
Recommendation Method Based on Heterogeneous Information Network and Multiple Trust Relationship

Abstract
1. Introduction
2. Literature Review
2.1. Content-Based Recommendation System
2.2. Recommendation System Based on Collaborative Filtering
2.3. Hybrid-Recommendation System
2.4. Hybrid-Recommendation System Based on Heterogeneous Information Network
3. Microblog Recommendation Method Based on Meta-Path and User Trust Relationship
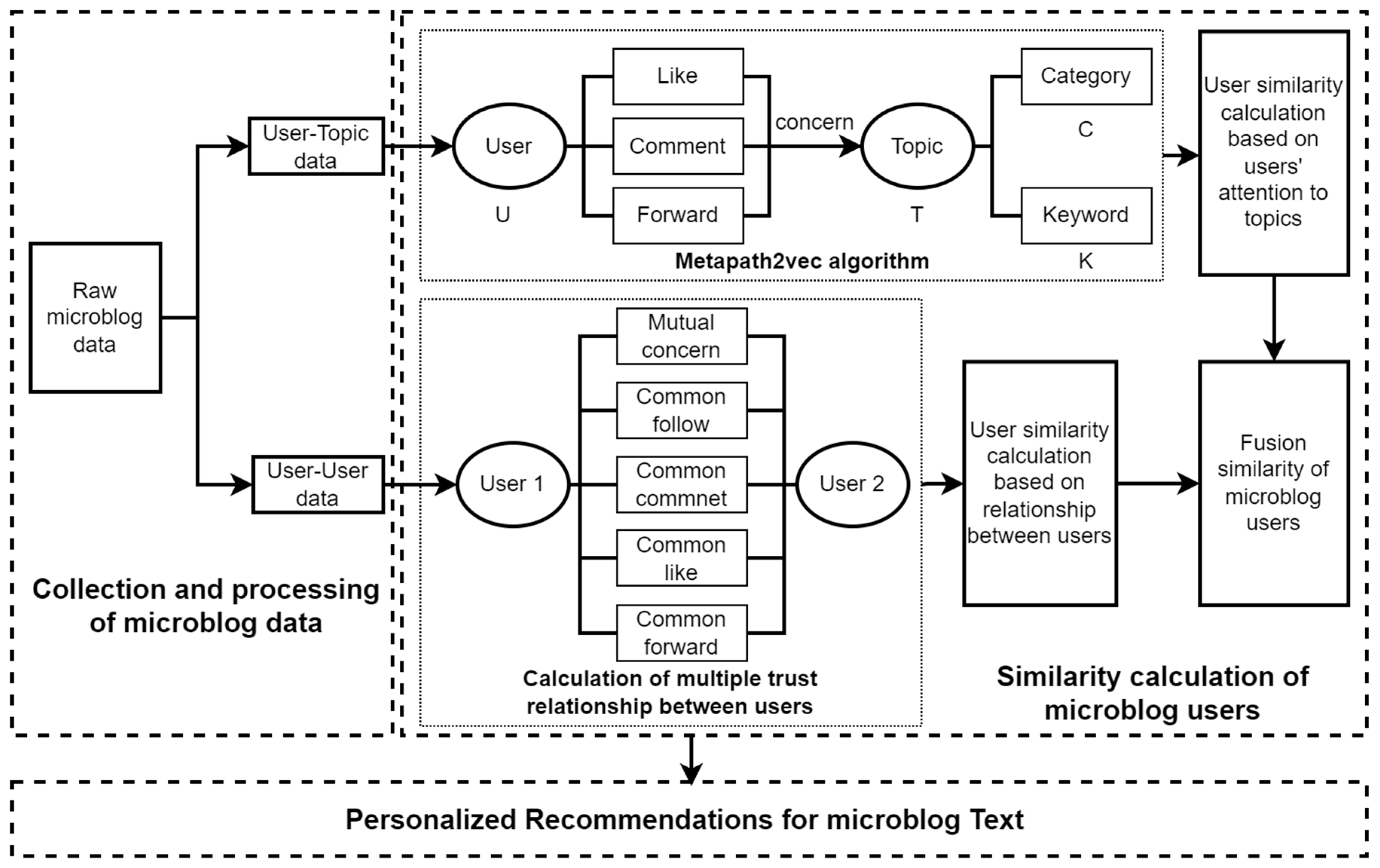
3.1. Framework of the Research
3.2. Construction of Metapath2Vec Model
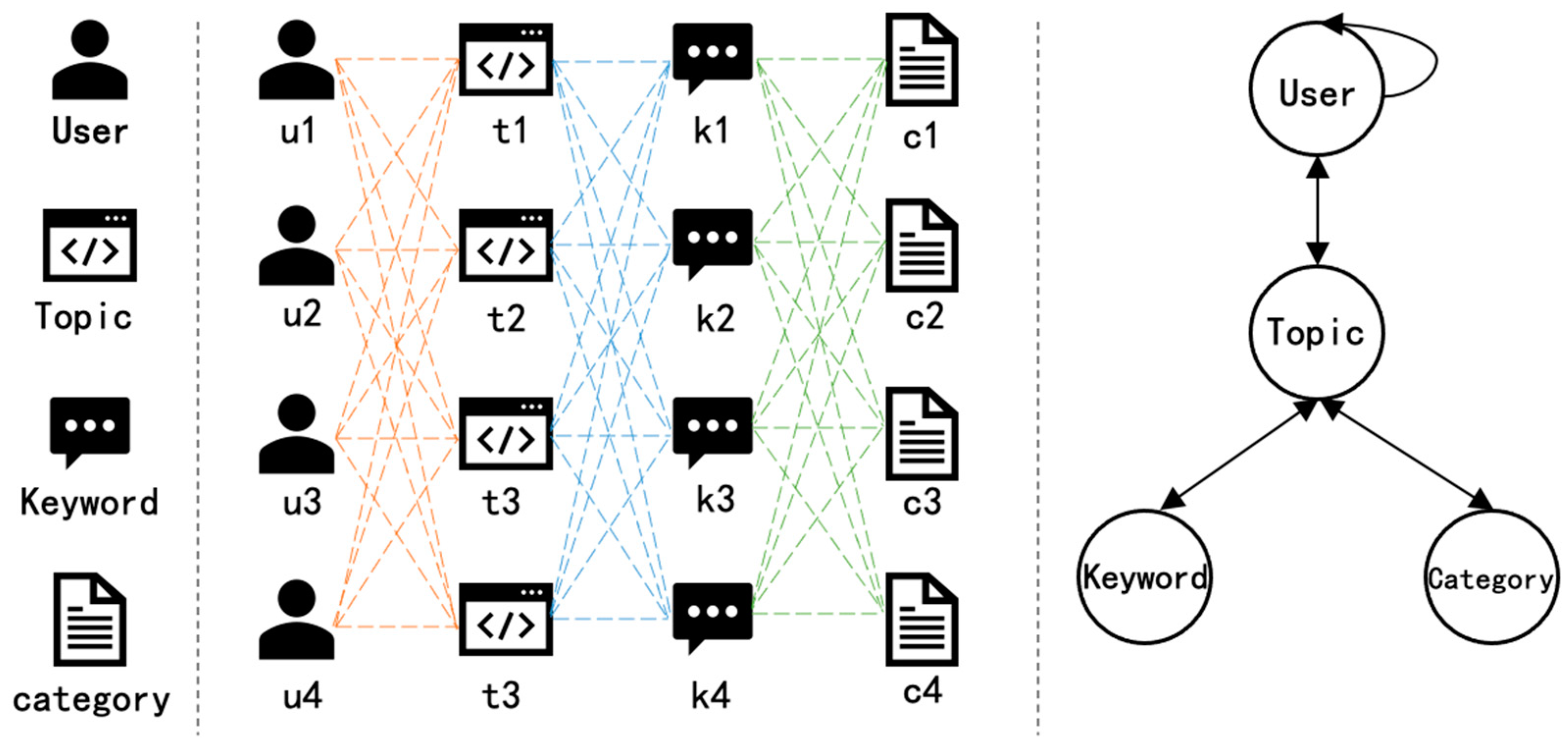
3.2.1. Construction of Microblog Topic-Network Model
3.2.2. Selection of Meta-Paths
3.2.3. Generation of Node Representation Vectors
3.2.4. Similarity Calculation Based on Users’ Attention to Topics
3.3. Calculation of Multiple Trust Relationships between Users
- (1)
- Calculation of trust strength of mutual-attention relationship between users
- (2)
- Calculation of trust strength of common concern relationship among users
- (3)
- Calculation of trust strength of common comment relationship between users.
- (4)
- Calculation of trust strength of common like relationship among users
- (5)
- Calculation of trust strength of mutual forwarding relationship between users
- (6)
- Calculation of fusion strength of multiple trust relationships among users
3.4. Personalized Recommendation of Microblog Text
4. Experimental Results and Analysis
4.1. Data Source and Preprocessing
4.2. Comparison Algorithm and Evaluation Index
- (1)
- MF [56]. Matrix factorization is a recommendation model based on the idea of collaborative filtering. The model takes only the user-item rating matrix as input, and then optimizes to obtain two low-rank matrices to predict unknown ratings.
- (2)
- PMF [56]. Probabilistic matrix factorization is a traditional rating-prediction model that assumes a Gaussian distribution for the latent vectors of users and items, and then performs matrix factorization.
- (3)
- Deepwalk [57]. In this method, the Skip-gram algorithm is applied to the graph network for the first time, and the node pairs in the k-hop field are obtained by uniform random walk on the homogeneous network to form the node sequence, and then the Skip-gram algorithm is used to learn the node representation. The experiment does not distinguish between user nodes and item nodes. After obtaining the representation of the node, the user node and the item node are used as the input of MLP, and the recommendation is made according to the prediction score.
- (4)
- Node2vecp [58]. This method is improved on the basis of the Deepwalk model. It combines the BFS and DFS strategies during random walk, defines parameters p and q to initialize the probability transition matrix, and walks according to the probability of obtaining a fixed-length node sequence, and then learns the low-dimensional embedded representation of the node. The recommended method after obtaining the node representation is the same as above.
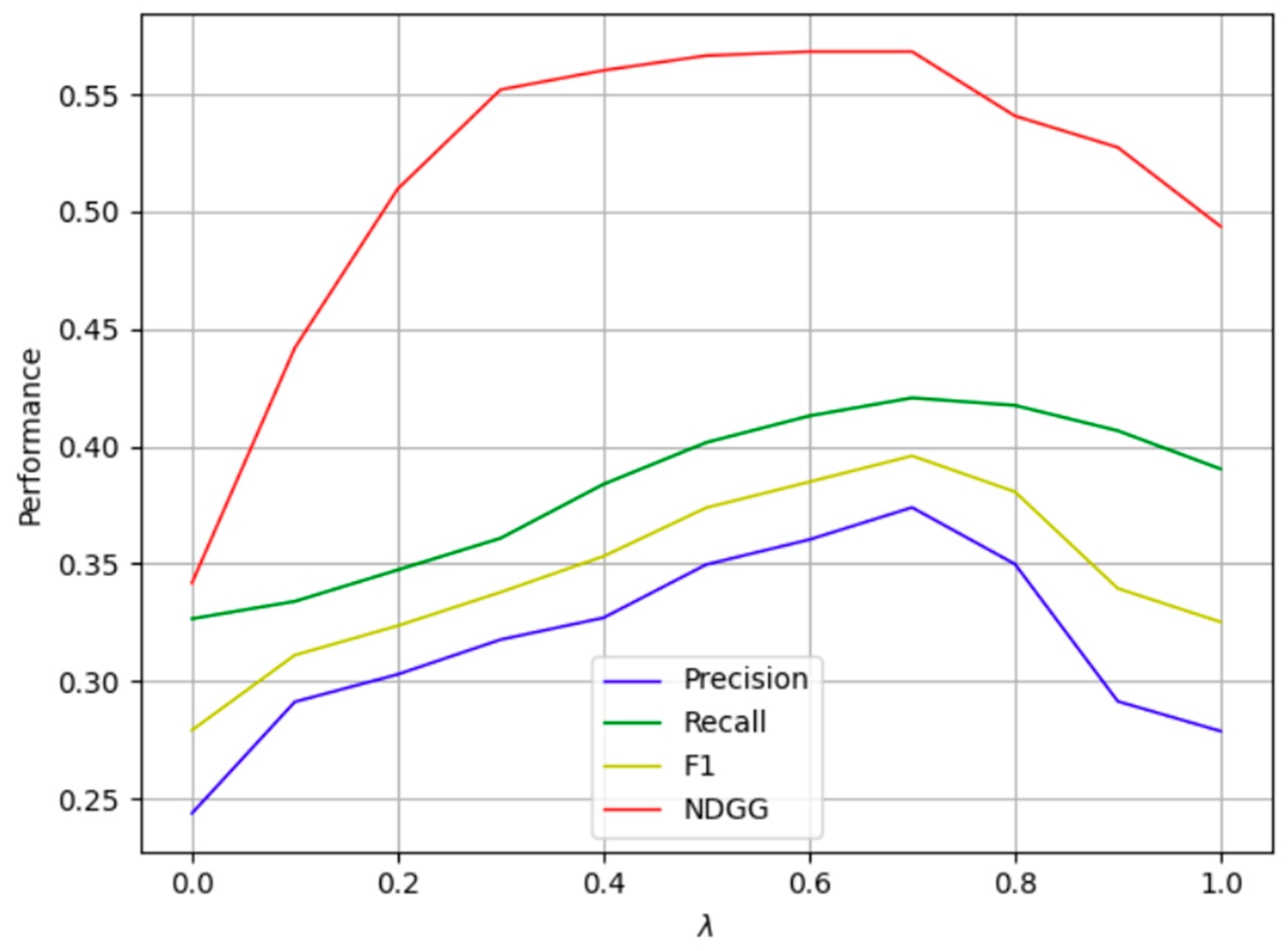
4.3. Selection of Parameter
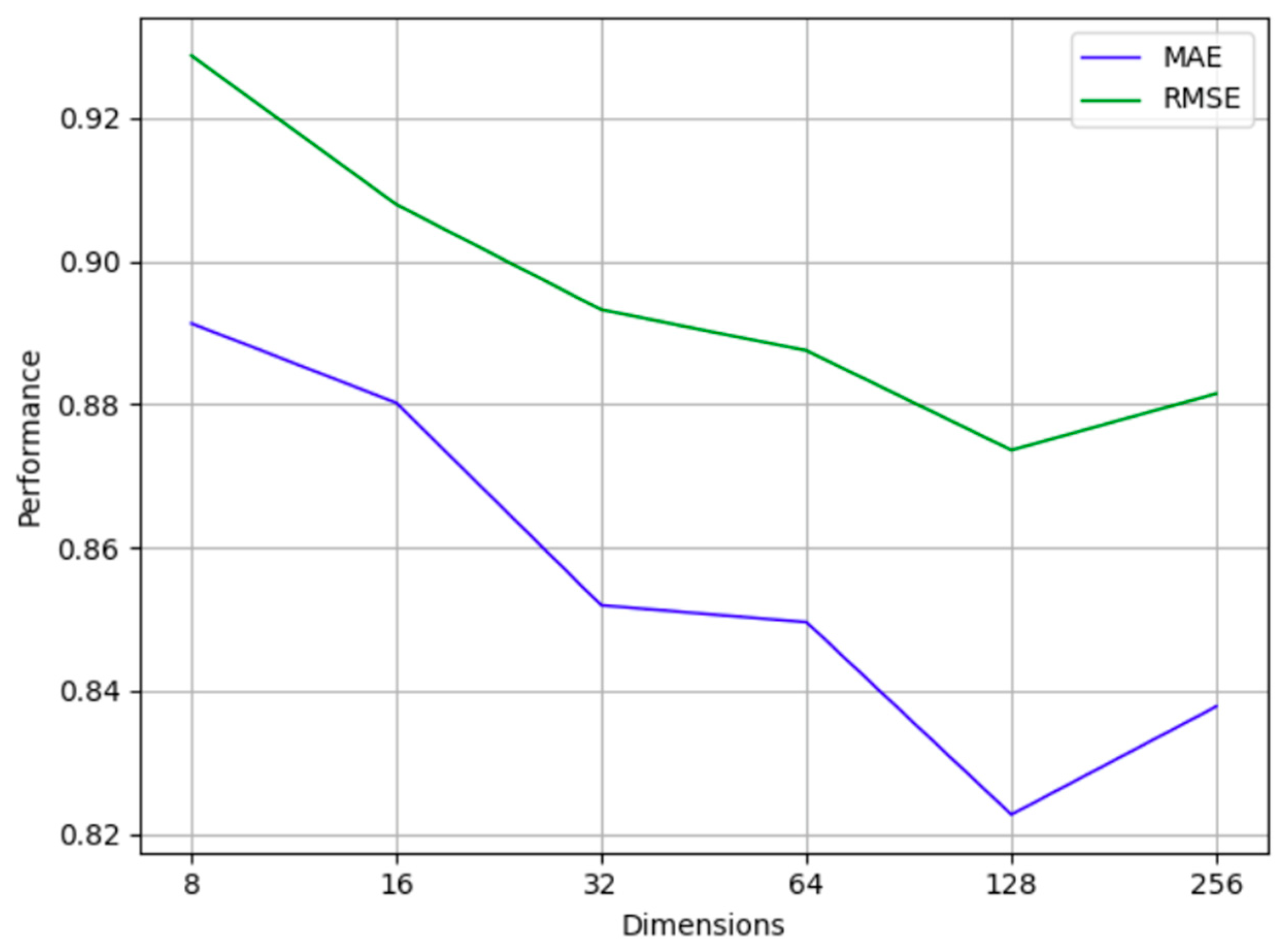
4.3.1. Selection of Word Vector Dimensions
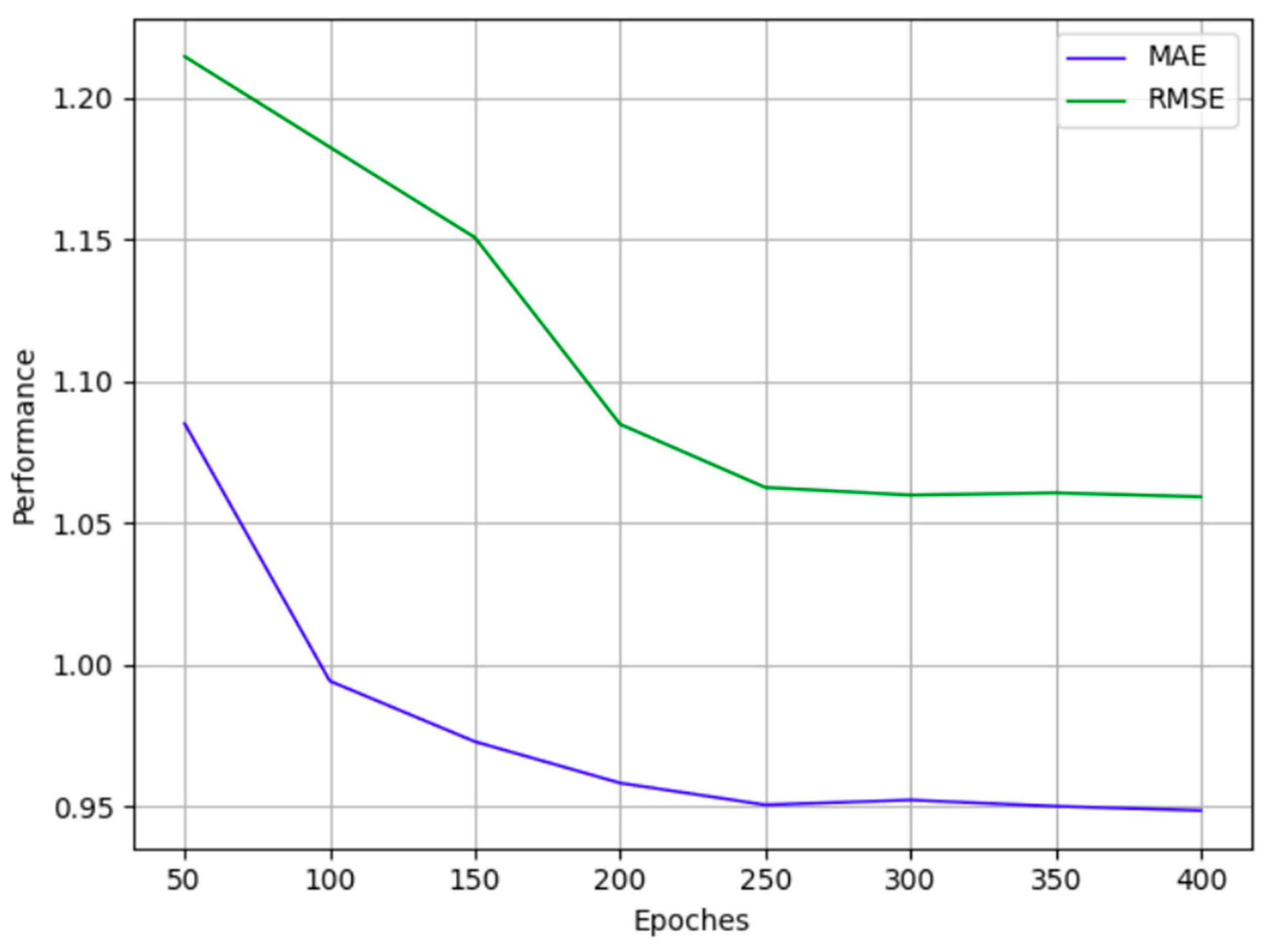
4.3.2. Selection of the Number of Iterations
4.4. Analysis of Experimental Results
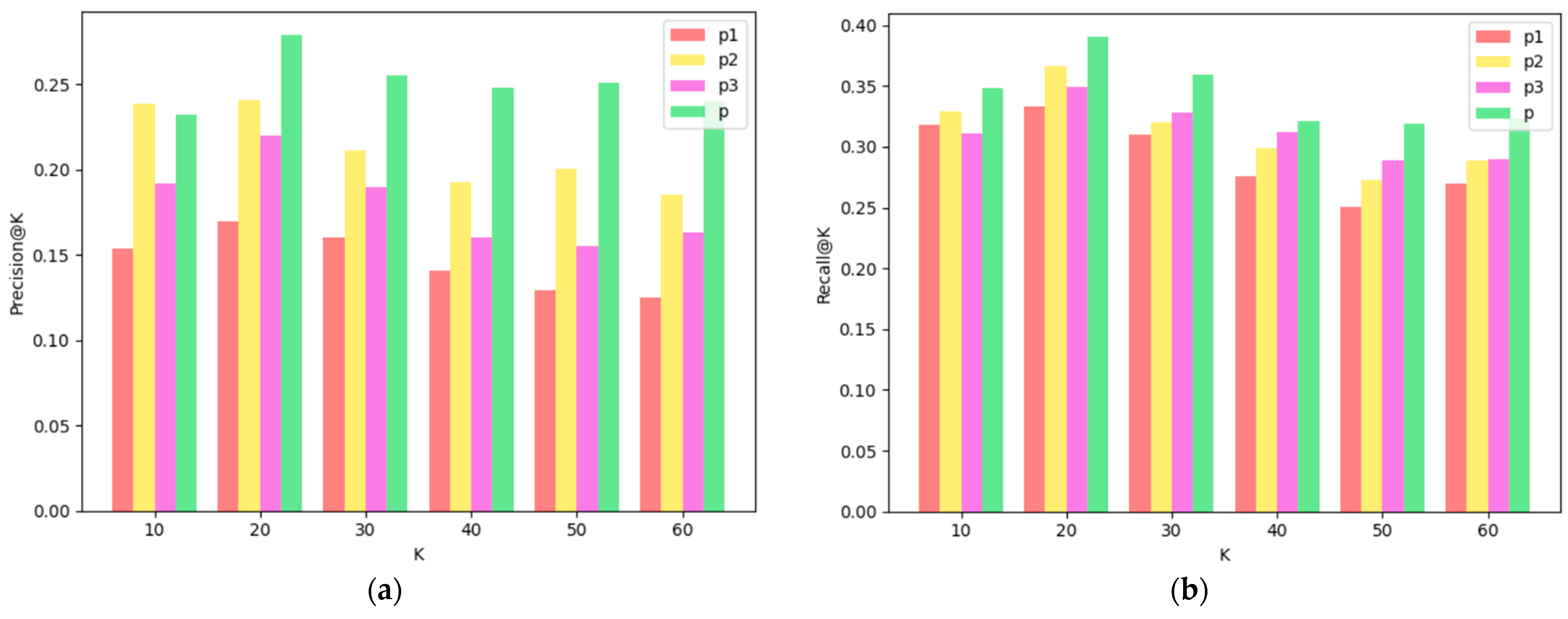
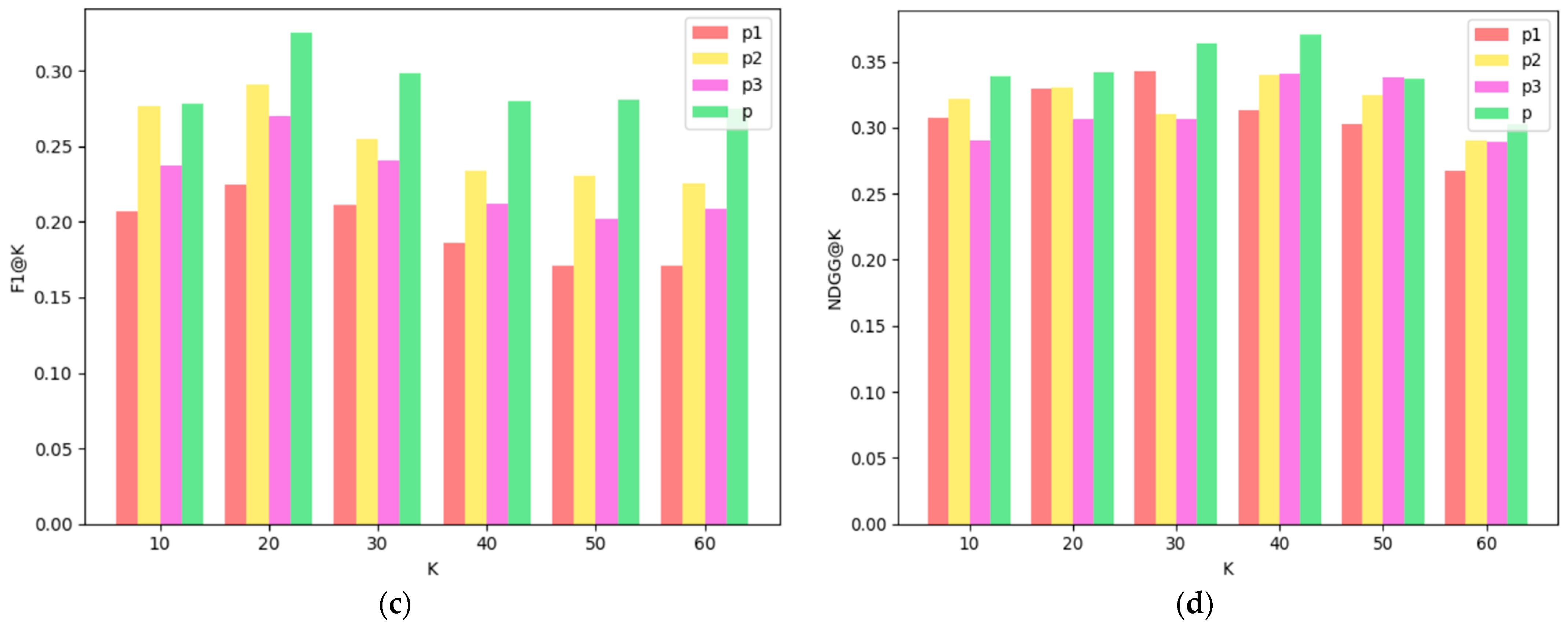
- (1)
- From a global perspective, the fusion-path method is better than other single paths in the results of each indicator, which shows that the fusion path can better combine the content, topic type and keyword information of the Microblog text to capture more information comprehensively.
- (2)
- From the comparison of the recommendation results of the single paths P1, P2 and P3, except for individual results, in most cases, the recommendation results of the path P2 based on topic keywords and the path P3 based on topic categories are better than the baseline path P1, that is to say, in general, the keywords and categories of topics can effectively mine users’ demand preferences for Microblog texts to a certain extent, and improve the accuracy of the recommendation results.
- (3)
- When k = 20, the precision rate, recall rate and F1 value under different paths all achieve the maximum value, indicating that when the number of Microblogs in the Microblog recommendation list is 20, the recommendation effect is the best.
- (1)
- On the whole, by comparing the average value of the evaluation indicators, it can be found that the algorithm proposed in this paper shows the best results in the four evaluation indicators.
- (2)
- Compared with the Deepwalk model and the Node2vec model, the average precision of the method in this paper is 0.3211, which is about 0.2 and 0.07 higher than the Deepwalk and Node2vec algorithms, respectively, which are both random-walk-related algorithms. The effect of the method proposed in this paper is better, indicating that the trust relationship between fusion users has a positive impact on the recommendation results.
- (3)
- From the three indicators of precision rate, recall rate and F1 value, when k = 20, the model in this paper has the best effect. In the actual situation, the number of user-focused Microblogs is limited, and the excessive number of Microblog texts in the recommendation list will reduce the accuracy of the recommendation, and the visualization method is not easy to view. When the number of Microblog text recommendations is too small, it may not be possible to cover users’ demands and preferences as much as possible. Therefore, according to the calculation results in this paper, in order to ensure the accuracy of the recommendation results, we choose to recommend 20 candidate Microblog-text lists for the user, which can satisfy the user’s demand preference to the greatest extent.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, C.Q.; Wu, F.; Sun, Q. Research on information spreading effects in the social interaction context. J. Manag. Eng. 2023, 37, 22–34. [Google Scholar]
- Zhou, J.J.; Zuo, M.Y. Research on the relationship between online and offline interaction, group differentiation and knowledge sharing—Empirical analysis based on virtual communities. China Manag. Sci. 2012, 20, 185–192. [Google Scholar]
- Bao, X.; Wang, M.R.; Liu, G.F. A novel text classification mathod based on topic model and transfer learning. J. Shandong Univ. Sci. Technol. Nat. Sci. 2021, 40, 80–88. [Google Scholar]
- Jiao, Y.Y.; Li, Z.Z.; Shen, Z.F. Research on the diffusion mechanism of new products in the context of social networks: Generation process based on peer influence. J. Manag. Eng. 2020, 34, 105–113. [Google Scholar]
- Lin, J.; Yang, Z.J. User’s network behavior characteristics and professional knowledge level—An empirical study based on registered users of “Auto Home”. Manag. Rev. 2021, 33, 331–340. [Google Scholar]
- Li, J.P.; Cao, N.; Zhang, Q.; Zhang, W.P.; Ji, S.J. Online social network groups discovery algorithm considering themes and time. J. Shandong Univ. Sci. Technol. Nat. Sci. 2021, 40, 95–102. [Google Scholar]
- Ding, Y.; Liu, J.; Jiang, C.Q.; Liang, C.Y. A study of friends recommendation algorithm considering users’ preference of making friends in the LBSN. Syst. Eng. Theory Pract. 2017, 37, 2975–2982. [Google Scholar]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; ACM Press: New York, NY, USA, 1999. [Google Scholar]
- Belkin, N.J.; Croft, W.B. Information filtering and information retrieval: Two sides of the same coin? Commun. ACM 1992, 35, 29–38. [Google Scholar] [CrossRef]
- Salton, G. Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer; Addison-Wesley: Reading, MA, USA, 1989; pp. 169–182. [Google Scholar]
- Lang, K. Newsweeder: Learning to filter netnews. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; Morgan Kaufmann: Burlington, MA, USA, 1995; pp. 331–339. [Google Scholar]
- Mooney, R.J.; Roy, L. Content-based book recommending using learning for text categorization. In Proceedings of the Fifth ACM Conference on Digital Libraries, San Antonio, TX, USA, 2–7 June 2000; pp. 195–204. [Google Scholar]
- Pazzani, M.; Billsus, D. Learning and revising user profiles: The identification of interesting web sites. Mach. Learn. 1997, 27, 313–331. [Google Scholar] [CrossRef]
- Li, L.; Chu, W.; Langford, J.; Schapire, R.E. A Contextual bandit Approach to Personalized News Article recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; ACM Press: New York, NY, USA, 2010; pp. 661–670. [Google Scholar]
- Jiang, S.H.; Xue, F.L. A content-based recommendation method based on collaborative filtering prediction and fuzzy similarity improvement. Data Anal. Knowl. Discov. 2014, 30, 41–47. [Google Scholar]
- Lei, K.; Liu, S.B.; Li, D. Content-based point of interest recommendation under real-time traffic conditions. Comput. Eng. 2017, 43, 147–152. [Google Scholar]
- Su, X.; Khoshgoftaar, T.M. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009, 109–118. [Google Scholar] [CrossRef]
- Billsus, D.; Pazzani, M.J. Learning Collaborative Information Filters. In Proceedings of the Fifteenth International Conference on Machine Learning, Madison, WI, USA, 24–27 July 1998; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1998; Volume 98, pp. 46–54. [Google Scholar]
- Marlin, B.M. Modeling user rating profiles for collaborative filtering. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2004; pp. 627–634. [Google Scholar]
- Pavlov, D.Y.; Pennock, D.M. A maximum entropy approach to collaborative filtering in dynamic, sparse, high-dimensional domains. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2003; pp. 1465–1472. [Google Scholar]
- Pearson, K.L., III. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Ungar, L.H.; Foster, D.P. Clustering methods for collaborative filtering. AAAI Workshop Recomm. Syst. 1998, 1, 114–129. [Google Scholar]
- Hofmann, T. Collaborative filtering via gaussian probabilistic latent semantic analysis. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; ACM: New York, NY, USA, 2003; pp. 259–266. [Google Scholar]
- Y, X.; He, Y.D.; Liang, H.T.; Jiang, F.; Du, J.W. A Top-k crowdsourcing developer recommendation method considering interest preference. J. Shandong Univ. Sci. Technol. Nat. Sci. 2021, 40, 58–70. [Google Scholar]
- Dwork, C. Differential privacy. In Proceedings of the 33rd International Colloquium on Automata, Languages and Programming, Venice, Italy, 10–14 July 2006; Springer: Berlin, Germany, 2006; pp. 1–12. [Google Scholar]
- Friedman, A.; Schuster, A. Data mining with differential privacy. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 493–502. [Google Scholar]
- Piao, C.; Shi, Y.; Yan, J.; Zhang, C.; Liu, L. Privacy-preserving governmental data publishing: A fog-computing-based differential privacy approach. Future Gener. Comput. Syst. 2019, 90, 158–174. [Google Scholar] [CrossRef]
- Hou, J.; Li, Q.; Cui, S.; Meng, S.; Zhang, S.; Ni, Z.; Tian, Y. Low-cohesion differential privacy protection for industrial internet. J. Supercomput. 2020, 76, 8450–8472. [Google Scholar] [CrossRef]
- McSherry, F.; Mironov, I. Differentially private recommender systems: Building privacy into the netflix prize contenders. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 627–636. [Google Scholar]
- He, M.; Chang, M.M.; Wu, X.F. A collaborative filtering recommendation method based on differential privacy protection. Comput. Res. Dev. 2017, 54, 1439–1451. [Google Scholar]
- Goldberg, K.; Roeder, T.; Gupta, D.; Perkins, C. Eigentaste: A constant time collaborative filtering algorithm. Inf. Retr. 2001, 4, 133–151. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, X.; Guo, L.; Chen, Z.M. Learing to recommend with collaborative matrix factorization for new users. J. Comput. Res. Dev. 2017, 54, 1813–1823. [Google Scholar]
- Liu, G.S.; Su, B. Collaborative filtering recommendation algorithm combining community structure and personal interests. Comput. Eng. Des. 2018, 39, 3420–3424. [Google Scholar]
- Wei, L.; Guo, X.Y. Personalized Recommendation Model of Knowledge Payment Platform Combining User Portrait and Collaborative Filtering. Inf. Stud. Theory Appl. 2021, 44, 188–193. [Google Scholar]
- Zhang, J. LA fusion collaborative filtering algorithm based on rating information entropy. J. Nanjing Univ. Posts Telecommun. 2021, 44, 76–81. [Google Scholar]
- Yang, X.W.; Guo, Y.; Liu, Y.; Steck, H. A Survey of Collaborative Filtering Based Social Recommender Systems. Comput. Commun. 2014, 41, 2–10. [Google Scholar] [CrossRef]
- Bao, J.; Zheng, Y.; Wilkie, D.; Mokbel, M. Recommendations in Location-Based Social Networks: A Survey. GeoInformatica 2015, 19, 525–565. [Google Scholar] [CrossRef]
- Guo, Q.Y.; Zhuang, F.Z.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A Survey on Knowledge Graph-Based Recommender Systems. IEEE Trans. Knowl. Data Eng. 2020, 34, 3549–3568. [Google Scholar] [CrossRef]
- Zhang, X.M.; Jiang, S.Y.; Li, X. Hybrid recommendation algorithm based on network and tag. Comput. Eng. Appl. 2015, 51, 119–124. [Google Scholar]
- Yang, S.; Wang, J. Improved hybrid recommendation algorithm based on stack noise reduction self-coder. Comput. Appl. 2018, 38, 42–47. [Google Scholar]
- Yuan, W.W.; Peng, D.L.; Wu, S.H. Hybrid recommendation algorithm supported by self-attention mechanism. Micro Comput. Syst. 2019, 7, 26–31. [Google Scholar]
- Zhao, C.; Zhang, K.H.; Liang, J.Y. Asymmetric Recommendation Algorithm in Heterogeneous Information Network. J. Front. Comput. Sci. Technol. 2020, 14, 939–946. [Google Scholar]
- Feng, W.; Wang, J.Y. Incorporating heterogeneous information for personalized tag recommendation in social tagging systems. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 1276–1284. [Google Scholar]
- Yu, X.; Ren, X.; Gu, Q.Q.; Sun, Y.; Han, J. Collaborative filtering with entity similarity regularization in heterogeneous information networks. In Proceedings of the IJCAI-13 Workshop on Heterogeneous Information Network Analysis, Beijing, China, 5 August 2013; p. 27. [Google Scholar]
- Shi, C.; Hu, B.B.; Zhao, W.X.; Yu, P.S. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2019, 31, 357–370. [Google Scholar] [CrossRef]
- Jamali, M.; Lakshmanan, L. HeteroMF: Recommendation in heterogeneous information networks using context dependent factor models. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 643–654. [Google Scholar]
- Suo, X.; Wei, F.; Yu, K. Entity Recommendation Via Integrating Multiple Types of Implicit Feedback in Heterogeneous Information Network. In Proceedings of the IEEE International Conference on Data Mining Workshops, New Orleans, LA, USA, 18–21 November 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 781–786. [Google Scholar]
- Zhu, X.; Zhang, Y.Q.; Hui, Q.Y. An Academic Literature Recommendation Method Based on Disciplinary Heterogeneous Knowledge Network. Libr. J. 2020, 39, 103–110. [Google Scholar]
- Niu, Y.Q.; Meng, Y.Y.; Niu, Q.F. Text Recommendation Based on Heterogeneous Attention Recurrent Neural Network. Comput. Eng. 2020, 46, 52–59. [Google Scholar]
- Zhao, J.L.; Zhao, Z.Y. Recommendation Algorithm Based on Heterogeneous Information Network Embedding and Attention Neural Network. Comput. Sci. 2021, 48, 72–79. [Google Scholar]
- Wang, Y.G.; Mei, X.W. Fuzzy Recommendation Algorithm for Asymmetric Heterogeneous Information Network. Comput. Eng. Appl. 2020, 56, 74–79. [Google Scholar]
- Sun, Y.; Han, J. Meta-path-based Search and Mining in Heterogeneous Information Networks. Tsinghua Sci. Technol. 2013, 18, 329–338. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. PathSim: Meta Path-based Top-K Similarity Search in Heterogeneous Information Networks. Proc. VLDB Endow. 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Xu, H.Y.; Wang, D.; Wang, F.H.; Wang, R.B. User relevance measure method combining latent Dirichlet allocation and meta-path analysis. J. Comput. Appl. 2019, 39, 3288–3292. [Google Scholar]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. In Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; Curran Associates: New York, NY, USA, 2007; pp. 1257–1264. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014. [Google Scholar]
- Grover, A.; Leskovec, J. Node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Definition |
|---|---|
| Category of node | |
| Node of specified type | |
| Type t neighborhood node of node | |
| Embedding vector of node | |
| Activation function of neural network | |
| The k-th negative sampling node of | |
| K | Negative sampling value |
| Node vector of user i | |
| Fusion coefficient of similarity between users | |
| Topic probability distribution of Microblog a | |
| T | Subject collection of interest of target user |
| Top k Microblog lists recommended for Microblog user u | |
| Normalization constant | |
| The relevance of Microblog text with position i in the recommendation list |
| Meta-Path | Meaning of Meta-Paths |
|---|---|
| P1 = UTU | Users who follow the same topic as the selected user |
| P2 = UTKTU | Users who follow a topic with the same keywords as a selected user’s topic of interest |
| P3 = UTCTU | Users who follow topics of the same type as a selected user’s topic |
| k | Precision@k | Recall@k | ||||||||
| MF | PMF | Deepwalk | Node2vec | Ours | MF | PMF | Deepwalk | Node2vec | Ours | |
| 10 | 0.0936 | 0.1205 | 0.0948 | 0.2320 | 0.3676 | 0.2901 | 0.3691 | 0.2376 | 0.3488 | 0.3974 |
| 20 | 0.0915 | 0.0963 | 0.1074 | 0.2786 | 0.3739 | 0.2677 | 0.3704 | 0.2419 | 0.3903 | 0.4206 |
| 30 | 0.0742 | 0.0805 | 0.1006 | 0.2549 | 0.3403 | 0.2372 | 0.3958 | 0.273 | 0.3596 | 0.4083 |
| 40 | 0.0537 | 0.0632 | 0.0941 | 0.2481 | 0.3168 | 0.2196 | 0.3641 | 0.2983 | 0.3212 | 0.3802 |
| 50 | 0.0396 | 0.0596 | 0.0733 | 0.2510 | 0.2907 | 0.2069 | 0.3216 | 0.2433 | 0.3187 | 0.3473 |
| 60 | 0.0248 | 0.0401 | 0.0603 | 0.2400 | 0.2432 | 0.1603 | 0.2804 | 0.2302 | 0.3232 | 0.3245 |
| Average | 0.0629 | 0.0767 | 0.0884 | 0.2508 | 0.3221 | 0.2303 | 0.3502 | 0.2541 | 0.3436 | 0.3797 |
| k | F1@k | NDCG@k | ||||||||
| MF | PMF | Deepwalk | Node2vec | Ours | MF | PMF | Deepwalk | Node2vec | Ours | |
| 10 | 0.1415 | 0.1817 | 0.1355 | 0.2786 | 0.3819 | 0.2337 | 0.2904 | 0.0936 | 0.3389 | 0.5473 |
| 20 | 0.1364 | 0.1529 | 0.1488 | 0.3251 | 0.3959 | 0.2418 | 0.3065 | 0.0718 | 0.3417 | 0.5519 |
| 30 | 0.113 | 0.1338 | 0.147 | 0.2983 | 0.3712 | 0.2602 | 0.3196 | 0.0606 | 0.3639 | 0.5794 |
| 40 | 0.0863 | 0.1077 | 0.1431 | 0.28 | 0.3456 | 0.2698 | 0.3318 | 0.0415 | 0.3702 | 0.5838 |
| 50 | 0.0665 | 0.1006 | 0.1127 | 0.2808 | 0.3165 | 0.2397 | 0.3037 | 0.0377 | 0.3368 | 0.5506 |
| 60 | 0.043 | 0.0702 | 0.0956 | 0.2754 | 0.278 | 0.2003 | 0.2836 | 0.0294 | 0.3024 | 0.5293 |
| Average | 0.0978 | 0.1245 | 0.1305 | 0.2897 | 0.3482 | 0.2409 | 0.3059 | 0.0558 | 0.3423 | 0.5571 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, C.; Liu, L. Recommendation Method Based on Heterogeneous Information Network and Multiple Trust Relationship. Systems 2023, 11, 169. https://doi.org/10.3390/systems11040169
Yan C, Liu L. Recommendation Method Based on Heterogeneous Information Network and Multiple Trust Relationship. Systems. 2023; 11(4):169. https://doi.org/10.3390/systems11040169
Chicago/Turabian StyleYan, Chun, and Lu Liu. 2023. "Recommendation Method Based on Heterogeneous Information Network and Multiple Trust Relationship" Systems 11, no. 4: 169. https://doi.org/10.3390/systems11040169
APA StyleYan, C., & Liu, L. (2023). Recommendation Method Based on Heterogeneous Information Network and Multiple Trust Relationship. Systems, 11(4), 169. https://doi.org/10.3390/systems11040169