Predicting the Performance of Students Using Deep Ensemble Learning


Abstract
1. Introduction
- Introducing an innovative method for predicting students’ academic performance using deep ensemble learning.
- Enhancing precision in forecasting students’ academic performance through the amalgamation of deep learning models, optimization, and reinforcement learning.
- Proposing a comprehensive and in-depth approach to predicting students’ academic performance across various domains by combining diverse learning models with different configurations.
2. Related Work
3. Research Method
3.1. Data Collection
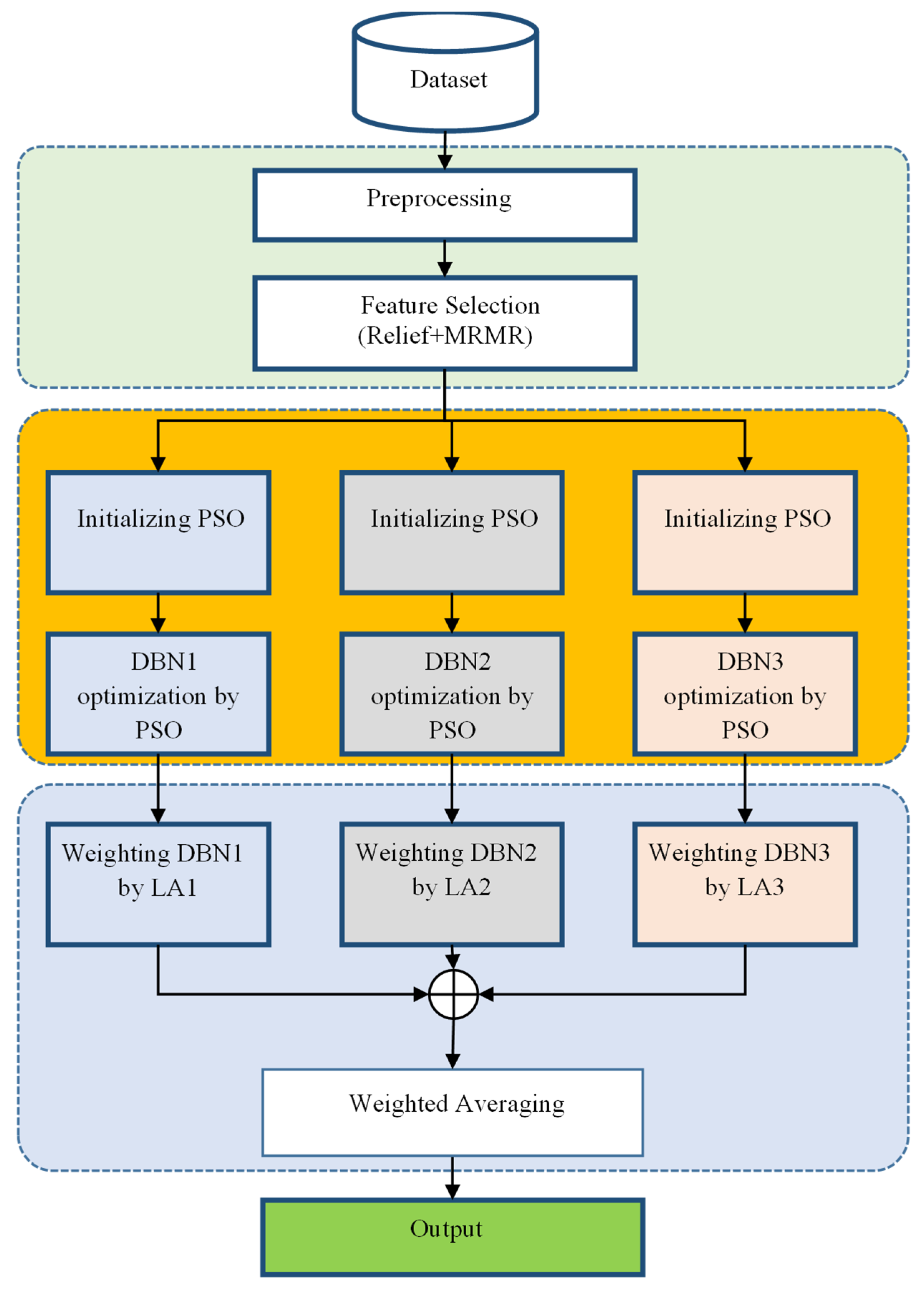
3.2. Proposed Method
- Data preparation and feature selection;
- Constructing an ensemble model of the DBN;
- Weighting learning components in the ensemble system based on reinforcement learning and prediction.
3.2.1. Preprocessing and Feature Selection
3.2.2. Constructing an Ensemble Model of DBNs
- First of all, the number of hidden layers in each DBN should be at least equal to 1 and not more than 3. To this end, the first segment of the solution vector consists of 1 to 3 elements, and the number in each of these elements of the first part of the solution vector indicates the number of neurons required for each layer.
- As a second point, every hidden layer in the DBN has a number of neurons ranging from 2 to 10. Henceforth, every element in the solution vector component number belongs to the natural numbers in the range of 2 to 10.
3.2.3. Weighting Learning Components in the Ensemble System Based on Reinforcement Learning
- The set of LAs in the proposed system is able to select weight values that have increased detection accuracy and can help the system move toward global optimization if the accuracy in the current iteration for the currently determined weights (environment response) is higher than the highest accuracy in previous iterations. The set of activities that the LA chose for this cycle are thus regarded as the best options. In this instance, each LA uses the connection (current action i is examined) to enhance the likelihood of choosing the final action (Farahani et al. 2022):
- If the accuracy in the current iteration is less than the highest accuracy in previous iterations, then the response generated in the recent cycle (and the weights selected by the LA) are considered to be non-optimal choices. In this case, each LA reduces the probability of selecting the last action using Equation (4) (Farahani et al. 2022).where the reward and punishment coefficients, respectively, are represented by the parameters a and b. These two parameters are assumed to be equal to 0.5 in the suggested procedure. Furthermore, K is the number of chosen actions in each automaton, and k is the discrete time index (the number of times probabilities are adjusted). The probability vector of every LA is updated after the application of the aforementioned criteria to each of the actions of the LA (individually for every DBN model). The procedures of selection, the assessment of the environment’s reaction, and updating the probability vector are carried out again from the first step once the LA models have been updated. This procedure keeps going until the algorithm’s iteration count hits the predefined threshold T. Consequently, the following are the phases of the suggested strategy for weighting DBN models using the reinforcement learning technique:
- Assign an LA to each DBN model in the ensemble system and set its initial weight to 1.
- For each LA, carry out the following steps:
- Define the automaton actions as , each of which corresponds to the states of updating the current weight of the DBN model.
- Set the automaton probabilities as P = {1/7, 1/7, 1/7, 1/7, 1/7, 1/7, 1/7}.
- Calculate the accuracy of the ensemble system based on unweighted averaging and store it in X (in this case, the weight of all DBN models is considered to be 1).
- Set the iteration counter to 1.
- For each LA, select the action with the highest probability in the P model of the automaton and update the weight value of the DBN model corresponding to it.
- Based on the weight values determined for each DBN model, perform weighted averaging and store the accuracy obtained in Y.
- If , then carry out the following steps:
- Update the highest accuracy obtained to X = Y.
- Store the weight values determined in the current iteration in W*.
- Reward the actions selected by the LA in the current iteration using Equation (3).
- Otherwise, if , then carry out the following steps:
- Penalize the actions selected by the LA in the current iteration using Equation (4).
- Increase the iteration counter by one (iteration++).
- If iteration < T, then go to step 5; otherwise, go to the next step.
- Return the weight values stored in W* as the optimal weights of the DBN models of the ensemble system.
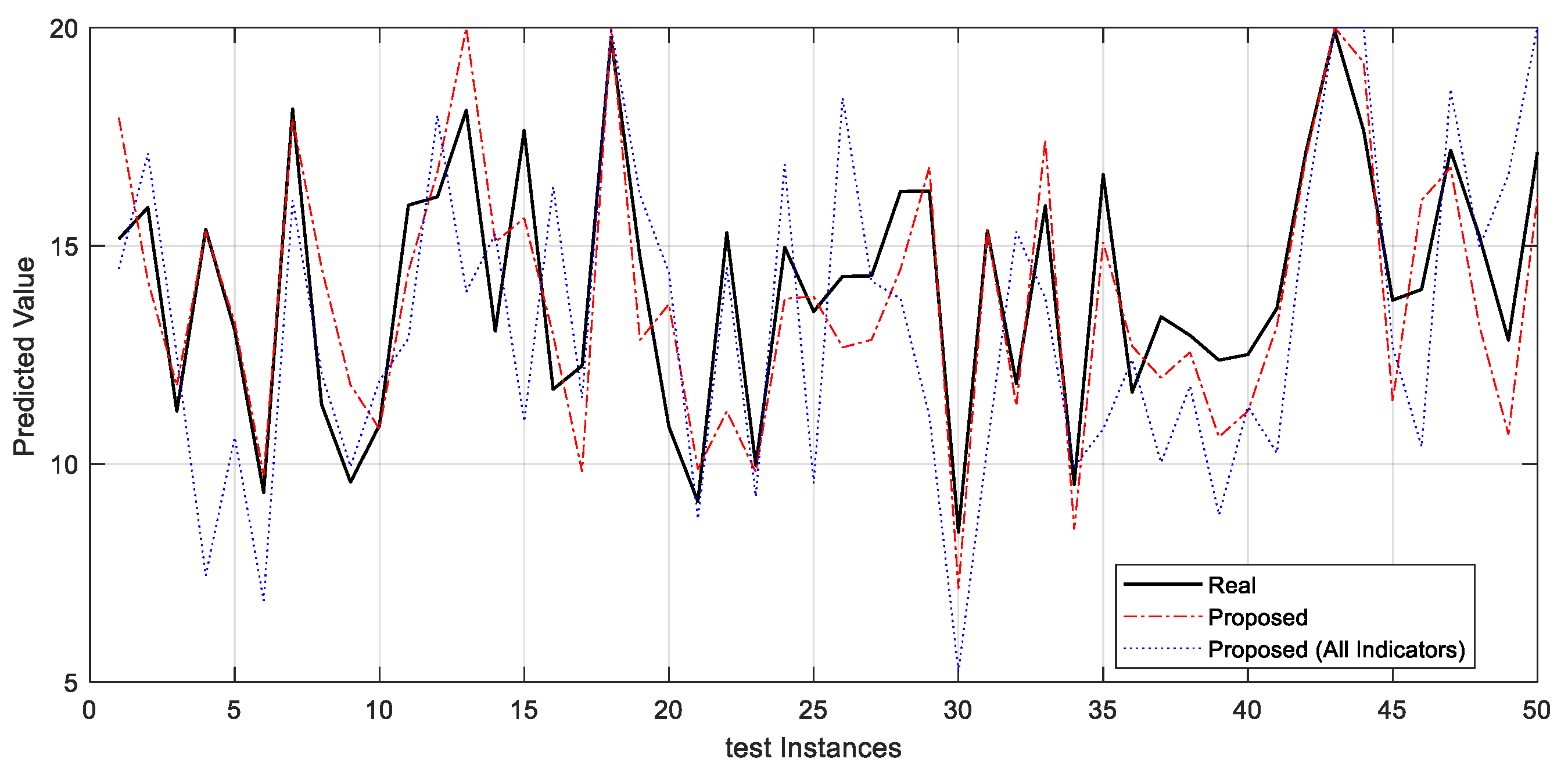
4. Research Findings
5. Discussion, Limitations, and Future Directions
5.1. Performance of the Proposed Model
5.2. Implications for Educational Practice
5.3. Limitations and Future Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Agnafors, Sara, Mimmi Barmark, and Gunilla Sydsjö. 2021. Mental health and academic performance: A study on selection and causation effects from childhood to early adulthood. Social Psychiatry and Psychiatric Epidemiology 56: 857–66. [Google Scholar] [CrossRef]
- Ahmed, Shams Forruque, M. Sakib Bin Alam, Maruf Hassan, Mahtabin Rodela Rozbu, Taoseef Ishtiak, Nazifa Rafa, M. Mofijur, A. B. M. Shawkat Ali, and Amir H. Gandomi. 2023. Deep learning modelling techniques: Current progress, applications, advantages, and challenges. Artificial Intelligence Review 56: 13521–617. [Google Scholar] [CrossRef]
- Alyahyan, Eyman, and Dilek Düştegör. 2020. Predicting academic success in higher education: Literature review and best practices. International Journal of Educational Technology in Higher Education 17: 3. [Google Scholar] [CrossRef]
- Antonopoulou, Marina, Maria Mantzorou, Aspasia Serdari, Konstantinos Bonotis, Giorgos Vasios, Eleni Pavlidou, Christina Trifonos, Konstantinos Vadikolias, Dimitris Petridis, and Constantinos Giaginis. 2020. Evaluating Mediterranean diet adherence in university student populations: Does this dietary pattern affect students’ academic performance and mental health? The International Journal of Health Planning and Management 35: 5–21. [Google Scholar] [CrossRef] [PubMed]
- Asaad, Renas Rajab, and Rasan Ismael Ali. 2019. Back Propagation Neural Network (BPNN) and sigmoid activation function in multi-layer networks. Academic Journal of Nawroz University 8: 1–6. [Google Scholar] [CrossRef]
- Asadollahfardi, Gholamreza. 2015. Artificial neural network. In Water Quality Management: Assessment and Interpretation. Berlin and Heidelberg: Springer, pp. 77–91. [Google Scholar]
- Asselman, Amal, Mohamed Khaldi, and Souhaib Aammou. 2023. Enhancing the prediction of student performance based on the machine learning XGBoost algorithm. Interactive Learning Environments 31: 3360–79. [Google Scholar] [CrossRef]
- Baker, Ryan S. D., Albert T. Corbett, and Vincent Aleven. 2008. More accurate student modeling through contextual estimation of slip and guess probabilities in bayesian knowledge tracing. Paper presented at Intelligent Tutoring Systems: 9th International Conference, ITS 2008, Montreal, QC, Canada, June 23–27; Proceedings 9. Berlin and Heidelberg: Springer, pp. 406–15. [Google Scholar]
- Beckham, Nicholas Robert, Limas Jaya Akeh, Giodio Nathanael Pratama Mitaart, and Jurike V. Moniaga. 2023. Determining factors that affect student performance using various machine learning methods. Procedia Computer Science 216: 597–603. [Google Scholar] [CrossRef]
- Bendangnuksung, Prabu P. 2018. Students’ performance prediction using deep neural network. International Journal of Applied Engineering Research 13: 1171–76. [Google Scholar]
- Bruffaerts, Ronny, Philippe Mortier, Glenn Kiekens, Randy P. Auerbach, Pim Cuijpers, Koen Demyttenaere, Jennifer G. Green, Matthew K. Nock, and Ronald C. Kessler. 2018. Mental health problems in college freshmen: Prevalence and academic functioning. Journal of Affective Disorders 225: 97–103. [Google Scholar] [CrossRef]
- Corbett, Albert T., and John R. Anderson. 1994. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Modeling and User-Adapted Interaction 4: 253–78. [Google Scholar] [CrossRef]
- Divyabharathi, Y., and P. Someswari. 2018. A Framework for Student Academic Performance Using Naïve Bayes Classification Technique. JAET 6: 1–4. [Google Scholar]
- Farahani, Mansoureh Ghiasabadi, Javad Akbari Torkestani, and Mohsen Rahmani. 2022. Adaptive personalized recommender system using learning automata and items clustering. Information Systems 106: 101978. [Google Scholar] [CrossRef]
- Foli, Sophia Korkor. 2018. Backward Elimination Algorithm for High Dimensional Variable Screening. Master’s thesis, The University of Texas at El Paso, El Paso, TX, USA. [Google Scholar]
- Francis, Bindhia K., and Suvanam Sasidhar Babu. 2019. Predicting academic performance of students using a hybrid data mining approach. Journal of Medical Systems 43: 162. [Google Scholar] [CrossRef]
- Gad, Ahmed G. 2022. Particle swarm optimization algorithm and its applications: A systematic review. Archives of Computational Methods in Engineering 29: 2531–61. [Google Scholar] [CrossRef]
- Gamao, Ariel O., and Bobby D. Gerardo. 2019. Prediction-based model for student dropouts using modified mutated firefly algorithm. International Journal of Advanced Trends in Computer Science and Engineering 8: 3461–69. [Google Scholar] [CrossRef]
- Gil, Jay S., Allemar Jhone P. Delima, and Ramcis N. Vilchez. 2020. Predicting students’ dropout indicators in public school using data mining approaches. International Journal of Advanced Trends in Computer Science and Engineering 9: 774–78. [Google Scholar] [CrossRef]
- Gimenez, Gregorio, Ángel Martín-Oro, and Jaime Sanaú. 2018. The effect of districts’ social development on student performance. Studies in Educational Evaluation 58: 80–96. [Google Scholar] [CrossRef]
- Gong, Yue, Joseph E. Beck, and Neil T. Heffernan. 2011. How to construct more accurate student models: Comparing and optimizing knowledge tracing and performance factor analysis. International Journal of Artificial Intelligence in Education 21: 27–46. [Google Scholar]
- González-Brenes, Jose, Yun Huang, and Peter Brusilovsky. 2014. General features in knowledge tracing to model multiple subskills, temporal item response theory, and expert knowledge. Paper presented at The 7th International Conference on Educational Data Mining, London, UK, July 4–7; Pittsburgh: University of Pittsburgh, pp. 84–91. [Google Scholar]
- Guan, Li. 2023. Evaluating teaching quality in colleges using combination of artificial neural networks (ANNs) and black hole optimization (BHO). Heliyon 9: e20687. [Google Scholar] [CrossRef] [PubMed]
- Gunn, Heather J., Panteha Hayati Rezvan, M. Isabel Fernández, and W. Scott Comulada. 2023. How to apply variable selection machine learning algorithms with multiply imputed data: A missing discussion. Psychological Methods 28: 452. [Google Scholar] [CrossRef]
- Gütter, Jonas, Anna Kruspe, Xiao Xiang Zhu, and Julia Niebling. 2022. Impact of training set size on the ability of deep neural networks to deal with omission noise. Frontiers in Remote Sensing 3: 932431. [Google Scholar] [CrossRef]
- Hasan, Raza, Sellappan Palaniappan, Abdul Rafiez Abdul Raziff, Salman Mahmood, and Kamal Uddin Sarker. 2018. Student academic performance prediction by using decision tree algorithm. Paper presented at 2018 4th International Conference on Computer and Information Sciences (ICCOINS), Kuala Lumpur, Malaysia, August 13–14; pp. 1–5. [Google Scholar]
- Hasan, Raza, Sellappan Palaniappan, Salman Mahmood, Ali Abbas, Kamal Uddin Sarker, and Mian Usman Sattar. 2020. Predicting student performance in higher educational institutions using video learning analytics and data mining techniques. Applied Sciences 10: 3894. [Google Scholar] [CrossRef]
- Hernández, Juan Antonio Caballero, Antonio B. Alberico, Manuel Palomo Duarte, Pablo Dellatorre, Antonio J. Reinoso, and Juan Manuel D. Beardo. 2020. Teamwork assessment in collaborative projects through process mining techniques. The International Journal of Engineering Education 36: 470–82. [Google Scholar]
- Jo, Insik, Sangbum Lee, and Sejong Oh. 2019. Improved measures of redundancy and relevance for mRMR feature selection. Computers 8: 42. [Google Scholar] [CrossRef]
- Lau, Erwin T., Licheng Sun, and Qingping Yang. 2019. Modelling, prediction and classification of student academic performance using artificial neural networks. SN Applied Sciences 1: 982. [Google Scholar] [CrossRef]
- Mengash, Hanan A. 2020. Using data mining techniques to predict student performance to support decision making in university admission systems. IEEE Access 8: 55462–70. [Google Scholar] [CrossRef]
- Minn, Sein, Yi Yu, Michel C. Desmarais, Feida Zhu, and Jill-Jenn Vie. 2018. Deep knowledge tracing and dynamic student classification for knowledge tracing. Paper presented at 2018 IEEE International Conference on Data Mining (ICDM), Singapore, November 17–20; pp. 1182–87. [Google Scholar]
- Mustapha, Ishamuddin, N. T. Van, Masoumeh Shahverdi, Muhammad Imran Qureshi, and Nohman Khan. 2021. Effectiveness of digital technology in education during COVID-19 pandemic. A bibliometric analysis. International Journal of Interactive Mobile Technologies (iJIM) 15: 136–54. [Google Scholar] [CrossRef]
- Nijman, Swj W. J., A. M. Leeuwenberg, I. Beekers, I. Verkouter, J. J. L. Jacobs, M. L. Bots, F. W. Asselbergs, Kgm G. M. Moons, and Tpa P. A. Debray. 2022. Missing data is poorly handled and reported in prediction model studies using machine learning: A literature review. Journal of Clinical Epidemiology 142: 218–29. [Google Scholar] [CrossRef] [PubMed]
- Pallathadka, Harikumar, Alex Wenda, Edwin Ramirez-Asís, Maximiliano Asís-López, Judith Flores-Albornoz, and Khongdet Phasinam. 2023. Classification and prediction of student performance data using various machine learning algorithms. Materials today: Proceedings 80: 3782–85. [Google Scholar] [CrossRef]
- Palomo-Duarte, Manuel, Juan Manuel Dodero, Inmaculada Medina-Bulo, Emilio J. Rodríguez-Posada, and Iván Ruiz-Rube. 2014. Assessment of collaborative learning experiences by graphical analysis of wiki contributions. Interactive Learning Environments 22: 444–66. [Google Scholar] [CrossRef]
- Pelánek, Radek. 2017. Bayesian knowledge tracing, logistic models, and beyond: An overview of learner modeling techniques. User Modeling and User-Adapted Interaction 27: 313–50. [Google Scholar] [CrossRef]
- Pisner, Derek A., and David M. Schnyer. 2020. Support vector machine. In Machine Learning. Cambridge: Academic Press, pp. 101–21. [Google Scholar]
- Priyanka, and Dharmender Kumar. 2020. Decision tree classifier: A detailed survey. International Journal of Information and Decision Sciences 12: 246–69. [Google Scholar] [CrossRef]
- Raihana, Z., and A. M. Farah Nabilah. 2018. Classification of students based on quality of life and academic performance by using support vector machine. Journal of Academia 6: 45–52. [Google Scholar]
- Ramaphosa, Khokhoni Innocentia Mpho, Tranos Zuva, and Raoul Kwuimi. 2018. Educational data mining to improve learner performance in Gauteng primary schools. Paper presented at 2018 International Conference on Advances in Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, August 6–7; pp. 1–6. [Google Scholar]
- Romero, Cristóbal, and Sebastián Ventura. 2020. Educational data mining and learning analytics: An updated survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 10: e1355. [Google Scholar] [CrossRef]
- Sapare, Naveen S., and Sahana M. Beelagi. 2021. Comparison study of Regression Models for the prediction of post-Graduation admissions using Machine Learning Techniques. Paper presented at 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, January 28–29; pp. 822–28. [Google Scholar]
- Sarwat, Samina, Naeem Ullah, Saima Sadiq, Robina Saleem, Muhammad Umer, Ala’ Abdulmajid Eshmawi, Abdullah Mohamed, and Imran Ashraf. 2022. Predicting students’ academic performance with conditional generative adversarial network and deep SVM. Sensors 22: 4834. [Google Scholar] [CrossRef] [PubMed]
- Singh, Randhir, and Saurabh Pal. 2020. Application of machine LearningAlgorithms to predict students performance. International Journal of Advanced Science andTechnology 29: 7249–61. [Google Scholar]
- Sutton, Richard S., and Andrew G. Barto. 2018. Reinforcement Learning: An Introduction. Cambridge: MIT Press. [Google Scholar]
- Tsiakmaki, Maria, Georgios Kostopoulos, Sotiris Kotsiantis, and Omiros Ragos. 2020. Transfer learning from deep neural networks for predicting student performance. Applied Sciences 10: 2145. [Google Scholar] [CrossRef]
- Urbanowicz, Ryan J., Melissa Meeker, William La Cava, Randal S. Olson, and Jason H. Moore. 2018. Relief-based feature selection: Introduction and review. Journal of Biomedical Informatics 85: 189–203. [Google Scholar] [CrossRef]
- Waheed, Hajra, Saeed-Ul Hassan, Naif Radi Aljohani, Julie Hardman, Salem Alelyani, and Raheel Nawaz. 2020. Predicting academic performance of students from VLE big data using deep learning models. Computers in Human behavior 104: 106189. [Google Scholar] [CrossRef]
- Wickramasinghe, Indika, and Harsha Kalutarage. 2021. Naive Bayes: Applications, variations and vulnerabilities: A review of literature with code snippets for implementation. Soft Computing 25: 2277–93. [Google Scholar] [CrossRef]
- Xiong, Xiaolu, Siyuan Zhao, Eric G. Van Inwegen, and Joseph E. Beck. 2016. Going deeper with deep knowledge tracing. Paper presented at the International Conference on Educational Data Mining (EDM), Raleigh, NC, USA, June 29–July 2. [Google Scholar]
- Yu, Hao, and Bogdan M. Wilamowski. 2018. Levenberg–marquardt training. In Intelligent Systems. Boca Raton: CRC Press, pp. 12-1–12-15. [Google Scholar]
- Zorić, Alisa Bilal. 2019. Predicting Students’ Success Using Neural Network. Paper presented at 2019 ENTRENOVA Conference Proceedings, Rovinj, Croatia, December 10. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Title | Type |
|---|---|---|
| I1 | Place of Study | Nominal (Discrete) |
| I2 | Gender | Nominal (Discrete) |
| I3 | Age | Continuous (Numeric) |
| I4 | Residence Status | Nominal (Discrete) |
| I5 | Number of Family Members | Discrete (Numeric) |
| I6 | Parents’ Marital Status | Nominal (Discrete) |
| I7 | Mother’s Education Level | Ordinal (Ranked) |
| I8 | Father’s Education Level | Ordinal (Ranked) |
| I9 | Mother’s Employment Status | Nominal (Discrete) |
| I10 | Father’s Employment Status | Nominal (Discrete) |
| I11 | Reason for Choosing Place of Study | Nominal (Discrete) |
| I12 | Legal Guardian | Nominal (Discrete) |
| I13 | Distance from Home to School | Continuous (Numeric) |
| I14 | Weekly Study Time | Continuous (Numeric) |
| I15 | Average Grades in Previous Term | Continuous (Numeric) |
| I16 | Scholarship Status | Nominal (Discrete) |
| I17 | Parental Financial Support for Education | Nominal (Discrete) |
| I18 | Use of Extracurricular Classes | Nominal (Discrete) |
| I19 | Participation in Extracurricular Activities | Nominal (Discrete) |
| I20 | Participation in Scientific Competitions | Nominal (Discrete) |
| I21 | Desire to Continue Education | Nominal (Discrete) |
| I22 | Internet Access at Residence | Nominal (Discrete) |
| I23 | Emotional Relationship Status | Nominal (Discrete) |
| I24 | Quality of Relationship with Family Members | Ordinal (Ranked) |
| I25 | Amount of Free Time After Classes | Continuous (Numeric) |
| I26 | Interaction with Classmates Outside of School | Nominal (Discrete) |
| I27 | Alcohol Consumption During Week | Nominal (Discrete) |
| I28 | Alcohol Consumption During Weekend | Nominal (Discrete) |
| I29 | Current Health Status | Ordinal (Ranked) |
| I30 | Number of Absences in Class | Continuous (Numeric) |
| - | Student’s Final Average Grades | Continuous (Numeric) |
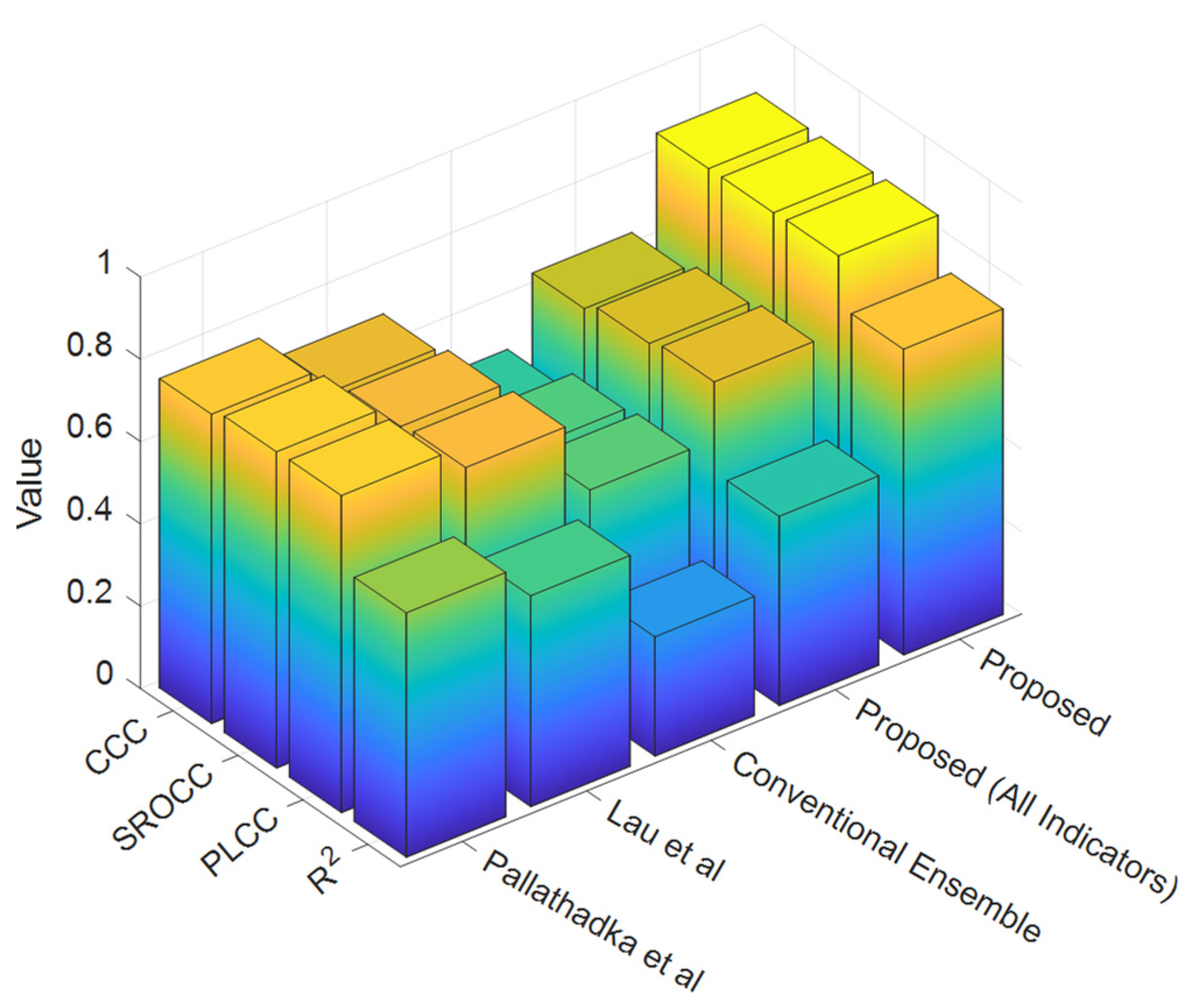
| Methods | RMSE | MAPE | R2 | PLCC | SROCC | CCC |
|---|---|---|---|---|---|---|
| Proposed | 1.6562 | 9.7532 | 0.7430 | 0.8619 | 0.8582 | 0.8571 |
| Proposed (All Indicators) | 3.0489 | 18.5643 | 0.4597 | 0.6780 | 0.6634 | 0.6397 |
| Conventional Ensemble | 4.0467 | 24.8950 | 0.2897 | 0.5383 | 0.5279 | 0.4788 |
| Lau et al. (2019) | 2.7256 | 16.4662 | 0.5122 | 0.7157 | 0.7074 | 0.6878 |
| Pallathadka et al. (2023) | 2.3228 | 13.9115 | 0.5936 | 0.7704 | 0.7685 | 0.7518 |
| Beckham et al. (2023) | 3.0828 | 18.7673 | 0.4355 | 0.6599 | 0.6485 | 0.6245 |
| Linear Regression | 6.7911 | 41.0622 | 0.0447 | 0.2115 | 0.2113 | 0.1513 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, B.; Li, S.; Zhao, C. Predicting the Performance of Students Using Deep Ensemble Learning. J. Intell. 2024, 12, 124. https://doi.org/10.3390/jintelligence12120124
Tang B, Li S, Zhao C. Predicting the Performance of Students Using Deep Ensemble Learning. Journal of Intelligence. 2024; 12(12):124. https://doi.org/10.3390/jintelligence12120124
Chicago/Turabian StyleTang, Bo, Senlin Li, and Changhua Zhao. 2024. "Predicting the Performance of Students Using Deep Ensemble Learning" Journal of Intelligence 12, no. 12: 124. https://doi.org/10.3390/jintelligence12120124
APA StyleTang, B., Li, S., & Zhao, C. (2024). Predicting the Performance of Students Using Deep Ensemble Learning. Journal of Intelligence, 12(12), 124. https://doi.org/10.3390/jintelligence12120124