
Steel-Reinforced Concrete Corrosion Crack Detection Method Based on Improved VGG16

Abstract
1. Introduction
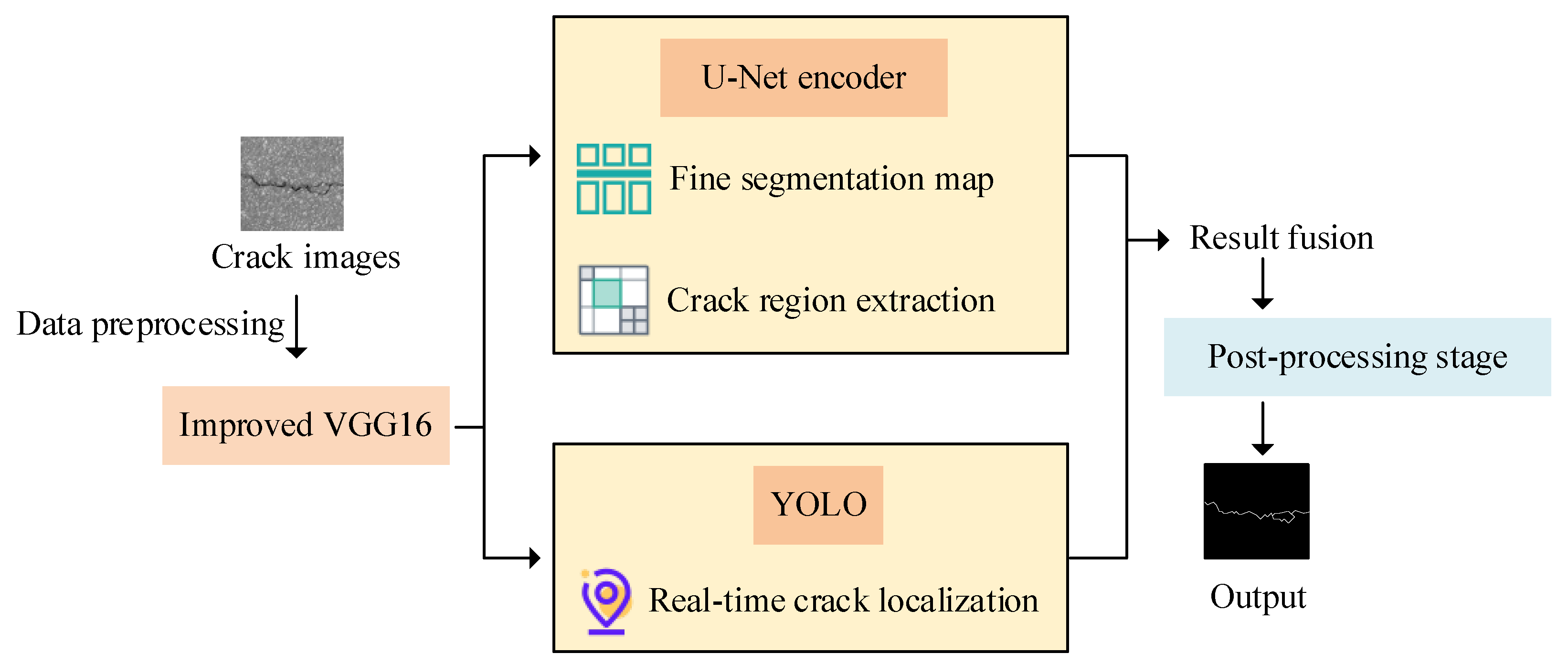
2. Steel-Reinforced Concrete Corrosion Crack Detection Model Based on Improved VGG16
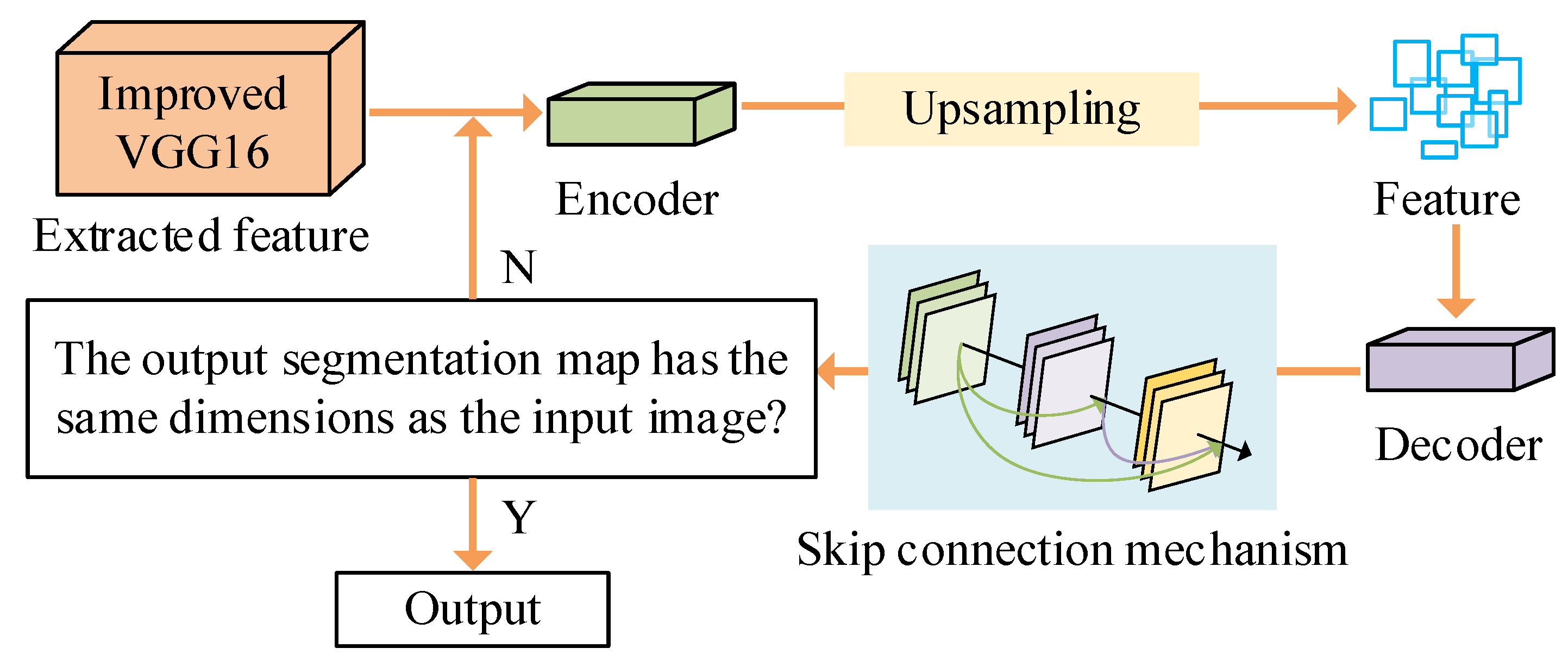
2.1. Image Segmentation Framework Combining Improved VGG16 and U-Net for Steel Surface Analysis
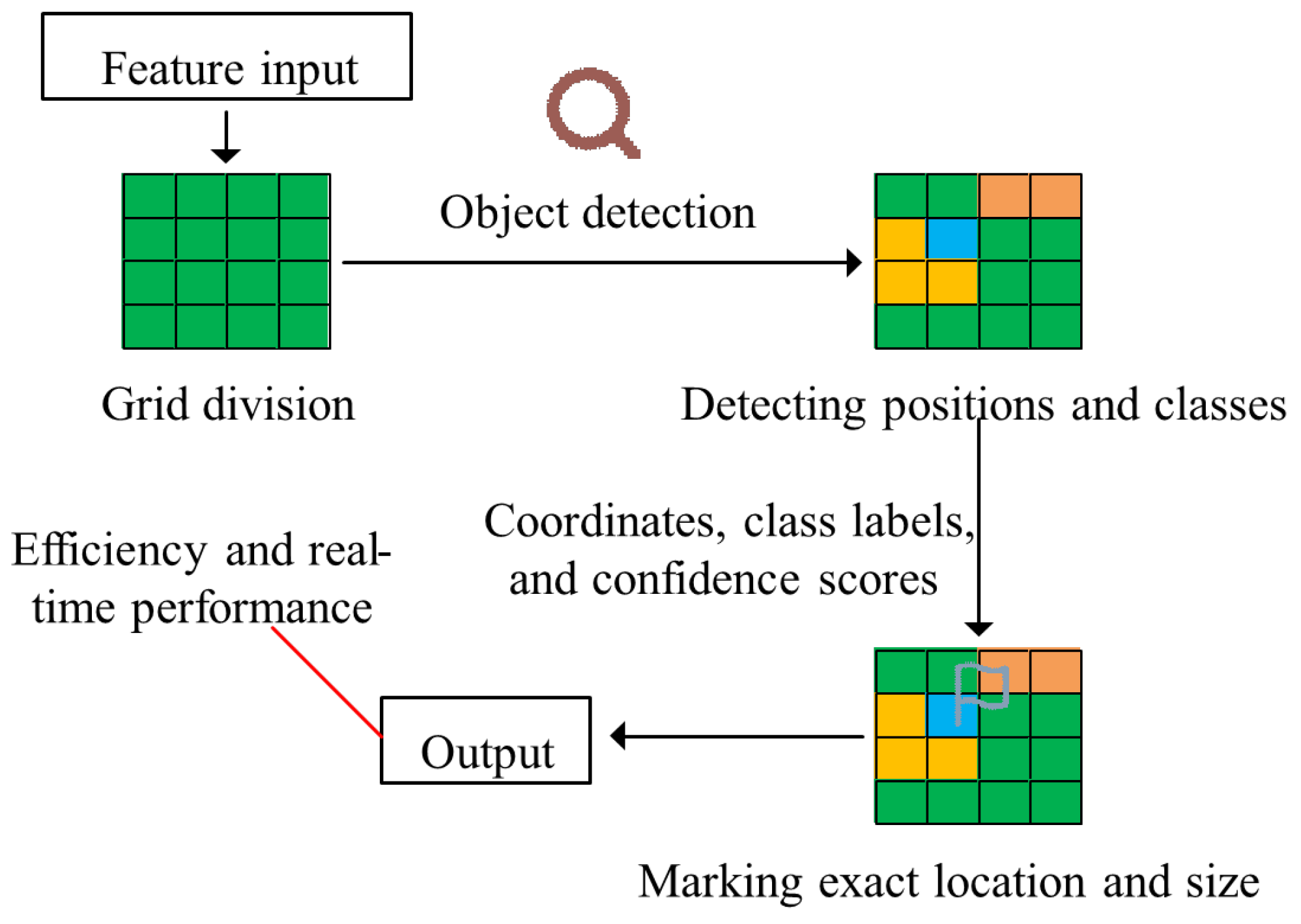
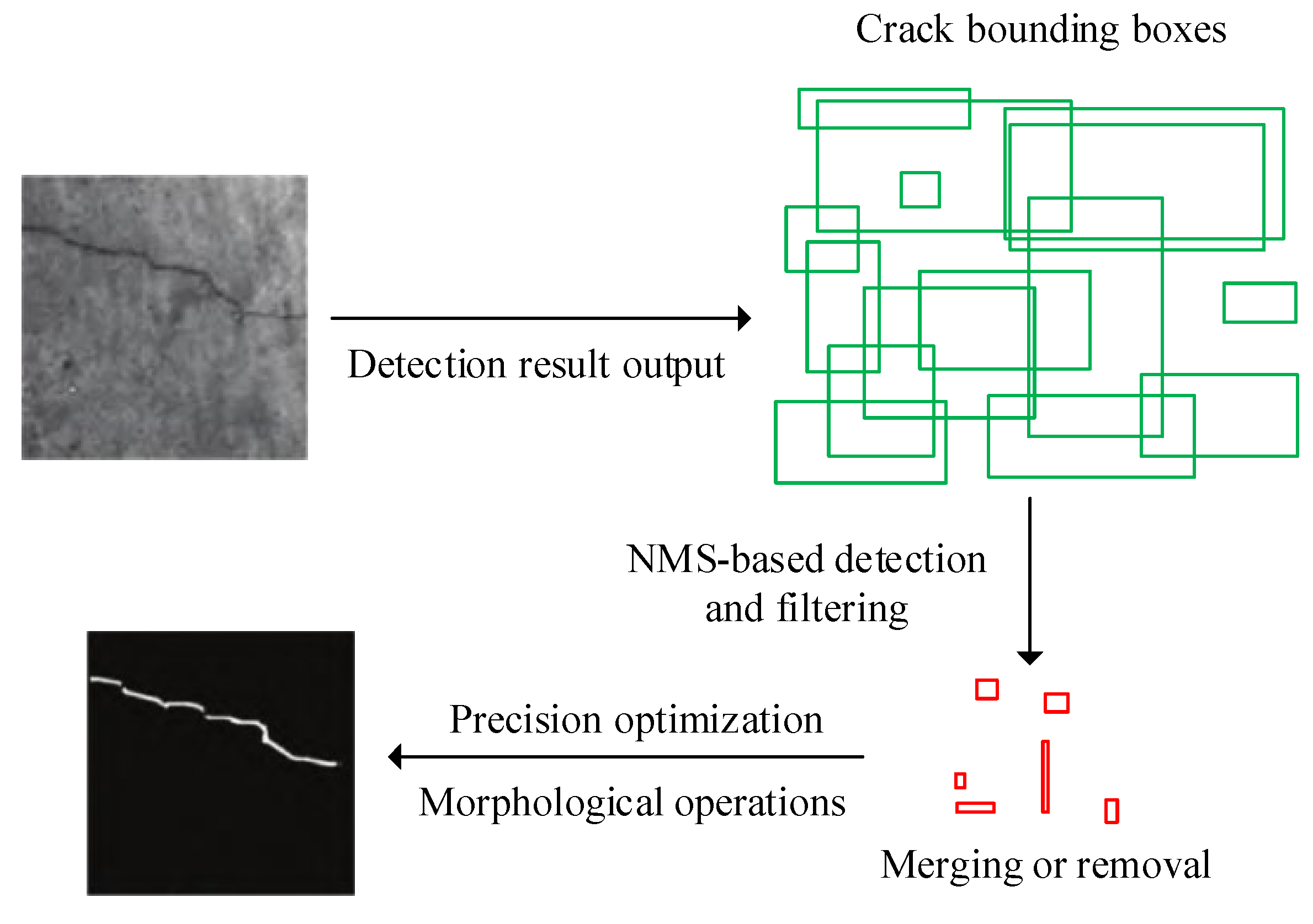
2.2. Steel-Reinforced Crack Detection Model Construction Integrating Image Segmentation and Target Detection
3. Performance Evaluation of UY-VGG16 Concrete Corrosion Crack Detection Model
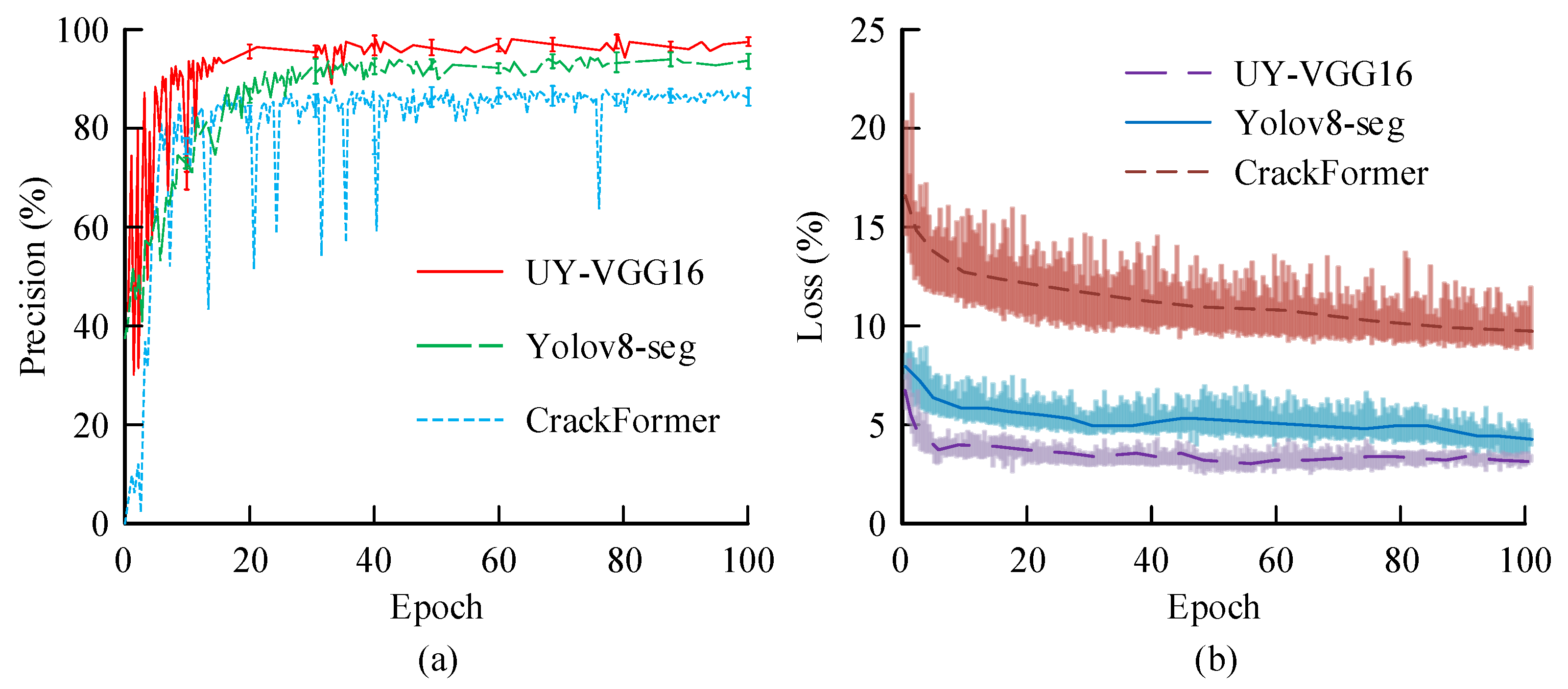
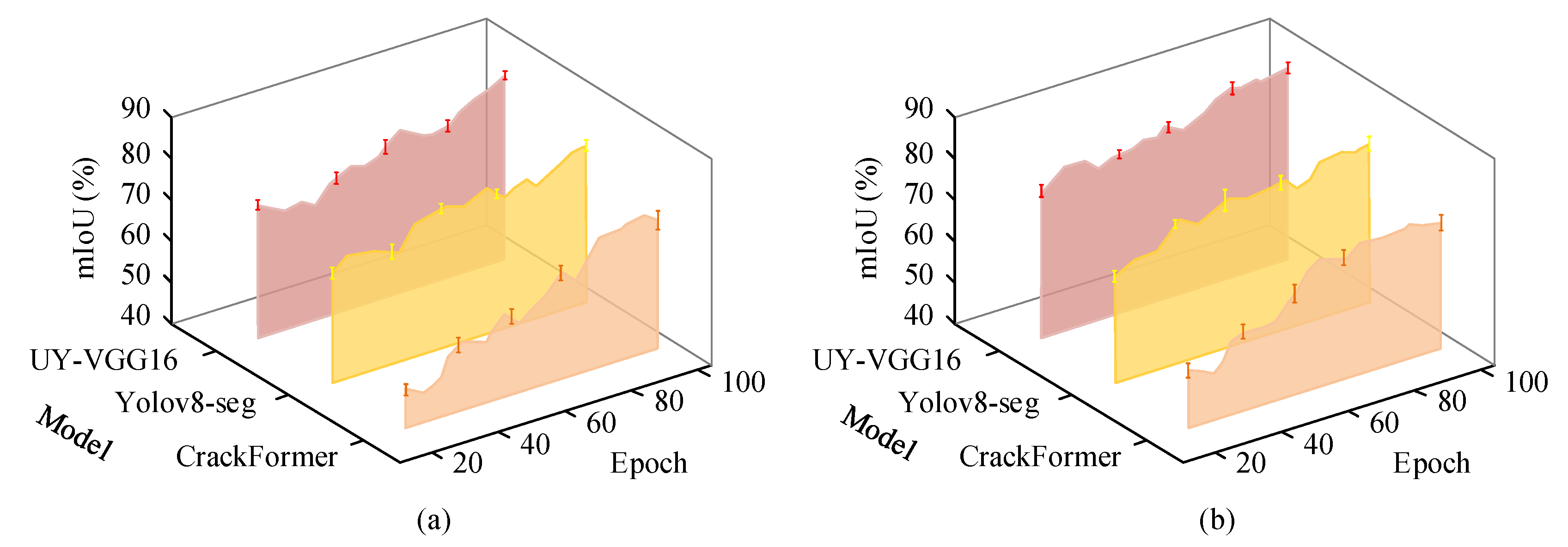
3.1. Comprehensive Performance Evaluation of UY-VGG16 During Training
3.2. Crack Size Detection and Environmental Adaptability Analysis of UY-VGG16
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VGG16 | Visual Geometry Group Network 16 |
| YOLO | You Only Look Once |
| UY-VGG16 | integrated model combining U-Net, You Only Look Once, and Visual Geometry Group Network 16 |
| mIoU | mean Intersection over Union |
| NMS | Non-Maximum Suppression |
| MAE | mean absolute error |
| YOLOv8-seg | You Only Look Once version 8-Segment |
| FPS | frames per second |
| AP | average precision |
| SNR | signal-to-noise ratios |
References
- Afanda, R.; Zaki, A. Effects of Repair Grouting and Jacketing on Corrosion Concrete Using Ultrasonic Method. SDHM Struct. Durab. Health Monit. 2025, 19, 266–284. [Google Scholar] [CrossRef]
- Kuchipudi, S.T.; Ghosh, D.; Ganguli, A. Imaging-based detection and classification of corrosion damages in reinforced concrete using ultrasonic shear waves. J. Build. Eng. 2025, 105, 112490. [Google Scholar] [CrossRef]
- Crognale, M.; De Iuliis, M.; Rinaldi, C.; Gattulli, V. Damage detection with image processing: A comparative study. Earthq. Eng. Eng. Vib. 2023, 22, 333–345. [Google Scholar] [CrossRef]
- Reyes, E.; Gálvez, J.C.; Planas, J. Final Report of RILEM Technical Committee TC 187-SOC: Experimental Determination of the Stress-Crack Opening Curve for Concrete in Tension; RILEM Publications: Paris, France, 2007. [Google Scholar]
- Brandtner-Hafner, M.H. Assessing the natural-healing behavior of adhesively bonded structures under dynamic loading. Eng. Struct. 2019, 196, 109303. [Google Scholar] [CrossRef]
- Liang, H.; Qiu, D.; Ding, K.L.; Zhang, Y.; Wang, Y.; Wang, X.; Wan, S. Automatic pavement crack detection in multisource fusion images using similarity and difference features. IEEE Sens. J. 2023, 24, 5449–5465. [Google Scholar] [CrossRef]
- Cui, J.; Qin, Y.; Wu, Y.; Shao, C.; Yang, H. Skip connection YOLO architecture for noise barrier defect detection using UAV-based images in high-speed railway. IEEE Trans. Intell. Transp. 2023, 24, 12180–12195. [Google Scholar] [CrossRef]
- Rehman, S.U.; Gruhn, V. A Sequential VGG16+ CNN based Automated Approach with adaptive input for efficient detection of knee Osteoarthritis stages. IEEE Access 2024, 12, 62407–62415. [Google Scholar] [CrossRef]
- Guo, B.; Zhang, J.; Li, X. River extraction method of remote sensing image based on edge feature fusion. IEEE Access 2023, 11, 73340–73351. [Google Scholar] [CrossRef]
- Koh, C.Y.; Ali, M.; Hendawi, A. CrackLens: Automated Sidewalk Crack Detection and Segmentation. IEEE Trans. Artif. Intell. 2024, 5, 5418–5430. [Google Scholar] [CrossRef]
- Luo, J.; Lin, H.; Wei, X.; Wang, Y. Adaptive canny and semantic segmentation networks based on feature fusion for road crack detection. IEEE Access 2023, 11, 51740–51753. [Google Scholar] [CrossRef]
- Mishra, A.; Gangisetti, G.; Khazanchi, D. An Investigation Into the Advancements of Edge-AI Capabilities for Structural Health Monitoring. IEEE Access 2024, 12, 25325–25345. [Google Scholar] [CrossRef]
- Li, B.; Guo, H.; Wang, Z.; Wang, F. Automatic Concrete Crack Identification based on Lightweight Embedded U-Net. IEEE Access 2024, 12, 148387–148404. [Google Scholar] [CrossRef]
- Gul, S.; Khan, M.S. A survey of audio enhancement algorithms for music, speech, bioacoustics, biomedical, industrial, and environmental sounds by image U-Net. IEEE Access 2023, 11, 144456–144483. [Google Scholar] [CrossRef]
- Hussain, M. Yolov1 to v8: Unveiling each variant—A comprehensive review of yolo. IEEE Access 2024, 12, 42816–42833. [Google Scholar] [CrossRef]
- Khankeshizadeh, E.; Mohammadzadeh, A.; Arefi, H.; Mohsenifar, A.; Pirasteh, S.; Fan, E.; Li, J. A novel weighted ensemble transferred U-Net based model (WETUM) for postearthquake building damage assessment from UAV data: A comparison of deep learning-and machine learning-based approaches. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–17. [Google Scholar] [CrossRef]
- Naseer, I.; Akram, S.; Masood, T.; Rashid, M.; Jaffar, A. Lung cancer classification using modified u-net based lobe segmentation and nodule detection. IEEE Access 2023, 11, 60279–60291. [Google Scholar] [CrossRef]
- He, M.; Lau, T.L. Crackham: A novel automatic crack detection network based on u-net for asphalt pavement. IEEE Access 2024, 12, 12655–12666. [Google Scholar] [CrossRef]
- Alruwaili, M.; Atta, M.N.; Siddiqi, M.H.; Khan, A.; Alhwaiti, Y.; Alanazi, S. Deep learning-based YOLO models for the detection of people with disabilities. IEEE Access 2023, 12, 2543–2566. [Google Scholar] [CrossRef]
- Bai, T.; Lv, B.; Wang, Y.; Gao, J.; Wang, J. Crack Detection of track slab based on RSG-YOLO. IEEE Access 2023, 11, 124004–124013. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | FPS | Processing Time (ms) | AP (%) |
|---|---|---|---|
| UY-VGG16 | 38 | 36 | 93.2 |
| UY-VGG16-Tiny | 47 | 24 | 84.6 |
| UY-VGG16-Fast | 40 | 28 | 89.7 |
| Yolov8-seg | 31 | 43 | 90.5 |
| CrackFormer | 16 | 67 | 82.4 |
| Model | UY-VGG16 (mm) | UY-VGG16-Tiny (mm) | UY-VGG16-Fast (mm) | |
|---|---|---|---|---|
| Surface roughness | Smooth | ±4.0 | ±5.3 | ±4.6 |
| Moderate | ±4.9 | ±6.7 | ±5.7 | |
| Rough | ±5.6 | ±8.3 | ±6.6 | |
| Interference | Soil-covered | ±5.4 | ±7.4 | ±6.1 |
| Partial occlusion | ±5.1 | ±6.8 | ±5.9 | |
| Water stain | ±4.8 | ±6.6 | ±5.6 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Wang, Z.; Liu, H. Steel-Reinforced Concrete Corrosion Crack Detection Method Based on Improved VGG16. Coatings 2025, 15, 641. https://doi.org/10.3390/coatings15060641
Chen L, Wang Z, Liu H. Steel-Reinforced Concrete Corrosion Crack Detection Method Based on Improved VGG16. Coatings. 2025; 15(6):641. https://doi.org/10.3390/coatings15060641
Chicago/Turabian StyleChen, Lingling, Zhiyuan Wang, and Huihui Liu. 2025. "Steel-Reinforced Concrete Corrosion Crack Detection Method Based on Improved VGG16" Coatings 15, no. 6: 641. https://doi.org/10.3390/coatings15060641
APA StyleChen, L., Wang, Z., & Liu, H. (2025). Steel-Reinforced Concrete Corrosion Crack Detection Method Based on Improved VGG16. Coatings, 15(6), 641. https://doi.org/10.3390/coatings15060641