
Mass Media as a Mirror of the COVID-19 Pandemic

 , ,
, ,  ,
,  ,
,  , ,
, ,
Abstract
1. Introduction
2. Related Work
3. Methods and Data
- (a)
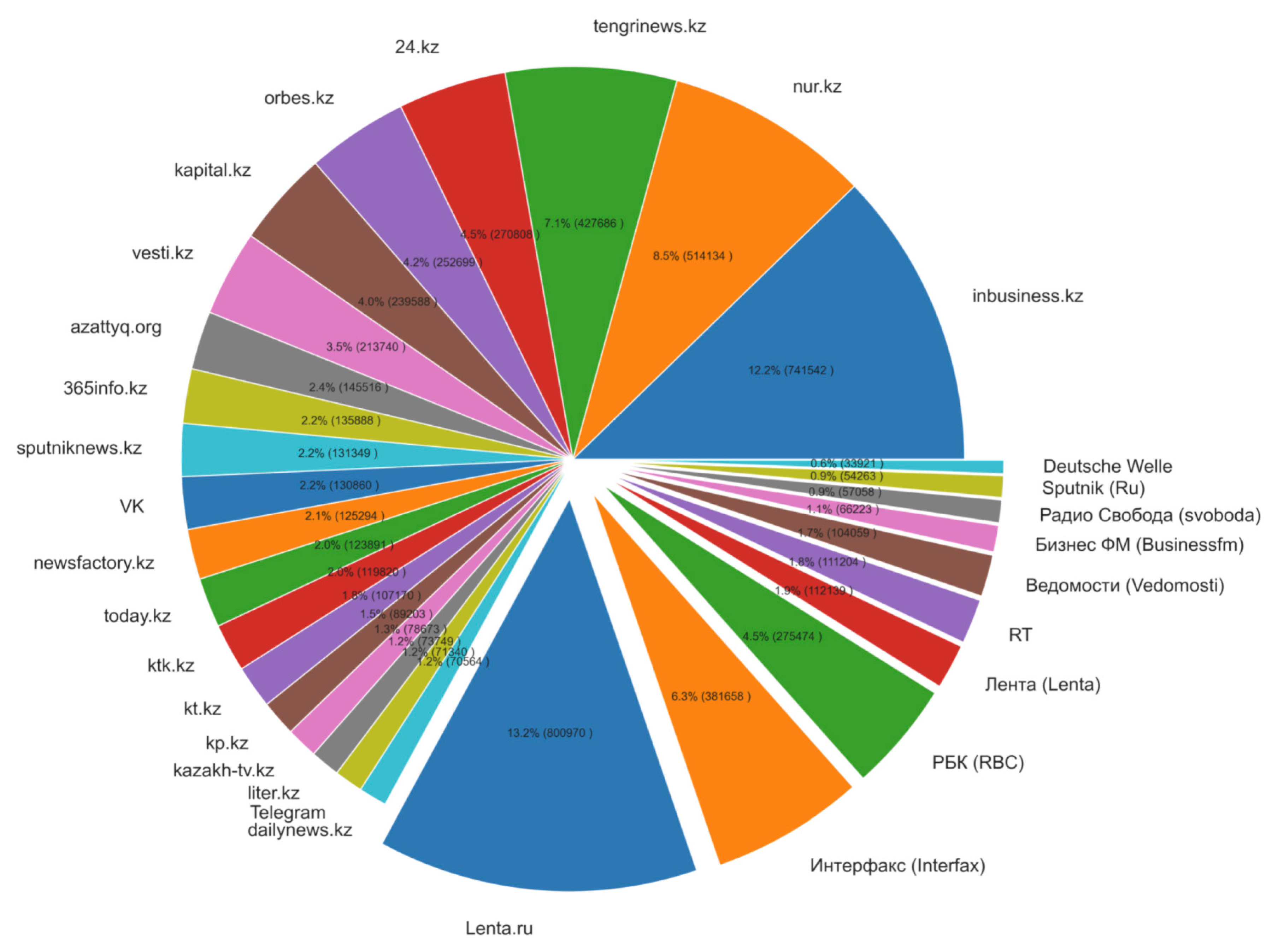
- Data collection. Mass media and social network news publications were gathered using automatic scrapping tools.
- (b)
- Text corpus processing was necessary to extract meaningful dynamic indicators of mass media publication activity. Three types of indicators were proposed; they were described in the section below: topics were obtained by a cascade of topic models, sentiment analysis, and analysis of full-text search queries.
- (c)
- Correlation analysis. We performed the assessment of pairwise correlation between two groups of dynamic indicators—mass media indicators obtained in step (b) and COVID-10 epidemiological indicators. We used COVID-19 indicators, which were processed and prepared by the Center for Systems Science and Engineering at Johns Hopkins University (JHU CSSE) [52].
3.1. COVID-19 Data
3.2. Methods
- Topic-modeling approach;
- Sentiment analysis;
- Analysis by search queries.
- The smoothing regularizer, based on the assumption that the matrix columns are generated by Dirichlet distributions with hyperparameters and (identical to the implementation of the LDA model, in which hyperparameters can only be positive);
- 2.
- By decreasing the regularizer coefficients, the reverse smoothing regularizer can be obtained:This aims to identify the significant subject words, so-called lexical kernels, in addition to subject topics in each document, zeroing out small probabilities.
- 3.
- The decorrelator Phi regularizer makes topics more “different”. The selection of topics allows the model to discard small, uninformative, duplicate, and dependent topics:
- The level-0 topic model, which mainly consisted of general topics, such as economy, medicine (in general), education, etc.
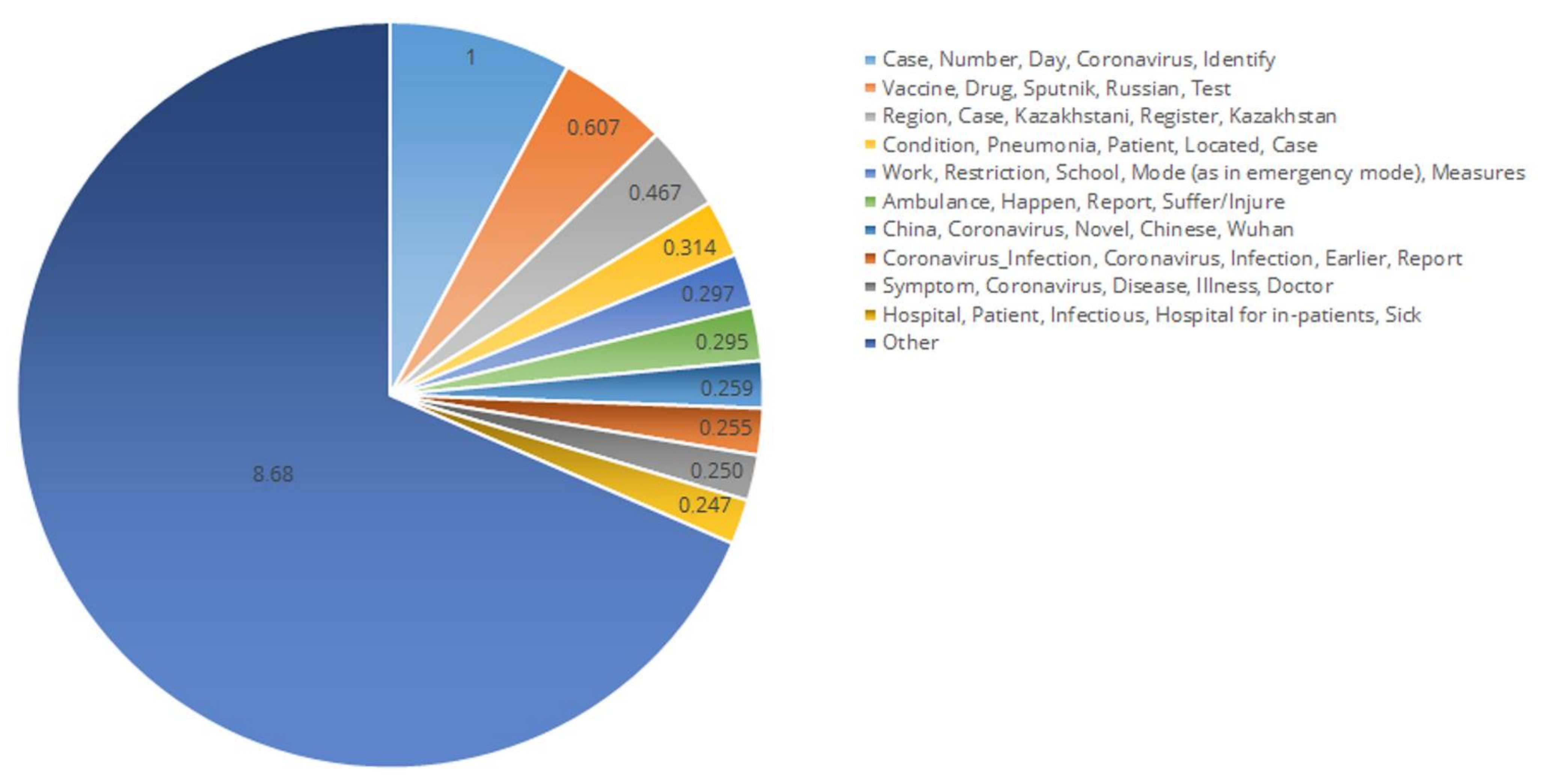
- The level-2 topic model comprised the topics related to medicine including the ones somehow related to medicine and the epidemiological situation, such as quarantine limitations in education, sport events and public life, the economic situation in the context of the pandemic, etc. (Figure 3)
- The level-3 topic model provided very high accuracy in classifying medicine- and healthcare-related topics and documents
- It considers the dynamic weight of only single topic, while it might be possible that some combination of topics according to other criteria may be more representative;
- Topic modelling cannot consider the expert opinion, and certain topics, which are considered to be important by experts, may not be distinguished automatically by the topic model, depending on its meta-parameters.
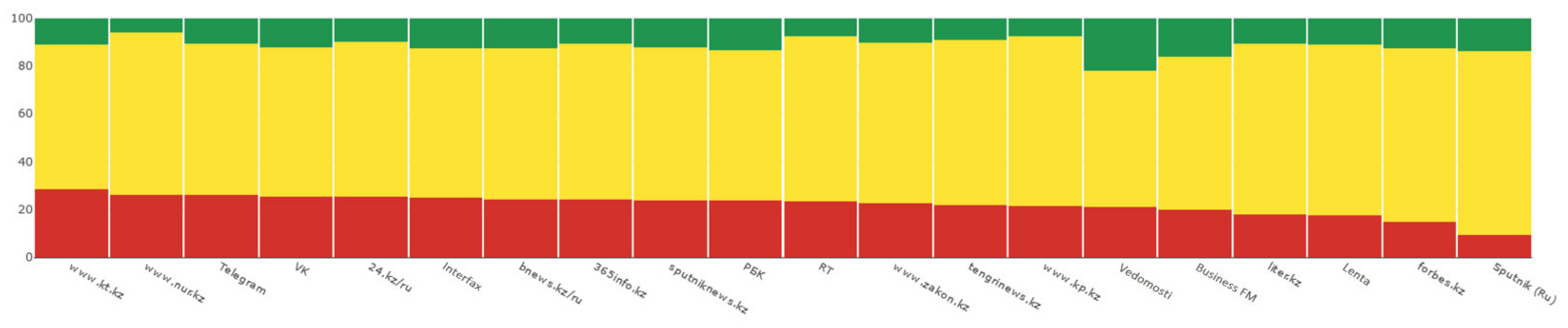
- Fake, disinformation, anti-vax;
- Unemployment, poverty;
- Crisis, economic decline;
- Famine, starvation, homeless, poverty;
- Remote education;
- Freelance, remote work, brain drain;
- Criminal, robbery, theft, homicide;
- Crisis, lending, debt, microcredits;
- Healthcare, hospitals, issues, healthcare scandals;
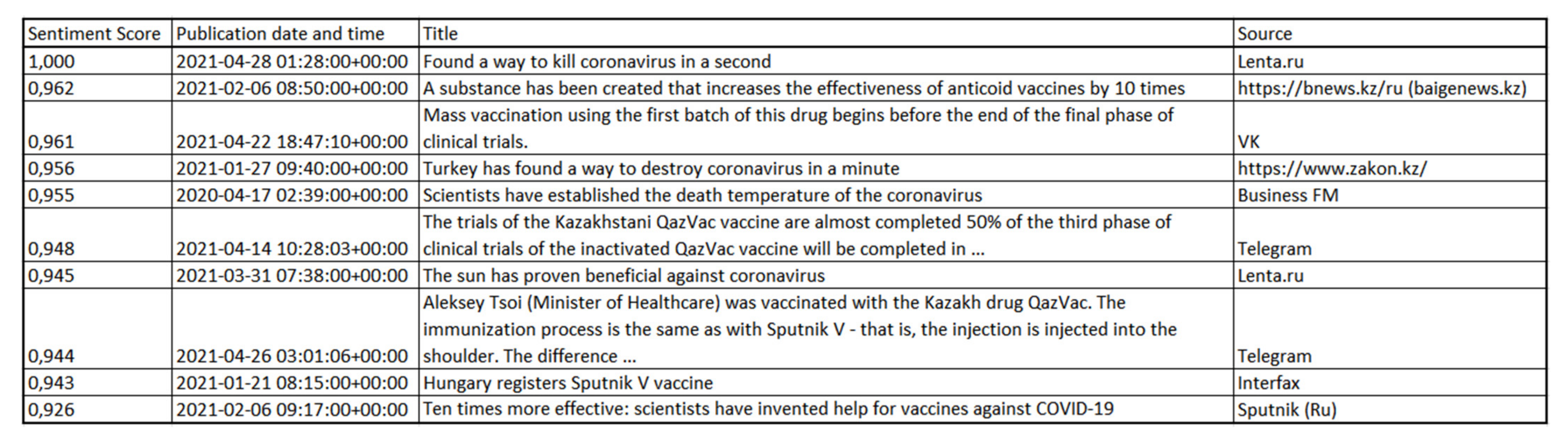
- Vaccination, COVID-19 vaccines.
- Experiments should be performed for Russia and Kazakhstan separately;
- Experiments should be performed for each of the topic models’ average daily sentiments using the level-2 topic model, and for each of the search queries separately;
- Experiments should be performed for each of seven COVID-19 indicators selected for analysis.
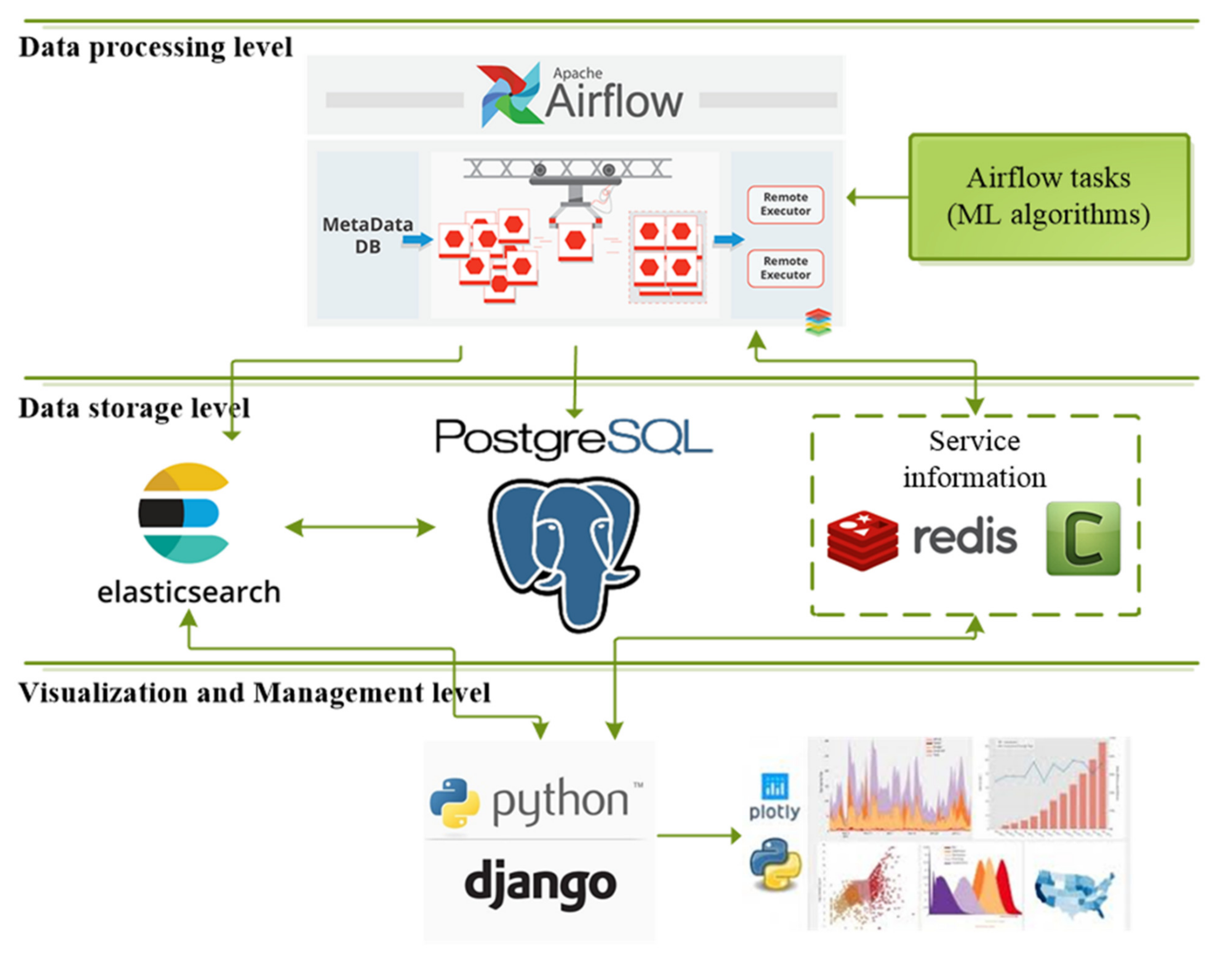
- The possibility of simultaneous calculations with the employment of several machines;
- Ability to flexibly plan the various data processing tasks;
- Ability to monitor tasks in real time, including prompt notification of exceptions;
- Flexibility in using the tools and technologies.
- PostgreSQL—performed the role of a persistent storage medium for structured data;
- ElasticSearch—in-memory NoSQL storage, dedicated to storing unstructured or poorly structured data, as well as fast search (including full-text), filtering, and streaming access;
- Redis—fast key-value storage, used for caching individual pages and elements, and for caching authorization sessions. Redis stored service data as well as page and element caches, which were often accessed.
4. Results and Discussion
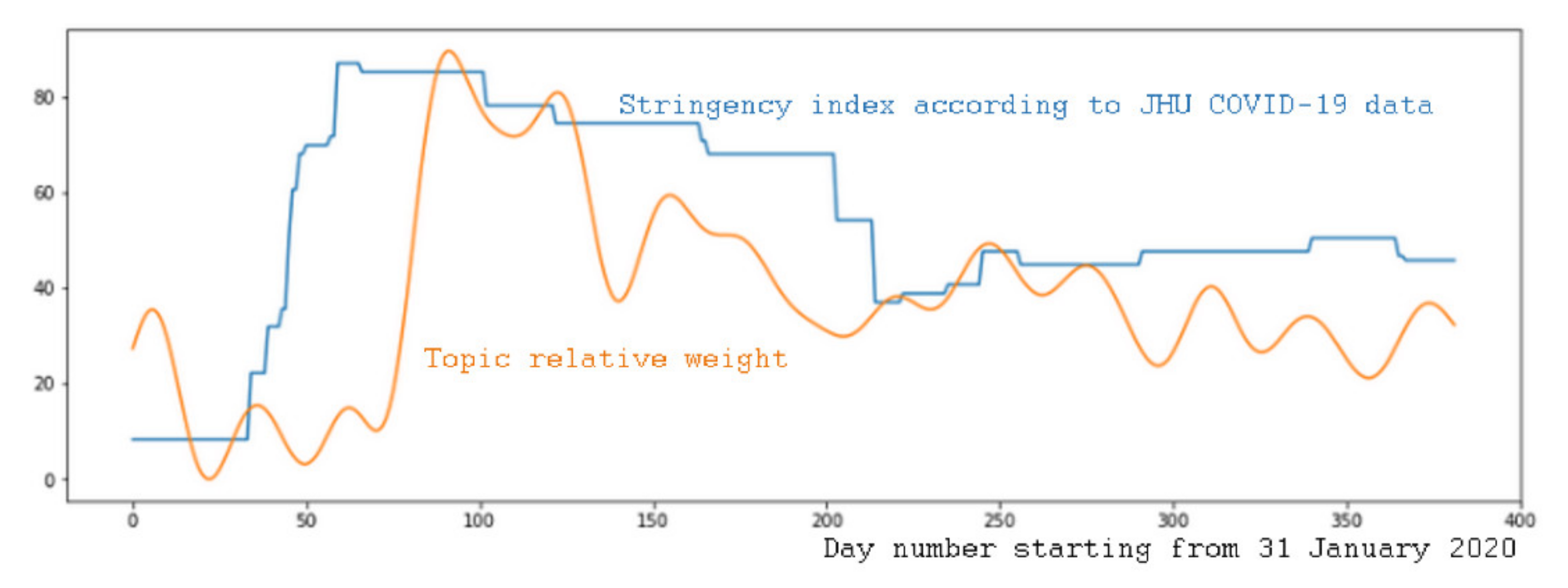
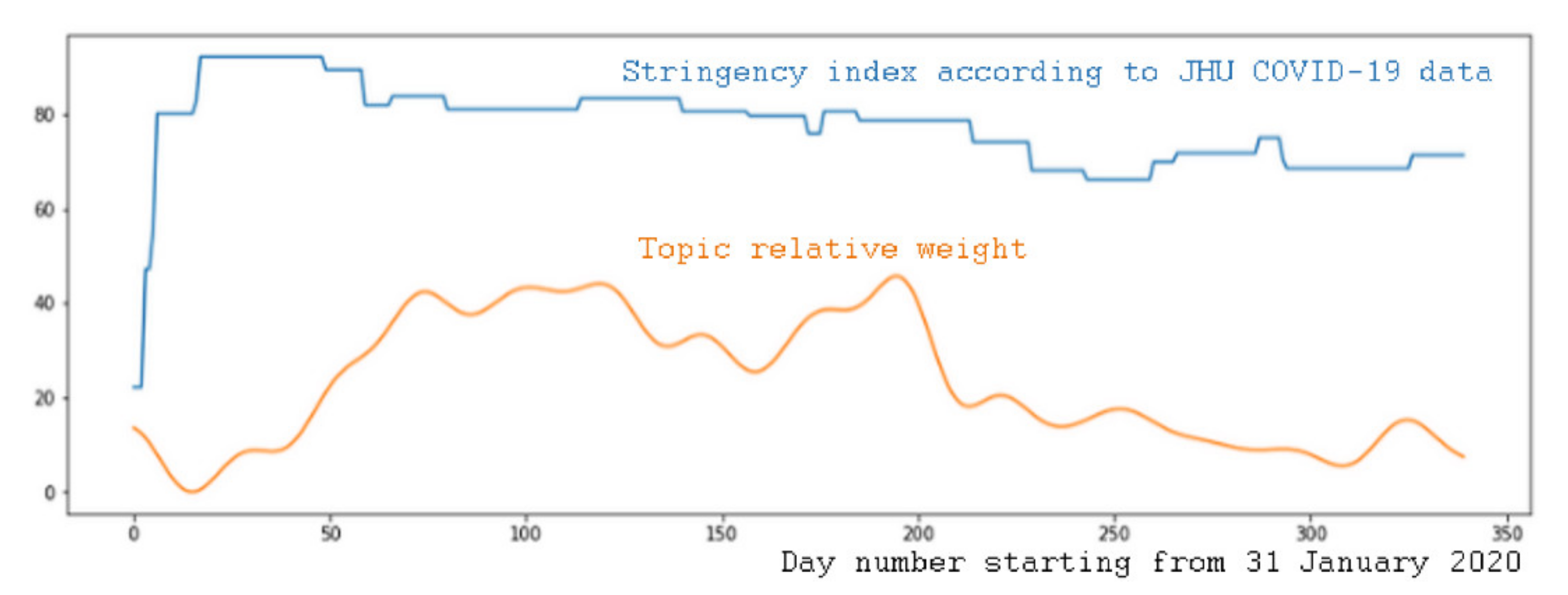
- Mass media received actual information rather promptly, and react to it operatively;
- There was some inherent lag in the analyzed COVID-19 indicators. For example, daily statistics may have actually contained some sort of aggregated information over several days due to imperfections in statistical data collection processes in Kazakhstan and Russia.
5. Conclusions and Future Research
- Attempt to build a model for the recognition of inaccuracies in official statistical indicators regarding the COVID-19 pandemic using mass media data as a reference;
- Conduct an analysis of the topical profile of the COVID-19 pandemic in different countries and explore how it evolved over time. Such an analysis can be used to assess its impact on the economy, education, politics, tourism, etc.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A





References
- Baldwin, R.; di Mauro, B.W. Economics in the time of COVID-19: A new eBook. VOX CEPR Policy Portal 2020, 2–3. [Google Scholar]
- Atun, R. Transitioning health systems for multimorbidity. Lancet 2015, 386, 721–722. [Google Scholar] [CrossRef]
- Orlov, E.M. The category of effectiveness in the health care system. Basic Res. 2010, 10, 70–75. [Google Scholar]
- Panch, T.; Szolovits, P.; Atun, R. Artificial intelligence, machine learning and health systems. J. Glob. Health 2018, 8, 020303. [Google Scholar] [CrossRef] [PubMed]
- The Socio-Economic Impact of AI in Healthcare. October 2020. Available online: https://www.medtecheurope.org/wp-content/uploads/2020/10/mte-ai_impact-in-healthcare_oct2020_report.pdf (accessed on 10 September 2021).
- Mukhamediev, R.I.; Symagulov, A.; Kuchin, Y.; Yakunin, K.; Yelis, M. From Classical Machine Learning to Deep Neural Networks: A Simplified Scientometric Review. Appl. Sci. 2021, 11, 5541. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef]
- Daniel, J.; Willie, R.; Copley, C. Towards automating healthcare question answering in a noisy multilingual low-resource setting. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 948–953. [Google Scholar] [CrossRef]
- Feng, L.; Xiaoli, W.; Qingfeng, W.; Jiaying, L.; Xueliang, Q.; Zhifeng, B. HQADeepHelper: A deep learning system for healthcare question answering. In Companion Proceedings of the Web Conference 2020 (WWW ’20); Association for Computing Machinery: New York, NY, USA, 2020; pp. 194–197. [Google Scholar] [CrossRef]
- Draganescu, O. Forms of Influencing Young People through Media Discourse. EIRP Proc. 2019, 13. Available online: http://www.proceedings.univ-danubius.ro/index.php/eirp/article/view/1965/2250 (accessed on 2 December 2021).
- Choudhary, V. Role of mass media in shaping public opinion. Aut Aut Res. J. 2020, XI, 398–404. [Google Scholar]
- Tasnim, S.; Hossain, M.; Mazumder, H. Impact of Rumors and Misinformation on COVID-19 in Social Media. J. Prev. Med. Public Health 2020, 53, 171–174. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Zheng, P.; Jia, Y.; Chen, H.; Mao, Y.; Chen, S.; Wang, Y.; Fu, H.; Dai, J. Mental health problems and social media exposure during COVID-19 outbreak. PLoS ONE 2020, 15, e0231924. [Google Scholar]
- Ghasiya, P.; Okamura, K. Investigating COVID-19 News across Four Nations: A Topic Modeling and Sentiment Analysis Approach. IEEE Access 2021, 9, 36645–36656. [Google Scholar] [CrossRef]
- Mukhamediev, R.I.; Yakunin, K.; Mussabayev, R.; Buldybayev, T.; Kuchin, Y.; Murzakhmetov, S.; Yelis, M. Classification of Negative Information on Socially Significant Topics in Mass Media. Symmetry 2020, 12, 1945. [Google Scholar] [CrossRef]
- Kirill, Y.; Mihail, I.G.; Sanzhar, M.; Rustam, M.; Olga, F.; Ravil, M. Propaganda Identification Using Topic Modelling. Proc. Comput. Sci. 2020, 178, 205–212. [Google Scholar] [CrossRef]
- Battineni, G.; Chintalapudi, N.; Amenta, F. Forecasting of COVID-19 epidemic size in four high hitting nations (USA, Brazil, India and Russia) by Fb-Prophet machine learning model. Appl. Comput. Inform. 2020. [Google Scholar] [CrossRef]
- Yakunin, K.; Murzakhmetov, S.; Mussabayev, R.; Muhamedyev, R. News popularity prediction using topic modelling. In Proceedings of the 2021 IEEE International Conference on Smart Information Systems and Technologies (SIST), Nur-Sultan, Kazakhstan, 28–30 April 2021. [Google Scholar] [CrossRef]
- Tatar, A.; Antoniadis, P.; de Amorim, M.D.; Fdida, S. Ranking news articles based on popularity prediction. In Proceedings of the 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Istanbul, Turkey, 26–29 August 2012; pp. 106–110. [Google Scholar]
- Bandari, R.; Asur, S.; Huberman, B. The pulse of news in social media: Forecasting popularity. In Proceedings of the International AAAI Conference on Web and Social Media, Dublin, Ireland, 4–7 June 2012. [Google Scholar]
- Edelman Trust Barometer. Available online: https://www.edelman.com/trust-barometer (accessed on 5 August 2021).
- Miller, D. Promotional strategies and media power. In Introduction to Media; Briggs, A., Cobley, P., Eds.; Longman: London, UK, 1998; pp. 65–80. ISBN 0582 27798 1. [Google Scholar]
- Bushman, B.; Whitaker, J. Media influence on behavior. In Encyclopedia of Human Behavior, 2nd ed.; Elsevier Inc.: Amsterdam, The Netherlands, 2012; pp. 571–575. [Google Scholar]
- Stacks, D.; Li, Z.C.; Spaulding, C. Media effects. In International Encyclopedia of the Social & Behavioral Sciences, 2nd ed.; Elsevier Inc.: Amsterdam, The Netherlands, 2015; pp. 29–34. [Google Scholar]
- Ko, H.; Hong, J.Y.; Kim, S.; Mesicek, L.; Na, I.S. Human-machine interaction: A case study on fake news detection using a backtracking based on a cognitive system. Cogn. Syst. Res. 2019, 55, 77–81. [Google Scholar] [CrossRef]
- Bushman, B.J.; Whitaker, J.L. Media Influence on Behavior. Reference Module in Neuroscience and Biobehavioral Psychology; Elsevier Inc.: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Giri, S.P.; Maurya, A.K. A neglected reality of mass media during COVID-19: Effect of pandemic news on individual’s positive and negative emotion and psychological resilience. Personal. Individ. Differ. 2021, 180, 110962. [Google Scholar] [CrossRef]
- Aslam, F.; Awan, T.M.; Syed, J.H.; Kashif, A.; Parveen, M. Sentiments and emotions evoked by news headlines of coronavirus disease (COVID-19) outbreak. Human. Soc. Sci. Commun. 2020, 7, 1–9. [Google Scholar] [CrossRef]
- Hamidein, Z.; Hatami, J.; Rezapour, T. How people emotionally respond to the news on COVID-19: An online survey. Basic Clin. Neurosci. 2020, 11, 171. [Google Scholar] [CrossRef]
- Jo, W.; Chang, D. Political Consequences of COVID-19 and Media Framing in South Korea. Front. Public Health 2020, 8, 425. [Google Scholar] [CrossRef] [PubMed]
- Ridhwan, K.M.; Hargreaves, C.A. Leveraging Twitter Data to Understand Public Sentiment for the COVID-19 Outbreak in Singapore. Int. J. Inf. Manag. Data Insights 2021, 1, 100021. [Google Scholar] [CrossRef]
- Casero-Ripollés, A. Impact of Covid-19 on the media system. Communicative and democratic consequences of news consumption during the outbreak. Prof. Inf. 2020, 29, e290223. [Google Scholar] [CrossRef]
- Tandoc, E.C., Jr. Tell me who your sources are: Perceptions of news credibility on social media. J. Pract. 2019, 13, 178–190. [Google Scholar] [CrossRef]
- Song, X.; Petrak, J.; Jiang, Y.; Singh, I.; Maynard, D.; Bontcheva, K. Classification aware neural topic model for COVID-19 disinformation categorisation. PLoS ONE 2021, 16, e0247086. [Google Scholar] [CrossRef]
- Sun, K.; Chen, J.; Viboud, C. Early epidemiological analysis of the coronavirus disease 2019 outbreak based on crowdsourced data: A population-level observational study. Lancet Digit. Health 2020, 2, e201–e208. [Google Scholar] [CrossRef]
- Gabrielyan, D.; Masso, J.; Uuskula, L. Mining news data for the measurement and prediction of inflation expectations. In Proceedings of the CARMA 2020—3rd International Conference on Advanced Research Methods and Analytics, Valencia, Spain, 8–9 July 2020. [Google Scholar] [CrossRef]
- Leombroni, M.; Vedolin, A.; Venter, G.; Whelan, P. Central bank communication and the yield curve. J. Financ. Econ. 2021. [Google Scholar] [CrossRef]
- Parkhomenko, P.A.; Grigor’yev, A.A.; Astrakhantsev, N.A. Review and experimental comparison of text clustering methods. Proc. Inst. Syst. Program. RAS 2017, 29, 161–200. [Google Scholar] [CrossRef]
- Vorontsov, K.; Frei, O.; Apishev, M.; Romov, P.; Dudarenko, M. Bigartm: Open source library for regularized multimodal topic modeling of large collections. In Proceedings of the International Conference on Analysis of Images, Social Networks and Texts, Yekaterinburg, Russia, 9–11 April 2015; pp. 370–381. [Google Scholar]
- Jelodar, H. Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Alsolamy, M.; Alotaibi, A.; Alabbas, A.; Abdullah, M. Topic based Sentiment Analysis for COVID-19 Tweets. Int. J. Adv. Comput. Sci. Appl. 2021, 12. [Google Scholar] [CrossRef]
- Xue, J.; Chen, J.; Chen, C.; Zheng, C.; Li, S.; Zhu, T. Public discourse and sentiment during the COVID 19 pandemic: Using Latent Dirichlet Allocation for topic modeling on Twitter. PLoS ONE 2020, 15, e0239441. [Google Scholar] [CrossRef]
- Tao, G.; Miao, Y.; Ng, S. COVID-19 topic modeling and visualization. In Proceedings of the 2020 24th International Conference Information Visualisation (IV), Melbourne, Australia, 7–11 September 2020; pp. 734–739. [Google Scholar]
- Mutanga, M.B.; Abayomi, A. Tweeting on COVID-19 pandemic in South Africa: LDA-based topic modelling approach. Afr. J. Sci. Technol. Innov. Dev. 2020, 1–10. [Google Scholar] [CrossRef]
- Tsao, S.-F.; Chen, H.; Tisseverasinghe, T.; Yang, Y.; Li, L.; Butt, Z.A. What social media told us in the time of COVID-19: A scoping review. Lancet Digit. Health 2021, 3, e175–e194. [Google Scholar] [CrossRef]
- Kuchler, T.; Russel, D.; Stroebel, J. JUE Insight: The geographic spread of COVID-19 correlates with the structure of social networks as measured by Facebook. J. Urban Econ. 2021, 103314. [Google Scholar] [CrossRef]
- Gupta, A.; Aeron, S.; Agrawal, A.; Gupta, H. Trends in COVID-19 Publications: Streamlining Research Using NLP and LDA. Front Digit Health 2021, 3, 686720. [Google Scholar] [CrossRef] [PubMed]
- Angelov, D. Top2vec: Distributed representations of topics. arXiv 2020, arXiv:2008.09470 2020. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692 2019. [Google Scholar]
- Chintalapudi, N.; Battineni, G.; Amenta, F. Sentimental Analysis of COVID-19 Tweets Using Deep Learning Models. Infect. Dis. Rep. 2021, 13, 329–339. [Google Scholar] [CrossRef]
- Chakraborty, A.K.; Das, S.; Kolya, A.K. Sentiment analysis of covid-19 tweets using evolutionary classification-based LSTM model. In Proceedings of Research and Applications in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2021; pp. 75–86. [Google Scholar]
- Dong, E.; Du, H.; Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect. Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- Yakunin, K.; Kalimoldayev, M.; Mukhamediev, R.; Mussabayev, R.; Barakhnin, V.; Kuchin, Y.; Murzakhmetov, S.; Buldybayev, T.; Ospanova, U.; Yelis, M.; et al. KazNewsDataset: Single Country Overall Digital Mass Media Publication Corpus. Data 2021, 6, 31. [Google Scholar] [CrossRef]
- Arroyo-Marioli, F.; Bullano, F.; Kucinskas, S.; Rondón-Moreno, C. Tracking R of COVID-19: A new real-time estimation using the Kalman filter. PLoS ONE 2021, 16, e0244474. [Google Scholar] [CrossRef]
- Vorontsov, K.V.; Potapenko, A.A. Regularization, robustness and sparsity of probabilistic thematic models. Comput. Res. Model. 2012, 4, 693–706. [Google Scholar] [CrossRef][Green Version]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Mimno, D.; Wallach, H.; Talley, E.; Leenders, M.; McCallum, A. Optimizing semantic coherence in topic models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 262–272. [Google Scholar]
- Segalovich, I. A fast morphological algorithm with unknown word guessing induced by a dictionary for a web search engine. MLMTA 2003, 2003, 273. [Google Scholar]
- Stop-Words 2018.7.23. Available online: https://pypi.org/project/stop-words/ (accessed on 13 November 2021).
- Krasnov, F.; Anastasiia, S. The number of topics optimization: Clustering approach. Mach. Learn. Knowl. Extr. 2019, 1, 416–426. [Google Scholar] [CrossRef]
- Haleem, A.; Mohd, J.; Raju, V. Effects of COVID-19 pandemic in daily life. Curr. Med. Res. Pract. 2020, 10, 78. [Google Scholar] [CrossRef] [PubMed]
- Fernandes, N. Economic Effects of Coronavirus Outbreak (COVID-19) on the World Economy. 2020. SSRN 3557504. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3557504 (accessed on 4 December 2021).
- Galanti, T.; Guidetti, G.; Mazzei, E.; Zappalà, S.; Toscano, F. Work from Home During the COVID-19 Outbreak: The Impact on Employees’ Remote Work Productivity, Engagement, and Stress. J. Occup. Environ. Med. 2021, 63, e426–e432. [Google Scholar] [CrossRef]
- Campedelli, G.; Alberto, A.; Serena, F. Exploring the immediate effects of COVID-19 containment policies on crime: An empirical analysis of the short-term aftermath in Los Angeles. Am. J. Crim. Justice 2021, 46, 704–727. [Google Scholar] [CrossRef] [PubMed]
- Apuke, D.; Bahiyah, O. Fake news and COVID-19: Modelling the predictors of fake news sharing among social media users. Telemat. Inform. 2021, 56, 101475. [Google Scholar] [CrossRef]
- Divya, M.; Shiv Kumar, G. ElasticSearch: An advanced and quick search technique to handle voluminous data. Compusoft 2013, 2, 171–175. [Google Scholar]
- Białecki, A.; Muir, R.; Ingersoll, G. Apache lucene. In Proceedings of the SIGIR 2012 Workshop on Open Source Information Retrieval, Portland, OR, USA, 16 August 2012; Volume 4, pp. 17–24. [Google Scholar]
- Barakhnin, V.; Kozhemyakina, O.; Mukhamedyev, R.; Borzilova, Y.; Yakunin, K. The design of the structure of the software system for processing text document corpus. Bus. Inform. 2019, 13, 60–72. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Purpose of Research | Method | Data Source | The Language of the Corpus of Publications |
|---|---|---|---|
| The impact of news about COVID-19 on people’s emotional state [27] | Statistical analysis | Online survey | English |
| Analysis of social media information during a pandemic [45] | LDA, Random Forest | Twitter, Sina Weibo | English, Chinese |
| Testing the hypothesis that COVID-19 is more likely to spread between regions with closer ties in social networks [46]. | Statistical analysis | data | |
| Understanding the discourse and psychological reactions of Twitter users to COVID-19 [42]. | LDA, sentiment analysis | data | |
| Identifying predominant themes and accompanying emotions [43] | LDA | English | |
| Identifying what topics are discussed by the public and how they affect the implementation of measures taken by the government [44] | LDA | Papers | English |
| Analysis of PubMed® publication topics and their evolution over time during the COVID-19 pandemic [47] | LDA | PubMed | English |
| Identification of the most representative themes and sentiment analysis [14] | Top2vec [48], RoBERTa [49] | The media | English |
| Assessing social media sentiment toward coronavirus [41] | LDA, sentiment analysis | English | |
| Analysis of Indian online users’ tweets during the COVID-19 lockdown to identify texts containing fear, sadness, anger, and joy [50] | Sentiment analysis based on BERT | English | |
| Sentiment predictions on Covid-19 data [51] | Sentiment analysis based on LSTM | English |
| Indicator | Description |
|---|---|
| Number of new tests | Daily number of new tests for COVID-19 |
| Positive rate | The share of COVID-19 tests that are positive, given as a rolling 7-day average (this is the inverse of tests per case indicator) |
| Number of new cases smoothed | New confirmed cases of COVID-19 (7-day smoothed) |
| Number of new deaths smoothed | New deaths attributed to COVID-19 (7-day smoothed) |
| Tests per case | Tests conducted per new confirmed case of COVID-19, given as a rolling 7-day average (this is the inverse of positive rate indicator) |
| Virus reproduction rate | Real-time estimate of the effective reproduction rate (R) of COVID-19 [54] |
| Stringency index | Government Response Stringency Index: composite measure based on 9 response indicators including school closures, workplace closures, and travel bans, rescaled to a value from 0 to 100 (100 = strictest response) |
| Topic Model | # Topics | # Documents | Membership Threshold | Perplexity | Contrast | Purity |
|---|---|---|---|---|---|---|
| Level-0 | 200 | 1679803 | - | 3165 | 0.48 | 0.203 |
| Level-1 | 150 | 285564 | 0.05 | 1853 | 0.505 | 0.207 |
| Level-2 | 100 | 241536 | 0.04 | 1895 | 0.509 | 0.244 |
| Level-3 | 50 | 194392 | 0.1 | 1859 | 0.503 | 0.284 |
| Correlation (Pearson/Spearman) | Topic Name (Top-Words) | Topic Volume (Documents) |
|---|---|---|
| 0.91/0.87 | Vaccine, Vaccination, Drug, Coronavirus, Test, Sputnik-V, Russian | 15,434 |
| 0.86/0.85 | Petersburg, Saint Petersburg, Petersburg, Leningrad region, Moscow, report deaths, COVID | 1495 |
| 0.77/0.69 | Health, Product, Doctor, Alcohol, Organism, Nutrition, Healthy | 8318 |
| 0.74/0.63 | Tell, Photo, Arrive, Depart, Tourism, Return, Go | 2693 |
| 0.67/0.49 | Temperature, Degree, Night, Snow, Weather, Air, Strong | 8196 |
| Russia | Kazakhstan | ||
|---|---|---|---|
| Indicator | Correlation Coefficient (Pearson/Spearman) | Indicator | Correlation Coefficient (Pearson/Spearman) |
| New deaths smoothed | 0.81/0.77 | New tests | 0.55/0.54 |
| New cases smoothed | 0.66/0.67 | New cases smoothed | 0.51/0.76 |
| Positive test rate | 0.57/0.54 | Positive test rate | 0.23/0.62 |
| New tests | 0.36/0.49 | New deaths smoothed | 0.22/0.58 |
| Reproduction rate | −0.007/−0.11 | Reproduction rate | −0.18/−0.43 |
| Stringency index | −0.12/−0.16 | Stringency index | −0.53/−0.56 |
| Tests per case | −0.13/−0.05 | Tests per case | −0.54/−0.58 |
| Russia | Kazakhstan | ||
|---|---|---|---|
| Indicator | Correlation Coefficient (Pearson/Spearman) | Indicator | Correlation Coefficient (Pearson/Spearman) |
| Reproduction rate | 0.71/0.72 | Tests per case | 0.42/0.36 |
| Stringency index | 0.65/0.57 | Stringency index | 0.41/0.75 |
| Tests per case | 0.08/0.26 | Reproduction rate | 0.16/0.42 |
| Positive test rate | 0.02/0.17 | Positive test rate | 0.14/−0.40 |
| New tests | −0.11/0.10 | New deaths smoothed | −0.29/−0.47 |
| New cases smoothed | −0.18/0.08 | New cases smoothed | −0.35/−0.47 |
| New deaths smoothed | −0.32/−0.10 | New tests | −0.56/−0.50 |
| Russia | Kazakhstan | ||
|---|---|---|---|
| Indicator | Correlation Coefficient (Pearson/Spearman) | Indicator | Correlation Coefficient (Pearson/Spearman) |
| New deaths smoothed | 0.84/0.71 | New cases smoothed | 0.50/0.63 |
| New cases smoothed | 0.70/0.68 | Positive test rate | 0.36/0.67 |
| Positive test rate | 0.68/0.62 | New deaths smoothed | 0.29/0.54 |
| New tests | 0.47/0.48 | New tests | 0.20/0.13 |
| Reproduction rate | 0.25/0.14 | Reproduction rate | −0.06/−0.43 |
| Stringency index | 0.05/−0.06 | Stringency index | −0.21/−0.11 |
| Tests per case | −0.14/−0.11 | Tests per case | −0.5/−0.63 |
| Russia | Kazakhstan | ||||
|---|---|---|---|---|---|
| Query | Top Indicator (Pearson/Spearman) | Correlation Coefficient (Pearson/Spearman) | Query | Top Indicator (Pearson/Spearman) | Correlation Coefficient (Pearson/Spearman) |
| Vaccination, COVID-19 vaccines | Positive rate/Positive rate | 0.76/0.78 | Healthcare, hospitals, issues, healthcare scandals | Stringency index/Stringency index | 0.42/0.32 |
| Healthcare, hospitals, issues, healthcare scandals | Positive rate/Reproduction rate | 0.67/0.53 | Crisis, lending, debt, microcredits | Tests per case/Stringency index | 0.41/0.46 |
| Crisis, lending, debt, microcredits | Reproduction rate/Stringency index | 0.56/0.54 | Vaccination, COVID-19 vaccines | Reproduction rate/Stringency index | 0.38/0.52 |
| Unemployment, poverty | Stringency index/Stringency ondex | 0.56/0.48 | Fake, disinformation, anti-vax | Tests per case/Reproduction rate | 0.33/0.21 |
| Crisis, economic decline | Tests per case/Stringency index | 0.49/0.44 | Crisis, economic decline | Tests per case/Stringency index | 0.29/0.47 |
| Freelance, remote work, brain drain | Stringency index/Stringency index | 0.39/0.35 | Remote education | New tests/Positive rate | 0.29/0.38 |
| Famine, starvation, homeless, poverty | Stringency index/Stringency index | 0.35/0.47 | Unemployment, poverty | Tests per case/Reproduction rate | 0.27/0.29 |
| Fake, disinformation, anti-vax | Tests per case/Tests per case | 0.33/0.39 | Freelance, remote work, brain drain | Stringency index/Stringency index | 0.26/0.46 |
| Remote education | Reproduction rate/Tests per case | 0.11/0.39 | Criminal, robbery, theft, homicide | New tests/New tests | 0.20/0.15 |
| Criminal, robbery, theft, homicide | New deaths/Positive rate | 0.07/0.10 | Famine, starvation, homeless, poverty | New tests/Positive rate | 0.09/0.16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yakunin, K.; Mukhamediev, R.I.; Zaitseva, E.; Levashenko, V.; Yelis, M.; Symagulov, A.; Kuchin, Y.; Muhamedijeva, E.; Aubakirov, M.; Gopejenko, V. Mass Media as a Mirror of the COVID-19 Pandemic. Computation 2021, 9, 140. https://doi.org/10.3390/computation9120140
Yakunin K, Mukhamediev RI, Zaitseva E, Levashenko V, Yelis M, Symagulov A, Kuchin Y, Muhamedijeva E, Aubakirov M, Gopejenko V. Mass Media as a Mirror of the COVID-19 Pandemic. Computation. 2021; 9(12):140. https://doi.org/10.3390/computation9120140
Chicago/Turabian StyleYakunin, Kirill, Ravil I. Mukhamediev, Elena Zaitseva, Vitaly Levashenko, Marina Yelis, Adilkhan Symagulov, Yan Kuchin, Elena Muhamedijeva, Margulan Aubakirov, and Viktors Gopejenko. 2021. "Mass Media as a Mirror of the COVID-19 Pandemic" Computation 9, no. 12: 140. https://doi.org/10.3390/computation9120140
APA StyleYakunin, K., Mukhamediev, R. I., Zaitseva, E., Levashenko, V., Yelis, M., Symagulov, A., Kuchin, Y., Muhamedijeva, E., Aubakirov, M., & Gopejenko, V. (2021). Mass Media as a Mirror of the COVID-19 Pandemic. Computation, 9(12), 140. https://doi.org/10.3390/computation9120140