1. Introduction
Bibliometrics is the branch of library science that applies mathematical and statistical techniques to analyze books, articles, and other documents [
1,
2]. The discipline is becoming increasingly popular. For bibliometric evidence of this claim, note that the correlation between the number of published articles on “bibliometrics” (via Google Scholar), and the year of publication (this century, through 2017) is positive and very strong (0.91).
Bibliometric techniques are also convenient, as the relevant data are both quantitative and readily available [
3]. Moreover, the field has high utility. Bibliometrics can be used to inform policy decisions [
4], allocate research funding [
5], assist libraries in prioritizing acquisitions [
6], and of course, evaluate scholarly activity [
7]. Even a “bibliometric study of literature on bibliometrics” has now been conducted [
8]. The field is therefore likely here to stay, and will continue to be a primary means of judging impact for articles, researchers, and journals.
The present article focuses on bibliometrics for the journal,
Intelligence. The journal was founded in 1977 by Douglas K. Detterman. Since then, it has published 1828 articles [
9], including two that feature bibliometric analyses. First, Wicherts [
10] analyzed Web of Science (WOS) citation counts for 797 articles in the journal, published between the years 1977 and 2007. The median citation count for these articles was 10, with a mode of 6. Wicherts also showed that the journal’s impact factor had been steadily rising each year, although it has since leveled off.
1 Finally, Wicherts reported a top 25 list of the most-cited papers in the journal to date. These articles had citation counts (via Google Scholar) ranging from 81 to 492.
Second, Pesta [
11] examined articles published after Wicherts’ study. He analyzed 619 papers, written by 1897 authors, and published between the years 2008 and 2015. Pesta reported citation counts for both articles and authors, and found the median citation rate for the former (i.e., 10) to be identical to that calculated by Wicherts (albeit, Pesta’s mean citation value was 17, with a mode of 6). Pesta also reported a list of the most prolific authors, and an updating of the 25 top, most-cited articles in the journal between the years 1977 and 2015. These articles had citation counts (via Google Scholar) ranging from 186 to 905.
Here we attempt to build upon existing bibliometric research for this journal. Our focus, however, is on the article keywords, versus the authors, or the articles themselves. Note that the journal began using keywords in the year 2000.
Why apply bibliometrics to article keywords? First, keywords represent the author’s opinion of the three to five (or so) most important words in their articles. Second, keyword analysis can potentially detect trending research topics both currently, and in the past. Third, bibliometric keyword analysis can answer several interesting questions. Some of these include (1) What research topics in this journal are the most frequent/popular; (2) Are certain keywords associated with an increased likelihood of a paper being cited; and (3) Has the use of specific keywords increased or decreased over time? Our goal is to provide bibliometric answers to these questions, focusing specifically on articles and keywords published in the journal, Intelligence.
2. Method
We coded all keyword-containing articles in the journal,
Intelligence, for the years 2000 to 2016. In line with other bibliometric studies on this journal [
10,
11], we included all articles except book reviews and obituaries. Note that the year 2000 was the first we found where the journal featured keywords, although only one such article appeared at this time (i.e., [
12]). We did not code post 2016 articles because we did not think they had enough time to accumulate a relative, representative number of citations. One of the prior bibliometric reviews of
Intelligence [
11] did similarly. Moreover, we excluded some other articles published after 2000 (e.g., book reviews, obituaries, and some editorials), because they did not contain keywords. In total, we ended up coding 916, keyword-containing articles.
For each article, we coded the title, first author’s name, and all listed keywords. Regarding keywords, we coded 4364 of them from the articles in the set. On 11 July 2018, we next coded each article’s Web of Science (WOS) citation count. We did not also code Google Scholar (GS) counts, as Pesta [
11] reported that these correlate 0.97 with WOS citation counts. In fact, GS counts are very close to double those reported by WOS. Note that these values come specifically from analyzing articles published in
Intelligence [
11].
We coded both citations overall and citations per year for every keyword in the set. The latter values adjust citation counts for the effects of “time since publication” on a paper’s current citation count [
11]. In line with a previous review [
11], this calculation involved dividing each article’s number of citations by (2018.53 minus the article’s year). We used 0.53 as the decimal because 11 July is the 192nd day of the year, and 192 divided by 365 equals 0.53.
Coding the keywords was sometimes not straightforward. For example, authors often used several different keywords to describe the same research topic (e.g., “g”, “g factor”, “general mental ability”, “general cognitive ability”, and “general intelligence”). This required us to form dozens of “keyword categories”, each containing all synonym keywords for the same underlying construct. An example of a keyword category would be “g factor” for the synonyms listed in parenthesis above.
Next, within articles, authors often used keywords that were redundant (e.g., “general intelligence” and “g”). In fact, redundant keywords comprised 763 of the 4364 (17.5%) keywords in the article set. However, counting all redundant keywords within articles would artificially inflate (i.e., double count) overall citation rates for both the articles and the keywords. We therefore did not analyze redundant keywords. Finally, a small number of keywords could logically be placed into more than one category (e.g., “speeded and un-speeded testing”). Although only eleven (2.50%) such keywords existed, we nonetheless excluded them from analyses.
The first two authors separately coded all keywords into categories. We then compared the codings to identify discrepancies. These were discussed until consensus was reached on every keyword category. Most discrepancies involved disagreements on how fine to delineate categories (e.g., whether to group “general intelligence” separate from “intelligence”). As such we did not calculate a reliability coefficient, since discordance often reflected a difference in level of analysis, not an inconsistency in classification.
Unexpectedly, judging from our preliminary review of the first couple of years of data, many of the resulting keyword categories turned out to have very small sample sizes (i.e., number of articles listing them). We therefore chose to analyze only keyword categories with at least 20 citations. There were 38 such unique keyword categories (37 after excluding “intelligence”), with 2699 (2161 after excluding “intelligence”) references to these keywords in the article set.
We ran three separate analyses on the keyword categories. The first was a simple frequency comparison of how many articles listed each keyword. This allowed us to identify the most frequent/popular research topics. The second involved mean difference tests of WOS citation counts for the articles citing each of the 37 keyword categories, together with regression analyses of the effect of keyword categories on citation counts. The goal here was to determine which categories were associated with highly cited papers.
Third, for the categories associated with the most paper citations (i.e., those categories with at least 50 paper citations; N = 20, which is 54% of the 37 keyword categories), we visualized WOS trends in citation counts across time. Specifically, we created plots with year on the x-axis and proportion on the y-axis. The proportion was simply the number of articles citing the keyword in a given year, divided by the total number of citing articles for that keyword. This approach allowed us to visually spot trends in keyword citations over the years.
3. Results
Table 1 lists frequency data for the 37 keyword categories (hereafter, “keywords”) that we analyzed. The third column shows how many times the keyword was listed by one of the 916 articles in the set. Also reported are standardized residuals. These can be interpreted as
Z scores [
13,
14]. Residuals of greater than plus or minus two indicate that the keyword’s observed frequency was significantly higher (or lower) than its expected frequency.
Not surprisingly, “intelligence” was the most frequently employed keyword. It was listed as a keyword by 59% of the articles in the set. Because “intelligence” is the primary focus of the journal, we decided not to include it in the analyses that follow.
Next, by a fair amount, the keyword associated with the most number of citations (excluding “intelligence”) was “g factor”. It was listed by 15% of the articles in the set. This is also not surprising, but it perhaps exemplifies the field’s sustained, direct focus on general intelligence, versus specific cognitive abilities. For example, only 7 of the 916 (0.01%) articles in the set included “non-g abilities” as a keyword (but see also the frequencies for crystallized and fluid intelligence in
Table 1).
“Psychometrics/statistics” was the second-most listed keyword in the set. This seems intuitive, as these are the tools researchers must use to get their data published in the journal. Next was the keyword, “education”. It ranked third on the list, which seemed surprising, given our perhaps outdated impression that educational researchers tend to eschew intelligence research. On the other hand, at least one seminal article on this topic appears in
Intelligence [
15]. The article is the third-most cited paper of all time for the journal. Moreover, “education” might attract relatively more research interest because the keyword is broadly multi-disciplinary. The supply of researchers able and interested in this topic may be greater than that for many of the other keywords in the article set. This explanation is admittedly speculative.
The fourth most-listed keyword was “IQ/achievement/aptitude tests”. This keyword is a hodgepodge, which likely explains its relatively high count. For example, the category contains 102 keyword synonyms total. Of these, 84 (82.4%) are unique (i.e., were listed by only one article in the entire set). Some of the many exemplars for this category include “AFQT”, “CAT”, “Draw a Person”, “GATB”, “GMAT scores”, “Stanford Binet”, “TIMSS”, “WAIS III”, “WISC”, and “Wonderlic”. Rounding out the top-five listed keywords in
Table 1 was “Race/ethnicity”. We attribute this keyword’s high frequency count partly to the work of Richard Lynn and colleagues; see, e.g., [
16], the authors of which have mapped out IQs for numerous ethnicities/national origins across the world.
Finally, we are reluctant to discuss the keywords in
Table 1 that have relatively low frequencies. These are misleading. Keywords like “emotional intelligence”, “politics”, and “Spearman’s hypothesis” have “low” citation counts, but only relative to the other keywords in
Table 1. Recall that
Table 1 presents just the top 37 out of 384 (9.6%) categories. Therefore, any keyword appearing in
Table 1 is indeed something multiple researchers have expressed interest in. Conversely, the keywords with relatively lower impact would be those that did not make
Table 1.
Table 2 shows WOS citation rates for the top 37 keywords in the set. Specifically, for every article listing a keyword, we coded that article’s WOS citation count, and then took the average of all article counts within each keyword. We report both citation counts overall, and then per year.
Interestingly, the top 5 keywords in
Table 2 are all different from those in
Table 1. Several of the keywords were associated with more citations, relative to keywords with higher frequencies of usage. For example, “spatial ability” ranked first (55.53 WOS cites) in
Table 2, but only 29.5th (32 counts) in
Table 1. Conversely, “psychometrics/statistics” ranked second in
Table 1, but only 15th in
Table 2. This led us to correlate the ranks across frequencies (
Table 1) and overall citations (
Table 2). Although the resulting correlation was actually negative (
r = −0.192), it was small and not significant (
p = 0.369). Still, the safest interpretation is perhaps interesting: publishing on a frequently-researched keyword does not guarantee that the article will yield the highest citation counts.
In
Table 2, the keyword associated with the second highest number of citations was “factor analysis”. We see this as paralleling “psychometrics/statistics” in
Table 1. Specifically, both keywords represent tools that researchers use when attempting to publish in this journal. Third, “executive function” is another example of a relatively infrequently used keyword associated with a high number of citations. However, the construct is very similar to “working memory” (we almost grouped these two keywords together—see, e.g., [
17]), which is a staple research topic in this journal. It has both a correspondingly high frequency and associated citation count (i.e., it ranked sixth of all keywords in both
Table 1 and
Table 2).
“Attention” was the keyword associated with the fourth highest number of citations. This is another illustration of a keyword with a relatively low frequency (25th in the rank) but a high number of citations. Moreover, the keyword has seven articles referencing it, each with at least 50 citations. Two of these [
18,
19] even fall on Pesta’s [
11] top 25 list of all time, with 224, and 479 overall citations, respectively. Finally, “IQ theories” was the keyword associated with the fifth highest number of citations. This keyword is also a hodgepodge (made up of, e.g., “multiple intelligences”, “VPR theory”, “practical intelligence”, and “Gf–Gc theory”), but we have no real explanation for why papers using these keywords amassed such high citation counts.
The top-five values for citations per year in
Table 2 are mostly similar to the values for citations overall in
Table 1. An exception is that “working memory” replaced “IQ theories” in cites per year versus cites overall. Also noteworthy is that the correlation between the two citation values for all keywords in
Table 2 is 0.91. In sum, no very large differences in ranks occurred when looking at citations overall versus per year.
Turning to statistical analyses, the
Table 2 grand mean for citations overall (
N = 2161) was 26.28 (
SD = 42.53). A one-way ANOVA on these data was significant:
F (36) = 2.49;
MSe = 1765. Similarly, the grand mean for citations per year was 2.89 (
SD = 3.51). This ANOVA was also significant:
F (36) = 3.30;
MSe = 11.90. For context, recall that both Wicherts [
10] and Pesta [
11] reported median citation counts of 10 for all articles in their sets. The keywords in
Table 2 (i.e., the top 37 in the entire journal) range from being cited 2.63 times to substantially more than that (e.g., papers listing “spatial ability” as a keyword averaged 55.53 citations each).
The one-way ANOVAs above each have 37 levels. This creates an awkward scenario when trying to determine how best to run post-hoc tests. Ultimately, we decided not to conduct Family Wise Error Rate tests, as the number of multiple comparisons here was too large: (37 × 36)/2 = 666. A correction like Bonferroni’s would have an unduly punitive effect on our statistical power. Specifically, the effective alpha rate with a Bonferroni correction on these data would be 0.05/666 (0.00008).
Instead, we employed the false discovery rate (FDR), which is particularly useful when researchers conduct many post hoc tests. The FDR is the proportion of Type I errors existing among all tests that resulted in rejecting the null hypothesis. This is in contrast to the typical reliance on the alpha level (i.e.,
p-value) to determine Type I error rates. Instead, the FDR focuses on the
q-value (i.e., the proportion of significant comparisons that are actually Type I errors). A
q-value of 0.05 means that 5% of the significant test results are likely Type I errors [
20,
21].
The Benjamini–Hochberg test [
21,
22] is a common procedure used to control for the FDR. It does so via calculation and interpretation of
q-values. We used it here for our post hoc tests. Following convention, we adopted 0.05 as our value for
q.
Fully 70 of the 666 (11%) post-hoc comparisons for overall citations were significant with
q-values of less than 0.05. The results for citations per year were similar, yielding 105 of 666 (16%) significant comparisons. The
Supplementary Materials lists all pairwise comparisons, both for citations overall, and then per year.
We next analyzed the effects of keywords on citation counts by running a regression model with keyword, publication year (and nonlinear transformations of this), and keyword count as independent variables. The dependent variable was the citation number. A reviewer suggested that we add a dummy variable for the editor to capture the effect of editorial preference; however, Doug Detterman was editor-in-chief from 2000 to 2016, when Richard Haier took over. As our data extends to 2016, there is little to no editorial variance (we also do not know who the action editor was for each paper). Results appear in
Table 3. Because the analysis involves the full population of
Intelligence papers (versus some sample of them), statistical significance is arguably not an important concern. Nonetheless, we asterisked those keywords that had
p-values <0.05, and then used these as a threshold to warrant further discussion. Results from other models are shown in the
Supplementary Materials. The model we selected here was geared toward finding the highest
R2-adj-value.
Results below parallel those observable from the FDR analyses. Papers dealing with “executive function”, “factor analysis”, “fluid intelligence”, “IQ theories”, “working memory”, and “spatial ability” were all cited as more than typical, while those dealing with “health”, “mental speed”, and “race/ethnicity” were cited as less than typical. It is no secret that “race/ethnicity” is an unattractive topic for many researchers, so it is perhaps not surprising that papers focusing here garner lower citations. The topic of cognitive epidemiology (“health”) may be similarly less popular. Finally, “mental speed” and “ECTs” were often conceptually overlapping categories, and both of their betas were negative. The reason for the negative effects of these topics is unclear.
Our final analysis involved looking at trends in citation counts over the years. That is, does a keyword’s popularity (operationalized as the mean citation count of the articles that listed it) change over time? A preliminary way of testing this is to simply correlate the year an instance of a keyword appeared with its corresponding WOS citation counts.
This correlational analysis included every exemplar (
N = 2161; “intelligence” excluded) of the top 37 keywords in
Table 2. The year of publication correlated moderately at −0.375 with overall WOS citations. However, in looking at the scatterplot (not displayed here), the inverse relationship occurred because many of the papers with very high citation counts were published prior to 2010. Consistent with this, the correlation between year of publication and citations per year (which corrects for time since publication) was only −0.148. This value, though, was still significant, given the large sample size.
A more revealing analysis involves plotting the change in citations for specific keywords across the years. We deemed that visual presentation of these data would be the easiest way to interpret them.
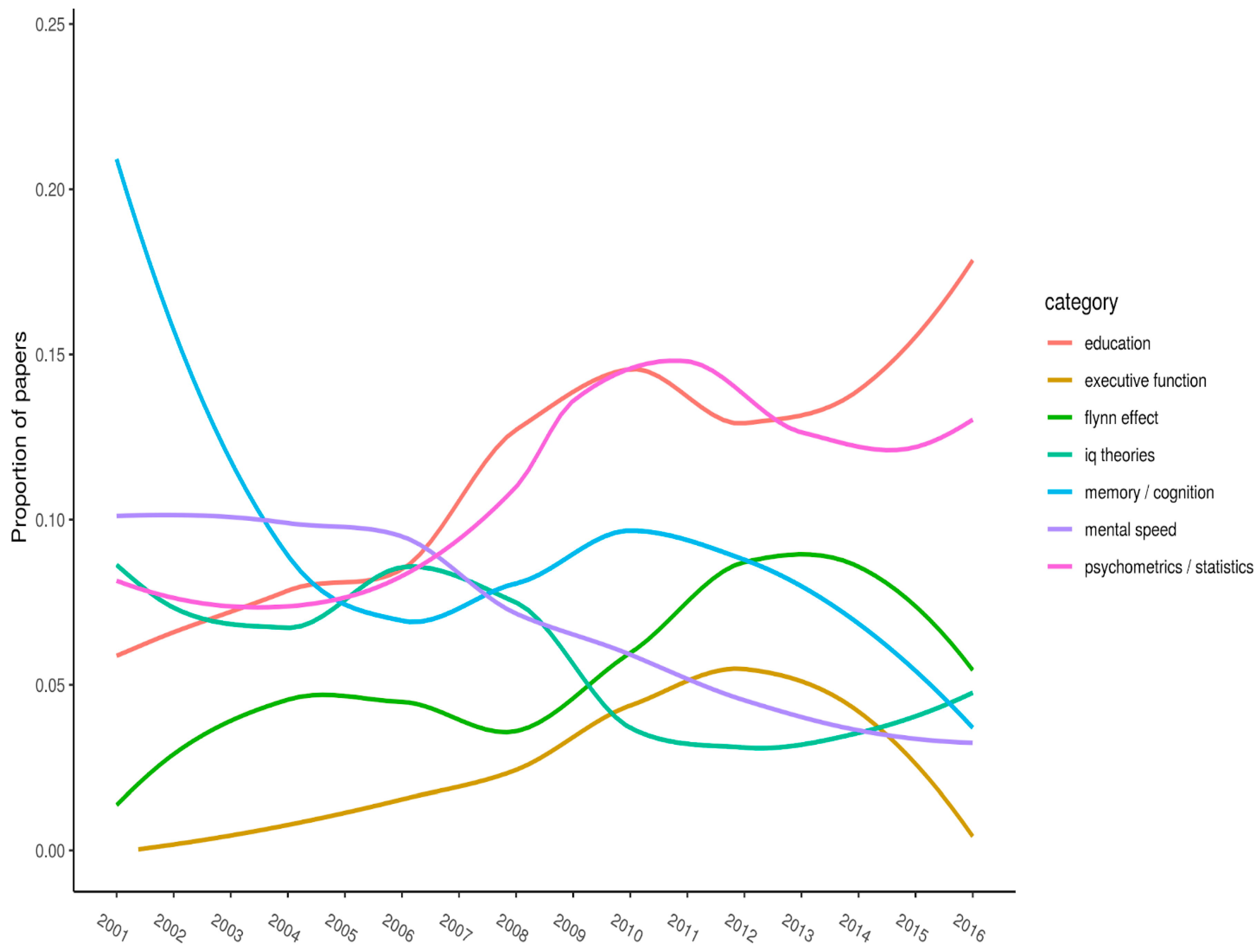
Figure 1,
Figure 2 and
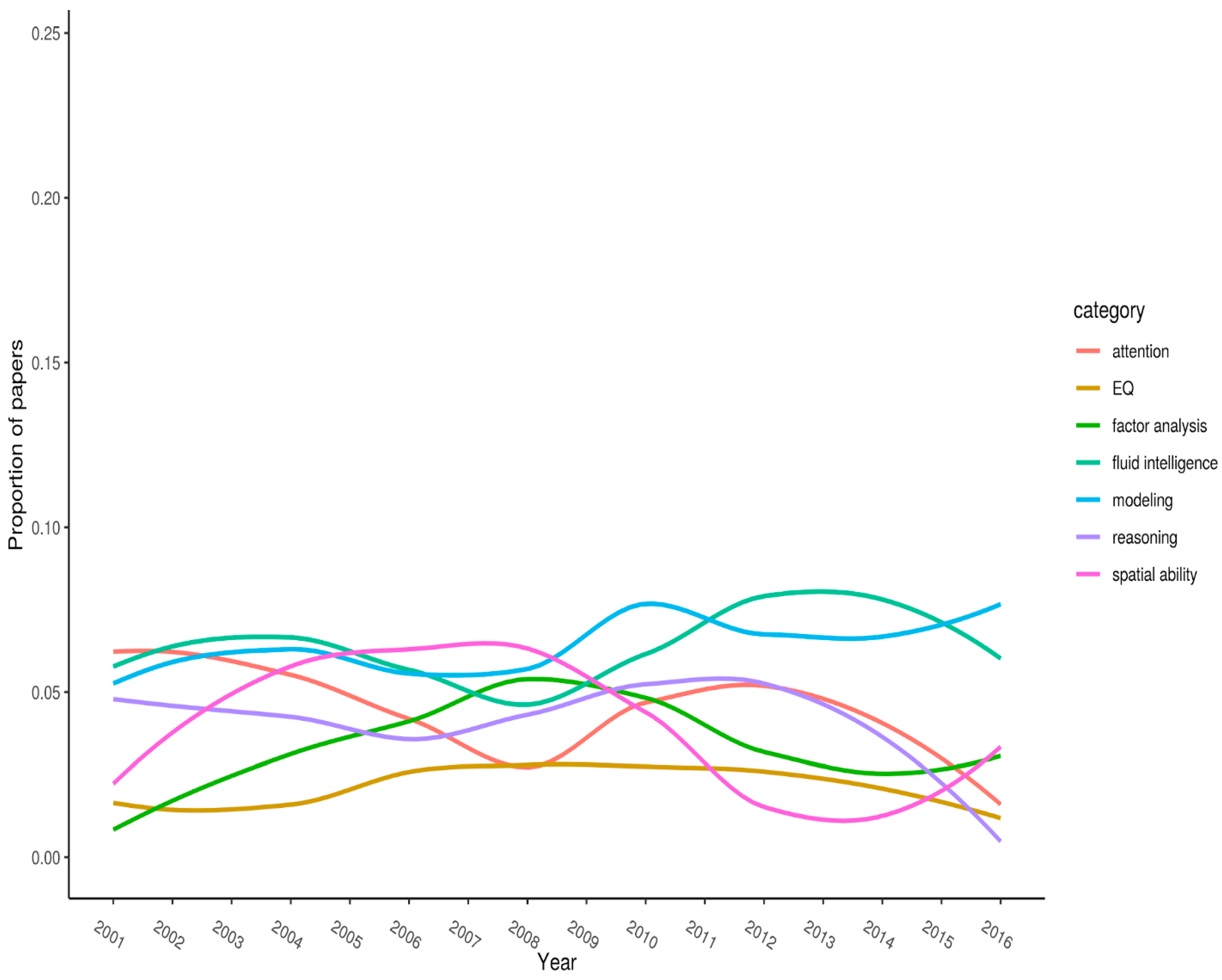
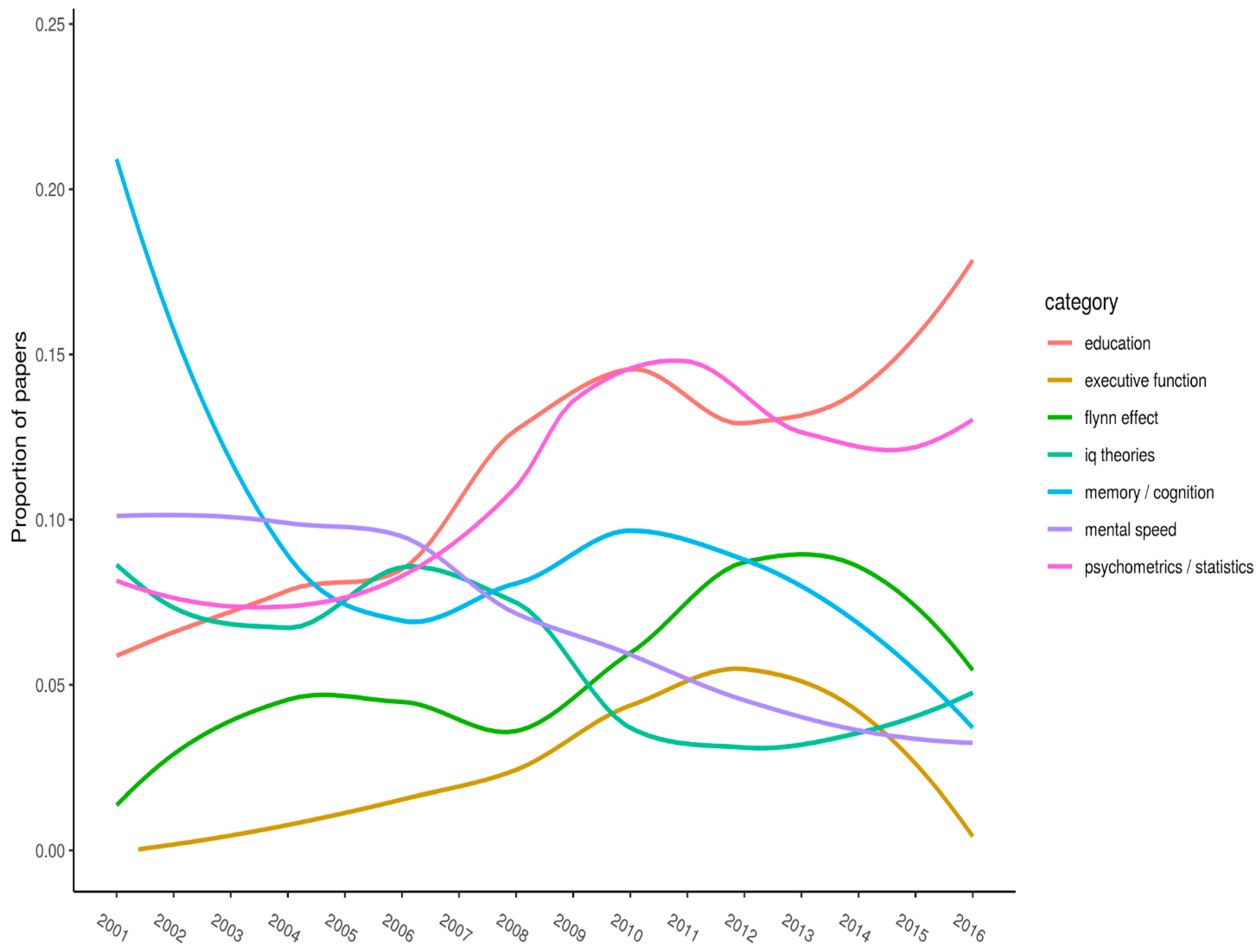
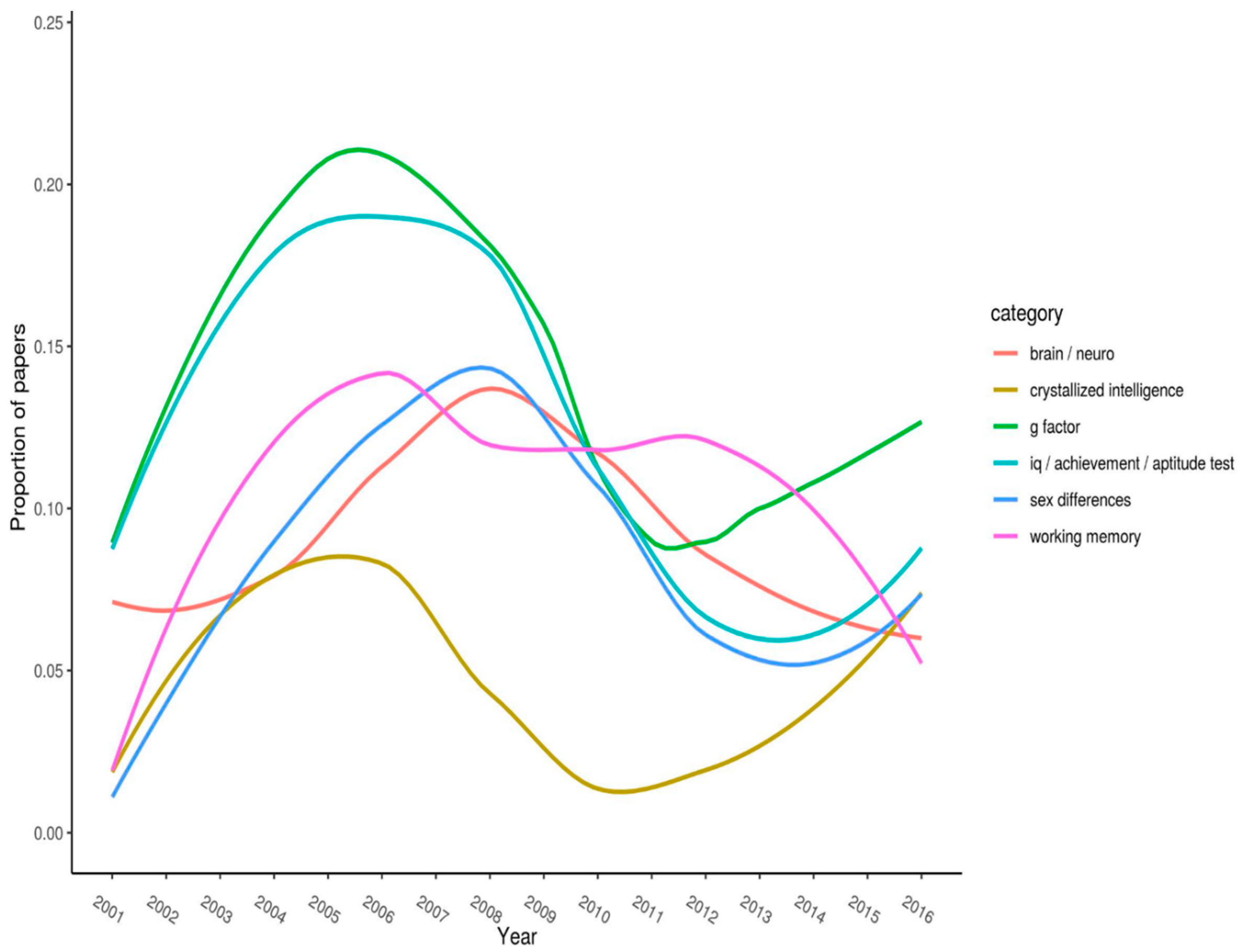
Figure 3 (split into three panels illustrating flat, parabolic, and increasing/decreasing trends, respectively) shows the top-20 keywords. Each keyword has
n > 50 citations overall. The year of publication is plotted on the x-axis, and the proportion of articles (published in the journal that year) with the specified keyword is plotted on the y-axis.
Note the timespan for where curves peak on the y-axis. Peaks represent when keywords received (proportionately, compared with all other articles published that year) their most amount of research attention. For example, “g-factor” peaked between 2004 and 2008, after which it steadily declined (it has, however, recovered somewhat over the last few of years).
Figure 1 displays keywords that appear to show little trend. These tend to have relatively low frequencies. This set includes “attention”, “EQ”, “factor analysis”, “fluid intelligence”, “modeling”, “reasoning”, “and spatial ability”.
Figure 2 shows keywords that appear to exhibit a marked nonlinear relation. Notably, between about 2004 and 2008, “g factor” and “IQ/achievement/ability tests” peaked. Likewise, around years 2007–2010, “brain/neuro” and “sex differences” hit their peaks. They thereafter trended downward. Finally, “crystallized intelligence” showed a strong drop off between 2009 and 2011 with a recovery over the last five years.
Figure 3 shows keywords that exhibit somewhat linear trends. “Education” is currently showing a strong trend upward, as is the “Flynn effect”, except for in the most recent years. Conversely, “memory and cognition” is showing a downward trend, as is “mental speed” and possibly “IQ theories”. Additionally, “psychometrics/statistics” has somewhat increased. This is a hodgepodge category, so little can be made of this trend. We included “executive function” in
Figure 3 as well, since it was increasing until just recently.
4. Discussion
For several reasons, we decided to conduct bibliometric analyses on keywords for articles (2000–2016) published in the journal Intelligence. First, we were interested in which keywords were most often employed by authors publishing articles in this journal. Next, we wondered if certain keywords were associated with greater or fewer citations for the papers that listed them. Lastly, we sought to identify trending keywords—ones that had increased or decreased in usage over the 17-year span where the journal started featuring them.
Summarizing, the five-most frequently listed keywords (
Table 1; “intelligence” excluded) were “g factor”, “psychometrics/statistics”, “education”, “IQ/achievement/aptitude tests”, and “race/ethnicity”. These keywords accounted for 574 of the 2161 (27%) total keyword instances in
Table 1.
Regarding WOS citations for articles by keywords, those with the highest means overall were “spatial ability”, “factor analysis”, “executive function”, “attention”, and “IQ theories”. Together, articles using these keywords averaged 47.1 citations overall. This is in contrast to a median citation rate of ten (for all articles in the journal), reported by both Wicherts [
10], and Pesta [
11]. However, we found it counter intuitive that the top-five most frequently listed keywords were all different from the top-five keywords with the highest mean citation values. We tentatively conclude there is a low correlation between a keyword’s frequency of use, and how many citations it will receive on average from the papers that list it.
But what could explain the discrepancy? A reviewer suggested a plausible scenario: An article using a low frequency keyword will tend to be one of only very few addressing the respective research question. Therefore, if others conduct research in this area, it is more likely that they will cite the article in their own work. Thus, this article might be cited relatively frequently despite the keyword being used infrequently overall. In contrast, an article using a very frequent keyword will probably be only one among many others that could be cited. Therefore, the article might have a relatively lower probability of being cited by newer papers in the area.
Our last analyses was an attempt to identify trends across time for the most frequently listed keywords in the article set. We visually displayed these trends in
Figure 1,
Figure 2 and
Figure 3. As might be expected, no keyword’s frequency increased (or decreased) monotonically across the years. Instead, all trends were curvilinear. Examples of keywords with notable increases in frequency across recent years included “crystallized intelligence” and “education”. Those with notable decreases were “brain/neuro” and “executive function”.
Regarding study limitations, perhaps the largest is that we had no other, similar journal’s keyword data to serve as a reference point or control group. We did, however, compare our findings with those in [
10,
11] where appropriate. Next, coding the keywords was not completely objective. Many authors used synonym keywords across articles, and/or redundant keywords within articles.
2 We attenuated this problem by having multiple raters rank and discuss each of the codings.
Nonetheless, we were forced to use keyword categories, versus each specific keyword itself, due to the high frequency of synonym keywords across papers. Perhaps the journal should implement a more standardized approach to author keyword selection. One way this could be achieved is for the journal to present a drop down list of keywords that authors select from when submitting their manuscripts. This approach could provide benefits beyond just the facilitation of bibliometric analyses. For example, standardizing keywords would help readers more efficiently find articles they are interested in.





{kind=link}
{kind=link}
{kind=link}