1. Introduction
Outdoor air pollution has become a serious environmental problem that has a significant impact on public health, climate change and the health of ecosystems with the growth of industrialization and urbanization. It has been continuously monitored through a wide network of monitoring stations [
1], which ranks the most polluted countries and regions based on average annual
(particulate matter) concentration. The presented rating shows that air pollution exceeds WHO recommendations by more than ten times in many developing countries, and this figure exceeds three–five times in Kazakhstan. Therefore, the study of the problems caused by air pollution and predicting the spread of harmful substances in the atmosphere is still relevant throughout the world.
Modeling the distribution of harmful substances in the atmosphere is an important tool for studying and predicting their behavior and impact on the environment and human health. Strategies can be developed and measures be taken to minimize the impact of harmful substances on the environment with the help of models. Factors such as sources of emissions (for example, industrial enterprises, vehicles), meteorological conditions (wind velocity and its direction, turbulence, and atmospheric stability) and the chemical properties of the substances themselves are usually taken into account when modeling the distribution of harmful substances in the atmosphere.
Modeling of air pollution based on the solution of partial differential equations is a fairly reliable and well-established approach [
2,
3,
4]. For example, Aydosov [
5] developed a mathematical model for dispersion and transport of pollutants from an instantaneous point source in the atmosphere with partial absorption of surface impurities using a transport equation with a source term. To study the diffusion model of an accidental release of harmful substances under various conditions of atmospheric stability, the authors of [
6] used the Reynolds-averaged Navier–Stokes model. The authors of [
7] developed a mathematical model of mesoscale atmospheric processes, the transport and transformation of pollutants, and also numerically implemented the finite difference method assuming that the domain is rectangular. This technique was then improved in [
8,
9] in the case of a more complex geometry of the domain. In [
3], a mathematical model was developed which is based on the equations of transfer and diffusion of aerosol emissions in the atmospheric boundary layer taking into account the terrain, weather and climatic factors. We also refer the reader to a comprehensive review [
10] of relevant concepts, methods and models for the atmospheric transport of chemical, biological and radiologically hazardous pollutants. Also, the authors of [
11] reviewed a number of methods for data analysis and modeling of air pollution and environmental impact, and identified the main parameters for choosing a method, namely the accuracy, interpretability, and spatiotemporal characteristics of the method. It should be noted that the accuracy of these models depends on the quality and reliability of input data such as emission data, meteorological conditions, topography and other parameters. It is also important to consider the uncertainty and variability of these parameters which can affect the accuracy of the model’s prediction. In practice, this is not always possible, since data are usually only available from stationary or mobile observation points which periodically measure the concentrations of pollutants at a few points.
Another approach for assessing and predicting the distribution of harmful substances in the atmosphere as well as managing air pollution is the use of machine learning algorithms. Machine learning analyzes a wealth of data such as meteorological conditions, geographic features, pollutant emissions and other factors to predict the spread of harmful substances and assess their impact on the environment and human health. Many studies have shown that this approach is effective due to its high robustness and accuracy, and it usually requires less labor.
The advantage of machine learning is that it helps to find patterns based on statistical data that are inherent in a particular area, depending on climatic and geographical features and terrain. For example, recent studies employed principal component analysis and an artificial neural network to predict
concentrations in Urmia, Iran [
12], the Harris Hawk multiobjective optimization algorithm to predict the hourly concentrations of
and
in Jinan, Nanjing, Chongqing [
13], Lagrange and Bayesian methods to predict hourly concentrations of
and
in Xingtai [
14], a hybrid remote sensing and machine learning approach to predict daily concentrations of
in the Beijing-Tianjin-Hebei region [
15], XGBoost, KNN, GNB, SVM and RF models to analyze and predict air quality in several cities in India [
16], a spatiotemporal graph neural network to predict ozone concentration based on the GraphSAGE paradigm in Houston-TX [
17], and a SVR-based model to predict
and
concentrations in Chile [
18]. Feng et al. [
19] used artificial neural networks and wavelet transform to predict
concentrations from geographic models. Li et al. used integrated reinforcement learning to predict daily concentration of
[
20]. Moreover, hybrid artificial intelligence models are also used to predict environmental pollution, such as EEMD-LSSVM [
21], PCA-CS-LSSVM [
22], WPD-PSO-BNN-AdaBoost [
23], PSO-ELM [
24], GA-RF-BPNN [
25], CEMD-PSOGSA-SVR-GRNN [
26], WPD-CEEMD-LSSVR-CPSOM-GSA [
27], VMD-SE-LSSVM [
28], CEEMD-CS-GWO-SVM [
29], WPD-Bi-LSTM-NSGA-II [
30] and many others. A comprehensive overview of deep learning methods for predicting the concentration of air pollutants can be found in the papers [
31,
32]. The work [
33] provides a comprehensive overview of the sources and impacts of pollutants on the environment and human health, on methods for predicting environmental pollution.
Some studies are aimed at a comparative analysis of machine learning algorithms in relation to the prediction of atmospheric pollution. For example, Kumar et al. [
16] showed that the XGBoost model shows the best results among other models such as KNN, GNB, SVM, RF and provides the highest linearity between predicted and actual data. Li et al. [
15] demonstrated that the proposed RSRF model provides better performance and relatively high prediction accuracy than the MLR, MARS and SVR models. Liang et al. [
34] concluded that stacking ensemble and AdaBoost can outperform methods such as SVM, RF, and ANN. Bekkar et al. [
35] compared the performance of deep learning algorithms such as LSTM, Bi-LSTM, GRU, Bi-GRU, CNN, and a CNN-LSTM hybrid model and showed through experimentation that the CNN-LSTM hybrid method produces more accurate predictions, and it has high precision and stability.
Note that the above approaches rely either on solving differential equations using measurement results as input data, or on machine learning models that allow for identifying a pattern in long-term measurement data and make a prediction of the pollutant distribution on their basis.
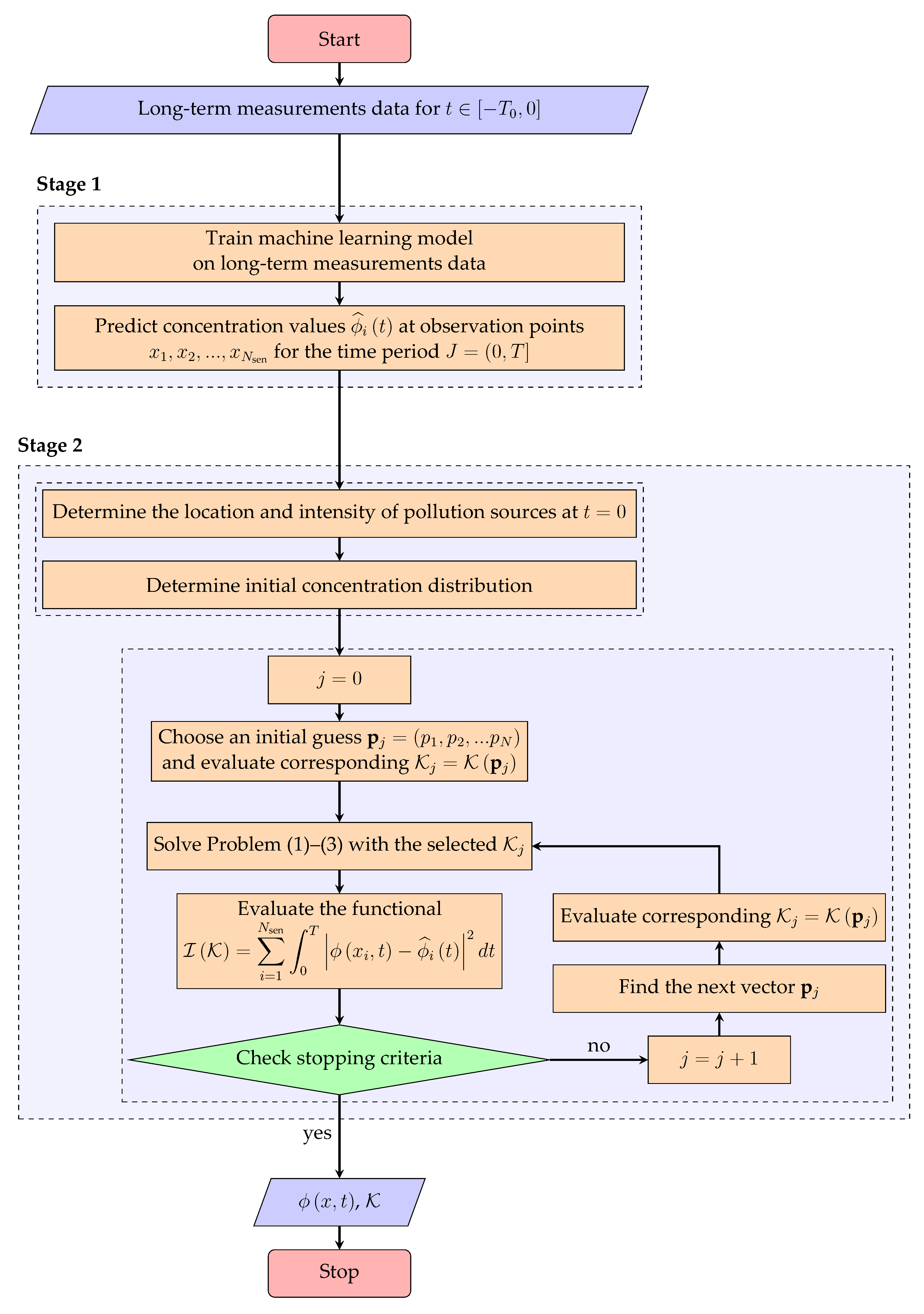
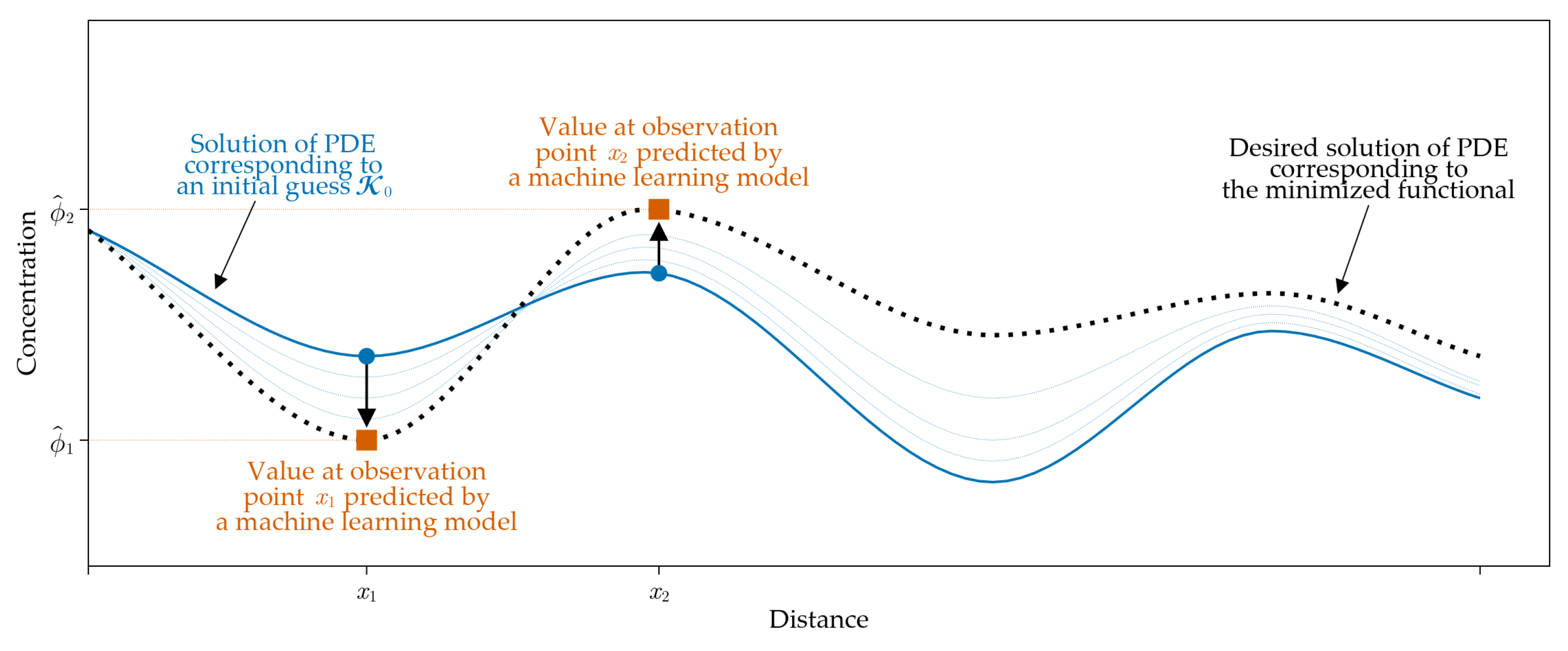
In this paper, we propose a new approach that combines both of these techniques. We assume that the process of pollutant propagation in the atmosphere is described by a differential equation of the convection-diffusion-reaction type. In addition, we assume that long-term measurement data of the concentration values at observation points are available, on the basis of which it is possible to make a forecast of future concentration values at these points by a machine learning algorithm. The essence of the proposed approach is based on the assumption that pollutant concentrations at observation points, predicted by a machine learning algorithm, can be used to refine the solution of a differential equation. This approach is reduced to minimizing a penalty function which is defined as the difference between the solution of the differential equation and the predicted values at observation points. We propose an effective numerical method to solve the resulting problem by a combined use of the parameter estimation technique and the finite element method.
The main hypothesis of the study is the assumption that the predicted concentration values at observation posts may serve as a good basis for refining the forecast results that are produced by solving differential equations.
The proposed methodology is tested on two cities of Kazakhstan, Ust-Kamenogorsk and Almaty. The choice of Ust-Kamenogorsk is justified by the fact that the most unfavorable situation was observed in this city according to the results of analysis of data obtained from stationary atmospheric air observation posts in 26 cities of Kazakhstan [
36]. Many studies have been carried out regarding the atmospheric state of Ust-Kamenogorsk [
7,
37,
38,
39,
40,
41,
42]. The fact that the city is located in a mountainous area is unfavorable, which prevents dispersion, and leads to the accumulation of harmful substances. Industrial processes in the East Kazakhstan region include a wide range of activities that lead to the emission of various harmful substances into the atmosphere [
43]. The state of atmospheric air in the second city, Almaty, has been studied in many works [
44,
45,
46,
47,
48,
49]. It is believed that the main sources of air pollution in the city are vehicles, thermal power plants, industrial enterprises, as well as private houses with their own heating system.
The present paper is structured as follows.
Section 2 describes the proposed approach to predicting the distribution of harmful substances in the atmosphere.
Section 3 presents the results of some numerical results to confirm the theoretical analysis. Finally, in
Section 4, we discuss the results obtained.
3. Results
In this section, we present some numerical results to verify the method proposed in
Section 2.
3.1. Analysis of the Long-Term Measurement Data
The proposed methodology was tested on two datasets containing long-term measurement data in two cities of Kazakhstan. The first dataset, which will be referred to as Dataset A, is based on measurements from five sensors located in the industrial city of Ust-Kamenogorsk that analyze air quality and measure concentrations of several pollutants in the atmosphere. Several industries are located in the northern part of the city, but significant pollution is believed to come from motor vehicles and the areas with a cluster of residential buildings with their own heating systems. The location of automated observation points in the city was chosen so as to cover the most polluted part of the city and give an objective assessment of the air condition in different parts of the city due to the spread of harmful substances.
The dataset covers the results of observation from 2005 to 2021 and contains the results of measuring the concentration of seven chemical compounds in the atmosphere with some periodicity. The frequency of measurements in the specified period was not always the same—the interval between measurements was 4 h to a greater extent, less often measurements were taken every 3 h, and exceptional cases were limited to only three measurements a day. The data collected also includes the ambient air temperature, atmospheric pressure, wind direction and its velocity, relative humidity, and an atmospheric phenomenon code. The atmospheric phenomenon is represented by an integer from 0 to 9, the values and description of which are given in
Table 1.
Table 2 lists the statistical characteristics of the pollutants in the dataset. The Count column indicates the number of values after the removal of deliberately incorrect values and outliers. The remaining columns characterize the mean, standard deviation, median, extreme values, and quartiles of the measured data.
The second dataset, Dataset B, contains the results of measurements of five chemical compounds at 30 observation posts of an industrial city (Almaty) from 2020 to 2022 with a period of 20 min. The statistical characteristics of the dataset are given in
Table 3.
3.2. Comparison of Machine Learning Models
Let us focus on the selection of features for training the machine learning models. It follows from the analysis of the correlation matrices presented in
Table 4 and
Table 5 that the values, in general, do not correlate well with each other in both datasets. However, the influence of temperature, atmospheric pressure, and, in some cases, wind velocity and atmospheric phenomenon is clearly traced. Therefore, these four parameters were taken as features along with the chemical compound under study.
Note that the direct application of the three machine learning models did not give consoling results with the selected features set. The models could not find a pattern of concentration behavior over time, and verification on test data led to a large discrepancy between the predicted values and actual measurements. Therefore, the time lag approach is employed in order to better catch the pattern. In other words, target values from previous periods were utilized as features in addition to the selected ones. Namely, three features according to the time lags equal to 364, 728 and 1092 days were added.
The models were trained on the first dataset corresponding to the time period up to 2020, and verification was carried out on the data of 2021. For completeness of the study, training was carried out for each automated observation post separately.
The number of estimators varied between 500 and 1000 when training the XGBoost model. The LightGBM model was trained with the following set of parameters: maximum depth was chosen to be 50, the number of leaves was 512, maximum bin was 512, the number of iterations was 200, and the boosting type was GBDT. The HistGradientBoosting model was trained with the following parameters: maximum iterations was chosen to be 600, and the iterations interrupted when no changes took place in the last 10 iterations.
Table 6 shows the coefficient of determination
obtained for the machine learning models and chemical compounds considered. It is clearly seen from the training results that all three models work quite well for chemical compounds in case the initial data is complete, and corresponding
scores are close to each other. In particular, for the top three rows of
Table 2,
and
, this indicator varied in the range of 0.91–0.95, which indicates a good trainability of the models considered.
However, in the case of chemical compounds for which the data were insufficient,
Table 6 clearly shows that the XGBoost model performed worse in training. In particular, for
and
, the XGBoost model showed the worst results where
was between 0.4 and 0.7. On the contrary, the LightGBM and HistGradientBoosting models trained quite well and the
scores on the specified data set ranged from 0.8 to 0.9. One can conclude that the LightGBM and HistGradientBoosting models are more resistant to data incompleteness, and therefore these models can be used to implement this stage of the proposed approach.
The mean absolute error (MAE) and root mean squared error (RMSE) indicators for the XGBoost, LightGBM and HistGradientBoosting models are shown in
Table 7.
Similarly, calculation results of the coefficient of determination for Dataset B are shown in
Table 8. Due to relative completeness of information,
score was mostly higher than 0.95. Occasionally, the dataset contained incomplete data for
,
,
and
on a few observation points. This was reflected in the coefficient of determination, and all three models showed fairly close values.
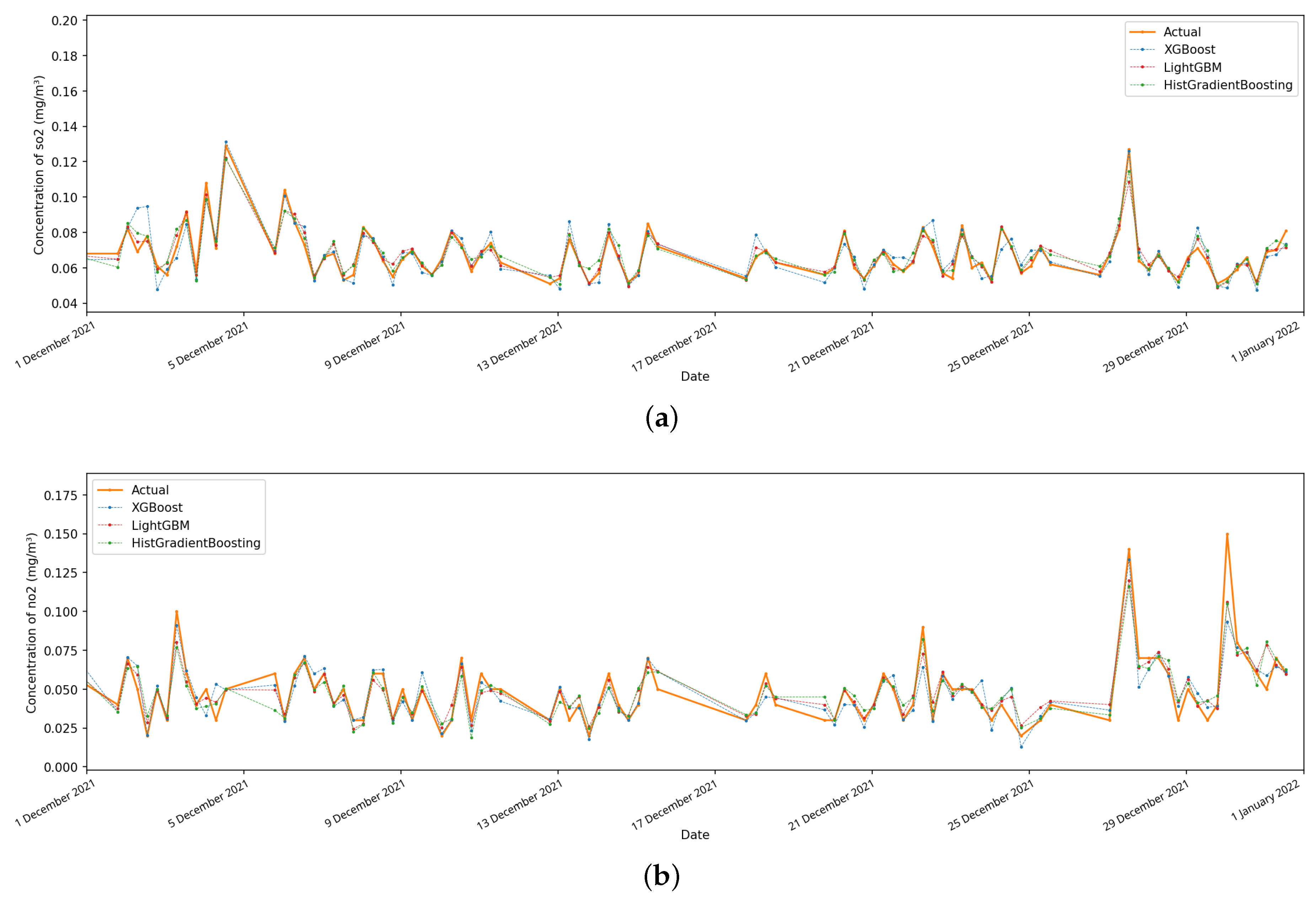
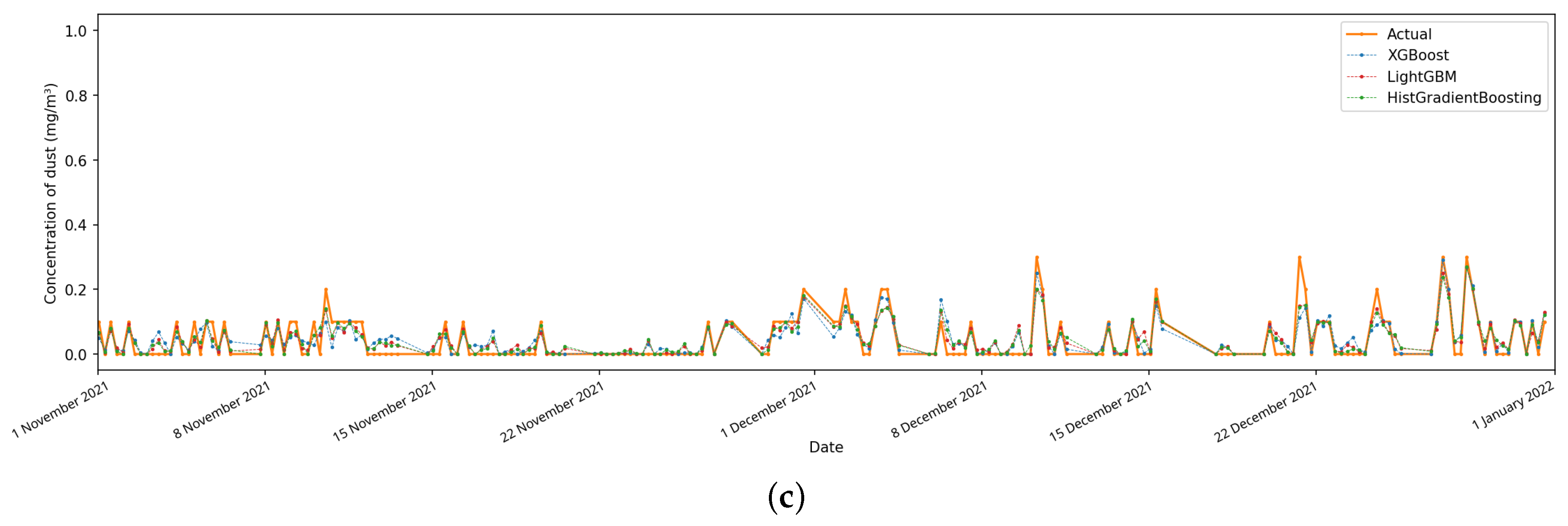
Now let us verify the predicted values on the test data over a monthly time interval from 1 December 2021 to 1 January 2022 and depict the forecast values obtained by the XGBoost, LightGBM and HistGradientBoosting models, as well as the actually measured data for the same period. The results of such an analysis for the chemical variables
,
and
at one of the automated posts are shown in
Figure 4. It can be seen from the results that all three models make it possible to predict future concentration values quite well in cases where the data is complete.
3.3. Identification of the Atmospheric Turbulence Coefficient
There are many atmospheric turbulence diffusion coefficients commonly used in modeling of propagation of impurities in the atmosphere. In this study, we consider a few slightly modified models [
66,
67]:
where
,
,
are some real parameters,
M is a positive integer,
is the distance function respresenting the downwind distance,
is the diffusivity of the long-term diffusion limit,
k is the wave number,
is the wave number corresponding to the largest turbulent eddies,
is a positive real number and
B is a dimensionless constant which were chosen to be
and
in [
66],
is the crosswind dispersion, and
U is the wind speed.
The aim of this computational experiment is to compare optimization algorithms in relation to the identification of atmospheric turbulence coefficient parameters based on the parameter estimation technique. To this end, consider Problem (
1)–(
4) in
with
,
,
and a known exact solution
in the following four cases depending on the atmospheric turbulence coefficients (
9)–(
12).
Case 1. Consider the model (
9) with
and let
be the pollution source. In this case,
depends on two unknown parameters
to be identified. In this numerical test, the right-hand side of Equation (
1) is chosen as
Thus, the atmospheric turbulence coefficient to be identified is
. The initial estimate for the parameters was chosen to be
. Then a series of initial boundary value problems (
1)–(
3) with different coefficients
,
was solved according to Stage 2 of the proposed approach presented in
Figure 1, where the subsequent values
were determined by optimization algorithms listed in
Section 2.3. The values of the exact solution at points
,
,
and time stamps
were utilized as the values of
in the functional (
4). Thus, the functional was evaluated with the use of 15 observation points in total.
Case 2. Consider the model (
10) where we restrict ourselves to the case
for simplicity of presentation. Then
depends on six unknown parameters
. The right-hand side of Equation (
1) was chosen as follows:
Therefore, the atmospheric turbulence coefficient to be identified is
The problem was solved with an initial estimate . The rest of the computational experiment was carried out in the same way as in Case 1.
Case 3. Consider (
11) with an unknown parameter
. The rest of the parameters are chosen as follows:
,
,
,
. The initial estimate for the parameter was chosen as
, then the computational experiment is continued as described in Case 1. The desired value of the parameter
is 4/3.
Case 4. Consider (
12) with unknown parameters
, where we assume that the pollution sources are located at points
and
,
and
. The computational experiment started with the initial estimate for the parameters
and continued as described in Case 1. The vector of the parameters to be identified is
.
Numerical solution of the initial boundary value problem (
1)–(
3) was performed with the use of quadratic finite elements on a quadrilateral mesh consisting of 400 elements and 1681 nodes according to
Section 2.4. The algorithm was implemented in the Julia programming language [
68] with the use of the Ferrite package [
69]. The time discretization parameter was chosen to be
. The solution of one initial boundary value problem on a 10 core computer with the Intel Core i9 processor and 64 GB of RAM took less than 1 s.
Optimization algorithms were compared according to three criteria:
- (1)
Number of iterations: since each iteration leads to the solution of the initial boundary value problem (
1)–(
3), choosing an algorithm with fewer number of iterations is preferable.
- (2)
The error of the identified parameters which was estimated using the formula , where is vector of exact parameter values.
- (3)
Total execution time.
The result of the computational experiment is summarized in
Table 9.
It can be seen that all the considered optimization algorithms make it possible to accurately identify the atmospheric turbulence coefficient when its parameters are positive multipliers (Cases 1 and 4). NEWUOA demonstrated an excellent result in terms of both iterations count and the execution time which allows it to be effectively used in this class of problems. The BOBYQA, L-BFGS, and Nelder-Mead algorithms required two–four times more iterations and time. In Case 3, when it was necessary to identify the degree of an expression, the Nelder-Mead algorithm failed to achieve convergence and NEWUOA is not applicable to identifying one parameter, while the BOBYQA, Conjugate Gradient and L-BFGS algorithms showed comparable results.
In Case 2, when the vector of unknown parameters contained both positive and negative coefficients, the BOBYQA and NEWUOA algorithms could not achieve convergence and the computational experiments were interrupted when the number of calls exceeded 20,000; the column “Error” indicates the best error indicator for the performed iterations in this case. In contrast, the Conjugate Gradient and L-BFGS algorithms were able to identify coefficients with almost the same accuracy. The obvious disadvantage of the conjugate gradient method in this test was the extremely slow convergence of the iterations.
In real atmospheric turbulence models, the parameters can take both positive and negative values. Therefore, this criterion was critical when choosing an algorithm. Overall, the L-BFGS algorithm turned out to be the most stable and successfully identified unknown parameters in a wide class of functions while achieving greater accuracy. Therefore, this algorithm was employed in subsequent numerical tests.
3.4. Forecasting the Spread of a Contaminant in the Atmosphere
We are now ready to apply the proposed approach to a more realistic problem. The goal of the first computational experiment is to predict the dynamics of the concentration field in the city of Ust-Kamenogorsk during one day, 31 December 2021.
As previously stated in
Section 3.1, there are five observation points in Ust-Kamenogorsk. According to the first step of the algorithm presented in
Figure 1, we first train a machine learning model to predict the
values at the observation points. We utilized the LightGBM model based on the analysis of the
score evaluated in
Section 3.2.
Further, according to the second step of the algorithm, the location and intensity of pollution sources of
,
and
are determined which are shown in
Table 10. We considered two cases in which the maximum sources count in (
7) was set to
and
, respectively. Overall, the coordinates found correspond to the real sources of air pollution in the city. For example, sulfur oxides are emitted to the atmosphere when coal, oil and natural gas are burned in thermal power plants, residential heating using wood and coal in the areas with a cluster of residential buildings, and metal smelting and sulfuric acid production. Indeed, most of the found points are close to the areas with a cluster of residential buildings, so in these areas there is territorial pollution from heating systems. In addition, the point with coordinates (49.977935, 82.643055) is located in close proximity to the Ust-Kamenogorsk metallurgical complex of Kazzinc LLP and Ulba Metallurgical Plant JSC. The point with coordinates (50.008971, 82.725308) is located near Ust-Kamenogorsk titanium-magnesium plant JSC and AES Sogrinskaya thermal power station LLP. In the area of the point with coordinates (50.008625, 82.576470) there is indeed a railway station, which is one of the sources of air pollutants. In addition, the source of formation of nitrogen oxides are the products of combustion of thermal power plants, vehicle exhausts, and waste from metallurgical industries.
To check the correctness of the sources found, we calculate the concentration values at the observation points again based on these sources and compare the obtained values with the actual values at the same points as described in
Section 2.5. Overall, one can conclude that the proposed method is able to quite accurately determine the sources of pollution based on the results of the comparison presented in
Table 11. However the identification error varied between
and
under an assumption of six pollution sources, and the error increased considerably when the maximum pollution sources count was set to two.
In addition, the initial concentration was approximated as described in
Section 2.5.
Further, a finite element mesh was introduced in the domain , and in the neighborhood of observation points and identified sources, the mesh was refined for a more detailed study of the solution near these points. Then, scattered interpolation by Shepard’s method was used to interpolate wind vector field in each element using information about the direction and velocity of the wind at the observation points.
In order to verify the adequacy of the proposed approach, we conduct the algorithm presented in
Figure 1 on the base of four observation points with internal numbers 5, 7, 8 and 12 to obtain the solution of Problem (
1)–(
3) satisfying the constraint (
4). Then we compare the obtained solution with a real measurement value at the fifth observation point with an internal number 1 which will serve as a control point. Assessing the proximity of these values will allow us to evaluate the correctness of the resulting solution. The reason for choosing the location of the control point was to verify the concentration in the inner part of the city near industrial facilities.
The model (
12) with
was accepted as the atmospheric turbulence coefficient. Therefore, the coefficient depended on three unknown parameters—
(
),
(m) and
(m), which we represent by a vector
. It was assumed that
and the vector
was taken as the initial estimate. This value was reported by the authors of [
7] who studied propagation of contaminants in the atmosphere of Ust-Kamenogorsk based on photochemical reactions. Based on the conclusions of
Section 3.3, subsequent vectors
,
in the iterative process of Stage 2 were found using the L-BFGS optimization algorithm.
In the time interval corresponding to 24 h, a uniform partition was introduced which contained 3200 time layers with a step of
s. The integrals in (
4) were evaluated by the trapezoidal rule; the value of the functional was calculated at four observation points every 6 h, which led to the minimization of a sum consisting of 16 terms. Moreover, in contrast to the problems considered earlier, we have replaced the boundary condition of the first kind with a homogeneous boundary condition of the second kind [
70].
The value of the functional
was approximately equal to 1.449949 for the chosen initial estimate vector. The value of the solution at the control point was equal to 0.067981 which differs from the actually measured value by 0.014019. The iterative process within Stage 2 was conducted until the objective function satisfied the condition
with
. This condition was achieved at the 1287th iteration, and the following values of the parameters were identified:
. The value of the objective function for these coefficients was approximately equal to 0.026079. The value of the solution at the fifth observation point was approximately equal to 0.081435 which differs from the actually measured value by 0.00281612 (
Table 12). However, the obtained result can be considered acceptable despite the simplicity of the adopted model of the atmospheric turbulence coefficient.
Verification of the proposed approach was conducted on Dataset B in a similar way. The goal was to predict
concentration on 1 November 2022. First, we set the maximum sources count
. The median identification error evaluated as in
Table 11 was equal to
.
Then we considered a subset of 10 observation points located in the center part of the city: Alm-002, Alm-005, Alm-007, Alm-008, Alm-010, PNZ-1, PNZ-2, PNZ-3, PNZ-5 and PNZ-6. The comparison of the solution was performed at Alm-002 and Alm-008, and the algorithm was conducted on the rest of the observation points. The sought coefficient depended on seven unknown parameters . Unfortunately, the literature review did not reveal studies aimed at determining the value of the turbulence coefficient for the city of Almaty. However, the surface roughness of the outskirts of the cities of Ust-Kamenogorsk and Almaty is identical, since both cities are surrounded on one side by the Altai and Alatau mountain ranges, respectively, and on the other side are plains. Therefore, it was expected that the nature of turbulent mixing of atmospheric air was approximately the same. In this regard, we took the vector with as defined above for the city of Ust-Kamenogorsk and as the initial estimate for Dataset B. The value of the functional was approximately equal to 1.199794 for the chosen initial estimate.
The stopping criterion (
13) was satisfied at the 1784th iteration; the resulting parameters vector was
, and the corresponding value of the objective function was equal to 0.068131. The values of the obtained solution at the two control points, Alm-002 and Alm-008, were equal to 0.008950 and 0.067400, respectively, which deviate from the actually measured values by 0.013 and 0.028, respectively. The result of the calculations made for Dataset B are presented in
Table 13.
4. Conclusions
Let us provide a few comments about the results obtained and outline future research directions.
(1) In general, the problem of determining the coefficient of atmospheric turbulence is quite complex, and the presence of a large number of different models of atmospheric turbulence indicates that there is still no unified method for its determination. Our work proposes one of the approaches that allows one to refine the parameters included in these models. In particular, in comparison with paper [
7], a refined value of the atmospheric turbulence coefficient was obtained. In the computational experiment carried out, the error in determining the concentration at the control point was reduced from 0.014019 to 0.002816.
(2) Ensemble models can be effectively used when training machine learning models in the problems of predicting the distribution of harmful substances in the atmosphere. It can be concluded from the analysis made that all three considered models, XGBoost, LightGBM and Histogram-Based Gradient Boosting, can effectively make a prediction of the concentration at observation points. This observation is also consistent with the conclusions of the papers [
71,
72,
73,
74]. Additionally, it has been observed that the LightGBM and Histogram-Based Gradient Boosting models are more resistant to data incompleteness, therefore it is recommended to use these models in this case.
(3) A more realistic problem of the spread of a harmful substance in the atmosphere has been solved on the example of the city of Ust-Kamenogorsk, Kazakhstan using the proposed approach. Due to the methodological nature of the work, the results of the forecast can be considered quite acceptable. Note that the relatively large value of the target functional obtained in
Section 3.4 may indicate that more significant factors were not taken into account when modeling the spread of a harmful substance. These may include orographic features of the area and high-rise buildings. In addition, the study uses data from a fairly small number of observation points. Another important factor is the use of a two-dimensional convection-diffusion-reaction model at a fixed height, as well as the use of the simplest Gaussian plume model in determining the initial distribution field.
(4) Since the approach is proposed for the first time, the technical methods used can be improved without significant difficulties. For example, a three-dimensional generalization of the governing equation with a more complex turbulence coefficient can be used, which can more accurately describe the motion of the harmful substance. Another possibility for improving the results is taking into account the terrain, high-rise buildings and other features of the area under study. These issues deserve a separate study, which will be the subject of a subsequent paper.
In general, despite many simplifying assumptions, the developed algorithm showed a plausible dispersion of the pollutant. Hence, we concluded that this algorithm can be taken as a basis when considering more complex models that take into account more factors.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}