
Spectroscopic Identification of Bacteria Resistance to Antibiotics by Means of Absorption of Specific Biochemical Groups and Special Machine Learning Algorithm

 , ,
, ,
Abstract
:1. Introduction
2. Results
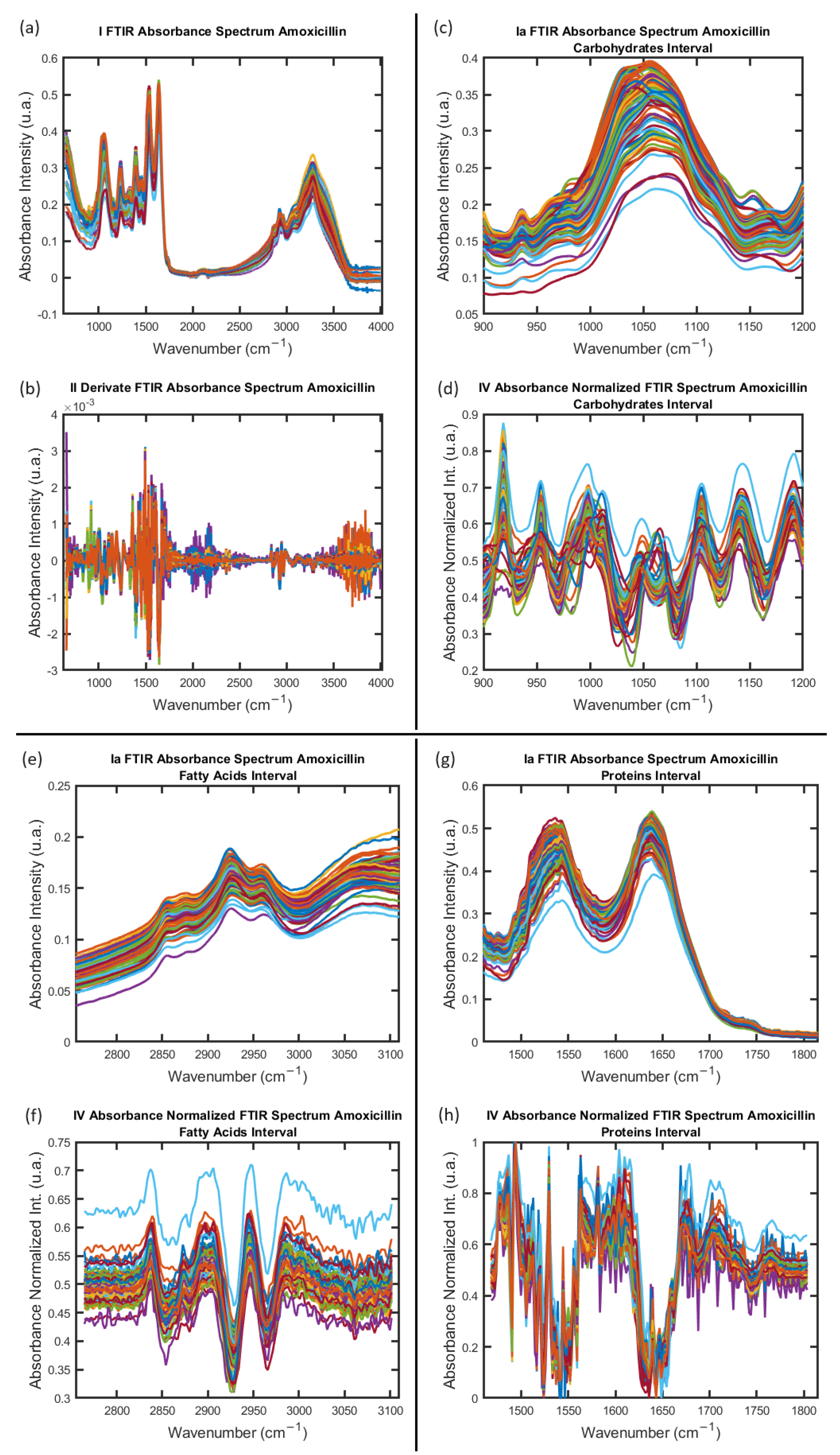
2.1. Acquisition, Cleaning, and Processing of Data from FTIR Absorption Spectra
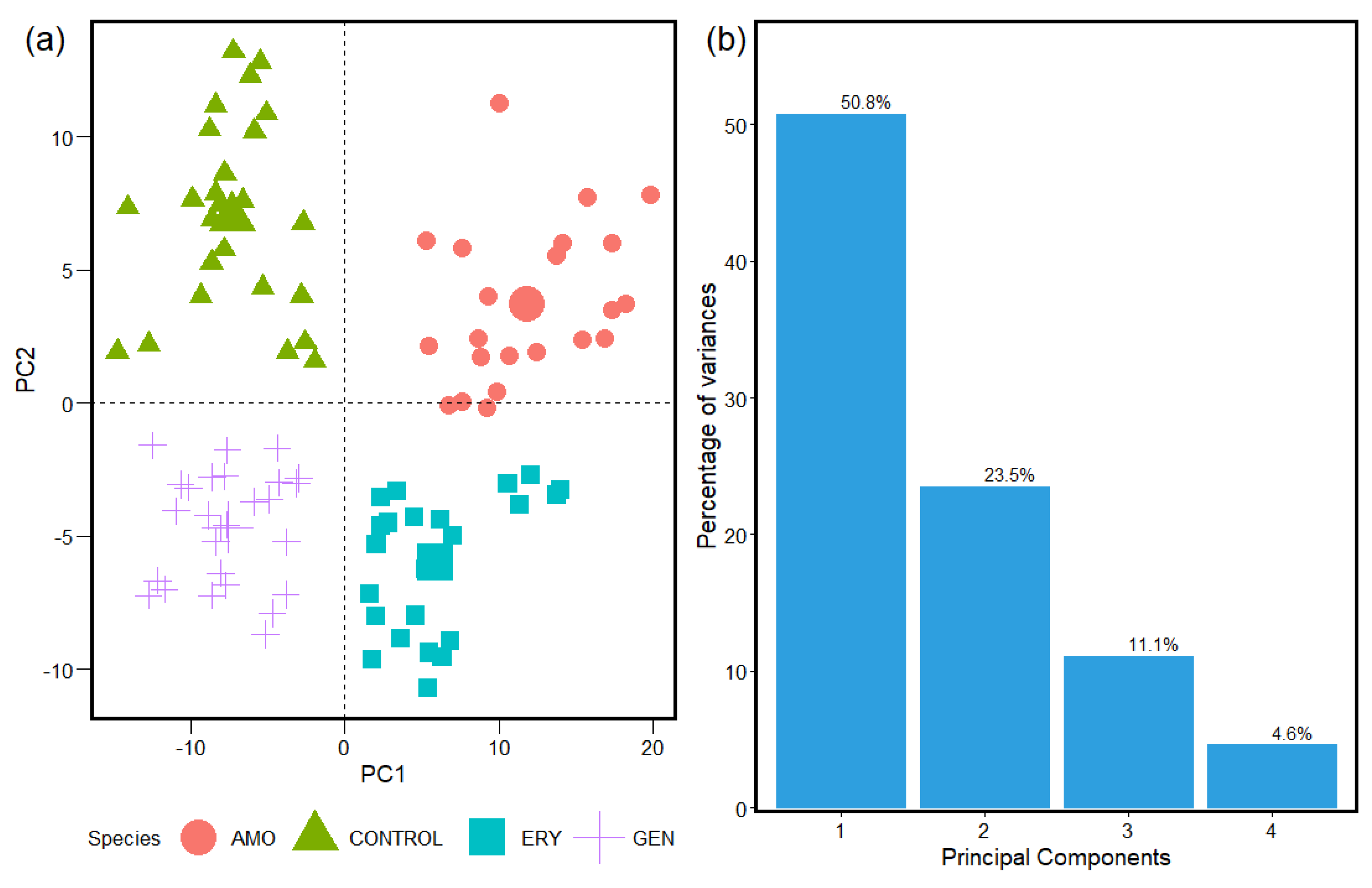
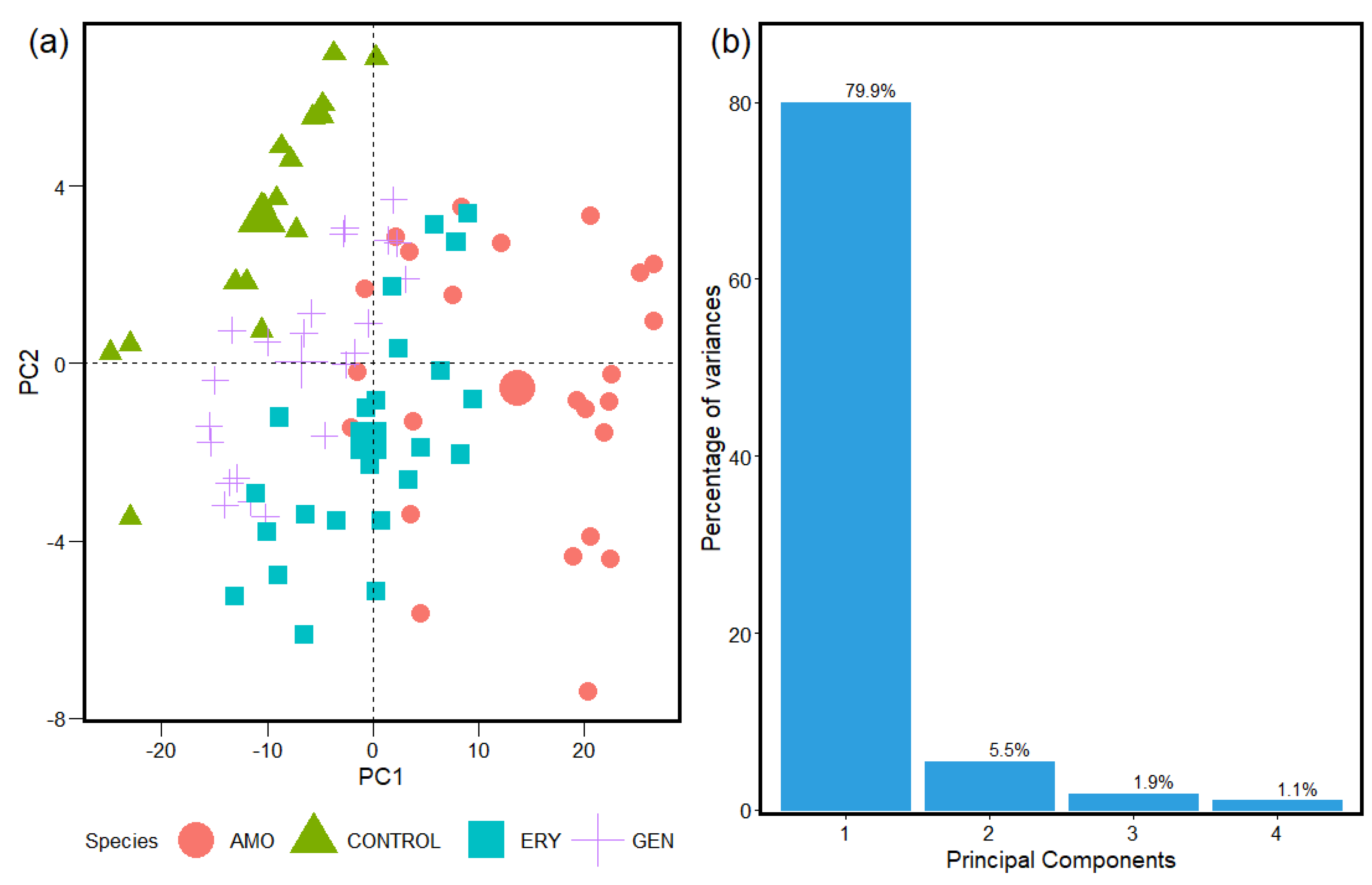
2.2. HCA and PCA Applied for the Study of FTIR Absorption Spectra
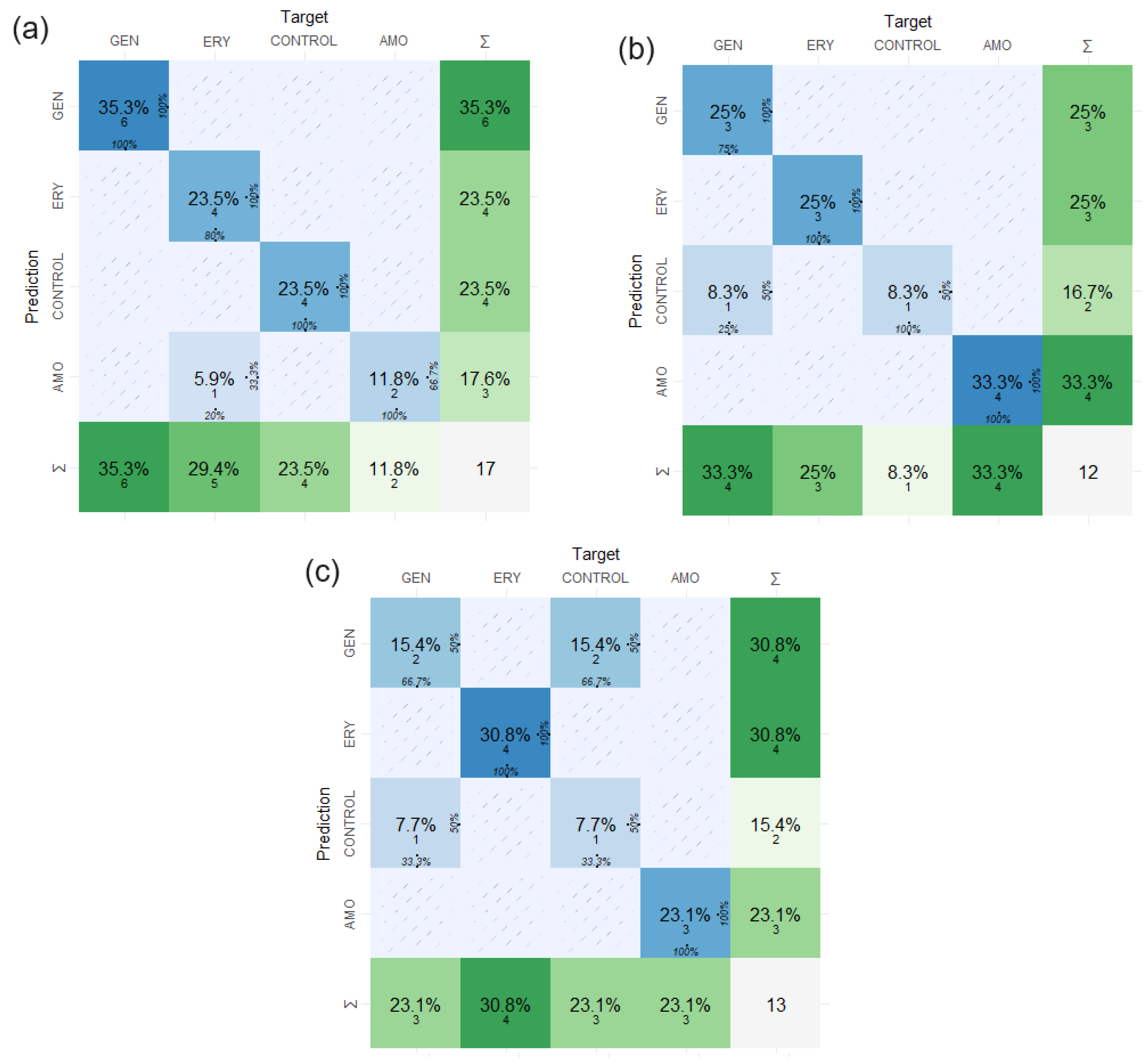
2.3. Confusion Matrix Results Applied in the Study of FTIR Absorption Spectrum
3. Discussion
4. Materials and Methods
4.1. FTIR Absorption Spectrum of S. aureus Acquisition and Data Process in MATLAB
- (i)
- FTIR absorption spectra acquisition one by one [1].
- (ii)
- Calculation of the second derivative for each spectrum individually for each species group of one hundred FTIR absorption spectra [37]. It was performed by means of the implementation of the second-order difference of dataset in MATLAB [27]. That means that each point in the spectrum dataset was associated to one vector (λ1, I1). It corresponded to one array formed by the wavelength value and its correspondent FTIR absorption intensity record value. Then, each vector was processed to compute the second-order difference. This method also allows for calculating differences between adjacent elements. The entire calculation process was developed with default functions available in MATLAB [27].
- (iii)
- Normalization by maximum value of FTIR absorption intensity [37]; process conducted in each spectrum individually.
- (iv)
- Extract the window interval group; it conformed the array of one hundred FTIR absorption spectra intensity with the same wavelength values [37].
4.2. Supervised/Unsupervised Machine Learning Algorithms Applied to Spectrum Analysis
4.3. Machine Learning Algorithms
4.4. Microorganism
4.5. Fourier Transformation Infrared Spectroscopy
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Soares, J.M.; Guimarães, F.E.G.; Yakovlev, V.V.; Bagnato, V.S.; Blanco, K.C. Physicochemical Mechanisms of Bacterial Response in the Photodynamic Potentiation of Antibiotic Effects. Sci. Rep. 2022, 12, 21146. [Google Scholar] [CrossRef]
- Soares, J.M.; Yakovlev, V.V.; Blanco, K.C.; Bagnato, V.S. Recovering the Susceptibility of Antibiotic-Resistant Bacteria Using Photooxidative Damage. Proc. Natl. Acad. Sci. USA 2023, 120, e2311667120. [Google Scholar] [CrossRef] [PubMed]
- Willis, J.A.; Cheburkanov, V.; Chen, S.; Soares, J.M.; Kassab, G.; Blanco, K.C.; Bagnato, V.S.; de Figueiredo, P.; Yakovlev, V.V. Breaking down Antibiotic Resistance in Methicillin-Resistant Staphylococcus Aureus: Combining Antimicrobial Photodynamic and Antibiotic Treatments. Proc. Natl. Acad. Sci. USA 2022, 119, e2208378119. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.Y.; Han, Y.Y.; Shih, P.H.; Lian, W.N.; Wang, H.H.; Lin, C.H.; Hsueh, P.R.; Wang, J.K.; Wang, Y.L. Rapid Bacterial Antibiotic Susceptibility Test Based on Simple Surface-Enhanced Raman Spectroscopic Biomarkers. Sci. Rep. 2016, 6, 23375. [Google Scholar] [CrossRef]
- Salman, A.; Sharaha, U.; Rodriguez-Diaz, E.; Shufan, E.; Riesenberg, K.; Bigio, I.J.; Huleihel, M. Detection of Antibiotic Resistant: Escherichia Coli Bacteria Using Infrared Microscopy and Advanced Multivariate Analysis. Analyst 2017, 142, 2136–2144. [Google Scholar] [CrossRef] [PubMed]
- Ciloglu, F.U.; Caliskan, A.; Saridag, A.M.; Kilic, I.H.; Tokmakci, M.; Kahraman, M.; Aydin, O. Drug-Resistant Staphylococcus Aureus Bacteria Detection by Combining Surface-Enhanced Raman Spectroscopy (SERS) and Deep Learning Techniques. Sci. Rep. 2021, 11, 18444. [Google Scholar] [CrossRef]
- Zhang, P.; Fu, Y.; Zhao, H.; Liu, X.; Wu, X.; Lin, T.; Wang, H.; Song, L.; Fang, Y.; Lu, W.; et al. Dynamic Insights into Increasing Antibiotic Resistance in Staphylococcus Aureus by Label-Free SERS Using a Portable Raman Spectrometer. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 273, 121070. [Google Scholar] [CrossRef]
- Vale de Macedo, G.H.R.; Costa, G.D.E.; Oliveira, E.R.; Damasceno, G.V.; Mendonça, J.S.P.; Silva, L.; Chagas, V.L.; Bazán, J.M.N.; Aliança, A.S.d.S.; Miranda, R.d.C.M.d.; et al. Interplay between ESKAPE Pathogens and Immunity in Skin Infections: An Overview of the Major Determinants of Virulence and Antibiotic Resistance. Pathogens 2021, 10, 148. [Google Scholar] [CrossRef]
- Imchen, M.; Moopantakath, J.; Kumavath, R.; Barh, D.; Tiwari, S.; Ghosh, P.; Azevedo, V. Current Trends in Experimental and Computational Approaches to Combat Antimicrobial Resistance. Front. Genet. 2020, 11, 563975. [Google Scholar] [CrossRef]
- Uysal Ciloglu, F.; Saridag, A.M.; Kilic, I.H.; Tokmakci, M.; Kahraman, M.; Aydin, O. Identification of Methicillin-Resistant: Staphylococcus Aureus Bacteria Using Surface-Enhanced Raman Spectroscopy and Machine Learning Techniques. Analyst 2020, 145, 7559–7570. [Google Scholar] [CrossRef]
- Kochan, K.; Nethercott, C.; Perez-Guaita, D.; Jiang, J.H.; Peleg, A.Y.; Wood, B.R.; Heraud, P. Detection of Antimicrobial Resistance-Related Changes in Biochemical Composition of Staphylococcus Aureus by Means of Atomic Force Microscopy-Infrared Spectroscopy. Anal. Chem. 2019, 91, 15397–15403. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Chau, J.; Yoon, J.; Hladky, J. Rapid, Label-Free Pathogen Identification System for Multidrug-Resistant Bacterial Wound Infection Detection on Military Members in the Battlefield. PLoS ONE 2022, 17, e0267945. [Google Scholar] [CrossRef] [PubMed]
- Yi, Y.; Han, Y.; Cheng, X.; Zhang, Z.; Sun, Y.; Zhang, K.; Xu, J.-J. Three-Dimensional Surface-Enhanced Raman Scattering Platform with Hotspots Built by a Nano-Mower for Rapid Detection of MRSA. Anal. Chem. 2022, 94, 17205–17211. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Tang, M.; Liu, Y.; Huang, J.; Liu, Z.; Tian, H.; Zheng, Y.; de la Chapelle, M.L.; Zhang, Y.; Fu, W. Surface-Enhanced Raman Scattering Method for the Identification of Methicillin-Resistant Staphylococcus Aureus Using Positively Charged Silver Nanoparticles. Microchim. Acta 2019, 186, 102. [Google Scholar] [CrossRef]
- Wang, K.; Li, S.; Petersen, M.; Wang, S.; Lu, X. Detection and Characterization of Antibiotic-Resistant Bacteria Using Surface-Enhanced Raman Spectroscopy. Nanomaterials 2018, 8, 762. [Google Scholar] [CrossRef]
- Wang, S.; Dong, H.; Shen, W.; Yang, Y.; Li, Z.; Liu, Y.; Wang, C.; Gu, B.; Zhang, L. Rapid SERS Identification of Methicillin-Susceptible and Methicillin-Resistant: Staphylococcus Aureus via Aptamer Recognition and Deep Learning. RSC Adv. 2021, 11, 34425–34431. [Google Scholar] [CrossRef] [PubMed]
- Dubes, R.; Jain, A.K. Clustering Methodologies in Exploratory Data Analysis. Adv. Comput 1980, 19, 113–228. [Google Scholar]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data Clustering. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Schaeffer, S.E. Graph Clustering. Comput. Sci. Rev. 2007, 1, 27–64. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S. Consensus Clustering in Complex Networks. Sci. Rep. 2012, 2, 336. [Google Scholar] [CrossRef]
- Fillbrunn, A.; Berthold, M.R. Diversity-Driven Widening of Hierarchical Agglomerative Clustering. In Advances in Intelligent Data Analysis XIV. IDA 2015. Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; Volume 14, pp. 84–94. [Google Scholar] [CrossRef]
- Hennig, C.; Meila, M.; Murtagh, F.; Rocci, R. Handbook of Cluster Analysis; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- King, R.S. Cluster Analysis and Data Mining: An Introduction; Mercury Learning and Information: Herndon, VA, USA, 2015. [Google Scholar]
- Wierzchoń, S.T.; Kłopotek, M.A. Modern Algorithms of Cluster Analysis; Springer: New York, NY, USA, 2018; Volume 34. [Google Scholar]
- Jaeger, A.; Banks, D. Cluster Analysis: A Modern Statistical Review. WIREs Comput. Stat. 2023, 15, e1597. [Google Scholar] [CrossRef]
- Tokuda, E.K.; Comin, C.H.; Costa, L. Revisiting Agglomerative Clustering. Phys. A Stat. Mech. Appl. 2022, 585, 126433. [Google Scholar] [CrossRef]
- MATLAB 2021. The MathWorks, Inc. Optimization Toolbox version: (R2021b). Accessed: 21 January 2023. Available online: https://www.mathworks.com (accessed on 16 July 2023).
- Chambers, J.M. Software for Data Analysis: Programming with R; Springer: Berlin/Heidelberg, Germany, 2008; Volume 2. [Google Scholar]
- Nguyen, G.; Dlugolinsky, S.; Bobák, M.; Tran, V.; López García, Á.; Heredia, I.; Malík, P.; Hluchý, L. Machine Learning and Deep Learning Frameworks and Libraries for Large-Scale Data Mining: A Survey. Artif. Intell. Rev. 2019, 52, 77–124. [Google Scholar] [CrossRef]
- Rizzo, M.L. Statistical Computing with R; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 16 July 2023).
- R Core Team, R. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013; Available online: https://www.R-project.org/ (accessed on 16 July 2023).
- Mair, P.; Hofmann, E.; Gruber, K.; Hatzinger, R.; Zeileis, A.; Hornik, K. Motivation, Values, and Work Design as Drivers of Participation in the R Open Source Project for Statistical Computing. Proc. Natl. Acad. Sci. USA 2015, 112, 14788–14792. [Google Scholar] [CrossRef] [PubMed]
- Fox, J. Aspects of the Social Organization and Trajectory of the r Project. R J. 2009, 1, 5. [Google Scholar] [CrossRef]
- Gareth, J.; Daniela, W.; Trevor, H.; Robert, T. An Introduction to Statistical Learning: With Applications in R; Spinger: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Ripley, B.D. The R Project in Statistical Computing. MSOR Connect. Newsl. LTSN Maths Stats OR Netw. 2001, 1, 23–25. [Google Scholar] [CrossRef]
- Naumann, D. Infrared Spectroscopy in Microbiology. Encycl. Anal. Chem. 2000, 102, 131. [Google Scholar]
- Kurt, I.; Ture, M.; Kurum, A.T. Comparing Performances of Logistic Regression, Classification and Regression Tree, and Neural Networks for Predicting Coronary Artery Disease. Expert Syst. Appl. 2008, 34, 366–374. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Radicchi, F.; Ramasco, J.J.; Fortunato, S. Finding Statistically Significant Communities in Networks. PLoS ONE 2011, 6, e18961. [Google Scholar] [CrossRef]
- Fortunato, S.; Newman, M.E.J. 20 Years of Network Community Detection. Nat. Phys. 2022, 18, 848–850. [Google Scholar] [CrossRef]
- Fortunato, S.; Hric, D. Community Detection in Networks: A User Guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef]
- Mitra, P.; Murthy, C.A.; Pal, S.K. Unsupervised Feature Selection Using Feature Similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 301–312. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal Component Analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Yang, J.; Yang, J. Why Can LDA Be Performed in PCA Transformed Space? Pattern Recognit. 2003, 36, 563–566. [Google Scholar] [CrossRef]
- Daffertshofer, A.; Lamoth, C.J.C.; Meijer, O.G.; Beek, P.J. PCA in Studying Coordination and Variability: A Tutorial. Clin. Biomech. 2004, 19, 415–428. [Google Scholar] [CrossRef] [PubMed]
- Jolliffe, I.T. Principal Component Analysis for Special Types of Data; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Ringnér, M. What Is Principal Component Analysis? Nat. Biotechnol. 2008, 26, 303–304. [Google Scholar] [CrossRef]
- Hoffmann, H. Kernel PCA for Novelty Detection. Pattern Recognit. 2007, 40, 863–874. [Google Scholar] [CrossRef]
- Wang, F.K.; Du, T.C.T. Using Principal Component Analysis in Process Performance for Multivariate Data. Omega 2000, 28, 185–194. [Google Scholar] [CrossRef]
- Murray, C.J.L.; Ikuta, K.S.; Sharara, F.; Swetschinski, L.; Robles Aguilar, G.; Gray, A.; Han, C.; Bisignano, C.; Rao, P.; Wool, E.; et al. Global Burden of Bacterial Antimicrobial Resistance in 2019: A Systematic Analysis. Lancet 2022, 399, 629–655. [Google Scholar] [CrossRef]
- Peterson, E.; Kaur, P. Antibiotic Resistance Mechanisms in Bacteria: Relationships Between Resistance Determinants of Antibiotic Producers, Environmental Bacteria, and Clinical Pathogens. Front. Microbiol. 2018, 9, 2928. [Google Scholar] [CrossRef]
- Blair, J.M.A.; Webber, M.A.; Baylay, A.J.; Ogbolu, D.O.; Piddock, L.J.V. Molecular Mechanisms of Antibiotic Resistance. Nat. Rev. Microbiol. 2015, 13, 42–51. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, D.; Frangi, A.F.; Yang, J. Two-Dimensional PCA: A New Approach to Appearance-Based Face Representation and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 131–137. [Google Scholar] [CrossRef]
- Monti, S.; Tamayo, P.; Mesirov, J.; Golub, T. Consensus Clustering: A Resampling-Based Method for Class Discovery and Visualization of Gene Expression Microarray Data. Mach. Learn. 2003, 52, 91–118. [Google Scholar] [CrossRef]
- Schmitt, J.; Flemming, H.-C. FTIR-Spectroscopy in Microbial and Material Analysis. Int. Biodeterior. Biodegrad. 1998, 41, 1–11. [Google Scholar] [CrossRef]
- Guo, Q.; Lu, X.; Gao, Y.; Zhang, J.; Yan, B.; Su, D.; Song, A.; Zhao, X.; Wang, G. Cluster Analysis: A New Approach for Identification of Underlying Risk Factors for Coronary Artery Disease in Essential Hypertensive Patients. Sci. Rep. 2017, 7, 43965. [Google Scholar] [CrossRef] [PubMed]
- Müllner, D. Modern Hierarchical, Agglomerative Clustering Algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Messner, P.; Schäffer, C.; Kosma, P. Bacterial cell-envelope glycoconjugates. Adv. Carbohydr. Chem. Biochem. 2013, 69, 209–272. [Google Scholar] [CrossRef] [PubMed]
- Kohanski, M.A.; Dwyer, D.J.; Collins, J.J. How Antibiotics Kill Bacteria: From Targets to Networks. Nat. Rev. Microbiol. 2010, 8, 423–435. [Google Scholar] [CrossRef]
- Aronson, J.K. Beta-Lactam Antibiotics. In Meyler’s Side Effects of Drugs, 16th ed.; Elsevier: Amsterdam, The Netherlands, 2016; pp. 928–956. ISBN 978-0-444-53716-4. [Google Scholar]
- Aronson, J.K. Erythromycin. In Meyler’s Side Effects of Drugs, 16th ed.; Elsevier: Amsterdam, The Netherlands, 2016; pp. 99–108. ISBN 978-0-444-53716-4. [Google Scholar]
- Krause, K.M.; Serio, A.W.; Kane, T.R.; Connolly, L.E. Aminoglycosides: An Overview. Cold Spring Harb. Perspect. Med. 2016, 6, a027029. [Google Scholar] [CrossRef]
- Egorov, A.M.; Ulyashova, M.M.; Rubtsova, M.Y. Microbial Enzyme Production. J. Ferment. Technol. 1988, 66, 365–366. [Google Scholar] [CrossRef]
- Gaynor, M.; Mankin, A. Macrolide Antibiotics: Binding Site, Mechanism of Action, Resistance. Curr. Top. Med. Chem. 2003, 3, 949–960. [Google Scholar] [CrossRef] [PubMed]
- Kong, K.-F.; Schneper, L.; Mathee, K. Beta-Lactam Antibiotics: From Antibiosis to Resistance and Bacteriology. APMIS 2010, 118, 1–36. [Google Scholar] [CrossRef] [PubMed]
- Carbonell, J.G.; Michalski, R.S.; Mitchell, T.M. Machine Learning: A Historical and Methodological Analysis. AI Mag. 1983, 4, 69. [Google Scholar] [CrossRef]
- Oyewole, G.J.; Thopil, G.A. Data Clustering: Application and Trends. Artif. Intell. Rev. 2022, 56, 6439–6475. [Google Scholar] [CrossRef]
- Bruce, P.; Bruce, A.; Gedeck, P. Practical Statistics for Data Scientists: 50+ Essential Concepts Using R and Python; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- Wackerly, D.; Mendenhall, W.; Scheaffer, R.L. Mathematical Statistics with Applications; Cengage Learning: Boston, MA, USA, 2014. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Kulkarni, S.R.; Harman, G. Statistical Learning Theory: A Tutorial. Wiley Interdiscip. Rev. Comput. Stat. 2011, 3, 543–556. [Google Scholar] [CrossRef]
- Dudoit, S.; Fridlyand, J. A Prediction-Based Resampling Method for Estimating the Number of Clusters in a Dataset. Genome Biol. 2002, 3, 1–21. [Google Scholar] [CrossRef]
- Kearns, M.J.; Vazirani, U. An Introduction to Computational Learning Theory; MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Jackson, J.E.; Hearne, F.T. Relationships Among Coefficients of Vectors Used In Principal Components. Technometrics 1973, 15, 601–610. [Google Scholar] [CrossRef]
- Buntine, W.L.; Jakulin, A. Applying Discrete PCA in Data Analysis. arXiv 2012, arXiv:1207.4125. [Google Scholar]
- Anderson, T.W. An Introduction to Multivariate Statistical Analysis; Wiley: New York, NY, USA, 1958. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hidden Sample | Window Group | Accuracy | Sensitivity | Specificity | Sample Susceptivity |
| SK | Carbohydrates | 0.938 | 0.95 | 0.987 | ERY |
| Fatty Acids | 0860 | 0.8 | 0.920 | ||
| Proteins | 0.704 | 0.745 | 0.861 | ||
| SW | Carbohydrates | 0.812 | 0.752 | 0.957 | AMO |
| Fatty Acids | 0.714 | 0.767 | 0.936 | ||
| Proteins | 0.818 | 0.7 | 0.960 | ||
| SX | Carbohydrates | 0.767 | 0.701 | 0.941 | Control |
| Fatty Acids | 0.775 | 0.65 | 0.901 | ||
| Proteins | 0.832 | 0.75 | 0.915 | ||
| SY | Carbohydrates | 0.915 | 0.87 | 0.962 | MRSA |
| Fatty Acids | 0.933 | 0.9 | 0.996 | ||
| Proteins | 0.715 | 0.833 | 0.916 | ||
| SZ | Carbohydrates | 0.941 | 0.91 | 0.972 | GEN |
| Fatty Acids | 0.904 | 0.86 | 0.948 | ||
| Proteins | 0.818 | 0.733 | 0.960 |
| Hidden Sample Name | Real Resistance | Detected Resistance | Resistance to | |
| 1. SK | Resistance | Resistance | ERY | Correct |
| 2. SW | Resistance | Resistance | AMO | Correct |
| 3. SX | No Resistance | No Resistance | NONE | Correct |
| 4. SY | Resistance | Resistance | MRSA | Correct |
| 5. SZ | Resistance | Resistance | GEN | Correct |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barrera-Patiño, C.P.; Soares, J.M.; Branco, K.C.; Inada, N.M.; Bagnato, V.S. Spectroscopic Identification of Bacteria Resistance to Antibiotics by Means of Absorption of Specific Biochemical Groups and Special Machine Learning Algorithm. Antibiotics 2023, 12, 1502. https://doi.org/10.3390/antibiotics12101502
Barrera-Patiño CP, Soares JM, Branco KC, Inada NM, Bagnato VS. Spectroscopic Identification of Bacteria Resistance to Antibiotics by Means of Absorption of Specific Biochemical Groups and Special Machine Learning Algorithm. Antibiotics. 2023; 12(10):1502. https://doi.org/10.3390/antibiotics12101502
Chicago/Turabian StyleBarrera-Patiño, Claudia P., Jennifer M. Soares, Kate C. Branco, Natalia M. Inada, and Vanderlei Salvador Bagnato. 2023. "Spectroscopic Identification of Bacteria Resistance to Antibiotics by Means of Absorption of Specific Biochemical Groups and Special Machine Learning Algorithm" Antibiotics 12, no. 10: 1502. https://doi.org/10.3390/antibiotics12101502
APA StyleBarrera-Patiño, C. P., Soares, J. M., Branco, K. C., Inada, N. M., & Bagnato, V. S. (2023). Spectroscopic Identification of Bacteria Resistance to Antibiotics by Means of Absorption of Specific Biochemical Groups and Special Machine Learning Algorithm. Antibiotics, 12(10), 1502. https://doi.org/10.3390/antibiotics12101502