
Hybrid Mamdani Fuzzy Rules and Convolutional Neural Networks for Analysis and Identification of Animal Images



Abstract
1. Introduction
- (1)
- collecting the data,
- (2)
- accepting the command parameters,
- (3)
- defining the neural network model,
- (4)
- adjusting the model via training.
2. Literature Review
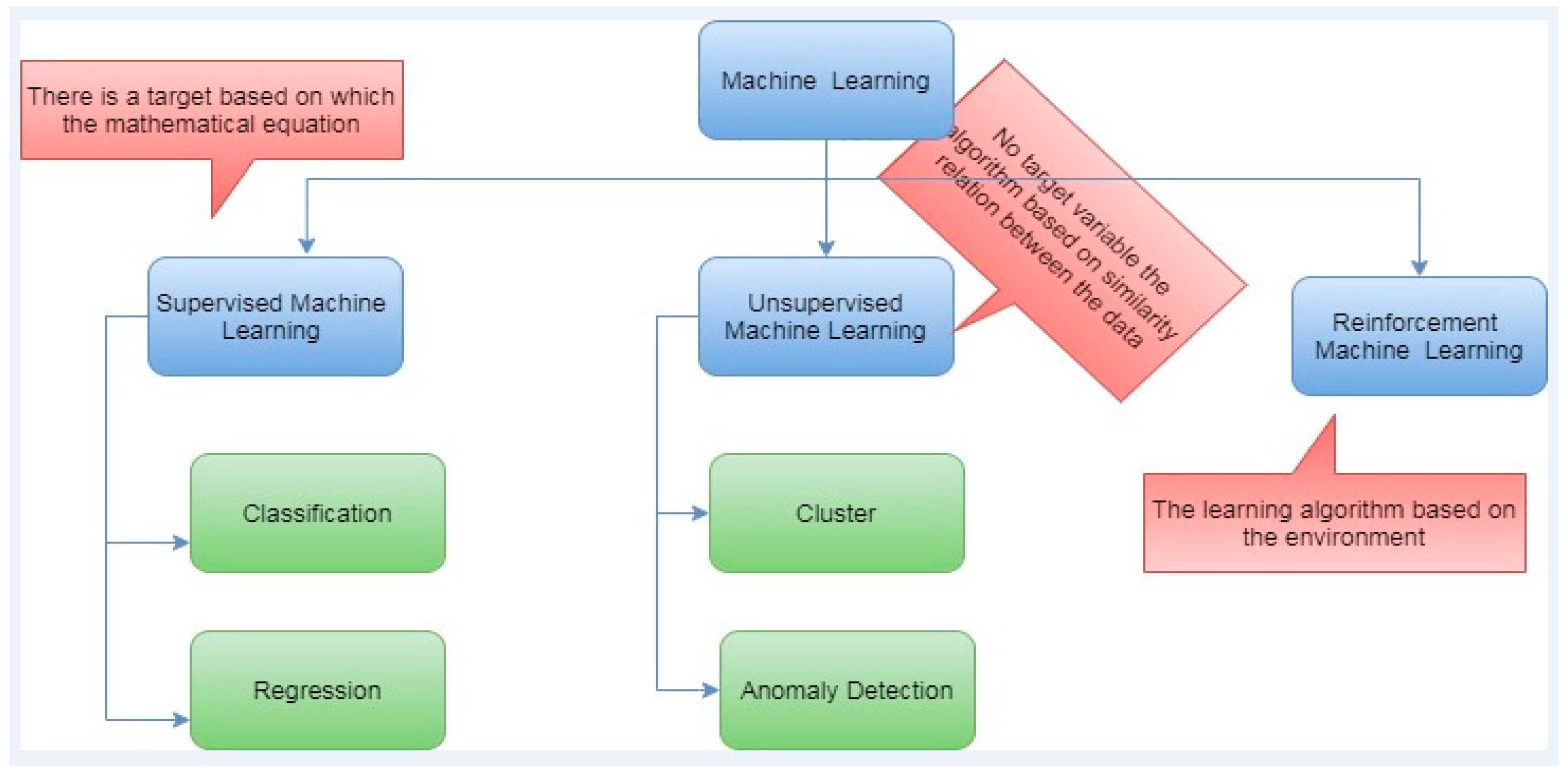
3. Materials and Methods
3.1. Methods
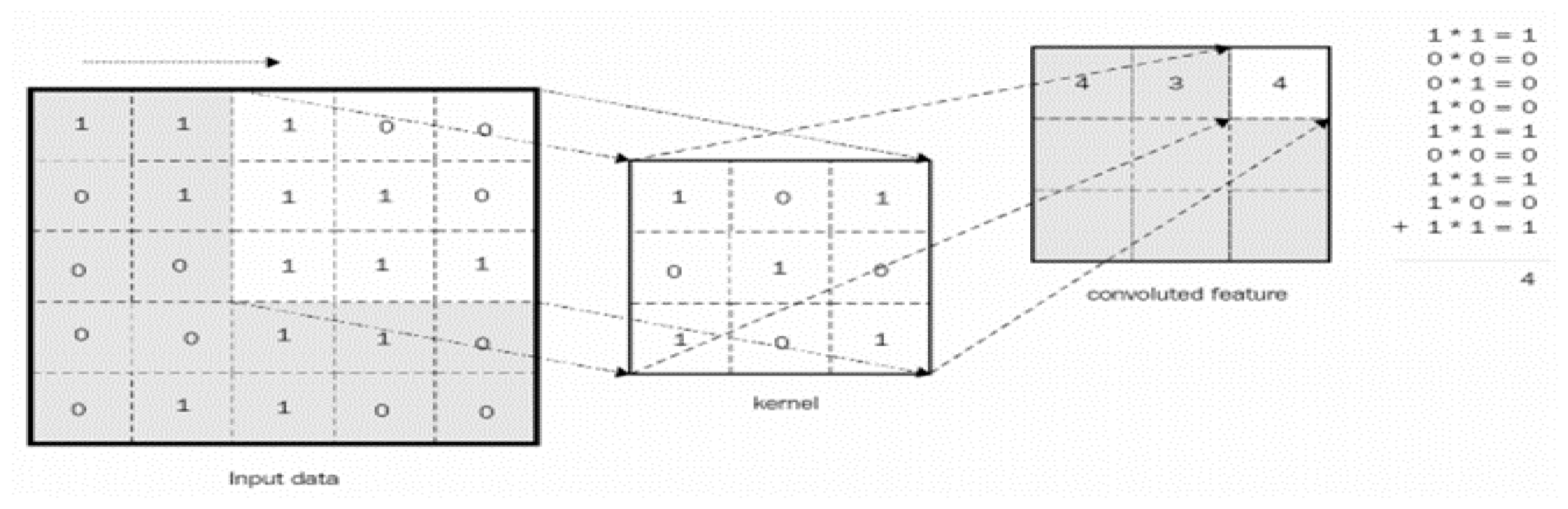
- The first stage is a sliding mask features and image matching patch,
- The second stage multiplies each input image pixel by the mask feature pixel,
- The third stage is summing all of them up and calculating the average of the results, and the final step is filling the results in a new matrix of features [26].
3.2. Materials
4. Proposed Work
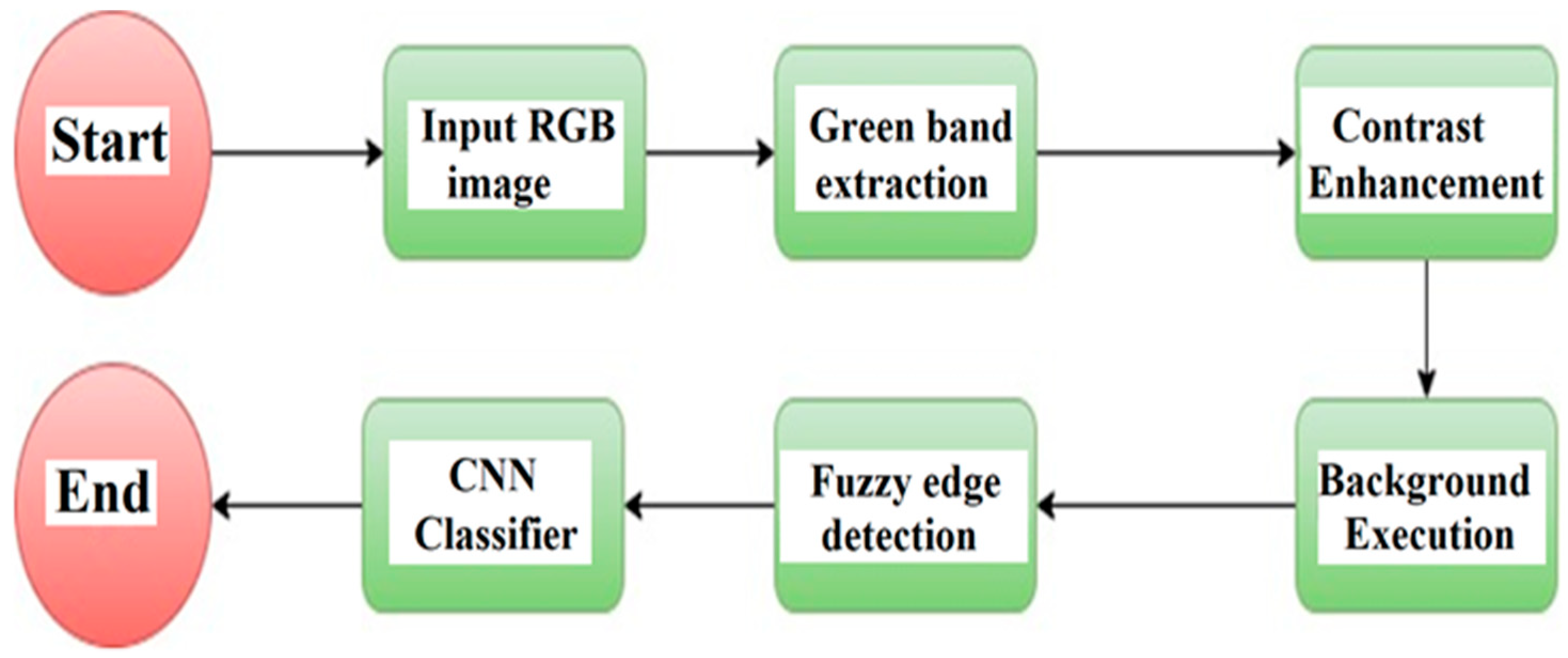
4.1. Mamdani Fuzzy Rules for Edge Detection
- Contrast Enhancing: Contrast Limited Adaptive Histogram Equalization (CLAHE) is very efficient, with tiny non-intersecting areas named tiles in images. For each such tile, histogram equalization is applied. In the end, neighboring tiles are gathered using bilinear interpolation to eliminate boundaries induced artificially [35].
- Excluding Background: Background fluctuations in image luminance are removed so that foreground objects can be easy to analyze. Median filtering used with a kernel of 25 * 25 sizes is employed for blurring the image and smoothing the foreground. The background image information is removed by the process of subtracting image contrast-enhanced [Icontrasted] from the median filtered image [fmedian] as in Equation (1):
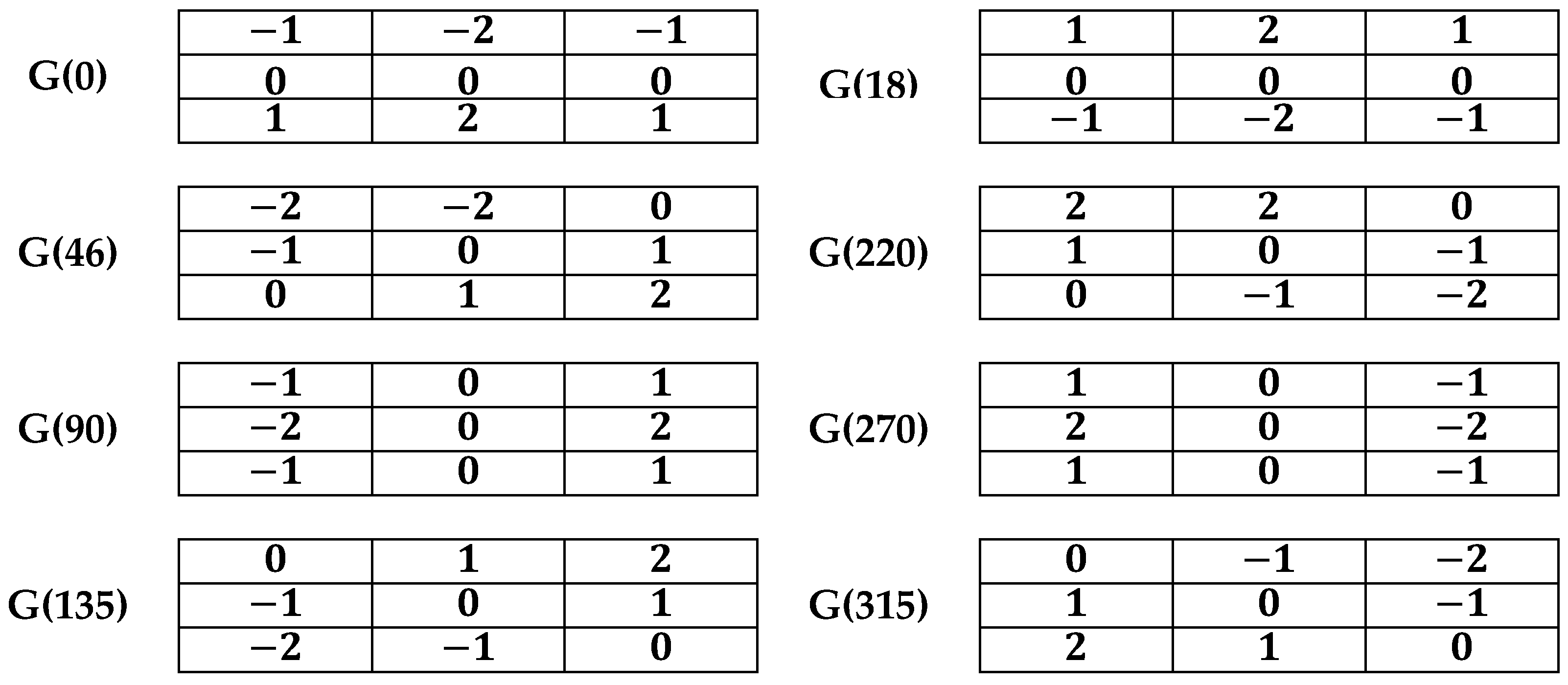
- Anti-diagonal Gradient Ik. In mathematics, an anti-diagonal matrix is a square matrix where all the entries are zero except those on the diagonal going from the lower-left corner to the upper-right corner (↗), known as the anti-diagonal.
- Diagonal Gradient Iz.
- Vertical Gradient Iy. Horizontal Gradient Ix.
- Performs Gaussian blurring with a 3 × 3 kernel for an input image.
- Divide the blurred image into a 3 × 3 pixel matrix.
4.2. Recognition of Moving Objects Using CNN
5. Experiments and Results
5.1. Edge Detection and Feature Extraction
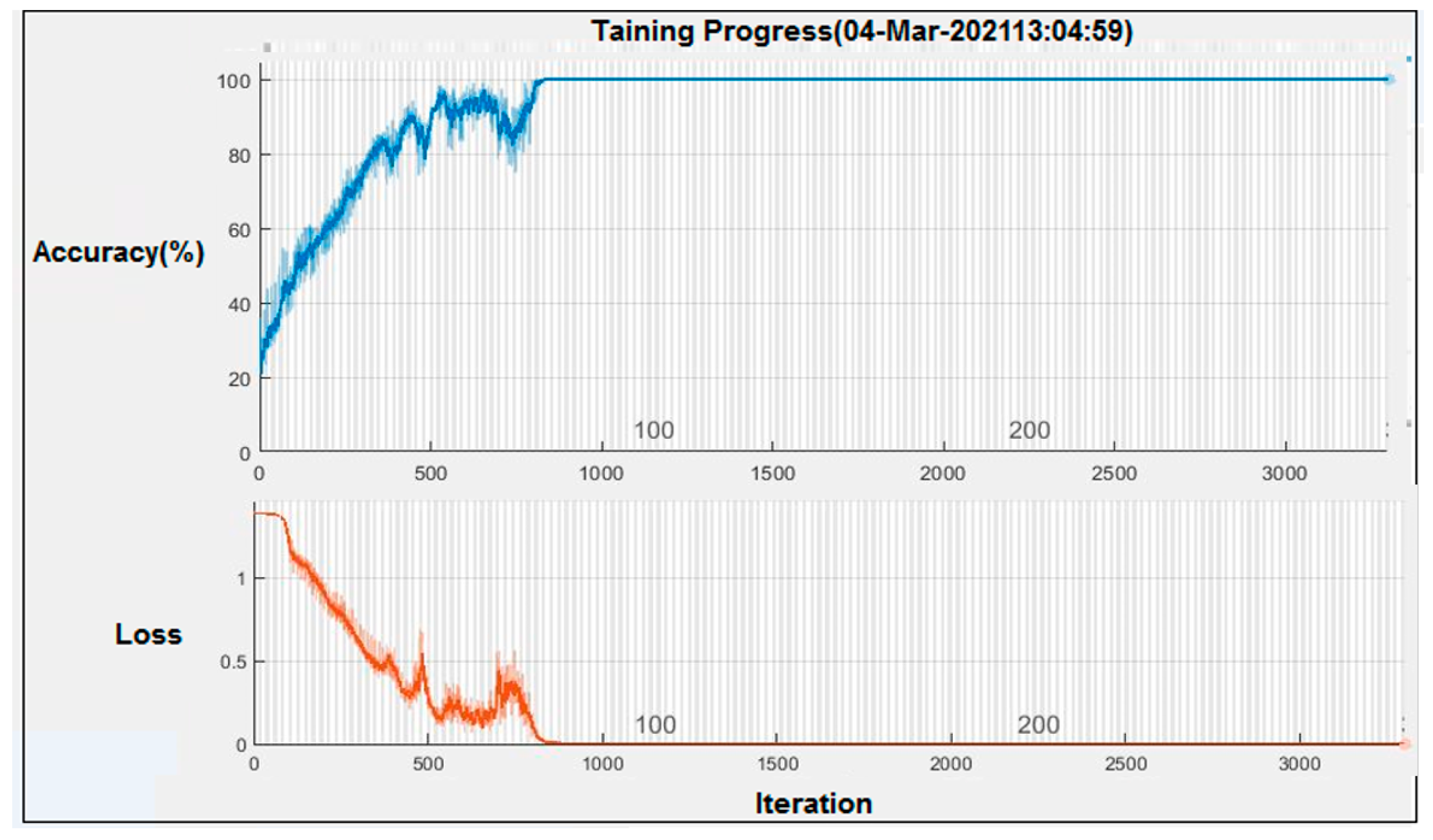
5.2. The Recognition of a Moving Object by CNN
5.3. Comparison of Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mark, E.; John, W. The pascal visual object classes challenge 2012 (voc2012) development kit. Pattern Anal. Stat. Model. Comput. Learn. Tech. Rep 2011, 8, 4–32. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Fogsgaard, K.K.; Røntved, C.M.; Sørensen, P.; Herskin, M.S. Sickness behavior in dairy cows during Escherichia coli mastitis. J. Dairy Sci. 2012, 95, 630–638. [Google Scholar] [CrossRef]
- Crispim-Junior, C.F.; Buso, V.; Avgerinakis, K.; Meditskos, G.; Briassouli, A.; Benois-Pineau, J.; Bremond, F. Semantic event fusion of different visual modality concepts for activity recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1598–1611. [Google Scholar] [CrossRef] [PubMed]
- Pirsiavash, H.; Ramanan, D. Detecting activities of daily living in first-person camera views. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Hasoon, F.N.; Yousif, J.H.; Hasson, N.N.; Ramli, A.R. Image Enhancement Using Nonlinear Filtering Based Neural Network. J. Comput. 2011, 3, 171–176. [Google Scholar]
- Chaabouni, S.; Benois-Pineau, J.; Hadar, O.; Amar, C.B. Deep learning for saliency prediction in natural video. arXiv 2016, arXiv:1604.08010. [Google Scholar]
- Parker, P.; Englehart, K.; Hudgins, B. Myoelectric signal processing for control of powered limb prostheses. J. Electromyogr. 2006, 16, 541–548. [Google Scholar] [CrossRef]
- Smith, L.H.; Hargrove, L.J.; Lock, B.A.; Kuiken, T.A.; Engineering, R. Determining the optimal window length for pattern recognition-based myoelectric control: Balancing the competing effects of classification error and controller delay. IEEE Trans. Neural Syst. 2010, 19, 186–192. [Google Scholar] [CrossRef] [PubMed]
- Al-Hatmi, M.O.; Yousif, J.H. A review of Image Enhancement Systems and a case study of Salt &pepper noise removing. Int. J. Comput. Appl. Sci. 2017, 2, 217–223. [Google Scholar]
- Guo, S.; Xu, P.; Miao, Q.; Shao, G.; Chapman, C.A.; Chen, X.; Sun, Y. Automatic identification of individual primates with deep learning techniques. Iscience 2020, 23, 101412. [Google Scholar] [CrossRef]
- Hou, J.; He, Y.; Yang, H.; Connor, T.; Gao, J.; Wang, Y.; Zheng, B. Identification of animal individuals using deep learning: A case study of giant panda. Biol. Conserv. 2020, 242, 108414. [Google Scholar] [CrossRef]
- Schofield, D.; Nagrani, A.; Zisserman, A.; Hayashi, M.; Matsuzawa, T.; Biro, D.; Carvalho, S. Chimpanzee face recognition from videos in the wild using deep learning. Sci. Adv. 2019, 5, eaaw0736. [Google Scholar] [CrossRef] [PubMed]
- Nayagam, M.G.; Ramar, K. Reliable object recognition system for cloud video data based on LDP features. Comput. Commun. 2020, 149, 343–349. [Google Scholar] [CrossRef]
- Leksut, J.T.; Zhao, J.; Itti, L. Learning visual variation for object recognition. Image Vis. Comput. 2020, 98, 103912. [Google Scholar] [CrossRef]
- Kumar, Y.S.; Manohar, N.; Chethan, H. Animal classification system: A block based approach. Procedia Comput. Sci. 2015, 45, 336–343. [Google Scholar] [CrossRef]
- Hendel, R.K.; Starrfelt, R.; Gerlach, C. The good, the bad, and the average: Characterizing the relationship between face and object processing across the face recognition spectrum. Neuropsychologia 2019, 124, 274–284. [Google Scholar] [CrossRef]
- Chen, C.; Min, W.; Li, X.; Jiang, S. Hybrid incremental learning of new data and new classes for hand-held object recognition. J. Vis. Commun. Image Represent. 2019, 58, 138–148. [Google Scholar] [CrossRef]
- Fang, W.; Ding, Y.; Zhang, F.; Sheng, V.S. DOG: A new background removal for object recognition from images. Neurocomputing 2019, 361, 85–91. [Google Scholar] [CrossRef]
- Boureau, Y.-L.; Ponce, J.; Le Cun, Y. A theoretical analysis of feature pooling in visual recognition. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- The MathWorks. MATLAB Documentation, Fuzzy Interference System Modeling. Available online: https://www.mathworks.com/help/fuzzy/fuzzy-inference-system-modeling.html (accessed on 5 March 2021).
- The MathWorks. MATLAB Documentation, Fuzzy Interference System Tuning. Available online: https://www.mathworks.com/help/fuzzy/fuzzy-inference-system-tuning.html?s_tid=CRUX_lftnav (accessed on 5 March 2021).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Kokalis, C.; Tasakos, A.; Kontargyri, T.; Vassiliki, T.S.; Giorgos, G.; Ioannis, F. Hydrophobicity classification of composite insulators based on convolutional neural networks. Eng. Appl. Artif. Intell. 2020, 91, 103613. [Google Scholar] [CrossRef]
- Shanthi, T.; Sabeenian, R.; Anand, R. Automatic diagnosis of skin diseases using convolution neural network. Microprocess. Microsyst. 2020, 76, 103074. [Google Scholar] [CrossRef]
- Khatami, A.; Nahavandi, S. A weight perturbation-based regularisation technique for convolutional neural networks and the application in medical imaging. Expert Syst. Appl. 2020, 149, 113196. [Google Scholar] [CrossRef]
- Zhou, D.-X. Theory of deep convolutional neural networks: Downsampling. Neural Netw. 2020, 124, 319–327. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the ICM 2010, Hyderabad, India, 19–27 August 2010. [Google Scholar]
- Ferreira, B. Online Dataset 1. 2020. Available online: https://hal.archives-ouvertes.fr/hal-03021776/document (accessed on 18 December 2020).
- Ferreira, B. Online Dataset 2. 2020. Available online: https://besjournals.onlinelibrary.wiley.com/doi/full/10.1111/2041-210X.13436 (accessed on 31 July 2020).
- Juzzy Wagner, C. A java based toolkit for type-2 fuzzy logic. In Proceedings of the 2013 IEEE Symposium on Advances in Type-2 Fuzzy Logic Systems (T2FUZZ), Singapore, 16–19 April 2013. [Google Scholar]
- Patwari, M.B.; Manza, R.R.; Rajput, Y.M.; Saswade, M.; Deshpande, N. Detection and counting the microaneurysms using image processing techniques. Int. J. Appl. Inf. Syst. (IJAIS) 2013, 6, 11–17. [Google Scholar]
- Saleh, M.D.; Eswaran, C.; Mueen, A. An automated blood vessel segmentation algorithm using histogram equalization and automatic threshold selection. J. Digit. Imaging 2011, 24, 564–572. [Google Scholar] [CrossRef] [PubMed]
- Zuiderveld, K. Contrast Limited Adaptive Histograph Equalization. In Vol. Graphic Gems IV; Academic Press Professional: San Diego, CA, USA, 1994. [Google Scholar]
- Saleh, M.D.; Eswaran, C. An efficient algorithm for retinal blood vessel segmentation using h-maxima transform and multilevel thresholding. Comput. Methods Biomech. Biomed. Eng. 2012, 15, 517–525. [Google Scholar] [CrossRef]
- Saini, D.K.; Jabar, H. Yousif. Fuzzy and Mathematical Effort Estimation Models for Web Applications. Appl. Comput. J. 2021, 1, 10–24. [Google Scholar]
- Huang, D.-Y.; Wang, C.-H. Optimal multi-level thresholding using a two-stage Otsu optimization approach. Pattern Recognit. Lett. 2009, 30, 275–284. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, D. Studies on centroid type-reduction algorithms for interval type-2 fuzzy logic systems. In Proceedings of the 2015 IEEE Fifth International Conference on Big Data and Cloud Computing 2015, Dalian, China, 26–28 August 2015; pp. 344–349. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M.S. Image Quality Assessment through FSIM, SSIM, MSE and PSNR—A Comparative Study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Vishwakarma, D.K. A two-fold transformation model for human action recognition using decisive pose. Cognit. Syst. Res. 2020, 61, 1–13. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Upper Membership Function | Membership Function | Lower Membership Function |
|---|---|---|
| Pixel: Black | Foreground | 0, 1 |
| Pixel: White | Background | 1, 0 |
| Membership Function | Lower Membership Function | Upper Membership Function |
|---|---|---|
| Edge | 0.005, 0.035 | 0.04 |
| Not Edge | 0.99, 1.0 | 0.98, 1.0 |
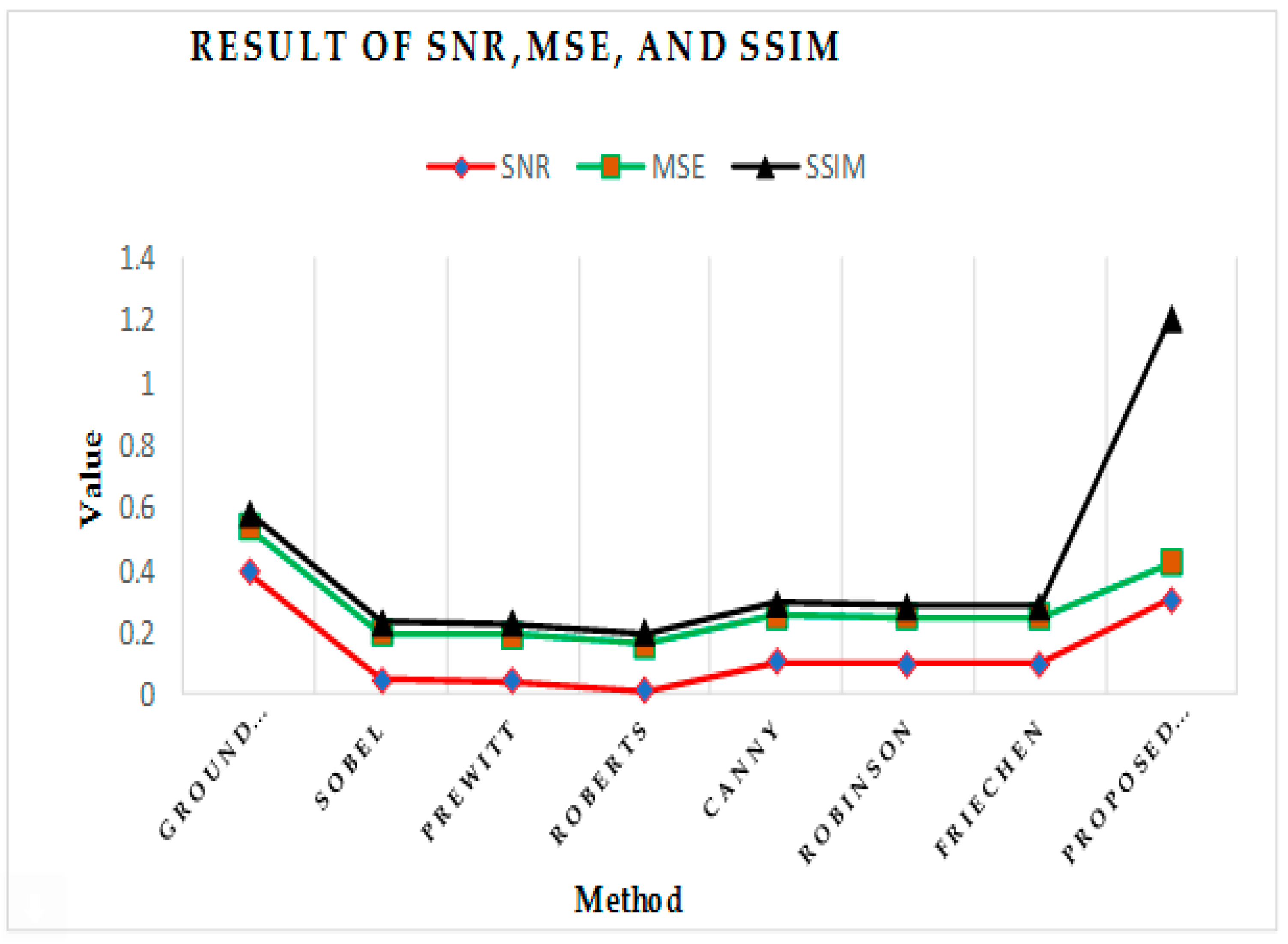
| PSNR | SNR | MSE | SSIM | |
|---|---|---|---|---|
| Ground truth | 6.44359723822 | 0.390523 | 0.1474757 | 0.04262958446 |
| Sobel | 6.40926093734 | 0.047160 | 0.1486463 | 0.0372840370 |
| Prewitt | 6.40886536226 | 0.043204 | 0.1486598 | 0.037262112483 |
| Roberts | 6.40575761207 | 0.012127 | 0.1487663 | 0.037137089 |
| Canny | 6.41505149913 | 0.105066 | 0.1484482 | 0.0393885 |
| Log | 6.4045448 | 9.64327 | 0.1488078 | 0.037097395897 |
| Robinson | 6.41454242 | 0.099975 | 0.1484656 | 0.038573626127 |
| FrieChen | 6.41454242 | 0.099975 | 0.1484656 | 0.03857362612 |
| Proposed fuzzy | 7.7161813 | 0.307274 | 0.1183464 | 0.784321825 |
| Layer | Name | Activations | Learnable | Properties |
|---|---|---|---|---|
| 1 | Image input | 100 * 100 * 1 | - | The zero-center normalization approach |
| 2 | Convolution1 | 96 * 96 * 1 | Weight 5 * 5 * 3 * 20Bias 1 * 1 * 20 | The convolution mask size is 5 * 5 with 20 filter and padding [ 0 0 0 0] and stride [1 1] |
| 3 | Relu1 | 96 * 96 * 1 | - | Relu1(x) = max(0,x) |
| 4 | Pool max1 | 48 * 48 * 20 | - | The pooling is tacking the max value in window2 × 2 with padding [0 0 0 0] and stride [2 2] |
| 5 | Convolution2 | 44 * 44 * 20 | Weight 5 * 5 * 20 * 20Bias 1 * 1 * 20 | The convolution mask size is 5 * 5 with 20 filter and padding [ 0 0 0 0] and stride [1 1] |
| 6 | Relu2 | 44 * 44 * 20 | - | Relu2(x) = max(0,x) |
| 7 | Pool max2 | 22 * 22 * 20 | - | The pooling is tacking the max value in window2 × 2 with padding [0 0 0 0] and stride [2 2] |
| 14 | Fully Connected Layer | 1 * 1 * 5 | - | Multiplies weight matrix by an input image and then adds a bias vector. |
| 15 | SoftMax Layer | 1 * 1 * 5 | - | activation function |
| 16 | Classification Layer | - | - | Calculates the cross-entropy |
| Model Type | Prediction | Reference | |
|---|---|---|---|
| Positive | Negative | ||
| CNN | True | 26,794 | 0 |
| False | 0 | 513 | |
| Statistic | Description | CNN + Kalman Filter |
|---|---|---|
| Accuracy | Rate of correctly predicted ACC = TP + TN/(TP + TN + FP + FN) | 0.98121 |
| True positive | Number of correctly predicted. | 26,794 |
| True Negative | Number of wrong objects which are correctly classified | 0 |
| False positive | Number of incorrectly predicted | 0 |
| False Negative | Number of wrong objects which are incorrectly predicted | 513 |
| Misclassification Rate | The percentage of incorrectly predicted = (FP + FN)/total | 0.018786 |
| Specificity | calculated as the number of correct negative predictions Specificity = TN/(TN + FP) | NaN |
| Precision | Calculated as the number of correct positive Precision = TP (TP + FP) | 1 |
| Sensitive Recall | Rate of correctly predicted malicious objects SensitiveRecall = TP/(TP + FN) | 0.98121 |
| F1_Score | Measure of accuracy of test. It considers the precision p and the recall (R) of the test for computing the score F1_Score = (2 * (Sensitive_Recall * Precision))/(Sensitive_Recall + Precision) | 0.99052 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammed, H.R.; Hussain, Z.M. Hybrid Mamdani Fuzzy Rules and Convolutional Neural Networks for Analysis and Identification of Animal Images. Computation 2021, 9, 35. https://doi.org/10.3390/computation9030035
Mohammed HR, Hussain ZM. Hybrid Mamdani Fuzzy Rules and Convolutional Neural Networks for Analysis and Identification of Animal Images. Computation. 2021; 9(3):35. https://doi.org/10.3390/computation9030035
Chicago/Turabian StyleMohammed, Hind R., and Zahir M. Hussain. 2021. "Hybrid Mamdani Fuzzy Rules and Convolutional Neural Networks for Analysis and Identification of Animal Images" Computation 9, no. 3: 35. https://doi.org/10.3390/computation9030035
APA StyleMohammed, H. R., & Hussain, Z. M. (2021). Hybrid Mamdani Fuzzy Rules and Convolutional Neural Networks for Analysis and Identification of Animal Images. Computation, 9(3), 35. https://doi.org/10.3390/computation9030035