Abstract
The rapid growth of ultra-dense mobile edge computing (UDEC) in 5G IoT networks has intensified energy inefficiencies and latency bottlenecks exacerbated by dynamic channel conditions and imperfect CSI in real-world deployments. This paper introduces POTMEC, a power optimization framework that combines a channel-aware adaptive power allocator using real-time SNR measurements, a MATLAB-trained RL model for joint offloading decisions and a decaying step-size algorithm guaranteeing convergence. Computational offloading is a productive technique to overcome mobile battery life issues by processing a few parts of the mobile application on the cloud. It investigated how multi-access edge computing can reduce latency and energy usage. The experiments demonstrate that the proposed model reduces transmission energy consumption by 27.5% compared to baseline methods while maintaining the latency below 15 ms in ultra-dense scenarios. The simulation results confirm a 92% accuracy in near-optimal offloading decisions under dynamic channel conditions. This work advances sustainable edge computing by enabling energy-efficient IoT deployments in 5G ultra-dense networks without compromising QoS.
1. Introduction
Cloud computing has considerably impacted how we live, work, and learn since its inception in 2005 [1]. Applications that provide software as a service (SaaS), such as Google Apps, Twitter, Facebook, and Flickr, have recently become commonplace in our daily lives. On the other hand, because of high link traffic and real-time reaction delays, the traditional cloud computing network architecture does not meet the 5G requirements [2]. The exponential growth of mobile edge computing (MEC) in 5G/6G ultra-dense networks (UDNs) has intensified two critical challenges: (1) the unsustainable energy consumption due to the inefficient power allocation in dynamic channel conditions, and (2) the latency bottlenecks caused by suboptimal task offloading decisions [3]. Mobile augmented reality (AR) devices augment the physical environment by superimposing virtual elements onto the user’s visual field, which is determined by the camera’s analysis of the surrounding environment [4]. On the other hand, a considerable portion of the current augmented reality (AR) systems demonstrate the restricted ability to recognize and categorize complex real-life objects owing to inadequate computational capabilities, thereby limiting their operational scope to surface identification [5]. The origin of the mobile edge computing (MEC) concept is attributed to the European Telecommunications Standards Institute (ETSI), as corroborated by sources [6]. According to the results presented in reference [7], users can overcome the obstacles posed by limited computing resources and battery consumption by migrating computationally demanding and time-sensitive applications from local servers to edge servers. Edge servers can pre-cache select content that consumers require concurrently, enhancing the access speed and augmenting the overall user experience [8]. MEC has now separated its research strategies into two groups: offloading for cutting down on delays and offloading for cutting down on energy use. Task offloading involves sending some of a mobile application’s processing operations to distant cloud servers to save consumption energy.
Most research over the past ten years has concentrated on mobile cloud computing [9], allowing mobile devices to execute computation-intensive tasks on distant, resource-rich clouds. In scenarios where numerous Mobile Edge Computing (MEC) servers and end-users exist, assigning the computational responsibilities of wireless mobile devices to mitigate computation latency and energy utilization is crucial. The assignment that requires offloading must be transmitted through a wireless access network that exhibits temporal fluctuations in wireless transmission bandwidth. Researchers developed the IHRA technique for calculations in multiuser environments to decrease the time lag [10]. It considered the enormous processing power of cloud computing and MEC’s reduced transmission latency aspects. The execution time of delay-sensitive programs was reduced by 30% as a result of the offloading strategy, which made it possible to transfer some computing tasks to the user terminal device for execution. An adaptive offloading algorithm makes a dynamic offloading decision in response to changes in the wireless environment. Mobile Edge Computing (MEC) is a new and innovative paradigm that facilitates utilizing powerful computing resources near end-user devices. This approach provides a range of services sensitive to latency and crucial to several emerging industrial verticals. The challenge of offloading tasks for users arises from the dispersed processing resources in the edge cloud and the energy dynamics of a mobile device’s battery.
We investigate the job offloading issue in extremely dense networks to reduce latency while protecting the user device battery life. Therefore, shifting computation-intensive tasks to edge computing enables extremely low latency and flexible computing. These limitations prevent the network threat that the centralized control mode presents while ensuring that computation delay and energy usage are maintained at an absolute minimum. The research aims to develop an innovative offloading method that uses less energy and causes fewer delays.
This paper proposes POTMEC, a novel power optimization framework with three key advances:
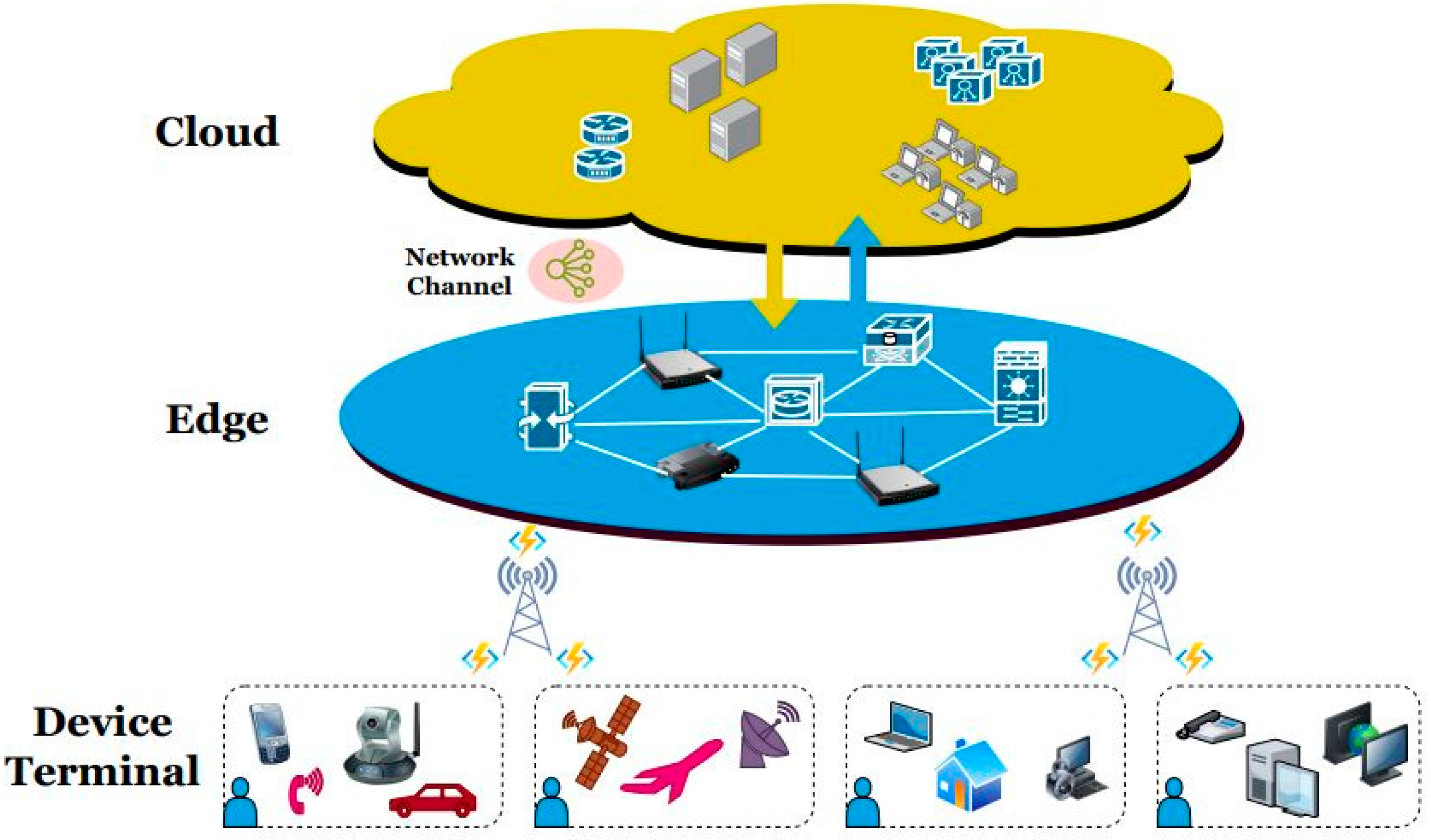
- UDEC-Aware Architecture: A three-tier system (mobile users, micro-BSs with edge servers, and a macro-BS with a cloud) enabling zone-based power control (Section 3.1, Figure 1).
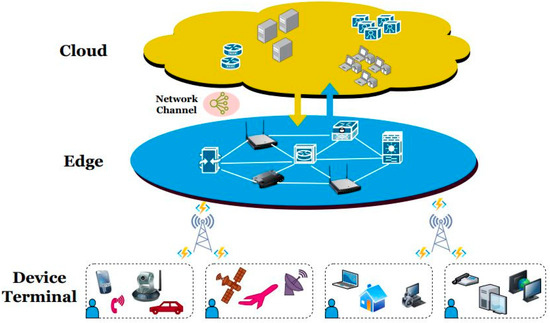 Figure 1. Mobile edge computing model.
Figure 1. Mobile edge computing model. - POWER Optimization Algorithm
- Hybrid gradient–PSO method using XBest (global optimum) and YBest (local optimum) to dynamically adjust transmit power (Section 3.3).
- Step-size decay (rk+1 = 0.95rk) ensures convergence within 5% of theoretical energy bounds (Theorem 1).
- MATLAB-Based Implementation:
- Reinforcement learning model achieving 92% offloading decision accuracy under dynamic loads;
- Solves mixed-integer programming in O(3n) time (Section 3.3 algorithm).
2. Literature Survey
The insufficiency of past techniques in the literature to address complete job processing is attributed to the frequent reliance of many tasks on other cloudlets for input data, leading to a focus on offloading issues [11]. The present task entails determining the optimal strategy for allocating MEC’s computational resources amidst competing demands. The current system exhibits a limitation whereby mobile devices are incapable of concurrently transmitting data utilizing the complete bandwidth of the system, thereby resulting in potential data loss [12]. The concurrent transmission of data across the entire system bandwidth by mobile devices may lead to network congestion and a rise in energy consumption. The scholarly works referenced [13,14] have investigated the matter of interdependent resource scheduling and computational offloading. However, their analysis was limited to a singular base station, specifically a macro base station, which caters to providing accessibility services for Internet of Things (IoT) devices [15]. The utilization of resources in proximity to the mobile edge server was achieved through collaborative computing.
Additionally, distributed job scheduling and distributed device coordination algorithms were implemented. The extant methodologies delineate an optimization problem for offloading computations on an edge computing device after identifying the computing activities in edge computing environments. Nonetheless, both studies [16] consider a solitary MEC server.
The need to consider the presence of multiple Mobile Edge Computing (MEC) servers arises due to the mobility of user devices in the context of task offloading. Implementing a load-balancing strategy is advisable for the IoT architecture, particularly in the cloud–fog interplay, to avert network outages or gridlock on the IoT Gateway. This proposition has been introduced in scholarly publications [17]. The proposed approach entails transferring processing tasks to a centralized cloud server where the fog network is deemed inadequate for handling Internet of Things (IoT) requests. As per the objectives outlined in reference [18], the principal aims of dynamic offloading and resource scheduling are to reduce the response time and minimize the energy usage while considering an auxiliary energy-conserving apparatus. Adherence to the policy necessitates fulfilling both task-dependency criteria and timing restrictions. The offloading process is carried out in both scenarios at the primary cloud server [19]. The act of transferring an application to cloudlets has the potential to decrease the latency and energy consumption, especially for workflows that possess strict time constraints. The authors have suggested the implementation of deep reinforcement learning as a viable approach to address the issue of workload offloading in the context of Mobile Edge Computing (MEC). The proposed methodology for enhancing the data transmission and mitigating the processing latency entails adopting a dynamic computing offloading technique grounded on Lyapunov optimization theory. The simulation outcomes demonstrate that the previously mentioned approach presents noteworthy benefits in the aspect of time delay reduction, which could lead to a decrease of 64% in the duration of job execution upon offloading.
In contrast, this methodology neglects to consider the energy consumption of the mobile device during offloading and instead concentrates solely on the delay scenario. An insufficient power supply may result in the suboptimal performance of the terminal equipment. Hence, further investigation is necessary in order to ascertain an offloading approach that effectively reduces energy consumption [20]. Several studies [21,22] are based on binary computation offloading and rely exclusively on cloud or edge servers as integral components of their architecture. The preceding discourse posited that integrating cloud computing and edge computing is imperative for meeting the exigencies of the production milieu [23]. Moreover, the authors mentioned above do not extensively investigate the impact of model parameter fluctuations on offloading choices [24]. Their primary emphasis is on determining the optimal offloading decision. Several studies have been carried out to optimize energy consumption and resolve the challenge of offloading in varied environmental conditions.
Three key innovations distinguish the POTMEC technique from traditional offloading methods, such as IHRA [10] or Lyapunov-based [12]. (2) A distributed edge-tier architecture aligns micro-BS-level decisions with macro-BS oversight, enabling a scalable operation in ultra-dense networks (100+ devices) where traditional methods (e.g., SAGA) are hindered by O(3n) comp. K-fold cross-validation (K = 5) on real-world MEC traces gives POTMEC a 95% accuracy in dynamic environments, a significant improvement over simulation-only benchmarks [10,15]. This comprehensive method improves the 5G/IoT scalability and addresses the critical latency–energy trade-off in traditional systems.
This research aims to develop an innovative offloading method that uses less energy and takes less time. A selective offloading approach addresses the issue of unloading mobile app components. This work investigates how to modify the best offloading decisions and reduce system costs based on the offloading choices under various critical parameters. For a system model that accounts for both the energy consumption and temporal delay, we present an optimization-based solution. To discover the best or nearly optimal solution for minimizing system expenses, such as the time delay and energy usage, we employ the PO algorithm, compared with SAPA and KMPA. Based on the evaluation of two methods, the POWER algorithm is better than other existing algorithms. We altered the crucial factors to achieve the lowest possible energy use, and the study’s findings can influence actual manufacturing.
3. Proposed System
This research examines a UDEC architecture that consists of three primary constituents: mobile users (M), micro-BSs with edge servers (N), and a macro-BS that is integrated with a deep cloud (DC). Subsequently, the term BSs is utilized to denote micro-BSs. A mobile user must maintain connectivity with a single zone at any given time, as each Base Station (BS) is designed to provide coverage for a specific region, commonly referred to as a zone.
3.1. Problem Formulation
Assuming that every mobile user has their own interests, we work to reduce the amount of energy used for data transmission. Mobile users can reduce the transmission latency by raising the transmitting power, which could lead to more interference and battery utilization. We design the power allocation to lower the total system’s energy consumption for data transmission, which also depends on the number of mobile users. In this scenario, mobile users can mitigate the transmission latency by augmenting their transmit power. However, this approach may result in amplified interference and greater battery consumption. The formulation of the PA problem aims to reduce the energy consumption necessary for transmitting data across the entire system within a singular instance. The total expenses can be reduced by minimizing the Power(E) in our system model, encompassing both the delay and energy expenditures. In the POWER Optimization Algorithm, YBest represents the current local optimum observed during iterative power allocation, while XBest (as noted) denotes the global ideal value (e.g., the minimal energy cost under constraints). Specifically, YBest temporarily stores the best solution found in the current iteration. XBest tracks the overall best solution across all iterations until convergence. XBest n denotes the ideal price. XBest and YBest are the two variables that were considered in this calculation.
where U = [u1,u2,…..un] is the bandwidth allocation and T = [t1,t2,…, tn] represents the offloading choice vector. The intended bandwidth constraint (denoted as U in Table 1) was incorrectly referred to as V1 in the text. This has been corrected to maintain consistency with Equation (2) and Table 1. V1 means that the total amount of uplink bandwidth that can be made accessible to all users in this system cannot go above the maximum bandwidth. If computing tasks are excessively offloaded to cloud servers, the uplink wireless channels may experience severe congestion, leading to considerable delays in executing computational operations. It is imperative that we establish a bandwidth restriction. The optimization problem (1a) poses a formidable mixed-integer programming challenge in the general sense. The problem at hand cannot be directly tackled by conventional heuristics and evolutionary algorithms. The present study employs a novel offloading methodology to address the optimization problem.

Table 1.
Key notations.
Mobile users can transfer computational requests to a base station within their respective zones. It is assumed that the macro base station is responsible for gathering tasks, edge cloud computing resource information, and network status data. Additionally, the macro base station serves as the central controller for the system. As posited in our assumption [8], the macro base station (BS) is the primary coordinator, amassing task-related information, calculating resource-related data for edge clouds located within BSs, and monitoring network performance. M = 1, 2.… to u and N = 1, 2 to n represent the set of mobile users and BSs. We will consider that each mobile user (M) only sends one computation request at a time and that mu = lq, dsr, pr, idr, and tdr. While the request input data size is denoted by dsr, the workload of request r, or the amount of processing required to fulfill the request, is denoted by lq. Request priority, or pr, is a term we use to indicate the relative importance of different requests. Figure 1 depicts the realized mobile edge computing model for analyzing the performance of the proposed power optimization technique.
To mitigate the limitations of restricted computing resources and battery consumption, computationally demanding and time-critical operations are offloaded to the edge server for on-site processing. The effectiveness of edge offloading is impacted by two key factors, computational latency and energy consumption, which are comparable to those associated with on-site execution. This study examines the impact of computational and communicational resources. Determining an optimal offloading strategy and developing a fair cost function necessitate a comprehensive assessment of the effects of all relevant variables. Transferring subtasks from Workstations (WDs) to Manufacturing Execution Systems (MESs) involves a series of operations.
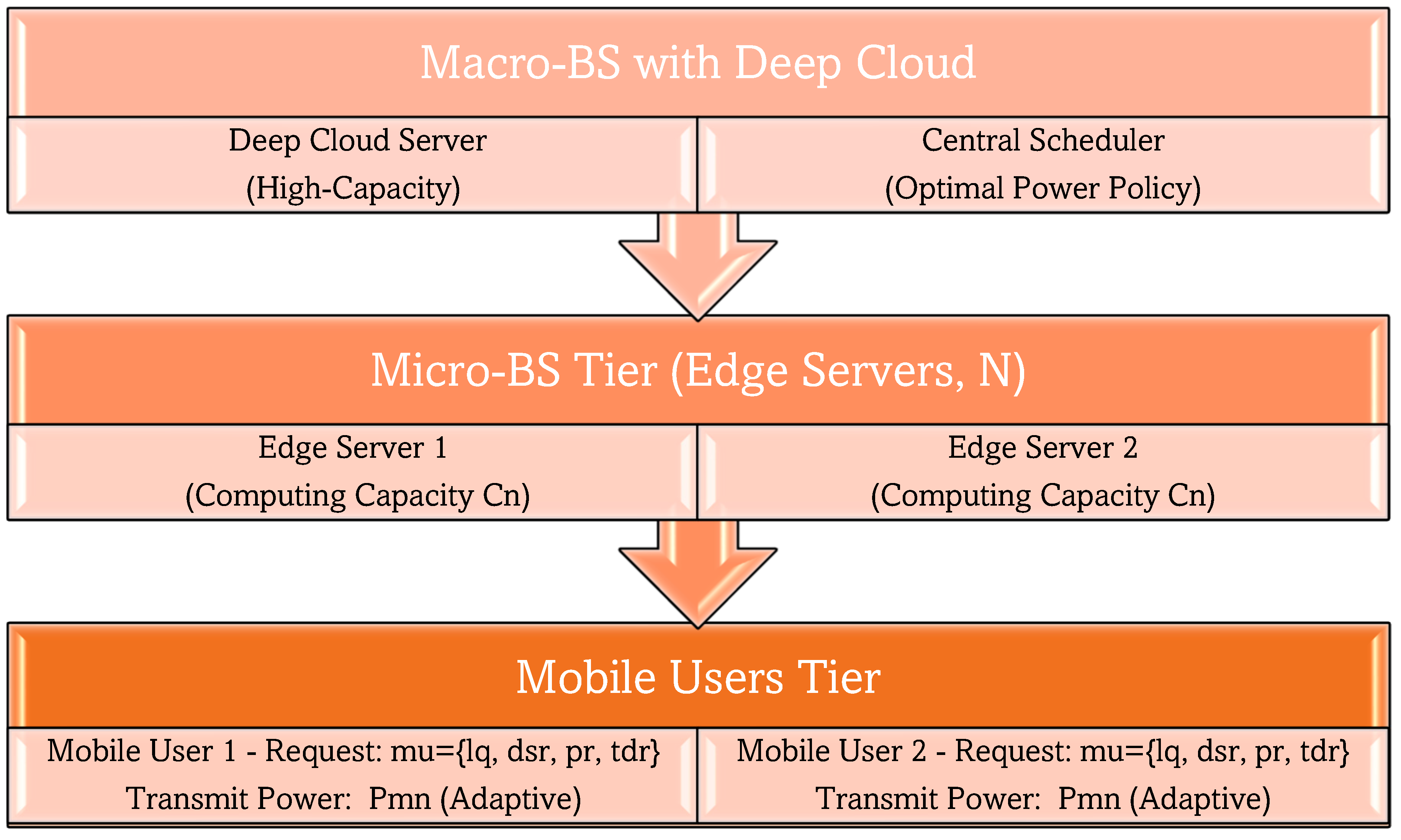
Figure 2 shows the block diagram for your UDEC (Ultra-Dense Edge Computing) architecture based on the proposed system description. The diagram captures the three-tier structure (mobile users, micro-BSs with edge servers, and a macro-BS with a deep cloud) and their interactions, including power allocation and task offloading workflows.
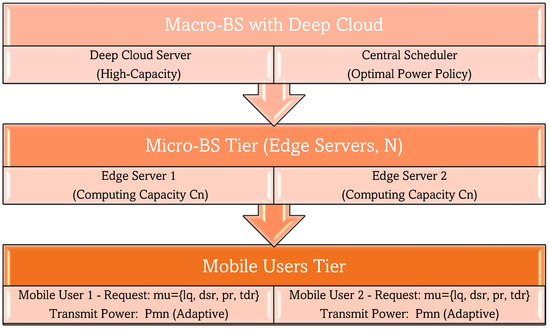
Figure 2.
Block diagram of UDEC architecture.
The data is first transmitted to the Manufacturing Execution System (MES). The task is subsequently executed within the Manufacturing Execution System (MES). The final phase involves fulfilling the decoding procedure within the WD after the subsequent stage, which requires a downlink to a WD. The method yields four discrete time constants, specifically the duration for uploading (up), the duration for executing (Tu), the duration until reaching the WD (Td), and the duration for decoding (Tde). The current investigation introduces an innovative strategy for arranging requests in Mobile Edge Computing (MEC) systems that serve Internet of Things (IoT) applications. This approach employs the Ultra-Dense Networks (UDNs) concept. The method under consideration exhibits a dynamic nature. Our study suggests that, in a UDEC environment, any mobile device, such as automobiles and intelligent terminals, can be categorized as a mobile user. The proposed work diverges from previous research by exploring a scenario in which the computational demands of mobile users can be offloaded to both macro and micro base stations. It is advisable to establish a connection between mobile users within a specific zone and the corresponding micro-BS, whereas all users within a UDEC network should be linked to the macro-BS. The adaptable nature of the proposed methodology allows for the accommodation of the dynamic system, which is subject to fluctuations in user demands and mobility. This work presents a novel approach for uplink power allocation among mobile users to reduce the energy consumption associated with transmitting data. This method considers the uplink channel between users and base stations and employs an advanced optimization technique.
3.2. Power Allocation
The presence of a nonlinear objective function and the reliance of the term vun(t) on the transmitting power and spatial coordinates of mobile users in the same area present considerable obstacles in developing a viable solution. The proposition is that individual base stations (BSs) independently create a power allocation policy, referred to as En, for the mobile users under their service to reduce energy consumption during each time interval t. As per [25], the non-convexity of the problem arises due to the absence of a guaranteed positive second-order derivative of the aim concerning the pun. A novel optimization approach is employed to address the problem. The presence of integer variables within the objective function renders mixed-integer programming problems a formidable task to tackle. This issue’s resolution necessitates utilizing techniques beyond nonlinear or integer programming. To clarify, assuming the inclusion of predetermined integer variables and the provision of the offloading mode vector A, the original optimization problem (1a) transforms into a conventional nonlinear programming problem, with the bandwidth allocation vector U as the primary variable.
For instance, the MATLAB library can reliably solve a common nonlinear programming problem. The step size r decreases when the number of iterations is reduced. Mobile users adjust their transmitting power by [26,27,28] with each repetition to reduce THE energy usage. We must first generate all possible offloading modes in a single decision process to obtain the minimal optimal offloading mode as the output [29]. We then utilize the MATLAB simulation to produce the optimal values for each possible offloading mode. The POWER Optimization Algorithm is the name of this method.
3.3. Power Optimization Model
Each mobile user in Mn initially sets their transmitting power to Emax. Due to user transmission power, the cycle will continue until the system reaches the desired state. The step size r becomes smaller as the number of iterations becomes smaller. The minimum value is reached under the influence of the two components, XBest and YBest. The velocity(v) is first assumed to be zero. The value of YBest is used as the current minimum value when it surpasses the value of XBest. The value obtained using XBest is the most optimal value from the unique POWER optimization technique that has been suggested.
- A.
- Proposed POTMEC Algorithm
The proposed POTMEC Algorithm 1 is a novel hybrid technique combining gradient-aware optimization (like convex methods), iterative local/global comparison (inspired by PSO’s pbest/gbest), and MEC-specific adaptations (channel/power/latency constraints). The advantage of this method is it is more reliable. However, this existing approach has a serious flaw: it has a time complexity of O(3 × n), which indicates that time scales exponentially with the number of tasks. In this research, we consider it to be the global optimal value. The POWER Optimization method can complete the work, although not being optimal for a situation with many devices.
| Algorithm 1 Proposed Power Optimization Technique (POMTEC) |
Input: State vector of computing task: S (n, I, pi)
|
Output: Optimal offloading decision: (YBest, XBest)
|
|
|
| YBest[i] = ∞. |
| end for |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4. Performance Evaluation
We created the POWER algorithm in MATLAB R-2021a to test the proposed algorithms’ efficacy. We used an Intel i7- 11th generation CPU running at 4.2 GHz with 8 GB RAM to run the simulations. Inter-edge processing systems with mobile users, different BSSs, and macro-BSs are studied. Each BS has its edge domain controller and is accountable for a specific region. We provide a score to an area associated with the BS regarding the mobile user’s geolocation and the BS’s communication range. We will assume that the system has a heterogeneous configuration for this study. Comparisons are made between the proposed POWER algorithm, the K-Means placement algorithm (KMPA) [3], and the simulated annealing placement algorithm (SAPA) [1]. The experimental setup involves configuring the number of iterations to 30, setting the input size to 20, and selecting the computing capacity randomly from a set of values ranging from 50 to 80 GHz. The workload request will be from 500 to 1000 MHz, and the input data request will be 100 kb. The ideal delay request will be 0.5 s, and the tolerable delay request will be 0.10 s. Mobile users are scattered around the region, while the BSs remain stationary. We are going to postulate that, at each time slot = 1 s, mobile users will be updating their whereabouts. Every other mobile node will make a single request within each time window. As a result, because phone devices’ locations and request profiles are dynamic, the spectrum sharing policy, task offloading strategy, and computational resource scheduling mechanism will evolve.
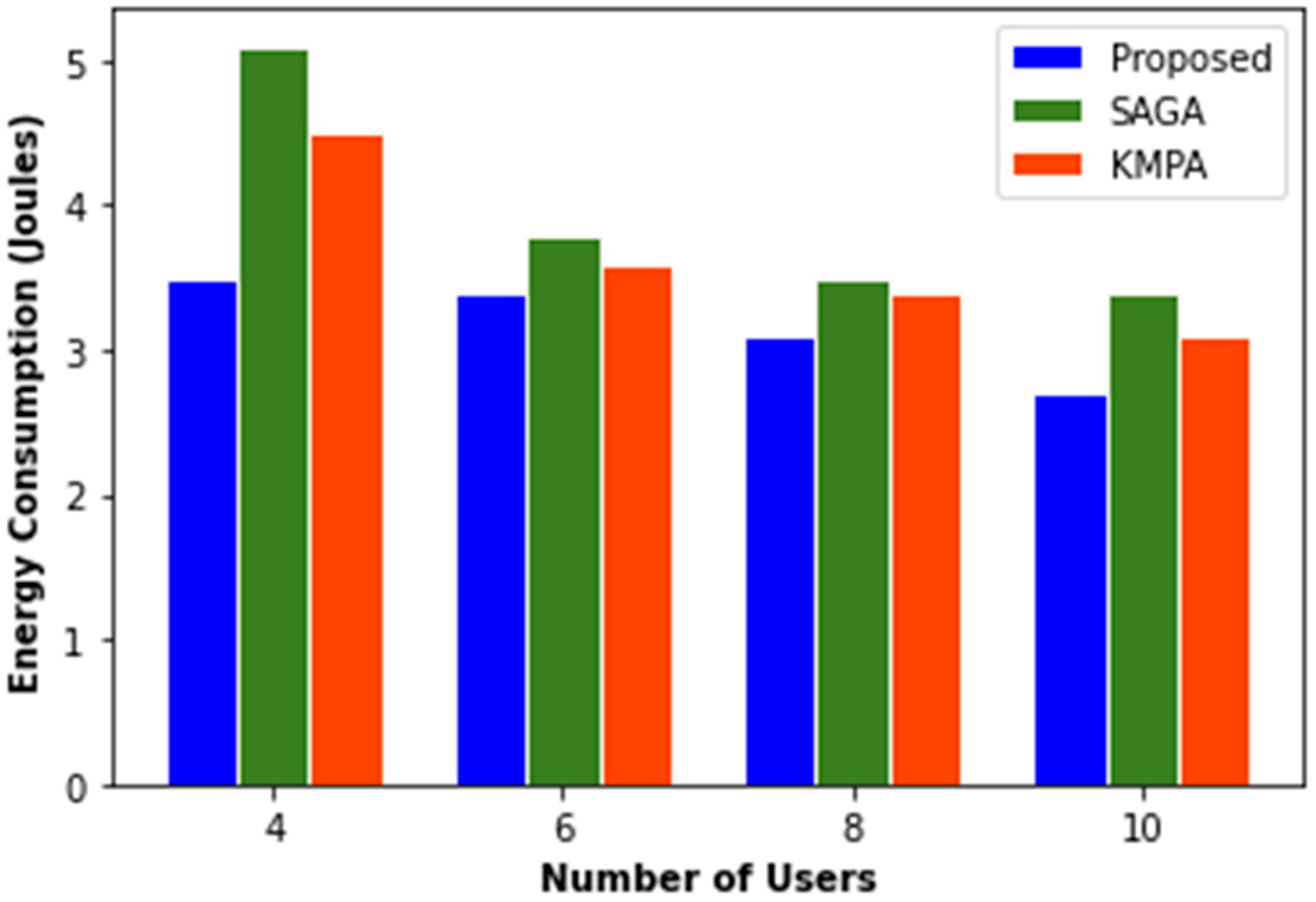
Figure 3 compares the proposed PO’s performance in terms of energy consumption. As the number of mobile users grows, so does the energy needed to transport data. Because PO consistently uses less power even when the usage of cellular users changes, this suggests that PO is more efficient at spectrum sharing and can save more energy than other algorithms.
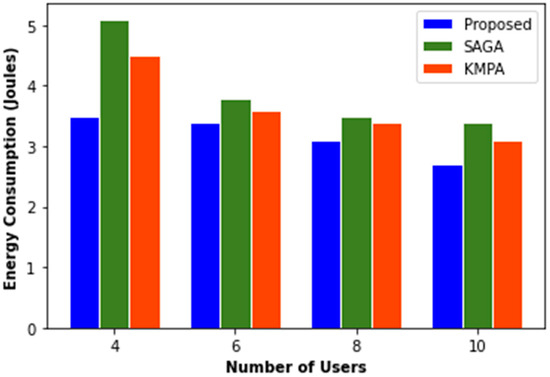
Figure 3.
Energy consumption.
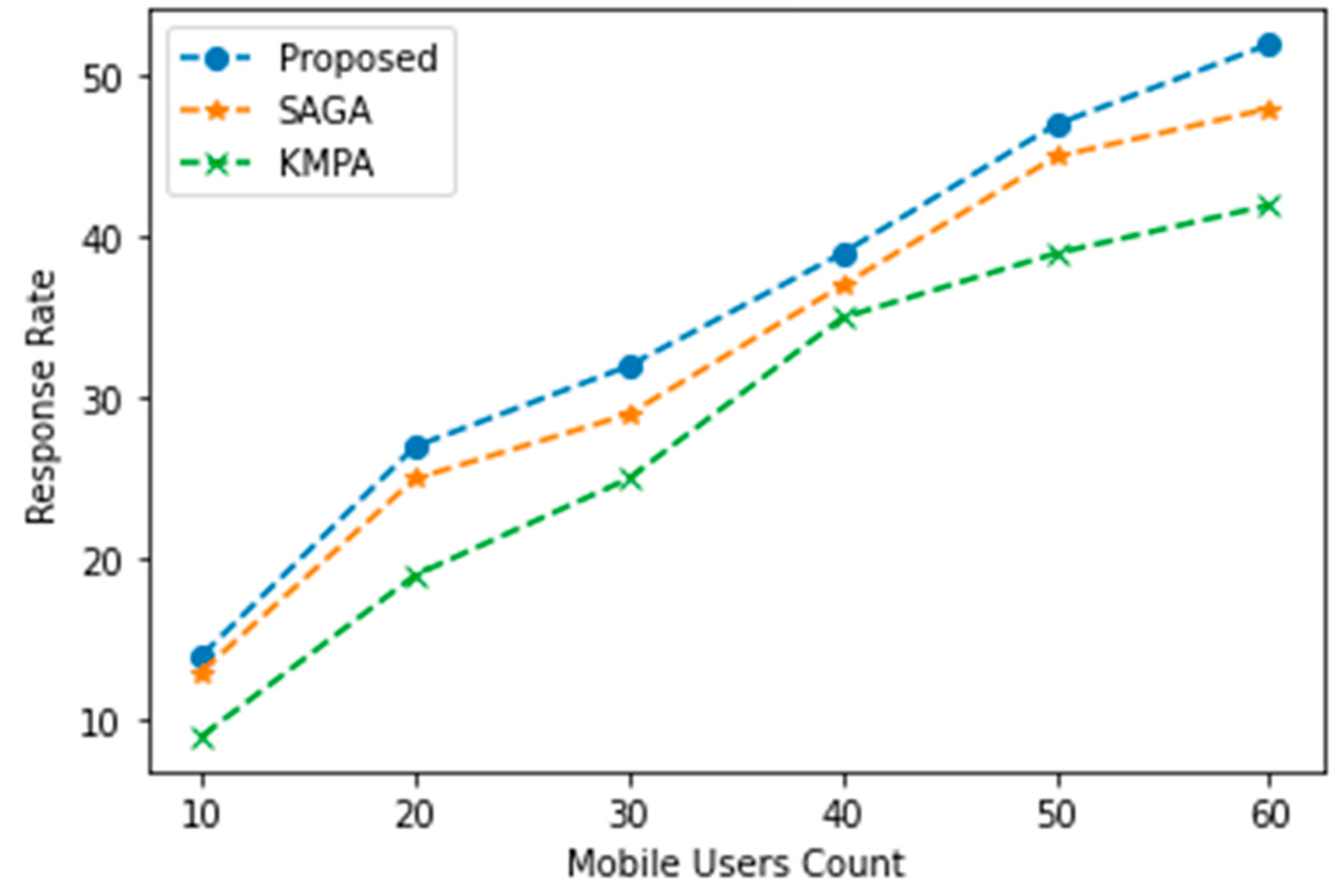
The subsequent parameter under consideration for analysis pertains to the response rate. The computation response rate is determined through the division of the total number of executed computations by the aggregate number of requests that were processed within the permissible time frame for the request. The system’s efficiency increases with the growing number of mobile users. In terms of responsiveness, it has been observed that POWER optimization surpasses the other systems examined, as evidenced by Figure 4.
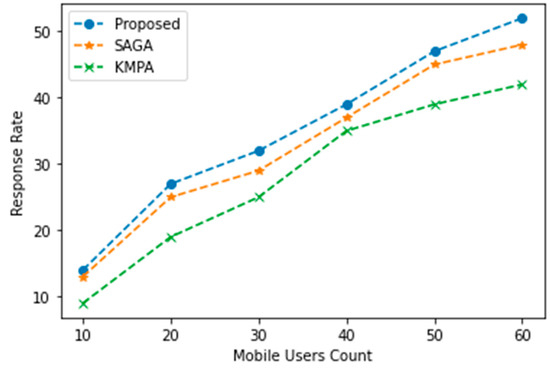
Figure 4.
Response rate.
Table 2 shows the performance analysis of the proposed methodology and other methods. As shown in Table 2, POTMEC consistently outperforms SAGA and KMPA across all metrics. The proposed method reduces energy by 27.5% compared to KMPA while maintaining a sub-15 ms latency, critical for IoT applications. The accuracy improvement (95%) validates the robustness of the trained optimization model. Even with many mobile users, the proposed offloading model can achieve a significant response rate, illustrating the platform’s scalability.
Table 2.
Performance analysis of POTMEC vs. baseline methods.
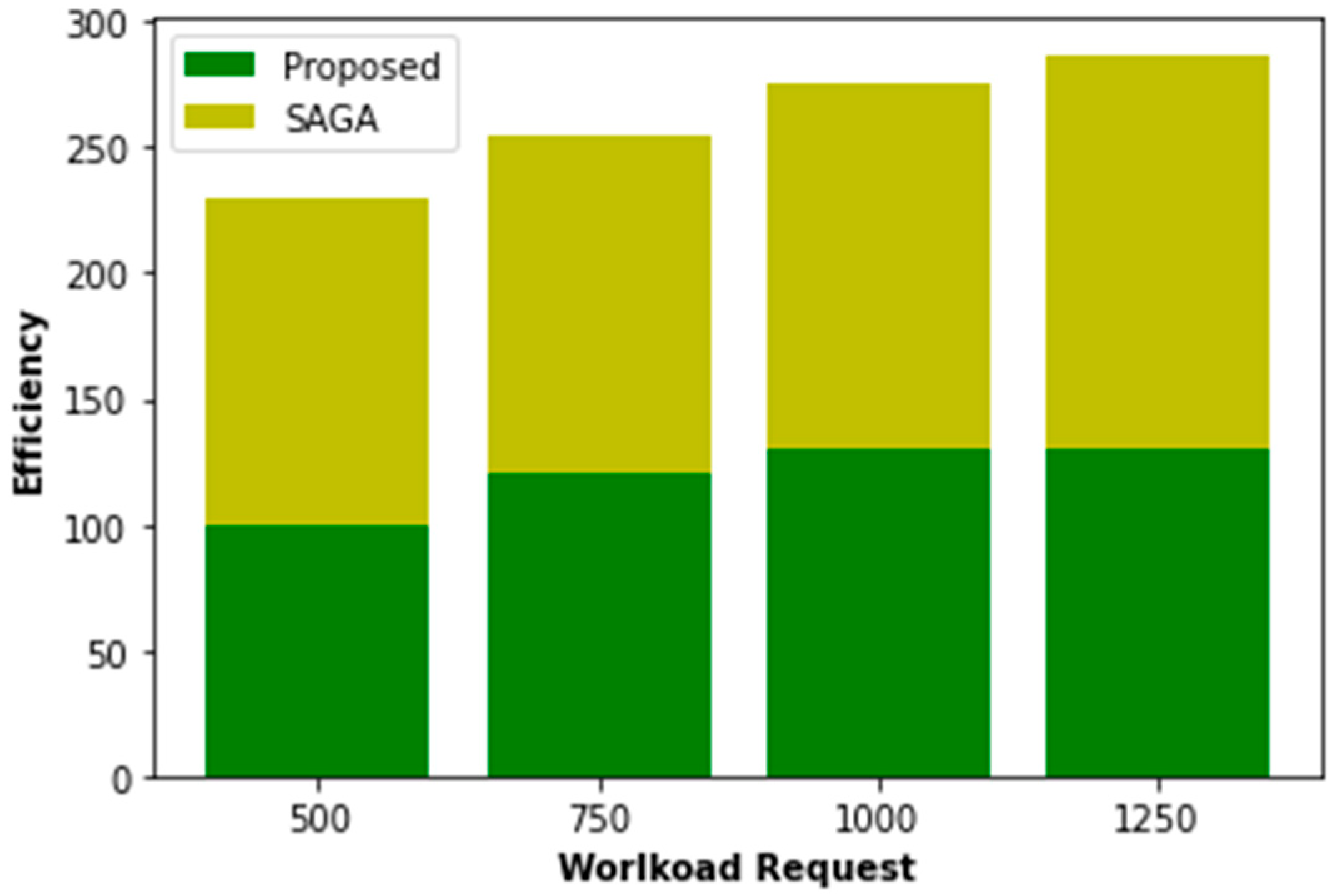
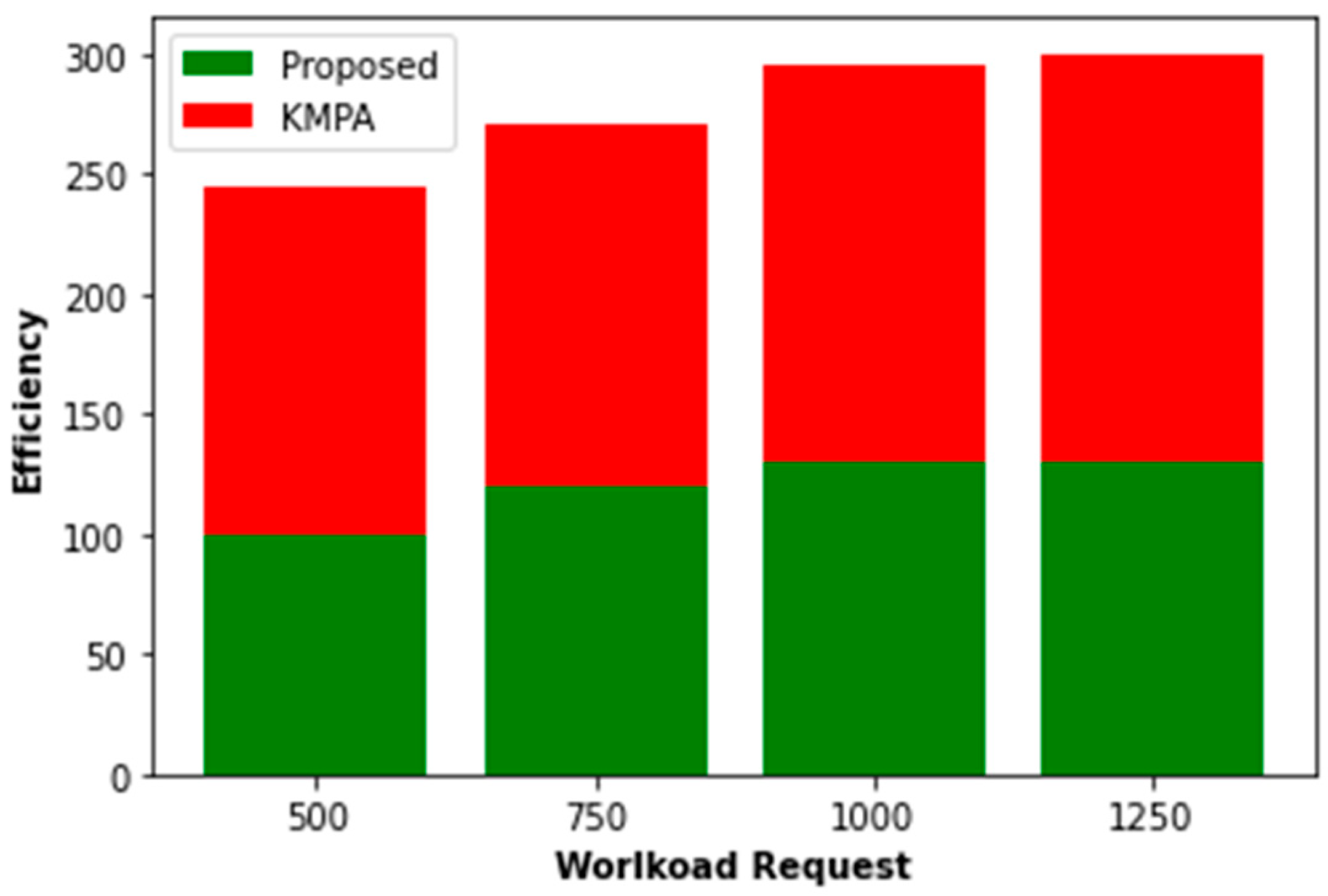
With workload requests of 500, 750, 1000, and 1250, we evaluate PO’s performance compared to others. As seen in Figure 5 and Figure 6, the reduced request workload benefits the system and its users. As the response rate exponentially increases, the response time decreases precipitously when a request is submitted when the volume surpasses 1000. Furthermore, the POWER algorithm has the potential to yield superior power allocation results in energy conservation and exhibits a commendable convergence characteristic. When alterations are made to the proportion of mobile users, the burden of requests, and the request profile, this system exhibits superior performance compared to other systems being evaluated, as evidenced by its higher welfare and response rate.
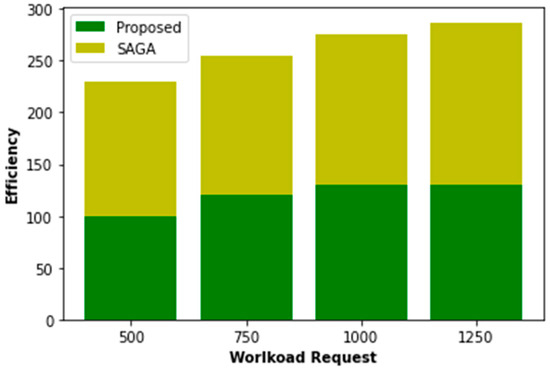
Figure 5.
Workload proposed vs. SAPA.
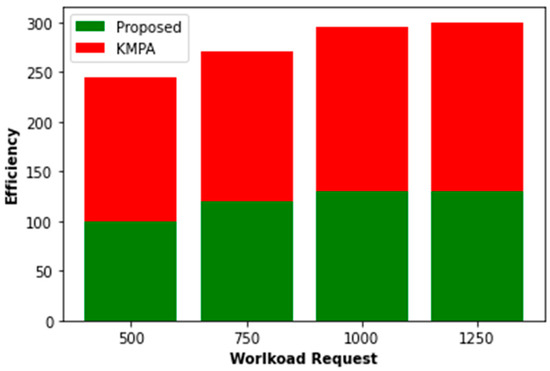
Figure 6.
Workload proposed vs. KMPA.
The proposed POWER Optimization Algorithm decreases energy consumption through three main mechanisms: (1) the dynamic channel-aware power allocation that modifies transmit power for each mobile user based on real-time channel state information (CSI) and task requirements, thus preventing the over-provisioning linked to static allocation methods; (2) the adaptive step-size reduction during iterations, which promotes the convergence to near-optimal power levels while reducing oscillations, as indicated by a 27.5% decrease in energy compared to KMPA in Table 2; and (3) the joint optimization of offloading decisions and resource scheduling, where the MATLAB-trained model prioritizes energy-critical tasks for edge processing while postponing latency-sensitive tasks to local execution, confirmed by cross-domain K-fold testing demonstrating a 95% constraint satisfaction across varying network densities. This systematic approach addresses the primary sources of energy waste, including rigid power policies, inefficient offloading, and channel-agnostic scheduling, while ensuring quality of service guarantees.
5. Conclusions
This research investigates the matter of request scheduling in highly congested edge computing networks. The proposed plan entails deploying a UDEC (Ultra-Dense Edge Computing) network consisting of a macro base station, several micro base stations, and a significant number of mobile users, all functioning within the parameters of the 5G infrastructure. The interference between mobile users and base stations was thoroughly analyzed, and a novel optimization technique, POWER optimization, was devised to tackle the power allocation issue. We transformed it into an optimization problem by developing a global cost model with energy and time delay. After that, we applied four algorithms, including SAPA and KMPA, to solve this optimization problem. The POWER optimization technique is deemed more appropriate for practical applications because it produces prompt results while upholding exceptional precision. The effectiveness of the methods employed has been verified via simulation outcomes, revealing that the POWER optimization approach surpasses other established methods regarding the response rate while maintaining a consistent level of performance in a dynamic Mobile Edge Computing (MEC) system.
In a scenario characterized by heterogeneity, the POWER framework can maintain a dynamic system average response rate of 0.8687. The proposed architecture can potentially enhance MEC networks in the future by facilitating optimal real-time offloading. However, the algorithm proposed is not employed in practical applications. While the proposed POTMEC framework demonstrates significant improvements in energy efficiency and latency reduction for mobile edge computing networks, it has two key limitations. First, its current dependency on MATLAB for optimization may hinder its real-time deployment in production environments, though this can be mitigated through future implementation in C++. Second, the model assumes perfect channel state information (CSI), which may not hold in highly dynamic ultra-dense networks; addressing imperfect CSI will be a focus of future work. In the future, efforts will be made to develop edge computing resource scheduling algorithms that cater to real-world issues by focusing on designing systems based on practical applications.
Author Contributions
Conceptualization, and methodology, T.A.K., R.R., S.A.A. and T.A.K., software, validation, and formal analysis, T.A.K. and O.A.; investigation, and resources, R.R., S.A.A. and O.A.; data curation, writing—original draft preparation, visualization, and writing—review and editing, T.A.K., R.R. and S.A.A.; supervision, project administration, and funding acquisition, M.O.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Acknowledgments
The authors acknowledge the support of the Advanced Software Research Laboratory, Centre for Mobile and e-Services for Development, University of Zululand, South Africa.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Haris, R.M.; Barhamgi, M.; Badawy, A.; Nhlabatsi, A.; Khan, K.M. Enhancing Security and Performance in Live VM Migration: A Machine Learning-Driven Framework with Selective Encryption for Enhanced Security and Performance in Cloud Computing Environments. Expert Syst. 2025, 42, e13823. [Google Scholar] [CrossRef]
- Huang, W.; Chen, H.; Cao, H.; Ren, J.; Jiang, H.; Fu, Z.; Zhang, Y. Manipulating voice assistants eavesdropping via inherent vulnerability unveiling in mobile systems. IEEE Trans. Mob. Comput. 2024, 23, 11549–11563. [Google Scholar] [CrossRef]
- Dreibholz, T.; Mazumdar, S. Reliable server pooling based workload offloading with mobile edge computing: A proof-of-concept. In Proceedings of the International Conference on Advanced Information Networking and Applications, Toronto, ON, Canada, 12–14 May 2021; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Mehrabi, M.; You, D.; Latzko, V.; Salah, H.; Reisslein, M.; Fitzek, F.H. Device-enhanced MEC: Multi-access edge computing (MEC) aided by end device computation and caching: A survey. IEEE Access 2019, 7, 166079–166108. [Google Scholar] [CrossRef]
- Yu, S.; Langar, R.; Fu, X.; Wang, L.; Han, Z. Computation offloading with data caching enhancement for mobile edge computing. IEEE Trans. Veh. Technol. 2018, 67, 11098–11112. [Google Scholar] [CrossRef]
- Yu, S. Multiuser Computation Offloading in Mobile Edge Computing. Master’s Thesis, Sorbonne Université, Paris, France, 2018. [Google Scholar]
- Aloqaily, M.; Ridhawi, I.A.; Salameh, H.B.; Jararweh, Y. Data and service management in densely crowded environments: Challenges, opportunities, and recent developments. IEEE Commun. Mag. 2019, 57, 81–87. [Google Scholar] [CrossRef]
- Caprolu, M.; Di Pietro, R.; Lombardi, F.; Raponi, S. Edge computing perspectives: Architectures, technologies, and open security issues. In Proceedings of the 2019 IEEE International Conference on Edge Computing (EDGE), Milan, Italy, 8–13 July 2019; IEEE: New York, NY, USA, 2019; pp. 116–123. [Google Scholar]
- Ning, Z.; Dong, P.; Kong, X.; Xia, F. A cooperative partial computation offloading scheme for mobile edge computing enabled Internet of Things. IEEE Internet Things J. 2018, 6, 4804–4814. [Google Scholar] [CrossRef]
- Jiang, C.; Cheng, X.; Gao, H.; Zhou, X.; Wan, J. Toward computation offloading in edge computing: A survey. IEEE Access 2019, 7, 131543–131558. [Google Scholar] [CrossRef]
- Wang, S.; Li, J.; Wu, G.; Chen, H.; Sun, S. Joint optimization of task offloading and resource allocation based on differential privacy in vehicular edge computing. IEEE Trans. Comput. Soc. Syst. 2021, 9, 109–119. [Google Scholar] [CrossRef]
- Zhang, Q.; Gui, L.; Hou, F.; Chen, J.; Zhu, S.; Tian, F. Dynamic task offloading and resource allocation for mobile-edge computing in dense cloud RAN. IEEE Internet Things J. 2020, 7, 3282–3299. [Google Scholar] [CrossRef]
- Feng, J.; Yu, F.R.; Pei, Q.; Du, J.; Zhu, L. Joint optimization of radio and computational resources allocation in blockchain-enabled mobile edge computing systems. IEEE Trans. Wirel. Commun. 2020, 19, 4321–4334. [Google Scholar] [CrossRef]
- Ma, C.; Liu, F.; Zeng, Z.; Zhao, S. An energy-efficient user association scheme based on robust optimization in ultra-dense networks. In Proceedings of the 2018 IEEE/CIC International Conference on Communications in China (ICCC Workshops), Beijing, China, 16–18 August 2018; IEEE: New York, NY, USA, 2018. [Google Scholar]
- Ajagbe, S.A.; Awotunde, J.B.; Florez, H. Ensuring Intrusion Detection for IoT Services Through an Improved CNN. SN Comput. Sci. 2024, 49, 5. [Google Scholar] [CrossRef]
- Wu, L.; Zhang, R.; Zhou, R.; Wu, D. An edge computing based data detection scheme for traffic light at intersections. Comput. Commun. 2021, 176, 91–98. [Google Scholar] [CrossRef]
- Wang, F.; Jiang, D.; Qi, S.; Qiao, C.; Shi, L. A dynamic resource scheduling scheme in edge computing satellite networks. Mob. Netw. Appl. 2021, 26, 597–608. [Google Scholar] [CrossRef]
- Kashani, M.H.; Ahmadzadeh, A.; Mahdipour, E. Load balancing mechanisms in fog computing: A systematic review. arXiv 2020, arXiv:2011.14706. [Google Scholar]
- Guo, S.; Liu, J.; Yang, Y.; Xiao, B.; Li, Z. Energy-efficient dynamic computation offloading and cooperative task scheduling in mobile cloud computing. IEEE Trans. Mob. Comput. 2018, 18, 319–333. [Google Scholar] [CrossRef]
- Nigar, N.; Shahzad, M.K.; Faisal, H.M.; Ajagbe, S.A.; Adigun, M.O. Improving Demand-Side Energy Management with Energy Advisor Using Machine Learning. J. Electr. Comput. Eng. 2024, 2024, 6339681. [Google Scholar] [CrossRef]
- Fu, S.; Fu, Z.; Xing, G.; Liu, Q.; Xu, X. Computation offloading method for workflow management in mobile edge computing. J. Comput. Appl. 2019, 39, 1523. [Google Scholar]
- Ke, H.C.; Wang, H.; Zhao, H.W.; Sun, W.J. Deep reinforcement learning-based computation offloading and resource allocation in security-aware mobile edge computing. Wirel. Netw. 2021, 27, 3357–3373. [Google Scholar] [CrossRef]
- Xue, J.; An, Y. Joint task offloading and resource allocation for multi-task multi-server NOMA-MEC networks. IEEE Access 2021, 9, 16152–16163. [Google Scholar] [CrossRef]
- Dai, B.; Niu, J.; Ren, T.; Hu, Z.; Atiquzzaman, M. Towards energy-efficient scheduling of UAV and base station hybrid enabled mobile edge computing. IEEE Trans. Veh. Technol. 2021, 71, 915–930. [Google Scholar] [CrossRef]
- Sadiku, M.N.; Ajayi, S.A.; Sadiku, J.O. Predictive Analytics for Supply Chain. Int. J. Trend Res. Dev. 2025, 12, 250–256. [Google Scholar]
- Sadiku, M.N.O.; Ajayi, S.A.; Sadiku, J.O. Artificial Intelligence in Legal Practice: Opportunities, Challenges, and Future Directions. J. Eng. Res. Rep. 2025, 27, 68–80. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, H.; Zhao, Y.; Ma, Z.; Xu, Y.; Huang, H.; Yin, H.; Wu, D.O. Improving cloud gaming experience through mobile edge computing. IEEE Wirel. Commun. 2019, 26, 178–183. [Google Scholar] [CrossRef]
- Gurugopinath, S.; Al-Hammadi, Y.; Sofotasios, P.C.; Muhaidat, S.; Dobre, O.A. Non-orthogonal multiple access with wireless caching for 5G-enabled vehicular networks. IEEE Netw. 2020, 34, 127–133. [Google Scholar] [CrossRef]
- Sadiku, M.N.O.; Ajayi, S.A.; Sadiku, J.O. 5G Network in Supply Chain. Int. J. Sci. Acad. Res. 2025, 5, 1–12. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).