
Artificial Neural Network for the Fast Screening of Samples from Suspected Urinary Tract Infections

 ,
,  , , ,
, , ,  and
and 
Abstract
1. Introduction
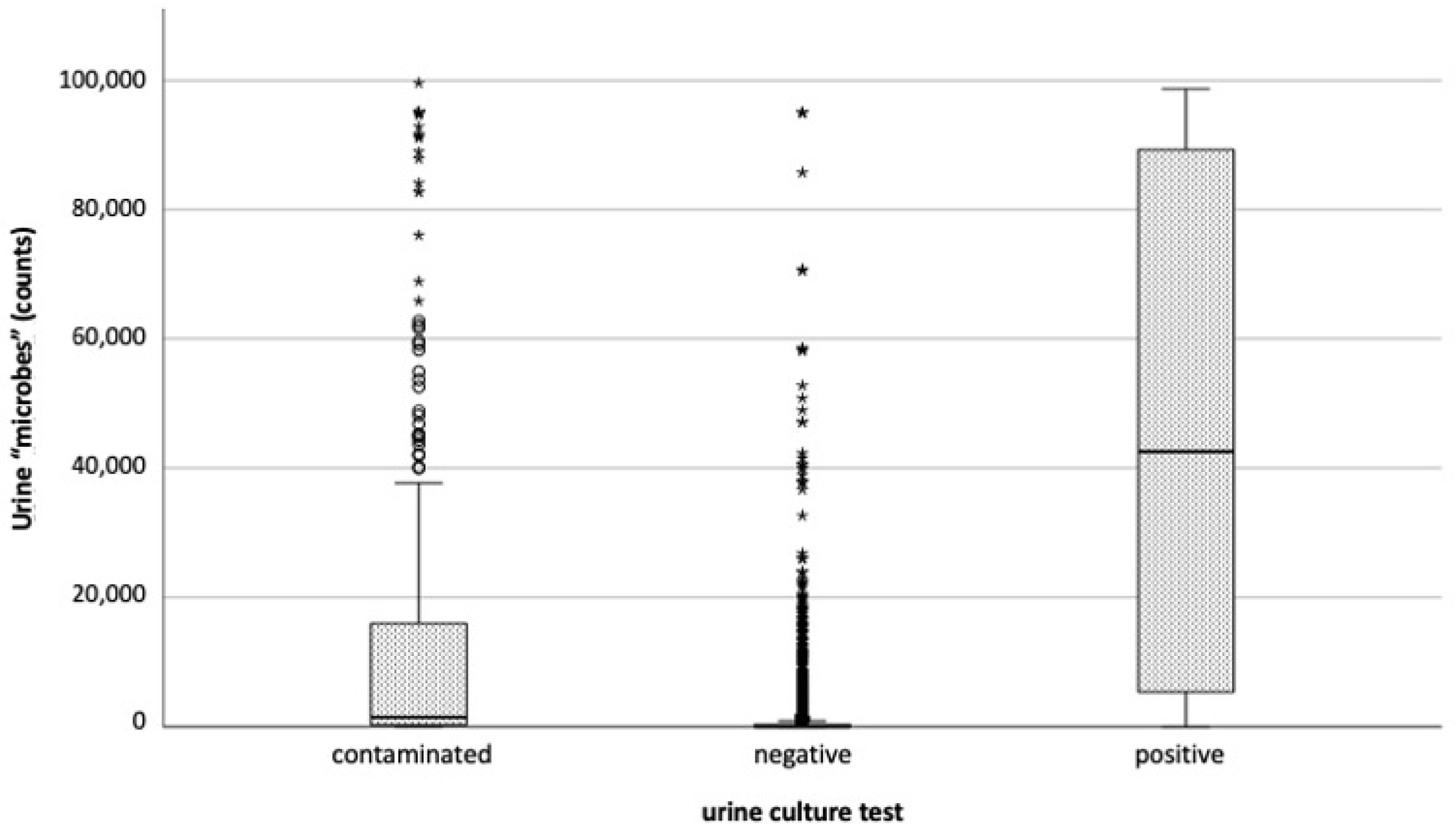
2. Results
3. Discussion
4. Materials and Methods
4.1. Study Design and Algorithm Used
- Patient: age (scale), gender (nominal);
- Urine aspect: color (nominal), aspect (nominal);
- Urine test strip: acidity (scale), specific gravity (scale), protein (discrete), sugar (discrete), ketones (discrete), bilirubin (discrete), urobilinogen (discrete), nitrite (dichotomic), esterases (discrete), hemoglobin (discrete);
- Urinalysis: leucocytes (scale), erythrocytes (scale), epithelial cells (scale), microbes (scale).
4.2. Sample Collection
4.3. The Sysmex UF-5000 Analysis
4.4. Microbiological Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mancuso, G.; Midiri, A.; Gerace, E.; Marra, M.; Zummo, S.; Biondo, C. Urinary Tract Infections: The Current Scenario and Future Prospects. Pathogens 2023, 12, 623. [Google Scholar] [CrossRef] [PubMed]
- Camporese, A. L’evoluzione Della Citofluorimetria Urinaria in Microbiologia, Da Metodo Di Screening a Insostituibile Strumento per La Validazione Clinica Dell’esame Colturale Delle Urine. La. Riv. Ital. Della Med. Lab.-Ital. J. Lab. Med. 2014, 10, 242–246. [Google Scholar] [CrossRef]
- Childers, R.; Liotta, B.; Brennan, J.; Wang, P.; Kattoula, J.; Tran, T.; Montilla-Guedez, H.; Castillo, E.M.; Vilke, G. Urine Testing Is Associated with Inappropriate Antibiotic Use and Increased Length of Stay in Emergency Department Patients. Heliyon 2022, 8, e11049. [Google Scholar] [CrossRef] [PubMed]
- Nicolai, E. Editorial for the Special Issue: “Current Technique for Antibiotic Susceptibility Test: Advantages and Limitations; Need for Next-Generation Test. ” Antibiotics 2023, 12, 750. [Google Scholar] [CrossRef]
- Boonen, K.J.M.; Koldewijn, E.L.; Arents, N.L.A.; Raaymakers, P.A.M.; Scharnhorst, V. Urine Flow Cytometry as a Primary Screening Method to Exclude Urinary Tract Infections. World J. Urol. 2013, 31, 547–551. [Google Scholar] [CrossRef] [PubMed]
- García-Coca, M.; Gadea, I.; Esteban, J. Relationship between Conventional Culture and Flow Cytometry for the Diagnosis of Urinary Tract Infection. J. Microbiol. Methods 2017, 137, 14–18. [Google Scholar] [CrossRef]
- Farashi, S.; Momtaz, H.E. Prediction of Urinary Tract Infection Using Machine Learning Methods: A Study for Finding the Most-Informative Variables. BMC Med. Inform. Decis. Mak. 2025, 25, 13. [Google Scholar] [CrossRef]
- Shen, L.; An, J.; Wang, N.; Wu, J.; Yao, J.; Gao, Y. Artificial Intelligence and Machine Learning Applications in Urinary Tract Infections Identification and Prediction: A Systematic Review and Meta-Analysis. World J. Urol. 2024, 42, 464. [Google Scholar] [CrossRef]
- Naik, N.; Talyshinskii, A.; Shetty, D.K.; Hameed, B.M.Z.; Zhankina, R.; Somani, B.K. Smart Diagnosis of Urinary Tract Infections: Is Artificial Intelligence the Fast-Lane Solution? Curr. Urol. Rep. 2024, 25, 37–47. [Google Scholar] [CrossRef]
- Nicolai, E.; Garau, S.; Favalli, C.; D’Agostini, C.; Gratton, E.; Motolese, G.; Rosato, N. Evaluation of BiesseBioscreen as a New Methodology for Bacteriuria Screening. New Microbiol. 2014, 37, 495–501. [Google Scholar]
- Oyaert, M.; Delanghe, J. Progress in Automated Urinalysis. Ann. Lab. Med. 2019, 39, 15–22. [Google Scholar] [CrossRef]
- Toosky, M.N.; Grunwald, J.T.; Pala, D.; Shen, B.; Zhao, W.; D’Agostini, C.; Coghe, F.; Angioni, G.; Motolese, G.; Abram, T.J.; et al. A Rapid, Point-of-Care Antibiotic Susceptibility Test for Urinary Tract Infections. J. Med. Microbiol. 2020, 69, 52–62. [Google Scholar] [CrossRef] [PubMed]
- Kass, E.H. Bacteriuria and the Diagnosis of Infections of the Urinary Tract; with Observations on the Use of Methionine as a Urinary Antiseptic. AMA Arch. Intern. Med. 1957, 100, 709–714. [Google Scholar] [CrossRef]
- Hilt, E.E.; Parnell, L.K.; Wang, D.; Stapleton, A.E.; Lukacz, E.S. Microbial Threshold Guidelines for UTI Diagnosis: A Scoping Systematic Review. Pathol. Lab. Med. Int. 2023, 15, 43–63. [Google Scholar] [CrossRef]
- Monsen, T.; Ryden, P. A New Concept and a Comprehensive Evaluation of SYSMEX UF-1000i Flow Cytometer to Identify Culture-Negative Urine Specimens in Patients with UTI. Eur. J. Clin. Microbiol. Infect. Dis. 2017, 36, 1691–1703. [Google Scholar] [CrossRef] [PubMed]
- Pieri, M.; Tomassetti, F.; Cerini, P.; Felicetti, R.; Ceccaroni, L.; Bernardini, S.; Calugi, G. A New Screening Approach For Fast And Accurate Prediction Of Positive And Negative Urine Cultures By SediMAX Compared With The Standard Urine Culture. Tech. Biochem. 2021, 1, 46–55. [Google Scholar] [CrossRef]
- Kufel, J.; Bargieł-Łączek, K.; Kocot, S.; Koźlik, M.; Bartnikowska, W.; Janik, M.; Czogalik, Ł.; Dudek, P.; Magiera, M.; Lis, A.; et al. What Is Machine Learning, Artificial Neural Networks and Deep Learning?-Examples of Practical Applications in Medicine. Diagnostics 2023, 13, 2582. [Google Scholar] [CrossRef]
- Murtagh, F. Multilayer Perceptrons for Classification and Regression. Neurocomputing 1991, 2, 183–197. [Google Scholar] [CrossRef]
- Weiss, R.; Karimijafarbigloo, S.; Roggenbuck, D.; Rödiger, S. Applications of Neural Networks in Biomedical Data Analysis. Biomedicines 2022, 10, 1469. [Google Scholar] [CrossRef]
- Kayalp, D.; Dogan, K.; Ceylan, G.; Senes, M.; Yucel, D. Can Routine Automated Urinalysis Reduce Culture Requests? Clin. Biochem. 2013, 46, 1285–1289. [Google Scholar] [CrossRef]
- Axelrod, C.; Cobian, J.; Montero, J. Positive Predictive Value of Urine Analysis with Reflex Criteria at a Large Community Hospital. Int. Urogynecol. J. 2024, 35, 341–346. [Google Scholar] [CrossRef] [PubMed]
- Richards, K.A.; Cesario, S.; Best, S.L.; Deeren, S.M.; Bushman, W.; Safdar, N. Reflex Urine Culture Testing in an Ambulatory Urology Clinic: Implications for Antibiotic Stewardship in Urology. Int. J. Urol. 2019, 26, 69–74. [Google Scholar] [CrossRef] [PubMed]
- Ialongo, C.; Pieri, M. Biological Matrices, Reagents and Turnaround-Time: The Full-Circle of Artificial Intelligence in the Pre-Analytical Phase. Comment on Turcic A; et al., Machine Learning to Optimize Cerebrospinal Fluid Dilution for Analysis of MRZH Reaction. Clin. Chem. Lab. Med. (CCLM) 2024, 62, e215–e217. [Google Scholar] [CrossRef] [PubMed]
- Ialongo, C.; Pieri, M.; Bernardini, S. Smart Management of Sample Dilution Using an Artificial Neural Network to Achieve Streamlined Processes and Saving Resources: The Automated Nephelometric Testing of Serum Free Light Chain as Case Study. Clin. Chem. Lab. Med. (CCLM) 2017, 55, 231–236. [Google Scholar] [CrossRef]
- Ialongo, C.; Pieri, M.; Bernardini, S. Artificial Neural Network for Total Laboratory Automation to Improve the Management of Sample Dilution: Smart Automation for Clinical Laboratory Timeliness. SLAS Technol. 2017, 22, 44–49. [Google Scholar] [CrossRef]
- Del Ben, F.; Da Col, G.; Cobârzan, D.; Turetta, M.; Rubin, D.; Buttazzi, P.; Antico, A. A Fully Interpretable Machine Learning Model for Increasing the Effectiveness of Urine Screening. Am. J. Clin. Pathol. 2023, 160, 620–632. [Google Scholar] [CrossRef]
- Juthani-Mehta, M.; Tinetti, M.; Perrelli, E.; Towle, V.; Quagliarello, V. Role of Dipstick Testing in the Evaluation of Urinary Tract Infection in Nursing Home Residents. Infect. Control Hosp. Epidemiol. 2007, 28, 889–891. [Google Scholar] [CrossRef]
- Chernaya, A.; Søborg, C.; Midttun, M. Validity of the Urinary Dipstick Test in the Diagnosis of Urinary Tract Infections in Adults. Dan. Med. J. 2021, 69, A07210607. [Google Scholar]
- Kouri, T.T.; Hofmann, W.; Falbo, R.; Oyaert, M.; Schubert, S.; Gertsen, J.B.; Merens, A.; Pestel-Caron, M. The EFLM European Urinalysis Guideline 2023. Clin. Chem. Lab. Med. (CCLM) 2024, 62, 1653–1786. [Google Scholar] [CrossRef]
- Nicolai, E.; Pieri, M.; Gratton, E.; Motolese, G.; Bernardini, S. Bacterial Infection Diagnosis and Antibiotic Prescription in 3 h as an Answer to Antibiotic Resistance: The Case of Urinary Tract Infections. Antibiotics 2021, 10, 1168. [Google Scholar] [CrossRef]
- Cerini, P.; Meduri, F.R.; Tomassetti, F.; Polidori, I.; Brugneti, M.; Nicolai, E.; Bernardini, S.; Pieri, M.; Broccolo, F. Trends in Antibiotic Resistance of Nosocomial and Community-Acquired Infections in Italy. Antibiotics 2023, 12, 651. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
| Males | Females | Aggregate | |
|---|---|---|---|
| N | 2968 | 5213 | 8181 |
| Age (years): | |||
| Average (SD) | 57.4 (18.2) | 46.4 (17.9) | 50.4 (18.8) |
| Median (IQR) | 61 (23) | 43 (27) | 51.0 (31) |
| Outpatients (%N) | 94.6 | 96.7 | 96.1 |
| Males | Females | Aggregate | |
|---|---|---|---|
| N | 2968 | 5213 | 8181 |
| Microbes: Positives (%N) | 5.5 | 7.7 | 6.9 |
| Microbes: Negatives (%N) | 92.6 | 87.9 | 89.6 |
| Microbes: Contaminated (%N) | 1.9 | 4.4 | 3.5 |
| Yeasts: Positives (%N) | 0.7 | 0.9 | 0.8 |
| Yeasts: Negatives (%N) | 99.3 | 99.1 | 99.2 |
| Variables (Inputs) in the Model | PPV% | (95%CI) | NPV% | (95%CI) | Accuracy% | F1% | MR% | UMC% |
|---|---|---|---|---|---|---|---|---|
| Full (18 inputs) * | 88.3 | (85.7 to 90.9) | 97.2 | (96.9 to 97.6) | 96.8 | 86.3 | 3.2 | 0.67 |
| microbes + color + urobilinogen | 86.9 | (84 to 89.7) | 96.6 | (96.3 to 97) | 96.2 | 83.1 | 3.8 | 0.67 |
| microbes + color | 84.6 | (81.6 to 87.6) | 96.7 | (96.4 to 97.1) | 96.1 | 83.1 | 3.9 | 0.63 |
| microbes + urobilinogen | 87.2 | (84.3 to 90.1) | 96.5 | (96.2 to 96.9) | 96.1 | 82.6 | 3.9 | 0.82 |
| Nitrite | |||
|---|---|---|---|
| Absent (%N) | Present (%N) | ||
| Urine culture test | Contaminated | 2.87 | 0.64 |
| Negative | 89.08 | 0.50 | |
| Positive | 3.37 | 3.53 | |
| Hidden Layer (Integration) | Output Layer | ||||||
|---|---|---|---|---|---|---|---|
| Input layer | H (1:1) | H (1:2) | H (1:3) | ||||
| bias | 0.042 | 0.821 | 0.107 | ||||
| microbes | 0.780 | 1.477 | 0.11 | ||||
| urobilinogen | −0.327 | −0.319 | −0.141 | ||||
| contaminated | negative | positive | |||||
| Hidden layer (integration) | bias | 0.010 | 1.208 | 0.140 | |||
| H (1:1) | −0.483 | −0.43 | 0.029 | ||||
| H (1:2) | 0.504 | −0.93 | 0.535 | ||||
| H (1:3) | −0.116 | 0.129 | 0.410 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ialongo, C.; Ciotti, M.; Giovannelli, A.; Tomassetti, F.; Pelagalli, M.; Di Carlo, S.; Bernardini, S.; Pieri, M.; Nicolai, E. Artificial Neural Network for the Fast Screening of Samples from Suspected Urinary Tract Infections. Antibiotics 2025, 14, 768. https://doi.org/10.3390/antibiotics14080768
Ialongo C, Ciotti M, Giovannelli A, Tomassetti F, Pelagalli M, Di Carlo S, Bernardini S, Pieri M, Nicolai E. Artificial Neural Network for the Fast Screening of Samples from Suspected Urinary Tract Infections. Antibiotics. 2025; 14(8):768. https://doi.org/10.3390/antibiotics14080768
Chicago/Turabian StyleIalongo, Cristiano, Marco Ciotti, Alfredo Giovannelli, Flaminia Tomassetti, Martina Pelagalli, Stefano Di Carlo, Sergio Bernardini, Massimo Pieri, and Eleonora Nicolai. 2025. "Artificial Neural Network for the Fast Screening of Samples from Suspected Urinary Tract Infections" Antibiotics 14, no. 8: 768. https://doi.org/10.3390/antibiotics14080768
APA StyleIalongo, C., Ciotti, M., Giovannelli, A., Tomassetti, F., Pelagalli, M., Di Carlo, S., Bernardini, S., Pieri, M., & Nicolai, E. (2025). Artificial Neural Network for the Fast Screening of Samples from Suspected Urinary Tract Infections. Antibiotics, 14(8), 768. https://doi.org/10.3390/antibiotics14080768