Multiple Attributes Group Decision-Making under Interval-Valued Dual Hesitant Fuzzy Unbalanced Linguistic Environment with Prioritized Attributes and Unknown Decision-Makers’ Weights

Abstract
1. Introduction
2. Literature Review on Hesitant Fuzzy Linguistic MADM Approaches
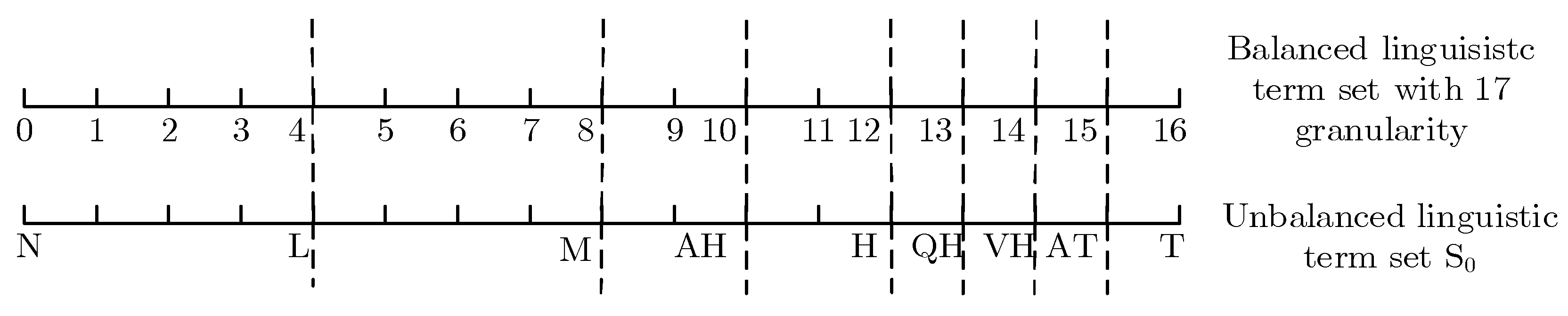
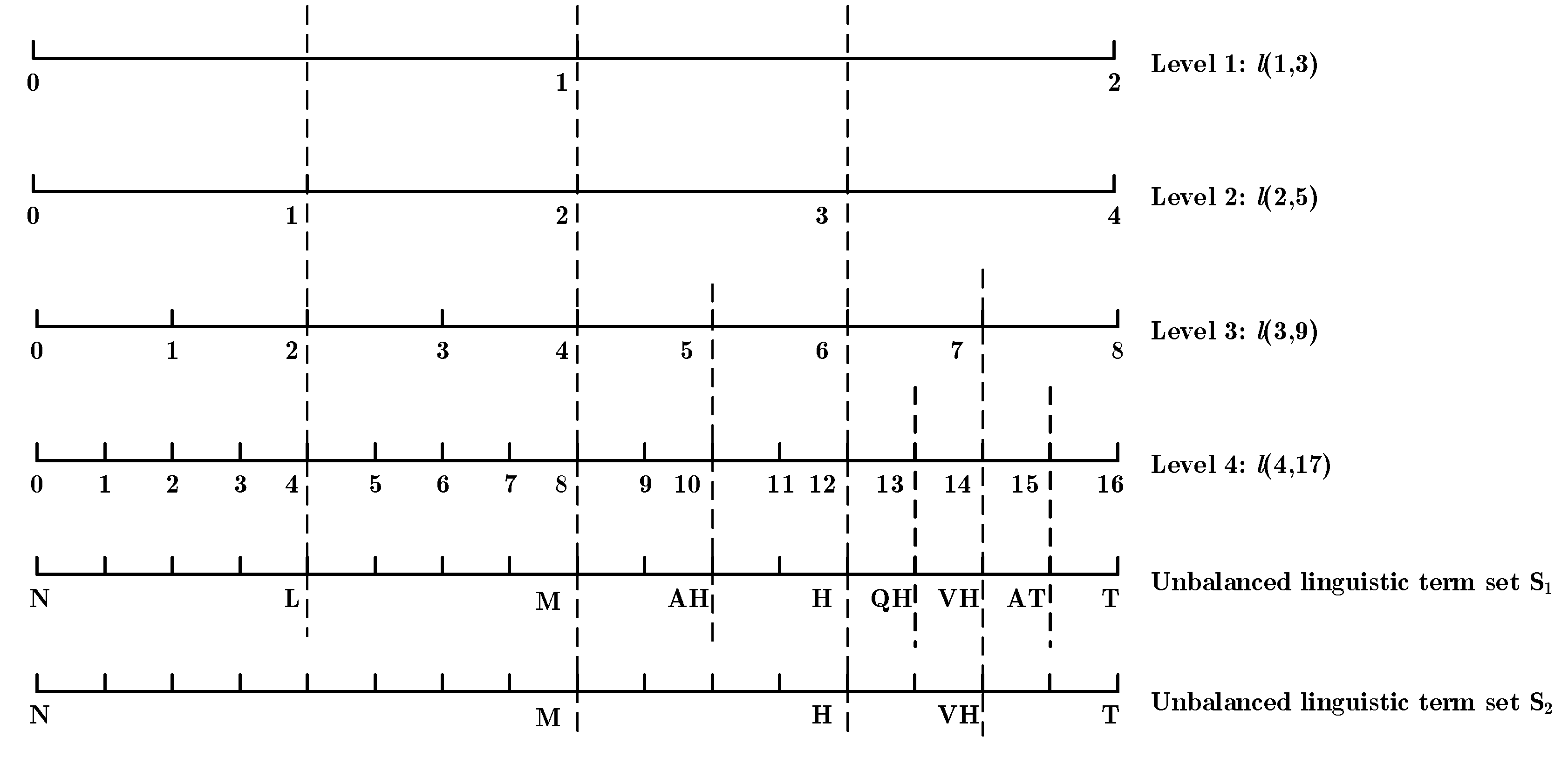
3. Preliminaries for IVDHFUBLS
- (1)
- (2)
- (3)
- (4)
- (1)
- If , then .
- (2)
- If , then
- (a)
- If , then ;
- (b)
- If , then .
4. Proposed Approach for MAGDM Based on IVDHFUBLS
4.1. Prioritized Average Aggregation Operator for IVDHFUBLS
- (1)
- When , obviously, it is right.
- (2)
- When ,So, when , Theorem 1 also is right.
- (3)
- Suppose that when , Theorem 1 is right; then, we haveThen, when ,So, when , Theorem 1 is right too.According to steps (1), (2), and (3), we get that Theorem 1 is right for all . ☐
- (1)
- Commutativity: Letbe any permutation of, then
- (2)
- Idempotency: Let, for all, then
- (3)
- Boundedness: the IVDHFUBLPWA operator lies between the max and min operators,
- (1)
- Assume that is any permutation of ; then, for each , there exists one and only one , such that and vice versa. Additionally, also we have . Thus, based on Theorem 1, we have
- (2)
- Since for all , then
- (3)
- Suppose , , in whichObviously,Additionally, for all , we haveMeanwhile, we haveThenAccording to Definition 4 and Theorem 1, we havewhich completes the proof. ☐
4.2. A Hybrid Model for Determining the Unknown Experts’ Weights
4.3. Algorithm for MAGDM Based on IVDHFUBLS with Prioritization Relation among Evaluative Attributes and Unknown Decision-Makers’ Weights
- Step I-1.
- Compute the weight vector for decision-makers by applying Equation (17).
- Step I-2.
- According to the prioritization relation, , among attributes, transform each individual decision matrix to the prioritized individual decision matrix ,, in which , .
- Step I-3.
- Calculate prioritized levels in prioritized individual IVDHFUBL decision matrices: , .Calculate the score values of according to Equation (3) in Definition 4, then compute the numerical prioritized levels in each prioritized individual IVDHFUBL decision matrix, in which
- Step I-4.
- Obtain aggregated results in prioritized individual decision matrices, , , by applying operator IVDHFUBLPWA.Utilize the IVDHFUBLPWA operator described in Definition 6 to aggregate so that we get the decision-maker’s decision result on the alternative , in which
- Step I-5.
- Obtain collective results of all alternatives by applying decision-makers’ weighting vector.Given the weighting vector for decision-makers, which has been determined in Step 1, we now aggregate all the individual overall decision values into the overall group decision values by use of the IVDHFUBLWA operator described in Equation (10), in which
- Step I-6.
- According to Definition 4, calculate the score value of the group overall assessments to alternatives , then rank all the alternatives and select the most desirable one(s).
5. Illustrative Examples
5.1. Applied Case Study on Green Supplier Selection Problem
- Step I-1.
- Compute the weight vector for decision-makers. Firstly, by solving the programming model (M-2), we obtain deviation-based weighting vector asThen, by applying Equation (11), we get the accuracy-measure based experts’ weighting vector asFinally, according to Equation (17), we here suppose ; then, the hybrid experts’ weighting vector is obtained as
- Step I-2.
- Step I-3.
- Calculate prioritized levels in each prioritized individual IVDHFUBL decision matrix by Equations (18) and (19), and then we have
- , ; , , , , , , ,
- , , , , , ; , , , , , , ,
- , , , , , , ; , , , , , , , ; , , , , ,
- Step I-4.
- Utilize the IVDHFUBLPWA operator described in Definition 6 to aggregate , so that we get the k th expert’s decision result on alternatives , in which
- = (,{[0.439,0.5428],[0.4392,0.5429],[0.4397,0.5438],[0.4399,0.5439]},{[0.1633,0.2744],[0.1633,0.2744],[0.1633,0.2745],[0.1633,0.2746],[0.1675,0.2744],[0.1675,0.2744],[0.1675,0.2745],[0.1675,0.2746],[0.2598,0.373],[0.2598,0.373],[0.2598,0.3731],[0.2598,0.3732],[0.2665,0.373],[0.2665,0.373],[0.2665,0.3731],[0.2665,0.3732]}});
- = (,{[0.5479,0.6638],[0.5483,0.6642],[0.5517,0.6676],[0.5521,0.6681],[0.5538,0.6676],[0.5542,0.668],[0.5576,0.6714],[0.558,0.6718],[0.5579,0.6728],[0.5583,0.6732],[0.5616,0.6766],[0.562,0.677],[0.5637,0.6765],[0.5641,0.677],[0.5673,0.6802],[0.5677,0.6806]},{[0.1152,0.2172],[0.1225,0.2252],[0.1152,0.225],[0.1225,0.2333]});
- = (,{[0.2778,0.383],[0.2789,0.3841],[0.2778,0.3927],[0.2789,0.3938],[0.3647,0.475],[0.3656,0.476],[0.3647,0.4832],[0.3656,0.4842]},{[0.2911,0.4718],[0.2948,0.4753],[0.3186,0.5093],[0.3227,0.5131]});
- = (,{[0.1186,0.3686],[0.1431,0.3885]},{[0.1649,0.2682],[0.165,0.2683],[0.2188,0.3278],[0.2189,0.3279]});
- = (,{[0.4817,0.6085],[0.483,0.6099]},{[0.1246,0.231],[0.1256,0.2326]});
- = (,{[0.4365,0.5779]},{[0.2377,0.3445],[0.2646,0.3745]});
- = (,{[0.4134,0.5925],[0.4139,0.5925]},{[0.235,0.3833],[0.2487,0.3997]});
- = (,{[0.4072,0.5418],[0.4106,0.5452],[0.4294,0.5685],[0.4327,0.5718],[0.4646,0.5954],[0.4676,0.5985],[0.4846,0.6191],[0.4876,0.6219]},{[0.1748,0.2911],[0.1777,0.2932]});
- = (,{[0.6027,0.7085]},{[0.1053,0.2225],[0.1284,0.2522]}).
- Step I-5.
- Aggregate all the individual overall decision values into the overall group decision values by use of the IVDHFUBLWA operator described in Equation (10) and experts’ weighting vector determined in Step 1. Taking as an example, we have
- ,{[0.4597,0.5809],[0.46,0.5811],[0.4597,0.583],[0.46,0.5833], [0.4815,0.6021],[0.4817,0.6023],[0.4815,0.6041],[0.4817,0.6043]},{[0.191,0.3273],[0.2047,0.3419],[0.1979,0.3364],[0.2121,0.3514],[0.1918,0.328],[0.2055,0.3427],[0.1987,0.3372],[0.2129,0.3522],[0.1966,0.3354],[0.2107,0.3504],[0.2037,0.3448],[0.2183,0.3601],[0.1974,0.3362],[0.2116,0.3512],[0.2046,0.3456],[0.2192,0.361]}}).
- Step I-6.
- Calculating scores of the alternatives , we haveAccordingly, then the ranking order of all the alternatives is determined asTherefore, solution is the most desirable green supplier.
5.2. Comparison with IVDHFUBLS-Based TOPSIS Method
- Step II-1.
- Obtaining individual decision matrices from decision-makers, we get .
- Step II-2.
- Aggregate individual decision matrices into individual overall evaluation values corresponding to each alternative according to IVDHFULWA operator. Here, assume , and
- Step II-3.
- Calculate separating measure from positive and negative ideal solutions.Determine positive ideal solution (PIS) and negative ideal solution (NIS) , in which , .Then, we calculate the separating measure from the PIS and NIS for each alternative according to the distance measure introduced in Equation (5), in whichNext, we can obtain
- Step II-4.
- Calculate the relative closeness to the ideal solution by
- Step II-5.
- Rank the green suppliers according to the descending order of ; then, we get the most desirable supplier.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zimmermann, H.J. Fuzzy Set Theory and Its Applications; Springer: Dordrecht, The Netherlands, 2001. [Google Scholar]
- Lin, R.-J. Using fuzzy dematel to evaluate the green supply chain management practices. J. Clean. Prod. 2013, 40, 32–39. [Google Scholar] [CrossRef]
- Qin, J.; Liu, X. 2-tuple linguistic muirhead mean operators for multiple attribute group decision making and its application to supplier selection. Kybernetes 2016, 45, 2–29. [Google Scholar] [CrossRef]
- Junior, F.R.L.; Osiro, L.; Carpinetti, L.C.R. A comparison between fuzzy AHP and fuzzy TOPSIS methods to supplier selection. Appl. Soft Comput. 2014, 21, 194–209. [Google Scholar] [CrossRef]
- Qi, X.; Liang, C.; Zhang, J. Generalized cross-entropy based group decision making with unknown expert and attribute weights under interval-valued intuitionistic fuzzy environment. Comput. Ind. Eng. 2015, 79, 52–64. [Google Scholar] [CrossRef]
- Ghazanfari, M.; Rouhani, S.; Jafari, M. A fuzzy topsis model to evaluate the business intelligence competencies of port community systems. Pol. Marit. Res. 2014, 21, 86–96. [Google Scholar] [CrossRef]
- Rouhani, S.; Ghazanfari, M.; Jafari, M. Evaluation model of business intelligence for enterprise systems using fuzzy topsis. Expert Syst. Appl. 2012, 39, 3764–3771. [Google Scholar] [CrossRef]
- Zhang, J.; Hegde, G.; Shang, J.; Qi, X. Evaluating emergency response solutions for sustainable community development by using fuzzy multi-criteria group decision making approaches: Ivdhf-topsis and ivdhf-vikor. Sustainability 2016, 8, 291. [Google Scholar] [CrossRef]
- Ju, Y.B.; Wang, A.H.; You, T.H. Emergency alternative evaluation and selection based on ANP, DEMATEL, and TL-TOPSIS. Nat. Hazards 2015, 75, 347–379. [Google Scholar] [CrossRef]
- Ju, Y.; Wang, A.; Liu, X. Evaluating emergency response capacity by fuzzy AHP and 2-tuple fuzzy linguistic approach. Expert Syst. Appl. 2012, 39, 6972–6981. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J.; Zhang, H.; Hu, J. A heterogeneous linguistic magdm framework to classroom teaching quality evaluation. Eurasia J. Math. Sci. Technol. Educ. 2017, 13, 4929–4956. [Google Scholar] [CrossRef]
- Xu, Y.P. Model for evaluating the mechanical product design quality with dual hesitant fuzzy information. J. Intell. Fuzzy Syst. 2016, 30, 1–6. [Google Scholar] [CrossRef]
- Başar, Ö.; Cengiz, K. Evaluation of renewable energy alternatives using hesitant fuzzy topsis and interval type-2 fuzzy AHP. In Soft Computing Applications for Renewable Energy and Energy Efficiency; Maria del Socorro García, C., Juan Miguel Sánchez, L., Antonio David Masegosa, A., Carlos Cruz, C., Eds.; IGI Global: Hershey, PA, USA, 2015; pp. 191–224. [Google Scholar]
- Liu, H.-C.; You, J.-X.; Lu, C.; Chen, Y.-Z. Evaluating health-care waste treatment technologies using a hybrid multi-criteria decision making model. Renew. Sustain. Energy Rev. 2015, 41, 932–942. [Google Scholar] [CrossRef]
- Mardani, A.; Jusoh, A.; Zavadskas, E.K. Fuzzy multiple criteria decision-making techniques and applications—Two decades review from 1994 to 2014. Expert Syst. Appl. 2015, 42, 4126–4148. [Google Scholar] [CrossRef]
- Kahraman, C.; Onar, S.C.; Oztaysi, B. Fuzzy multicriteria decision-making: A literature review. Int. J. Comput. Intell. Syst. 2015, 8, 637–666. [Google Scholar] [CrossRef]
- Montazer, G.A.; Saremi, H.Q.; Ramezani, M. Design a new mixed expert decision aiding system using fuzzy electre III method for vendor selection. Expert Syst. Appl. 2009, 36, 10837–10847. [Google Scholar] [CrossRef]
- Chen, T.-Y. An interval type-2 fuzzy promethee method using a likelihood-based outranking comparison approach. Inf. Fusion 2015, 25, 105–120. [Google Scholar] [CrossRef]
- Park, J.H.; Park, I.Y.; Kwun, Y.C.; Tan, X.G. Extension of the topsis method for decision making problems under interval-valued intuitionistic fuzzy environment. Appl. Math. Model. 2011, 35, 2544–2556. [Google Scholar] [CrossRef]
- Zhang, X.L.; Xu, Z.S. The todim analysis approach based on novel measured functions under hesitant fuzzy environment. Knowl.-Based Syst. 2014, 61, 48–58. [Google Scholar] [CrossRef]
- Zhang, X.L.; Xu, Z.S. Hesitant fuzzy qualiflex approach with a signed distance-based comparison method for multiple criteria decision analysis. Expert Syst. Appl. 2015, 42, 873–884. [Google Scholar] [CrossRef]
- Chen, N.; Xu, Z.S. Hesitant fuzzy electre II approach: A new way to handle multi-criteria decision making problems. Inf. Sci. 2015, 292, 175–197. [Google Scholar] [CrossRef]
- Peng, J.-J.; Wang, J.-Q.; Wang, J.; Yang, L.-J.; Chen, X.-H. An extension of electre to multi-criteria decision-making problems with multi-hesitant fuzzy sets. Inf. Sci. 2015, 307, 113–126. [Google Scholar] [CrossRef]
- Turksen, I.B. Interval valued fuzzy sets based on normal forms. Fuzzy Sets Syst. 1986, 20, 191–210. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Atanassov, K.T.; Gargov, G. Interval valued intuitionistic fuzzy sets. Fuzzy Sets Syst. 1989, 31, 343–349. [Google Scholar] [CrossRef]
- Torra, V.; Narukawa, Y. On hesitant fuzzy sets and decision. In Proceedings of the 18th IEEE International Conference on Fuzzy Systems, Jeju Island, Korea, 20–24 August 2009; pp. 1378–1382. [Google Scholar]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Zhu, B.; Xu, Z.S.; Xia, M.M. Dual hesitant fuzzy sets. J. Appl. Math. 2012, 2012. [Google Scholar] [CrossRef]
- Farhadinia, B. Correlation for dual hesitant fuzzy sets and dual interval-valued hesitant fuzzy sets. Int. J. Intell. Syst. 2014, 29, 184–205. [Google Scholar] [CrossRef]
- Zhu, B.; Xu, Z.S. Some results for dual hesitant fuzzy sets. J. Intell. Fuzzy Syst. 2014, 26, 1657–1668. [Google Scholar]
- Ju, Y.B.; Liu, X.Y.; Yang, S.H. Interval-valued dual hesitant fuzzy aggregation operators and their applications to multiple attribute decision making. J. Intell. Fuzzy Syst. 2014, 27, 1203–1218. [Google Scholar]
- Herrera, F.; Herrera-Viedma, E.; Martínez, L. A fusion approach for managing multi-granularity linguistic term sets in decision making. Fuzzy Sets Syst. 2000, 114, 43–58. [Google Scholar] [CrossRef]
- Tao, Z.; Liu, X.; Chen, H.; Zhou, L. Using new version of extended t-Norms and s-Norms for aggregating interval linguistic labels. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 3284–3298. [Google Scholar] [CrossRef]
- Martínez, L.; Herrera, F. An overview on the 2-tuple linguistic model for computing with words in decision making: Extensions, applications and challenges. Inf. Sci. 2012, 207, 1–18. [Google Scholar] [CrossRef]
- Wang, J.Q.; Wu, J.T.; Wang, J.; Zhang, H.Y.; Chen, X.H. Interval-valued hesitant fuzzy linguistic sets and their applications in multi-criteria decision-making problems. Inf. Sci. 2014, 288, 55–72. [Google Scholar] [CrossRef]
- Lin, R.; Zhao, X.F.; Wang, H.J.; Wei, G.W. Hesitant fuzzy linguistic aggregation operators and their application to multiple attribute decision making. J. Intell. Fuzzy Syst. 2014, 27, 49–63. [Google Scholar]
- Zhang, N. Hesitant fuzzy linguistic information aggregation in decision making. Int. J. Oper. Res. 2014, 21, 489–507. [Google Scholar] [CrossRef]
- Zhang, W.; Ju, Y.; Liu, X. Multiple criteria decision analysis based on shapley fuzzy measures and interval-valued hesitant fuzzy linguistic numbers. Comput. Ind. Eng. 2017, 105, 28–38. [Google Scholar] [CrossRef]
- Yang, S.H.; Ju, Y.B. Dual hesitant fuzzy linguistic aggregation operators and their applications to multi-attribute decision making. J. Intell. Fuzzy Syst. 2014, 27, 1935–1947. [Google Scholar]
- Qi, X.; Liang, C.; Zhang, J. Multiple attribute group decision making based on generalized power aggregation operators under interval-valued dual hesitant fuzzy linguistic environment. Int. J. Mach. Learn. Cybern. 2016, 7, 1147–1193. [Google Scholar] [CrossRef]
- Herrera-Viedma, E.; López-Herrera, A.G. A model of an information retrieval system with unbalanced fuzzy linguistic information. Int. J. Intell. Syst. 2007, 22, 1197–1214. [Google Scholar] [CrossRef]
- Martínez, L.; Espinilla, M.; Liu, J.; Pérez, L.G.; Sánchez, P.J. An evaluation model with unbalanced linguistic information applied to olive oil sensory evaluation. J. Mult.-Valued Log. Soft Comput. 2009, 15, 229–251. [Google Scholar]
- Herrera, F.; Herrera-Viedma, E.; Martinez, L. A fuzzy linguistic methodology to deal with unbalanced linguistic term sets. IEEE Trans. Fuzzy Syst. 2008, 16, 354–370. [Google Scholar] [CrossRef]
- Meng, D.; Pei, Z. On weighted unbalanced linguistic aggregation operators in group decision making. Inf. Sci. 2013, 223, 31–41. [Google Scholar] [CrossRef]
- Dong, Y.; Li, C.C.; Herrera, F. An optimization-based approach to adjusting unbalanced linguistic preference relations to obtain a required consistency level. Inf. Sci. 2015, 292, 27–38. [Google Scholar] [CrossRef]
- Qi, X.; Zhang, J.; Liang, C. Multiple attributes group decision-making approaches based on interval-valued dual hesitant fuzzy unbalanced linguistic set and their applications. Complexity 2018, 2018. [Google Scholar] [CrossRef]
- Ju, Y.B.; Wang, A.H. Emergency alternative evaluation under group decision makers: A method of incorporating ds/ahp with extended topsis. Expert Syst. Appl. 2012, 39, 1315–1323. [Google Scholar] [CrossRef]
- Yager, R.R. Prioritized aggregation operators. Int. J. Approx. Reason. 2008, 48, 263–274. [Google Scholar] [CrossRef]
- Wei, G. Hesitant fuzzy prioritized operators and their application to multiple attribute decision making. Knowl.-Based Syst. 2012, 31, 176–182. [Google Scholar] [CrossRef]
- Yager, R.R. Prioritized owa aggregation. Fuzzy Optim. Decis Mak. 2009, 8, 245–262. [Google Scholar] [CrossRef]
- Yu, D.; Wu, Y.; Lu, T. Interval-valued intuitionistic fuzzy prioritized operators and their application in group decision making. Knowl.-Based Syst. 2012, 30, 57–66. [Google Scholar] [CrossRef]
- Yu, X.H.; Xu, Z.S. Prioritized intuitionistic fuzzy aggregation operators. Inf. Fusion 2013, 14, 108–116. [Google Scholar] [CrossRef]
- Yu, D.J. Prioritized information fusion method for triangular intuitionistic fuzzy set and its application to teaching quality evaluation. Int. J. Intell. Syst. 2013, 28, 411–435. [Google Scholar] [CrossRef]
- Zhao, Q.Y.; Chen, H.Y.; Zhou, L.G.; Tao, Z.F.; Liu, X. The properties of fuzzy number intuitionistic fuzzy prioritized operators and their applications to multi-criteria group decision making. J. Intell. Fuzzy Syst. 2015, 28, 1835–1848. [Google Scholar]
- Peng, D.H.; Wang, T.D.; Gao, C.Y.; Wang, H. Multigranular uncertain linguistic prioritized aggregation operators and their application to multiple criteria group decision making. J. Appl. Math. 2013, 2013. [Google Scholar] [CrossRef]
- Ren, Z.; Wei, C. A multi-attribute decision-making method with prioritization relationship and dual hesitant fuzzy decision information. Int. J. Mach. Learn. Cybern. 2017, 8, 755–763. [Google Scholar] [CrossRef]
- Wu, J.T.; Wang, J.Q.; Wang, J.; Zhang, H.Y.; Chen, X.H. Hesitant fuzzy linguistic multicriteria decision-making method based on generalized prioritized aggregation operator. Sci. World J. 2014. [Google Scholar] [CrossRef] [PubMed]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning-I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy Syst. 2012, 20, 109–119. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. A group decision making model dealing with comparative linguistic expressions based on hesitant fuzzy linguistic term sets. Inf. Sci. 2013, 241, 28–42. [Google Scholar] [CrossRef]
- Beg, I.; Rashid, T. Topsis for hesitant fuzzy linguistic term sets. Int. J. Intell. Syst. 2013, 28, 1162–1171. [Google Scholar] [CrossRef]
- Wang, J.-Q.; Wu, J.-T.; Wang, J.; Zhang, H.-Y.; Chen, X.-H. Multi-criteria decision-making methods based on the hausdorff distance of hesitant fuzzy linguistic numbers. Soft Comput. 2016, 20, 1621–1633. [Google Scholar] [CrossRef]
- Saaty, T.L. The Analytic Hierarchy Process; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Chinese Government. Regulations on Natural Disaster Rscue and Assistance; The-Ministry-of-Civil-Affairs, Chinese Government: Beijing, China, 2010. Available online: http://www.mca.gov.cn/article/zwgk/fvfg/jzjj/201008/20100800095101.shtml (accessed on 13 June 2018).
- Chinese Government. Emergency Plan for Natural Disaster Rescue, Modified ed.; The-Ministry-of-Civil-Affairs, Chinese Government: Beijing, China, 2011. Available online: http://www.mca.gov.cn/article/zwgk/fvfg/jzjj/201111/20111100191129.shtml (accessed on 13 June 2018).
- Momoh, J.A.; Zhang, Y.; Fanara, P.; Kurban, H.; Iwarere, L.J. Social impact based contingency screening and ranking. Int. J. Crit. Infrastruct. 2007, 3, 124–141. [Google Scholar] [CrossRef]
- Kelly, C. Quick Guide: Rapid Environmental Impact Assessment in Disaster; Benfield Hazard Research Centre, University College London and CARE International: London, UK, 2003; pp. 1–43. [Google Scholar]
- Kelly, C. Guidelines for Rapid Environmental Impact Assessment in Disasters; Benfield Greig Hazard Research Centre, University College London and CARE International: London, UK, 2005; pp. 1–86. [Google Scholar]
- Zhou, X.Q.; Li, Q.G. Generalized hesitant fuzzy prioritized einstein aggregation operators and their application in group decision making. Int. J. Fuzzy Syst. 2014, 16, 303–316. [Google Scholar]
- Ye, J. Prioritized aggregation operators of trapezoidal intuitionistic fuzzy sets and their application to multicriteria decision-making. Neural Comput. Appl. 2014, 25, 1447–1454. [Google Scholar] [CrossRef]
- Chen, L.; Xu, Z. A new prioritized multi-criteria outranking method: The prioritized promethee. J. Intell. Fuzzy Syst. 2015, 29, 2099–2110. [Google Scholar] [CrossRef]
- Wang, Y.M. Using the method of maximizing deviations to make decision for multi-indices. Syst. Eng. Electron. 1997, 8, 21–26. [Google Scholar]



{kind=link}
{kind=link}
| Authors | Methodology Properties | |||||
|---|---|---|---|---|---|---|
| Linguistic Variable | Description of Hesitancy | Prioritized Attributes | Unknown Decision-Makers’ Weights | |||
| Balanced | Unbalanced | Hesitant Fuzzy Set | Dual Hesitant Fuzzy Set | |||
| Lin, et al. [37] | √ | × | √ | × | × | Single-person MADM |
| Wang, et al. [36] | √ | × | √ | × | √ | Single-person MADM |
| Yang and Ju [40] | √ | × | × | √ | √ | Single-person MADM |
| Qi, et al. [41] | √ | × | × | √ | × | √ |
| Wang, et al. [63] | √ | × | √ | × | × | × |
| Qi, et al. [47] | √ | √ | √ | √ | × | Power aggregation-based method |
| This paper | √ | √ | √ | √ | √ | Deviation-maximizing method |
| (VH,{[0.2,0.3]}, {[0.2,0.4],[0.3,0.4]}) | (H,{[0.5,0.6]}, {[0.2,0.3]}) | (M,{[0.3,0.4]}, {[0.4,0.5],[0.5,0.6]}) | (T,{[0.2,0.4]}, {[0.5,0.6]}) | |
| (AT,{[0.4,0.5],[0.5,0.6]}, {[0.2,0.3],[0.2,0.4]}) | (T,{[0.6,0.7]}, {[0.1,0.2]}) | (L,{[0.6,0.7], [0.7,0.8]},{[0.1,0.2]}) | (QH,{[0.3,0.5]}, {[0.2,0.3]}) | |
| (L,{[0.1,0.2],[0.1,0.3]}, {[0.6,0.7]}) | (H,{[0.2,0.3]}, {[0.5,0.6],[0.6,0.7]}) | (AH,{[0.4,0.5]}, {[0.2,0.3]}) | (VH,{[0.6,0.7]}, {[0.1,0.2],[0.2,0.3]}) | |
| (L,{[0.4,0.5]}, {[0.1,0.2],[0.4,0.5]}) | (M,{[0.1,0.2],[0.3,0.5]}, {[0.3,0.5]}) | (AH,{[0.4,0.5],[0.5,0.6]}, {[0.2,0.3],[0.2,0.4]}) | (L,{[0.1,0.3]}, {[0.4,0.6]}) | |
| (M,{[0.6,0.7]}, {[0.1,0.2]}) | (VH,{[0.2,0.4],[0.5,0.6]}, {[0.2,0.3]}) | (L,{[0.5,0.6],[0.7,0.8]}, {[0.1,0.2]}) | (H,{[0.5,0.7]}, {[0.1,0.2],[0.2,0.3]}) | |
| (M,{[0.4,0.5],[0.6,0.7]}, {[0.1,0.3]}) | (H,{[0.3,0.4]}, {[0.4,0.5]}) | (QH,{[0.4,0.5],[0.5,0.6]}, {[0.3,0.4]}) | (VH,{[0.4,0.6]}, {[0.3,0.4]}) |
| (M,{[0.3,0.5]}, {[0.1,0.2]}) | (AH,{[0.1,0.4]}, {[0.2,0.3],[0.3,0.4]}) | (H,{[0.2,0.4]}, {[0.4,0.5]}) | (QH,{[0.2,0.4]}, {[0.5,0.6]}) | |
| (AT,{[0.4,0.7]}, {[0.2,0.3] }) | (L,{[0.5,0.6]}, {[0.1,0.2] }) | (AH,{[0.6,0.7],[0.7,0.8]}, {[0.1,0.2]}) | (M,{[0.2,0.3]}, {[0.5,0.6],[0.6,0.7]}) | |
| (AT,{[0.6,0.8]}, {[0.1,0.2]}) | (H,{[0.4,0.5]}, {[0.3,0.4],[0.4,0.5]}) | (H,{[0.4,0.5]}, {[0.2,0.3]}) | (AH,{[0.4,0.5]}, {[0.2,0.3]}) | |
| (M,{[0.1,0.2],[0.2,0.3]}, {[0.1,0.2]}) | (L,{[0.6,0.7]}, {[0.1,0.2]}) | (H,{[0.3,0.4]}, {[0.2,0.3],[0.4,0.5]}) | (M,{[0.5,0.7]}, {[0.2,0.3]}) | |
| (VH,{[0.6,0.7]}, {[0.1,0.2]}) | (AT,{[0.2,0.3]}, {[0.5,0.7]}) | (H,{[0.5,0.8]}, {[0.1,0.2]}) | (AT,{[0.3,0.5]}, {[0.3,0.4]}) | |
| (QH,{[0.4,0.5]}, {[0.3,0.4]}) | (L,{[0.7,0.8]}, {[0.1,0.2]}) | (VH,{[0.2,0.5]}, {[0.3,0.4]}) | (H,{[0.3,0.5]}, {[0.3,0.4]}) |
| (M,{[0.6,0.8]}, {[0.1,0.2]}) | (H,{[0.4,0.5]}, {[0.4,0.5]}) | (H,{[0.2,0.4],[0.3,0.4]}, {[0.2,0.3]}) | (M,{[0.7,0.8]}, {[0.1,0.2]}) | |
| (T,{[0.3,0.4]}, {[0.4,0.6]}) | (M,{[0.4,0.5],[0.5,0.6]}, {[0.2,0.3] }) | (VH,{[0.6,0.7]}, {[0.1,0.3]}) | (H,{[0.1,0.3],[0.2,0.4]}, {[0.3,0.5]}) | |
| (VH,{[0.4,0.5]}, {[0.1,0.2],[0.3,0.4]}) | (VH,{[0.7,0.8]}, {[0.1,0.2]}) | (H,{[0.6,0.8]}, {[0.1,0.2]}) | (M,{[0.6,0.7]}, {[0.1,0.3]}) | |
| (T,{[0.2,0.5]}, {[0.3,0.5]}) | (VH,{[0.6,0.7]}, {[0.2,0.3]}) | (M,{[0.1,0.2]}, {[0.5,0.8]}) | (VH,{[0.3,0.4]}, {[0.1,0.3],[0.2,0.5]}) | |
| (M,{[0.4,0.6], [0.5,0.7]},{[0.1,0.2]}) | (VH,{[0.3,0.6]}, {[0.1,0.3],[0.2,0.4]}) | (H,{[0.4,0.6]}, {[0.3,0.4]}) | (VH,{[0.7,0.8]}, {[0.1,0.2]}) | |
| (VH,{[0.6,0.7]}, {[0.1,0.2]}) | (M,{[0.5,0.6]}, {[0.3,0.4]}) | (H,{[0.3,0.5]}, {[0.4,0.5]}) | (H,{[0.6,0.7]}, {[0.1,0.3]}) |
| (H,{[0.5,0.6]}, {[0.2,0.3]}) | (L,{[0.4,0.5]}, {[0.1,0.2],[0.4,0.5]}) | (VH,{[0.2,0.3 0.2,0.4],[0.3,0.4]}) | (L,{[0.1,0.3]}, {[0.4,0.6]}) | |
| (T,{[0.6,0.7]}, {[0.1,0.2]}) | (M,{[0.6,0.7]}, {[0.1,0.2]}) | (AT,{[0.4,0.5],[0.5,0.6]}, {[0.2,0.3],[0.2,0.4]}) | (H,{[0.5,0.7]}, {[0.1,0.2],[0.2,0.3]}) | |
| (H,{[0.2,0.3]}, {[0.5,0.6],[0.6,0.7]}) | (M,{[0.4,0.5],[0.6,0.7]}, {[0.1,0.3]}) | (L,{[0.1,0.2],[0.1,0.3]}, {[0.6,0.7]}) | (VH,{[0.4,0.6]}, {[0.3,0.4]}) | |
| (T,{[0.2,0.4]}, {[0.5,0.6]}) | (M,{[0.1,0.2],[0.3,0.5]}, {[0.3,0.5]}) | (AH,{[0.4,0.5],[0.5,0.6]}, {[0.2,0.3],[0.2,0.4]}) | (M,{[0.3,0.4]}, {[0.4,0.5],[0.5,0.6]}) | |
| (QH,{[0.3,0.5]}, {[0.2,0.3]}) | (VH,{[0.2,0.4],[0.5,0.6]}, {[0.2,0.3]}) | (L,{[0.5,0.6],[0.7,0.8]}, {[0.1,0.2]}) | (L,{[0.6,0.7],[0.7,0.8]}, {[0.1,0.2]}) | |
| (VH,{[0.6,0.7]}, {[0.1,0.2],[0.2,0.3]}) | (H,{[0.3,0.4]}, {[0.4,0.5]}) | (QH,{[0.4,0.5],[0.5,0.6]}, {[0.3,0.4]}) | (AH,{[0.4,0.5]}, {[0.2,0.3]}) |
| (AH,{[0.1,0.4]}, {[0.2,0.3],[0.3,0.4]}) | (M,{[0.1,0.2], [0.2,0.3]},{[0.1,0.2]}) | (M,{[0.3,0.5]}, {[0.1,0.2]}) | (M,{[0.5,0.7]}, {[0.2,0.3]}) | |
| (L,{[0.5,0.6]}, {[0.1,0.2] }) | (VH,{[0.6,0.7]}, {[0.1,0.2]}) | (AT,{[0.4,0.7]}, {[0.2,0.3] }) | (AT,{[0.3,0.5]}, {[0.3,0.4]}) | |
| (H,{[0.4,0.5]}, {[0.3,0.4],[0.4,0.5]}) | (QH,{[0.4,0.5]}, {[0.3,0.4]}) | (AT,{[0.6,0.8]}, {[0.1,0.2]}) | (H,{[0.3,0.5]}, {[0.3,0.4]}) | |
| (QH,{[0.2,0.4]}, {[0.5,0.6]}) | (L,{[0.6,0.7]}, {[0.1,0.2]}) | (H,{[0.3,0.4]}, {[0.2,0.3],[0.4,0.5]}) | (H,{[0.2,0.4]}, {[0.4,0.5]}) | |
| (M,{[0.2,0.3]}, {[0.5,0.6],[0.6,0.7]}) | (AT,{[0.2,0.3]}, {[0.5,0.7]}) | (H,{[0.5,0.8]}, {[0.1,0.2]}) | (AH,{[0.6,0.7],[0.7,0.8]}, {[0.1,0.2]}) | |
| (AH,{[0.4,0.5]}, {[0.2,0.3]}) | (L,{[0.7,0.8]}, {[0.1,0.2]}) | (VH,{[0.2,0.5]}, {[0.3,0.4]}) | (H,{[0.4,0.5]}, {[0.2,0.3]}) |
| (H,{[0.4,0.5]}, {[0.4,0.5]}) | (T,{[0.2,0.5]}, {[0.3,0.5]}) | (M,{[0.6,0.8]}, {[0.1,0.2]}) | (VH,{[0.3,0.4]}, {[0.1,0.3],[0.2,0.5]}) | |
| (M,{[0.4,0.5],[0.5,0.6]}, {[0.2,0.3] }) | (M,{[0.4,0.6], [0.5,0.7]},{[0.1,0.2]}) | (T,{[0.3,0.4]}, {[0.4,0.6]}) | (VH,{[0.7,0.8]}, {[0.1,0.2]}) | |
| (VH,{[0.7,0.8]}, {[0.1,0.2]}) | (VH,{[0.6,0.7]}, {[0.1,0.2]}) | (VH,{[0.4,0.5]}, {[0.1,0.2],[0.3,0.4]}) | (H,{[0.6,0.7]}, {[0.1,0.3]}) | |
| (M,{[0.7,0.8]}, {[0.1,0.2]}) | (VH,{[0.6,0.7]}, {[0.2,0.3]}) | (M,{[0.1,0.2]}, {[0.5,0.8]}) | (H,{[0.2,0.4],[0.3,0.4]}, {[0.2,0.3]}) | |
| (H,{[0.1,0.3],[0.2,0.4]}, {[0.3,0.5]}) | (VH,{[0.3,0.6]}, {[0.1,0.3],[0.2,0.4]}) | (H,{[0.4,0.6]}, {[0.3,0.4]}) | (VH,{[0.6,0.7]}, {[0.1,0.3]}) | |
| (M,{[0.6,0.7]}, {[0.1,0.3]}) | (M,{[0.5,0.6]}, {[0.3,0.4]}) | (H,{[0.3,0.5]}, {[0.4,0.5]}) | (H,{[0.6,0.8]}, {[0.1,0.2]}) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, X.-W.; Zhang, J.-L.; Liang, C.-Y. Multiple Attributes Group Decision-Making under Interval-Valued Dual Hesitant Fuzzy Unbalanced Linguistic Environment with Prioritized Attributes and Unknown Decision-Makers’ Weights. Information 2018, 9, 145. https://doi.org/10.3390/info9060145
Qi X-W, Zhang J-L, Liang C-Y. Multiple Attributes Group Decision-Making under Interval-Valued Dual Hesitant Fuzzy Unbalanced Linguistic Environment with Prioritized Attributes and Unknown Decision-Makers’ Weights. Information. 2018; 9(6):145. https://doi.org/10.3390/info9060145
Chicago/Turabian StyleQi, Xiao-Wen, Jun-Ling Zhang, and Chang-Yong Liang. 2018. "Multiple Attributes Group Decision-Making under Interval-Valued Dual Hesitant Fuzzy Unbalanced Linguistic Environment with Prioritized Attributes and Unknown Decision-Makers’ Weights" Information 9, no. 6: 145. https://doi.org/10.3390/info9060145
APA StyleQi, X.-W., Zhang, J.-L., & Liang, C.-Y. (2018). Multiple Attributes Group Decision-Making under Interval-Valued Dual Hesitant Fuzzy Unbalanced Linguistic Environment with Prioritized Attributes and Unknown Decision-Makers’ Weights. Information, 9(6), 145. https://doi.org/10.3390/info9060145