From Complex System Analysis to Pattern Recognition: Experimental Assessment of an Unsupervised Feature Extraction Method Based on the Relevance Index Metrics





Abstract
1. Introduction
- Use an unsupervised approach to extract relevant features that can be used to solve supervised classification problems.
- Perform an in-depth analysis of the results that the -based approach to feature extraction can yield, by applying it to data from different real-world case studies.
2. State of the Art
- Feature selection chooses a subset of m features out of the original s ones.
- Feature extraction creates a set of new features from the original attributes through some function mappings.
- Feature construction augments the space of features by inferring or creating additional attributes.
3. Theoretical Background
- the Integration in the context of the Relevance Index metrics;
- the motivation to use the metric;
- the evolutionary algorithm we implemented to compute the ;
- the sieving procedure used to iterate the computation; and
- the application of the to the unsupervised feature extraction problem.
3.1. Integration as a Relevance Index Metric
3.2. Motivation to Use the
- to use only the integration, which, by itself, provides a measure of the tightness of the interaction between variables belonging to the same subset; and
- to adopt a normalization procedure by considering the average value and the standard deviation of the metric, whose computation can be accelerated thanks to the theoretical hints described in the following.
3.3. Computation through an Evolutionary Algorithm
3.4. Iterative Sieving Procedure
4. -Based Feature Extraction
4.1. Possible Encoding Schemata
- It depends on the order in which bits are taken into consideration: bits that are remapped as more significant have a larger weight in the final encoding. The ratio between the weight of the most significant bit (MSB) and the least significant bit (LSB) increases exponentially with the number of bits, up to making the LSB virtually irrelevant.
- Topological relationships are not preserved. Neighborhoods of the encoding of a given string S may not (and usually do not) include the encoding of the same elements included in the neighborhood of S.
5. Experimental Evaluation on Real-World Datasets
- Are the properties of the variable sets detected using the index, which have already been demonstrated to be effective in their original role of detecting functional blocks in complex systems, as relevant when such sets are used to build classification-oriented representations?
- How well do such representations compare with other representations which can be obtained by more classical feature selection/extraction methods?
- How data- or classifier-dependent are the results provided by such representations?
5.1. Experimental Setup
5.1.1. Feature Extraction/Selection Methods
- Principal Component Analysis (PCA) [36], which uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values representing the projection of the data onto an orthogonal base of linearly uncorrelated principal components.
- Information Gain (IG) [37], which is the conditional expected value of the Kullback–Leibler divergence of the univariate probability distribution of one variable from the conditional distribution of such a variable given the other ones.
- Chi-squared test () [38], which is a statistical hypothesis test where the sampling distribution of the test statistic is a chi-squared distribution when the null hypothesis is true.
- Univariate feature selection (F_VAL) [39], which is a feature selection method based on univariate statistical tests.
5.1.2. Classifiers
- Random Forest (RF) [40], which is an ensemble learning method that constructs a multitude of decision trees at training time and outputs as its final decision (i.e., class) the mode of all the decisions taken by the trees.
- Decision trees (C4.5) [41], which is a tree classifier where nodes hierarchically partition the pattern space, each node based on the values of a single feature, until a leaf node, representing a decision, is reached.
- K-Nearest Neighbors (KNN) [36], which is a non-parametric method where an object is classified by applying a majority vote strategy to the decisions of its neighbors in the training set, resulting in the object being assigned to the class most frequently represented by its K nearest neighbors.
- Radial Basis Function (SVM) [36], which is a supervised learning model where the examples, represented as points in the pattern space, are mapped using a Radial Basis Function kernel, such that the margin (distance) between boundary examples representing different classes is maximized.
5.1.3. Datasets
5.1.4. Evaluation Procedure
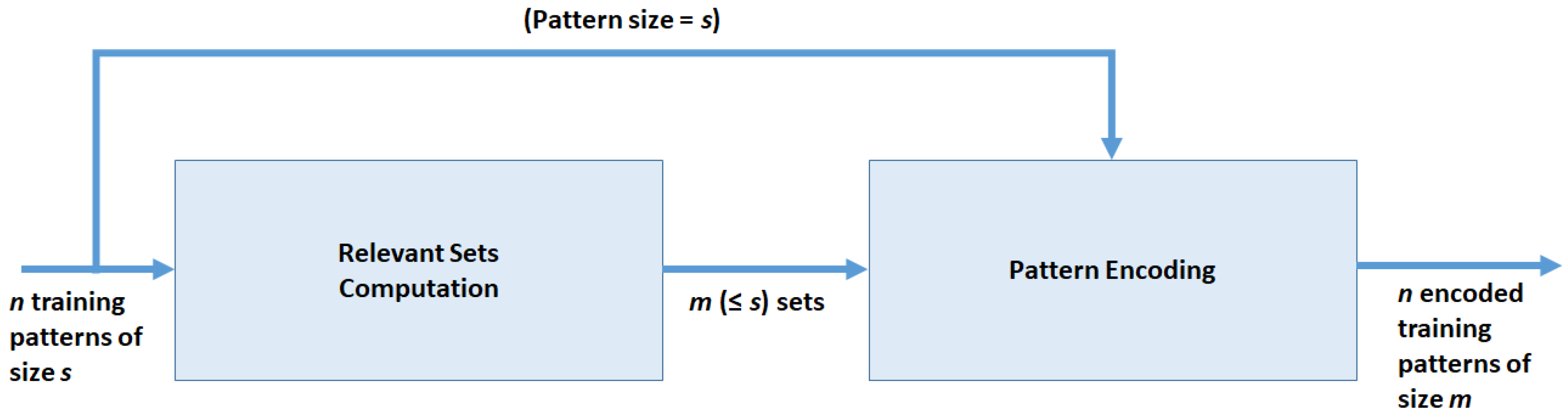
- Compute the Relevant Sets by iteratively applying HyReSS to the training set, as described in Section 3.3 and Section 3.4. Starting from an initial representation in which all correspond to a single feature of the original dataset, in each iteration, we merge into a new set the from the previous iteration whose union has the largest possible value. From then on, and until it is involved in a new merger, HyReSS will treat the newly-created variable set as a single variable (group variable) in the representation of data, which will substitute its components in the list. Thus, after each iteration, the number of variables () used to represent data decreases while the average size of the increases.
- Encode the training and test data, as described in Section 4.1, according to the feature sets extracted up to the current iteration of HyReSS.
- For each of the reference methods, and for each iteration of ZIFF, consider the feature sets, extracted or selected by the method under consideration, having the same size as the number of found by ZIFF, and compute the corresponding representation of the benchmark datasets.
- Apply the classifiers to such representations for testing the effectiveness of the corresponding feature set using the classification accuracy as a quality criterion.
- Stop iterating when the of the new group variable deriving from the merger “proposed” by HyReSS falls below a pre-set threshold.
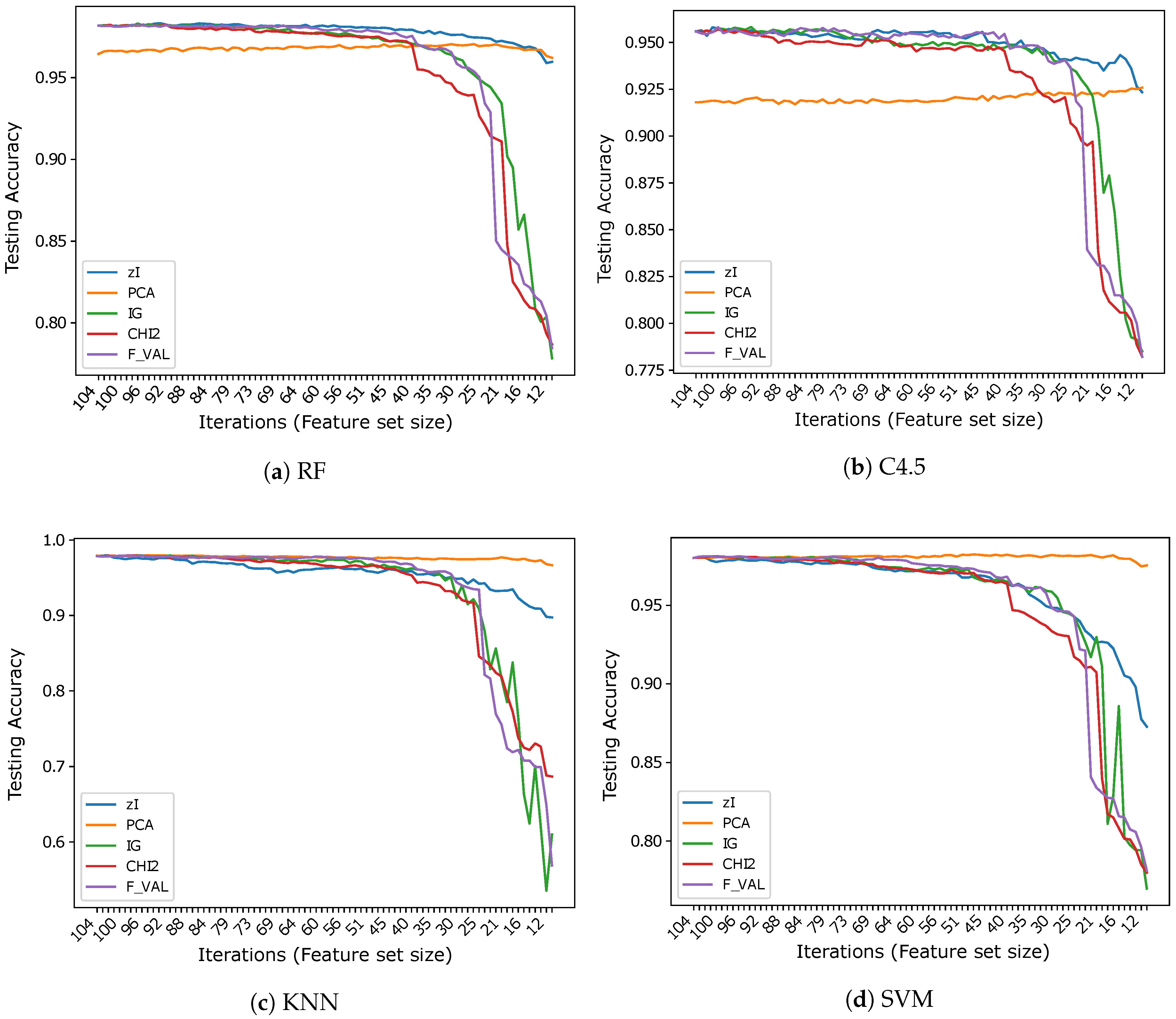
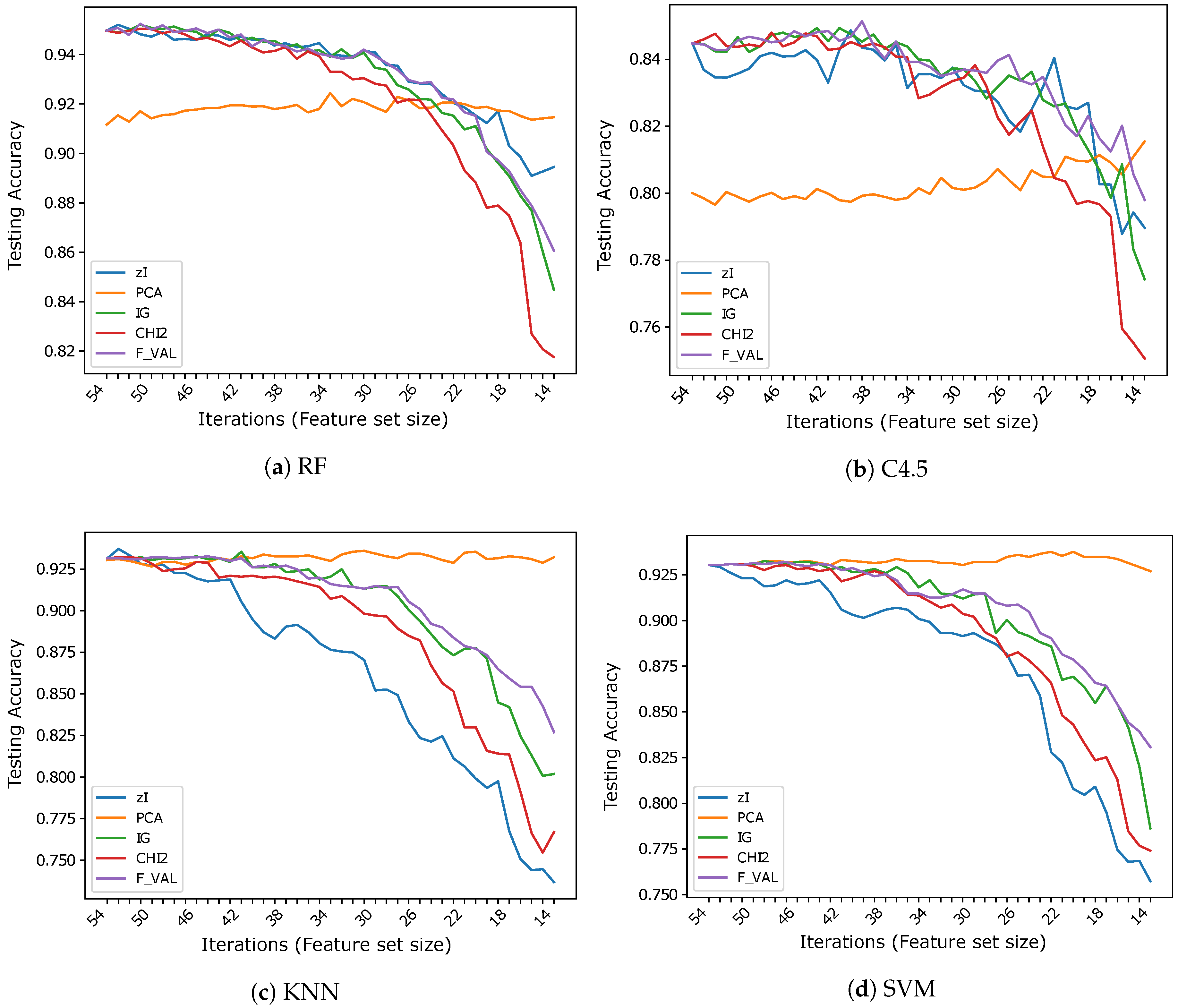
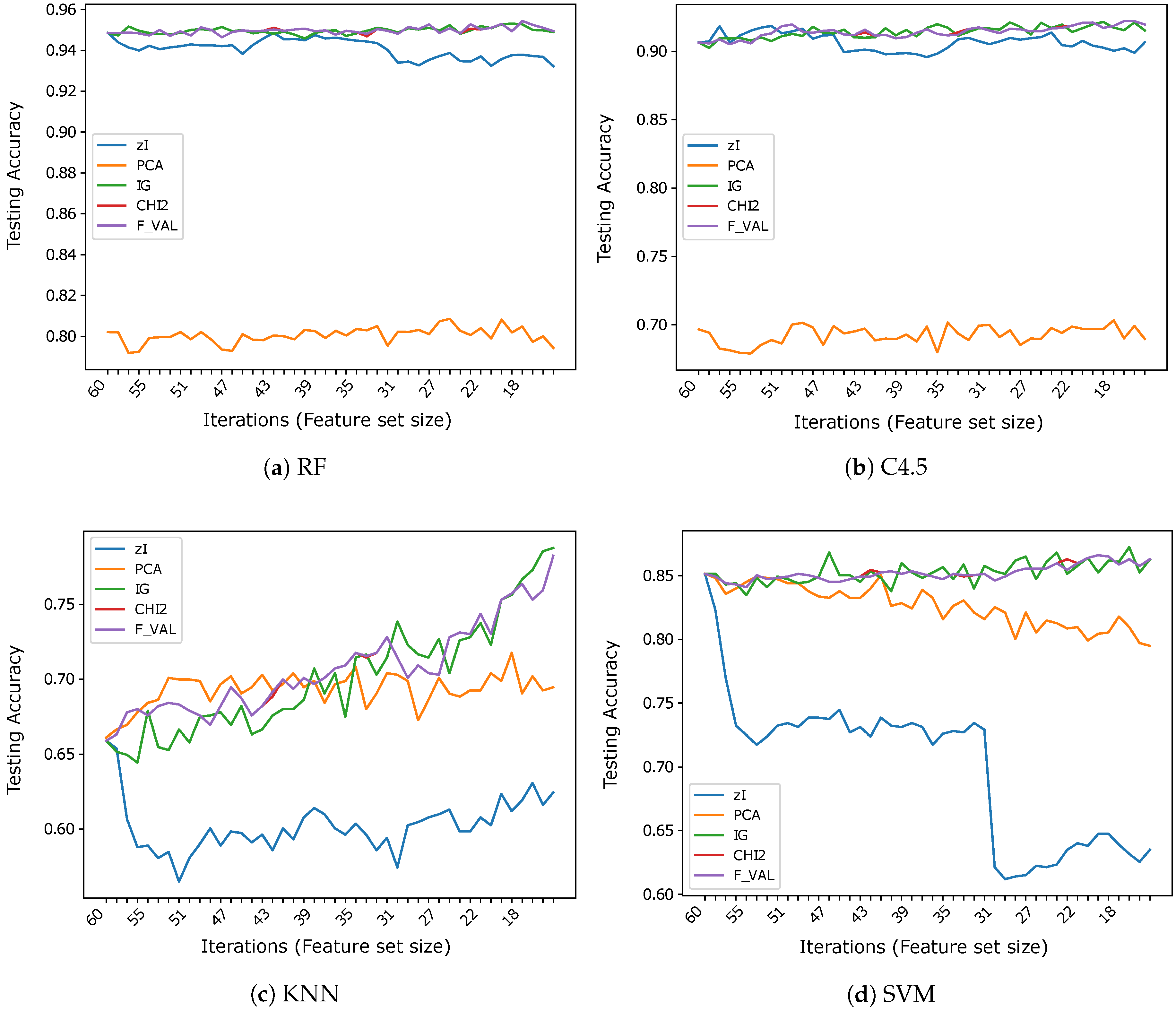
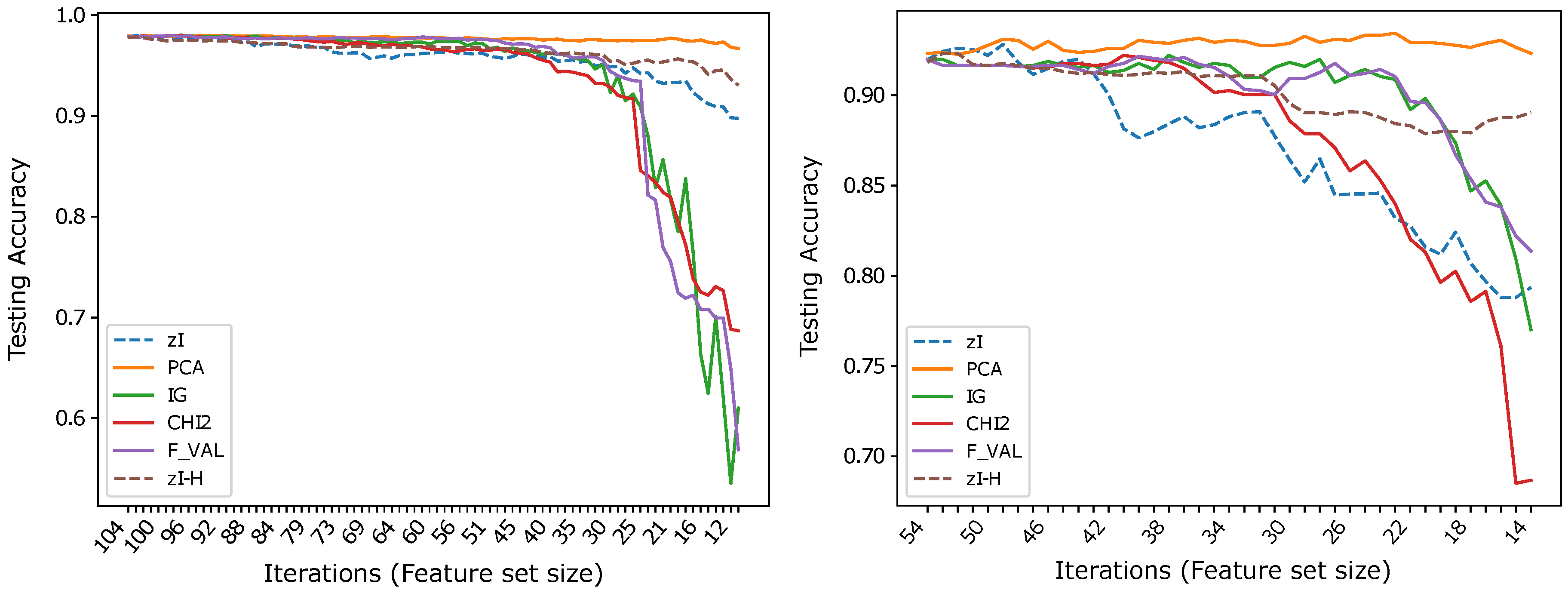
5.2. Results and Comparisons
6. Discussion and Conclusions
Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Filisetti, A.; Villani, M.; Roli, A.; Fiorucci, M.; Serra, R. Exploring the organisation of complex systems through the dynamical interactions among their relevant subsets. In Proceedings of the European Conference on Artificial Life 2015; The MIT Press: Cambridge, MA, USA, 2015; pp. 286–293. [Google Scholar]
- Sani, L.; D’Addese, G.; Pecori, R.; Mordonini, M.; Villani, M.; Cagnoni, S. An Integration-Based Approach to Pattern Clustering and Classification. In AI*IA 2018—Advances in Artificial Intelligence; Ghidini, C., Magnini, B., Passerini, A., Traverso, P., Eds.; Springer: Cham, Switzerland, 2018; pp. 362–374. [Google Scholar]
- Sani, L.; Pecori, R.; Vicari, E.; Amoretti, M.; Mordonini, M.; Cagnoni, S. Can the Relevance Index be Used to Evolve Relevant Feature Sets? In International Conference on the Applications of Evolutionary Computation; Sim, K., Kaufmann, P., Eds.; Springer: Cham, Switzerland, 2018; pp. 472–479. [Google Scholar]
- Sani, L.; Amoretti, M.; Vicari, E.; Mordonini, M.; Pecori, R.; Roli, A.; Villani, M.; Cagnoni, S.; Serra, R. Efficient Search of Relevant Structures in Complex Systems. In Conference of the Italian Association for Artificial Intelligence; Springer: Cham, Switzerland, 2016; pp. 35–48. [Google Scholar] [CrossRef]
- Vicari, E.; Amoretti, M.; Sani, L.; Mordonini, M.; Pecori, R.; Roli, A.; Villani, M.; Cagnoni, S.; Serra, R. GPU-based parallel search of relevant variable sets in complex systems. In Italian Workshop on Artificial Life and Evolutionary Computation; Springer: Cham, Switzerland, 2017; pp. 14–25. [Google Scholar] [CrossRef]
- Villani, M.; Sani, L.; Pecori, R.; Amoretti, M.; Roli, A.; Mordonini, M.; Serra, R.; Cagnoni, S. An iterative information-theoretic approach to the detection of structures in complex systems. Complexity 2018, 2018, 3687839. [Google Scholar] [CrossRef]
- Cang, S.; Yu, H. Mutual information based input feature selection for classification problems. Decis. Support Syst. 2012, 54, 691–698. [Google Scholar] [CrossRef]
- Motoda, H.; Liu, H. Feature Selection Extraction and Construction; Communication of IICM; Institute of Information and Computing Machinery: Taipei, Taiwan, 2002. [Google Scholar]
- Zhang, H.; Ho, T.B.; Zhang, Y.; Lin, M.S. Unsupervised Feature Extraction for Time Series Clustering Using Orthogonal Wavelet Transform. Informatica 2006, 30, 305–319. [Google Scholar]
- Qiao, T.; Yang, Z.; Ren, J.; Yuen, P.; Zhao, H.; Sun, G.; Marshall, S.; Benediktsson, J.A. Joint bilateral filtering and spectral similarity-based sparse representation: A generic framework for effective feature extraction and data classification in hyperspectral imaging. Pattern Recognit. 2018, 77, 316–328. [Google Scholar] [CrossRef]
- Franchini, S.; Charogiannis, A.; Markides, C.N.; Blunt, M.J.; Krevor, S. Calibration of astigmatic particle tracking velocimetry based on generalized Gaussian feature extraction. Adv. Water Resour. 2019, 124, 1–8. [Google Scholar] [CrossRef]
- Zhan, S.; Wu, J.; Han, N.; Wen, J.; Fang, X. Unsupervised feature extraction by low-rank and sparsity preserving embedding. Neural Netw. 2019, 109, 56–66. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Yu, J.; Tao, D. Local Deep-Feature Alignment for Unsupervised Dimension Reduction. IEEE Trans. Image Process. 2018, 27, 2420–2432. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, J.; Chen, C.; Wang, Z.; Cai, Z.; Wang, L. SuperPCA: A Superpixelwise PCA Approach for Unsupervised Feature Extraction of Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4581–4593. [Google Scholar] [CrossRef]
- Sari, C.T.; Gunduz-Demir, C. Unsupervised Feature Extraction via Deep Learning for Histopathological Classification of Colon Tissue Images. IEEE Trans. Med. Imaging 2019, 38, 1139–1149. [Google Scholar] [CrossRef]
- Taguchi, Y.H. Tensor Decomposition-Based Unsupervised Feature Extraction Can Identify the Universal Nature of Sequence-Nonspecific Off-Target Regulation of mRNA Mediated by MicroRNA Transfection. Cells 2018, 7, 54. [Google Scholar] [CrossRef]
- Taguchi, Y.H. Tensor decomposition-based and principal-component-analysis-based unsupervised feature extraction applied to the gene expression and methylation profiles in the brains of social insects with multiple castes. BMC Bioinform. 2018, 19, 99. [Google Scholar] [CrossRef] [PubMed]
- Jimenez-Rodriguez, L.O.; Arzuaga-Cruz, E.; Velez-Reyes, M. Unsupervised Linear Feature-Extraction Methods and Their Effects in the Classification of High-Dimensional Data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 469–483. [Google Scholar] [CrossRef]
- Fleming, M.K.; Cottrell, G.W. Categorization of faces using unsupervised feature extraction. In Proceedings of the 1990 IJCNN International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990; Volume 2, pp. 65–70. [Google Scholar]
- Fisher, J.W.; Principe, J.C. A methodology for information theoretic feature extraction. In Proceedings of the 1998 IEEE International Joint Conference on Neural Networks, Anchorage, AK, USA, 4–9 May 1998; Volume 3, pp. 1712–1716. [Google Scholar]
- Goldberger, J.; Gordon, S.; Greenspan, H. Unsupervised image-set clustering using an information theoretic framework. IEEE Trans. Image Process. 2006, 15, 449–458. [Google Scholar] [CrossRef] [PubMed]
- Hild, K.E.; Erdogmus, D.; Torkkola, K.; Principe, J.C. Feature extraction using information-theoretic learning. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1385–1392. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Sha, F. Information-theoretical Learning of Discriminative Clusters for Unsupervised Domain Adaptation. In Proceedings of the 29th International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012; pp. 1275–1282. [Google Scholar]
- Villani, M.; Roli, A.; Filisetti, A.; Fiorucci, M.; Poli, I.; Serra, R. The Search for Candidate Relevant Subsets of Variables in Complex Systems. Artif. Life 2015, 21, 412–431. [Google Scholar] [CrossRef] [PubMed]
- Tononi, G.; Sporns, O.; Edelman, G.M. A measure for brain complexity: Relating functional segregation and integration in the nervous system. Proc. Natl. Acad. Sci. USA 1994, 91, 5033–5037. [Google Scholar] [CrossRef] [PubMed]
- Tononi, G.; McIntosh, A.; Russel, D.; Edelman, G. Functional clustering: Identifying strongly interactive brain regions in neuroimaging data. Neuroimage 1998, 7, 133–149. [Google Scholar] [CrossRef]
- Villani, M.; Filisetti, A.; Benedettini, S.; Roli, A.; Lane, D.; Serra, R. The detection of intermediate-level emergent structures and patterns. In Artificial Life Conference Proceedings 13; The MIT Press: Cambridge, MA, USA, 2013; pp. 372–378. [Google Scholar]
- Villani, M.; Sani, L.; Amoretti, M.; Vicari, E.; Pecori, R.; Mordonini, M.; Cagnoni, S.; Serra, R. A Relevance Index Method to Infer Global Properties of Biological Networks. In Artificial Life and Evolutionary Computation; Pelillo, M., Poli, I., Roli, A., Serra, R., Slanzi, D., Villani, M., Eds.; Springer: Cham, Switzerland, 2018; pp. 129–141. [Google Scholar]
- Sani, L.; Lombardo, G.; Pecori, R.; Fornacciari, P.; Mordonini, M.; Cagnoni, S. Social Relevance Index for Studying Communities in a Facebook Group of Patients. In Applications of Evolutionary Computation; Sim, K., Kaufmann, P., Eds.; Springer: Cham, Switzerland, 2018; pp. 125–140. [Google Scholar]
- Passaro, A.; Starita, A. Particle Swarm Optimization for Multimodal Functions: A Clustering Approach. J. Artif. Evol. Appl. 2008, 2008, 482032. [Google Scholar] [CrossRef]
- Silvestri, G.; Sani, L.; Amoretti, M.; Pecori, R.; Vicari, E.; Mordonini, M.; Cagnoni, S. Searching Relevant Variable Subsets in Complex Systems Using K-Means PSO. In Artificial Life and Evolutionary Computation; Pelillo, M., Poli, I., Roli, A., Serra, R., Slanzi, D., Villani, M., Eds.; Springer: Cham, Switzerland, 2018; pp. 308–321. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing); Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Wilks, S.S. The Large-Sample Distribution of the Likelihood Ratio for Testing Composite Hypotheses. Ann. Math. Stat. 1938, 9, 60–62. [Google Scholar] [CrossRef]
- Papoulis, A.; Pillai, S.U. Probability, Random Variables, and Stochastic Processes; McGraw-Hill: Boston, MA, USA, 2015. [Google Scholar]
- Owen, A. Empirical Likelihood Ratio Confidence Regions. Ann. Stat. 1990, 18, 90–120. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition And Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Greenwood, C.; Nikulin, M.S. A Guide to Chi-Squared Testing; Wiley: Hoboken, NJ, USA, 1996. [Google Scholar]
- Everitt, B. The Cambridge Dictionary of Statistics; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- CUDA Toolkit. Available online: http://developer.nvidia.com/cuda-toolkit (accessed on 6 August 2019).
- Kohonen, T. Self-Organizing Maps, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Poli, R.; Langdon, W.B.; McPhee, N.F.; Koza, J.R. A Field Guide to Genetic Programming; Lulu Press: Morrisville, NC, USA, 2008. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Scholkopf, B.; Smola, A.J. Learning With Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Data Type | # Input Features | # Classes | Training Data | Test Data |
|---|---|---|---|---|---|---|
| Printed characters | B | 104 | 10 | 6024 | 5010 | |
| Handwritten characters | N/B | 64 | 10 | 3823 | 1797 | |
| DNA sequences | N | 60 | 3 | 2230 | 956 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sani, L.; Pecori, R.; Mordonini, M.; Cagnoni, S. From Complex System Analysis to Pattern Recognition: Experimental Assessment of an Unsupervised Feature Extraction Method Based on the Relevance Index Metrics. Computation 2019, 7, 39. https://doi.org/10.3390/computation7030039
Sani L, Pecori R, Mordonini M, Cagnoni S. From Complex System Analysis to Pattern Recognition: Experimental Assessment of an Unsupervised Feature Extraction Method Based on the Relevance Index Metrics. Computation. 2019; 7(3):39. https://doi.org/10.3390/computation7030039
Chicago/Turabian StyleSani, Laura, Riccardo Pecori, Monica Mordonini, and Stefano Cagnoni. 2019. "From Complex System Analysis to Pattern Recognition: Experimental Assessment of an Unsupervised Feature Extraction Method Based on the Relevance Index Metrics" Computation 7, no. 3: 39. https://doi.org/10.3390/computation7030039
APA StyleSani, L., Pecori, R., Mordonini, M., & Cagnoni, S. (2019). From Complex System Analysis to Pattern Recognition: Experimental Assessment of an Unsupervised Feature Extraction Method Based on the Relevance Index Metrics. Computation, 7(3), 39. https://doi.org/10.3390/computation7030039