
Deep Multi-Component Neural Network Architecture



Abstract
1. Introduction
1.1. Research Background
1.2. Literature Review
1.3. Main Contributions
- Avoiding Overfitting: DMCNN effectively mitigates overfitting by leveraging a multi-component architecture that enhances important features while reducing the weight of unimportant ones.
- Multimodal Input Handling: Unlike traditional models, DMCNN integrates multimodal data (e.g., speech, text, and signals) as additional components, using complementary information to achieve higher accuracy.
- Dimension Flexibility: DMCNN eliminates the need for standardizing input lengths, making it suitable for datasets with varying dimensions.
- Feature Selection: The architecture dynamically identifies and prioritizes the most informative features, ensuring optimal classification performance with minimal trainable parameters.
1.4. Paper Structure
- -
- Section 2: Provides an overview of related works, discussing existing architectures and their limitations.
- -
- Section 3: Describes the proposed methodology in detail, including the architecture and mathematical formulations.
- -
- Section 4: Presents the experimental setup, results, and comparisons with prior works.
- -
- Section 5: Concludes the paper with a summary of findings and potential directions for future research.
2. Related Works
2.1. Multimodal Architectures
2.2. Vision Transformers
2.3. Binary Neural Networks
2.4. Nesting Transformers
2.5. Other Relevant Models
- -
- -
- -
3. Materials and Methods
3.1. Specialized Layers
- Forward Propagation:
- Backward Propagation:
3.2. Directive Layer
- Forward Propagation:
- Backward Propagation:
3.3. Fusing Layer
- Forward Propagation:
- Backward Propagation:
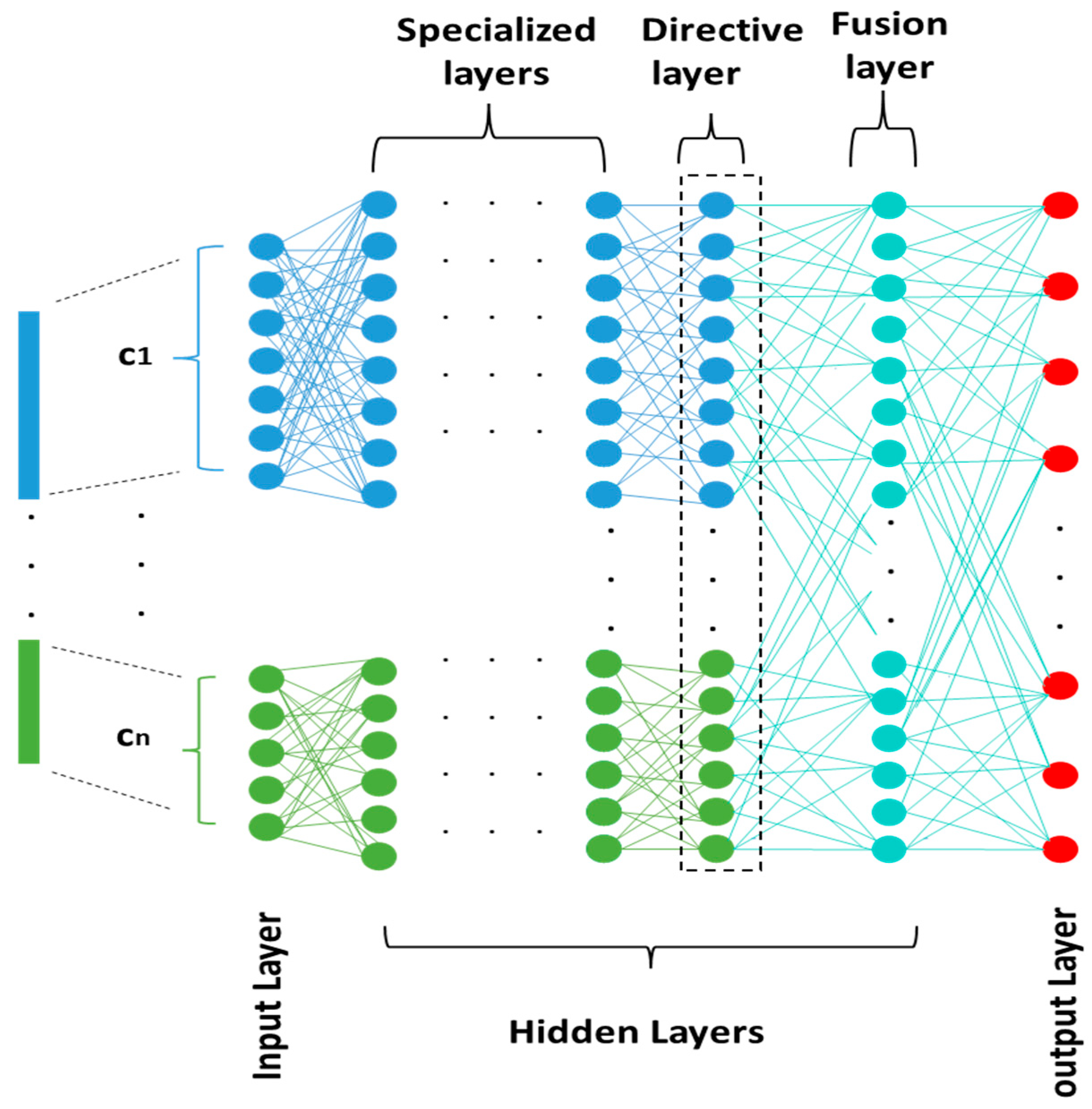
4. Proposed Architecture for DMCNN
4.1. Specialized Layers
4.2. Enhancing Important Features (Not a Layer)
- vol: vector output layer
- c: indices of component
- : weight vector
- n: is the length of a vector W refers to the number of components
- threshold: :
4.3. Fusing Layer
4.4. Extraction Component
4.4.1. Case 1: A Multimodality
4.4.2. Case 2: A Single Modality
4.5. Fusion Component
4.5.1. Case 1: A Multimodality
4.5.2. Case 2: A Single Modality
5. Experimental Findings and Comparisons
5.1. Computational Environment
5.2. Dataset
5.2.1. Multimodal
5.2.2. A Single Modality
5.3. Evaluation Metrics
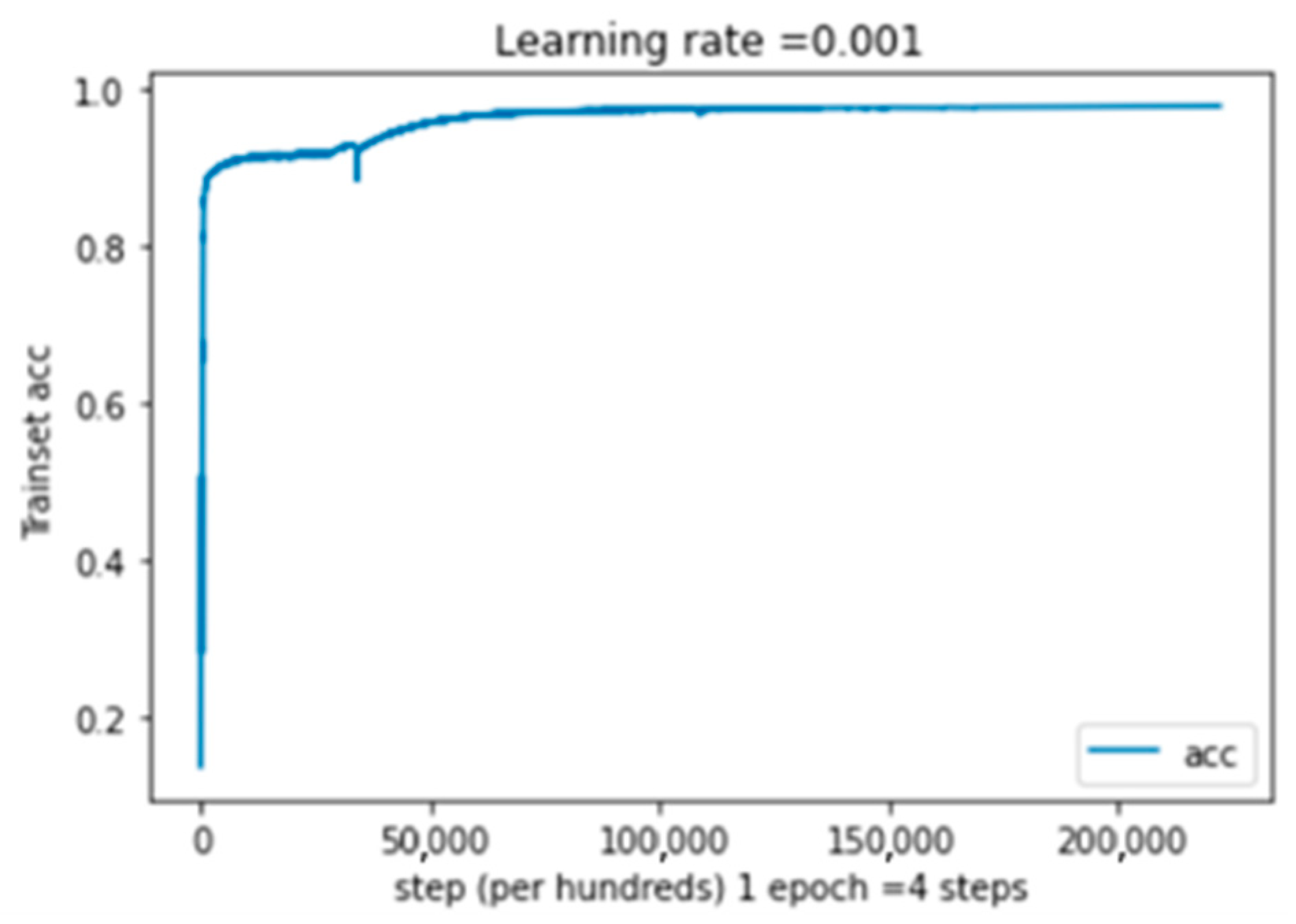
5.4. Performance Evaluation
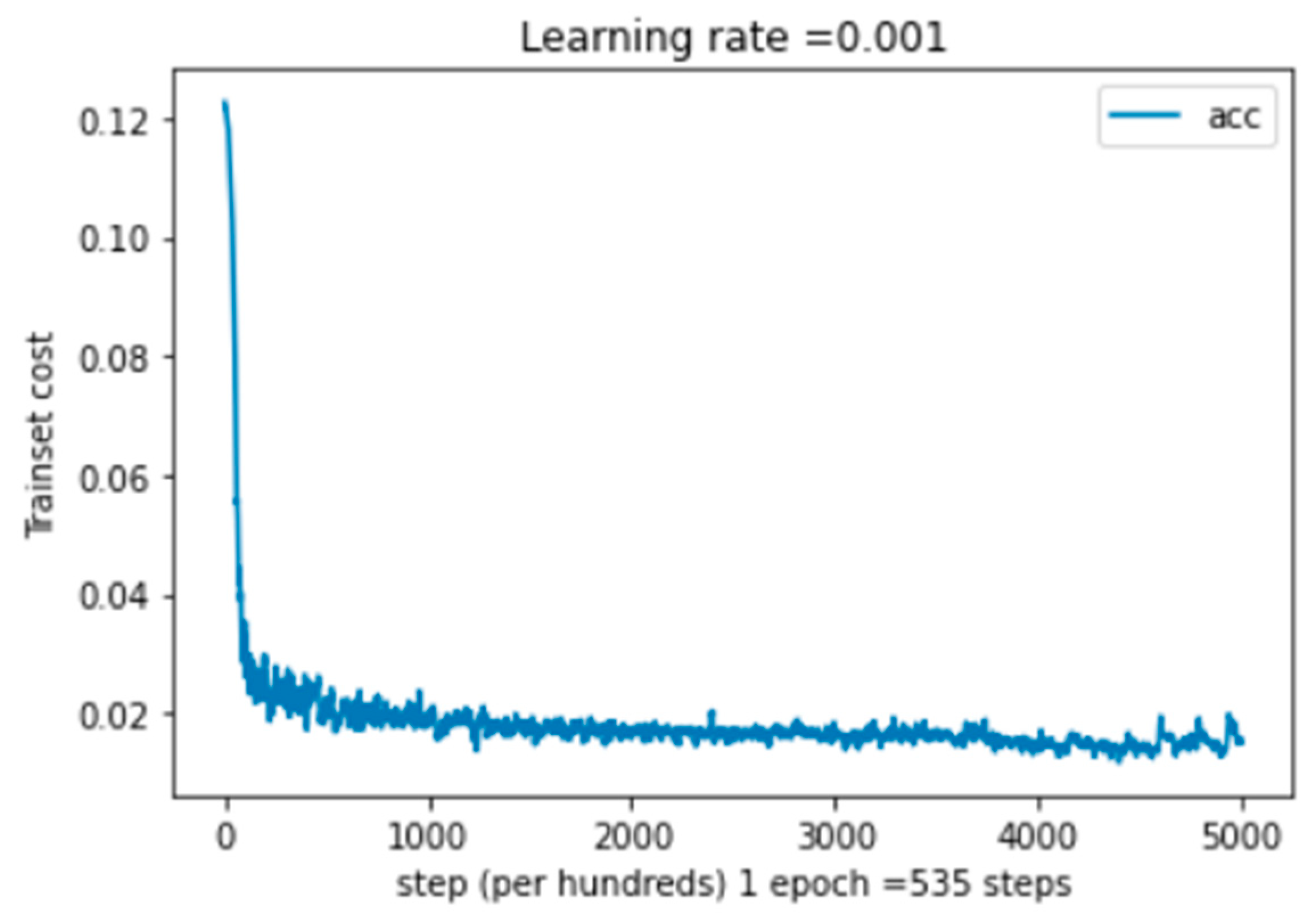
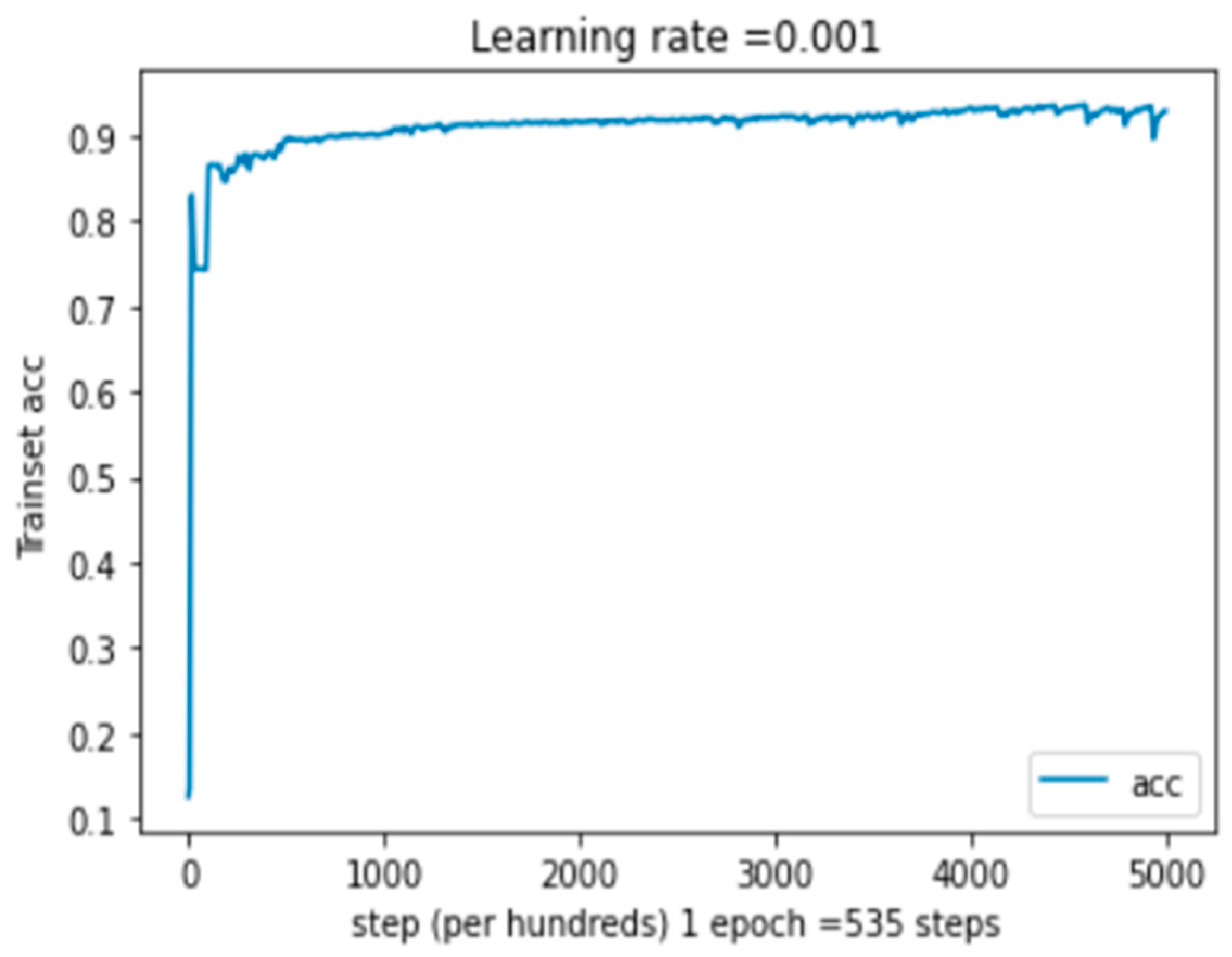
5.4.1. Performance Study on Multimodal System
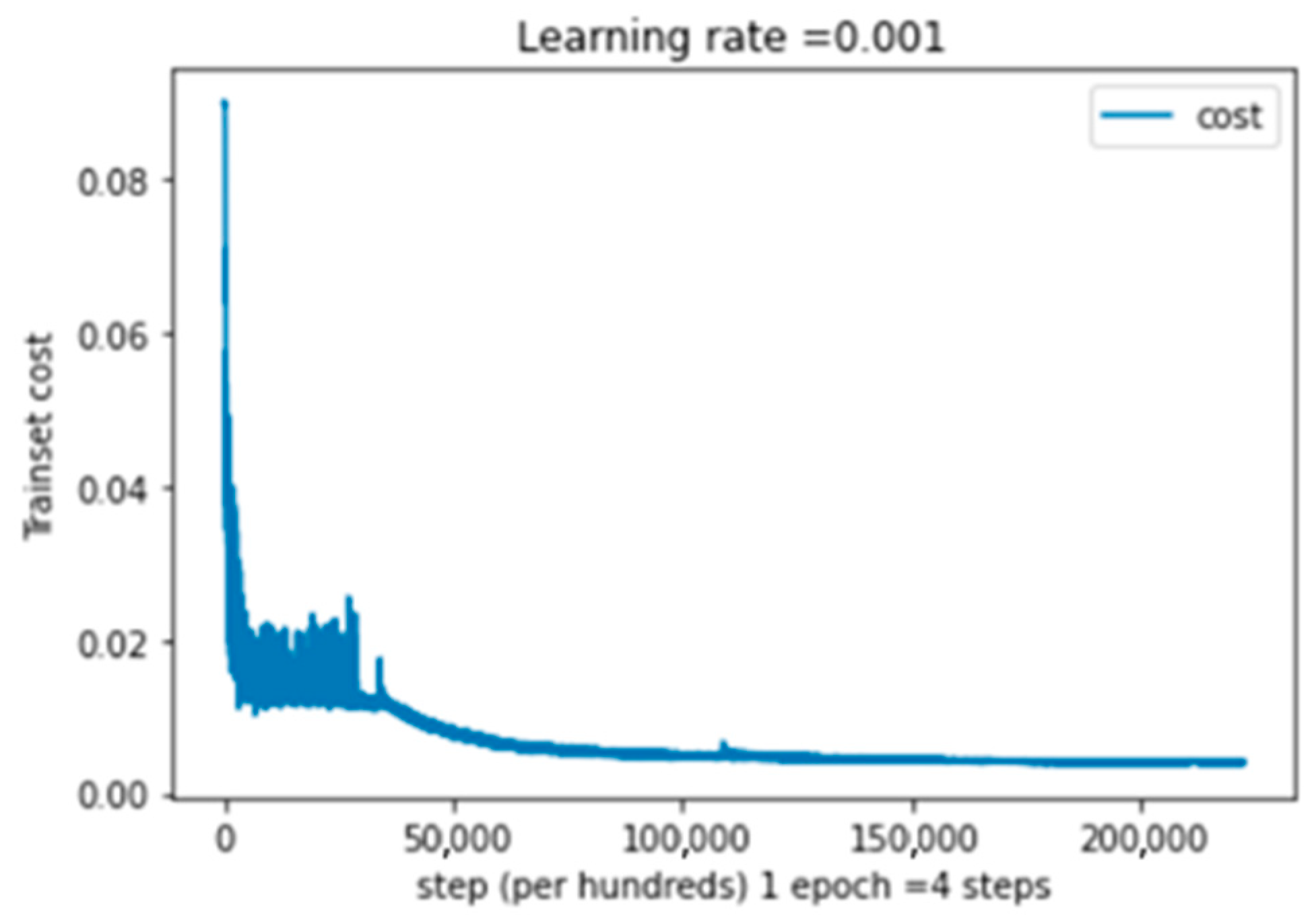
5.4.2. Performance Results on Single Modality System
5.5. Comparison with State-of-the-Art Methods
6. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, X. Learning Multi-channel Deep Feature Representations for Face Recognition. JMLR Workshop Conf. Proc. 2015, 44, 60–71. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Saxena, A. An Introduction to Convolutional Neural Networks. Int. J. Res. Appl. Sci. Eng. Technol. 2022, 10, 943–947. [Google Scholar] [CrossRef]
- Sabour, S.; Hinton, G.E. Dynamic Routing Between Capsules. arXiv 2017, arXiv:1710.09829. [Google Scholar]
- Sun, J.; Fard, A.P.; Mahoor, M.H. XnODR and XnIDR: Two Accurate and Fast Fully Connected Layers for Convolutional Neural Networks. arXiv 2021, arXiv:2111.10854. [Google Scholar] [CrossRef]
- Jeevan, P.; Sethi, A. Vision Xformers: Efficient Attention for Image Classification. arXiv 2021, arXiv:2107.02239. [Google Scholar] [CrossRef]
- Chen, T.; Zhang, Z.; Ouyang, X.; Liu, Z.; Shen, Z.; Wang, Z. “BNN - BN = ?”: Training binary neural networks without batch normalization. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 4614–4624. [Google Scholar] [CrossRef]
- Filali, H.; Riffi, J.; Aboussaleh, I.; Mahraz, A.M.; Tairi, H. Meaningful Learning for Deep Facial Emotional Features. Neural Process. Lett. 2021, 54, 387–404. [Google Scholar] [CrossRef]
- Filali, H.; Riffi, J.; Boulealam, C.; Mahraz, M.A.; Tairi, H. Multimodal Emotional Classification Based on Meaningful Learning. Big Data Cogn. Comput. 2022, 6, 95. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhang, Z.; Zhang, H.; Zhao, L.; Chen, T.; Pfister, T. Aggregating Nested Transformers. arXiv 2021, arXiv:2105.12723. [Google Scholar] [CrossRef]
- Deng, W.; Feng, Q.; Gao, L.; Liang, F.; Lin, G. Non-convex learning via replica exchange stochastic gradient MCMC. In Proceedings of the 37 th International Conference on Machine Learning, Online, 13–18 July 2020; pp. 2452–2461. [Google Scholar]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Choe, J.; Yoo, Y. CutMix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; Volume 2019, pp. 6022–6031. [Google Scholar] [CrossRef]
- Lu, Z.; Member, S.; Sreekumar, G.; Goodman, E.; Banzhaf, W.; Deb, K.; Boddeti, V.N. Neural Architecture Transfer. arXiv 2020, arXiv:2005.05859. [Google Scholar] [CrossRef] [PubMed]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. Meld: A multimodal multi-party dataset for emotion recognition in conversations. arXiv 2018, arXiv:1810.02508. [Google Scholar]
- Chen, S.-Y.; Hsu, C.-C.; Kuo, C.-C.; Ku, L.-W. Emotionlines: An emotion corpus of multi-party conversations. arXiv 2018, arXiv:1802.08379. [Google Scholar]
- Xiong, Y.; Zeng, Z.; Chakraborty, R.; Tan, M.; Fung, G.; Li, Y.; Singh, V. Nyströmformer: A nyström-based algorithm for approximating self-attention. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 14138–14148. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Li, J.; Zhang, H.; Xie, C. ViP: Unified Certified Detection and Recovery for Patch Attack with Vision Transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 573–587. [Google Scholar]
- Kim, W.; Son, B.; Kim, I. Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 5583–5594. [Google Scholar]
- Fedorov, I.; Giri, R.; Rao, B.D.; Nguyen, T.Q. Robust Bayesian method for simultaneous block sparse signal recovery with applications to face recognition Proc. Int. Conf. Image Process. 2016, 2016, 3872–3876. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 94–101. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| class 1 | 0.98 | 1 | 0.99 | 4710 |
| class 2 | 1 | 1 | 1 | 25,470 |
| class 3 | 0.87 | 0.94 | 0.9 | 268 |
| class 4 | 0.95 | 0.94 | 0.95 | 684 |
| class 5 | 0.99 | 0.95 | 0.97 | 1743 |
| class 6 | 0.89 | 0.96 | 0.92 | 271 |
| class 7 | 0.98 | 0.93 | 0.96 | 1108 |
| Macro Avg | 0.95 | 0.96 | 0.95 | — |
| Weighted Avg | 0.99 | 0.99 | 0.99 | 34,254 |
| Predicted | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Actual | |||||||
| 0 | 4702 | 9 | 12 | 5 | 27 | 5 | 17 |
| 1 | 1 | 25,448 | 0 | 4 | 14 | 3 | 7 |
| 2 | 1 | 2 | 251 | 4 | 19 | 0 | 10 |
| 3 | 2 | 5 | 0 | 644 | 13 | 0 | 15 |
| 4 | 2 | 2 | 2 | 2 | 1650 | 0 | 10 |
| 5 | 0 | 4 | 2 | 10 | 10 | 259 | 16 |
| 6 | 2 | 0 | 2 | 4 | 10 | 4 | 1033 |
| Models | Dataset | Parameters | Size (MB) | Accuracy (%) |
| DMCNN (our method) | MELD [15,16] | 529,888 | 12.13 | 99.22 |
| MNN [8,9] | MELD [15,16] | 528,948 | 12.11 | 98.43 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| class 1 | 0.98 | 0.98 | 0.98 | 4027 |
| class 2 | 0.99 | 0.99 | 0.99 | 4021 |
| class 3 | 0.98 | 0.97 | 0.97 | 3970 |
| class 4 | 0.97 | 0.97 | 0.97 | 4067 |
| class 5 | 0.97 | 0.97 | 0.97 | 4067 |
| class 6 | 0.96 | 0.97 | 0.96 | 3985 |
| class 7 | 0.99 | 0.98 | 0.98 | 4004 |
| class 8 | 0.97 | 0.98 | 0.97 | 3983 |
| class 9 | 0.99 | 0.99 | 0.99 | 3983 |
| class 10 | 0.98 | 0.99 | 0.99 | 3960 |
| Macro Avg | 0.98 | 0.98 | 0.98 | — |
| Weighted Avg | 0.98 | 0.98 | 0.98 | 40,000 |
| Predicted | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Actual | ||||||||||
| 0 | 3959 | 5 | 21 | 9 | 0 | 5 | 0 | 11 | 11 | 11 |
| 1 | 3 | 3983 | 1 | 2 | 0 | 1 | 0 | 3 | 5 | 5 |
| 2 | 10 | 0 | 3835 | 13 | 21 | 0 | 1 | 9 | 6 | 6 |
| 3 | 7 | 22 | 16 | 3962 | 25 | 0 | 16 | 0 | 1 | 6 |
| 4 | 8 | 27 | 27 | 8 | 3849 | 27 | 14 | 5 | 1 | 3 |
| 5 | 3 | 18 | 18 | 26 | 12 | 3983 | 9 | 1 | 1 | 4 |
| 6 | 6 | 12 | 4 | 1 | 31 | 9 | 3914 | 2 | 3 | 3 |
| 7 | 15 | 1 | 5 | 3 | 2 | 3 | 1 | 3917 | 2 | 3 |
| 8 | 12 | 6 | 5 | 4 | 1 | 3 | 3 | 5 | 3947 | 3 |
| 9 | 25 | 6 | 1 | 5 | 3 | 4 | 3 | 3 | 3 | 3914 |
| Models | Parameters | Size (MB) | Top 1 Accuracy (%) | Top 5 Accuracy (%) | GPU (GB) |
|---|---|---|---|---|---|
| DMCNN (ours) | 12,960 | 0.30 | 97.78 | 98.58 | 4 (CPU) |
| MNN [8,9] | 12,960 | 0.30 | 97.21 | 98.27 | 4 (CPU) |
| Vision Transformers | |||||
| ViT [10] | 624,970 | 213.15 | 77.06 | 98.46 | 13.9 |
| ViP [19] | 662,410 | 77.14 | 79.50 | 98.91 | 4.9 |
| ViL [20] | 506,186 | 69.69 | 63.17 | 96.13 | 2.3 |
| ViN [17] | 621,402 | 77.13 | 77.81 | 98.61 | 4.3 |
| Compact Convolutional Transformers | |||||
| CCT [18] | 905,547 | 225.47 | 82.23 | 99.04 | 14.7 |
| CCP [18] | 907,083 | 101.48 | 82.48 | 99.06 | 4.3 |
| CCL [18] | 790,859 | 94.04 | 80.05 | 98.92 | 3.5 |
| CCN [3] | 906,075 | 101.48 | 83.36 | 99.07 | 4.2 |
| Convolutional Vision Transformer | |||||
| CvT [18] | 1,099,78 | 173.21 | 79.93 | 99.02 | 12.8 |
| CvP [18] | 827,914 | 100.17 | 83.19 | 99.20 | 4.8 |
| CvL [18] | 711,690 | 92.73 | 72.58 | 97.81 | 2.6 |
| CvN [18] | 826,906 | 100.17 | 83.26 | 99.14 | 4.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boulealam, C.; Filali, H.; Riffi, J.; Mahraz, A.M.; Tairi, H. Deep Multi-Component Neural Network Architecture. Computation 2025, 13, 93. https://doi.org/10.3390/computation13040093
Boulealam C, Filali H, Riffi J, Mahraz AM, Tairi H. Deep Multi-Component Neural Network Architecture. Computation. 2025; 13(4):93. https://doi.org/10.3390/computation13040093
Chicago/Turabian StyleBoulealam, Chafik, Hajar Filali, Jamal Riffi, Adnane Mohamed Mahraz, and Hamid Tairi. 2025. "Deep Multi-Component Neural Network Architecture" Computation 13, no. 4: 93. https://doi.org/10.3390/computation13040093
APA StyleBoulealam, C., Filali, H., Riffi, J., Mahraz, A. M., & Tairi, H. (2025). Deep Multi-Component Neural Network Architecture. Computation, 13(4), 93. https://doi.org/10.3390/computation13040093