Comparative Analysis of Machine Learning Models for Nanofluids Viscosity Assessment


 ,
,  and
and
Abstract
1. Introduction
2. Data Collection
3. Model Development
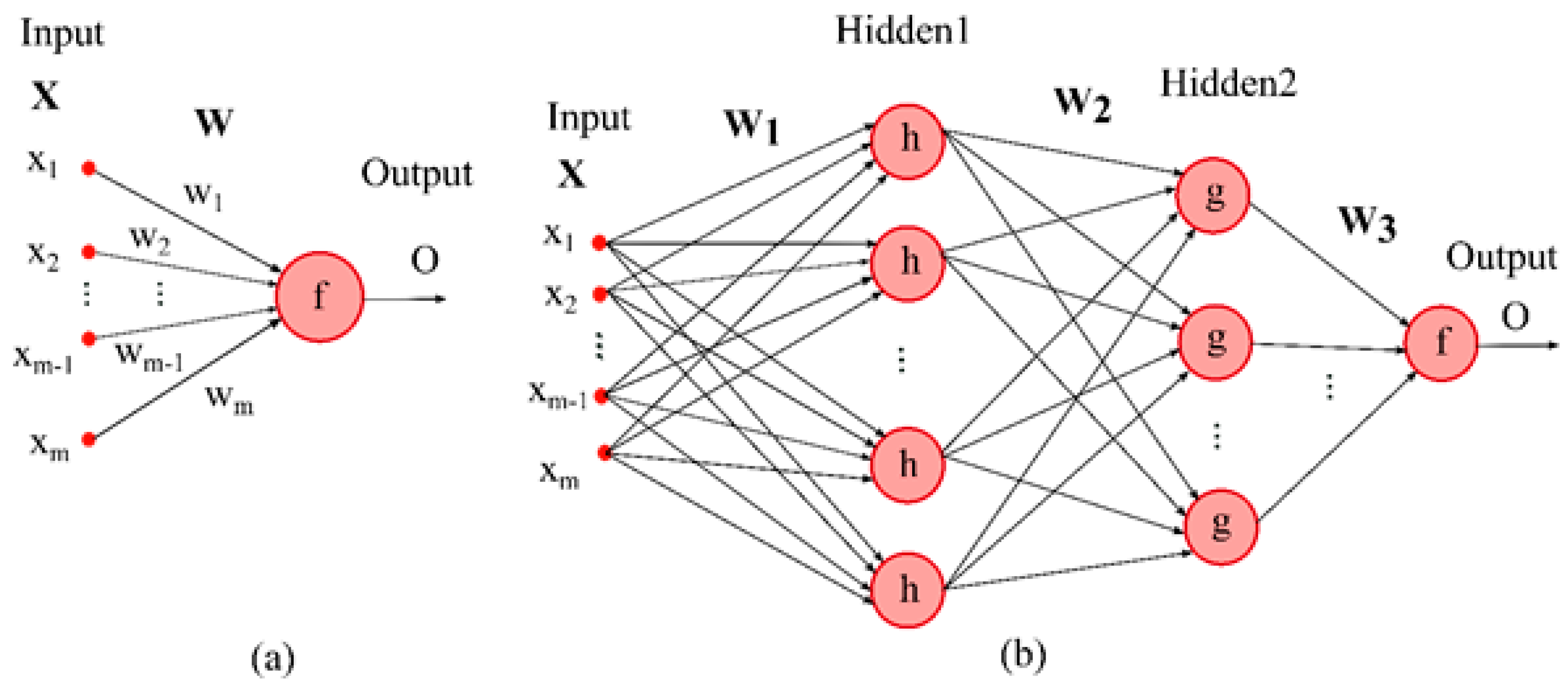
3.1. Multilayer Perceptron Network
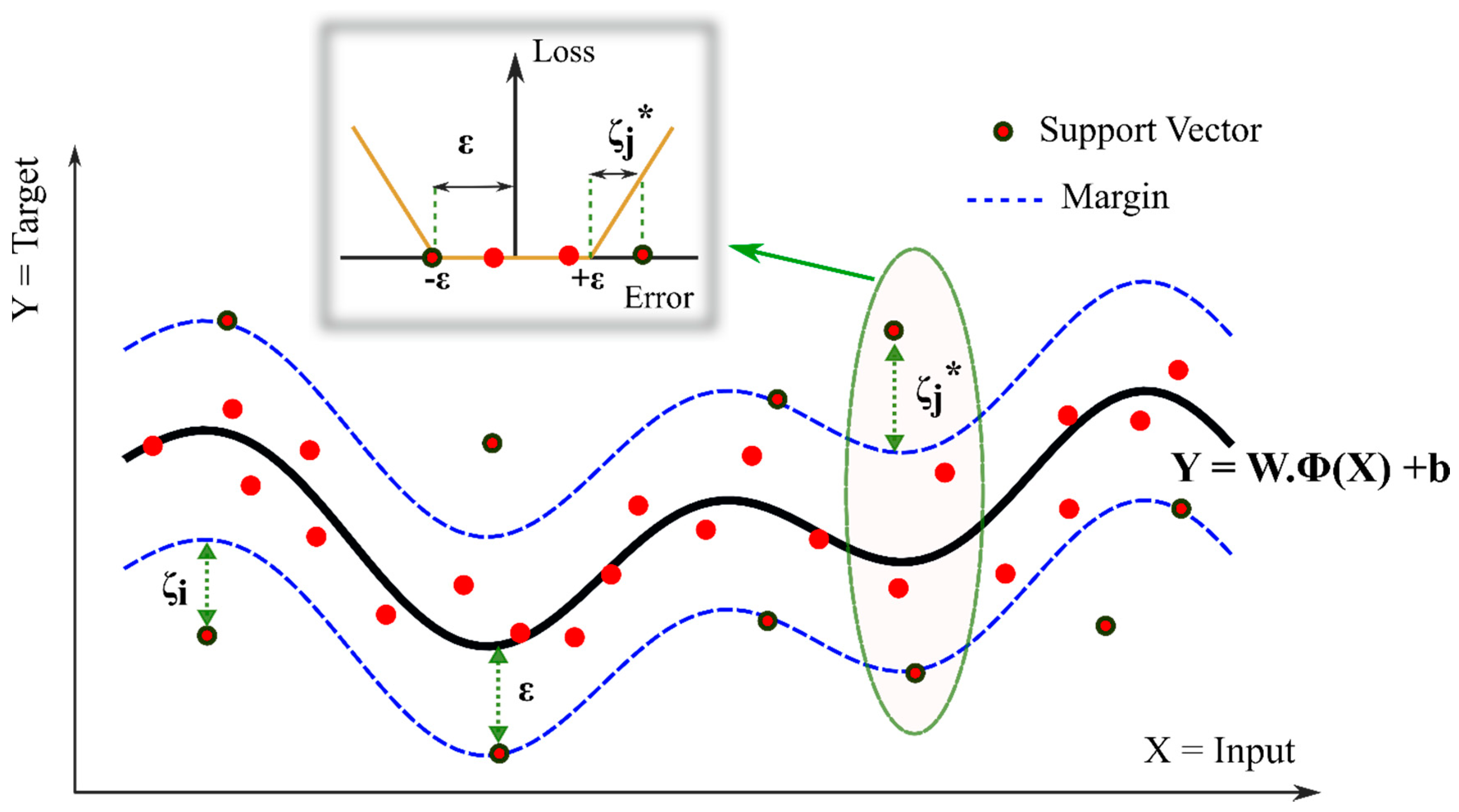
3.2. Support Vector Machine for Regression
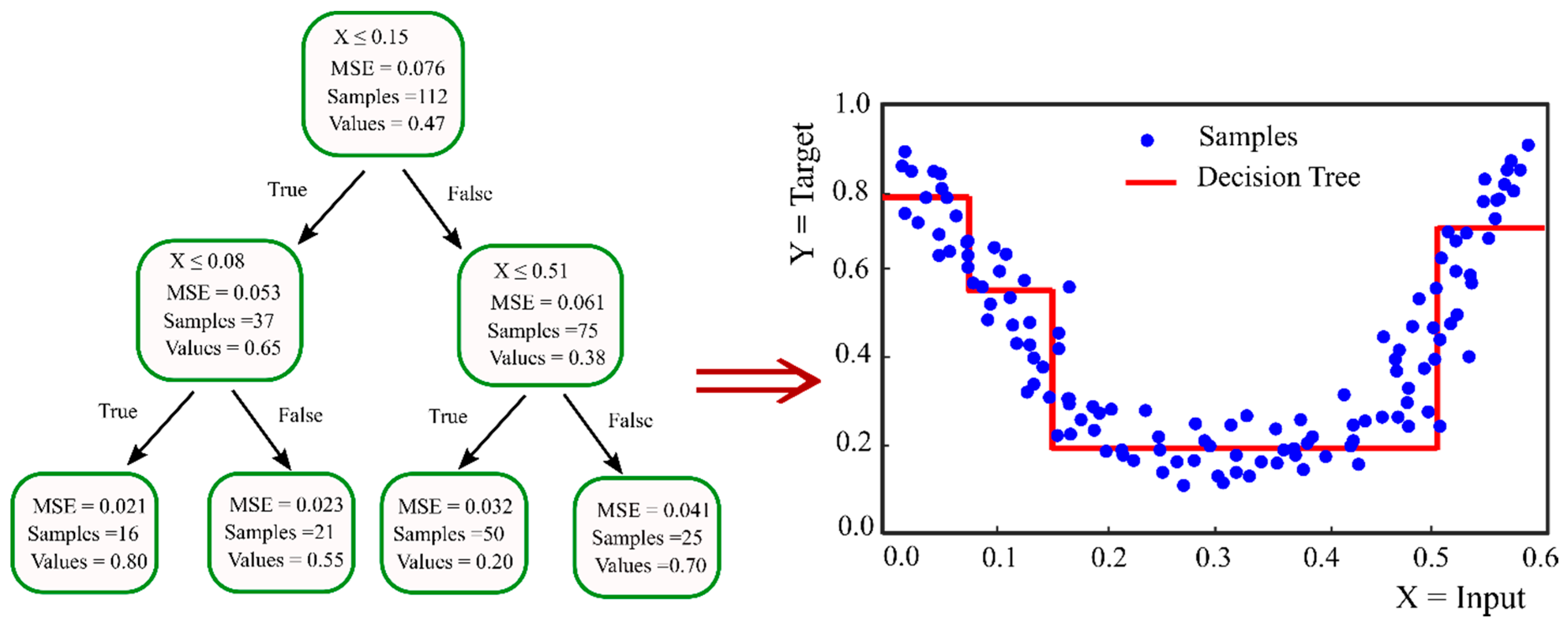
3.3. Decision Tree
3.4. Random Forest and Extra Trees
3.5. Optimization Methods
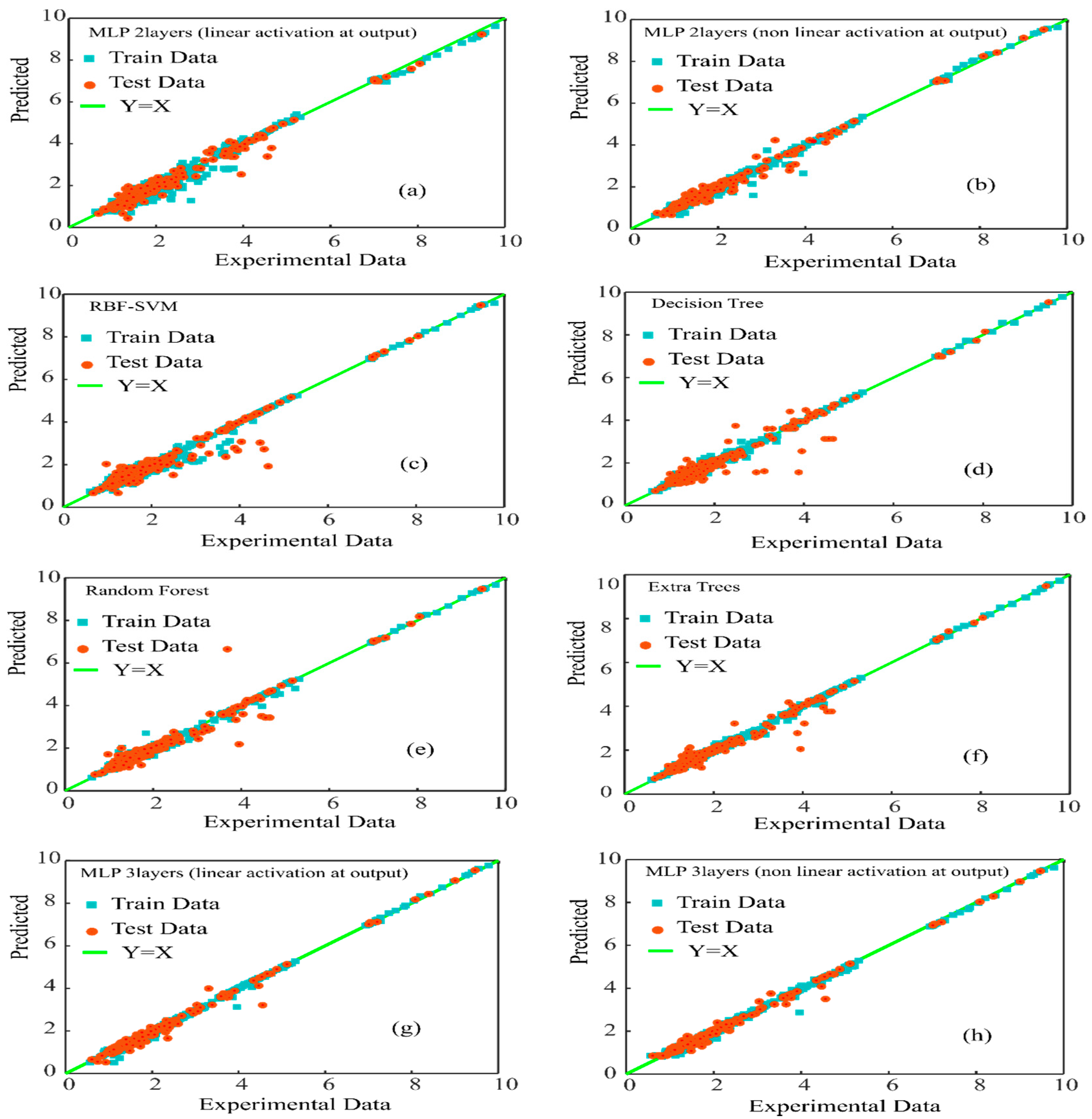
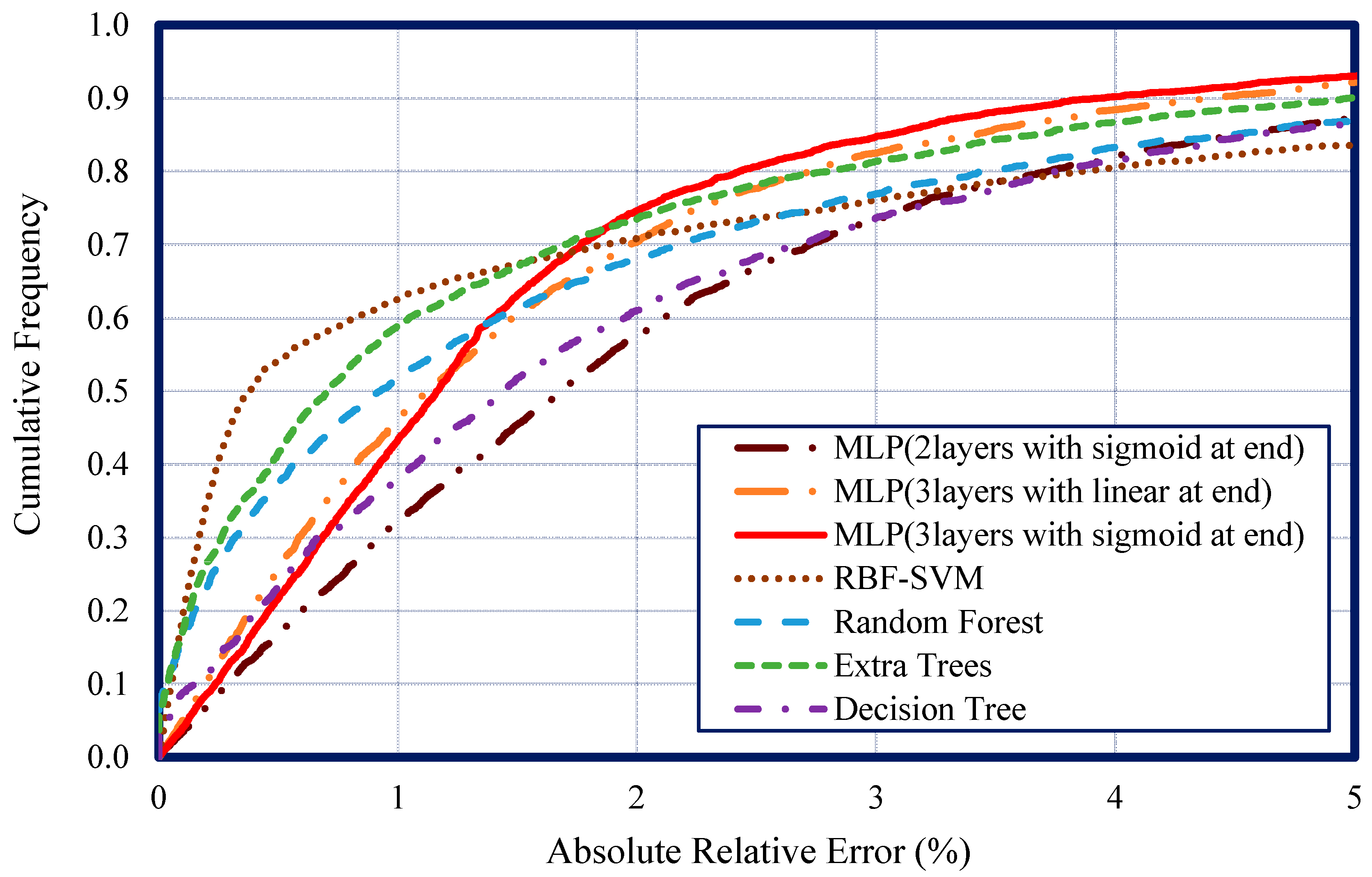
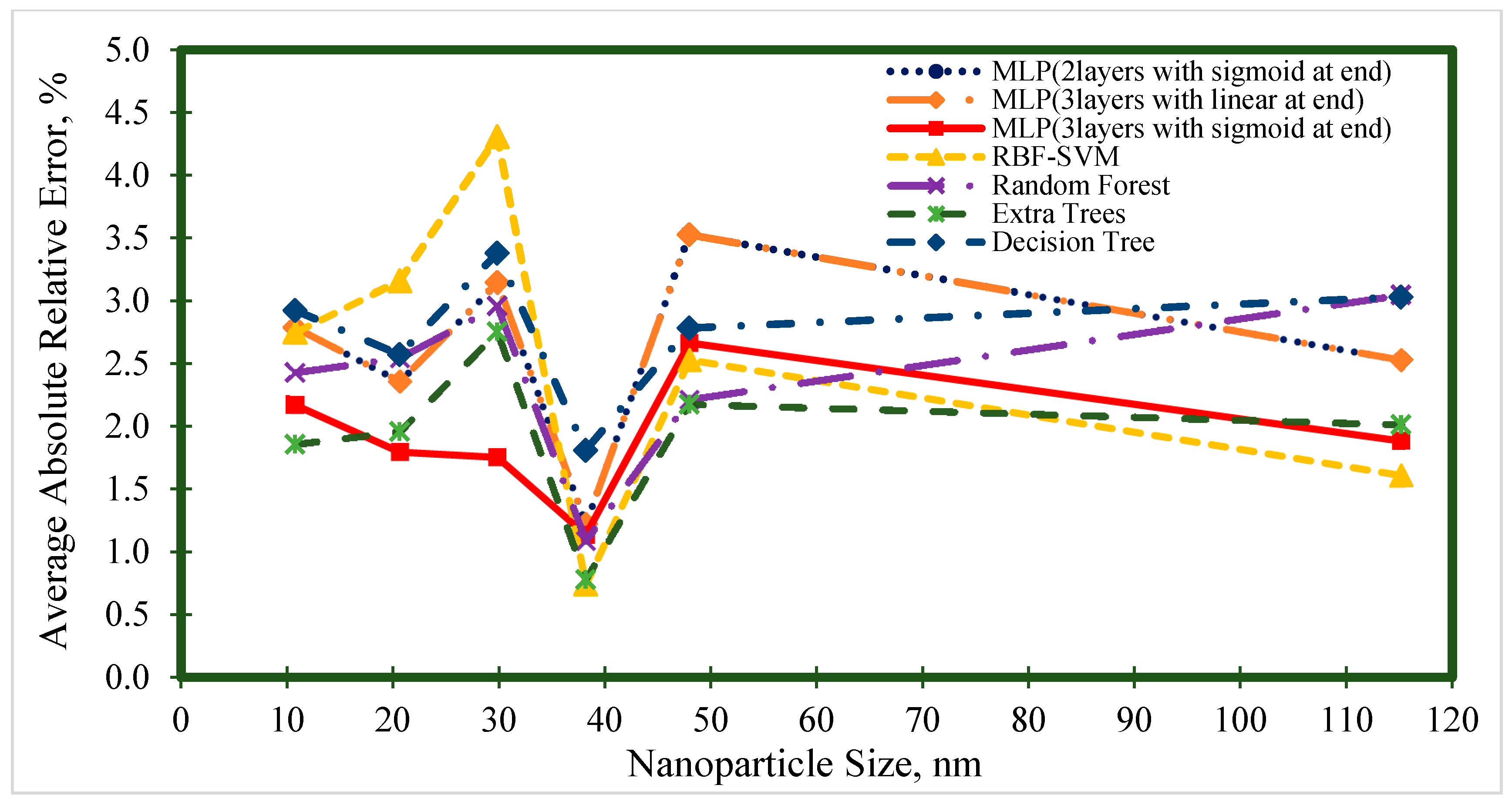
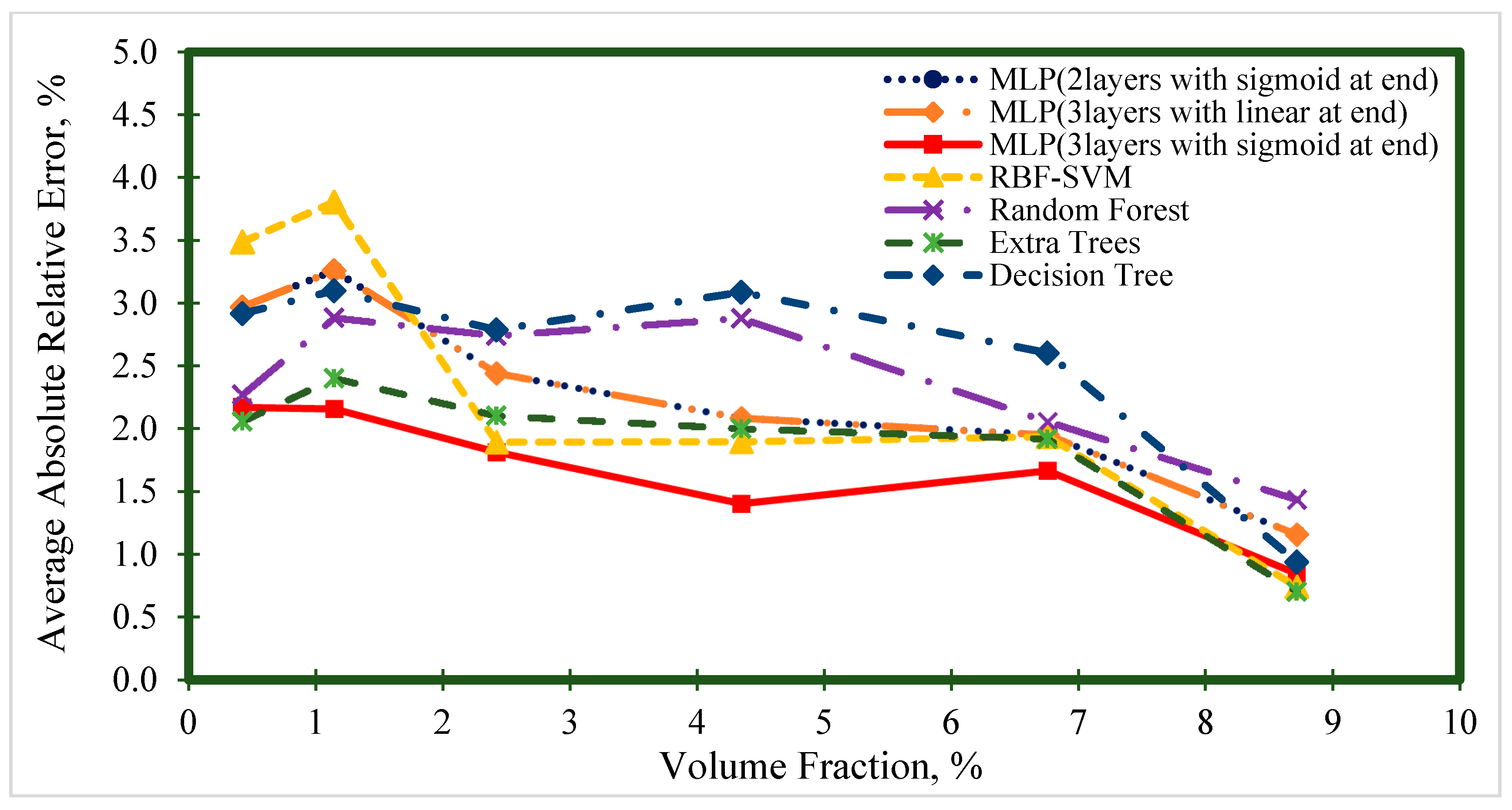
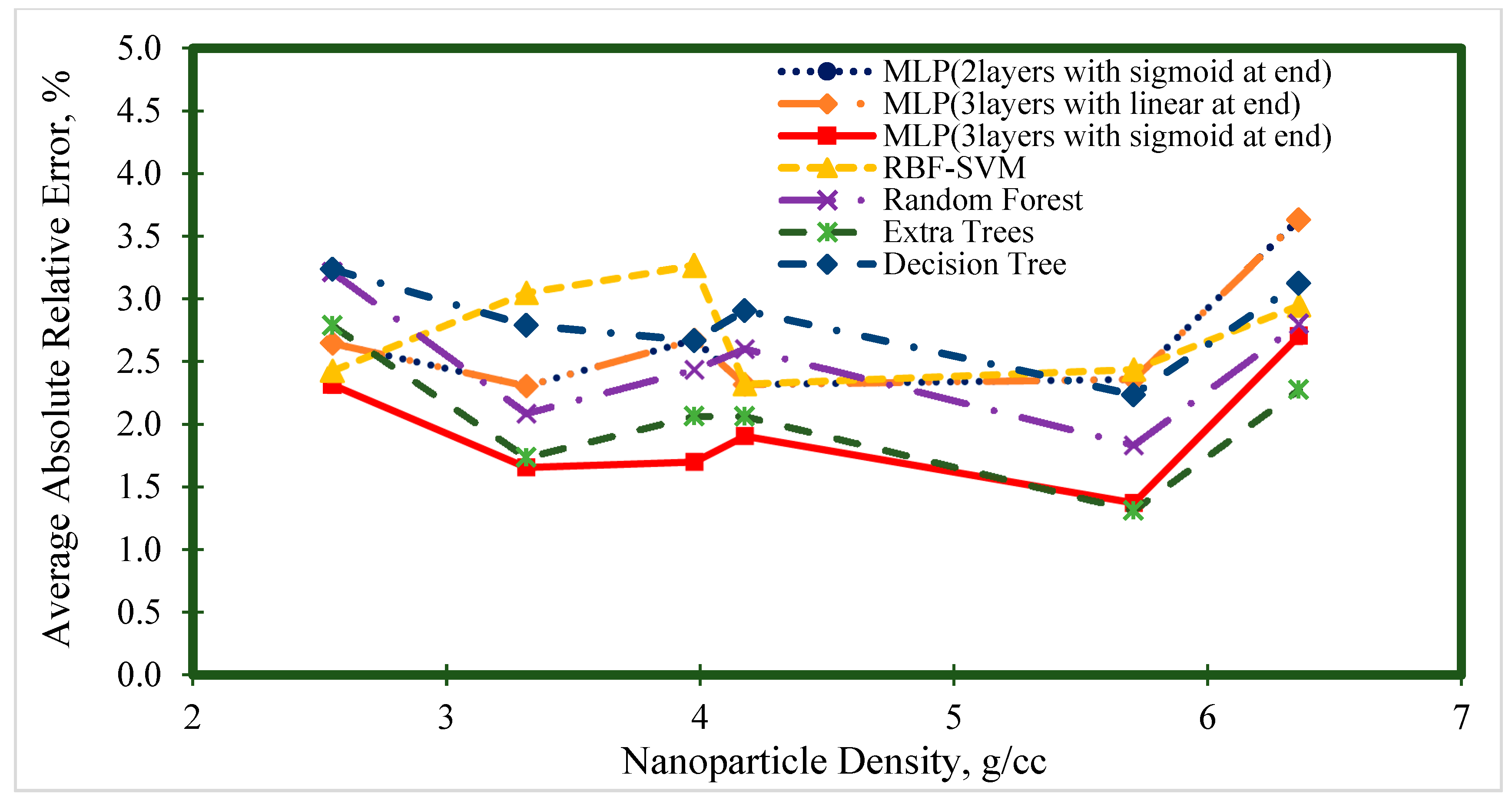
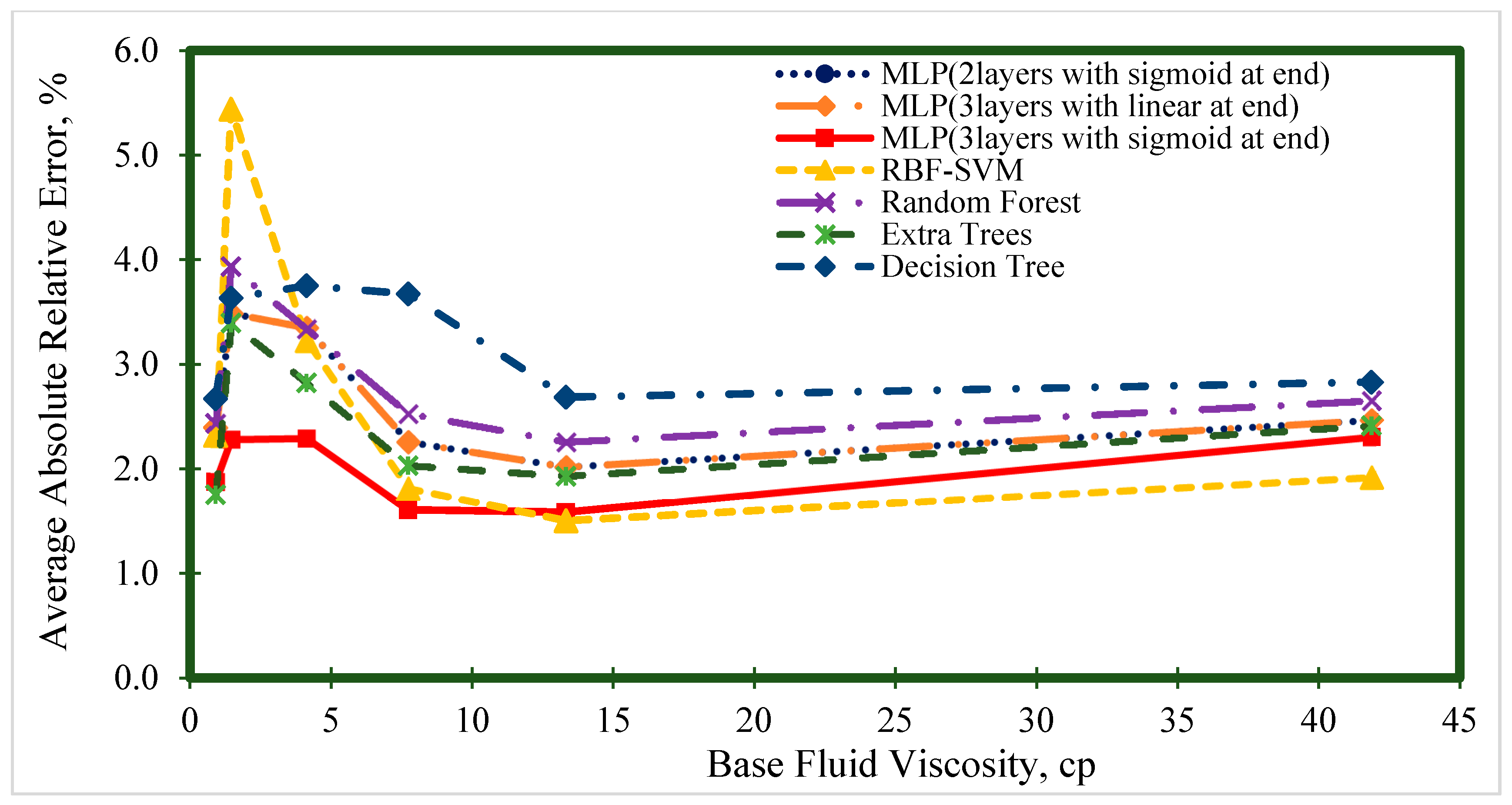
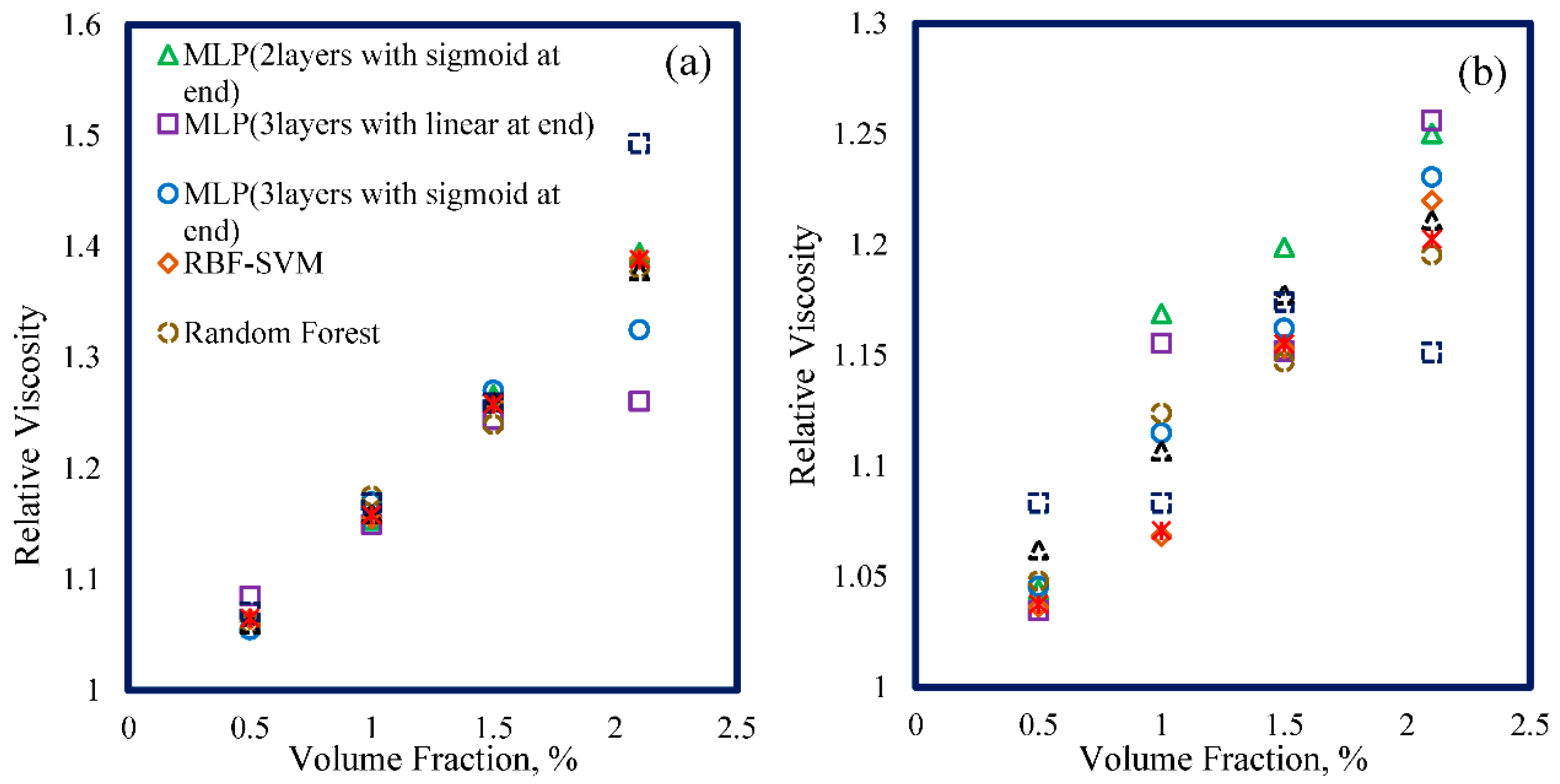
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hemmati-Sarapardeh, A.; Varamesh, A.; Husein, M.M.; Karan, K. On the evaluation of the viscosity of nanofluid systems: Modeling and data assessment. Renew. Sustain. Energy Rev. 2018, 81, 313–329. [Google Scholar] [CrossRef]
- Yang, L.; Xu, J.; Du, K.; Zhang, X. Recent developments on viscosity and thermal conductivity of nanofluids. Powder Technol. 2017, 317, 348–369. [Google Scholar] [CrossRef]
- Divandari, H.; Hemmati-Sarapardeh, A.; Schaffie, M.; Ranjbar, M. Integrating functionalized magnetite nanoparticles with low salinity water and surfactant solution: Interfacial tension study. Fuel 2020, 281, 118641. [Google Scholar] [CrossRef]
- Rezaei, A.; Abdollahi, H.; Derikvand, Z.; Hemmati-Sarapardeh, A.; Mosavi, A.; Nabipour, N. Insights into the Effects of Pore Size Distribution on the Flowing Behavior of Carbonate Rocks: Linking a Nano-Based Enhanced Oil Recovery Method to Rock Typing. Nanomaterials 2020, 10, 972. [Google Scholar] [CrossRef] [PubMed]
- Corredor-Rojas, L.M.; Hemmati-Sarapardeh, A.; Husein, M.M.; Dong, M.; Maini, B.B. Rheological behavior of surface modified silica nanoparticles dispersed in partially hydrolyzed polyacrylamide and xanthan gum solutions: Experimental measurements, mechanistic understanding, and model development. Energy Fuels 2018, 32, 10628–10638. [Google Scholar] [CrossRef]
- Moghadasi, R.; Rostami, A.; Hemmati-Sarapardeh, A.; Motie, M. Application of Nanosilica for inhibition of fines migration during low salinity water injection: Experimental study, mechanistic understanding, and model development. Fuel 2019, 242, 846–862. [Google Scholar] [CrossRef]
- Moldoveanu, G.M.; Ibanescu, C.; Danu, M.; Minea, A.A. Viscosity estimation of Al2O3, SiO2 nanofluids and their hybrid: An experimental study. J. Mol. Liq. 2018, 253, 188–196. [Google Scholar] [CrossRef]
- Gholami, E.; Vaferi, B.; Ariana, M.A. Prediction of viscosity of several alumina-based nanofluids using various artificial intelligence paradigms-Comparison with experimental data and empirical correlations. Powder Technol. 2018, 323, 495–506. [Google Scholar] [CrossRef]
- Einstein, A. A new determination of molecular dimensions. Ann. Phys. 1906, 19, 289–306. [Google Scholar] [CrossRef]
- Brinkman, H. The viscosity of concentrated suspensions and solutions. J. Chem. Phys. 1952, 20, 571. [Google Scholar] [CrossRef]
- Lundgren, T.S. Slow flow through stationary random beds and suspensions of spheres. J. Fluid Mech. 1972, 51, 273–299. [Google Scholar] [CrossRef]
- Frankel, N.; Acrivos, A. On the viscosity of a concentrated suspension of solid spheres. Chem. Eng. Sci. 1967, 22, 847–853. [Google Scholar] [CrossRef]
- Batchelor, G. The effect of Brownian motion on the bulk stress in a suspension of spherical particles. J. Fluid Mech. 1977, 83, 97–117. [Google Scholar] [CrossRef]
- Thomas, C.U.; Muthukumar, M. Three—body hydrodynamic effects on viscosity of suspensions of spheres. J. Chem. Phys. 1991, 94, 5180–5189. [Google Scholar] [CrossRef]
- Chen, H.; Ding, Y.; He, Y.; Tan, C. Rheological behaviour of ethylene glycol based titania nanofluids. Chem. Phys. Lett. 2007, 444, 333–337. [Google Scholar] [CrossRef]
- Maïga, S.E.B.; Nguyen, C.T.; Galanis, N.; Roy, G. Heat transfer behaviours of nanofluids in a uniformly heated tube. Superlattices Microstruct. 2004, 35, 543–557. [Google Scholar] [CrossRef]
- Varamesh, A.; Hemmati-Sarapardeh, A. Viscosity of nanofluid systems—A critical evaluation of modeling approaches. In Nanofluids and Their Engineering Applications; CRC Press: Boca Raton, FL, USA; Taylor & Francis Group: Abingdon, UK, 2019. [Google Scholar]
- Mazloom, M.S.; Rezaei, F.; Hemmati-Sarapardeh, A.; Husein, M.M.; Zendehboudi, S.; Bemani, A. Artificial Intelligence Based Methods for Asphaltenes Adsorption by Nanocomposites: Application of Group Method of Data Handling, Least Squares Support Vector Machine, and Artificial Neural Networks. Nanomaterials 2020, 10, 890. [Google Scholar] [CrossRef]
- Karimi, H.; Yousefi, F.; Rahimi, M.R.J.H.; Transfer, M. Correlation of viscosity in nanofluids using genetic algorithm-neural network (GA-NN). Heat Mass Transf. 2011, 47, 1417–1425. [Google Scholar] [CrossRef]
- Mehrabi, M.; Sharifpur, M.; Meyer, J.P. Viscosity of nanofluids based on an artificial intelligence model. Int. Commun. Heat Mass Transf. 2013, 43, 16–21. [Google Scholar] [CrossRef]
- Atashrouz, S.; Pazuki, G.; Alimoradi, Y. Estimation of the viscosity of nine nanofluids using a hybrid GMDH-type neural network system. Fluid Phase Equilibria 2014, 372, 43–48. [Google Scholar] [CrossRef]
- Meybodi, M.K.; Naseri, S.; Shokrollahi, A.; Daryasafar, A. Prediction of viscosity of water-based Al2O3, TiO2, SiO2, and CuO nanofluids using a reliable approach. Chemom. Intell. Lab. Syst. 2015, 149, 60–69. [Google Scholar] [CrossRef]
- Zhao, N.; Wen, X.; Yang, J.; Li, S.; Wang, Z. Modeling and prediction of viscosity of water-based nanofluids by radial basis function neural networks. Powder Technol. 2015, 281, 173–183. [Google Scholar] [CrossRef]
- Adio, S.A.; Mehrabi, M.; Sharifpur, M.; Meyer, J.P. Experimental investigation and model development for effective viscosity of MgO–ethylene glycol nanofluids by using dimensional analysis, FCM-ANFIS and GA-PNN techniques. Int. Commun. Heat Mass Transf. 2016, 72, 71–83. [Google Scholar] [CrossRef]
- Atashrouz, S.; Mozaffarian, M.; Pazuki, G. Viscosity and rheological properties of ethylene glycol+water+Fe3O4 nanofluids at various temperatures: Experimental and thermodynamics modeling. Korean J. Chem. Eng. 2016, 33, 2522–2529. [Google Scholar] [CrossRef]
- Barati-Harooni, A.; Najafi-Marghmaleki, A. An accurate RBF-NN model for estimation of viscosity of nanofluids. J. Mol. Liq. 2016, 224, 580–588. [Google Scholar] [CrossRef]
- Heidari, E.; Sobati, M.A.; Movahedirad, S. Accurate prediction of nanofluid viscosity using a multilayer perceptron artificial neural network (MLP-ANN). Chemom. Intell. Lab. Syst. 2016, 155, 73–85. [Google Scholar] [CrossRef]
- Longo, G.A.; Zilio, C.; Ortombina, L.; Zigliotto, M. Application of Artificial Neural Network (ANN) for modeling oxide-based nanofluids dynamic viscosity. Int. Commun. Heat Mass Transf. 2017, 83, 8–14. [Google Scholar] [CrossRef]
- Bahiraei, M.; Hangi, M. An empirical study to develop temperature-dependent models for thermal conductivity and viscosity of water-Fe3O4 magnetic nanofluid. Mater. Chem. Phys. 2016, 181, 333–343. [Google Scholar] [CrossRef]
- Barati-Harooni, A.; Najafi-Marghmaleki, A.; Mohebbi, A.; Mohammadi, A.H. On the estimation of viscosities of Newtonian nanofluids. J. Mol. Liq. 2017, 241, 1079–1090. [Google Scholar] [CrossRef]
- Aminian, A. Predicting the effective viscosity of nanofluids for the augmentation of heat transfer in the process industries. J. Mol. Liq. 2017, 229, 300–308. [Google Scholar] [CrossRef]
- Vakili, M.; Khosrojerdi, S.; Aghajannezhad, P.; Yahyaei, M. A hybrid artificial neural network-genetic algorithm modeling approach for viscosity estimation of graphene nanoplatelets nanofluid using experimental data. Int. Commun. Heat Mass Transf. 2017, 82, 40–48. [Google Scholar] [CrossRef]
- Ansari, H.R.; Zarei, M.J.; Sabbaghi, S.; Keshavarz, P. A new comprehensive model for relative viscosity of various nanofluids using feed-forward back-propagation MLP neural networks. Int. Commun. Heat Mass Transf. 2018, 91, 158–164. [Google Scholar] [CrossRef]
- Derakhshanfard, F.; Mehralizadeh, A. Application of artificial neural networks for viscosity of crude oil-based nanofluids containing oxides nanoparticles. J. Pet. Sci. Eng. 2018, 168, 263–272. [Google Scholar] [CrossRef]
- Karimipour, A.; Ghasemi, S.; Darvanjooghi, M.H.K.; Abdollahi, A. A new correlation for estimating the thermal conductivity and dynamic viscosity of CuO/liquid paraffin nanofluid using neural network method. Int. Commun. Heat Mass Transf. 2018, 92, 90–99. [Google Scholar] [CrossRef]
- Murshed, S.M.S.; Leong, K.C.; Yang, C. Investigations of thermal conductivity and viscosity of nanofluids. Int. J. Therm. Sci. 2008, 47, 560–568. [Google Scholar] [CrossRef]
- Lee, J.-H.; Hwang, K.S.; Jang, S.P.; Lee, B.H.; Kim, J.H.; Choi, S.U.S.; Choi, C.J. Effective viscosities and thermal conductivities of aqueous nanofluids containing low volume concentrations of Al2O3 nanoparticles. Int. J. Heat Mass Transf. 2008, 51, 2651–2656. [Google Scholar] [CrossRef]
- Singh, M.; Kundan, L. Experimental study on thermal conductivity and viscosity of Al2O3–nanotransformer oil. Int. J. Theo. App. Res. Mech. Eng. 2013, 2, 125–130. [Google Scholar]
- Nguyen, C.T.; Desgranges, F.; Roy, G.; Galanis, N.; Maré, T.; Boucher, S.; Angue Mintsa, H. Temperature and particle-size dependent viscosity data for water-based nanofluids–Hysteresis phenomenon. Int. J. Heat Fluid Flow 2007, 28, 1492–1506. [Google Scholar] [CrossRef]
- Chandrasekar, M.; Suresh, S.; Chandra Bose, A. Experimental investigations and theoretical determination of thermal conductivity and viscosity of Al2O3/water nanofluid. Exp. Therm. Fluid Sci. 2010, 34, 210–216. [Google Scholar] [CrossRef]
- Tavman, I.; Turgut, A.; Chirtoc, M.; Schuchmann, H.; Tavman, S. Experimental investigation of viscosity and thermal conductivity of suspensions containing nanosized ceramic particles. Arch. Mater. Sci. 2008, 34, 99–104. [Google Scholar]
- Zhou, S.-Q.; Ni, R.; Funfschilling, D. Effects of shear rate and temperature on viscosity of alumina polyalphaolefins nanofluids. J. Appl. Phys. 2010, 107, 054317. [Google Scholar] [CrossRef]
- Mena, J.B.; Ubices de Moraes, A.A.; Benito, Y.R.; Ribatski, G.; Parise, J.A.R. Extrapolation of Al2O3–water nanofluid viscosity for temperatures and volume concentrations beyond the range of validity of existing correlations. Appl. Therm. Eng. 2013, 51, 1092–1097. [Google Scholar] [CrossRef]
- Pak, B.C.; Cho, Y.I. Hydrodynamic and heat transfer study of dispersed fluids with submicron metallic oxide particles. Exp. Heat Transf. Int. J. 1998, 11, 151–170. [Google Scholar] [CrossRef]
- Syam Sundar, L.; Venkata Ramana, E.; Singh, M.K.; Sousa, A.C.M. Thermal conductivity and viscosity of stabilized ethylene glycol and water mixture Al2O3 nanofluids for heat transfer applications: An experimental study. Int. Commun. Heat Mass Transf. 2014, 56, 86–95. [Google Scholar] [CrossRef]
- Yiamsawas, T.; Dalkilic, A.S.; Mahian, O.; Wongwises, S. Measurement and correlation of the viscosity of water-based Al2O3 and TiO2 nanofluids in high temperatures and comparisons with literature reports. J. Dispers. Sci. Technol. 2013, 34, 1697–1703. [Google Scholar] [CrossRef]
- Yiamsawas, T.; Mahian, O.; Dalkilic, A.S.; Kaewnai, S.; Wongwises, S. Experimental studies on the viscosity of TiO2 and Al2O3 nanoparticles suspended in a mixture of ethylene glycol and water for high temperature applications. Appl. Energy 2013, 111, 40–45. [Google Scholar] [CrossRef]
- Chiam, H.W.; Azmi, W.H.; Usri, N.A.; Mamat, R.; Adam, N.M. Thermal conductivity and viscosity of Al2O3 nanofluids for different based ratio of water and ethylene glycol mixture. Exp. Therm. Fluid Sci. 2017, 81, 420–429. [Google Scholar] [CrossRef]
- Anoop, K.; Kabelac, S.; Sundararajan, T.; Das, S.K. Rheological and flow characteristics of nanofluids: Influence of electroviscous effects and particle agglomeration. J. Appl. Phys. 2009, 106, 034909. [Google Scholar] [CrossRef]
- Sekhar, Y.R.; Sharma, K. Study of viscosity and specific heat capacity characteristics of water-based Al2O3 nanofluids at low particle concentrations. J. Exp. Nanosci. 2015, 10, 86–102. [Google Scholar] [CrossRef]
- Pastoriza-Gallego, M.; Casanova, C.; Páramo, R.; Barbés, B.; Legido, J.; Piñeiro, M. A study on stability and thermophysical properties (density and viscosity) of Al2O3 in water nanofluid. J. Appl. Phys. 2009, 106, 064301. [Google Scholar] [CrossRef]
- Kulkarni, D.P.; Das, D.K.; Vajjha, R.S. Application of nanofluids in heating buildings and reducing pollution. Appl. Energy 2009, 86, 2566–2573. [Google Scholar] [CrossRef]
- Naik, M.; Sundar, L.S. Investigation into thermophysical properties of glycol based CuO nanofluid for heat transfer applications. World Acad. Sci. Eng. Technol. 2011, 59, 440–446. [Google Scholar]
- Pastoriza-Gallego, M.J.; Casanova, C.; Legido, J.L.; Piñeiro, M.M. CuO in water nanofluid: Influence of particle size and polydispersity on volumetric behaviour and viscosity. Fluid Phase Equilibria 2011, 300, 188–196. [Google Scholar] [CrossRef]
- Namburu, P.K.; Kulkarni, D.P.; Misra, D.; Das, D.K. Viscosity of copper oxide nanoparticles dispersed in ethylene glycol and water mixture. Exp. Therm. Fluid Sci. 2007, 32, 397–402. [Google Scholar] [CrossRef]
- Jia-Fei, Z.; Zhong-Yang, L.; Ming-Jiang, N.; Ke-Fa, C. Dependence of nanofluid viscosity on particle size and pH value. Chin. Phys. Lett. 2009, 26, 066202. [Google Scholar] [CrossRef]
- Chevalier, J.; Tillement, O.; Ayela, F. Rheological properties of nanofluids flowing through microchannels. Appl. Phys. Lett. 2007, 91, 3103. [Google Scholar] [CrossRef]
- Jamshidi, N.; Farhadi, M.; Ganji, D.; Sedighi, K. Experimental investigation on viscosity of nanofluids. Int. J. Eng. 2012, 25, 201–209. [Google Scholar] [CrossRef]
- Rudyak, V.Y.; Dimov, S.V.; Kuznetsov, V.V. On the dependence of the viscosity coefficient of nanofluids on particle size and temperature. Tech. Phys. Lett. 2013, 39, 779–782. [Google Scholar] [CrossRef]
- Abdolbaqi, M.K.; Sidik, N.A.C.; Rahim, M.F.A.; Mamat, R.; Azmi, W.H.; Yazid, M.N.A.W.M.; Najafi, G. Experimental investigation and development of new correlation for thermal conductivity and viscosity of BioGlycol/water based SiO2 nanofluids. Int. Commun. Heat Mass Transf. 2016, 77, 54–63. [Google Scholar] [CrossRef]
- Lee, S.W.; Park, S.D.; Kang, S.; Bang, I.C.; Kim, J.H. Investigation of viscosity and thermal conductivity of SiC nanofluids for heat transfer applications. Int. J. Heat Mass Transf. 2011, 54, 433–438. [Google Scholar] [CrossRef]
- Duangthongsuk, W.; Wongwises, S. Measurement of temperature-dependent thermal conductivity and viscosity of TiO2-water nanofluids. Exp. Therm. Fluid Sci. 2009, 33, 706–714. [Google Scholar] [CrossRef]
- Chen, H.; Ding, Y.; Tan, C. Rheological behaviour of nanofluids. New J. Phys. 2007, 9, 367. [Google Scholar] [CrossRef]
- Abdolbaqi, M.K.; Sidik, N.A.C.; Aziz, A.; Mamat, R.; Azmi, W.H.; Yazid, M.N.A.W.M.; Najafi, G. An experimental determination of thermal conductivity and viscosity of BioGlycol/water based TiO2 nanofluids. Int. Commun. Heat Mass Transf. 2016, 77, 22–32. [Google Scholar] [CrossRef]
- Khedkar, R.S.; Shrivastava, N.; Sonawane, S.S.; Wasewar, K.L. Experimental investigations and theoretical determination of thermal conductivity and viscosity of TiO2–ethylene glycol nanofluid. Int. Commun. Heat Mass Transf. 2016, 73, 54–61. [Google Scholar] [CrossRef]
- Singh, R.; Sanchez, O.; Ghosh, S.; Kadimcherla, N.; Sen, S.; Balasubramanian, G. Viscosity of magnetite–toluene nanofluids: Dependence on temperature and nanoparticle concentration. Phys. Lett. A 2015, 379, 2641–2644. [Google Scholar] [CrossRef]
- Syam Sundar, L.; Singh, M.K.; Sousa, A.C.M. Investigation of thermal conductivity and viscosity of Fe3O4 nanofluid for heat transfer applications. Int. Commun. Heat Mass Transf. 2013, 44, 7–14. [Google Scholar] [CrossRef]
- Esfe, M.H.; Saedodin, S.; Asadi, A.; Karimipour, A. Thermal conductivity and viscosity of Mg (OH) 2-ethylene glycol nanofluids. J. Therm. Anal. Calorim. 2015, 120, 1145–1149. [Google Scholar] [CrossRef]
- Mariano, A.; Pastoriza-Gallego, M.J.; Lugo, L.; Mussari, L.; Piñeiro, M.M. Co3O4 ethylene glycol-based nanofluids: Thermal conductivity, viscosity and high pressure density. Int. J. Heat Mass Transf. 2015, 85, 54–60. [Google Scholar] [CrossRef]
- Sundar, L.S.; Hortiguela, M.J.; Singh, M.K.; Sousa, A.C.M. Thermal conductivity and viscosity of water based nanodiamond (ND) nanofluids: An experimental study. Int. Commun. Heat Mass Transf. 2016, 76, 245–255. [Google Scholar] [CrossRef]
- Sundar, L.S.; Singh, M.K.; Sousa, A.C.M. Enhanced thermal properties of nanodiamond nanofluids. Chem. Phys. Lett. 2016, 644, 99–110. [Google Scholar] [CrossRef]
- Hemmat Esfe, M.; Saedodin, S. An experimental investigation and new correlation of viscosity of ZnO–EG nanofluid at various temperatures and different solid volume fractions. Exp. Therm. Fluid Sci. 2014, 55, 1–5. [Google Scholar] [CrossRef]
- Pastoriza-Gallego, M.J.; Lugo, L.; Cabaleiro, D.; Legido, J.L.; Piñeiro, M.M. Thermophysical profile of ethylene glycol-based ZnO nanofluids. J. Chem. Thermodyn. 2014, 73, 23–30. [Google Scholar] [CrossRef]
- Rosenblatt, F. Principles of Neurodymanics: Perceptrons and the Theory of Brain Mechanisms; Spartan Books; Cornell Aeronautical Laboratory, Inc.: Buffalo, NY, USA, 1962. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Karlik, B.; Olgac, A.V. Performance analysis of various activation functions in generalized MLP architectures of neural networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.J.; Vapnik, V. Support vector regression machines. In Advances in Neural Information Processing Systems; MIT Press: Camberidge, MA, USA, 1997; pp. 155–161. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Loh, W.-Y. Fifty years of classification and regression trees. Int. Stat. Rev. 2014, 82, 329–348. [Google Scholar] [CrossRef]
- Song, Y.-Y.; Ying, L. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar]
- Patel, N.; Upadhyay, S. Study of various decision tree pruning methods with their empirical comparison in WEKA. Int. J. Comput. Appl. 2012, 60, 20–25. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Nesterov, Y. A method for unconstrained convex minimization problem with the rate of convergence O (1/k^2). In Doklady AN USSR; American Mathematical Society: Providence, RI, USA, 1983; pp. 543–547. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Zeiler, M.D. ADADELTA: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam; Natural Hazards 3, no. 2; Stanford University: Stanford, CA, USA, 2016; pp. 437–453. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Al2O3 | CuO | SiO2 | SiC | TiO2 | Fe3O4 | MgO | Mg(OH)2 | Co3O4 | Nanodiamond | ZnO | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| References | [36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51] | [39,49,52,53,54,55] | [41,56,57,58,59,60] | [61] | [36,44,46,47,62,63,64,65] | [66,67] | [24] | [68] | [69] | [70,71] | [72,73] |
| Base fluid | Water DI water Transformer oil R11 refigerant Polyalphaolefins EG EG/W 20:80 wt% EG/W 40:60 wt% EG/W 20:80 wt% W/EG 60:40 vol% W/EG 50:50 vol% W/EG 40:60 vol% | Water EG PG/W 30:70 vol% EG/W 60:40 wt% | Water Ethanol DI water Transformer oil EG EG/W 25:75% EG/W 50:50% BG/W 20:80 vol% BG/W 30:70 vol% | DI water | Water DI water EG EG/W 20:80 wt% BG/W 20:80 vol% BG/W 30:70 vol% | Water Toluene | EG | EG | EG | water EG/W 20:80 wt% EG/W 60:40 wt% EG/W 40:60 wt% | EG |
| T (°C) | 0–72 | −35–67 | 19–80 | 30 | 9.85–80 | 20–60 | 20–70 | 23–65 | 10–50 | 0–60 | 10–50 |
| φ (%) | 0.01–10 | 0–9 | 0–8.4 | 0–3 | 0.2–10 | 0.04–2 | 0.1–5 | 0.1–2 | 0.9–5.7 | 0.2–1 | 0.25–5 |
| dp (nm) | 8–120 | 11–152 | 7–190 | 100 | 6–50 | 10–13 | 21–125 | 20 | 17 | 11.83–19.27 | 4.6–48 |
| ρP (gr/cm3) | 3.69–4 | 6.31 | 2.22–2.65 | 3.21 | 4.18–4.23 | 5.17–5.81 | 3.58 | 2.34 | 6.11 | 3.1 | 5.61–13.61 |
| μnf (cp) | 0.44–610.46 | 0.46–447.35 | 0.59–37.36 | 0.93–1.60 | 0.46–28.41 | 0.32–1.65 | 3.70–30.60 | 4.82–23.02 | 8.06–44.76 | 25.51 | 6.14–49.30 |
| μbf (cp) | 0.39–452.60 | 0.42–99.54 | 0.54–18.53 | 0.8 | 0.42–23.01 | 0.3–0.79 | 3.63–21.11 | 1.02–1.60 | 1.02–1.44 | 0.24–13.74 | 6.08–35.44 |
| No. of data points | 1197 | 500 | 278 | 5 | 308 | 121 | 198 | 35 | 25 | 357 | 122 |
| Model | ARE (%) | AARE (%) | RMSE | SD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Total | Train | Test | Total | Train | Test | Total | Train | Test | Total | |
| CMIS [1] | −0.382 | −0.515 | −0.409 | 3.933 | 4.036 | 3.954 | 0.094 | 0.088 | 0.093 | 0.062 | 0.061 | 0.062 |
| MLP [1]: (5)(Tanh,12)(Sigmoid,8)(Linear,1)-BR | −0.440 | −0.179 | −0.387 | 4.557 | 4.931 | 4.632 | 0.100 | 0.113 | 0.103 | 0.069 | 0.074 | 0.070 |
| LSSVM [1]: Optimized by CSA | −0.921 | −1.029 | −1.011 | 5.342 | 6.630 | 5.488 | 0.187 | 0.047 | 0.193 | 0.070 | 0.017 | 0.108 |
| MLP: (5)(Tanh,32)(Sigmoid,64)(Linear,1)-Nadam | 1.596 | 1.555 | 1.587 | 4.076 | 4.818 | 4.238 | 0.012 | 0.015 | 0.013 | 0.064 | 0.080 | 0.067 |
| MLP: (5)(Tanh,32)(Sigmoid,64)(Sigmoid,1)-Nadam | −0.206 | −0.457 | −0.260 | 2.369 | 3.876 | 2.697 | 0.008 | 0.012 | 0.009 | 0.040 | 0.062 | 0.046 |
| RBF-SVM: C = 1; gamma = 2.3 | 0.089 | −0.131 | 0.041 | 2.120 | 4.740 | 2.690 | 0.010 | 0.023 | 0.014 | 0.051 | 0.096 | 0.064 |
| Decision Tree: max depth = 14, max feature = 4, min samples split = 3, max leaf nodes = 450 | −0.103 | 0.321 | −0.011 | 2.043 | 4.579 | 2.595 | 0.005 | 0.022 | 0.011 | 0.032 | 0.087 | 0.050 |
| Random Forest: max depth = 18, max feature = 4 | −0.204 | −0.499 | −0.268 | 1.746 | 3.945 | 2.225 | 0.006 | 0.020 | 0.011 | 0.036 | 0.080 | 0.049 |
| Extra Trees: max depth = 20, max feature = 5, min samples split = 4, max leaf nodes = 1000 | −0.149 | −0.335 | −0.189 | 1.244 | 3.597 | 1.756 | 0.004 | 0.016 | 0.008 | 0.023 | 0.070 | 0.038 |
| MLP: (5)(Tanh,64)(Sigmoid,128)(Sigmoid,16)(Linear,1)-AdaMax | 1.063 | 1.181 | 1.088 | 1.632 | 2.914 | 1.911 | 0.005 | 0.010 | 0.006 | 0.030 | 0.051 | 0.036 |
| MLP: (5)(Tanh,64)(Sigmoid,128)(Sigmoid,16)(Sigmoid,1)-AdaMax | −0.507 | −0.635 | −0.535 | 1.583 | 2.855 | 1.860 | 0.005 | 0.009 | 0.006 | 0.029 | 0.049 | 0.035 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shateri, M.; Sobhanigavgani, Z.; Alinasab, A.; Varamesh, A.; Hemmati-Sarapardeh, A.; Mosavi, A.; S, S. Comparative Analysis of Machine Learning Models for Nanofluids Viscosity Assessment. Nanomaterials 2020, 10, 1767. https://doi.org/10.3390/nano10091767
Shateri M, Sobhanigavgani Z, Alinasab A, Varamesh A, Hemmati-Sarapardeh A, Mosavi A, S S. Comparative Analysis of Machine Learning Models for Nanofluids Viscosity Assessment. Nanomaterials. 2020; 10(9):1767. https://doi.org/10.3390/nano10091767
Chicago/Turabian StyleShateri, Mohammadhadi, Zeinab Sobhanigavgani, Azin Alinasab, Amir Varamesh, Abdolhossein Hemmati-Sarapardeh, Amir Mosavi, and Shahab S. 2020. "Comparative Analysis of Machine Learning Models for Nanofluids Viscosity Assessment" Nanomaterials 10, no. 9: 1767. https://doi.org/10.3390/nano10091767
APA StyleShateri, M., Sobhanigavgani, Z., Alinasab, A., Varamesh, A., Hemmati-Sarapardeh, A., Mosavi, A., & S, S. (2020). Comparative Analysis of Machine Learning Models for Nanofluids Viscosity Assessment. Nanomaterials, 10(9), 1767. https://doi.org/10.3390/nano10091767