
Optimal Asynchronous Dynamic Policies in Energy-Efficient Data Centers


Abstract
:1. Introduction
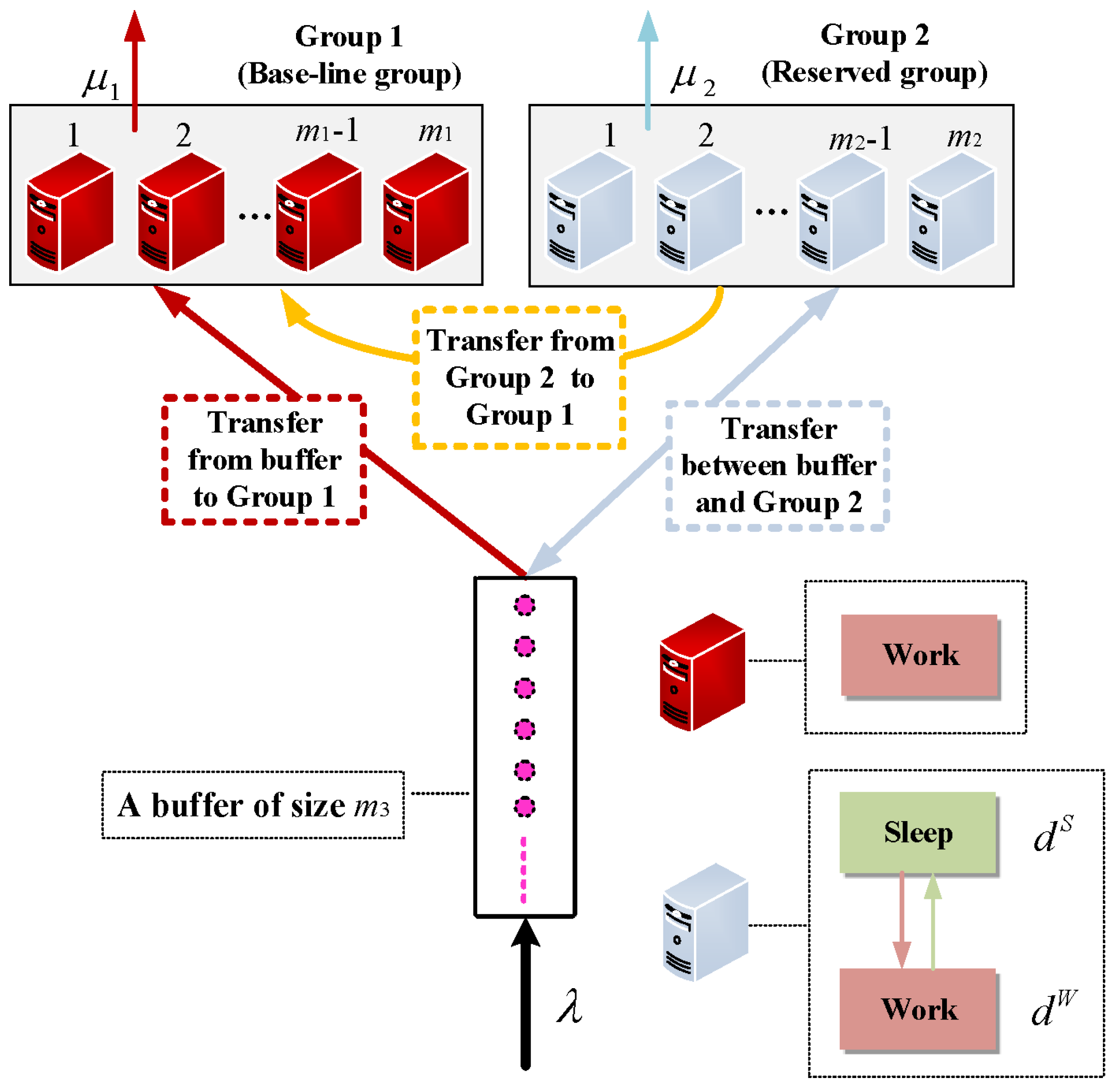
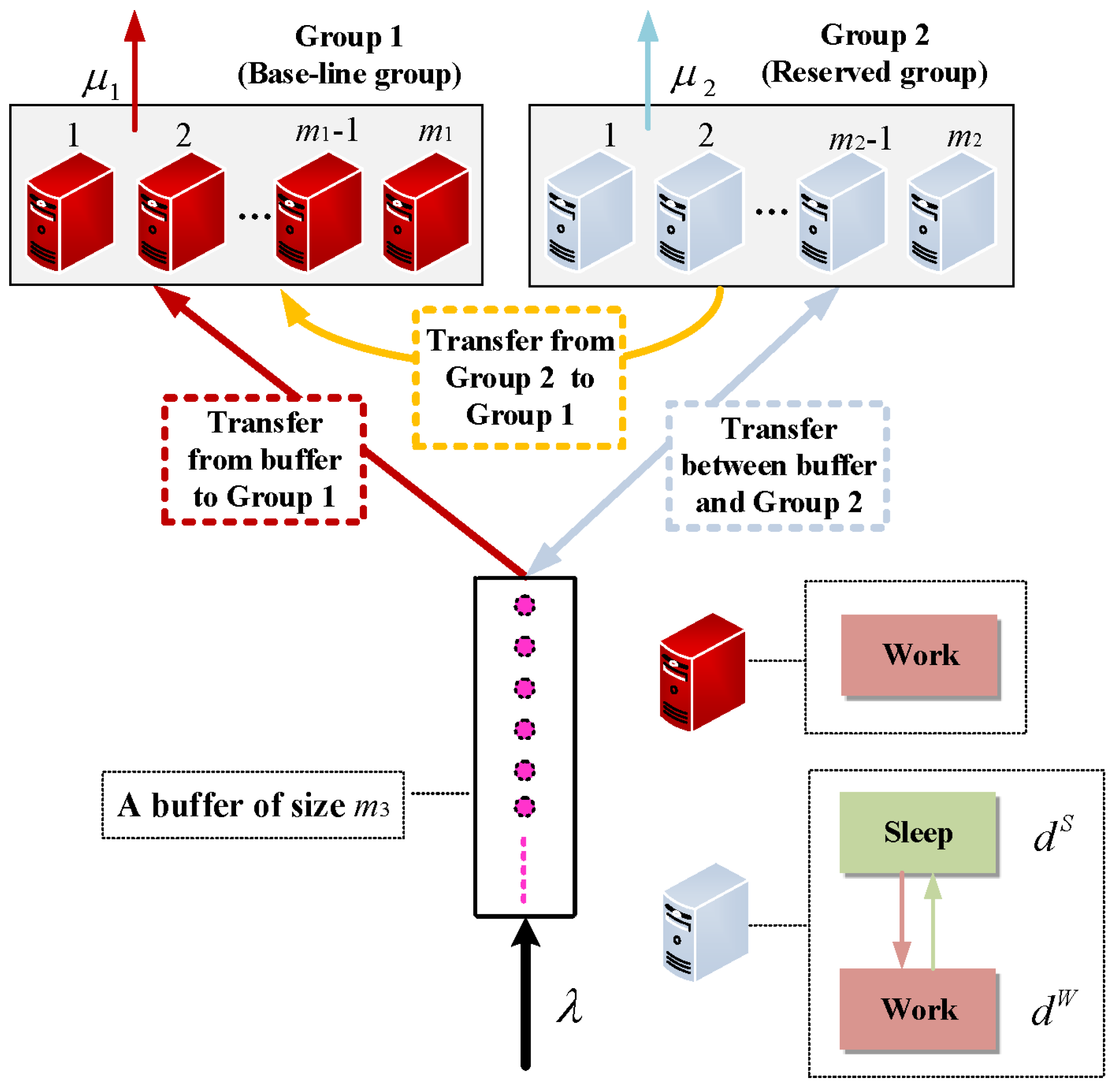
2. Model Description
3. Optimization Model Formulation
3.1. A Policy-Based Block-Structured Continuous-Time Markov Process
3.2. The Reward Function
4. The Block-Structured Poisson Equation
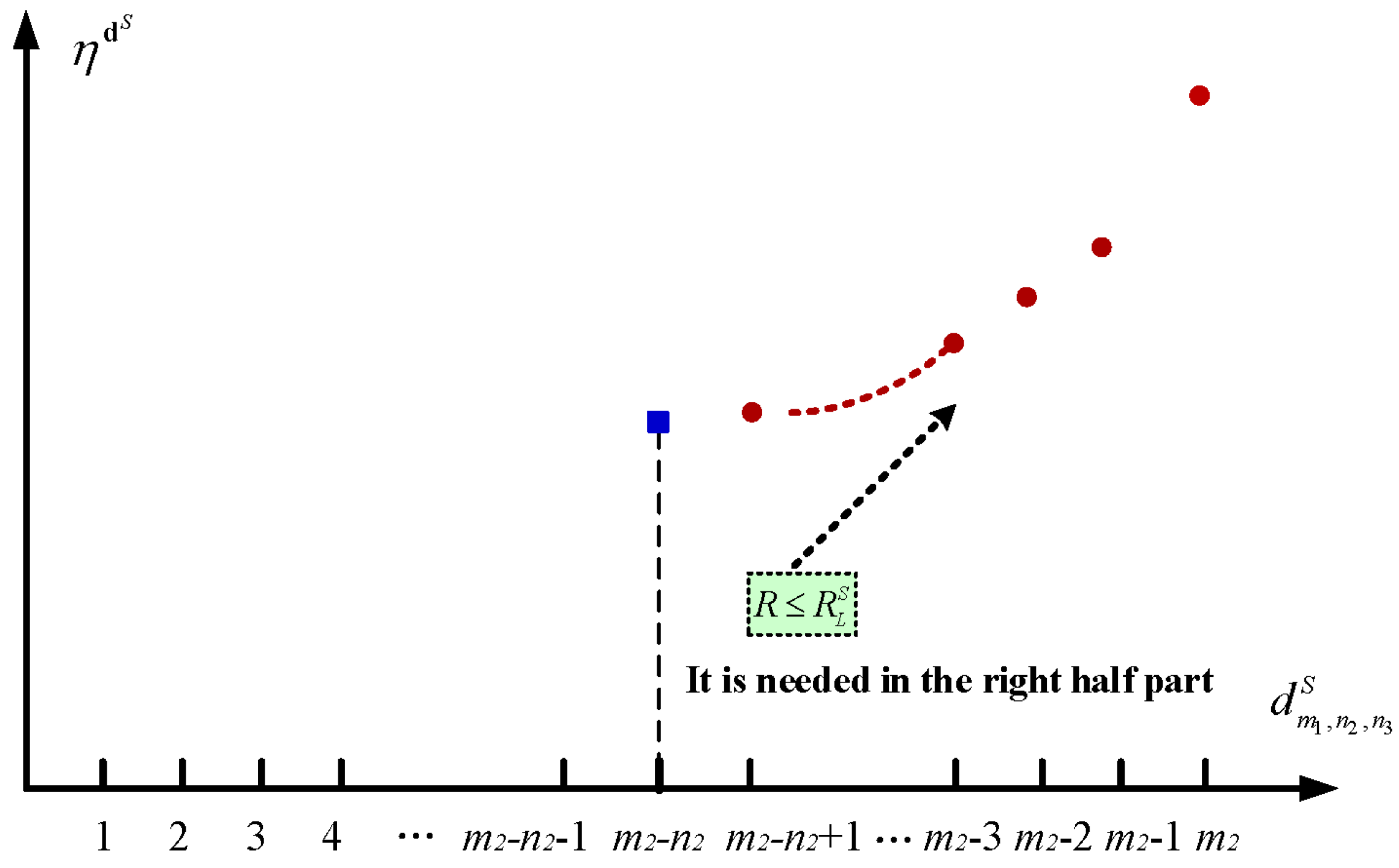
5. Impact of the Service Price
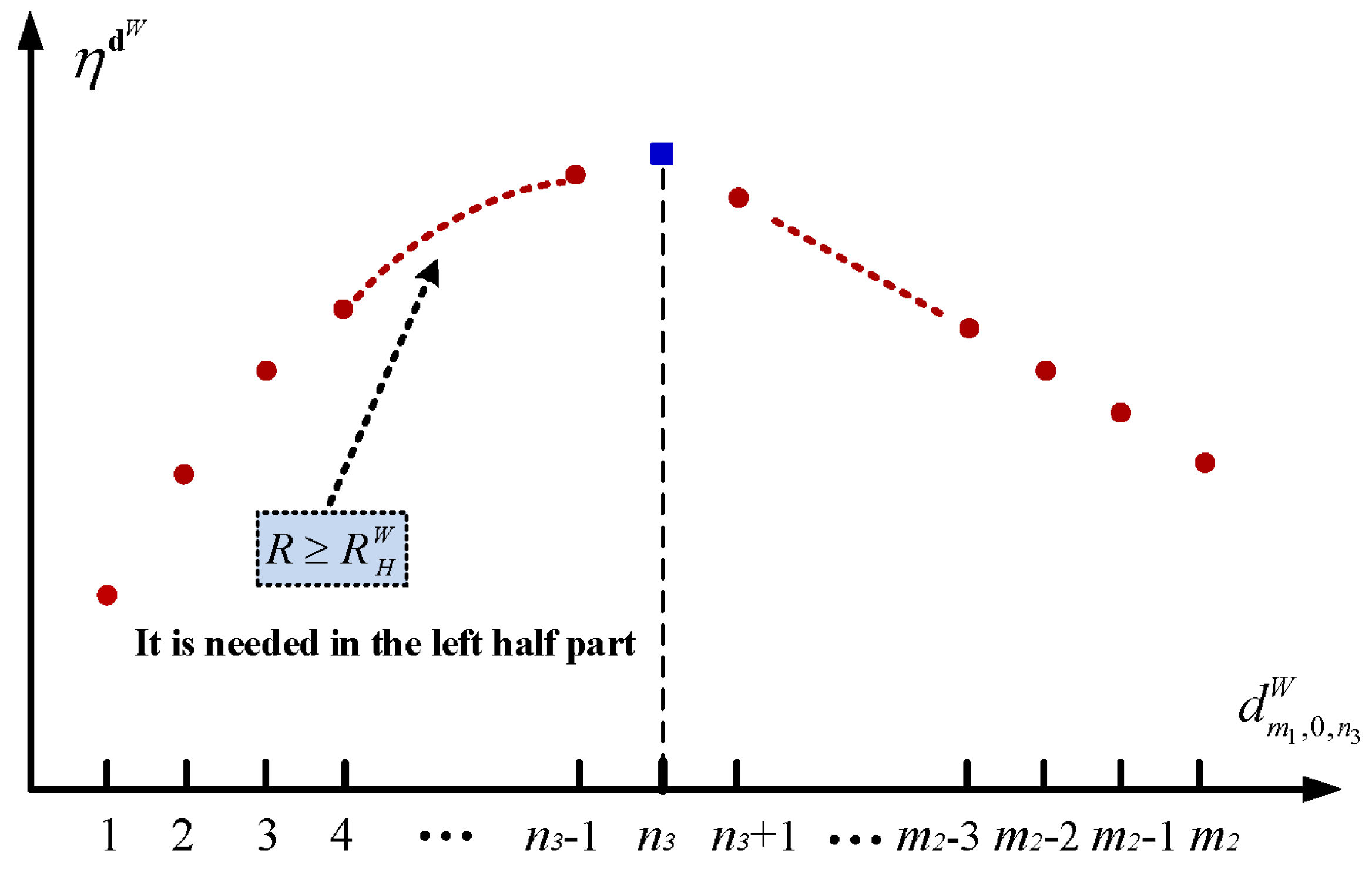
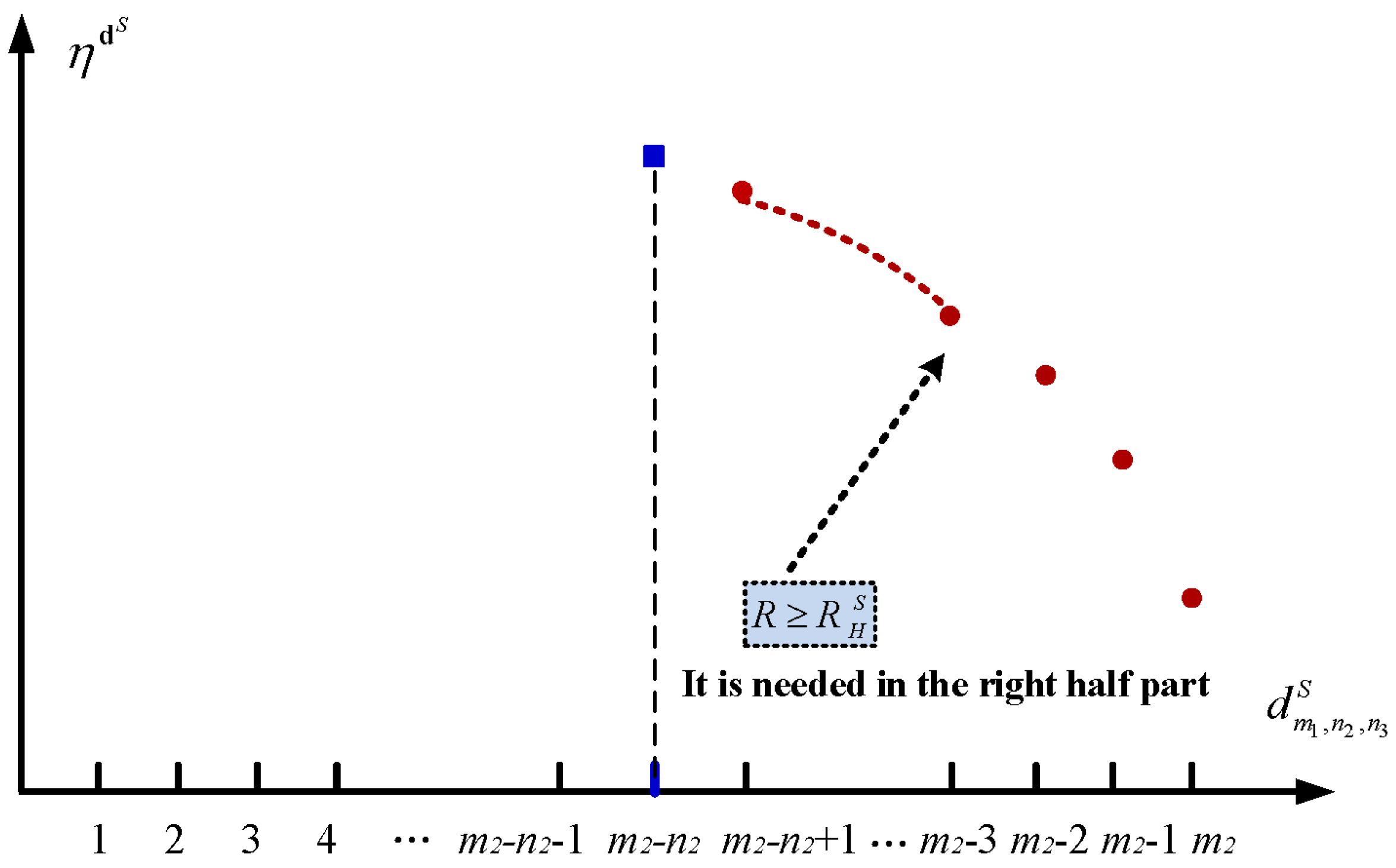
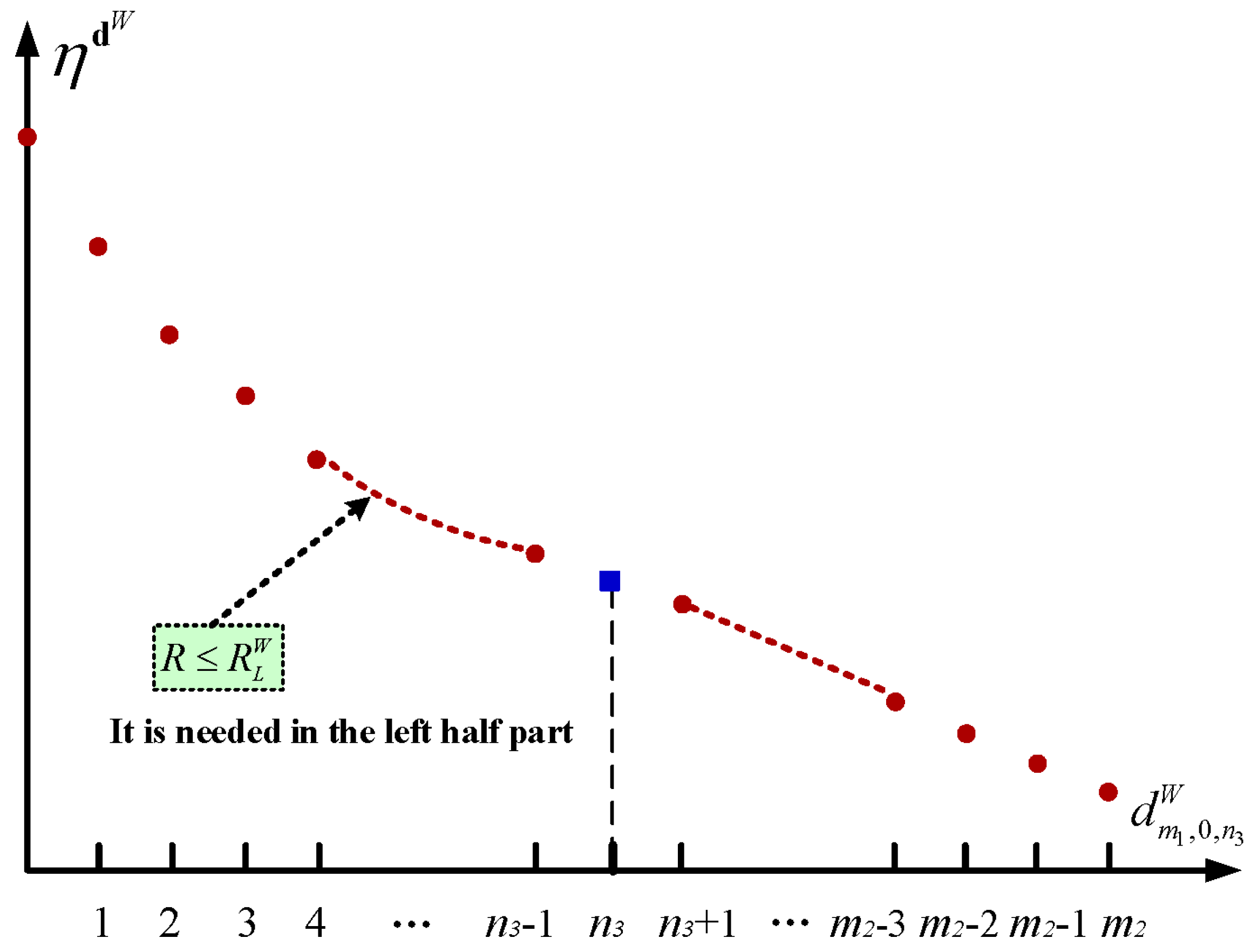
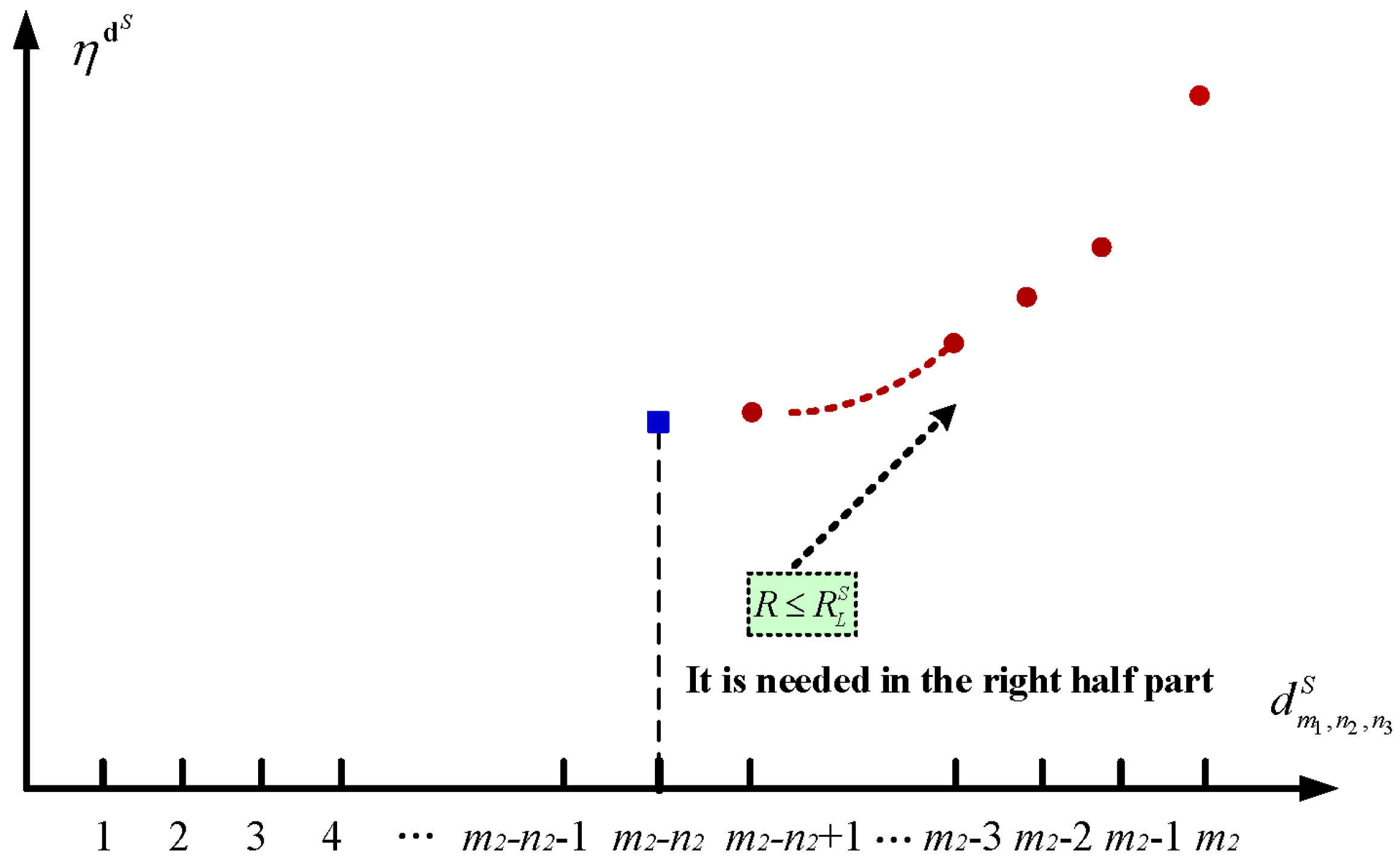
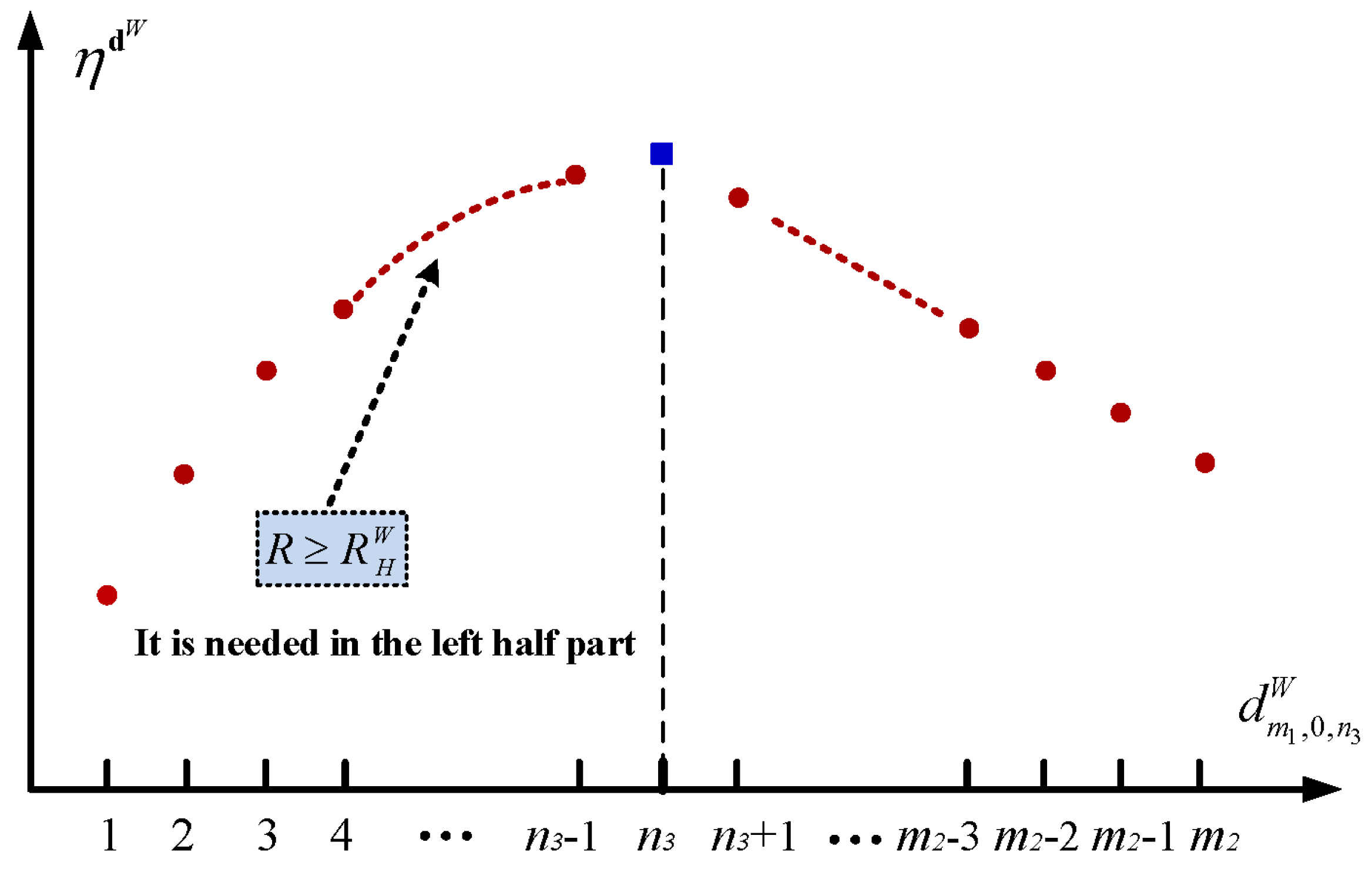
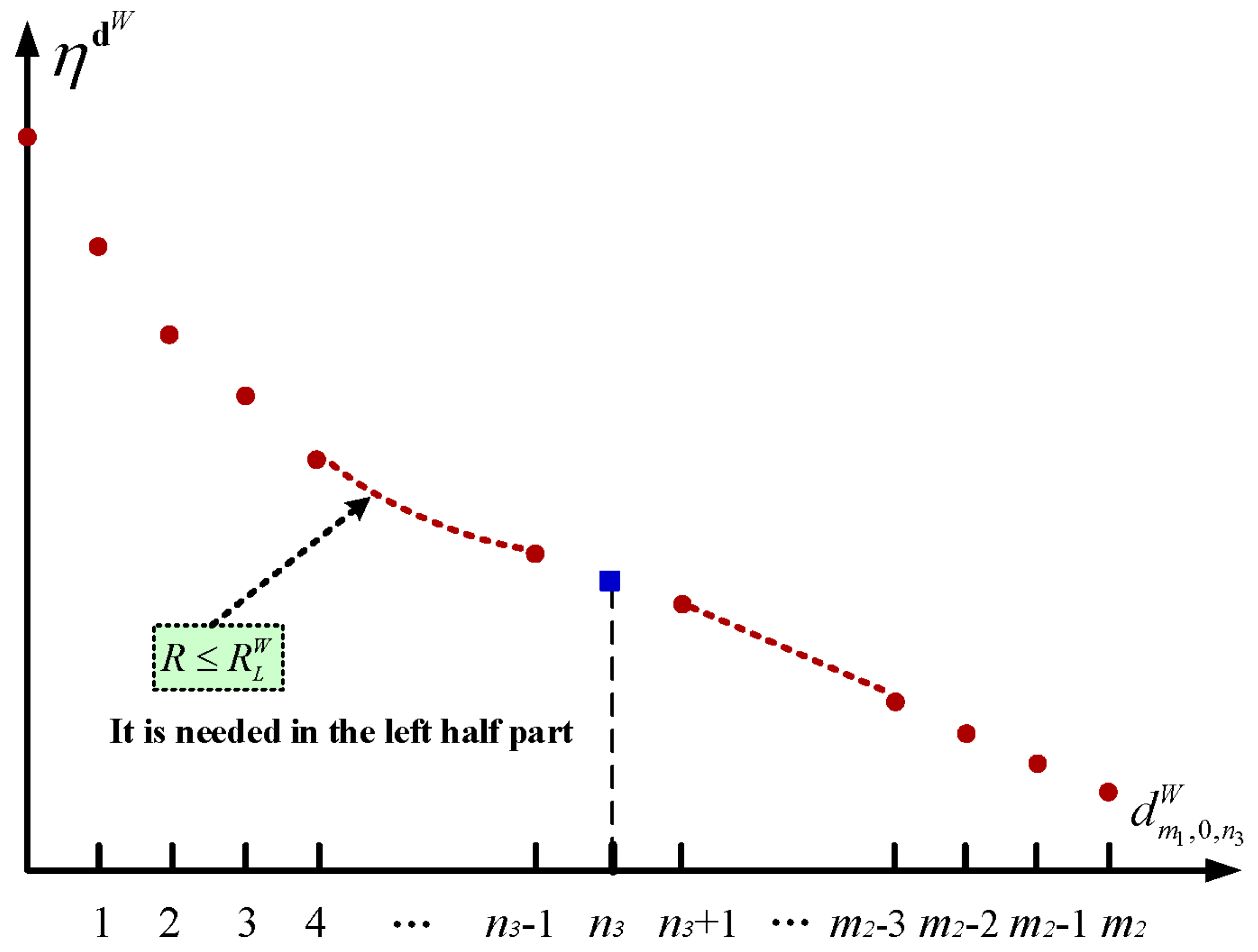
5.1. The Setup Policy
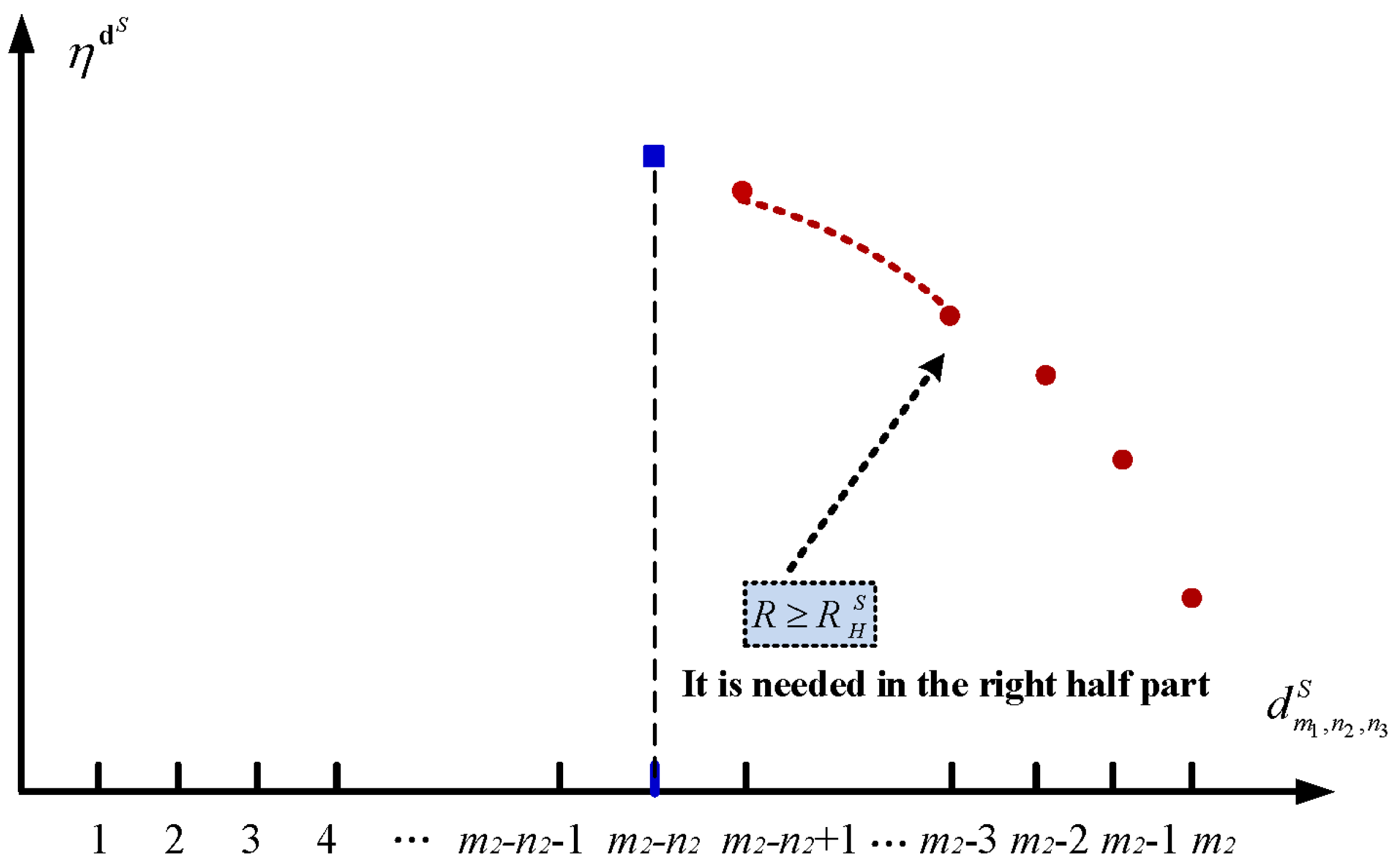
5.2. The Sleep Policy
6. Monotonicity and Optimality
6.1. The Service Price
6.1.1. The Setup Policy with
6.1.2. The Sleep Policy with
6.2. The Service Price
6.2.1. The Setup Policy with
6.2.2. The Sleep Policy with
6.3. The Service Price
6.3.1. The Setup Policy with
6.3.2. The Sleep Policy with
7. The Maximal Long-Run Average Profit
8. Conclusions
- Analyzing non-Poisson inputs such as Markovian arrival processes (MAPs) and/or non-exponential service times, e.g., the PH distributions;
- Developing effective algorithms for finding the optimal dynamic policies of the policy-based block-structured Markov process (i.e., block-structured MDPs);
- Discussing the fact that the long-run performance is influenced by the concave or convex reward (or cost) function;
- Studying individual optimization for the energy-efficient management of data centers from the perspective of game theory.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A. Special Cases
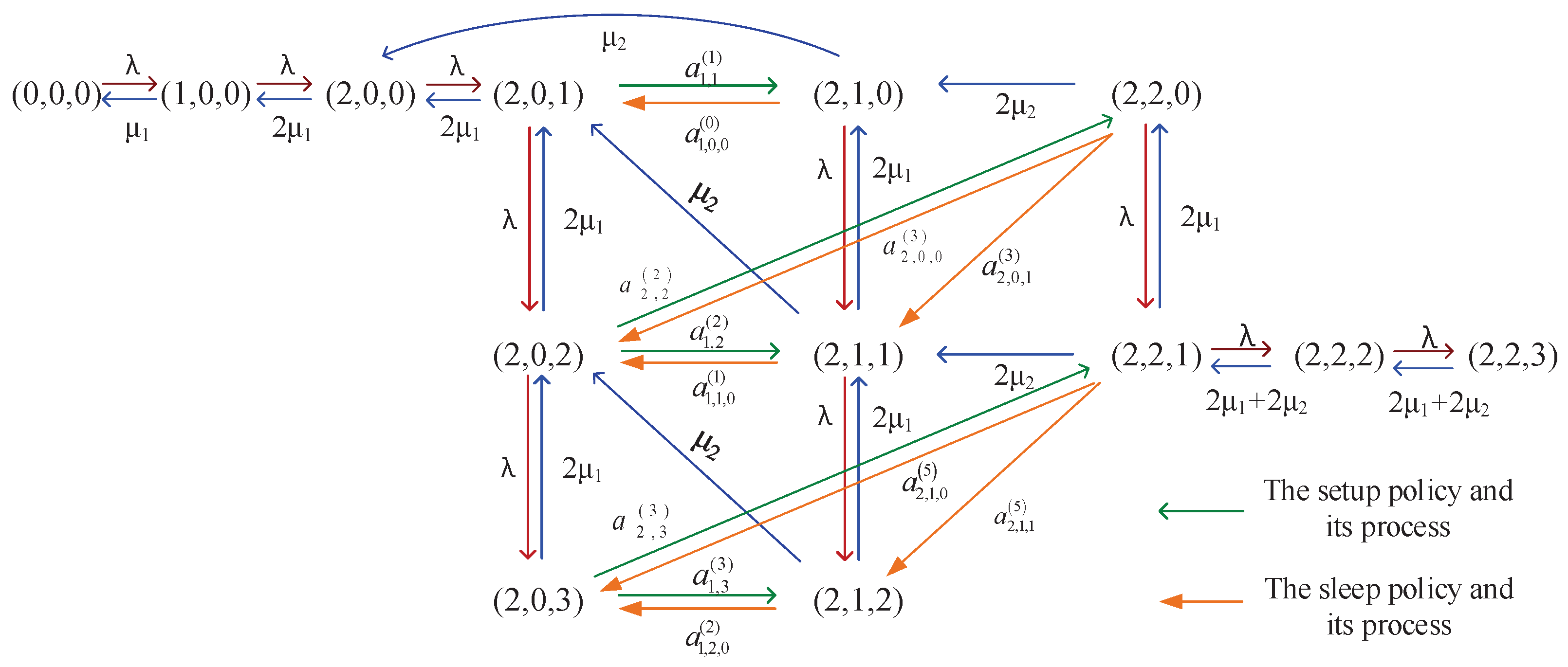
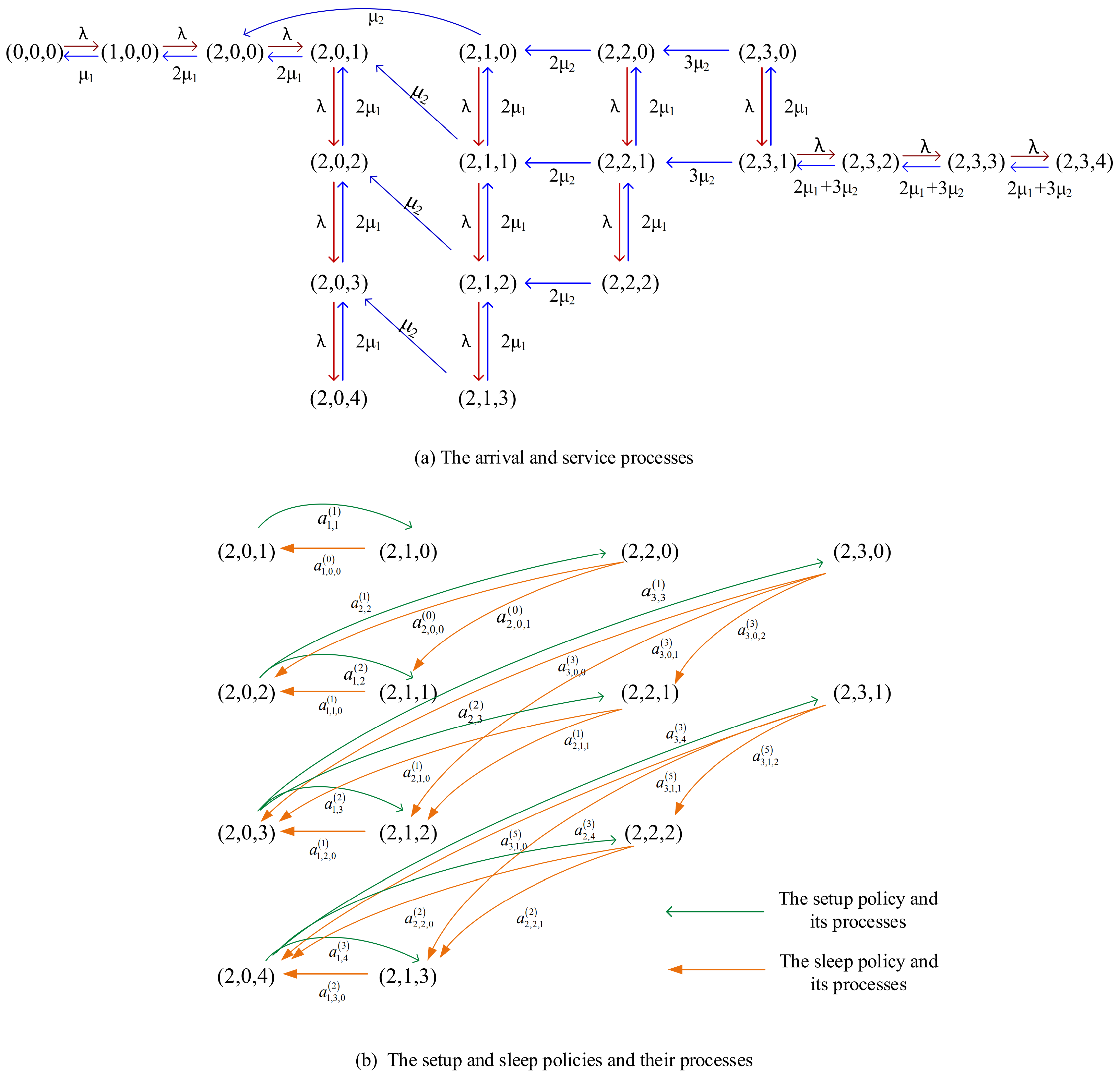
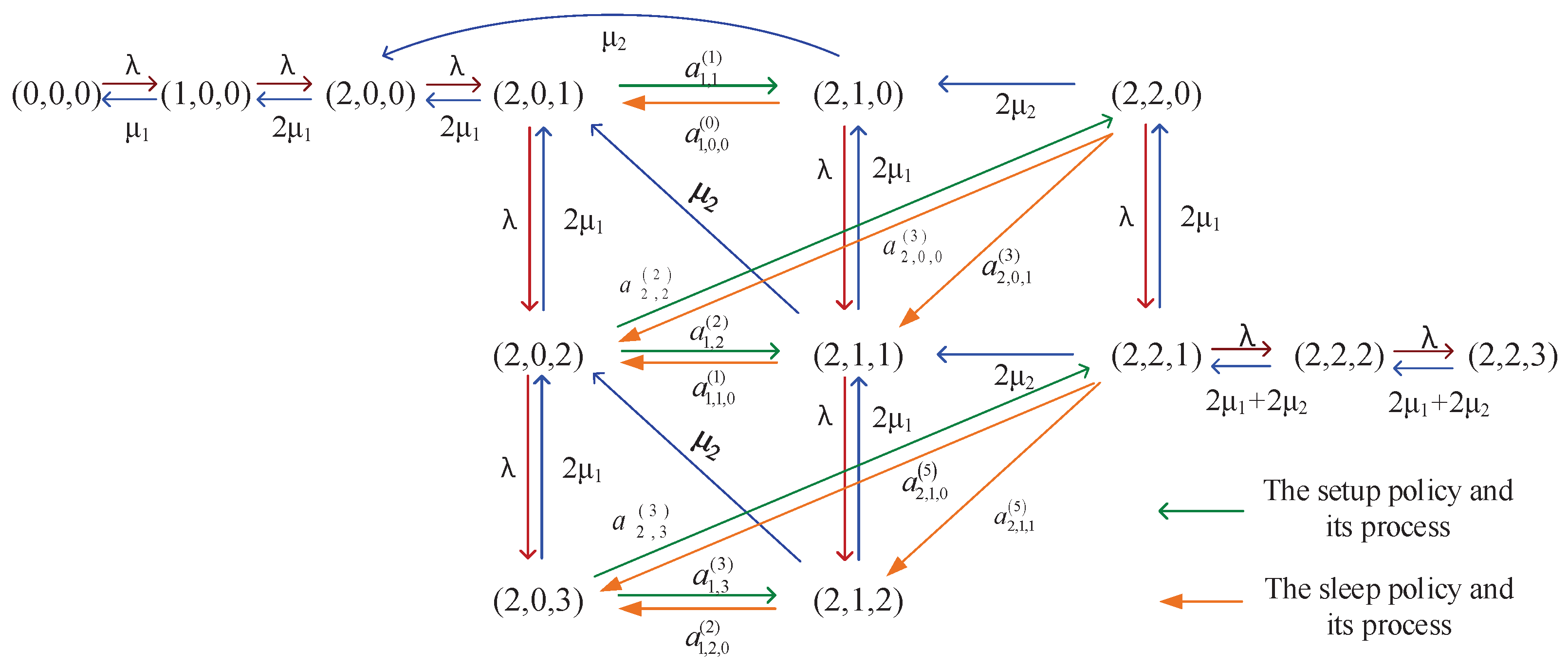
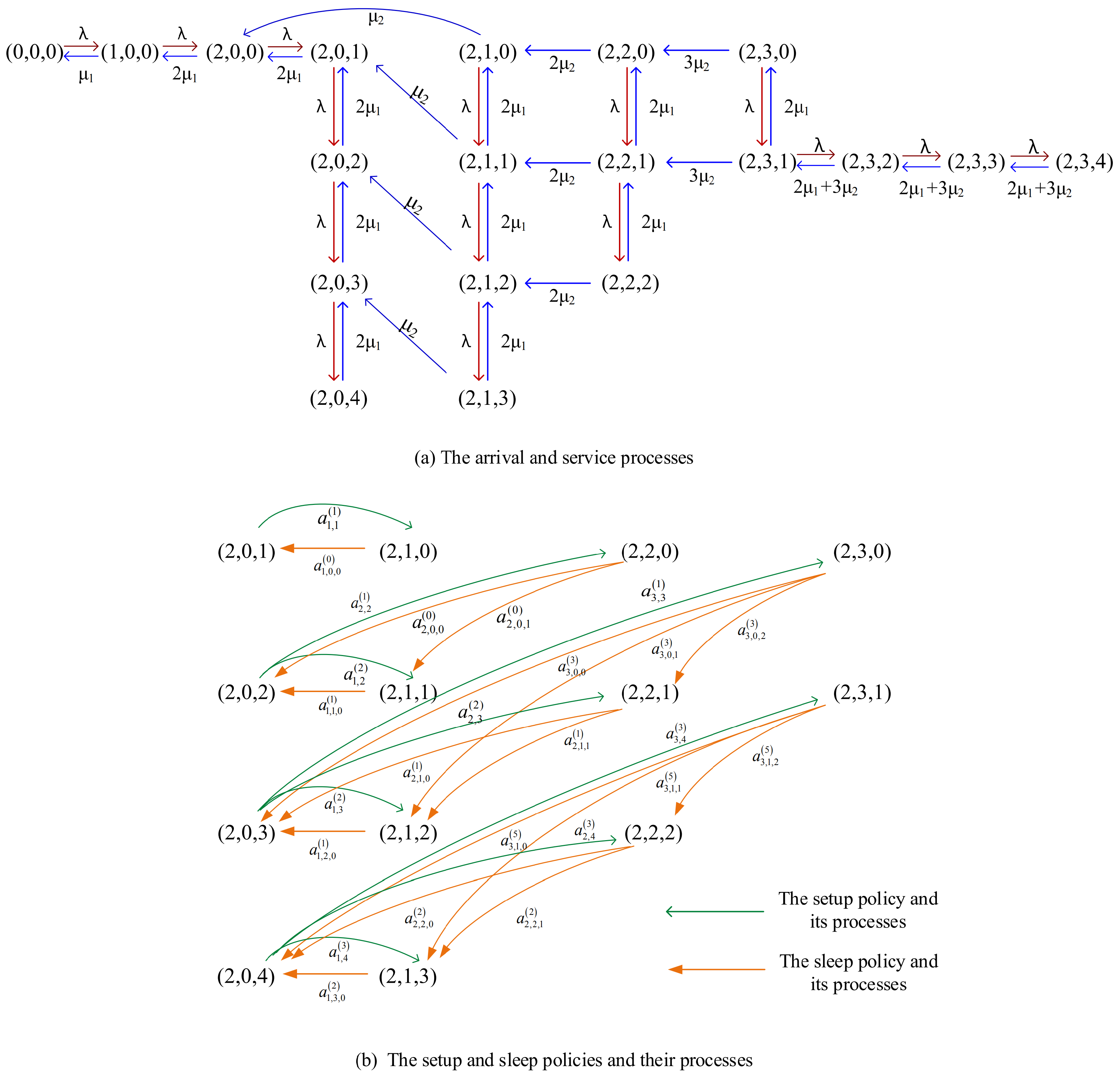
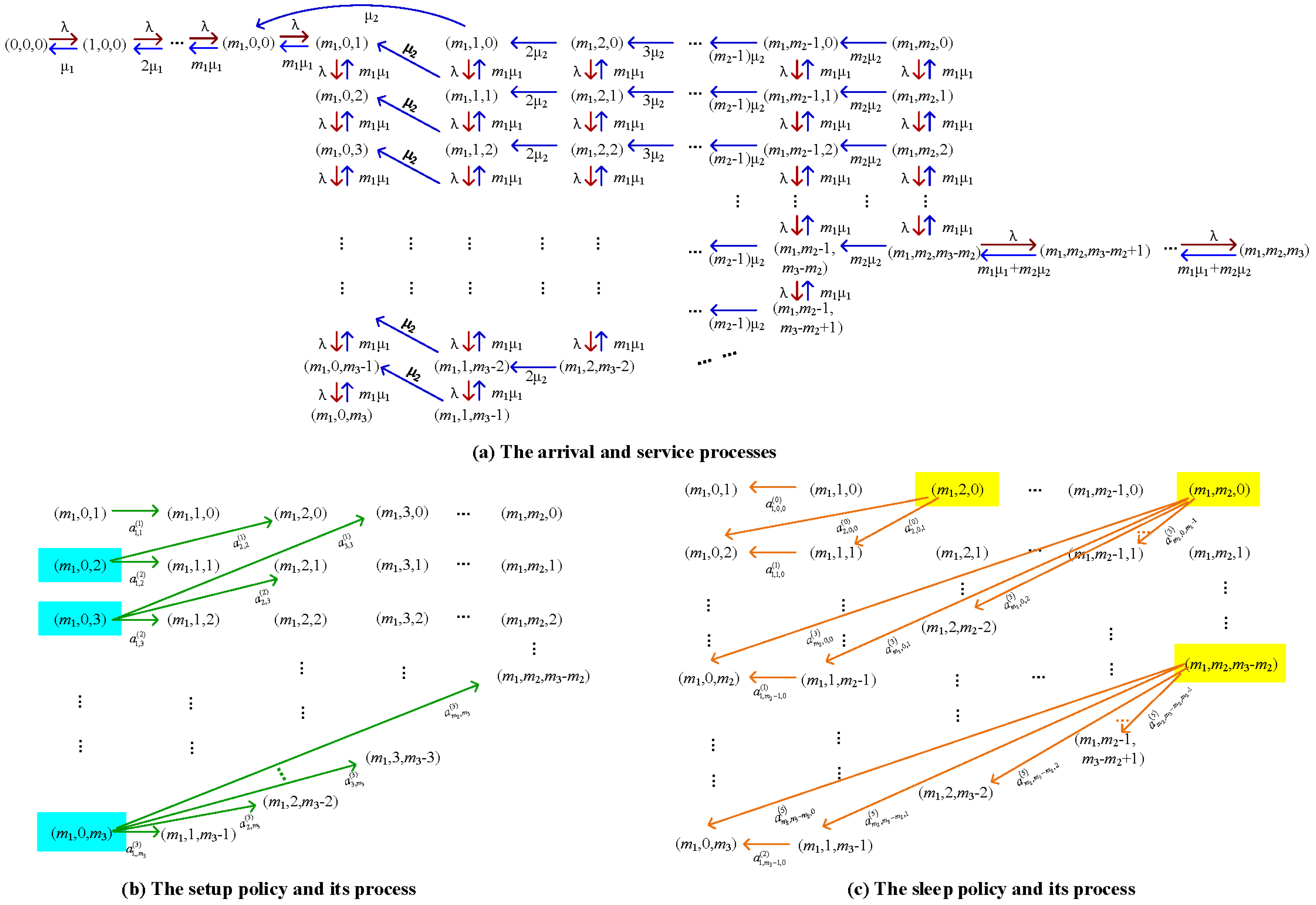
Appendix B. State Transition Relations
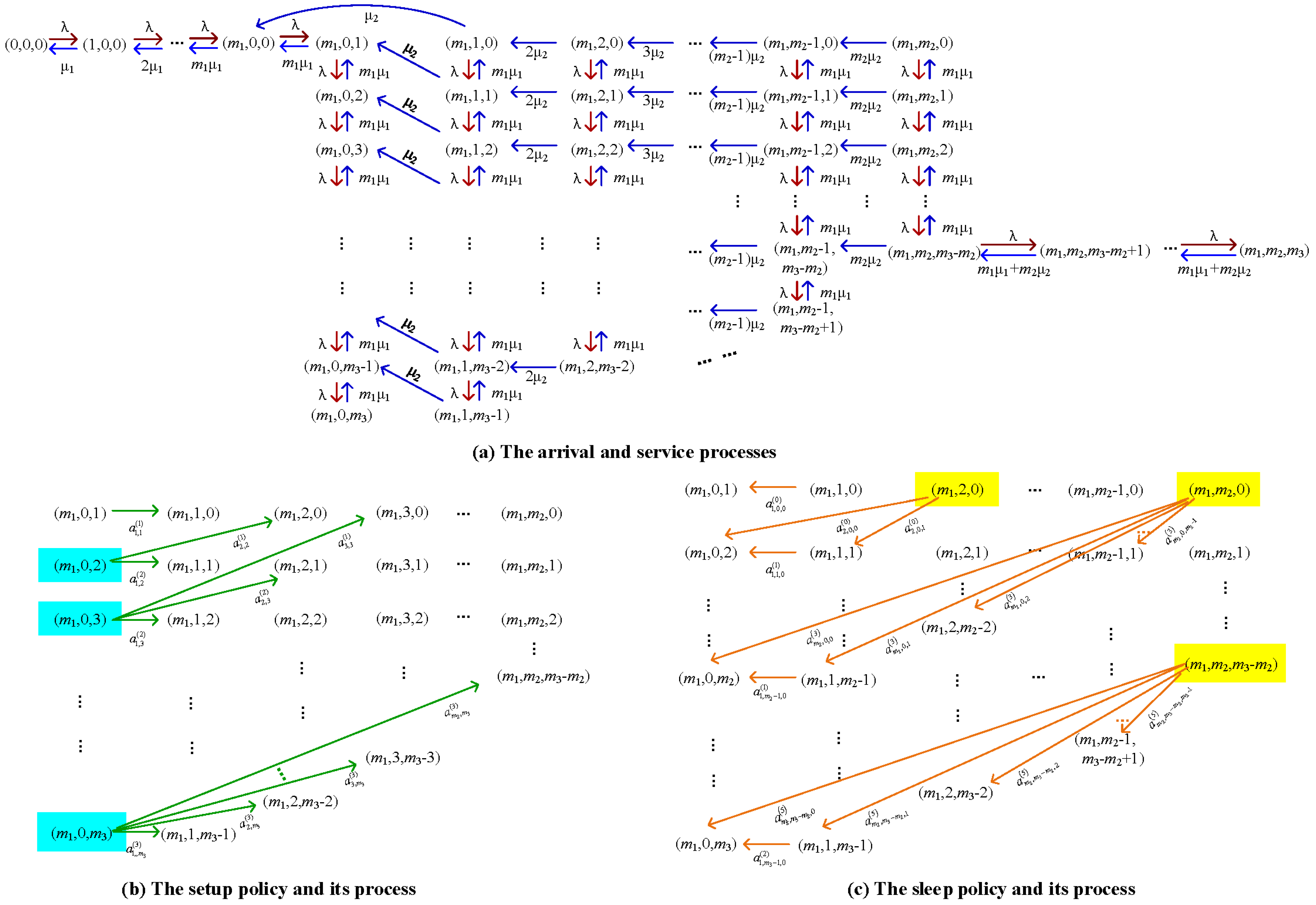
Appendix C. Block Elements in Q(d)
References
- Masanet, E.; Shehabi, A.; Lei, N.; Smith, S.; Koomey, J. Recalibrating global data center energy-use estimates. Science 2020, 367, 984–986. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Meng, Z.; Hong, X.; Zhan, Y.; Liu, J.; Dong, J.; Bai, T.; Niu, J.; Deen, M.J. A survey on data center cooling systems: Technology, power consumption modeling and control strategy optimization. J. Syst. Archit. 2021, 119, 102253. [Google Scholar] [CrossRef]
- Nadjahi, C.; Louahlia, H.; Lemasson, S. A review of thermal management and innovative cooling strategies for data center. Sustain. Comput. Inform. Syst. 2018, 19, 14–28. [Google Scholar] [CrossRef]
- Koot, M.; Wijnhoven, F. Usage impact on data center electricity needs: A system dynamic forecasting model. Appl. Energy 2021, 291, 116798. [Google Scholar] [CrossRef]
- Shirmarz, A.; Ghaffari, A. Performance issues and solutions in SDN-based data center: A survey. J. Supercomput. 2020, 76, 7545–7593. [Google Scholar] [CrossRef]
- Li, Q.L.; Ma, J.Y.; Xie, M.Z.; Xia, L. Group-server queues. In Proceedings of the International Conference on Queueing Theory and Network Applications, Qinhuangdao, China, 21–23 August 2017; pp. 49–72. [Google Scholar]
- Harchol-Balter, M. Open problems in queueing theory inspired by data center computing. Queueing Syst. 2021, 97, 3–37. [Google Scholar] [CrossRef]
- Barroso, L.A.; Hölzle, U. The case for energy-proportional computing. Computer 2007, 40, 33–37. [Google Scholar] [CrossRef]
- Kuehn, P.J.; Mashaly, M.E. Automatic energy efficiency management of data center resources by load-dependent server activation and sleep modes. Ad Hoc Netw. 2015, 25, 497–504. [Google Scholar] [CrossRef]
- Gandhi, A. Dynamic Server Provisioning for Data Center Power Management. Ph.D. Thesis, School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA, 2013. [Google Scholar]
- Gandhi, A.; Doroudi, S.; Harchol-Balter, M.; Scheller-Wolf, A. Exact analysis of the M/M/k/setup class of Markov chains via recursive renewal reward. Queueing Syst. 2014, 77, 177–209. [Google Scholar] [CrossRef]
- Gandhi, A.; Gupta, V.; Harchol-Balter, M.; Kozuch, M.A. Optimality analysis of energy-performance trade-off for server farm management. Perform. Eval. 2010, 67, 1155–1171. [Google Scholar] [CrossRef] [Green Version]
- Gandhi, A.; Harchol-Balter, M.; Adan, I. Server farms with setup costs. Perform. Eval. 2010, 67, 1123–1138. [Google Scholar] [CrossRef]
- Maccio, V.J.; Down, D.G. On optimal policies for energy-aware servers. Perform. Eval. 2015, 90, 36–52. [Google Scholar] [CrossRef] [Green Version]
- Maccio, V.J.; Down, D.G. Exact analysis of energy-aware multiserver queueing systems with setup times. In Proceedings of the IEEE 24th International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems, London, UK, 19–21 September 2016; pp. 11–20. [Google Scholar]
- Phung-Duc, T. Exact solutions for M/M/c/setup queues. Telecommun. Syst. 2017, 64, 309–324. [Google Scholar] [CrossRef] [Green Version]
- Phung-Duc, T.; Kawanishi, K.I. Energy-aware data centers with s-staggered setup and abandonment. In Proceedings of the International Conference on Analytical and Stochastic Modeling Techniques and Applications, Cardiff, UK, 24–26 August 2016; pp. 269–283. [Google Scholar]
- Gebrehiwot, M.E.; Aalto, S.; Lassila, P. Optimal energy-aware control policies for FIFO servers. Perform. Eval. 2016, 103, 41–59. [Google Scholar] [CrossRef]
- Gebrehiwot, M.E.; Aalto, S.; Lassila, P. Energy-performance trade-off for processor sharing queues with setup delay. Oper. Res. Lett. 2016, 44, 101–106. [Google Scholar] [CrossRef]
- Gebrehiwot, M.E.; Aalto, S.; Lassila, P. Energy-aware SRPT server with batch arrivals: Analysis and optimization. Perform. Eval. 2017, 15, 92–107. [Google Scholar] [CrossRef]
- Mitrani, I. Service center trade-offs between customer impatience and power consumption. Perform. Eval. 2011, 68, 1222–1231. [Google Scholar] [CrossRef]
- Mitrani, I. Managing performance and power consumption in a server farm. Ann. Oper. Res. 2013, 202, 121–134. [Google Scholar] [CrossRef]
- Kamitsos, I.; Ha, S.; Andrew, L.L.; Bawa, J.; Butnariu, D.; Kim, H.; Chiang, M. Optimal sleeping: Models and experiments for energy-delay tradeoff. Int. J. Syst. Sci. Oper. Logist. 2017, 4, 356–371. [Google Scholar] [CrossRef]
- Hipp, S.K.; Holzbaur, U.D. Decision processes with monotone hysteretic policies. Oper. Res. 1988, 36, 585–588. [Google Scholar] [CrossRef]
- Lu, F.V.; Serfozo, R.F. M/M/1 queueing decision processes with monotone hysteretic optimal policies. Oper. Res. 1984, 32, 1116–1132. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, S.; Wu, X.; Ran, Y.; Xi, H. Online learning-based server provisioning for electricity cost reduction in data center. IEEE Trans. Control Syst. Technol. 2017, 25, 1044–1051. [Google Scholar] [CrossRef]
- Ding, D.; Fan, X.; Zhao, Y.; Kang, K.; Yin, Q.; Zeng, J. Q-learning based dynamic task scheduling for energy-efficient cloud computing. Future Gener. Comput. Syst. 2020, 108, 361–371. [Google Scholar] [CrossRef]
- Liang, Y.; Lu, M.; Shen, Z.J.M.; Tang, R. Data center network design for internet-related services and cloud computing. Prod. Oper. Manag. 2021, 30, 2077–2101. [Google Scholar] [CrossRef]
- Xia, L.; Chen, S. Dynamic pricing control for open queueing networks. IEEE Trans. Autom. Control 2018, 63, 3290–3300. [Google Scholar] [CrossRef]
- Xia, L.; Miller, D.; Zhou, Z.; Bambos, N. Service rate control of tandem queues with power constraints. IEEE Trans. Autom. Control 2017, 62, 5111–5123. [Google Scholar] [CrossRef]
- Ma, J.Y.; Xia, L.; Li, Q.L. Optimal energy-efficient policies for data centers through sensitivity-based optimization. Discrete Event Dyn. Syst. 2019, 29, 567–606. [Google Scholar] [CrossRef] [Green Version]
- Chi, C.; Ji, K.; Marahatta, A.; Song, P.; Zhang, F.; Liu, Z. Jointly optimizing the IT and cooling systems for data center energy efficiency based on multi-agent deep reinforcement learning. In Proceedings of the 11th ACM International Conference on Future Energy Systems, Virtual Event, Australia, 22–26 June 2020; pp. 489–495. [Google Scholar]
- Li, Q.L. Constructive Computation in Stochastic Models with Applications: The RG-Factorizations; Springer: Beijing, China, 2010. [Google Scholar]
- Cao, X.R. Stochastic Learning and Optimization—A Sensitivity-Based Approach; Springer: New York, NY, USA, 2007. [Google Scholar]
- Xia, L.; Zhang, Z.G.; Li, Q.L. A c/μ-rule for for job assignment in heterogeneous group-server queues. Prod. Oper. Manag. 2021, 1–18. [Google Scholar] [CrossRef]
- Li, Q.L.; Li, Y.M.; Ma, J.Y.; Liu, H.L. A complete algebraic transformational solution for the optimal dynamic policy in inventory rationing across two demand classes. arXiv 2019, arXiv:1908.09295v1. [Google Scholar]
- Ma, J.Y.; Li, Q.L. Sensitivity-based optimization for blockchain selfish mining. In Proceedings of the International Conference on Algorithmic Aspects of Information and Management, Dallas, TX, USA, 20–22 December 2021; pp. 329–343. [Google Scholar]
- Xia, L. Risk-sensitive Markov decision processes with combined metrics of mean and variance. Prod. Oper. Manag. 2020, 29, 2808–2827. [Google Scholar] [CrossRef]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley& Sons: New York, NY, USA, 2014. [Google Scholar]
- Budhiraja, A.; Friedlander, E. Diffusion approximations for controlled weakly interacting large finite state systems with simultaneous jumps. Ann. Appl. Probab. 2018, 28, 204–249. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cost | Necessary Interpretation |
|---|---|
| The power consumption price | |
| The holding cost for a job in Group 1 per unit of sojourn time | |
| The holding cost for a job in Group 2 per unit of sojourn time | |
| The holding cost for a job in the buffer per unit of sojourn time | |
| The setup cost for a server switching from the sleep state to the work state | |
| The transferred cost for a incomplete-service job returning to the buffer | |
| The transferred cost for a job in Group 2 is transferred to Group 1 | |
| The opportunity cost for each lost job | |
| R | The service price from the served job |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.-Y.; Li, Q.-L.; Xia, L. Optimal Asynchronous Dynamic Policies in Energy-Efficient Data Centers. Systems 2022, 10, 27. https://doi.org/10.3390/systems10020027
Ma J-Y, Li Q-L, Xia L. Optimal Asynchronous Dynamic Policies in Energy-Efficient Data Centers. Systems. 2022; 10(2):27. https://doi.org/10.3390/systems10020027
Chicago/Turabian StyleMa, Jing-Yu, Quan-Lin Li, and Li Xia. 2022. "Optimal Asynchronous Dynamic Policies in Energy-Efficient Data Centers" Systems 10, no. 2: 27. https://doi.org/10.3390/systems10020027
APA StyleMa, J.-Y., Li, Q.-L., & Xia, L. (2022). Optimal Asynchronous Dynamic Policies in Energy-Efficient Data Centers. Systems, 10(2), 27. https://doi.org/10.3390/systems10020027