
Systemic Modeling and Prediction of Port Container Throughput Using Hybrid Link Analysis in Complex Networks


Abstract
1. Introduction
2. Literature Review
3. Methods
3.1. Theory of Complex Networks
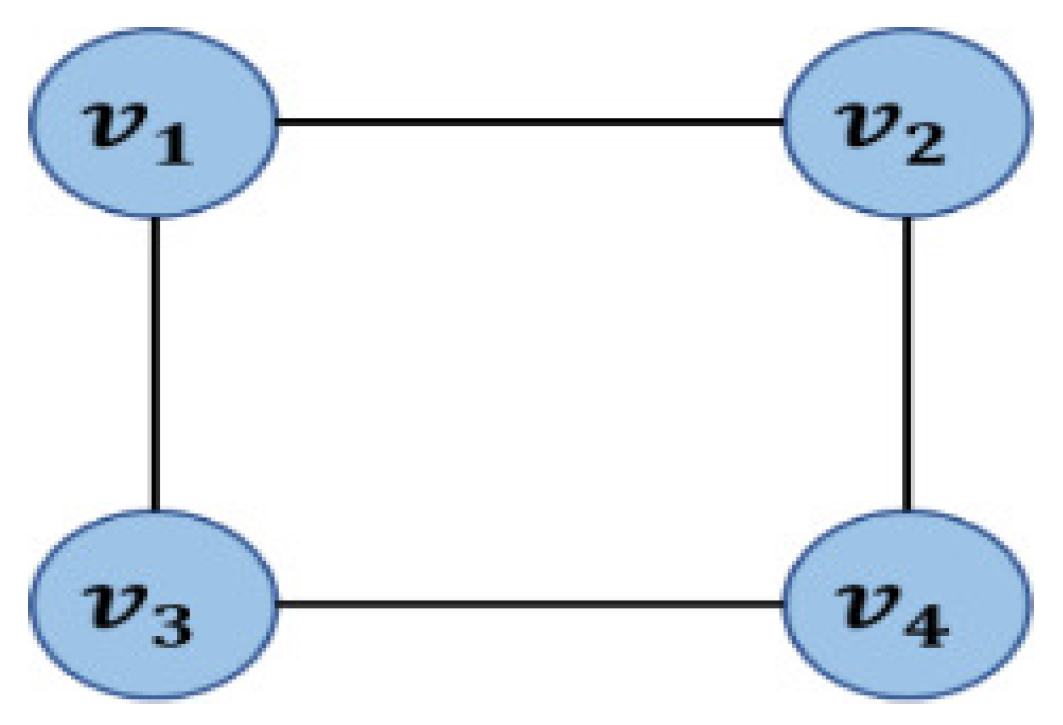
3.1.1. Complex Networks and Their Topological Properties
- (1)
- The Degree
- (2)
- Average Degree
- (3)
- Average Path Length
- (4)
- Clustering Coefficient
3.1.2. Visual Graph Algorithm
- (1)
- Connectivity: Every node is viewable to at least its closest neighbors, forming an interconnected network;
- (2)
- Undirectedness: Links are not directed;
- (3)
- Stability: If the horizontal and vertical coordinates of the time series are scaled, the principle of visibility remains unchanged.
3.2. Concepts of Link Prediction
3.2.1. Description of Link Prediction Problem
3.2.2. Measurement of Network Structural Similarity
- (1)
- Index: The similarity between two nodes is defined as the number of shared neighbors between the two nodes [15]. This index defines the similarity function as follows:where represents the set of common neighbors between node and node , and the symbol denotes the number of elements in a set;
- (2)
- Index: This similarity measure aims to quantify the similarity between two entities based on their shared features [16]. If we consider neighbors as features, it can be expressed as:where represents the set of common neighbors between node and node , | is the number of common neighbors , and the logarithmic function is used to reduce the weight of nodes with a large number of neighbors;
- (3)
- Index: The idea behind such an index is to compare the challenge of creating connections inside a network to the process of allocating resources [17]. It simulates the transfer of resources between two disconnected nodes and through neighboring nodes. The similarity function is expressed as:where represents the set of common neighbors between node and node , and is the number of common neighbors ;
- (4)
- Index: This index is based on the assumption that new connections in the network are more likely to occur between nodes that already have a higher number of connections. According to this assumption, a likelihood score is derived for the existence of a link between two nodes [18]. The similarity is defined as:where and are the degrees of nodes and , respectively;
- (5)
- Index: This frequently used coefficient is used to compare the variety and similarity of sample sets in information retrieval systems [19]. It calculates the proportion of unique neighbors in two nodes’ combined neighborhoods to the common neighbors between them. It is defined as:where is the number of common neighbors between node and node , and is the total number of neighbors for both nodes;
- (6)
- Index: This index was introduced to address modularity in metabolic networks, characterized by a hierarchical structure where interconnected modules are isolated from each other [20]. The primary objective of this similarity measure is to discourage link formation between hub nodes while encouraging link formation between low-degree nodes. The specific definition of the index is not provided in the given context. It is defined as:
- (1)
- Local Random Walk () Index: is a technique based on random walks, simulating a random walker starting from a source node and moving to neighboring nodes with a certain probability, continuing until a specific number of steps or conditions are met. The walker records the sequence of nodes traversed, typically considering only nodes reached within a certain number of steps. It is defined as:where and represent the number of common neighbors of nodes and , is the total number of edges in the network, denotes the probability of visiting node at step , and is the probability of visiting node at step ;
- (2)
- Superimposed Random Walk () Index: This index considers the degree of overlap between random walk paths between two nodes [21]. This behavior can be captured by summing the contributions of each walker as follows:
- (3)
- Index: Just like the Local Path Index, is a quasi-local metric based on path counts between nodes of interest [22]. This method incorporates normalization and additional path-length penalty mechanisms. The similarity between two nodes and is calculated as follows:where is the path length, is the maximum path length, represents the number of paths of length from node to node , and represents the total number of nodes in the graph.
- (1)
- Index: This measure penalizes longer paths according to their length by adding up the influence of all feasible paths between two nodes [23]. It is defined as:where is the set of paths of length between nodes and , and is the decay factor corresponding to these path lengths, satisfying 0 < < 1;
- (2)
- The Average Commute Time () Index: This measure represents the average number of steps needed for a random walker to start at node i, go to node j, and then return to node i. It has the following definition:where is the graph’s overall number of nodes, is the th non-zero eigenvalue of the Laplacian matrix, and and are components of the eigenvector corresponding to the th eigenvalue for nodes and , respectively;
- (3)
- Index: In addition to the number of shared neighbors, the degree of those neighbors also influences the probability of an edge living among both two nodes. The following is the computation formula:
- (4)
- Index: The main concept of this index is to construct a “matching forest”, which is a set of node pairs that exist in both graphs and exhibit similar connection patterns. The following is the calculating formula:where stands for the identity matrix, and represents the Laplacian matrix.
3.2.3. Link Prediction Considering Second-Order Path Information
3.3. The Maximum Relevance Minimum Redundancy Algorithm
3.4. Artificial Intelligence Algorithms
3.4.1. Support Vector Machine (SVM)
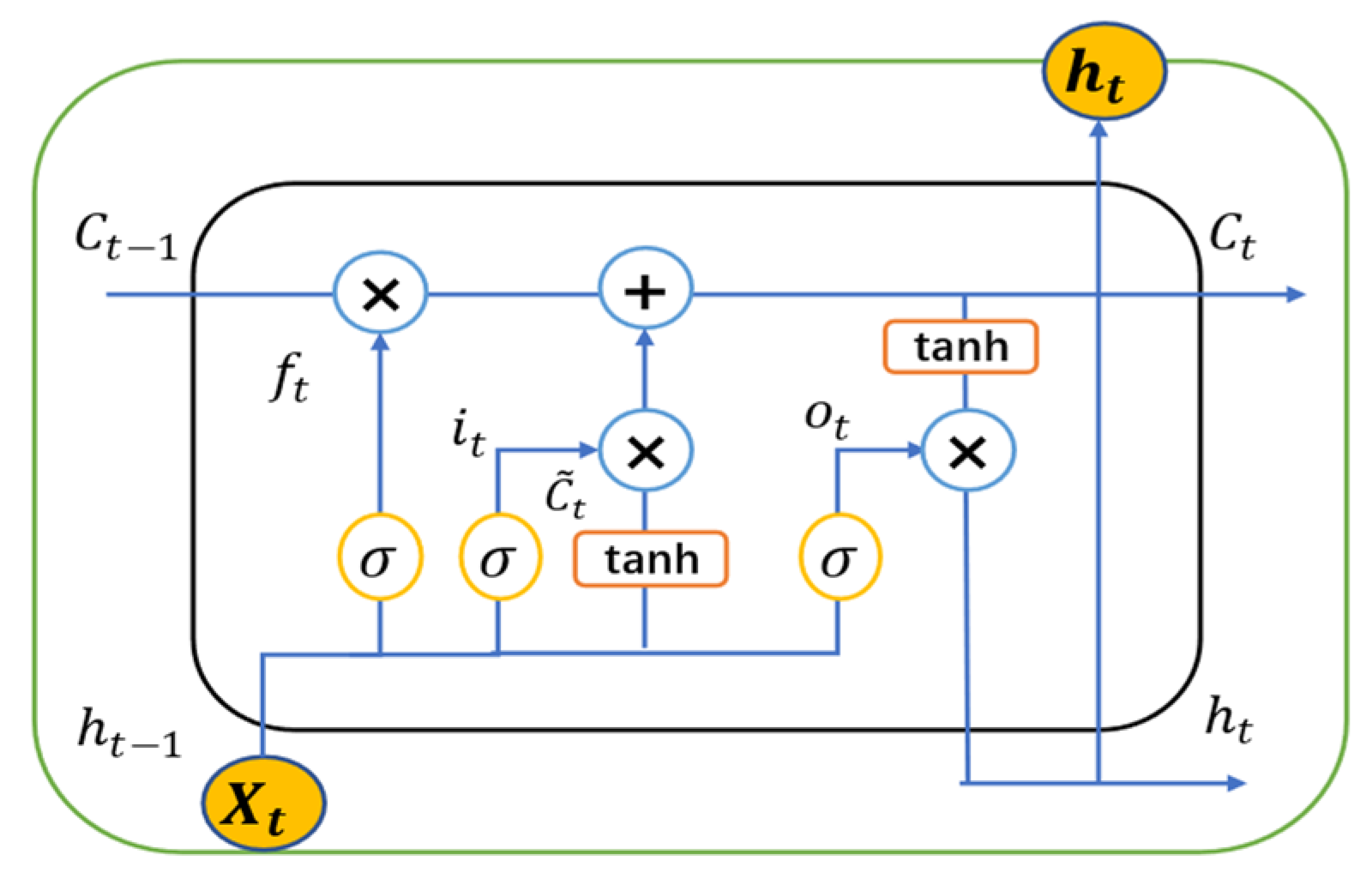
3.4.2. Long Short-Term Memory (LSTM)
- (1)
- The forget gate is a key component of the LSTM model, and its primary role is to control the memory storage within the network to better handle long sequential information. The forget gate first linearly transforms the output from time with the input at time . It then uses a sigmoid activation function to map the output to the [0, 1] interval, indicating the degree of forgetting the previous time step’s memory state. When the output of the forget gate is close to 1, the memory state from time is fully retained. When the forget gate’s output is nearly 0, the memory state from time is completely forgotten. The formula for the forget gate is:
- (2)
- The input gate is used to determine which information from the input data will be passed to the subsequent time step at the previous time step. The input gate uses the same calculating technique as the forget gate. The formula for the input gate is:
- (3)
- The state unit of LSTM is an important internal variable used to store information at time t and is updated through the control of the forget gate, input gate, and output gate. The formula for calculating the internal state at the current time step is:
- (4)
- The output gate of the LSTM model is used to determine which information will be transmitted to the next time step. The output gate is made up of a multiplication of elements and a sigmoid activation function. The function of sigmoid responsible for determining the information to be output, while the element-wise multiplication regulates the importance of other information in the output state. Therefore, the output gate controls which information is passed to the output. The formula for the output gate is:where is the Sigmoid activation function, is the hyperbolic tangent function, , , and are the weight matrices for the respective layers, represents the concatenation of the previous time step’s output and the current time step’s input , is the internal state at time , is the internal state at time , is the forget gate, is the input gate, and is the input state at time .
3.4.3. Deep Neural Network (DNN)
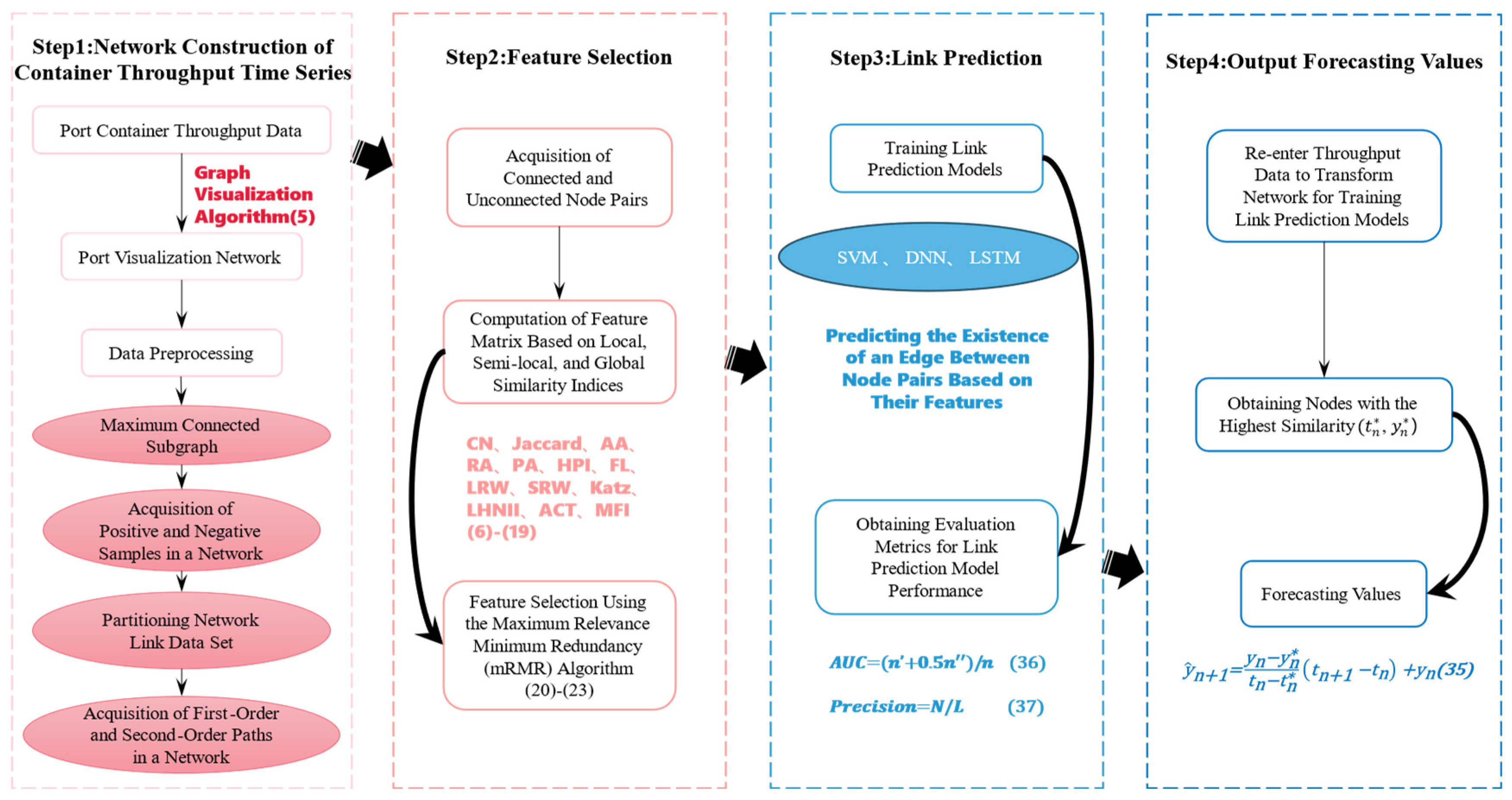
3.5. Overall Prediction Framework
- (1)
- Network construction of container throughput time series: Initially, the port container throughput time series is transformed into a corresponding visual graph network using the visual graph algorithm (as shown in Equation (5)) in complex networks. The monthly dataset of port container throughput is examined to examine the network’s topological properties, including clustering coefficient and network diameter. Subsequently, the link dataset is partitioned based on the transformed visual graph network, and first-order and second-order path information of the corresponding network’s largest connected component is obtained;
- (2)
- Feature selection: Connected and unconnected node pairs are extracted from the obtained network. Thirteen similarity metrics, proposed from the perspectives of local, semi-local, and global network structural similarity (as shown in Equations (6)–(18)), are used as the feature set for complex networks. Feature selection is performed using the Maximum Relevance Minimum Redundancy method to extract properties of the structural network and capture latent information within the network (as shown in Equations (20)–(23));
- (3)
- Link Prediction: The selected features are used as inputs for training SVM, DNN, and LSTM models to perform link prediction. This means predicting whether there is an edge (1 for existence, 0 for non-existence) between each pair of nodes based on their features;
- (4)
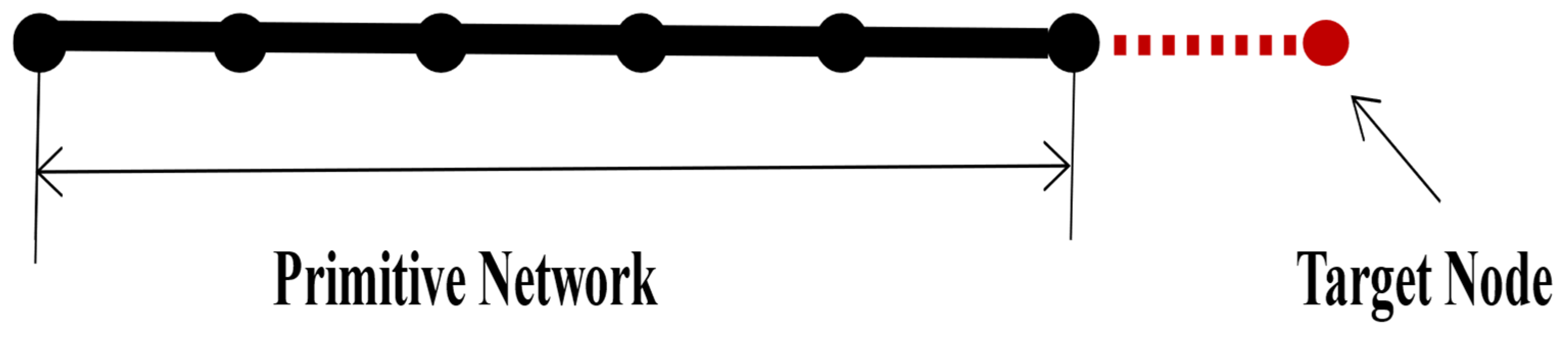
- Output Prediction Values: Based on the predicted target node and the similarity to other nodes, the node with the highest similarity, denoted as (), is added to the network. In this process, one edge is connected to the last node in the network (as adjacent nodes are connected in the visual graph algorithm). In Figure 6, as shown by the red dashed line, the target node is linked to the last node to be incorporated into the network. Another edge links the node () to the node. For example, in Figure 7, the 3rd node (highest similarity node) is linked to the 6th node via the red dashed line, and the green solid line indicates that the 7th node is determined by the 3rd and 6th nodes (adjacent nodes). To avoid using nodes that could produce inaccurate estimations, the nodes with the highest similarity are selected to anticipate future throughput [28]. Time series (, ) are predicted using Equation (35) and are then compared with other algorithms.
4. Empirical
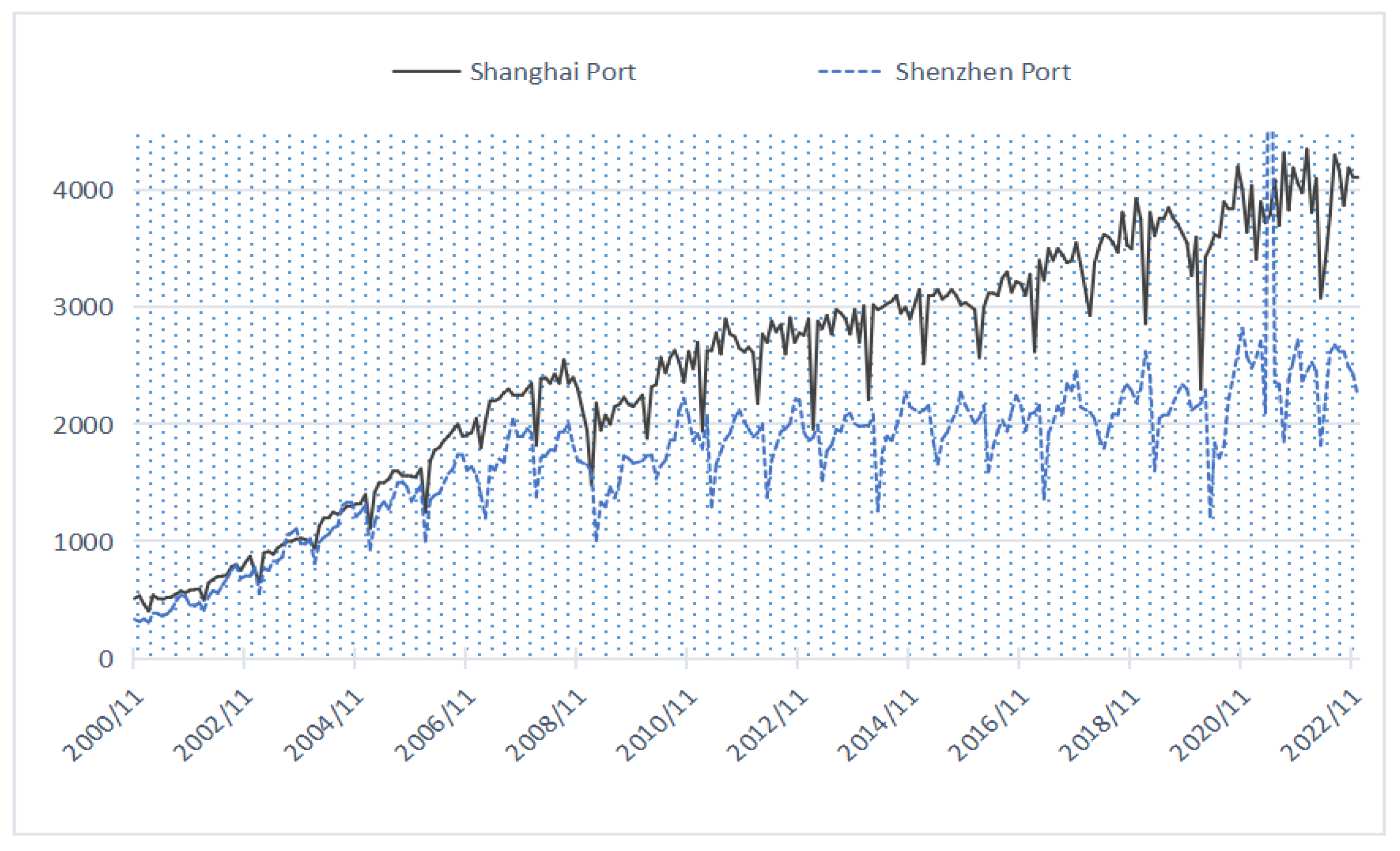
4.1. Data Description
4.2. Experimental Setup
4.3. Performance Metrics
4.4. Results and Analysis
4.4.1. Construction of Container Throughput Time Series Network
4.4.2. Link Prediction Dataset Splitting
4.4.3. Path Information Order Determination and Feature Selection Analysis
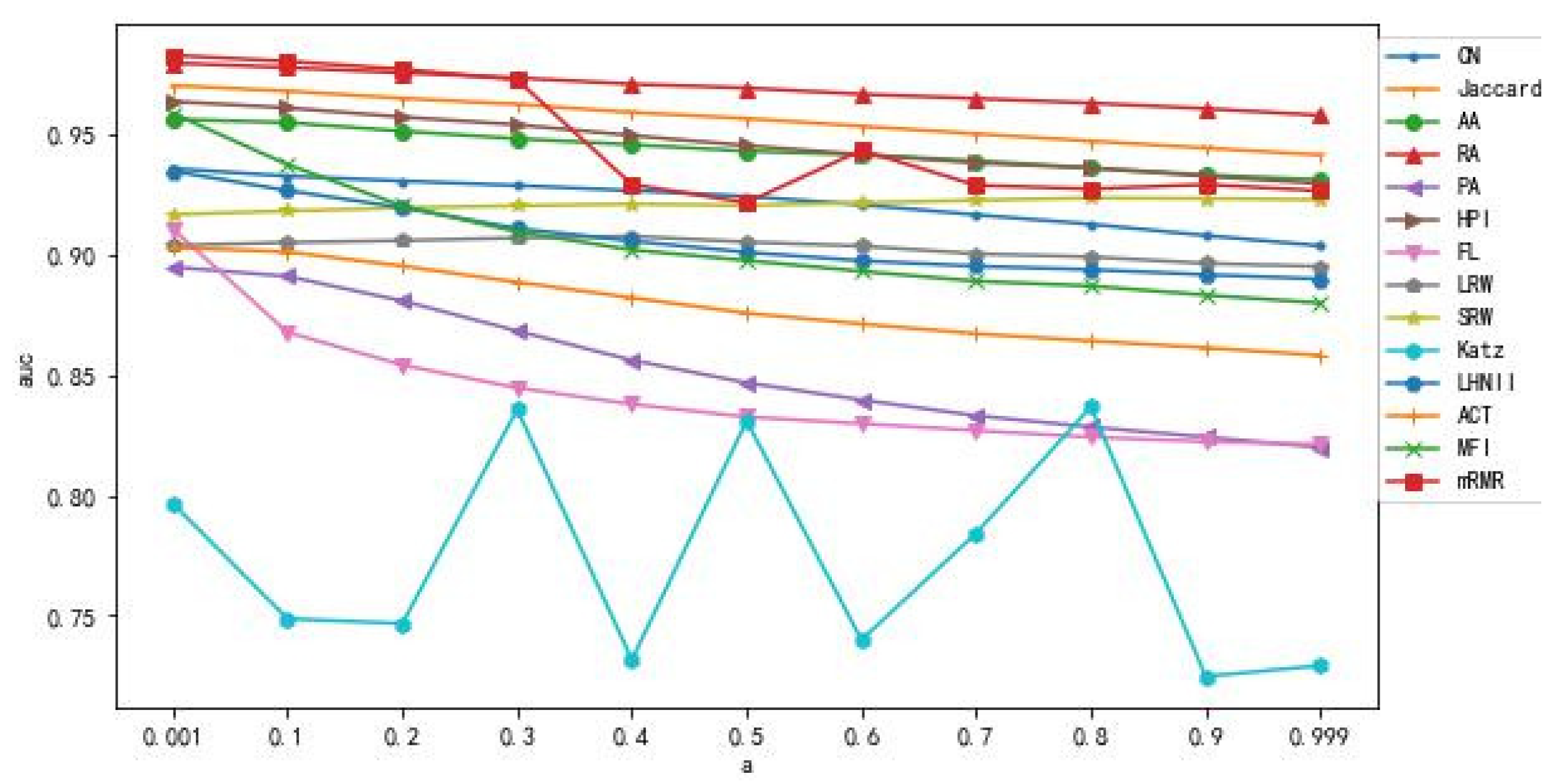
- (1)
- From Figure 11 and Figure 12, it can be observed that in the Shanghai Port dataset, predictive models using single metrics (such as RA, Jaccard, HPI, and AA) perform well, and the values remain stable with changes in . The Katz metric exhibits significant fluctuations in values with changes in α, reaching its maximum when = 0.8. Except for the SRW metric, the values of other metrics show a decreasing trend as increases. However, in the Shenzhen Port dataset, there is relatively larger variability in the overall feature performance compared to the Shanghai Port dataset, especially in that the LRW, SRW, FL, ACT, and CN metrics show a sharp decline after = 0.1. Additionally, it can be observed that for some single metric algorithms with good predictive accuracy (such as RA), the performance improvement of models based on mRMR feature selection is not significant, and may even have a negative or near-zero improvement. This is because these algorithms already have a good definition of network structural information, providing high predictive accuracy. However, for algorithms with lower predictive performance (such as KATZ, HPI, FL) models based on mRMR feature selection can provide more structural information about similarity measures, resulting in better performance in predictions. In conclusion, with α = 0.1 and 90% of the network’s links serving as the training set, the predictive performance of the mRMR-based feature selection model is ideal;
- (2)
- The different values of not only affect the choice of similarity feature metrics but also influence the overall model performance. From Figure 11 and Figure 12, we can observe that as α values get closer to 0, the values become higher. In the Shanghai Port dataset, the features selected based on mRMR are primarily dominated by global information-based metrics like LNHII and ACT, as well as semi-local metrics like SRW and FL. In the Shenzhen Port dataset, the features selected by mRMR are mainly based on global information, particularly LNHII, and semi-local information, particularly FL features. In both datasets, measures based on local information like CN, RA, PA, and Jaccard appear very infrequently, indicating that, in the chosen dataset networks and constructed prediction models in this study, similarity metrics based on global and semi-local information provide better quantification of network properties;
- (3)
- From Figure 11 and Figure 12, it can be observed that as α increases, the change in values for various feature algorithms does not strictly exhibit a decreasing trend. The relationship between the adjustable parameter α and differs slightly for the two networks in this research. The link prediction accuracy of the suggested technique is better for networks with comparatively high average clustering coefficients. The significant fluctuation in the parameter for the Shenzhen Port network is due to its inherent characteristics, making second-order path information crucial for prediction. In denser networks, second-order path information has a more significant impact. However, the fluctuation in the curve shown in Figure 12 does not directly correlate with the network’s average clustering coefficient. Despite the Shanghai Port visual network’s comparatively high average clustering coefficient, the consideration of second-order path information has a less noticeable impact on it. This suggests that second-order path information has limitations for certain networks and cannot cover all the relevant information.
4.4.4. Different Prediction Model Comparison Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Du, D.; Liu, T.; Guo, C. Analysis of Container Terminal Handling System Based on Petri Net and ExtendSim. Promet-Traffic Transp. 2023, 35, 87–105. [Google Scholar] [CrossRef]
- Singh, S.N.; Mohapatra, A. Repeated Wavelet Transform Based ARIMA Model for Very Short-Term Wind Speed Forecasting. Renew. Energy 2019, 136, 758–768. [Google Scholar]
- Wang, J.; Niu, X.; Liu, Z.; Zhang, L. Analysis of the Influence of International Benchmark Oil Price on China’s Real Exchange Rate Forecasting. Eng. Appl. Artif. Intell. 2020, 94, 103783. [Google Scholar] [CrossRef]
- Du, P.; Wang, J.; Hao, Y.; Niu, T.; Yang, W. A Novel Hybrid Model Based on Multi-objective Harris Hawks Optimization Algorithm for Daily PM2.5 and PM10 Forecasting. Appl. Soft Comput. 2020, 96, 106620. [Google Scholar] [CrossRef]
- Fan, Y.Y.; Yu, S.Q. Port Container Throughput Forecast Based on NARX Neural Network. J. Shanghai Marit. Univ. 2015, 1636, 012024. [Google Scholar]
- Huang, A.; Lai, K.; Li, Y.; Wang, S. Forecasting Container Throughput of Qingdao Port with a Hybrid Model. J. Syst. Sci. Complex. 2015, 28, 105–121. [Google Scholar] [CrossRef]
- Lacasa, L. From Time Series to Complex Networks: The Visibility Graph. Proc. Natl. Acad. Sci. USA 2008, 105, 4972–4975. [Google Scholar] [CrossRef]
- Zhou, T.; Jin, N. Time Series Network Model Based on Finite Traversal Visual Graph. Acta Phys. Sin. 2012, 61, 86–96. [Google Scholar]
- Ma, Z. Identification of Complex Network for ECG Signals of Healthy and Myocardial Infarction Patients Based on Multichannel Visual Graphs. Acta Phys. Sin. 2022, 71, 48–57. [Google Scholar] [CrossRef]
- He, Y.; Liu, J.N.K.; Hu, Y.; Wang, X.-Z. OWA Operator Based Link Prediction Ensemble for Social Network. Expert Syst. Appl. 2015, 42, 21–50. [Google Scholar] [CrossRef]
- Zhang, Q.; Tong, T.; Wu, S. Hybrid Link Prediction via Model Averaging. Phys. A 2020, 556, 124772. [Google Scholar] [CrossRef]
- Ayoub, J.; Lotfi, D.; Marraki, M.E.; Hammouch, A. Accurate Link Prediction Method Based on Path Length Between a Pair of Unlinked Nodes and Their Degree. Soc. Netw. Anal. Min. 2020, 10, 1–13. [Google Scholar] [CrossRef]
- Güneş, İ.; Gündüz-Öğüdücü, Ş.; Çataltepe, Z. Link Prediction Using Time Series of Neighborhood-Based Node Similarity Scores. Data Min. Knowl. Discov. 2016, 30, 147–180. [Google Scholar] [CrossRef]
- Agarwal, A.; Marwan, N.; Maheswaran, R.; Merz, B.; Kurths, J. Quantifying the Roles of Single Stations within Homogeneous Regions Using Complex Network Analysis. J. Hydrol. 2018, 563, 802–810. [Google Scholar] [CrossRef]
- Liben-Nowell, D.; Kleinberg, J. The Link Prediction Problem for Social Networks. In Proceedings of the Twelfth International Conference on Information and Knowledge Management, New Orleans, LA, USA, 3–8 November 2003; pp. 556–559. [Google Scholar]
- Adamic, L.A.; Adar, E. Friends and Neighbors on the Web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting Missing Links via Local Information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef]
- Jaccard, P. Etude Comparative de la Distribution Florale dans une Portion des Alpes et des Jura. Bull. Soc. Vaud. Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Ravasz, E.; Somera, A.L.; Mongru, D.A.; Oltvai, Z.N.; Barabasi, A.-L. Hierarchical Organization of Modularity in Metabolic Networks. Science 2002, 297, 1551–1555. [Google Scholar] [CrossRef]
- Liu, W.; Lü, L. Link Prediction Based on Local Random Walk. Europhys. Lett. 2010, 89, 58007. [Google Scholar] [CrossRef]
- Papadimitriou, A.; Symeonidis, P.; Manolopoulos, Y. Fast and Accurate Link Prediction in Social Networking Systems. J. Syst. Softw. 2012, 85, 2119–2132. [Google Scholar] [CrossRef]
- Katz, L. A New Status Index Derived from Sociometric Analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Guo, J.; Meng, Y.Y. A Link Prediction Algorithm Using Relative Entropy to Measure Node Structural Similarity. J. Lanzhou Jiaotong Univ. 2022, 1955, 012078. [Google Scholar]
- Abdourahamane, Z.S.; Acar, R.; Serkan, Ş. Wavelet–Copula-Based Mutual Information for Rainfall Forecasting Applications. Hydrol. Process. 2019, 33, 1127–1142. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Schmidhuber, J.; Hochreiter, S. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Zhang, R.; Ashuri, B.; Shyr, Y.; Deng, Y. Forecasting Construction Cost Index Based on Visibility Graph: A Network Approach. Phys. A Stat. Mech. Its Appl. 2018, 493, 239–252. [Google Scholar] [CrossRef]
- Lü, L.Y. Link Prediction in Complex Networks. J. Univ. Electron. Sci. Tech. China 2010, 39, 651–661. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Port | Nodes Number N | Edges Number M | Average Degree <k> | Average Clustering Coefficient <c> | Path Length <d> |
|---|---|---|---|---|---|
| Shanghai Port | 261 | 954 | 7.31 | 0.737 | 10 |
| Shenzhen Port | 263 | 971 | 7.38 | 0.752 | 6 |
| Port | Model | 7:3 | 8:2 | 9:1 | |||
|---|---|---|---|---|---|---|---|
| Shanghai Port | SVM | 0.965 | 0.859 | 0.968 | 0.849 | 0.981 | 0.857 |
| DNN | 0.936 | 0.856 | 0.944 | 0.849 | 0.955 | 0.857 | |
| LSTM | 0.938 | 0.856 | 0.935 | 0.845 | 0.944 | 0.857 | |
| Shenzhen Port | SVM | 0.994 | 0.963 | 0.994 | 0.970 | 0.999 | 0.989 |
| DNN | 0.994 | 0.963 | 0.995 | 0.969 | 1.000 | 0.990 | |
| LSTM | 0.995 | 0.963 | 0.995 | 0.969 | 1.000 | 0.990 | |
| Feature Selection | SVM | DNN | LSTM | |
|---|---|---|---|---|
| 0.1 | ‘AA’, ‘MFI’, ‘SRW’, ‘ACT’ | 0.9807 | 0.9716 | 0.9494 |
| 0.2 | ‘AA’, ‘SRW’, ‘FL’, ‘ACT’ | 0.9774 | 0.9653 | 0.9453 |
| 0.3 | ‘AA’, ‘FL’, ‘ACT’, ‘LHNII’ | 0.9730 | 0.9616 | 0.9474 |
| 0.4 | ‘LRW’, ‘FL’, ‘LHNII’, ‘Katz’ | 0.9231 | 0.9310 | 0.9289 |
| 0.5 | ‘SRW’,’MFI’, ‘ACT’, ‘LHNII’ | 0.9060 | 0.9206 | 0.9189 |
| 0.6 | ‘SRW’, ‘FL’, ‘ACT’, ‘LHNII’ | 0.9250 | 0.9334 | 0.9226 |
| 0.7 | ‘SRW’, ‘FL’, ‘ACT’, ‘LHNII’ | 0.9264 | 0.9344 | 0.9248 |
| 0.8 | ‘SRW’, ‘FL’, ‘ACT’, ‘LHNII’ | 0.9276 | 0.9379 | 0.9243 |
| 0.9 | ‘LRW’, ‘FL’, ‘LHNII’, ‘Katz’ | 0.9244 | 0.9260 | 0.9272 |
| Feature Selection | SVM | DNN | LSTM | |
|---|---|---|---|---|
| 0.1 | ‘LRW’, ‘FL’, ‘LHNII’, ‘Jaccard’ | 0.9997 | 0.9997 | 1.0000 |
| 0.2 | ‘LRW’, ‘FL’, ‘ACT’, ‘LHNII’ | 0.9940 | 0.9901 | 0.9843 |
| 0.3 | ‘LRW’, ‘FL’, ‘LHNII’, ‘Katz’ | 0.9805 | 0.9707 | 0.9599 |
| 0.4 | ‘AA’, ‘PA’, ‘LHNII’, ‘HPI’ | 0.9901 | 0.9890 | 0.9856 |
| 0.5 | ‘LRW’, ‘FL’, ‘ACT’, ‘LHNII’ | 0.9876 | 0.9718 | 0.9568 |
| 0.6 | ‘LRW’, ‘FL’, ‘LHNII’, ‘SRW’ | 0.9878 | 0.9831 | 0.9725 |
| 0.7 | ‘SRW’, ‘FL’, ‘ACT’, ‘LHNII’ | 0.9545 | 0.9810 | 0.9782 |
| 0.8 | ‘SRW’, ‘MFI’, ‘ACT’, ‘Katz’ | 0.9871 | 0.9874 | 0.9890 |
| 0.9 | ‘SRW’, ‘FL’, ‘ACT’, ‘LHNII’ | 0.9549 | 0.9385 | 0.9549 |
| Shanghai Port | Shenzhen Port | |||||
|---|---|---|---|---|---|---|
| RMSE | MAPE | MAE | RMSE | MAPE | MAE | |
| SVM | 261.38 | 0.110 | 208.07 | 424.92 | 0.242 | 298.54 |
| DNN | 248.61 | 0.070 | 163.85 | 382.72 | 0.109 | 193.51 |
| LSTM | 243.09 | 0.077 | 174.42 | 387.32 | 0.108 | 178.32 |
| CN1-SVM | 104.38 | 0.028 | 64.73 | 107.46 | 0.034 | 58.72 |
| CN1-DNN | 74.21 | 0.020 | 47.09 | 110.49 | 0.037 | 63.40 |
| CN1-LSTM | 72.25 | 0.020 | 46.13 | 110.26 | 0.036 | 62.69 |
| CN2-SVM | 72.25 | 0.020 | 46.13 | 107.46 | 0.034 | 58.72 |
| CN2-DNN | 72.25 | 0.020 | 46.13 | 109.98 | 0.036 | 62.45 |
| CN2-LSTM | 72.25 | 0.020 | 46.13 | 117.62 | 0.035 | 61.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, X.; Wang, Y.; Yang, M. Systemic Modeling and Prediction of Port Container Throughput Using Hybrid Link Analysis in Complex Networks. Systems 2024, 12, 23. https://doi.org/10.3390/systems12010023
Liang X, Wang Y, Yang M. Systemic Modeling and Prediction of Port Container Throughput Using Hybrid Link Analysis in Complex Networks. Systems. 2024; 12(1):23. https://doi.org/10.3390/systems12010023
Chicago/Turabian StyleLiang, Xiaozhen, Yingying Wang, and Mingge Yang. 2024. "Systemic Modeling and Prediction of Port Container Throughput Using Hybrid Link Analysis in Complex Networks" Systems 12, no. 1: 23. https://doi.org/10.3390/systems12010023
APA StyleLiang, X., Wang, Y., & Yang, M. (2024). Systemic Modeling and Prediction of Port Container Throughput Using Hybrid Link Analysis in Complex Networks. Systems, 12(1), 23. https://doi.org/10.3390/systems12010023