Ensem-HAR: An Ensemble Deep Learning Model for Smartphone Sensor-Based Human Activity Recognition for Measurement of Elderly Health Monitoring

 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
2. Literature Review
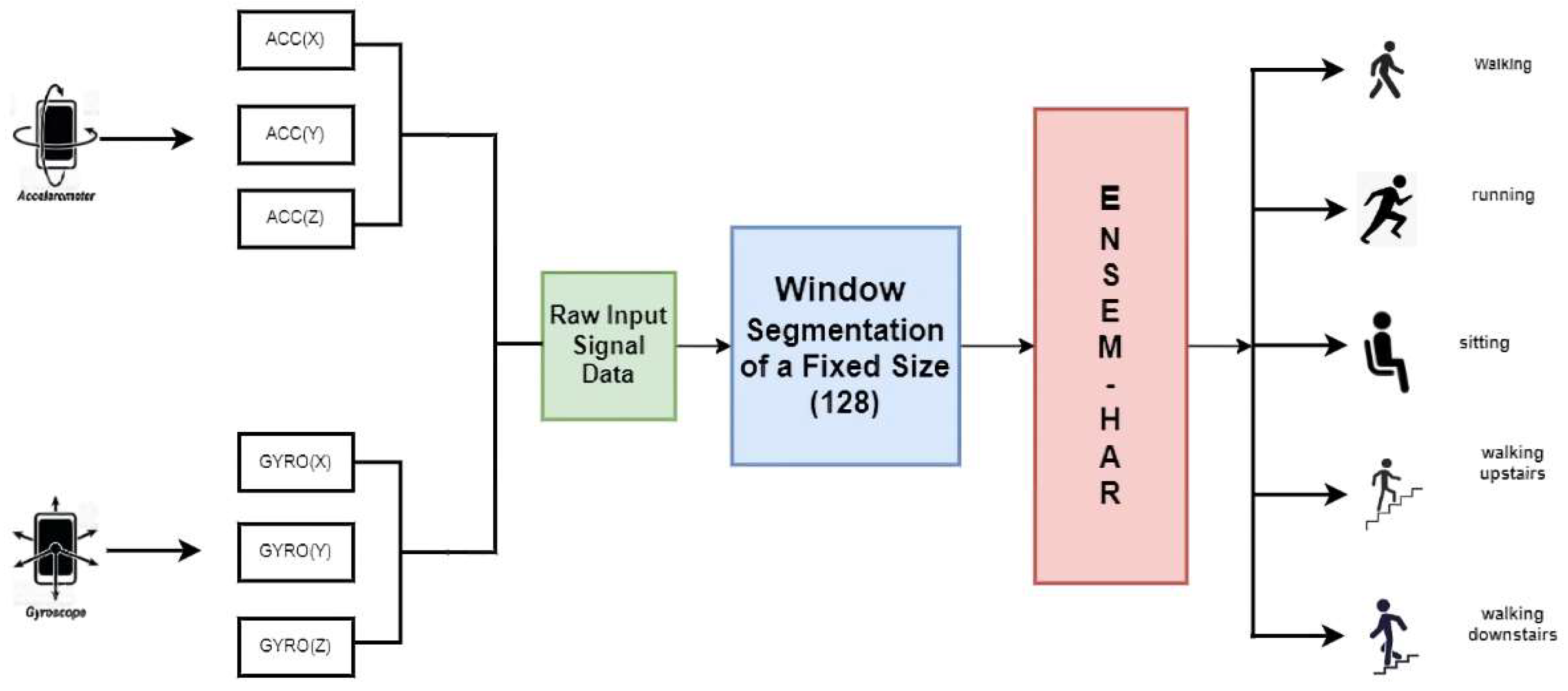
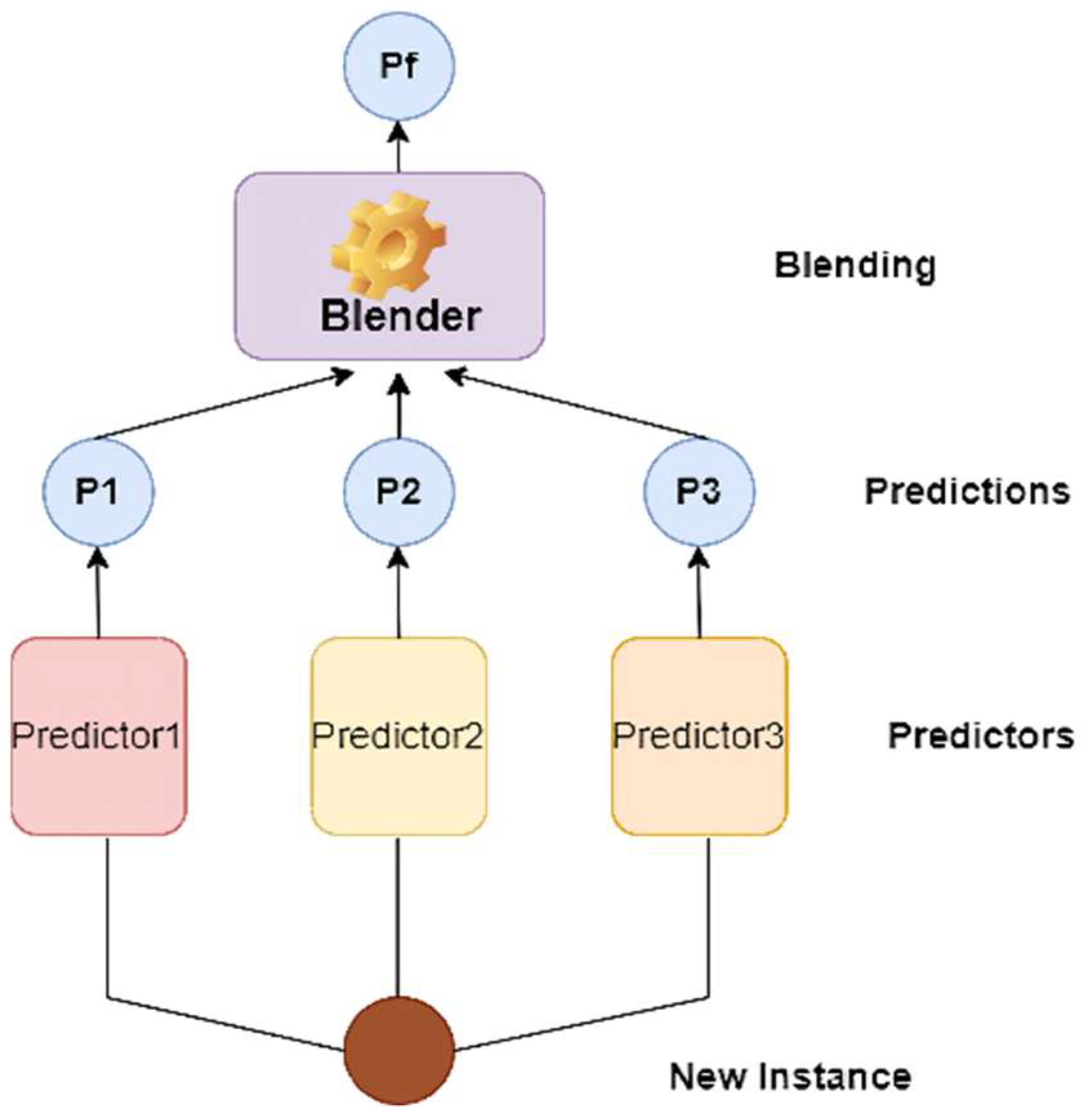
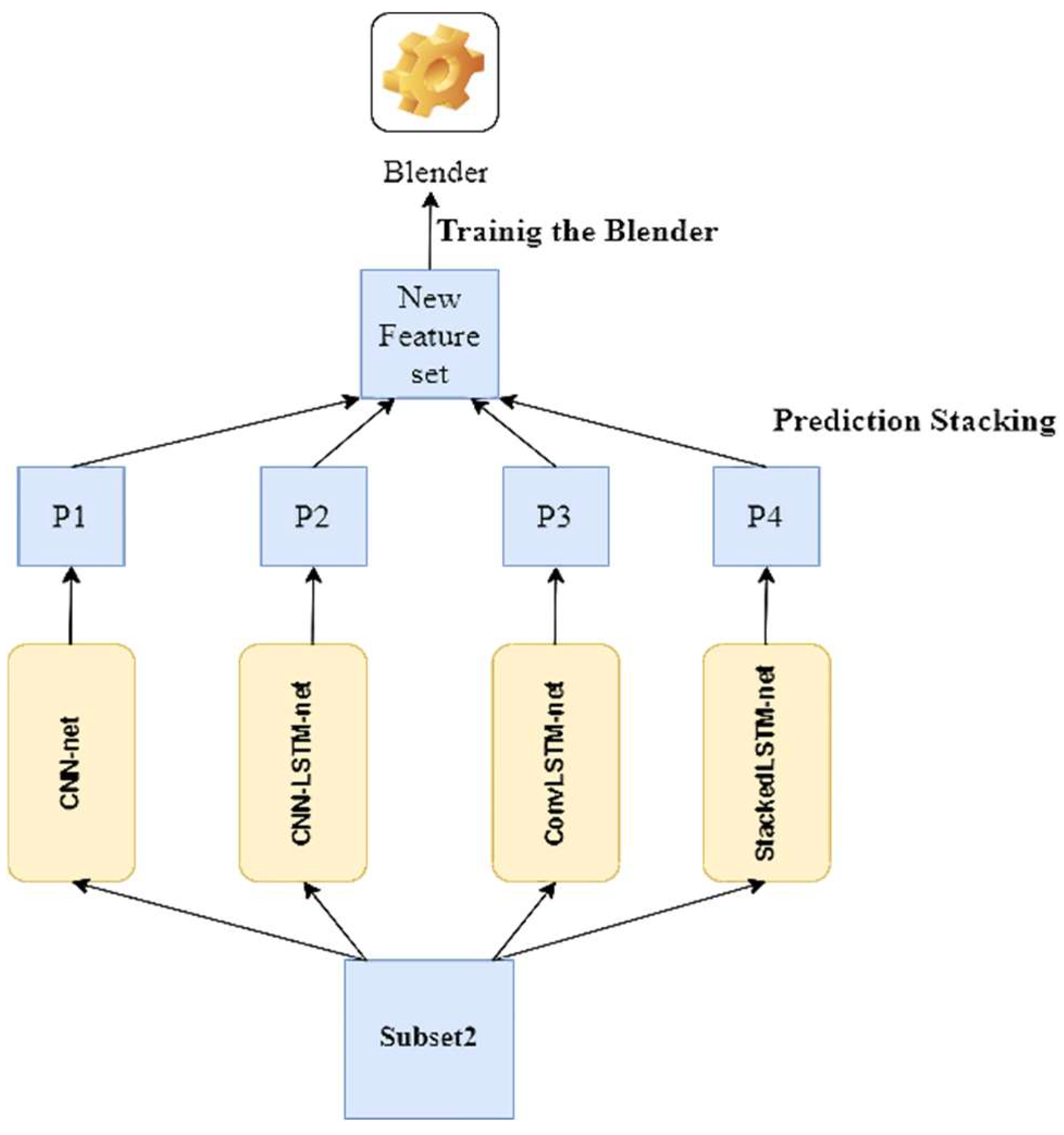
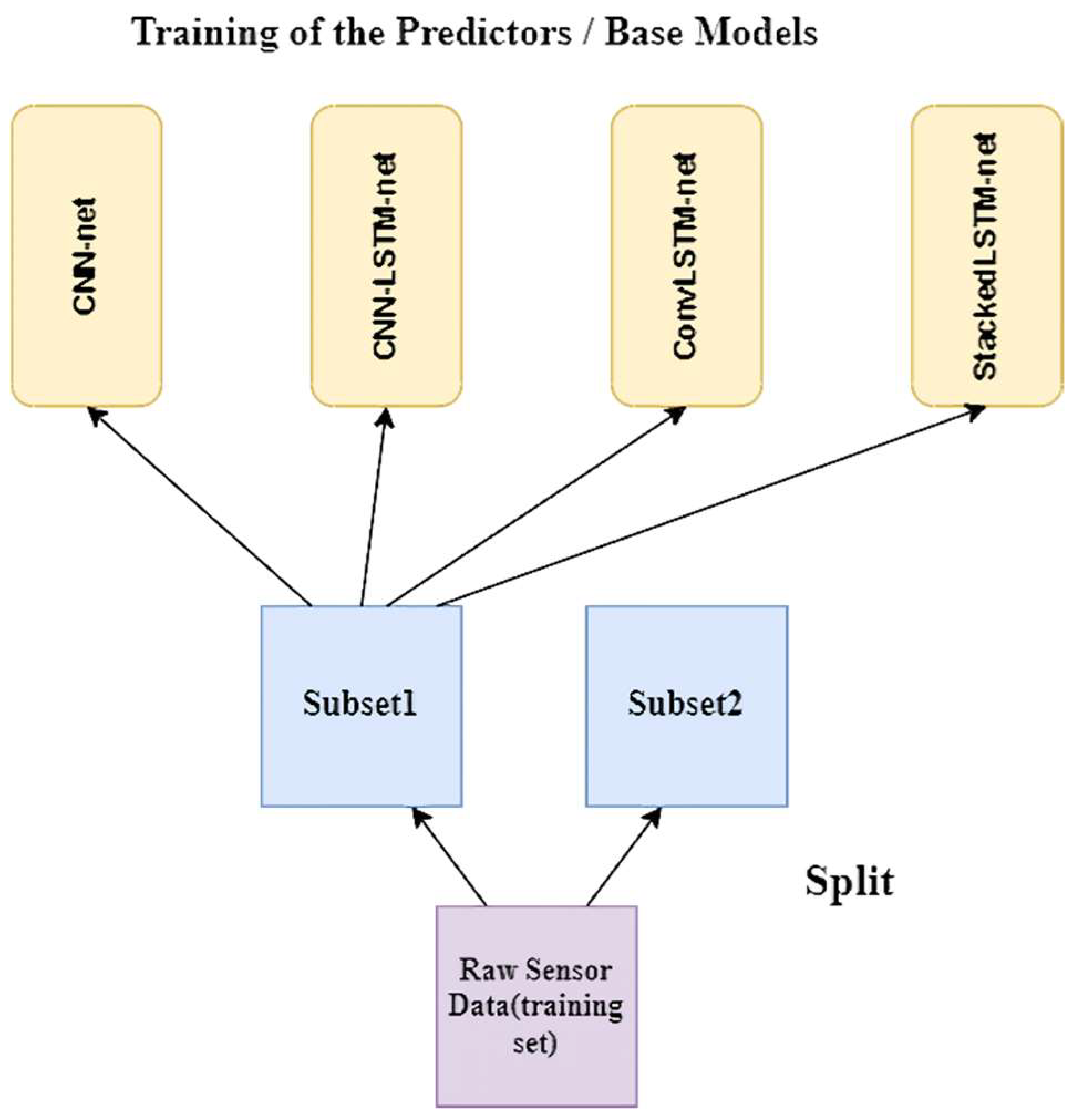
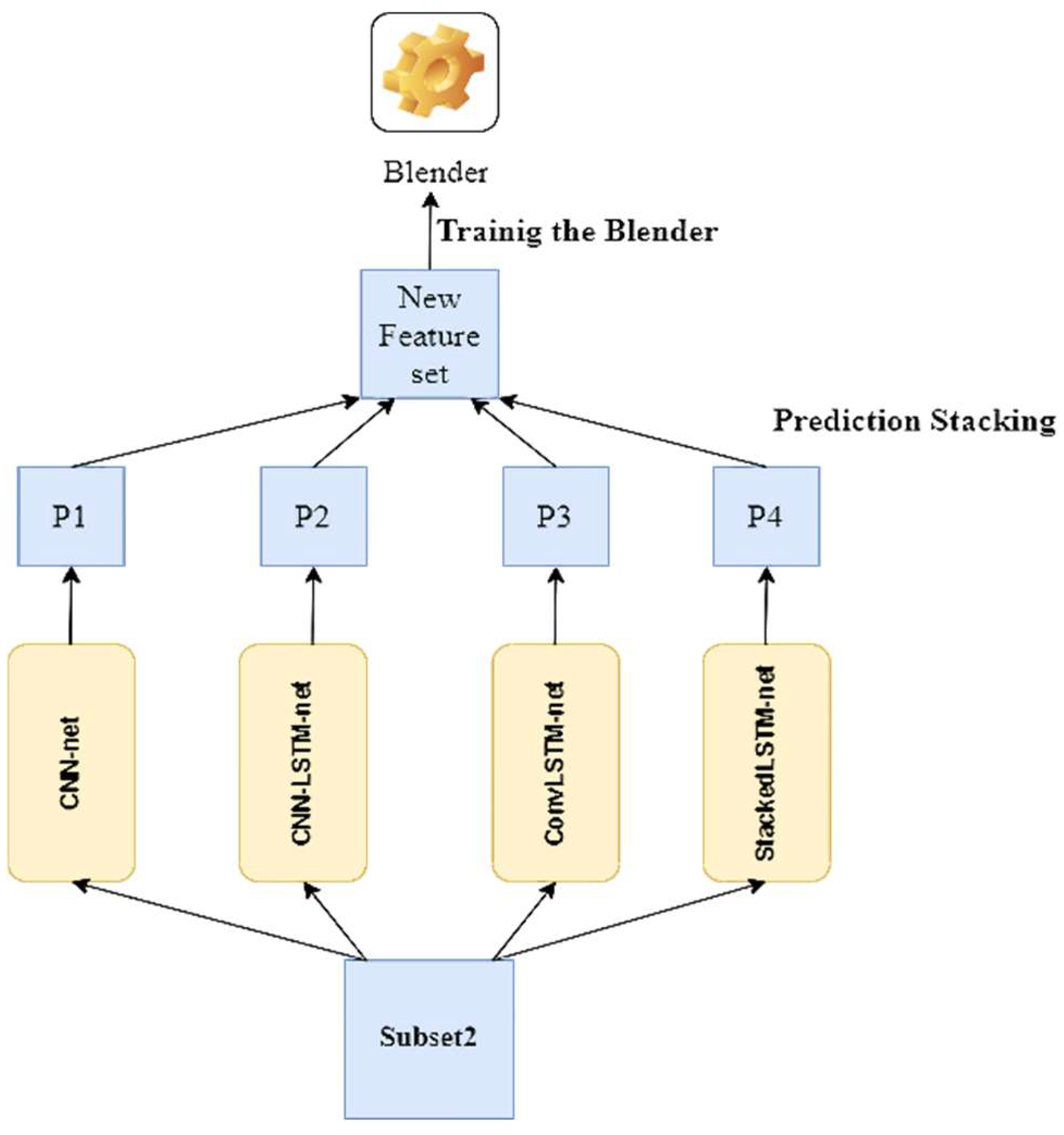
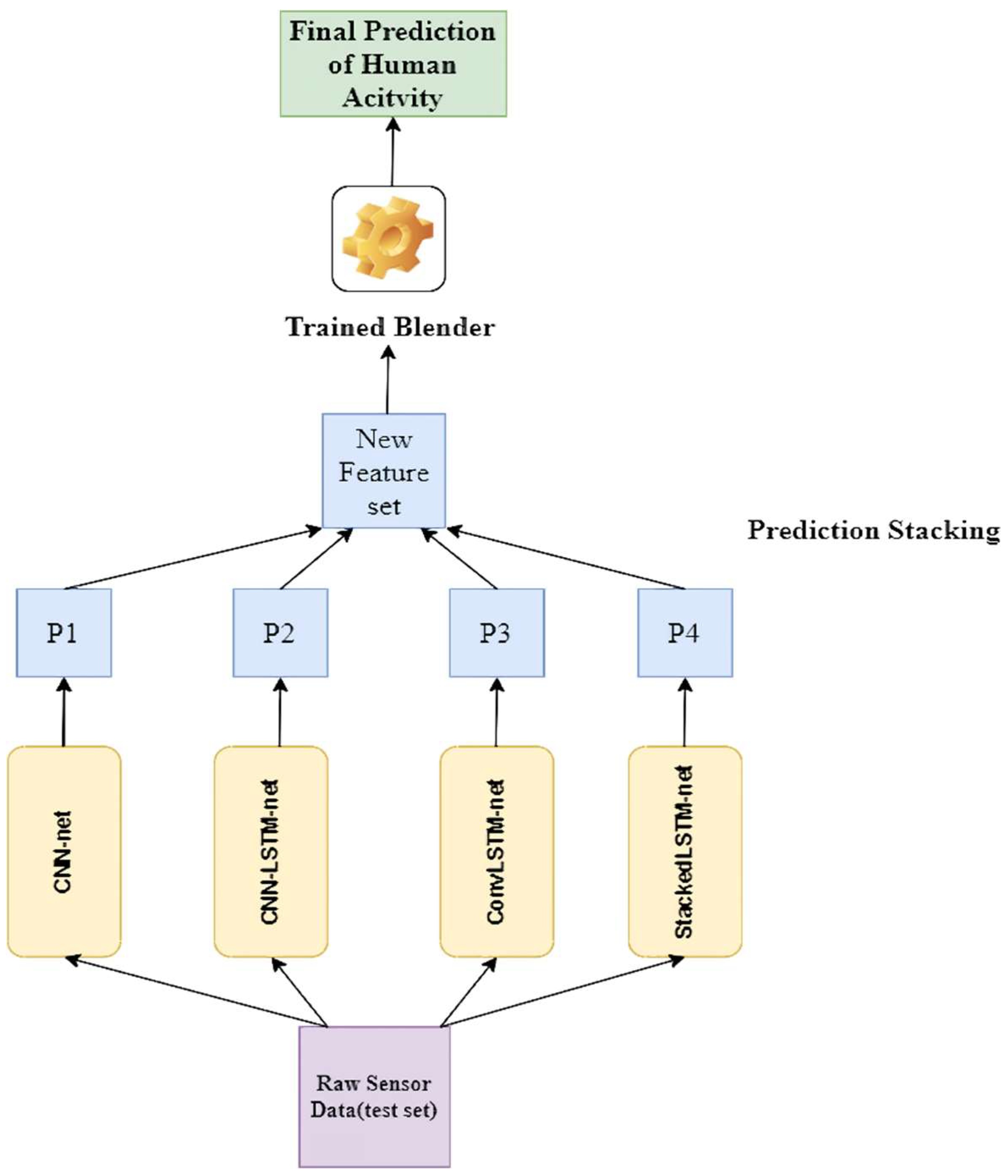
3. Materials and Methods
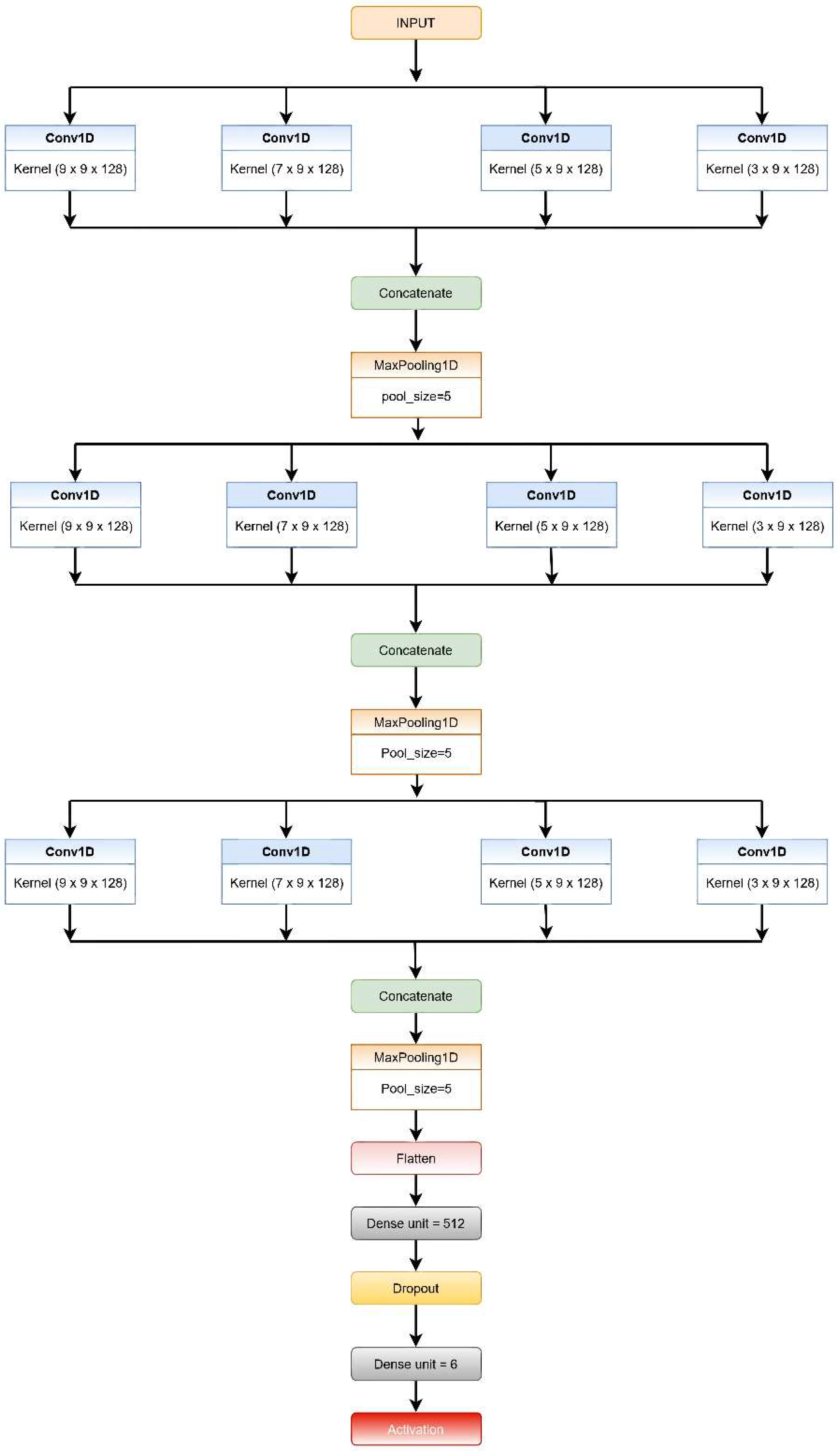
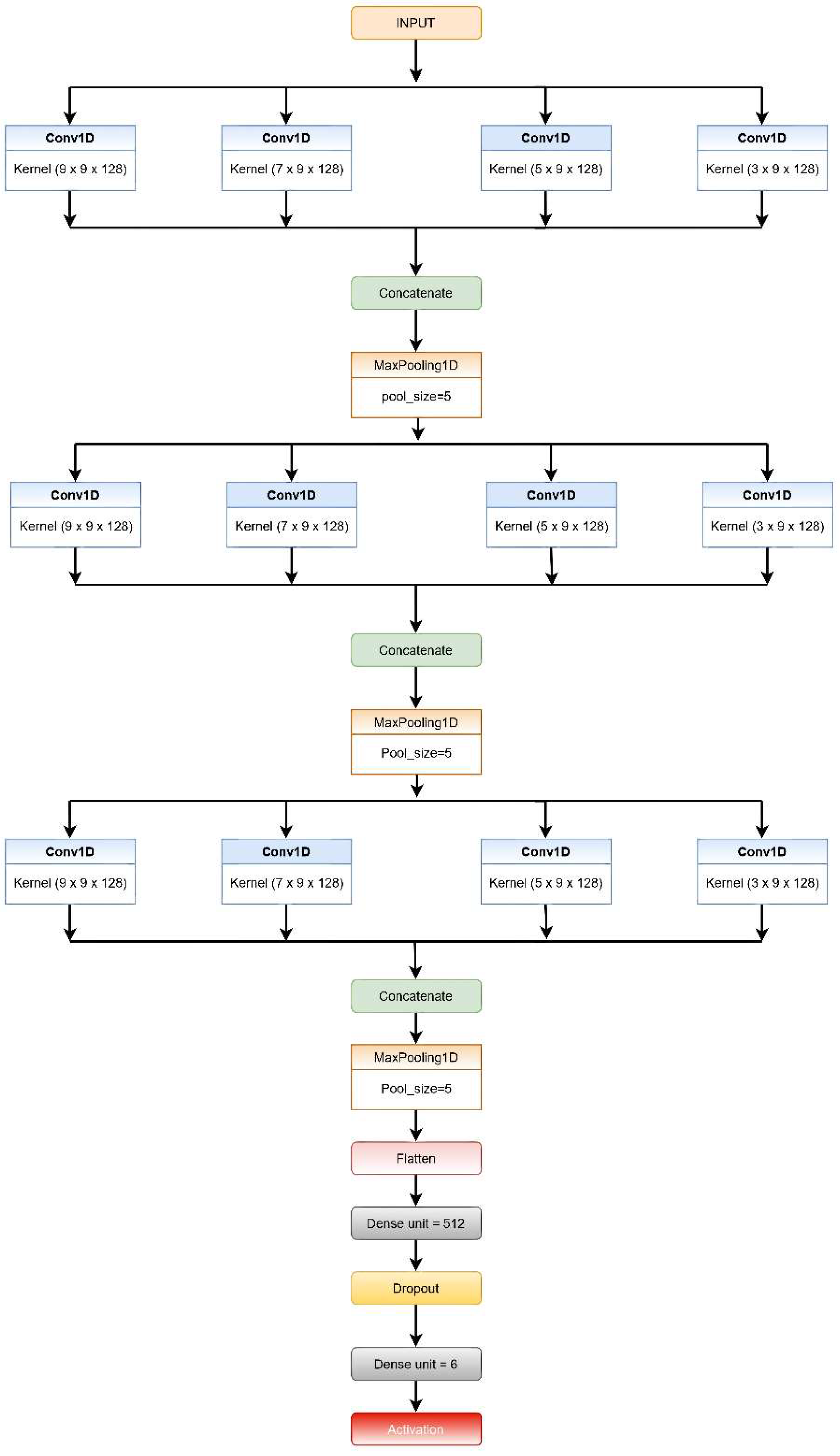
3.1. CNN-Net Model
- Each CNN level consists of four convolution layers (1D) and incorporates the ReLU activation function, which reduces non-linearity. The filters are of different kernel sizes for each layer, while the number of filters is the same for each level.
- At the very first level, every convolution layer present extracts features from the input windows based on different sized kernels. The features retrieved from each layer in the first level are concatenated, then a max-pooling layer with a five-size pool generates a summary of the extracted features provided by the convolution layers reducing the computation costs.
- The features extracted from the first MaxPool layer are then fed into the second and third set of a four-layered CNN consecutively in a similar fashion. The layers in both the second and third levels have different sizes of kernels, as in the first level; however, the count of filters used in each layer is the same for the respective levels (64 and 32).
- The output from the third MaxPool layer is flattened and fed to the classification layer. This layer is made up of two fully connected (FC) layers that use the SoftMax Activation function on their inputs.
- The addition of dropout after the first layer of the FC layer is performed for regularization, i.e., to minimize the likelihood of overfitting. The Adam optimization method is used by all of the systems for weight updating and loss computation.
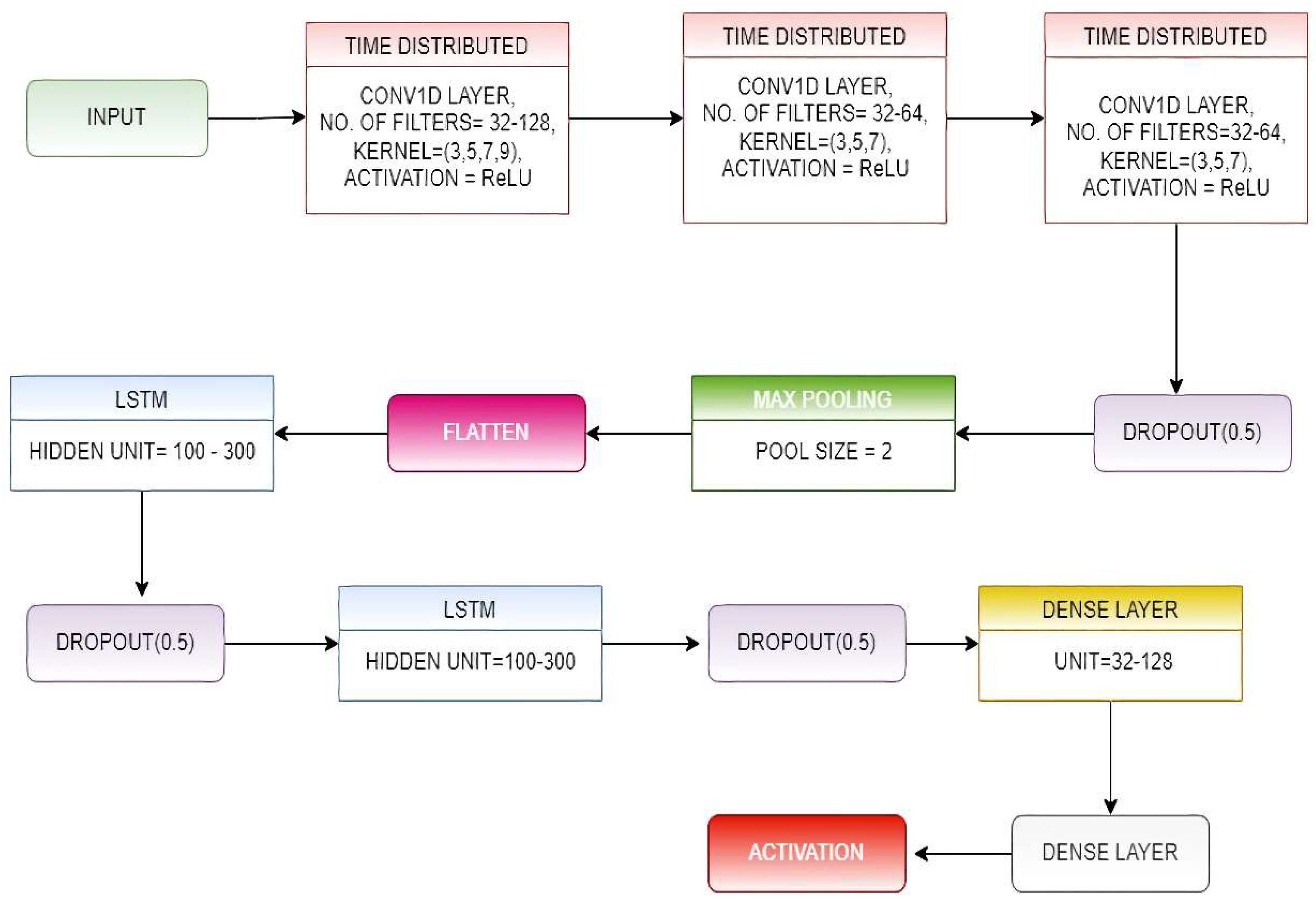
3.2. CNN-LSTM-Net Model
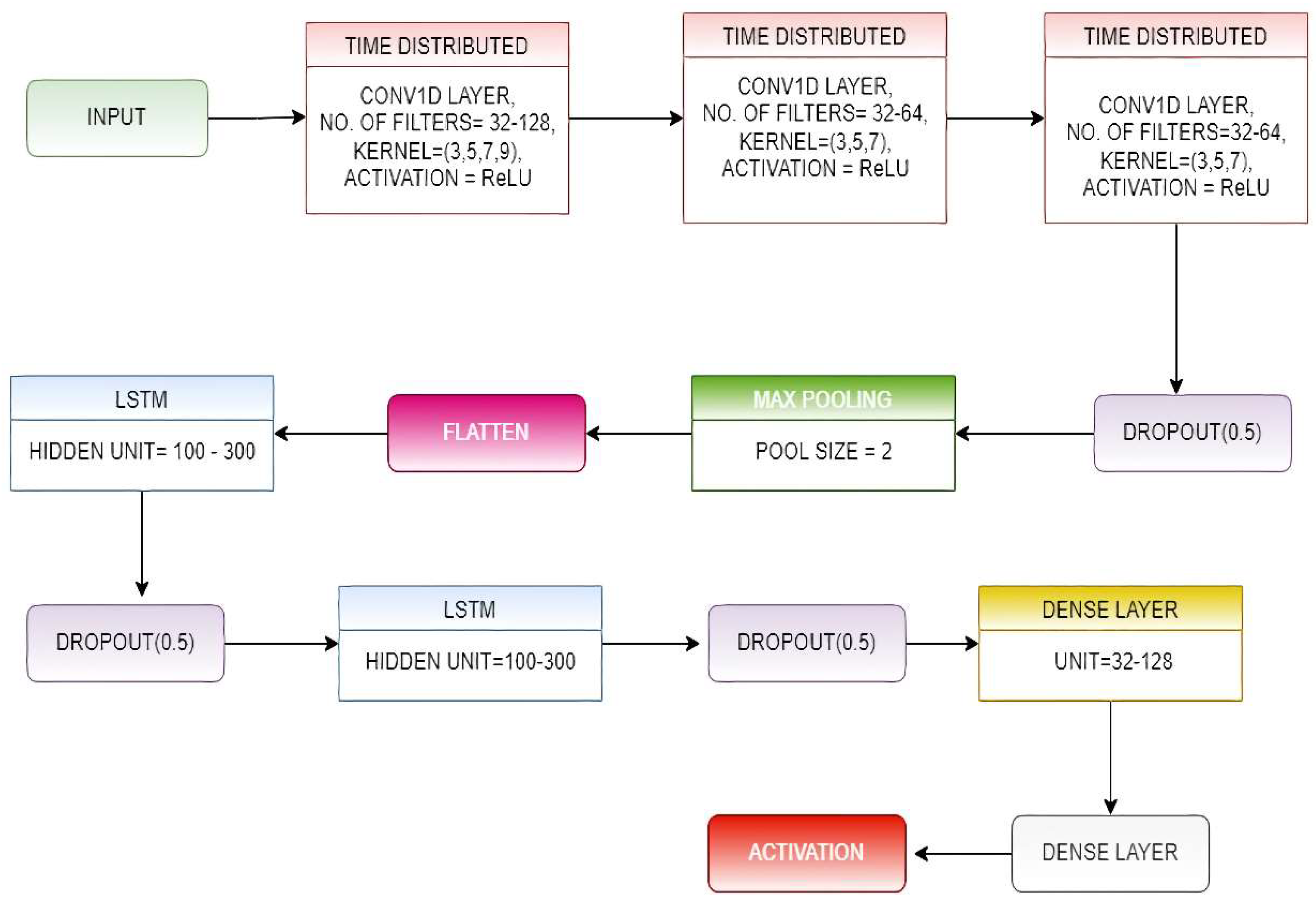
3.3. ConvLSTM-Net Model
- We wrapped the complete CNN model in a time-distributed layer, allowing it to read in each of the four sub-sequences.
- In the proposed model, we have used three time-distributed layers of the mentioned type, and the output from them was provided to a two-layer stacked LSTM.
- The output obtained from the LSTM layer was forwarded to the classification layer, which was made up of two fully connected (FC)layers that use the SoftMax Activation function on their inputs.
- The number of filters and kernel size of the 1D convolutional layers and the number of hidden units present in the LSTM layers were determined by implementing a random search for a range of values for these parameters.
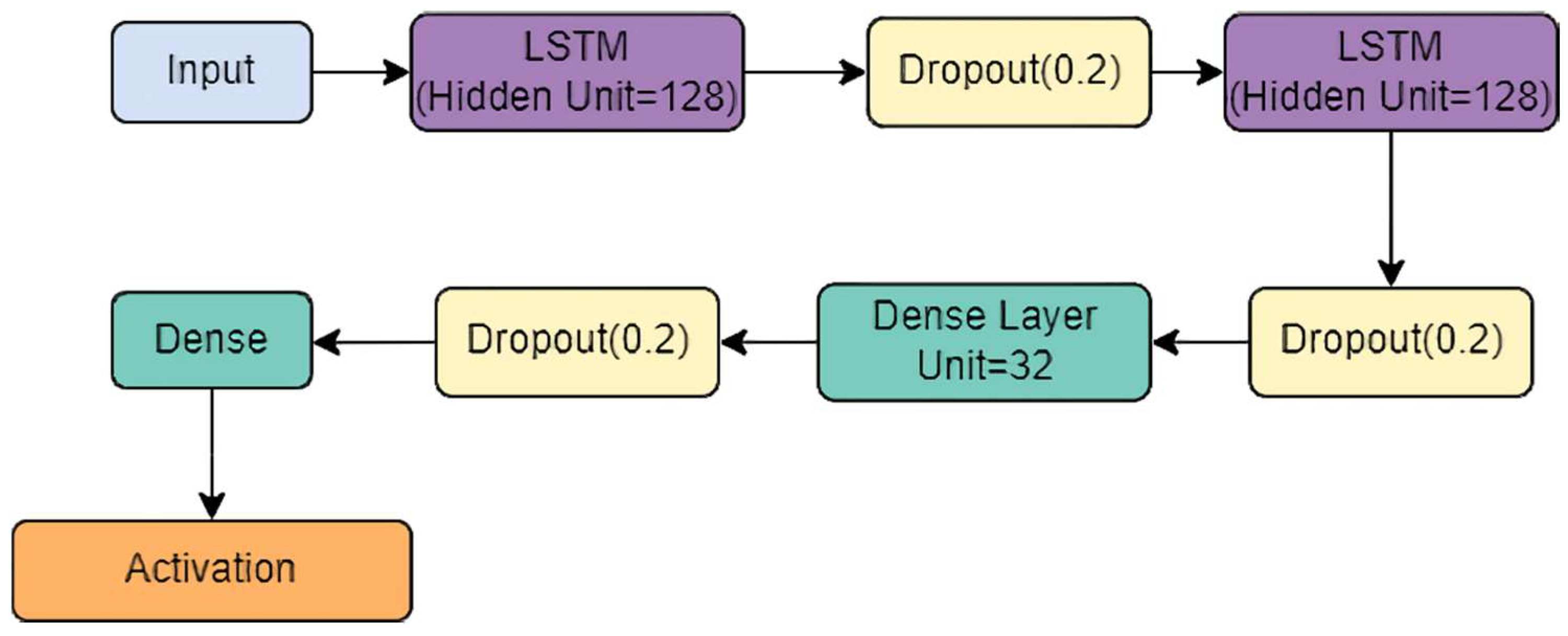
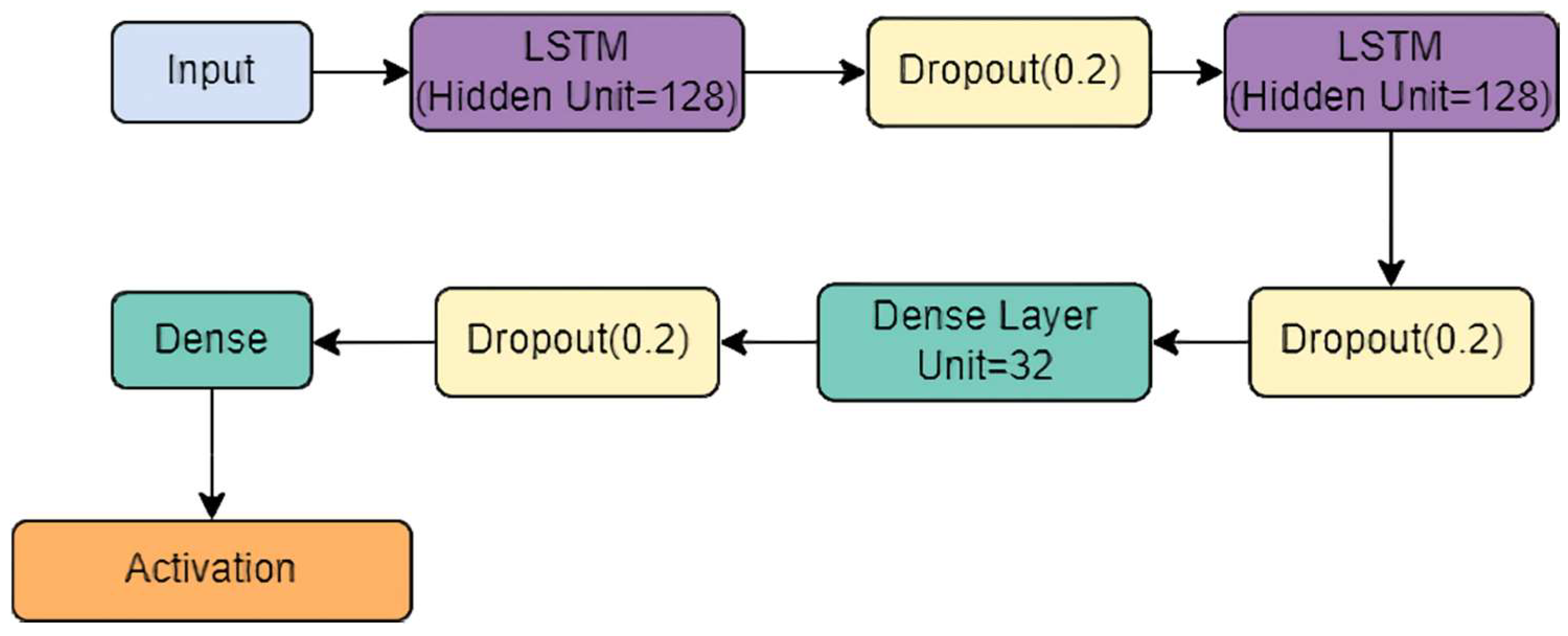
3.4. StackedLSTM-Net Model
- Each LSTM layer consisted of 128 hidden units and a dropout layer added to reduce overfitting.
- Batch normalization was added after each LSTM layer to standardize the inputs to a layer for each mini-batch.
- The output from the stacked-LSTM was fed to the classification layer, comprising two fully connected (FC) layers, which subject their inputs to the SoftMax activation function.
4. Result and Analysis
4.1. Dataset Description
4.1.1. WISDM Dataset
4.1.2. PAMAP2 Dataset
4.1.3. UCI-HAR Dataset
4.2. Machine Specification
4.3. Evaluation Metrics
4.4. Analysis on Conventional Datasets
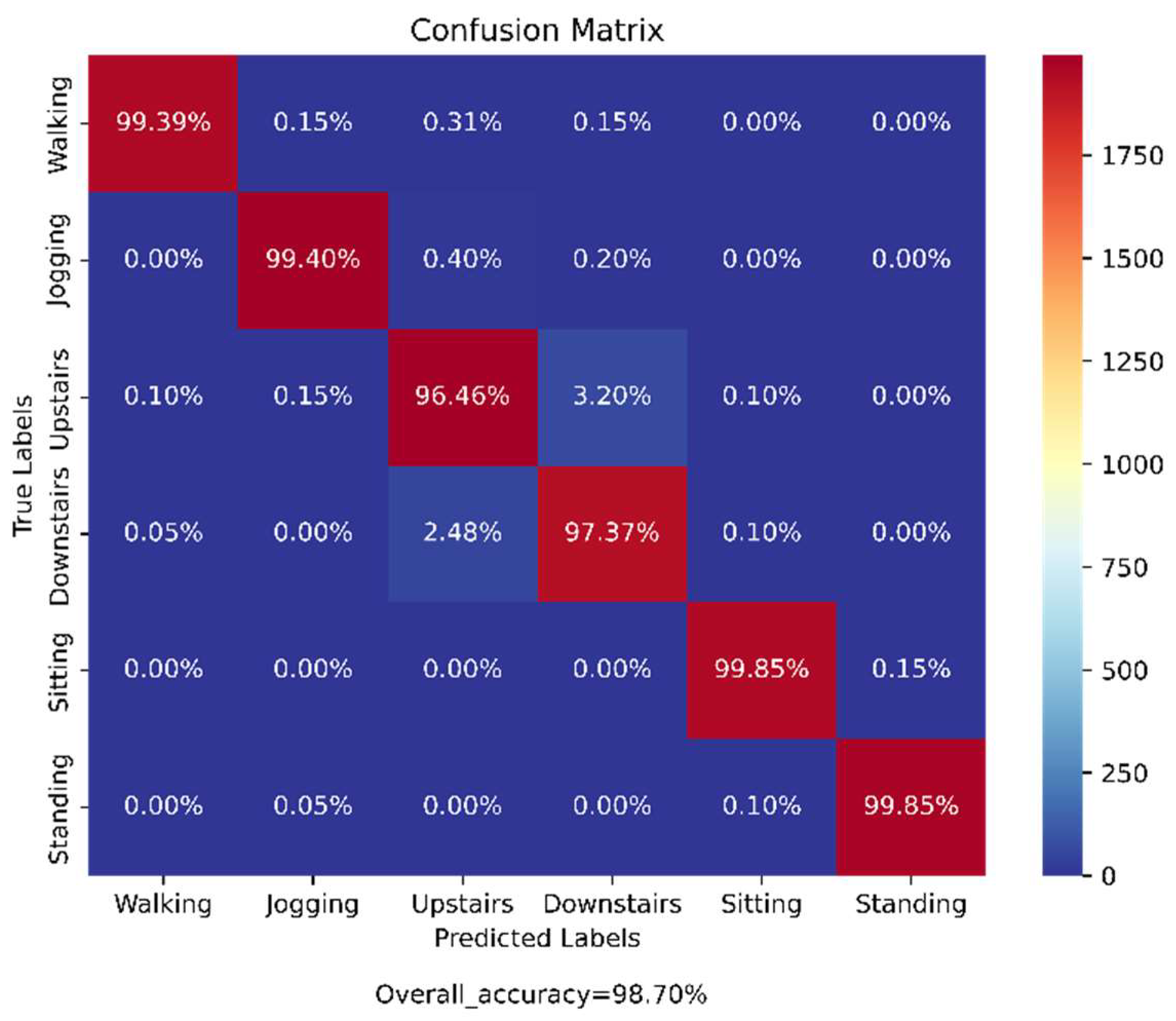
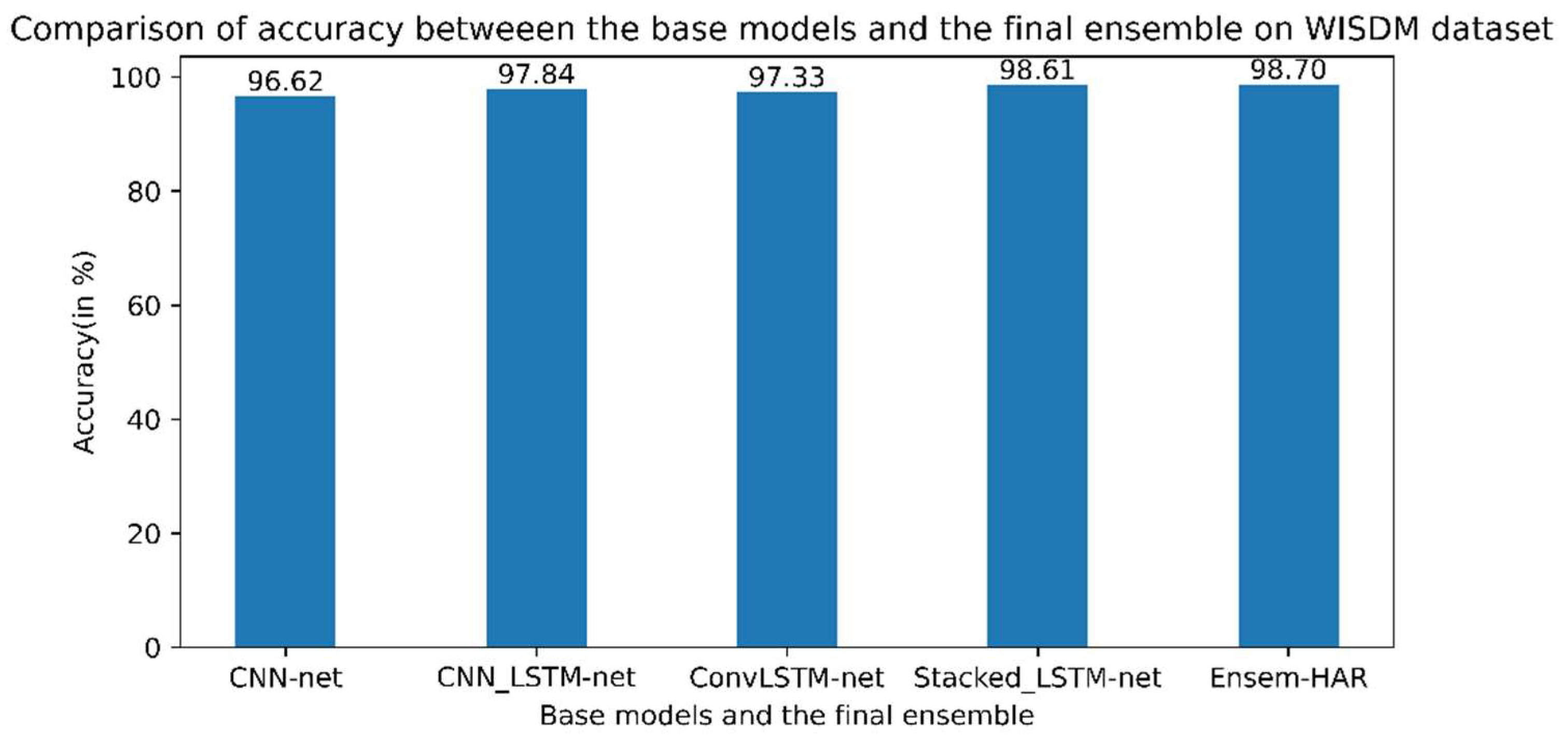
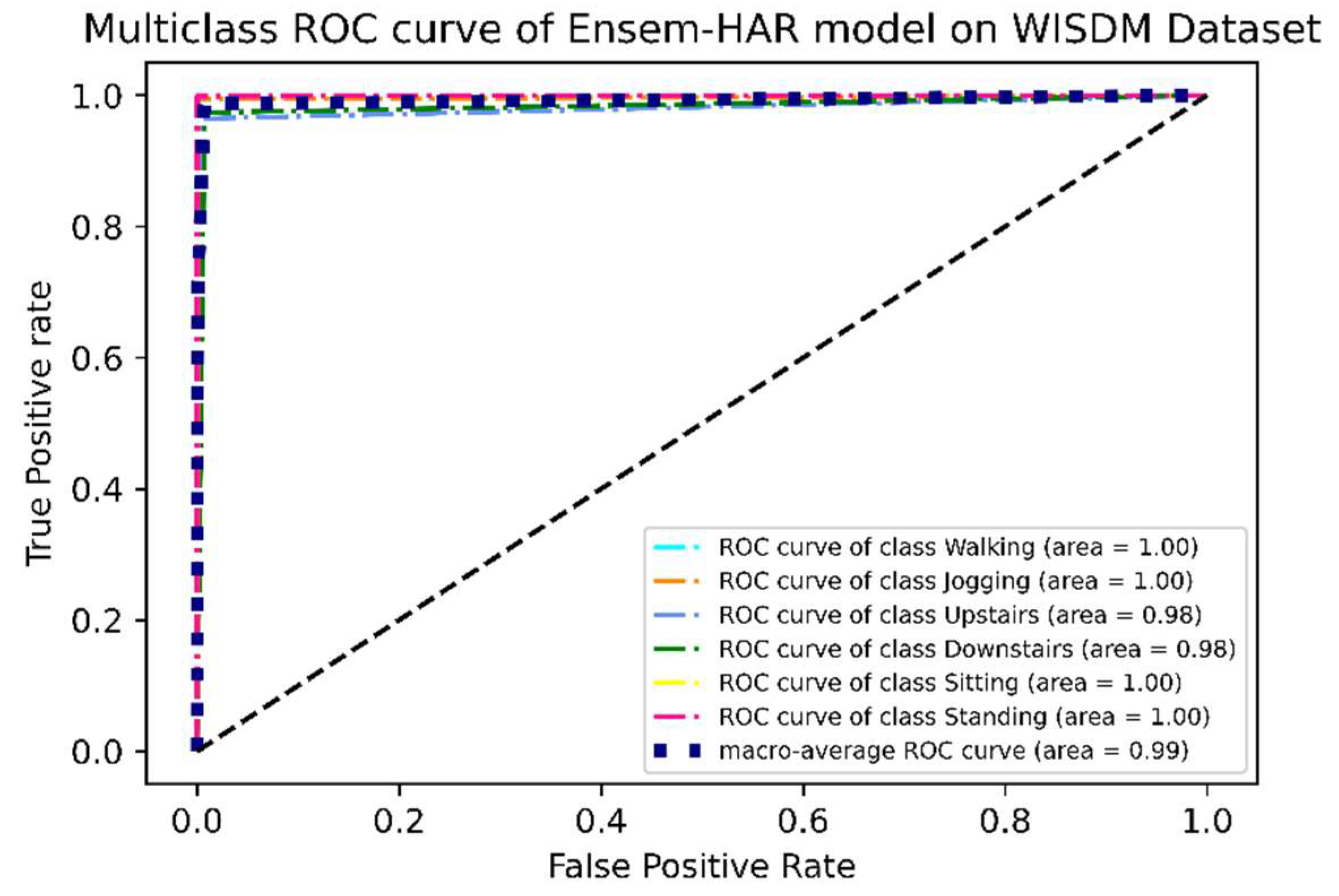
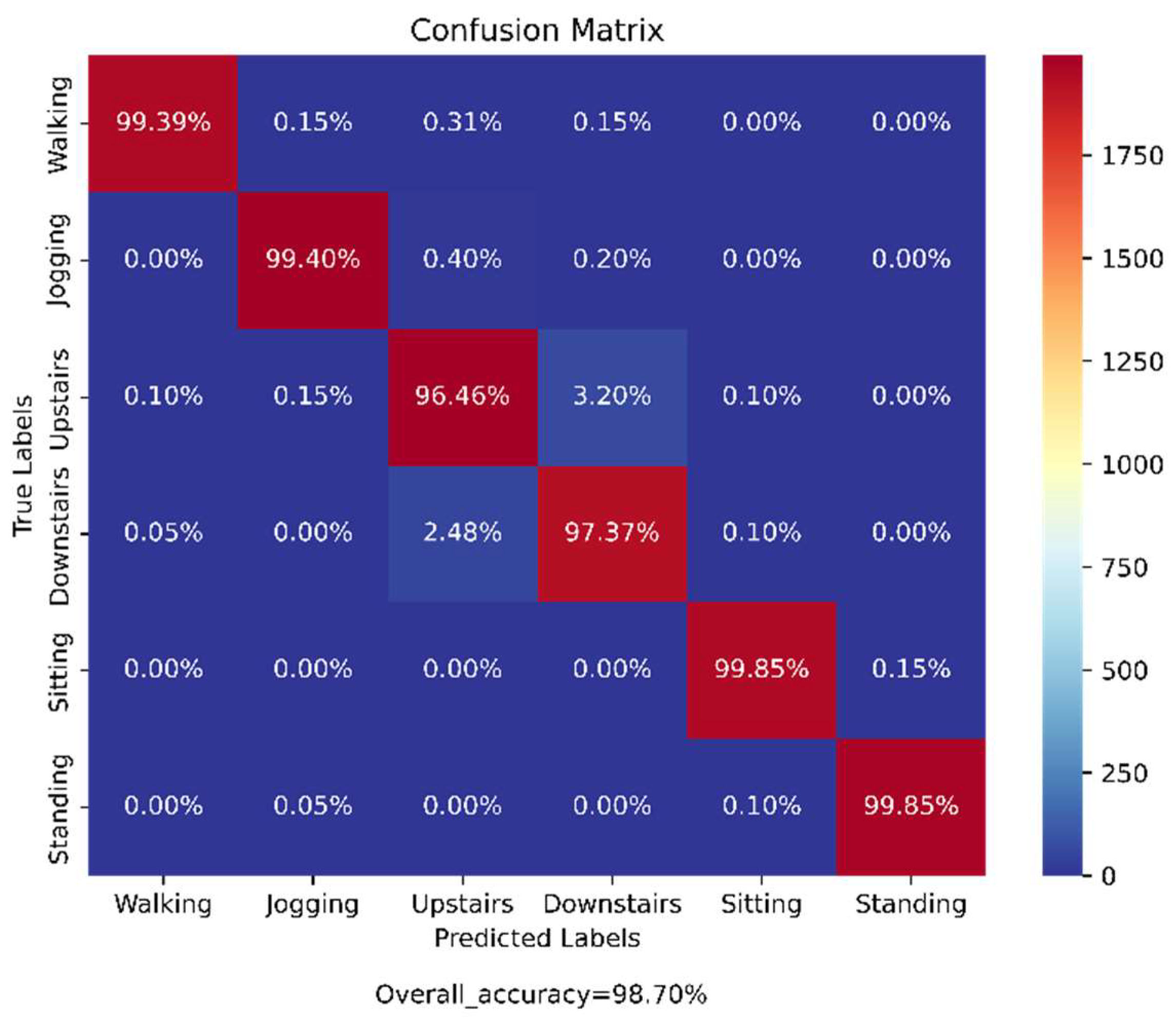
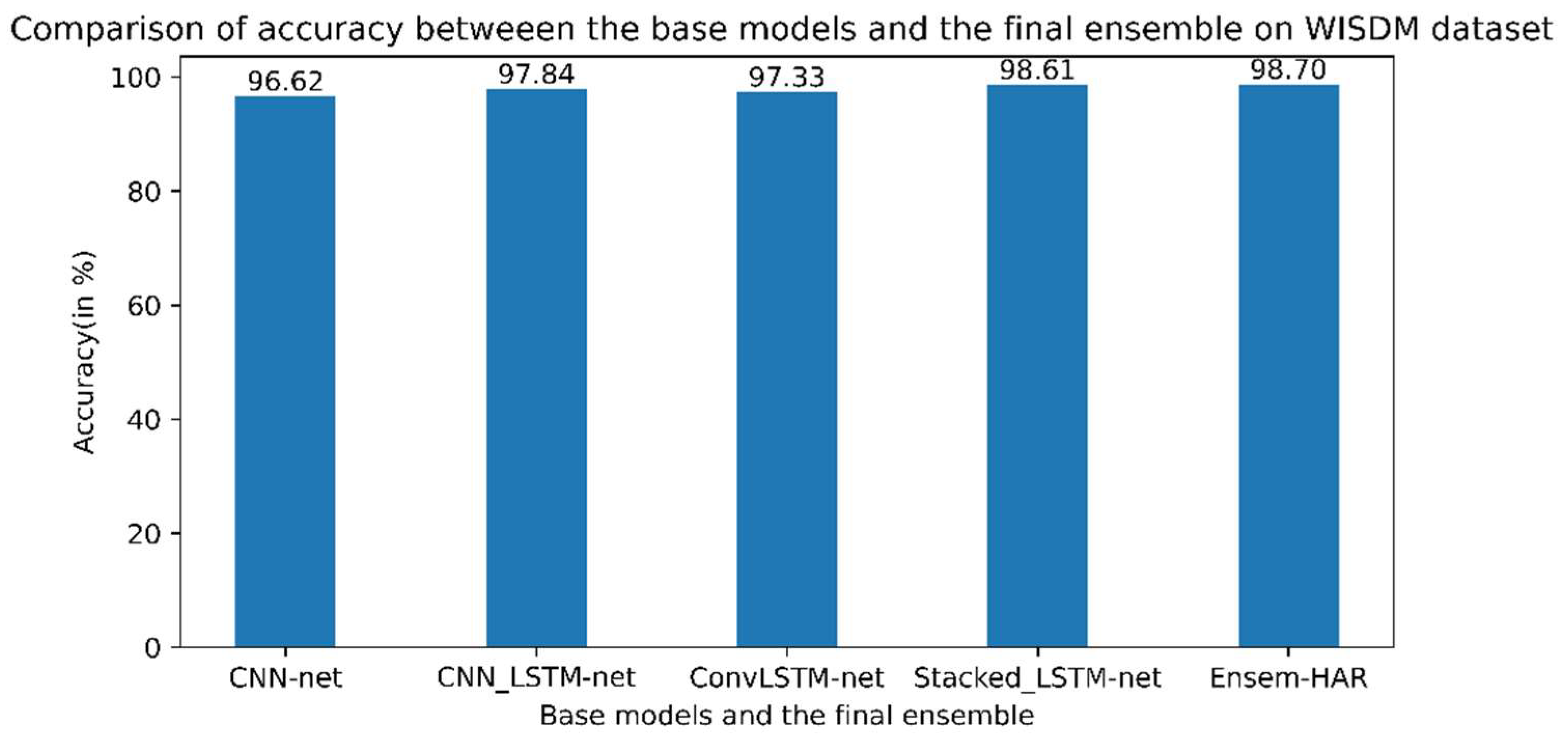
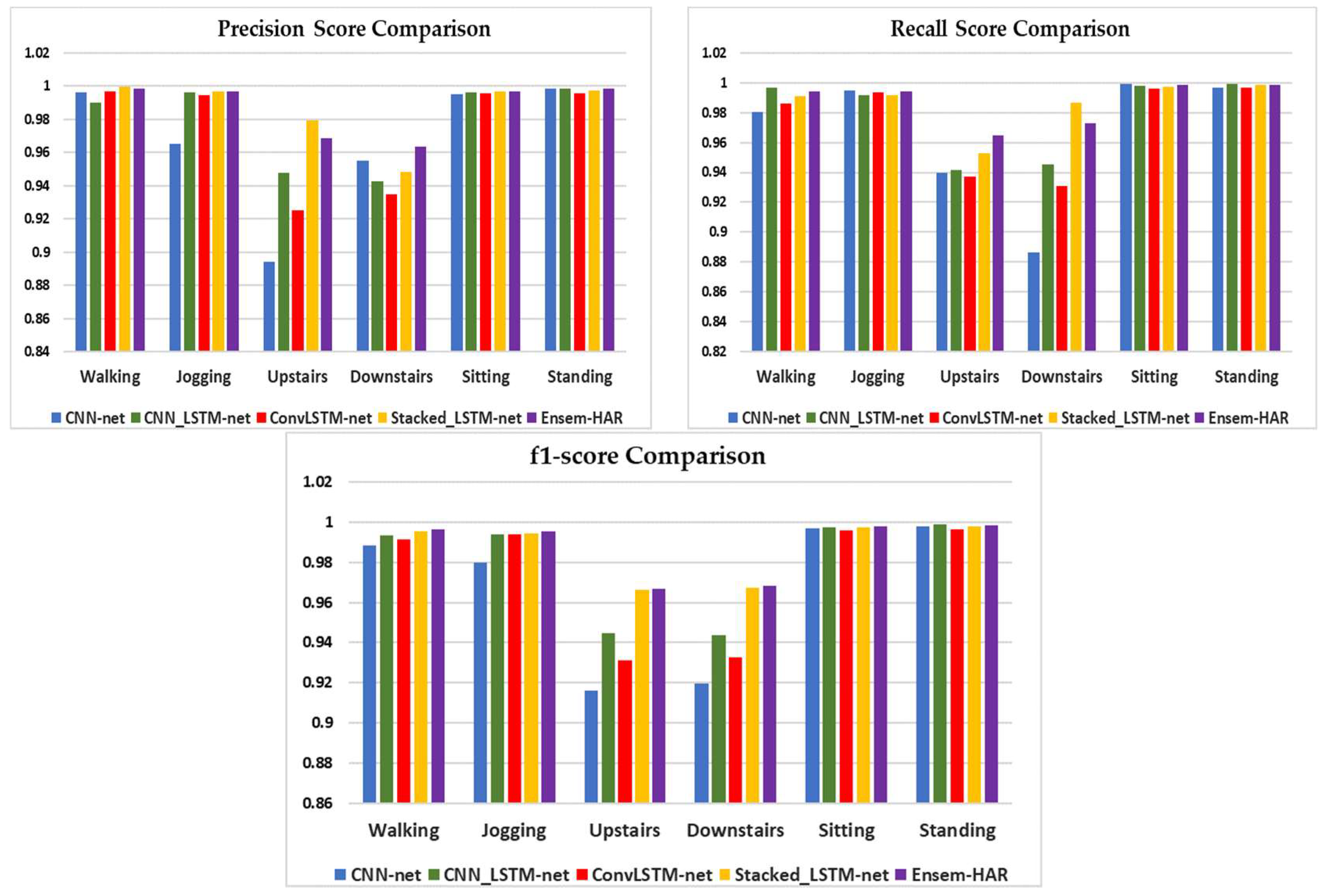
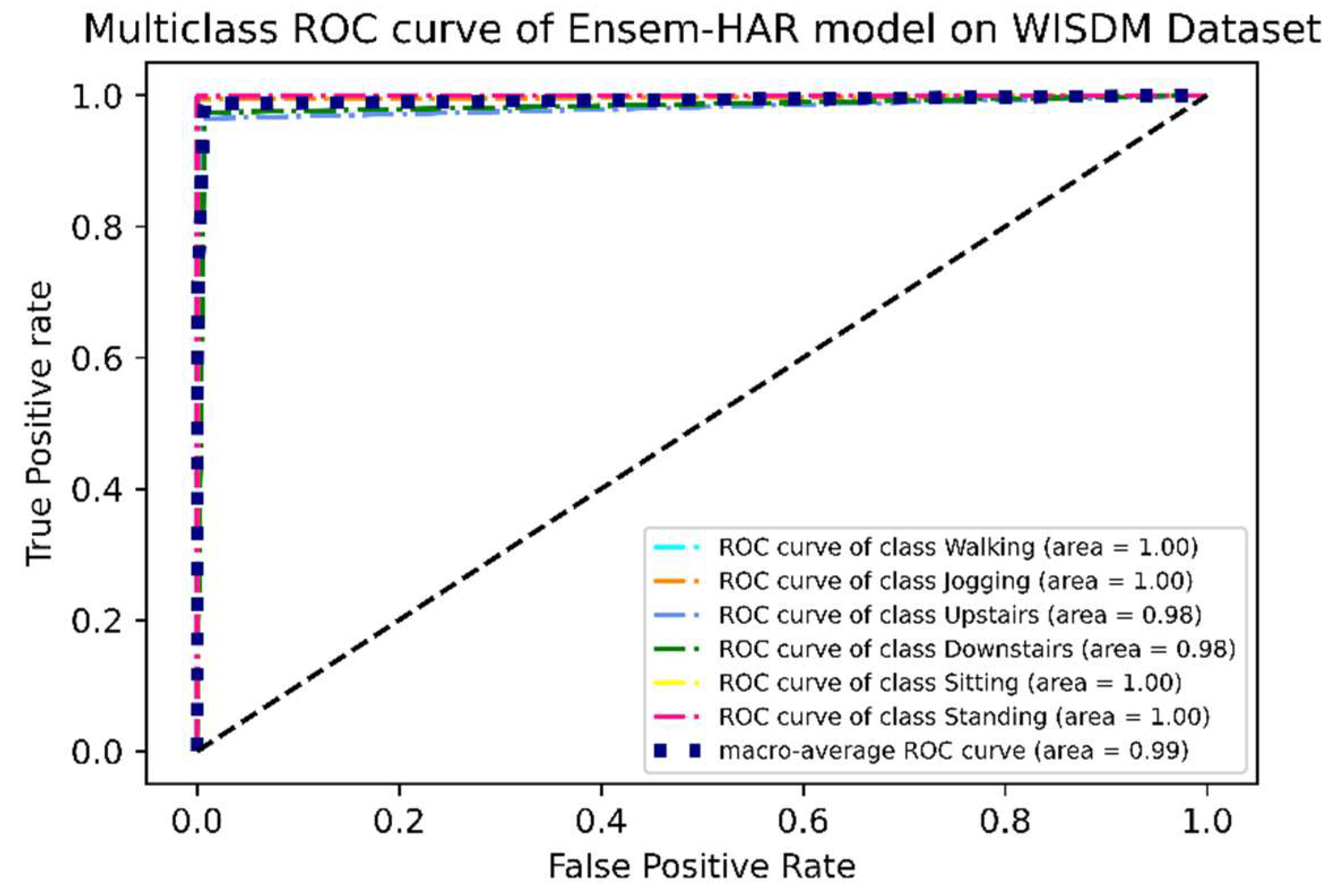
4.4.1. Analysis on WISDM Dataset
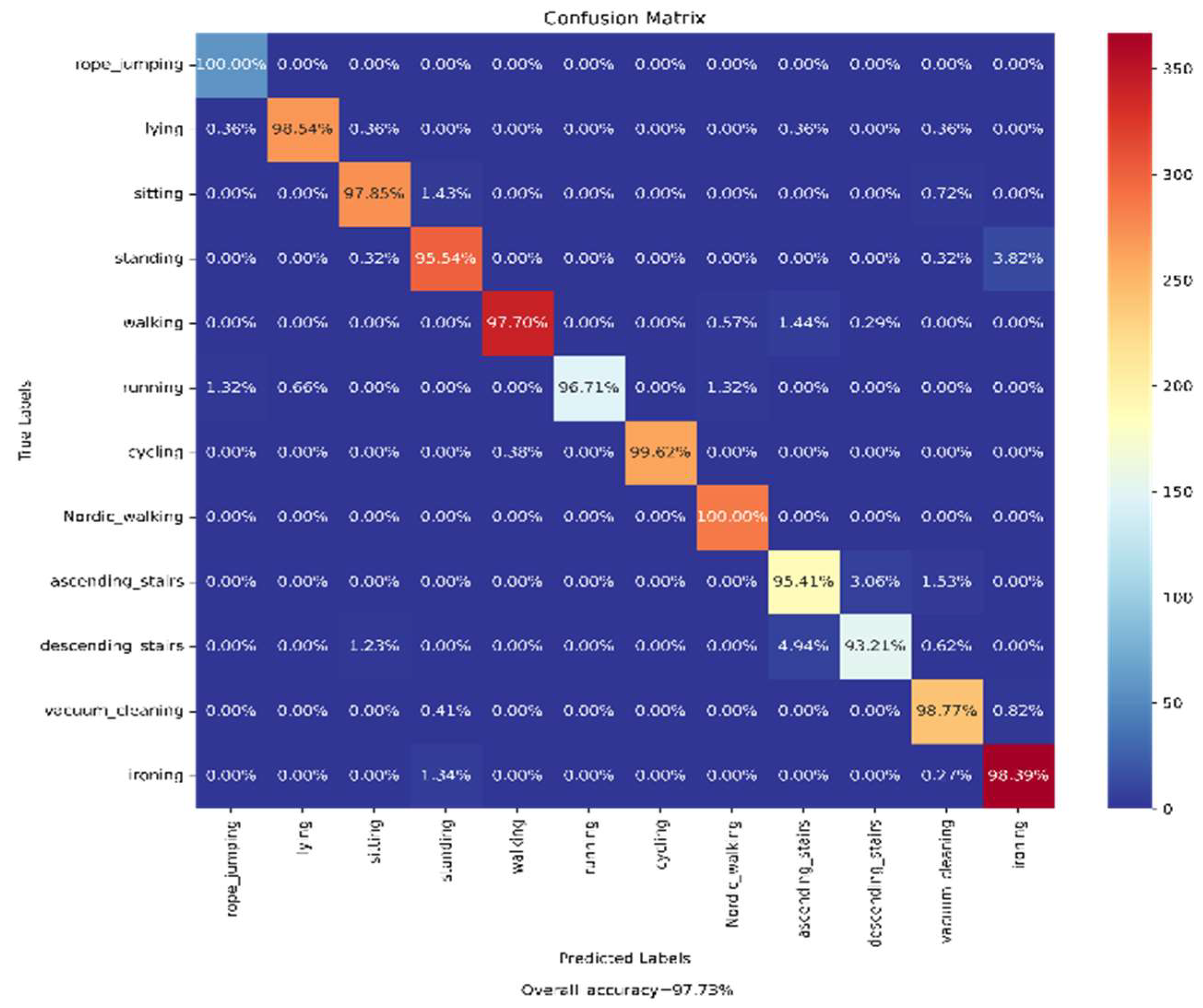
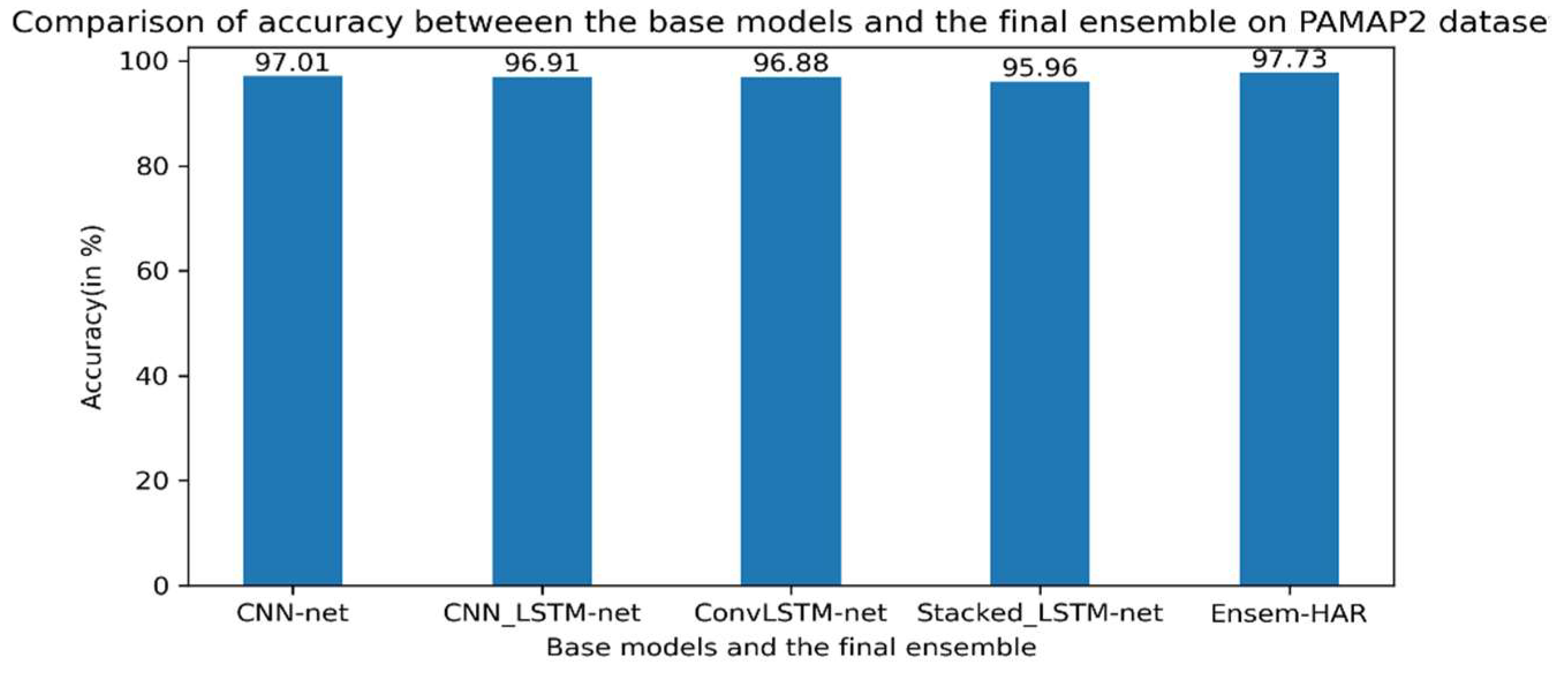
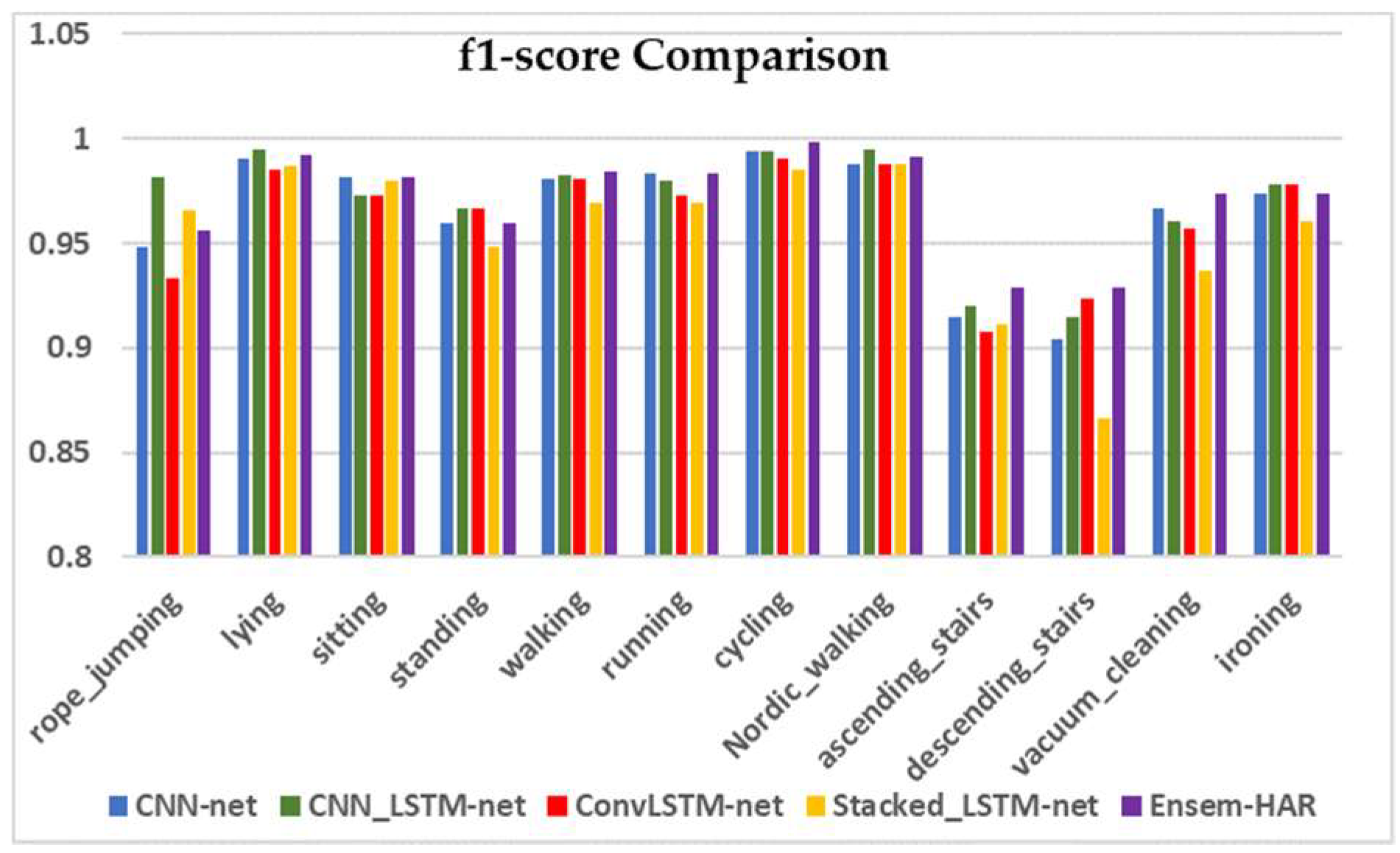
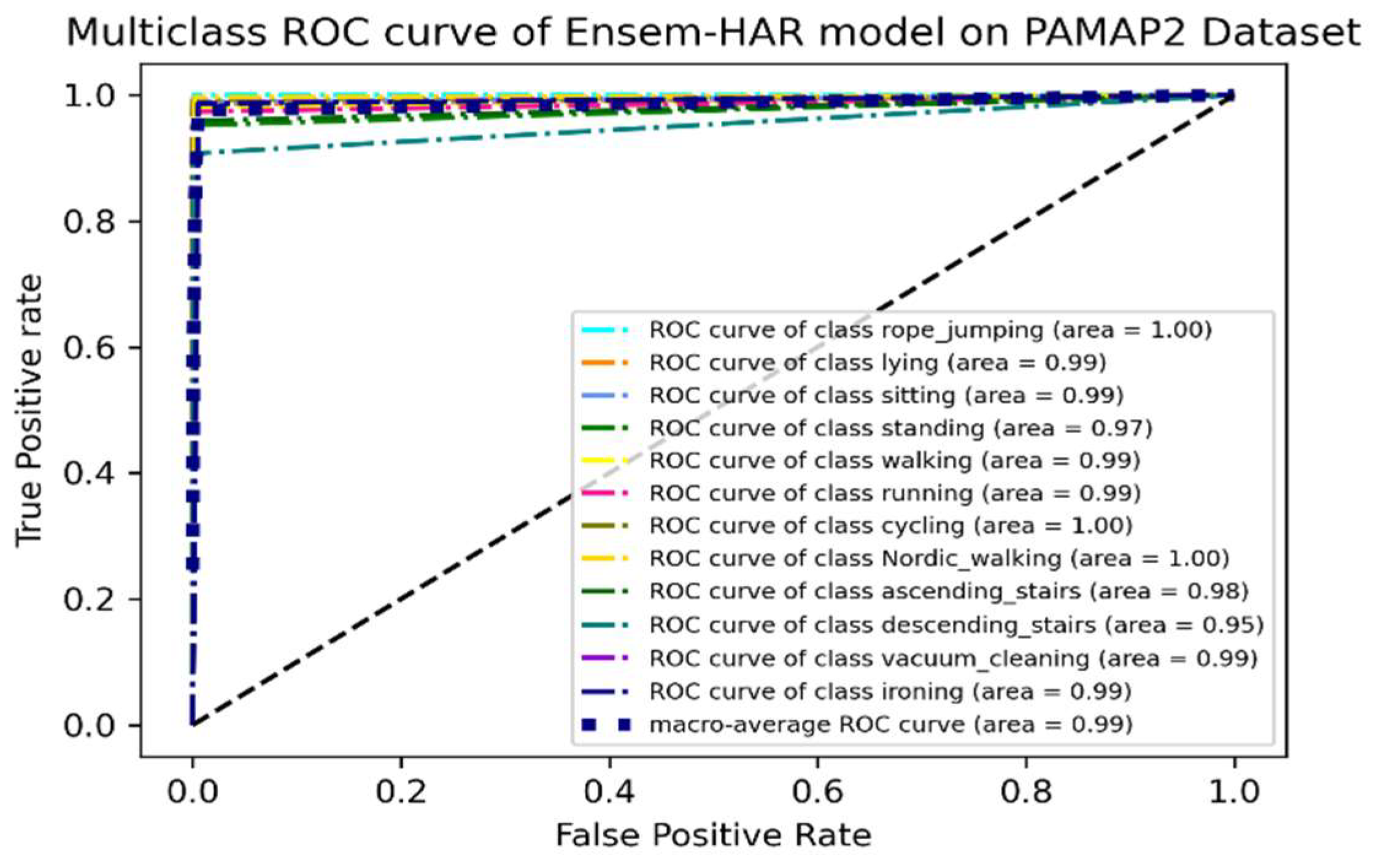
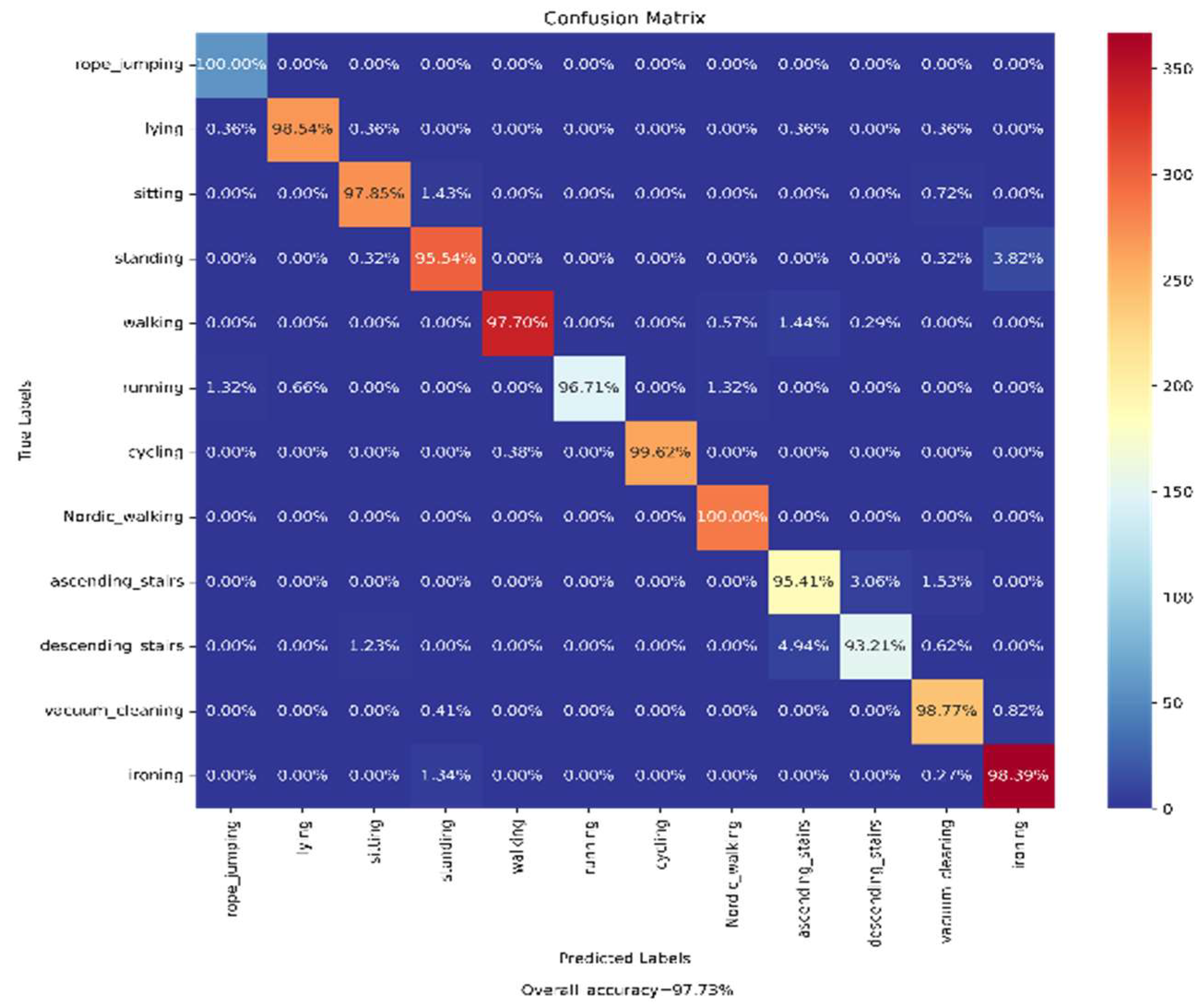
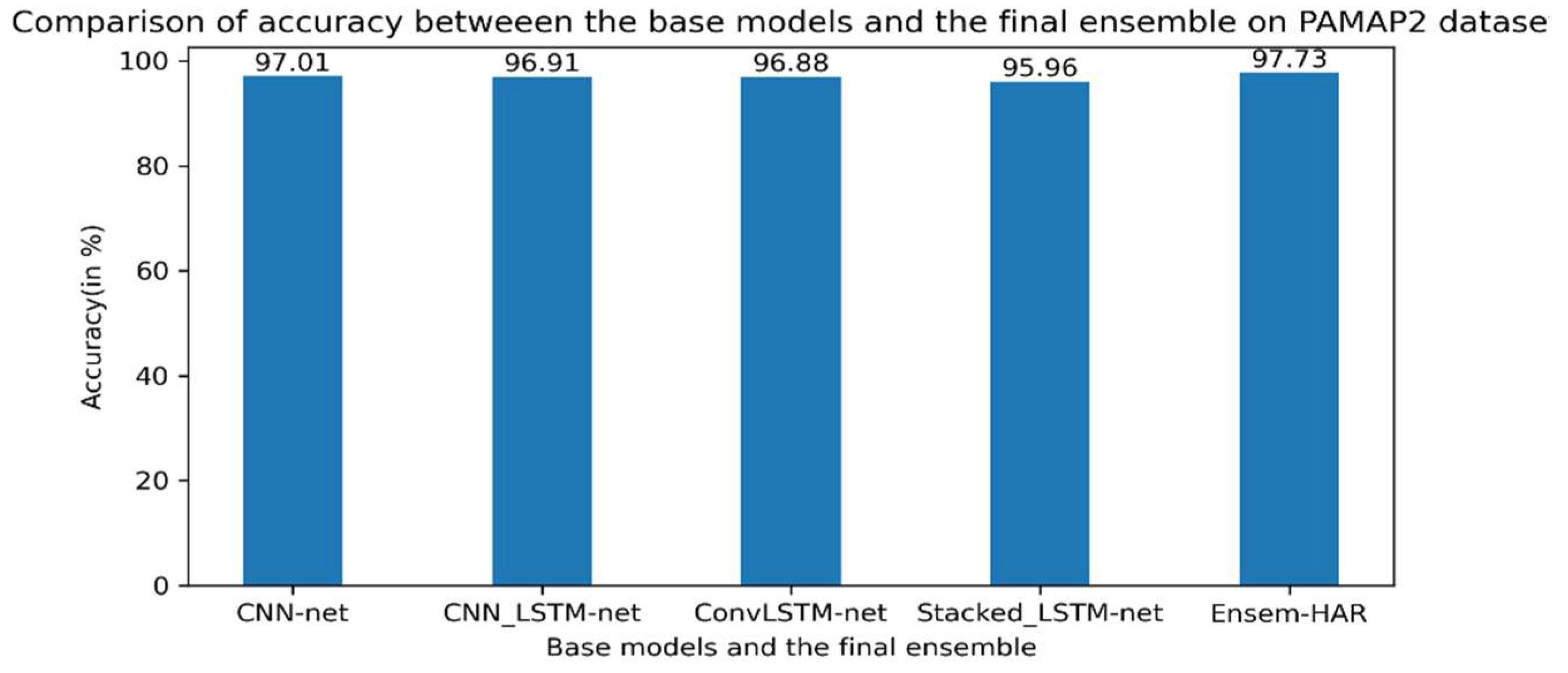
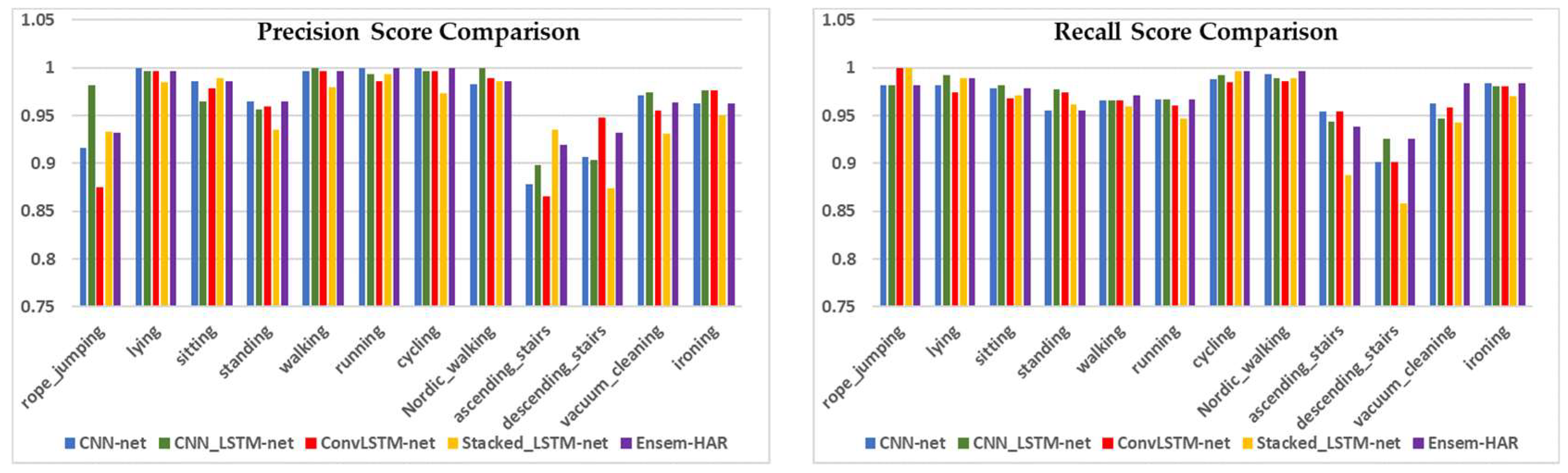
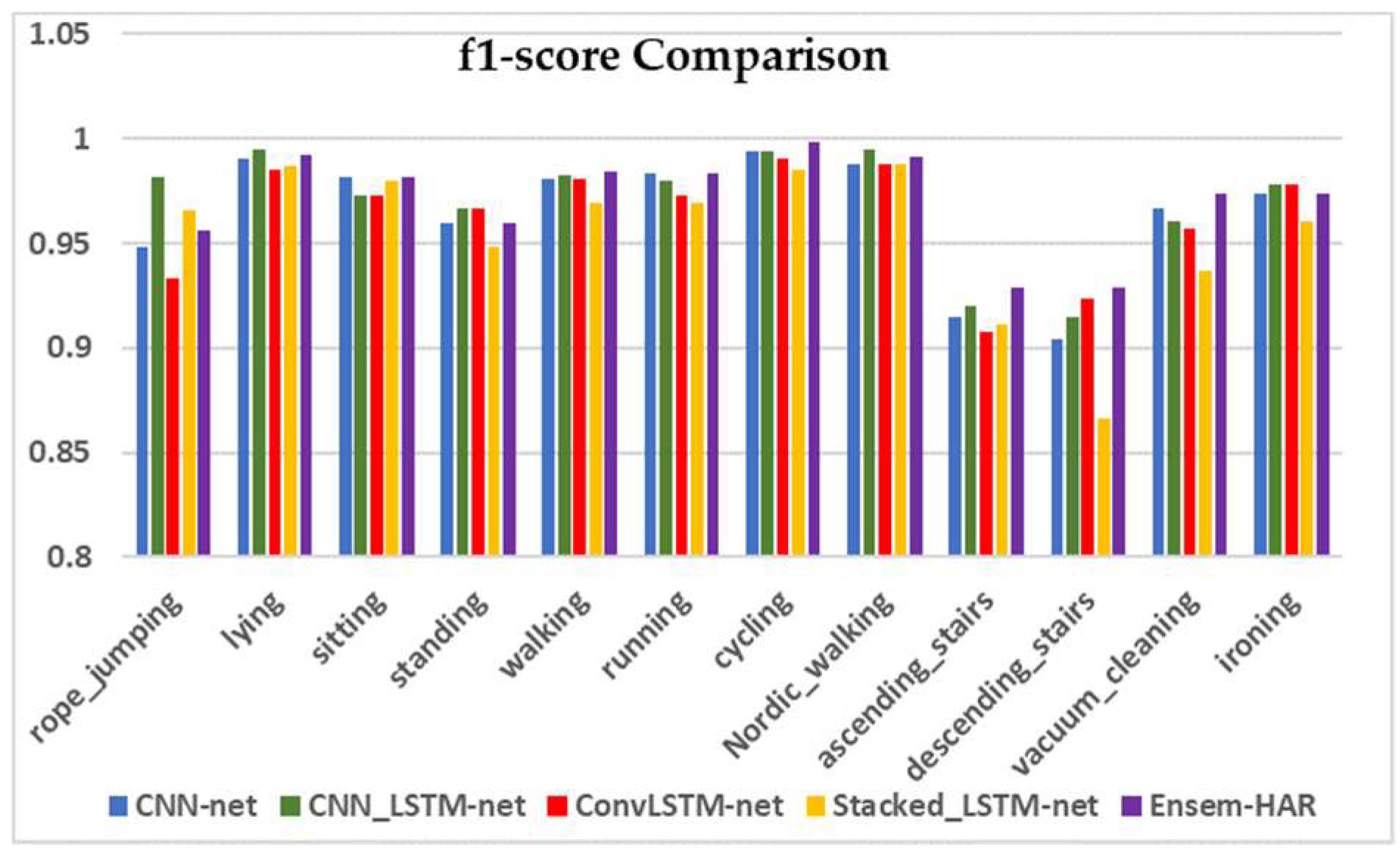
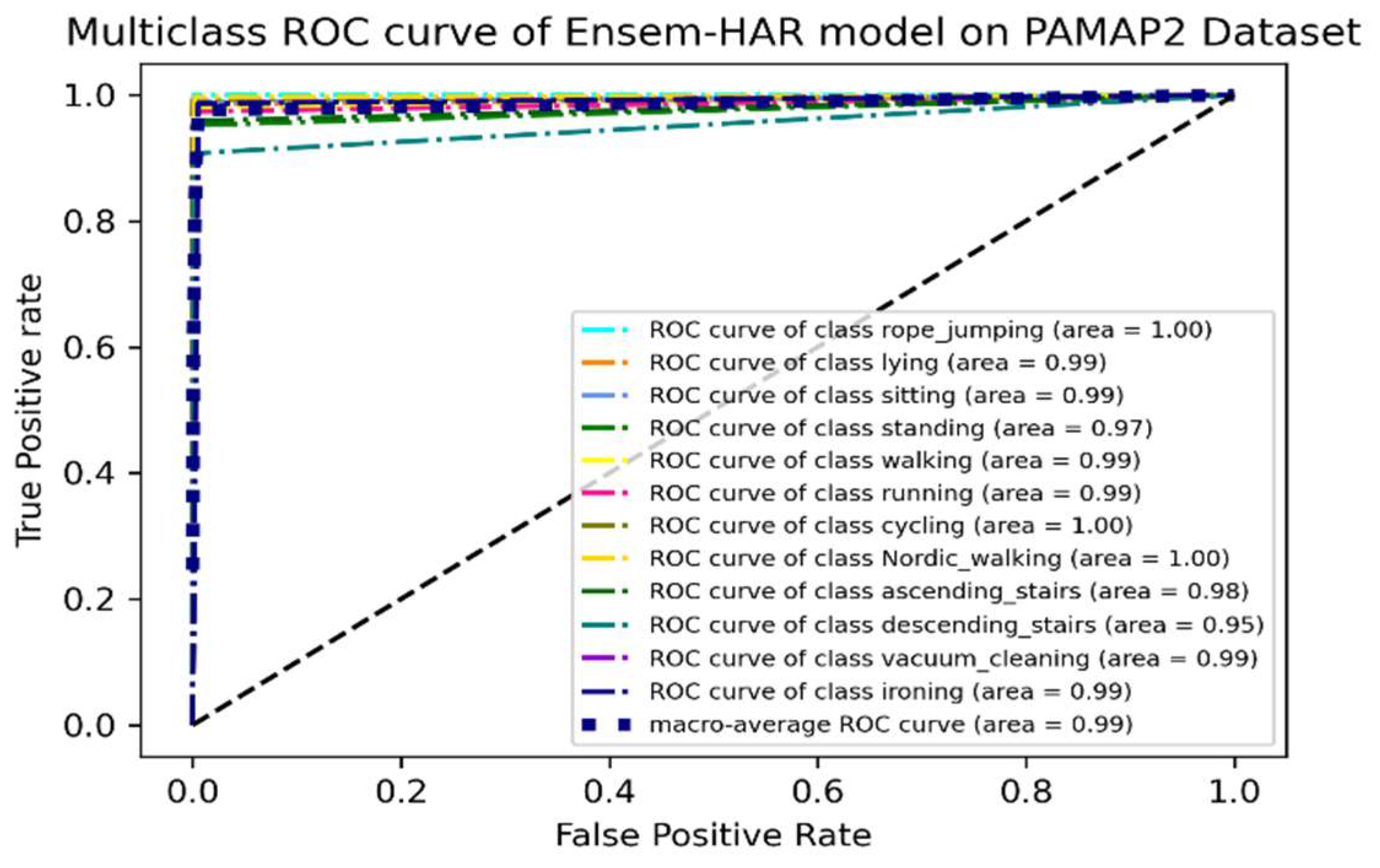
4.4.2. Analysis on PAMAP2 Dataset
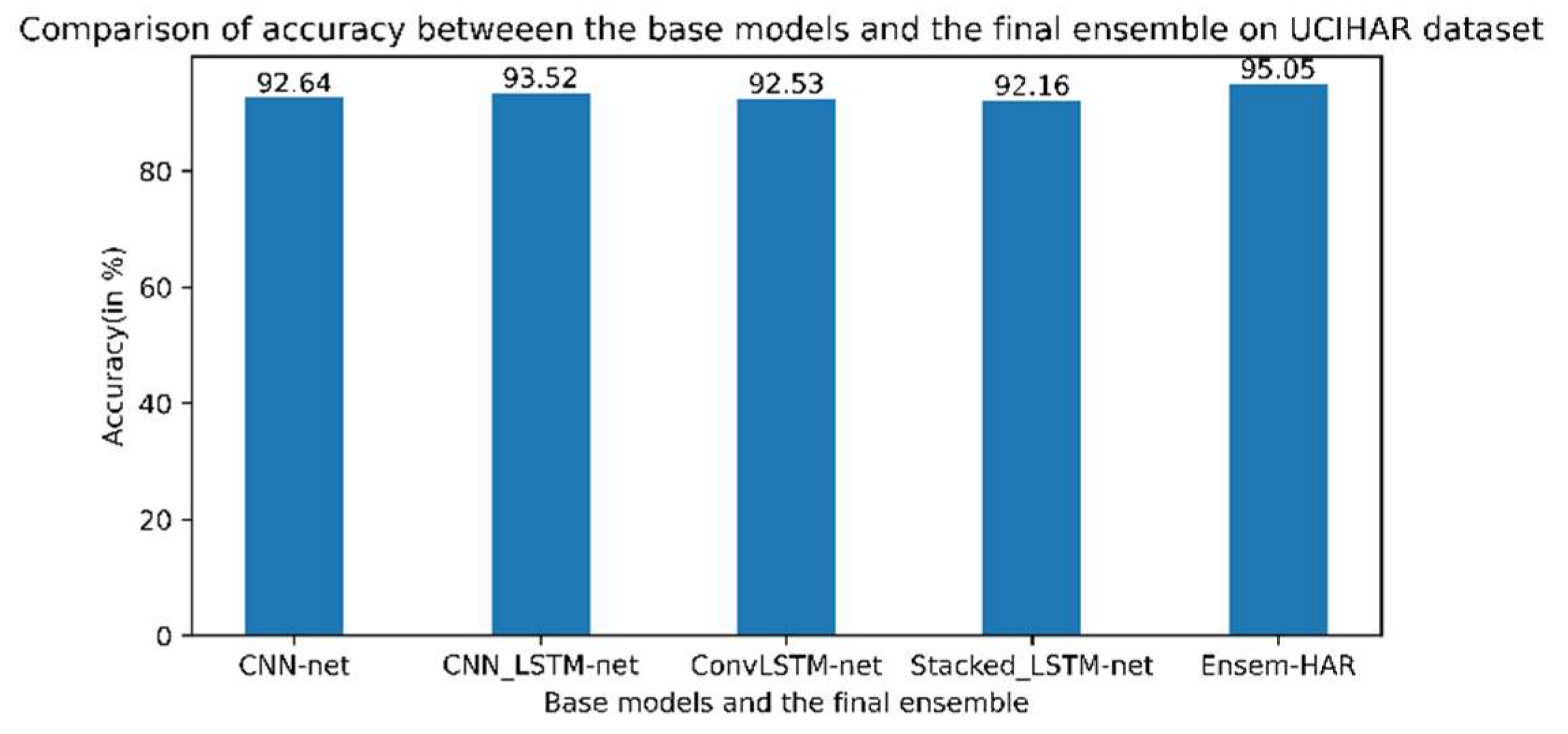
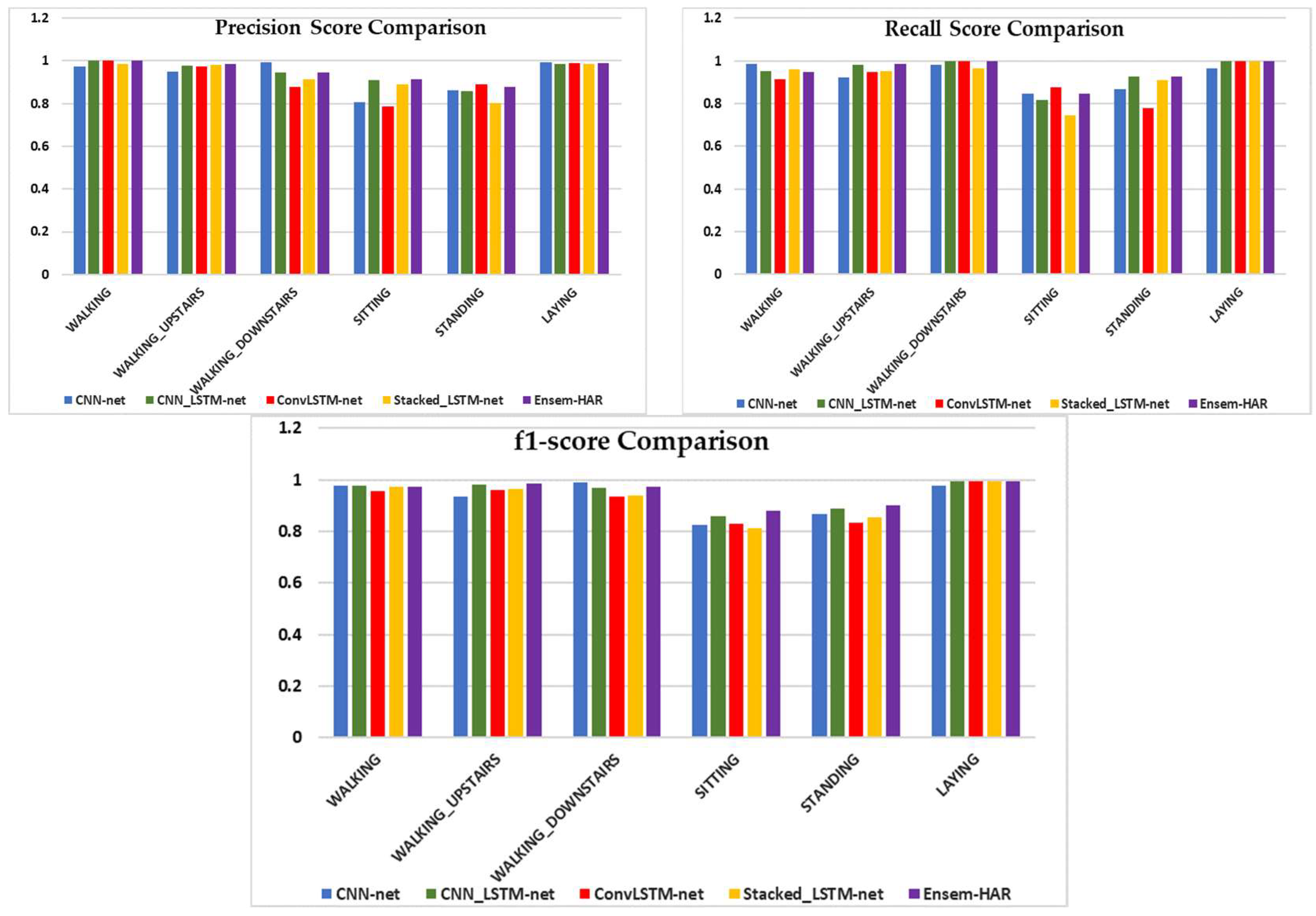
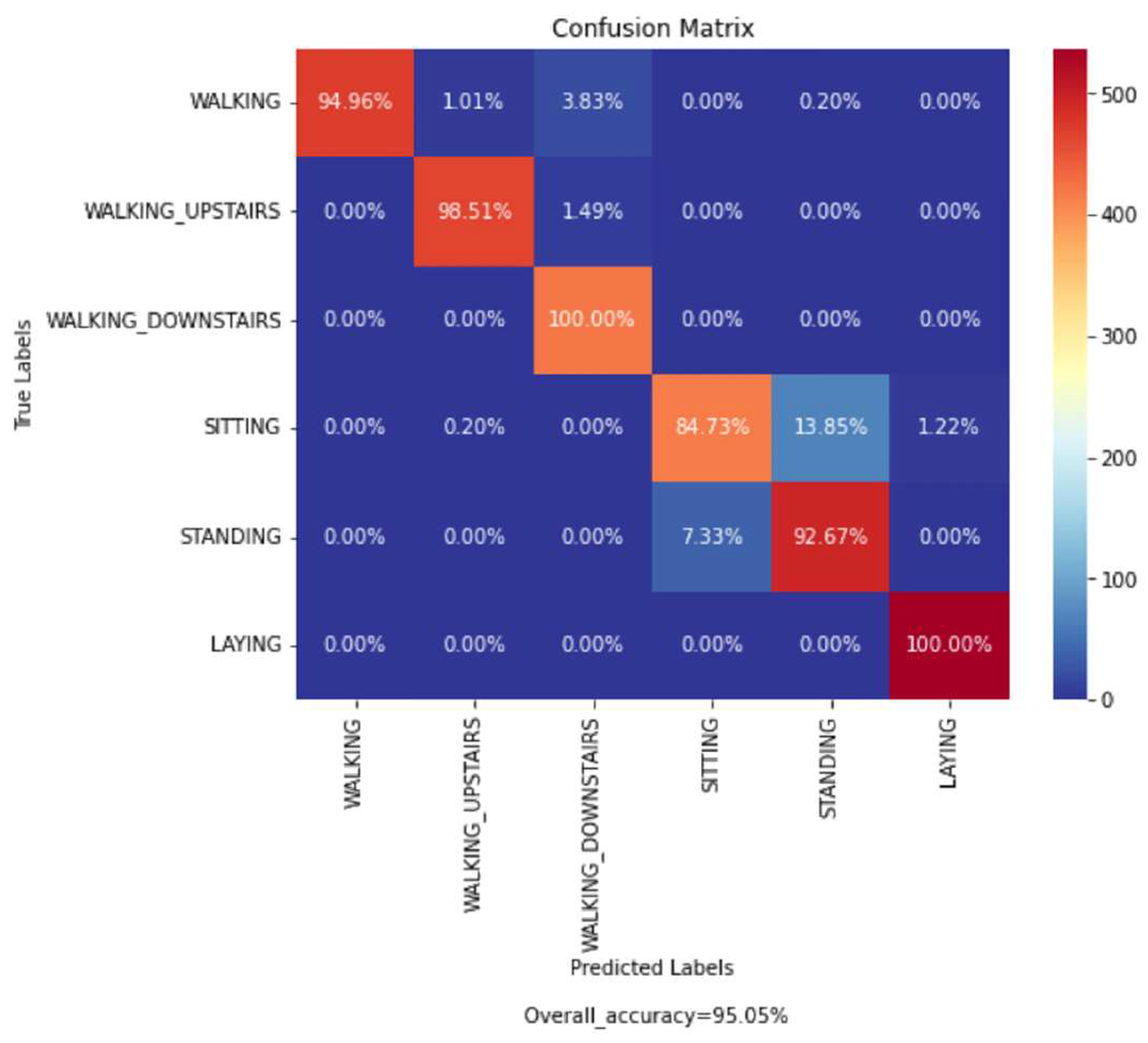
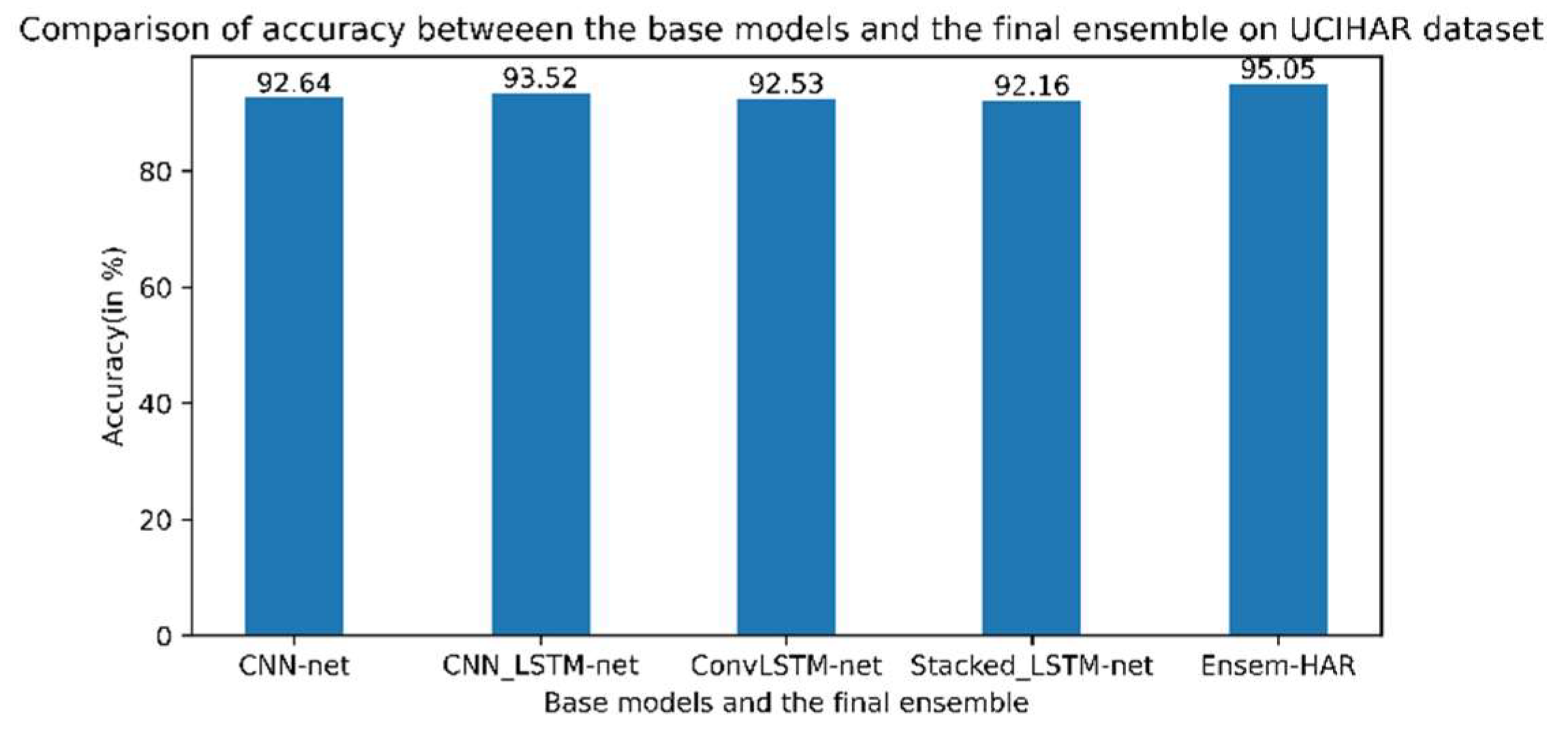
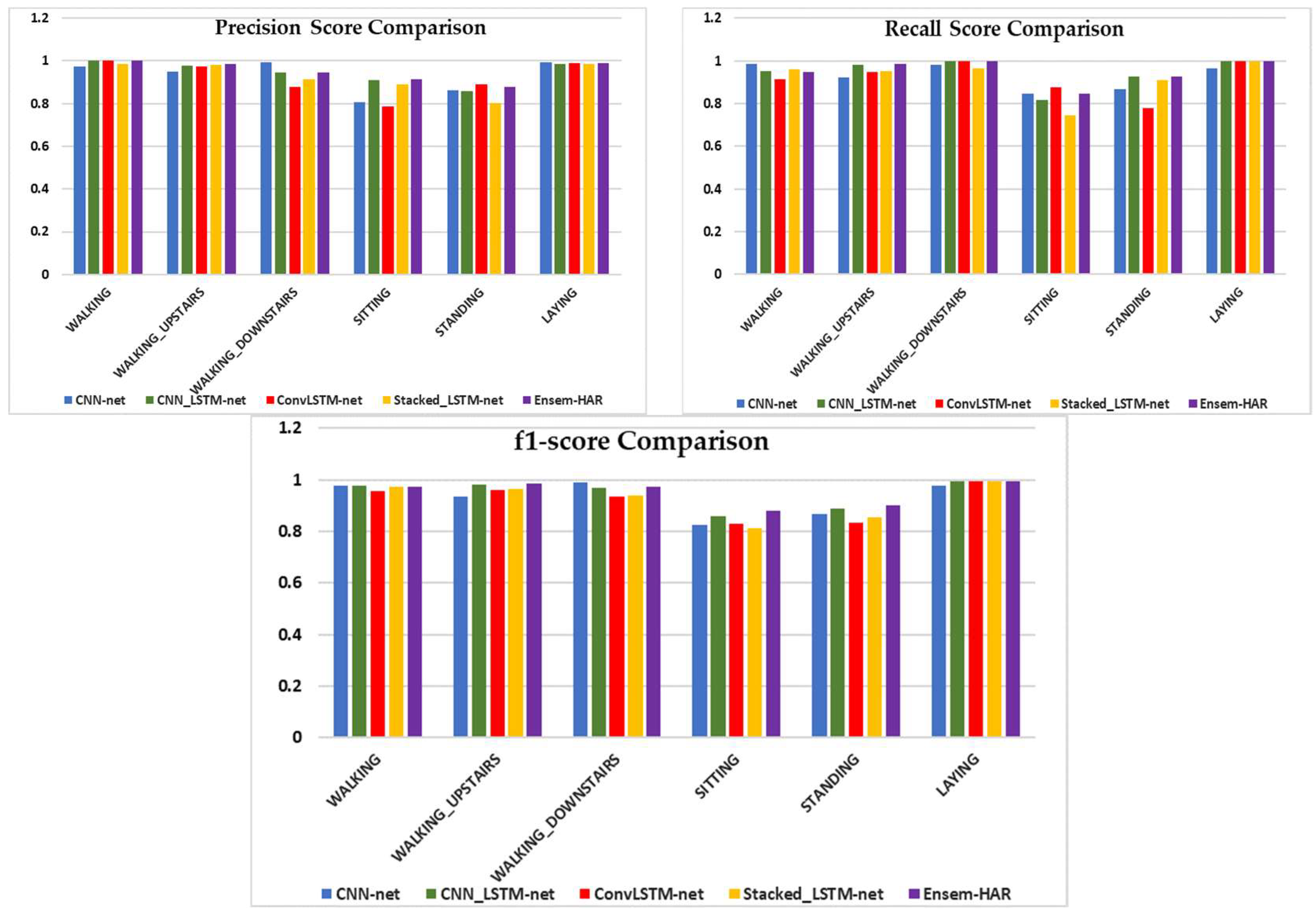
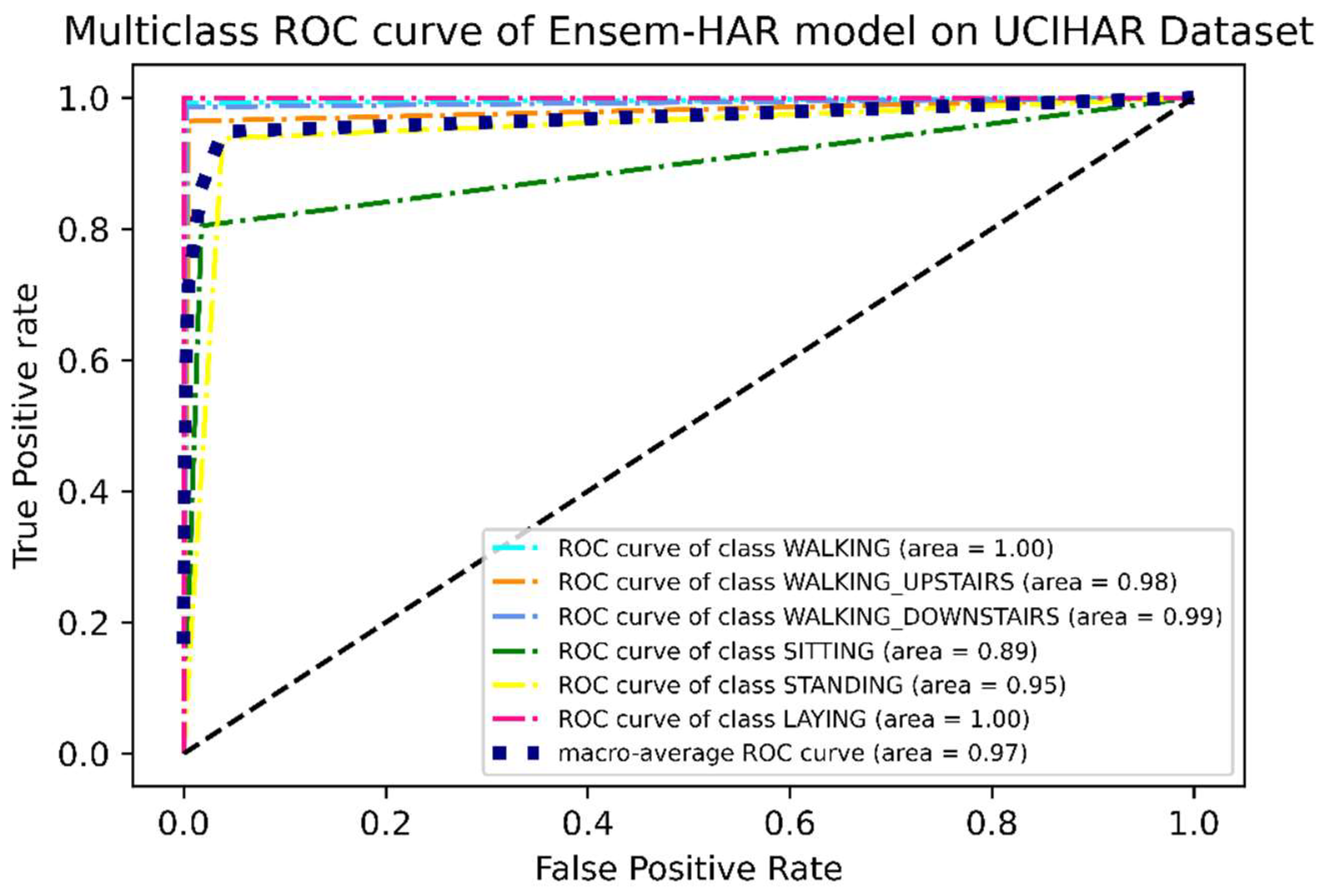
4.4.3. Analysis on UCI-HAR Dataset
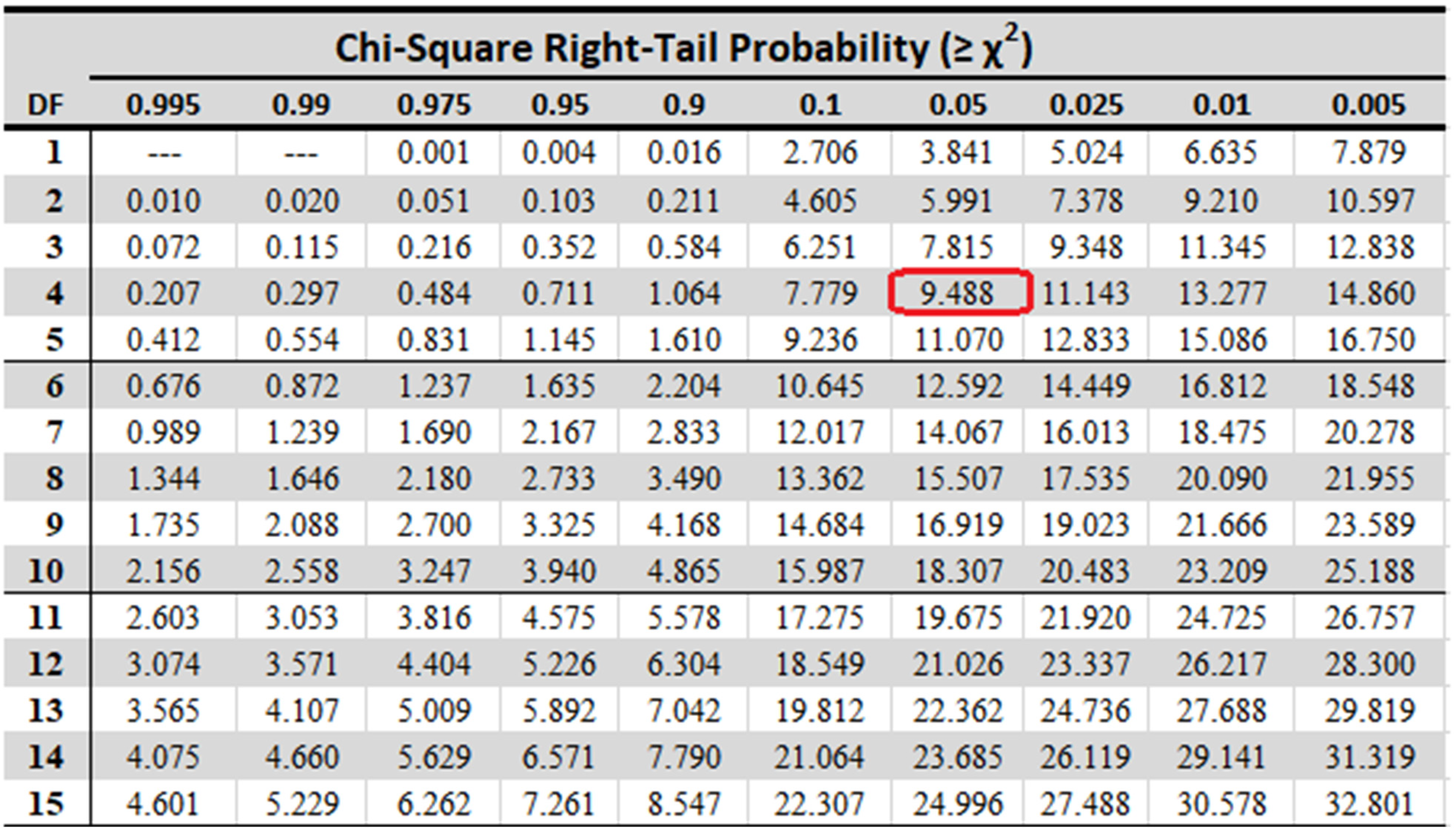
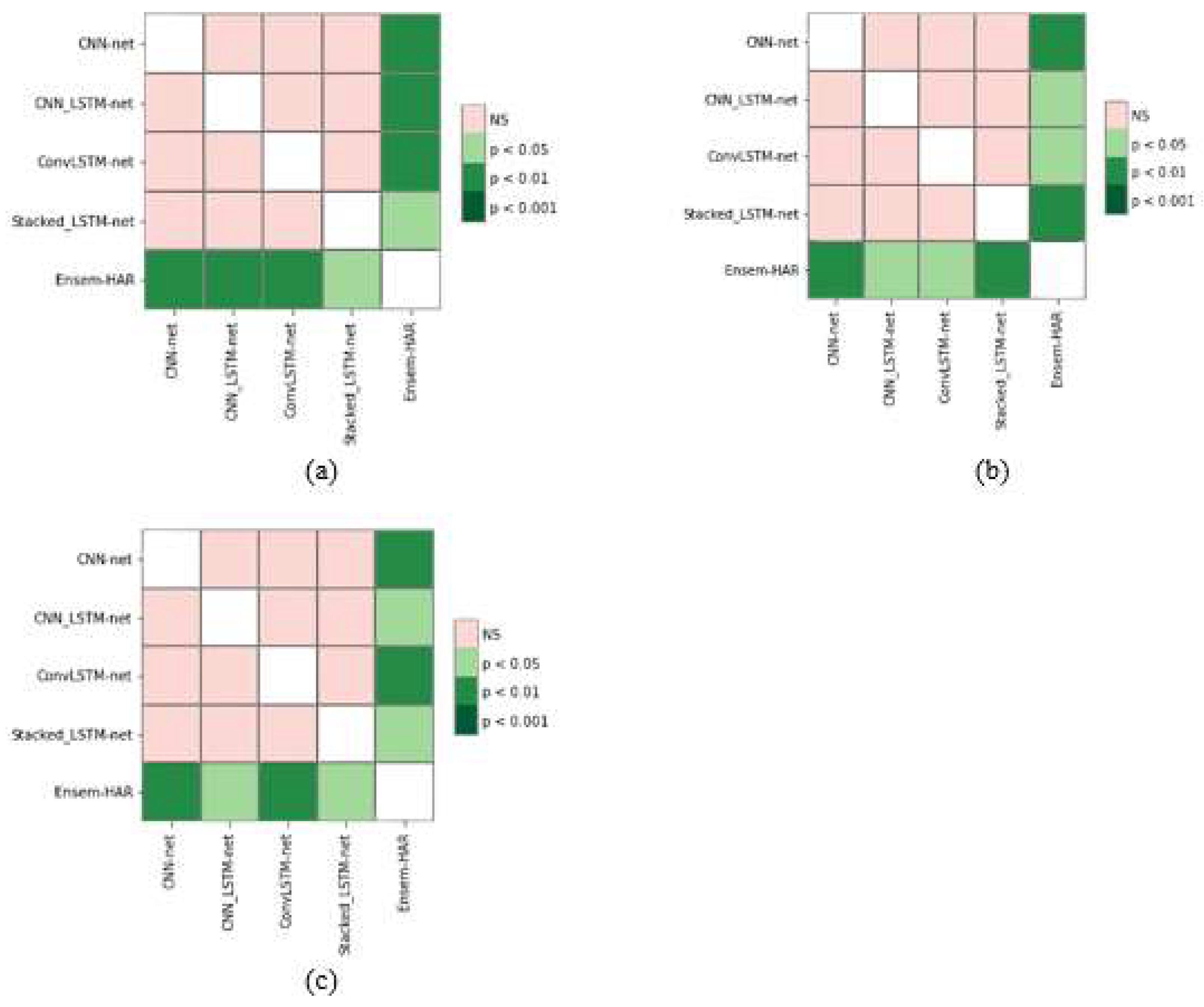
4.5. Statistical Test
4.6. Performance Comparison to Cutting-Edge HAR Methods
4.7. Performance Comparison with Other Ensemble Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Code Availability
References
- Bhattacharya, S.; Shaw, V.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. SV-NET: A Deep Learning Approach to Video Based Human Activity Recognition. In Proceedings of the International Conference on Soft Computing and Pattern Recognition; Springer: Cham, Switzerland, 2020; pp. 10–20. [Google Scholar] [CrossRef]
- Singh, P.K.; Kundu, S.; Adhikary, T.; Sarkar, R.; Bhattacharjee, D. Progress of Human Action Recognition Research in the Last Ten Years: A Comprehensive Survey. Arch. Comput. Methods Eng. 2021, 29, 2309–2349. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Proceedings of the International Workshop on Multiple Classifier Systems, Cagliari, Italy, 9–11 June 2000; pp. 1–15. [Google Scholar] [CrossRef] [Green Version]
- Mukherjee, D.; Mondal, R.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. EnsemCon-vNet: A Deep Learning approach for Human Activity Recognition Using Smartphone Sensors for Healthcare Applica-tions. Multimed. Tools Appl. 2020, 79, 31663–31690. [Google Scholar] [CrossRef]
- Das, A.; Sil, P.; Singh, P.K.; Bhateja, V.; Sarkar, R. MMHAR-EnsemNet: A Multi-Modal Human Activity Recognition Model. IEEE Sens. J. 2020, 21, 11569–11576. [Google Scholar] [CrossRef]
- Mondal, R.; Mukhopadhyay, D.; Barua, S.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. A study on smartphone sensor-based Human Activity Recognition using deep learning approaches. In Handbook of Computational Intelligence in Biomedical Engineering and Healthcare; Nayak, J., Naik, B., Pelusi, D., Das, A.K., Eds.; Academic Press Publishers: Cambridge, MA, USA; Elsevier: Amsterdam, The Netherlands, 2021; Chapter 14; pp. 343–369. [Google Scholar] [CrossRef]
- Chen, Y.; Xue, Y. A Deep Learning Approach to Human Activity Recognition Based on Single Accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 1488–1492. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.-B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SIGKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Quispe, K.G.M.; Lima, W.S.; Batista, D.M.; Souto, E. MBOSS: A Symbolic Representation of Human Activity Recognition Using Mobile Sensors. Sensors 2018, 18, 4354. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zhang, Y.; Zhang, Z.; Bao, J.; Song, Y. Human Activity Recognition Based on Time Series Analysis Using U-Net. 2020. Available online: https://arxiv.org/abs/1809.08113 (accessed on 1 July 2020).
- Pienaar, S.W.; Malekian, R. Human Activity Recognition using LSTM-RNN Deep Neural Network Architecture. In Proceedings of the 2019 IEEE 2nd Wireless Africa Conference (WAC), Pretoria, South Africa, 18–20 August 2019; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Ignatov, A. Real-time human activity recognition from accelerometer data using Convolutional Neural Networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep Learning Models for Real-time Human Activity Recognition with Smartphones. Mob. Netw. Appl. 2019, 25, 743–755. [Google Scholar] [CrossRef]
- Avilés-Cruz, C.; Ferreyra-Ramírez, A.; Zúñiga-López, A.; Villegas-Cortéz, J. Coarse-Fine Convolutional Deep-Learning Strategy for Human Activity Recognition. Sensors 2019, 19, 1556. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Teng, Q.; Zhang, L.; Min, F.; He, J. Efficient convolutional neural networks with smaller filters for human activity recognition using wearable sensors. arXiv 2020, arXiv:2005.03948. [Google Scholar]
- Cheng, X.; Zhang, L.; Tang, Y.; Liu, Y.; Wu, H.; He, J. Real-Time Human Activity Recognition Using Conditionally Parametrized Convolutions on Mobile and Wearable Devices. IEEE Sens. J. 2022, 22, 5889–5901. [Google Scholar] [CrossRef]
- Zhu, R.; Xiao, Z.; Li, Y.; Yang, M.; Tan, Y.; Zhou, L.; Lin, S.; Wen, H. Efficient Human Activity Recognition Solving the Confusing Activities Via Deep Ensemble Learning. IEEE Access 2019, 7, 75490–75499. [Google Scholar] [CrossRef]
- Challa, S.K.; Kumar, A.; Semwal, V.B. A multibranch CNN-BiLSTM model for human activity recognition using wearable sensor data. Vis. Comput. 2021, 1–15. [Google Scholar] [CrossRef]
- Dua, N.; Singh, S.N.; Semwal, V.B. Multi-input CNN-GRU based human activity recognition using wearable sensors. Computing 2021, 1–18. [Google Scholar] [CrossRef]
- Tang, Y.; Teng, Q.; Zhang, L.; Min, F.; He, J. Layer-Wise Training Convolutional Neural Networks With Smaller Filters for Human Activity Recognition Using Wearable Sensors. IEEE Sens. J. 2020, 21, 581–592. [Google Scholar] [CrossRef]
- Agarwal, P.; Alam, M. A Lightweight Deep Learning Model for Human Activity Recognition on Edge Devices. Procedia Comput. Sci. 2020, 167, 2364–2373. [Google Scholar] [CrossRef]
- Rashid, N.; Demirel, B.U.; Al Faruque, M.A. AHAR: Adaptive CNN for Energy-efficient Human Activity Recognition in Low-power Edge Devices. IEEE Internet Things J. 2022, 1–13. [Google Scholar] [CrossRef]
- Zhao, Y.; Yang, R.; Chevalier, G.; Xu, X.; Zhang, Z. Deep Residual Bidir-LSTM for Human Activity Recognition Using Wearable Sensors. Math. Probl. Eng. 2018, 2018, 1–13. [Google Scholar] [CrossRef]
- Sun, J.; Fu, Y.; Li, S.; He, J.; Xu, C.; Tan, L. Sequential Human Activity Recognition Based on Deep Convolutional Network and Extreme Learning Machine Using Wearable Sensors. J. Sens. 2018, 2018, 1–10. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Wang, K.I.-K.; Wang, H.; Yang, L.T.; Jin, Q. Deep-Learning-Enhanced Human Activity Recognition for Internet of Healthcare Things. IEEE Internet Things J. 2020, 7, 6429–6438. [Google Scholar] [CrossRef]
- Guha, R.; Khan, A.H.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. CGA: A new feature selection model for visual human action recognition. Neural Comput. Appl. 2021, 33, 5267–5286. [Google Scholar] [CrossRef]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN Architecture for Human Activity Recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Wang, L.; Liu, R. Human Activity Recognition Based on Wearable Sensor Using Hierarchical Deep LSTM Networks. Circuits Syst. Signal Process. 2019, 39, 837–856. [Google Scholar] [CrossRef]
- Cruciani, F.; Vafeiadis, A.; Nugent, C.; Cleland, I.; McCullagh, P.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R. Feature learning for Human Activity Recognition using Convolutional Neural Networks. CCF Trans. Pervasive Comput. Interact. 2020, 2, 18–32. [Google Scholar] [CrossRef] [Green Version]
- Mondal, R.; Mukherjee, D.; Singh, P.K.; Bhateja, V.; Sarkar, R. A New Framework for Smartphone Sensor based Human Activity Recognition using Graph Neural Network. IEEE Sens. 2021, 21, 11461–11468. [Google Scholar] [CrossRef]
- He, J.; Zhang, Q.; Wang, L.; Pei, L. Weakly Supervised Human Activity Recognition From Wearable Sensors by Recurrent Attention Learning. IEEE Sens. J. 2018, 19, 2287–2297. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, Z.; Soh, Y.C. A Novel Semisupervised Deep Learning Method for Human Activity Recognition. IEEE Trans. Ind. Inform. 2018, 15, 3821–3830. [Google Scholar] [CrossRef]
- Li, Y.; Wang, L. Human Activity Recognition Based on Residual Network and BiLSTM. Sensors 2022, 22, 635. [Google Scholar] [CrossRef] [PubMed]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. Adv. Neural Inf. Processing Syst. 2015, 2015, 802–810. [Google Scholar]
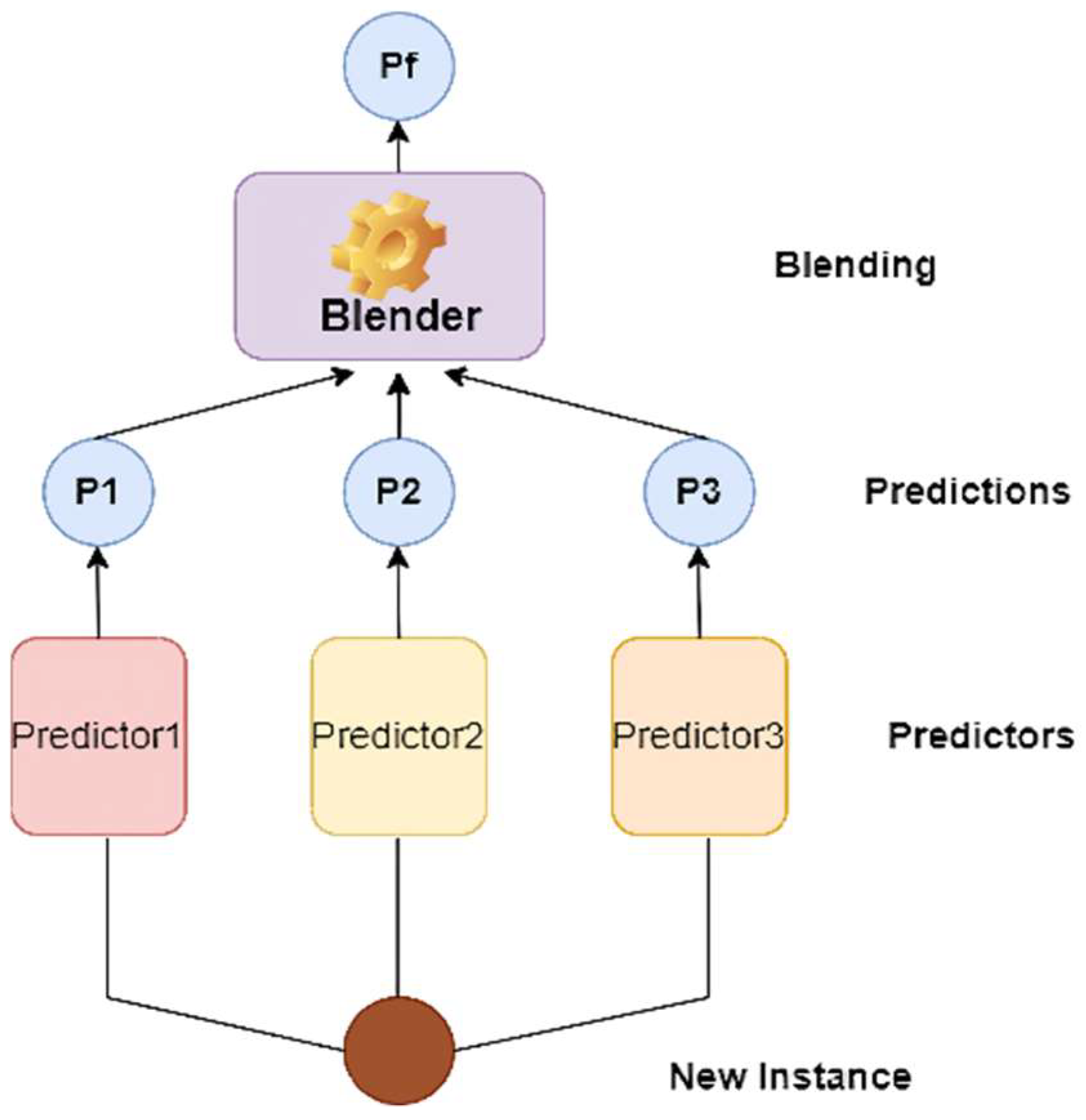
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra-Llanas, X.; Reyes-Ortiz, J. A public domain dataset for human activity recognition using smartphones. In Proceedings of the 21th International European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Singh, P.K.; Sarkar, R.; Nasipuri, M. Significance of non-parametric statistical tests for comparison of classifiers over multiple datasets. Int. J. Comput. Sci. Math. 2016, 7, 410–422. [Google Scholar] [CrossRef]
- Singh, P.K.; Sarkar, R.; Nasipuri, M. Statistical Validation of multiple classifiers over multiple datasets in the field of pattern recognition. Int. J. Appl. Pattern Recognit. 2015, 2, 1–23. [Google Scholar]
- Abdel-Basset, M.; Hawash, H.; Chakrabortty, R.K.; Ryan, M.; Elhoseny, M.; Song, H. ST-DeepHAR: Deep Learning Model for Human Activity Recognition in IoHT Applications. IEEE Internet Things J. 2020, 8, 4969–4979. [Google Scholar] [CrossRef]
- Nair, N.; Thomas, C.; Jayagopi, D.B. Human Activity Recognition Using Temporal Convolutional Network. In Proceedings of the 5th international Workshop on Sensor-based Activity Recognition and Interaction, Berlin, Germany, 20–21 September 2018. [Google Scholar] [CrossRef]
- Wang, Z.; Oates, T. Encoding time series as images for visual inspection and classification using tiled convolutional neural networks. AAAI Workshop-Tech. Rep. 2015, WS-15-14, 40–46. [Google Scholar]
- Chakraborty, S.; Mondal, R.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. Transfer learning with fine tuning for human action recognition from still images. Multimed. ToolsAppl. 2021, 80, 20547–20578. [Google Scholar] [CrossRef]
- Banerjee, A.; Bhattacharya, R.; Bhateja, V.; Singh, P.K.; Lay-Ekuakille, A.; Sarkar, R. COFE-Net: An ensemble strategy for Computer-Aided Detection for COVID-19. Measurement 2022, 187, 110289. [Google Scholar] [CrossRef]
- Noor, M.H.M.; Tan, S.Y.; Ab Wahab, M.N. Deep Temporal Conv-LSTM for Activity Recognition. Neural Process. Lett. 2022, 1–23. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year of Publication | Model/Classifier | Accuracy (in %) |
|---|---|---|---|
| Kwapisz et al. [9] | 2010 | MLP | 91.7% |
| Zhang et al. [11] | 2018 | U-Net | 97% |
| Quispe et al. [10] | 2018 | KNN | 96.2% |
| Pienaar et al. [12] | 2020 | RNN-LSTM | 94% |
| Author | Year of Publication | Model/Classifier | Accuracy (in %) |
|---|---|---|---|
| Challa et al. [19] | 2021 | CNN-BiLSTM | 94.29% |
| Dua et al. [20] | 2021 | CNN-GRU | 95.27% |
| Wan et al. [14] | 2020 | CNN | 91% |
| Tang et al. [21] | 2019 | CNN with Lego Bricks with lower Dimensional filter | 91.40% |
| Author | Year of Publication | Model/Classifier | Accuracy (in %) |
|---|---|---|---|
| Zhao et al. [24] | 2018 | Residual Bi LSTM | 93.6% |
| Xia et al. [28] | 2020 | LSTM-CNN | 95.78% |
| Wang and Liu [29] | 2020 | Hierarchical Deep LSTM | 91.65% |
| Cruciani et al. [30] | 2020 | CNN | 91.98% |
| Model | Mean Rank of Each Model for Each HAR Dataset | ||
|---|---|---|---|
| WISDM | PAMAP2 | UCI-HAR | |
| CNN-net | 3.55 | 3.65 | 3.65 |
| CNN-LSTM-net | 3.5 | 3.55 | 3.45 |
| ConvLSTM-net | 3.2 | 3.40 | 3.60 |
| StackedLSTM-net | 3.55 | 3.35 | 3.15 |
| Proposed Ensem-HAR | 1.2 | 1.05 | 1.15 |
| Dataset | Friedman Statistic Value |
|---|---|
| WISDM | 14.04 |
| PAMAP2 | 15.39 |
| UCI-HAR | 16.47 |
| Dataset | Author | Year | Model/Classifier | Accuracy | Description |
|---|---|---|---|---|---|
| WISDM | Pienaar &Malekian | 2019 | RNN-LSTM [12] | 94% | Raw data sampled into fixed-sized windows with 50% overlap |
| Zhang et al. | 2020 | U-Net [11] | 97% | Raw data sampled into fixed-sized windows with 50% overlap | |
| Abdel-Basset et al. | 2021 | ST-deepHAR [41] | 98.9% | Raw data sampled into fixed-sized windows with 50% overlap | |
| Bhattacharya et al. | 2022 | Ensem-HAR | 98.70% | Raw data sampled into fixed-sized windows with 50% overlap, and also oversampling done to remove class imbalance | |
| PAMAP2 | Wan et al. | 2020 | CNN [14] | 91% | Raw data sampled into fixed-sized windows with 50% overlap |
| Challa et al. | 2021 | CNN-BiLSTM [19] | 94.27% | Raw data sampled into fixed-sized windows with 50% overlap | |
| Dua et al. | 2021 | CNN-GRU [20] | 95.27% | Raw data sampled into fixed-sized windows with 50% overlap | |
| Bhattacharya et al. | 2022 | Ensem-HAR | 97.45% | Raw data sampled into fixed-sized windows with 50% overlap | |
| UCI-HAR | Cruciani et al. | 2020 | CNN [30] | 91.98% | 70% for training and 30% for testing |
| Nair et al. | 2018 | ED-TCN [42] | 94.6% | 70% for training and 30% for testing | |
| Zhang et al. | 2020 | U-Net [11] | 98.4% | 70% for training and 30% for testing | |
| Bhattacharya et al. | 2022 | Ensem-HAR | 95.05% | 70% for training and 30% for testing |
| Dataset | Ensemble Method | Accuracy |
|---|---|---|
| WISDM | Max Voting | 98.50% |
| Average | 97.90% | |
| Weighted Average | 98.20% | |
| Ensem-HAR | 98.71% | |
| PAMAP2 | Max Voting | 97.26% |
| Average | 97.01% | |
| Weighted Average | 97.07% | |
| Ensem-HAR | 97.73% | |
| UCI-HAR | Max Voting | 94.26% |
| Average | 93.98% | |
| Weighted Average | 94.60% | |
| Ensem-HAR | 95.05% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhattacharya, D.; Sharma, D.; Kim, W.; Ijaz, M.F.; Singh, P.K. Ensem-HAR: An Ensemble Deep Learning Model for Smartphone Sensor-Based Human Activity Recognition for Measurement of Elderly Health Monitoring. Biosensors 2022, 12, 393. https://doi.org/10.3390/bios12060393
Bhattacharya D, Sharma D, Kim W, Ijaz MF, Singh PK. Ensem-HAR: An Ensemble Deep Learning Model for Smartphone Sensor-Based Human Activity Recognition for Measurement of Elderly Health Monitoring. Biosensors. 2022; 12(6):393. https://doi.org/10.3390/bios12060393
Chicago/Turabian StyleBhattacharya, Debarshi, Deepak Sharma, Wonjoon Kim, Muhammad Fazal Ijaz, and Pawan Kumar Singh. 2022. "Ensem-HAR: An Ensemble Deep Learning Model for Smartphone Sensor-Based Human Activity Recognition for Measurement of Elderly Health Monitoring" Biosensors 12, no. 6: 393. https://doi.org/10.3390/bios12060393
APA StyleBhattacharya, D., Sharma, D., Kim, W., Ijaz, M. F., & Singh, P. K. (2022). Ensem-HAR: An Ensemble Deep Learning Model for Smartphone Sensor-Based Human Activity Recognition for Measurement of Elderly Health Monitoring. Biosensors, 12(6), 393. https://doi.org/10.3390/bios12060393