Multichannel Acoustic Spectroscopy of the Human Body for Inviolable Biometric Authentication



Abstract
:1. Introduction
2. Related Work
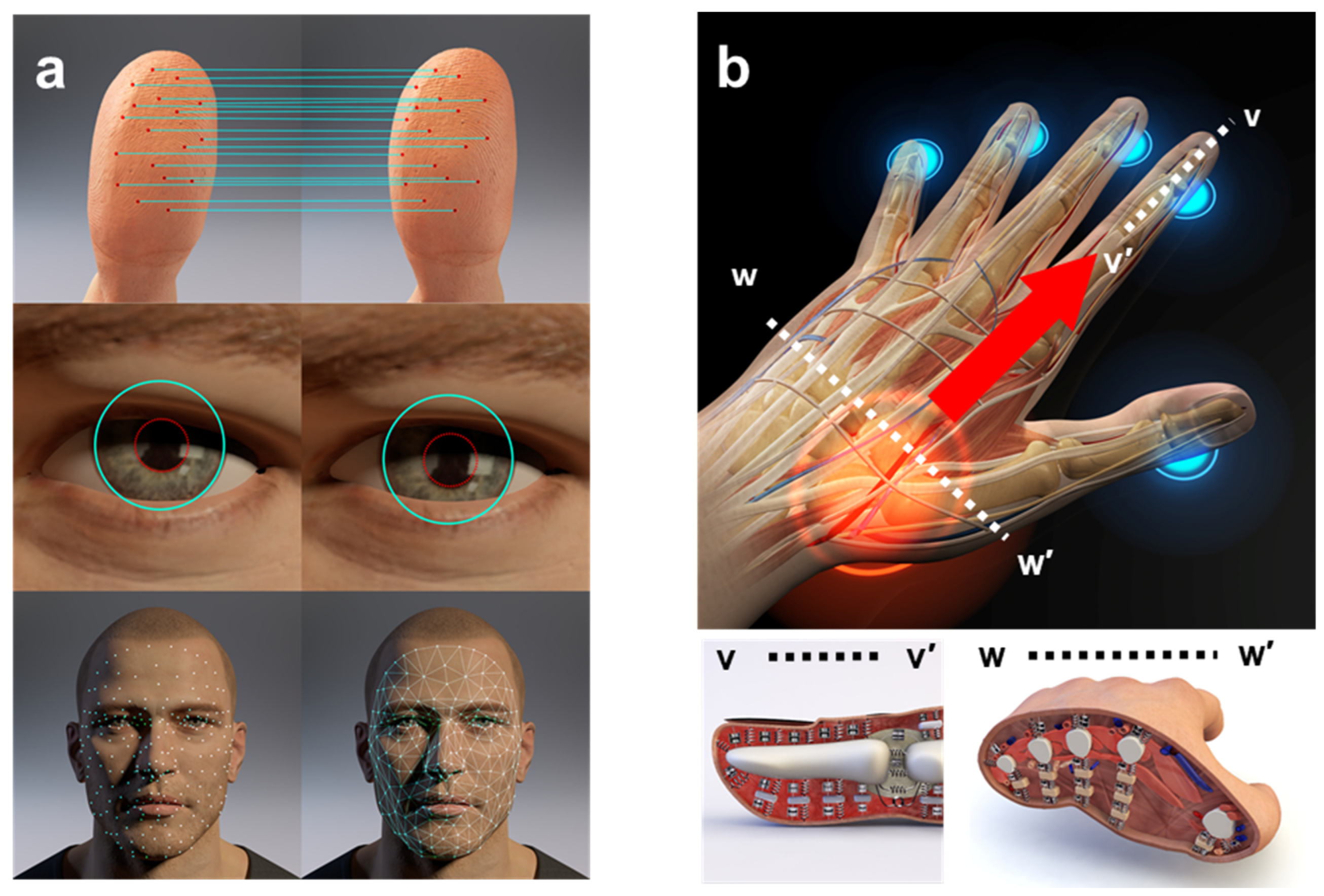
2.1. Liveness Detection Techniques
2.2. Acoustic System Identification and Imaging
2.3. Bioacoustics for Biomechanical Characterization
3. Multichannel Bioacoustic Identity Authentication
3.1. Multichannel Bioacoustic Identity Authentication System
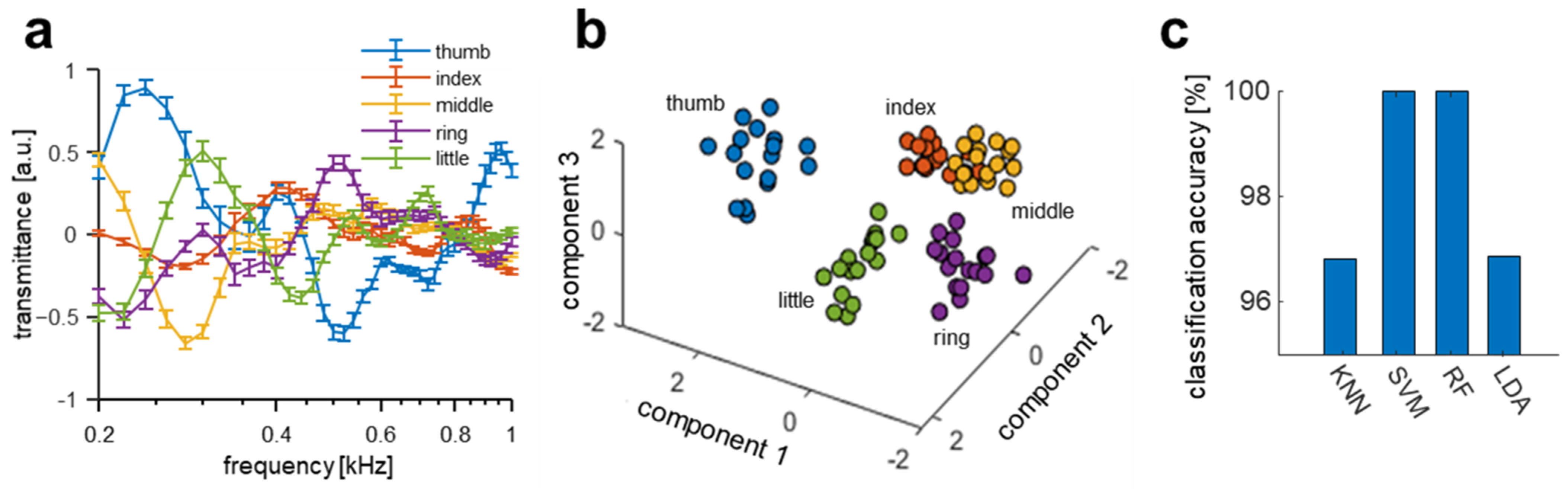
3.2. Multichannel Biodynamic Response
3.3. Interpersonal Variation of Multichannel Biodynamic Response
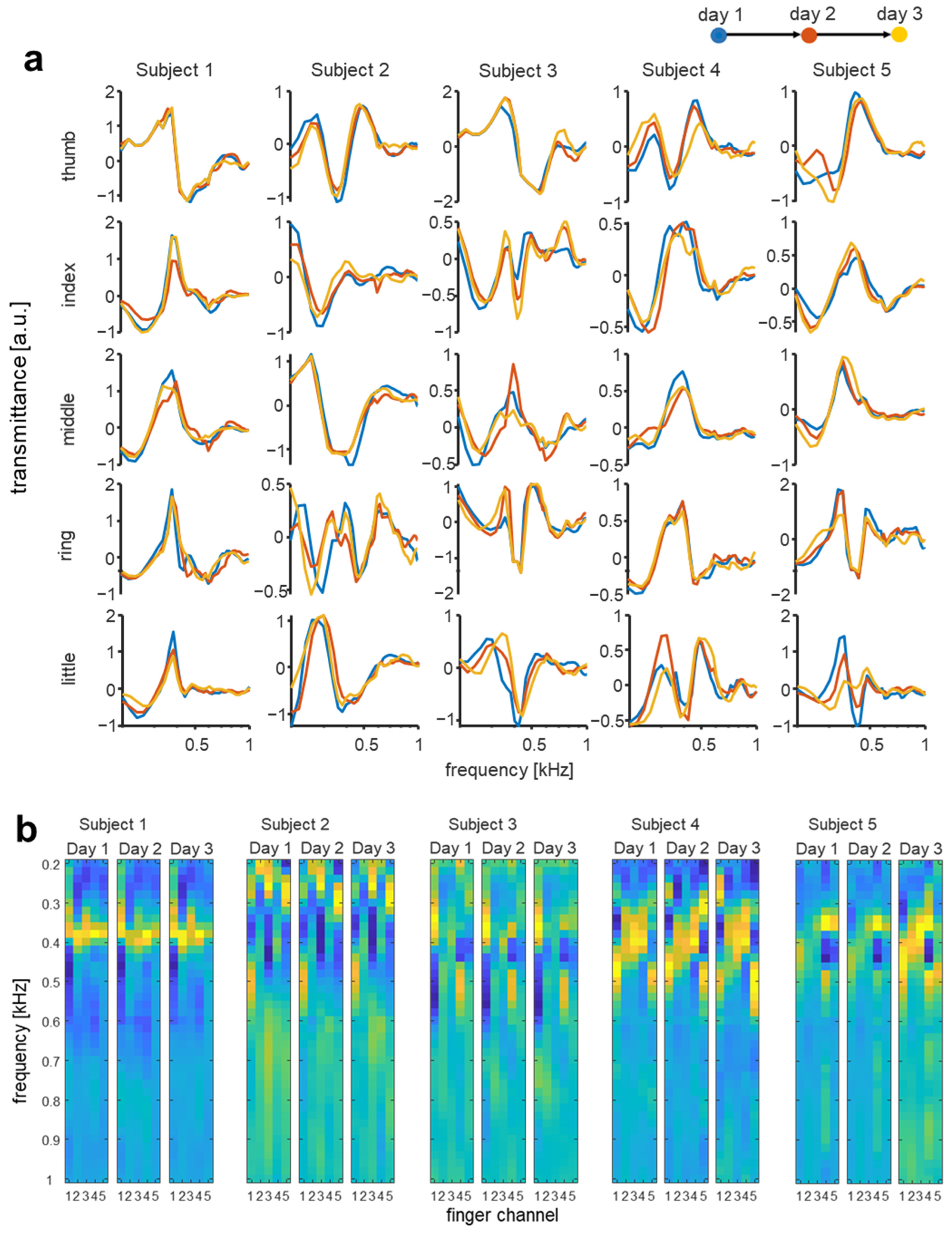
3.4. Temporal Changes of Multichannel Biodynamic Response
4. Biometric Authentication Using Multichannel Bioacoustic Signals
4.1. Machine Learning Algorithms
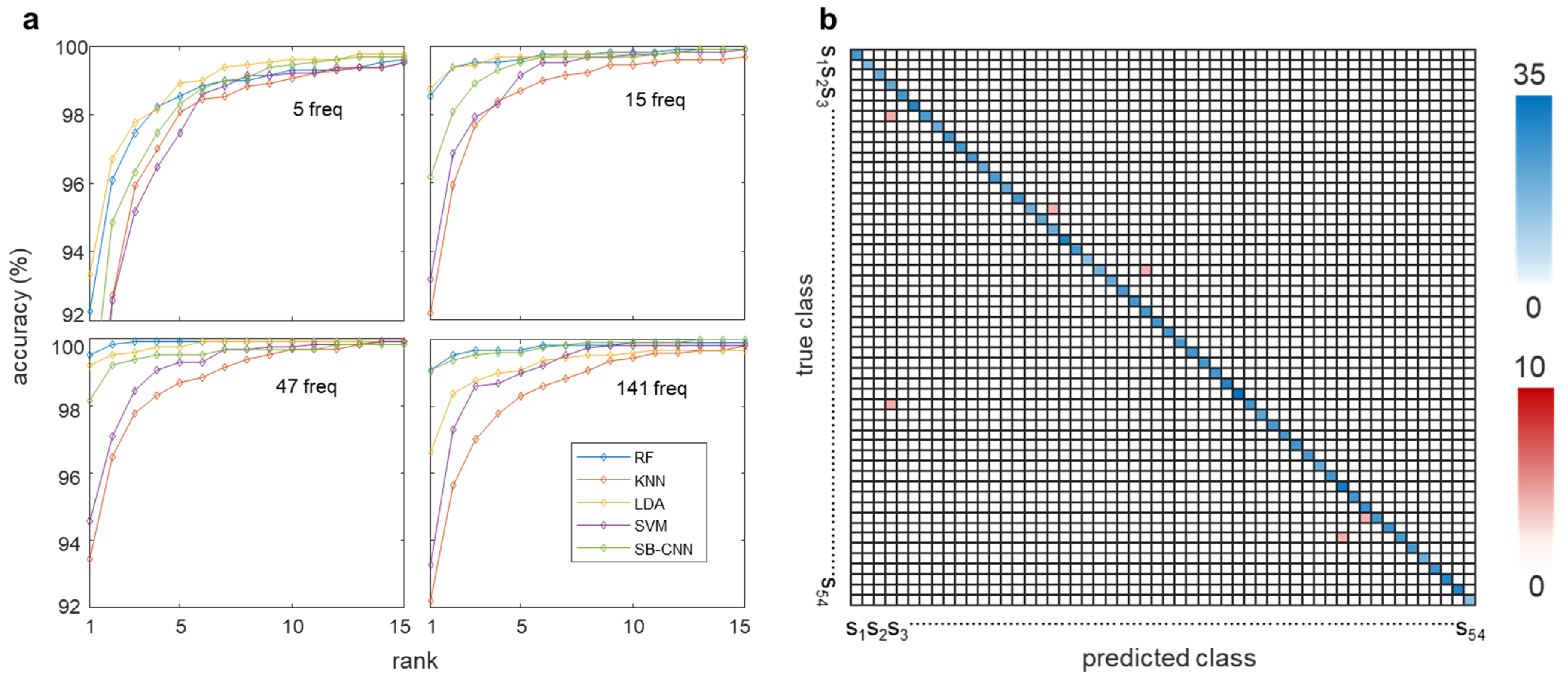
4.2. Biometric Authentication with Increasing Finger Channels
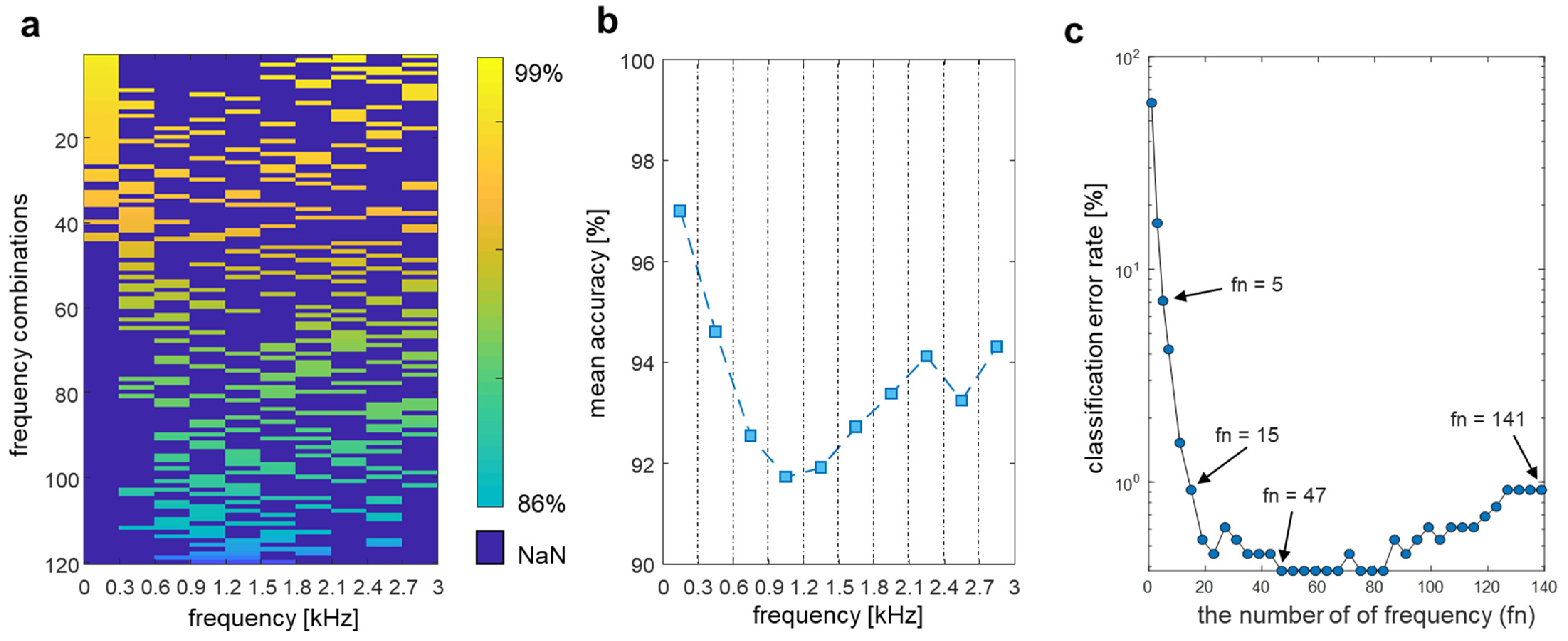
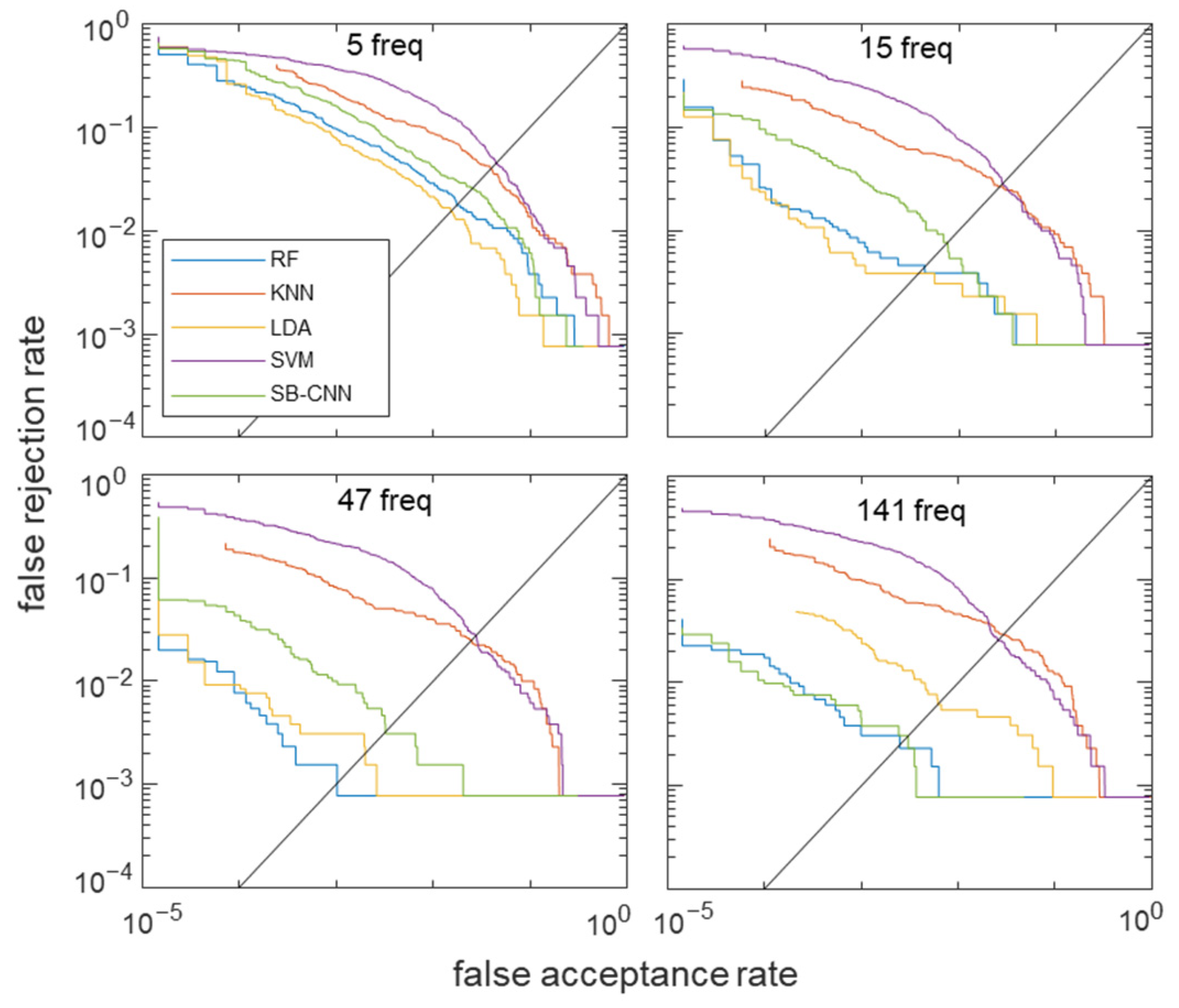
4.3. Frequency Feature Selection
4.4. Deep Learning Implementation of Multichannel Bioacoustic Identity Authentication
4.5. Computational Time for Classifiers
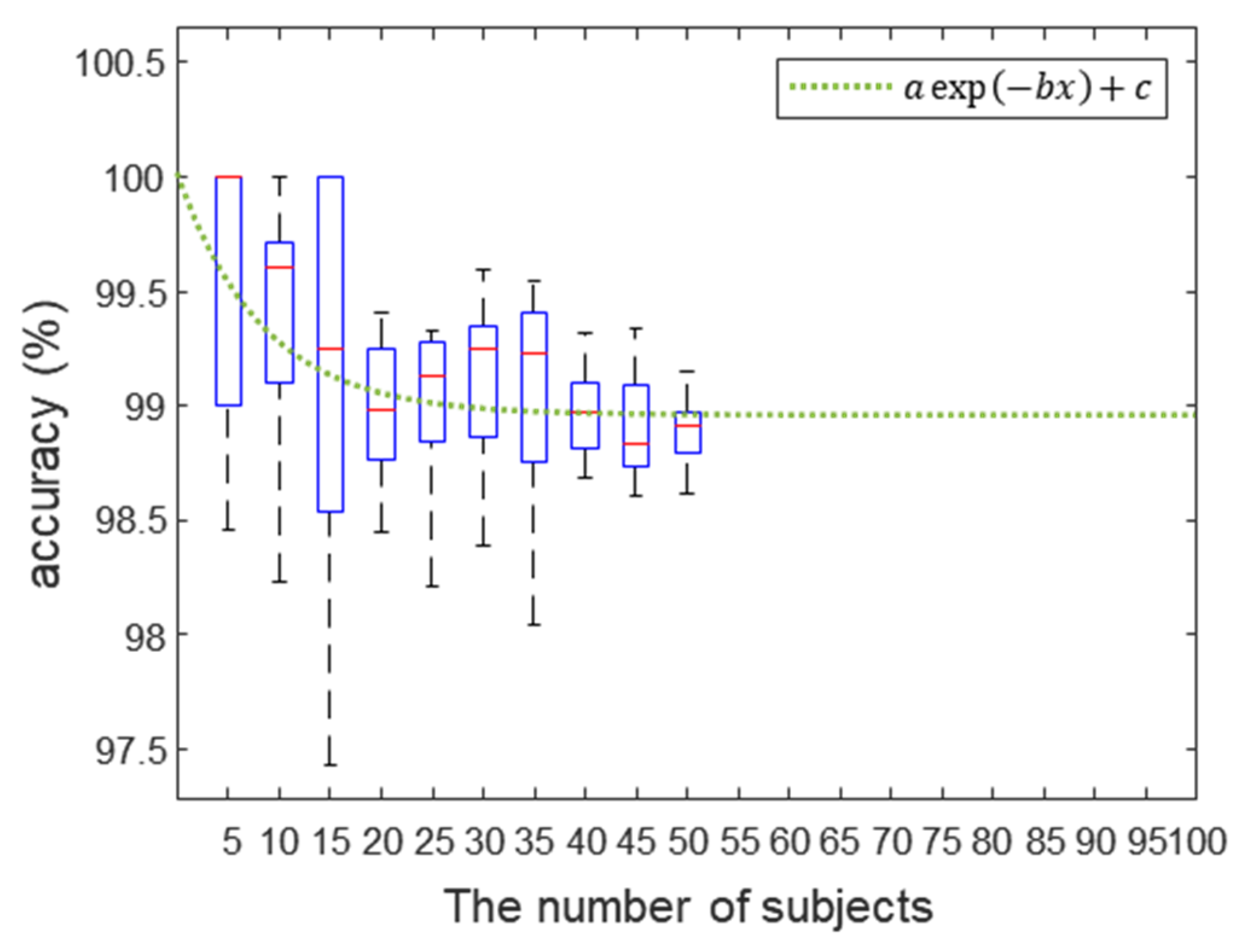
4.6. Scalability Analysis
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bolle, R.M.; Connell, J.H.; Pankanti, S.; Ratha, N.K.; Senior, A.W. Guide to Biometrics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; ISBN 978-1-4757-4036-3. [Google Scholar]
- Jain, A.K.; Ross, A.; Prabhakar, S. An Introduction to Biometric Recognition. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 4–20. [Google Scholar] [CrossRef]
- Patel, V.M.; Ratha, N.K.; Chellappa, R. Cancelable Biometrics: A Review. IEEE Signal Process. Mag. 2015, 32, 54–65. [Google Scholar] [CrossRef]
- Akhtar, Z.; Micheloni, C.; Foresti, G.L. Biometric Liveness Detection: Challenges and Research Opportunities. IEEE Secur. Priv. 2015, 13, 63–72. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Yoon, H.S.; Pham, T.D.; Park, K.R. Spoof Detection for Finger-Vein Recognition System Using NIR Camera. Sensors 2017, 17, 2261. [Google Scholar] [CrossRef]
- Mohsin, A.H.; Zaidan, A.A.; Zaidan, B.B.; Albahri, O.S.; Bin Ariffin, S.A.; Alemran, A.; Enaizan, O.; Shareef, A.H.; Jasim, A.N.; Jalood, N.S.; et al. Finger Vein Biometrics: Taxonomy Analysis, Open Challenges, Future Directions, and Recommended Solution for Decentralised Network Architectures. IEEE Access 2020, 8, 9821–9845. [Google Scholar] [CrossRef]
- Toygar, Ö.; Babalola, F.O.; Bitirim, Y. FYO: A Novel Multimodal Vein Database With Palmar, Dorsal and Wrist Biometrics. IEEE Access 2020, 8, 82461–82470. [Google Scholar] [CrossRef]
- Faltaous, S.; Liebers, J.; Abdelrahman, Y.; Alt, F.; Schneegass, S. VPID: Towards Vein Pattern Identification Using Thermal Imaging. i-com 2019, 18, 259–270. [Google Scholar] [CrossRef]
- Bok, J.Y.; Suh, K.H.; Lee, E.C. Detecting Fake Finger-Vein Data Using Remote Photoplethysmography. Electronics 2019, 8, 1016. [Google Scholar] [CrossRef]
- Drahansky, M. Liveness Detection in Biometrics. In Advanced Biometric Technologies; IntechOpen: Rijeka, Croatia, 2011; pp. 179–198. [Google Scholar] [CrossRef]
- Xu, Y.; Lu, Y.; Lu, G.; Li, J.; Zhang, D. Fast Pore Comparison for High Resolution Fingerprint Images Based on Multiple Co-Occurrence Descriptors and Local Topology Similarities. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 5721–5731. [Google Scholar] [CrossRef]
- Fei, L.; Lu, G.; Jia, W.; Teng, S.; Zhang, D. Feature Extraction Methods for Palmprint Recognition: A Survey and Evaluation. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 346–363. [Google Scholar] [CrossRef]
- Paul, P.P.; Gavrilova, M.L.; Alhajj, R. Decision Fusion for Multimodal Biometrics Using Social Network Analysis. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 1522–1533. [Google Scholar] [CrossRef]
- Shen, C.; Zhang, H.; Yang, Z.; Guan, X. Modeling Multimodal Biometric Modalities for Continuous User Authentication. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 001894–001899. [Google Scholar]
- Kim, N.; Steele, C.R.; Puria, S. The Importance of the Hook Region of the Cochlea for Bone-Conduction Hearing. Biophys. J. 2014, 107, 233–241. [Google Scholar] [CrossRef] [PubMed]
- Aibara, R.; Welsh, J.T.; Puria, S.; Goode, R.L. Human Middle-Ear Sound Transfer Function and Cochlear Input Impedance. Hear. Res. 2001, 152, 100–109. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. (Eds.) An Introduction to Statistical Learning: With Applications in R; Springer Texts in Statistics; Springer: New York, NY, USA, 2013; ISBN 978-1-4614-7137-0. [Google Scholar]
- Bermingham, M.L.; Pong-Wong, R.; Spiliopoulou, A.; Hayward, C.; Rudan, I.; Campbell, H.; Wright, A.F.; Wilson, J.F.; Agakov, F.; Navarro, P.; et al. Application of High-Dimensional Feature Selection: Evaluation for Genomic Prediction in Man. Sci. Rep. 2015, 5, 10312. [Google Scholar] [CrossRef] [PubMed]
- Sim, J.Y.; Noh, H.W.; Goo, W.; Kim, N.; Chae, S.; Ahn, C. Identity Recognition Based on Bioacoustics of Human Body. IEEE Trans. Cybern. 2019, 51, 2761–2772. [Google Scholar] [CrossRef]
- Busch, C. Facing the Future of Biometrics: Demand for Safety and Security in the Public and Private Sectors Is Driving Research in This Rapidly Growing Field. EMBO Rep. 2006, 7, S23–S25. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Hu, J.; Zheng, G.; Valli, C. Security and Accuracy of Fingerprint-Based Biometrics: A Review. Symmetry 2019, 11, 141. [Google Scholar] [CrossRef]
- Parthasaradhi, S.T.V.; Derakhshani, R.; Hornak, L.A.; Schuckers, S.A.C. Time-Series Detection of Perspiration as a Liveness Test in Fingerprint Devices. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2005, 35, 335–343. [Google Scholar] [CrossRef]
- Martinsen, O.G.; Clausen, S.; Nysaether, J.B.; Grimnes, S. Utilizing Characteristic Electrical Properties of the Epidermal Skin Layers to Detect Fake Fingers in Biometric Fingerprint Systems Mdash;A Pilot Study. IEEE Trans. Biomed. Eng. 2007, 54, 891–894. [Google Scholar] [CrossRef]
- Tan, X.; Li, Y.; Liu, J.; Jiang, L. Face Liveness Detection from a Single Image with Sparse Low Rank Bilinear Discriminative Model. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 504–517. [Google Scholar]
- Menotti, D.; Chiachia, G.; Pinto, A.; Schwartz, W.R.; Pedrini, H.; Falcão, A.X.; Rocha, A. Deep Representations for Iris, Face, and Fingerprint Spoofing Detection. IEEE Trans. Inf. Forensics Secur. 2015, 10, 864–879. [Google Scholar] [CrossRef]
- Kose, N.; Dugelay, J.-L. Reflectance Analysis Based Countermeasure Technique to Detect Face Mask Attacks. In Proceedings of the 2013 18th International Conference on Digital Signal Processing (DSP), Fira, Greece, 1–3 July 2013; pp. 1–6. [Google Scholar]
- Galbally, J.; Marcel, S.; Fierrez, J. Image Quality Assessment for Fake Biometric Detection: Application to Iris, Fingerprint, and Face Recognition. IEEE Trans. Image Process. 2014, 23, 710–724. [Google Scholar] [CrossRef]
- Sidek, K.A.; Khalil, I.; Jelinek, H.F. ECG Biometric with Abnormal Cardiac Conditions in Remote Monitoring System. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 1498–1509. [Google Scholar] [CrossRef]
- Pinto, J.R.; Cardoso, J.S.; Lourenço, A. Evolution, Current Challenges, and Future Possibilities in ECG Biometrics. IEEE Access 2018, 6, 34746–34776. [Google Scholar] [CrossRef]
- Pinto, J.R.; Cardoso, J.S.; Lourenço, A.; Carreiras, C. Towards a Continuous Biometric System Based on ECG Signals Acquired on the Steering Wheel. Sensors 2017, 17, 2228. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.W.; Ahn, C.-G.; Kong, H.-J.; Sim, J.Y. Ratiometric Impedance Sensing of Fingers for Robust Identity Authentication. Sci. Rep. 2019, 9, 13566. [Google Scholar] [CrossRef]
- Wahabi, S.; Pouryayevali, S.; Hari, S.; Hatzinakos, D. On Evaluating ECG Biometric Systems: Session-Dependence and Body Posture. IEEE Trans. Inf. Forensics Secur. 2014, 9, 2002–2013. [Google Scholar] [CrossRef]
- Zhang, C.; Bedri, A.; Reyes, G.; Bercik, B.; Inan, O.T.; Starner, T.E.; Abowd, G.D. TapSkin: Recognizing On-Skin Input for Smartwatches. In Proceedings of the 2016 ACM International Conference on Interactive Surfaces and Spaces, Niagara Falls, ON, Canada, 6–9 November 2016; ACM: New York, NY, USA, 2016; pp. 13–22. [Google Scholar]
- Harrison, C.; Tan, D.; Morris, D. Skinput: Appropriating the Body As an Input Surface. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; ACM: New York, NY, USA, 2010; pp. 453–462. [Google Scholar]
- Mujibiya, A.; Cao, X.; Tan, D.S.; Morris, D.; Patel, S.N.; Rekimoto, J. The Sound of Touch: On-Body Touch and Gesture Sensing Based on Transdermal Ultrasound Propagation. In Proceedings of the 2013 ACM International Conference on Interactive Tabletops and Surfaces, St. Andrews, UK, 6–9 October 2013; ACM: New York, NY, USA, 2013; pp. 189–198. [Google Scholar]
- Chauhan, J.; Hu, Y.; Seneviratne, S.; Misra, A.; Seneviratne, A.; Lee, Y. BreathPrint: Breathing Acoustics-Based User Authentication. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, Niagara Falls, NY, USA, 19–23 June 2017; ACM: New York, NY, USA, 2017; pp. 278–291. [Google Scholar]
- Das, S.; Laput, G.; Harrison, C.; Hong, J.I. Thumprint: Socially-Inclusive Local Group Authentication Through Shared Secret Knocks. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; ACM: New York, NY, USA, 2017; pp. 3764–3774. [Google Scholar]
- Laput, G.; Xiao, R.; Harrison, C. ViBand: High-Fidelity Bio-Acoustic Sensing Using Commodity Smartwatch Accelerometers. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016; ACM: New York, NY, USA, 2016; pp. 321–333. [Google Scholar]
- Adeli, H.; Jiang, X. Dynamic Fuzzy Wavelet Neural Network Model for Structural System Identification. J. Struct. Eng. 2006, 132, 102–111. [Google Scholar] [CrossRef]
- Ghanem, R.; Shinozuka, M. Structural-System Identification. I: Theory. J. Eng. Mech. 1995, 121, 255–264. [Google Scholar] [CrossRef]
- Szabo, T.L. Diagnostic Ultrasound Imaging: Inside out; Academic Press: Cambridge, MA, USA, 2004; ISBN 978-0-12-680145-3. [Google Scholar]
- Naranjo, F.J.R. Body Percussion Basic, Bapne; Body Music Percussion Press: Alicante, Spain, 2018; ISBN 978-84-09-00983-1. [Google Scholar]
- Naranjo, R.; Javier, F. Science & Art of Body Percussion: A Review. J. Hum. Sport Exerc. 2013, 8, 442–457. [Google Scholar] [CrossRef] [Green Version]
- Sim, J.Y.; Ahn, C.-G.; Jeong, E.-J.; Kim, B.K. In Vivo Microscopic Photoacoustic Spectroscopy for Non-Invasive Glucose Monitoring Invulnerable to Skin Secretion Products. Sci. Rep. 2018, 8, 1059. [Google Scholar] [CrossRef]
- Gazzah, H.; Regalia, P.A.; Delmas, J.-P.; Abed-Meraim, K. A Blind Multichannel Identification Algorithm Robust to Order Overestimation. IEEE Trans. Signal Process. 2002, 50, 1449–1458. [Google Scholar] [CrossRef]
- Abed-Meraim, K.; Cardoso, J.-F.; Gorokhov, A.Y.; Loubaton, P.; Moulines, E. On Subspace Methods for Blind Identification of Single-Input Multiple-Output FIR Systems. IEEE Trans. Signal Process. 1997, 45, 42–55. [Google Scholar] [CrossRef]
- Perrier, S.S.; Champoux, Y.; Drouet, J.-M. The Influence of a Human Hand-Arm System on the Vibrational Dynamic Behaviour of a Compliant Mechanical Structure. J. Vib. Control 2017, 23, 329–342. [Google Scholar] [CrossRef]
- Knez, L.; Slavič, J.; Boltežar, M. A Sequential Approach to the Biodynamic Modeling of a Human Finger. Shock. Vib. 2017, 2017, 8791406. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal Component Analysis: A Review and Recent Developments. Philos. Transact. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Das, P.; Holsopple, L.; Rissacher, D.; Schuckers, M.; Schuckers, S. Iris Recognition Performance in Children: A Longitudinal Study. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 138–151. [Google Scholar] [CrossRef]
- Johnson, M.; Yambay, D.; Rissacher, D.; Holsopple, L.; Schuckers, S. A Longitudinal Study of Iris Recognition in Children. In Proceedings of the 2018 IEEE 4th International Conference on Identity, Security, and Behavior Analysis (ISBA), Singapore, 11–12 January 2018; pp. 1–7. [Google Scholar]
- Deb, D.; Nain, N.; Jain, A.K. Longitudinal Study of Child Face Recognition. In Proceedings of the 2018 International Conference on Biometrics (ICB), Gold Coast, QLD, Australia, 20–23 February 2018; IEEE: Piscataway, NJ, USA; pp. 225–232. [Google Scholar]
- Geiger, J.T.; Schuller, B.; Rigoll, G. Large-Scale Audio Feature Extraction and SVM for Acoustic Scene Classification. In Proceedings of the 2013 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 20–23 October 2013; pp. 1–4. [Google Scholar]
- Mao, K.Z. Orthogonal Forward Selection and Backward Elimination Algorithms for Feature Subset Selection. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2004, 34, 629–634. [Google Scholar] [CrossRef] [PubMed]
- Salamon, J.; Bello, J.P. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, L.; Wang, G.; et al. Recent Advances in Convolutional Neural Networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Kůrková, V.; Manolopoulos, Y.; Hammer, B.; Iliadis, L.; Maglogiannis, I. Artificial Neural Networks and Machine Learning—ICANN 2018: 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018, Proceedings; Springer: Berlin/Heidelberg, Germany, 2018; ISBN 978-3-030-01421-6. [Google Scholar]
- Karthik, S.; Paul, A.; Karthikeyan, N. Deep Learning Innovations and Their Convergence with Big Data; IGI Global Hershey: Lancaster, PA, USA, 2017; ISBN 978-1-5225-3016-9. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Scarpino, M. TensorFlow For Dummies; John Wiley & Sons: Hoboken, NJ, USA, 2018; ISBN 978-1-119-46621-5. [Google Scholar]
- Zhou, T.; Ruan, S.; Canu, S. A Review: Deep Learning for Medical Image Segmentation Using Multi-Modality Fusion. Array 2019, 3–4, 100004. [Google Scholar] [CrossRef]
- DeCann, B.; Ross, A. Relating ROC and CMC Curves via the Biometric Menagerie. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–8. [Google Scholar]
- Grother, P.; Phillips, P.J. Models of Large Population Recognition Performance. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004, Washington, DC, USA, 27 June 2004–2 July 2004; Volume 2, p. II. [Google Scholar]
- Phillips, P.; Grother, P.; Micheals, R.; Blackburn, D.M.; Elham, T.; Bone, J.M. FRVT 2002: Facial Recognition Vendor Test. Technol. Rep. DoD 2003. [Google Scholar] [CrossRef]
- Phillips, P.J.; Moon, H.; Rizvi, S.A.; Rauss, P.J. The FERET Evaluation Methodology for Face-Recognition Algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1090–1104. [Google Scholar] [CrossRef]
- Bolle, R.M.; Connell, J.H.; Pankanti, S.; Ratha, N.K.; Senior, A.W. The Relation between the ROC Curve and the CMC. In Proceedings of the Fourth IEEE Workshop on Automatic Identification Advanced Technologies (AutoID’05), Buffalo, NY, USA, 17–18 October 2005; pp. 15–20. [Google Scholar]
- Koike-Akino, T.; Mahajan, R.; Marks, T.K.; Wang, Y.; Watanabe, S.; Tuzel, O.; Orlik, P. High-Accuracy User Identification Using EEG Biometrics. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 854–858. [Google Scholar]
- Behavioural Biometrics in VR|Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems. Available online: https://dl.acm.org/doi/10.1145/3290605.3300340 (accessed on 16 January 2021).
- Kemelmacher-Shlizerman, I.; Seitz, S.M.; Miller, D.; Brossard, E. The MegaFace Benchmark: 1 Million Faces for Recognition at Scale. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4873–4882. [Google Scholar]
- Su, K.; Yang, G.; Wu, B.; Yang, L.; Li, D.; Su, P.; Yin, Y. Human Identification Using Finger Vein and ECG Signals. Neurocomputing 2019, 332, 111–118. [Google Scholar] [CrossRef]
- Benaliouche, H.; Touahria, M. Comparative Study of Multimodal Biometric Recognition by Fusion of Iris and Fingerprint. Sci. World J. 2014, 2014, e829369. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fn* | Accuracy [%] | EER [%] | AUC | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Classifier | 5 | 15 | 47 | 141 | 5 | 15 | 47 | 141 | 5 | 15 | 47 | 141 | |
| RF | 92.28 | 98.55 | 99.62 | 99.08 | 1.7584 | 0.4479 | 0.0887 | 0.2423 | 0.9975 | 0.9993 | 0.9996 | 0.9998 | |
| kNN | 87.54 | 92.20 | 93.43 | 92.20 | 3.9755 | 2.6758 | 2.4465 | 2.9052 | 0.9930 | 0.9963 | 0.9967 | 0.9957 | |
| LDA | 93.35 | 98.78 | 99.24 | 96.64 | 1.5291 | 0.3823 | 0.2135 | 0.6203 | 0.9986 | 0.9996 | 0.9997 | 0.9994 | |
| SVM | 85.17 | 93.20 | 94.57 | 93.27 | 4.5107 | 2.8901 | 2.7501 | 2.5828 | 0.9908 | 0.9955 | 0.9959 | 0.9956 | |
| SB-CNN | 88.99 | 96.18 | 98.17 | 99.08 | 2.5871 | 0.7645 | 0.3109 | 0.3058 | 0.9974 | 0.9997 | 0.9997 | 0.9999 | |
| Classifier | Processing Time | |
|---|---|---|
| Training (s) | Prediction (ms) | |
| RF | 2.1114 | 40.54 |
| kNN | 0.1028 | 2.34 |
| LDA | 0.2623 | 24.60 |
| SVM | 17.4162 | 212.16 |
| SB-CNN | 2460 (41 min)/2000 epoch | 0.16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noh, H.W.; Ahn, C.-G.; Chae, S.-H.; Ku, Y.; Sim, J.Y. Multichannel Acoustic Spectroscopy of the Human Body for Inviolable Biometric Authentication. Biosensors 2022, 12, 700. https://doi.org/10.3390/bios12090700
Noh HW, Ahn C-G, Chae S-H, Ku Y, Sim JY. Multichannel Acoustic Spectroscopy of the Human Body for Inviolable Biometric Authentication. Biosensors. 2022; 12(9):700. https://doi.org/10.3390/bios12090700
Chicago/Turabian StyleNoh, Hyung Wook, Chang-Geun Ahn, Seung-Hoon Chae, Yunseo Ku, and Joo Yong Sim. 2022. "Multichannel Acoustic Spectroscopy of the Human Body for Inviolable Biometric Authentication" Biosensors 12, no. 9: 700. https://doi.org/10.3390/bios12090700
APA StyleNoh, H. W., Ahn, C.-G., Chae, S.-H., Ku, Y., & Sim, J. Y. (2022). Multichannel Acoustic Spectroscopy of the Human Body for Inviolable Biometric Authentication. Biosensors, 12(9), 700. https://doi.org/10.3390/bios12090700