The data collection and experiments that were conducted in the study are described in this section.
3.2. Methods
First, data pre-processing was performed, because the variables needed to be encoded and scaled equally in a process called feature scaling. Missing values were replaced with the mean (average) of the column where they were located. The experiments were performed on both the DNN and MLP churn models by changing the activation functions that were used in the hidden layers and the output layer. The batch sizes were the number of rows to be propagated to the network at once. It is through the training algorithm that the model learned, and different algorithms were comparatively assessed by changing the optimizer values. Samples of training data consisting of the independent variables (13 parameters) and the dependent variable (which was either 1 or 0 (1 to leave the bank or 0 to stay in the bank) in each instance were fed into the machine learning models of the DNN and the MLP models for each time. To help preserve the statistical properties of the original dataset and ensure that the unbalanced dataset had a good balance between the size and representation of the training and test sets [
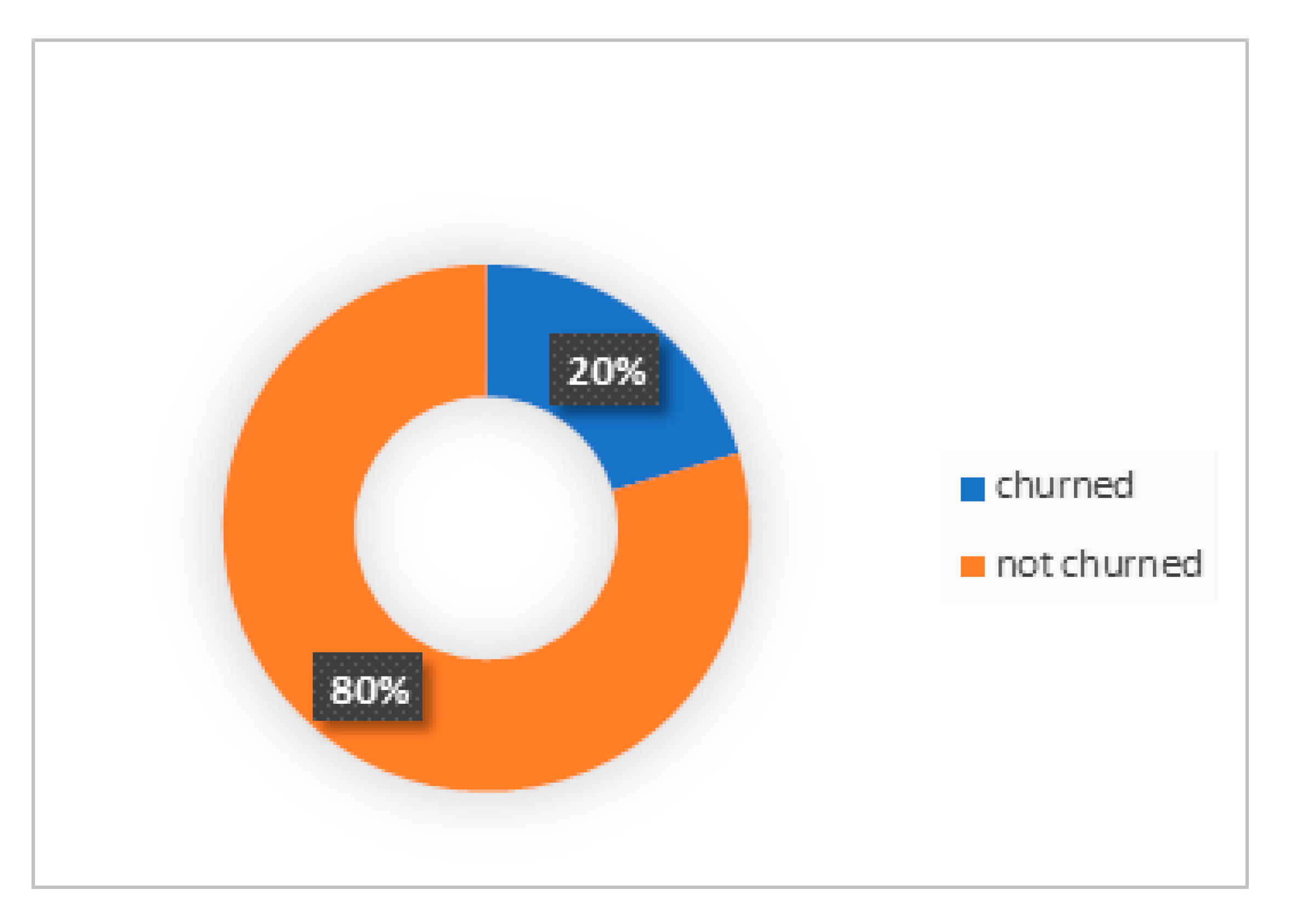
45], the data collected was divided into a training set (80%) and a test set (20%). The choice of an 80:20 dataset split ratio was firstly influenced by the fact that the number of data instances was considered to be sufficiently large. Secondly, with the large data instances, there would be no significant difference in using an 80:20 data split compared to a 90:10 or 70:30 data split for a computationally intensive operation using a DNN for churn modeling. Generally, having less training data led to greater variance in the parameter estimates, while less testing data led to greater variance in the static performance. The goal was to ensure that the data being split into training and test sets led to a variance that was not too high, which could be achieved by an 80:20 ratio data split for 10,000 data instances. From the thirteen (13) independent variables, ten (10) of them (CreditScore, Geography, Gender, Age, Tenure, Balance, NumOfProducts, HasCrCard, IsActiveMember, and EstimatedSalary), which were considered to have the most impact on the churn model, were chosen to compose the input layer.
Geography and gender were the two categorical variables which were encoded into numbers to enable the network to process them. It is noteworthy that, when encoded to numbers, these categorical variables had equal relational order (i.e., Cape Town is not more important than Durban, or male is not more important than female) for the network. The cities were encoded into numbers 0, 1, and 2, and the genders were assigned values such as 0 and 1 randomly. Feature scaling (data normalization) was performed to prevent some column values dominating other column values (credit score, for instance, being dominated by balance because of the disparity between these values). All the values in the dataset were rescaled in the range from −1 to 1 using standardization and feature scaling.
The rescaled values (see
Table 3) were then used as input into the deep neural network (DNN) model. The ten (10) normalized values were inserted into the input layer, and the last column (Exited) was used to train the model, classifying them as churner or non-churner. The confusion matrix was set to a threshold of 0.5. If the classification was greater than the threshold, the customer was classified as a churner; otherwise, the customer was classified as a non-churner.
By taking from the best practices in backpropagation training, as advocated by LeCun et al. [
46], the six-step procedure that we followed to train the DNN model was as follows:
Initialize the weights close to 0 (but not 0)
Input one observation at a time (one feature in one input node);
Use forward propagation to determine how important each neuron is by the weights to get y;
Compare the results to the actuals result and measure the margin of error;
Backpropagate the error to the artificial neural network to adjust the weights;
Repeat Steps 1–5 for each observation.
3.3. Experiment Design and Validation
The experimental set-up for the study was performed using a DNN. The input layer was made of 10 nodes, each one of them connected to every node of the first hidden layer. There were six fully connected nodes on each hidden layer, and all the nodes on the second hidden layer were connected to the single output layer, which produced the binary output. Thus, the DNN had a 10-6-6-1 neural architecture. The input layer received the pre-processed data, which were already rescaled in the form of batches and sent to the hidden layers. The batch size was the hyperparameter that set the number of samples that were propagated to the network at each epoch. Each node on the hidden layers had an activation function, which was responsible for introducing nonlinearity to the output layer. This was of crucial value because most datasets available in real life are nonlinear. These functions set the output to be within a pre-specified interval or threshold. The output layer had the output function, which mapped the inputs coming from the last hidden layer into a specific class of churner or non-churner.
Three experiments were performed in an attempt to address the three research objectives (RO1, RO2, RO3) that were specified for the study.
Experiment 1: Activation Function (Objective 1)
The first experiment involved trying different activation function configurations for the DNN and comparing how it performed against an MLP during the training and testing phases. This was to address the first objective of the study, which was to determine the effects that various configurations of monotonic activation functions had on the training of a DDN churn model in the banking sector.
A brief description of the main three nonlinear monotonic functions is as follows:
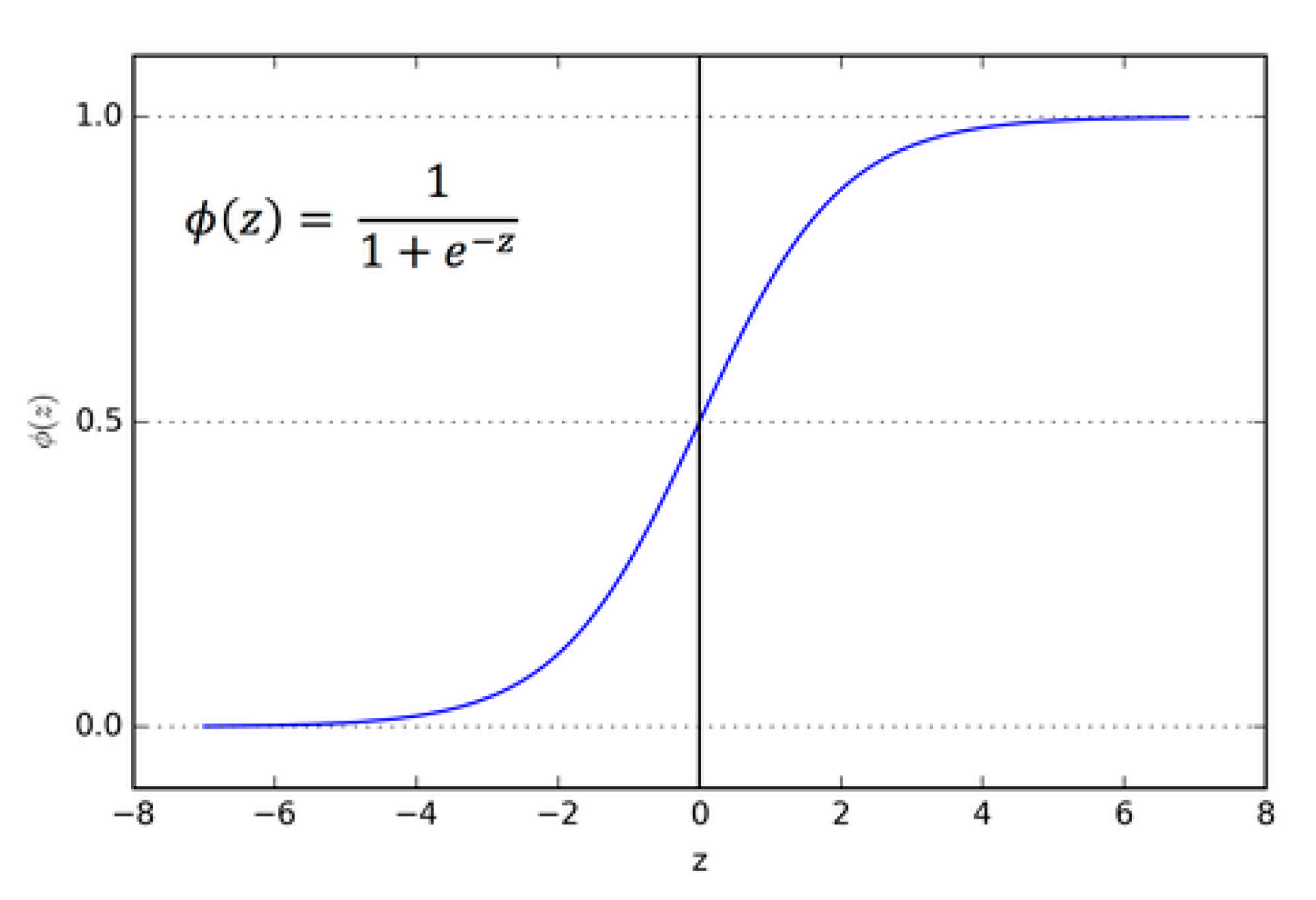
The sigmoid takes a value and squashes it to between 0 and 1. It is a very useful function because it provides probabilities, which is good for classification problems whose output is a binary outcome [
45]. The sigmoid function fits well for churn prediction because the model can set a threshold to be churner = x ≥ 0.5 and non-churner = x ≤ 0.5. The sigmoid (see
Figure 1) is denoted by
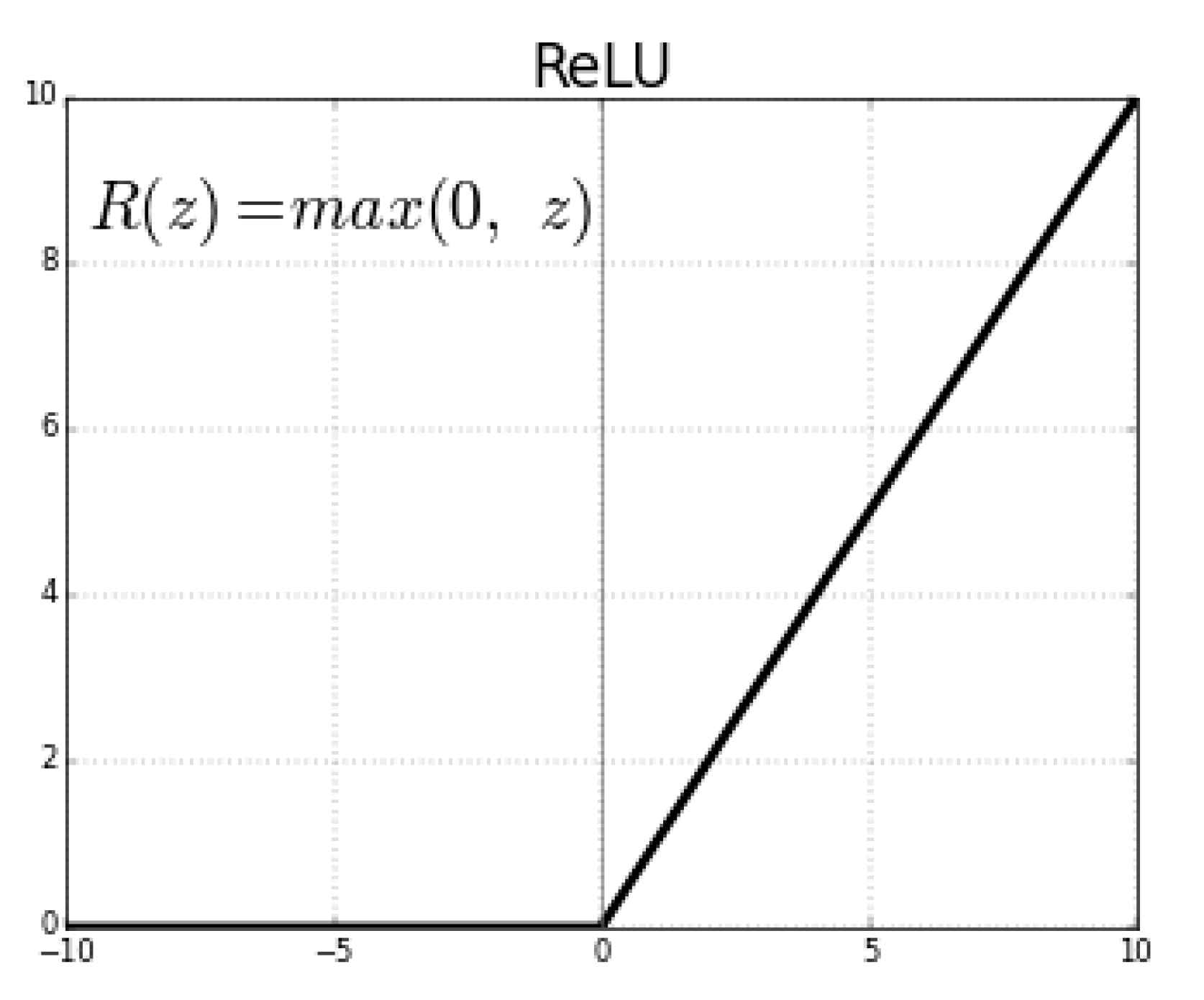
The rectified linear unit (see
Figure 2) takes a real value and thresholds it to 0, replacing negative values with zero as well. This was useful for the activation function because during training, the values coming from the input were sometimes negative, and the model was oftentimes configured to work with scaled real or positive numbers [
4]. This is denoted as
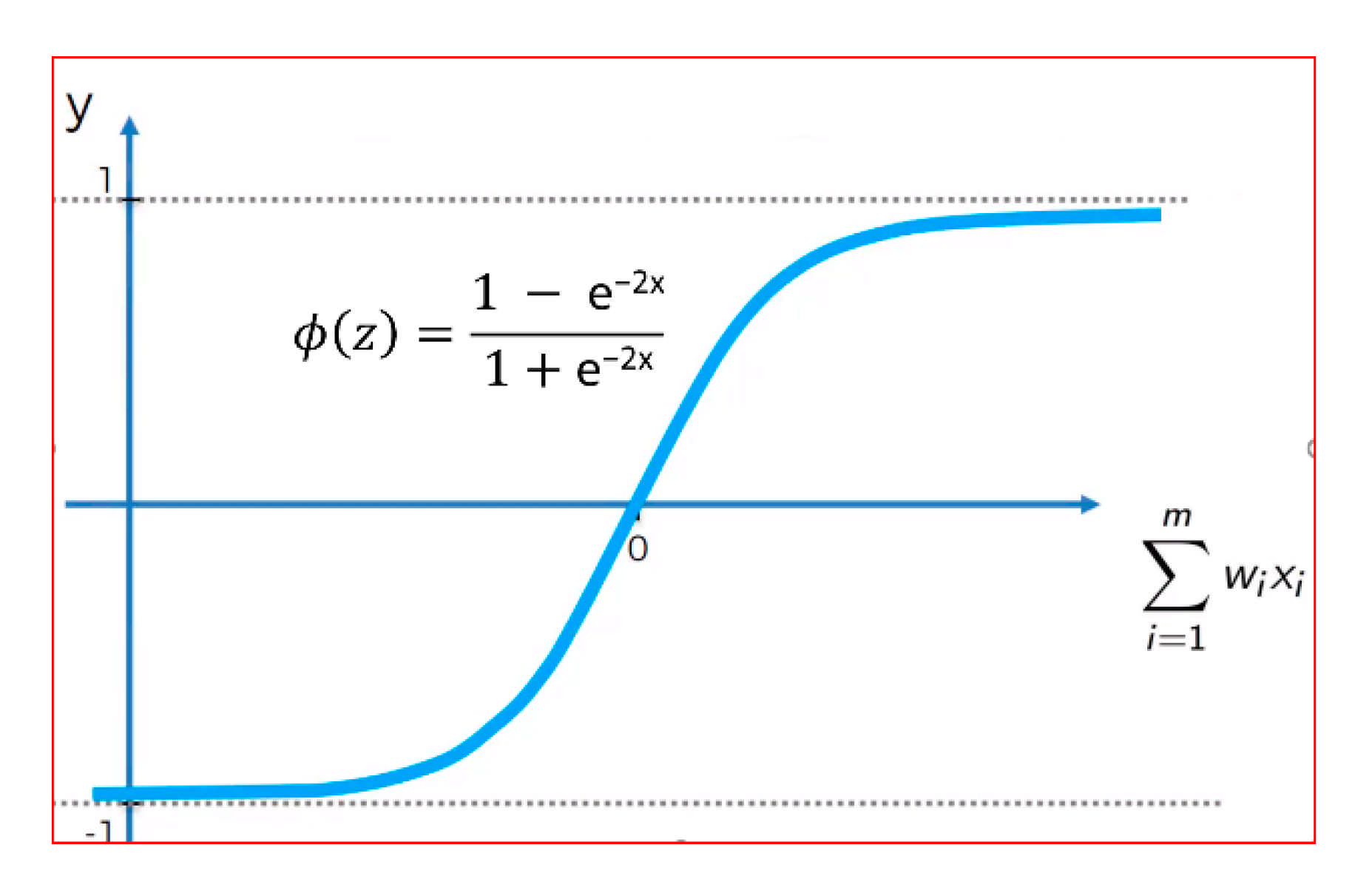
A hyperbolic tangent (tanh) takes a real number and squashes it to a range between −1 and 1 (see
Figure 3). This was a useful function for the hidden layer because the negative values would not be scaled like in the rectifier functions (to zero), and the input was mapped as strongly negative [
4]. This is denoted as
The combination of the activation functions used in the hidden layers and the output layers of the DNN and the MLP is shown in
Table 4.
Experiment 2: Batch Sizes (Objective 2)
In the second experiment, batch sizes (number of rows) set the number of samples that were propagated through the network at each epoch during the training phase (see
Table 5). The batch size values were incremented gradually to see how the DNN model performed against the MLP. This experiment aligned with the second objective of the study, which was to determine the effect of different batch sizes in the training of a DNN in the banking sector. The goal was to examine the effect of larger data sizes on the computation of the DNN and the MLP.
Experiment 3: Training Algorithms (Objective 3)
The third experiment aligned with the third research objective, which was to evaluate the overall performance of the DNN model by trying three different training algorithms. During the training phase, the dataset was split into 10 folds, with the model training on the ninth fold and testing on the tenth fold (K-fold cross-validation). The k-fold cross-validation process enabled the model to be trained much more precisely because, instead of only testing on the test set, the model trained and tested at the same time, causing the error backpropagation to adjust the weights optimally. The algorithms that were used were stochastic gradient descent (SGD), an adaptive gradient algorithm (AdaGrad), and its variants such as Adadelta, root mean square propagation (RMSProp), Adam, and AdaMax.
SGD is a simple but efficient method for fitting linear algorithms and regressors under convex loss functions, such as a (linear) SVM and logistic regression. SGD performed a parameter update for each training example [
47]. The authors in [
48] described adaptive moment estimation (Adam) as an algorithm for first-order, gradient-based optimization of stochastic objective functions, based on the adaptive estimates of lower-order moments. Adam computes adaptive learning rates for each parameter and keeps an exponentially decaying average of past gradients. The adaptive gradient algorithm (AdaGrad) [
49] is an algorithm that helps decay the learning rate very aggressively as the denominator grows. In other words, it is a gradient-based optimization algorithm that adapts the learning rate to the parameters, performing smaller updates (low learning rates) for parameters associated with frequently occurring features and larger updates (high learning rates) for parameters associated with infrequent features. It is for this reason that AdaGrad performs well even with sparse data. Adadelta [
50] is an extension of AdaGrad that seeks to reduce its aggressive, monotonically decreasing learning rate. Instead of accumulating all past squared gradients, Adadelta restricts the window of accumulated past gradients to some fixed size. Root mean square propagation (RMSProp) is an extension of AdaGrad that deals with its radically diminishing learning rates. It is identical to Adadelta, except that Adadelta uses the RMSProp of parameter updates in the numerator update rule. AdaMax is a variant of Adam based on the infinity norm. The SGD, AdaGrad, Adadelta, Adam, Adamax, and RMSProp methods were used variously with the DNN and MLP.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}