1. Introduction
Infectious diseases have been the focus of multiple fields of research. In public health and epidemiology, efforts are directed at establishing transmission dynamics, the characteristics of infectious agents, and the populations most affected by pathogens, among others, which are of high importance for science [
1]. In recent decades, research on infectious diseases has involved the application of complex theories from mathematics and engineering. In particular, the use of network models has allowed explanations of the spread of diseases from infected people (nodes) and their links with others (edges) [
2].
Network models establish the connection between population groups, which is useful not only in the field of public health or epidemiology, but also in engineering and social sciences [
3] (see [
4,
5,
6,
7,
8]). In the health field, being a theoretical approach, the importance of recognizing the complexities of community structures has been discussed in order to understand social dynamics in the spread of infectious diseases [
9]. For example, Magelinski et al. developed a model to estimate the role played by certain nodes in community structures [
10], while Ghalmane et al. included the dimension of centrality in complex networks [
11].
Regarding the COVID-19 pandemic, a series of models have been developed which allow the projection and establishment of the progress of this infectious disease based on the data available from different information sources (see, for instance, [
12]). In this sense, Manríquez et al. propose the use of weighted graphs at the edges, giving the network model, from a stochastic approach, the possibility of identifying the most important variables in the spread of COVID-19 with real data in a city in Chile [
13]. The same authors, in order to classify the importance of the nodes, propose the generalization of the measure of importance of the line with the use of degree of centrality (DIL-W
), improving the understanding of the network from a local perspective [
14].
On the other hand, the same network models have served to search for protection strategies for populations, generally related to the processes of immunization or isolation of people (see [
15,
16,
17,
18,
19,
20]).
Scientific evidence supports immunization strategies being useful in both homogeneous and heterogeneous networks [
21]. The strategies seek, first, to develop a dynamic experimental model that includes the classic compartmental systems in epidemiology (SIR, SEIR, SIS, among others) and then to establish immunization measures across the nodes. Immunization measures can be applied in static and dynamic networks, in a random or targeted immunization [
22].
Random immunization refers to random strategies, without determining a particular population in the protection process [
23]. In contrast, targeted immunization recognizes nodes with a higher degree of connection with other nodes [
24]. Nian et al. conclude, through computational simulations in a free scale graph (Model BA), that targeted immunization is more effective than randomized [
21]. In the same direction, Wang et al. conclude that, even if the immunization strategy is imperfect or incomplete, it manages to generate positive impacts on the protection of the network [
25]. Another investigation by Xia et al. determined that targeted immunization in two rounds of selection provides a greater protective effect compared to progressive strategies [
24].
According to the above, a study conducted by Ghalmane et al. proposed an immunization strategy considering the influence of the nodes, the number of communities and the links between them [
26]. Along the same lines, Gupta et al. analyzed the importance of protection strategies using information from community networks [
27]. Since edge-weighted graphs have been an important way of understanding epidemic diseases, Manríquez et al. measure the effectiveness of DIL-W
with the recognition of bridge nodes. The effectiveness of DIL-W
is high compared to other proposals on four real networks [
28].
For all the above, studies that include immunization measures together with community/local network models are highly relevant for public health, both for establishing measures to mitigate epidemic diseases and for the development of vaccination optimization policies to more quickly achieve herd immunization and, therefore, overcome diseases such as COVID-19. This is supported by Zhao et al., who argue that this framework allows for the optimization of immunization resources [
29].
This study aims to analyze the protection effect against COVID-19 using the DIL-W
ranking with real data from a city in Chile (Olmué-City), obtained from the Epidemiological Surveillance System of the Ministry of Health of Chile, from which we obtain an edge-weighted graph, denoted by
, according to the method proposed in [
13]. We apply the protection to the
network, according to the importance ranking list produced by DIL-W
, considering different protection budgets. For the ranking DIL-W
, we consider three different values for
; they are 0,
and 1. In this way, we compare how the protection performs according to the value of
. We use a graph-based SIR model, namely, each individual is represented by a vertex in
. At time
t, each vertex
is in a state
belonging to
, where
and
represent the three discrete states: Susceptible (S), Infected (I) and Recovered or Removed (R). Five hundred simulations were performed on
; the initial population contains one infected node and all the simulations, considering
(recovered rate).
This paper is organized as follows:
Section 2 contains generalities about graph theory, includes a graph from a database, and the DIL-W
ranking is explained. In
Section 3, we obtain the graph from a real database from a city in Chile (Olmué-City), and we set the protection strategy. In
Section 4, the results of the study are presented.
Section 5 provides a discussion of the results and potentialities of the method used. Finally,
Section 6 provides the conclusions.
2. Basic Definitions
In this section, we establish the definitions and elements used throughout this paper. We summarize the symbols and notations in
Table 1.
2.1. Graphs
The following definitions come from [
30,
31].
Definition 1. A graph G is a finite nonempty set V of objects called vertices, together with a possibly empty set E of 2-element subsets of V called edges.
To indicate that a graph G has vertex set V and edge set E, we write . If the set of vertices is , then the edge between vertex and vertex is denoted by .
If is an edge of G, then and are adjacent vertices. Two adjacent vertices are referred to as neighbors of each other. The set of neighbors of a vertex v is called the open neighborhood of v (or simply the neighborhood of v) and is denoted by . If and are distinct edges in G, then and are adjacent edges.
Definition 2. The number of vertices in a graph G is the order of G and the number of edges is the size of G.
Definition 3. The degree of a vertex v in a graph G, denoted by , is the number of vertices in G that are adjacent to v. Thus, the degree of v is the number of vertices in its neighborhood .
Definition 4. Let G be a graph of order n, where . The adjacency matrix of G is the zero-one matrix , or simply , where On the other hand, an important generalization of the simple graph consists of the definition of a weighted graph, more specifically an edge-weighted graph. Informally, an edge-weighted graph is a graph whose edges have been assigned a weight.
Definition 5. An edge-weighted graph is a pair , where is a graph and is a weight function. If then .
Definition 6. The strength of a vertex , denoted by , is defined as the sum of the weights of all edges incident to it, this is to say, The following definition comes from [
32].
Definition 7 (Degree centrality [
32])
. The degree centrality of of an edge-weighted graph , denoted by , is defined aswhere . The parameter is called the tuning parameter. Notice that, when , then and, when , then .
2.2. DIL-W Ranking
We briefly describe the DIL-W
ranking in this Section. The DIL ranking is a tool for evaluating the node importance based on degree and the importance of lines (DIL) proposed by Liu et al. in [
33] for an undirected and unweighted network. Recently, Manríquez et al. in [
14] propose DIL-W
rank. This ranking method of node importance for undirected and edge-weighted is a generalization of the measure of line importance (DIL) based on the centrality degree (Definition 7) proposed by Opsahl in [
32].
The following comes from [
14].
Let us consider an undirected weighted graph with and .
Definition 8 (Importance edge [
14])
. The importance of an edge , denoted by , is defined aswhere, for , with p being the number of triangles, one edge of the triangle is , is the weight of the sum of the edges incident to that form a triangle with and . In order to illustrate the above Definition, let us consider the edge-weighted graph in
Figure 1. Moreover, we consider the edges
and
. Notice that they both have the same weight (three). For this example, we set
. Applying Definition 7, we get:
In the same way with the edge
, we obtain
In conclusion, edge is more important than edge .
The latter is reasonable because the edge is a bridging edge of the graph.
Definition 9 (Contribution [
14])
. The contribution that makes to the importance of the edge , denoted by , is defined aswhere is the weight of . We have calculated the importance of the edge
of the graph in
Figure 1. The contribution that
makes to it is given by Definition 9:
In the same way, the contribution that
makes to
is:
The above means that the node contributes more to the edge than node .
Definition 10 (Importance of vertex DIL-W
[
14])
. The importance of a vertex , denoted by , is defined as Remark 1. From the definition of Degree centrality (Definition 7) proposed by Opsahl in [32], we can see that, when the tuning parameter α is 0
, the Definitions 8–10 are the same than the proposed by Liu et al. In order to illustrate the above Definition, we compute the importance of
and
in the graph of
Figure 1.
and
Since , then node is more important than node (according to DIL-W ranking).
2.3. Graph from a Database
The authors of [
13] provide a way to obtain an edge-weighted graph from a database, which we briefly detail.
Let be a set of people registered in a database, denoted by , with K different variables, denoted by . These variables are separated into two categories: the characteristic variables (CHAR) and the relationship variables (REL) (which are those that allow us to assume that some person meets another). Let us denote by the number of relationship variables and the response of the person to the variable .
Definition 11. We will say that a person is related to a person if and only if there exists for such that and .
To define the weight of each link between two persons, we assume that each has an associated inherent weight, this is to say, it is possible to discriminate some hierarchical order between the variables. Let be the weight associated to the variable for .
Definition 12. We will say that for , is related to , denoted by , if and only if .
Definition 13. Let be the different classes that are defined by the different weights and and its respective cardinalities. Hence,for all . We denoted by the number of times that one person is related to another (or the number of variables that matches between them).
Definition 14. Let be such that is related to and is the weight of the variable in which and match, for . We will say thatis the weight of the link between and . Finally, the weighted adjacency matrix, which defines the graph obtained from the database, is the
matrix
, where
Example 1. In the following example, Table 2 simulates a database with 20 registered people. The data hosted correspond to the city in which they live (City), the workplace (considering school and university as a workplace), gender (Gen.), age, extracurricular activity (EC activity), address, whether they drink alcohol (Drin.), whether they are smokers (Sm.) and marital status (MS). Let us consider A and B as two different cities, and and h as different people’s addresses. Moreover, in the table, Y = Yes, N = No, IC = in couple, M = married, S = single, W = widower. From Table 2, we have that , where City, Workplace, E.P. activity, Address, Sm., Dri., Gen., M.S. and Age. Then, we obtain the sets: - 1.
and
- 2.
.
In our criteria, the hierarchical order of the variables in descending form is , and . Moreover, we consider that the variables and have the same weight. Hence, , , and are the different classes that are defined by the different weights. Hence, by Definition 13 To construct the graph, we must resort to Definition 11. For instance, person 17
is related to all the people who live in city A or who work at Workplace 8 or who have music as an extra curricular activity or whose address is k. With respect to the weights of the edges, Equation (6) in Definition 14 gives us the answer. For instance, person 6 matches person 11
in the answers of the variables and , this is to say, both people live in city A and have the same workplace. Then, the edge has weight . Figure 2 shows the obtained graph. 3. Method
The data that are modeled correspond to the city of Olmué (Valparaíso region, Chile) and were obtained from the database of the Epidemiological Surveillance System of the Ministry of Health of Chile, which included the notified cases (positive or negative) and their contacts from 3 March 2020 to 15 January 2021 with a total of 3866 registered persons.
We denote by the database of the Epidemiological Surveillance System of the Ministry of Health of Chile. From the total of variables included in () 7 of them are relationship variables (). They are: full address (); the street where the people live (); town (); place of work (); workplace section (); health facility where they were treated () and the region of the country where the test was taken to confirm, or not, the contagion ().
In our criteria, the hierarchical order of the seven variables in descending form is
. Moreover, we consider that the variables
and
have the same weight. In the same way, we also consider the variables
and
with equal weight. Hence,
,
,
and
are the different classes that are defined by the different weights. Hence, by Definition 13.
Let us denote by the graph obtained from database .
Strategy Protection
In this section, we provide definitions of the protection of a graph when disease spreads on it. Moreover, we state the protection strategy used in the graph
obtained in the previous Section. The following definitions come from [
28].
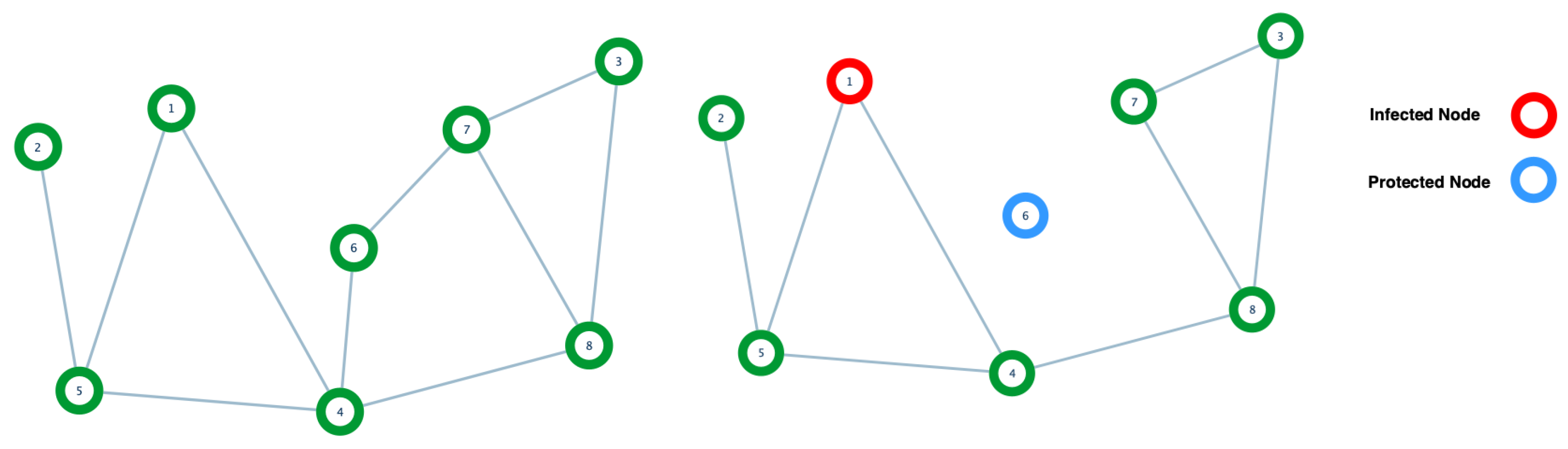
Definition 15. Protecting a vertex means removing all of its corresponding edges. (See Figure 4). It is also possible to find in the literature that protecting a vertex means removing the vertex from the graph. See, for instance, [
20].
Definition 16. The number of vertices that are allowed to protect is called the protection budget, denoted by k.
Definition 17. We will say that the survival rate, denoted by σ, is the ratio of vertices that remain uninfected at the end of the disease over the total numbers of vertices.
Therefore, our problem is: given a graph
, SIR model, and a protection budget
k, the goal is to find a set of vertices
, such that
with
. However, the problem (
4) is NP-Hard (see [
34]).
Our chosen protection strategy corresponds to the DIL-W
ranking (see [
14]). It is well known that an index to measure the connection of a graph is the efficiency of the networks (see [
35]). High connectivity of the graph indicates high efficiency. In [
14], the authors show that the DIL-W
ranking provides good results regarding the rate of decline in network efficiency (for more detail see [
36]), when it comes to eliminating the best positioned nodes by this ranking. One of the good qualities of the DIL-W
ranking is that it recognizes the importance of bridge nodes (see more in [
37]). This quality is inherited from the version of the DIL ranking for graphs not weighted at the edges (see [
33]). Furthermore, [
28] evaluated the effectiveness of the DIL-W
ranking in the immunization of nodes that are attacked by an infectious disease that spreads on an edge-weighted graph using a graph-based SIR model.
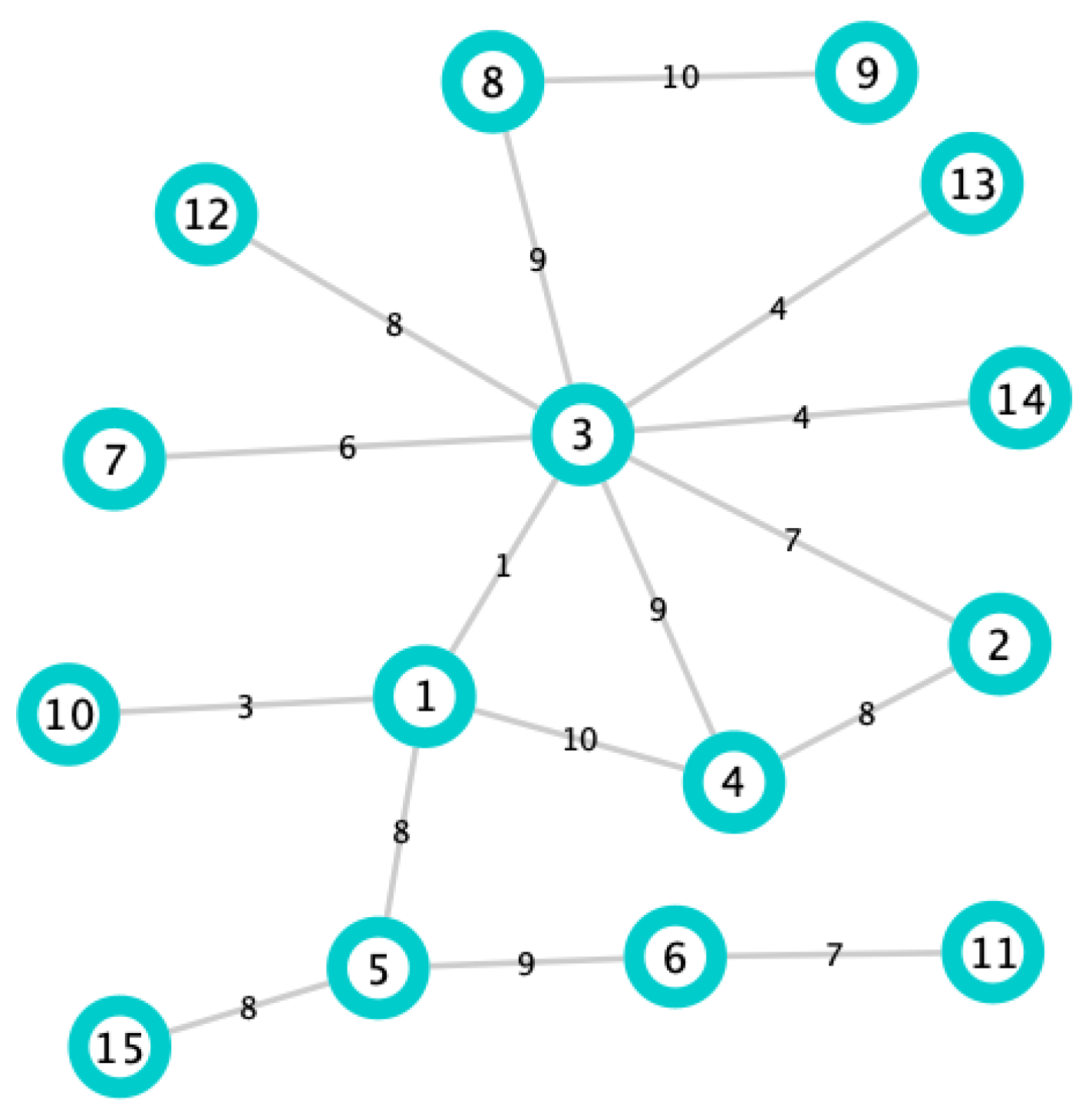
Finally, in order to illustrate in a simple way why the DIL-W
ranking has been chosen, let us consider the graph of
Figure 5 with 16 edges, 15 nodes, and the respective weights on the edges. When we apply the DIL-W
ranking, the first 3 places are occupied by nodes 3, 5 and 1, respectively. These nodes are precise bridge nodes and, when protecting them, according to Definition 15, the graph loses connectivity (see
Figure 6). If we apply the Strength ranking, the first three places are occupied by nodes 3, 1 and 4, respectively. Note that the order in which it positions the nodes and the importance it gives to node 4 makes the loss of network connectivity lower than the loss when applying DIL-W
(see
Figure 6).
In summary, we apply the protection to the network, according to the importance ranking list produced by DIL-W, considering different protection budgets. For the ranking DIL-W, we consider three different values for ; they are 0, and 1. In this way, we compare how the protection performs according to the value of .
4. Results
In this paper, we use a graph-based SIR model in the same way as in [
13,
28], namely, each individual is represented by a vertex in
. At time
t, each vertex
is in a state
belonging to
, where
and
represent the three discrete states: Susceptible (S), Infected (I) and Recovered or Removed (R). We set
At time , the vertex will change state according to probabilistic rules:
The probability (
) that a susceptible vertex
is infected by one of its neighbors is given by
where
is a purely biological factor and representative of the disease and
is the weight of the edge
.
The probability (
) that an infected vertex
at time
t will recover is given by
where
is the recovery rate.
Moreover, we assume that the disease is present for a certain period of time and that, when individuals recover, they are immune, that is, reinfection is not considered.
The initial population contains one infected node and all the simulations that consider
. Five hundred simulations were performed on
with
.
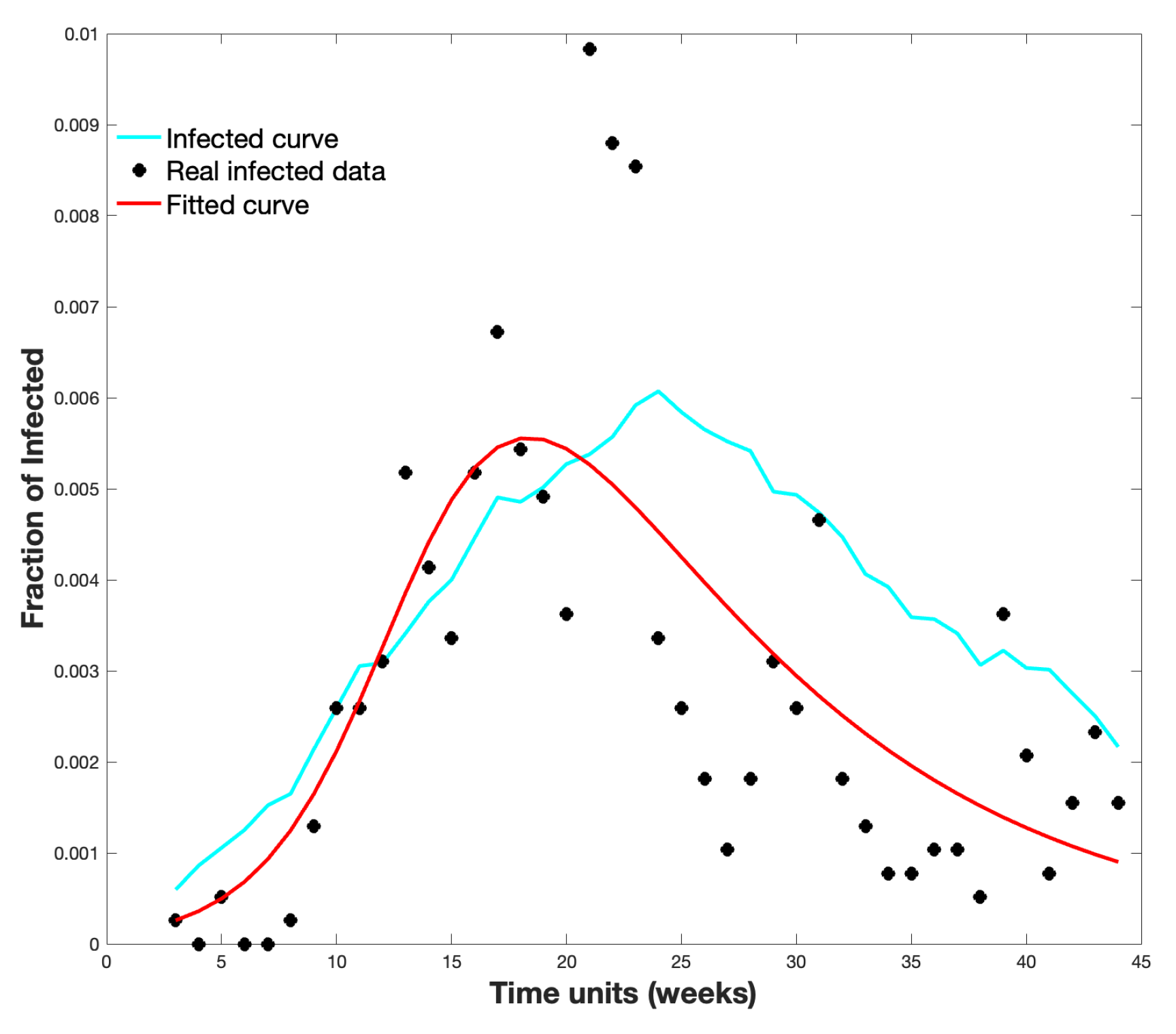
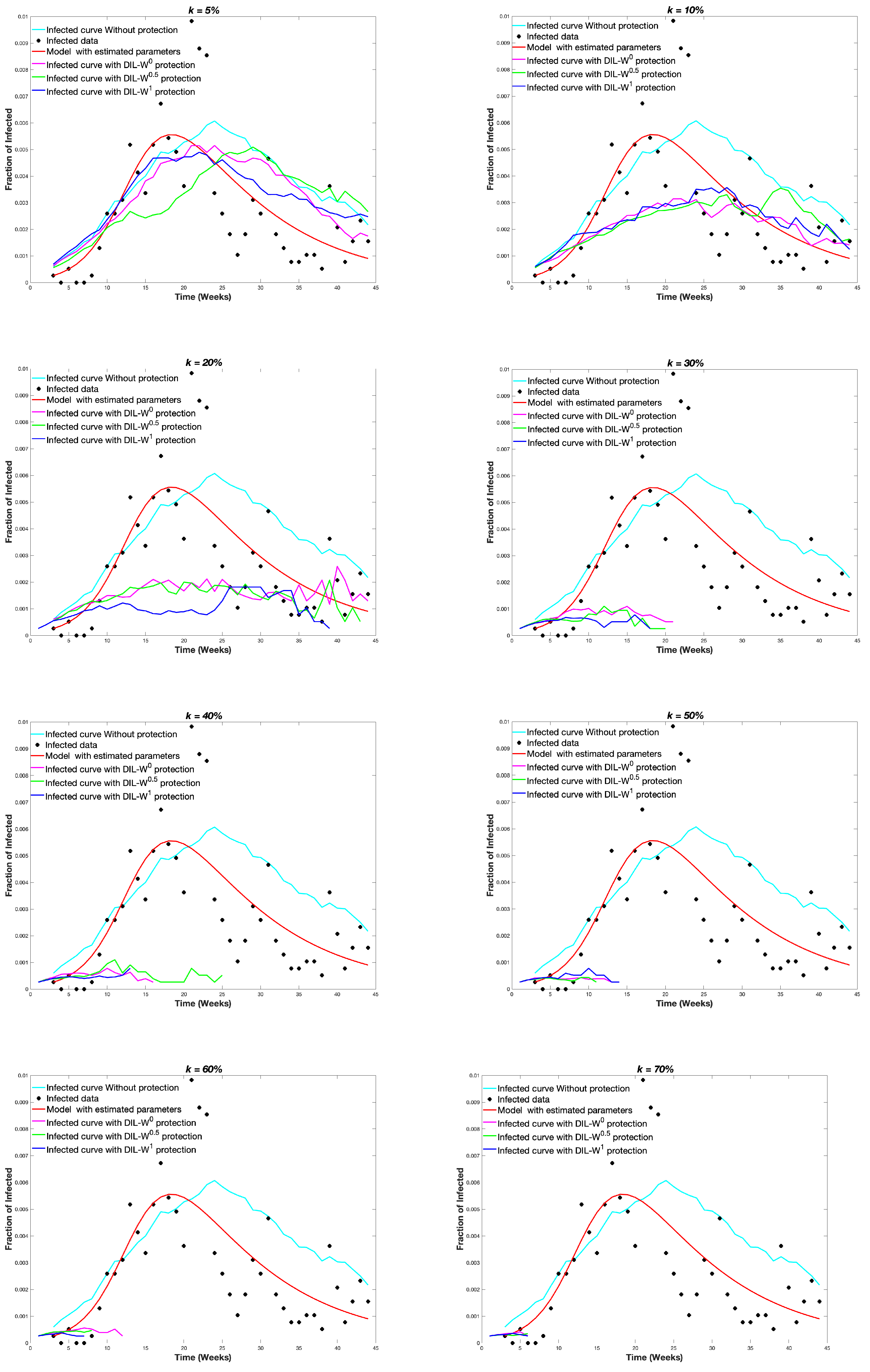
Figure 7 shows the average infected curve and the real infected data in
. Moreover, it shows a curve fitted to the data following the SIR model; for this, we used the classic method of least squares to compare with our proposal.
The graph
was protected with different protection budgets according to the importance of the DIL-W
, DIL-W
and DIL-W
rankings. Protection is carried out in week 1, this is to say, at the beginning of the spread of the disease.
Figure 8 shows the results.
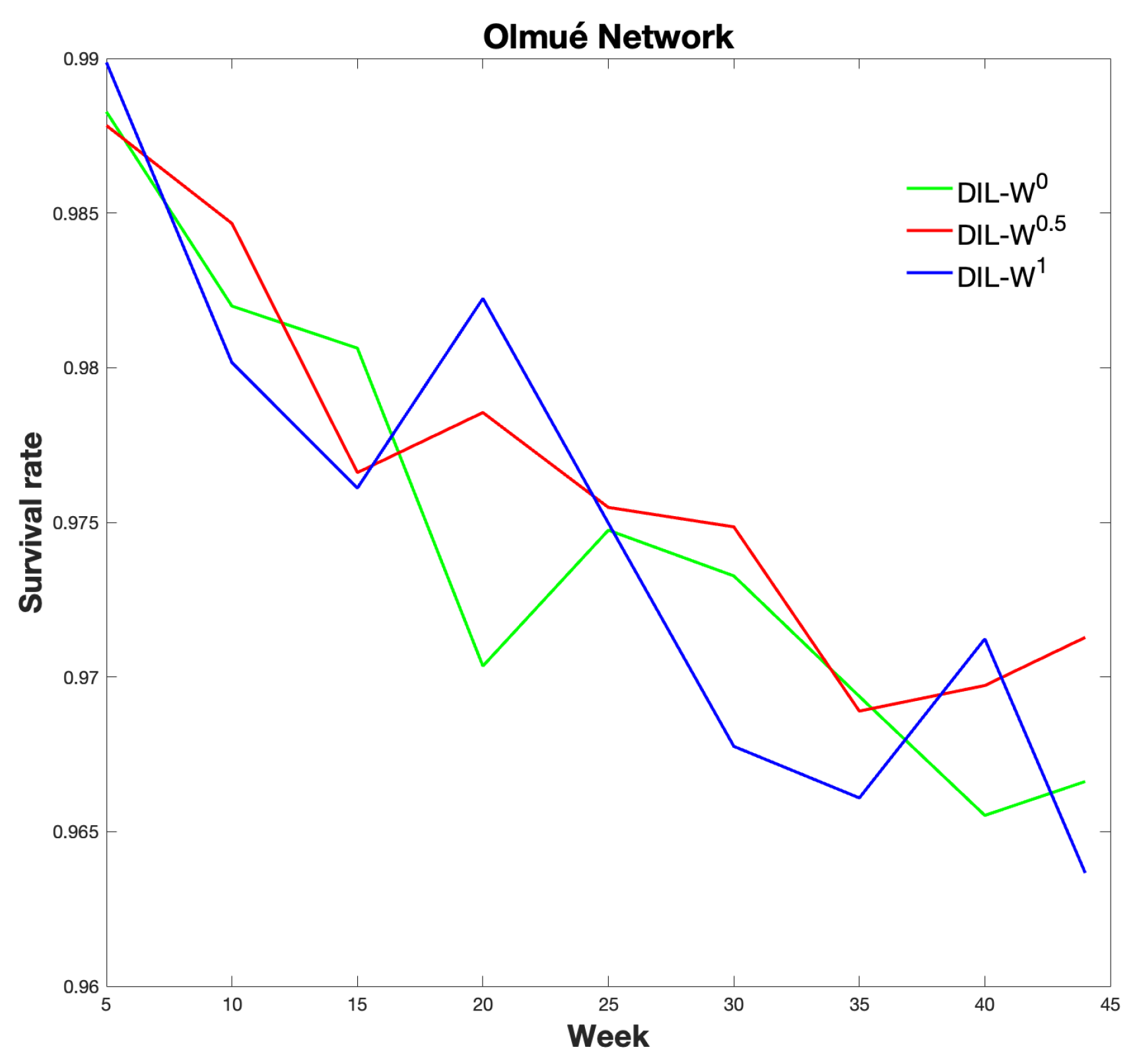
We can see the survival rate in
Figure 9.
Figure 10 shows the relationship between the real infected (450 people) and those immunized according to our proposal.
We can see that 80% of the real infected are located in 60% of the top ranked according to DIL-W. We think that this is a way to recognize those who will get sick; however, it is not the solution.
Another element that we have considered investigating is the time at which the protection takes place. We modified the protection in the graph as the weeks advanced. In
Figure 11, we can see the different infected curves, considering the 10% protection according to the DIL-W
ranking.
Figure 12 shows the relationship between the survival rate and the week in which the protection is carried out with our proposal.
The survival rate is clearly decreasing.
5. Discussion
The results of the present investigation are directed towards the analysis of the effectiveness of immunization using the DIL-W
ranking with real COVID-19 data from the city of Olmué-in Chile. Depending on the importance of the rankings, the immunization results were similar, despite the percentage of protection proposed in the simulations. Our method, therefore, goes in the direction of finding new optimization algorithms in network protection strategies [
38].
At the level of protection, it is evident that when the percentage of initial coverage is higher, the epidemic ends with a smaller fraction of people affected by COVID-19. This event is related not only to the random increase in immunization, but also to the possibility, in the model, of recognizing the bridge nodes to increase the effectiveness of vaccination. This is consistent with other investigations that indicate that the recognition of central nodes or high-risk individuals improves the efficiency of immunization strategies in real networks, a situation that favors the protection of the network and the best use of vaccine doses [
39,
40]. The best use of doses is a challenge for the current scenario of vaccine shortages worldwide, mainly in poor nations [
41].
On the other hand, the level of effectiveness of the DIL-W
ranking, given the percentage of protection, is established in the recognition of the bridging nodes in a regular vaccination process. The results using the
parameters of DIL-W
indicate a high survival rate. DIL-W
achieves better results with 70% protection and is positioned with the best survival rate, but DIL-W
and DIL-W
show good results. The difference between the different values of
is marginal and can be explained by the adequate representation that the DIL-W
model has and by the values of
, which do not generate excessive differences in the ranking. This is similar to the results of the research by Ophsal et al. who, through Freeman’s EIES network, mention that the centrality degree (Definition 7) is relatively stable among the different
parameters [
32].
In a real and regular immunization strategy situation, such as the administration of vaccines, determining the population that infects most frequently is relevant since it allows optimization of these processes. Among our findings, it stands out that 80% of the real infected in the Olmué-Chile commune were located in 60% of the top of the DIL-W
ranking. Consequently, our proposal recognizes the heterogeneity of the network, approaching the reality of human interactions and achieving similar results in complex homogeneous networks [
40].
Regarding immunization with 10% protection, a decrease in the survival rate is established by 4% from weeks 5 to 45 of protection. Likewise, with the same percentage of protection, the effectiveness of the immunity strategy tends to be important until week 20. After 20 weeks, the fraction of infected is similar with or without protection. Consequently, our model is strongly effective as a measure of rapid recognition of the epidemic outbreak in a given territory.
Therefore, according to the findings of our research, there are two important variables for the success and effectiveness of immunity strategies against COVID-19: (1) Recognition of bridging nodes (people with the highest probability of contagion) to apply measures of protection; and (2) the development time of this strategy.
Regarding the recognition of bridging nodes, there is evidence to support that targeted immunization schemes significantly reduce epidemic outbreaks [
42]. This opens the possibility of changing the traditional perspective of immunization by protecting a small proportion of the population over a long period of time [
43]. It is important, therefore, not only to direct COVID-19 immunity efforts towards the population most affected by mortality, but also in those population groups that tend to infect with greater force.
The time of development of the immunization strategy continues to be a variable under discussion in the scientific community regarding the slowness worldwide of the vaccination process, which risks not achieving herd immunity [
44]. In summary, both at a theoretical and empirical level, the execution time of immunization strategies is important in overcoming the COVID-19 pandemic.
Finally, our model helps to establish a ranking of bridge nodes in a non-homogeneous network, so it is highly replicable with real COVID-19 dissemination data and it is useful to establish more focused strategies given the reduced number of vaccines available.
6. Conclusions
In this paper, we evaluate the effectiveness of the DIL-W ranking in the immunization of nodes that are attacked by an infectious disease (COVID-19) that spreads on an edge-weighted graph obtained from the database of the Epidemiological Surveillance System of the Chilean Ministry of Health, using a graph-based SIR model.
Considering survival rates, the DIL-W ranking performs better (by a small margin) than DIL-W and DIL-W rankings, subject to the protection budget being equal to 10% of the network nodes.
The period in which immunization or protection is given plays a key role in stopping the spread of the disease (see
Figure 11) since around week 25 immunization does not generate a great impact and as time progresses the survival rate decreases almost linearly.
An interesting and complex task to solve is to determine which value of
to choose in the network so that the ranking generated is the optimal one. The same value does not always make the performance the best. One way to explore this is to continue with the ideas proposed in [
45], where the selection standard of the optimal turning parameters is proposed for the centrality degree, but is not for DIL-W
ranking. However, when considering this method, there are as many rankings as there are numbers between 0 and 1.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}