14], undersampling [
15], and hybrid sampling [
16]. Oversampling involves increasing the number of minority class samples, while undersampling reduces the number of majority class samples. Hybrid sampling combines both strategies. Resampling techniques have gained widespread application due to their simplicity and strong operability but still have notable drawbacks. Oversampling may introduce a significant amount of sample noise or lead to model overfitting due to the generation of duplicate samples. In contrast, undersampling may lead to the loss of important samples. Unlike data-level processing, algorithm-level processing aims to enhance traditional classifiers to better adapt to the specific classification requirements of imbalanced datasets. This approach can generally be categorized into cost-sensitive learning and ensemble learning. Cost-sensitive learning introduces the concept of misclassification cost, assigning higher misclassification costs to minority class samples to enhance their importance, thus addressing the problem of learning bias that traditional models may face when dealing with imbalanced datasets [
17]. Ensemble learning refers to the combination of decisions from multiple base classifiers to achieve superior performance compared to a single model. Representative techniques in this category include random forests, adaptive boosting, and gradient boosting trees algorithms [
18,
19,
20].
XGBoost, as a gradient boosting tree (GBDT)-based ensemble learning algorithm, has been increasingly applied in the field of financial distress prediction in recent years. Zieba et al. (2016) [
21] proposed a novel method utilizing an XGBoost model to predict bankruptcy events in Polish companies. Xia et al. (2017) [
22] introduced a sequence ensemble credit scoring model based on the XGBoost model, employing a Bayesian hyperparameter optimization method, the Tree-structured Parzen Estimator (TPE), to fine-tune the model’s hyperparameters. Huang et al.’s (2019) [
23] search indicated that among supervised, unsupervised, and mixed supervised-unsupervised algorithms, the XGBoost algorithm provided the most accurate financial distress predictions. Qian et al. (2022) [
24] proposed a heuristic algorithm—permutation importance (PIMP)—and found that the PIMP-XGBoost model outperformed other benchmark methods in most evaluation metrics, serving as an effective tool for corporate decision-makers. To address the performance interpretability challenge, Liu et al. (2022, 2023) [
25,
26] introduced a cost-sensitive XGBoost model for financial distress prediction. Building upon the XGBoost framework, they incorporated a weighted loss function into the cross-entropy loss function, achieving cost-sensitive financial distress prediction.
In addition to the widespread adoption of computer algorithms and models trained on imbalanced data, innovations in early warning research have also been focused on incorporating non-financial early warning indicators into predictive information sets. Early warning research, in its initial stages, primarily emphasized financial metrics of enterprises [
27]. In recent years, various non-financial metrics related to corporate operations, repayment, and other aspects have been introduced into financial distress early warning models in both academic and practical literature [
28,
29,
30]. Recent studies indicate that systemic risk, as a non-financial indicator, may have a significant impact on real economic activities, leading to a deterioration of financial indicators such as liquidity and solvency for enterprises. Consequently, this increases the probability of enterprises facing financial distress [
31]. The underlying reasons for this phenomenon are as follows: firstly, when financial markets experience risk shocks, banks often limit the scale of lending [
32], which may adversely affect the liquidity and debt-servicing capacity of certain enterprises, thus increasing their risk of facing financial distress. Secondly, the shock from systemic risk can also influence consumer behavior [
33], thereby negatively impacting the financial condition of enterprises from the demand side. Chinese enterprises often use equity collateral to secure operating capital, but a decline in stock prices triggered by systemic risk may necessitate additional margin calls [
34], leading to liquidity risk and further triggering financial distress. Therefore, the introduction of systemic risk indicators may contribute to optimizing the measurement and prediction of corporate financial risk. Jia et al. (2020), by comprehensively considering enterprise financial metrics, market performance, and systemic risk, applied a Logit model to predict future US corporate bankruptcy events [
35]. Their research results indicate that systemic risk indicators significantly enhance the predictive performance of corporate bankruptcy models. Yang et al. (2022) found that systemic risk exhibits significant predictive capabilities regarding financial distress in midstream and downstream Chinese enterprises [
36]. They demonstrated excellent performance in predicting financial distress caused by long-term losses by combining systemic risk factors with a random forest model framework.
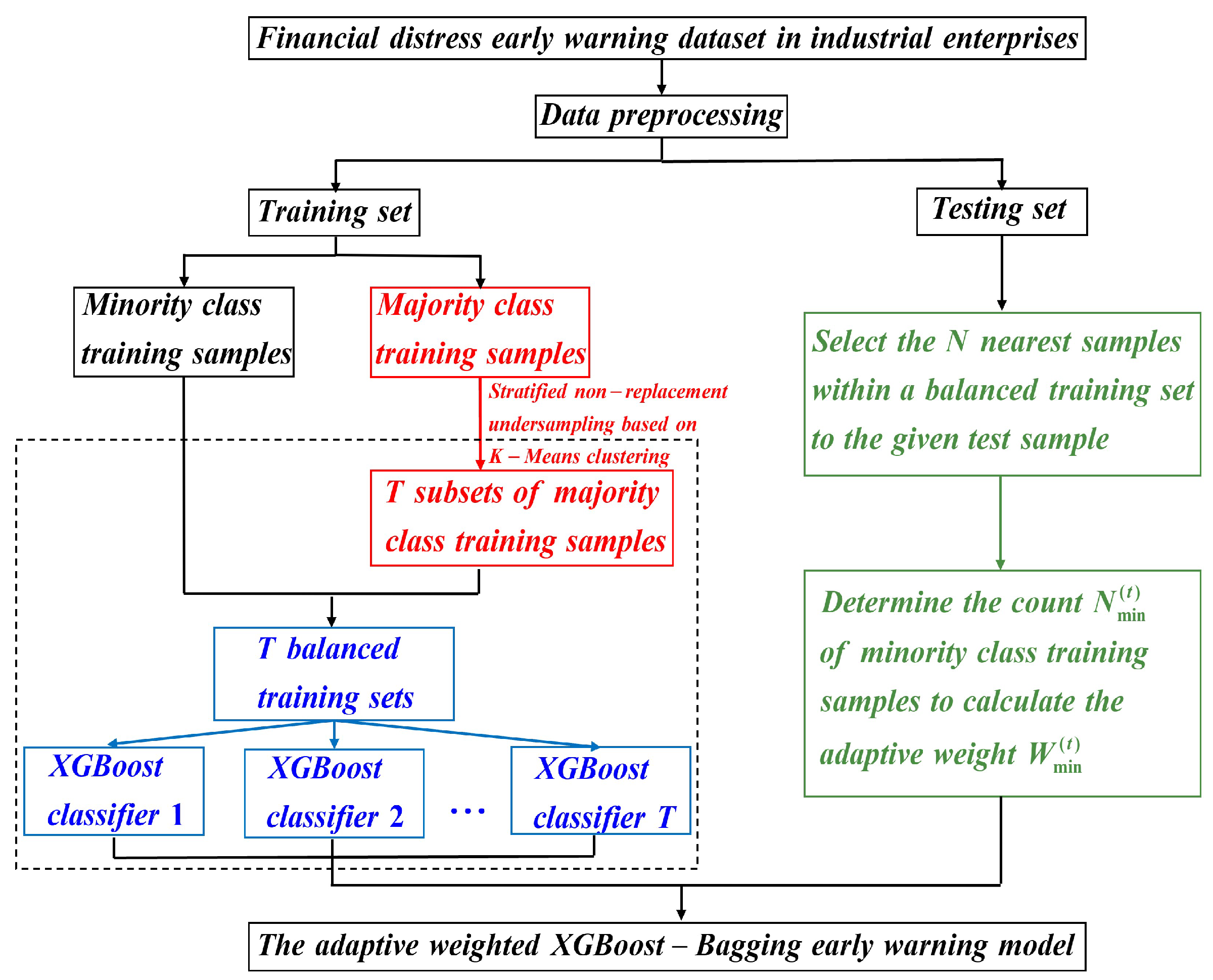
In view of this, this paper attempts to make beneficial supplements based on existing research, combining the reality of the Chinese economy to extend the accounting-systemic risk model proposed by Yang et al. (2022) [
36]. Addressing the issue of low recognition rates of financial crises in industrial sector enterprises due to imbalance in early warning data, this paper constructs an early warning model based on the adaptive weighted XGBoost-Bagging algorithm, thoroughly examining the predictive ability of systemic risk indicators for financial distress in Chinese industrial enterprises. Firstly, based on the traditional Logit regression model, this paper analyzes the linear relationship between systemic risk and the probability of financial distress in Chinese industrial enterprises. Subsequently, random forest and gradient boosting algorithms are employed to capture the nonlinear features of the relationship between systemic risk and the probability of financial distress in Chinese industrial enterprises, thereby exploring the potential of systemic risk indicators as non-financial early warning indicators for the industrial sector. Furthermore, drawing on the testing approach of Petropoulos et al. (2020) [
37], using the adaptive weighted XGBoost-Bagging model constructed in this paper, out-of-sample testing and out-of-time testing are conducted to compare and optimize the predictive models for financial distress in Chinese industrial enterprises. Through out-of-sample testing and out-of-time testing, compared to the models such as random forest used by Yang et al. (2022) [
36], the adaptive weighted XGBoost-Bagging model combined with systemic risk predicts financial distress in Chinese industrial enterprises with higher efficiency. Moreover, when considering the impact of the extreme event of the 2015 Chinese stock market crash on systemic risk in Chinese industrial enterprises, the predictive accuracy of the adaptive weighted XGBoost-Bagging model incorporating systemic risk significantly improves by comparing the predictive accuracy before and after the extreme event. This indicates that the model can better capture the significant impact of systemic risk on financial distress. Additionally, this paper proposes relevant suggestions for improving the regulation of listed companies in China and effectively warning of corporate financial distress.
3. Empirical Results and Analysis
3.1. Data Source and Sample Description
This study focuses on Chinese industrial enterprises listed on the A-share market in China between 2008 and 2022 and regards special treatment (ST or ∗ST) designation as a signal of corporate financial distress. According to regulations in the Chinese A-share market, ST stocks refer to those of enterprises that have incurred losses for two consecutive years and are subjected to special treatment, while ∗ST stocks refer to enterprises with losses for three consecutive years, warranting a delisting warning. Such enterprises often exhibit abnormal financial conditions or have already entered a distress, facing difficulties in capital turnover and an inability to meet debt obligations. Therefore, in this study, enterprises labeled as ST or ∗ST are considered to be those facing financial distress. In 2007, the Ministry of Finance of China implemented new accounting standards for business enterprises, leading to more standardized and comprehensive financial data disclosure by listed companies. Considering that it takes some time for these regulations to be effectively enforced, the research commences from the year 2008. Furthermore, in accordance with GB/T 4754-2017 Industrial Classification for National Economic Activities and China Industry Statistical Yearbook 2022, China’s industrial sector encompasses mining; manufacturing; and electricity, heat, gas, and water production and supply, identified by industry codes ranging from B06 to D46. Hence, the selection of A-share listed companies is based on these industry codes. The resulting sample comprises 509 ST enterprises and 5090 non-ST enterprises. Notably, this sample set represents an imbalanced dataset, with ST enterprises being the minority class and non-ST enterprises as the majority class.
Drawing from the methodology outlined in Tinoco et al. (2018) [
42], the study aims to forecast whether a given enterprise will undergo special treatment (ST or ∗ST) in year
t based on annual data for systemic risk indicators and financial metrics from the enterprise’s
year. To achieve this, we have selected samples of enterprises spanning 2010 to 2022, and matched their systemic risks and financial data from 2008 to 2020, resulting in the final dataset. It is important to note that all variables in the sample undergo winsorization at the 1st and 99th percentiles to address potential outliers.
In terms of systemic risk indicators, a total of 6 initial indicators have been selected, each denoted as follows: Value at Risk (VaR) as
, Conditional Value at Risk (CoVaR) as
, Change in Conditional Value at Risk (ΔCoVaR) as
, Expected Shortfall (ES) as
, Marginal Expected Shortfall (MES) as
, and Beta coefficient as
. It is important to note that VaR, CoVaR, ΔCoVaR, ES, and MES are all annual computed values at the 5th percentile. Taking inspiration from the practices outlined in Qian et al. (2022) [
24] and Liu et al. (2022) [
25] in the context of financial metrics and considering data availability, we have selected a total of 31 initial metrics from the domains of solvency, operational efficiency, profitability, growth capacity, and risk level, as detailed in
Table 2.
3.2. Dual Significance Tests for Initial Indicators
This study categorizes financially distressed ST enterprises as “1” and healthy non-ST enterprises as “0” to obtain two sets of samples. Subsequently, in order to assess the effectiveness of the initial indicators in distinguishing between ST and non-ST enterprises, dual significance tests are conducted on the two sample groups, namely, the two-sample Kolmogorov–Smirnov (K-S) test and Mann–Whitney U (MW-U) test. The two-sample K-S test aims to determine whether there is a significant difference in the distributions between the two groups, while the MW-U test examines whether there is a significant difference in the means of the two groups. The results of the dual significance tests for the initial indicators are presented in
Table 3 and
Table 4.
To ensure the rigor of the indicator selection, an indicator is only eliminated when it shows non-significance in both the K-S test and the MW-U test. According to the results of the dual significance tests, all indicators exhibit p-values less than ; thus, all indicators are retained.
3.3. Principal Components Extraction and Its Importance Analysis
Given to the advantages of composite indicators in terms of predictive power and robustness, the study draws from the methodology outlined in Nucera (2016) [
43] by employing principal component analysis (PCA) to extract pertinent information from systemic risk indicators and financial metrics, respectively. Utilizing an
cumulative variance contribution rate as the extraction criterion, we conduct PCA for dimensionality reduction on the entire dataset. For systemic risk indicators, the Kaiser–Meyer–Olkin (KMO) statistic yields a value of
, and the Bartlett sphericity test indicates a significance level of 0. Consequently, two principal components, denoted as SystemicRisk1 and SystemicRisk2, are selected, collectively contributing to a cumulative variance of
. For financial metrics, the KMO statistic yields a value of
, and the Bartlett sphericity test indicates a significance level of 0. A total of ten principal components are chosen: Accounting1, Accounting2, through Accounting10, collectively contributing to a cumulative variance of
.
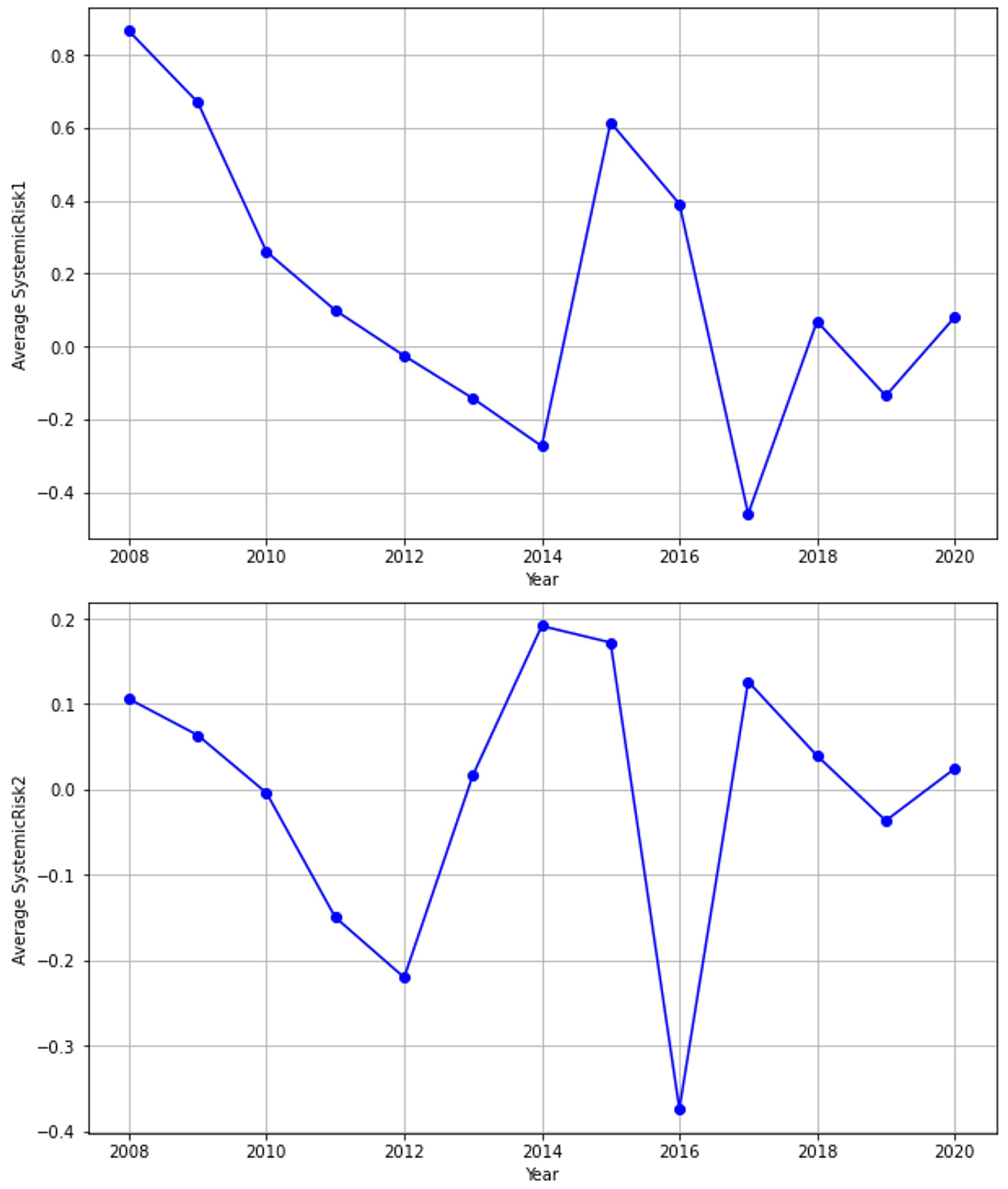
Figure 2 shows the annual averages of SystemicRisk1 and SystemicRisk2 for all industrial enterprises. In the past decade, the annual averages of SystemicRisk1 and SystemicRisk2 in 2015, 2018, and 2020 are all positive, indicating that the systemic risks in the industrial sector are relatively high in these years. This result confirms the conclusion of Yang (2020) [
44].
Subsequently, the Logit model is employed to assess the predictive capacity of systemic risk on corporate financial distress. Both columns (1) and (2) in
Table 5 illustrate that, in the absence of control variables, the coefficients for SystemicRisk1 and SystemicRisk2 are significantly positive at the
level. This suggests that systemic risk indicators demonstrate predictive potential independently of financial information, functioning as effective non-financial early warning indicators. Columns (3) and (4) of
Table 5 demonstrate that, even after incorporating control variables, the coefficients for SystemicRisk1 and SystemicRisk2 remain significantly positive at the
level. Consequently, it can be deduced that systemic risk indicators exhibit substantial predictive capability for corporate financial distress in China’s industrial sector, signifying that the influence of systemic risk enhances the likelihood of a firm encountering financial distress.
The results of the Logit regression analysis can only identify a linear association between systemic risk indicators and the probability of a corporate financial distress. In order to explore the non-linear relationships between systemic risk indicators, financial metrics, and the occurrence of corporate financial distress, the study employs Random Forest and Gradient Boosting models to calculate the relative importance of the principal components of systemic risks and financial data. This assessment aims to evaluate their explanatory capacity in predicting corporate financial distress.
Table 6 reveals that in both the Random Forest and Gradient Boosting models, SystemicRisk1, the primary component of systemic risk indicators, demonstrates relative importance values of
(ranking third) and
(ranking third), respectively. Likewise, SystemicRisk2, the secondary component of systemic risk indicators, demonstrates relative importance values of
(ranking fifth) and
(ranking fifth), respectively. This suggests that systemic risk indicators possess predictive capabilities independently of financial information, and they can serve as effective non-financial early warning indicators for China’s industrial sector.
3.4. Performance Analysis of Models Incorporating Systemic Risk Indicators
To assess the predictive performance before and after the introduction of systemic risk indicators, a random of the samples are selected as the testing dataset, while the remaining are utilized as the training dataset to construct the adaptive weighted XGBoost-Bagging model, hereafter referred to as XGBoost-Bagging. Within the framework of XGBoost-Bagging, the number of clusters K in K-Means, the quantity of XGBoost classifiers T, and the number of nearest training samples to a given test sample N are all considered as undetermined hyperparameters. Through the employment of the NSGA-II algorithm, the optimal hyperparameter combination is determined as follows: .
To thoroughly validate the predictive performance, a comparative analysis is conducted among five models: Random Forest, a model employing the Bagging technique; XGBoost, a model employing the Boosting technique; XGBoost-SMOTE, which integrates the SMOTE method for oversampling; XGBoost-KMeans, which integrates K-Means clustering for undersampling; and XGBoost-Bagging. In order to mitigate the potential bias introduced by random partitioning of the training and testing datasets, a five-fold cross-validation approach is employed.
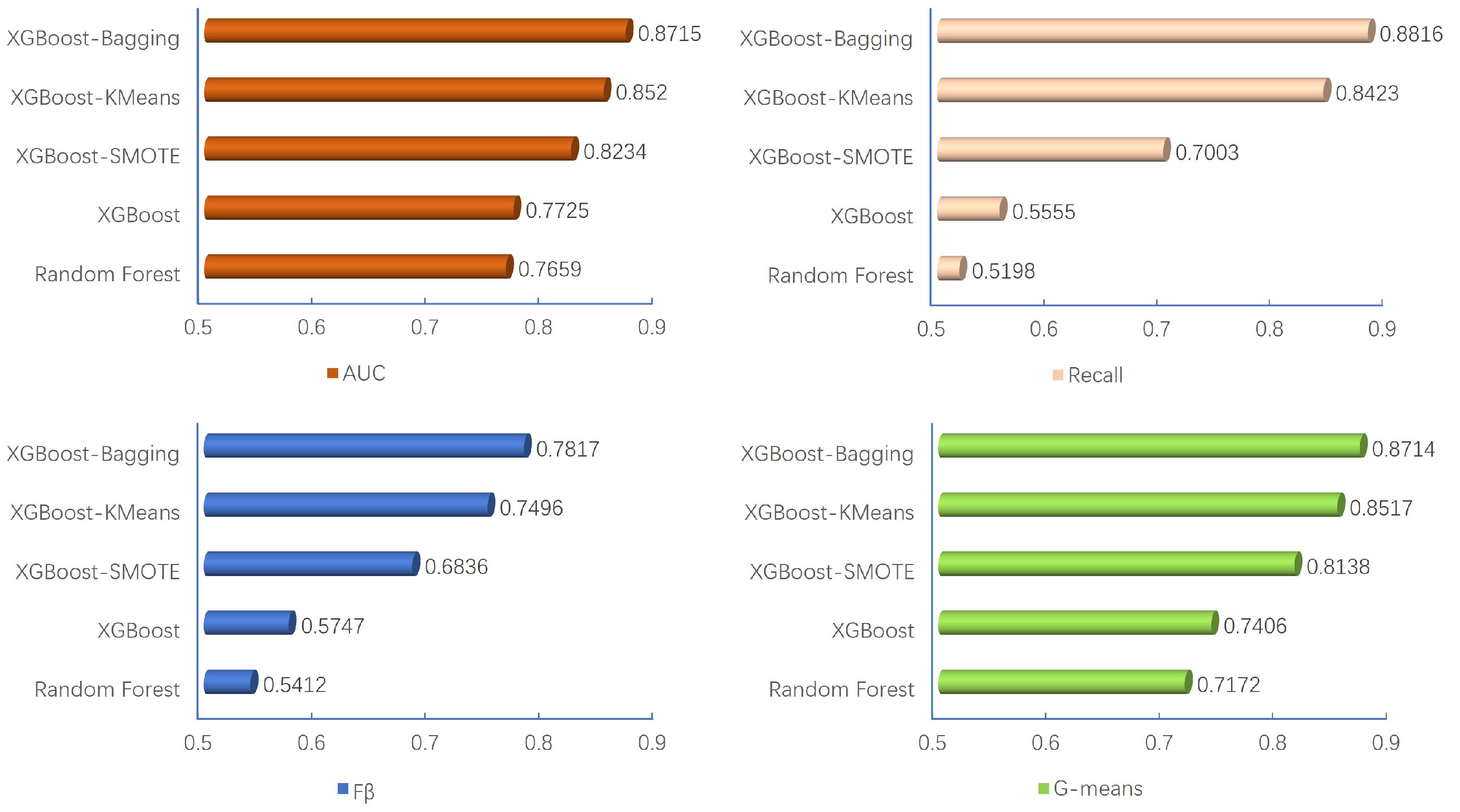
As indicated in
Table 7, upon the inclusion of systemic risk indicators, each model demonstrates notable improvements in evaluation metrics. Specifically, AUC and
G-Means exhibit an increment of approximately
to
, while Recall and
score experience enhancements of approximately
to
. These findings underscore the significant enhancement in the predictive accuracy of the early warning models when systemic risk indicators are included.
Furthermore, as illustrated in
Figure 3, from any evaluation criterion, with the inclusion of systemic risk indicators, the hierarchy of the model’s predictive performance excellence is consistently as follows: XGBoost-Bagging > XGBoost-KMeans > XGBoost-SMOTE > XGBoost > Random Forest. In the context of Recall, when compared to the Random Forest and XGBoost models without incorporating sampling methods, XGBoost-Bagging demonstrates an increase in predictive accuracy of
and
for ST enterprises, respectively. This highlights the necessity of addressing class imbalance when dealing with imbalanced sample classification problems. When compared to the XGBoost-SMOTE model, which integrates oversampling methods, XGBoost-Bagging exhibits a
enhancement in predictive accuracy for ST enterprises. This improvement can be attributed to the potential introduction of noisy information when synthesizing a large number of ST enterprise samples through oversampling, which can adversely affect the classification performance of XGBoost-SMOTE. Additionally, when compared to the XGBoost-KMeans model, which combines undersampling methods, XGBoost-Bagging yields a
increase in predictive accuracy for ST enterprises. This indicates that enhancing model diversity while undersampling can indeed improve the predictive performance for minority class samples to some extent.
The events of the 2015 Chinese stock market crash, the 2018 Sino-US trade friction, and the 2020 COVID-19 pandemic led to a substantial increase in systemic risks in China’s industrial sector. Subsequent to these critical time points, financial distress in industrial enterprises became more prevalent. Consequently, drawing inspiration from the testing approach proposed by Petropoulos (2020) [
37], we conduct out-of-sample tests based on these time points to analyze the predictive efficacy of XGBoost-Bagging for financial distress events in industrial enterprises two years later (i.e., in 2017, 2020, and 2022), with the financial distress events in 2016 serving as a reference. Specifically, for 2016, we use samples preceding that year as the training set and samples from 2016 as the testing set to construct the XGBoost-Bagging model. Similar procedures were applied for 2017, 2020, and 2022. To ensure robust results, we repeat the process of constructing and predicting with XGBoost-Bagging 100 times and then compute the mean of accurate predictions and the mean of Recall for ST enterprises within these respective years. The results are presented in
Table 8.
According to
Table 8, in the year 2017, there were a total of 25 ST industrial enterprises. The XGBoost-Bagging, when incorporating systemic risk indicators, can accurately predict an average of 24.9 ST industrial enterprises, resulting in Recall of
. Compared to the XGBoost-Bagging without the inclusion of systemic risk indicators, there is an average reduction of
misclassified ST industrial enterprises, leading to a
increase in Recall. Similarly, with the introduction of systemic risk, the recall rates for XGBoost-Bagging in 2020 and 2022 increased by
and
, respectively. This outcome clearly established that the inclusion of systemic risk indicators in the framework of the adaptive weighted XGBoost-Bagging model significantly enhances its efficacy in identifying high-risk industrial enterprises.
Furthermore, when comparing the recall rate improvements in 2016 after introducing systemic risk to those in 2017, 2020, and 2022, there is a relatively smaller increase of . This indicates that as systemic risk intensifies, the efficiency of XGBoost-Bagging, incorporating systemic risk, when predicting financial distress in industrial enterprises two years later, becomes more pronounced.



{kind=link}
{kind=link}
{kind=link}