1. Introduction
Non-performing loans (hereafter, NPLs) are, in the main category of loans whose collection by banks is uncertain, exposures in a state of insolvency.
As Resti and Sironi [
1] underline, an effective recovery depends on a series of factors, peculiar to the credit (presence of guarantees, etc.), peculiar to the counterparty (sector, country, etc.), peculiar to the creditor (such as the efficiency in recovering money), as well as macroeconomic factors such as the state of the economy.
There is an NPL market that offers banks the opportunity to get rid of non-performing loans by selling them to specialized operators who deal with recovery.
The main method for determining the value of non-performing loans is that of discounted financial flows, according to which the value of the loans is equal to the sum of the expected income flows, discounted at a rate consistent with the expected unlevered return of the investor and net of the related recovery costs.
In the case of a performing loan, the borrower is expected to pay principal and interest at the agreed deadlines with a high level of probability (one minus the probability of default, generally low). In this case, the uncertainty in the valuation is limited to the determination of the discount rate, which takes into account the general market circumstances of the rates and the specific risk of the debtor.
In the case of non-performing loans, the uncertainty concerns not only the discount rate but also the amount that will be returned and the time of return. In fact, the probability of default is now equal to one, in the case in which the transition to non-performing loans has already occurred, or is in any case very high, if the credit is in the other categories of impaired loans (unlikely to pay).
The valuation methodologies currently used on the market are therefore based primarily on forecast models of the amount of net repayments expected from receivables and related collection times. The operation is not trivial and is carried out with different models. The choice of how to model the expected net flows essentially depends on the type of credit and on the information available to the evaluator. It is first necessary to consider whether a real guarantee (typically a mortgage or pledge) on an existing asset with a market value covers the credit. In this case, the flow forecast model is based on the lesser of the value of the asset covered by the guarantee, the amount of the guarantee, and the value of the credit, and on the timing for its judicial sale. The valuation methods to be applied are those based mainly on the compulsory recovery of the credit, while also providing for the possibility of recovering the credit through an out-of-court agreement in some cases.
Forecast models are generally based on: the information available to the creditor, public information, and information acquired and processed as part of the analysis.
The availability of one type of information over another radically changes the articulation and degree of detail that the evaluator can give to the flow forecasting models and consequently to the evaluation methods.
The forecast models with the aforementioned limits use all the relevant information available to determine the estimated flows and related timing. They can be traced back to three types, which can be partially combined with each other: models based on judicial recovery, models based on the debtor’s restitution capacity, and statistical forecasting models.
The estimation methodology for recovery rate, which we are interested in for NPLs, was addressed in the more general context of Basel II. The Basel Committee proposed an internal ratings-based (IRB) approach to determining capital requirements for credit risk [
2,
3]. This IRB approach allows banks to use their own risk models to calculate regulatory capital. According to the IRB approach, banks are required to estimate the following risk components: probability of default (PD), loss given default (LGD), exposure to default (EAD), and maturity (M). Given that LGD has a large impact on the calculation of the capital requirement, financial institutions have placed greater emphasis on modeling this quantity. In any case, LGD modeling for banks is important because it is useful for internal risk monitoring and pricing credit risk contracts, although internal modeling of LGD and EAD for regulatory purposes will soon be limited [
4,
5].
Given that the borrower has already defaulted, LGD is defined as the proportion of money financial institutions fail to gather during the collection period, and conversely, recovery rate (RR) is defined as the proportion of money financial institutions successfully collect. That means LGD = 1 − RR. Despite the importance of LGD, little work has been done on it in comparison to PD, as summarized below.
The recovery rate (or LGD) can be estimated using both parametric and non-parametric statistical learning methods. Mainly, the recovery rate is estimated using parametric methods and considering a one-year time horizon.
Methods used in literature, among others, are: classical linear regression, regularized regression such as Lasso, Ridge, Elastic-net, etc. [
6], support vector regression [
7], beta regression, inflated beta regression, two-stage model combining beta mixture model with a logistic regression model [
8], and other machine learning methods [
9,
10,
11,
12].
Recently, in order to compare different methods to model the recovery rate, in [
13] authors give an overview of the existing literature with focus on regression models, decision trees, neural networks and mixture models and reach the conclusion that the latter approach is the one giving the better results.
Reference papers for a comprehensive overview of regression models, neural networks, regression trees, and similar approaches are the comparative studies of [
14], who conclude that non-linear techniques, and in particular support vector machines and neural networks, perform significantly better than more traditional linear techniques, and [
15], who state that non-parametric methods (regression tree and neural network) perform better than parametric methods.
Among parametric models, linear regression is the most common and simplest technique used to predict the mean, whereas to model the overall LGD distribution, or at least certain quantiles of it, linear quantile regression [
16,
17] and mixture distributions [
8,
18,
19,
20,
21,
22] are proposed.
Due to interest payments, high collateral recoveries, or administrative and legal costs, the LGD value can exceed one or be below zero. A way to solve these cases can be multistage modeling, as for instance in [
23]. Other evidence of multistage models is in [
7,
24,
25,
26].
In the case of NPLs, in our opinion, in investigating the recovery process of defaulted exposures the focus must be not only on the recovered amounts but also on the duration of the recovery process, the so-called time to liquidate (TTL), and we believe that this type of approach needs to be explored further.
Devjak [
27] refers to both size and time of future repayments in a simple model only considering NPLs for which the recovery process was finished. Cheng and Cirillo [
10] propose a model that can learn, using a Bayesian update in a machine learning context, how to predict the possible recovery curve of a counterpart. They introduce a special type of combinatory stochastic process based on a complex system of assumptions, referring to a discretization of recovery rates in
m levels. Betz, Kellner, and Rosch [
28] develop a joint modeling framework for default resolution time (duration of loans) and LGD, also considering the censoring effects of unresolved loan contracts. They develop a hierarchical Bayesian model for joint estimation of default resolution time and LGD, including survival modeling techniques applicable to duration processes. Previous examples of the usage of survival techniques to study the impact of the duration of loans on LGD are in [
29,
30,
31].
Our purpose is to study a particular nonparametric method to measure the performance of an NPL portfolio in terms of recovery rate (RR) and time to liquidate (TTL) jointly, without assuming any particular model and/or discretization of the RR. The idea is to represent the recovery process as a curve showing how the RR is distributed over time without assuming a particular parametric model. We will also consider a method to estimate such a curve when some data are censored, i.e., when the repayment history for some NPLs is known only until a particular data. The algorithm we propose corresponds to applying the actuarial mortality tables method [
32] by considering each currency unit as an individual, and it can be considered a different motivation from the approach exploited in [
30]. The actuarial mortality tables method has been applied in [
33] in the context of corporate bonds and in [
29] for an NPL portfolio owned by a Portuguese bank. In this paper, we go beyond these works in several directions. Firstly, by smoothing the curve by using non-parametric statistical learning techniques. Secondly, by testing the performance of the proposal through a simulation study that is compared with other methods. Finally, by applying our method to real financial data consisting of two large NPL portfolios dismissed by banks and taken over by a specialized operator. To our best knowledge, there are no published studies analyzing the recovery rate timing of this kind of NPLs. This analysis will reveal important differences with the results obtained in [
29] for an NPL portfolio owned by a bank.
The plan of the paper is the following: In
Section 2.1, we show how the recovery curve is defined. The method of estimation in the case of censored data is discussed in
Section 2.2 and improved in
Section 2.3 by smoothing the curves by using regression splines. In
Section 3.1, the effectiveness of the proposal is shown through a simulation study. In
Section 3.2, we apply our method to real data, while some conclusions and final remarks are discussed in
Section 4.
This is the full paper version of [
34] and a completion of the working paper [
35].
2. Materials and Methods
2.1. Recovery Rate and Time to Liquidate of a Portfolio
The definition and computation of RR and TTL of an NPL portfolio are not trivial because the two quantities are strictly related. To make clear what we mean by “recovery rate” and “time to liquidate” and how they are related in the case of a portfolio, we have to answer several questions about the RR. For example: when do we measure the RR? When the last NPL in the portfolio has been liquidated or after a given period? Moreover, in the latter case, how do we choose the length of the period? Similarly, for the TTL: when do we measure the TTL? When the last NPL has been liquidated or when a significant part of the portfolio has been recovered? Finally, in the latter case, how much is the significant part?
The above questions make clear that the measurement of the RR cannot disregard the measurement of the TTL and vice versa. How do we deal with this problem?
Since it is crucial to decide when to measure the RR and TTL—that is, when each NPL in the portfolio has been entirely liquidated or after a given period to be defined—the measurement of the RR cannot disregard the measurement of the TTL and vice versa.
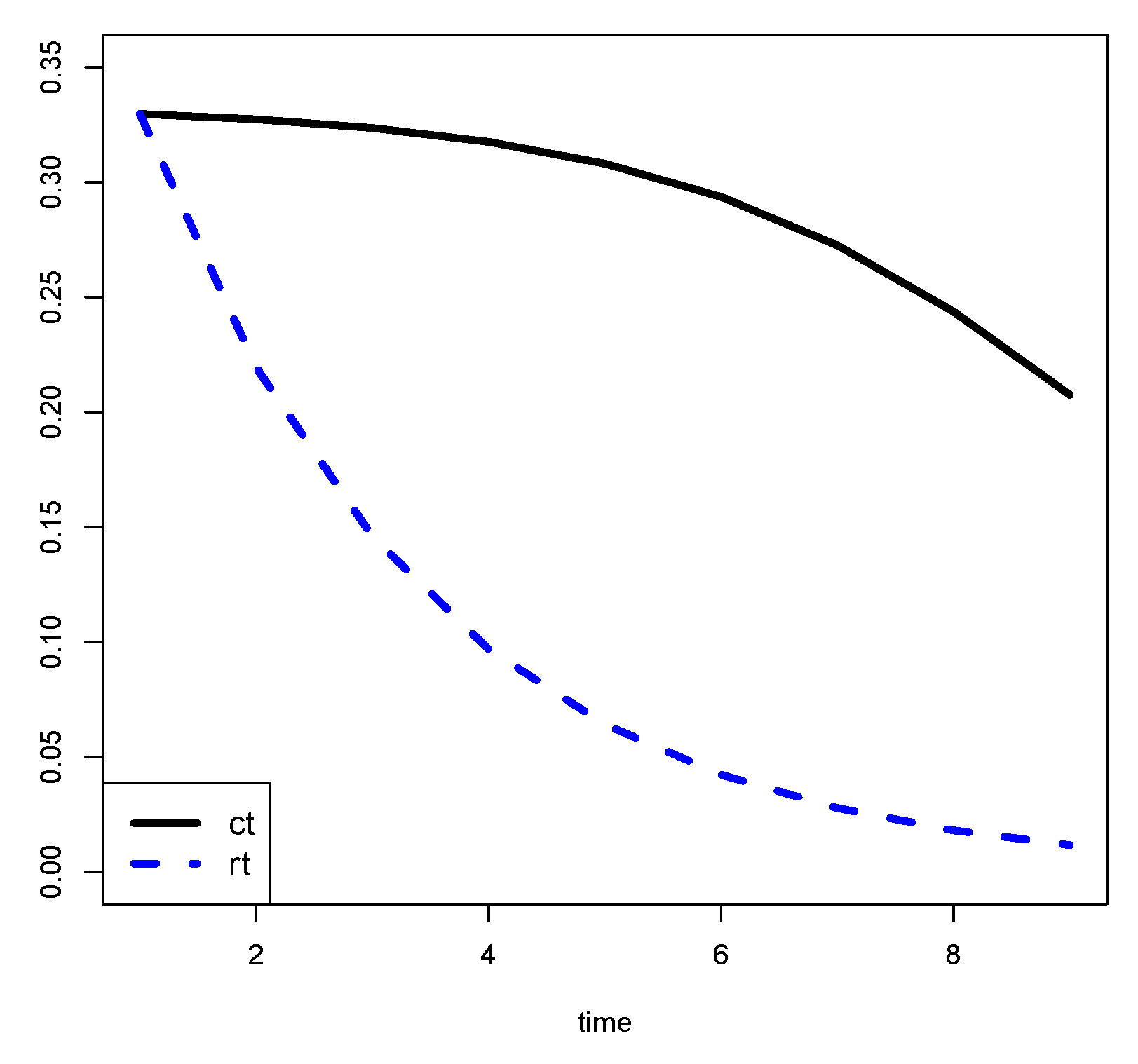
First, we note that measuring the TTL when the last NPL has been liquidated could lead to measures that are highly affected and biased by anomalous NPLs with long TTLs and small EAD. It follows that the TTL should be measured when the RR becomes significant. It remains to understand what is “significant”. Second, in many cases, the user needs more complete information rather than only two numbers: RR and TTL. It would be better to know how the RR increases over time. This would also help in choosing at what RR point to measure the TTL. For the aforementioned reasons, we decided to measure the behavior of the RR over time through what we called the “recovery curve”. Such a curve is built in the following way.
Let us consider a portfolio of
NPLs. For each of the
NPLs, the debt exposure at default is
(exposure at default of the
NPL) and the total exposure for the portfolio is
. Assume
discrete-time intervals of equal length (of the delay of payment) from the default, in time
, to time
, i.e., the valuation date. Let
be the recovery of the
NPL, in the
interval (of delay), i.e.,
, with
and
. The portfolio recovery in time interval
equals
, that is the total recovery, for all the
debt positions, in the
time interval of delay. Consequently, after
time intervals of delay, i.e., by the end of the interval
, we define
as the total portfolio “recovery value until time
t”, i.e., the total recovery, for all the
debt positions, in the first
periods from the default date.
We could also define the total recovery
, being
the value of
evaluated at an appropriate interest rate, since in measuring the recovery rate the net cash flows must be finally discounted with a discount rate appropriately reflecting the risk [
36]. Anyway, in this initial study, we (like many others, i.e., [
8,
27]) do not consider any discounting because we consider recovery time and recovery rate jointly, because the recovery curve, even if lower, would have the same trend, and—above all—because we can consider the discounted values in a future version of the work.
We define
as the portfolio “recovery rate until time
”, while
equals the portfolio recovery rate in the
time interval of delay
.
Since we can refer in an equivalent way to or to , being (for ) and .
Let us consider the following example.
Consider a portfolio with debt positions. We are interested in measuring its performances in years after default, i.e., periods of delay.
The data are in the following
Table 1.
The portfolio performance can be measured in terms of recovery rates until year
t (
Rt) as shown in
Table 2.
We see that, for example, in the first 2 years, the portfolio recovers 15.5% of the total initial exposure: 8% in the first year and 7.5% in the second.
Sometimes the available data are incomplete, in particular right censored, because the is not available from a particular date on for some . In this case, it is not possible to compute the recovery curve for the complete portfolio. However, in the next section, we will see how to estimate the recovery curve from incomplete data.
2.2. Estimating the Recovery Rate Curve from Censored Data
The estimation of the recovery curve in the presence of censored data is carried out in a way similar to the estimation of a survival curve (for example, [
32]). First, we note that sometimes it is interesting to consider the “conditional recovery rate”
in each delay period
. Let
be the effective portfolio exposure at the beginning of period
that means
with
by convention.
The conditional recovery rate of the portfolio at time
t is defined as
In words, it is the recovery rate with respect to the effective portfolio exposure at the beginning of the period () rather than to the initial one ().
We observe that it is possible to obtain
from
and
:
It means that the recovery rate is the conditional recovery of the percentage of how much still has to be recovered.
In our example we have the results in
Table 3.
From the previous table, we see that the performances of our portfolio are better in the second year than in the first one if they are evaluated with respect to effective exposure.
It is interesting to note that it is possible to compute
also in this way
because
being
. In the example
This way of computing
is convenient when there are censored data in the database, i.e., for some NPLs, the recoveries
s are observed only until a particular time. In this case, the idea is to apply Formula (7) by computing the conditional recovery rate
using only the available data. In detail, let us suppose that:
is the subset of indexes
corresponding to the NPLs for which at delay time
the value
is not censored. In this case, the effective portfolio exposure, for
, is a generalization of (4):
and the conditional recovery rate is
The recovery rate in the time interval of delay is computed as or (for ) with , since Formula (3) cannot be used.
Let us consider the previous example where another year of delay has been added to the available data, being
censored as in
Table 4.
If we want to consider more than 3 intervals of delay, assuming we are interested in measuring the performances in 4 years, i.e.,
periods of delay, then the performances of our portfolio are in
Table 5.
In the example,
so that
and
This method of measuring performances allows not only to measure jointly the recovery rate and the time to liquidate but also to deal with censored data. It corresponds to the product limit estimate used in the actuarial lifetime tables computation [
29,
30,
32].
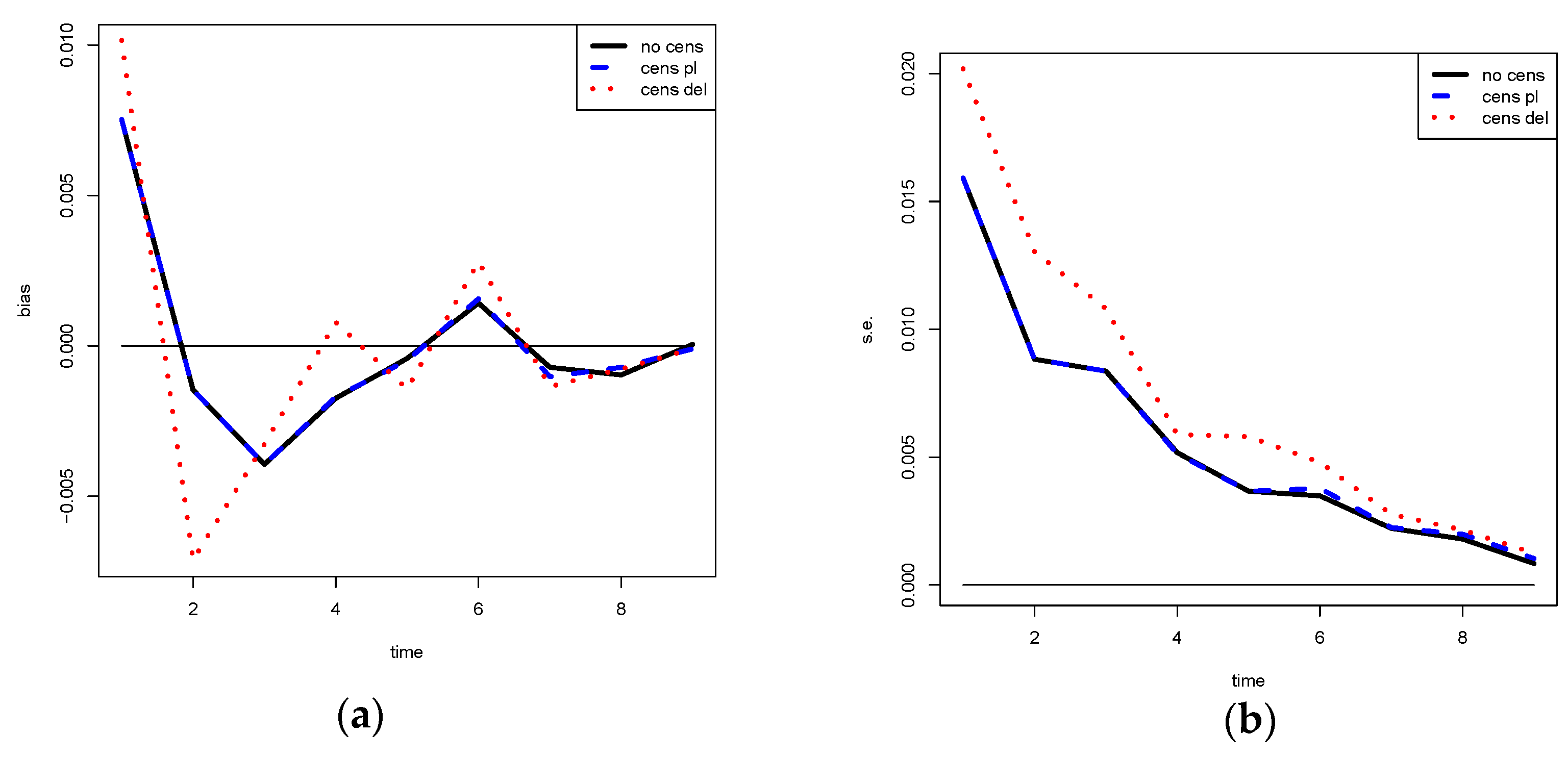
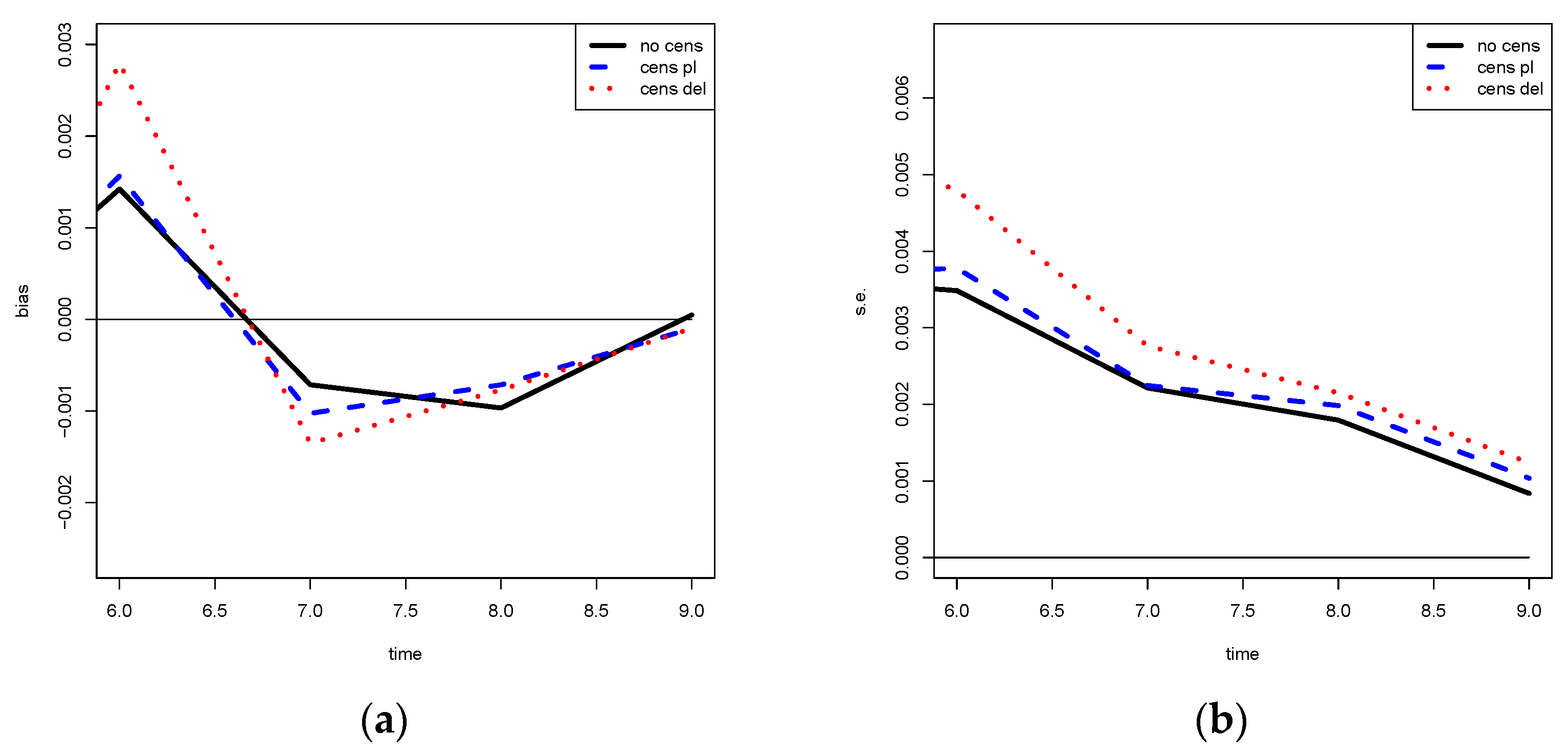
The results would have been different if we simply did not consider in the portfolio the NPLs for which the data are censored.
In the previous example, with
periods of delay, we would have the same results as before, whereas considering
periods of delay excluding
(as, for example, proposed in [
8]) would lead to different results for all the durations, as shown in
Table 6. Such estimates are of lower quality than the proposed ones because they were obtained using fewer data, i.e., information.
If we exclude the NPL with censored data, we obtain different results for all the years of observations, as reported in
Table 7, since we consider a different portfolio (with a lower number of loans).
Obviously, it is wrong to imagine the censored data equal to 0, meaning no inflows instead of no information about that inflow.
With the same example, substituting
, we would obtain the data in
Table 8 and the results in
Table 9.
The results in
Table 9 are the same results of
Table 5 for the first 3 years, whereas for
we get different results.
Considering no inflow instead of no information about the inflow could lead to an underestimation of the true curve.
2.3. Spline Smoothing on the s
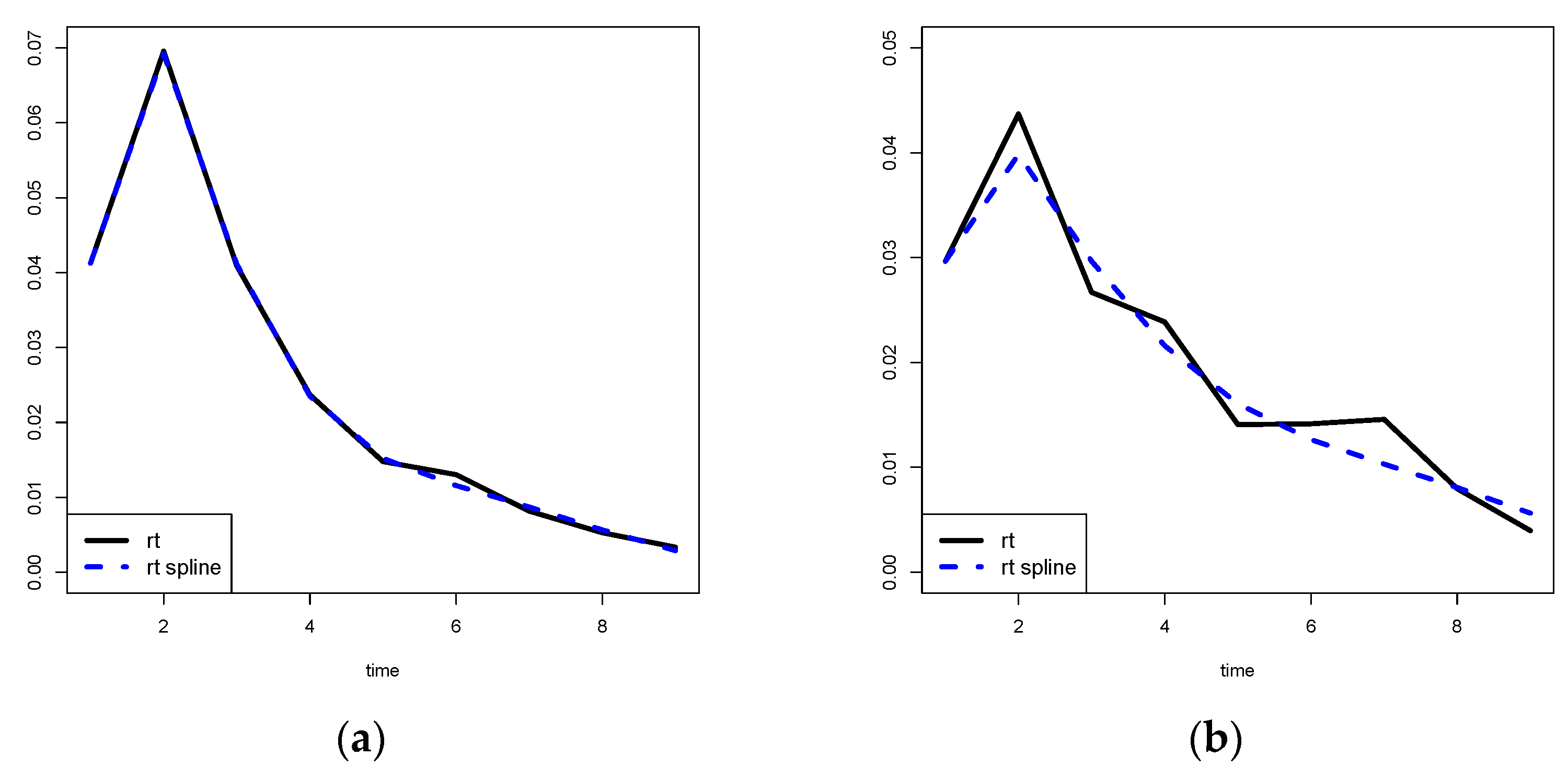
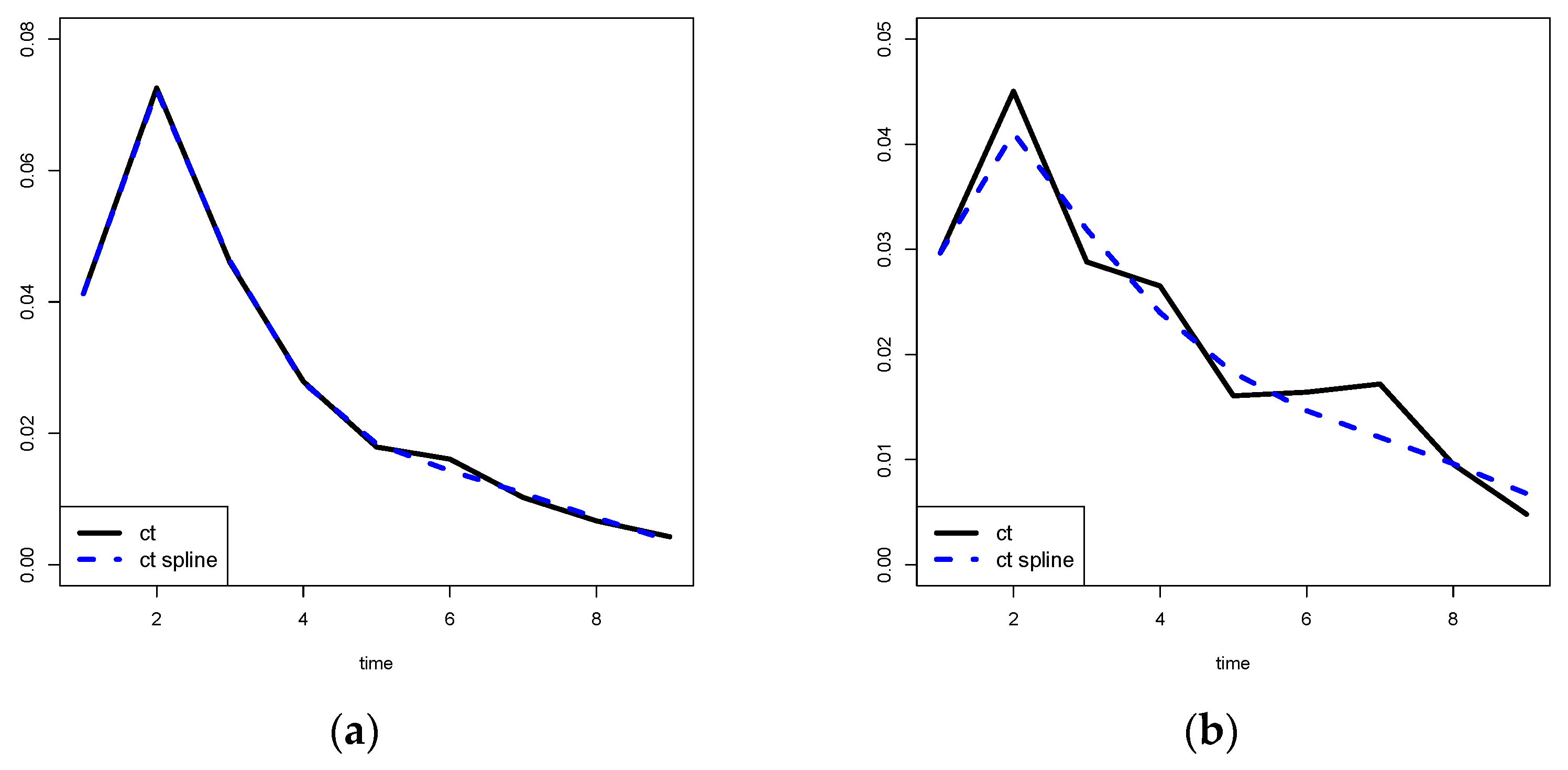
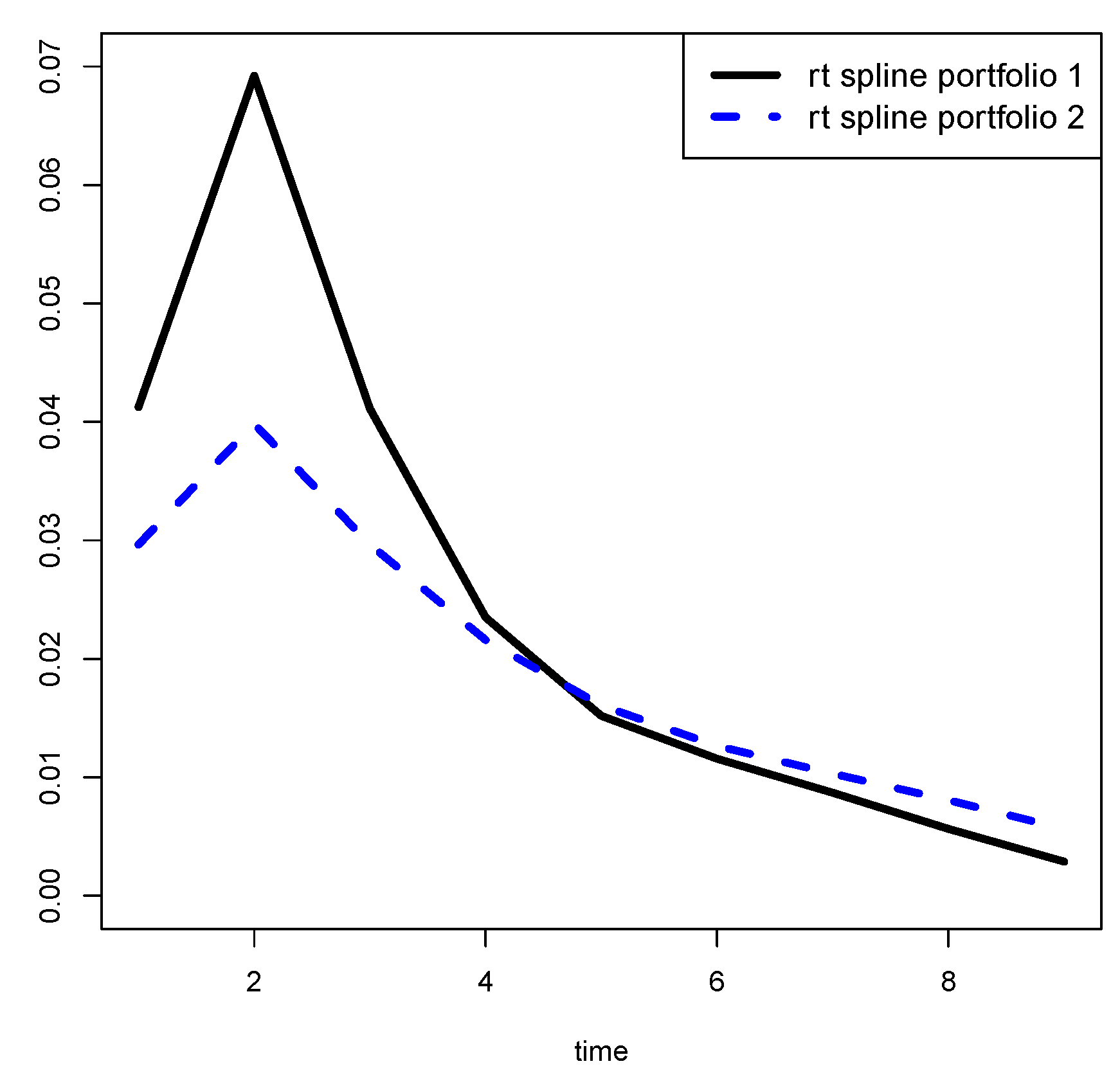
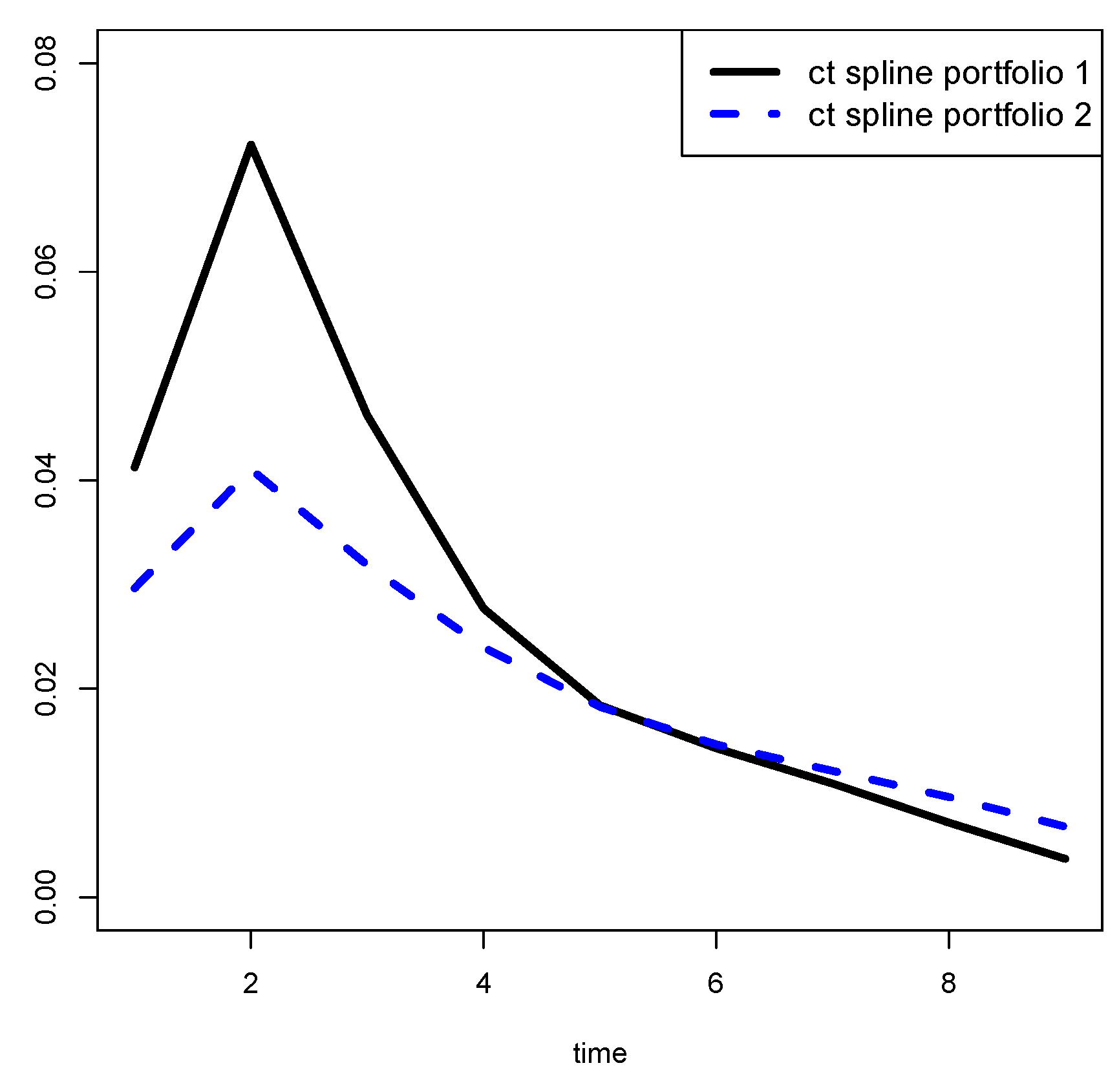
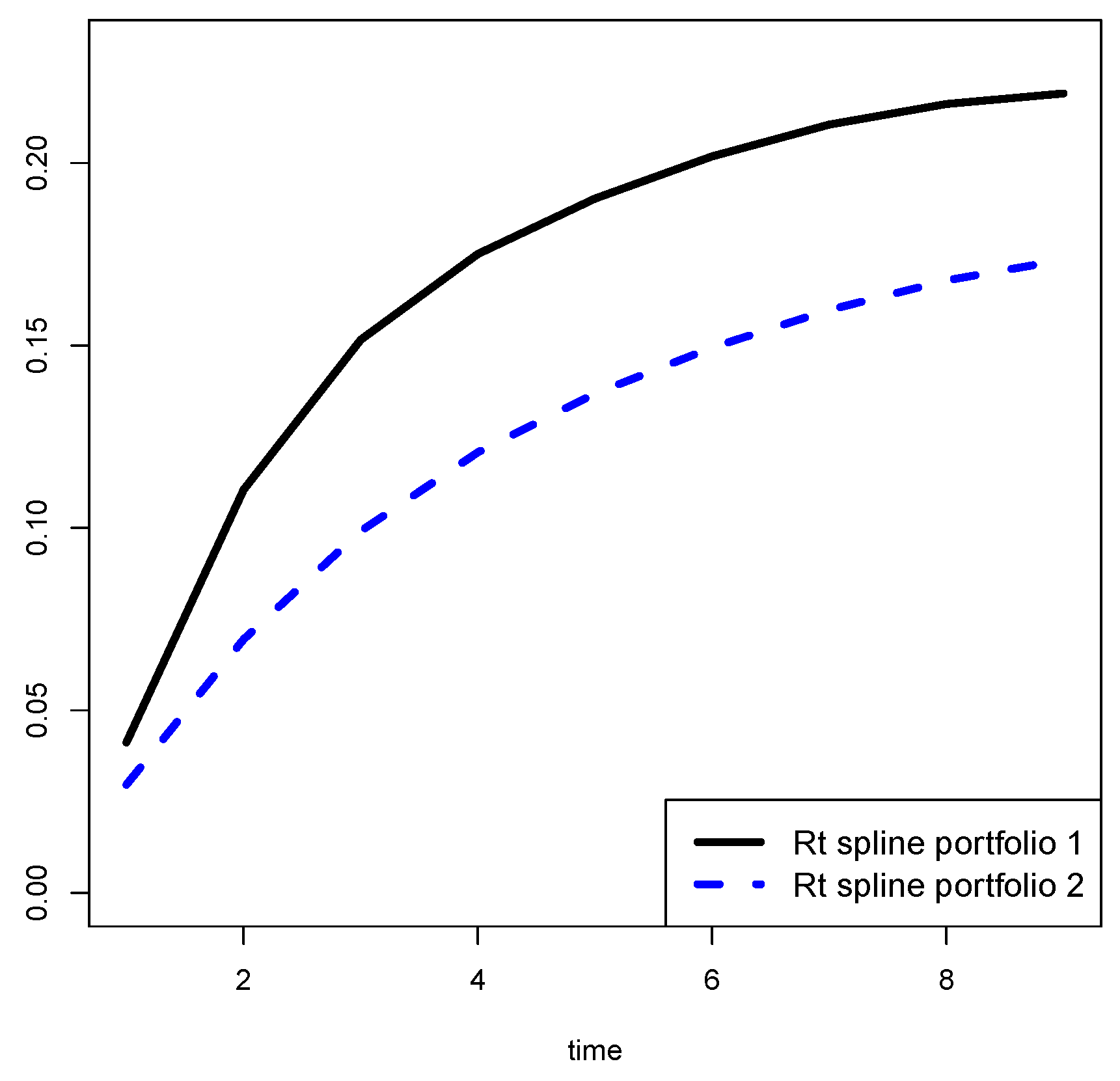
In general, when we plot the (and the ), for , we expect to see a smooth curve. Then, it would be opportune to produce smoothed estimates of the s.
To this end, first we note that the portfolio conditional recovery rate
is a weighted average of the NPLs conditional recovery rates
It follows that the
s minimizes the least squares loss.
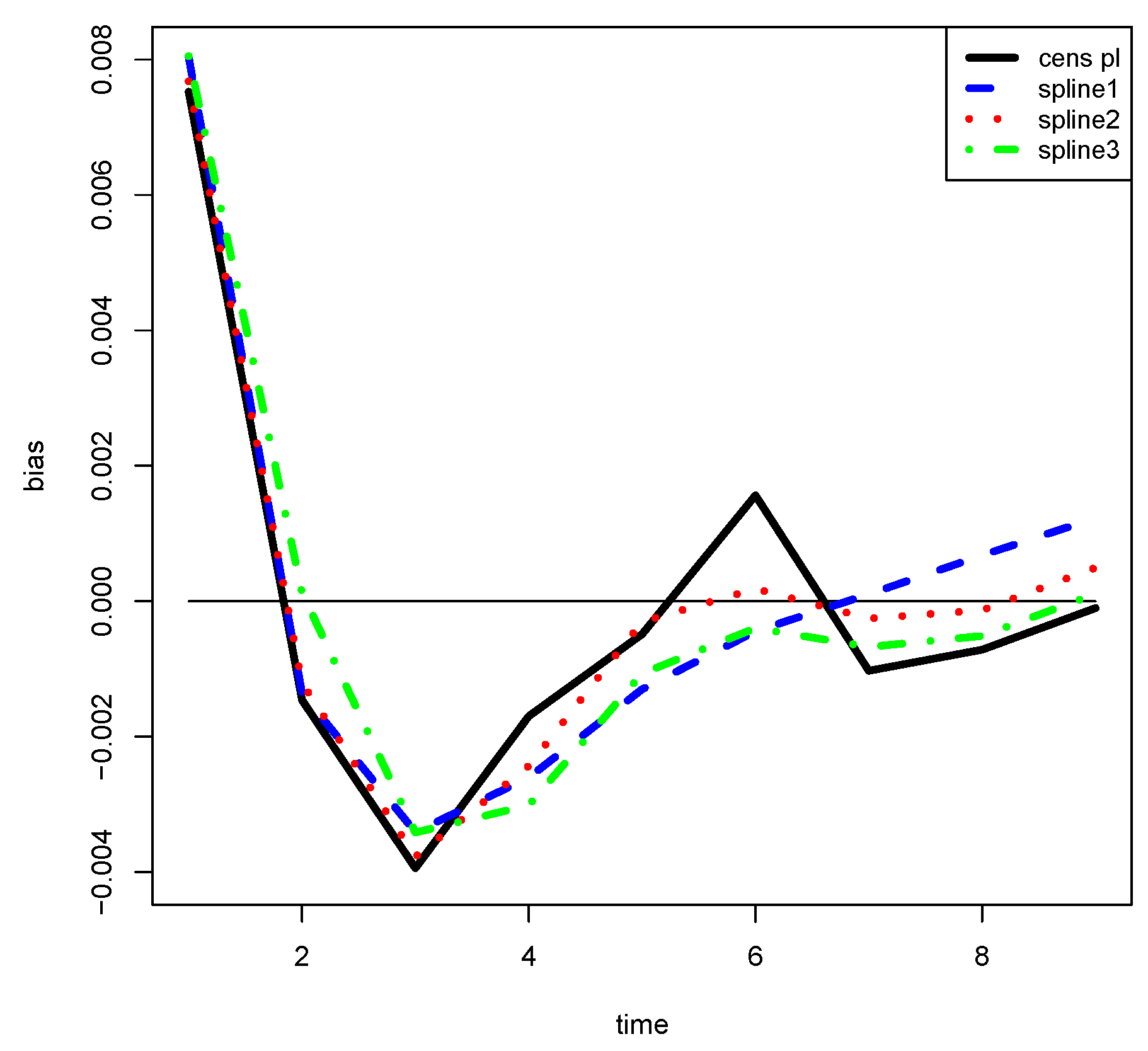
Our idea is to estimate the s by using a non-parametric regression technique.
In particular, we propose to use penalized regression splines by minimizing the loss (spline 1)
where
is the “smoothed” version of
.
In practical applications, the choice of
is crucial, as large values reduce the variability of the estimator but increase its bias while small values reduce the bias but increase the variance. In our implementation, we use the R [
37] package MGCV (mixed GAM computation vehicle with automatic smoothness estimation) [
38]. The smoothing parameter is selected using the GCV (generalized cross-validation) criterion.
It is interesting to note that the loss (13) is equal to
It follows that the second addendum of (14) gives a loss equivalent to (13). We name this loss spline 2. Although the two losses are equivalent with respect to minimization, in our implementation they give different results because they are not equivalent with respect to the choice of .
Another possibility is given by the minimization of the loss (spline 3)
where
is an estimate of the variance of the
s. It corresponds to weight the “observations” by the inverse of their variances.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}