
Modelling and Intelligent Decision of Partially Observable Penetration Testing for System Security Verification


Abstract
1. Introduction
- Formalising the penetration testing process as a partially observable Markov decision process, allowing the exploration and study of observational locality and observational uncertainty in adversarial scenarios. This approach is more in line with the realities of the “fog of war” and the subjective decision process based on observations in the field of intelligent decision.
- To address the new uncertainty challenges posed by partially observable conditions, an intelligent penetration path decision method based on the combination of deep reinforcement learning and recurrent neural networks is proposed. This method enhances the learning capability of sequential attack experience under partially observable conditions.
2. Related Works
3. Problem Description and Theoretical Analysis
4. Methodology
4.1. POMDP Modelling
4.1.1. State Modelling
- Topological location information: Topological location information includes subnet identifiers and host identifiers. For the scenario in Figure 1, the capacity of the subnet identifier field can be set to 4 and the capacity of the host identifier field can be set to 5. Thus, the dimension of the topological location field is 9, with the first 4 dimensions identifying the subnet in which the target host is located, and the remaining 5 dimensions identifying the location of the host within the subnet. For example, the topological location encoding for the honeypot host (3,2) is (0010 00100).
- Compromised state information: Compromised state information is encoded by a 6-dimensional vector, including whether compromised, accessible, discovered, compromise reward, discovery reward, and compromised privileges (user or root).
- Operating system, service, and process information: These three categories of information are closely related to vulnerabilities and attack methods. In the scenario shown in Figure 1, the target host is configured with 2 types of operating systems, 3 types of services, and 2 types of processes, as shown in Table 1. Of course, based on the requirements of a particular scenario, this can be extended to more detailed types, such as adding software version numbers to identify Windows 7 and Windows 10 as two different types of operating systems, corresponding to a more dimensional encoding field for operating systems. This can be more useful for detailed mapping of vulnerabilities and attack methods. Common Vulnerabilities and Exploits (CVEs) [18] and Common Attack Pattern Enumeration and Classification (CAPEC) [19] can be introduced to identify these mappings. Using the honeypot host (3,2) as an example, the operating system is encoded as (01), the service is encoded as (101), and the process is encoded as (01).
4.1.2. Action and Reward Modelling
4.1.3. Partially Observable Condition Modelling
- Observational locality. Observational locality means that the information obtained by the PT agent about the target network or host is only related to the current action and does not make any assumptions about global perspectives. With this in mind, we define the information acquisition capability for each attack action type by local observation items h. Each attack action can only obtain information about the target host associated with the corresponding local observation item. For example, the privilege escalation action PE, depending on whether the escalation is successful, encodes new host information with an updated compromised privileges field and adds it to the observation trajectory . On the other hand, the subnet scan action subnet_scan may add several newly discovered h, depending on how many hosts are discovered. That is, each POMDP state s contains a collection of n local observation items h. The observation trajectory is recorded sequentially.Since we use one-hot encoding for host information (see Section 4.1.1), the merging of multiple local observation items does not cause confusion. This modelling approach helps to shield the influence of global information on the dimensions of observation states, making the algorithm more scalable.
- Observational uncertainty. Observational uncertainty refers to the fact that the observations obtained by the PT agent may not be accurate. In this paper, we model this observational uncertainty by introducing random changes to the target fields of the local observation items h. A Partially Observable Module (PO Module) is designed to introduce random changes to certain fields of the observation state with a certain probability . The pseudocode for the PO Module is shown in Algorithm 1. We define a field-specific random change strategy for each type of attack. For example, we introduce random changes to the compromised privileges field of the compromised state information for the privilege escalation action PE, and introduce random changes to the topological location field for the subnet scan action subnet_scan.
| Algorithm 1 Partially Observable Module |
| Input: Action a, Actual state , Observational Uncertainty Factor Output: Observation state
|
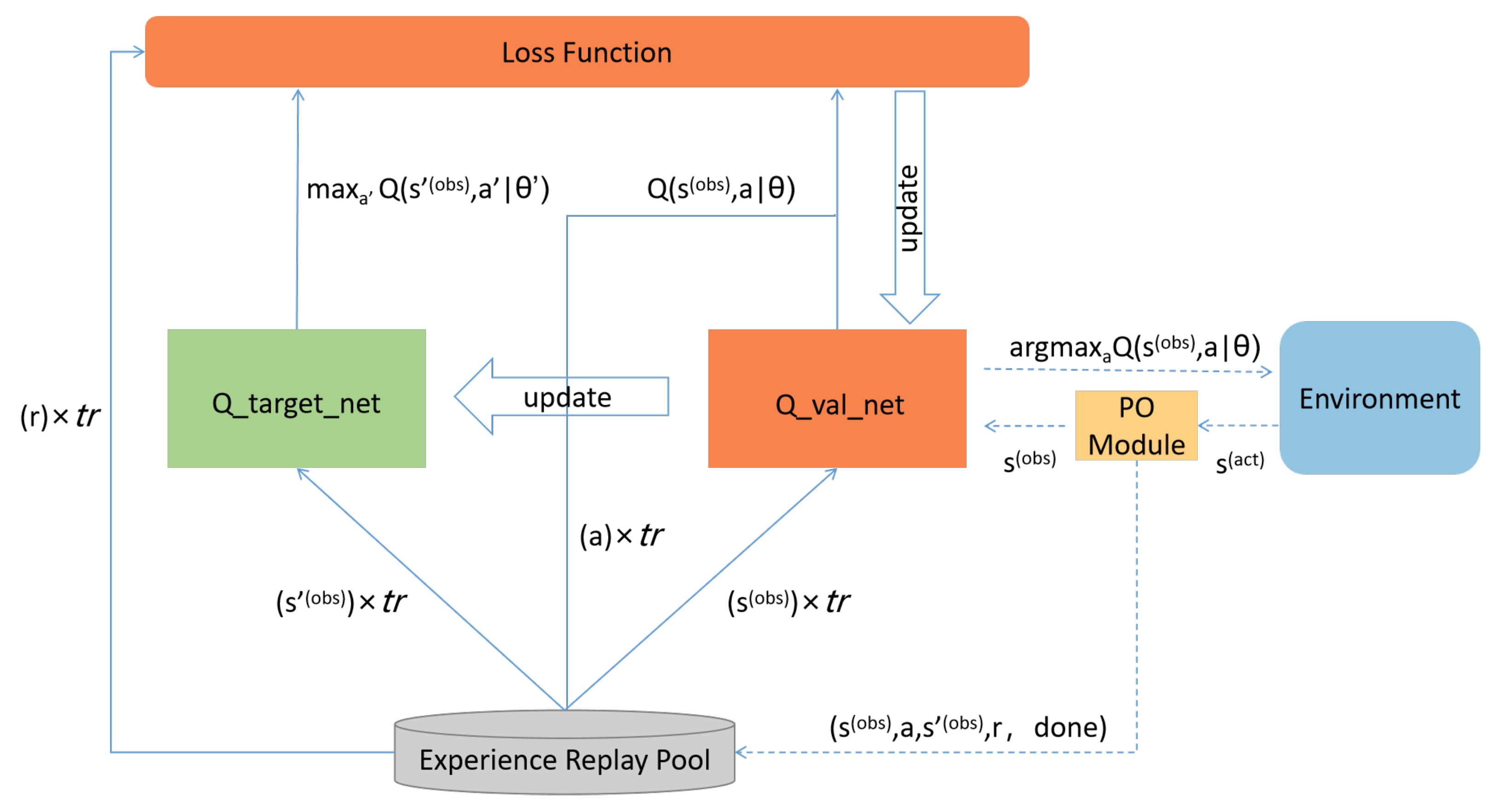
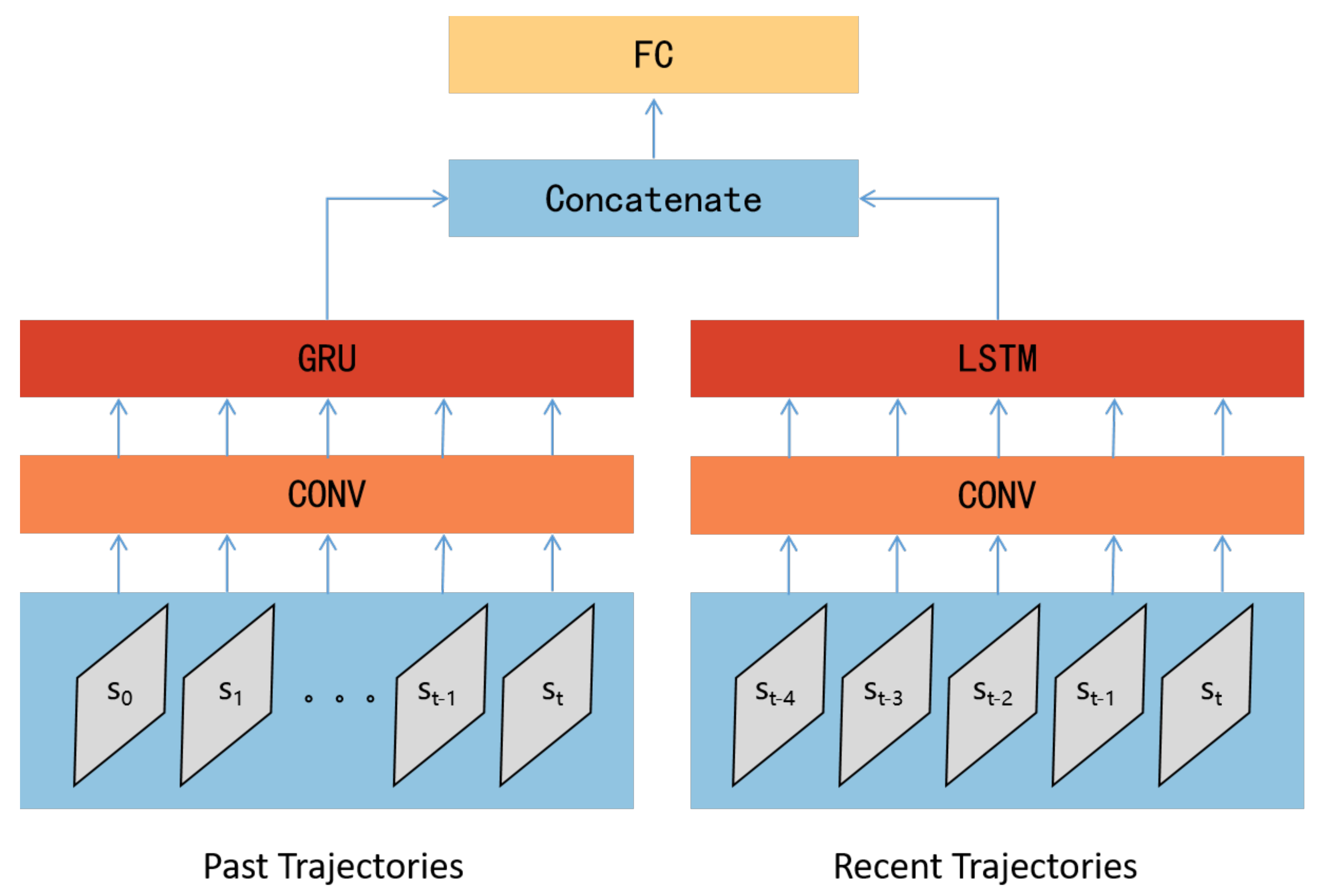
4.2. PO−IPPD Method
| Algorithm 2 Memory_Func |
| Input: Experience Replay Pool M, Memory Pointer , Observation state , Action a, Next Observation state , Reward r, Success Indicator Output: Experience Replay Pool M
|
| Algorithm 3 Sampling_Func |
| Input: Experience Replay Pool M, Sampling Size Output: Observation state sample , Action sample , Next Observation state sample , Reward sample , Success Indicator sample
|
| Algorithm 4 PO−IPPD training algorithm |
| Input: Experience Replay Pool M, Training Episodes N, Exploration Rate , Target Network , Evaluation Network Output: Target Network
|
5. Experiment and Discussion
- RQ1: Does the lack of global observation capability indeed have a negative impact on penetration testing, and does the proposed PO−IPPD method have the ability to mitigate this negative impact?
- RQ2: Does the proposed PO−IPPD have scalability within different network scales?
- RQ3: How can we evaluate the impact and contribution of each component in the model on PO−IPPD performance?
5.1. Experiment Environment
- The addition of a Partial Observation Module to simulate observational locality and observational uncertainty as described in Section 4.1.3 and Algorithm 1.
- Modifications are made to the experience replay pool, as in Algorithms 2–4, adding trajectory experience records for the PO−IPPD method.
- Average Reward (Reward): The total reward value is calculated for each episode to assess the economic cost of penetration, including the sum of all action rewards and action costs. The average is calculated every 500 episodes.
- Average Steps (Steps): The number of attack steps required for successful penetration in each episode is calculated to assess the time cost of penetration. Similarly, the average is calculated every 500 episodes.
- Average Reward per Step (Reward/Step): The average reward per step is calculated to assess the average penetration efficiency. It is derived from the average episode reward (Reward) and the average episode steps (Steps).
- Average Loss (Loss): The value of the loss function (Formula (3)) in each episode is calculated to assess the relationship between the training process and the state of convergence. Similarly, the average is calculated every 500 episodes.
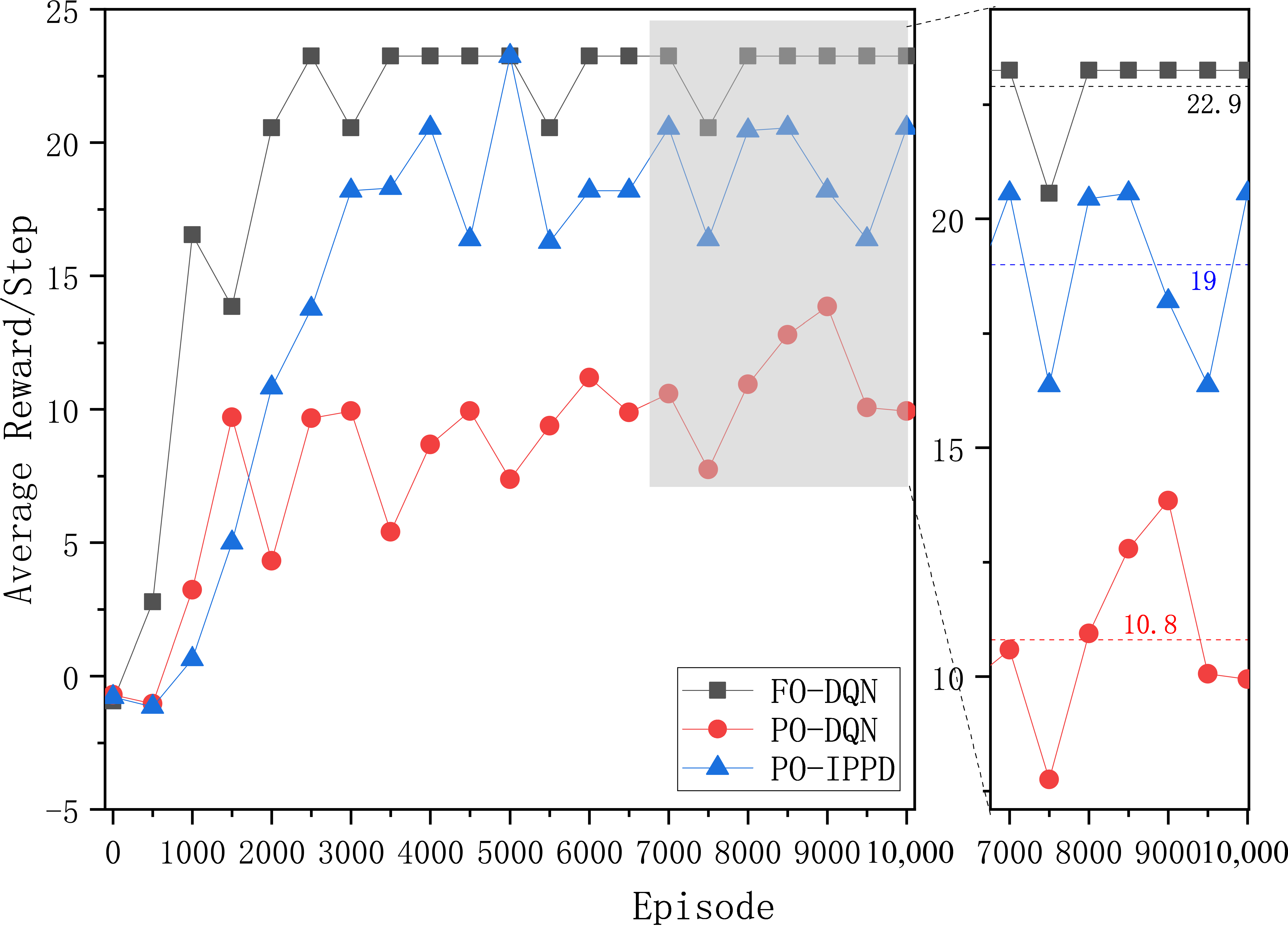
5.2. Functional Effectiveness Experiment for Answering RQ1
- By comparing the performance of FO-DQN and PO-DQN, it can be validated if the lack of global observation capability does indeed have a negative impact on penetration testing.
- By comparing the performance of PO-DQN and PO−IPPD, it can be validated if our enhancements to DQN can effectively mitigate the negative impact of partially observable conditions on penetration test decision.
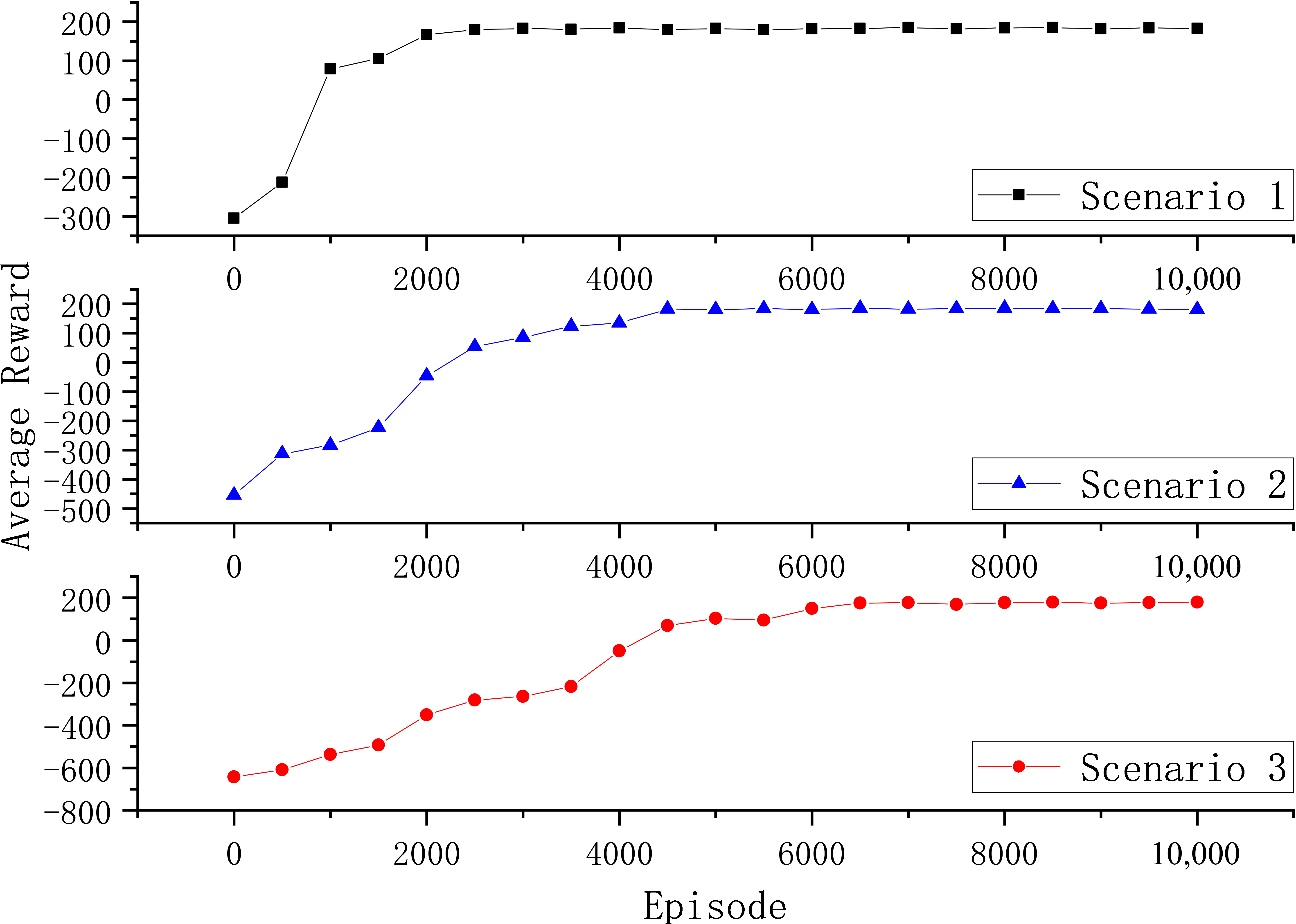
5.3. Scalability Experiment for Answering RQ2
5.4. Ablation Experiment for Answering RQ3
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alhamed, M.; Rahman, M.M.H. A Systematic Literature Review on Penetration Testing in Networks: Future Research Directions. Appl. Sci. 2023, 13, 6986. [Google Scholar] [CrossRef]
- Greco, C.; Fortino, G.; Crispo, B.; Choo, K.-K.R. AI-enabled IoT penetration testing: State-of-the-art and research challenges. Enterp. Inf. Syst. 2023, 17, 2130014. [Google Scholar] [CrossRef]
- Ghanem, M.C.; Chen, T.M.; Nepomuceno, E.G. Hierarchical reinforcement learning for efficient and effective automated penetration testing of large networks. J. Intell. Inf. Syst. 2023, 60, 281–303. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, T.; Zhu, J.; Wang, Q. Domain-Independent Intelligent Planning Technology and Its Applicaion to Automated Penetration Testing Oriented Attack Path Discovery. J. Electron. Inf. Technol. 2020, 42, 2095–2107. [Google Scholar]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Spaan, M.T.J. Partially observable Markov decision processes. In Reinforcement Learning: State-of-the-Art; Springer: Berlin/Heidelberg, Germany, 2012; pp. 387–414. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Ghojogh, B.; Ghodsi, A. Recurrent neural networks and long short-term memory networks: Tutorial and survey. arXiv 2023, arXiv:2304.11461. [Google Scholar]
- Wang, Y.; Li, Y.; Xiong, X.; Zhang, J. DQfD-AIPT: An Intelligent Penetration Testing Framework Incorporating Expert Demonstration Data. Secur. Commun. Netw. 2023, 2023, 5834434. [Google Scholar] [CrossRef]
- Schwartz, J.; Kurniawati, H. Autonomous penetration testing using reinforcement learning. arXiv 2019, arXiv:1905.05965. [Google Scholar]
- Zhou, S.; Liu, J.; Zhong, X.; Lu, C. Intelligent Penetration Testing Path Discovery Based on Deep Reinforcement Learning. Comput. Sci. 2021, 48, 40–46. [Google Scholar]
- Nguyen, H.V.; Teerakanok, S.; Inomata, A.; Uehara, T. The Proposal of Double Agent Architecture using Actor-critic Algorithm for Penetration Testing. In Proceedings of the 7th International Conference on Information Systems Security and Privacy, Vienna, Austria, 11–13 February 2021; pp. 440–449. [Google Scholar]
- Zeng, Q.; Zhang, G.; Xing, C.; Song, L. Intelligent Attack Path Discovery Based on Hierarchical Reinforcement Learning. Comput. Sci. 2023, 50, 308–316. [Google Scholar]
- Schwartz, J.; Kurniawati, H.; El-Mahassni, E. Pomdp+ information-decay: Incorporating defender’s behaviour in autonomous penetration testing. In Proceedings of the International Conference on Automated Planning and Scheduling, Nancy, France, 14–19 June 2020; Volume 30, pp. 235–243. [Google Scholar]
- Sarraute, C.; Buffet, O.; Hoffmann, J. Penetration testing== POMDP solving? arXiv 2013, arXiv:1306.4714. [Google Scholar]
- Shmaryahu, D.; Shani, G.; Hoffmann, J.; Steinmetz, M. Partially observable con-tingent planning for penetration testing. In Proceedings of the Iwaise: First International Workshop on Artificial Intelligence in Security, Melbourne, Australia, 20 August 2017; Volume 33. [Google Scholar]
- Mairh, A.; Barik, D.; Verma, K.; Jena, D. Honeypot in network security: A survey. In Proceedings of the 2011 International Conference on Communication, Computing & Security, Odisha, India, 12–14 February 2011; pp. 600–605. [Google Scholar]
- Common Vulnerabilities and Exploits. Available online: https://cve.mitre.org/ (accessed on 28 November 2024).
- Common Attack Pattern Enumeration and Classification. Available online: https://capec.mitre.org/ (accessed on 28 November 2024).
- Common Vulnerability Scoring System. Available online: https://www.first.org/cvss/v4.0/specification-document (accessed on 28 November 2024).
- Backes, M.; Hoffmann, J.; Kunnemann, R.; Speicher, P.; Steinmetz, M. Simulated Penetration Testing and Mitigation Analysis. arXiv 2017, arXiv:1705.05088. [Google Scholar]
- Rabinowitz, N.; Perbet, F.; Song, F.; Zhang, C.; Eslami, S.M.A.; Botvinick, M. Machine theory of mind. In Proceedings of the International Conference on Machine Learning. PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4218–4227. [Google Scholar]
- Chowdhary, A.; Huang, D.; Mahendran, J.S.; Romo, D.; Deng, Y.; Sabur, A. Autonomous security analysis and penetration testing. In Proceedings of the 2020 16th International Conference on Mobility, Sensing and Networking (MSN), Tokyo, Japan, 17–19 December 2020; pp. 508–515. [Google Scholar]
- Zhou, S.; Liu, J.; Hou, D.; Zhong, X.; Zhang, Y. Autonomous penetration testing based on improved deep q-network. Appl. Sci. 2021, 11, 8823. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Host | OS | Service | Process |
|---|---|---|---|
| (1,0) | Linux | HTTP | — |
| (2,0) (4,0) | Linux | SSH, FTP | Tomcat |
| (3,0) (3,3) | Windows | FTP | — |
| (3,1) (3,2) | Windows | FTP, HTTP | Daclsvc |
| (3,4) | Windows | FTP | Daclsvc |
| Type | Name | Prerequisites | Results | |||
|---|---|---|---|---|---|---|
| OS | Service | Process | Prob | Privileges | ||
| VE | E_SSH | Linux | SSH | — | 0.9 | User |
| E_FTP | Windows | FTP | — | 0.6 | User | |
| E_HTTP | — | HTTP | — | 0.9 | User | |
| PE | P_Tomcat | Linux | — | Tomcat | 1 | Root |
| P_Daclsvc | Windows | — | Daclsvc | 1 | Root | |
| Type | Settings |
|---|---|
| CONV1: | |
| Kernel_size=3;Stride=1;Outchannels=16 | |
| Conv Structure | CONV2: |
| Kernel_size=3;Stride=1;Outchannels=32 | |
| AdaptiveAvgPool1d: | |
| output_size=1 | |
| GRU | Input=32;Hidden_size=64 |
| LSTM | Input=32;Hidden_size=64 |
| FC1: | |
| FC Structure | In_features:128,Out_features:64 |
| FC2: | |
| In_features:64,Out_features:action_space | |
| Learn Rate | 0.0001 |
| Batch_size | 64 |
| M.size | 100,000 |
| Discount factor | 0.9 |
| Method capacity | 4-dimension subnet field |
| 5-dominion host field |
| Scenarios | Hosts | Subnets | Reward |
|---|---|---|---|
| Scenario 1 | 8 | 4 | 100 × 2 |
| Scenario 2 | 16 | 4 | 100 × 2 |
| Scenario 3 | 16 | 8 | 100 × 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Zhang, Y.; Li, W.; Gu, W. Modelling and Intelligent Decision of Partially Observable Penetration Testing for System Security Verification. Systems 2024, 12, 546. https://doi.org/10.3390/systems12120546
Liu X, Zhang Y, Li W, Gu W. Modelling and Intelligent Decision of Partially Observable Penetration Testing for System Security Verification. Systems. 2024; 12(12):546. https://doi.org/10.3390/systems12120546
Chicago/Turabian StyleLiu, Xiaojian, Yangyang Zhang, Wenpeng Li, and Wen Gu. 2024. "Modelling and Intelligent Decision of Partially Observable Penetration Testing for System Security Verification" Systems 12, no. 12: 546. https://doi.org/10.3390/systems12120546
APA StyleLiu, X., Zhang, Y., Li, W., & Gu, W. (2024). Modelling and Intelligent Decision of Partially Observable Penetration Testing for System Security Verification. Systems, 12(12), 546. https://doi.org/10.3390/systems12120546