Abstract
The k-means problem is one of the most popular models in cluster analysis that minimizes the sum of the squared distances from clustered objects to the sought cluster centers (centroids). The simplicity of its algorithmic implementation encourages researchers to apply it in a variety of engineering and scientific branches. Nevertheless, the problem is proven to be NP-hard which makes exact algorithms inapplicable for large scale problems, and the simplest and most popular algorithms result in very poor values of the squared distances sum. If a problem must be solved within a limited time with the maximum accuracy, which would be difficult to improve using known methods without increasing computational costs, the variable neighborhood search (VNS) algorithms, which search in randomized neighborhoods formed by the application of greedy agglomerative procedures, are competitive. In this article, we investigate the influence of the most important parameter of such neighborhoods on the computational efficiency and propose a new VNS-based algorithm (solver), implemented on the graphics processing unit (GPU), which adjusts this parameter. Benchmarking on data sets composed of up to millions of objects demonstrates the advantage of the new algorithm in comparison with known local search algorithms, within a fixed time, allowing for online computation.
1. Introduction
1.1. Problem Statement
The aim of a clustering problem solving is to divide a given set (sample) of objects (data vectors) into disjoint subsets, called clusters, so that each cluster consists of similar objects, and the objects of different clusters have significant dissimilarities [1,2]. The clustering problem belongs to a wide class of unsupervised machine learning problems. Clustering models involve various similarity or dissimilarity measures. The k-means model with the squared Euclidean distance as a dissimilarity measure is based exclusively on the maximum similarity (minimum sum of squared distances) among objects within clusters.
Clustering methods can be divided into two main categories: hierarchical and partitioning [1,3]. Partitioning clustering, such as k-means, aims at optimizing the clustering result in accordance with a pre-defined objective function [3].
The k-means problem [4,5], also known as minimum sum-of-squares clustering (MSSC), assumes that the objects being clustered are described by numerical features. Each object is represented by a point in the feature space (data vector). It is required to find a given number k of cluster centers (called centroids), such as to minimize the sum of the squared distances from the data vectors to the nearest centroid.
Let A1, …, AN ∈ be data vectors, N be the number of them, and S = {X1, …, Xk} ⊂ be the set of sought centroids. The objective function (sum of squared errors, SSE) of the k-means optimization problem formulated by MacQueen [5] is:
Here, is the Euclidean distance, integer k must be known in advance.
A cluster in the k-means problem is a subset of data vectors for which the specified centroid is the nearest one:
We assume that a data vector cannot belong to two clusters at the same time. At an equal distance for several centroids, the question of assignment to a cluster can be solved by clustering algorithms in different ways. For example, a data vector belongs to a cluster lower in number:
Usually, for practical problems with sufficiently accurate measured values of data vectors, the assignment to a specific cluster is not very important.
The objective function may also be formulated as follows:
or
Equations (3) and (4) correspond to continuous and discrete statements of our problem, respectively.
Such clustering problem statements have a number of drawbacks. In particular, the number of clusters k must be given in advance, which is hardly possible for the majority of practically important problems. Furthermore, the adequacy of the result in the case of a complex cluster shapes is questionable (this model is proved to work fine with the ball-shaped clusters [6]). The result is sensitive to the outliers (standalone objects) [7,8] and depends on the chosen distance measure and the data normalization method. This model does not take into account the dissimilarity between the objects in different clusters, and the application of the k-means model results in some solution X1, …, Xk even in the cases with no cluster structure in the data [9,10]. Moreover, the NP-hardness [11,12] of the problem makes the exact methods [6] applicable only for very small problems.
Nevertheless, the simplicity of the most commonly used algorithmic realization as well as the interpretability of the results make the k-means problem the most popular clustering model. Developers’ efforts are focused on the design of heuristic algorithms that provide acceptable and attainable values of the objective function.
1.2. State of the Art
The most commonly used algorithm for solving problem (1) is the Lloyd’s procedure proposed in 1957 and published in 1982 [4], also known as the k-means algorithm, or alternate location-allocation (ALA) algorithm [13,14]. This algorithm consists of two simple alternating steps, the first of which solves the simplest continuous (quadratic) optimization problem (3), finding the optimal positions of the centroids X1, …, Xk for a fixed composition of clusters. The second step solves the simplest combinatorial optimization problem (4) by redistributing data vectors between clusters at fixed positions of the centroids. Both steps aim at minimizing the SSE. Despite the theoretical estimation of the computational complexity being quite high [15,16,17], in practice, the algorithm quickly converges to a local minimum. The algorithm starts with some initial solution S = {X1, …, Xk}, for instance, chosen at random, and its result is highly dependent on this choice. In the case of large-scale problems, this simple algorithm is incapable of obtaining the most accurate solutions.
Various clustering models are widely used in many engineering applications [18,19], such as energy loss detection [20], image segmentation [21], production planning [22], classification of products such as semiconductor devices [23], recognition of turbulent flow patterns [24], and cyclical disturbance detection in supply networks [25]. Clustering is also used as a preprocessing step for the supervised classification [26].
In [27], Naranjo et al. use various clustering approaches including the k-means model for automatic classification of traffic incidents. The approach proposed in [28] uses the k-means clustering model for the optimal scheduling of public transportation. Sesham et al. [29] use factor analysis methods in a combination with the k-means clustering for detecting cluster structures in transportation data obtained from the interview survey. Such data include the geographic information (home addresses) and general route information. The use of GPS sensors [30] for collecting traffic data provides us with large data arrays for such problems as the travel time prediction, traffic condition recognition [31], etc.
The k-means problem can be classified as a continuous location problem [32,33]: it is aimed at finding the optimal location of centroids in a continuous space.
If we replace squared distances with distances in (1), we deal with the very similar continuous k-median location problem [34] which is also a popular clustering model [35]. The k-medoids [36,37] problem is its discrete version where cluster centers must be selected among the data vectors only, which allows us to calculate the distance matrix in advance [38]. The k-median problem was also formulated as a discrete location problem [39] on a graph. The similarity of these NP-hard problems [40,41] enables us to use similar approaches to solve them. In the early attempts to solve the k-median problem (its discrete version) by exact methods, researchers used a branch and bound algorithm [42,43,44] for solving very small problems.
Metaheuristic approaches, such as genetic algorithms [45], are aimed at finding the global optimum. However, in large-scale instances, such approaches require very significant computational costs, especially if they are adapted to solving continuous problems [46].
With regard to discrete optimization problems, local search methods, which include Lloyd’s procedure, have been developed since the 1950s [47,48,49,50]. These methods have been successfully used to solve location problems [51,52]. The progress of local search methods is associated with both new algorithmic schemes and new theoretical results in the field of local search [50].
A standard local search algorithm starts with some initial solution S and goes to a neighboring solution if this solution turns out to be superior. Moreover, finding the set of neighbor solutions n(S) is the key issue. Elements of this set are formed by applying a certain procedure to a solution S. At each local search step, the neighborhood function n(S) specifies the set of possible search directions. Neighborhood functions can be very diverse, and the neighborhood relation is not always symmetric [53,54].
For a review of heuristic solution techniques applied to k-means and k-median problems, the reader can refer to [32,55,56]. Brimberg, Drezner, and Mladenovic and Salhi [57,58,59] presented local search approaches including the variable neighborhood search (VNS) and concentric search. In [58], Drezner et al. proposed heuristic procedures including the genetic algorithm (GA), for rather small data sets. Algorithms for finding the initial solution for the Lloyd’s procedure [60,61] are aimed at improving the average resulting solution. For example, in [62], Bhusare et al. propose an approach to spread the initial centroids uniformly so that the distance among them is as far as possible. The most popular kmeans++ initialization method introduced by Arthur and Vassilvitskii [60] is a probabilistic implementation of the same idea. An approach proposed by Yang and Wang [63] improves the traditional k-means clustering algorithm by choosing initial centroids with a min-max similarity. Gu et al. [7] provide a density-based initial cluster center selection method to solve the problem of outliers. Such smart initialization algorithms reduce the search area for local search algorithms in multi-start modes. Nevertheless, they do not guarantee an optimal or near optimal solution of the problem (1).
Many authors propose approaches based on reducing the amount of data [64]: simplification of the problem by random (or deterministic) selection of a subset of the initial data set for a preliminary solution of the k-means problem, and using these results as an initial solution to the k-means algorithm on the complete data set [65,66,67]. Such aggregation approaches, summarized in [68], as well as reducing the number of the data vectors [69], enable us to solve large-scale problems within a reasonable time. However, such approaches lead to a further reduction in accuracy. Moreover, many authors [70,71] name their algorithm “exact” which does not mean the ability to achieve an exact solution of (1). In such algorithms, the word “exact” means the exact adherence to the scheme of the Lloyd’s procedure, without any aggregation, sampling, and relaxation approaches. Thus, such algorithms may be faster than the Lloyd’s procedure due to the use of triangle inequality, storing the results of distance calculations in multidimensional data sets or other tricks [72], however they are not intended to get the best value of (1). In our research, aimed at obtaining the most precise solutions, we consider only the methods which estimate the objective function (1) directly, without aggregation or approximation approaches.
The main idea of the variable neighborhood search algorithms proposed by Hansen and Mladenovic [73,74,75] is the alternation of neighborhood functions n(S). Such algorithms include Lloyd’s procedure, which alternates finding a locally optimal solution of a continuous optimization problem (3) with a solution of a combinatorial problem (4). However, as applied to the k-means problem, the VNS class traditionally involves more complex algorithms.
The VNS algorithms are used for a wide variety of problems [3,76,77] including clustering [78] and work well for solving k-means and similar problems [50,79,80,81,82].
Agglomerative and dissociative procedures are separate classes of clustering algorithms. Dissociative (divisive) procedures [83] are based on splitting clusters into smaller clusters. Such algorithms are commonly used for small problems due to their high computing complexity [83,84,85], most often in hierarchical clustering models. The agglomerative approach is the most popular in hierarchical clustering, however, it is also applied in other models of cluster analysis. Agglomerative procedures [86,87,88,89,90] combine clusters sequentially, i.e., in relation to the k-means problem, they sequentially remove centroids. The elements of the clusters, related to the removed centroids, are redistributed among the remaining clusters. The greedy strategies are used to decide which clusters are most similar to be merged together [3] at each iteration of the agglomerative procedure. An agglomerative procedure starts with some solution S containing an excessive number of centroids and clusters k + r, where integer r is known in advance or chosen randomly. The r value (number of excessive centroids in the temporary solution) is the most important parameter of the agglomerative procedure. Some algorithms, including those based on the k-means model [91], involve both the agglomerative and dissociative approaches. Moreover, such algorithms are not aimed at achieving the best value of the objective function (1), and their accuracy is not high in this sense.
1.3. Research Gap
Many transportation and other problems (e.g., clustering problems related to computer vision) require online computation within a fixed time. As mentioned above, Lloyd’s procedure, the most popular k-means clustering algorithm, is rather fast. Nevertheless, for specific data sets including geographic/geometrical data, this algorithm results in a solution which is very far from the global minimum of the objective function (1), and the multi-start operation mode does not improve the result significantly. More accurate k-means clustering methods are much slower. Nevertheless, recent advances in high-performance computing and the use of massively parallel systems enable us to work through a large amount of computation using the Lloyd’s procedure embedded into more complex algorithmic schemes. Thus, the demand for clustering algorithms that compromise on the time spent for computations and the resulting objective function (1) value is apparent. Nevertheless, in some cases, when solving problem (1), it is required to obtain a result (a value of the objective function) within a limited fixed time, which would be difficult to improve on by known methods without a significant increase in computational costs. Such results are required if the cost of error is high, as well as for evaluating faster algorithms, as reference solutions.
Agglomerative procedures, despite their relatively high computational complexity, can be successfully integrated into more complex search schemes. They can be used as a part of the crossover operator of genetic algorithms [46,88] and as a part of the VNS algorithms. Moreover, such algorithms are a compromise between the solution accuracy and time costs. In this article, by accuracy, we mean exclusively the ability of the algorithm (solver) to obtain the minimum values of the objective function (1).
The use of VNS algorithms, that search in the neighborhoods, formed by applying greedy agglomerative procedures to a known (current) solution S, enables us to obtain good results in a fixed time acceptable for interactive modes of operation. The selection of such procedures, their sequence and their parameters remained an open question. The efficiency of such procedures has been experimentally shown on some test and practical problems. Various versions of VNS algorithms based on greedy agglomerative procedures differ significantly in their results which makes such algorithm difficult to use in practical problems. It is practically impossible to forecast the relative performance of a specific VNS algorithm based on such generalized numerical features of the problem as the sample size and the number of clusters. Moreover, the efficiency of such procedures depends on their parameters. However, the type and nature of this dependence has not been studied.
1.4. Our Contribution
In this article, we systematize approaches to the construction of search algorithms in neighborhoods, formed by the use of greedy agglomerative procedures.
In this work, we proceeded from the following assumptions:
- (a)
- The choice of parameter r value (the number of excessive centroids, see above) of the greedy agglomerative heuristic procedure significantly affects the efficiency of the procedure.
- (b)
- Since it is hardly possible to determine the optimal value of this parameter based on such numerical parameters of the k-means problem as the number of data vectors and the number of clusters, reconnaissance (exploratory) search with various values of r can be useful.
- (c)
- Unlike the well-known VNS algorithms that use greedy agglomerative heuristic procedures with an increasing value of the parameter r, a gradual decrease in the value of this parameter may be more effective.
Based on these assumptions, we propose a new VNS algorithm involving greedy agglomerative procedures for the k-means problem, which, by adjusting the initial r parameter of such procedures, enables us to obtain better results in a fixed time which exceed the results of known VNS algorithms. Due to self-adjusting capabilities, such an algorithm should be more versatile, which should increase its applicability to a wider range of problems in comparison with known VNS algorithms based on greedy agglomerative procedures.
1.5. Structure of this Article
The rest of this article is organized as follows. In Section 2, we present an overview of the most common local search algorithms for k-means and similar problems, and introduce the notion of neighborhoods SWAPr and GREEDYr. It is shown experimentally that the search result in these neighborhoods strongly depends on the neighborhood parameter r (the number of simultaneously alternated or added centroids). In addition, we present a new VNS algorithm which performs the local search in alternating GREEDYr neighborhoods with the decreasing value of r and its initial value estimated by a special auxiliary procedure. In Section 3, we describe our computational experiments with the new and known algorithms. In Section 4, we consider the applicability of the results on the adjustment of the GREEDYr neighborhood parameter in algorithmic schemes other than VNS, in particular, in evolutionary algorithms with a greedy agglomerative crossover operator. The conclusions are given in Section 5.
2. Materials and Methods
For constructing a more efficient algorithm (solver), we used a combination of such algorithms as Lloyd’s procedure, greedy agglomerative clustering procedures, and the variable neighborhood search. The most computationally expensive part of this new algorithmic construction, Lloyd’s procedure, was implemented on graphic processing units (GPU).
2.1. The Simplest Approach
Lloyd’s procedure, the simplest and most popular algorithm for solving the k-means problem, is described as follows (see Algorithm 1).
| Algorithm 1.Lloyd(S) |
| Require: Set of initial centroids S = {X1, …, Xk}. If S is not given, then the initial centroids are selected randomly from the set of data vectors {A1, …, AN}. |
| repeat |
| 1. For each centroid Xj, , define its cluster in accordance with (2); // I.e. assign each data vector to the nearest centroid |
| 2. For each cluster Cj, , calculate its centroid as follows: |
| until all centroids stay unchanged. |
Formally, the k-means problem in its formulation (1) or (3) is a continuous optimization problem. With a fixed composition of clusters Cj, the optimal solution is found in an elementary way, see Step 2 in Algorithm 1, and this solution is the local optimum of the problem in terms of the continuous optimization theory, i.e., local optimum in the -neighborhood. A large number of such optima forces the algorithm designers to systematize their search in some way. The first step of Lloyd’s algorithm solves a simple combinatorial optimization problem (3) on the redistribution of data vectors among clusters, that is, it searches in the other neighborhood.
The simplicity of Lloyd’s procedure enables us to apply it to a wide range of problems, including face detection, image segmentation, signal processing and many others [92]. Frackiewicz et al. [93] presented a color quantization method based on downsampling of the original image and k-means clustering on a downsampled image. The k-means clustering algorithm used in [94] was proposed for identifying electrical equipment of a smart building.
In many cases, researchers do not distinguish between the k-means model and the k-means algorithm, as Lloyd’s procedure is also called. Nevertheless, the result of Lloyd’s procedure may differ from the results of other more advanced algorithms many times in the objective function value (1). For finding a more accurate solution, a wide range of heuristic methods were proposed [55]: evolutionary and other bio-inspired algorithms, as well as local search in various neighborhoods.
Modern scientific literature offers many algorithms to speed up the solution of the k-means problem. Algorithm named k-indicators [95] promoted by Chen et al. is a semi-convex-relaxation algorithm for approximate solution of big-data clustering problems. In the distributed implementation of the k-means algorithm proposed in [96], the algorithm considers a set of agents, each of which is equipped with a possibly high-dimensional piece of information or set of measurements. In [97,98], the researchers improved algorithms for the data streams. In [99], Hedar et al. present a hierarchical k-means method for better clustering performance in the case of big data problems. This approach enables us to mitigate the poor scaling behavior with regard to computing time and memory requirements. Fast adaptive k-means subspace clustering algorithm with an adaptive loss function for high-dimensional data was proposed by Wang et al. [100]. Nevertheless, the usage of the massively parallel systems is the most efficient way to achieve the most significant acceleration of computations, and the original Lloyd’s procedure (Algorithm 1) can be seamlessly parallelized on such systems [101,102].
Metaheuristic approaches for the k-means and similar problems include genetic algorithms [46,103,104], the ant colony clustering hybrid algorithm proposed in [105], particle swarm optimization algorithms [106]. Almost all of these algorithms in one way or another use the Lloyd’s procedure or other local search procedures. Our new algorithm (solver) is not an exception.
2.2. Local Search in SWAP Neighborhoods
Local search algorithms differ in forms of neighborhood function n(S). A local minimum in one neighborhood may not be a local minimum in another neighborhood [50]. The choice of a neighborhood of lower cardinality leads to a decrease in the complexity of the search step, however, a wider neighborhood can lead to a better local minimum. We have to find a balance between these conflicting requirements [50].
A popular idea when solving k-means, k-medoids, k-median problems is to search for a better solution in SWAP neighborhoods. This idea was realized, for instance, in the J-means procedure [80] proposed by Hansen and Mladenovic, and similar I-means algorithm [107]. In SWAP neighborhoods, the set n(S) is the set of solutions obtained from S by replacing one or more centroids with some data vectors.
Let us denote the neighborhood, where r centroids must be simultaneously replaced, by SWAPr(S). The SWAPr neighborhood search can be regular (all possible substitutions are sequentially enumerated), as in the J-means algorithm, or randomized (centroids and data vectors for replacement are selected randomly). In both cases, the search in the SWAP neighborhood always alternates with the Lloyd’s procedure: if an improved solution is found in the SWAP neighborhood, the Lloyd’s procedure is applied to this new solution, and then the algorithm returns to the SWAP neighborhood search. Except for very small problems, regular search in SWAP neighborhoods, with the exception of the SWAP1 neighborhood and sometimes SWAP2, is almost never used due to the computational complexity: in each of iterations, all possible replacement options must be tested. A randomized search in SWAPr neighborhoods can be highly efficient for sufficiently large problems, which can be demonstrated by the experiment described below. Herewith, the correct choice of r is of great importance.
As can be seen on Figure 1, for various problems from the clustering benchmark repository [108,109], the best results are achieved with different values of r, although in general, such a search provides better results in comparison with Lloyd’s procedure. Our computational experiments are described in detail in Section 2.5, Section 2.6 and Section 2.7.
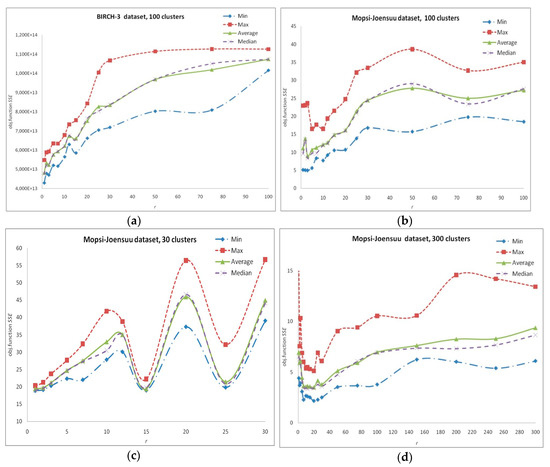
Figure 1.
Search in SWAPr neighborhoods. Dependence of the result on r: (a) BIRCH3 data set, 100 clusters, 105 data vectors, time limitation 10 s; (b–d) Mopsi-Joensuu data set, 30, 100 and 300 clusters, 6014 data vectors, time limitation 5 s.
2.3. Agglomerative Approach and GREEDYr Neyborhoods
When solving the k-means and similar problems, the agglomerative approach is often successful. In [86], Sun et al. propose a parallel clustering method based on MapReduce model which implements the information bottleneck clustering (IBC) idea. In the IBC and other agglomerative clustering algorithms, clusters are sequentially removed one-by-one, and objects are redistributed among the remaining clusters. Alp et al. [88] presented a genetic algorithm for facility location problems, where evolution is facilitated by a greedy agglomerative heuristic procedure. A genetic algorithm with a faster greedy heuristic procedure for clustering and location problems was also proposed in [90]. In [46], two genetic algorithm approaches with different crossover procedures are used to solve k-median problem in continuous space.
Greedy agglomerative procedures can be used as independent algorithms, as well as being embedded into genetic operators [110] or VNS algorithms [79]. The basic greedy agglomerative procedure for the k-means problem can be described as follows (see Algorithm 2).
| Algorithm 2.BasicGreedy(S) |
| Require: Set of initial centroids S = {X1, …, XK}, K > k, required final number of centroids k. |
| while |S| > k do |
| for do |
| end for |
| Select a subset of rtoremove centroids with the minimum values of the corresponding |
| variables Fi; // By default, rtoremove = 1. |
| end while. |
In its most commonly used version, with rtoremove = 1, this procedure is rather slow for large-scale problems. It tries to remove the centroids one-by-one. At each iteration, it eliminates such centroids that their elimination results in the least significant increase in the SSE value. Further, this procedure involves the Lloyd’s procedure which can be also slow in the case of rather large problems with many clusters. To improve the performance of such a procedure, the number of simultaneously eliminated centroids can be calculated as . In [90], Kazakovtsev and Antamoshkin used the elimination coefficient value = 0.2. This means that at each iteration, up to 20% of the excessive centroids are eliminated, and such values are proved to make the algorithm faster. In this research, we use the same value.
In [79,90,110], the authors embed the BasicGreedy() procedure into three algorithms which differ in r value only. All of these algorithms can be described as follows (see Algorithm 3):
| Algorithm 3.Greedy (S,S2,r) |
| Require: Two sets of centroids S, S2, |S| = |S2| = k, the number of centroids r of the solution S2 which are used to obtain the resulting solution, . |
| Fordo |
| 1. Select a subset . |
| 2. |
| 3. if SSE(S’) < SSE(S) then end if; |
| end for |
| returnS. |
Such procedures use various values of r from 1 up to k. If r = 1 then the algorithm selects a subset (actually, a single element) of S2 regularly: {X1} in the first iteration, {X2} in the second one, etc. In this case, nrepeats = k. If r = k then obviously S’ = S2, and nrepeat =1. Otherwise, r is selected randomly, , and nrepeats depends on r: nrepeats = max{1,}.
If the solution S2 is fixed, then all possible results of applying the Greedy(S,S2,r) procedure form a neighborhood of the solution S, and S2 as well as r are parameters of such a neighborhood. If S2 is a randomly chosen locally optimal solution obtained by Lloyd(S2’) procedure applied to a randomly chosen subset , then we deal with a randomized neighborhood.
Let us denote such a neighborhood by GREEDYr(S). Our experiments in Section 3 demonstrate that the obtained result of the local search in GREEDYr neighborhoods strongly depends on r.
2.4. Variable Neighborhood Search
The dependence of the local search result on the neighborhood selection reduces if we use a certain set of neighborhoods and alternate them. This approach is the basis for VNS algorithms. The idea of alternating neighborhoods is easy to adapt to various problems [76,77,78] and highly efficient, which makes it very useful for solving NP-hard problems including clustering, location, and vehicle routing problems. In [111,112], Brimberg and Mladenovic and Miskovic et al. used the VNS for solving various facility location problems. Cranic et al. [113] as well as Hansen and Mladenovic [114] proposed and developed a parallel VNS algorithm for the k-median problem. In [115], a VNS algorithm was used for a vehicle routing and driver scheduling problems by Wen et al.
The ways of neighborhood alternation may differ significantly. Many VNS algorithms are not even classified by their authors as VNS algorithms. For example, the algorithm in [57] alternates between discrete and continuous problems: when solving a discrete problem, the set of local optima is replenished, and then such local optima are chosen as elements of the initial solution of the continuous problem. A similar idea of the recombinator k-means algorithm was proposed by C. Baldassi [116]. This algorithm restarts the k-means procedure, using the results of previous runs as a reservoir of candidates for the new initial solutions, exploiting the popular k-means++ seeding algorithm to piece them together into new, promising initial configurations. Thus, the k-means search alternates with the discrete problem of finding an optimal initial centroid combination.
VNS class includes a very efficient abovementioned J-Means algorithm [80], which alternates search in a SWAP neighborhood and the use of Lloyd’s procedure. Even when searching only in the SWAP1 neighborhood, the J-Means results can be many times better than the results of Lloyd’s procedure launched in the multi-start mode, as shown in [62,97].
In [50], Kochetov et al. describe such basic schemes of VNS algorithms as variable neighborhood descent (VND, see Algorithm 4) [117] and randomized Variable Neighborhood Search (RVNS, see Algorithm 5) [50].
| Algorithm 4.VND(S) |
| Require: Initial solution S, selected neighborhoods nl, . |
| repeat |
| ; |
| whiledo |
| search for |
| if f(S’) < f(S) then else end if; |
| end while; |
| until the stop conditions are satisfied. |
| Algorithm 5.RVNS(S) |
| Require: Initial solution S, selected neighborhoods nl, . |
| repeat |
| ; |
| While do |
| select randomly |
| if f(S’) < f(S) then else end if; |
| end while; |
| until the stop conditions are satisfied. |
Algorithms of the RVNS scheme are more efficient when solving large-scale problems [50], when the use of deterministic VND requires too large computational costs per each iteration. In many efficient algorithms, lmax = 2. For example, the J-Means algorithm combines a SWAP neighborhood search with Lloyd’s procedure.
As a rule, algorithm developers propose to move from neighborhoods of lower cardinality to wider neighborhoods. For instance, in [79], the authors propose a sequential search in the neighborhoods GREEDY1 GREEDYrandom GREEDYk GREEDY1 … Here, GREEDYrandom is a neighborhood with randomly selected . In this case, the initial neighborhood type has a strong influence on the result [79]. However, the best initial value of parameter r is hardly predictable.
In this article, we propose a new RVNS algorithm which involves GREEDYr neighborhood search with a gradually decreasing r and automatic adjustment of the initial r value. Computational experiments show the advantages of this algorithm in comparison with the algorithms searching in SWAP neighborhoods as well as in comparison with known search algorithms with GREEDYr neighborhoods.
2.5. New Algorithm
A search in a GREEDYr neighborhood with a fixed r values, on various practical problems listed in the repositories [108,109,118], shows that the result (the value of the objective function) essentially depends on r, and this dependence differs for various problems, even if the problems have similar basic numerical characteristics, such as the number of data vectors N, their dimension d, and the number of clusters k. The results are shown on Figure 2 and Figure 3. At the same time, our experiments show that at the first iterations, the use of Algorithm 3 almost always leads to an improvement in the SSE value, and then the probability of such a success decreases. Moreover, the search in neighborhoods with large r values stops giving improving results sooner, while the search in neighborhoods with small r, in particular, with r = 1, enables us to obtain the improved solutions during a longer time. The search in the GREEDY1 neighborhood corresponds to the adjustment of individual centroid positions. Thus, the possible decrement of the objective function value is not the same for different values of r.
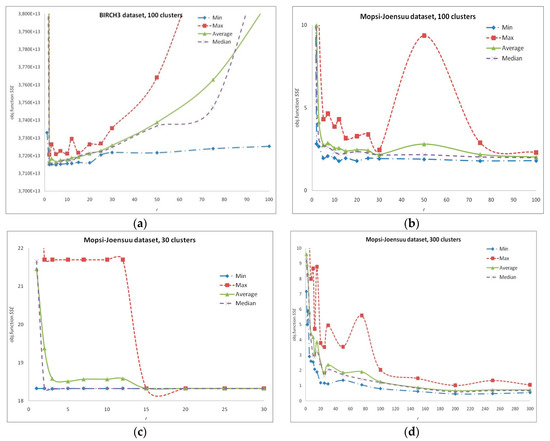
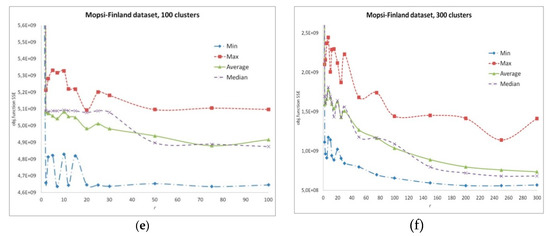
Figure 2.
Search in GREEDYr neighborhoods. Dependence of the result on r: (a) BIRCH3 data set, 100 clusters, 105 data vectors, time limitation 10 s; (b–d) Mopsi-Joensuu data set, 30, 100 and 300 clusters, 6014 data vectors, time limitation 5 s; (e–f) Mopsi-Finland data set, 100 and 300 clusters, 13,467 data vectors, time limitation 5 s.
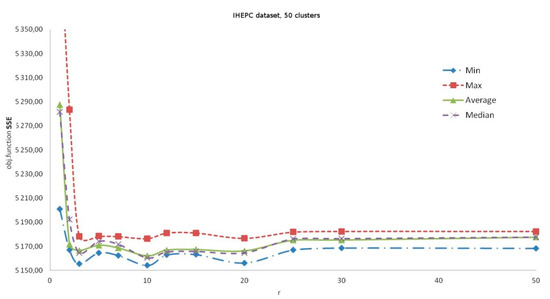
Figure 3.
Search in GREEDYr neighborhoods. Dependence of the result on r: Individual Household Electric Power Consumption (IHEPC) data set, 50 clusters, 2,075,259 data vectors, time limitation 5 min.
We propose the following sequence of neighborhoods: GREEDYr0 GREEDYr1 GREEDYr2 … GREEDY1 GREEDYk Here, r values gradually decrease: r0 > r1 > r2…. After reaching r = 1, the search continues in the GREEDYk neighborhood, and after that the value of r starts decreasing again. Moreover, the r value fluctuates within certain limits at each stage of the search.
This algorithm can be described as follows (Algortithm 6).
| Algorithm 6.DecreaseGreedySearch(S,r0) |
| Require: Initial solution S, initial . |
| select randomly , ||= k; |
| repeat |
| nrepeats max{1,}; |
| for do |
| 1. select randomly |
| 2. |
| 3. if SSE(S’) < SSE(S) then end if; |
| endfor; |
| select randomly , || = k; |
| if Steps 1–3 have not changed S |
| then |
| if then else end if; |
| end if; |
| until the stop conditions are satisfied (time limitation). |
Genetic algorithms with greedy agglomerative heuristics are known to perform better than VNS algorithms with sufficient computation time [79,90] which results in better SSE values. Despite this, the limited time and computational complexity of the Greedy() procedure as a genetic crossover operator leads to a situation when genetic algorithms may have enough time to complete a very limited number of crossover operations and often only reach the second or third generation of solutions. Under these conditions, VNS algorithms are a reasonable compromise of the computation cost and accuracy.
The choice of the initial value of parameter r0 is highly important. Such a choice is quite simply carried out by a reconnaissance search with different r0 values. The algorithm with such an automatic adjustment of the parameter r0 by performing a reconnaissance search is described as follows (Algorithm 7).
| Algorithm 7.AdaptiveGreedy (S) solver |
| Require: the number of reconnaissance search iterations nrecon. select randomly , |S| = k; |
| fordo |
| select randomly , || = k; |
| end for; |
| r |
| repeat |
| ; nrepeats max{1,}; |
| for do |
| for do |
| if SSE(S’) < SSE() then end if; |
| end for; |
| end for; |
| ; |
| until; |
| select the value r with minimum value of SSE(); |
| ; |
| DecreaseGreedySearch(). |
Results of computational experiments described in the next Section show that our new algorithm, which sequentially decreases the value of the parameter r0, has an advantage over the known VNS algorithms.
2.6. CUDA Implementation
The greedy agglomerative procedure (BasicGreedy) is computationally expensive. In Algorithm 2, the objective function calculation Fi′←SSE() is performed more than (K − k) · k times in each iteration, and after that, Lloyd() procedure is executed. Therefore, such algorithms are traditionally considered as methods for solving comparatively small problems (hundreds of thousands of data points and hundreds of clusters). However, the rapid development of the massive parallel processing systems (GPUs) enables us to solve the large-scale problems with reasonable time expenses (seconds). Parallel (CUDA) implementation of the algorithms for the Lloyd() procedure is known [101,102], and we used this approach in our experiments.
Graphic processing units (GPUs) accelerate computations with the use of multi-core computing architecture. The CUDA (compute unified device architecture) is the most popular programming platform which enables us to use general-purpose programming languages (e.g., C++) for compiling GPU programs. The programming model uses the single instruction multiple thread (SIMT) principle [119]. We can declare a function in the CUDA program a “kernel” function and run this function on the steaming multiprocessors. The threads are divided into blocks. Several instances of a kernel function are executed in parallel on different nodes (blocks) of a computation grid. Each thread can be identified by special threadIdx variable. Each thread block is identified by blockIdx variable. The number of threads in a block is identified by blockDim variable. All these variables are 3-dimensional vectors (dimensions x, y, z). Depending on the problem solved, the interpretation of these dimensions may differ. For processing 2D graphical data, x and y are used for identifying pixel coordinates.
The most computationally expensive part of Lloyd’s procedure is distance computation and comparison (Step 1 of Algorithm 1). This step can be seamlessly parallelized if we calculate distances from each individual data vector in a separate thread. Thus, threadIdx.x and blockIdx.x must indicate a data vector. The same kernel function prepares data needed for centroid calculation (Step 2 of Algorithm 1). Such data are the sum of data vector coordinates in a specific cluster and the cardinality of the cluster counterj = . Here, j is the cluster number. Variable sumj is a vector (1-dimensional array in program realization).
To perform Step 1 of Algorithm 1 on a GPU, after initialization sumj and counterj , the following procedure (Algorithm 8) runs on nodes of computation grid, with blockDim.x threads in each block (in our experiments, blockDim.x = 512):
| Algorithm 8.CUDA kernel implementation of Step 1 in Lloyd’s procedure (Algorithm 1) |
ifi > N then return end if; Dnearest // distance from Ai to the nearest centroid for do if then Dnearest n end if end for; sumn sumn + An; countern countern + 1; SSE SSE+ // objective function adder |
If sumj and counterj are pre-calculated for each cluster then Step 2 of Algorithm 1 is reduced to a single arithmetic operation for each cluster: Xj = sumj/counterj. If the number of clusters is not huge, this operation does not take significant computation resources. Nevertheless, its parallel implementation is even simpler: we organize k treads, and each thread calculates Xj for an individual cluster. Outside Lloyd’s procedure, we use Algorithm 8 for SSE value estimation (variable SSE must be initialized by 0 in advance).
The second computationally expensive part of the BasicGreegy() algorithm is estimation of the objective function value after eliminating a centroid [120]: Fi′ = SSE(). Having calculated SSE(S), we may calculate as SSE() as
where
For calculating (5) on a GPU, after initializing Fi , the following kernel function (Algorithm 9) runs for each data vector.
| Algorithm 9.CUDA kernel implementation of calculating Fi ← SSE() in BasicGreedy procedure (Algorithm 2) |
| Require: index i of centroid being eliminated. if l > N then return end if; Dnearest // distance from Al to the nearest centroid except Xi for do if then Dnearest end if end for; Fi ← Fi + ; |
All distance calculations for GREEDYr neighborhood search are performed by Algorithms 8 and 9. A similar kernel function was used for accelerating the local search in SWAP neighborhoods. In this function, after eliminating a centroid, a data point is included in solution S as a new centroid.
All other parts of new and known algorithms were implemented on the CPU.
2.7. Benchmarking Data
In all our experiments, we used the classic data sets from the UCI Machine Learning and Clustering basic benchmark repositories [108,109,118]:
- (a)
- Individual household electric power consumption (IHEPC)—energy consumption data of households during several years (more than 2 million data vectors, 7 dimensions), 0–1 normalized data, “date” and “time” columns removed;
- (b)
- BIRCH3 [121]: one hundred of groups of points of random size on a plane (105 data vectors, 2 dimensions);
- (c)
- S1 data set: Gaussian clusters with cluster overlap (5000 data vectors, 2 dimensions);
- (d)
- Mopsi-Joensuu: geographic locations of users (6014 data vectors, 2 dimensions) in Joensuu city;
- (e)
- Mopsi-Finland: geographic locations of users (13,467 data vectors, 2 dimensions) in Finland.
Mopsi-Joensuu and Mopsi-Finland are “geographic” data sets with a complex cluster structure, formed under the influence of natural factors such as the geometry of the city, transport communications, and urban infrastructure (Figure 4).
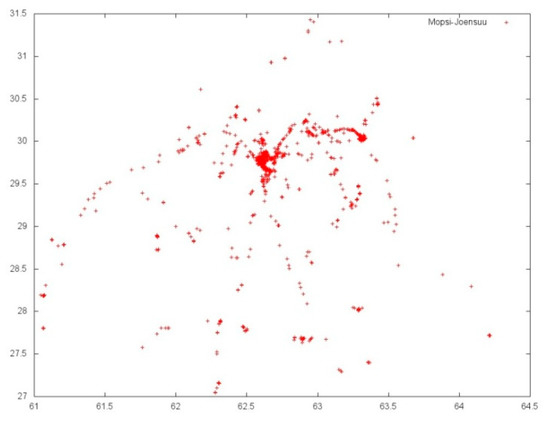
Figure 4.
Mopsi-Joensuu data set visualization.
In our study, we do not take into account the true labeling provided by the data set (if it is known), i.e., the given predictions for known classes, and focus on the minimization of SSE only.
2.8. Computational Environment
For our computational experiments, we used the following test system: Intel Core 2 Duo E8400 CPU, 16GB RAM, NVIDIA GeForce GTX1050ti GPU with 4096 MB RAM, floating-point performance 2138 GFLOPS. This choice of the GPU hardware was made due to its prevalence, and also one of the best values of the price/performance ratio. The program code was written in C++. We used Visual C++ 2017 compiler embedded into Visual Studio v.15.9.5, NVIDIA CUDA 10.0 Wizards, and NVIDIA Nsight Visual Studio Edition CUDA Support v.6.0.0.
3. Results
For all data sets, 30 attempts were made to run each of the algorithms (see Table 1 and Table A1, Table A2, Table A3, Table A4, Table A5, Table A6, Table A7, Table A8, Table A9, Table A10 and Table A11 in Appendix A).

Table 1.
Comparative results for all data sets (best of known algorithms vs. new algorithm).
For comparison, we ran local search in various GREEDYr neighborhoods at fixed r value. In addition, we ran various known Variable Neighborhood Search (VNS) algorithms with GREEDYr neighborhoods [79], see algorithms GH-VNS1-3. These algorithms use the same sequence of neighborhood types (GREEDY1→GREEDYrandom→GREEDYk) and differ in the initial neighborhood type: GREEDY1 for GH-VNS1, GREEDYrandom for GH-VNS2, and GREEDYk GH-VNS3. Unlike our new AdaptiveGreedy() algorithm, GH-VNS1-3 algorithms increase r values, and this increase is not gradual. In addition, we included the genetic algorithm (denoted “GA-1” in Table A1, Table A2, Table A3, Table A4, Table A5, Table A6, Table A7, Table A8, Table A9, Table A10 and Table A11) with the single-point crossover [103], real-valued genes encoded by centroid positions, and the uniform random mutation (probability 0.01). For algorithms launched in the multi-start mode (j-Means algorithm and Lloyd’s procedure), only the best results achieved in each attempt were recorded. In Table A1, Table A2, Table A3, Table A4, Table A5, Table A6, Table A7, Table A8, Table A9, Table A10 and Table A11, such algorithms are denoted Lloyd-MS and j-Means-MS, respectively.
The minimum, maximum, average, and median objective function values and its standard deviation were summarized after 30 runs. For all algorithms, we used the same realization of the Lloyd() procedure which consume the absolute majority of the computation time.
The best average and median values of the objective function (1) are underlined. We compared the new AdaptiveGreedy() algorithm with the known algorithm which demonstrated the best median and average results (Table 1). For comparison, we used the t-test [122,123] and non-parametric Wilcoxon-Mann-Whitney U test (Wilcoxon rank sum test) [124,125] with z approximation.
To compare the results obtained by our new algorithm, we tested the single-tailed null hypothesis H0: SSEAdaptiveGreedy = SSEknown (the difference in the results is statistically insignificant) and the research hypothesis H1: SSEAdaptiveGreedy < SSEknown (statistically different results, the new algorithm has an advantage). Here, SSEAdaptiveGreedy are results ontained by AdaptiveGreedy() algorithm, SSEknown are results of the best-known algorithm. For t-test comparison, we selected the algorithm lowest in average SSE value, and for Wilcoxon–Mann–Whitney U test comparison, we selected the algorithm with the lowest SSE median value. For both tests, we calculated the p-values (probability of the null-hypothesis acceptance), see pt for the t-test and pu for the Wilcoxon–Mann–Whitney U test in Table 1, respectively. At the selected significance level psig = 0.01, the null hypothesis is accepted if pt > 0.01 or pU > 0.01. Otherwise, the difference in algorithm results should be considered statistically significant. If the null hypothesis was accepted, we also tested a pair of single-tailed hypotheses SSEAdaptiveGreedy = SSEknown and SSEAdaptiveGreedy > SSEknown.
In some cases, the Wilcoxon–Mann–Whitney test shows the statistical significance of the differences in results, while the t-test does not confirm the benefits of the new algorithm. Figure 5 illustrates such a situation. Both algorithms demonstrate approximately the same results. Both algorithms periodically produce results that are far from the best SSE values, which is expressed in a sufficiently large value of the standard deviation. However, the results of the new algorithm are often slightly better, which is confirmed by the rank test.
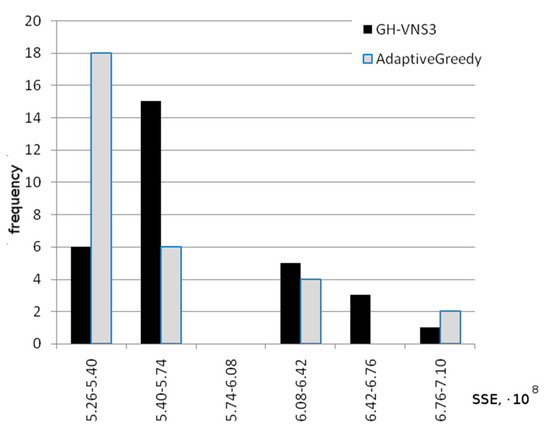
Figure 5.
Frequency diagram of the results (our new algorithm vs. the best of other tested algorithms, GH-VNS3), Mopsi-Finland data set, 300 clusters, 13,467 data vectors, time limitation 5 s, 30 runs of each algorithm.
In the comparative analysis of algorithm efficiency, the choice of the unit of time plays an important role. The astronomical time spent by an algorithm strongly depends on its implementation, the ability of the compiler to optimize the program code, and the fitness of the hardware to execute the code of a specific algorithm. Algorithms are often estimated by comparing the number of iterations performed (for example, the number of population generations for a GA) or the number of evaluations of the objective function.
However, the time consumption for a single iteration of a local search algorithm depends on the neighborhood type and number of elements in the neighborhood, and this dependence can be exponential. Therefore, comparing the number of iterations is unacceptable. Comparison of the objective function calculations is also not quite correct. Firstly, the Lloyd() procedure which consumes almost all of the processor time, does not calculate the objective function (1) directly. Secondly, during the operation of the greedy agglomerative procedure, the number of centroids changes (decreases from k + r down to k), and the time spent on computing the objective function also varies. Therefore, we nevertheless chose astronomical time as a scale for comparing algorithms. Moreover, all the algorithms use the same implementation of the Lloyd() algorithm launched under the same conditions.
In our computational experiments, the time limitation was used as the stop condition for all algorithms. For all data sets except the largest one, we have chosen a reasonable time limit to use the new algorithm in interactive modes. For IHEPC data and 50 clusters, a single run of the BasicGreedy() algorithm on the specified hardware took approximately 0.05 to 0.5 s. It is impossible to evaluate the comparative efficiency of the new algorithm in several iterations, since in this case, it does not have enough time to change the neighborhood parameter r at least once. We have increased the time to a few minutes. This time limit does not correspond to modern concepts of interactive modes of operation. Nevertheless, the rapid development of parallel computing requires the early creation of efficient algorithmic schemes. Our experiments were performed on a mass-market system. Advanced systems may cope with such large problems much faster.
As can be seen from Figure 6, the result of each algorithm depends on the elapsed time. Nevertheless, an advantage of the new algorithm is evident regardless of the chosen time limit.
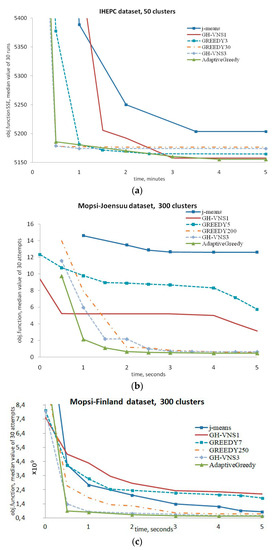
Figure 6.
Comparative analysis of the convergence speed. Dependence of the median result on computation time for: (a) Individual Household Electric Power Consumption (IHEPC) data set, 50 clusters, 2,075,259 data vectors, time limitation 5 min; (b) Mopsi-Joensuu data set, 300 clusters, 6014 data vectors, time limitation 5 s; (c) Mopsi-Finland data set, 300clusters, 13,467 data vectors, time limitation 5 s.
To test the scalability of the proposed approach and the efficiency of the new algorithm on other hardware, we carried out additional experiments with NVIDIA GeForce 9600GT GPU, 2048 MB RAM, 336 GFLOPS. The declared performance of this simpler equipment is approximately 6 times lower. The results of experiments with proportional increase of time limitation are shown in Table 2. The difference with the results in Table 1 is obviously insignificant.
Table 2.
Additional benchmarking on NVIDIA GeForce 9600GT GPU. Comparative results for Mopsi- Finland data set.13,467 data vectors in , time limitation 30 s.
The ranges of SSE values in the majority of Table A1, Table A2, Table A3, Table A4, Table A5, Table A6, Table A7, Table A8, Table A9, Table A10 and Table A11 are narrow, nevertheless, the differences are statistically significant in several cases, see Table 1. In all cases, our new algorithm outperforms known ones or demonstrates approximately the same efficiency (difference in the results is statistically insignificant). Moreover, the new algorithm demonstrates the stability of its results (narrow range of objective function values).
Search results in both SWAPr and GREEDYr neighborhoods depend on a correct choice of parameter r (the number of replaced or added centroids). However, in general, local search algorithms with GREEDYr neighborhoods outperform the SWAPr neighborhood search. A simple reconnaissance search procedure enables the further improvement of the efficiency.
4. Discussion
The advantages of our algorithm are statistically significant for a large problem (IHEPC data), as well as for problems with a complex data structure (Mopsi-Joensuu and Mopsi-Finland data). The Mopsi data sets contain geographic coordinates of Mopsi users, which are extremely unevenly distributed in accordance with the natural organization of the urban environment, depending on street directions and urban infrastructure (Figure 6). In this case, the aim of clustering is to find some natural groups of users according to a geometric/geographic principle for assigning them to k service centers (hubs) such as shopping centers, bus stops, wireless network base stations, etc.
Often, geographical data sets show such a disadvantage of Lloyd’s procedure as its inability to find a solution close to the exact one. Often, on such data, the value of the objective function found by the Lloyd’s procedure in the multi-start mode turns out to be many times greater than the values obtained by other algorithms, such as J-Means or RVNS algorithms with SWAP neighborhoods. As can be seen from Table A2, Table A3 and Table A5 in Appendix A, for such data, GREEDYrneighborhoods search provides significant advantages within a limited time, and our new self-adjusting AdaptiveGreedy() solver enhances these advantages.
The VNS algorithmic framework is useful for creating effective computational tools intended to solve complex practical problems. Embedding the most efficient types of neighborhoods in this framework depends on the problem type being solved. In problems such as k-means, the search in neighborhoods with specific parameters strongly depends not only on the generalized numerical parameters of the problems, such as the number of clusters, number of data vectors, and the search space dimensionality, but also on the internal data structure. In general, the comparative efficiency of the search in GREEDYr neighborhoods for certain types of practical problems and for specific data sets remains an open question. Nevertheless, the algorithm presented in this work, which automatically performs the adjustment of the most important parameter of such neighborhoods, enables its user to obtain the best result which the variable neighborhood search in GREEDYr is able to provide, without preliminary experiments in all possible GREEDYr neighborhoods. Thus, the new algorithm is a more versatile computational tool in comparison with the known VNS algorithms.
Greedy agglomerative procedures are widely used as crossover operators in genetic algorithms [46,88,90,110]. In this case, most often, the “parent” solutions are merged completely to obtain an intermediate solution with an excessive number of centers or centroids [46,88], which corresponds to the search in the GREEDYk neighborhood (one of the crossed “parent” solutions acts as the parameter S2), although, other versions of the greedy agglomerative crossover operator are also possible [90,110]. Such algorithms successfully compete with the advanced local search algorithms discussed in this article.
Self-configuring evolutionary algorithms [126,127,128] have been widely used for solving various optimization problems. An important direction of the further research is to study the possibility of adjusting the parameter r in greedy agglomerative crossover operators of genetic algorithms. Such procedures with self-adjusting parameter r could lead to a further increase in the accuracy of solving the k-means problem with respect to the achieved value of the objective function. Such evolutionary algorithms could also involve a reconnaissance search, which would then continue by applying the greedy agglomerative crossover operator with r values chosen from the most favorable range.
In addition, the similarity in problem statements of the k-means, k-medoids and k-median problems promises us a reasonable hope for the applicability of the same approaches to improving the accuracy of algorithms, including VNS algorithms, by adjusting the parameter r of the neighborhoods similar with GREEDYr.
5. Conclusions
The process of introducing machine learning methods into all spheres of life determines the need to develop not only fast, but also the most accurate algorithms for solving related optimization problems. As practice shows, including this study, when solving some problems, the most popular clustering algorithm gives a result extremely far from the optimal k-means problem solution.
In this research, we introduced GREEDYr search neighborhoods and found that searching in both SWAP and GREEDYr neighborhoods has advantages over the simplest Lloyd’s procedure. However, the results strongly depend on the parameters of such neighborhoods, and the optimal values of these parameters differ significantly for test problems. Nevertheless, searching in GREEDYr neighborhoods outperforms searching in SWAP neighborhoods in terms of accuracy.
We hope that our new variable neighborhood search algorithm (solver) for GPUs, which is more versatile due to its self-adjusting capability and has an advantage with respect to the accuracy of solving the k-means problem over known algorithms, will encourage researchers and practitioners in the field of machine learning to build competitive systems with the lowest possible error within a limited time. Such systems should be in demand when clustering geographic data, as well as when solving a wide range of problems with the highest cost of error.
Author Contributions
Conceptualization, L.K. and I.R.; methodology, L.K.; software, L.K.; validation, I.R. and E.T.; formal analysis, I.R. and A.P.; investigation, I.R.; resources, L.K. and E.T.; data curation, I.R.; writing—original draft preparation, L.K. and I.R.; writing—review and editing, L.K., E.T., and A.P.; visualization, I.R.; supervision, L.K.; project administration, L.K.; funding acquisition, L.K. and A.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by The Ministry of Science and Higher Education of the Russian Federation, project No. FEFE-2020-0013.
Conflicts of Interest
The authors declare no conflict of interest. The funder had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| NP | Non-deterministic polynomial-time |
| MSSC | Minimum Sum-of-Squares Clustering |
| SSE | Sum of Squared Errors |
| ALA algorithm | Alternate Location-Allocation algorithm |
| VNS | Variable Neighborhood Search |
| GA | Genetic Algorithm |
| IBC | Information Bottleneck Clustering |
| VND | Variable Neighborhood Descent |
| RVNS | Randomized Variable Neighborhood Search |
| GPU | Graphics Processing Unit |
| CPU | Central Processing Unit |
| RAM | Random Access Memory |
| CUDA | Compute Unified Device Architecture |
| IHEPC | Individual Household Electric Power Consumption |
| Lloyd-MS | Lloyd’s procedure in a multi-start mode |
| J-means-MS | J-Means algorithm in a multi-start mode (SWAP1+Lloyd VND) |
| GREEDYr | A neighborhood formed by applying greedy agglomerative procedures with r excessive clusters, and the RVNS algorithm which combines search in such neighborhood with Lloyd’s procedure |
| SWAPr | A neighborhood formed by replacing r centroids by data vectors, and the RVNS algorithm which combines search in such neighborhood with Lloyd’s procedure |
| GH-VNS1 | VNS algorithm with GREEDYr neighborhoods and GREEDY1 for the initial neighborhood type |
| GH-VNS2 | VNS algorithm with GREEDYr neighborhoods and GREEDYrandom for the initial neighborhood type |
| GH-VNS3 | VNS algorithm with GREEDYr neighborhoods and GREEDYk for the initial neighborhood type |
| GA-1 | Genetic algorithm with the single-point crossover, real-valued genes encoded by centroid positions, and the uniform random mutation |
| AdaptiveGreedy | New algorithm proposed in this article |
Appendix A. Results of Computational Experiments
Table A1.
Comparative results for Mopsi-Joensuu data set. 6014 data vectors in , k = 30 clusters, time limitation 5 s.
Table A1.
Comparative results for Mopsi-Joensuu data set. 6014 data vectors in , k = 30 clusters, time limitation 5 s.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std.dev | |
| Lloyd-MS | 35.5712 | 43.3993 | 39.1185 | 38.7718 | 2.9733 |
| j-Means-MS | 18.4076 | 23.7032 | 20.3399 | 19.8533 | 1.8603 |
| GREEDY1 | 18.3253 | 27.6990 | 21.4555 | 21.6629 | 3.1291 |
| GREEDY2 | 18.3253 | 21.7008 | 19.3776 | 18.3254 | 1.6119 |
| GREEDY3 | 18.3145 | 21.7007 | 18.5817 | 18.3254 | 0.9372 |
| GREEDY5 | 18.3253 | 21.7007 | 18.5129 | 18.3254 | 0.7956 |
| GREEDY7 | 18.3253 | 21.7008 | 18.5665 | 18.3255 | 0.9021 |
| GREEDY10 | 18.3253 | 21.7010 | 18.5666 | 18.3255 | 0.9021 |
| GREEDY12 | 18.3254 | 21.7009 | 18.5852 | 18.3256 | 0.9362 |
| GREEDY15 | 18.3254 | 18.3257 | 18.3255 | 18.3255 | 0.0001 |
| GREEDY20 | 18.3254 | 18.3263 | 18.3257 | 18.3257 | 0.0002 |
| GREEDY25 | 18.3254 | 18.3257 | 18.3255 | 18.3255 | 0.0001 |
| GREEDY30 | 18.3254 | 18.3261 | 18.3258 | 18.3258 | 0.0002 |
| GH-VNS1 | 18.3147 | 18.3255 | 18.3238 | 18.3253 | 0.0039 |
| GH-VNS2 | 18.3253 | 21.7008 | 19.3776 | 18.3254 | 1.6119 |
| GH-VNS3 | 18.3146 | 21.6801 | 18.5634 | 18.3254 | 0.8971 |
| SWAP1 (the best of SWAPr) | 18.9082 | 20.3330 | 19.4087 | 18.9967 | 0.6019 |
| GA-1 | 18.6478 | 21.1531 | 19.9555 | 19.9877 | 0.6632 |
| AdaptiveGreedy | 18.3146 | 18.3258 | 18.3240 | 18.3253 | 0.0037 |
Table A2.
Comparative results for Mopsi-Joensuu data set. 6014 data vectors in , k = 100 clusters, time limitation 5 s.
Table A2.
Comparative results for Mopsi-Joensuu data set. 6014 data vectors in , k = 100 clusters, time limitation 5 s.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std.dev | |
| Lloyd-MS | 23.1641 | 34.7834 | 27.5520 | 27.1383 | 3.6436 |
| j-Means-MS | 1.7628 | 31.8962 | 11.1832 | 2.4216 | 11.7961 |
| GREEDY1 | 20.6701 | 35.5447 | 28.9970 | 29.2429 | 5.0432 |
| GREEDY2 | 2.8264 | 29.0682 | 9.9708 | 5.3363 | 9.6186 |
| GREEDY3 | 2.6690 | 10.5998 | 4.1444 | 3.0588 | 2.2108 |
| GREEDY5 | 1.9611 | 4.3128 | 2.7385 | 2.7299 | 0.6135 |
| GREEDY7 | 2.0837 | 4.6443 | 2.8730 | 2.6358 | 0.7431 |
| GREEDY10 | 1.9778 | 3.8635 | 2.5613 | 2.3304 | 0.6126 |
| GREEDY12 | 1.7817 | 4.3023 | 2.5639 | 2.2009 | 0.8730 |
| GREEDY15 | 1.9564 | 3.1567 | 2.3884 | 2.2441 | 0.3620 |
| GREEDY20 | 1.7937 | 3.2809 | 2.4542 | 2.3500 | 0.4746 |
| GREEDY25 | 1.9532 | 3.3874 | 2.4195 | 2.2575 | 0.5470 |
| GREEDY30 | 1.9274 | 2.4580 | 2.1723 | 2.1458 | 0.2171 |
| GREEDY50 | 1.8903 | 9.3675 | 2.8047 | 2.1614 | 2.0838 |
| GREEDY75 | 1.7878 | 2.8855 | 2.1775 | 2.0272 | 0.4023 |
| GREEDY100 | 1.8021 | 2.2942 | 2.0158 | 1.9849 | 0.1860 |
| GH-VNS1 | 2.8763 | 17.1139 | 7.3196 | 4.3341 | 5.7333 |
| GH-VNS2 | 2.8264 | 29.0682 | 9.9708 | 5.3363 | 9.6186 |
| GH-VNS3 | 1.7643 | 2.7357 | 2.0513 | 1.9822 | 0.2699 |
| SWAP3 (the best of rand. SWAPr) | 4.9739 | 23.6572 | 9.0159 | 8.3907 | 4.1351 |
| GA-1 | 4.8922 | 19.1543 | 8.5914 | 7.1764 | 4.1096 |
| AdaptiveGreedy | 1.7759 | 2.3265 | 1.9578 | 1.9229 | 0.1523 |
Table A3.
Comparative results for Mopsi-Joensuu data set. 6014 data vectors in , k = 300 clusters, time limitation 5 s.
Table A3.
Comparative results for Mopsi-Joensuu data set. 6014 data vectors in , k = 300 clusters, time limitation 5 s.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std.dev | |
| Lloyd-MS | 4.1789 | 14.7570 | 9.1143 | 9.3119 | 3.0822 |
| j-Means-MS | 7.0119 | 22.3126 | 14.2774 | 12.6199 | 5.5095 |
| GREEDY1 | 7.1654 | 15.3500 | 9.6113 | 9.2176 | 2.5266 |
| GREEDY2 | 4.9896 | 14.4839 | 8.9197 | 8.2013 | 3.3072 |
| GREEDY3 | 5.8967 | 14.1110 | 8.3260 | 8.0441 | 2.2140 |
| GREEDY5 | 2.9115 | 10.2536 | 5.8012 | 5.7305 | 2.2740 |
| GREEDY7 | 2.6045 | 7.9868 | 4.4201 | 4.0548 | 1.4841 |
| GREEDY10 | 2.5497 | 8.6758 | 4.1796 | 2.9639 | 1.8494 |
| GREEDY12 | 2.0753 | 4.7134 | 3.0383 | 2.8777 | 0.8348 |
| GREEDY15 | 1.8975 | 8.7890 | 3.8615 | 3.2661 | 1.8064 |
| GREEDY20 | 1.1878 | 3.7944 | 2.4577 | 2.4882 | 0.9554 |
| GREEDY25 | 1.1691 | 3.5299 | 1.8489 | 1.6407 | 0.7460 |
| GREEDY30 | 1.1151 | 4.9425 | 2.3711 | 2.0582 | 1.1501 |
| GREEDY50 | 1.3526 | 3.5471 | 1.8635 | 1.7114 | 0.6046 |
| GREEDY75 | 1.0533 | 5.5915 | 1.9129 | 1.4261 | 1.2082 |
| GREEDY100 | 0.8047 | 2.0349 | 1.2602 | 1.1994 | 0.3811 |
| GREEDY150 | 0.6243 | 1.4755 | 0.8743 | 0.8301 | 0.2447 |
| GREEDY200 | 0.4555 | 1.0154 | 0.6746 | 0.5882 | 0.2103 |
| GREEDY250 | 0.4789 | 1.3368 | 0.7233 | 0.6695 | 0.2164 |
| GREEDY300 | 0.5474 | 1.0472 | 0.7228 | 0.6657 | 0.1419 |
| GH-VNS1 | 1.6219 | 5.2528 | 3.0423 | 3.1332 | 1.0222 |
| GH-VNS2 | 1.2073 | 8.6144 | 3.2228 | 2.3501 | 2.4014 |
| GH-VNS3 | 0.4321 | 0.6838 | 0.6024 | 0.6139 | 0.0836 |
| SWAP12 (the best of SWAP by median) | 2.6016 | 5.5038 | 3.6219 | 3.3612 | 1.0115 |
| SWAP20 (the best of SWAP by avg.) | 2.1630 | 5.1235 | 3.4958 | 3.4076 | 0.8652 |
| GA-1 | 5.4911 | 12.6950 | 8.8799 | 7.7181 | 2.5384 |
| AdaptiveGreedy | 0.3128 | 0.6352 | 0.4672 | 0.4604 | 0.1026 |
Table A4.
Comparative results for Mopsi-Finland data set. 13,467 data vectors in , k = 30 clusters, time limitation 5 s.
Table A4.
Comparative results for Mopsi-Finland data set. 13,467 data vectors in , k = 30 clusters, time limitation 5 s.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std.dev | |
| Lloyd-MS | 4.79217 × 1010 | 6.36078 × 1010 | 5.74896 × 1010 | 5.79836 × 1010 | 3.69760 × 109 |
| j-Means-MS | 3.43535 × 1010 | 4.26830 × 1010 | 3.66069 × 1010 | 3.60666 × 1010 | 1.75725 × 109 |
| GREEDY1 | 3.43195 × 1010 | 3.70609 × 1010 | 3.51052 × 1010 | 3.48431 × 1010 | 7.42 636 × 108 |
| GREEDY2 | 3.43194 × 1010 | 3.49405 × 1010 | 3.44496 × 1010 | 3.44140 × 1010 | 1.64 360 × 108 |
| GREEDY3 | 3.43195 × 1010 | 3.49411 × 1010 | 3.44474 × 1010 | 3.44140 × 1010 | 1.71131 × 108 |
| GREEDY5 | 3.43195 × 1010 | 3.48411 × 1010 | 3.44663 × 1010 | 3.44141 × 1010 | 1.65153 × 108 |
| GREEDY7 | 3.42531 × 1010 | 3.47610 × 1010 | 3.44091 × 1010 | 3.43504 × 1010 | 1.76023 × 108 |
| GREEDY10 | 3.42560 × 1010 | 3.48824 × 1010 | 3.45106 × 1010 | 3.43573 × 1010 | 2.36526 × 108 |
| GREEDY12 | 3.42606 × 1010 | 3.48822 × 1010 | 3.44507 × 1010 | 3.43901 × 1010 | 1.68986 × 108 |
| GREEDY15 | 3.42931 × 1010 | 3.47817 × 1010 | 3.43874 × 1010 | 3.43901 × 1010 | 8.31510 × 107 |
| GREEDY20 | 3.42954 × 1010 | 3.48826 × 1010 | 3.44186 × 1010 | 3.43905 × 1010 | 1.28972 × 108 |
| GREEDY25 | 3.43877 × 1010 | 3.44951 × 1010 | 3.43982 × 1010 | 3.43907 × 1010 | 2.57320 × 107 |
| GREEDY30 | 3.43900 × 1010 | 3.48967 × 1010 | 3.45169 × 1010 | 3.43979 × 1010 | 1.93565 × 108 |
| GH-VNS1 | 3.42626 × 1010 | 3.48724 × 1010 | 3.45244 × 1010 | 3.44144 × 1010 | 2.00510 × 108 |
| GH-VNS2 | 3.42528 × 1010 | 3.48723 × 1010 | 3.44086 × 1010 | 3.43474 × 1010 | 1.54771 × 108 |
| GH-VNS3 | 3.42528 × 1010 | 3.47955 × 1010 | 3.43826 × 1010 | 3.43474 × 1010 | 1.02356 × 108 |
| SWAP1 (the best of SWAPr) | 3.43199 × 1010 | 3.55777 × 1010 | 3.46821 × 1010 | 3.46056 × 1010 | 3.22711 × 108 |
| GA-1 | 3.48343 × 1010 | 3.81846 × 1010 | 3.65004 × 1010 | 3.64415 × 1010 | 1.00523 × 109 |
| AdaptiveGreedy | 3.42528 × 1010 | 3.47353 × 1010 | 3.43385 × 1010 | 3.43473 × 1010 | 1.03984 × 108 |
Table A5.
Comparative results for Mopsi- Finland data set. 13,467 data vectors in , k = 300 clusters, time limitation 5 s.
Table A5.
Comparative results for Mopsi- Finland data set. 13,467 data vectors in , k = 300 clusters, time limitation 5 s.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std.dev | |
| Lloyd-MS | 5.41643 × 109 | 6.89261 × 109 | 6.25619 × 109 | 6.24387 × 109 | 3.23827 × 108 |
| j-Means-MS | 6.75216 × 108 | 1.38889 × 109 | 8.92782 × 108 | 8.35397 × 108 | 1.86995 × 108 |
| GREEDY1 | 4.08445 × 109 | 9.07208 × 109 | 5.89974 × 109 | 5.59903 × 109 | 1.47601 × 108 |
| GREEDY2 | 1.11352 × 109 | 2.10247 × 109 | 1.59229 × 109 | 1.69165 × 109 | 2.89625 × 108 |
| GREEDY3 | 9.63842 × 108 | 2.15674 × 109 | 1.61490 × 109 | 1.60123 × 109 | 3.06567 × 108 |
| GREEDY5 | 9.11944 × 108 | 2.36799 × 109 | 1.66021 × 109 | 1.70448 × 109 | 3.68575 × 108 |
| GREEDY7 | 1.17328 × 109 | 2.44476 × 109 | 1.77589 × 109 | 1.80948 × 109 | 2.68354 × 108 |
| GREEDY10 | 1.14221 × 109 | 2.00426 × 109 | 1.67586 × 109 | 1.69601 × 109 | 2.14822 × 108 |
| GREEDY12 | 9.41133 × 108 | 2.28940 × 109 | 1.59715 × 109 | 1.62288 × 109 | 3.01841 × 108 |
| GREEDY15 | 8.86983 × 108 | 2.29776 × 109 | 1.53989 × 109 | 1.43319 × 109 | 3.70138 × 108 |
| GREEDY20 | 1.02224 × 109 | 2.11636 × 109 | 1.62601 × 109 | 1.64029 × 109 | 2.45576 × 108 |
| GREEDY25 | 9.07984 × 108 | 1.87134 × 109 | 1.42878 × 109 | 1.42864 × 109 | 2.74744 × 108 |
| GREEDY30 | 8.44247 × 108 | 2.22882 × 109 | 1.50817 × 109 | 1.56015 × 109 | 3.52497 × 108 |
| GREEDY50 | 7.98191 × 108 | 1.68198 × 109 | 1.26851 × 109 | 1.17794 × 109 | 2.67082 × 108 |
| GREEDY75 | 6.97650 × 108 | 1.74139 × 109 | 1.16422 × 109 | 1.16616 × 109 | 2.82454 × 108 |
| GREEDY100 | 6.55465 × 108 | 1.44162 × 109 | 1.03643 × 109 | 1.09001 × 109 | 1.95246 × 108 |
| GREEDY150 | 5.94256 × 108 | 1.45317 × 109 | 8.88898 × 108 | 7.96787 × 108 | 2.33137 × 108 |
| GREEDY200 | 5.60885 × 108 | 1.41411 × 109 | 7.96908 × 108 | 7.20282 × 108 | 2.26191 × 108 |
| GREEDY250 | 5.58602 × 108 | 1.13946 × 109 | 7.58434 × 108 | 6.81196 × 108 | 1.65511 × 108 |
| GREEDY300 | 5.68646 × 108 | 1.41338 × 109 | 7.35067 × 108 | 6.83004 × 108 | 1.76126 × 108 |
| GH-VNS1 | 1.40141 × 109 | 2.86919 × 109 | 2.16238 × 109 | 2.10817 × 109 | 3.42105 × 108 |
| GH-VNS2 | 8.22679 × 108 | 2.12228 × 109 | 1.40322 × 109 | 1.39457 × 109 | 2.96599 × 108 |
| GH-VNS3 | 5.33373 × 108 | 7.29800 × 108 | 5.74914 × 108 | 5.48427 × 108 | 5.05346 × 107 |
| SWAP1 (the best of. SWAPr) | 6.69501 × 108 | 9.06507 × 108 | 7.48932 × 108 | 7.35532 × 108 | 6.74846 × 107 |
| GA-1 | 4.54419 × 109 | 7.11460 × 109 | 5.67688 × 109 | 5.61135 × 109 | 5.99687 × 108 |
| AdaptiveGreedy | 5.27254 × 108 | 7.09410 × 108 | 5.60867 × 108 | 5.38952 × 108 | 4.89257 × 107 |
Table A6.
Comparative results for BIRCH3 data set. 105 data vectors in , k = 100 clusters, time limitation 10 s.
Table A6.
Comparative results for BIRCH3 data set. 105 data vectors in , k = 100 clusters, time limitation 10 s.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std.dev | |
| Lloyd-MS | 8.13022 × 1013 | 9.51129 × 1013 | 8.96327 × 1013 | 9.06147 × 1013 | 4.84194 × 1012 |
| j-Means-MS | 4.14627 × 1013 | 6.25398 × 1013 | 4.78063 × 1013 | 4.55711 × 1013 | 6.89734 × 1012 |
| GREEDY1 | 3.73299 × 1013 | 5.64559 × 1013 | 4.13352 × 1013 | 3.90845 × 1013 | 5.19021 × 1012 |
| GREEDY2 | 3.71499 × 1013 | 3.72063 × 1013 | 3.71689 × 1013 | 3.71565 × 1013 | 2.44802 × 1010 |
| GREEDY3 | 3.71518 × 1013 | 3.72643 × 1013 | 3.71840 × 1013 | 3.71545 × 1013 | 4.12818 × 1010 |
| GREEDY5 | 3.71485 × 1013 | 3.72087 × 1013 | 3.71644 × 1013 | 3.71518 × 1013 | 2.22600 × 1010 |
| GREEDY7 | 3.71518 × 1013 | 3.72267 × 1013 | 3.71755 × 1013 | 3.71658 × 1013 | 2.24845 × 1010 |
| GREEDY10 | 3.71555 × 1013 | 3.72119 × 1013 | 3.71771 × 1013 | 3.71794 × 1013 | 1.90289 × 1010 |
| GREEDY12 | 3.71556 × 1013 | 3.72954 × 1013 | 3.71892 × 1013 | 3.71693 × 1013 | 3.91673 × 1010 |
| GREEDY15 | 3.71626 × 1013 | 3.72169 × 1013 | 3.71931 × 1013 | 3.71963 × 1013 | 1.86102 × 1010 |
| GREEDY20 | 3.71600 × 1013 | 3.72638 × 1013 | 3.72118 × 1013 | 3.72153 × 1013 | 2.69206 × 1010 |
| GREEDY25 | 3.72042 × 1013 | 3.72690 × 1013 | 3.72284 × 1013 | 3.72228 × 1013 | 2.14437 × 1010 |
| GREEDY30 | 3.72180 × 1013 | 3.73554 × 1013 | 3.72586 × 1013 | 3.72471 × 1013 | 4.33818 × 1010 |
| GREEDY50 | 3.72166 × 1013 | 3.76422 × 1013 | 3.73883 × 1013 | 3.73681 × 1013 | 16.1061 × 1010 |
| GREEDY75 | 3.72399 × 1013 | 3.84870 × 1013 | 3.76286 × 1013 | 3.74750 × 1013 | 41.6632 × 1010 |
| GREEDY100 | 3.72530 × 1013 | 3.91589 × 1013 | 3.80730 × 1013 | 3.84482 × 1013 | 61.9706 × 1010 |
| GH-VNS1 | 3.71914 × 1013 | 3.77527 × 1013 | 3.73186 × 1013 | 3.72562 × 1013 | 18.3590 × 1010 |
| GH-VNS2 | 3.71568 × 1013 | 3.73791 × 1013 | 3.72116 × 1013 | 3.72051 × 1013 | 6.08081 × 1010 |
| GH-VNS3 | 3.71619 × 1013 | 3.73487 × 1013 | 3.72387 × 1013 | 3.72282 × 1013 | 5.96618 × 1010 |
| SWAP1 (the best of SWAPr) | 4.28705 × 1013 | 5.48014 × 1013 | 4.82383 × 1013 | 4.75120 × 1013 | 3.90128 × 1012 |
| GA-1 | 3.84317 × 1013 | 4.08357 × 1013 | 3.97821 × 1013 | 3.97088 × 1013 | 7.43642 × 1011 |
| AdaptiveGreedy | 3.71484 × 1013 | 3.72011 × 1013 | 3.71726 × 1013 | 3.71749 × 1013 | 2.02784 × 1010 |
Table A7.
Comparative results for BIRCH3 data set. 105 data vectors in , k = 300 clusters, time limitation 10 s.
Table A7.
Comparative results for BIRCH3 data set. 105 data vectors in , k = 300 clusters, time limitation 10 s.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std.dev | |
| Lloyd-MS | 3.49605 × 1013 | 4.10899 × 1013 | 3.74773 × 1013 | 3.77191 × 1013 | 2.32012 × 1012 |
| j-Means-MS | 1.58234 × 1013 | 2.02926 × 1013 | 1.75530 × 1013 | 1.70507 × 1013 | 1.43885 × 1012 |
| GREEDY1 | 1.48735 × 1013 | 2.63695 × 1013 | 1.71372 × 1013 | 1.60354 × 1013 | 2.98555 × 1012 |
| GREEDY2 | 1.31247 × 1013 | 1.45481 × 1013 | 1.37228 × 1013 | 1.36745 × 1013 | 4.01697 × 1011 |
| GREEDY3 | 1.34995 × 1013 | 1.49226 × 1013 | 1.39925 × 1013 | 1.39752 × 1013 | 4.85917 × 1011 |
| GREEDY5 | 1.33072 × 1013 | 1.45757 × 1013 | 1.39069 × 1013 | 1.38264 × 1013 | 4.46890 × 1011 |
| GREEDY7 | 1.34959 × 1013 | 1.49669 × 1013 | 1.41606 × 1013 | 1.41764 × 1013 | 4.92200 × 1011 |
| GREEDY10 | 1.31295 × 1013 | 1.42722 × 1013 | 1.35970 × 1013 | 1.35318 × 1013 | 3.70511 × 1011 |
| GREEDY12 | 1.32677 × 1013 | 1.49028 × 1013 | 1.35561 × 1013 | 1.33940 × 1013 | 4.44283 × 1011 |
| GREEDY15 | 1.32077 × 1013 | 1.41079 × 1013 | 1.34102 × 1013 | 1.33832 × 1013 | 2.16247 × 1011 |
| GREEDY20 | 1.31994 × 1013 | 1.43160 × 1013 | 1.35420 × 1013 | 1.34096 × 1013 | 3.43684 × 1011 |
| GREEDY25 | 1.31078 × 1013 | 1.37699 × 1013 | 1.33571 × 1013 | 1.33040 × 1013 | 2.16378 × 1011 |
| GREEDY30 | 1.32947 × 1013 | 1.45967 × 1013 | 1.37618 × 1013 | 1.36729 × 1013 | 3.92767 × 1011 |
| GREEDY50 | 1.32284 × 1013 | 1.38691 × 1013 | 1.34840 × 1013 | 1.33345 × 1013 | 2.70770 × 1011 |
| GREEDY75 | 1.30808 × 1013 | 1.33266 × 1013 | 1.31857 × 1013 | 1.31833 × 1013 | 7.22941 × 1010 |
| GREEDY100 | 1.30852 × 1013 | 1.32697 × 1013 | 1.31250 × 1013 | 1.31067 × 1013 | 4.94315 × 1010 |
| GREEDY150 | 1.30754 × 1013 | 1.31446 × 1013 | 1.30971 × 1013 | 1.30952 × 1013 | 1.82873 × 1010 |
| GREEDY200 | 1.30773 × 1013 | 1.31172 × 1013 | 1.30916 × 1013 | 1.30912 × 1013 | 1.08001 × 1010 |
| GREEDY250 | 1.30699 × 1013 | 1.31073 × 1013 | 1.30944 × 1013 | 1.30990 × 1013 | 1.18367 × 1010 |
| GREEDY300 | 1.30684 × 1013 | 1.31068 × 1013 | 1.30917 × 1013 | 1.30933 × 1013 | 1.21748 × 1010 |
| GH-VNS1 | 1.40452 × 1013 | 1.56256 × 1013 | 1.45212 × 1013 | 1.42545 × 1013 | 55.7231 × 1010 |
| GH-VNS2 | 1.32287 × 1013 | 1.38727 × 1013 | 1,34654 × 1013 | 1,34568 × 1013 | 2,01065 × 1011 |
| GH-VNS3 | 1.30996 × 1013 | 1.31378 × 1013 | 1.31158 × 1013 | 1.31138 × 1013 | 1.44998 × 1010 |
| SWAP2 (the best of SWAPr by median) | 2.18532 × 1013 | 3.25705 × 1013 | 2.54268 × 1013 | 2.37312 × 1013 | 3.78491 × 1012 |
| SWAP7 (the best of SWAPr by avg.) | 2.24957 × 1013 | 2.86883 × 1013 | 2.46775 × 1013 | 2.47301 × 1013 | 1.51198 × 1012 |
| GA-1 | 1.38160 × 1013 | 1.71472 × 1013 | 1.55644 × 1013 | 1.54336 × 1013 | 9.21217 × 1011 |
| AdaptiveGreedy | 1.30807 × 1013 | 1.31113 × 1013 | 1.30922 × 1013 | 1.30925 × 1013 | 0.87731 × 1010 |
Table A8.
Comparative results for S1 data set. 5000 data vectors in , k = 15 clusters, time limitation 1 s.
Table A8.
Comparative results for S1 data set. 5000 data vectors in , k = 15 clusters, time limitation 1 s.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std.dev | |
| Lloyd-MS | 8.91703 × 1012 | 8.91707 × 1012 | 8.91704 × 1012 | 8.91703 × 1012 | 1.31098 × 107 |
| j-Means-MS | 8.91703 × 1012 | 14.2907 × 1012 | 12.1154 × 1012 | 13.3667 × 1012 | 2.38947 × 1012 |
| GREEDY1 | 8.91703 × 1012 | 13.2502 × 1012 | 9.27814 × 1012 | 8.91703 × 1012 | 1.25086 × 1012 |
| GREEDY2 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 0.00000 |
| GREEDY3 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 0.00000 |
| GREEDY5 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 4.03023 × 105 |
| GREEDY7 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 4.87232 × 105 |
| GREEDY10 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 5.12234 × 105 |
| GREEDY12 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 3.16158 × 105 |
| GREEDY15 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 5.01968 × 105 |
| GH-VNS1 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 0.00000 |
| GH-VNS2 | 8.91703 × 1012 | 8,91703 × 1012 | 8,91703 × 1012 | 8.91703 × 1012 | 0.00000 |
| GH-VNS3 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 4.03023 × 105 |
| SWAP1 (the best of SWAP) | 8.91703 × 1012 | 8.91709 × 1012 | 8.91704 × 1012 | 8.91703 × 1012 | 8.67594 × 106 |
| GA-1 | 8.91703 × 1012 | 8.91707 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 9.04519 × 106 |
| AdaptiveGreedy | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 8.91703 × 1012 | 0.00000 |
Table A9.
Comparative results for S1 data set. 5000 data vectors in , k = 50 clusters, time limitation 1 s.
Table A9.
Comparative results for S1 data set. 5000 data vectors in , k = 50 clusters, time limitation 1 s.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std.dev | |
| Lloyd-MS | 3.94212 × 1012 | 4.06133 × 1012 | 3.99806 × 1012 | 3.99730 × 1012 | 4.52976 × 1010 |
| j-Means-MS | 3.96626 × 1012 | 4.40078 × 1012 | 4.12311 × 1012 | 4.07123 × 1012 | 14.81090 × 1010 |
| GREEDY1 | 3.82369 × 1012 | 4.19102 × 1012 | 3.91601 × 1012 | 3.88108 × 1012 | 9.82433 × 1010 |
| GREEDY2 | 3.74350 × 1012 | 3.76202 × 1012 | 3.75014 × 1012 | 3.74936 × 1012 | 6.10139 × 109 |
| GREEDY3 | 3.74776 × 1012 | 3.76237 × 1012 | 3.75455 × 1012 | 3.75456 × 1012 | 5.24513 × 109 |
| GREEDY5 | 3.74390 × 1012 | 3.77031 × 1012 | 3.75345 × 1012 | 3.75298 × 1012 | 7.17733 × 109 |
| GREEDY7 | 3.74446 × 1012 | 3.77208 × 1012 | 3.75277 × 1012 | 3.75190 × 1012 | 7.40052 × 109 |
| GREEDY10 | 3.74493 × 1012 | 3.76031 × 1012 | 3.75159 × 1012 | 3.75185 × 1012 | 5.26553 × 109 |
| GREEDY15 | 3.74472 × 1012 | 3.77922 × 1012 | 3.75426 × 1012 | 3.75519 × 1012 | 9.79855 × 109 |
| GREEDY20 | 3.75028 × 1012 | 3.76448 × 1012 | 3.75586 × 1012 | 3.75573 × 1012 | 3.97310 × 109 |
| GREEDY25 | 3.74770 × 1012 | 3.76224 × 1012 | 3.75500 × 1012 | 3.75572 × 1012 | 4.95370 × 109 |
| GREEDY30 | 3.75014 × 1012 | 3.76010 × 1012 | 3.75583 × 1012 | 3.75661 × 1012 | 3.45280 × 109 |
| GREEDY50 | 3.74676 × 1012 | 3.77396 × 1012 | 3.76021 × 1012 | 3.75933 × 1012 | 9.09159 × 109 |
| GH-VNS1 | 3.74310 × 1012 | 3.76674 × 1012 | 3.74911 × 1012 | 3.74580 × 1012 | 6.99859 × 109 |
| GH-VNS2 | 3,75106 × 1012 | 3,77369 × 1012 | 3,75792 × 1012 | 3,75782 × 1012 | 6,67960 × 109 |
| GH-VNS3 | 3.75923 × 1012 | 3.77964 × 1012 | 3.76722 × 1012 | 3.76812 × 1012 | 6.00125 × 109 |
| SWAP3 (the best of SWAP) | 3.75128 × 1012 | 3.79170 × 1012 | 3.77853 × 1012 | 3.77214 × 1012 | 4.53608 × 109 |
| GA-1 | 3.84979 × 1012 | 3.99291 × 1012 | 3.92266 × 1012 | 3.92818 × 1012 | 4.56845 × 1012 |
| AdaptiveGreedy | 3.74340 × 1012 | 3.76313 × 1012 | 3.74851 × 1012 | 3.75037 × 1012 | 5.56298 × 109 |
Table A10.
Comparative results for Individual Household Electric Power Consumption (IHEPC) data set. 2,075,259 data vectors in , k = 15 clusters, time limitation 5 min.
Table A10.
Comparative results for Individual Household Electric Power Consumption (IHEPC) data set. 2,075,259 data vectors in , k = 15 clusters, time limitation 5 min.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | AVERAGE | Median | Std.dev | |
| Lloyd-MS | 12,874.8652 | 12,880.0703 | 12,876.0219 | 12,874.8652 | 2.2952 |
| j-Means-MS | 12,874.8652 | 13,118.6455 | 12,984.7081 | 12,962.1323 | 75.6539 |
| all GREEDY1-15 (equal results) | 12,874.8633 | 12,874.8633 | 12,874.8633 | 12,874.8633 | 0.0000 |
| GH-VNS1 | 12,874.8633 | 12,874.8633 | 12,874.8633 | 12,874.8633 | 0.0000 |
| GH-VNS2 | 12,874.8633 | 12,874.8633 | 12,874.8633 | 12,874.8633 | 0.0000 |
| GH-VNS3 | 12,874.8633 | 12,874.8633 | 12,874.8633 | 12,874.8633 | 0.0000 |
| GA-1 | 12,874.8643 | 12,874.8652 | 12,874.8644 | 12,874.8643 | 0.0004 |
| AdaptiveGreedy | 12,874.8633 | 12,874.8633 | 12,874.8633 | 12,874.8633 | 0.0000 |
Table A11.
Comparative results for Individual Household Electric Power Consumption (IHEPC) data set. 2,075,259 data vectors in , k = 50 clusters, time limitation 5 min.
Table A11.
Comparative results for Individual Household Electric Power Consumption (IHEPC) data set. 2,075,259 data vectors in , k = 50 clusters, time limitation 5 min.
| Algorithm or Neighborhood | Achieved SSE Summarized After 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std.dev | |
| Lloyd-MS | 5605.0625 | 5751.1982 | 5671.0820 | 5660.4429 | 54.2467 |
| j-Means-MS | 5160.2700 | 6280.6440 | 5496.6539 | 5203.5679 | 493.7311 |
| GREEDY1 | 5200.9268 | 5431.3647 | 5287.4101 | 5281.7300 | 77.0460 |
| GREEDY2 | 5167.1482 | 5283.3894 | 5171.6509 | 5192.1274 | 7.7203 |
| GREEDY3 | 5155.5166 | 5178.4063 | 5166.5360 | 5164.6045 | 8.1580 |
| GREEDY5 | 5164.6040 | 5178.4336 | 5170.8829 | 5174.0938 | 6.0904 |
| GREEDY7 | 5162.5381 | 5178.1269 | 5168.7218 | 5171.8292 | 6.4518 |
| GREEDY10 | 5154.2017 | 5176.4502 | 5162.0460 | 5160.4014 | 7.2029 |
| GREEDY12 | 5162.8715 | 5181.0281 | 5166.8952 | 5165.3295 | 6.0172 |
| GREEDY15 | 5163.2500 | 5181.1333 | 5167.3385 | 5165.8037 | 5.7910 |
| GREEDY20 | 5156.2852 | 5176.6855 | 5166.2013 | 5164.6323 | 7.8749 |
| GREEDY25 | 5166.9820 | 5181.8529 | 5175.0317 | 5176.2136 | 6.1471 |
| GREEDY30 | 5168.6309 | 5182.4351 | 5175.2414 | 5176.4512 | 6.4635 |
| GREEDY50 | 5168.3887 | 5182.4321 | 5177.5249 | 5177.6855 | 5.4437 |
| GH-VNS1 | 5155.5166 | 5164.6313 | 5158.6549 | 5157.6812 | 3.7467 |
| GH-VNS2 | 5159.8818 | 5176.6855 | 5167.3365 | 5166.9512 | 5.6808 |
| GH-VNS3 | 5171.2969 | 5182.4321 | 5175.0468 | 5174.0752 | 3.6942 |
| GA-1 | 5215.9521 | 5248.4521 | 5230.2839 | 5226.0386 | 13.2694 |
| AdaptiveGreedy | 5153.5640 | 5163.9316 | 5157.0822 | 5155.5198 | 3.6034 |
References
- Berkhin, P. Survey of Clustering Data Mining Techniques; Accrue Software: New York, NY, USA, 2002. [Google Scholar]
- Cormack, R.M. A Review of Classification. J. R. Stat. Soc. Ser. A 1971, 134, 321–367. [Google Scholar] [CrossRef]
- Tsai, C.Y.; Chiu, C.C. A VNS-based hierarchical clustering method. In Proceedings of the 5th WSEAS International Conference on Computational Intelligence, Man-Machine Systems and Cybernetics (CIMMACS’06), Venice, Italy, 20–22 November 2006; World Scientific and Engineering Academy and Society (WSEAS): Stevens Point, WI, USA, 2006; pp. 268–275. [Google Scholar]
- Lloyd, S.P. Least Squares Quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- MacQueen, J.B. Some Methods of Classification and Analysis of Multivariate Observations. In Proceedings of the 5th Berkley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965 and 27 December 1965–7 January 1966; Volume 1, pp. 281–297. [Google Scholar]
- Drineas, P.; Frieze, A.; Kannan, R.; Vempala, S.; Vinay, V. Clustering large graphs via the singular value decomposition. Mach. Learn. 2004, 56, 9–33. [Google Scholar] [CrossRef]
- Gu, Y.; Li, K.; Guo, Z.; Wang, Y. Semi-supervised k-means ddos detection method using hybrid feature selection algorithm. IEEE Access 2019, 7, 351–365. [Google Scholar] [CrossRef]
- Guo, X.; Zhang, X.; He, Y.; Jin, Y.; Qin, H.; Azhar, M.; Huang, J.Z. A Robust k-Means Clustering Algorithm Based on Observation Point Mechanism. Complexity 2020, 2020, 3650926. [Google Scholar] [CrossRef]
- Milligan, G.W. Clustering validation: Results and implications for applied analyses. In Clustering and Classification; Arabie, P., Hubert, L.J., Soete, G., Eds.; World Scientific: River Edge, NJ, USA, 1996; pp. 341–375. [Google Scholar]
- Steinley, D.; Brusco, M. Choosing the Number of Clusters in K-Means Clustering. Psychol. Methods 2011, 16, 285–297. [Google Scholar] [CrossRef] [PubMed]
- Garey, M.; Johnson, D.; Witsenhausen, H. The complexity of the generalized Lloyd—Max problem (Corresp. ) IEEE Trans. Inf. Theory 1982, 28, 255–256. [Google Scholar] [CrossRef]
- Aloise, D.; Deshpande, A.; Hansen, P.; Popat, P. NP-hardness of Euclidean sum-of-squares clustering. Mach. Learn. 2009, 75, 245–248. [Google Scholar] [CrossRef]
- Cooper, L. Heuristic methods for location-allocation problems. SIAM Rev. 1964, 6, 37–53. [Google Scholar] [CrossRef]
- Jiang, J.L.; Yuan, X.M. A heuristic algorithm for constrained multi-source Weber problem. The variational inequality approach. Eur. J. Oper. Res. 2007, 187, 357–370. [Google Scholar] [CrossRef]
- Arthur, D.; Manthey, B.; Roglin, H. k-Means Has Polynomial Smoothed Complexity. In Proceedings of the 2009 50th Annual IEEE Symposium on Foundations of Computer Science (FOCS’09), Atlanta, GA, USA, 25–27 October 2009; IEEE Computer Society: Washington, DC, USA, 2009; pp. 405–414. [Google Scholar] [CrossRef]
- Sabin, M.J.; Gray, R.M. Global convergence and empirical consistency of the generalized Lloyd algorithm. IEEE Trans. Inf. Theory 1986, 32, 148–155. [Google Scholar] [CrossRef]
- Emelianenko, M.; Ju, L.; Rand, A. Nondegeneracy and Weak Global Convergence of the Lloyd Algorithm in Rd. SIAM J. Numer. Anal. 2009, 46, 1423–1441. [Google Scholar] [CrossRef][Green Version]
- Pham, D.T.; Afify, A.A. Clustering techniques and their applications in engineering. Proceedings of the Institution of Mechanical Engineers, Part C. J. Mech. Eng. Sci. 2007, 221, 1445–1459. [Google Scholar] [CrossRef]
- Fisher, D.; Xu, L.; Carnes, J.R.; Reich, Y.; Fenves, J.; Chen, J.; Shiavi, R.; Biswas, G.; Weinberg, J. Applying AI clustering to engineering tasks. IEEE Expert 1993, 8, 51–60. [Google Scholar] [CrossRef]
- Gheorghe, G.; Cartina, G.; Rotaru, F. Using K-Means Clustering Method in Determination of the Energy Losses Levels from Electric Distribution Systems. In Proceedings of the International Conference on Mathematical Methods and Computational Techniques in Electrical Engineering, Timisoara, Romania, 21–23 October 2010; pp. 52–56. [Google Scholar]
- Kersten, P.R.; Lee, J.S.; Ainsworth, T.L. Unsupervised classification of polarimetric synthetic aperture radar images using fuzzy clustering and EM clustering. IEEE Trans. Geosci. Remote Sens. 2005, 43, 519–527. [Google Scholar] [CrossRef]
- Cesarotti, V.; Rossi, L.; Santoro, R. A neural network clustering model for miscellaneous components production planning. Prod. Plan. Control 1999, 10, 305–316. [Google Scholar] [CrossRef]
- Kundu, B.; White, K.P., Jr.; Mastrangelo, C. Defect clustering and classification for semiconductor devices. In Proceedings of the 45th Midwest Symposium on Circuits and Systems, Tulsa, Oklahoma, 4–7 August 2002; Volume 2, pp. II-561–II-564. [Google Scholar] [CrossRef]
- Vernet, A.; Kopp, G.A. Classification of turbulent flow patterns with fuzzy clustering. Eng. Appl. Artif. Intell. 2002, 15, 315–326. [Google Scholar] [CrossRef]
- Afify, A.A.; Dimov, S.; Naim, M.M.; Valeva, V. Detecting cyclical disturbances in supply networks using data mining techniques. In Proceedings of the 2nd European Conference on Management of Technology, Birmingham, UK, 10–12 September 2006; pp. 1–8. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Naranjo, J.E.; Saha, R.; Tariq, M.T.; Hadi, M.; Xiao, Y. Pattern Recognition Using Clustering Analysis to Support Transportation System Management, Operations, and Modeling. J. Adv. Transp. 2019. [Google Scholar] [CrossRef]
- Kadir, R.A.; Shima, Y.; Sulaiman, R.; Ali, F. Clustering of public transport operation using K-means. In Proceedings of the 2018 IEEE 3rd International Conference on Big Data Analysis (ICBDA), Shanghai, China, 9–12 March 2018; pp. 427–532. [Google Scholar]
- Sesham, A.; Padmanabham, P.; Govardhan, A. Application of Factor Analysis to k-means Clustering Algorithm on Transportation Data. IJCA 2014, 95, 40–46. [Google Scholar] [CrossRef]
- Deb Nath, R.P.; Lee, H.J.; Chowdhury, N.K.; Chang, J.W. Modified K-Means Clustering for Travel Time Prediction Based on Historical Traffic Data. LNCS 2010, 6276, 511–521. [Google Scholar] [CrossRef]
- Montazeri-Gh, M.; Fotouhi, A. Traffic condition recognition using the k-means clustering method. Sci. Iran. 2011, 18, 930–937. [Google Scholar] [CrossRef]
- Farahani, R.Z.; Hekmatfar, M. Facility Location Concepts, Models, Algorithms and Case Studies; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Drezner, Z.; Hamacher, H. Facility Location: Applications and Theory; Springer: Berlin, Germany, 2004; pp. 119–143. [Google Scholar]
- Klastorin, T.D. The p-Median Problem for Cluster Analysis: A Comparative Test Using the Mixture Model Approach. Manag. Sci. 1985, 31, 84–95. [Google Scholar] [CrossRef]
- Brusco, M.J.; Kohn, H.F. Optimal Partitioning of a Data Set Based on the p-Median Model. Psychometrica 2008, 73, 89–105. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Clustering by means of Medoids. In Statistical Data Analysis Based on the L1–Norm and Related Methods; Dodge, Y., Ed.; Birkhäuser Basel: Basel, Switzerland, 1987; pp. 405–416. [Google Scholar]
- Schubert, E.; Rousseeuw, P. Faster k-Medoids Clustering: Improving the PAM, CLARA, and CLARANS Algorithms. arXiv 2019, arXiv:1810.05691. [Google Scholar]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Hakimi, S.L. Optimum Locations of Switching Centers and the Absolute Centers and Medians of a Graph. Oper. Res. 1964, 12, 450–459. [Google Scholar] [CrossRef]
- Masuyama, S.; Ibaraki, T.; Hasegawa, T. The Computational Complexity of the m-Center Problems on the Plane. Trans. Inst. Electron. Commun. Eng. Japan 1981, 64E, 57–64. [Google Scholar]
- Kariv, O.; Hakimi, S.L. An Algorithmic Approach to Network Location Problems. II: The P medians. SIAM J. Appl. Math. 1979, 37, 539–560. [Google Scholar] [CrossRef]
- Kuenne, R.E.; Soland, R.M. Exact and approximate solutions to the multisource Weber problem. Math. Program. 1972, 3, 193–209. [Google Scholar] [CrossRef]
- Ostresh, L.M., Jr. The Stepwise LocationAllocation Problem: Exact Solutions in Continuous and Discrete Spaces. Geogr. Anal. 1978, 10, 174–185. [Google Scholar] [CrossRef]
- Rosing, K.E. An optimal method for solving the (generalized) multi-Weber problem. Eur. J. Oper. Res. 1992, 58, 414–426. [Google Scholar] [CrossRef]
- Blum, C.; Roli, A. Metaheuristics in combinatorial optimization: Overview and conceptual comparison. ACM Comput. Surv. 2001, 35, 268–308. [Google Scholar] [CrossRef]
- Neema, M.N.; Maniruzzaman, K.M.; Ohgai, A. New Genetic Algorithms Based Approaches to Continuous p-Median Problem. Netw. Spat. Econ. 2011, 11, 83–99. [Google Scholar] [CrossRef]
- Hoos, H.H.; Stutzle, T. Stochastic Local Search Foundations and Applications; Springer: Berlin, Germany, 2005. [Google Scholar]
- Bang-Jensen, J.; Chiarandini, M.; Goegebeur, Y.; Jorgensen, B. Mixed Models for the Analysis of Local Search Components. In Proceedings of the Engineering Stochastic Local Search Algorithms International Workshop, Brussels, Belgium, 6–8 September 2007; pp. 91–105. [Google Scholar]
- Cohen-Addad, V.; Mathieu, C. Effectiveness of local search for geometric optimization. In Proceedings of the 31st International Symposium on Computational Geometry, SoCG-2015, Eindhoven, The Netherlands, 22–25 June 2015; pp. 329–343. [Google Scholar]
- Kochetov, Y.; Mladenović, N.; Hansen, P. Local search with alternating neighborhoods. Discret. Anal. Oper. Res. 2003, 2, 11–43. (In Russian) [Google Scholar]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. A local search approximation algorithm for k-means clustering. Comput. Geom. Theory Appl. 2004, 28, 89–112. [Google Scholar] [CrossRef]
- Page, E.S. On Monte Carlo methods in congestion problems. I: Searching for an optimum in discrete situations. Oper. Res. 1965, 13, 291–299. [Google Scholar] [CrossRef]
- Hromkovic, J. Algorithmics for Hard Problems: Introduction to Combinatorial Optimization, Randomization, Approximation, and Heuristics; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Ng, T. Expanding Neighborhood Tabu Search for facility location problems in water infrastructure planning. In Proceedings of the 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), San Diego, CA, USA, 5–8 October 2014; pp. 3851–3854. [Google Scholar] [CrossRef]
- Mladenovic, N.; Brimberg, J.; Hansen, P.; Moreno-Perez, J.A. The p-median problem: A survey of metaheuristic approaches. Eur. J. Oper. Res. 2007, 179, 927–939. [Google Scholar] [CrossRef]
- Reese, J. Solution methods for the p-median problem: An annotated bibliography. Networks 2006, 48, 125–142. [Google Scholar] [CrossRef]
- Brimberg, J.; Drezner, Z.; Mladenovic, N.; Salhi, S. A New Local Search for Continuous Location Problems. Eur. J. Oper. Res. 2014, 232, 256–265. [Google Scholar] [CrossRef]
- Drezner, Z.; Brimberg, J.; Mladenovic, N.; Salhi, S. New heuristic algorithms for solving the planar p-median problem. Comput. Oper. Res. 2015, 62, 296–304. [Google Scholar] [CrossRef]
- Drezner, Z.; Brimberg, J.; Mladenovic, N.; Salhi, S. Solving the planar p-median problem by variable neighborhood and concentric searches. J. Glob. Optim. 2015, 63, 501–514. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-Means++: The Advantages of Careful Seeding. In Proceedings of the SODA’07, SIAM, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Bradley, P.S.; Fayyad, U.M. Refining Initial Points for K-Means Clustering. In Proceedings of the Fifteenth International Conference on Machine Learning (ICML ‘98), Madison, WI, USA, 24–27 July 1998; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1998; pp. 91–99. [Google Scholar]
- Bhusare, B.B.; Bansode, S.M. Centroids Initialization for K-Means Clustering using Improved Pillar Algorithm. Int. J. Adv. Res. Comput. Eng. Technol. 2014, 3, 1317–1322. [Google Scholar]
- Yang, J.; Wang, J. Tag clustering algorithm lmmsk: Improved k-means algorithm based on latent semantic analysis. J. Syst. Electron. 2017, 28, 374–384. [Google Scholar]
- Mishra, N.; Oblinger, D.; Pitt, L. Sublinear time approximate clustering. In Proceedings of the 12th SODA, Washington, DC, USA, 7–9 January 2001; pp. 439–447. [Google Scholar]
- Eisenbrand, F.; Grandoni, F.; Rothvosz, T.; Schafer, G. Approximating connected facility location problems via random facility sampling and core detouring. In Proceedings of the SODA’2008, San Francisco, CA, USA, 20–22 January 2008; ACM: New York, NY, USA, 2008; pp. 1174–1183. [Google Scholar] [CrossRef]
- Jaiswal, R.A.; Kumar, A.; Sen, S. Simple D2-Sampling Based PTAS for k-Means and Other Clustering Problems. Algorithmica 2014, 70, 22–46. [Google Scholar] [CrossRef]
- Avella, P.; Boccia, M.; Salerno, S.; Vasilyev, I. An Aggregation Heuristic for Large Scale p-median Problem. Comput. Oper. Res. 2012, 39, 1625–1632. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; Wiley: New York, NY, USA, 1990. [Google Scholar]
- Francis, R.L.; Lowe, T.J.; Rayco, M.B.; Tamir, A. Aggregation error for location models: Survey and analysis. Ann. Oper. Res. 2009, 167, 171–208. [Google Scholar] [CrossRef]
- Pelleg, D.; Moore, A. Accelerating Exact k-Means with Geometric Reasoning [Technical Report CMU-CS-00-105]; Carnegie Melon University: Pittsburgh, PA, USA, 2000. [Google Scholar]
- Borgelt, C. Even Faster Exact k-Means Clustering. LNCS 2020, 12080, 93–105. [Google Scholar] [CrossRef]
- Lai, J.Z.C.; Huang, T.J.; Liaw, Y.C. A Fast k-Means Clustering Algorithm Using Cluster Center Displacement. Pattern Recognit. 2009, 42, 2551–2556. [Google Scholar] [CrossRef]
- Mladenovic, N.; Hansen, P. Variable Neighborhood Search. Comput. Oper. Res. 1997, 24, 1097–1100. [Google Scholar] [CrossRef]
- Hansen, P. Variable Neighborhood Search. Search Methodology. In Search Metodologies; Bruke, E.K., Kendall, G., Eds.; Springer: New York, NY, USA, 2005; pp. 211–238. [Google Scholar] [CrossRef]
- Hansen, P.; Mladenovic, N. Variable Neighborhood Search. In Handbook of Heuristics; Martí, R., Pardalos, P., Resende, M., Eds.; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Brimberg, J.; Hansen, P.; Mladenovic, N. Attraction Probabilities in Variable Neighborhood Search. 4OR-Q. J. Oper. Res 2010, 8, 181–194. [Google Scholar] [CrossRef]
- Hansen, P.; Mladenovic, N.; Perez, J.A.M. Variable Neighborhood Search: Methods and Applications. 4OR-Q. J. Oper. Res. 2008, 6, 319–360. [Google Scholar] [CrossRef]
- Hansen, P.; Brimberg, J.; Urosevic, D.; Mladenovic, N. Solving Large p-Median Clustering Problems by Primal Dual Variable Neighborhood Search. Data Min. Knowl. Discov. 2009, 19, 351–375. [Google Scholar] [CrossRef]
- Rozhnov, I.P.; Orlov, V.I.; Kazakovtsev, L.A. VNS-Based Algorithms for the Centroid-Based Clustering Problem. Facta Univ. Ser. Math. Inform. 2019, 34, 957–972. [Google Scholar]
- Hansen, P.; Mladenovic, N. J-Means: A new local search heuristic for minimum sum-of-squares clustering. Pattern Recognit. 2001, 34, 405–413. [Google Scholar] [CrossRef]
- Martins, P. Goal Clustering: VNS Based Heuristics. Available online: https://arxiv.org/abs/1705.07666v4 (accessed on 24 October 2020).
- Carrizosa, E.; Mladenovic, N.; Todosijevic, R. Variable neighborhood search for minimum sum-of-squares clustering on networks. Eur. J. Oper. Res. 2013, 230, 356–363. [Google Scholar] [CrossRef]
- Roux, M. A Comparative Study of Divisive and Agglomerative Hierarchical Clustering Algorithms. J. Classif. 2018, 35, 345–366. [Google Scholar] [CrossRef]
- Sharma, A.; López, Y.; Tsunoda, T. Divisive hierarchical maximum likelihood clustering. BMC Bioinform. 2017, 18, 546. [Google Scholar] [CrossRef]
- Venkat Reddy, M.; Vivekananda, M.; Satish, R.U.V.N. Divisive Hierarchical Clustering with K-means and Agglomerative Hierarchical Clustering. IJCST 2017, 5, 6–11. [Google Scholar]
- Sun, Z.; Fox, G.; Gu, W.; Li, Z. A parallel clustering method combined information bottleneck theory and centroid-based clustering. J. Supercomput. 2014, 69, 452–467. [Google Scholar] [CrossRef]
- Kuehn, A.A.; Hamburger, M.J. A heuristic program for locating warehouses. Manag. Sci. 1963, 9, 643–666. [Google Scholar] [CrossRef]
- Alp, O.; Erkut, E.; Drezner, Z. An Efficient Genetic Algorithm for the p-Median Problem. Ann. Oper. Res. 2003, 122, 21–42. [Google Scholar] [CrossRef]
- Cheng, J.; Chen, X.; Yang, H.; Leng, M. An enhanced k-means algorithm using agglomerative hierarchical clustering strategy. In Proceedings of the International Conference on Automatic Control and Artificial Intelligence (ACAI 2012), Xiamen, China, 3–5 March 2012; pp. 407–410. [Google Scholar] [CrossRef]
- Kazakovtsev, L.A.; Antamoshkin, A.N. Genetic Algorithm with Fast Greedy Heuristic for Clustering and Location Problems. Informatica 2014, 3, 229–240. [Google Scholar]
- Pelleg, D.; Moore, A. X-means: Extending K-means with Efficient Estimation of the Number of Clusters. In Proceedings of the International Conference on Machine Learning ICML, Sydney, Australia, 8–12 July 2002. [Google Scholar]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means Algorithm: A Comprehensive Survey and Performance Evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Frackiewicz, M.; Mandrella, A.; Palus, H. Fast Color Quantization by K-Means Clustering Combined with Image Sampling. Symmetry 2019, 11, 963. [Google Scholar] [CrossRef]
- Zhang, G.; Li, Y.; Deng, X. K-Means Clustering-Based Electrical Equipment Identification for Smart Building Application. Information 2020, 11, 27. [Google Scholar] [CrossRef]
- Chen, F.; Yang, Y.; Xu, L.; Zhang, T.; Zhang, Y. Big-Data Clustering: K-Means or K-Indicators? 2019. Available online: https://arxiv.org/pdf/1906.00938.pdf (accessed on 18 October 2020).
- Qin, J.; Fu, W.; Gao, H.; Zheng, W.X. Distributed k-means algorithm and fuzzy c -means algorithm for sensor networks based on multiagent consensus theory. IEEE Trans. Cybern. 2016, 47, 772–783. [Google Scholar] [CrossRef]
- Shindler, M.; Wong, A.; Meyerson, A. Fast and accurate k-means for large datasets. In Proceedings of the 24th International Conference on Neural Information Processing Systems (NIPS’11), Sydney, Australia, 13–16 December 2011; Curran Associates Inc.: Red Hook, NY, USA, 2011; pp. 2375–2383. [Google Scholar]
- Hedar, A.R.; Ibrahim, A.M.M.; Abdel-Hakim, A.E.; Sewisy, A.A. K-Means Cloning: Adaptive Spherical K-Means Clustering. Algorithms 2018, 11, 151. [Google Scholar] [CrossRef]
- Xu, T.S.; Chiang, H.D.; Liu, G.Y.; Tan, C.W. Hierarchical k-means method for clustering large-scale advanced metering infrastructure data. IEEE Trans. Power Deliv. 2015, 32, 609–616. [Google Scholar] [CrossRef]
- Wang, X.D.; Chen, R.C.; Yan, F.; Zeng, Z.Q.; Hong, C.Q. Fast adaptive k-means subspace clustering for high-dimensional data. IEEE Access 2019, 7, 639–651. [Google Scholar] [CrossRef]
- Zechner, M.; Granitzer, M. Accelerating K-Means on the Graphics Processor via CUDA. In Proceedings of the International Conference on Intensive Applications and Services, Valencia, Spain, 20–25 April 2009; pp. 7–15. [Google Scholar] [CrossRef]
- Luebke, D.; Humphreys, G. How GPUs work. Computer 2007, 40, 96–110. [Google Scholar] [CrossRef]
- Maulik, U.; Bandyopadhyay, S. Genetic Algorithm-Based Clustering Technique. Pattern Recognit. 2000, 33, 1455–1465. [Google Scholar] [CrossRef]
- Krishna, K.; Murty, M. Genetic K-Means algorithm. IEEE Trans. Syst. Man Cybern. Part B 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed]
- Singh, N.; Singh, D.P.; Pant, B. ACOCA: Ant Colony Optimization Based Clustering Algorithm for Big Data Preprocessing. Int. J. Math. Eng. Manag. Sci. 2019, 4, 1239–1250. [Google Scholar] [CrossRef]
- Merwe, D.W.; Engelbrecht, A.P. Data Clustering Using Particle Swarm Optimization. In Proceedings of the 2003 Congress on Evolutionary Computation, Canberra, Australia, 8–12 December 2003; pp. 215–220. [Google Scholar]
- Nikolaev, A.; Mladenovic, N.; Todosijevic, R. J-means and I-means for minimum sum-of-squares clustering on networks. Optim. Lett. 2017, 11, 359–376. [Google Scholar] [CrossRef]
- Fränti, P.; Sieranoja, S. K-means properties on six clustering benchmark datasets. Appl. Intell. 2018, 48, 4743–4759. [Google Scholar] [CrossRef]
- Clustering Basic Benchmark. Available online: http://cs.joensuu.fi/sipu/datasets/ (accessed on 15 September 2020).
- Kazakovtsev, L.; Shkaberina, G.; Rozhnov, I.; Li, R.; Kazakovtsev, V. Genetic Algorithms with the Crossover-Like Mutation Operator for the k-Means Problem. CCIS 2020, 1275, 350–362. [Google Scholar] [CrossRef]
- Brimberg, J.; Mladenovic, N. A variable neighborhood algorithm for solving the continuous location-allocation problem. Stud. Locat. Anal. 1996, 10, 1–12. [Google Scholar]
- Miskovic, S.; Stanimirovich, Z.; Grujicic, I. An efficient variable neighborhood search for solving a robust dynamic facility location problem in emergency service network. Electron. Notes Discret. Math. 2015, 47, 261–268. [Google Scholar] [CrossRef]
- Crainic, T.G.; Gendreau, M.; Hansen, P.; Hoeb, N.; Mladenovic, N. Parallel variable neighbourhood search for the p-median. In Proceedings of the 4th Metaheuristics International conference MIC’2001, Porto, Portugal, 16–21 July 2001; pp. 595–599. [Google Scholar]
- Hansen, P.; Mladenovic, N. Variable neighborhood search for the p-median. Locat. Sci. 1997, 5, 207–226. [Google Scholar] [CrossRef]
- Wen, M.; Krapper, E.; Larsen, J.; Stidsen, T.K. A multilevel variable neighborhood search heuristic for a practical vehicle routing and driver scheduling problem. Networks 2011, 58, 311–323. [Google Scholar] [CrossRef]
- Baldassi, C. Recombinator-k-Means: Enhancing k-Means++ by Seeding from Pools of Previous Runs. Available online: https://arxiv.org/abs/1905.00531v1 (accessed on 18 September 2020).
- Duarte, A.; Mladenović, N.; Sánchez-Oro, J.; Todosijević, R. Variable Neighborhood Descent. In Handbook of Heuristics; Martí, R., Panos, P., Resende, M., Eds.; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository 2019. Available online: http://archive.ics.uci.edu/ml (accessed on 30 September 2020).
- Molla, M.M.; Nag, P.; Thohura, S.; Khan, A. A Graphics Process Unit-Based Multiple-Relaxation-Time Lattice Boltzmann Simulation of Non-Newtonian Fluid Flows in a Backward Facing Step. Computation 2020, 8, 83. [Google Scholar] [CrossRef]
- Kazakovtsev, L.A.; Rozhnov, I.P.; Popov, E.A.; Karaseva, M.V.; Stupina, A.A. Parallel implementation of the greedy heuristic clustering algorithms. IOP Conf. Ser. Mater. Sci. Eng. 2019, 537, 022052. [Google Scholar] [CrossRef]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An Efficient Data Clustering Method for Very Large Databases. In Proceedings of the 1996 ACM SIGMOD International Conference on Management of data (SIGMOD’96), Montreal, QC, Canada, 4–6 June 1996; ACM: New York, NY, USA, 1996; pp. 103–114. [Google Scholar] [CrossRef]
- Smucker, M.D.; Allan, J.; Carterette, B.A. Comparison of Statistical Significance Tests for Information Retrieval. In Proceedings of the Sixteenth ACM Conference on Information and Knowledge Management (CIKM ‘07), Lisbon, Portugal, 6–10 November 2007; ACM: New York, NY, USA, 2007; pp. 623–632. [Google Scholar]
- Park, H.M. Comparing Group Means: The t-Test and One-way ANOVA Using STATA, SAS, and SPSS; Indiana University: Bloomington, Indiana, 2009. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a Test of Whether one of Two Random Variables is Stochastically Larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Fay, M.P.; Proschan, M.A. Wilcoxon-Mann-Whitney or t-Test? On Assumptions for Hypothesis Tests and Multiple Interpretations of Decision Rules. Stat. Surv. 2010, 4, 1–39. [Google Scholar] [CrossRef]
- Burke, E.; Gendreau, M.; Hyde, M.; Kendall, G.; Ochoa, G.; Ozkan, E.; Qu, R. Hyper-heuristics: A survey of the state of the art. J. Oper. Res. Soc. 2013, 64, 1695–1724. [Google Scholar] [CrossRef]
- Stanovov, V.; Semenkin, E.; Semenkina, O. Self-configuring hybrid evolutionary algorithm for fuzzy imbalanced classification with adaptive instance selection. J. Artif. Intell. Soft Comput. Res. 2016, 6, 173–188. [Google Scholar] [CrossRef]
- Semenkina, M.; Semenkin, E. Hybrid Self-configuring Evolutionary Algorithm for Automated Design of Fuzzy Classifier. LNCS 2014, 8794, 310–317. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).